1
國
立
交
通
大
學
管理學院(資訊管理學程)碩士班
碩 士 論 文
運用文字探勘技術在社群行為上之人格預測
Using text mining to predict personality based on social
behavior
研 究 生:張曉珍
指導教授:李永銘 博士
2
運用文字探勘技術在社群行為上之人格預測
Using text mining to predict personality based on social behavior
研 究 生:張曉珍 Student:Xiao- Zhen Chang
指導教授:李永銘 Advisor:Dr. Yung-Ming Li
國 立 交 通 大 學
管理學院 (資訊管理學程)碩士班
碩 士 論 文
A ThesisSubmitted to Institute of Information Management College of Management
National Chiao Tung University In Partial Fulfillment of the Requirements
For the Degree of Master of Science
in
Information Management June 2013
Hsinchu, Taiwan, the Republic of China
I
運用文字探勘技術在社群行為上之人格預測
研究生:張曉珍 指導教授:李永銘 博士
國立交通大學管理學院(資訊管理學程) 碩士班
摘要
現今網路無遠弗界,人與人溝通或社交行為,已由早前的書面作業或面
對面交談,漸漸成為線上作業。因時代的變遷,人們已較常在社群網路上發
表文章及紓發自已的情緒,這些個人行為會透過文字的表達呈現於文章中。
本研究資料來源透過 Facebook 社群行為中文語料的部份進行人格分析,採
用最被廣為接受 Costa & McCrae(1985)的五大人格特質構面 (Five Factor
Model,the Big Five) 。此五大人格特質,分為神經質型、外向型、開放型、
隨和型、嚴謹型五大類。
研究方法採用二種方法進行研究及比較,方法一為關鍵詞彙預測法,透
過中研究的 BOW
- WordNet 擴充詞彙;方法二為機器學習預測法,採用自行
開發的程式利用變型的貝氏理論加以研究及實作。研究結果顯示,針對顯著
人格加以分析比較,方法一有 61%的準確率,方法二有 80%的準確率。方法
二的實驗結果所預測的準確率高於方法一的預測結果,二項方法當詞彙數夠
多時,更可增進研究分析的準確性。另研究透過方法二學習訓練後的詞彙,
用來自動擴充方法一的詞彙。在使用測試集的資料加以驗證後,結果顯示有
效的增進方法一的預測結果,由 66.67%增至 73.33%。故本研究證實透過在
Facebook 的中文貼文可有效的分析個人在社群網路上的人格特質,未來可供
後續研究者參考,以及企業應徵人員的參考依據等效益。
Using text mining to predict personality based on social behavior
Student:Xiao-Zhen Chang
Advisors:Dr. Yung-Ming Li
Master Program of Institute of Information Management
College of Management
National Chiao Tung University
Abstract
Nowadays Internet is used for communication widely. People prefer
communicating via Internet Services over talking face-to-face or writing
letters. They are more often writing blogs or posting messages on social
networks and the personality will be presented by habitual vocabularies they
used. This research is analyzing Chinese vocabularies to predict personality from
posted contents by Facebook users. The personality classification is based on
Five Factor Model (Costa & McCrae, 1985). The five categories are Neuroticism,
Extraversion, Openness, Agreeableness and Conscientiousness.
This research compares two methods. Method one is key vocabulary
prediction by using SINICA BOW-WordNet. Method two is machine learning
prediction by using compact Bayes theorem. The results show that the accuracy of
method two (80%) is better than method one ( 61%). The accuracy of method two
will be better when the sample is enough. The result could be used to extend
vocabularies of method one and improvements accuracy from 66.67% to 73.33%.
This research demonstrates a different way to analyze personality by
analyzing posted contents on Facebook from traditional questionnaire and the
contribution of this research can provide helpful reference to HR of enterprise
when recruiting employees.
誌
謝
在校二年時間要忙於修課、忙於工作、忙於家庭。以前沒發生的事,似
乎所有的事全在這段時間發生了,一週課程排得很滿,對於坐火車通勤的我,
真得很難熬。尤其完課回到家已快 11 點,隔天又得趕坐 7 點的火車,僅有
的空閒時間大概只剩在火車上及假日了。假日跟家人相處出遊的時間不多,
大多是用來寫作業或參加班上活動的時間,對於家人的包容、體諒真得非常
地感激。
求學過程雖然很辛苦,但這二年過得真得很充實,雖然很累,但學到很
多,不管是在校所學的專業知識或是跟同學相處的互動。感受到交大資管所
的師生真得很優秀,很專業,也一直趕在時代尖端,求新求變。指導教授李
永銘老師的名言,眼高手黑、站在巨人的肩膀上等,能夠體會這些話的含意
真得收益良多。
很感謝指導教授在論文上及課堂上的教導,也很感謝資管所各位教授的
教學及指導,還有同學間這段時間的相處。能夠在工作一陣子又回到學校上
課,這種經驗真得很難得,會是我人生中一個很重要的回憶,謝謝您們。
最後非常感謝論文口試委員陳安斌教授、劉敦仁教授、金必煌教授及指
導教授李永銘教授的指導,使論文最後能呈現的更完整,謝謝您們。
目
錄
中文提要 ... I
英文提要 ... II
誌謝 ... III
目錄 ... IV
表目錄 ... V
圖目錄 ... VI
一、緒論 ... 1
1.1 研究背景 ... 1
1.2 研究動機與目的 ... 1
1.3 研究範圍 ... 2
1.4 論文架構 ... 2
二、相關研究 ... 4
2.1 社群網站 ... 4
2.2 人格心理學 ... 6
2.2.1 人格 ... 6
2.2.2 人格特質 ... 7
2.2.3 特質論 ... 7
2.2.4 五大人格特質 ... 9
2.3 習慣領域 ... 11
2.3.1 習慣與習慣領域 ... 11
2.3.2 習慣領域與五大人格關係 ... 13
2.4 資料探勘 ... 14
2.4.1 資料探勘的起源 ... 17
2.4.2 資料探勘與知識發現 ... 18
2.4.3 資料探勘功能 ... 18
2.4.4 資料探勘分類模式 ... 19
2.4.5 貝氏分類法 ... 20
2.4.6 單純貝氏分類法 ... 20
三、設計與方法 ... 22
3.1 系統架構(方法一:關鍵字詞預測法) ... 22
3.1.1 Big Five 特徵詞彙 ... 23
3.1.2 BOW - WordNet ... 23
3.1.3 特徵詞彙擴充 ... 23
3.1.4 特徵詞彙資料庫 ... 25
3.1.5 FB 資料截取 ... 26
3.1.6 CKIP 斷詞斷句 ... 26
3.1.7 TF﹣IDF ... 28
3.1.8 五大人格預測 ... 28
3.2 系統架構(方法二:機器學習預測法) ... 29
3.2.1 系統架構(方法二)流程說明 ... 30
3.2.2 方法二(機器學習預測法)演算 ... 30
3.3 問卷來源 ... 32
3.4 軟體及平台使用 ... 32
四、系統實作及資料驗證 ... 34
4.1 Facebook 資料截取及處理 ... 34
4.2 資料驗證 - 心理測驗結果 ... 37
4.3 方法一(關鍵字詞預測法) ... 40
4.4 方法二(機器學習預測法) ... 42
五、實驗結果與分析 ... 48
5.1 方法一(關鍵字詞預測法) ... 48
5.2 方法二(機器學習預測法) ... 49
5.3 方法二支援方法一 ... 53
六、結論及建議 ... 57
6.1 結論 ... 57
6.2 建議 ... 59
6.3 效益 ... 60
參考資料 ... 61
自
傳
... 63
附錄一 ... 65
附錄二 ... 67
附錄三 ... 69
表
目
錄
表 1:人格定義... 7
表 2:習慣領域四概念 ... 12
表 3:例子:習慣領域特性與五大人格關係 ... 14
表 4:截取 FB 資料之程式開發步驟 ... 26
表 5:FACEBOOK
資料截取及處理步驟 ... 34
表 6:FB STORY、MESSAGE、PLACE
功能描述 ... 35
表 7:方法二實作前置步驟 ... 43
表 8:方法二實作步驟 ... 43
表 9:方法二詞彙分類範例 ... 45
表 10:方法一擴充結果比較表 ... 55
表 11:方法一擴充前後準確率比對 ... 56
表 12:中研院平衡語料庫詞類標記集 ... 66
表 13:心理測驗衡量評分表 ... 69
圖
目
錄
圖 1:系統架構... 3
圖 2:社群網站用戶數據排名 ... 5
圖 3:全球社群網路使用分佈圖 ... 5
圖 4:五大人格特質 ... 10
圖 5:習慣與習慣領域關聯圖 ... 13
圖 6:習慣、習慣領域、五大人格關聯圖 ... 14
圖 7:KDUNGGETS 票選於 2012 年使用資料探勘技術的行業 ... 16
圖 8:KDUNGGETS 票選於 2012 年使用資料探勘熱門主題 ... 16
圖 9:資料探勘與其它領域關係圖 ... 17
圖 10:資料探勘四大核心技術 ... 17
圖 11:知識發現過程 ... 18
圖 12:分類模式圖 ... 20
圖 13:系統架構(方法一) ... 22
圖 14:WORDNET ﹣中文查詢介面 ... 24
圖 15:WORDNET﹣英文查詢介面 ... 25
圖 16:中研院中文斷詞系統 ... 27
圖 17:語料庫詞類標記取得 ... 27
圖 18:系統架構(方法二) ... 29
圖 19:FACEBOOK
中文貼文資料截取 ... 35
圖 20:FACEBOOK
中文貼文資料檔 ... 35
圖 21:截取
MESSAGE、STORY、PLACE對應內文 ... 36
圖 22:CKIPCLIENT
字詞切割 ... 36
圖 23:COUNTWORDFREQ
詞頻計算 ... 37
圖 24:心理測驗問卷格式 ... 38
圖 25:心理測驗問卷回覆 ... 39
圖 26:心理測驗結果分類 ... 39
圖 27:方法一個人用詞資料檔 ... 40
圖 28:方法一之 IMPORTER
程式 ... 41
圖 29:方法一特徵詞資料庫 ... 41
圖 30:方法一人格分類實例 ... 41
圖 31:方法二實作介面 ... 42
圖 32:方法二匯入文字檔內容 ... 44
圖 33:方法二實作 ... 45
圖 34:方法二詞彙分類 ... 46
圖 35:方法二詞彙 NORMALIZE
及權重值 ... 47
圖 36:方法二詞彙 GRADE
計算 ... 47
圖 37:方法二類別預測結果 ... 47
圖 38:方法一研究結果(1) ... 48
圖 39:方法一研究結果(2) ... 49
圖 40:方法二測試集個人預測結果(1) ... 50
圖 41:方法二測試集個人預測結果(2) ... 50
圖 42:方法二測試集個人預測結果(3) ... 51
圖 43:方法二測試集個人預測結果(4) ... 51
圖 44:方法二五大人格分類統計表 ... 52
圖 45:方法二(機器學習預測法)預測結果 ... 53
圖 46:方法二擴充詞彙截取 ... 54
圖 47:方法一擴充詞彙資料產生 ... 54
圖 48:方法一擴充結果比較圖 ... 55
圖 49:二方法顯著人格預測比較 ... 57
圖 50:擴充詞彙方法關聯圖 ... 58
圖 51:擴充詞彙人格預測比較趨勢圖 ... 58
一、緒論
1.1 研究背景
目前社群網站的興起,以 Facebook 而言,截至 2013 年一月全球註冊人數已達 到九億八千萬,而台灣註冊人數約為一千三百三拾萬人,而大多數上網有臉書帳號 的人比比皆是。使用範圍無論是社群照片分享、發表文章、尋找資訊、推薦、尋找 朋友等已廣泛被使用,且融入人們的生活中,可說是不可或缺的朋友或為具影響力 的媒體了。1.2 研究動機與目的
隨著時代變遷,伴隨著資訊科技的蓬勃發展,網路世界已成為人與人溝通的媒 介,所以社群網路因此而展開。由於透過社群網路有其方便性及可讀性,所以人們 較常在社群網路上發表文章及紓發自已的情緒。現今社群網路可說已達到成熟的階 段,社群行為分析及預測亦已漸漸被重視及研究。 Facebook 檔案能顯露出應徵者未來工作的表現,在近期的一項研究中,學者邀 請人資專員人工瀏覽應徵者的 Facebook 檔案,並問卷依照內容所顯現的人格特質 來評比未來工作表現。結果顯示與當初人資專員依照 Facebook 檔案所作出的預測 極為接近,準確度甚至超過了性向測驗結果。 另在 2011 年的研究顯示有 90%的聘雇者曾經檢閱過工作應徵者的 Facebook 檔 案。學者表示運用 Facebook 在聘雇員工時有其價值和實用性,但需進行更多的實 證[3]。故本研究開發經 Facebook 授權允許,程式自動截取 Facebook 中文內文, 依據五大人格特質構面來分析此用戶的五大人格。 本研究針對 Facebook 社群行為中文語料的部份進行人格分析,採用最被廣為 接受 Costa & McCrae(1985)的五大人格特質構面 (Five Factor Model,the Big Five) 。此五大人格特質,分為神經質型、外向型、開放型、 隨和型、嚴謹型五 大類。網路世界無遠弗界,從使用 Facebook 的文字行為可分析每個人在社群網路 上的人格特質。本研究運用文字探勘技術在社群行為上預測人格特質,可供後續研 究參考及企業應徵人員的參考依據。1.3 研究範圍
研究對象針對個人及朋友臉書的中文貼文,開發程式截取臉書資料,再以資料 探勘分析方法,預測人格特質。1.4 論文架構
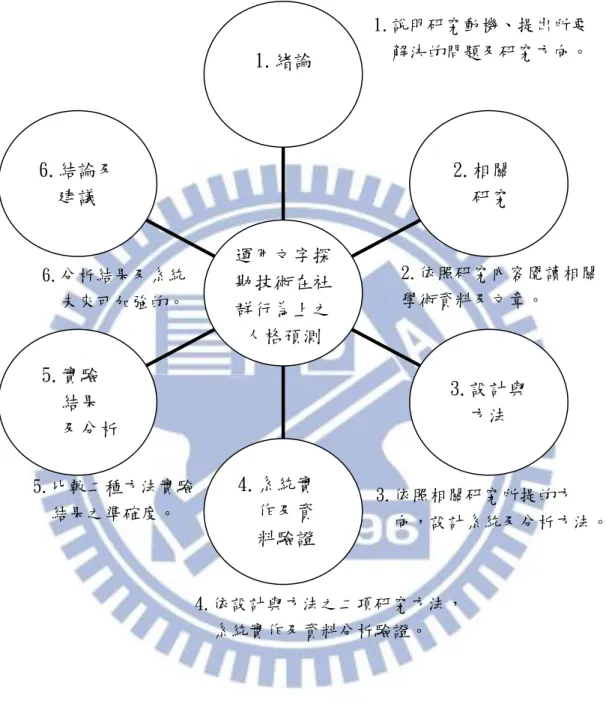
本論文研究設計採用關鍵字詞預測法及學習預測法二種方式,第一種方式之關 鍵字詞預測法,主要依據五大人格特質之五大類別中的各個特質,挑選可具代表此 五類的相關特徵詞,接著利用中央研究院的中英雙語知識本體詞網依據此特徵詞再 加以擴充更多的特徵詞,以增加研究分析結果的準確度。再來從 Facebook 裡截取 貼文後,再利用中研院 CKIP 中文斷詞系統,進行斷詞動作及詞頻計算,以取得五 大人格特質的歸類。第二種方式之機器學習預測法,透過自動開發機器學習的方式, 以百分之八十為訓練資料,由 FaceBook 之 Big Data 中抓取動詞及形容詞,依據已 知類別對應相關之特徵字詞加以訓練 ,用以計算權重,而百分之二十之測試資料, 則依據訓練集訓練後的特徵詞歸類,依據個人常用特徵詞預測個人於五大人格之類 別。本論文之系統架構如下圖 1,分為緒論、相關研究、設計與方法、系統實作及 資料驗證、實驗結果及分析、結論及建議共六大部份。
圖 1:系統架構 資料來源:本研究自行整理 6.結論及 建議 5.實驗 結果 及分析 4.系統實 作及資 料驗證 3.設計與 方法 2.相關 研究 1.緒論 運用文字探 勘技術在社 群行為上之 人格預測 2.依照研究內容閱讀相關 學術資料及文章。 3.依照相關研究所提的方 向,設計系統及分析方法。 1.說明研究動機、提出所要 解決的問題及研究方向。 6.分析結果及系統 未來可加強的。 5.比較二種方法實驗 結果之準確度。 4.依設計與方法之二項研究方法, 系統實作及資料分析驗證。
二、相關研究
本研究結合社群網站,並依據人格心理學及習慣領域的理論,使用資料探勘的 分析方法,預測 Facebook 用戶於社群行為之人格特質。2.1 社群網站
社群網站是以建立線上社群的方式,透過虛擬空間,提供平台讓志同道合的人 群聚在一起,交流互動、維繫情感、分享、討論資訊等功能。 較廣為人知的社群網站如 Facebook、Google+、Plurk、微博、Twitter 等,而 以 Facebook 為較多用戶使用。 根據全球著名的人力資源網站 Glassdoor 調查指出,全球 50 大最佳職場的企 業中 Facebook 排名第 1 名,Facebook 公司的標語為"Challenged every day to do your best work"。該公司領導層真正相信 Facebook 的使命,是使世界變得更加 開放和連接。Facebook 廣受歡迎及使用的原因正是如此,也是成功的原因之一。 使用 Facebook 的動機包含有好奇心、跟上時代潮流、免費、方便操作、人性 化等。而使用者使用 Facebook 所得到的好處則有歸屬感、商機、炫耀、虛榮心、 增加曝光、聊天、展現自我、聯繫感情、拉近彼此關係、分享生活即時動態及資訊、 拓展交友圈、調劑時間、休閒愉樂、尋找朋友、宣揚理念、推動社會運動等等,這 些優勢已讓 Facebook 成為大多數人民生活的一部份[16][17]。 Globalwebindex 數據估計,Facebook 全球 31 個市場在 16-65 歲中有九億三百 萬用戶。而於 2012 年 12 月止臉書使用戶亦佔全球社群網站之冠,相關統計數據, 如下圖 2。圖 2:社群網站用戶數據排名 資料來源:Globalwebindex 根據VINCOSBLOG分析指出截至 2012/12,臉書以十億的有效使用戶數,在 137 個國家中佔了 127 個領先地位。其中以亞洲為最重要的成長關鍵,使用者高達 2 億 7 千 8 百萬,超過了歐洲的 2 億 5 千 1 百萬使用者,成為臉書最大的版圖,如下圖 3。 圖 3:全球社群網路使用分佈圖 資料來源:VINCOSBLOG
2.2 人格心理學
若今天你去面試一家公司時,或許有人問你,請描述自己是怎樣一個性格的人 呢?這問題你會如何回答?遇到這種問題時,其實很多人對自己都不是很了解,因 為一個人可能會有多重性格存在,對於回答的答案準確性有多高? 其實有待確認, 但可確定的是,每個人的人格表現可由平常的行為中所展露。Christopher Nave(1960)研究指出人格特質從小時候至年老基本上是相同的。顯示小學一年級的 個性是關鍵期,從那時開始往後反映至成人時之行為,可說性格伴隨人的一生,不 因時空及成長背景而有所改變。當然各方心理學家對於人格有不同的定義,但最終 存在兩個基本概念,一為獨特性,另一為行為模式,也就是所謂的個人獨特的行為 模式,這人與人之間的差異性正是人格心理學研究之處。2.2.1 人格
人格為性格傾向呈現穩定的表徵,意指「一個人內容相當持久的特質、性格或 特徵,使得這個人的行為顯示一致性」。人格心理學家已經找出許多研究人格的方 法,某些人格理論家致力於長時間的、深入的研究個體的人格。另一些則努力發展 心理測驗,來測量許多人的人格,還有另一些理論家研究某些人們所共有的人格特 質[1]。 人格廣義指存在於個體內的特質、動機、情緒、自我價值、因應策略等內涵 (Ryff,Kwan, & Singer, 2001) 。因此,可用某些特質及動機的強弱來描述一個人 的人格,因人格可以是存在於個體身心系統中的一種動力組織,及是決定個體行為 與思想特質所在(Allport,1961) [2]。人格可分為類型及特質,類型指類似五大人 格分類的開放型,外向型,嚴謹型,內向型,隨和型。特質指描述五大人格類型, 例如快樂的,開心的,憂鬱的等等。 而性格的本質具有一致性及特殊性二種,也就是說,一個人在不同時間及情境 下仍然表現出與以往相同的行為,以及在同一情境或不同情境下會有不同以往的表 現,而因先天或後天造成,會影響一個人的性格特質,而所謂人格特質,是用以區 別個人心理特色的綜合體。心理學家主張人格特質的測量是研究人格的首要工作, 且多採用標準化的測驗方式來測量人格特質[2] 。 至於人格心理學大致可分為五大理論:心理動力論、行為論、特質論、人本論、 以及互動論等,特質可以發揮統括、預測、解釋個人的行為舉止三種主要的功能。自 1980 年代以來,許多學者研究證實,選擇適當特質,可利用特質來預測行為 (Darley, 1994)。以下表 1 為多位學者對人格的定義,從學者對於人格的定義中 可得之。人格特質的行為表現為一個人成長過程所形成的個人獨特性,在在與個人 的生活習性及基因有關,而本論文以特質論為研究重心,排除以往的人工標準化測 驗,採用專家知識庫及機器訓練的方式,結合社群,截取日常行為的活動記載以預 測人格特質。 提出者 年度 定義 Carl Jung 1921 原型:一種遺傳傾向、人們普遍共有、特定行動等 Allport 1937 即一個人之心理及生理系統所形成的內在動態組織,決定個人 對於環境獨特的適應性 Karen Horney 1941 人格結構是真我、實我和理想我的組合 Cattell 1965 可以預測一個人在某一個情境中將表現的行為 Eysenck 1970 指個人性格、氣質、智慧及體質等,一個穩定而有持續性的組 織 Scott & Mitchell 1972 是一種人類心理成長及發展的過程 Pervin & John 1997 為形成一個人經常性的行為、思想等特性 表 1:人格定義 資料來源:本研究整理[14][15]
2.2.2 人格特質
人格特質是指個人在成年後的一切行事作風、人際關係、語言表達上,皆有每 個人的表現模式,此稱為人格特質。比方會說某人平常待人很熱心、不情緒化、很 開朗等,種種皆為形容一個人的人格特質[4]。2.2.3 特質論
針對人格特質之相關研究學者眾多,且各方皆有其一定的研究領域,本研究僅以目前較受注意的特質論來研究個人之人格特質。而特質論對人格的觀點如下: 特質:指人與人之間之不同,構成獨特自我特性[1]。 來源:1.先天遺傳性格。 2.後天環境的影響。 特質區分二種派別: 1.普遍共有:每個人皆擁有相同一組特質,每個人會有差異於所表現的所有特 質程度的多少,所以可解釋特質是普遍共有的[1]。 2.個人不一:每個人有不同的特質組合,所以是有差異的,因此有可能每一個 人存在的特質皆不相同[1]。
以下於特質論中針對 Gordon Allport 、Carl Jung 及 Karen Horney 三位心理學家 的理論加以介紹如下[1]: Gordon Allport (1961)將個人特質分為三大類: 1. 首要特質:指最具代表性的個人獨特性質。此特質是一種單一特質,且強 烈支配個體的人格,反應於個人行為上,例如:泰瑞莎修女首要特質為富有 憐憫心。 2. 中心特質:針對個人的人格及行為是影響力重大,且此中心特質是指構成 人格特質的核心部份。如同形容個人負責任、樂觀、誠實等皆是歸屬於中 心特質。 3. 次要特質:此特質指在某種情況下才會表現出來的特徵,對人格及行為的 影響不甚明顯,亦較不重要的人格特質。 Carl Jung 的分析心理學將心智可分為二層面,顯示人是有潛意識的[1]: 1.意識層面 2.潛意識層面 第一層:個人潛意識 為個人累積的經驗形成,包含被壓抑及被忽略的記憶。 第二層:集體潛意識 為人類所共享的記憶及行為的相關記憶。
Carl Jung 從傳說、信仰及文化習俗中,找到一種傾向,這傾向是人們普遍都 有的知覺或特有方式或行動等相關的遺傳因子,此為 Carl Jung 所稱的原型,而這 個原型是存在於人們所謂的集體潛意識之中[1]。 Carl Jung 認為對人類生活而言,特別具重要的原型包括以下幾點[1]: 1.面具:也是指人們將人格表現於外,願意公開且與人分享。 2.陰影:隱藏自己的一些恐懼、怨恨、邪惡等的念頭,不對外公開,僅存於個 人內心裡,或許連自己都不清楚自己有此念頭。 3.陰性基質:指男性人格中含括部分女性特質,在男性中顯示出溫柔的一面等 正是陰性基質的呈現。 4.陽性基質:指女性人格中含括部分男性特質,在女性中顯示出理性的一面等 正是陽性基質的呈現。 綜上可得,每個人從生來就具有每個人一些獨特特質,由遺傳得到這些特質或 由成長過程中發展出這些特質,這些特質是潛藏於個人潛意識中,會不由自主的第 一個反應於個人的行為之中。而佛洛伊德:潛意識決定重要決策;狄克斯特霍斯、 凡歐登:潛意識思考理論,讓潛意識來思考決定問題。所以有研究顯示,個人特質 由基因及童年的經驗決定,通常不太會變,且會影響各方面的行為,包含了休閒活 動、創意、健康、言語、行動及幽默感等行為[9]。所以本研究由個人於社群行為 中的文字書寫內容,運用文字探勘來分析及預測此人之人格分類。 另外人們會好奇想問,心理學家皆有一套心理學理論,但他們都是如何衡鑑人 格的呢?心理學家一般以人格投影測驗來衡鑑人格:也就是以心理動力論(心理動 力論者認為行為由內部力量所驅動)為基礎的方式,利用人格測驗,試著探索人們 潛意識的部份,以完成對個案人格之評估。所以傳統皆以人格分析表為測量工具, 現今可由科學的方式,利用開發工具截取相關個人訊息,亦可達到衡鑑人格的目 的。
2.2.4 五大人格特質
從 20 世紀 80 年代以來,人格研究者們在人格描述模式上達成了比較一致的共 識,提出了人格五因素模式,被稱為“Big Five"。近年來相當多研究顯示在許多 學者所歸納人格特質以五種廣泛的因素解釋五大人格,五大人格模式為目前為止最被廣泛接受的(Digman, 1990; Goldberg, 1992)。現今五大人格模式已成為研究 人格的典範(Blue, 2000; Costa & McCrae 1992; Howard & Howard, 1995)。
故歷經多年的研究證實五大人格的確存在,而這些特質可了解自己及他人,因 而科學研究人員研究務實且有效的方法,他們相信人心的袐密結構是潛藏在語言中 的,他們猜測人類用於形容自己與他人的詞彙,應是反應於人的個性的基本面。而 於一九三O年代,一群專業的研究者挑選可用於形容人的個性的字詞,共整理了一 萬八千多字,接著找出重要字眼,總共有四千多個,至一九四O年代,另一批研究 者利用電腦分析降低維度,將原先四千多個字詞,縮減為二百字左右,而往後的四 十年來,數千人因此利用此形容詞來分析及評估人類的五大人格特質[9]。 五大人格特質分為外向型、隨和型、神經質型、嚴謹型及開放型五大類別,如 圖 4。 圖 4:五大人格特質 資料來源:本研究整理 五大人格特質描述如下:McCrae 和 Costa(1987,1997,1999)[4][9] 外向型 指受外界與他人的刺激的需要。直率、喜歡社交、生氣勃勃、友善、 有自信且合群等是這類型的表徵。 神經質型 指情緒穩定與抗壓的程度。容易焦慮、具有敵意、自我意識較高、容易
外向型
隨和型
嚴謹型
開放型
神經質型
有不安全感、脆弱易受傷。 開放型 指一個人追求與欣賞新奇、有趣、罕見經驗的程度。開放性跟好奇心、 較具彈性、有豐富的想像力、有藝術家的敏感以及不墨守成規的態度有 關。 隨和型 此類型的人常表現於關懷他人的程度,比如有同情心、值得信任、較合 群、謙虛且正直。 嚴謹型 指做事有條理、堅持不懈、自律的程度。謹慎的人比較勤奮、有規律、計 畫周詳、守時且較可靠。 五大人格有五個面向,每個面向皆有高低面向,而本研究以五大人格模式之顯 著人格,也就是取高分者為主要人格的研究方向,透過人類行為反應於文字,分析 語句以找出人類個性的主要面向。
2.3 習慣領域
習慣領域指動態的念頭和思路(凡指做法、反應、觀念等),經一段時間會漸 穩定,且會停於固定範圍內。而這些範圍所包含動態和組織,也就是所稱的習慣領 域。而習慣領域的形成,除非有重大事情或新的訊息產生或刻意擴展習慣領域,否 則此習慣領域皆是在穩定的固定範圍之中的[6]。2.3.1 習慣與習慣領域
一個人平常的習慣及行為的養成是經年累月所產生於個人的大腦中的,人類的 大腦有一千億個腦細胞,而大腦又是主宰人類行為的中樞,可說人類的行為是受大 腦的指令所控制。大腦運作時會有明暗變化所組成的網狀,也就是所稱的電網,每 個電網的變化,反應於一個行為,而這些動作是受長期習慣所養成,且不知不覺的 控制我們的行為。 習慣與習慣領域不同。習慣指的是那些強有力的電網產生的行為,也就是潛在 領域,指的是潛藏在你大腦裡經年累月所累積的思路及念頭。習慣是習慣領域的一 小部份,習慣領域不僅包含習慣的潛在領域,亦包含實際領域、可發概率及可達領域共四種,如圖 5 所示。 以下介紹將習慣領域四概念,及將習慣領域舉例應用於個人於 FaceBook 貼文 時的對應關係,如表 2 所示。 習慣領域 四概念 定義 例子(當你在 FB 貼文時) 潛在領域 總和潛藏在腦海裡的所有電網 你腦海裡所有知道的詞彙 實際領域 目前時點正占領我們注意力的電網 此時此刻你會引用何詞彙 為你貼文的內容 可發概率 每個電網實際占有注意力的機率 此詞彙被你引用的機率 可達領域 由實際領域所延伸的電網 實際引用的的詞彙後,會引 發一些其它的情緒及想法 等的詞彙產生 表 2:習慣領域四概念 資料來源:參考習慣領域[6],本研究自行整理
2.3.2 習慣領域與五大人格關係
習慣領域中先天的電網是與生俱來的,當我們漸漸長大時,到十多歲時,電網 會越漸加強,至近二十歲時,此時電網會變得更強而有力,這些先天的電網是不容 易被改變的。而後天的電網是透過學習及經驗累積而來,亦受環境的影響很大,故 不同文化不同國家的人種會有所不同。但可知的是,這些不管是先天或後天形成的 電網,都可由個人的行為反應表現出來,只是個人受哪個時期的電網影響較大,即 表現在個人特質上會越明顯。 習慣影響一個人的行為,而由一個人的平常行為特徵可預測這個人的人格特質, 當想法等電網被使用的越多時,其實越容易被取出,也就越容易表現於行為之中, 所以預測人格的準確度更可提升,可更了解自己及他人。這些行為特徵,往往受個 人的平常習慣所影響。好的修養習慣,會讓一個人自尊自愛、沈重穩重、有耐心。 待人處世習慣好的人,會樂於助人、有親和力、坦率、有關愛的心亦富同情心。而 有好的生活習慣的人,會有自信、樂觀、勇於前進的精神。 以上可了解每個人的行為習慣不同、習慣領域不同,潛在領域及實際領域的表 現亦不同,因此呈現於個人的人格會有所差異。如表 3 所示,習慣領域最終可反應實際領域
可發概率
可達領域
潛在領域
習慣 習慣領域 圖 5:習慣與習慣領域關聯圖 資料來源:本研究自行整理於人格的表現,所以我們在研究五大人格特質的同時,其實需先了解人類的習慣、 習慣領域,這三者是相輔相成的。 如圖 6 可呈現習慣→習慣領域→五大人格關係。也就是個人從小養成的習慣, 這些潛在因素是造成人格發展的起因,再加上後天的環境的影響及重大事物的造成, 皆看此重大影響層度的大小而定,以決定個人習慣領域的範圍大小。所以習慣再加 上習慣領域會造就一個人的不同人格特質,本研究以五大人格特質加以分析。 習慣領域特性 五大人格特質 懂得感恩 隨和型 求新求變 開放型 熱心 外向型 自律性強 嚴謹型 易怒 神經質型 表 3:例子:習慣領域特性與五大人格關係 資料來源:本研究自行整理 圖 6:習慣、習慣領域、五大人格關聯圖 資料來源:本研究自行整理
2.4 資料探勘
資料探勘,亦稱資料採礦,為近年來資料庫領域熱門的議題,是利用統計以及 機械學習的演算法,啟發性地從大量資料中找尋隱藏具有商業價值的知識與規律,五大人格
習慣領域
習慣
以作為自動化商業策略之應用。另資料探勘是啟發性透過演算法主動搜尋有意義的 規則,而讓資料說話,以及與傳統統計最大的差異在於它具有商業化以及行動的意 涵[5] 。 資料探勘其中包含文字探勘及網頁探勘等,文字探勘為處理非結構化資料,通 常字句長短不一定,且訊息的記載文字是很自由的,可說每一筆資料沒有共通的結 構性。關鍵詞是表現文件意義的最小單位,因此文字探勘技術所使用之自動處理, 如自動分類等應用彼彼皆是。自由文句在做文件分類時,常將文件切成一個一個語 意單位,稱為特徵詞彙,從這些特徵詞彙與類別來找出彼此對應關係。網頁探勘為 從 Web 資料發掘本質關係(即有趣與有用資訊)的流程,以文字、連結或使用資訊形 式表示,而 Web 為世上最大的資料儲存庫,其資料為 HTML、XML、文字格式[11]。 資料探勘領域含括資料庫技術及機器學習技術,許多研究人員及產業人員,認 為資料探勘領域是增加企業潛能的重要指標,因透過資料探勘技術是可挖掘出具有 意義的資訊,可做為決策之用,更可增加企業的競爭力,是企業的愛好者。圖 7 為 Kdunggets 票選於 2012 年使用資料探勘技術的行業,HR 為佔了第二名,本研究針 對 Facebook 行為預測性格分析,可應用於 HR 招募時人格分析。 本研究以預測類別變數之社群文字分析為研究重心。如圖 8 所示於Kdunggets 票選於 2012 年使用資料探勘熱門主題,社群分析佔前三排名,可顯示社群尚是目 前熱門的研究對象之一。
圖 7:Kdunggets 票選於 2012 年使用資料探勘技術的行業 資料來源:Kdunggets 圖 8:Kdunggets 票選於 2012 年使用資料探勘熱門主題 資料來源:Kdunggets
2.4.1 資料探勘的起源
傳統資料分析技術常會遭遇無法處理的資料問題如大量資料、高維度問題、異 常型態資料等問題,而資料探勘的起源就是研究者為了解決傳統資料分析所帶來的 問題,故使用方法論及演算法發展出這資料探勘的分析工具,這工具可有效處理大 量資料及不同資料型態的資料。 資料探勘其實包含了統計學的假設檢定、人工智慧、學習理論等,而與其它領 域之間可說扮演很重要的關鍵角色,如圖 9 所示。研究者另針對資料探勘的工作分 為四種核心技術,分別為分群分析、預測模式、關聯規則分析及異常偵測四種,如 圖 10 所示,在此四種核心技術中,本研究以預測模式的分類模式為研究方法。 圖 9:資料探勘與其它領域關係圖 資料來源:本研究整理資料探勘
資料庫
技術
人工智慧
機器學習
視覺化
統計學
預測模式 分群分析 異常偵測 關聯規則分析 資料 圖 10:資料探勘四大核心技術 資料來源:本研究整理2.4.2 資料探勘與知識發現
資料探勘為知識發掘的過程之一,知識發展整個部份包含將資料轉換成有用的 資訊的一個過程,也就是這部份包含了資料前置處理至資料採礦後的後處理的一個 轉換過程,如圖 11 所示[19]。 圖 11:知識發現過程 資料來源:資料探勘[7]P.1-32.4.3 資料探勘功能
資料探勘的規則型態可區分為六種模式[10] 分類(Classification) 預測類別變數的一種過程稱為分類,分類是資料探勘中最普遍的一種模式, 也是人類為了溝通,會將事物加以分類,是人類在產生知識規則最初始的型態。 在大多數所謂的分類技術中,是依據已知的結果來分類,但資料探勘中的分類 則為預測的技術,也就是要在事物發生前,需事前預測分類結果,這是資料探 勘分類與一般分類最大的不同點。分類模型可再細分為決策樹、叢集演算法、 以及貝氏機率分類等演算方法。 資料輸入 資料前處理 資料探勘 後處理 資訊 選取特徵、降低維度、正規化、 資料分組 過澽樣式、視覺化、樣式解釋推估(Estimation) 推估為預測連續數值之相關屬性資料。使用的演算方法,包含迴歸分析及 類神經網路分析等方法。 群集化(Cluster) 依據相似度,將相似資訊歸於同群,可將原複雜且大量的資料,將以分群 後可大幅簡化,此過程即稱為群集化,而物以類聚是形容群集化再好不過了。 群集化是對未知的事實找出內部相似性加以分群,而分類則是依據已知的類 別,來預測未知的事實。 同質分組(Affinity Group) 同質分組亦可稱為關聯規則,從眾多物件中,找出哪些物件是被關聯且應 發生在一起的,故同質分組可找出各組之間的差異程度。最著名為啤酒與尿布 例子。 序列(Sequential) 序列亦可稱為時間序列,為在同質分組中找出事物相互關聯之先後發生順 序,可協助找出事物的生命週期,利用不同時點的因應措施,供決策分析使用。 描述(Description) 無需透過複雜演算法去計算,此描述指的是透過人類對資料的敏銳度及資 料視覺化的呈現,亦可同時找出資料的潛在規則。
2.4.4 資料探勘分類模式
資料探勘原型為預測,預測類別變數(不連續)的過程稱為分類,而預測連續變 數(連續數值)的過程稱為推估。本研究採預測類別變數,由於 FaceBook 中的中文 貼文字詞為不連續值,故將以六大模式中的分類為研究重點以預測五大人格分類。 分類是指建立一個學習目標函數 f,使得這學習函數可由 x 屬性對應至 y 類別, 如圖 12 所示,而分類法的目的是將一個物件指定至其中一個已預設的分類中[7]。 如同本研究中利用人的常用語,只取中文部份,而後加以分類,歸屬此人為五大人 格中五大類的哪個類別。圖 12:分類模式圖 資料來源:本研究整理
2.4.5 貝氏分類法
貝氏定理由機率所推導而出,在假設條件獨立的情況下,依據已知的事件發生 之機率來推測未知資料的類別。貝氏定理包含二種分類法,單純貝氏分類法及貝氏 信念網路二種。 貝氏分類法中,其中一方法為單純貝氏定理也是本研究參考部份理論之研究範 圍之一,因以往研究者研究顯示單純貝氏判別對於大量資料分析具有高效率與高準 確率。2.4.6 單純貝氏分類法
單純貝氏定理是獨立假說,也就是假設屬性間對同一類別之影響力是獨立的, 而由於計算簡化,故稱為單純的原因[8]。( | )
( | ) ( ) ( ) (1) 公式(1)表示 P(H|X)是在X條件下H的事後機率 P(H)為假設H的事前機率OutPut
分類標記(y)
資料探勘
分類模式
Input
屬性集(x)
要驗證事後機率的正確性不容易,需大量訓練資料或適量屬性資訊,貝氏理論 有一定有效度及準確度的原因是因為貝氏允許以事前機率 P(H)、P(X)及類別的條件 機率 P(H|X)為主,來預測事後的機率[7],如上公式(1)。 單純貝氏分類法為假設在類別 y 中,屬性與屬性間具有條件獨立的特性,依此 來計算機率值[7]。條件獨立公式如下公式(2)。
( | ∏
(
| )
(2) X={X1,X2,….Xd}包含 d 個屬性值 條件獨立 假設 X、Y、Z 是隨機變數集合,X 中的變數在 Z 情況下和 Y 是相互獨立的。條 件如下公式(3)。( | ) ( | )
(3) 本研究方法二的公式將採用變型之單純貝氏分類法的方式預測其五大人格分 類,由於研究分析之條件欄位並非多個,僅以詞彙分類,故無需耗用貝氏分類法實 作,但研究方法會參考貝氏分類法之機率原則加以分類,將於後續第三章之設計與 方法中介紹。三、設計與方法
3.1 系統架構(方法一:關鍵字詞預測法)
圖 13:系統架構(方法一) 資料來源:此圖本研究自行整理 Big five 特徵詞 彙 BOW - WordNet 特徵詞彙擴充 特徵詞彙資料 庫 CKIP 斷詞斷句 FB 資料截取 資料前置處理 TF﹣IDF 權重計算 人格分析結果 FB3.1.1 Big Five 特徵詞彙
依據研究中最廣為接受的 McCrae 和 Costa(1985)五大人格特質(開放型、 嚴謹型、外向型、隨和型、神經質型)此五類人格特質依諸位研究人員所描述此五 大類特徵,經整理後共 403 個特徵詞[12][13][21][22][23]。3.1.2 BOW - WordNet
本研究之方法一選用「中央研究院中英雙語知識本體詞網」(The Academia Sinica Bilingual Ontological Wordnet (BOW)), 因 BOW 之語言座標,是以台灣 通用的中文為出發點。且 BOW 之開發成員及資料來源來自國內外知名之知識團隊, 為本研究所用之因。目前此網站開放使用的系統功能是由「數位典藏」國家型計畫 下的「語言座標」計畫所建構完成。而所謂語言座標指可讓不同來源的典藏知識內 容,可以轉換成互通的訊息,將成為下一代語意網中不可或缺的基礎架構。BOW 引 用的資料除了中央研究院詞庫小組(資訊所),文獻語料庫(語言所)及計算中心 開發的資料外。國外則有 IEEE 批准執行的 SUMO 知識本體(teknowledge.com 管理), 及普林斯頓(Princeton University)的 WordNet。國內主要有來自遠見科技股份 有限公司,包括該公司自有資料及與中研院共同開發資料,以及教育部國語會的辭 典[25]。3.1.3 特徵詞彙擴充
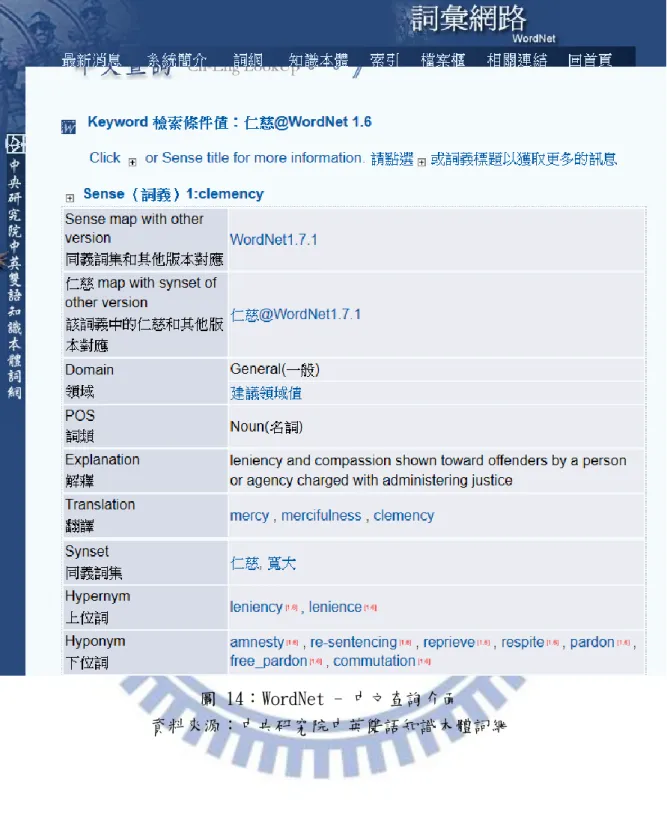
本研究依所整理之特徵詞,透過中央研究院中英雙語知識本體詞網﹣WordNet 網站,如圖 14 及圖 15 所示,利用中英對照,將 403 個特徵詞,依同義詞/上位詞/ 下位詞,擴充至 2731 個特徵詞。不考慮反義詞,因學者所提出之潛意識思考理論, 人的第一反應出來的行為,即來自於大腦中潛意識所驅使,所呈現於行為、言語、 文字中。例如一個外向型的人,平常用語會多以呈現快樂的字眼,當他不快樂時, 會以呈現我"不快樂",而較不會呈現我很"憂鬱"等字眼,但平常就比較會想到 負面情況的人,例如神經質型的人,他的使用字眼會以"憂鬱"呈現,而較不會以 "不快樂"呈現。故本研究不考慮反義詞的原因在於此。 利用 BOW 特徵詞擴充,例如:“仁慈“於中文查詢,得到同義詞有“寬大"、 “慈愛“等上位詞有“寬恕(leniency)",而下位詞有“恩赦(amnesty)"[18]。圖 14:WordNet ﹣中文查詢介面 資料來源:中央研究院中英雙語知識本體詞網
圖 15:WordNet﹣英文查詢介面 資料來源:中央研究院中英雙語知識本體詞網
3.1.4 特徵詞彙資料庫
將擴充後之特徵詞彙存入 SQL Server 2008 資料庫中,供後續抓取特徵詞來預 測五大人格類別使用。特徵詞彙資料量越大,則分類準確度越大,故建議可擴充更 多的特徵詞彙於資料庫中。3.1.5 FB 資料截取
文字探勘,是以抓取文字為主,為將非結構化資料處理成有意義的資料,文字 字句長短不一,資料的記載是很自由的,這些自由文句在做分類時,常將內容資料 切成一個一個語意單位,這些語意單位被稱為特徵詞彙,可從這些特徵詞彙與類別 來找出彼此特徵詞彙之間的對應關係,可應用於文字的探勘技術自動處理,例如自 動分類等之應用[11]。本研究以文字探勘為研究範圍。 本研究透過 C#.Net 程式開發,自動抓取 Facebook 朋友之相關資訊記載於 SQL Server 2008 資料庫中。截取 FB 資料之程式開發步驟,如表 4 所示。 截 取 FB 開 發 步 驟 1.設定 APP ID 2.設定使用權限3.C# Web Browser 元件登入及取得 Access Token 4.透過 Graph API 找朋友 5.找朋友的貼文等資訊 表 4:截取 FB 資料之程式開發步驟 資料來源:本研究自行整理
3.1.6 CKIP 斷詞斷句
本研究使用中研院之 CKIP 斷詞斷句,截取資料利用所提供之工具計算各詞彙 之詞頻[20][26]。形容五大人格分類詞性以動詞及形容詞的詞性為主,故只取動詞 及形容詞的詞類為 A、ADV、Nv、Vi、Vt 五種詞類,詞類如下圖 17(刪除線為本研究 排除之詞類,而詳細之中研院平衡語料庫詞類標記集請參照附錄一)。而資料前置 處理則只取中文字詞,依據 CKIP 計算後結果,排除無需之詞類、單一字元、英文、 標號後,由最初的 93636 筆的詞彙,減少為 45467 筆的詞彙,詞類排除非 A、ADV、 Nv、Vi、Vt 五種詞類後,最終取 32880 筆詞彙,而後依據每筆詞彙計算 TFIDF 將資 料存入資料庫中。中研院所提供之 CKIP 斷詞斷句功能,需先申請服務帳號後,才 可執行所下載之 CKIPClient 及 CountWordFreq 程式,中研院所提供的中文斷詞系 統之服務畫面如下圖 16。圖 16:中研院中文斷詞系統
資料來源:中研院中文斷詞系統-線上資源
圖 17:語料庫詞類標記取得
3.1.7 TF﹣IDF
詞頻(term frequency,TF)指某一個詞彙出現在文章中的頻率。 TF 如下公式(4)∑
(4) 分子指詞彙在文件 中出現的次數,而分母為文件 中所有字詞出現次數總和
逆向文件頻率(Inverse Document Frequency,IDF) 指某詞彙出現於多少篇文 章數,分之總文章數,某詞彙算出之 IDF 越大,則說明此詞彙具有很好的類別區分 能力。 IDF 如下公式(5)
| | | | (5) 分子D表示語料庫中的文件總數 分母表示包含詞彙 的文件數目
TFIDF(term frequency–inverse document frequency)是一種常用的加權 技術,常被使用資訊檢索及本文挖掘上。表示就是如果某個詞彙在某篇文章中出現 的頻率高,且在其他篇文章中較少出現時,則認為此詞彙具有很好的類別區分能力, 較適合用來做分類,可用來計算某個詞彙在文章中的相對重要程度,防止的影響力 過強。 TFIDF 如下公式(6)
(6)
3.1.8 五大人格預測
五大人格預測公式如下公式(7) (∑ ( ) ) ( ) P 為計算後之最大類別。C 為五大分類集合{C,A,N,O,E}。Vc 為某人格的特徵詞 彙。I 為受測者使用過的詞彙。{Xci~XcN}∈ I∩Vc。 ( )為各類別特徵詞彙之 TFIDF 值。i 為詞彙數,由 1 至 n 個。3.2 系統架構(方法二:機器學習預測法)
圖 9 圖 18:系統架構(方法二) 資料來源:此圖自行整理 特徵詞彙資料庫 CKIP 斷詞斷句 FB 資料截取 詞頻計算 資料前置處理 取得特徵詞彙 Mapping 五分類 FB 80%訓練資料 實際人格:問卷 20%測試資料 取得特徵詞彙 計算權重 Mapping 特徵詞 彙資料庫 計算權重 人格預測結果機器學習理論主要是透過設計、分析使得計算機可以自動學習,可從數據中自 動分析獲得規律,以預測未知數據,已廣泛的應用,例如: 資料探勘[20]。 本研究運用資料探勘技術透過計算機可以自動學習,從未分類數據中訓練學習 獲得分類數據,以預測未知人格分類,故方法二以機器學習預測法命名。
3.2.1 系統架構(方法二)流程說明
步驟一:透過自行開發程式,截取 Facebook 朋友資訊,接著透過中研院 CKIP 程式 執行斷詞斷句後計算詞頻,之後去除單一字元、標點符號及只取動詞及形 容詞。 步驟二:問卷採用心理測驗結果為抽樣者實際人格特質。 步驟三:將資料抽樣切成 80﹪為訓練集及 20﹪為測試集。 步驟四:將 80﹪的抽樣訓練集資料,依據抽樣者個人實際人格類別結果, 計算詞頻權重,取得每個特徵詞彙的詞類,將之維度降低為五大分類為 C、 A、N、O、E,將結果寫入特徵詞彙資料庫中。 C:嚴謹型(Conscientiousness) A:隨和型(Agreeableness) N:神經質型(Neuroticism) O:開放型(Openness) E:外向型(Extraversion) 步驟五:接著將 20﹪的測試集資料截取特徵詞對應於特徵詞彙資料庫 中是何詞彙,取得特徵分類。 步驟六:依據詞頻計算權重後得出人格分析結果。3.2.2 方法二(機器學習預測法)演算
步驟一: 依據抽樣訓練者個別詞彙及人格類別出現的次數,演算詞彙歸屬五大人格分類 的次數,以及詞彙被每一抽樣者使用的次數。 V:詞彙(Vocabulary)∈{V1,V2,V3,…Vn} T:人格分類(Type) ∈{C、A、N、O、E} VCt:人格分類的詞計量,亦為詞彙在某一人格(Type)出現的次數,如下公式(8)VCt = Count(Vt) (8) t ∈ T Count:抽樣者使用此詞彙次數 步驟二: 依據步驟一計算後的值,將數值正規化(Normalize),使之值介於 0~1 之間, 以及算出每個詞彙的權重值。 計算每個詞彙於各分類正規化後的值,如下公式(9) VN(Normalize 詞彙值): ∑ (9) n ∈ T t ∈ T 例如:VNA
∑ ,為取得類別 A 正規化後的數值。 而各詞彙於分類後正規化的值加總應為 1,如下公式(10) ∑ ( ) 計算每個詞彙權重值,為每一詞彙出現的次數佔總次數的比重,如下公式(11) Vw
∑
(11) W:權重 i ∈{所有出現的詞彙} VC = 每個詞彙出現的次數 步驟三: 測試集內的人員五大人格預測,取測試集內依每個人所用詞彙的詞頻、各類別 正規化後的值、詞彙權重三者相乘積後的總和,如公式(12)。最後取最大值的類別, 為預測結果。 五大人格預測如下公式(13)
(∑( ( ) ( ) ) ( ) ( ) ( ) P:人格預測(Personality prediction) T:人格分類(Type),t ∈{C、A、N、O、E} V ={V1,V2,V3,…Vn}受測者使用過且出現在詞彙庫裡的詞彙集合。 Tg:人格分類級別(grade of type) t ∈ T i:抽樣者所有使用過的詞彙 W:權重 VN(Vi):Vi正規化(Normalize)後的詞彙值
3.3 問卷來源
本研究依據 103 位朋友,實際回收 75 份心理測驗結果,回收率 73%,研究結果 以五大人格模式之顯著人格為研究重心,也就是取心理測驗結果高分者之實際人格 與於 Facebook 預測主要人格相驗證。 驗證數據之心理問卷資料,取自英國著名的心理學教授──李察‧韋斯曼 (Richard Wiseman)於 2009 年著作之書籍。Richard Wiseman 研究領域致力於運用 科學方法,研究許多日常生活裡看似無法以理性角度去理解的一些行為,以個性這 章節而言,則以直覺的方式用心理學科學方法進行研究探討。 Richard Wiseman 目前於英國賀福郡大學心理系研究單位任職,著有多本心理 學相關暢銷書,Richard Wiseman 的研究領域在許多世界級的頂尖學期刊都報導過, 亦在多個國際媒體以專題方式介紹過,如:《時代雜誌》、《每日電訊報》等。在 BBC 等著名媒體上對成千或上萬研究對象進行大規模實驗,也曾上過金氏世界記錄, 為一本有信度的科學書籍[9]。心理問卷格式如附錄二。3.4 軟體及平台使用
1. FaceBook 2. SQL Server 20083. Visual Studio 2008 4. 中研院 CKIPClient 5. 中研院 CountWordFreq
四、系統實作及資料驗證
本研究利用二種研究方法來實作及驗證其準確率,採用方法一為關鍵字詞預測 法及方法二為機器學習預測法二種。 方法一:關鍵字詞預測法,透過 BOW 手動擴充詞彙的方式進行研究,且因每個 人有可能會有多重人格表現,故將資料驗證部份再細分為顯著人格分析及多重人格 分析二種方式驗證其準確率。 顯著人格分析:取心理測驗分數,有達到高分者,且取最顯著之人格分類。 多重人格分析:取心理測驗分數,有達到高分之所有分類。 方法二:機器學習預測法,使用機器學習的方式,將抽樣資料分為 80%為訓練 集,20%為測試集,訓練取 Facebook 中文貼文內容常用詞彙,存於詞彙資料庫中, 以供測試資料預測其人格分類。4.1 Facebook 資料截取及處理
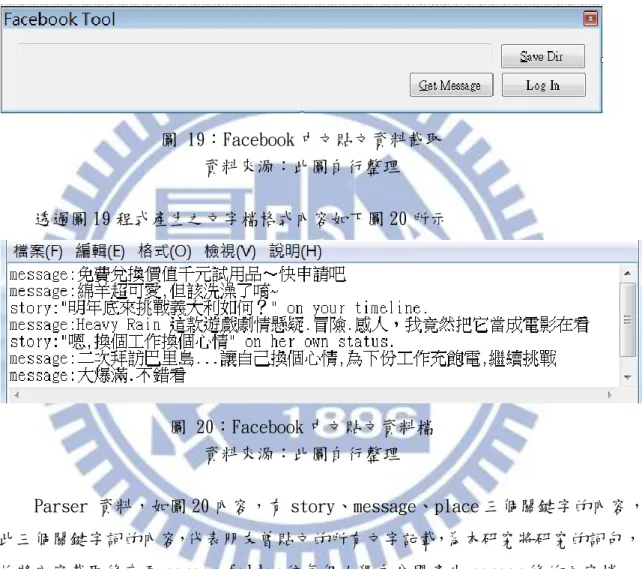
Facebook 程式開發及資料處理儲存步驟,如下表 5 所示。 步 驟 描述 範例圖示 步 驟 一 程式開發截取朋友 Facebook 之中文貼文。 GUI 畫面 如圖 19 所示 步 驟 二 依個人資料分別存至各個 Facebook 中文貼文資料 檔(.txt)。 Facebook 中文貼文 資料檔內容 如圖 20 所示 步 驟 三 Parser 中文貼文資料檔,截取關鍵字 message、 story、place 對應之中文內文。 如圖 21 所示 表 5:Facebook 資料截取及處理步驟 資料來源:本研究自行整理圖 19 截取朋友 Facebook 之中文貼文功能解說 Log In:Login 使用 Facebook graph API 授權。
Get Message:資料截取每個朋友 Facebook 貼文 story、place、message 三種 行為內容,程式依每個朋友各自產生對應的檔案。 Save Dir:指定產生後的檔案儲存路徑。 圖 19:Facebook 中文貼文資料截取 資料來源:此圖自行整理 透過圖 19 程式產生之文字檔格式內容如下圖 20 所示 圖 20:Facebook 中文貼文資料檔 資料來源:此圖自行整理 Parser 資料,如圖 20 內容,有 story、message、place 三個關鍵字的內容, 此三個關鍵字詞的內容,代表朋友曾貼文的所有文字記載,為本研究將研究的詞句, 故將內容截取後存至 parser folder 依每個人獨自分開產生 parser 後的文字檔, parser 後的文字檔內容如圖 21 所示。 以下針對 story、message、place 三個關鍵字記載的內容加以描述如表 6 所示。 Graph API 描述 Story 主題貼文之下的貼文回覆 Message 主題貼文內容描述 Place 地方打卡的文字描述 表 6:FB story、message、place 功能描述 資料來源:本研究自行整理
圖 21:截取 message、story、place 對應內文 資料來源:此圖自行整理 產生欲處理的檔案之後,開始呼叫 CKIPClient 字詞切割程式去執行每個文字 檔的斷詞斷句,執行完後產生的檔案內容如圖 22 所示。 圖 22:CKIPClient 字詞切割 資料來源:此圖自行整理 接下來針對斷詞斷句後的結果,呼叫 CountWordFreq 程式計算各字詞詞頻,產 生後之檔案內容如圖 23 所示。
圖 23:CountWordFreq 詞頻計算 資料來源:此圖自行整理
4.2 資料驗證 - 心理測驗結果
驗證部份透過 Richard Wiseman (2009)著作之一本有信度之心理測驗試題,依 此測驗結果為依據計算其準確率。
問卷平台使用,選用 Google Doc 來製作,因 Google Doc 是簡易設計且易上手 的線上問卷製作平台。運用此設計心理測驗,供朋友快速完成測驗,不需超過 1 分 鐘即可完成一份 10 題的心理測驗,且 Google Doc 於使用者點選"提交"時,即可 即時回傳至設計者 server 端,供即時查閱,可快速達到心理測驗的結果供後續研 究分析。 本研究資料驗證採用 Google Doc 製作心理測驗試題,其格式如下圖 24,至於 試題完整內容,請參照附錄二。
圖 24:心理測驗問卷格式 資料來源:此圖參照[9]後自行整理
心理測驗結果所回覆的內容及格式如下圖 25 所示。 圖 25:心理測驗問卷回覆 資料來源:此圖自行整理 依據心理測驗結果計算取得顯著人格及多重人格分類,如圖 26 所示。 圖 26:心理測驗結果分類 資料來源:此圖自行整理
4.3 方法一(關鍵字詞預測法)
依計算詞頻後的字詞,取詞性為動詞及形容詞,另外去除單一字元及標點符號 之後計算 TFIDF,TFIDF 計算公式,請參照公式(6)。最後將 id、term、TFIDF 資料 存至資料庫中,如圖 27 所示。 由於個資法,基於資料保護的原則,本研究中將以真實 id 以 Mapping 成流水 號的方法顯示,以保障個人資料的安全性。 圖 27:方法一個人用詞資料檔 資料來源:此圖自行整理 透過中央研究院中英雙語知識本體詞網﹣WordNet 網站特徵詞擴充,利用中英 對照將 403 個特徵詞,依同義詞/上位詞/下位詞,擴充至 2731 個特徵詞,最後減 低維度,將之歸屬五大類別。擴充後結果透過自行開發之 importer 程式,如圖 28, 將檔案讀取及解析後,此支程式將會把結果存於特徵詞資料庫中,供後續研究使 用。 圖 28 功能解說 File Path:選擇預匯入之檔案路徑Connection String:資料庫之連結設定 Import:Parser 檔案資料後匯入資料庫中 圖 28:方法一之 Importer 程式 資料來源:此圖自行整理 圖 29 為 Importer 程式匯入特徵詞資料庫的資料呈現。 圖 29:方法一特徵詞資料庫 資料來源:此圖自行整理 依個人用詞資料檔之字詞 Mapping 特徵詞資料庫中的字詞,以預測人格分類結 果,如圖 30 所示,依個人類別取加總後之 TFIDF 最大者,則為此人之分類,此時 預測出來的分類為 A(隨和型)。 圖 30:方法一人格分類實例 資料來源:此圖自行整理
依據回覆結果,計算人格分類,如圖 26 所示,由於一個人可能會有多重人格 產生,故本研究將方法一之驗證結果,利用二種分析方式去驗證,採用顯著人格分 析及多重人格分析二種方式驗證結果。 圖 30 為例,預測結果為五大人格分類之 A(隨和型),於心理測驗後的人格分 類,顯著人格分類為 A(隨和型);多重人格分類為 C(嚴謹型)、A(隨和型)、N(神 經質型),如下圖。故顯著人格分類與預測結果相同,故屬預測正確;另 A(隨和型) 有落於多重人格分類之其中一分類,故多重人格分類屬預測正確。本研究方法一, 以此類推算出所有朋友之人格分類後加以統計分類結果,以計算其準確率。
4.4 方法二(機器學習預測法)
圖 31 為針對方法二(機器學習預測法)所開發的程式,此程式的設計原則為 將資料依 80/20 法則,將有回填心理測驗問卷資料的 80%為訓練資料集,而將剩餘 20%的資料列為測試資料集,目的為了將 80%訓練後所得到的五大分類的詞彙記載於 資料庫中,供 20%測試集資料預測五大人格分類。 圖 31 功能解說 Directory:選擇欲匯入方法二的文字檔目錄 Connection String:資料庫連結設定 Exec:開始執行機器學習預測法 圖 31:方法二實作介面 資料來源:此圖自行整理執行 Method2 程式前的前置動作,需先完成以下表 7 步驟。Method2 程式的 GUI 畫面如圖 31。 步驟 描述 步驟一 Facebook 資料截取 步驟二 CKIP 斷詞斷句 步驟三 詞頻計算 步驟四 心理測試問卷結果 步驟五 將心理測試問卷結果所得之人格分類,將之寫入斷詞斷句後的詞頻文 字檔中,供後續 Method2 程式分析使用 表 7:方法二實作前置步驟 資料來源:本研究自行整理 首先將資料抽樣切分為 80%訓練集及 20%測試集,相關內部作業如下表 8。 資料集 步驟 描述 訓練集 80% 步驟一 批次讀取抽樣 80%已執行斷詞斷句後的文字檔案內容 步驟二 Parser 每份訓練集文字檔,截取個人 ID、詞彙、詞頻、人 格類別此四欄位寫入資料庫中 步驟三 將維度降低為五大類別,依步驟二所產生的資料,再去計算 訓練集每個詞彙分佈在五大人格分類 T∈{C、A、N、O、E}的 總數 步驟四 Normalize 個人五大類別權重,使數字介於 0~1 之間 測試集 20% 步驟一 批次讀取抽樣 20%已執行斷詞斷句後的文字檔案內容(不重 覆訓練集資料) 步驟二 Parser 每份測試集文字檔,截取個人 ID、詞彙、詞頻、人 格類別此四欄位寫入資料庫中 步驟三 依照步驟二該抽樣者所使用的詞彙出現次數╳該詞彙個人 人格的比重╳詞彙出現的權重 步驟四 依步驟三計算後的值取個人五大類中數值最大者為個人之 人格分類預測結果 表 8:方法二實作步驟 資料來源:本研究自行整理
依每個人心理測驗回傳結果,經計算分數後,取最高分者,將符合的類別寫入 已斷字斷詞後的文字檔的第一行,以供程式抓取後續判別使用,有可能個人最高分 數有相同類別相同分數,如下圖 32 此抽樣者之最高分數 E 及 N 分數相同,故此人 屬 E 及 N 二種人格。 文字檔內容資料及格式如圖 32。 圖 32:方法二匯入文字檔內容 資料來源:此圖自行整理 Method2 讀取每位朋友的文字檔內容資料,依序 Parser 相關字詞,取動詞及形 容詞的詞類且資料內容以取中文字詞為主,排除無用之詞類、單一字元、英文、標 號之後,寫入資料庫中的欄位包含個人 ID、詞彙、詞頻、五大人格類別,資料內容 呈現如圖 33。
圖 33:方法二實作 資料來源:此圖自行整理 詞彙分類計算以下表 9 為例,"快快樂樂"這個詞彙,出現在 C 類人格有 4 次, 出現在 A 類人格有 2 次,出現在 N 類人格有 3 次,出現在 O 類人格有 1 次,出現在 E 類人格有 2 次,Count 為"快快樂樂" 詞彙總共出現的次數。 舉例來說,如果某一抽樣者同時有 E 及 N 的人格,則 VCA 及 VCN 各會被加 1, 而 Count 當時只會被加 1,所以 VCc+VCA+VCN+VCO+VCE與 Count 值不一定相同。 V VCc VCA VCN VCO VCE Count 快快樂樂 4 2 3 1 2 8 表 9:方法二詞彙分類範例 資料來源:本研究自行整理 程式實際執行後所產生之詞彙分類結果如下圖 34 所呈現,例如詞彙為"生日 快樂"這個字詞,在 A(隨和型)人格出現的次數是最多的,也就是隨和型最常引用 此字詞祝福別人,故"生日快樂"於本研究中詞彙歸屬於 A 類,以此類推其它詞彙 之分類統計。
圖 34:方法二詞彙分類 資料來源:此圖自行整理 計算每個詞彙於各分類正規化後的值,及其權重值。 接續上例,以"生日快樂"這個詞彙為言,於詞彙分類計算後的數值為 N=327, E=104,O=398,A=516,C=289。 Normalize 詞彙分類數值,使之介於 0~1 之間,套用公式(9)計算如下: 詞彙"生日快樂"於五大類別加總後的值為:1634,以下針對 N、E、O、A、C 五大類計算後的數值各為 N=327/1634=0.200122399020808 E=104/1634=0.0636474908200734 O=398/1634=0.243574051407589 A=516/1634=0.315789473684211 C=289/1634=0.176866585067319 每個詞彙的權重值計算如公式(11)所示,為每個詞彙出現次數佔所有詞彙出現 次數的比重,以詞彙"生日快樂"為例,生日快樂出現的次數為 1269 次,佔所有 詞彙出現的總次數的比重值,算出來"生日快樂"的權重為 0.228525121555916。 計算後 Normalize 詞彙分類數值及每個詞彙的權重,如下圖 35 所示。
圖 35:方法二詞彙 Normalize 及權重值 資料來源:此圖自行整理
由公式(12)計算出每位測試者之 N、E、O、A、C 五大類的 Grade 值,而 Type 為心理測驗之實際人格分類,如下圖 36 所示。 圖 36:方法二詞彙 Grade 計算 資料來源:此圖自行整理 由圖 36 中的資料取得每位測試者之 N、E、O、A、C 五大類的 Grade 加總值中 取最大者,為預測結果。 以圖 37 為例,N Grade 的值為此位測試者最大值,故預測結果屬 N(神經質型), 而與 Type(實際人格分類)N 比對是相同的,故預測結果正確。 圖 37:方法二類別預測結果 資料來源:此圖自行整理
五、實驗結果與分析
5.1 方法一(關鍵字詞預測法)
方法一:關鍵字詞預測法,經統計後,其顯著人格分析(Method1)有 61%準確率, 多重人格分析(Method2)有 70%準確率,如圖 38 所示。 圖 38:方法一研究結果(1) 資料來源:此圖自行整理 由於朋友大多以 A(隨和型)的朋友居多,可以由顯著人格分析(Method1)及多重 人格分析(Method2)的心理測驗結果可得知,故預測後的結果以 A(隨和型)所佔的比 率最高,如圖 39 所示。此研究亦可證實物以類聚這個情況,也就如圖 30 所示,本 人之五大人格分類屬 A(隨和型),相對自己的朋友亦以類別為 A(隨和型)的居多, 相同性格的人、志同道合的人會相聚成群。 61% 70% 顯著人格分析 多重人格分析圖 39:方法一研究結果(2) 資料來源:此圖自行整理
5.2 方法二(機器學習預測法)
方法二之機器學習預測法,以機器學習的方式,將抽樣數的 80%為訓練資料集, 透過學習將詞彙與已知之人格類別,加以訓練後,將每一詞彙歸屬於五大人格類別 {C、A、N、O、E}之中,而五大類別所對應的名稱為,C:嚴謹型、A:隨和型、N: 神經質型、O:開放型、E:外向型。對應後的詞彙及類別為用來預測 20%測試集資 料的分類結果。 圖 40~43 舉例測試集中其中三個人的預測結果,加以說明此三個人實際人格與 預測人格比對,以驗證比對後為預測正確或預測錯誤。 以圖 44 統計測試集所有抽樣者之人格分佈,可代表本研究方法二的預測分類 結果分佈情況,以五大人格分類統計表顯示,可清楚顯示預測結果,而預測出的結 果以 A(隨和型)的朋友居多,與方法一的結果相同。 本研究之方法二的預測結果,以顯著人格分析的預測為主,取人格分數之最高 分者為顯著人格表現,預測準確率有 80%,高於方法一 61%的顯著人格預測準確率, 方法二的預測結果如圖 45 所示。 方法二透過訓練學習的方式,所取得之五大人格詞彙表,這部份的資料可用於 知識庫中詞彙資料的擴充,當詞彙量越大時,更可增加其分類的準確度,對預測五 大人格類別有更大的幫助。 0.00% 10.00% 20.00% 30.00% 40.00% 50.00% 60.00% 70.00% 80.00% 90.00% O C E A N 預測 Method1 Method2ID 為 000001 這個朋友的實際人格計算出來最高分者,同時有二個,屬 A(隨和 型)及 O(開放型)二種人格表現,本研究預測值只會取最大值者為此預測分類結果, 故預測後結果為 A(隨和型),A(隨和型)於 A(隨和型)及 O(開放型)其中一類,故本 研究將此預測歸屬為預測正確,ID(000001)預測結果如圖 40 所示。 圖 40:方法二測試集個人預測結果(1) 資料來源:此圖自行整理 ID 為 000002 這個朋友的實際人格計算出來取最高分的值,屬 A(隨和型),而 預測後結果亦為 A(隨和型),預測與實際一致,故歸屬為預測正確,ID(000002)預 測結果如圖 41 所示。 圖 41:方法二測試集個人預測結果(2) 資料來源:此圖自行整理 0 0.1 0.2 0.3 0.4 0.5 N E O A C ID(000001) Actual(O,A) Prediction(A) 0 0.5 1 1.5 2 2.5 N E O A C ID(000002) Actual(A) Prediction(A)
ID 為 000015 這個朋友的實際人格計算出來取最高分的值,屬 N(神經質型), 而預測後結果亦為 N(神經質型),預測與實際一致,故歸屬為預測正確,ID(000015) 預測結果如圖 42 所示。 圖 42:方法二測試集個人預測結果(3) 資料來源:此圖自行整理 ID 為 000011 這個朋友的實際人格計算出來取最高分的值,屬 N(神經質型), 而預測後結果卻為 A(隨和型),預測與實際不一致,故歸屬為預測錯誤,ID(000011) 預測結果如圖 43 所示。 圖 43:方法二測試集個人預測結果(4) 資料來源:此圖自行整理 0 0.0005 0.001 0.0015 0.002 N E O A C ID(000015) Actual(N) Prediction(N) 0 0.05 0.1 0.15 0.2 0.25 N E O A C ID(000011) Actual(N) Prediction(A)



![圖 24:心理測驗問卷格式 資料來源:此圖參照[9]後自行整理](https://thumb-ap.123doks.com/thumbv2/9libinfo/8741135.204231/48.892.171.777.129.900/圖24心理測驗問卷格式資料來源此圖參照9後自行整理.webp)


