产品介绍
文档版本 01
发布日期 2022-01-05
非经本公司书面许可,任何单位和个人不得擅自摘抄、复制本文档内容的部分或全部,并不得以任何形式传 播。
商标声明
和其他华为商标均为华为技术有限公司的商标。
本文档提及的其他所有商标或注册商标,由各自的所有人拥有。
注意
您购买的产品、服务或特性等应受华为公司商业合同和条款的约束,本文档中描述的全部或部分产品、服务或 特性可能不在您的购买或使用范围之内。除非合同另有约定,华为公司对本文档内容不做任何明示或暗示的声 明或保证。
由于产品版本升级或其他原因,本文档内容会不定期进行更新。除非另有约定,本文档仅作为使用指导,本文 档中的所有陈述、信息和建议不构成任何明示或暗示的担保。
目 录
1 图解 MapReduce 服务... 1
2 什么是 MRS... 3
3 MRS 与自建 Hadoop 对比优势... 7
4 应用场景...11
5 组件介绍...14
5.1 MRS 组件版本一览表... 14
5.2 Alluxio... 17
5.3 CarbonData... 18
5.4 ClickHouse... 20
5.4.1 图解 ClickHouse...21
5.4.2 ClickHouse... 23
5.5 DBService... 26
5.5.1 DBService 基本原理... 26
5.5.2 DBService 与其他组件的关系...27
5.6 Flink... 27
5.6.1 Flink 基本原理... 28
5.6.2 Flink HA 方案介绍... 33
5.6.3 Flink 与其他组件的关系... 35
5.6.4 Flink 开源增强特性...36
5.6.4.1 窗口... 36
5.6.4.2 Job Pipeline... 38
5.6.4.3 配置表...43
5.6.4.4 Stream SQL Join... 45
5.6.4.5 Flink CEP in SQL... 45
5.7 Flume... 47
5.7.1 Flume 基本原理... 47
5.7.2 Flume 与其他组件的关系... 50
5.7.3 Flume 开源增强特性... 51
5.8 HBase... 51
5.8.1 HBase 基本原理... 51
5.8.2 HBase HA 方案介绍... 56
5.8.3 HBase 与其他组件的关系... 57
5.8.4 HBase 开源增强特性...58
5.9 HDFS...65
5.9.1 HDFS 基本原理...65
5.9.2 HDFS HA 方案介绍... 68
5.9.3 HDFS 与其他组件的关系... 69
5.9.4 HDFS 开源增强特性... 71
5.10 Hive... 77
5.10.1 Hive 基本原理... 77
5.10.2 Hive CBO 原理介绍... 80
5.10.3 Hive 与其他组件的关系... 84
5.10.4 Hive 开源增强特性... 84
5.11 Hudi...85
5.12 Hue... 87
5.12.1 Hue 基本原理... 87
5.12.2 Hue 与其他组件的关系... 89
5.12.3 Hue 开源增强特性... 91
5.13 Impala... 91
5.14 Kafka... 91
5.14.1 Kafka 基本原理... 91
5.14.2 Kafka 与其他组件的关系...94
5.14.3 Kafka 开源增强特性... 95
5.15 KafkaManager... 95
5.16 KrbServer 及 LdapServer...95
5.16.1 KrbServer 及 LdapServer 基本原理...96
5.16.2 KrbServer 及 LdapServer 开源增强特性... 99
5.17 Kudu... 99
5.18 Loader... 100
5.18.1 Loader 基本原理... 100
5.18.2 Loader 与其他组件的关系... 102
5.18.3 Loader 开源增强特性...102
5.19 Manager... 103
5.19.1 Manager 基本原理... 104
5.19.2 Manager 关键特性... 106
5.20 MapReduce...107
5.20.1 MapReduce 基本原理...107
5.20.2 MapReduce 与其他组件的关系... 109
5.20.3 MapReduce 开源增强特性... 109
5.21 Oozie... 112
5.21.1 Oozie 基本原理... 112
5.21.2 Oozie 开源增强特性... 114
5.22 OpenTSDB... 114
5.23 Presto... 115
5.24 Ranger...116
5.24.1 Ranger 基本原理... 116
5.24.2 Ranger 与其他组件的关系... 118
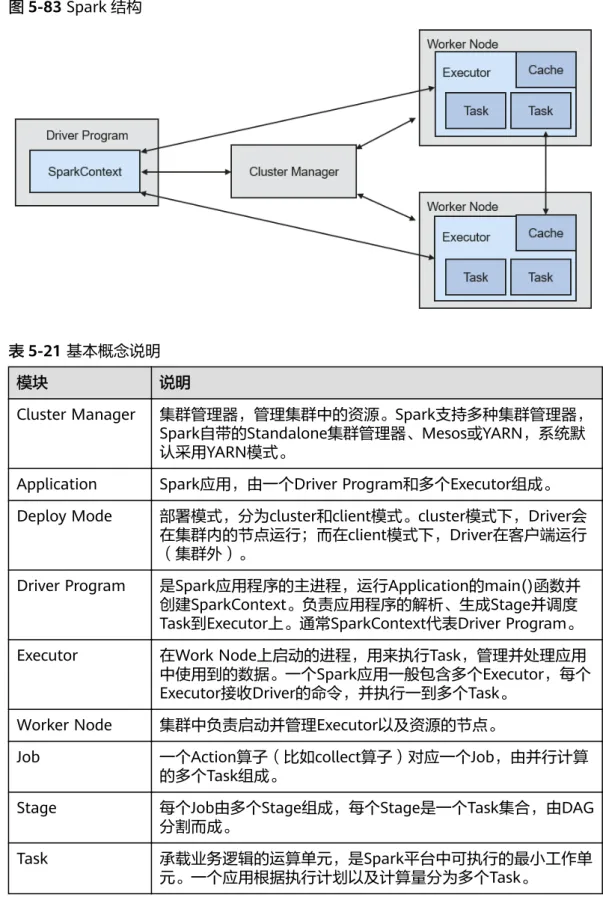
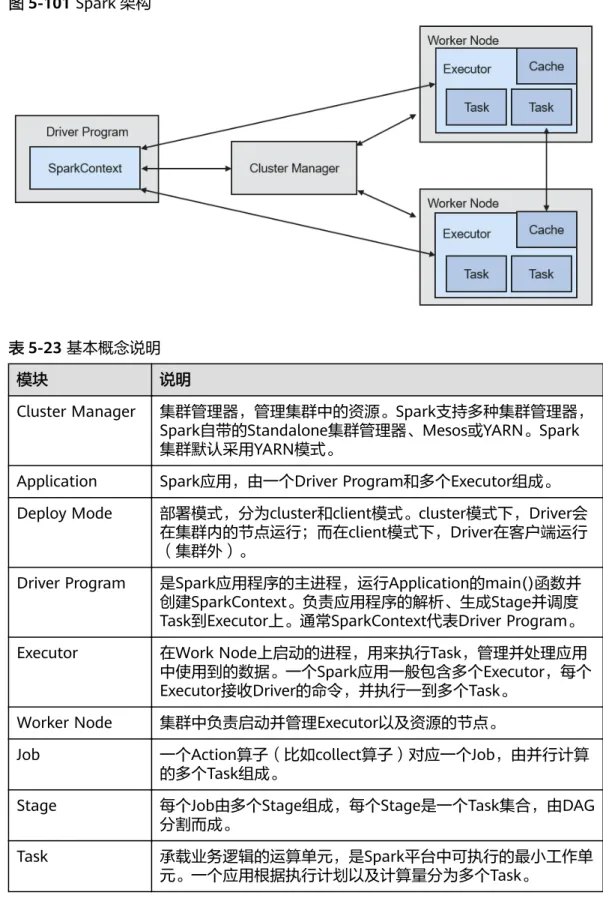
5.25 Spark...118
5.25.1 Spark 基本原理...118
5.25.2 Spark HA 方案介绍... 133
5.25.3 Spark 与 HDFS 和 YARN 的关系... 138
5.25.4 Spark 开源增强特性:跨源复杂数据的 SQL 查询优化...142
5.26 Spark2x... 144
5.26.1 Spark2x 基本原理... 144
5.26.2 Spark2x HA 方案介绍...158
5.26.2.1 Spark2x 多主实例...158
5.26.2.2 Spark2x 多租户... 161
5.26.3 Spark2x 与组件的关系... 164
5.26.4 Spark2x 开源新特性... 168
5.26.5 Spark2x 开源增强特性... 168
5.26.5.1 CarbonData 简介... 168
5.26.5.2 跨源复杂数据的 SQL 查询优化... 170
5.27 Storm... 172
5.27.1 Storm 基本原理... 172
5.27.2 Storm 与其他组件的关系...176
5.27.3 Storm 开源增强特性... 177
5.28 Tez... 177
5.29 YARN...178
5.29.1 YARN 基本原理...178
5.29.2 YARN HA 方案介绍... 182
5.29.3 Yarn 与其他组件的关系...184
5.29.4 YARN 开源增强特性... 187
5.30 ZooKeeper...193
5.30.1 ZooKeeper 基本原理...193
5.30.2 ZooKeeper 与其他组件的关系... 195
5.30.3 ZooKeeper 开源增强特性... 198
6 产品功能... 202
6.1 多租户... 202
6.2 安全增强... 203
6.3 组件 WebUI 便捷访问...205
6.4 可靠性增强... 205
6.5 作业管理... 206
6.6 自定义引导操作... 206
6.7 企业项目管理... 207
6.8 元数据... 207
6.9 集群管理... 208
6.9.1 集群生命周期管理... 208
6.9.2 集群扩缩容... 209
6.9.3 自动弹性伸缩...210
6.9.4 创建 Task 节点... 211
6.9.5 升级 Master 节点规格...211
6.9.6 隔离主机... 211
6.9.7 标签管理... 212
6.10 集群运维... 212
6.11 消息通知... 213
7 约束与限制... 215
8 技术支持... 217
9 计费说明... 218
10 权限管理... 220
11 与其他云服务的关系...224
12 配额说明... 227
13 常见概念... 228
1 图解 MapReduce 服务
2 什么是 MRS
大数据是人类进入互联网时代以来面临的一个巨大问题:社会生产生活产生的数据量 越来越大,数据种类越来越多,数据产生的速度越来越快。传统的数据处理技术,比 如说单机存储,关系数据库已经无法解决这些新的大数据问题。为解决以上大数据处 理问题,Apache基金会推出了Hadoop大数据处理的开源解决方案。Hadoop是一个开 源分布式计算平台,可以充分利用集群的计算和存储能力,完成海量数据的处理。企 业自行部署Hadoop系统有成本高,周期长,难运维和不灵活等问题。
针对上述问题,华为云提供了大数据MapReduce服务(MRS),MRS是一个在华为云 上部署和管理Hadoop系统的服务,一键即可部署Hadoop集群。MRS提供租户完全可 控的一站式企业级大数据集群云服务,完全兼容开源接口,结合华为云计算、存储优 势及大数据行业经验,为客户提供高性能、低成本、灵活易用的全栈大数据平台,轻 松运行Hadoop、Spark、HBase、Kafka、Storm等大数据组件,并具备在后续根据业 务需要进行定制开发的能力,帮助企业快速构建海量数据信息处理系统,并通过对海 量信息数据实时与非实时的分析挖掘,发现全新价值点和企业商机。
产品架构
MRS组件版本情况请参见MRS组件版本一览表。
MRS逻辑架构如图2-1所示。
说明
MRS 3.x及之后版本暂不支持在管理控制台执行补丁管理操作。
图2-1 MRS 架构
MRS架构包括了基础设施和大数据处理流程各个阶段的能力。
● 基础设施
MRS基于华为云弹性云服务器ECS构建的大数据集群,充分利用了其虚拟化层的高 可靠、高安全的能力。
– 虚拟私有云(VPC)为每个租户提供的虚拟内部网络,默认与其他网络隔 离。
– 云硬盘(EVS)提供高可靠、高性能的存储。
– 弹性云服务器(ECS)提供的弹性可扩展虚拟机,结合VPC、安全组、EVS数 据多副本等能力打造一个高效、可靠、安全的计算环境。
● 数据集成
数据集成层提供了数据接入到MRS集群的能力,包括Flume(数据采集)、
Loader(关系型数据导入)、Kafka(高可靠消息队列),支持各种数据源导入数 据到大数据集群中。
● 数据存储
MRS支持结构化和非结构化数据在集群中的存储,并且支持多种高效的格式来满 足不同计算引擎的要求。
– HDFS是大数据上通用的分布式文件系统。
– OBS是对象存储服务,具有高可用低成本的特点。
– HBase支持带索引的数据存储,适合高性能基于索引查询的场景。
● 数据计算
MRS提供多种主流计算引擎:MapReduce(批处理)、Tez(DAG模型)、Spark
(内存计算)、SparkStreaming(微批流计算)、Storm(流计算)、Flink(流 计算),满足多种大数据应用场景,将数据进行结构和逻辑的转换,转化成满足 业务目标的数据模型。
● 数据分析
基于预设的数据模型,使用易用SQL的数据分析,用户可以选择Hive(数据仓 库),SparkSQL以及Presto交互式查询引擎。
● 数据呈现调度
用于数据分析结果的呈现,并与数据湖工厂(DLF)集成,提供一站式的大数据协 同开发平台,帮助用户轻松完成数据建模、数据集成、脚本开发、作业调度、运 维监控等多项任务,可以极大降低用户使用大数据的门槛,帮助用户快速构建大 数据处理中心。
● 集群管理
以Hadoop为基础的大数据生态的各种组件均是以分布式的方式进行部署,其部 署、管理和运维复杂度较高。
MRS集群管理提供了统一的运维管理平台,包括一键式部署集群能力,并提供多 版本选择,支持运行过程中集群在无业务中断条件下,进行扩缩容、弹性伸缩。
同时MRS集群管理还提供了作业管理、资源标签管理,以及对上述数据处理各层 组件的运维,并提供监控、告警、配置、补丁升级等一站式运维能力。
产品优势
MRS服务拥有强大的Hadoop内核团队,基于华为FusionInsight大数据企业级平台构 筑。历经行业数万节点部署量的考验,提供多级用户SLA保障。
MRS具有如下优势:
● 高性能
MRS支持自研的CarbonData存储技术。CarbonData是一种高性能大数据存储方 案,以一份数据同时支持多种应用场景,并通过多级索引、字典编码、预聚合、
动态Partition、准实时数据查询等特性提升了IO扫描和计算性能,实现万亿数据 分析秒级响应。同时MRS支持自研增强型调度器Superior,突破单集群规模瓶 颈,单集群调度能力超10000节点。
● 低成本
基于多样化的云基础设施,提供了丰富的计算、存储设施的选择,同时计算存储 分离,提供了低成本海量数据存储方案。MRS可以按业务峰谷,自动弹性伸缩,
帮助客户节省大数据平台闲时资源。MRS集群可以用时再创建、用时再扩容,用 完就可以销毁、缩容,确保成本最优。
● 高安全
MRS服务拥有企业级的大数据多租户权限管理能力,拥有企业级的大数据安全管 理特性,支持按照表/按列控制访问权限,支持数据按照表/按列加密。
● 易运维
MRS提供可视化大数据集群管理平台,提高运维效率。并支持滚动补丁升级,可 视化补丁发布信息,一键式补丁安装,无需人工干预,不停业务,保障用户集群 长期稳定。
● 高可靠
MRS服务经过大规模的可靠性、长稳验证,满足企业级高可靠要求,同时支持数 据跨AZ/跨Region自动备份的数据容灾能力,自动反亲和技术,虚拟机分布在不同 物理机上。
首次使用 MRS
如果您是首次使用MRS的用户,建议您学习并了解如下信息:
● 基础知识了解
通过MRS组件介绍和产品功能章节的内容,了解MRS相关的基础知识,包含MRS 各组件的基本原理和增强特性介绍,以及MRS服务的特有概念和功能的详细介 绍。
● 入门使用
您可以参考《快速入门》学习并上手使用MRS。《快速入门》提供了样例的详细 操作指导,您可以基于此操作指导,创建和使用MRS集群。
● 使用更多的功能,并查看其相关操作指导
如果您是一个MRS集群使用和运维人员,可以参考用户指南完成集群的生命周期 管理、扩缩容以及作业管理等操作。集群中组件的使用指导可以详细参考组件操 作指南。
如果您是一个开发者,可以参考MRS提供的开发指南操作指导及样例工程开发并 运行调测自己的应用程序。您也可以通过API调用完成MRS集群管理、作业执行等 相关操作,您可以参考《API参考》获取详情。
3 MRS 与自建 Hadoop 对比优势
MapReduce服务(MRS)提供租户完全可控的企业级大数据集群云服务,轻松运行 Hadoop、Spark、HBase、Kafka、Storm等大数据组件,用户无需关注硬件的购买和 维护。MRS服务拥有强大的Hadoop内核团队,基于华为FusionInsight大数据企业级平 台构筑,历经行业数万节点部署量的考验,提供多级用户SLA保障。与自建Hadoop集 群相比,MRS还具有以下优势:
1. MRS支持一键式创建、删除、扩缩容集群,并通过弹性公网IP便携访问MRS集群 管理系统,让大数据集群更加易于使用。
– 用户自建大数据集群面临成本高、周期长、运维难和不灵活等问题。针对这 些问题,MRS支持一键式创建、删除、扩容和缩容集群的能力,用户可以自 定制集群的类型,组件范围,各类型的节点数、虚拟机规格、可用区、VPC 网络、认证信息,MRS将为用户自动创建一个符合配置的集群,全程无需用 户参与。同时支持用户快速创建多应用场景集群,比如快速创建Hadoop分析 集群、HBase集群、Kafka集群。MRS支持部署异构集群,在集群中存在不同 规格的虚拟机,允许在CPU类型,硬盘容量,硬盘类型,内存大小灵活组 合。
– MRS提供了基于弹性公网IP来便捷访问组件WebUI的安全通道,并且比用户 自己绑定弹性公网IP更便捷,只需界面鼠标操作,即可简化原先用户需要自 己登录虚拟私有云添加安全组规则,获取公网IP等步骤,减少了用户操作步 骤。
– MRS提供了自定义引导操作,用户可以以此为入口灵活配置自己的集群,通 过引导操作用户可以自动化地完成安装MRS还没支持的第三方软件,修改集 群运行环境等自定义操作。
– MRS支持WrapperFS特性,提供OBS的翻译能力,兼容HDFS到OBS的平滑迁 移,解决客户将HDFS中的数据迁移到OBS后,即可实现客户端无需修改自己 的业务代码逻辑的情况下,访问存储到OBS的数据。
2. MRS支持自动弹性伸缩,相对自建Hadoop集群的使用成本更低。
MRS可以按业务峰谷,自动弹性伸缩,在业务繁忙时申请额外资源,业务不繁忙 时释放闲置资源,让用户按需使用,帮助用户节省大数据平台闲时资源,尽可能 的帮助用户降低使用成本,聚焦核心业务。
在大数据应用,尤其是周期性的数据分析处理场景中,需要根据业务数据的周期 变化,动态调整集群计算资源以满足业务需要。MRS的弹性伸缩规则功能支持根 据集群负载对集群进行弹性伸缩。此外,如果数据量为周期有规律的变化,并且 希望在数据量变化前提前完成集群的扩缩容,可以使用MRS的资源计划特性。
MRS服务支持规则和时间计划两种弹性伸缩的策略:
– 弹性伸缩规则:根据集群实时负载对Task节点数量进行调整,数据量变化后 触发扩缩容,有一定的延后性。
– 资源计划:若数据量变化存在周期性规律,则可通过资源计划在数据量变化 前提前完成集群的扩缩容,避免出现增加或减少资源的延后。
弹性伸缩规则与资源计划均可触发弹性伸缩,两者即可同时配置也可单独配置。
资源计划与基于负载的弹性伸缩规则叠加使用可以使得集群节点的弹性更好,足 以应对偶尔超出预期的数据峰值出现。
3. MRS支持存算分离,大幅提升大数据集群资源利用率。
针对传统存算一体大数据架构中扩容困难、资源利用率低等问题,MRS采用计算 存储分离架构,存储基于公有云对象存储实现11个9的高可靠,无限容量,支撑企 业数据量持续增长;计算资源支持0~N弹性扩缩,百节点快速发放。存算分离 后,计算节点可实现真正的极致弹性伸缩;数据存储部分基于OBS的跨AZ等能力 实现更高可靠性,无需担心地震、挖断光纤等突发事件。存储和计算资源可以灵 活配置,根据业务需要各自独立进行弹性扩展,可使资源匹配更精准、更合理,
让大数据集群资源利用率大幅提升,综合分析成本降低50%。
同时通过高性能的计算存储分离架构,打破存算一体架构并行计算的限制,最大 化发挥对象存储的高带宽、高并发的特点,对数据访问效率和并行计算深度优化
(元数据操作、写入算法优化等),实现性能提升。
4. MRS支持自研CarbonData和自研超级调度器Superior Scheduler,性能更优。
– MRS支持自研的CarbonData存储技术。CarbonData是一种高性能大数据存 储方案,以一份数据同时支持多种应用场景,并通过多级索引、字典编码、
预聚合、动态Partition、准实时数据查询等特性提升了IO扫描和计算性能,
实现万亿数据分析秒级响应。
– MRS支持自研超级调度器Superior Scheduler,突破单集群规模瓶颈,单集群 调度能力超10000节点。Superior Scheduler是一个专门为Hadoop YARN分 布式资源管理系统设计的调度引擎,是针对企业客户融合资源池,多租户的 业务诉求而设计的高性能企业级调度器。Superior Scheduler可实现开源调度 器、Fair Scheduler以及Capacity Scheduler的所有功能。另外,相较于开源 调度器,Superior Scheduler在企业级多租户调度策略、租户内多用户资源隔 离和共享、调度性能、系统资源利用率和支持大集群扩展性方面都做了针对 性的增强,让Superior Scheduler直接替代开源调度器。
5. MRS基于鲲鹏处理器进行软硬件垂直优化,充分释放硬件算力,实现高性价比。
MRS支持华为自研鲲鹏服务器,充分利用鲲鹏多核高并发能力,提供芯片级的全 栈自主优化能力,使用华为自研的操作系统EulerOS、华为JDK及数据加速层,充 分释放硬件算力,为大数据计算提供高算力输出。在性能相当情况下,端到端的 大数据解决方案成本下降30%。
6. MRS支持多种隔离模式及企业级的大数据多租户权限管理能力,安全性更高。
– MRS服务支持资源专属区内部署,专属区内物理资源隔离,用户可以在专属 区内灵活地组合计算存储资源,包括专属计算资源+共享存储资源、共享计算 资源+专属存储资源、专属计算资源+专属存储资源。MRS集群内支持逻辑多 租户,通过权限隔离,对集群的计算、存储、表格等资源按租户划分。
– MRS支持Kerberos安全认证,实现了基于角色的安全控制及完善的审计功 能。
– MRS支持对接华为云云审计服务(CTS),为用户提供MRS资源操作请求及 请求结果的操作记录,供用户查询、审计和回溯使用。支持所有集群操作审 计,所有用户行为可溯源。
– MRS支持与主机安全服务对接,针对主机安全服务,做过兼容性测试,保证 功能和性能不受影响的情况下,增强服务的安全能力。
– MRS支持基于WebUI的统一的用户登录能力,Manager自带用户认证环节,
用户只有通过Manager认证才能正常访问集群。
– MRS支持数据存储加密,所有用户账号密码加密存储,数据通道加密传输,
服务模块跨信任区的数据访问支持双向证书认证等能力。
– MRS大数据集群提供了完整的企业级大数据多租户解决方案。多租户是MRS 大数据集群中的多个资源集合(每个资源集合是一个租户),具有分配和调 度资源(资源包括计算资源和存储资源)的能力。多租户将大数据集群的资 源隔离成一个个资源集合,彼此互不干扰,用户通过“租用”需要的资源集 合,来运行应用和作业,并存放数据。在大数据集群上可以存在多个资源集 合来支持多个用户的不同需求。
– MRS支持细粒度权限管理,结合华为云IAM服务提供的一种细粒度授权的能 力,可以精确到具体服务的操作、资源以及请求条件等。基于策略的授权是 一种更加灵活的授权方式,能够满足企业对权限最小化的安全管控要求。例 如:针对MRS服务,管理员能够控制IAM用户仅能对集群进行指定的管理操 作。如不允许某用户组删除集群,仅允许操作MRS集群基本操作,如创建集 群、查询集群列表等。同时MRS支持多租户对OBS存储的细粒度权限管理,
根据多种用户角色来区分访问OBS桶及其内部的对象的权限,实现MRS用户 对OBS桶下的目录权限控制。
– MRS支持企业项目管理。企业项目是一种云资源管理方式,企业管理
(Enterprise Management)提供面向企业客户的云上资源管理、人员管 理、权限管理、财务管理等综合管理服务。区别于管理控制台独立操控、配 置云产品的方式,企业管理控制台以面向企业资源管理为出发点,帮助企业 以公司、部门、项目等分级管理方式实现企业云上的人员、资源、权限、财 务的管理。MRS支持已开通企业项目服务的用户在创建集群时为集群配置对 应的项目,然后使用企业项目管理对MRS上的的资源进行分组管理。此特性 适用于客户针对多个资源进行分组管理,并对相应的企业项目进行诸如权限 控制、分项目费用查看等操作的场景。
7. MRS管理节点均实现HA,支持完备的可靠性机制,让系统更加可靠。
MRS在基于Apache Hadoop开源软件的基础上,在主要业务部件的可靠性方面进 行了优化和提升。
– 管理节点均实现HA
Hadoop开源版本的数据、计算节点已经是按照分布式系统进行设计的,单节 点故障不影响系统整体运行;而以集中模式运作的管理节点可能出现的单点 故障,就成为整个系统可靠性的短板。
MRS对所有业务组件的管理节点都提供了类似的双机的机制,包括 Manager、Presto、HDFS NameNode、Hive Server、HBase HMaster、
YARN Resources Manager、Kerberos Server、Ldap Server等,全部采用主 备或负荷分担配置,有效避免了单点故障场景对系统可靠性的影响。
– 完备的可靠性机制
通过可靠性分析方法,梳理软件、硬件异常场景下的处理措施,提升系统的 可靠性。
▪
保障意外掉电时的数据可靠性,不论是单节点意外掉电,还是整个集群 意外断电,恢复供电后系统能够正常恢复业务,除非硬盘介质损坏,否 则关键数据不会丢失。▪
硬盘亚健康检测和故障处理,对业务不造成实际影响。▪
自动处理文件系统的故障,自动恢复受影响的业务。▪
自动处理进程和节点的故障,自动恢复受影响的业务。▪
自动处理网络故障,自动恢复受影响的业务。8. MRS提供统一的可视化大数据集群管理界面,让运维人员更加轻松。
– MRS提供统一的可视化大数据集群管理界面,包括服务启停、配置修改、健 康检查等能力,并提供可视化、便捷的集群管理监控告警功能;支持一键式 系统运行健康度巡检和审计,保障系统的正常运行,降低系统运维成本。
– MRS联合消息通知服务(SMN),在配置消息通知后,可以实时给用户发送 MRS集群健康状态,用户可以通过手机短信或邮箱实时接收到MRS集群变更 及组件告警信息,帮助用户轻松运维,实时监控,实时发送告警。
– MRS支持滚动补丁升级,可视化补丁发布信息,一键式补丁安装,无需人工 干预,不停业务,保障用户集群长期稳定。
– MRS服务支持运维授权的功能,用户在使用MRS集群过程中,发生问题可以 在MRS页面发起运维授权,由运维人员帮助客户快速定位问题,用户可以随 时收回该授权。同时用户也可以在MRS页面发起日志共享,选择日志范围共 享给运维人员,以便运维人员在不接触集群的情况下帮助定位问题。
– MRS支持将创建集群失败的日志转储到OBS,便于运维人员获取日志进行分 析。
9. MRS具有开放的生态,支持无缝对接周边服务,快速构建统一大数据平台。
– 以全栈大数据MRS服务为基础,企业可以一键式构筑数据接入、数据存储、
数据分析和价值挖掘的统一大数据平台,并且与数据湖治理中心 DGC及数据 可视化等服务对接,为客户轻松解决数据通道上云、大数据作业开发调度和 数据展现的困难,使客户从复杂的大数据平台构建和专业大数据调优和维护 中解脱出来,更加专注行业应用,使客户完成一份数据多业务场景使用的诉 求。DGC是数据全生命周期一站式开发运营平台,提供数据集成、数据开 发、数据治理、数据服务、数据可视化等功能。MRS数据支持连接DGC台,
并基于可视化的图形开发界面、丰富的数据开发类型(脚本开发和作业开 发)、全托管的作业调度和运维监控能力,内置行业数据处理pipeline,一键 式开发,全流程可视化,支持多人在线协同开发,极大地降低了用户使用大 数据的门槛,帮助用户快速构建大数据处理中心,对数据进行治理及开发调 度,快速实现数据变现。
– MRS服务100%兼容开源大数据生态,结合周边丰富的数据及应用迁移工具,
能够帮助客户快速完成自建平台的平滑迁移,整个迁移过程可做到“代码0修 改,业务0中断”。
4 应用场景
大数据在人们的生活中无处不在,在IoT、电子商务、金融、制造、医疗、能源和政府 部门等行业均可以使用华为云MRS服务进行大数据处理。
海量数据分析场景
海量数据分析是现代大数据系统中的主要场景。通常企业会包含多种数据源,接入后 需要对数据进行ETL(Extract-Transform-Load)处理形成模型化数据,以便提供给各 个业务模块进行分析梳理,这类业务通常有以下特点:
● 对执行实时性要求不高,作业执行时间在数十分钟到小时级别。
● 数据量巨大。
● 数据来源和格式多种多样。
● 数据处理通常由多个任务构成,对资源需要进行详细规划。
例如在环保行业中,可以将天气数据存储在OBS,定期转储到HDFS中进行批量分析,
在1小时内MRS可以完成10TB的天气数据分析。
图4-1 环保行业海量数据分析场景
该场景下MRS的优势如下所示。
● 低成本:利用OBS实现低成本存储。
● 海量数据分析:利用Hive实现TB/PB级的数据分析。
● 可视化的导入导出工具:通过可视化导入导出工具Loader,将数据导出到DWS,
完成BI分析。
海量数据存储场景
用户拥有大量结构化数据后,通常需要提供基于索引的准实时查询能力,如车联网场 景下,根据汽车编号查询汽车维护信息,存储时,汽车信息会基于汽车编号进行索 引,以实现该场景下的秒级响应。通常这类数据量比较庞大,用户可能保存1至3年的 数据。
例如在车联网行业,某车企将数据储存在HBase中,以支持PB级别的数据存储和毫秒 级的数据详单查询。
图4-2 车联网行业海量数据存储场景
该场景下MRS的优势如下所示。
● 实时:利用Kafka实现海量汽车的消息实时接入。
● 海量数据存储:利用HBase实现海量数据存储,并实现毫秒级数据查询。
● 分布式数据查询:利用Spark实现海量数据的分析查询。
实时数据处理
实时数据处理通常用于异常检测、欺诈识别、基于规则告警、业务流程监控等场景,
在数据输入系统的过程中,对数据进行处理。
例如在梯联网行业,智能电梯的数据,实时传入到MRS的流式集群中进行实时告警。
图4-3 梯联网行业低时延流式处理场景
该场景下MRS的优势如下所示。
● 实时数据采集:利用Flume实现实时数据采集,并提供丰富的采集和存储连接方 式。
● 海量的数据源接入:利用Kafka实现万级别的电梯数据的实时接入。
5 组件介绍
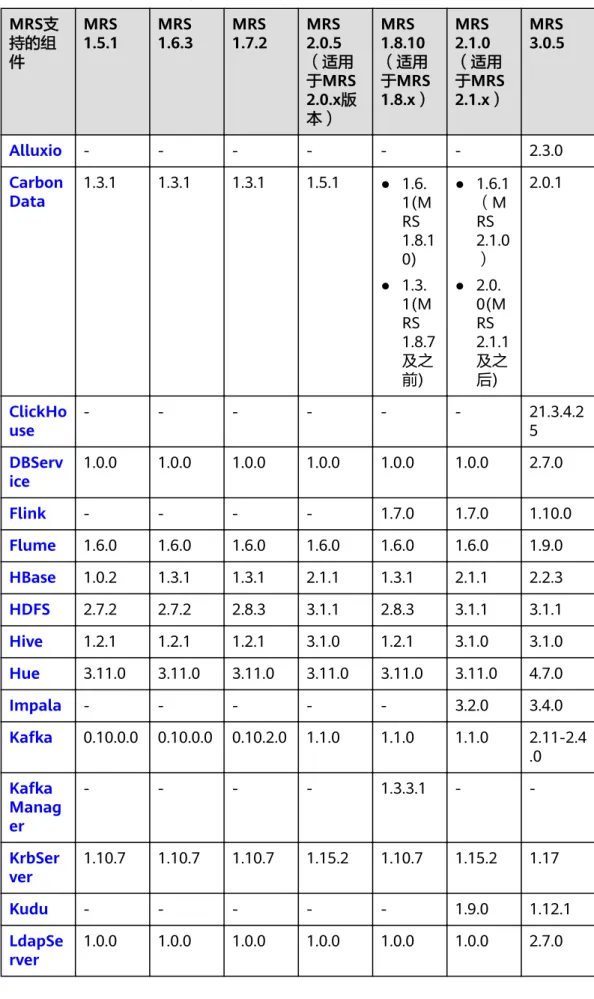
5.1 MRS 组件版本一览表
组件及版本号信息
MRS各集群版本配套的组件及版本号信息表5-1所示。
说明
● Hadoop包括:HDFS、YARN、Mapreduce。
● DBService、ZooKeeper、KrbServer及LdapServer为集群内部使用的组件,在创建集群时不 呈现。
● MRS组件的版本号与组件开源版本号保持一致。
表5-1 MRS 组件版本信息
MRS支持的组件 MRS 1.9.2(适用于MRS
1.9.x) MRS 3.1.0
Alluxio 2.0.1 -
CarbonData 1.6.1 2.0.1
ClickHouse - 21.3.4.25
DBService 1.0.0 2.7.0
Flink 1.7.0 1.12.0
Flume 1.6.0 1.9.0
HBase 1.3.1 2.2.3
HDFS 2.8.3 3.1.1
Hive 2.3.3 3.1.0
Hudi - 0.8.0
MRS支持的组件 MRS 1.9.2(适用于MRS
1.9.x) MRS 3.1.0
Hue 3.11.0 4.7.0
Impala - 3.4.0
Kafka 1.1.0 2.11-2.4.0
KafkaManager 1.3.3.1 -
KrbServer 1.15.2 1.17
Kudu - 1.12.1
LdapServer 1.0.0 2.7.0
Loader 2.0.0 -
MapReduce 2.8.3 3.1.1
Oozie - 5.1.0
Opentsdb 2.3.0 -
Presto 0.216 333
Phoenix(集成在HBase 中)
- 5.0.0
Ranger 1.0.1 2.0.0
Spark 2.2.2 -
Spark2x - 2.4.5
Sqoop - 1.4.7
Storm 1.2.1 -
Tez 0.9.1 0.9.2
YARN 2.8.3 3.1.1
ZooKeeper 3.5.1 3.5.6
MRS Manager 1.9.2 -
FusionInsight Manager - 8.1.0
组件及版本号信息(已下线版本)
MRS已下线集群版本配套的组件及版本号信息如表5-2所示。
表5-2 MRS 组件版本信息(已下线版本)
MRS支 持的组 件
MRS1.5.1 MRS
1.6.3 MRS
1.7.2 MRS 2.0.5
(适用于MRS 2.0.x版 本)
MRS1.8.10
(适用于MRS 1.8.x)
MRS2.1.0
(适用于MRS 2.1.x)
MRS3.0.5
Alluxio - - - 2.3.0
Carbon
Data 1.3.1 1.3.1 1.3.1 1.5.1 ● 1.6.
1(MRS 1.8.1 0)
● 1.3.
1(MRS 1.8.7 及之前)
● 1.6.1
(MRS 2.1.0
)
● 2.0.
0(MRS 2.1.1 及之后)
2.0.1
ClickHo
use - - - 21.3.4.2
5 DBServ
ice 1.0.0 1.0.0 1.0.0 1.0.0 1.0.0 1.0.0 2.7.0
Flink - - - - 1.7.0 1.7.0 1.10.0
Flume 1.6.0 1.6.0 1.6.0 1.6.0 1.6.0 1.6.0 1.9.0 HBase 1.0.2 1.3.1 1.3.1 2.1.1 1.3.1 2.1.1 2.2.3 HDFS 2.7.2 2.7.2 2.8.3 3.1.1 2.8.3 3.1.1 3.1.1 Hive 1.2.1 1.2.1 1.2.1 3.1.0 1.2.1 3.1.0 3.1.0 Hue 3.11.0 3.11.0 3.11.0 3.11.0 3.11.0 3.11.0 4.7.0
Impala - - - 3.2.0 3.4.0
Kafka 0.10.0.0 0.10.0.0 0.10.2.0 1.1.0 1.1.0 1.1.0 2.11-2.4 .0 Kafka
Manag er
- - - - 1.3.3.1 - -
KrbSer
ver 1.10.7 1.10.7 1.10.7 1.15.2 1.10.7 1.15.2 1.17
Kudu - - - 1.9.0 1.12.1
LdapSe
rver 1.0.0 1.0.0 1.0.0 1.0.0 1.0.0 1.0.0 2.7.0
MRS支 持的组 件
MRS1.5.1 MRS
1.6.3 MRS
1.7.2 MRS 2.0.5
(适用于MRS 2.0.x版 本)
MRS1.8.10
(适用于MRS 1.8.x)
MRS2.1.0
(适用于MRS 2.1.x)
MRS3.0.5
Loader 2.0.0 2.0.0 2.0.0 2.0.0 2.0.0 2.0.0 1.99.3 MapRe
duce 2.7.2 2.7.2 2.8.3 3.1.1 2.8.3 3.1.1 3.1.1
Oozie - - - 5.1.0
Opents
db - - - - 2.3.0 - -
Presto - - - 308 0.215 308 333
Phoenix - - - 5.0.0
Ranger - - - 2.0.0
Spark 2.1.0 2.1.0 2.2.1 2.3.2 2.2.1 2.3.2 - Spark2
x - - - 2.4.5
Storm 1.0.2 1.0.2 1.0.2 1.2.1 1.2.1 1.2.1 1.2.1 Tez - - - 0.9.1 - 0.9.1 0.9.2 YARN 2.7.2 2.7.2 2.8.3 3.1.1 2.8.3 3.1.1 3.1.1 ZooKee
per 3.5.1 3.5.1 3.5.1 3.5.1 3.5.1 3.5.1 3.5.6 MRSManag
er
1.5.1 1.6.3 1.7.2 2.0.5 1.8.10 2.1.0 -
FusionI nsight Manag er
- - - 8.0.2.1
5.2 Alluxio
Alluxio是一个面向基于云的数据分析和人工智能的数据编排技术。在MRS的大数据生 态系统中,Alluxio位于计算和存储之间,为包括Apache Spark、Presto、Mapreduce 和Apache Hive的计算框架提供了数据抽象层,使上层的计算应用可以通过统一的客户 端API和全局命名空间访问包括HDFS和OBS在内的持久化存储系统,从而实现了对计 算和存储的分离。
图5-1 Alluxio 架构
优势:
● 提供内存级 I/O 吞吐率,同时降低具有弹性扩张特性的数据驱动型应用的成本开 销
● 简化云存储和对象存储接入
● 简化数据管理,提供对多数据源的单点访问
● 应用程序部署简易
有关Alluxio的详细信息,请参见:https://docs.alluxio.io/os/user/stable/cn/
Overview.html。
5.3 CarbonData
CarbonData是一种新型的Apache Hadoop本地文件格式,使用先进的列式存储、索 引、压缩和编码技术,以提高计算效率,有助于加速超过PB数量级的数据查询,可用 于更快的交互查询。同时,CarbonData也是一种将数据源与Spark集成的高性能分析 引擎。
图5-2 CarbonData 基本架构
使用CarbonData的目的是对大数据即席查询提供超快速响应。CarbonData是一个 OLAP引擎,采用类似于RDBMS中的表来存储数据。用户可将大量(10TB以上)的数 据导入以CarbonData格式创建的表中,CarbonData将以压缩的多维索引列格式自动 组织和存储数据。数据被加载到CarbonData后,就可以执行即席查询,CarbonData 将对数据查询提供秒级响应。
CarbonData将数据源集成到Spark生态系统,用户可使用Spark SQL执行数据查询和分 析,也可以使用Spark提供的第三方工具ThriftServer连接到Spark SQL。
CarbonData特性
● SQL功能:CarbonData与Spark SQL完全兼容,支持所有可以直接在Spark SQL上 运行的SQL查询操作。
● 简单的Table数据集定义:CarbonData支持易于使用的DDL(数据定义语言)语 句来定义和创建数据集。CarbonData DDL十分灵活、易于使用,并且足够强大,
可以定义复杂类型的Table。
● 便捷的数据管理:CarbonData为数据加载和维护提供多种数据管理功能,支持加 载历史数据以及增量加载新数据。CarbonData加载的数据可以基于加载时间进行 删除,也可以撤销特定的数据加载操作。
● CarbonData文件格式是HDFS中的列式存储格式。该格式具有许多新型列存储文 件的特性。例如,分割表,压缩模式等。
CarbonData独有的特点
● 伴随索引的数据存储:由于在查询中设置了过滤器,可以显著加快查询性能,减 少I/O扫描次数和CPU资源占用。CarbonData索引由多个级别的索引组成,处理 框架可以利用这个索引来减少需要安排和处理的任务,也可以通过在任务扫描中 以更精细的单元(称为blocklet)进行skip扫描来代替对整个文件的扫描。
● 可选择的数据编码:通过支持高效的数据压缩和全局编码方案,可基于压缩/编码 数据进行查询,在将结果返回给用户之前,才将编码转化为实际数据,这被称为
“延迟物化”。
● 支持一种数据格式应用于多种用例场景:例如交互式OLAP-style查询,顺序访问
(big scan),随机访问(narrow scan)。
CarbonData关键技术和优势
● 快速查询响应:高性能查询是CarbonData关键技术的优势之一。CarbonData查 询速度大约是Spark SQL查询的10倍。CarbonData使用的专用数据格式围绕高性 能查询进行设计,其中包括多种索引技术、全局字典编码和多次的Push down优 化,从而对TB级数据查询进行最快响应。
● 高效率数据压缩:CarbonData使用轻量级压缩和重量级压缩的组合压缩算法压缩 数据,可以减少60%~80%数据存储空间,大大节省硬件存储成本。
关于CarbonData的架构和详细原理介绍,请参见:https://
carbondata.apache.org/。
5.4 ClickHouse
5.4.1 图解 ClickHouse
5.4.2 ClickHouse
ClickHouse 简介
ClickHouse是一款开源的面向联机分析处理的列式数据库,其独立于Hadoop大数据体 系,最核心的特点是极致压缩率和极速查询性能。同时,ClickHouse支持SQL查询,
且查询性能好,特别是基于大宽表的聚合分析查询性能非常优异,比其他分析型数据 库速度快一个数量级。
ClickHouse核心的功能特性介绍如下:
完备的DBMS功能
ClickHouse拥有完备的数据库管理功能,具备一个DBMS(Database Management System,数据库管理系统)基本的功能,如下所示。
● DDL (数据定义语言):可以动态地创建、修改或删除数据库、表和视图,而无 须重启服务。
● DML(数据操作语言):可以动态查询、插入、修改或删除数据。
● 权限控制:可以按照用户粒度设置数据库或者表的操作权限,保障数据的安全 性。
● 数据备份与恢复:提供了数据备份导出与导入恢复机制,满足生产环境的要求。
● 分布式管理:提供集群模式,能够自动管理多个数据库节点。
列式存储与数据压缩
ClickHouse是一款使用列式存储的数据库,数据按列进行组织,属于同一列的数据会 被保存在一起,列与列之间也会由不同的文件分别保存。
在执行数据查询时,列式存储可以减少数据扫描范围和数据传输时的大小,提高了数 据查询的效率。
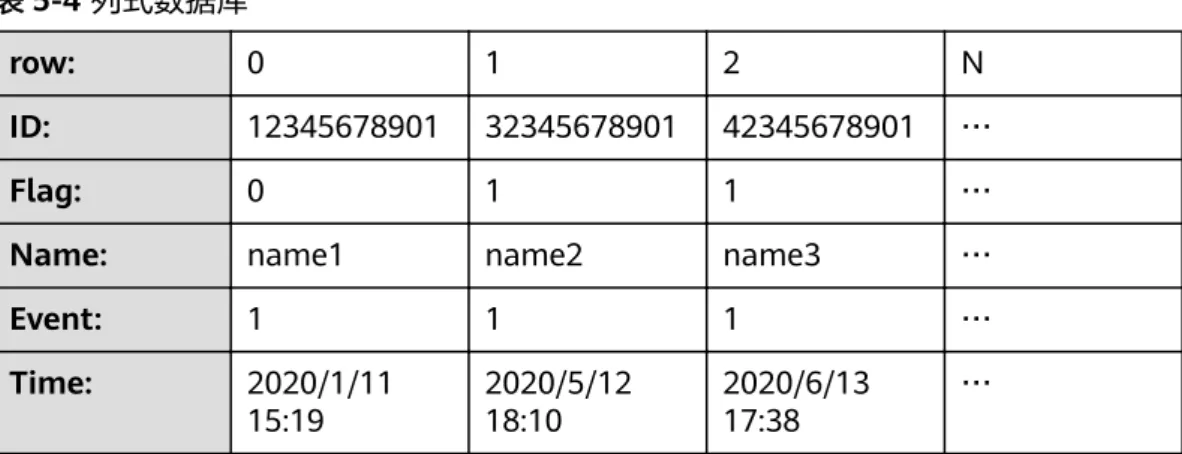
例如在传统的行式数据库系统中,数据按如下表5-3顺序存储:
表5-3 行式数据库
row ID Flag Name Event Time
0 123456789
01 0 name1 1 2020/1/11
15:19 1 323456789
01 1 name2 1 2020/5/12
18:10 2 423456789
01 1 name3 1 2020/6/13
17:38
N … … … … …
行式数据库中处于同一行中的数据总是被物理的存储在一起,而在列式数据库系统 中,数据按如下表5-4顺序存储:
表5-4 列式数据库
row: 0 1 2 N
ID: 12345678901 32345678901 42345678901 …
Flag: 0 1 1 …
Name: name1 name2 name3 …
Event: 1 1 1 …
Time: 2020/1/11
15:19 2020/5/12
18:10 2020/6/13
17:38 …
该示例中只展示了数据在列式数据库中数据的排列方式。对于存储而言,列式数据库 总是将同一列的数据存储在一起,不同列的数据也总是分开存储,列式数据库更适合 于OLAP(Online Analytical Processing)场景。
向量化执行引擎
ClickHouse利用CPU的SIMD指令实现了向量化执行。SIMD的全称是Single Instruction Multiple Data,即用单条指令操作多条数据,通过数据并行以提高性能的一种实现方 式 ( 其他的还有指令级并行和线程级并行 ),它的原理是在CPU寄存器层面实现数据的 并行操作。
关系模型与SQL查询
ClickHouse完全使用SQL作为查询语言,提供了标准协议的SQL查询接口,使得现有的 第三方分析可视化系统可以轻松与它集成对接。
同时ClickHouse使用了关系模型,所以将构建在传统关系型数据库或数据仓库之上的 系统迁移到ClickHouse的成本会变得更低。
数据分片与分布式查询
ClickHouse集群由1到多个分片组成,而每个分片则对应了ClickHouse的1个服务节 点。分片的数量上限取决于节点数量(1个分片只能对应1个服务节点)。
ClickHouse提供了本地表 (Local Table)与分布式表 (Distributed Table)的概念。
一张本地表等同于一份数据的分片。而分布式表本身不存储任何数据,它是本地表的 访问代理,其作用类似分库中间件。借助分布式表,能够代理访问多个数据分片,从 而实现分布式查询。
ClickHouse 应用场景
ClickHouse是Click Stream + Data WareHouse的缩写,起初应用于一款Web流量分析 工具,基于页面的点击事件流,面向数据仓库进行OLAP分析。当前ClickHouse被广泛 的应用于互联网广告、App和Web流量、电信、金融、物联网等众多领域,非常适用 于商业智能化应用场景,在国内外有大量的应用和实践,具体请参考:https://
clickhouse.tech/docs/en/introduction/adopters/。
ClickHouse 开源增强特性
MRS ClickHouse具备“手动挡”集群模式升级、平滑弹性扩容、高可用HA部署架构等 优势能力,具体详情如下:
● 手动挡集群模式升级
如图5-3所示,多个ClickHouse节点组成的集群,没有中心节点,更多的是一个静 态资源池的概念,业务要使用ClickHouse集群模式,需要预先在各个节点的配置 文件中定义cluster信息,等所有参与的节点达成共识,业务才可以正确的交互访 问,也就是说配置文件中的cluster才是我们通常理解的“集群”概念。
图5-3 ClickHouse 集群
常见的数据库系统,隐藏了表级以下的数据分区、副本存储等细节,用户是无感 知的,而ClickHouse则要求用户主动来规划和定义数据分片(shard)、分区
(partition)、副本(replica)位置等详细配置。它的这种类似“手动挡”的属 性,给用户带来极不友好的体验,所以MRS服务的ClickHouse实例对这些工作做 了统一的打包处理,适配成了“自动挡”,实现了统一管理,灵活易用。具体部 署形态上,一个ClickHouse实例将包含3个Zookeeper节点和多个ClickHouse节 点,采用Dedicated Replica模式,数据双副本高可靠。
图5-4 ClickHouse 的 cluster 结构
● 平滑的弹性扩容能力
随着业务的快速增长,面对集群存储容量或者CPU计算资源接近极限等场景,
MRS服务提供了平滑的弹性扩容能力,能快速满足客户业务增长诉求。在用户对 集群进行扩容ClickHouse节点时,MRS提供了一键式数据Balance均衡工具,并把 数据均衡的主动权交给用户,由用户根据业务的特点,自由决定数据均衡的方式 和时间点,以便保障业务可用性,实现了更加平滑的扩容能力。
● 高可用HA部署架构
MRS服务提供了基于ELB的HA部署架构,可以将用户访问流量自动分发到多台后 端节点,扩展系统对外的服务能力,实现更高水平的应用容错。如图5-5所示,客
户端应用请求集群时,使用ELB(Elastic Load Balance)来进行流量分发,通过 ELB的轮询机制,写不同节点上的本地表(Local Table),读不同节点上的分布式 表(Distributed Table),这样,无论集群写入的负载、读的负载以及应用接入 的高可用性都具备了有力的保障。
ClickHouse集群发放成功后,每个ClickHouse实例节点对应一个副本replica,两 个副本组成一个shard逻辑分片。如创建ReplicatedMergeTree引擎表时,可以指 定分片,相同分片内的两个副本数据就可以自动进行同步。
图5-5 高可用 HA 部署架构图
5.5 DBService
5.5.1 DBService 基本原理
DBService 简介
DBService是一个高可用性的关系型数据库存储系统,适用于存储小量数据(10GB左 右),比如:组件元数据。DBService仅提供给集群内部的组件使用,提供数据存储、
查询、删除等功能。
DBService是集群的基础组件,Hive、Hue、Oozie、Loader和Redis组件将元数据存储 在DBService上,并由DBService提供这些元数据的备份与恢复功能。
DBService 结构
DBService组件在集群中采用主备模式部署两个DBServer实例,每个DBServer实例包 含三个模块:HA、Database和Floatip。
其逻辑结构如图5-6所示。
图5-6 DBService 结构
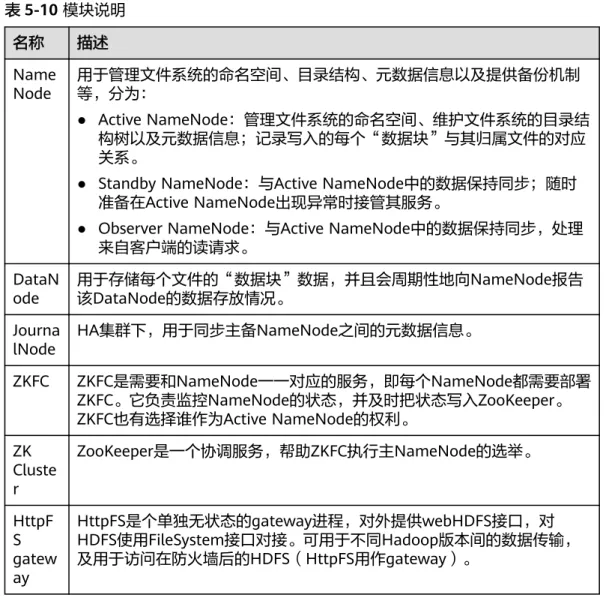
图5-6中各模块的说明如表5-5所示。
表5-5 模块说明
名称 描述
HA 高可用性管理模块,主备DBServer通过HA进行管理。
Databas
e 数据库模块,存储Client模块的元数据。
FloatIP 浮动IP,对外提供访问功能,只在主DBServer实例上启动浮动IP,Client 模块通过该IP访问Database。
Client 使用DBService组件的客户端,部署在组件实例节点上,通过Floatip连接 数据库,执行元数据的增加、删除、修改等操作。
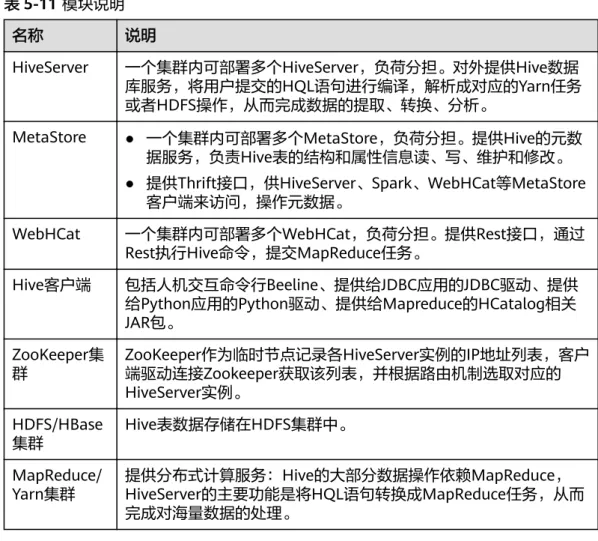
5.5.2 DBService 与其他组件的关系
DBService是集群的基础组件,Hive、Hue、Oozie、Loader、Metadata和Redis组件 将元数据存储在DBService上,并由DBService提供这些元数据的备份与恢复功能。
5.6 Flink
5.6.1 Flink 基本原理
Flink 简介
Flink是一个批处理和流处理结合的统一计算框架,其核心是一个提供了数据分发以及 并行化计算的流数据处理引擎。它的最大亮点是流处理,是业界最顶级的开源流处理 引擎。
Flink最适合的应用场景是低时延的数据处理(Data Processing)场景:高并发 pipeline处理数据,时延毫秒级,且兼具可靠性。
Flink技术栈如图5-7所示。
图5-7 Flink 技术栈
Flink在当前版本中重点构建如下特性:
● DataStream
● Checkpoint
● 窗口
● Job Pipeline
● 配置表
其他特性继承开源社区,不做增强,具体请参考:https://ci.apache.org/projects/
flink/flink-docs-release-1.12/。
Flink 结构
Flink结构如图5-8所示。
图5-8 Flink 结构
Flink整个系统包含三个部分:
● Client
Flink Client主要给用户提供向Flink系统提交用户任务(流式作业)的能力。
● TaskManager
Flink系统的业务执行节点,执行具体的用户任务。TaskManager可以有多个,各 个TaskManager都平等。
● JobManager
Flink系统的管理节点,管理所有的TaskManager,并决策用户任务在哪些 Taskmanager执行。JobManager在HA模式下可以有多个,但只有一个主 JobManager。
如果您想了解更多关于Flink架构的信息,请参考链接:https://ci.apache.org/
projects/flink/flink-docs-master/docs/concepts/flink-architecture/。
Flink 原理
● Stream & Transformation & Operator
用户实现的Flink程序是由Stream和Transformation这两个基本构建块组成。
a. Stream是一个中间结果数据,而Transformation是一个操作,它对一个或多 个输入Stream进行计算处理,输出一个或多个结果Stream。
b. 当一个Flink程序被执行的时候,它会被映射为Streaming Dataflow。一个 Streaming Dataflow是由一组Stream和Transformation Operator组成,它类 似于一个DAG图,在启动的时候从一个或多个Source Operator开始,结束于 一个或多个Sink Operator。
图5-9为一个由Flink程序映射为Streaming Dataflow的示意图。
图5-9 Flink DataStream 示例
图5-9中“FlinkKafkaConsumer”是一个Source Operator,Map、KeyBy、
TimeWindow、Apply是Transformation Operator,RollingSink是一个Sink Operator。
● Pipeline Dataflow
在Flink中,程序是并行和分布式的方式运行。一个Stream可以被分成多个Stream 分区(Stream Partitions),一个Operator可以被分成多个Operator Subtask。
Flink内部有一个优化的功能,根据上下游算子的紧密程度来进行优化。
– 紧密度低的算子则不能进行优化,而是将每一个Operator Subtask放在不同 的线程中独立执行。一个Operator的并行度,等于Operator Subtask的个 数,一个Stream的并行度(分区总数)等于生成它的Operator的并行度,如 图5-10所示。
图5-10 Operator
– 紧密度高的算子可以进行优化,优化后可以将多个Operator Subtask串起来 组成一个Operator Chain,实际上就是一个执行链,每个执行链会在 TaskManager上一个独立的线程中执行,如图5-11所示。
图5-11 Operator chain
▪
图5-11中上半部分表示的是将Source和map两个紧密度高的算子优化后串成一个Operator Chain,实际上一个Operator Chain就是一个大的 Operator的概念。图中的Operator Chain表示一个Operator,keyBy表 示一个Operator,Sink表示一个Operator,它们通过Stream连接,而每 个Operator在运行时对应一个Task,也就是说图中的上半部分有3个 Operator对应的是3个Task。
▪
图5-11中下半部分是上半部分的一个并行版本,对每一个Task都并行化为多个Subtask,这里只是演示了2个并行度,Sink算子是1个并行度。
Flink 关键特性
● 流式处理
高吞吐、高性能、低时延的实时流处理引擎,能够提供ms级时延处理能力。
● 丰富的状态管理
流处理应用需要在一定时间内存储所接收到的事件或中间结果,以供后续某个时 间点访问并进行后续处理。Flink提供了丰富的状态管理相关的特性支持,其中包 括
– 多种基础状态类型:Flink提供了多种不同数据结构的状态支持,如
ValueState、ListState、MapState等。用户可以基于业务模型选择最高效、
合适状态类型。
– 丰富的State Backend:State Backend负责管理应用程序的状态,并根据需 要进行Checkpoint。Flink提供了不同State Backend,State可以存储在内存 上或RocksDB等上,并支持异步以及增量的Checkpoint机制。
– 精确一次语义:Flink的Checkpoint和故障恢复能力保证了任务在故障发生前 后的应用状态一致性,为某些特定的存储支持了事务型输出的功能,即使在 发生故障的情况下,也能够保证精确一次的输出。
● 丰富的时间语义支持
时间是流处理应用的重要组成部分,对于实时流处理应用来说,基于时间语义的 窗口聚合、检测、匹配等运算是非常常见的。Flink提供了丰富的时间语义支持。
– Event-time:使用事件本身自带的时间戳进行计算,使乱序到达或延迟到达 的事件处理变得更加简单。
– Watermark支持:Flink引入Watermark概念,用以衡量事件时间的发展。
Watermark也为平衡处理时延和数据完整性提供了灵活的保障。当处理带有 Watermark的事件流时,在计算完成之后仍然有相关数据到达时,Flink提供 了多种处理选项,如将数据重定向(side output)或更新之前完成的计算结 果。
– Processing-time和Ingestion-time支持。
– 高度灵活的流式窗口支持:Flink能够支持时间窗口、计数窗口、会话窗口,
以及数据驱动的自定义窗口,可以通过灵活的触发条件定制,实现复杂的流 式计算模式。
● 容错机制
分布式系统,单个task或节点的崩溃或故障,往往会导致整个任务的失败。Flink 提供了任务级别的容错机制,保证任务在异常发生时不会丢失用户数据,并且能 够自动恢复。
– Checkpoint:Flink基于Checkpoint实现容错,用户可以自定义对整个任务的 Checkpoint策略,当任务出现失败时,可以将任务恢复到最近一次
Checkpoint的状态,从数据源重发快照之后的数据。
– Savepoint:一个Savepoint就是应用状态的一致性快照,Savepoint与 Checkpoint机制相似,但Savepoint需要手动触发,Savepoint保证了任务在 升级或迁移时,不丢失掉当前流应用的状态信息,便于任何时间点的任务暂 停和恢复。
● Flink SQL
Table API和SQL借助了Apache Calcite来进行查询的解析,校验以及优化,可以 与DataStream和DataSet API无缝集成,并支持用户自定义的标量函数,聚合函 数以及表值函数。简化数据分析、ETL等应用的定义。下面代码实例展示了如何使 用Flink SQL语句定义一个会话点击量的计数应用。
SELECT userId, COUNT(*) FROM clicks
GROUP BY SESSION(clicktime, INTERVAL '30' MINUTE), userId
有关Flink SQL的更多信息,请参见:https://ci.apache.org/projects/flink/
flink-docs-master/dev/table/sqlClient.html。
● CEP in SQL
Flink允许用户在SQL中表示CEP(Complex Event Processing)查询结果以用于模 式匹配,并在Flink上对事件流进行评估。
CEP SQL 通过MATCH_RECOGNIZE的SQL语法实现。MATCH_RECOGNIZE子句自 Oracle Database 12c起由Oracle SQL支持,用于在SQL中表示事件模式匹配。
CEP SQL使用举例如下:
SELECT T.aid, T.bid, T.cid FROM MyTable
MATCH_RECOGNIZE ( PARTITION BY userid ORDER BY proctime MEASURES A.id AS aid, B.id AS bid, C.id AS cid PATTERN (A B C) DEFINE
A AS name = 'a', B AS name = 'b', C AS name = 'c' ) AS T
5.6.2 Flink HA 方案介绍
Flink HA 方案介绍
每个Flink集群只有单个JobManager,存在单点失败的情况。Flink有YARN、
Standalone和Local三种模式,其中YARN和Standalone是集群模式,Local是指单机模 式。但Flink对于YARN模式和Standalone模式提供HA机制,使集群能够从失败中恢 复。这里主要介绍YARN模式下的HA方案。
Flink支持HA模式和Job的异常恢复。这两项功能高度依赖ZooKeeper,在使用之前用 户需要在“flink-conf.yaml”配置文件中配置ZooKeeper,配置ZooKeeper的参数如 下:
high-availability: zookeeper
high-availability.zookeeper.quorum: ZooKeeperIP地址:2181 high-availability.storageDir: hdfs:///flink/recovery
YARN模式
Flink的JobManager与YARN的Application Master(简称AM)是在同一个进程下。
YARN的ResourceManager对AM有监控,当AM异常时,YARN会将AM重新启动,启 动后,所有JobManager的元数据从HDFS恢复。但恢复期间,旧的业务不能运行,新 的业务不能提交。ZooKeeper上还是存有JobManager的元数据,比如运行Job的信 息,会提供给新的JobManager使用。对于TaskManager的失败,由JobManager上 Akka的DeathWatch机制监听处理。当TaskManager失败后,重新向YARN申请容器,
创建TaskManager。
YARN模式的HA方案的更多信息,可参考链接:http://hadoop.apache.org/docs/
r3.1.1/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.html。
关于YARN的yarn-site.xml设置,可参考链接:https://ci.apache.org/projects/
flink/flink-docs-release-1.12/ops/jobmanager_high_availability.html。
Standalone模式
对于Standalone模式的集群,可以启动多个JobManager,然后通过ZooKeeper选举出 leader作为实际使用的JobManager。该模式下可以配置一个主JobManager(Leader JobManager)和多个备JobManager(Standby JobManager),这能够保证当主 JobManager失败后,备的某个JobManager可以承担主的职责。图5-12为主备 JobManager的恢复过程。
图5-12 恢复过程
TaskManager恢复
对于TaskManager的失败,由JobManager上Akka的DeathWatch机制监听处理。当 TaskManager失败后,由JobManager负责创建一个新TaskManager,并把业务迁移到 新的TaskManager上。
JobManager恢复
Flink的JobManager与YARN的Application Master(简称AM)是在同一个进程下。
YARN的ResourceManager对AM有监控,当AM异常时,YARN会将AM重新启动,启 动后,所有JobManager的元数据从HDFS恢复。但恢复期间,旧的业务不能运行,新 的业务不能提交。
Job恢复
Job的恢复必须在Flink的配置文件中配置重启策略。当前包含三种重启策略:fixed- delay、failure-rate和none。只有配置fixed-delay、failure-rate,job才可以恢复。另 外,如果配置了重启策略为none,但job设置了Checkpoint,默认会将重启策略改为 fixed-delay,且重试次数是配置项“restart-strategy.fixed-delay.attempts”配置为
“Integer.MAX_VALUE”。
三种策略的具体信息请参考Flink官网:https://ci.apache.org/projects/flink/flink- docs-release-1.12/dev/task_failure_recovery.html。配置策略的参考如下:
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 3 restart-strategy.fixed-delay.delay: 10 s
以下场景的异常,都会导致job重新恢复:
● 当JobManager失败后,所有Job会停止,直到新的JobManager起来后,所有Job 恢复。
● 当某一TaskManager失败后,这个TaskManager上的所有作业都将停止,然后等 待有可用资源后重启。
● 当某个Job的Task失败后,整个Job也会重启。
说明
有关Job的配置重启策略,具体内容请参见https://ci.apache.org/projects/flink/flink- docs-release-1.12/ops/jobmanager_high_availability.html。
5.6.3 Flink 与其他组件的关系
Flink 与 YARN 的关系
Flink支持基于YARN管理的集群模式,在该模式下,Flink作为YARN上的一个应用,提 交到YARN上执行。
Flink基于YARN的集群部署如图5-13所示。
图5-13 Flink 基于 YARN 的集群部署
1. Flink YARN Client首先会检验是否有足够的资源来启动YARN集群,如果资源足 够的话,会将jar包、配置文件等上传到HDFS。
2. Flink YARN Client首先与YARN Resource Manager进行通信,申请启动
Application Master(以下简称AM)的Container,并启动AM。等所有的YARN的 Node Manager将HDFS上的jar包、配置文件下载后,则表示AM启动成功。
3. AM在启动的过程中会和YARN的RM进行交互,向RM申请需要的Task Manager Container,申请到Task Manager Container后,启动TaskManager进程。
4. 在Flink YARN的集群中,AM与Flink JobManager在同一个Container中。AM会将 JobManager的RPC地址通过HDFS共享的方式通知各个TaskManager,
TaskManager启动成功后,会向JobManager注册。
5. 等所有TaskManager都向JobManager注册成功后,Flink基于YARN的集群启动成 功,Flink YARN Client就可以提交Flink Job到Flink JobManager,并进行后续的 映射、调度和计算处理。
5.6.4 Flink 开源增强特性
5.6.4.1 窗口
Flink 开源特性增强:窗口
本节主要介绍滑动窗口,并提供滑动窗口优化方式。窗口的详细内容请参见官网:
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/stream/
operators/windows.html。
窗口介绍
窗口中数据的保存形式主要有中间结果和原始数据两种,对窗口中的数据使用公共算 子,如sum等操作时(window(SlidingEventTimeWindows.of(Time.seconds(20), Time.seconds(5))).sum)仅会保留中间结果;当用户使用自定义窗口时
(window(SlidingEventTimeWindows.of(Time.seconds(20), Time.seconds(5))).apply(new UDF))时保存所有的原始数据。
用户使用自定义SlidingEventTimeWindow和SlidingProcessingTimeWindow时,数据 以多备份的形式保存。假设窗口的定义如下:
window(SlidingEventTimeWindows.of(Time.seconds(20), Time.seconds(5))).apply(new UDFWindowFunction)
当一个数据到来时,会被分配到20/5=4个不同的窗口中,即:数据在内存中保存了4 份。当窗口大小/滑动周期非常大时,冗余现象非常严重,难以接受。
图5-14 窗口原始结构示例
假设一个数据在102秒时到来,它将会被分配到[85, 105)、[90, 110)、[95, 115)以及 [100, 120)四个不同的窗口中。
窗口优化
针对上述SlidingEventTimeWindow和SlidingProcessingTimeWindow在保存原始数据 时存在的数据冗余问题,对保存原始数据的窗口进行重构,优化存储,使其存储空间 大大降低,具体思路如下:
1. 以滑动周期为单位,将窗口划分为若干相互不重合的pane。
每个窗口由一到多个pane组成,多个pane对窗口构成了覆盖关系。所谓一个pane 即一个滑动周期,如:在窗口
window(SlidingEventTimeWindows.of(Time.seconds(20), Time.seconds.of(5))) 中pane的大小为5秒,假设这个窗口为[100, 120),则包含的pane为[100, 105), [105, 110), [110, 115), [115, 120)。
图5-15 窗口重构示例
2. 当某个数据到来时,并不分配到具体的窗口中,而是根据自己的时间戳计算出该 数据所属的pane,并将其保存到对应的pane中。
一个数据仅保存在一个pane中,内存中只有一份。
图5-16 窗口保存数据示例
3. 当需要触发某个窗口时,计算该窗口包含的所有pane,并取出合并成一个完整的 窗口计算。
图5-17 窗口触发计算示例
4. 当某个pane不再需要时,将其从内存中删除。
图5-18 窗口删除示例
通过优化,可以大幅度降低数据在内存以及快照中的数量。
5.6.4.2 Job Pipeline
Flink 开源增强特性:Job Pipeline
通常情况下,会将与某一方面业务相关的逻辑代码放在一个比较大的Jar包中,这种Jar 包称为Fat Jar。Fat Jar具有以下缺点:
● 随着业务逻辑越来越复杂,Jar包的大小也不断增加。
● 协调难度增大,所有的业务开发人员都在同一套业务逻辑上开发,虽然可以将整 个业务逻辑划分为几个模块,单各模块之间是一种紧耦合的关系,当需求更改 时,需要重新规划整个流图。
拆分成多个作业目前还存在问题。
● 通常情况下,作业之间可以通过Kafka实现数据传输,如作业A可以将数据发送到 Kafka的Topic A下,然后作业B和作业C可以从Topic A下读取数据。该方案简单易 行,但是延迟很难做到100ms以内。
● 采用TCP直接相连的方式,算子在分布式环境下,可能会调度到任意节点,上下游 之间无法感知其存在。
Job Pipeline流图结构
Pipeline是由Flink的多个Job通过TCP连接起来,上游Job可以直接向下游Job发送数 据。这种发送数据的流图称为Job Pipeline,如图5-19所示。
图5-19 Job Pipeline 流图
Job Pipeline原理介绍 图5-20 Job Pipeline 原理图
● NettySink和NettySource
Pipeline中上下游Job是直接通过Netty进行通信,上游Job的Sink算子作为 Server,下游Job的Source算子作为Client。上游Job的Sink算子命名为 NettySink,下游Job的Source算子命名为NettySource。
● NettyServer和NettyClient
NettySink作为Netty的服务器端,内部NettyServer实现服务器功能;
NettySource作为Netty的客户端,内部NettyClient实现客户端功能。
● 发布者
通过NettySink向下游Job发送数据的Job称为发布者。
● 订阅者
通过NettySource接收上游Job发送的数据的Job称为订阅者。
● 注册服务器
保存NettyServer的IP、端口以及NettySink的并发度信息的第三方存储器。
● 总体架构是一个三层结构,由外到里依次是:
– NettySink->NettyServer->NettyServerHandler – NettySource->NettyClient->NettyClientHandler Job Pipeline功能介绍
● NettySink
NettySink由以下几个重要模块组成:
– RichParallelSinkFunction
NettySink继承了RichParallelSinkFunction,使其具有Sink算子的属性。主要 通过RichParallelSinkFunction的接口来实现以下功能:
▪
启动NettySink算子。▪
运行NettySink算子,从本job的上游算子接收数据。▪
取消NettySink算子运行等。也可以通过其属性获取以下信息:
▪
NettySink算子各个并发度的subtaskIndex信息。▪
NettySink算子的并发度是多少。– RegisterServerHandler
该组件主要是与注册服务器交互的部件,在平台中定义了一系列接口,包括 以下几种接口:
▪
“start();” :启动RegisterServerHandler,与第三方RegisterServer建 立联系。▪
“createTopicNode();” :创建Topic节点。▪
“register();”: 将IP、端口及并发度信息注册到Topic节点下。▪
“deleteTopicNode();”: 删除Topic节点。▪
“unregister();”: 删除注册信息。▪
“query(); ”:查询注册信息。▪
“isExist();”: 查找某个信息是否存在。▪
“shutdown(); ”:关闭RegisterServerHandler,与第三方 RegisterServer断开连接。说明
● RegisterServerHandler接口实现了ZooKeeper作为RegisterServer的Handler,用 户可以根据自己的需求,实现自己的Handler,ZooKeeper中信息的保存形式如下 图所示:Namespace
|---Topic-1 |---parallel-1 |---parallel-2 |....
|---parallel-n
|---Topic-2 |---parallel-1 |---parallel-2 |....
|---parallel-m
|...
● Namespace的信息通过“flink-conf.yaml”的以下配置项获取:
nettyconnector.registerserver.topic.storage: /flink/nettyconnector
● ZookeeperRegisterServerHandler与ZooKeeper之间的SASL认证通过Flink的框架 实现。
● 用户必须自己保证每个Job有一个唯一的TOPIC,否则会引起作业间订阅关系的混 乱。
● 在ZookeeperRegisterServerHandler调用shutdown()时,首先删除本并发度的注 册信息,然后尝试删除TOPIC节点,如果TOPIC节点为非空,则放弃删除TOPIC节 点,说明其他并发度还未退出。
– NettyServer
该模块是NettySink算子的核心之一,主要作用是创建一个NettyServer并接 收NettyClient的连接申请。将同一Job中上游算子发送过来的数据,经由 NettyServerHandler发送出去。 另外,NettyServer的端口及子网需要在
“flink-conf.yaml”配置文件中配置:
▪
端口范围nettyconnector.sinkserver.port.range: 28444-28943
▪
子网nettyconnector.sinkserver.subnet: 10.162.222.123/24 说明
nettyconnector.sinkserver.subnet默认配置为Flink客户端所在节点子网,若客户 端与TaskManager不在同一个子网则有可能导致错误,需手动配置为
TaskManager所在网络子网(业务IP)。
– NettyServerHandler
该Handler是NettySink与订阅者交互的通道,当NettySink接收到消息时,该 Handler负责将消息发送出去。为保证数据传输的安全性,该通道通过SSL加 密。另外设置一个Netty Connector的功能开关,只有当Flink的SSL总开关被 打开以及配置“nettyconnector.ssl.enabled”为“true”的时候才开启SSL加 密,否则不开启。
● NettySource
NettySource由以下几个重要模块组成:
– RichParallelSourceFunction
NettySource继承了RichParallelSinkFunction,使其具有Source算子的属性,
主要通过RichParallelSourceFunction接口来实现以下功能: