第四章 音訊前處理與研究理論
第一節 聲音聽覺理論
4.1.1 聲學簡介
聲音訊號(audio signal)簡稱『音訊』,泛指由人耳聽到的各種聲 音的訊號。
人類把悅耳且高低起伏不同的聲音,音質、音色不同的聲波組合 起來,便形成了動人的音樂。當然,音樂的悅耳與否的判定上乃加入 了許多主觀因素的結果。此類經由透過每個人主觀意識上不同感受之 心理學效應,給予聽覺及聲音另一層意義,而不在我們的討論範疇當 中。能聽到聲音並不如我們想像的那麼單純容易。不同頻率的聲波傳 進耳朵裡,可刺激不同位置的耳內神經,再經由大腦不同位置的解 析,方可聽到不同的聲音。這其中耳朵把原先的聲波轉變成電波,而 大腦及耳內神經所扮演著的就如同音譜分析儀一樣,把一個聲音的各 個頻率分析出來,來辨別聲音的本質,如此我們才能區別甲和乙說話 的聲音特色是不一樣的,而不是單純聽到聲音而已。
聲音是研究一維訊號的重要對象,最常見的傳播聲音的介質是空 氣。聲波和電磁波於本質上有很大的不同,例如電磁波是利用電磁感 應的方式來傳播,而聲波的傳播方式則通常是機械式的,當介質如空 氣受到某處震源的壓迫時,被壓迫的空氣分子,就對其平衡位置產生 位移,並引起附近空氣分子也對其平衡位置產生位移。如所受的壓迫 是週期性的,而且其頻率在聲波範圍內,此時,空氣中就產生聲波。
聲波通常是指振動頻率在人能感應範圍以內的波動,稱為可聞波 (audible sound)。當頻率高於可聞聲時稱超音波 (ultrasound),其能量 較高,一般可用於醫學或工程之檢測或塑膠等材料加工,至於頻率比 可聞波低時稱為低音波 (infrasound),例如地震所引起的地震波。
一般來說,發音體會產生振動,此振動會對空氣產生壓縮與伸張 的效果,形成聲波,聲音傳播的速度與介質的性質和溫度有關,在空 氣溫度為 0 度時,聲波的速度為 331.5m/s,如果空氣溫度每升高 1 度時,則聲音傳播的速度約增加 0.6m/s。因此在常溫(25°C)下以 每秒大約 345 公尺的速度在空氣中傳播,故聲波的速度顯然比光波 慢的多。當此聲波傳遞到人耳,耳膜會感覺到一縮一放的壓力訊號,
內耳神經再將此訊號傳遞到大腦,並由大腦進行解析與判讀,來分辨 此 訊 號 的 意 義 。 如 果 我 們 把 人 類 的 語 音 訊 號 透 過 正 交 轉 換 映 射
(mapping)到頻譜上來分析,可以看到在頻譜上人類語音訊號大都 集中於某一個區段有較高的能量,這也意味著這個能量較高的頻帶就 是人類聲腔的共鳴區域。我們通常稱音源振動時的頻率為基本頻率簡 稱『基頻』(fundamental frequency),每個人聲音的基本頻率因為天生 的口腔結構而有所不同,通常小孩子的基本頻率在 250~400 Hz 左 右,成年女子約在 200~300Hz 左右,而成年男子則約在 100~150Hz 左右,因此男高音較為少見,也就是這個原因。
當人類發出聲音時,如果有利用到聲帶振動來發音,則稱為有聲 音(voiced sound),否則稱之為無聲音 (unvoiced sound),而語音中又 可分為具有穩定聲道激發共鳴振動的母音以及音源振動變化較多較 雜亂的子音。
對人類耳朵而言,其能夠接受的音頻範圍很窄,大約在 10Hz 到
20 kHz 左右,而其中在 100 Hz 到 1.4 kHz 左右是聽覺最敏銳的頻 帶,而在此頻帶之前,人耳對較低的頻率並不敏感,隨著頻率越高,
人耳便越聽得清楚,亦即人耳對高頻的聲音有自動增益(AGC)的效 果。因此如果我們用手來回揮動空氣,如此低頻的振盪,是無法發出 人耳可以發覺的聲音,除非我們鼓掌,在拍手的過程中,兩手迅速的 撞繫並將空氣擠壓出去,這種較短的脈衝式振動,其中包含了高頻的 空氣振動,因此人耳便能夠聽到拍手的聲音。
相對的人的嘴唇構造卻較無法發出高頻的聲音,隨著發出的聲音 頻率越高,嘴中所發出的強度即隨之而減弱,因此當我們在作語音訊 號取樣時,並不需要將取樣頻率取得太高,一般而言,使用 11 kHz 即 告足夠,因為語音中高頻的部份很少,聲音的變化不快,但音樂就不 同了,音樂資料變化性通常很大,一般取樣頻率是使用 22KHz,如 此重新播放出來時人耳聽來才不致於有失真的感覺。但是為了更嚴苛 的標準,我們將無失真的取樣頻率訂定為 44.1kHz。而一般對音訊要 求不高的情況下我們會採用以 8kHz 為取樣頻率的聲音來當作音訊輸 入。
4.1.2 人耳的遮蔽效應
人耳聽覺系統非常複雜,迄今爲止人類對它的生理結構和聽覺特 性還不能從生理解剖角度完全解釋清楚。所以,對人耳聽覺特性的研 究目前僅限於在心理聲學和語言聲學。
人耳對不同強度、不同頻率聲音的聽覺範圍稱爲聲域。在人耳的 聲域範圍內,聲音聽覺心理的主觀感受主要有響度、音高、音色等特 徵和掩蔽效應、高頻定位等特性。其中響度、音高、音色可以在主觀 上用來描述具有振幅、頻率和相位三個物理量的任何複雜的聲音,故
又稱爲聲音“三要素"這三要素將於下節中闡明;而在多種音源場 合,人耳掩蔽效應等特性更重要,它是心理聲學的基礎。
一個較弱的聲音(被掩蔽音)的聽覺感受被另一個較強的聲音(掩 蔽音)影響的現象稱爲人耳的“遮蔽效應"。被掩蔽音單獨存在時的 聽閥分貝值,或者說在安靜環境中能被人耳聽到的純音的最小值稱爲 絕對聞閥。實驗表明,3kHz--5kHz 絕對聞閥值最小,即人耳對它的微 弱聲音最敏感;而在低頻和高頻區絕對聞閥值要大得多。在 800Hz 至 1500Hz 範圍內聞閥隨頻率變化最不顯著,即在這個範圍內語言的 可儲度最高。在掩蔽情況下,提高被掩蔽弱音的強度,使人耳能夠聽 見時的聞閥稱爲掩蔽聞閥(或稱掩蔽門檻),被掩蔽弱音必須提高的分 貝值稱爲掩蔽量(或稱閥移)。
1.掩蔽效應
已有實驗表明,純音對純音、噪音對純音的掩蔽效應結論如下:
A.純音間的掩蔽
1.對處於中等強度時的純音最有效的掩蔽是出現在它的頻率附 近。
2.低頻的純音可以有效地掩蔽高頻的純音,而反過來則作用很小。
B.噪音對純音的掩蔽噪音是由多種純音組成,具有無限寬的頻譜。
若掩蔽聲爲寬帶雜訊,被掩蔽聲爲純音,則它産生的掩蔽門 檻在低頻段一般高於雜訊功率譜密度 17dB,且較平坦;超過 500Hz 時大約每十倍頻寬約增大 10dB。若掩蔽聲爲窄帶雜訊,被掩蔽聲爲 純音,則情況較複雜。其中位於被掩蔽音附近的由純音分量組成的窄
帶雜訊即臨界頻帶的掩蔽作用最明顯。所謂臨界頻帶是指當某個純音 被以它爲中心頻率,且具有一定帶寬的連續雜訊所掩蔽時,如果該純 音剛好能被聽到時的功率等於這一頻帶內雜訊的功率,那麽這一帶寬 稱爲臨界頻帶寬度。臨界頻帶的單位叫巴克(Bark),1Bark=一個臨界 頻帶寬度。頻率小於 500Hz 時,1Bark 約等於 freq/100;頻率大於 500Hz 時,1Bark 約等於 9+41og(freq/1000),即約爲某個純音中心頻 率的 20%。 一般認爲,20Hz 至 16kHz 範圍內會存在有 24 個子臨界 頻帶。而當某個純音位於掩蔽聲的臨界頻帶之外時,掩蔽效應仍然存 在。
2.掩蔽類型
(1)頻域掩蔽
所謂頻域掩蔽是指掩蔽聲與被掩蔽聲同時作用時發生掩蔽 效應,又稱為同時掩蔽。此時,掩蔽聲在掩蔽效應發生期間一直起作 用,是一種較強的掩蔽效應。通常,頻域中的一個強音會掩蔽與之同 時發聲的附近的弱音。弱音離強音越近,一般越容易被掩蔽;反之,
離強音較遠的弱音不容易被掩蔽。例如,—個 1000Hz 的音比另一個 900Hz 的音高 18dB,則 900Hz 的音將被 1000Hz 的音掩蔽。而若 1000Hz 的音比離它較遠的另一個 1800Hz 的音高 18dB,則這兩個音將同時被 人耳聽到。若要讓 1800Hz 的音聽不到,則 1000Hz 的音要比 1800Hz 的音高 45dB。一般來說,低頻的音容易掩蔽高頻的音,在距離強音 較遠處,絕對聞閥比該強音所引起的掩蔽閥值高,這時,雜訊的掩蔽 閥值應取絕對聞閥。
(2)時域掩蔽
所謂時域掩蔽是指掩蔽效應發生在掩蔽聲與被掩蔽聲不同時 出現時,又稱異時掩蔽。異時掩蔽又分爲導前掩蔽和滯後掩蔽。若掩 蔽聲音出現之前的一段時間內發生掩蔽效應,則稱爲導前掩蔽;否則 稱爲滯後掩蔽。産生時域掩蔽的主要原因是人的大腦處理資訊需要花 費一定的時間,異時掩蔽也隨著時間的推移很快會衰減,是一種弱掩 蔽效應。一般情況下,導前掩蔽只有 3ms--20ms,而滯後掩蔽卻可以 持續 50ms--100ms。
第二節 聲音訊號之特性
首先介紹音訊三大基本性質如下:
音量(volume):聲音的大小稱為音量,又稱為響度(loudness)、
聲強(intensity)或是能量(energy)。音量越大,代表音訊波形的振 幅越大。 但是我們人耳對於音量的感覺並非和振幅成正比而是和振 幅的對數成正比。所以我們在計量聲音大小的時候採用的是依照功率 比值取對數而得到的分貝制。聲音的響度一般用聲壓(達因/平方釐 米)或聲強(瓦特/平方釐米)來計量,聲壓的單位爲帕(Pa),它與基準 聲壓比值的對數值稱爲聲壓級,單位是分貝(dB)。響度是聽覺的基 礎 。 正 常 人 聽 覺 的 強 度 範 圍 爲 -5dB--130dB( 也 有 人 認 爲 是 0dB—140dB)。固然,超出人耳的可聽頻率範圍(即頻域)的聲音,即 使響度再大,人耳也聽不出來(即響度爲零)。但在人耳的可聽頻域內,
若聲音弱到或強到一定程度,人耳同樣是聽不到的。當聲音減弱到人 耳剛剛可以聽見時,此時的聲音強度稱爲“聽閥"或稱為“聞閥"。
一般以 1kHz 純音爲准進行測量,人耳剛能聽到的聲壓爲 0dB(通常大 於 0.3dB 即有感受)、聲強爲 10--16W/cm2 時的響度級定爲 0。而當
聲音增強到使人耳感到疼痛時,這個閥值稱爲“痛閥"。仍以 1kHz 純音爲准來進行測量,使人耳感到疼痛時的聲壓級約達到 140dB 左 右。
實驗表明,聞閥和痛閥是隨聲壓、頻率變化的。聞閥和痛閥隨 頻率變化的等響度曲線(Fletcher-Munson curves)之間的區域就是人耳 的聽覺範圍。通常認爲,對於 1kHz 純音,0dB--20dB 爲寧靜聲,
30dB--40dB 爲微弱聲,50dB--70dB 爲正常聲,80dB--100dB 爲響音 聲,110dB--130dB 爲極響聲。而對於 1kHz 以外的可聽聲,在同一級 等響度曲線上有無數個等效的聲壓—頻率值,例如,200Hz 的 30dB 的聲音和 1kHz 的 10dB 的聲音在人耳聽起來具有相同的響度,這就 是所謂的“等響"。小於 0dB 聞閥和大於 140dB 痛閥時爲不可聽聲,
即使是人耳最敏感頻率範圍的聲音,人耳也覺察不到。人耳對不同頻 率的聲音聞閥和痛閥不一樣,靈敏度也不一樣。人耳的痛閥受頻率的 影響不大,而聞閥隨頻率變化相當劇烈。人耳對 3kHz--5kHz 聲音最 敏感,幅度很小的聲音訊號都能被人耳聽到,而在低頻區(如小於 800Hz)和高頻區(如大於 5kHz)人耳對聲音的靈敏度要低得多。響度級 較小時,高、低頻聲音靈敏度降低較明顯,而低頻段比高頻段靈敏度 降低更加劇烈,一般應特別重視加強低頻音量。通常 200Hz--3kHz 語 音 聲 壓 級 以 60dB--70dB 爲 宜 , 頻 率 範 圍 較 寬 的 音 樂 聲 壓 以 80dB--90dB 最佳。
音量大小的計算可由一個音框內的訊號振幅大小來類比,基本上 有以下兩種方式來計算:
1.每個音框的絕對值的總和:這種方法的計算較簡單,只需要整 數運算,適合用於低階平台(如微電腦等)。
2.每個音框的平方值的總和,再取以 10 為底之對數值,再乘以 10。這種方法得到的值是以分貝(decibels)為單位,是一個相對強 度的值,比較符合人耳對於大小聲音的感覺。基本上我們可以使用這 計算所得的音量來表示聲音的強弱,但是前述兩種計算音量的方法,
只是用數學的公式來逼近人耳的感覺,和人耳的感覺有時候會有相當 大的落差,為了區分,我們使用「主觀音量」來表示人耳所聽到(感 覺到)的音量大小。例如,人耳對於同樣振幅但不同頻率的聲音,所 產生的主觀音量就會非常不一樣。若把以人耳為測試主體的「等主觀 音量曲線」(curves of equal loudness)畫出來,就可以得到下面這一 張圖:
圖 4-1 人耳之等主觀音量曲線圖
主觀音量容易受到頻率和音色的影響,因此我們在進行語音或歌 聲合成時,常常根據聲音的頻率和內容來對音訊的振幅進行校正,以 免造成主觀音量忽大忽小的情況。
音高(pitch):亦稱為音調,表示人耳對聲音調子高低的主觀感 受。客觀上聲音的基本頻率(fundamental frequency)越高,代表音高 越高(例如女高音的歌聲);相反的,聲音的基本頻率越低,代表音 高越低(例如男低音的歌聲)。單位用赫茲(Hz)表示。主觀感覺的音 高單位是“美"(Mel),通常定義響度爲 40 方的 1kHz 純音的音高爲 1000 美。赫茲與美同樣是表示音高的兩個不同概念而又有聯繫的單 位。人耳對響度的感覺有一個從聞閥到痛閥的範圍。人耳對頻率的感 覺同樣有一個從最低可聽頻率 20Hz 到最高可聽頻率別 20kHz 的範 圍。響度的測量是以 1kHz 純音爲基準,同樣,音高的測量是以 40dB 聲強的純音爲基準。實驗證明,音高與頻率之間的變化並非線性關 係,除了頻率之外,音高還與聲音的響度及波形有關。音高的變化與 兩個頻率相對變化的對數成正比。不管原來頻率多少,只要兩個 40dB 的純音頻率都增加 1 個倍頻程(即 1 倍),人耳感受到的音高變化則相 同。在音樂聲學中,音高的連續變化稱爲滑音,一個倍頻程相當於樂 音提高了一個八度音階。根據人耳對音高的實際感受,人的語音頻率 範圍可放寬到 80Hz--12kHz,樂音較寬,效果音則更寬。有關基本頻 率的說明,將在本章其後各小節說明之。而我們也可以發現到人耳對 於聲音高低的感覺是與基本頻率的對數成正比。例如以鋼琴的鍵盤而 言,在鋼琴中的每個全音階包含七個白鍵和五個黑鍵,共十二個半音
(semitone)。其中中央 La 的頻率是 440Hz,而高八度的中央 La 則是 880Hz,低八度的中央 La 則是 220Hz。以 MIDI 的標準而言中央 La 的半音值為 69;對應頻率為 440Hz 的情況下我們可以寫出半音和頻 率之間的轉換公式如下 4-1 式所示:
69 12 * log (2 ) 440 frequency
smitone= + (4-1)
而在一段聲音當中來求取其音高,在音訊處理上稱為音高追蹤
(pitch tracking)。這在音訊處理上是很重要的一環,相關的應用層面 有音調辨識、語音合成和旋律辨識等等。
音色(timber):音色又稱音品,由聲音波形的諧波頻譜和包絡決 定。聲音波形的基頻所産生的聽得最清楚的音稱爲基音,各次諧波的 微小振動所産生的聲音稱泛音。單一頻率的音稱爲純音,具有諧波的 音稱爲複音。每個基音都有固有的頻率和不同響度的泛音,借此可以 區別其他具有相同響度和音調的聲音。聲音波形各次諧波的比例和隨 時間的衰減大小決定了各種聲源的音色特徵,其包絡是每個周期波峰 間的連線,包絡的陡緩影響聲音強度的瞬態特性。聲音的音色色彩紛 呈,變化萬千,高保真(Hi—Fi)音響的目標就是要盡可能準確地傳輸、
還原重建原始聲場的一切特徵,使人們其實地感受到諸如聲源定位 感、空間包圍感、層次厚度感等各種臨場聽感的立體環繞聲效果。因 此,音訊波形在每個週期內的變化,就形成了此音訊的音色。不同的 音色即代表不同的音訊內容,例如不同的字有不同的發音,或是不同 的歌手有不同的特色,這些都是由於音色不同而產生。
第三節 音頻訊號資料之前處理
4.3.1 取樣與量化
將連續的類比訊號加以離散取樣成為離散時間訊號(discrete-time signal ) 的 動 作 叫 做 類 比 數 位 轉 換 取 樣 ( analog-digital convert sampling,ADCS),簡稱『取樣』(sampling)。我們熟悉的數位訊號 處理之分析其實都是以離散時間訊號來代替數位訊號加以分析。這個 分析就是『量化』(quantization)而如果在量化的位階數目(number of
quantization levels)夠大的情況下,量化誤差可以忽略不計。則 此時可以只考慮討論訊號取樣的步驟。
所謂取樣,就是以固定的時間間隔,將類比訊號的振幅記錄下 來,從數學上來看,就是將類比訊號乘上一個週期性的脈衝訊號,得 到一序列的脈衝,其脈衝的大小就是在該取樣的時間點上類比訊號的 振幅。
給 定 一 個 類 比 訊 號 x(t) , 現 將 此 一 訊 號 x(t) 以 取 樣 間 隔
(sampling interval)為 Ts 秒加以取樣可得離散時間訊號,其中取 樣點之間的時間間隔稱為取樣間隔,取樣間隔的倒數則稱為取樣頻率
(sampling frequency):符號 fs = 1/Ts
當聲音訊號資料之取樣量化的位元數為 8 時,可以得到 256 個 音階,而取樣位元數為 16 時,則擁有 65536 個音階,較高的取樣頻 率與較多的取樣位元數意謂著較高的品質,但同樣的也表示較昂貴的 裝備和較大的記備空間。
對語音而言,使用 8 KHz 取樣頻率, 4 bit 取樣位元,記錄一 分鐘語音再予壓縮後大約要花掉 62 KB 的記憶體。對收音機的聲音 而言,使用 11 KHz 取樣頻率記錄一分鐘則佔用 322 KB 的記憶體,
而在記錄調幅合成時,使用 22 KHz 取樣頻率,則要佔去 1291KB 的 記憶體。至於若要達到雷射唱片的品質要求,則使用 44.1 KHz 取樣 頻率, 16 bit 取樣位元數,因此記錄一分鐘便要 5167 KB 的記憶 體。在沒有壓縮的情況下,一張光碟也只能儲存七十六分鐘的音樂而 已。
由於 PC 喇叭為早期的個人電腦標準配備,早期個人電腦的教學
軟體及電動玩具程式,是直接利用個人電腦上面的喇叭把電動玩具的 音樂播放出來,雖然表現的效果比不上聲霸卡的真實動聽,但其容量 不像現在的音效軟體動輒數片光碟片,為什麼它所佔的資料檔很小 呢?這是因為個人電腦上喇叭裝置不像聲霸卡有 256 或更高的音 階,它只有一個位元,亦即只有兩種狀態:開與關,也許有人會懷疑 只是將喇叭做開與關的動作真的能夠產生音樂嗎?然而代表聲音訊 號特色的兩個要素:"頻率"與"音量"來看,"頻率"這個要素無疑的是 重要了許多。因此我們將音樂波形轉換成各種不同頻率的方波後,推 動喇叭來發音,仍然可以得到近似的聲音,例如想產生高音時只需將 喇叭的開與關動作加速,就可以產生較高頻的聲音,同樣的,如果想 要產生低音時則將喇叭開與關的速度放慢,就可以產生較低頻的聲 音,由於音量無法控制,因此在比較高頻的音效裡,其所包含的能量 較多,聽起來一定比低頻的聲音大聲。
取樣必須滿足奈奎斯特取樣定理(Nyquist sampling theorem)
否則會因為交疊 (aliasing) 的現象,而導致訊號失真。取樣定理是 指訊號取樣時若要做到將來能夠回復原訊號而無失真的條件時,則取 樣頻率必須大於或等於原訊號最高頻率的兩倍。因為如此一來每個被 複製的頻帶將會互相獨立,不致產生干擾,我們只需使用一個低通濾 波器即可順利將原訊號取出,而無失真。相反的,如果取樣頻率太低,
那麼每個被複製的頻帶將會互相干擾,為之交疊現象,而導致訊號失 真,如下圖 4-2(c)所示,那時候即使我們使用低通濾波器將訊號取 出,也不是原來應有的訊號形狀了。
(a) 符合奈奎斯特取樣定理的取樣
(b) 取樣頻率少於奈奎斯特取樣之取樣
(c)因取樣頻率過低所造成之訊號失真
圖 4-2 取樣原理相關示意圖
4.3.2 語音編碼(Speech coding)
數位電子聲音技術中有一項很重要的工作就是編碼的方法,常見 的編碼方法有脈波碼調制 (pulse code modulation,PCM) 以及高階脈 波數位碼調制 (advanced pulse code modulation,ADPCM),目前像雷 射唱盤、數位錄音帶、通信衛星、電話通信,都是各式各樣的 PCM 技 術 應 用 的 具 體 例 子 。 影 響 PCM 的 效 果 的 因 素 一 為 取 樣 頻 率
(sampling rate),一為取樣位元數(sampling bits),這兩者的數值大小 都與人類的聽覺與語音傳播能力有關。
自然界中的聲音非常複雜,波形極其複雜,而為了於電腦上以離 散的數位訊號來表示連續的類比訊號,則必須透過編碼的方式進行。
語音波形編碼即是將當時每個波形的振幅轉換成一個數值來表示,因 此沿著取樣時間的數位化數值便可描述聲音訊號的波形,最基本的波 形編碼,是採用脈碼調變(plus code modulation,PCM)的方式來記 錄聲音波形。PCM 通過抽樣、量化、編碼三個步驟將連續變化的訊 號轉換為數字。他是用固定的取樣頻率,在每個取樣點以固定位元數 來表示波形的振幅,雖然可以保持原始波形的成分,但是相對的需要 儲存的資料量也較大,所以在傳遞時也佔用較大的頻寬。因此數位音 訊處理上也發展出了許多壓縮編碼的方法希望降低其位元率。新的聲 音訊號壓縮編碼的技術是利用人耳對於聲音訊號感知的特性。將重複 性的資訊與聽不到的聲音訊號去除。雖然這種參數模型法會改變原始 波形的成分,但是人耳聽起來的效果卻幾乎一模一樣。此種編碼能有 效的降低位元率,使得儲存的資料量減少許多。而後來更出現混合參 數模型法編碼及波形編碼的編碼方式。這種混合式編碼可以低於 16kbps 碼率得到高品質的合成語音。利用這種混合式編碼的有:基於
按照預測分析來合成的線性預測(LPAS):採用聽覺加權技術,在閉環 基 礎 上 尋 找 主 觀 失 真 最 小 的 激 勵 向 量 。 多 脈 衝 線 性 預 測 編 碼 (MP-LPC): 1982 年,9.6kbps 衛星導航通訊標準。碼激勵線性預測 (CELP):1984 年,使用向量量化(VQ),能在 4.8kbps 以上的碼率獲得 較高品質的語音。CCITT G.728:1992 年,使用貝爾實驗室的 LD-CELP
(低延遲碼激勵線性預測)演算法,以 16 kbps 編碼語音。而後來又 陸續開發了許多壓縮比更好失真率更低的編碼,例如:MP3 編碼、
MP3PRO 編碼、OGG 編碼、MPC 編碼等等。
4.3.3 越零率
越零率的定義為一段語音波形和時間交越的次數,即相鄰兩個樣 本點,其振幅值正負號不同號的次數,以正負不同號式子表示為
[ ( )] [ ( 1)]
sign x n ≠ sign x n + (4-2)
其中sign x n[ ( )]表示語音訊號 x(n)之正負符號,如果大於零則為 正,反之為負。因此若前後兩個取樣訊號的正負號相異則越零率的累 進計數加 1。
有時語音聲段當中有鼻音、子音等,雖然這些亦屬語音的訊號,
但通常這些部分的語音的能量都很小,所以常會被誤判為靜音的部 分,而加以刪除,造成端點偵測的錯誤。若加上了越零率這個資訊,
就可較正確的分辨出子音和靜音的不同了。因為靜音時,也就是使用 者沒有說話時,只有背景雜訊,而雜訊的越零率較低,而在子音訊號 裡,越零率有一定的數值,所以越零率如選擇的適當,可決定某一語 音段為子音段或是靜音段,以輔助能量判斷的不足之處。越零率臨界 值在實作上以下列兩個方法決定:(a) 實驗或經驗數據;(b) 以能量
低於能量臨界值的部分,測量越零率。當兩個方法量測完畢,選用較 小值作為越零率的臨界值。
有些錄音設備的電路沒有作好處理,使得聲波能量振幅的中心不 為 0,就會使波形有 DC offset,使波形整個偏移。此結果必然會影響 越零率的值,形成量測值誤差,故估算越零率時,必先求取音框的 DC offset,扣除 DC 對越零率的影響。
4.3.4 音框(Frame)與音窗(Window)
由於語音辨識或語音增強當中對於音訊的預處理當中有三大步 驟,分別為取音框、預強調和乘上音窗。其中的預強調是為了對高頻 非雜訊成分做補償,並非必要的動作,故在此並不贅述。只針對音框 與音窗做一簡介。
在聲音訊號的處理中,通常假設聲音的特徵是緩慢變化的,因此 可以導出「短時距」的處理方法。我們將一段聲音訊號分成若干個短 時距,並且假設短時距內的聲音訊號其特徵值是不變的。這個短時距 習慣上被稱為一個「音框」(frame)。其定義為將 N 個取樣點(通常 N 的值是 256 或 512)集合成一個觀測單位,此觀測單位稱為音框
(frame),涵蓋的時間約為 20~40 ms 左右。(於 8kHz 取樣頻率下)
在切音框的過程中,為了避免相鄰兩音框的變化過大,我們允許 左右音框的部分重疊(overlap),此重疊區域包含了 M 個取樣點,
通常 M 的值約是 N 的一半或 1/3。以語音辨識常用的音訊的取樣頻 率為 8 KHz 或 16 KHz 為例,在 8 KHz 時,若音框長度為 256 個取 樣點,則對應的時間長度是 256/8000*1000 = 32 ms。再者,我們定 義「音框率」(frame rate)為每秒鐘所出現的音框個數,如果取樣
頻率是 11025,音框長度是 256 點,重疊點數是 84,那麼音框率就 是 11025/(256-84) = 64,換句話說,我們的電腦要能夠每秒鐘處理 64 個音框,才能達到「即時處理」的目的。音框之重疊與切割示意 圖如下圖所示。
圖 4-3 音框之重疊與分割示意圖
我們讓音框重疊的目的,只是希望相鄰音框之間的變化不會太 大,使抓出來的音高曲線更具有連續性。但是在實際應用時,音框的 重疊也不能太大,否則會造成計算量的過大。在選擇音框的大小時,
有以下兩個考量因素:
(1)音框長度至少必須包含 2 個基本週期以上,才能顯示語音 的特性。已知人聲的音高範圍大約在 50 Hz 至 1000 Hz 之間,因此 對於每個不同的取樣頻率,我們都可以計算出音框長度的最小值如 後。例如,若取樣頻率 fs = 8000 Hz,那麼當音高 f = 50 Hz(例如男 低音的歌聲)時,每個基本週期的點數是 fs/f = 8000/50 = 160,因此 音框必須至少是 320 點;若音高是 1000 Hz(例如女高音的歌聲)
時,每個基本週期的點數是 8000/1000 = 8,因此音框必須至少是 16 點。
(2)音框長度也不能太大,太長的音框無法抓到音訊的特性隨 時間而變化的細微現象,同時計算量也會變大。
(3)音框之間的重疊完全是看電腦的運算能力來決定,若重疊 多,音框率就會變大,計算量就跟著變大。若重疊少(甚至可以不重 疊或跳點),音框率就會變小,計算量也跟著變小。
而語音訊號通常是需要做轉換才能被處理的,短時距的轉換等於 是把原來的訊號加上一個「窗」(window)。例如將每一個音框乘上漢 明窗,則可以增加音框左端和右端的連續性。窗的作用,在時域上等 於是從一個波形中取出一段訊號出來,而在頻域的處理上則等同於被 某個濾波系統處理過。
一般常見的窗有三種:
a.矩形窗(rectangular window)
( ) 1 , 0 -1
W n = ≤ ≤n N
( ) 0 ,
W n = n=otherwise
b. 漢尼窗(hanning window)
漢尼窗為一種餘弦型態的音窗,其公式如下所示:
( ) 0.5 0.5 cos( 2 ) , 0 -1 1
W n n n N
N
= − π ≤ ≤
−
( ) 0 ,
W n = n=otherwise
c.漢明窗(Hamming window)
漢明窗是由上述之漢尼窗所進一步改進而來的餘弦型態音窗,其 可以在對應第一零點的寬度一樣的情況下,使得能量更為集中。為了 不使窗內外不會有太劇烈的變化,通常我們會使用漢明窗,它具有壓 抑短時距訊號的兩端而保持中間段的特性。在乘上漢明窗後,可以加 強音框左端和右端的連續性,這是因為在進行 FFT 時,都是假設一 個音框內的訊號是代表一個週期性訊號,如果這個週期性不存在,FFT 會為了要符合左右端不連續的變化,而產生一些不存在原訊號的能量 分佈,造成分析上的誤差。當然,如果我們在取音框時,能夠使音框 中的訊號就已經包含基本週期的整數倍,這時候的音框左右端就會是 連續的,那就可以不需要額外乘上漢明窗了。但是在實作上,由於基 本週期的計算會需要額外的時間,而且也容易算錯,因此我們都用漢 明窗來達到類似的效果。
漢明窗的公式如下所示:
( ) 0.54 0.46 cos( 2 ) , 0 -1 1
W n n n N
N
= − π ≤ ≤
−
( ) 0 ,
W n = n=otherwise
(上式為 ALTHA 係數用 0.46 代入之結果)
下圖為在不同的 ALTHA 係數下產生的漢明窗
圖 4-4 在不同 ALTHA 係數下之漢明窗
除了上述常見的三種音窗外尚有其他如布萊克曼窗(blackman window)和凱薩窗(kaiser window)。
4.3.5 頻譜與聲譜
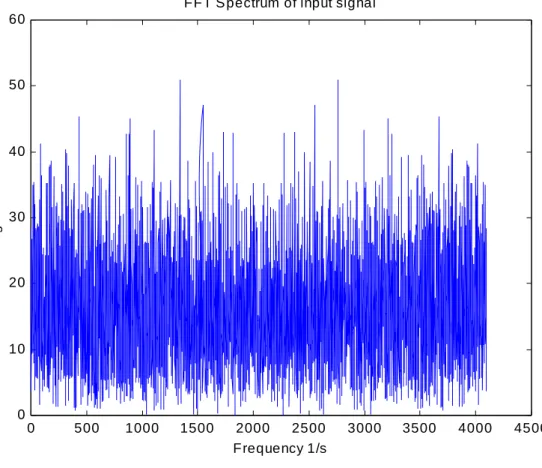
我們在語音的各種研究領域當中常常會用到頻譜(spectrum)與 聲譜(spectrogram)分析,透過上述的兩種分析可以讓我們得知聲音 訊號的頻率分佈情形以及其諧波成分並且可以藉此判定音訊的穩定 度。這對於語音訊號之處理是非常的有幫助的。首先,如下圖 4-5 所 示,我們透過離散傅立葉轉換可以取得頻譜分佈,然後通過不同的濾 波器後可以分離不同的頻帶。
圖 4-5 透過頻譜分析與濾波器作頻帶分析示意圖
這在早期數位訊號處理尚未蓬勃發展時就已經被人們所廣泛應 用。當時是利用濾波器組取出各頻帶的音強,並且沿著時間軸繪製出 其音強分佈情形而得到其聲譜。到了近年來則以電腦透過數位訊號處 理的方式,將時域中的音訊波形轉換成頻譜,在頻域中繪圖呈現。圖 4-6 中的頻譜圖是一個類似白色雜訊聲音波形所對應的頻譜,頻譜曲 線是沿著頻率頻率軸的音強變化(在此以增益代替音強),曲線的高 點就是聲音能量的集中處。頻譜的密集程度則代表其頻率,越密集表 示頻率越高。
Time domain
Yt(M)
t DCT ω
Spectrum ω
ω
ω
Yt(1)
Yt(2)
xt(n) Xt(k) n = 0,1,....L-1 k = 0,1,....
圖 4-6 隨機雜訊之頻譜圖
而如果我們進一步將頻譜曲線的高低改用顏色的深淺來表示,並 且沿著時間軸繪製出來則可以得到聲譜圖。聲譜圖是一個二維的表達 方式,橫軸就是時間,直軸是頻率,在一個時間點上畫一條垂直線,
則此直線上的深淺就代表著該時間點上的頻譜曲線,故我們沿著聲譜 圖的時間軸垂直方向就可以看見該時間點上頻譜的變化。聲譜圖如下 圖 4-7 所示:
0 500 1000 1500 2000 2500 3000 3500 4000 4500 0
10 20 30 40 50 60
FFT S pectrum of input signal
gain
Frequency 1/s
圖 4-7 隨機雜訊之聲譜圖
第四節 離散餘弦轉換
4.4.1 簡介
轉換的目的是在於將原本時域當中不易或無法解決的問題轉移 至另一個領域(例如傅立葉轉換後的頻域或是小波轉換後的時間拓展 域)來使得問題更易於處理,一般說來我們希望轉換具有以下三種特 性:
1.相關性的變換與打散,這是希望能夠把大部分的能量與特徵集
中在極少數的轉換係數上,進而能達成消除原空間的冗餘性。
2.適當的基底函數,透過選擇與數位訊號本身契合的基底,可以 使得轉換後的結果即使經過逆轉換而回復至原值域的失真性最低。並 且使得兩個值域的運算都可以成立。像是目前所發展出來的 KL 轉換 (Kaehunen Loe’ve Transform)雖然號稱是所有轉換當中最佳的一個,也 常被用來判斷一個轉換的優劣,但是因為其沒有獨立的基底函數,故 其實際價值並不高。
3.轉換的準確性與複雜度:對於同樣大小的 samples 點數,我們 希望採用的是一個複雜度最低而準確性最高的轉換,然而兩者本身即 是一種取捨(trade off),而對於要同時滿足對複雜計算效率精確性和 即時性的要求的轉換法於本研究當中是十分重要的。我們考慮所考慮 的轉換有離散傅立葉變換和離散餘弦轉換。分別簡介如下:
離散傅立葉變換(DFT)允許在頻域當中表示所有訊號,即使是小 於 1 秒鐘的訊號亦可。而其傅立葉頻率分量更比其他指數型級數能夠 有效的描述語音訊號。但是計算 DFT 會利用到許多的乘法與加法,
快速傅立葉變換則能夠有效的減少其運算複雜度,以 1024 個點的 DFT 與 FFT 作比較,其計算量可以減少約 200 倍。
離散餘弦變換(discrete cosine transform,DCT)簡稱 DCT。是任何 連續的實對稱函數的傅立葉變換(fourier transform)中只含餘弦項的 正交轉換,因此餘弦變換與傅立葉變換一樣具有明確的物理量意義。
它在一些訊號處理的應用上特別地有用。因為此轉換可以把把二維影 像資料或是一維聲音資料由空間定義域 (space domain) 轉換到頻率 定義域 (frequency domain),使得資料的特性(例如對稱性,頻率分 佈,能量集中度)可以透過不同的頻率域彰顯出來,以利我們作資料
的分析。(例如探討每個頻率下的訊號能量變更),例如語音域視頻的 數據壓縮傳輸以及 EEG 與 ECG 等各種生物醫學語音訊號的紀錄,還 可以用於模式識別。而在這些運用當中只利用到最有效的分量。因 此,要求所使用的位元數會變少,以加快傳輸,對於一個良好的變換 形式而言我們會去考慮其壓縮效率,計算複雜度,以及誤差率(最小 均方誤差)。DCT 剛好符合以上的需求
而且 DCT 不但同時兼顧了效能與轉換速度上的優點。例如就其 轉換能力而言,一般數位訊號經過 DCT 轉換後的表現和 KLT 幾乎沒 有什麼差異,而且又不像離散傅立葉轉換會將一筆資料轉換成複數 值。在速度方面,於 1970 年間,許多的 DCT 快速演算法被提出以上 的種種因素也使得 DCT 成為 JPEG 當時制定標準時的最佳選擇。
4.4.2 DCT 的定義
我們知道 DCT 其實為離散傅立葉轉換(DFT)的實數序列正交轉 換,我們以下列這個一般化之有限長度轉換表示式為例
1
* 0
[ ] [ ] [ ]
N
k n
A k − x n φ n
=
=
∑
(4-3)
1
0
[ ] 1 [ ] [ ]
N
k k
x n A k n
N − φ
=
=
∑
(4-4)
其中序列φk[ ]n ,被稱為基底序列(Basis Sequence),彼此間相互 正交;亦即:
1
* 1 , ,
0 , .
0
1 [ ] [ ] {
N
m k
k m m k
n
n n
N − φ φ =≠
=
∑
=(4-5)
在 DFT 的情況中,那些基底序列為複數週期性序列ej2πkn N/ 。而
DCT 的形式就如同上面(4-3)(4-4)兩個式子的形式,它的基底序 列φk[ ]n 為餘弦函數所構成。因餘弦具週期性而且偶對稱的函數,在合 成方程式(4-5)中的x n[ ]在
0≤ ≤n (N−1)的範圍之外將會具有週期性和對稱性。換句話說,
正如同 DFT 有週期性的特性,DCT 也同時具有週期性和偶對稱性的 特性。DFT 表現有限序列的方式為先組成週期性的序列,從該週期性 的序列中我們可獨一無二地還原出該有限長度的序列,然後用週期性 的複數指數函數來作拓展的動作。在 DCT 對應一個有限長度序列來 組成一個週期且對稱的序列時,亦可用類似的方式來達成。而且原來 的那個有限長度的序列可以被獨一無二的還原回來。因為要達成這個 目標的方法有很多種,所以 DCT 的定義也有許多個(8 個)。其中以 它的第一(DCT-1)、第二種類型(DCT-2),最常被訊號處理和圖像 處理所使用,用於對訊號和圖像(包括靜止圖像和動態圖像)進行有損 耗形式之數據壓縮。這是由於離散餘弦變換具有很強的"能量集中"的 特性:大多數的自然訊號(包括聲音和圖像)的能量都集中在離散餘弦 變換後的低頻部分,而且當訊號具有接近馬爾科夫過程(Markov processes)的統計特性時,離散餘弦變換的去相關性接近於 K-L 變換 (Karhunen-Loève 變換--它具有最優的去相關性)的性能。
例如,在靜止圖像編碼標準 JPEG 中,在運動圖像編碼標準 MJPEG 和 MPEG 的各個標準中都使用了離散餘弦變換。在這些標準制中都使 用了二維的第二種類型離散餘弦變換,並將結果進行量化之後進行熵 編碼。這時對應第二種類型離散餘弦變換中的 n 通常是 8,並用該公 式對每個 8x8 塊的每行進行變換,然後每列進行變換。得到的是一個 8x8 的變換係數矩陣。其中(0,0)位置的元素就是直流分量,矩陣中的 其他元素根據其位置表示不同頻率的交流分類。
一個類似的變換, 改進的離散餘弦變換被用在高級音頻編碼 (AAC for Advanced Audio Coding),Vorbis 和 MP3 音頻壓縮當中。
而在本論文當中對於由時域分析轉換至頻域分析時之轉換所採 用的是 DCT-1 形式。DCT-1 形式可定義成以下的轉換配對:
( )
1 1
0
[ ] 2 [ ] [ ] c o s , 0 1
1
N c
n
X k n x n k n k N
N α π
−
=
=
∑
− ≤ ≤ −(4-7)
1
1 0
[ ] 1 [ ] [ ] c o s , 0 1
1 1
N
c k
X n k X k k n n N
N N
α π
−
=
⎛ ⎞
= −
∑
⎜⎝ − ⎟⎠ ≤ ≤ −(4-8)
其中
{
1,0.5, 1 1, 1,[ ] n
n N Nα =
n = 0 and ≤ ≤ − −(4-9)
第五節 語音品質評量
任何一種語音處理的方法最後必定希望建立起一道評估的手 續,語音增強而言,我們希望最後得到的結果越接近原始無噪的語音 或是越清晰的語音(在沒有乾淨的語音可以比較的環境下)。那麼語 音品質要怎樣評量呢?基本上有兩種量測方式,一種是主觀的品質量 測(subjective quality measure)這是由人來聽,以評量其品質。一是 客觀的品質量測(objective quality measure),這是從訊號中計算噪音 成分的多少所得來的,噪音成分越少表示聲音的品質越好。但是有時 候客觀的量測並不準確,因為噪音的成分多寡並非完全決定了語音品 質的好壞,而必須如同前面所說的必須端看此時噪音的組成頻率和能
量密集程度來加以判斷。下面是語音品質評量的一些方法:
4.5.1 主觀品質評量
主觀品質評量是找一群人來聽,並且訂定一套標準的程式,由受 測者對於所聽到的聲音打分數,最後計算出一個分數出來,用以表示 聲音品質的好壞。對於這種主觀品質量測,通常適用評量一個具有高 可聽度的系統,常用的量測有以下幾種:
(1)押韻測試 (rhyme test)
此方法通常用於語音合成以及語音編碼上的評量。給一組同樣韻 母的詞,但是其前面的子音不同,讓受測者判斷其子音,分辨這一組 詞,這種測試通常會限定一定數量的詞,如六個,讓受測者從中選其 一,這種方式叫做修正式押韻測試(modified rhyme test,MRT)。另 一種測試方法是一次出現一對只有子音不同的詞,如英文中的 Veal 與 peel、bean 與 peen,受測者要分辨這兩個詞的聲音,這叫做診斷式 押韻測試(diagnostic rhyme test,DRT)。
(2)平均主觀分數 (mean opinion score,MOS)
這個方法是用來評量一個語音處理系統的品質,受測者會就其 所聽到的聲音作五級分的評量,打 1-5 分。在受測開始前先讓受測者 先聽過五種級分的聲音品質語音,讓受測者知道怎樣品質的聲音應該 給多少分。然後再用未知等級的語音讓受測者來評分。此法亦為我們 之後研究當中用來鑑定噪音消除效果的主觀評量方法。修改後適用於 本論文研究的平均主觀分數量度表如下表所示:
主觀評定等級表
語音質量等級 分數 噪音分辨等級
優 5 人耳不可聽聞噪音
良 4
需明顯集中注意力 可感覺有點失真
滿意(正常) 3
中等程度的注意力 可聽見噪音 。
差 2
不需要集中注意力 亦可在語音中聽聞 噪音。
劣 1 噪音非常明顯甚至
遮蓋原始語音
表 4-1 平均主觀分數量度表
(3)診斷式接受度量測(diagnostic acceptability measure,DAM)
這是一個比較完整的評量方法,他的評量計分方式是分成十六個 不同的項目,從各個不同尺度來評量語音的品質,每個項目以 0~100 分作評分,最後整體評量其可聽辨程度,聲音的愉悅程度以及可接受 程度。此一評量方法通常用於聲學研究以及業界。
4.5.2.客觀品質評量
客觀的品質量測主要是計算含噪音成分的多寡,或是訊號的頻譜 失真(spectral distortion)的程度。
(1)訊噪比(signal-to-noise ratio,SNR) (與 DAM 相關係數:0.24 )
一般語音訊號的訊噪比量測,是針對編碼語音或增強後的語音,
以瞭解編碼系統或語音增強演算法的性能與效果。因為原始語音在作 編碼之後或是語音訊號作增強之後,與原始語音之間的差異,也被視 為對原始語音上加上噪音。
( ) ( ) ( )
x n =x n +d n (4-10)
這個差異訊號 d(n)的能量,就被視為噪音訊號。
2 0
[ ( )]
d n
ξ ∞ d n
=
=
∑
(4-11)而訊號能量的計算則是訊號振幅平方的累積。
2 0
[ ( )]
x n
ξ ∞ x n
=
=
∑
(4-12)訊噪比(SNR)就是前兩式之比值,以 dB 值表示。
2 0
10 10
2 0
[ ( )]
10 log 10 log
[ ( ) ( )]
x n
d
n
x n SNR
x n x n ξ
ξ
∞
=
∞
=
= ⋅ = ⋅
−
∑
∑
(4-13)這樣的計算結果並不能真實的表達噪音影響的效果,舉例來說,
若在一段語音中無語音的靜音(silence)時間越長,SNR 就越小,所 以得到相同的 SNR 值的兩段不同語音不見得噪音強度就是一樣的。所 以又有另外兩種 SNR 的表示法。
(2)分段式訊噪比(與 DAM 相關係數:0.77)
分段式訊噪比(segmental SNR),因為將語音分段是一個比較真 實觀察噪音成分的算法,對每一段分別計算其訊噪比,然後平均,其 計算公式如下:
1
10 0
( )
1 {10 log }
( )
M
x
m d
SNR m
M m
ξ ξ
−
=
=
∑
⋅ (4-14)其中ξx( )m 和ξd( )m 表示在 m 段中的訊號能量和噪音能量。
(3)頻率加權之分段式訊噪比(與 DAM 相關係數:0.93)
頻率加權之分段式訊噪比(frequency weighted segmented SNR)
是將訊號分成若干頻帶,通常是依照臨界頻帶(critical bands)的 分法,在各頻帶當中分別計算分段訊噪比,而各頻帶的分段訊噪比再 以加權方式作平均,其計算公式如下:
1 10 1 0
1
( , )
[10 log ]
( , )
1 { }
L
x M mk
k d
fw L
m
mk k
w m k SNR m k
M w
ξ ξ
− =
=
=
⋅
=
∑
∑ ∑
(4-15)( , )
x m k
ξ 與ξd( , )m k 分別表示在 m 段當中取第 k 個頻帶的訊號能量
與噪音能量。
(4)頻譜失真量測(spectral distortion measure)
頻譜失真量測主要是用於判斷語音編碼或語音增強後的頻譜差 異,常常是計算原始語音頻譜與處理後的頻譜之間的均方差值,我們 無法採取頻譜量測的評量方式是因為我們並沒有辦法得到一個原始 的無噪音污染的訊號來作比對的工作。
4.5.3 本研究之主、客觀評量方式
主觀評量必須要事先作仔細的規劃,要有額外的受測人和具有公 信力的量測依據。客觀評量雖然是可以量化的計算,通常比較不具有 爭議性,但是也只能作為系統改進的參考。真正聲音的品質好壞,勢 必要用人耳聽覺判斷。在前述的主觀評量當中 DAM 的方法是最為仔 細的,比較不受因人而異的影響,各項目的評分也可以詳細看出聲音 品質的優劣。但是其實其判定過程較為複雜,對於本研究而言並不需 要如此複雜的評量方式。因此本研究於主觀評量上所採取的方法為平 均主觀分數法(MOS)。請數位同學來當聽眾,並且對每次不同的實 驗方法都透過評分的方式來進行分數上的比較,從而判定此時噪音的 消除程度。而客觀音訊品質評量當中,頻率加權的分段訊噪比可以明 確的指出聲音好壞,其相關性和 DAM 法亦為最高,可達 0.93。而只 算分段式訊噪比的相關性約 0.77,若不分段的相關係數只能達到 0.24 左右。因此我們選擇用分段訊噪比的改良來量測語音訊號的品質。
改良的方法為我們在能量計算時,將時域上噪音與含有噪音之音 訊同一段的能量求出,假設ξx( )m 和ξd( )m 表示在 m 段中的訊號能量和 噪音能量,則我們計算消噪率(noise canceling rate,NCR)的公式如 下:
1
0
( ) ( )
1 { } 100%
( )
M
x d
m x
m m
NCR M m
ξ ξ ξ
−
=
=
∑
− i (4-16)不用 dB 值的表示是由於為了避免複雜的運算,以及程式由 PC 浮點數版本改為嵌入式平台的整數版時方便處理之故。