國立交通大學
電機與控制工程學系
碩士論文
結合影像及語音
之雙模情緒辨識系統
Bimodal Emotion Recognition System
Using Image and Speech Information
研 究 生:許晉懷
結合影像及語音
之雙模情緒辨識系統
Bimodal Emotion Recognition System
Using Facial Image and Speech Information
研 究 生:許晉懷 Student: Jing-Huai Hsu
指導教授:宋開泰 博士 Advisor: Dr. Kai-Tai Song
國 立 交 通 大 學 電 機 與 控 制 工 程 學 系
碩 士 論 文
A Thesis
Submitted to Department of Electrical and Control Engineering College of Electrical and Computer Engineering
National Chiao Tung University in Partial Fulfillment of the Requirements
for the Degree of Master in
Electrical and Control Engineering July 2006
Hsinchu, Taiwan, Republic of China
結合影像及語音之雙模情緒辨識系統
學生:許晉懷 指導教授:宋開泰 博士 國立交通大學電機與控制工程學系摘要
本論文研究結合人臉影像及語音之雙模情緒辨識系統。文中提出一種新的雙模辨識 策略:透過兩種資訊辨識情緒,對辨識的可靠度設定不同的權重,用以決定要該採用何 種資訊。雙模資訊權重的數值,是透過 SVM 理論中測試資料距超平面的距離,以及訓 練資料之標準差,接著再經由訓練資料距超平面的平均距離正規化後決定,此權重係數 即可以判斷分類的可靠度。由於需要辨識多種情緒,在辨識某兩類的情緒時,採用權重 較高資訊的辨識結果,可以修正其它資訊錯誤的分類,而原本被修正的資訊在下一步辨 識另兩類情緒時,可能其權重較高,亦可修正另一方的資訊辨識結果,如此可以提高原 有單一資訊辨識的準確性。在以人臉表情辨識方面,基於以 SVM 兩兩表情辨識之設計, 本論文提出針對不同表情進行關鍵特徵辨識。整套系統已在實驗室開發的嵌入式數位訊 號處理器(DSP)平台予以實現,擷取特徵後予以分類辨識,完成高興、生氣、普通、傷 心與驚訝五種情緒即時辨識系統,雙模辨識率可達 86.85%,比只用人臉影像辨識高 5.1%。Bimodal Emotion Recognition System Using
Image and Speech Information
Student: Jing-Huai Hsu Advisor: Dr. Kai-Tai Song
Department of Electrical and Control Engineering National Chiao Tung University
ABSTRACT
A bimodal emotion recognition system has designed and realized by combining image and speech information. This thesis proposes a new bimodal recognition strategy by setting different weights to each mode based on their recognition reliability. The weights are determined by the distance between test data and hyperplane and the standard deviation of training data. The weights are normalized by the mean distance between training data and hyperplane, representing the classification reliability of different information. Five emotions are to be recognized, we adopt recognition result with higher weight, which corrects the other information. At the next step, the corrected information may correct wrong classification result of the other mode of information. It can raise the accuracy of single modal information. Further, regarding facial expression recognition, we propose to use key features for the design of facial expressions classification in SVM theorem. The whole procedures have been implemented on an embedded image system. After extracting the features, classification is applied to recognize five emotion expressions: happiness, anger, neutral, sadness, and surprise. The experimental results show that bimodal emotion recognition rate is 86.85%, an increase of 5% compared with using single modal image emotion recognition.
誌謝
謹向我的指導教授宋開泰博士致上感謝之意,感謝他兩年來在專業上的指導,以他 豐富的學識與經驗,配合理論的應用,使得本論文得以順利完成。感謝口試委員胡竹生 教授、楊谷洋教授與范欽雄教授的指導與意見,讓本論文能夠更加嚴謹。 感謝與我共同奮鬥的同學宏宜、忠憲及鎮謙的相互鼓勵及提攜,以及學弟富聖、 濬尉、振暘、俊瑋及志昇在生活上帶來的樂趣,同時感謝學長孟儒、嘉豪、奇謚及崇民 在實作與理論上的指點。 感謝我的朋友們的勉勵與支持,並在研究上相互討論,讓我獲益良多。特別感謝 女友宜珊對我的體諒以及生活上的照顧,並在我最無助及失意的時候給予我意見及鼓 勵。最後,感謝我的父母與家人,由於他們的辛苦栽培,在生活上給予我細心地關懷與 照料,使得我才得以順利完成此論文,在此我願以此論文獻給我最感激的父母親。目錄
中文摘要 ...i 英文摘要 ...ii 誌謝 ...iii 目錄 ...iv 圖例 ...vi 表格 ...viii 第一章 緒論 ...1 1.1 研究動機 ... 1 1.2 相關研究回顧 ... 2 1.3 問題描述 ... 6 1.4 系統架構與章節說明 ... 7 第二章 語音特徵擷取 ...10 2.1 語音信號前置處理 ... 10 2.1.1 語音信號取樣 ... 10 2.1.2 端點偵測(Endpoint Detection)... 10 2.1.3 取音框(Frame) ... 14 2.2 語音特徵參數計算 ... 14 2.2.1 音高(Pitch) ... 14 2.2.2 能量(Energy) ... 16 2.2.3 語音特徵值計算 ... 16 2.3 本章總結 ... 17 第三章 人臉影像特徵擷取 ...18 3.1 人臉偵測 ... 18 3.1.1 膚色搜尋及選取 ... 19 3.1.2 專注式串聯法 ... 21 3.1.3 人臉偵測結果 ... 22 3.2 人臉特徵點擷取 ... 22 3.2.1 眼睛特徵點擷取 ... 233.2.2 眉毛特徵點擷取 ... 27 3.2.3 嘴唇特徵點擷取 ... 29 3.2.4 臉部影像特徵值選取 ... 29 第四章 雙模情緒辨識系統演算法 ...31 4.1 SVM 分類—線性可分割問題 ... 32 4.2 關鍵性特徵辨識人臉表情... 34 4.3 SVM 分類—線性不可分割問題... 40 4.4 結合影像及語音之雙模情緒辨識決策 ... 42 第五章 實驗結果 ...46 5.1 嵌入式影像平台 ... 46 5.2 建立資料庫... 48 5.3 SVM 搭配關鍵性特徵辨識結果 ... 50 5.4 柔性邊界 SVM 用在結合語音及人臉表情的情緒辨識結果 ... 52 5.5 即時情緒辨識結果... 54 第六章 結論與未來展望 ...57 6.1 結論 ... 57 6.2 未來展望 ... 57 參考文獻 ...59
圖例
圖 1-1 臉部的 Action Units[8] ...3 圖 1-2 系統架構圖 ...8 圖 2-1 端點偵測 ...11 圖 2-2 端點偵測之結果 ...12 圖 2-3 自相關函數計算結果 ...14 圖 2-4 音高測試結果 ...16 圖 3-1 人臉偵測系統流程圖 ...17 圖 3-2 膚色分割及投影 ...19 圖 3-3 人臉偵測專注式串聯法 ...20 圖 3-4 正面人臉偵測實驗結果 ...21 圖 3-5 人臉特徵點的選取 ...22 圖 3-6 眼睛特徵點偵測方塊圖 ...22 圖 3-7 眼睛區域定位 ...23 圖 3-8 雙眼 6 個特徵點 ...25 圖 3-9 眉毛特徵點偵測方塊圖 ...26 圖 3-10 眉毛與雙眼 10 個特徵點 ...27 圖 3-11 嘴唇偵測方塊圖 ...28 圖 3-12 嘴唇區域作 IOD、二值化,找出特徵點 ...28 圖 3-13 臉部 12 個特徵值 ...29 圖 4-1 情緒辨識系統架構 ...31 圖 4-2 SVM 示意圖...32 圖 4-3 訓練和測試資料複雜度與辨識誤差的關係... 35 圖 4-4 資料重疊部分變少 ...35 圖 4-5 驚訝與傷心表情的比較 ...36 圖 4-6 傷心與生氣表情的比較 ...36 圖 4-7 普通與高興表情的比較 ...36 圖 4-8 生氣與高興表情的比較 ...37圖 4-9 驚訝與高興表情的比較 ...37 圖 4-10 驚訝與普通表情的比較 ...38 圖 4-11 驚訝與生氣表情的比較 ...38 圖 4-12 傷心與普通表情的比較 ...39 圖 4-13 傷心與高興表情的比較 ...39 圖 4-14 普通與生氣表情的比較 ...40 圖 4-15 鬆弛變數導入 SVM 示意圖...41 圖 4-16 資料在空間中的不同分佈狀況說明 ...43 圖 4-17 SVM 辨識流程...43 圖 4-18 Bimodal 情緒辨識流程 ...44 圖 5-1 DSP 影像平台系統架構圖...47 圖 5-2 DSK6416 Codec 介面[35] ...48 圖 5-3 資料庫建立情形 ...49 圖 5-4 資料庫影像範例 ...49 圖 5-5 全部特徵與關鍵性特徵兩兩分類的辨識率結果比較 ...51 圖 5-6 全部特徵與關鍵性特徵的辨識率結果比較 ...51 圖 5-7 SVM 辨識流程...52 圖 5-8 柔性邊界 SVM 情緒辨識率...53 圖 5-9 五位受測者 ...55 圖 5-10 五種情緒即時測試情形 ...55
表格
表 2-1 語音的 12 個特徵 ...16 表 3-1 人臉的 12 個特徵值 ...30 表 4-1 第一組關鍵性特徵 ...35 表 4-2 第二組關鍵性特徵 ...37 表 4-3 第三組關鍵性特徵 ...38 表 4-4 第四組關鍵性特徵 ...39 表 4-5 第五組關鍵性特徵 ...40 表 5-1 全部特徵與關鍵性特徵辨識率結果 ...51 表 5-2 柔性邊界 SVM 用在語音特徵分類結果...53 表 5-3 柔性邊界 SVM 用在人臉影像特徵分類結果...53 表 5-4 兩種方法的辨識率比較 ...54 表 5-5 即時表情辨識的結果 ...55 表 5-6 即時雙模情緒辨識的結果 ...55第一章 緒論
1.1 研究動機
近年來在人口老化的衝擊下,藉由機器人提供的照護與娛樂功能逐漸受到重 視[1]。其中娛樂型機器人在這幾年最為人所津津樂道,像是 Sony 開發的 AIBO 寵物型機器狗,具有獨立行動能力,能夠識別主人的名字,聲音和面貌,還可以 自動充電;和人們的互動中,它可以表現情緒,藉此達到娛樂甚至安慰人們的功 能[2]。Sony 另外開發的 Qrio 雙足機器人[3],其設計的用意是在提供家庭娛樂, 它會辨別主人的樣子與聲音,並且可以與人簡單對話。日本產業技術綜合研究所 (AIST)開發的海豹型機器人”Paro”[4],它的臉部表情豐富,還能做出伸展身體、 眨眼睛等小動作,更重要的是,它對人動作的反應相當靈敏,其主要的特點是可 以對人的觸摸產生交互的反應,達到安慰人的目的,進而具有治療的作用[4-5]。 由上述的例子看來,寵物機器人朝向智慧化與多元化邁進,將與人們共同生活, 提供家庭娛樂且撫慰人心。 機器人要能感測從外界得來的資訊,以便可以和人有所互動且自主決定其行 為,其中最重要的功能之一是需要一個可靠的人機介面,能從外界擷取重要的訊 息,讓機器人知道下一步的行為為何。而要使得機器人和人之間能夠更自然地互 動,可以藉由情緒辨識讓機器人偵測到人類的情緒狀態,並依照人類不同反應有 其對應的自主式行為,使得機器人不再是冷冰冰的機器,讓人可以對機器人能夠 感興趣,經由進一步的互動後進而產生感情。而寵物機器人可以辨識人類的情緒 反應,就像是一個真實的寵物,陪在人類身旁能夠提供娛樂甚至是撫慰人心的功 能,使得人與機器人間的互動更為自然。 人類表達情緒包含多種形式,包含肢體語言、聲音和臉部表情,而主要還是 透過臉部表情和聲音的語調表達情緒,因此本論文將設計一個結合人臉影像和語 音辨識人類情緒的方法,提高單一人臉影像或單一語音的辨識率,使得人與機器 人之間的溝通更為有效且更加自然。1.2 相關研究回顧
目前已有相當多數的語音與人臉影像情緒辨識研究,幾乎都是單一模組辨 識,單純只靠語音特徵[17-22]或臉部影像特徵[7-16]來辨識情緒,雙模辨識方法, 即結合語音及人臉影像的特徵,在辨識架構上能達到資訊互補,提高辨識率的效 果,然而這方面的研究報告並不多[23-29]。。
在單一模式人臉影像表情辨識上,最早是 Ekman 和 Friesen[6]發展了 Facial Action Coding System(FACS),根據人在表達不同表情時會牽動不同臉部肌肉的 原理,定義出 44 種不同的 Action Unit (AU),如圖 1-1 所示,圖(a)是上半臉 Action Unit 和一些 Action Unit 的組合,圖(b)是下半臉的 Action Unit 種類,根據特定 Action Unit 的組合,人臉的表情即可以被描述出來。多數的研究都採用 FACS 的 理論來判斷臉部表情, Song et al. [7]提出了一個基於小波轉換的 Multi-resolution 性質設計,可以將雜訊從二值化的影像中移除,二值化後的邊緣影像可以用來辨 識多個不同的 Action Unit。Cohn et al. [8] and Seyedarabi et al. [9] 使用 Optical flow 追蹤多個特徵點的移動,這些特徵點是在影像序列中的第一張影像中手動 設置。在第一張與最後一張影像中,每個特徵點位移組合而成的特徵向量則用來 辨識不同的 Action Unit 及臉部表情。
Tian et al. [10]和 Donato et al. [11]也都採用 FACS 理論,不同的是在臉部特 徵擷取與辨識分類方法的選擇上。Tian et al.將臉部的特徵分為常在與瞬間特徵, 常在特徵是眼睛與嘴巴的變化,瞬間特徵是眉間、雙頰與嘴角上端的皺紋變化, 先手動設置好這些特徵點的初始位置,再追蹤將這些點的變化,用類神經網路作 辨識。雖然辨識的效果很好,但以 FACS 為基礎的完全自動表情辨識方法尚未被 提出。
在特徵擷取上,人臉的特徵大致上可以分為 Appearance based 與 Feature based 兩種方法,Appearance based 的特徵擷取,常見的為用主成份分析法 (Principal Component Analysis, PCA)、獨立成份分析法(Independent Component Analysis, ICA)對整個臉部影像作特徵擷取。Wilhelm et al.[12]就用 Appearance
(a)上半臉的 Action Units 和 Action Unit 的組合
(b)下半臉的 Action Units 圖 1-1 臉部的 Action Units[10]
based 方法作特徵擷取,採用 PCA 與 ICA 擷取特徵,減少輸入分類器的資料量, 並計算投影向量的合適性,選取具有分辨性的特徵向量作分類,以提高辨識的準 確性,再分別採用 Nearest Neighbor(NN)分類器、Multi Layer Perceptron(MLP)和 Radial Basis Function(RBF)網路當作表情的分類器。使用 Appearance based 的方
法作人臉資料庫的建立與表情辨識,可以減少載眼鏡與人臉鬍鬚的影響。 Buciu[13]等人採用 ICA 以及 Gabor 小波轉換擷取人臉影像的特徵,實驗結果證 實採用 Gabor 小波轉換結合 support vector machine (SVM)可以大幅提高辨識的效 果。
利用 Appearance based 方法辨識表情,可能會因為臉部在影像中位置的改變 而影響到辨識的結果,於是 Y. Zhang[14]等人利用整張臉部影像,計算 PCA、ICA 與 Linear Discriminant Analysis(LDA)得到臉部的表情特徵,接著算出臉部資料庫 與測影像的差異性權重矩陣,在變化較大的地方給予較小的權重;反之給予較大 的權重,用 Nearest Neighbor 辨識 4 種表情,實驗結果證實 LDA 結合權重矩陣 效果比單純用 eigenface 辨識好。除了 Appearance based 作特徵擷取的方法,還 有 Feature based[15-16]方法,擷取人臉特徵點,像是眼睛、眉毛和嘴巴各設置一 些特徵點,再將各特徵點之間的距離或是特徵點在影像中的位移當作分辨不同表 情的特徵。 在語音的情緒辨識上,主要是選擇帶有情緒資訊的特徵,像是聲韻(Prosody) 特性和能量相關的特徵,最常見的特徵是音高(Pitch)和能量(Energy)[17-20],少 數文獻採用共振峰(Formant)[19],主要是根據這些特徵的統計值當作不同情緒分 類的特徵,像是平均值、標準差、最大值、最小值、梯度變化等。Schuller et al.[20] 即根據線性鑑別分析對不同統計方式的特徵進行排名,用音高相關的特徵明顯比 能量相關的特徵更能分辨出不同的情緒種類。採用梅爾倒頻譜係數(Mel-scale Frequency Cepstral Coefficients, MFCC ) 或 線 性 預 估 參 數 (Linear predictor coefficient, LPC)[21-22]也都可以找到關於情緒的訊息,透過分類方法可以辨識出 語音中帶有的情緒,辨識方法上包括類神網路[20]、隱藏式馬可夫模型(Hidden Markov Model, HMM)[17][18][22] 、 高 斯 混 合 模 型 (Gaussian Mixture Model, GMM)[20-21]、線性鑑別分析[22]等。
結合語音與臉部影像的情緒辨識,其架構和單模組的語音或臉部影像辨識相 同,首先經過特徵擷取,接下來為特徵的分析與分類,最後為情緒的決定,只是
在特徵的擷取上需要語音和人臉影像的輸入,以及在情緒的決策上較單一模式複 雜。 De Silva et al.[23]分別利用兩種語言測試在表達情緒時,若是影像與語音兩 種資訊辨識出的結果不同時,觀察是臉部影像還是語音具有支配性(Dominant)的 地位,實驗結果發現傷心和害怕兩種情緒是聽覺支配(Auditory dominant),表示 當語音辨識情緒為傷心或害怕時,而臉部影像卻辨識為其他不同的情緒時,則主 要採信語音的辨識結果。而其他情緒可能是影像支配(Visually dominant)或是沒有 固定的支配地位,因此可以運用這些要素給予臉部影像和語音在不同表情上有著 不同的權重值,設計一個給各個表情及模式的權重矩陣,屬於 Rule-based 的分類 方法。
Chen et al.[24]也是承接著 De Silva et al.的 Rule-based 方法繼續研究,他們透 過語音與人臉影像之間的互補特性作辨識,例如音高最大值座落在某一範圍內, 可能會是某兩種情緒,再透過人臉影像資料對這兩種表情作辨識。但可能是文 化、語言或是個人問題,這一套結合方法並不適用於每一個人。 後來 De Silva[25]發現在負面情緒上,像是生氣、害怕與傷心的臉部表情很 接近,辨識分類的效果不可靠,於是即根據上一篇的實驗結果,將負面情緒:生 氣、憎惡、害怕與傷心設為聽覺支配,高興和驚訝設為影像支配,結合語音與臉 部影像作辨識。語音部分用 Hidden Markov Model(HMM)辨識語音訊號的特徵, 臉部影像用類神經網路辨識臉部特徵點的位移量,在辨識結果決策上,首先若語 音辨識為負面情緒中的一種,但影像辨識結果不同,即完全採用語音部分的結 果;反之,影像辨識為正面情緒,而語音辨識結果不同,則完全採用影像部分結 果,如此大幅提高負面情緒的辨識可靠度,也提高了所有表情的辨識率。 Go et al.[26]採用類神經網路,直接將分別輸入的語音特徵與人臉影像特徵 結合辨識,得到一個辨識的輸出結果。不同的是語音的特徵擷取上,先將語音信 號用小波轉換分成不同頻段,針對不同頻段擷取 MFCC、能量和過零率的特徵;
單一模組和雙模組的差異,因此未能知道雙模組辨識是否有其必要性,可以提升 辨識率。
Song et al.[27]提出用 Tripled HMM (THMM)辨識結合語音及影像的情緒,語 音特徵採用音高和能量的相關特徵,影像特徵則是臉部特徵點的位移特徵, THMM 將語音及影像分開平行處理,最後再根據特徵的信號雜訊比(SNR)設定權 重,計算辨識的結果。用 THMM 的優點是語音及影像在辨識的狀態過程中允許 非同步輸入,仍保持信號間的相關性,且兩種不同的特徵訊號都用同一套辨識系 統,減少辨識系統的複雜度。
Wang et al.[28]將語音與臉部影像的特徵串接起來,語音特徵採用 Pitch 和 MFCC 的相關特徵,臉部影像採用 Gabor 小波轉換係數,根據歐幾里德距離,選 出顯著的特徵,對每一種表情採用一對多(One-against-all;OAA)的 LDA 辨識, 算出每一種表情的機率值。不同的是在辨識的決定上,設定了幾個大規則,第一: 若是只有一類表情的機率大於 50%,則結果為此類表情,第二:若是沒有任一表 情超過 50%,則會再採用一個全部表情分類器;若是有 2 種以上的表情機率都大 於 50%,則會針對這幾種表情再作分類,找出機率最大的表情。 吳鑑峰[29]在語音特徵上採用音高、共振峰、能量和過零率,並計算這四種 特徵的趨勢與統計特徵,影像特徵是用臉部特徵點之間的距離當作特徵,用主成 份分析法選出具代表性的特徵,而語音與臉部影像兩類特徵分別用 Continuous Density Support Vector Machine(CDSVM)作辨識,根據測試資料與訓練資料距超 平面的距離以及訓練資料的正確率,計算測試資料為各種情緒的機率。最後再計 算語音與臉部影像分類後的機率值的幾和平均,得到總情緒機率值,辨識效果比 單一模組的語音和人臉影像要好。
1.3 問題描述
功能成為在應用上的發展目標。而要使得機器人和人之間能夠互動地更加自然, 希望讓機器人可以自然地偵測到人類的情緒狀態,因此它可以有對應的自主性行 為娛樂人類甚至達到安撫的功能。目前情緒辨識的研究多是採用單一模式,即只 靠語音或臉部影像來辨識不同的情緒,而這兩類資料都可以辨識不同情緒,表示 這兩類資訊具有一定的相關性,在辨識不同情緒應該會有互補的作用。 所以本論文的目標為建構一個雙模式情緒辨識系統,結合這兩類不同的資訊 作情緒辨識,提出辨識策略以提高辨識準確性。我們採用 SVM 演算法辨識不同 情緒,SVM 可以根據訓練資料將兩種不同情緒用訓練出的 hyperplane 分割開來, 再利用資料在空間中距 hyperplane 距離和分佈狀態這兩種訊息,提供我們該類資 料分類的可靠度,如此在人臉影像和語音情緒分類不同時,即可知該信任語音或 是人臉影像的辨識結果,以修正某一組錯誤的辨識結果。 在人臉影像特徵的擷取上,以 Appearance-based 作特徵擷取的方法,其計算 量相當大,且人臉表情的影像必須要一致,但在實際應用中,人臉的位置與大小 常常是未知的,所以本論文採用 Feature-based 方法擷取人臉特徵點,將各特徵 點之間的位移向量,當作分辨不同表情的特徵,即使人臉在影像中的大小不一, 擷取出的人臉特徵依然可以有效代表不同情緒。
1.4 系統架構與章節說明
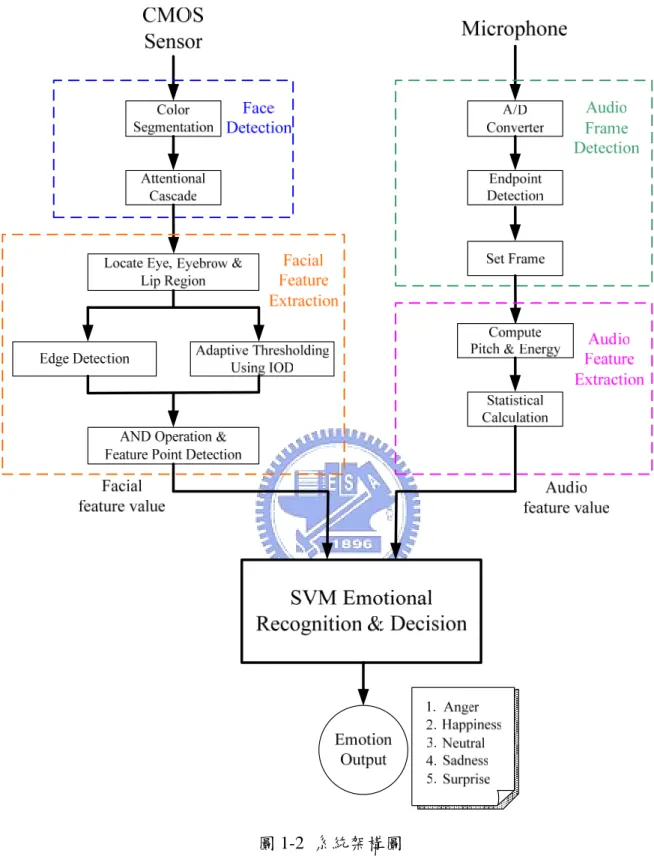
系統架構圖如圖 1-2 所示,主要分為三個部分,分別是語音的特徵擷取、人 臉影像的特徵擷取以及將兩類特徵結合的辨識決策部分。結合語音與人臉影像情 緒辨識中特徵擷取的方法,目的在擷取出每種表情具有代表性和獨特性的語音和 人臉影像特徵,使得在辨識階段能夠區分出彼此間的差別,辨識出正確的情緒。 在語音特徵的擷取上,經由麥克風將情緒語音輸入後,將類比信號取樣轉 為類比信號,由於不是整段信號都是有效的資料,因為這段信號可能包含真正的 語音資料和剩餘的靜音或雜訊部分,所以要先計算出語音資料的起點與終點,圖 1-2 系統架構圖
對這有效的語音信號設置音框(frame)。再以音框為單位,計算每一個音框內具有 情緒資訊的特徵:音高(pitch)與能量(energy),計算出基於音高和能量的統計特 徵。人臉特徵的擷取上,經由膚色和人臉規則資訊作為人臉偵測的依據,找到人 臉位置後,根據瞳孔在正面上半臉影像灰階值強度最低的資訊,找出的瞳孔的確
切位置,再根據瞳距和瞳孔位置定出眼睛和眉毛可能區域,利用影像灰階值強度 和邊緣偵測找出眼睛與眉毛特徵點的位置。而嘴巴的特徵點是利用它在人臉的幾 何位置和影像強度找出,再將各特徵點之間的特徵向量作為分辨不同表情的依 據。 得到這兩類的特徵後,便可進入情緒辨識決策階段,本論文採用 SVM 演算 法,分別得到兩類特徵的辨識結果,若是兩類資料分類結果不同,即根據分類情 形決定該採用何種辨識結果,得到受測者表現的情緒狀態。 本論文共分六章,第一章為介紹相關研究背景及研究動機。第二章介紹語音 的情緒特徵擷取。第三章介紹人臉影像特徵的擷取。第四章介紹雙模式情緒辨識 的演算法和辨識決策,根據SVM理論中資料距hyperplane的距離和在空間中的分 佈狀態做決定。第五章為實驗的方法和結果,包括介紹硬體平台、資料庫的建立、 用SVM的關鍵性特徵的表情辨識,以及用柔性邊界SVM的bimodal情緒辨識配合 設計的辨識決策。第六章為結論與未來展望。
10
第二章 語音特徵擷取
語音特徵擷取目的在於取出每種情緒具有代表性和獨特性的特徵,使得在辨識 階段能夠區分出彼此間的差別,辨識出正確的情緒。首先經由麥克風將情緒語音輸 入後,將類比信號取樣轉為類比信號,由於整段信號可能包含真正的語音資料和剩 餘的靜音或雜訊部分,所以要先由端點偵測計算出語音資料的起點與終點,利用短 時距能量(Short time energy)和越零率(Zero crossing rate)作為判斷的標準。接著對 這有效的語音信號設置音框,以音框為單位,計算每一個音框內具有情緒資訊的特 徵:音高(pitch)與能量(energy),計算出基於音高和能量的統計特徵,作為之後辨識 語音情緒的依據。2.1 語音信號前置處理
語音信號之前置處理是語音信號在作特徵擷取之前,以語音處理之方法將 所需之語音段落擷取出來,便於之後的特徵擷取,其中最主要的步驟是端點偵 測,在此我們參考實驗室顏坤銘學長[30]論文所使用的方法。2.1.1 語音信號取樣
語音信號藉由麥克風介面輸入,為準位在數十毫伏特之類比電壓信號,之 後再經過放大。取得之語音類比訊號在經過取樣(Sampling)的動作之後,可以得 到離散化的數位語音訊號。由於一般人說話的頻譜多集中在 4KHz 以下,根據 取樣定理,取樣頻率(Sampling frequency)的設定至少要設定在信號頻寬的兩倍 以上,才不會造成失真的現象,所以設定為 8KHz。2.1.2 端點偵測(Endpoint Detection)
得到一段原始的數位語音訊號後,並不是整段訊號都是有效的資料,因為 這段訊號可能包括真正的語音資料和剩餘的靜音或雜訊部分,所以需要先知道 語音資料的起點和終點位於何處,一方面可以找出有效的語音段,另一方面可以減少不必要的資料。因此,端點偵測可以說是最重要的前置過程,若是不正 確地抓取語音段的端點,將會影響後續計算的特徵值,影響辨識的成功率。端 點偵測主要依靠的是短時距能量(Short time energy)及越零率(Zero crossing rate) 兩項資訊作為偵測的依據標準,兩者的說明如下所述。 短時距能量是把每一小段(Frame)的語音信號切出來。每一Frame之短時距 能量E(k)可以定義為第 k 個音框內之 N 個信號樣本x(n)之能量取平方後相加, 如式(2-1)所示。但是取平方後之數值有可能會太大。因此採用另一種定義,即 能量值先取絕對值後再作相加,如式(2-2)所示。若E(k)超過了預先設定好之能 量的臨界值,則認為此音框是真正含有語音資訊的,因為通常真正有說話的段 落,其能量值會明顯高於其他靜音部份。
∑
− = + = 1 0 2 ) ( ) ( N m m n x k E (2-1)∑
− = + = 1 0 ) ( ) ( N m m n x k E (2-2) 越零率Z(k)的定義是信號通過原點的次數,即相鄰信號樣本之振幅值若有 一正一負的變化則越零率累計值加一,如式(2-3)、(2-4)所示,Z(k)是第 k 個音 框之越零率值,S(n)是音框中之取樣點,音框長度為N 。而從越零率的次數大 致上可以反映出信號之頻率範圍。越零率的偵測是為了輔助短時距能量偵測在 判斷上的不足之處,例如說話時之摩擦音、鼻音、子音,因為在能量的表現上 並不足夠超越短時距能量偵測的臨界值,所以會產生端點誤判之情形。∑
− = − + − + = 1 0 )) 1 ( sgn( )) ( sgn( 2 1 ) ( N m m n S m n S k Z (2-3)[
]
⎭ ⎬ ⎫ ⎩ ⎨ ⎧ < − ≥ = 0 ) ( 1 0 ) ( 1 ) ( sgn n S if n S if n S (2-4) 基本上,越零率偵測可以分出有聲語音跟無聲語音的分別,無聲語音如摩 擦音能量多集中在3KHz以上,所以越零率值會比較高,反之,若越零率值低則 為有聲語音,因此,如圖2-1所示,先利用短時距能量偵測大致判斷出有聲語音 的開始與結尾處,再利用越零率偵測找出語音段之真正的開頭跟結尾處。找尋12
圖2-1 端點偵測
之規則列出如下:
(1)若E(k)小於短時距能量之低臨界值(Energy low threshold),則認定是非語音段 的部份。
(2)若E(k)大於短時距能量之低臨界值(Energy low threshold),且也高於短時距能 量高臨界值(Energy high threshold),則認定為語音段之起點。
(3)若E(k)小於短時距能量之高臨界值(Energy high threshold),則必須要再加上 越零率臨界值(Zero crossing rate threshold)來加以輔助,Z(k)大於越零率臨界 值(Zero crossing rate threshold)可以判定為語音段之起點。
(4)要找尋語音段終點時,則是從抓取信號之尾端開始作反向搜尋,若E(k')大於 短時距能量之低臨界值(Energy low threshold),則認定是語音段之終點部份。
利 用 這 兩 個 參 數 來 偵 測 端 點 , 首 先 必 須 要 分 別 找 出 兩 者 適 合 的 臨 界 值 time(s) time(s) Zero Crossing rate Energy Low threshold High threshold Threshold
Start point End point
(Threshold),臨界值的取得必須經由反覆測試才能得到各個系統之適用值,且臨 界值會受到系統採用之麥克風種類等等因素影響而有所不同,因此,不同的系 統所使用的臨界值並不一定相同。為使臨界值能夠隨著擷取到的語音信號作出 調整,本論文之做法是利用擷取到的最初一段語音信號的偵測值作為判斷的基 準。利用這一小段時間之能量作為短時距能量偵測的低臨界值,而高臨界值則 是低臨界值乘上一個倍數,如式(2-5)、式(2-6) ,N1為取基準所設定之Frame大 小。越零率臨界值的決定則是同樣的方式,以得到之基準為越零率臨界值如式 (2-7)、式(2-8)。至於乘上之倍數(Factor)是經由反覆測試而決定。依據上述步驟, 圖2-2為實際端點偵測後之結果,圖中兩側之粗黑線為鎖定之語音段起點及終 點,如圖中所示一般可以正確地標註出語音段之兩側端點。
∑
− = + = 1 0 1 ) ( N m m n S threshold low Energy (2-5) 圖2-2 端點偵測之結果14 factor threshold low Energy threshold high Energy = × (2-6)
∑
− = − + − + = 1 0 1 )) 1 ( sgn( )) ( sgn( 2 1 threshold rate crossing Zero N m m n S m n S (2-7)[
]
⎭ ⎬ ⎫ ⎩ ⎨ ⎧ < − ≥ = 0 ) ( 1 0 ) ( 1 ) ( sgn n S if n S if n S (2-8)2.1.3 取音框(Frame)
在得到端點資訊之後,由於語音是一時變(Time variant)的訊號,藉由觀察 可以知道語音訊號在短時間內的變化是很緩慢的。所以一般都會採取語音信號 是在短時間內維持穩定的假設,即以固定的取樣點數來形成一個音框(Frame), 作為後續處理、分析的基本單位。為了使得一個個音框之間的移動不至於產生 太突兀的變化,並保持連貫性,所以音框之間會有部分的重疊,一般會採用二 分之一或是三分之一的重疊。2.2 語音特徵參數計算
語音信號經過前置處理後,將語音段落擷出來並設成一段一段的音框,接 著就進行特徵擷取,計算每段音框的音高(Pitch)和能量(Energy),統計能表示每 段音框的特徵值,得到一組可以在辨識時區分出不同情緒的特徵值。2.2.1 音高(Pitch)
音高(Pitch)代表者聲音頻率的高低,而此頻率指的是聲腔在發出聲音時的共 鳴率,也稱為「基本頻率」(Fundamental Frequency)。對整段語音訊號進行抓取音 高的過程,通常稱為「音高追蹤」(Pitch Tracking)[31],音高追蹤的基本流程如下: 首先將整段聲音訊號切成多個音框,相鄰音框之間可以重疊,接著算出每個音框所 對應的音高,排除不穩定的音高值,得到整段的音高值。 音高追蹤的方法可以分為時域和頻域兩大類,由於時域方法中的自相關函數 (Autocorrelation function; ACF)運算量較少,在實作上也比較容易,所以本論文採用自相關函數計算整段音訊的音高值。自相關函數是把一段序列的訊號與訊號本身的 延遲作運算,我們先將整段音訊切成一段一段的音框x[n],一段音框總共有 N 個信 號,再針對每段音框計算自相關係數,公式如式(2-9)所示,x(n)是一段音框信號, k 是信號位移的大小,音框內信號乘上它的移位信號再全部相加,算出每次移位後 的自相關係數R(k)。
∑
−− = + ⋅ = N k k k n x n x k R 1 0 ) ( ) ( ) ( (2-9) 音高追蹤用自相關函數運算的意義在於找尋當訊號移位多少時,訊號會最接近 於原本的訊號,也就是尋找訊號的週期,如圖所示自相關函數的計算結果,可由圖 2-3 中看出,除了原點之外,最高點出現在第 41 點,因此這個音框的音高為 fs/(49-1)= 8000/52= 153.85Hz。 圖 2-3 自相關函數計算結果16
2.2.2 能量(Energy)
這邊指的能量就是端點偵測時的短時距能量,先把每一個音框切割出來, 對一個音框內的能量取絕對值後再作相加,如式(2-10)所示,算出整段有效語音 內每一音框的能量E(k),k 為音框之編號,音框內信號x(n)共有 N 個信號樣本。∑
− = + = 1 0 ) ( ) ( N m m n x k E (2-10)2.2.3 語音特徵值計算
計算出每個音框的音高和能量,由於一段語音訊號內有許多音框,所以根 據每個音框的音高和能量,統計出整段語音信號的特徵值,如表 2-1 所示,包 括平均值、標準差、最大值、最小值以及梯度變化[18-20]。可以藉這些特徵看 出音高和能量的分佈與變化情況,從梯度變化的特徵值可以看出特徵變化的趨 勢。像是類似語調上揚的語音,如驚訝時發出的驚嘆聲,其音高變化為逐漸往 上提高,如圖 2-4(a)所示;反之,當生氣時發出的情緒聲,為語調下挫的語音, 表 2-1 語音的 12 個特徵 1. Pave: Average pitch2. Pstd: Standard deviation of pitch 3. Pmax: Maximum pitch
4. Pmin: Minimum pitch
5. PDave: Average of pitch derivation
6. PDstd: Standard deviation of pitch derivation Pitch
7. PDmax: Maximum of pitch derivation 8. Eave: Average energy
9. Estd: Standard deviation of energy 10. Emax: Maximum energy
11. EDave: Average of energy derivation Energy
其音高變化為漸漸變低,如圖 2-4(b)所示;而當沒有情緒時,說話呈現語調平穩, 音高大致上是一致的,如圖 2-4(c)所示。而從其他的統計特徵,像是平均值、標 準差、最大值與最小值,可以知道音高和能量的分佈情形,像是聲量小時,能 量相關的特徵值較小;反之,能量相關特徵值相對上會比較大。
2.3 本章總結
本章節主要完成的部分為語音特徵擷取,先是利用越零率和短時距能量作 端點偵測,找出有效語音的起點和終點,對這段有效語音設置音框,以音框為 單位計算音高和能量,對整段有效語音內每個音框的音高和能量統計出 12 個語 音特徵,以供後續辨識決策階段辨識不同的情緒。 (a) (b) (c) 圖 2-4 音高測試結果 Frame Frame Frame Pit ch (Hz) Pitch ( H z) Pitch ( H z)18
第三章 人臉影像特徵擷取
人臉影像特徵擷取,目的在於取出每種表情具有代表性和獨特性的特徵,使得 在辨識階段能夠區分出彼此間的差別,辨識出正確的情緒。人臉特徵的擷取上,經 由影像的前置處理,藉由膚色和人臉規則資訊作為人臉偵測的依據,找到人臉位置。 接著根據瞳孔在正面上半臉影像灰階值強度最低的資訊,找出的瞳孔的確切位置, 再根據瞳距和瞳孔位置定出眼睛和眉毛可能區域,利用影像灰階值強度和邊緣偵測 找出眼睛與眉毛特徵點的位置。而嘴巴的特徵點是利用位於人臉的幾何位置和影像 強度找出,找出所有特徵點之後,定出 12 個特徵點之間的距離當作影像特徵,作為 分辨不同表情的依據。3.1 人臉偵測
當 CMOS sensor 取得臉部影像後,首先需要人臉偵測,找出人臉的位置以便作 接下來的人臉特徵點擷取,在此我們採用實驗室周崇民學長論文[32]設計的人臉偵 測方法,流程如圖 3-1 所示。為了使系統能夠快速的搜尋到人臉位置,在進行人臉 偵測之前,我們會先將輸入的 320×240 彩色影像縮小為 160×120 彩色影像,以減少 人臉偵測所需的時間。在人臉偵測的過程當中,系統會先將輸入的影像進行膚色的 CMOS sensor NO Candidate is face or not YES Color Segmentation Morphology Closing Color Region Mapping Attentional Cascade Face feature extraction 圖 3-1 人臉偵測系統流程圖色彩分割,並且透過形態學的閉合運算(Closing)填滿膚色區域內空洞及不連續之 處。接著我們透過膚色區域投影將屬於膚色的區域框選出來,並且利用投影的長寬 比先排除可能不屬於人臉的區域,再將可能屬於人臉的區域交由專注式串聯法 (Attentional Cascade)[33]來判別此區域是否為正面的人臉。以下各章節將對圖 3-1 的各元件分別加以說明。
3.1.1 膚色搜尋及選取
色彩分割就是找出膚色收斂的範圍並且設定膚色之色彩分佈上下閥值,若設定 的範圍太大,則會將不屬於膚色的背景判定為膚色像素。因為膚色為人臉偵測的第 一個步驟,必須先找到膚色分佈才可以進行色彩分割,所以我們根據在不同的環境 及光源的膚色色彩分佈的情況,調整其膚色分佈閥值。圖 3-2(a)為膚色分割測試圖, 圖 3-2(b)將膚色分割出來。接下來透過形態學的閉合運算(Closing)填滿膚色區域 內空洞及不連續之處,如圖 3-2(c)所示。 接著我們希望從這些二值化的影像中找出可能為人臉的區域,以縮小搜尋的範 圍,即利用先前所求得的色彩分割後的資訊Iskin進行可能人臉區域的判別。我們利 用色彩分割後的資訊作水平軸與垂直軸上的投影以找出符合要求的區域。前面我們 已求得的特定色彩資訊Iskin為一 M×N 的矩陣,其中 M 為影像高,N 為影像寬, 1 ) , ( Iskin x y = 表示影像中(x,y)座標上的像素屬於膚色的色彩分佈,反之,則為非膚色。我們將Iskin在 Y 軸上進行投影求得Iskin在 Y 軸上的投影量 H(y)
∑
= = M x skin x y I y H 0 ) , ( ) ( (3-1) 從 H(y)中根據設定最小的人臉長,選出 K 個 Y 方向的區間,接著我們再對這 K 個 Y 區間內的膚色資訊利用式(3-2)各別進行 X 軸上的投影,其投影量各別為 Wi(x), i 為 1 到 K,YS 為起始投影 Y 值,YE 為最終投影 Y 值。∑
= = i i YE YS y skin i x I x y W( ) ( , ),i=1~K (3-2) 從 Wi (x)根據設定的最小的人臉寬進行分割,分割出數個可能為人臉的區間,如圖20 (a)膚色分割測試圖 (b)膚色分割結果 (c)閉合運算 (d)第一次投影 (e)第二次投影 圖 3-2 膚色分割及投影 3-2(d)所示,經由第一次的投影,框選出 A1 及 A2 兩個區域,然後再對這兩個區域 進行第二次的投影,如圖 3-2(e)所示,用意在於移除不是膚色的區域。
A1
A2
A1
A2
3.1.2 專注式串聯法
透過上一節將屬於膚色的區域框選出來,並且利用投影的長寬比先排除可 能不屬於人臉的區域,再將可能屬於人臉的區域交由專注式串聯法(Attentional Cascade)來判別此區域是否為正面的人臉。專注式串聯法可解決過多的運算量浪費 在判斷非人臉影像視窗的問題。在此人臉偵測器主要是使用數個簡單的臉部特徵, 稱 為 簡 易 分 類 器 ( Simple Classifier ), 串 聯 成 為 一 個 複 雜 分 類 器 ( Complex Classifier)。愈前面的分類器規則愈容易,所需運算量也愈少,但是具有快速判斷影 像視窗為人臉或者是背景之效果;愈後面特徵則是愈複雜人臉規則,所以運算量也 隨之提高,不過當層數愈多時,人臉偵測的準確性也會提高。以圖 3-3 來說明,在 判斷的過程中以 T 來表示通過某一層特徵的檢測,若為 F 則表示偵測失敗,也就是 此影像視窗不是屬於人臉。 透過色彩投影及臉部長寬比初步的篩選之後,我們將可能為人臉區域送入串聯 法判斷此區域是否為正面的人臉。我們用以下幾點規則做為判斷條件: 1) 人臉投影之長寬比為 1 到 2 倍。 2) 人臉上半部兩眼區域與兩眉之間之灰階值總和會小於下半部灰階值的總和。 3) 眼睛區域的灰階值總和會小於眉毛中間灰階值的總和。 4) 在兩側臉頰相鄰的上下區域其灰階值總和會小於某閥值。 利用串聯的方法來判斷輸入的影像視窗是否為正面的人臉,因為結合了膚色的 條件,所以在人臉偵測時不必進行全域的掃描,如此可以減少運算量以達到即時偵 測人臉的效果。
1
2
3
Sub-window sReject Sub-w indow s
T T T F F F
n
T T F Face 圖 3-3 人臉偵測專注式串聯法22
3.1.3 人臉偵測結果
圖 3-4 為正面人臉偵測之結果。圖 3-4(a)為原始之測試影像,利用色彩分割將 屬於膚色的範圍分割出來且作閉合運算,圖 3-4 (b)即為運算之後的結果。圖 3-4 (c) 為利用膚色投影之後所框選之區域,圖 3-4 (d)為加入人臉特徵判斷之後得到的結 果,黑色框框表示找到的人臉位置。3.2 人臉特徵點擷取
經過人臉偵測後,可以找出人臉的位置和大小,若是將整個人臉影像當作表情 辨識特徵作判斷,有過多冗餘的資料,計算量會過大;另外,我們也不能確定人臉 (a) 原始測試像影 (b) 膚色分割 (c) 膚色投影 (d) 加入特徵判斷之處理結果 圖 3-4 正面人臉偵測實驗結果在影像中的大小,所以必須找出幾個足以代表人臉表情的特徵點,利用這些特徵點 位置的變化當作特徵,除去不必要的資訊,減少運算量。 圖 3-5 為人臉特徵點的選取[34],利用人眼及眉毛會在上半臉出現,嘴巴會在 下半臉出現,找尋各特徵點的位置,共有 14 個特徵點,左右眼睛各 3 個,左右眉毛 各 2 個,嘴巴有 4 個特徵點,找到這些特徵點的位置後,利用它們之間的距離當作 特徵,辨識臉部表情。
3.2.1 眼睛特徵點擷取
眼睛特徵點擷取方法如圖 3-6 所示,經由人臉偵測找到人臉後,首先要找出 瞳孔的確切位置,由於瞳孔和上半臉附近區域比較起來,會有較黑的顏色,灰階值 是最低的部分,因此針對上半臉區域眼睛所在的可能區域,我們是設定在臉部寬 8 1 到 8 7,長為由上 12 1 到 12 6 的區域內,如圖 3-7(a)所示,計算出灰階值分佈的直方圖 圖 3-5 人臉特徵點的選取 a b d c g h i k l j e f m n24 圖 3-6 眼睛特徵點偵測方塊圖 (a) 人眼可能位置 (b) IOD 動態閥值二值化 (c) 人眼位置投影 (d) 框選出眼睛範圍 圖 3-7 眼睛區域定位 8 1 8 7 12 1 12 6
(histogram),決定臨界值取出最黑的像素。但環境的亮度會有所變動,要取出最黑 的像素點即需要動態地設置臨界值,我們採用 IOD(Integral Optical Density)[35], D 為眼睛區域,Yk(u,v)為以 k 為閥值之眼睛區域 f( vu, )的二值化影像: ⎩ ⎨ ⎧ ≤ > = k v u f if k v u f if v u Yk ) , ( 1 ) , ( 0 ) , ( (3-3) 由直方圖中灰階值最低的部份開始算起,累加到此區域像素個數總和的 3% (IOD=0.03),將此像素的灰階值 k 設為臨界值
∫∫
∫∫
= D D k dudv dudv v u Y IOD ) , ( (3-4) 最後將小於臨界值則將影像灰階值二值化設為 1,否則設為 0,如圖 3-7(b)所示。接 著對二值化後的眼睛區域影像兩端分別作水平投影 H(y)與垂直投影 V(x),M 為眼睛 區域的影像高,N 為眼睛區域的影像二分之一寬∑
= = M x eye x y I y H 0 ) , ( ) ( (3-5)∑
= = N y eye x y I x V 1 ) , ( ) ( (3-6) 分別找出投影量最大值,即為找到瞳孔的確切位置,如圖 3-7(c)所示,並依照 瞳孔距離的大小比例,框選出眼睛和眉毛的範圍,眼睛區域的高度為三分之一瞳距, 寬度為三分之二瞳距,而找到眼睛的區域後,也一道將眉毛的區域框選出來,眉毛 區域的高度為二分之一瞳距,寬度同樣為三分之二瞳距,如圖 3-7 (d)所示。 找到眼睛所在區域後,為了要能穩健地找出眼睛的上下與內側特徵點,先對眼 睛區域內找出亮度最深的部分,用 IOD 動態地設置臨界值 Th1 找出眼睛,如式(3-7) 所示,這裡我們設眼睛區域像素達像素總和的 25%為臨界值,結果如圖 3-8(a)所示。 ⎩ ⎨ ⎧ < = otherwise Th y x I if Ieye , 0 1 ) , ( 1 (3-7)26 另一方面,對眼睛區域作邊緣偵測且用 IOD 作二值化找出眼睛的輪廓,臨界值 設為達像素總和的 50%。邊緣偵測是應用影像中連續像素之間的灰階值達到某種程 度的變化,也就是在某一像素上的梯度變化大於某個閥值,此像素可視為邊緣影像 的一部分。影像的梯度變化是有 x 方向和 y 方向所組成,梯度向量可由式(3-8)表示, 梯度大小可由式(3-9)表示。 ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ = ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ ∂ ∂ ∂ ∂ = ∇ y x G G y y x I x y x I y x I ) , ( ) , ( ) , ( (3-8)
(a) IOD 設閥值二值化 (b) 邊緣偵測與 IOD 設閥值二值化
(c) 圖(a)與圖(b)作 AND 運算 (d) 找出雙眼的上下與內側特徵點
y x G G f = + ∇ (3-9) 梯度的運算元有兩個,分別是水平邊緣檢測運算元G ,和垂直邊緣檢測運算元x G ,y 我們是採用 Sobel 運算元,將原始灰階影像 I 分別和水平與垂直運算元作摺積運算 得到 Ix及 Iy。 x x I G I = * (3-10) y y I G I = * (3-11) ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎣ ⎡− − − = 1 2 1 0 0 0 1 2 1 x G , ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎣ ⎡ − − − = 1 0 1 2 0 2 1 0 1 y G (3-12) 邊緣影像 Iedge為 Ix與 Iy的絕對值之和,再用 IOD 決定的閥值 Th2 濾掉較小的 梯度值,如圖 3-8(b)所示。 ⎩ ⎨ ⎧ + > = otherwise Th y x I y x I if y x Iedge x y , 0 2 | ) , ( | | ) , ( | 1 ) , ( (3-13) 最後再將兩者作 AND 運算,如圖 3-8(c)所示,找出眼睛的確切位置,找出上、下與 內側的特徵點,如圖 3-8(d)所示。 ) , ( & & ) , ( ) , ( _ x y I x y I x y
Ieye contour = eye edge (3-14)
3.2.2 眉毛特徵點擷取
找尋眉毛特徵點的方法大致上和眼睛相同,偵測流程圖如圖 3-9 所示,由於眉 毛會位在眼睛上方的區域,所以先根據前一節所述找到眼睛的可能區域後,接著在 眼睛的上方定出眉毛的可能區域,高度為二分之一瞳距,寬度與眼睛同樣為三分之 二瞳距。接著用 IOD 動態設置臨界值並二值化眉毛區域影像,臨界值設為達像素總 和 30%的灰階值,找出眉毛的大致位置。為了要穩健地找出眉毛位置,同樣與加上28
邊緣偵測作二值化後的影像作 AND 運算,邊緣偵測的臨界值設為像素總和 40%的 灰階值,最後找出雙眉的中心與內側特徵點,過程如圖 3-10 所示。
(a) IOD 設閥值二值化 (b) 邊緣偵測與 IOD 設閥值二值化
(c) 圖(a)與圖(b)作 AND 運算 (d) 找出眉毛的內側與中心特徵點 圖 3-10 眉毛與雙眼 10 個特徵點 Face image Locate eyebrow region Adaptive thresholding using IOD Edge detection AND operation Adaptive thresholding using IOD Feature point detection Locate eye region 圖 3-9 眉毛特徵點偵測方塊圖
3.2.3 嘴唇特徵點擷取
在下半臉的可能區域裡找尋嘴唇特徵點,由於 CMOS sensor 取得的影像在色彩 的表現上不是很鮮豔,造成原本要用色彩資訊找尋嘴唇位置的困難,於是只用影像 灰階值強度找尋嘴唇,偵測方塊圖如圖 3-11 所示。首先根據人臉的比例定出一個區 域,我們是設定在臉部寬 16 3 到 16 13 ,長為由上 10 6 到底部的區域內,如圖 3-12(a)所示。 因嘴唇的灰階值大致比臉頰和下巴暗,故採用 IOD 動態設置臨界值作二值化,臨界 值設為達像素總和 25%的灰階值。接著對這個區域作水平與垂直投影,找出嘴唇的 上下左右的特徵點位置,如圖 3-12(b)(c)所示。 圖3-11 嘴唇偵測流程圖 (a) (b) (c) 圖 3-12 嘴唇區域作 IOD、二值化,找出特徵點3.2.4 臉部影像特徵值選取
經由前兩節所述的方法擷取出人臉特徵點後,需要決定可以表達人臉表情變化 的特徵值,由於表情的變化多是靠著眼睛、眉毛與嘴巴的大小及位置變化,所以在 特徵值的決定上就根據這個原則定出 12 個特徵值,為眉毛到眼睛的距離、眼睛與嘴30 巴大小和眼睛到嘴巴距離,如圖 3-13 所示,描述如表 3-1 所述。但由於人臉與 CMOS sensor 之間距離的不同,會造成影像中人臉大小的不同,影響特徵值的大小,所以 特徵值需要針對距離作正規化(normalized),減少因距離的不同造成的影響。由於雙 眼內眼角的距離是固定不變的,這個不變的距離即當作基準,每個特徵除以這個距 離,得到正規化後的特徵值。 圖 3-13 臉部 12 個特徵值 編號 特徵 描述 1 E1 右眉中心與右眼中心距離 2 E2 右眉內側與雙眼平行線距離 3 E3 左眉內側與雙眼平行線距離 4 E4 左眉中心與左眼中心距離 5 E5 右眼上下距離 6 E6 左眼上下距離 7 E7 雙眉內側距離 8 E8 右嘴角與雙眼平行線距離 9 E9 上嘴角與雙眼平行線距離 10 E10 左嘴角與雙眼平行線距離 11 E11 上下嘴角距離 12 E12 左右嘴角距離 表 3-1 人臉的 12 個特徵 1 2 3 4 7 8 9 11 12 10 5 6
第四章 雙模情緒辨識系統演算法
本章說明雙模式情緒辨識系統設計概念,圖 4-1 為辨識系統架構圖。對 CMOS sensor 取得的影像作人臉偵測後,並接著計算出人臉表情的 12 個特徵值, 同樣地經由麥克風取得帶有情緒的聲音,經由前置處理後,以音框為單位來計算 並統計出語音的 12 個特徵值。這兩類特徵先經由 SVM 分類,計算出每筆特徵 距 hyperplane 的距離,並與資料庫中的訓練資料的距離比較並正規化,比較語音 和人臉影像的權重大小,即選擇權重較大的分類結果,即可決定出較可靠的分類 結果,得到受測者表現的情緒狀態。 圖 4-1 情緒辨識系統架構圖4.1 SVM 分類—線性可分割問題
取得人臉影像和語音資料後,擷取代表這筆資料的特徵,接著就需要作特 徵的比對分類,所以提供特徵分類的方法是一個重要的問題。在分類方法上,我 們採用SVM(Support Vector Machines)[36-37]的分類方法,是一種以統計學習理論 (Statistical Learning Theory)為基礎,而發展出來的機器學習系統,設計概念是用 於處理兩類的分類問題,優點是具有清楚的理論與完整的架構,並且實作分類效 果良好。SVM首先要經由訓練的過程,用訓練的資料算出分開兩類資料的分割 平面(hyperplane),在辨識過程即用這訓練出的hyperplane分類。
在圖 4-2 中,表示在這個空間中有多筆資料xi(i=1~l),經由一個線性函數 定義 hyperplane 的位置,將所有的輸入資料x 區分為兩類,標記為i yi ={+1,−1}, hyperplane 的函數定義為w⋅x+b=0,w為 hyperplane 之法向量(Normal Vector)。 距離 hyperplane 最近的幾筆資料就是所謂的 support vector,代入 hyperplane 的函 數即等於+1 或–1,就是圖中的兩條虛線。在處理可區分為二類的資料時,SVM 會找尋一個具有最大邊界距離的分隔平面,符合下列兩個限制式[37]: 1 + ≥ + ⋅x b w i for yi =+1 (4-1) 1 − ≤ + ⋅x b w i for yi =−1 (4-2) 可將(4-1)與(4-2)二式結合為以下不等式: 圖4-2 SVM示意圖 Hyperplane: Support vector 1 − = + ⋅x b w 1 + = + ⋅x b w 0 = + ⋅x b w
(
w⋅x +b)
−1≥0yi i ∀i (4-3)
Support vector 與 hyperplane 的距離為
w 1 ,因此可以得到不只一個 hyperplane 可將兩類資料分開,為求得具有最大邊界的 hyperplane,邊界距離為 w 2 ,在符 合限制式(4-3)的條件下,因此要求得 2 2 w 的最小值。在線性不等式的限制下求 最佳化問題,根據 Karush-Kuhn-Tucker 條件,把原本最佳化問題轉為其對應的對 偶(dual)問題。它的拉格蘭吉(Lagrange)為
(
)
1] [ 2 1 ) , , ( 1 2 − + ⋅ − ≡∑
= l i i i i y w x b w b w L α α (4-4) 其中拉格蘭吉係數(Lagrange Multipliers)αi,i=1,...,l,且αi ≥0。且要滿足 0 ) , , ( = ∂ ∂ w b w L α , 得到∑
= = l i i i iy x w 1 α (4-5) 0 ) , , ( = ∂ ∂ b b w L α , 得到∑
= = l i i iy 1 0 α (4-6) 將(4-5)(4-6)代入(4-4)式後,得到∑
∑
= = ⋅ − = l j i j i j i j i l i i y y x x b w L 1 , 1 2 1 ) , , ( α α α α (4-7) 原本求L(w,b,α)的最小值問題,其對偶問題變為求最大值,限制式為(4-5)(4-6) 和αi ≥0。 在求對偶問題的最佳解時,每一個拉格蘭吉係數αi都有對應每一筆訓練資 料;如果αi >0表示該資料是此問題的支持向量,會落在分隔平面的邊界上,將 i α 代 入 (4-5) 式 可 求 得 w 。 為 了 求 得 b , 可 以 利 用 Fletcher 提 出 的 Karush-Kuhn-Tucker complementarity conditions:(
)
(
yi w⋅xi +b −1)
=0 i α ∀i (4-8) 最後得到一個可以處理分類問題的函數:( )
(
)
⎟ ⎠ ⎞ ⎜ ⎝ ⎛ ⋅ ⋅ + =∑
= b x x y x f l i i i i 1 sgn α (4-9) 當 f( )
x >0時,表示該資料與標註為”+1”的資料屬於同一類;反之則屬於另一類。4.2 關鍵性特徵辨識人臉表情
我們是採用 SVM 當分類器,是由多個兩個不同的表情的分類器作分類, 可以看出每組比對的兩種表情在選定的特徵上的不同變化程度。另外,由於 SVM 要分類資料的類別已經決定,屬於監督式學習(Supervised learning),常會 有如圖 4-3 的情況發生,使用分類的資訊複雜度愈高,像是特徵的維度愈高, 分類器在分類資料時會過於精確,完全適合於訓練資料分佈情形的分類,使 得訓練資料分類錯誤的情形會愈少;然而,對於測試資料卻會造成較高的誤 差[38]。因此在分類上選定 Model 的複雜度愈高,並非測試資料的錯誤率就 愈低。另一方面,將分類的問題從機率的角度來看,通常使用貝氏分類器 (Bayes classifier)來做分類決定,其決策方式如下: If p(C1|x)> p(C2 |x) then 判定為第一類 (4-10) If p(C2 |x)> p(C1|x) then 判定為第二類 (4-11) 其中 p(⋅)表示機率函式,C1與C2分別表示第一、二類,x表示已知的特徵。 以圖 4-4 為例,根據貝氏分類器可以得到分類的臨界點Thr 與a Thr ,然後靠b 判斷x與Thr 或a Thr 間的大小關係來決定所屬類別。在圖(a)中,由於兩類之b 機率分佈重疊較大,因此其判斷所屬類別之誤差將較大;反之,在圖(b)中,由 於分佈重疊較小,因此其判斷所屬類別之誤差將較小。這結果說明了在分類時, 若能選定兩類的機率函式中是屬於較分開者,那將會使得分類後的誤差較 小。 基於以上兩個理由,根據要比較的兩類表情,挑選出機率函式重疊部份 較小者,也就是肉眼可觀察到變化較明顯的部份作為具代表性的關鍵性特徵 (Key feature),取代原有的 12 個全特徵(All feature)。如此設計一方面使得兩 類機率函式之間的重疊部分減少提高辨識效果;另一方面亦可以提高辨識的 執行速度。圖 4-3 訓練和測試資料複雜度與辨識誤差的關係 圖 4-4 資料重疊部分變少 選用表 4-1 的 8 個特徵當作下列 4 組表情比對用的關鍵性特徵,主要是 在於這幾組表情的眉毛眼睛之間的距離變化、眼睛大小與嘴巴的高度變化較 明顯。 表 4-1 第一組關鍵性特徵 1 右眉中心與右眼中心距離 E1 5 右眼上下距離 E5 2 右眉內側與雙眼平行線距離 E2 6 左眼上下距離 E6 3 左眉內側與雙眼平行線距離 E3 7 雙眉內側距離 E7 4 左眉中心與左眼中心距離 E4 8 上下嘴角距離 E11 Thrb Thra
Model Complexity
High LowPrediction
Error
Test Sample Training Sample x P(x) P(C1| x) P(C2| x) x P(x) P(C1| x) P(C2| x)Surprise vs. Sadness 圖 4-5 驚訝與傷心表情的比較 Sadness vs. Anger 圖 4-6 傷心與生氣表情的比較 Neutral vs. Happiness 圖 4-7 普通與高興表情的比較 1 2 3 4 7 8 5 6 1 2 3 4 8 5 6 7 1 2 3 4 7 8 5 6 1 2 3 4 7 8 5 6 1 2 3 4 7 8 5 6 1 2 3 4 7 8 5 6
Anger vs. Happiness 圖 4-8 生氣與高興表情的比較 選用表 4-2 的 8 個特徵當作下列 1 組表情比對用的關鍵性特徵,除了嘴 巴的變化由高度變化改為左右大小變化,特徵的選取和第一組是相同的,主 要在於強調驚訝和快樂時的嘴形左右寬度不同。 表 4-2 第二組關鍵性特徵 1 右眉中心與右眼中心距離 E1 5 右眼上下距離 E5 2 右眉內側與雙眼平行線距離 E2 6 左眼上下距離 E6 3 左眉內側與雙眼平行線距離 E3 7 雙眉內側距離 E7 4 左眉中心與左眼中心距離 E4 8 左右嘴角距離 E12 Surprise vs. Happiness 圖 4-9 驚訝與高興表情的比較 1 2 3 4 7 8 5 6 1 2 3 4 8 5 6 7 1 2 3 4 7 8 5 6 1 2 3 4 8 5 6 7
選用表 4-3 的 6 個特徵當作下列 2 組表情比對用的關鍵性特徵,主要是 在於眉毛眼睛之間的距離變化與嘴巴的高度變化,像是驚訝通常都會眉毛上 揚,相對於普通情緒狀態來說,這部分就會很明顯;而生氣通常會皺眉頭, 這部分和驚訝的眉毛上揚就有很明顯的差別。 表 4-3 第三組關鍵性特徵 1 右眉中心與右眼中心距離 E1 4 左眉中心與左眼中心距離 E4 2 右眉內側與雙眼平行線距離 E2 5 雙眉內側距離 E7 3 左眉內側與雙眼平行線距離 E3 6 上下嘴角距離 E11 Surprise vs. Neutral 圖 4-10 驚訝與普通表情的比較 Surprise vs. Anger 圖 4-11 驚訝與生氣表情的比較 1 2 3 4 5 6 1 2 3 4 5 6 1 2 3 4 5 6 1 2 3 4 5 6
選用表 4-4 的 7 個特徵當作下列 2 組表情比對用的關鍵性特徵,主要是 在於眉毛眼睛之間的距離變化、眼睛大小與嘴巴的高度變化,像是傷心會使 得眼睛下看,造成眼睛相對上較小,嘴巴也會內縮,和其他情緒狀態相比, 這部分就會很明顯。 表 4-4 第四組關鍵性特徵 1 右眉中心與右眼中心距離 E1 5 右眼上下距離 E5 2 右眉內側與雙眼平行線距離 E2 6 左眼上下距離 E6 3 左眉內側與雙眼平行線距離 E3 7 上下嘴角距離 E11 4 左眉中心與左眼中心距離 E4 Sadness vs. Neutral 圖 4-12 傷心與普通表情的比較 Sadness vs. Happiness 圖 4-13 傷心與高興表情的比較 1 2 3 4 7 5 6 1 2 3 4 7 5 6 1 2 3 4 7 5 6 1 2 3 4 7 5 6
選用表 4-5 的 7 個特徵當作下列 1 組表情比對用的關鍵性特徵,主要是 在於眉毛眼睛之間的距離變化與眼睛大小,像是生氣會皺眉,和普通狀態相 比,這部分就很明顯,而嘴巴的改變不明顯就不採用。 表 4-5 第五組關鍵性特徵 1 右眉中心與右眼中心距離 E1 5 右眼上下距離 E5 2 右眉內側與雙眼平行線距離 E2 6 左眼上下距離 E6 3 左眉內側與雙眼平行線距離 E3 7 雙眉內側距離 E7 4 左眉中心與左眼中心距離 E4 Neutral vs. Anger 圖 4-14 普通與生氣表情的比較
4.3 SVM 分類—線性不可分割問題
前一節敘述的方法,是在兩類資料在可線性分割的情況下作分類,但資料 若是線性不可分割的兩類資料(Nonseparable classes),前一節的分類方法就不能 有效分類,因此在原來的 hyperplane 限制式中加上鬆弛變數(Slack variable:0 ≥ i ξ )[37], 原本的最大邊界的限制式變為式(4-12)與(4-13),稱為柔性邊界(soft margin)。 i i b x w⋅ + ≥+1−ξ for yi =+1 (4-12) i i b x w⋅ + ≤−1+ξ for yi =−1 (4-13) 1 2 3 4 7 5 6 1 2 3 4 7 5 6
可將(4-12)和(4-13)合併為 i b x w yi( ⋅ i + )≥1−ξi ∀ (4-14) 可由上式看出,當訓練資料在分類發生錯誤時,ξi會大於零,使得所有資料能落 在w⋅xi +b=±1之間的間距之外,如圖 4-15 所示。因此在計算分割平面時,
∑
i i ξ 是希望愈小愈好,所以原本要求得 2 2 w 的最小值,變為求∑
= + l i i C w 1 2 2 ξ 的最小 值,且要符合式(4-14)的限制式。利用上一節的概念,最佳化的問題轉換為最大 化式(4-15) ) 1 ( 2 1 ) , , , ( 1 , 1 ij l j i j i j i j i l i i C x x y y b w L ξ α =∑
α −∑
αα ⋅ + δ = = (4-15) where ⎩ ⎨ ⎧ = = others j i if ij 0 1 δ 限制式為∑
= = l i i i iy x w 1 α (4-16)∑
= = l i i iy 1 0 α (4-17) 剩餘計算w和 b 的方法和上一節都一樣,將αi代入式(4-16)求得w,再利用Karush-Kuhn-Tucker complementarity conditions 求得 b:
(
)
(
i ⋅ i + −1+ i)
=0 i y w x b ξ α ∀i (4-18) ξ Hyperplane: Support vector 1 + = + ⋅ bx w 1 − = + ⋅x b w ξ 0 = + ⋅x b w4.4 結合影像及語音之雙模情緒辨識決策
經由特徵擷取後,得到語音和人臉影像這兩特徵,分別經由 SVM 分類,可 以得到兩類的分類結果。當分類的結果不同時,該採用何者的分類結果,是要解 決的問題。根據 SVM 的理論,受測資料在空間中距 hyperplane 的距離較遠,誤 判的機會較小,分類結果的可靠度會較高;反之,離 hyperplane 距離較近,誤判 的可能性較高,另外,若同類資料在空間中分佈分散,表示資料變異的程度很大, 即使訓練資料距 hyperplane 有一段距離,但可能某筆資料很接近 hyperplane,誤 判的可能性相對來說也比較大。圖 4-16 分別有人臉影像及語音兩類訓練資料訓 練出來的 hyperplane,這兩類訓練資料計算出的平均距離DFave、DAave都相同, 但資料在空間中分佈的情形不同,人臉影像的資料分佈較集中,而語音資料分佈 鬆散,有些資料甚至已相當接近 hyperplane,相較之下,即使兩類的平均距離相 同,但還是要考慮到資料的分佈狀況。所以基於以上的概念來設計本論文中的辨 識決策: 1. 分別統計出語音與人臉影像訓練資料距 hyperplane 的平均距離Dave和標準差 σ ,每筆資料計算出距 hyperplane 的距離。 人臉影像特徵 語音特徵 訓練資料 DFave, σF DAave, σA 測試資料 DFi for i=1~ N DAi for i=1~ N 2. 計算並正規化人臉影像權重Z 與語音資料權重Fi Z Ai for i N D D Z F Fave F Fi Fi − =1~ − = σ σ N i for D D Z A Aave A Ai Ai − =1~ − = σ σ 3. 若是兩類資料分類結果不同,即比較兩類的權重大小,即可決定出較可靠的 分類結果,得到受測者表現的情緒狀態: ZFi ≥ZAi 則採用人臉影像特徵辨識結果圖 4-16 資料在空間中的不同分佈狀況說明
ZFi <ZAi 則採用語音特徵辨識結果
我們採用 SVM 當作情緒分類器,整個辨識流程如圖 4-17 所示,比對的順 序和排法是根據 SVM 的辨識結果而定,將辨識率較高的一組表情優先比對,於 5-3 節的實驗結果作介紹。首先,輸入的未知情緒經由分類決定是 Happiness 抑 或是 Sadness,同時也分類決定是 Surprise 或是 Neutral,假設辨識結果分別是 Sadness 和 Neutral,接著 Neutral 再和 Angry 作判斷,分類的結果最後再和 Sadness 作分類,決定這個未知情緒是屬於哪一類。由於分別有人臉影像和語音兩類資訊 分別作分類,用提出的辨識策略結合兩類資訊辨識,若是在人臉影像在辨識某兩 類情緒時分類錯誤,還可以透過語音資料修正錯誤的分類,繼續完成後續的分類, 圖 4-17 SVM 辨識流程 F




![圖 5-2 DSK6416 Codec 介面[39]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8637455.192950/58.892.144.788.111.431/圖52DSK6416Codec介面39.webp)




