第五章 第五章
第五章 第五章 心電圖辨識軟體系統設計 心電圖辨識軟體系統設計 心電圖辨識軟體系統設計 心電圖辨識軟體系統設計
本章節分為兩小節,第一節為心電圖的特徵抽取的基本概念與介紹,
並且利用其統計特性加以分析。第二小節則是針對第一節的特徵抽取加強 了R-R interval之間的資訊,並且針對特殊病症區分析所增加的特徵,另外 我們更探討這些特徵在空間上分佈的情形。
5.1 特徵值抽取與統計分析特徵值抽取與統計分析特徵值抽取與統計分析特徵值抽取與統計分析
一、特徵值抽取:
根據所分群的病症資料,做特徵的擷取,其計算特徵值的流程如圖5-1 所示。主要的方法分為頻域分析和觀察病症波形等特性,針對此兩種方式 分別說明:
E C G S ig n a l
F r e q u e n c y D o m a in ( W a v e le t T r a n s f o r m )
F e a tu r e S e le c t io n
F e a t u r e V e c t o r
T im e D o m a in ( W a v e C o n d it io n )
F e a t u r e S e le c t io n
圖 5-1 特徵擷取流程圖
使用小波轉換做三階頻帶分解如圖5-2所示。分別取出A1、A2、A3、
D1、D2、D3等頻帶係數。在心電圖的分解過程中,圖5-3分別表示其中的 各個頻帶的波形。心電圖訊號中的不連續點或轉折點處經過小波轉換,能 夠在多重解析度中呈現明顯且不一樣的特徵,利用這一點,對有尖銳波形
的QRS波使用小波轉換,則會在多重解析中會有明顯的正負落差。圖(a)為 原始波形,圖(b)、圖(d)和圖(f)分別表示一階、二階和三階的低頻的波形,
圖(c)、圖(e)和圖(g)分別表示一階、二階和三階的高頻的波形。在低頻的部 份,逐漸能凸顯波形中較細微的部份,而高頻部份,對變化較劇烈的特徵 凸顯出來。
g
h
g
h 2
2 D1 (100) One Beat
ECG signal 2
2 g
h D2 (50)
2 2
D3 (25) (200)
A2 (50) A1
(100)
A3 (25)
圖 5-2 心電圖訊號的小波分解
50 100 150 200
-200 0 200
(a)
20 40 60 80 100
-200 0 200
(b)
20 40 60 80 100
-200 0 200
(c)
10 20 30 40 50
-200 0 200
(d)
10 20 30 40 50
-500 0 500
(e)
5 10 15 20 25
-100 0 100
(f)
5 10 15 20 25
-500 0 500
(g)
圖 5-3 心電圖訊號的小波分解取樣圖
依據上敍的小波轉換頻帶和波形本身的特性,計算出特別的特徵值共 33個,如表5-1所示。由於心電圖做頻帶分解後,每一個頻帶中包含有其特 徵性,所以除了每個頻帶的係數之外還有再擷取其每一頻帶的絕對值的平
均值、最大值、平均能量值、差準差及頻帶之間平均值的比值。第一項、
第二項及第三項表示訊號頻率的分佈;第四項和第五項表示訊號頻率的變 化。再來討論有關心電圖中波形和波形之間的關係,其重要的包括了心電 圖中週期的關連性,包括了R-R之間的距離,還有心電圖的週期是否有一 致性,包括了取前五筆的週期的平均,前後距離的比值,對正常波形週期 的正規化。
The feature type The number of feature values
The mean values of the absolute values of the coefficients in each sub-band
6 The maximum values of the absolute values of
the coefficients in each sub-band
6 The average energy of the wavelet coefficients
in each sub-band
6 The standard deviation of the coefficients in
each sub-band
6 The ratio of the absolute mean values of
adjacent sub-bands
5 The R-R interval of the beat 1 The average R-R interval of five last beats. 1 The R-R interval ratio between the previous
beat and next beat
1 The R-R interval ratio between the normal one
and the current beat
1 表5-1 心電圖辨識波形特徵
由於使用了小波轉換分解病症訊號各個頻率的波形,利用這樣的方式 擷取每個頻帶中的數值當為特徵值(350個),除了小波轉換另外還觀察病症 的特性,分別取出了頻域和週期相關的特徵值(33個),總共383個特徵向 量。如圖5-4。其中 fi表示特徵值,i表示維度,一個病症的最原始被抽出
的特徵向量長度為383維度。
f1 f2 f3 f4 fi f382 f383
圖 5-4 特徵向量的示意圖
二、特徵值的統計分析:
接下來是特徵的統計分析,由於SVM的長處在於將兩個類別的特徵映 射到高維度後,線性切割以辨認出兩個類別。所以必須先計算每個類別每 個特徵維度的平均值,其中共有12類的病症,分為72個次類別,特徵向量 為383。首先本研究定義一個評估特徵值方程式:
n m n
m where
k v for
v u u
k m k
m k n k k m
n m
≠
≤
<
= +
= −
, 72 , 1
383 , , 1 ),
) ( ) ((
) (
2 2
2
, L
σ
(公式
5-1)
描述如下:統計出第1類別之第1個維度的平均值u11,統計出第1類別 之第2個維度的平均值u12,類推到第1類第383維的平均值u1383。統計出第2 類別之第1個維度的平均值u12,統計出第2類別之第2個維度的平均值u22, 類推到第2類第383維的平均值u2383。同理類推到第72類的第383維的平均值
383
u72 。其中uij的μ代表平均值,i代表維度,j代表類別。
計算完平均值後接著計算每個類別之特徵維度的變異數。統計出第1 類別之第1個維度的變異數v11,統計出第1類別之第2個維度的變異數v12, 類推到第1類第383維的變異數ν1383。統計出第2類別之第1個維度的變異數
1
v2,統計出第2類別之第2個維度的變異數v22,類推到第2類第383維的變異 數v3832 。同理類推到第72類的第383維的變異數v38372 。其中vij的ν代表變異 數,i代表維度,j代表類別。ν代表變異數 (variations)。
當我們有了平均值與變異數後,計算同一個維度對不同類別之間的差 異。利用算出的平均值來計算差異值。計算出來的差異值越大表示兩類間 差別越大。dmk,n表示平均值相減的平方。我們會得到(72×71) / 2 = 2556個不 同兩類間差異的d向量,如圖5-5所示,其中k表示所屬的特徵維度,下標的 兩個數字m、n表示所要分類的兩個類別。其中d的計算方式由公式5-2得到:
n m n
m where
k for u
u dmkn mk nk
≠
≤
<
=
−
=
, 72 , 1
383 , , 1 ,
)
( 2
, L
(公式 5-2)
1 2 ,
d1 d12,2 d13,2 d14,2 d15,2 ··· d1382,2 d1383,2
1 3 ,
d1 d12,3 d13,3 d14,3 d15,3 ··· d1382,3 d1383,3
1 36 ,
d35 d352,36 d353,36 d354,36 d355,36 ··· d35382,36 d35383,36
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
1 72 ,
d71 d712,72 d713,72 d714,72 d715,72 ··· d71382,72 d71383,72
2556
383
圖 5-5 兩兩之間平均值差異的平方的向量示意圖
計算完dmk,n後,就可以利用剛剛產生的dmk,n與之前計算的變異數來計 算可以用來區別兩類的特徵區別值σ。計算方法如下列公式5-3。根據公式 來看,若是同類之間的變異數越小,表示兩類之間自己與自己類越相像。
而兩類間的dmk,n越大就表示這兩類越不像。因此,若是所計算出來的σ值 越大,表示這個值越可以區分出這兩類,這個特徵越重要。
,
2 2
, , 1, ,383
(( ) ( ) )
1 , 72,
k
k m n
k k
m n
m n
d for k
v v
where
m n m n
σ = =
+
< ≤ ≠
L
(公式 5-3)
1 2 ,
σ1 2 2 ,
σ1 3 2 ,
σ1 4 2 ,
σ1 5 2 ,
σ1 383
2 ,
σ1
··· σ1382,2
1 3 ,
σ1 2 3 ,
σ1 3 3 ,
σ1 4 3 ,
σ1 5 3 ,
σ1 383
3 ,
σ1
··· σ1382,3
1 36 ,
σ35 2 36 ,
σ35 3 36 ,
σ35 4 36 ,
σ35 5 36 ,
σ35 383
36 ,
σ35
··· σ35382,36
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
·
1 72 ,
σ71 2 72 ,
σ71 3 72 ,
σ71 4 72 ,
σ71 5 72 ,
σ71 383
72 ,
σ71
··· σ71382,72
2556
383
圖 5-6 兩兩之間特徵區別值的向量示意圖
計算完兩類與兩類之間的特徵區別值σ後,我們就可以知道針對不同 的兩個類別,哪一個特徵維度的特徵值是對於分辨這兩類有幫助的,值越 大表示對於分類越有利。知道這個資訊後我們就做Sort 排序,經過排序後 我們就可以知道,使用哪幾個特徵維度可以最佳辨識兩類所對應的兩類如 圖5-6所示。
由於是兩類與兩類之間的辨識,針對不同的兩個類別取相對應此兩類 的最佳分類特徵維度的做法就會比一般將所有類別一起訓練出一個分類 模型的分類效果來的好,而且可以用到更少的特徵。取多少特徵維度來辨 認則是取決於當初訓練時最佳的辨識率是落在哪個維度。若都很好時則取 最少維度以減低計算量。下表5-1為用來分辨類別所選用的特徵維度,以第 一類與其他類之分類為例。Ci−j表示這幾個特徵是用來分辨第i與第j類,後
面的數值為特徵向量中選用的特徵值fk,也就是fk中的下標k。而最左邊的 值表示所屬的σ值最大值,表5-1所顯示的為σ值取前12大的特徵維度。
表 5-2 分類所選用之維度
C1-2 66 353 232 65 357 358 338 67 315 64 279 356 C1-3 66 232 65 67 315 64 354 233 279 358 231 339 C1-4 337 275 151 66 232 338 65 67 315 64 233 277 C1-5 66 232 65 67 354 315 353 64 233 231 355 357 C1-6 66 232 65 67 315 64 233 231 338 339 279 316 C1-7 66 232 65 67 315 64 233 231 279 316 354 339 C1-8 66 232 354 356 67 357 315 355 64 358 233 353 C1-9 66 232 65 67 315 64 233 231 279 339 63 316 C1-10 66 232 65 67 315 64 233 231 316 63 279 339 C1-11 339 279 354 353 277 355 159 338 155 278 158 311 C1-12 151 275 337 66 232 65 338 67 315 64 233 231 C1-13 66 232 65 67 315 64 231 233 63 316 339 68 C1-14 151 275 337 66 232 65 67 315 279 64 233 339 C1-15 151 152 275 337 338 279 277 159 53 339 373 66 C1-16 277 338 53 155 52 225 226 339 279 312 51 159 C1-17 66 232 65 67 315 277 155 64 233 152 338 231 C1-18 337 338 154 275 277 279 152 339 159 151 357 66 C1-19 354 353 355 279 66 339 356 232 159 357 65 67 C1-20 354 353 66 357 355 232 65 376 339 276 67 358 C1-21 338 151 277 275 337 155 53 52 279 66 339 232 C1-22 66 232 65 67 315 64 233 231 316 63 357 358 C1-23 66 232 65 67 315 64 233 231 316 63 357 358 C1-24 66 232 65 67 315 357 354 64 233 356 358 231 C1-25 66 232 65 67 315 64 233 231 316 354 63 279 C1-26 66 232 65 67 315 64 233 231 339 63 316 279 C1-27 66 232 65 357 67 315 358 356 354 64 233 231 C1-28 66 232 65 339 67 279 315 64 233 159 231 278 C1-29 66 232 65 67 315 64 233 231 316 339 63 279 C1-30 66 232 338 65 67 315 277 358 64 233 357 231 C1-31 66 232 67 315 64 233 231 354 355 316 63 357 C1-32 66 232 65 67 315 64 233 231 316 63 339 68 C1-33 152 337 275 156 151 278 157 339 66 232 65 279
C1-34 66 232 65 67 315 358 357 64 233 231 356 316 C1-35 66 232 65 67 315 277 233 64 358 316 231 338 C1-36 66 232 65 67 315 64 233 231 316 63 339 68 C1-37 66 232 65 279 277 339 155 67 315 159 64 233 C1-38 66 232 339 279 65 67 315 358 159 64 233 338 C1-39 66 232 65 67 315 64 233 231 354 316 339 279 C1-40 344 66 232 67 340 65 290 345 233 278 315 289 C1-41 355 66 354 232 67 65 233 353 316 315 68 223 C1-42 66 232 65 315 67 64 231 233 63 316 62 230 C1-43 66 232 65 67 315 233 353 354 64 316 344 359 C1-44 353 66 354 232 279 65 339 67 315 64 355 357 C1-45 279 339 159 98 248 323 158 97 99 96 247 95 C1-46 66 232 339 340 65 67 279 275 53 226 151 54 C1-47 53 226 52 275 151 339 54 340 312 55 225 279 C1-48 275 151 339 340 53 226 52 54 279 66 337 312 C1-49 279 339 159 158 66 232 344 65 67 354 345 315 C1-50 66 232 67 65 233 315 316 64 68 357 231 358 C1-51 66 232 67 65 233 315 316 64 68 231 339 63 C1-52 66 232 65 67 315 64 233 231 358 316 63 357 C1-53 66 232 67 65 315 233 64 316 231 68 63 339 C1-54 66 232 65 67 315 64 233 231 344 316 68 63 C1-55 66 67 232 233 65 316 315 68 64 339 231 234 C1-56 66 232 65 67 315 64 231 233 63 344 316 68 C1-57 340 67 66 233 232 316 68 65 75 279 237 76 C1-58 321 244 89 90 88 243 91 245 87 322 92 349 C1-59 354 339 353 279 159 355 46 345 158 222 291 290 C1-60 66 232 65 315 67 64 231 233 63 316 354 62 C1-61 339 66 279 232 278 65 158 157 159 315 67 64 C1-62 279 339 159 158 344 278 345 157 354 290 355 353 C1-63 66 232 65 67 279 315 64 233 231 159 158 358 C1-64 339 53 52 279 226 54 66 159 232 312 65 225 C1-65 354 353 66 232 67 355 65 233 340 316 315 311 C1-66 66 232 65 67 315 233 64 231 316 339 63 68 C1-67 353 354 66 232 65 315 355 67 64 356 231 357 C1-68 66 232 65 354 67 315 353 64 233 279 339 231 C1-69 354 353 344 345 66 355 232 67 65 233 290 291 C1-70 66 232 65 67 315 64 231 233 63 279 339 316
C1-71 345 291 67 233 282 66 353 316 76 68 77 237 C1-72 313 57 228 56 314 58 227 229 61 60 230 59
5.2 特徵抽取改進與特性特徵抽取改進與特性特徵抽取改進與特性特徵抽取改進與特性分析分析分析 分析
本實驗進一步改進演算法,將抽取的特徵改進為 446 維。如圖 5-7,我 們採用 6 階小波轉換,並且增加特徵抽取如下表 5-2。最後的辨識結果為 98.09%。而本實驗更進一步做了一些驗證,將所有分成 72 子類的心電圖 轉為 12 類。以不分子類的情形來測試,結果發現總辨識率為 98.22%。
g
h
g
h 2
2 D1 One Beat (96)
ECG signal
2
2 g
h D2 (48)
2 g
h 2
D3 (24)
2 2 D4
(12) (192)
A2 (48) A1
(96)
A3
(24) g
h
2 D5 (6) A4
(12) g
h 2
2 D6 (3)
A6 (3) A5
2 (6)
圖 5-7 6 階小波轉換
本特徵抽取增加了 R-R interval 之間的觀念在裡面,除了增加了小波係 數以外,更增加了每段 segmentation 之間的關係,以偵測到的 R 波為基準 抽出特徵。而以下說明所增加的特徵的原因。
1. The R-R interval ratio between the previous beat and next beat:
為了加強辨識 fusion 類的病症,當心跳的 QRS 是出現一組快一組慢,
那前後的 RR-interval 比可以提供當作特徵。
2.The R-R interval ratio between the normal one and the current beat:
為了加強心房及心室過早激發之辨認,利用正常 R-R interval 與每 一段 R-R interval 做比較,正常 R-R interval 為取前五組的 R-R interval 平 均值。 ratio = normal / current (如果過早激發,此特徵容易大於 1)
3.The amplitude of P and R wave:
雖然在小波係數有記錄 P and R wave 的位置,但有些波形漂移太 嚴重或是 P 波不明顯的各波形,利用 ratio of P and R wave 當作特徵,加 強 P and R wave 之間的關係。P wave 偵測是利用 PR 區間正常在 0.12 秒到 0.2 秒之間,轉換成程式為第 17 點到第 62 點搜尋最高點為 P 波。
4.The amplitude of R and S wave 和 The distance of R and S Wave:
這兩個特徵純粹是加強 QRS 波的特徵描述。因為 aberrate artial premature beat 的唯一特徵就是 QRS 形狀特別奇怪,而且沒有 P 波,因此 我們加強了此特徵。S wave 偵測是利用 R 波之後 30 點搜尋最低點即為 S 波。
5. The ratio of the R-R interval and R-S interval和 The ratio the R-R interval and P-R interval:
這兩個特徵是針對 juntional 類的病徵,所抽取的特徵。所謂的 juntional 就是一個或是一連串的跳脫心跳,而利用 R-R interval 和 R-S interval 和 P-R interval 的比例來加強 juntional 的特徵。
非以上五大類的特徵都是別人的 paper 上有提過的方法,因此我們加 了上面五大類的特徵,分別是針對以下三大類的病徵。我們有三大類的病 徵在第一次辨識的時候辨識率並不佳,如下:Premature 類、Fusion 類和 Junctional 類。因此我們利用 2、4 來加強 Premature 類的辨識,而 1 加強 Fusion 類的辨識,最後 5 加強 Junctional 類的辨識。
The feature type The number of feature values
The mean values of the absolute values of the coefficients in each sub-band
12
The maximum values of the absolute values of the coefficients in each sub-band
12
The average energy of the wavelet coefficients in each sub-band
12
The standard deviation of the coefficients in each sub-band
12
The ratio of the absolute mean values of adjacent sub-bands
11
The R-R interval of the beat 1 The average R-R interval of five
last beats.
1
The R-R interval ratio between the previous beat and next beat
1
The R-R interval ratio between the normal one and the current beat
1
The ratio of P and R wave 1
The amptitude of R and S wave 1 The ratio of the R-R interval and
R-S interval
1
The ratio of the R-R interval and P-R interval
1
The dinstance of R and S wave 1 表 5-3 改進後的特徵抽取
圖 5-8 為對 Support Vector Number 的統計,由此圖可看出大部分的 SV Number 小於 80,而平均值為 11.53404。因此可以分析出大部份的 SV Number 都沒有很大,表示大部份的 hyper-palne 可以容易分類。
表 5-3 改進後的特徵抽取
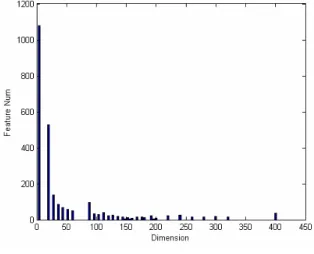
圖 5-8 SV Number
圖 5-9 則為對 Feature Number 的統計,由此圖可看出大部分的 Feature Number小於 250,而平均值為49.65571。而Feature Number的部分,我們也 可以看出利用 Feature Selection 的方法我們將維度 383 降至 49.65571 維,
不但增加正確率而且增加計算速度。我們測過一組切段心電圖大約為 0.00864 sec,而做抽係數大約為 0.015 sec,最後做預測為0.156 sec。
圖 5-9 Feature Number