國立臺灣大學工學院機械工程學系 碩士論文
Department of Mechanical Engineering College of Engineering
National Taiwan University Master Thesis
以多重性能偏移特性辨識與校準複雜系統參數之方法 Identification and Calibration of Complex Model
Parameters via Multiple Performance Deviations
李旻憲 Min-Hsien Lee
指導教授:詹魁元博士 Advisor: Kuei-Yuan Chan, Ph.D.
中華民國 107 年 8 月
August, 2018
誌謝
研究所的這兩年受到許多人的幫助,使我能夠順利度過中間的困難 和瓶頸,事非經過不知難,最後能完成這本碩士論文,我心中充滿了 感謝。
謝謝我的指導教授詹魁元老師耐心的指導和協助,不論是研究還是 做人處事方面,我都從老師學習到很多,未來的日子我也會把老師的 教誨放在心上。謝謝吳文方老師和劉霆老師擔任我的口試委員,兩位 老師給予的建議和指點,使我的論文的內容能更加完善。
謝謝實驗室的同仁,SoLab 就像一個大家庭,大家總是熱心的互相 幫助,謝謝學長姐們,彥智、子頡、米約瑟、柏伸、岳羿、柏安、柏 伸、冠霖、右均、顯主、盈樺、欣怡、冠龍,自己也成為學長時,更 能體會學長姐們的經驗傳承有多重要。謝謝同屆的夥伴們,穎寬、峻 廷、世哲,我們共同度過了許多難關,互相扶持走到了最後一哩路。
謝謝學弟妹們,柏宇、員成、心婷,實驗室有你們歡樂許多。謝謝助 理期璟、柏賢幫忙處理許多實驗室事務。
謝謝家人的支持和陪伴,你們是我堅持下去的動力來源,完成這階 段性任務後,我要踏上另一段旅程了。
i
摘要
參數數值無法確定是影響系統性能及可靠度的主要原因之一,本研 究建立辨識校準參數的流程,以確認運行系統之各參數數值。然而校 準參數在複雜系統應用上可能會遇到問題有 (1) 參數過多造成校準困 難,(2) 參數校準準確率不足,以及 (3) 參數校準結果信心水準不足。
本研究藉由主因素分析找出系統的重要參數,降低複雜系統的分析難 度,根據系統性能偏移,以類神經網路校準參數數值,再利用多個根 據不同性能偏移以類神經網路校準參數的結果,以決策樹提升校準準 確率,並以信賴區間評估參數的校準結果。研究以一車輛動態測試的 工程案例作為演示,車輛參數校準方均根誤差最小可達 0.136%,本研 究所提出之方法可有效校準偏移之參數,並提供校準複雜系統參數的 完整分析流程。
關 : 複雜系統分析、參數不確定因素、參數數值估計、主因素分
析、類神經網路、決策樹
Abstract
Parameter uncertainty plays an important role in system performance and robustness. This research builds up a procedure for calibrating deviated pa- rameters. However, there may be difficulties applying parameter calibration in complex system,namely (1) computation inefficiency due to a large num- ber of parameters, (2) inaccuracy in parameter calibration, and (3) low con- fidence in calibration result. This research selects important parameters by main effect analysis and uses the neural network to calibrate parameters via performance deviation. After getting calibration results via different perfor- mance deviation, we use the decision tree to increase the accuracy of cali- bration and evaluate the result by applying confidence interval. The method is demonstrated in an engineering case: vehicle dynamic test, the minimum mean square error of calibration is 0.136%.
Keywords:complex system analysis, parameter uncertainty, parameter cali- bration, main effect analysis, neural network, decision tree
目錄
誌謝 ... i
摘要 ... ii
Abstract ... iii
目錄 ... iv
圖目錄 ... vii
表目錄 ... ix
符號列表 ... xi
第一章 緒論 ... 1
1.1 研究背景 ... 1
1.2 研究動機與目的 ... 2
1.2.1 研究動機 ... 2
1.2.2 研究目的 ... 3
1.3 論文架構 ... 4
第二章 文獻回顧 ... 6
2.1 參數估計方法 ... 6
2.2 參數估計問題 ... 12
2.3 小結 ... 13
第三章 校準方法概念 ... 15
3.1 校準參數方法一:正向校準 ... 15
3.2 校準參數方法二:逆向校準 ... 18
3.3 參數校準檢驗方法 ... 20
第四章 研究方法 ... 23
4.1 方法流程 ... 23
4.2 找出重要參數 ... 24
4.3 建立訓練集、驗證集、測試集 ... 28
4.4 建立正向校準模型 ... 30
4.5 建立逆向校準模型 ... 33
4.6 提升參數校準準確率 ... 36
4.7 校準參數 ... 40
第五章 案例探討 ... 42
5.1 車輛工程案例 ... 42
5.1.1 找出重要參數 ... 45
5.1.2 建立訓練集、驗證集、測試集 ... 48
5.1.3 建立正向校準模型 ... 48
5.1.4 建立逆向校準模型 ... 52
5.1.5 校準參數 ... 55
5.1.6 結果與討論 ... 59
第六章 結論 ... 62
6.1 研究貢獻 ... 62
6.2 未來展望 ... 63
參考文獻 ... 64
圖目錄
1.1 汽車系統示意圖 . . . 2
1.2 物理模型與真實系統 . . . 3
1.3 論文架構圖 . . . 4
2.1 系統參數估計流程 . . . 7
2.2 神經網路結構示意圖 . . . 11
2.3 決策樹示意圖 . . . 12
3.1 E1分布圖 . . . 17
3.2 參數分布圖 . . . 19
3.3 pm1 搜尋範圍 . . . 20
3.4 pm2, pm3 搜尋範圍 . . . 20
3.5 信賴區間 . . . 21
3.6 pm1 搜尋範圍 . . . 22
3.7 pm2 搜尋範圍 . . . 22
3.8 pm3 搜尋範圍 . . . 22
4.1 主流程圖 . . . 24
4.2 主因素分析示意圖 1 . . . 25
4.3 主因素分析示意圖 2 . . . 26
4.4 神經網路架構示意圖 1 . . . 30
4.5 預測結果示意圖 . . . 32
4.6 Eset接受域和拒絕域 . . . 33
4.7 神經網路架構示意圖 2 . . . 34
4.8 使用更多訓練資料結果示意圖 . . . 36
4.9 差異性小的性能輸出示意圖 . . . 37
4.10 差異性大的性能輸出示意圖 . . . 38
4.11 使用不同性能輸出結果示意圖 . . . 38
4.12 使用更多測試方法示意圖 . . . 39
4.13 使用更多測試方法結果示意圖 . . . 40
4.14 校準參數流程 . . . 40
5.1 Matlab Simulink 示意圖 . . . 42
5.2 車輛模型示意圖 . . . 43
5.3 性能輸出計算流程 . . . 43
5.4 動力計算 . . . 44
5.5 動力分配 . . . 44
5.6 性能輸出計算 . . . 45
5.7 測試方法 . . . 45
5.8 新測試方法 . . . 46
5.9 原 y1m1 . . . 49
5.10 移除重複值後的 y1m1 . . . 49
5.11 Eset分布圖 . . . 52
5.12 逆向校準誤差分布 . . . 54
5.13 位於接受域的參數分布 . . . 57
5.14 pm5, pm6 接受域分布 . . . 58
5.15 pm5 接受域分布 . . . 59
5.16 使用更多訓練資料結果 . . . 60
5.17 使用更多測試方法結果 . . . 61
表目錄
3.1 單邊信賴區間 z 值表 . . . 21
4.1 設計變數分布 . . . 27
4.2 主因素分析結果 . . . 27
4.3 校準模型預測結果 (MSE=0.0414) . . . 27
4.4 校準模型預測結果 (MSE=0.0023) . . . 28
4.5 設計變數分布 . . . 35
5.1 量測輸出 . . . 46
5.2 主因分析參數 . . . 47
5.3 主因素排名 . . . 47
5.4 參數設定值 . . . 48
5.5 參數標準化結果 . . . 48
5.6 剩下性能輸出數值的數量 . . . 50
5.7 保留模型數量 . . . 51
5.8 接受域 . . . 52
5.9 驗證集單一性能輸出方均根誤差 . . . 53
5.10 驗證集決策樹方均根誤差 . . . 54
5.11 驗證集誤差 . . . 55
5.12 接受域搜尋範圍 . . . 55
5.13 拒絕域搜尋範圍 . . . 55
5.14 參數實際值 . . . 55
5.15 參數預測值 . . . 56
5.16 參數搜尋範圍 . . . 56
5.17 更新參數校準結果 . . . 56
5.18 參數搜尋範圍 . . . 58
5.19 訓練集、驗證集、測試集方均根誤差 . . . 59
5.20 測試集單一性能輸出方均根誤差 . . . 61
5.21 測試集決策樹方均根誤差 . . . 61
符號列表
Eset 估計性能輸出之誤差值 fe(pe; x) 真實系統函數
fm(pm; x) 物理模型函數
fˆkdt(pset) 以保留的物理模型參數估計值 pset 預測第 k 個參數 ˆpmk 的決策樹模型函數 fˆi,jf wd(pm) 以參數 pm預測第 i 個性能輸出第 j 個值 ˆymi,j的正向校準模型函數
fˆi,kinv(ymi) 以第 i 個性能輸出 ymi 預測第 k 個參數 ˆpmk 的逆向校準模型函數 ne 真實系統參數數量
nf 保留正向模型數量 ni 保留逆向模型數量 nm 重要參數數量
np 物理模型參數數量
ns 取樣數量
nset 參數組合數量 ntest 測試集數量
ntrain 訓練集數量
nval 驗證集數量 nx 測試方式數量 ny 性能輸出數量 pe 真實系統所有參數 pek 真實系統第 k 個參數
pm 物理模型所有參數
prm 第 r 次實驗物理模型參數設定 pˆm 物理模型所有參數估計值 pmk 物理模型第 k 個參數
ˆ
pmk 物理模型第 k 個參數估計值
Ri,j 物理模型第 i 個性能輸出的第 j 項之標準化常數 Rset 保留的物理模型性能輸出值之標準化常數
Rset,i 保留的物理模型性能輸出值之標準化常數第 i 項
x 測試方式
yei 真實系統第 i 個性能輸出
yei,j 真實系統第 i 個性能輸出的第 j 項 ˆ
yei,j 真實系統第 i 個性能輸出的第 j 項估計值 ymi 物理模型第 i 個性能輸出
ymi,j 物理模型第 i 個性能輸出的第 j 項 ˆ
ymi,j 物理模型第 i 個性能輸出的第 j 項估計值 ymk+
i,j 第 k 個參數高水準第 i 個性能輸出的第 j 項之值 ymk−
i,j 第 k 個參數低水準第 i 個性能輸出的第 j 項之值
¯
ymi,j 參數為原設定值時第 i 個性能輸出的第 j 項之值
yrmi,j 第 r 次虛擬實驗,物理模型第 i 個性能輸出的第 j 項估計值 yset 保留的物理模型性能輸出值
ˆyset 保留的物理模型性能輸出估計值
yset,i 保留的物理模型性能輸出值第 i 項之值
ˆ
yset,i 保留的物理模型性能輸出估計值第 i 項之值
εmaxk 驗證集中預測第 k 個參數 pmk 的誤差最大值 εsk 驗證集中預測第 k 個參數 pmk 的誤差標準差
第 一 章
緒論
1.1 研究背景
分析模型是工程領域了解系統特性的重要工具,利用物理、數學原理建立和 系統相近的物理模型,例如汽車動態模型、飛機流場模型等,藉由這些模型的模 擬結果了解系統特性,可以減少製造測試用的原型與實驗成本,是開發工程系統 時常見的方法 [1] [2] [3]。
在複雜系統的分析上,模型更是可以快速的了解系統行為、評估系統性能偏 差原因的方法。以汽車這一個典型的複雜系統為例,我們會建立汽車動態模型模 擬汽車系統,如圖1.1,這些系統又可分為車體系統、傳動系統、煞車系統、轉向 系統等主要子系統,而這些子系統下又有更多的細部子系統,例如傳動系統下還 有引擎系統、變速箱系統。這些細部子系統的參數眾多,函數複雜,因此不論是 要了解各細部子系統間的交互作用或是掌握其參數數值,都是艱鉅的任務。
圖 1.1: 汽車系統示意圖
1.2 研究動機與目的
1.2.1 研究動機
在真實世界的複雜系統運行時更受許多不確定因素的影響,使其性能發生偏 移而不如原先期望,常見的不確定因素有:
1. 製造過程不確定:元件在製造時受加工精度、組裝偏差影響,而和原設計有 差異,例如:輪胎的鋼絲因為組裝偏差有不同的張力。
2. 材料性質不確定:特定材料的性質因材料的來源,處理的過程不同而有所差 異,例如:輪胎的橡膠彈性係數會因為原材料批號不同而有差異。
3. 環境參數不確定:假設的環境參數因環境發生變異,與實際情形不同,例 如:輪胎在道路乾燥和濕滑時有不同的的滾動阻力。
這些不確定因素會造成系統參數偏移原本的設定值,系統參數偏移又會導致 實際運行時系統性能發生偏移,造成與原本期望結果的差異。當系統的性能表現 和原本期望的結果不同時,我們通常藉由調整系統參數使系統的性能表現和期望 結果一致,而系統參數經過適當的的調整,亦能穩定系統的性能表現,提升系統
的可靠度。因此不論是為了改善系統的性能表現,或是提升系統的可靠度,正確 掌握系統參數都是重要的一環。
然而真實世界的系統中有許多參數不易量測,例如車輛的轉動慣量、輪胎的 滾動阻力,若尚需考慮參數的量測誤差以及系統性能的量測誤差,系統性能輸出 偏移和系統參數偏移之實際關係將非常難以得知。由於我們多數時間僅能靠系統 的性能輸出推估系統的參數值,建立物理模型是常見的替代作法。
系統與物理模型的關係如圖1.2,假設系統有 np個參數,全共為 pe1, pe2, ..., penp, 可表示為 pe; 以及 ny 個性能輸出,ye1, ye2, ..., yeny,可表示為 ye,經由測試方式 x,每個性能輸出產生 nx個值。而物理模型有 np 個參數,pm1, pm2, ..., pmnp,可表 示為 pm; 以及 ny 個性能輸出,ym1, ym2, ..., ymny,可表示為 ym,亦經由測試方式 x,每個性能輸出產生 nx個值,其中下標 e 代表 experiment、m 代表 model、p 代 表 parameter、y 代表性能輸出、x 代表測試方式。
圖 1.2: 物理模型與真實系統
以物理模型模擬系統,雖可掌握各細部子系統的函數,但子系統函數之間的 交互作用複雜,參數眾多,造成難以直接藉由性能輸出,以數學方程式回推參數 數值,此外,系統的性能偏差可能存在多種潛在的參數組合 [4],眾多的參數、函 數複雜的交互作用、多種潛在的參數組合都增加了掌握參數的困難。
1.2.2 研究目的
綜合上述討論結果,校準系統參數的準確率及效率仍有問題尚待解決,本研 究的重點有:
1. 針對複雜系統的眾多參數,找出對系統性能影響較大的重要參數,將問題聚 焦到校準重要參數上。
2. 針對參數校準的困難之處,提出解決方法,以提升參數校準的準確率及效 率。
3. 針對參數校準結果,建立檢驗校準結果的方法。
4. 針對複雜系統參數偏移辨識與校準,建立完整的分析流程。
本論文建立一套分析方法,協助工程師經由系統輸出有效推估系統參數,進而了 解實際影響系統輸出偏差的主要不確定因素。
1.3 論文架構
本研究共分為六個章節,架構如圖1.3所示:
圖 1.3: 論文架構圖
1. 第一章 緒論
介紹研究主題,並敘述研究的動機與目的。
2. 第二章 文獻回顧
探討複雜系統參數校準的相關方法與文獻。
3. 第三章 校準方法概念
說明參數校準方法概念,以及如何檢驗校準結果。
4. 第四章 研究方法
說明參數校準的方法,並詳細介紹其細節。
5. 第五章案例探討
利用一車輛工程案例探討研究方法的成效。
6. 第六章 結論
整理本研究之研究成果與討論,並敘述後續研究的方向。
第 二 章
文獻回顧
2.1 參數估計方法
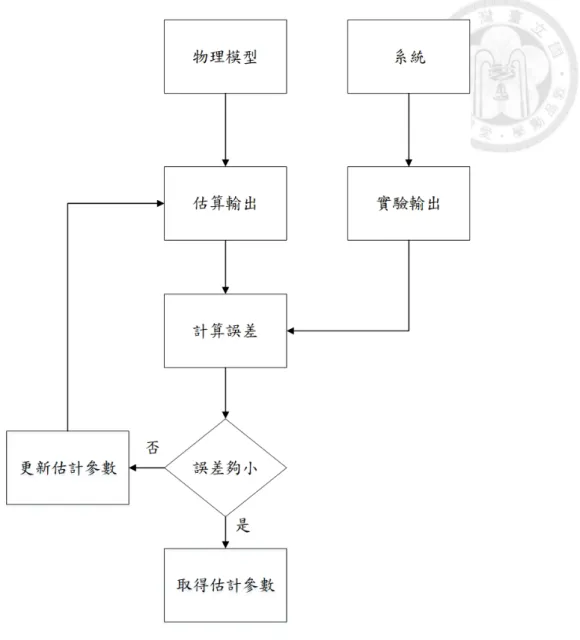
無論是實驗量測或是物理模型,我們都是希望找到真實系統的現象,而兩者 之間又有一定的差距,暫且將這差距定義為誤差,若誤差太大我們認為物理模型 模擬結果和實驗結果不一致,因此重新調整模擬參數設定,直至誤差小於一某可 接受範圍,則我們認為物理模型有足夠代表性重現系統的行為。圖2.1說明我們如 何以物理模型估算系統的實驗輸出,取代實際的實驗,並校準偏移參數的方法概 念。在圖2.1中,我們以物理模型估算系統輸出,並和系統實驗輸出進行比較,若 誤差小於一某可接受範圍,則取得估計參數,否則更新估計參數,重新估算系統 輸出。
圖 2.1: 系統參數估計流程
針對以物理模型估算實驗輸出,匹配實際實驗輸出,進行參數估計的方法,
常見的方法有:最大似然法、貝氏推估、神經網路、決策樹,本節將介紹這些方 法的原理及優缺點。
1. Maximum Likelihood Methods 最大似然法 [5]
最大似然法以機率的概念找出最可重現實驗結果的參數組合,似然函數可表 示為式2.1,y 為量測值,θ 為欲估計之參數,
藉由找出能最大化似然函數的 ˆθ如式2.2,似然函數有最大值的必要條件為 式2.3,以此法達成估計參數 θ ,若假設的似然函數與真實情形不符,則無 法獲得準確結果。
L(y|θ) (2.1)
L(y|θ)|θ= ˆθ (2.2)
∂
∂θL(y|θ)|θ= ˆθ = 0 (2.3) 以 估 計 y 的 平 均 值 µ 和 標 準 差 σ2 為 例, 假 設 y 為 高 斯 分 布 (Gaussian Distribution),則 y 之似然函數如式2.4,對 y 進行 m 次量測,藉由最大化似 然函數,求 y 的平均值和標準差 µ, σ2。
L(y|µ, σ2) = ( 1
2πσ2 )m2
e−
∑m i=1(yi−µ)2
2σ2 (2.4)
為滿足似然函數最大值的必要條件,將 L(y|µ, σ2)對 µ、σ2 進行偏微分,其 結果等同於將 ln[L(y | µ, σ2)]對 µ、σ2 進行偏微分。將 ln[L(y | µ, σ2)]對 µ 偏微分如式2.5,可推得 ˆµ如式2.6,而將 ln[L(y|µ, σ2)]對 σ2 偏微分如式2.7,
可推得 ˆσ2 如式2.8。
∂
∂µln[L(y|µ, σ2)] = 0 (2.5)
ˆ
µ = ¯y =
∑m i=1
yi/n (2.6)
∂
∂σ2 ln[L(y|µ, σ2)] = 0 (2.7)
ˆ σ2 =
∑m i=1
(yi− ˆµ)2
m (2.8)
2. Bayesian Estimation 貝氏推估
貝式推估結合似然率和條件機率的概念,若有 A 和 B 兩事件,則 B 事件發 生的情況下,A 事件發生的機率為 p(A|B) 如式2.9,而 A 事件發生的情況 下,B 事件發生的機率為 p(B|A) 如式2.10。
由於 p(A∩ B) = p(B ∩ A) 如式2.11,我們可將 p(A|B) 改寫如式2.12。我們 稱 p(A) 為假設的先驗機率,p(A|B) 為的後驗機率,為對 p(A) 的進一步了 解,而 p(B|A) 為假設的似然率,因此貝氏推估亦需考量似然函數假設的正 確性,此外,先驗機率的正確性也會影響貝氏推估的結果 [6]。
p(A|B) = p(A∩ B)
p(B) (2.9)
p(B|A) = p(B∩ A)
p(A) (2.10)
p(A∩ B) = p(B ∩ A) = p(A|B)p(B) = p(B|A)p(A) (2.11)
p(A|B) = p(B|A)p(A)
p(B) (2.12)
現欲推估參數 θ 原先的機率分布為 p(θ),此為 θ 的先驗機率分布。今已知
p(y) 後,可更新其機率分布為 p(θ|y) 如式2.13,此為 θ 的後驗機率分布,以
此方法估計 θ 之值。
p(θ|y) = p(y|θ)p(θ)
p(y) (2.13)
貝氏推估應用於參數推估的案例:2015 年,Green 等人 [7],以貝氏推估估 計震盪器 (oscillator) 的參數數值。
3. Neural Network 神經網路
近年由於電腦運算力的提升,機器學習成為熱門的工具,其中神經網路 (Neural Network) 被廣泛的使用,其優點有不必對系統有全面的了解,且能 產生複雜模型 [8],具強擬和能力,但須避免過擬和的情形發生。
神經網路的構成由輸入層 (input layer),一或多個隱藏層 (hidden layer) 及輸 出層 (ouput layer) 構成,如圖2.2,輸入層為輸入神經網路的參數,輸出層
為神經網路輸出結果,隱藏層具有多個神經元,每個神經元具有激勵函數 (activation function),目的是增加神經網路的非線型,提升神經網路的擬和 能力,常使用的激勵函數如式2.14
F (x) = 1
1 + e−x (2.14)
由於參數估計屬於回歸問題,因此輸出層神經元的激勵函數為式 2.15。
F (x) = x (2.15)
若第 i− 1 層有 ni−1 個神經元,則第 i 層的第 j 個神經元之值為式 2.16,再 經過激勵函數處理即為最終輸出值。
xi,j =
ni−1
∑
k=1
wi,j × xi−1,k+ bi,j (2.16)
而輸出層之誤差利用反向傳播 (back propagation),回傳至隱藏層,調整隱藏 層神經元的權重 wi,j, bi,j,反向傳播的概念可參見 [9]。神經網路於參數推估 的應用:
1990 年 Narendra 提出運用神經網路進行參數推估的方法 [10],2014 年 Wei 等人以神經網路預測電池之剩餘電量 [11],2017 年 Boada 等人以神經網路 預測車輛的轉角值 [12]。
圖 2.2: 神經網路結構示意圖
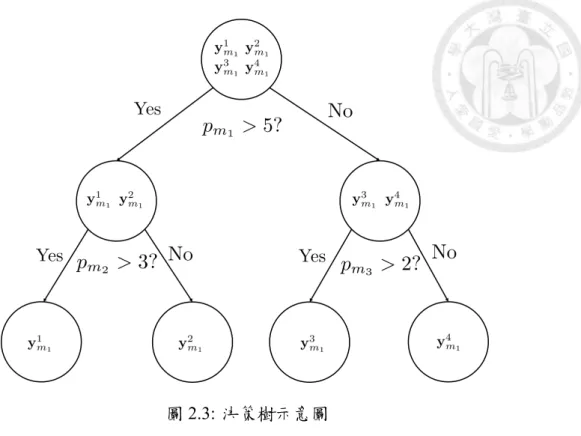
4. Decision Tree 決策樹
決策樹的基本演算法為:根據實驗數據特徵訂定指標,依據指標將實驗數據 分為數個子集合,在子集合中重複此過程,其流程示意圖如圖2.3,雖然決 策樹的複雜程度不如神經網路,但相較於神經網路,能產生較容易理解的規 則:以 x 之值作為分類的依據。以決策樹推估系統性能的案例如:2007 年,
Geoffrey 等人以決策樹推估系統消耗電量 [13]。
圖 2.3: 決策樹示意圖
總結以上討論,貝氏推估、最大似然法皆需考量似然函數假設的正確性,若 假設的似然函數與真實情形不符,則無法獲得準確結果,此外,先驗資訊的準確 率也會影響貝氏推估的結果。神經網路由於能產成複雜的模型,具強大的擬和能 力,因此相當適合分析複雜系統,但須避免過擬和的現象,而決策樹雖無神經網 路強大的擬和能力,但較神經網路易產生容易理解的規則。
2.2 參數估計問題
無論使用何種推估性能輸出的方法,例如:最大似然法、貝氏推估、神經網 路、決策樹,目的皆是最小化實際性能輸出和估算性能輸出之誤差,以進行參數 估計,在這樣推估的過程中,常見的問題有:
1. 無法找到全域最佳解:參數校準結果為區域最佳解。
2. 參數有多組可能解:有多組參數對應相似的性能輸出。
3. 參數校準準確率不足:參數校準結果和實際參數數值不符。
最小化實際性能輸出和估算性能輸出之誤差的過程中,實際性能輸出和估算 性能輸出之誤差即為目標函數,由於目標函數可能為非凸 (noncovex) 函數,最小
化目標函數的過程中,可能找到目標函數的區域最佳解 [14] [15],為找到全域最 佳解,可使用多個隨機的起始點,以避免解為區域最佳解,但隨著參數數量增 加,搜尋範圍變得更大,使用多個起始點的方法效率低落且不切實際 [16]。此外,
若有多組參數對應相似的性能輸出,也就是參數有多組解,如何判斷參數是否為 可能的解,更提升了參數推估的困難性 [4]。本研究將針對以上問題,在第三章說 明如何提升尋搜尋參數解的效率及檢驗其可信度的方法。
本 研 究 亦 重 視 參 數 校 準 準 確 率 的 問 題, 為 提 升 校 準 參 數 數 值 的 準 確 率,
Bayarri [6]、Gábor [17] 等人提出以精確的先驗資訊提升參數校準的準確度,然而 在推論參數前,大多數情形難以獲得準確的先驗資訊。對應此困難,Arendt [18]、
Conti [19] 等人建議使用多個測試實驗,提升參數校準準確率,本研究將在第四章 說明完整的研究方法及提升參數校準準確率的策略。
2.3 小結
根據文獻內容,針對參數校準的問題,尚有以下問題需要解決:
1. 如何有效率的校準多個參數:
需校準之參數有 pm1, pm2, ..., pmnp,在眾多參數中,應設法找出應優先校準 的參數。
2. 如何有效率的搜尋參數的多組解:
當有多組參數的估算性能輸出 ˆym 和實際性能輸出 ym 相似,這些具有相似 性能輸出的參數,都有可能是實際的參數,需以有效率的方法找到所有可能 的參數。
3. 如何檢驗參數校準的結果:
即判斷估算性能輸出 ˆym 和實際性能輸出 ym 相似的方法,需訂定估算性能 輸出和實際性能輸出可接受的誤差範圍,以評估校準參數結果。
4. 如何提升參數校準的準確率:
需降低 ˆpm和 pm的誤差,以更精確的掌握系統參數的實際狀況。
本研究將建立藉由性能偏移,校準參數的完整分析流程,並對以上問題提出 解決方法。
第 三 章
校準方法概念
本章先定義校準實驗的意義,接著說明正向校準參數和逆向校準參數的概念,
分析其優缺點和可互補之處,以及如何提升參數校準的效率,最後探討如何以假 設檢定的方法,進一步檢驗參數校準的準確性。
若以實際實驗作為校準實驗,進行參數校準會有以下缺點:
1. 需考慮參數以及系統性能的量測誤差:參數及系統性能的量測結果與實際情 形不符。
2. 系統性能輸出偏移和系統參數偏移之實際關係不明:參數和系統性能的量測 誤差造成難以判斷系統性能偏移的原因。
3. 較高的時間、金錢成本:使用硬體及耗材進行實際實驗需付出額外成本。
因此本研究以物理模型的模擬結果作為虛擬實驗結果,替代實際實驗,並根 據虛擬實驗結果,建立校準參數的方法,當虛擬實驗的性能表現不如期望時,將 其原因視為參數偏移造成,並校準參數。
3.1 校準參數方法一:正向校準
即使以物理模型的虛擬實驗結果取代實際實驗,受限於時間因素,我們仍無 法進行無限次虛擬實驗,只能以有限次數的虛擬實驗,估計在不同參數設定下,
對應的虛擬實驗結果。我們以估計值 ˆym,匹配虛擬實驗結果 ym,藉由最小化 ˆym 和 ym之誤差,進行參數校準,本研究中將此方法稱為正向校準參數。
以 ym 其中一性能輸出 ym1 進行正向校準為例,ym1 = [ym1,1, ym1,2, ..., ym1,nx],
由 於 測 試 方 式 x 皆 相 同, 我 們 將 ym1,1, ym1,2, ..., ym1,nx 表 示 為 參 數 pm 的 函 數,ym1 和 pm 的 關 係 如 式3.1, 藉 由 找 出 ym1 和 pm 的 關 係, 也 就 是 估 算 f1,1(pm), f1,2(pm), ..., f1,nx(pm),即可獲得性能輸出估計值 ˆym1,1, ˆym1,2, ..., ˆym1,nx。
ym1,1= f1,1(pm) ym1,2= f1,2(pm)
...
ym1,nx = f1,nx(pm)
(3.1)
求得性能輸出的估計值 ˆym1 後,我們計算估計值和虛擬實驗結果的誤差,以 評估兩者相似程度。定義性能輸出 ˆym1 和 ym1 之誤差 E1 如式3.2
E1 =
nx
∑
i=1
(ˆym1,i− ym1,i)2 (3.2)
為了找出有較小性能誤差 E1 對應的 ˆpm,我們搜尋許多不同的 ˆpm,估算這些 ˆpm對應的性能輸出 ˆym1,並計算性能輸出誤差 E1的數值。搜尋許多 ˆpm 後,我們 得到多個 E1的數值,分別對應不同的 ˆym1,假設 E1 的數值分布如圖3.1,較小的 E1數值代表當參數值為其對應的 ˆpm時,ˆym1 和 ym1 相似,則我們將 ˆpm 視為可能 的參數值,以此方法進行正向校準參數。
圖 3.1: E1 分布圖
然而正向校準會面臨的問題是,隨著參數數量 np 增加,pm 參數組合數量呈 指數成長 [20],參數組合數量 nset 如式3.3,其中 c 為參數解析度,代表搜尋時不 同 ˆpm 的差值,參數的差值越小,解析度越高,可更精確的校準參數,但搜尋的 參數也越多,需花費較多計算時間。
nset ∝ cnp (3.3) 此外,若有多組參數 ˆpm 可產生相似 ym1 的性能輸出,使用最佳化方法時容易 陷入區域最佳解,若想要找出所有可能的 ˆpm,在不確定是否有多組解的情形下,
需藉由以多個不同起始點進行搜尋,效率差且耗費計算資源,
綜合以上討論,正向校準參數尚有以下問題需要解決,以提升參數校準的效 率:
1. 判斷參數是否有多組解:若參數為唯一解,則可不必搜尋多組解。
2. 決定搜尋參數的初始值:以接近實際參數值作為搜尋的初始值。
3. 縮減搜尋參數的範圍:根據搜尋的初始值決定對應的搜尋範圍。
3.2 校準參數方法二:逆向校準
為解決正向校準參數的困難之處,我們需提供一可靠之初始值,縮減正向校 準的搜尋範圍,並需判斷該系統輸出是否有多組參數解之可能,承前章節之符 號,我們令物理模型函數及其輸出為 ym = fm(pm; x),由於測試方式 x 皆相同,
我們藉由求反函數 pm = f−1(ym)推估參數 ˆpm,這種以反函數推估參數 ˆpm 的方 法,在本研究中稱為逆向校準方法。
以 ym其中一性能輸出 ym1 進行逆向校準為例,我們將 pm表示為式3.4,藉由 求得 f1−1(ym1), f2−1(ym1), ..., fn−1p(ym1),即可推估 ˆpm。
pm1 = f1−1(ym1) pm2 = f2−1(ym1)
...
pmnp = fn−1p(ym1)
(3.4)
由於對應特定性能輸出的參數可能有多組解,無法保證能以逆向校準方法準 確求得 ˆpm1, ˆpm2, ..., ˆpmnp。但配合正向校準方法,逆向校準參數可解決以下問題:
1. 判斷參數是否有多組解
若逆向校準的準確率高,可推測參數應為唯一解,若逆向校準參數準確低,
可能原因為:1. 參數有多組解、2. 逆向校準本身誤差
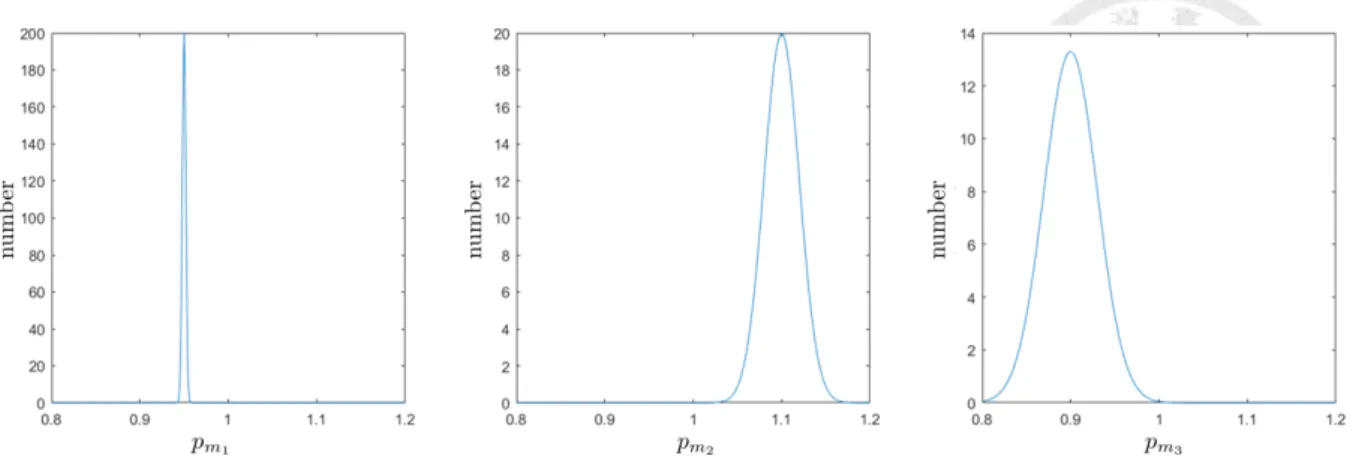
假設一物理模型共有 3 個參數,分別為 pm1, pm2, pm3,以該物理模型進行一 次虛擬實驗,得性能輸出 ym1,以正向校準方法估計 pm1, pm2, pm3 在不同設 定值下,對應的性能輸出 ˆym1,這些不同 pm1, pm2, pm3 的設定值中,有部分 可產生和 ym1 相似的性能輸出,為可能的參數設定值。我們將可能的參數 設定值對應的 pm1, pm2, pm3 分別畫出分布圖,假設分布圖如圖3.2,可見 pm1 有較小的分布範圍,pm1 可能的數值分布於 0.94 至 0.96,pm2, pm3 有較大的 分布範圍,pm2 可能的數值分布於 1.0 至 1.2,pm3 可能的數值分布於 0.8 至 1.0,由此推論,pm1 應為唯一解,pm2, pm3 應有多組解。
圖 3.2: 參數分布圖
若以逆向校準參數方法能準確校準 pm1,可得知 pm1 應為唯一解,若 pm1 逆 向校準的準確率低,而以正向校準方式檢驗,pm1 的分布如圖3.2,顯示 pm1 應為唯一解,則可判斷準確率低的原因為逆向校準本身誤差,此時應設法提 升逆向校準結果。
而 pm2, pm3 由於有多組解,將導致逆向校準方法無法準確校準參數,若 pm2, pm3 逆向校準的準確率低,而以正向校準方式檢驗結果 pm2, pm3 的分布 如圖3.2,顯示 pm2, pm3 有多組解,則可判斷準確率低原因可能為 pm2, pm3 有 多組解。
2. 提供正向校準初始值及搜尋範圍
逆向校準方法藉由反函數推估 ˆpm,作為正向校準參數搜尋的初始值,但由 於不知道 ˆpm 和 pm的誤差大小,正向校準方法的參數搜尋範圍未知。本研 究建議依據逆向校準之準確率,決定正向校準時參數 pm1, pm2, ..., pmnp 的搜 尋範圍。
ˆ
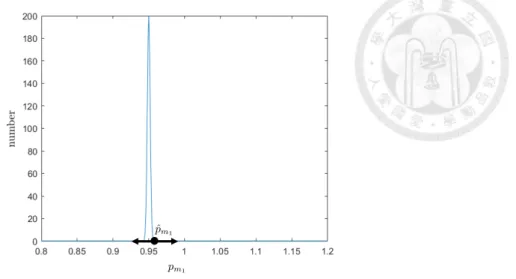
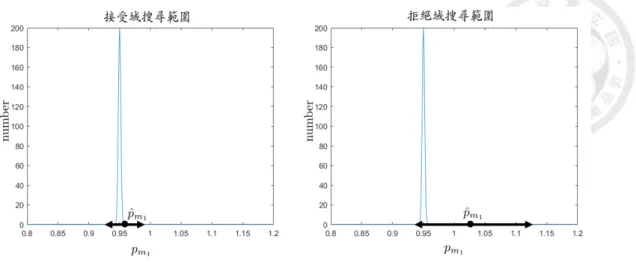
pm1 pˆm2 pˆm3 假設 pm1 逆向校準準確率高,代表逆向校準 pm1 大多數情形接 近真實值,因此將會有較小的搜尋範圍,如圖3.3,假設逆向校準 pm2, pm3 準確率低,則 pm2, pm3 會有較大的搜尋範圍,如圖3.4。
圖 3.3: pm1 搜尋範圍
圖 3.4: pm2, pm3 搜尋範圍
3.3 參數校準檢驗方法
逆向校準雖然可不經由疊代運算,以反函數快速推估參數,但參數是否準確 未知,本研究建議配合正向校準方法,以假設檢定判斷是否接受逆向校準的結 果。
以 ym其中一性能輸出 ym1 檢驗逆向校準結果為例,以正向校準方法估計逆向 校準所得 ˆpm 對應之性能輸出 ym1,若 ˆpm ≡ pm,則性能輸出誤差 E1 值應為 0,
但由於需考量正向校準的性能輸出估計誤差,故性能輸出誤差 E1 不為 0。假設正
向校準的估計誤差為常態分布,我們隨機取樣 ns組 pm,計算 ns組性能輸出誤差 E1,其平均值為 ¯E1,標準差為 s1,我們希望估算性能輸出和實際性能輸出盡可能 相似,也就是較小的性能輸出誤差 E1,因此接受性能輸出誤差 E1 位於接受域的 ˆpm,為決定接受域大小,首先須決定顯著水準 α,一般使用 α=0.05,對應單邊的 95% 信賴區間,常使用的 α 及對應的 zα值如表3.1,
表 3.1: 單邊信賴區間 z 值表 信賴區間 α zα
90% 0.1 1.282 95% 0.05 1.645 99% 0.001 2.326
若 E1 滿足式3.5,代表性能輸出誤差 E1位於接受域,信任校準結果,若否則 代表 E1位於拒絕域,不信任校準結果,如圖3.5。
E1 < ¯E1+ zα× s1 (3.5)
圖 3.5: 信賴區間
若信任逆向校準結果,代表 ˆpm 應相當接近 pm,此時只須搜尋 ˆpm 附近之參 數即可,若不信任逆向校準結果,代表 ˆpm可能和 pm誤差較大,則應擴大搜尋範 圍,如圖3.6、3.7、3.8。
圖 3.6: pm1 搜尋範圍
圖 3.7: pm2 搜尋範圍
圖 3.8: pm3 搜尋範圍
第 四 章
研究方法
本章延續第三章內容,結合正、逆向校準參數方法進行參數校準,首先介紹 參數校準的整體流程,接著分別說明各步驟的細部執行方法,以及使用多項性能 輸出提升校準參數準確率的方法。
4.1 方法流程
本研究以神經網路建立正、逆向校準模型,進行參數校準,流程如圖4.1
1. 找出重要參數:
評估參數對系統性能之影響,找出對系統性能影響較大的重要參數,忽略其 他參數的影響,以降低分析的複雜度,提升參數校準的效率。
2. 建立訓練集、驗證集、測試集:
決定重要參數的分布情形,以物理模型進行虛擬實驗,建立訓練集、驗證 集、測試集,避免校準模型發生過度擬合的情形,提升參數校準的準確率。
3. 建立正向校準模型:
根據訓練集建立正向校準模型,正向校準模型可依據重要參數數值,估計性 能輸出,藉由最小化估計性能輸出和實際性能輸出誤差,回推參數數值,並 評估校準結果的準確率。
4. 建立逆向校準模型:
根據訓練集建立逆向校準模型,逆向模型可依據性能輸出,直接推估重要參 數數值,並提供正向校準參數時參數的初始值和搜尋範圍,提升校準的效 率。
5. 校準參數:
根據虛擬實驗結果,以正、逆向校準模型進行參數校準。
圖 4.1: 主流程圖
4.2 找出重要參數
同時回推所有參數是艱鉅的任務,本研究以主因素分析找出對性能輸出影響 大的重要參數,並忽略其他參數的影響,降低分析複雜系統的困難度,由於物理 模型可能有多項性能輸出,本研究建議對在意之性能輸出進行主因素分析,以汽 車模型為例,假設性能輸出有扭力、馬達轉速、油耗表現,而我們最在意的是汽 車的油耗表現,則對油耗表現進行主因素分析。
1. 主因素分析:
主因素分析進行方法為:為參數設定兩水準,分別為高水準和低水準,藉由 分析參數在不同水準下性能輸出的表現,找出重要參數。若參數 pmk 無明確 資訊,建議設定高水準為 pmk × 110%,低水準為 pmk × 90%。
若在意之性能輸出為第 i 個性能輸出的第 j 項 ymi,j,當所有參數為原設定值 時,物理模型 fm(x, pm)模擬結果 ymi,j 之值為 ¯ymi,j,當參數 pmk 為高水準 時,ymi,j之值為 ymk+i,j,參數 pmk 為低水準時,ymi,j之值為 ymk−i,j,如圖4.2。
圖 4.2: 主因素分析示意圖 1
依序對所有參數進行主因素分析,如圖4.3,參數 pmk 之主因素為 yk+m
i,j − ymk−
i,j,主因素絕對值較大值,代表該參數偏移對性能輸出影響較大,為重要 參數,最後共從 np 個參數中選出 nm 個重要參數。
圖 4.3: 主因素分析示意圖 2
2. 重要參數分類:
’ 使用模型校準以識別複雜系統參數數值之方法’ [20],建議將重要參數進一 步分為:直接量測參數及模型校準參數。
有些重要參數易於量測,易於量測之重要參數可直接量測,不易量測之重要 參數則以模型校準,然而,重要參數間的交互作用未知,若忽略易於量測之 重要參數的影響,可能造成無法校準不易量測之重要參數,因此本研究建議 進行虛擬實驗時,仍需考量易於量測的重要參數偏移對性能輸出之影響,但 在校準時可以量測結果替代校準結果,進一步提升校準準確率。
本研究建議仍可使用量測方式獲得直接量測參數數值,但校準參數時,需考 慮所有重要參數偏移之影響,並以一數學案例說明原因。
假設一簡單系統,性能輸出 ym1 有 2 個值,分別為 ym1,1及 ym1,2,系統有三 個參數,分別為 pm1、pm2、pm3。
ym1,1 及 ym1,2分別為:
ym1,1= 2pm1 + (pm2 + 1) + 0.005pm3 (4.1a) ym1,2= 4pm1 + (pm2 + 1)2+ 0.005pm3 (4.1b)
假設 pm1、pm2、pm3 原設計點為 1.0,受不確定因素影響,最小值為 0.9,最 大值為 1.1,分布為均勻分布 (uniform distribution),如表4.1
表 4.1: 設計變數分布
設計變數 分布類型 原設計點 最小值 最大值
pm1 均勻分布 1.0 0.9 1.1
pm2 均勻分布 1.0 0.9 1.1
pm3 均勻分布 1.0 0.9 1.1
假設 ym1,2為關心的性能輸出,進行主因素分析後,結果如表5.3
表 4.2: 主因素分析結果 參數 主因素
pm1 0.805 pm2 0.805 pm3 0.005
假設 pm2 易於量測,而 pm3 之影響可以忽略,依據 [20] 之作法則僅需校準 pm1,將 pm1 設定為最小值 0.9,最大值 1.1 之均勻分布,pm2、pm3 設定為原 設計點 1,隨機產生 50 筆資料建立逆向校準模型,另將 pm1、pm2、pm3 設 定為最小值 0.9,最大值 1.1 之均勻分布,隨機產生 10 筆資料,ˆpm1 之值。
校準模型預測結果如表4.3,
表 4.3: 校準模型預測結果 (MSE=0.0414) 資料編號 pm1 pˆm1
1 0.9222 0.9001 2 1.0472 1.0092 3 1.0530 1.0931 4 0.9320 0.9470 5 1.0008 1.0265 6 1.0695 1.0194 7 1.0538 1.1177 8 0.9684 0.8991 9 0.9874 1.0242 10 1.0416 1.0403
雖然 pm2 可直接量測,但結果顯示若不考慮 pm2 之變動,則無法準確 ˆpm1。
現在將 pm1、pm2 設定為最小值 0.9,最大值 1.1 之均勻分布,pm3 設定為原 設計點 1 隨機產生 50 筆資料建立逆向校準模型,ˆpm1 之值。
預測結果如表4.4,可準確 ˆpm1,結果顯示即使忽略 pm3 變動之影響,仍可準 確 ˆpm1,但若忽略重要參數 pm2 之影響,則無法準確 ˆpm1,因此應考量所有 重要參數偏移造成性能輸出之影響。
表 4.4: 校準模型預測結果 (MSE=0.0023) 資料編號 pm1 pˆm1
1 0.9222 0.9212 2 1.0472 1.0465 3 1.0530 1.0561 4 0.9320 0.9316 5 1.0008 1.0045 6 1.0695 1.0664 7 1.0538 1.0505 8 0.9684 0.9679 9 0.9874 0.9866 10 1.0416 1.0390
4.3 建立訓練集、驗證集、測試集
為避免校準模型過度擬合訓練集資料,需使用驗證集資料檢驗校準模型準確 率,並對校準模型做出調整,最後使用模型完全測試集資料評估模型預測未見 資料的準確率,以提升校準參數的準確率,建立訓練集、驗證集、測試集方法如 下。
1. 設定重要參數分布情形:
建立訓練集時,若只能進行較少的實驗次數,建議以直交表設定重要參數分 布情形,若允許較多次的實驗次數,建議以蒙地卡羅法隨機產生重要參數分 布情形,而建立驗證集及測試集時皆使用蒙地卡羅法隨機產生重要參數分布 情形。
2. 建立訓練集、驗證集、測試集:
依據重要參數分布情形,將重要參數分別設定為 p1m, p2m, ..., pnmtrain,以物理 模型 fm(pm; x) 進行 ntrain次虛擬實驗,產生 ntrain組實驗數據,作為訓練集。
每組虛擬實驗數據共有 ny 個性能輸出。
第 1 組為:y1m1, y1m2, ..., y1mny 第 2 組為:y2m1, y2m2, ..., y2mny 第 ntrain組為:ynmtrain1 , ynmtrain2 , ..., ynmtrainny
接下來分別進行 nval次虛擬實驗,作為驗證集,及 ntest次虛擬實驗,做為測
試集。ntrain, nval, ntest建議數量為 2:1:1。
3. 模型預測能力評估:
• 訓練集:
根據訓練集的資料,以神經網路建立預測模型,由於神經網路能產生 複雜的模型,因此容易發生過擬合的現象,過擬合的原因為在訓練過 程中,模型過度擬合訓練集的資料,過擬合造成模型對於訓練資料的 預測能力表現良好,但對於未見過的資料預測能力表現得很差,而對 未見過資料的預測能力稱為模型的泛化能力,
• 驗證集:
為了避免過擬合的現象,使用驗證集檢驗模型的泛化能力,並做出調 整是必要的。雖然驗證集的資料並未用來訓練模型,但利用驗證集檢 驗模型泛化能力,做出相應調整,使驗證集和訓練集的預測準確率更 為接近時,亦有可能對驗證集產生些微的過擬合現象。
• 測試集:
為了客觀的評估模型泛化能力,最後會使用測試集進行檢驗,測試集 在訓練模型以及調整模型的過程中皆未曾使用,僅用於評估最終模型 的泛化能力。一般而言,雖然藉由調整模型,使驗證集和訓練集的預 測準確率更為接近,相較於訓練集的準確率,驗證集的準確率仍然較 差,而測試集之準確率又略遜驗證集的準確率,但差距通常會小於驗 證集和測試集的差距,若模型的泛化能力佳,驗證集的準確率亦有可 能高於測試集。
4.4 建立正向校準模型
正向校準模型可推估參數對應的性能輸出,藉由尋找性能輸出和實際性能輸 出相似的參數,達成校準參數的目的,若有多個參數性能輸出和實際性能輸出相 似,也可使用正向校準模型找出所有可能的參數組合。
1. 建立模型:
由於以物理模型進行虛擬實驗需花費較久時間,本研究以神經網路建立正向 校準模型,快速推估物理模型 ym1, ym2, ..., ymny 等性能輸出。
以推估性能輸出 ym1 為例,以 pm作為輸入層,ym1,1作為輸出層,神經網路 架構如圖4.4
圖 4.4: 神經網路架構示意圖 1
接著分別以 ym1,2, ..., ym1,nx 作為輸出層,以神經網路建立 nx 個正向校準模
型。
ˆ
ym1,1= ˆf1,1f wd(pm) (4.2a) ˆ
ym1,2= ˆf1,2f wd(pm) (4.2b) ˆ
ym1,nx = ˆf1,nf wdx(pm) (4.2c)
仍以 pm作為輸入層,對 ym2, ..., ymny 以相同作法建立正向校準模型:
ˆ
ym2,1 = ˆf2,1f wd(pm) (4.3a) ˆ
ym2,2 = ˆf2,2f wd(pm) (4.3b) ˆ
ym2,nx = ˆf2,nf wdx(pm) (4.3c)
ˆ
ymny,1 = ˆfnf wdy,1(pm) (4.4a) ˆ
ymny,2 = ˆfnf wd
y,2(pm) (4.4b) ˆ
ymny,nx = ˆfnf wdy,nx(pm) (4.4c)
最後共建立 nx× ny 個正向校準模型。
2. 保留預測準確率高的模型:
由於建立之模型不一定皆能準確推估性能輸出,我們以驗證集檢驗模型,只 保留可準確推估性能輸出的正向校準模型,如圖4.5。

![圖 2.2: 神經網路結構示意圖 4. Decision Tree 決策樹 決策樹的基本演算法為:根據實驗數據特徵訂定指標,依據指標將實驗數據 分為數個子集合,在子集合中重複此過程,其流程示意圖如圖2.3,雖然決 策樹的複雜程度不如神經網路,但相較於神經網路,能產生較容易理解的規 則:以 x 之值作為分類的依據。以決策樹推估系統性能的案例如:2007 年, Geoffrey 等人以決策樹推估系統消耗電量 [13]。](https://thumb-ap.123doks.com/thumbv2/9libinfo/9603784.630087/24.892.290.607.116.633/神經網路結構示意Decision決策決策樹的基本演算法為根據數個子系統消.webp)
![圖 3.1: E 1 分布圖 然而正向校準會面臨的問題是,隨著參數數量 n p 增加,p m 參數組合數量呈 指數成長 [20],參數組合數量 n set 如式3.3,其中 c 為參數解析度,代表搜尋時不 同 ˆp m 的差值,參數的差值越小,解析度越高,可更精確的校準參數,但搜尋的 參數也越多,需花費較多計算時間。 n set ∝ c n p (3.3) 此外,若有多組參數 ˆ p m 可產生相似 y m 1 的性能輸出,使用最佳化方法時容易 陷入區域最佳解,若想要找出所有可能的 ˆ p m ,在不確定是](https://thumb-ap.123doks.com/thumbv2/9libinfo/9603784.630087/30.892.200.776.120.540/E分布然而正向校準會面臨的問題是隨著參數數增加參數組合數量.webp)
![圖 4.3: 主因素分析示意圖 2 2. 重要參數分類: ’ 使用模型校準以識別複雜系統參數數值之方法’ [20],建議將重要參數進一 步分為:直接量測參數及模型校準參數。 有些重要參數易於量測,易於量測之重要參數可直接量測,不易量測之重要 參數則以模型校準,然而,重要參數間的交互作用未知,若忽略易於量測之 重要參數的影響,可能造成無法校準不易量測之重要參數,因此本研究建議 進行虛擬實驗時,仍需考量易於量測的重要參數偏移對性能輸出之影響,但 在校準時可以量測結果替代校準結果,進一步提升校準準確率。 本研究建](https://thumb-ap.123doks.com/thumbv2/9libinfo/9603784.630087/39.892.274.792.115.446/主因素分析示意圖重要參數分類使用模型校準以識參數間進一步提升.webp)

