产品介绍
文档版本 01
发布日期 2022-02-17
版权所有 © 华为技术有限公司 2022。 保留一切权利。
非经本公司书面许可,任何单位和个人不得擅自摘抄、复制本文档内容的部分或全部,并不得以任何形式传 播。
商标声明
和其他华为商标均为华为技术有限公司的商标。
本文档提及的其他所有商标或注册商标,由各自的所有人拥有。
注意
您购买的产品、服务或特性等应受华为公司商业合同和条款的约束,本文档中描述的全部或部分产品、服务或 特性可能不在您的购买或使用范围之内。除非合同另有约定,华为公司对本文档内容不做任何明示或暗示的声 明或保证。
由于产品版本升级或其他原因,本文档内容会不定期进行更新。除非另有约定,本文档仅作为使用指导,本文 档中的所有陈述、信息和建议不构成任何明示或暗示的担保。
目 录
1 什么是应用运维管理... 1
2 产品架构...3
3 产品功能...4
4 应用场景...6
5 指标总览...9
5.1 简介... 9
5.2 网络指标及其维度... 10
5.3 磁盘指标及其维度... 11
5.4 磁盘分区指标...11
5.5 文件系统指标及其维度... 12
5.6 主机指标及其维度... 13
5.7 集群指标及其维度... 15
5.8 容器组件指标及其维度... 17
5.9 虚机组件指标及其维度... 19
5.10 实例指标及其维度... 21
5.11 服务指标及其维度... 21
5.12 性能指标及其维度... 21
5.13 Grafana 普罗指标... 22
6 约束与限制...32
7 隐私与敏感信息保护声明... 37
8 与其他服务的关系... 38
9 基本概念...42
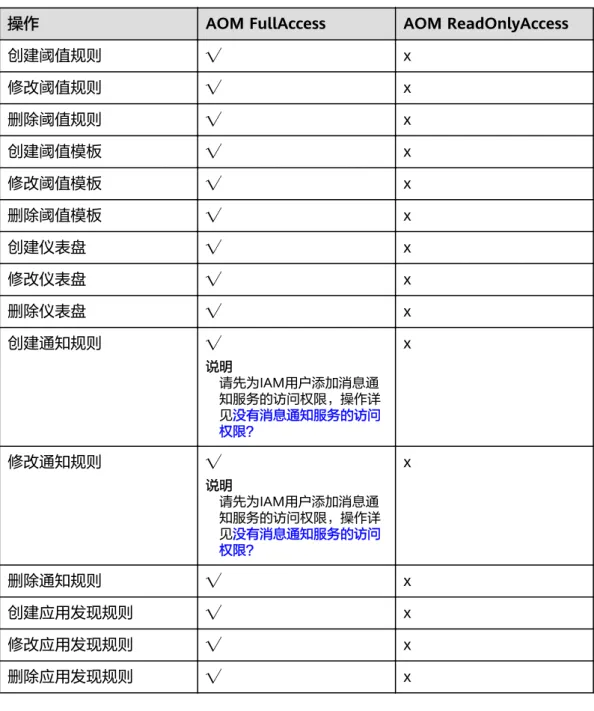
10 权限管理... 45
11 计费说明... 48
12 修订记录... 49
1 什么是应用运维管理
运维遇到挑战
随着容器技术的普及,越来越多的企业通过微服务框架开发应用,业务实现更多使用 云上服务,运维也转向云上的运维服务。对于云上应用的运维也提出了新的挑战。
图1-1 运维现有问题
● 运维人员技能要求高,配置繁杂,同时需要维护多套系统。对于分布式追踪系 统,学习和使用成本高,并且稳定性差。
● 云化场景下的分布式应用问题分析困难主要表现在如何可视化微服务间的依赖关 系、如何提高应用性能体验、如何将散落的日志进行关联分析、如何快速追踪问 题。
AOM 帮您解决
图1-2 一站式运维平台
应用运维管理(Application Operations Management,简称AOM)是云上应用的一 站式立体化运维管理平台,实时监控您的应用及相关云资源,分析应用健康状态,提 供灵活丰富的数据可视化功能,帮助您及时发现故障,全面掌握应用、资源及业务的 实时运行状况。
AOM 有哪些优势
图1-3 AOM 优势 1
图1-4 AOM 优势 2
● 海量日志管理
高性能搜索和业务分析,自动将关联的日志聚类,可按应用、主机、文件名称、
实例等维度快速过滤。
● 关联分析
应用和资源层层自动关联,通过应用、组件、实例、主机和事务等多视角分析关 联指标和告警数据,直击异常。
● 生态开放
开放了运营、运维数据查询接口和采集标准,支持自主开发。
2 产品架构
AOM是一个以资源数据为中心并关联日志、指标、资源、告警和事件等数据的立体运 维服务。AOM从架构上主要分为数据采集接入层、传输存储层和业务计算层。
采用三层架构
● 数据采集接入层 – ICAgent采集数据
给主机安装ICAgent(插件式的数据采集器)并通过ICAgent上报相关的运维 数据。
– API接入数据
通过AOM提供的OpenAPI接口或者Exporter接口,将业务指标作为自定义指 标,接入到AOM。
● 传输存储层
– 数据传输:AOM Access是用来接收运维数据的代理服务,运维数据接收上来 之后,会将数据投放到Kafka队列中,利用Kafka高吞吐的能力,实时将数据 传输给业务计算层。
– 数据存储:运维数据经过AOM后端服务的处理,将数据写入到数据库中,其 中Cassandra用来存储时序的指标数据,Redis用来查询缓存,ETCD用来存储 AOM的配置数据,ElasticSearch用来存储资源、日志、告警和事件。
● 业务计算层
AOM提供告警、日志、监控、指标等基础运维服务,同时也提供异常检测与分析 等AI服务。
3 产品功能
应用监控
应用监控是针对资源和应用的监控,通过应用监控您可以及时了解应用的资源使用情 况、趋势和告警,使用这些信息,您可以快速响应,保证应用流畅运行。
应用监控是逐层下钻设计,层次关系为:应用列表->应用详情->组件详情->实例详情-
>容器详情->进程详情。即在应用监控中,将应用、组件、实例、容器、进程做了层层 关联,在界面上就可以直接得知各层关系。
主机监控
主机监控是针对主机的监控,通过主机监控您可以及时了解主机的资源使用情况、趋 势和告警,使用这些信息,您可以快速响应,保证主机流畅运行。
主机监控的设计类似应用监控,主机的层级关系为:主机列表->主机详情。详情页面 包含了当前主机上所发现的所有实例,显卡,网卡,磁盘,文件系统。
应用自动发现
您在主机上部署应用后,在主机上安装的ICAgent将自动收集应用信息,包括进程名 称,组件名称,容器名称,Kubernetes pod名称等,自动发现的应用在界面上以图形 化方式展示,支持您自定义别名和分组对资源进行管理。
仪表盘
通过仪表盘可将不同图表展示到同一个屏幕上,通过不同的仪表形式来展示资源数 据,例如,曲线图、数字图、TopN图表等,进而全面、深入地掌握监控数据。
例如,可将重要资源的关键指标添加到仪表盘中,从而实时地进行监控。还可将不同 资源的同一指标展示到同一个图形界面上进行对比。另外,对于例行运维需要查看的 指标,可添加到仪表盘中,以便再次打开AOM时无需重新选择指标就可进行例行检查 任务。
告警列表
告警列表是告警和事件的管理平台,支持自定义通知动作,即您可通过邮件、短信等 方式获得告警信息,可帮您在第一时间发现异常及其根因。除华北-北京一、华北-北京 四、华东-上海一、华东-上海二、华南-广州和华南-深圳以外的其他区域,对于重点资 源的指标您可以创建阈值规则,华北-北京一、华北-北京四、华东-上海一、华东-上海
二、华南-广州和华南-深圳区域,对于重点资源的指标您可以创建告警规则,当指标数 据满足阈值条件时,AOM会产生阈值告警。
日志管理
AOM提供强大的日志管理能力。日志检索功能可帮您快速在海量日志中查询到所需的 日志;日志转储帮您实现长期存储;通过创建日志统计规则实现关键词周期性统计,
并生成指标数据,实时了解系统性能及业务等信息;通过配置分词可将日志内容按照 分词符切分为多个单词,在日志搜索时可使用切分后的单词进行搜索。
4 应用场景
AOM应用广泛,下面介绍AOM的两个典型应用场景,以便您深入了解。
巡检与问题定界
日常运维中,遇到异常难定位、日志难获取等问题,需要一个监控平台对资源、日 志、应用性能进行全方位的监控。
AOM深度对接应用服务,一站式收集基础设施、中间件和应用实例的运维数据,通过 指标监控、日志分析、事件报警等功能,支持日常巡检资源、应用整体运行情况,及 时发现并定界应用与资源的问题。
优势
● 应用自动发现:自动部署采集器,针对应用的运行环境,主动发现应用并进行监 控。
● 跨云服务的分布式应用监控:对于同时使用了多种云服务的分布式应用,提供统 一的运维平台,便于您对业务进行立体排查。
● 事件告警灵活通知:提供多种异常检测策略并支持丰富的异常事件触发方式及 API。
图4-1 巡检与问题定界
立体化运维
您需全方位掌控系统的运行状态,并快速响应各类问题。
AOM提供从云平台到资源,再到应用的监控和微服务调用链的立体化运维分析能力。
优势
● 体验保障:实时掌控业务KPI健康状态,对异常事务根因分析。
● 故障快速诊断:分布式调用追踪,快速找到异常故障点。
● 资源运行保障:实时监控容器、磁盘、网络等上百种资源运维指标 集群->虚机->
应用->容器异常关联分析。
图4-2 立体化运维
5 指标总览
5.1 简介
指标是对资源性能的数据描述或状态描述,指标由命名空间、维度、指标名称和单位 组成。指标分为系统指标和自定义指标。
● 系统指标:AOM提供的基础指标,例如:CPU使用率、CPU内核占用等。
● 自定义指标:您自己定义的指标。可参考如下两种方式上报自定义指标。
– 方式一:通过AOM提供的接口上报自定义指标,接口详见添加监控数据和查 询监控数据。
– 方式二:在CCE创建容器应用时,通过对接普罗米修斯上报自定义指标,详 细内容请参见对接普罗米修斯(自定义监控)。
指标命名空间
指标命名空间是对一组资源和对象产生的指标的抽象整合,不同命名空间中的指标彼 此独立,因此来自不同应用程序的指标不会被错误地汇聚到相同的统计信息中。
● 系统指标的命名空间:命名空间是固定不变的,均以“PAAS.”开头,如表5-1所 示。
表5-1 系统指标命名空间 命名空间名称 说明
PAAS.AGGR 集群指标的命名空间。
PAAS.NODE 主机指标、网络指标、磁盘指标和文件系统指标的命名空间。
PAAS.CONTA
INER 组件指标、实例指标、进程指标和容器指标的命名空间。
PAAS.SLA SLA指标的命名空间。
● 自定义指标的命名空间:需要您自定义,自定义时命名空间必须以字母开头,但 不能以“PAAS.”、“SYS.”和“SRE.”开头,且以0~9、a~z、A~Z或下划线
(_)组成的格式为XX.XX的3~32位字符串。
指标维度
维度是指标的分类。每个指标都包含用于描述该指标的特定特征,可以将维度理解为 这些特征的类别。
● 系统指标维度:维度是固定不变的,不同类型的指标维度不同,维度信息请分别 参见后续章节。
● 自定义指标维度:维度为1~32位的字符串,需要您自定义。
5.2 网络指标及其维度
表5-2 网络指标
指标名称 指标含义 取值范
围
单位
下行Bps
(recvBytesRate) 该指标用于统计测试对象的入方向网络
流速。 ≥0 字节/秒(Bytes/
Second)
下行Pps
(recvPackRate) 每秒网卡接收的数据包个数。 ≥0 个/秒(Packets/
Second)
下行错包率
(recvErrPackRate) 每秒网卡接收的错误包个数。 ≥0 个/秒(Packets/
Second)
上行Bps
(sendBytesRate) 该指标用于统计测试对象的出方向网络
流速。 ≥0 字节/秒(Bytes/
Second)
上行错包率
(sendErrPackRate) 每秒网卡发送的错误包个数。 ≥0 个/秒(Packets/
Second)
上行Pps
(sendPackRate) 每秒网卡发送的数据包个数。 ≥0 个/秒(Packets/
Second)
总Bps(totalBytesRate) 该指标用于统计测试对象出方向和入方 向的网络流速之和。
≥0 字节/秒(Bytes/
Second)
表5-3 网络指标维度
维度 说明
clusterId 集群ID。
hostID 主机ID。
nameSpace 集群的命名空间。
netDevice 网卡名称。
nodeIP 主机IP。
nodeName 主机名称。
5.3 磁盘指标及其维度
表5-4 磁盘指标
指标名称 指标含义 取值范
围 单位
磁盘读取速率
(diskReadRate) 该指标用于统计每秒从磁盘读出的数据
量。 ≥0 千字节/秒(Kilobytes/
Second)
磁盘写入速率
(diskWriteRate) 该指标用于统计每秒写入磁盘的数据
量。 ≥0 千字节/秒(Kilobytes/
Second)
表5-5 磁盘指标维度
维度 说明
clusterId 集群ID。
diskDevice 磁盘名称。
hostID 主机ID。
nameSpace 集群的命名空间。
nodeIP 主机IP。
nodeName 主机名称。
5.4 磁盘分区指标
说明
当主机类型为“CCE”时,可以查看磁盘分区指标,支持的系统为:CentOS 7.x版本、EulerOS 2.5。
表5-6 磁盘分区指标
指标名称 指标含义 取值范
围
单位
Thin pool 元数据空间使用率
( aom_host_diskpartition_thinpool _data_percent)
该指标用于统计CCE节点 上thinpool元数据空间使 用百分比。
≥0 百分比(Percent)
Thin pool 数据空间使用率
( aom_host_diskpartition_thinpool _metadata_percent)
该指标用于统计CCE节点 上thinpool数据空间使用 百分比。
≥0 百分比(Percent)
指标名称 指标含义 取值范 围
单位
Thin pool 磁盘分区容量
( aom_host_diskpartition_total_ca pacity_megabytes)
该指标用于统计CCE节点
上thinpool总空间容量。 ≥0 兆字节(Megabytes)
5.5 文件系统指标及其维度
表5-7 文件系统指标
指标名称 指标含义 取值范
围
单位
可用磁盘空间
(diskAvailableCapacit y)
还未经使用的磁盘空间。 ≥0 兆字节(Megabytes)
磁盘空间容量
(diskCapacity) 总的磁盘空间容量。 ≥0 兆字节(Megabytes)
磁盘读写状态
(diskRWStatus) 该指标用于统计主机上磁盘的读写状
态。 0、1
● 0表 示读 写
● 1表 示只 读
无
磁盘使用率
(diskUsedRate) 已使用的磁盘空间占总的磁盘空间容量 百分比。
≥0 百分比(Percent)
表5-8 文件系统指标维度
维度 说明
clusterId 集群ID。
clusterName 集群名称。
fileSystem 文件系统。
hostID 主机ID。
mountPoint 挂载点。
nameSpace 集群的命名空间。
维度 说明
nodeIP 主机IP。
nodeName 主机名称。
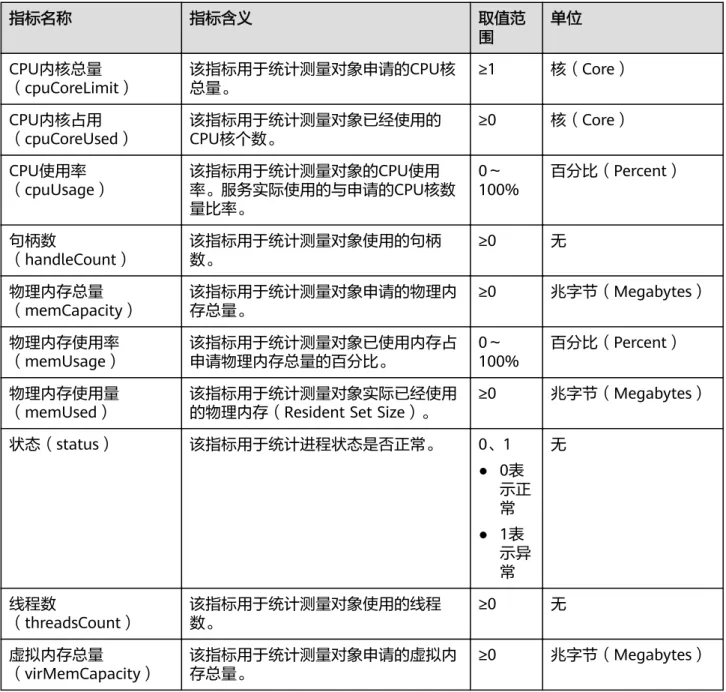
5.6 主机指标及其维度
表5-9 主机指标
指标名称 指标含义 取值范
围
单位
CPU内核总量
(cpuCoreLimit) 该指标用于统计测量对象申请的CPU核
总量。 ≥1 核(Core)
CPU内核占用
(cpuCoreUsed) 该指标用于统计测量对象已经使用的
CPU核个数。 ≥0 核(Core)
CPU使用率
(cpuUsage) 该指标用于统计测量对象的CPU使用
率。 0~
100% 百分比(Percent)
可用物理内存
(freeMem) 该指标用于统计测量对象上的尚未被使
用的物理内存。 ≥0 兆字节(Megabytes)
可用虚拟内存
(freeVirMem) 该指标用于统计测量对象上的尚未被使 用的虚拟内存。
≥0 兆字节(Megabytes)
显存容量(gpuMemCapacity) 该指标用于统计测量对象的显存容量。 >0 兆字节(Megabytes)
显存使用率
(gpuMemUsage) 该指标用于统计测量对象已使用的显存 占显存容量的百分比。
0~100% 百分比(Percent)
显存使用量
(gpuMemUsed) 该指标用于统计测量对象已使用的显 存。
≥0 兆字节(Megabytes)
GPU使用率(gpuUtil) 该指标用于统计测量对象的GPU使用
率。 0~
100% 百分比(Percent)
NPU存储容量
(npuMemCapacity) 该指标用于统计测量对象的NPU存储容
量。 >0 兆字节(Megabytes)
NPU存储使用率
(npuMemUsage) 该指标用于统计测量对象已使用的NPU 存储占NPU存储容量的百分比。 0~
100% 百分比(Percent)
NPU存储使用量
(npuMemUsed) 该指标用于统计测量对象已使用的NPU
存储。 ≥0 兆字节(Megabytes)
NPU使用率(npuUtil) 该指标用于统计测量对象的NPU使用
率。 0~
100% 百分比(Percent)
NPU温度
(temperature) 该指标用于统计NPU的温度。 - 摄氏度(℃)
指标名称 指标含义 取值范 围
单位
物理内存使用率
(memUsedRate) 该指标用于统计测量对象已使用内存占 申请物理内存总量的百分比。 0~
100% 百分比(Percent)
主机状态(nodeStatus) 该指标用于统计主机状态是否正常。 ● 0表 示正 常
● 1表 示异 常
无
NTP偏移量
(ntpOffset) 该指标用于统计主机本地时间与NTP服 务器时间的偏移量,NTP偏移量越接近 于0,主机本地时间与NTP服务器时间 越接近。
无 毫秒(ms)
NTP服务器状态
(ntpServerStatus) 该指标用于统计主机是否成功连接上
NTP服务器。 0、1
● 0表 示已 连接
● 1表 示未 连接
无
NTP同步状态
(ntpStatus) 该指标用于统计主机本地时间与NTP服
务器时间是否同步。 0、1
● 0表 示同 步
● 1表 示未 同步
无
进程数量(processNum) 该指标用于统计测量对象上的进程数
量。 ≥0 无
显卡温度(temperature) 该指标用于统计显卡的温度。 - 摄氏度(℃)
物理内存容量
(totalMem) 该指标用于统计测量申请的物理内存总
量。 ≥0 兆字节(Megabytes)
虚拟内存容量
(totalVirMem) 该指标用于统计测量对象上的虚拟内存
总量。 ≥0 兆字节(Megabytes)
虚拟内存使用率
(virMemUsedRate) 该指标用于统计测量对象已使用虚拟内 存占虚拟内存总量的百分比。 0~
100% 百分比(Percent)
物理磁盘总容量
(aom_node_phy_disk _total_capacity_megab ytes)
该指标用于统计主机的磁盘总容量。 ≥0 兆字节(Megabytes)
指标名称 指标含义 取值范 围
单位
物理磁盘已使用总容量
(aom_node_physical_
disk_total_used_mega bytes)
该指标用于统计主机已使用的磁盘总容
量。 ≥0 兆字节(Megabytes)
说明
内存使用率 = (物理内存容量 - 可用物理内存) / 物理内存容量;虚拟内存使用率 = ((物理 内存容量 + 虚拟内存总量) - (可用物理内存 + 可用虚拟内存)) / (物理内存容量 + 虚拟内 存总量)。
目前创建的虚机默认虚拟内存为0,在未配置虚拟内存的情况下,监控页面内存使用率,虚拟内 存使用率相同。
表5-10 主机指标维度
维度 说明
clusterId 集群ID。
clusterName 集群名称。
gpuName GPU名称。
gpuID GPU ID。
npuName NPU名称。
npuID NPU ID。
hostID 主机ID。
nameSpace 集群的命名空间。
nodeIP 主机IP。
nodeName 主机名称。
5.7 集群指标及其维度
表5-11 集群指标
指标名称 指标含义 取值范
围
单位
CPU内核总量
(cpuCoreLimit) 该指标用于统计测量对象申请的CPU核
总量。 ≥1 核(Core)
指标名称 指标含义 取值范 围
单位
CPU内核占用
(cpuCoreUsed) 该指标用于统计测量对象已经使用的
CPU核数。 ≥0 核(Core)
CPU使用率
(cpuUsage) 该指标用于统计测量对象的CPU使用
率。 0~
100% 百分比(Percent)
可用磁盘空间
(diskAvailableCapacit y)
还未经使用的磁盘空间。 ≥0 兆字节(Megabytes)
磁盘空间容量
(diskCapacity) 总的磁盘空间容量。 ≥0 兆字节(Megabytes)
磁盘使用率
(diskUsedRate) 已使用的磁盘空间占总的磁盘空间容量
百分比。 ≥0 百分比(Percent)
可用物理内存
(freeMem) 该指标用于统计测量对象上的尚未被使
用的物理内存。 ≥0 兆字节(Megabytes)
可用虚拟内存
(freeVirMem) 该指标用于统计测量对象上的尚未被使 用的虚拟内存。
≥0 兆字节(Megabytes)
显存容量(gpuMemCapacity) 该指标用于统计测量对象的显存容量。 >0 兆字节(Megabytes)
显存使用率
(gpuMemUsage) 该指标用于统计测量对象已使用的显存 占显存容量的百分比。
0~100% 百分比(Percent)
显存使用量
(gpuMemUsed) 该指标用于统计测量对象已使用的显 存。
≥0 兆字节(Megabytes)
GPU使用率(gpuUtil) 该指标用于统计测量对象的GPU使用
率。 0~
100% 百分比(Percent)
物理内存使用率
(memUsedRate) 该指标用于统计测量对象已使用内存占 申请物理内存总量的百分比。 0~
100% 百分比(Percent)
下行Bps
(recvBytesRate) 该指标用于统计测试对象的入方向网络
流速。 ≥0 字节/秒(Bytes/
Second)
上行Bps
(sendBytesRate) 该指标用于统计测试对象的出方向网络
流速。 ≥0 字节/秒(Bytes/
Second)
物理内存容量
(totalMem) 该指标用于统计测量申请的物理内存总
量。 ≥0 兆字节(Megabytes)
虚拟内存容量
(totalVirMem) 该指标用于统计测量对象上的虚拟内存
总量。 ≥0 兆字节(Megabytes)
虚拟内存使用率
(virMemUsedRate) 该指标用于统计测量对象已使用虚拟内 存占虚拟内存总量的百分比。 0~
100% 百分比(Percent)
表5-12 集群指标维度
维度 说明
clusterId 集群ID。
clusterName 集群名称。
projectId ID。
5.8 容器组件指标及其维度
表5-13 容器指标
指标名称 指标含义 取值范
围
单位
CPU内核总量
(cpuCoreLimit) 该指标用于统计测量对象申请的CPU核 总量。
≥1 核(Core)
CPU内核占用
(cpuCoreUsed) 该指标用于统计测量对象已经使用的
CPU核个数。 ≥0 核(Core)
CPU使用率
(cpuUsage) 该指标用于统计测量对象的CPU使用 率。服务实际使用的与申请的CPU核数 量比率。
0~100% 百分比(Percent)
磁盘读取速率
(diskReadRate) 该指标用于统计每秒从磁盘读出的数据
量。 ≥0 千字节/秒(Kilobytes/
Second)
磁盘写入速率
(diskWriteRate) 该指标用于统计每秒写入磁盘的数据
量。 ≥0 千字节/秒(Kilobytes/
Second)
文件系统可用
(filesystemAvailable
)
该指标用于统计测量对象文件系统的可 用大小。仅支持1.11及其更高版本的 kubernetes集群中驱动模式为 devicemapper的容器。
≥0 兆字节(Megabytes)
文件系统容量
(filesystemCapacity) 该指标用于统计测量对象文件系统的容 量。仅支持1.11及其更高版本的 kubernetes集群中驱动模式为 devicemapper的容器。
≥0 兆字节(Megabytes)
文件系统使用率
(filesystemUsage) 该指标用于统计测量对象文件系统使用 率。实际使用量与文件系统容量的百分 比。仅支持1.11及其更高版本的 kubernetes集群中驱动模式为 devicemapper的容器。
0~100% 百分比(Percent)
显存容量(gpuMemCapacity) 该指标用于统计测量对象的显存容量。 >0 兆字节(Megabytes)
显存使用率
(gpuMemUsage) 该指标用于统计测量对象已使用的显存
占显存容量的百分比。 0~
100% 百分比(Percent)
指标名称 指标含义 取值范 围
单位
显存使用量
(gpuMemUsed) 该指标用于统计测量对象已使用的显
存。 ≥0 兆字节(Megabytes)
GPU使用率(gpuUtil) 该指标用于统计测量对象的GPU使用
率。 0~
100% 百分比(Percent)
NPU存储容量
(npuMemCapacity) 该指标用于统计测量对象的NPU存储容
量。 >0 兆字节(Megabytes)
NPU存储使用率
(npuMemUsage) 该指标用于统计测量对象已使用的NPU 存储占NPU存储容量的百分比。 0~
100% 百分比(Percent)
NPU存储使用量
(npuMemUsed) 该指标用于统计测量对象已使用的NPU
存储。 ≥0 兆字节(Megabytes)
NPU使用率(npuUtil) 该指标用于统计测量对象的NPU使用
率。 0~
100% 百分比(Percent)
物理内存总量
(memCapacity) 该指标用于统计测量对象申请的物理内
存总量。 ≥0 兆字节(Megabytes)
物理内存使用率
(memUsage) 该指标用于统计测量对象已使用内存占 申请物理内存总量的百分比。
0~100% 百分比(Percent)
物理内存使用量
(memUsed) 该指标用于统计测量对象实际已经使用
的物理内存(Resident Set Size)。 ≥0 兆字节(Megabytes)
下行Bps
(recvBytesRate) 该指标用于统计测试对象的入方向网络 流速。
≥0 字节/秒(Bytes/
Second)
下行Pps
(recvPackRate) 每秒网卡接收的数据包个数。 ≥0 个/秒(Packets/
Second)
下行错包率
(recvErrPackRate) 每秒网卡接收的错误包个数。 ≥0 个/秒(Packets/
Second)
容器错包个数
(rxPackErrors) 该指标用于统计测量对象收到错误包的
数量。 ≥0 个(Packets)
上行Bps
(sendBytesRate) 该指标用于统计测试对象的出方向网络
流速。 ≥0 字节/秒(Bytes/
Second)
上行错包率
(sendErrPackRate) 每秒网卡发送的错误包个数。 ≥0 个/秒(Packets/
Second)
上行Pps
(sendPackRate) 每秒网卡发送的数据包个数。 ≥0 个/秒(Packets/
Second)
指标名称 指标含义 取值范 围
单位
状态(status) 该指标用于统计Docker容器状态是否正
常。 0、1
● 0表 示正 常
● 1表 示异 常
无
表5-14 容器指标维度
维度 说明
appID 服务ID。
appName 服务名称。
clusterId 集群ID。
clusterName 集群名称。
containerID 容器ID。
containerName 容器名称。
deploymentName k8s Deployment名称。
kind 应用类型。
nameSpace 集群的命名空间。
podID 实例ID。
podName 实例名称。
serviceID 存量ID。
gpuID GPU ID。
npuName NPU名称。
npuID NPU ID。
5.9 虚机组件指标及其维度
AOM中,虚机组件指的是进程,虚机组件指标指的就是进程指标。
表5-15 进程指标
指标名称 指标含义 取值范
围
单位
CPU内核总量
(cpuCoreLimit) 该指标用于统计测量对象申请的CPU核
总量。 ≥1 核(Core)
CPU内核占用
(cpuCoreUsed) 该指标用于统计测量对象已经使用的
CPU核个数。 ≥0 核(Core)
CPU使用率
(cpuUsage) 该指标用于统计测量对象的CPU使用 率。服务实际使用的与申请的CPU核数 量比率。
0~100% 百分比(Percent)
句柄数(handleCount) 该指标用于统计测量对象使用的句柄
数。 ≥0 无
物理内存总量
(memCapacity) 该指标用于统计测量对象申请的物理内 存总量。
≥0 兆字节(Megabytes)
物理内存使用率
(memUsage) 该指标用于统计测量对象已使用内存占 申请物理内存总量的百分比。
0~100% 百分比(Percent)
物理内存使用量
(memUsed) 该指标用于统计测量对象实际已经使用
的物理内存(Resident Set Size)。 ≥0 兆字节(Megabytes)
状态(status) 该指标用于统计进程状态是否正常。 0、1
● 0表 示正 常
● 1表 示异 常
无
线程数(threadsCount) 该指标用于统计测量对象使用的线程
数。 ≥0 无
虚拟内存总量
(virMemCapacity) 该指标用于统计测量对象申请的虚拟内
存总量。 ≥0 兆字节(Megabytes)
表5-16 进程指标维度
维度 说明
appName 服务名称。
clusterId 集群ID。
clusterName 集群名称。
nameSpace 集群的命名空间。
processID 进程ID。
维度 说明
processName 进程名称。
serviceID 存量ID。
5.10 实例指标及其维度
实例指标是由容器或进程指标汇聚而来的,其指标维度与容器或进程指标维度相同,
详见容器组件指标及其维度和虚机组件指标及其维度。
5.11 服务指标及其维度
服务指标是由实例指标汇聚而来的,其指标维度与实例指标维度相同,详见实例指标 及其维度。
5.12 性能指标及其维度
说明
本章节中的性能指标是AOM为您提供的产品特性,并非AOM本身的服务等级。
表5-17 性能指标
指标名称 指标含义 取值范
围
单位
成功率(successRate) 一个统计周期内所有接口调用的成功比 例。
0~100% 百分比(%)
平均时延(tp99) TP99时延=完成99%的网络请求所需要 的最短耗时。
举例:假设总请求数为100个,它们的 请求耗时分别为1s、2s、3s、4s……
98s、99s、100s。若要完成99%的请 求,至少需要99s,故TP99为99s。
计算:将所有请求按照耗时从小到大排 序,第(99%*总请求数)个请求的耗 时即为TP99时延。
≥0 毫秒(ms)
错误调用次数
(errors) 一个统计周期内所有接口调用的失败次 数。
≥0 次(Count)
吞吐量(throughput) 指定时间内接口调用的总次数。 ≥0 次/分(Transaction/
Minute)
Apdex(apdex) 该指标表示应用性能满意度,数值越大 表示满意度越高。
0~1 无
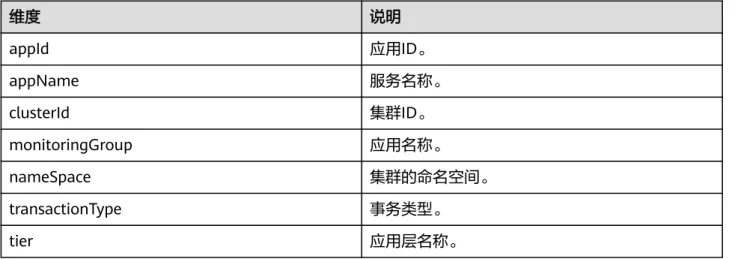
表5-18 性能指标维度
维度 说明
appId 应用ID。
appName 服务名称。
clusterId 集群ID。
monitoringGroup 应用名称。
nameSpace 集群的命名空间。
transactionType 事务类型。
tier 应用层名称。
5.13 Grafana 普罗指标
表5-19 主机指标
指标名称 指标含义 取值范围 单位
下行Bps
(aom_node_network_receive_byte s)
该指标用于统计测试对象 的入方向网络流速。
≥0 字节/秒(Bytes/
Second)
下行Pps
(aom_node_network_receive_pack ets)
每秒网卡接收的数据包个 数。
≥0 个/秒(Packets/
Second)
下行错包率
(aom_node_network_receive_erro r_packets)
每秒网卡接收的错误包个
数。 ≥0 个/秒(Packets/
Second)
上行Bps
(aom_node_network_transmit_byt es)
该指标用于统计测试对象
的出方向网络流速。 ≥0 字节/秒(Bytes/
Second)
上行错包率
(aom_node_network_transmit_err or_packets)
每秒网卡发送的错误包个
数。 ≥0 个/秒(Packets/
Second)
上行Pps
(aom_node_network_transmit_pa ckets)
每秒网卡发送的数据包个
数。 ≥0 个/秒(Packets/
Second)
总Bps(aom_node_network_total_bytes
)
该指标用于统计测试对象 出方向和入方向的网络流 速之和。
≥0 字节/秒(Bytes/
Second)
指标名称 指标含义 取值范围 单位 磁盘读取速率
(aom_node_disk_read_kilobytes) 该指标用于统计每秒从磁
盘读出的数据量。 ≥0 千字节/秒
(Kilobytes/
Second)
磁盘写入速率
(aom_node_disk_write_kilobytes
)
该指标用于统计每秒写入
磁盘的数据量。 ≥0 千字节/秒
(Kilobytes/
Second)
可用磁盘空间
(aom_node_disk_available_capaci ty_megabytes)
还未经使用的磁盘空间。 ≥0 兆字节
(Megabytes)
磁盘空间容量
(aom_node_disk_capacity_megab ytes)
总的磁盘空间容量。 ≥0 兆字节
(Megabytes)
磁盘读写状态
(aom_node_disk_rw_status) 该指标用于统计主机上磁 盘的读写状态。
0、1
● 0表示读 写
● 1表示只 读
无
磁盘使用率
(aom_node_disk_usage) 已使用的磁盘空间占总的 磁盘空间容量百分比。
≥0 百分比(Percent)
CPU内核总量
(aom_node_cpu_limit_core) 该指标用于统计测量对象
申请的CPU核总量。 ≥1 核(Core)
CPU内核占用
(aom_node_cpu_used_core) 该指标用于统计测量对象
已经使用的CPU核个数。 ≥0 核(Core)
CPU使用率
(aom_node_cpu_usage) 该指标用于统计测量对象
的CPU使用率。 0~100% 百分比(Percent)
可用物理内存
(aom_node_memory_free_megab ytes)
该指标用于统计测量对象 上的尚未被使用的物理内 存。
≥0 兆字节
(Megabytes)
可用虚拟内存
(aom_node_virtual_memory_free_
megabytes)
该指标用于统计测量对象 上的尚未被使用的虚拟内 存。
≥0 兆字节
(Megabytes)
显存容量(aom_node_gpu_memory_free_m egabytes)
该指标用于统计测量对象
的显存容量。 >0 兆字节
(Megabytes)
显存使用率
(aom_node_gpu_memory_usage
)
该指标用于统计测量对象 已使用的显存占显存容量 的百分比。
0~100% 百分比(Percent)
显存使用量
(aom_node_gpu_memory_used_m egabytes)
该指标用于统计测量对象 已使用的显存。
≥0 兆字节
(Megabytes)
指标名称 指标含义 取值范围 单位 GPU使用率
(aom_node_gpu_usage) 该指标用于统计测量对象
的GPU使用率。 0~100% 百分比(Percent)
NPU存储容量
(aom_node_npu_memory_free_m egabytes)
该指标用于统计测量对象
的NPU存储容量。 >0 兆字节
(Megabytes)
NPU存储使用率
(aom_node_npu_memory_usage
)
该指标用于统计测量对象 已使用的NPU存储占NPU 存储容量的百分比。
0~100% 百分比(Percent)
NPU存储使用量
(aom_node_npu_memory_used_
megabytes)
该指标用于统计测量对象
已使用的NPU存储。 ≥0 兆字节
(Megabytes)
NPU使用率
(aom_node_npu_usage) 该指标用于统计测量对象
的NPU使用率。 0~100% 百分比(Percent)
NPU温度
(aom_node_npu_temperature_cen tigrade)
该指标用于统计NPU的温 度。
- 摄氏度(℃)
物理内存使用率
(aom_node_memory_usage) 该指标用于统计测量对象 已使用内存占申请物理内 存总量的百分比。
0~100% 百分比(Percent)
主机状态(aom_node_status) 该指标用于统计主机状态
是否正常。 ● 0表示正
常
● 非0表示 异常
无
NTP偏移量
(aom_node_ntp_offset_ms) 该指标用于统计主机本地 时间与NTP服务器时间的 偏移量,NTP偏移量越接 近于0,主机本地时间与 NTP服务器时间越接近。
无 毫秒(ms)
NTP服务器状态
(aom_node_ntp_server_status) 该指标用于统计主机是否
成功连接上NTP服务器。 ● 0、10表 示已连接
● 1表示未 连接
无
NTP同步状态
(aom_node_ntp_status) 该指标用于统计主机本地 时间与NTP服务器时间是 否同步。
● 0、10表 示同步
● 1表示未 同步
无
进程数量(aom_node_process_number) 该指标用于统计测量对象
上的进程数量。 ≥0 无
显卡温度(aom_node_gpu_temperature_cen tigrade)
该指标用于统计显卡的温
度。 - 摄氏度(℃)
指标名称 指标含义 取值范围 单位 物理内存容量
(aom_node_memory_total_mega bytes)
该指标用于统计测量申请
的物理内存总量。 ≥0 兆字节
(Megabytes)
虚拟内存容量
(aom_node_virtual_memory_total _megabytes)
该指标用于统计测量对象
上的虚拟内存总量。 ≥0 兆字节
(Megabytes)
虚拟内存使用率
(aom_node_virtual_memory_usag e)
该指标用于统计测量对象 已使用虚拟内存占虚拟内 存总量的百分比。
0~100% 百分比(Percent)
表5-20 容器指标
指标名称 指标含义 取值范
围
单位
CPU内核总量
(aom_container_cpu_
limit_core)
该指标用于统计测量对象申请的CPU核
总量。 ≥1 核(Core)
CPU内核占用
(aom_container_cpu_
used_core)
该指标用于统计测量对象已经使用的
CPU核个数。 ≥0 核(Core)
CPU使用率
(aom_container_cpu_
usage)
该指标用于统计测量对象的CPU使用 率。服务实际使用的与申请的CPU核数 量比率。
0~100% 百分比(Percent)
磁盘读取速率
(aom_container_disk _read_kilobytes)
该指标用于统计每秒从磁盘读出的数据
量。 ≥0 千字节/秒(Kilobytes/
Second)
磁盘写入速率
(aom_container_disk _write_kilobytes)
该指标用于统计每秒写入磁盘的数据
量。 ≥0 千字节/秒(Kilobytes/
Second)
文件系统可用
(aom_container_files ystem_available_capac ity_megabytes)
该指标用于统计测量对象文件系统的可 用大小。仅支持1.11及其更高版本的 kubernetes集群中驱动模式为 devicemapper的容器。
≥0 兆字节(Megabytes)
文件系统容量
(aom_container_files ystem_capacity_mega bytes)
该指标用于统计测量对象文件系统的容 量。仅支持1.11及其更高版本的 kubernetes集群中驱动模式为 devicemapper的容器。
≥0 兆字节(Megabytes)
文件系统使用率
(aom_container_files ystem_usage)
该指标用于统计测量对象文件系统使用 率。实际使用量与文件系统容量的百分 比。仅支持1.11及其更高版本的 kubernetes集群中驱动模式为 devicemapper的容器。
0~100% 百分比(Percent)
指标名称 指标含义 取值范 围
单位
显存容量(aom_container_gpu_
memory_free_megaby tes)
该指标用于统计测量对象的显存容量。 >0 兆字节(Megabytes)
显存使用率
(aom_container_gpu_
memory_usage)
该指标用于统计测量对象已使用的显存
占显存容量的百分比。 0~
100% 百分比(Percent)
显存使用量
(aom_container_gpu_
memory_used_megaby tes)
该指标用于统计测量对象已使用的显
存。 ≥0 兆字节(Megabytes)
GPU使用率
(aom_container_gpu_
usage)
该指标用于统计测量对象的GPU使用 率。
0~100% 百分比(Percent)
NPU存储容量
(aom_container_npu_
memory_free_megaby tes)
该指标用于统计测量对象的NPU存储容
量。 >0 兆字节(Megabytes)
NPU存储使用率
(aom_container_npu_
memory_usage)
该指标用于统计测量对象已使用的NPU 存储占NPU存储容量的百分比。 0~
100% 百分比(Percent)
NPU存储使用量
(aom_container_npu_
memory_used_megaby tes)
该指标用于统计测量对象已使用的NPU
存储。 ≥0 兆字节(Megabytes)
NPU使用率
(aom_container_npu_
usage)
该指标用于统计测量对象的NPU使用 率。
0~100% 百分比(Percent)
物理内存总量
(aom_container_me mory_request_megaby tes)
该指标用于统计测量对象申请的物理内
存总量。 ≥0 兆字节(Megabytes)
物理内存使用率
(aom_container_me mory_usage)
该指标用于统计测量对象已使用内存占 申请物理内存总量的百分比。 0~
100% 百分比(Percent)
物理内存使用量
(aom_container_me mory_used_megabytes
)
该指标用于统计测量对象实际已经使用
的物理内存(Resident Set Size)。 ≥0 兆字节(Megabytes)
下行Bps
(aom_container_net work_receive_bytes)
该指标用于统计测试对象的入方向网络 流速。
≥0 字节/秒(Bytes/
Second)
指标名称 指标含义 取值范 围
单位
下行Pps
(aom_container_net work_receive_packets
)
每秒网卡接收的数据包个数。 ≥0 个/秒(Packets/
Second)
下行错包率
(aom_container_net work_receive_error_pa ckets)
每秒网卡接收的错误包个数。 ≥0 个/秒(Packets/
Second)
容器错包个数
(aom_container_net work_rx_error_packets
)
该指标用于统计测量对象收到错误包的 数量。
≥0 个(Packets)
上行Bps
(aom_container_net work_transmit_bytes)
该指标用于统计测试对象的出方向网络
流速。 ≥0 字节/秒(Bytes/
Second)
上行错包率
(aom_container_net work_transmit_error_p ackets)
每秒网卡发送的错误包个数。 ≥0 个/秒(Packets/
Second)
上行Pps
(aom_container_net work_transmit_packets
)
每秒网卡发送的数据包个数。 ≥0 个/秒(Packets/
Second)
容器状态(aom_container_stat us)
该指标用于统计Docker容器状态是否正
常。 ● 0、
10表 示正 常
● 1表 示异 常
无
表5-21 进程指标
指标名称 指标含义 取值范
围
单位
CPU内核总量
(aom_process_cpu_li mit_core)
该指标用于统计测量对象申请的CPU核
总量。 ≥1 核(Core)
CPU内核占用
(aom_process_cpu_us ed_core)
该指标用于统计测量对象已经使用的
CPU核个数。 ≥0 核(Core)
指标名称 指标含义 取值范 围
单位
CPU使用率
(aom_process_cpu_us age)
该指标用于统计测量对象的CPU使用 率。服务实际使用的与申请的CPU核数 量比率。
0~100% 百分比(Percent)
句柄数(aom_process_handle _count)
该指标用于统计测量对象使用的句柄
数。 ≥0 无
物理内存总量
(aom_process_memo ry_request_megabytes
)
该指标用于统计测量对象申请的物理内
存总量。 ≥0 兆字节(Megabytes)
物理内存使用率
(aom_process_memo ry_usage)
该指标用于统计测量对象已使用内存占 申请物理内存总量的百分比。
0~100% 百分比(Percent)
物理内存使用量
(aom_process_memo ry_used_megabytes)
该指标用于统计测量对象实际已经使用
的物理内存(Resident Set Size)。 ≥0 兆字节(Megabytes)
进程状态(aom_process_status
)
该指标用于统计进程状态是否正常。 ● 0、
10表 示正 常
● 1表 示异 常
无
线程数(aom_process_thread _count)
该指标用于统计测量对象使用的线程
数。 ≥0 无
虚拟内存总量
(aom_process_virtual _memory_total_megab ytes)
该指标用于统计测量对象申请的虚拟内
存总量。 ≥0 兆字节(Megabytes)
表5-22 集群指标
指标名称 指标含义 取值范
围
单位
CPU内核总量
(aom_cluster_cpu_li mit_core)
该指标用于统计测量对象申请的CPU核
总量。 ≥1 核(Core)
CPU内核占用
(aom_cluster_cpu_us ed_core)
该指标用于统计测量对象已经使用的
CPU核数。 ≥0 核(Core)
指标名称 指标含义 取值范 围
单位
CPU使用率
(aom_cluster_cpu_us age)
该指标用于统计测量对象的CPU使用
率。 0~
100% 百分比(Percent)
可用磁盘空间
(aom_cluster_disk_av ailable_capacity_mega bytes)
还未经使用的磁盘空间。 ≥0 兆字节(Megabytes)
磁盘空间容量
(aom_cluster_disk_ca pacity_megabytes)
总的磁盘空间容量。 ≥0 兆字节(Megabytes)
磁盘使用率
(aom_cluster_disk_us age)
已使用的磁盘空间占总的磁盘空间容量 百分比。
≥0 百分比(Percent)
可用物理内存
(aom_cluster_memor y_free_megabytes)
该指标用于统计测量对象上的尚未被使
用的物理内存。 ≥0 兆字节(Megabytes)
可用虚拟内存
(aom_cluster_virtual_
memory_free_megaby tes)
该指标用于统计测量对象上的尚未被使
用的虚拟内存。 ≥0 兆字节(Megabytes)
显存容量(aom_cluster_gpu_m emory_free_megabyte s)
该指标用于统计测量对象的显存容量。 >0 兆字节(Megabytes)
显存使用率
(aom_cluster_gpu_m emory_usage)
该指标用于统计测量对象已使用的显存 占显存容量的百分比。
0~100% 百分比(Percent)
显存使用量
(aom_cluster_gpu_m emory_used_megabyte s)
该指标用于统计测量对象已使用的显 存。
≥0 兆字节(Megabytes)
GPU使用率
(aom_cluster_gpu_us age)
该指标用于统计测量对象的GPU使用
率。 0~
100% 百分比(Percent)
物理内存使用率
(aom_cluster_memor y_usage)
该指标用于统计测量对象已使用内存占 申请物理内存总量的百分比。 0~
100% 百分比(Percent)
下行Bps
(aom_cluster_networ k_receive_bytes)
该指标用于统计测试对象的入方向网络
流速。 ≥0 字节/秒(Bytes/
Second)
指标名称 指标含义 取值范 围
单位
上行Bps
(aom_cluster_networ k_transmit_bytes)
该指标用于统计测试对象的出方向网络
流速。 ≥0 字节/秒(Bytes/
Second)
物理内存容量
(aom_cluster_memor y_total_megabytes)
该指标用于统计测量申请的物理内存总
量。 ≥0 兆字节(Megabytes)
虚拟内存容量
(aom_cluster_virtual_
memory_total_megab ytes)
该指标用于统计测量对象上的虚拟内存
总量。 ≥0 兆字节(Megabytes)
虚拟内存使用率
(aom_cluster_virtual_
memory_usage)
该指标用于统计测量对象已使用虚拟内 存占虚拟内存总量的百分比。
0~100% 百分比(Percent)
表5-23 APM 指标
指标名称 指标含义 取值范
围
单位
成功率(aom_sla_success_rat e)
一个统计周期内所有接口调用的成功比
例。 0~
100% 百分比(%)
平均时延(aom_sla_tp99) TP99时延=完成99%的网络请求所需要 的最短耗时。
举例:假设总请求数为100个,它们的 请求耗时分别为1s、2s、3s、4s……
98s、99s、100s。若要完成99%的请 求,至少需要99s,故TP99为99s。
计算:将所有请求按照耗时从小到大排 序,第(99%*总请求数)个请求的耗 时即为TP99时延。
≥0 毫秒(ms)
错误调用次数
(aom_sla_error_count
)
一个统计周期内所有接口调用的失败次
数。 ≥0 次(Count)
吞吐量(aom_sla_throughput
)
指定时间内接口调用的总次数。 ≥0 次/分(Transaction/
Minute)
Apdex
(aom_sla_apdex) 该指标表示应用性能满意度,数值越大
表示满意度越高。 0~1 无
表5-24 其他指标
指标名称 指标含义 取值范
围
单位
主机数量(aom_billing_hostUse d)
一天内接入的主机数量。 ≥0 无
6 约束与限制
操作系统使用限制
AOM支持多个操作系统,在购买主机时您需选择AOM支持的操作系统,详见表6-1,
否则无法使用AOM对主机进行监控。
表6-1 AOM 支持的操作系统及版本 操作系
统
版本
SUSE SUSE Enterprise 11 SP4 64bit
SUSEEnterprise 12 SP1 64bit
SUSEEnter prise 12SP2 64bit
SUSE Enterprise 12 SP3 64bit
OpenSU
SE 13.2 64bit 42.2 64bit 15.0 64bit(该版本暂不支持syslog日志采 集)
EulerOS 2.2 64bit 2.3 64bit 2.5 64bit CentOS 6.3 64bit 6.5 64bit 6.8
64bit 6.9 64bit 6.10 64bit 7.1 64bit 7.2 64bit 7.3
64bit 7.4 64bit 7.5 64bit 7.6 64bit Ubuntu 14.04
server 64bit
16.04 server
64bit 18.04 server 64bit
Fedora 24 64bit 25 64bit 29 64bit Debian 7.5.0 32bit 7.5.0 64bit 8.2.0
64bit 8.8.0
64bit 9.0.0 64bit
说明
● 对于Linux x86_64服务器,AOM支持上表中所有的操作系统及版本。
● 对于Linux ARM服务器,CentOS操作系统仅支持7.4 及其以上版本,上表所列的其他操作系 统对应版本均支持。
资源使用限制
在使用AOM时,您需注意以下使用限制,详见表6-2。使用限制中部分内容属于配 额,关于什么是配额以及怎样查看与修改配额,详见关于配额。
表6-2 资源使用限制
分类 对象 使用限制
仪表盘 仪表盘 1个区域中最多可创建50个仪表盘。
仪表盘中的图
表 1个仪表盘中最多可添加20个图表。
仪表盘中图表 可选资源、阈 值规则、组件 或主机的个数
● 1个曲线图中最多可添加100个资源,且资源可 跨集群选择。
● 1个数字图只能添加1个资源。
● 1个阈值状态图表最多可添加10个阈值规则。
● 1个主机状态图表最多可添加10个主机。
● 1个组件状态图表最多可添加10个组件。
指标 指标数据 ● 基础规格:指标数据在数据库中最多保存7 天。
● 专业规格:指标数据在数据库中最多保存30 天。
指标项 资源(例如,集群、组件、主机等)被删除后,
其关联的指标项在数据库中最多保存30天。
维度 每个指标的维度最多为20个。
指标查询接口 单次最大可同时查询20个指标。
统计周期 最大统计周期为1小时。
单次查询返回
指标数据 单个指标单次查询最大返回1440个数据点。
自定义指标 无限制。
上报自定义指
标 单次请求数据最大不能超过40KB,上报指标所带 时间戳不能超前于标准UTC时间10分钟,不接收 乱序指标,即有新指标上报后,旧指标上报将会 失败。
分类 对象 使用限制 应用指标
JOB指标
● 每个主机的容器个数超过1000个时,ICAgent 将停止采集该主机应用指标,并发送
“ICAgent停止采集应用指标”告警(告警 ID:34105)。
● 每个主机的容器个数缩减到1000个以内时,
ICAgent将恢复该主机应用指标采集,并清除
“ICAgent停止采集应用指标”告警 。 由于JOB在完成任务之后,会自动退出。如果您 需要监控JOB指标,要保证存活时间大于90秒才 能采集到指标数据。
采集器资源消 耗
采集器在采集基础指标时的资源消耗情况和容 器、进程数等因素有关,在未运行任何业务的VM 上,采集器将消耗30M内存、1% CPU。为保证 采集可靠性,单节点上运行的容器个数应小于 1000。
阈值规则
(除华北-北京 一、华北-北京 四、华东-上海 一、华东-上海 二、华南-广州 和华南-深圳区 域外的其他区 域)
阈值规则 一个项目下最多可创建1000个阈值规则。
发送通知可选
择主题数 每个阈值规则最多可选择5个主题。
告警规则
(华北-北京 一、华北-北京 四、华东-上海 一、华东-上海 二、华南-广州 和华南-深圳区 域)
告警规则 告警规则(包含静态阈值规则和事件类告警规 则)最多可创建1000个。
阈值模板 静态模板最多可创建50个。
通知规则(除 华北-北京一、
华北-北京四、
华东-上海一、
华东-上海二、
华南-广州和华 南-深圳外的其 他区域)
发送通知可选
择主题数 每个通知规则最多可选择5个主题。
日志 单条日志大小 每条日志最大10KB,超出后ICAgent将不会采集 该条日志,即该条日志会被丢弃。
分类 对象 使用限制
日志流量 每个租户在每个Region的日志流量不能超过 10MB/s。如果超过10MB/s,则可能导致日志丢 失。
如果您有更多的日志流量需求,请提交工单处 理,操作详见如何提交工单。
日志文件 只支持采集文本类型日志文件,不支持采集其他 类型日志文件(例如二进制文件)。
每个通过卷挂载日志的路径下,ICAgent最多采集 20个日志文件。
每个ICAgent最多采集1000个容器标准输出日志 文件,容器标准输出日志只支持json-file类型。
采集日志文件 的资源消耗
日志文件采集采集时消耗的资源和日志量、文件 个数及网络带宽、backend服务处理能力等多种 因素强相关。
日志丢失 采集器使用多种机制保证日志采集的可靠性,尽 可能保证数据不丢失,但在如下场景可能导致日 志丢失。
● 日志文件未使用CCE提供的logPolicy轮转策 略。
● 日志文件轮转速度过快,如1秒轮转一次。
● 系统安全设置或syslog自身原因导致无法转发 日志。
● 容器运行时间过短,例如小于30s。
● 单节点总日志产生速度过快,超过了单节点网 络发送带宽或日志采集速度,建议单节点总日 志产生速度<5M/s。
日志丢弃 当单行日志长度超过10240字节时,此行会被丢 弃。
日志重复 当采集器被重启后,重启时间点附近可能会产生 一定的数据重复。
日志 统计规则 一个日志桶下最多可创建5条统计规则。
历史日志 日志数据存储时长与您选择的版本有关,且收费 不同,详见价格详情。
告警中心 告警 您最多可查询最近30天的告警。
事件 您最多可查询最近30天的事件。
服务使用限制
在使用AOM时,当AMS-Access服务出现断电、或者异常重启的时候,部分主机、组 件、容器等资源会出现一个采集周期的指标数据断点,该数据断点对于用户来讲监控
页面上能看到一个断点,没有其他影响。如果对断点有要求,可以在“监控”->“指 标浏览”页面中查看指标曲线时,将插值方式设置为0或者average,系统会自动补 点,如图1 所示
图6-1 插值方式修改
7 隐私与敏感信息保护声明
由于AOM会将运维数据内容展示到AOM控制台,请您在使用过程中,注意您的隐私及 敏感信息数据保护,不建议将隐私或敏感数据上传到AOM,必要时请加密保护。
采集器部署
在弹性云服务器 ECS上手动部署ICAgent过程中,安装命令中会使用到您的AK/SK作为 输入参数,安装前请您关闭系统的历史纪录收集,以免泄露隐私。安装后ICAgent会加 密存储您的AKSK,有效保护敏感信息。
容器监控
在CCE容器监控场景下,AOM的采集器(ICAgent)必须以特权容器的方式运行,请合 理的评估特权容器的安全风险,谨慎识别您的容器业务场景。如:节点对外提供的业 务属于逻辑多租的共享容器方式,建议采用开源Prometheus等工具进行监控,避免使 用AOM的采集器监控您的业务。
8 与其他服务的关系
AOM可与消息通知服务、分布式消息服务、云审计等服务配合使用。例如,通过消息 通知服务您可将AOM的阈值规则状态变更信息通过短信或电子邮件的方式发送给相关 人员。同时AOM对接了虚拟私有云、弹性负载均衡等中间件服务,通过AOM您可对这 些中间件服务进行监控。AOM还对接了云容器引擎、云容器实例等服务,通过AOM您 可对这些服务的基础资源和应用进行监控,并且还可查看相关的日志和告警。
图8-1 AOM 与其他服务关系图
消息通知服务
消息通知服务(Simple Message Notification,简称SMN)可以依据您的需求主动推 送通知消息,最终您可以通过短信、电子邮件、应用等方式接收通知信息。您也可以 在应用之间通过消息通知服务实现应用的功能集成,降低系统的复杂性。
AOM使用SMN提供的消息发送机制,当您因不在现场而无法通过AOM查询阈值规则 状态的变更信息时,能及时将该变更信息以邮件或短信的方式发送给相关人员,以便 您及时获取资源运行状态等信息并采取相应措施,避免因资源问题造成业务损失。详 细内容请参见创建静态阈值规则。
对象存储服务
对象存储服务(Object Storage Service,简称OBS)是一个基于对象的海量存储服 务,为客户提供海量、安全、高可靠、低成本的数据存储能力,包括:创建、修改、
删除桶,上传、下载、删除对象等。
AOM支持将日志转储到OBS的桶中,以便长期存储。详细内容请参见添加日志转储。
云审计服务
云审计服务(Cloud Trace Service,简称CTS)为您提供云账户下资源的操作记录,通 过操作记录您可以实现安全分析、资源变更、合规审计、问题定位等场景。您可以通 过配置OBS对象存储服务,将操作记录实时同步保存至OBS,以便保存更长时间的操 作记录。
通过CTS您可记录与AOM相关的操作,便于日后的查询、审计和回溯。CTS记录AOM 的相关操作详见应用运维管理的关键操作列表。
统一身份认证服务
统一身份认证服务(Identity and Access Management,简称IAM)是提供身份认 证、权限分配、访问控制等功能的身份管理服务。
通过IAM可对AOM进行认证鉴权及细粒度授权。
云监控服务
云监控服务(Cloud Eye)为您提供一个针对弹性云服务器、带宽等资源的立体化监控 平台。使您全面了解云上的资源使用情况、业务的运行状况,并及时收到异常告警做 出反应,保证业务顺畅运行。
AOM通过调用云监控服务的接口来获取弹性负载均衡服务、虚拟私有云服务、关系型 数据库服务和分布式缓存服务的监控数据,并展现在AOM界面,以便在AOM界面统一 对这些服务进行监控。
应用性能管理服务
应用性能管理服务(Application Performance Management,简称APM)是实时监控 并管理云应用性能和故障的云服务,提供专业的分布式应用性能分析能力,可以帮助 运维人员快速解决应用在分布式架构下的问题定位和性能瓶颈等难题,为您的体验保 驾护航。
为了更好的监控、管理应用,AOM集成了APM的相关功能。
虚拟私有云服务
虚拟私有云服务(Virtual Private Cloud,简称VPC)为弹性云服务器构建隔离的、您 自主配置和管理的虚拟网络环境,提升您云中资源的安全性,简化您的网络部署。
当您开通了VPC后,无需额外安装其他插件,即可在AOM界面监控VPC的运行状态及 各种指标。
弹性负载均衡服务
弹性负载均衡服务(Elastic Load Balance,简称ELB)是将访问流量根据转发策略分 发到后端多台云服务器流量分发控制服务。弹性负载均衡可以通过流量分发扩展应用 系统对外的服务能力,通过消除单点故障提升应用系统的可用性。
当您开通了ELB后,无需额外安装其他插件,即可在AOM界面监控ELB的运行状态及各 种指标。
关系型数据库服务
关系型数据库服务(Relational Database Service,简称RDS)是一种基于云计算平台 的即开即用、稳定可靠、弹性伸缩、便捷管理的在线关系型数据库服务。
当您开通了RDS后,无需额外安装其他插件,即可在AOM界面监控RDS的运行状态及 各种指标。
分布式缓存服务
分布式缓存服务(Distributed Cache Service,简称DCS)是华为云提供的一款内存数 据库服务,兼容了Redis、Memcached和内存数据网格三种内存数据库引擎,为您提 供即开即用、安全可靠、弹性扩容、便捷管理的在线分布式缓存能力,满足高并发及 数据快速访问的业务诉求。
当您开通了DCS后,无需额外安装其他插件,即可在AOM界面监控DCS的运行状态及 各种指标。
云容器引擎服务
云容器引擎服务(Cloud Container Engine,简称CCE)是提供高性能可扩展的容器服 务,基于云服务器快速构建高可靠的容器集群,深度整合网络和存储能力,兼容 Kubernetes及Docker容器生态。帮助您轻松创建和管理多样化的容器工作负载,并提 供容器故障自愈,监控日志采集,自动弹性扩容等高效运维能力。
通过AOM界面您可监控CCE的基础资源和运行在其上的应用,同时在AOM界面还可查 看相关的日志和告警。
云容器实例服务
云容器实例服务(Cloud Container Instance,简称CCI)提供 Serverless Container
(无服务器容器)引擎,让您无需创建和管理服务器集群即可直接运行容器。
通过AOM界面您可监控CCI的基础资源和运行在其上的应用,同时在AOM界面还可查 看相关的日志和告警。
应用编排服务
应用编排服务(Application Orchestration Service,简称AOS)通过图形化设计器,
直观便捷的进行云服务资源开通和应用部署,将复杂的云服务资源配置和应用部署配 置通过模板描述,从而实现一键式云资源与应用的开通与复制;同时在示例模板中提 供了海量的免费应用模板,覆盖各热点云服务应用场景,方便您直接使用或为您设计 个性化模板提供参考。
通过AOM界面您可监控AOS的基础资源和运行在其上的应用,同时在AOM界面还可查 看相关的日志和告警。
应用管理与运维平台
应用管理与运维平台(ServiceStage)是面向企业的一站式PaaS平台服务,提供应用 云上托管解决方案,帮助企业简化部署、监控、运维和治理等应用生命周期管理问 题;提供微服务框架,兼容主流开源生态,不绑定特定开发框架和平台,帮助企业快 速构建基于微服务架构的分布式应用。
通过AOM界面您可监控ServiceStage的基础资源和运行在其上的应用,同时在AOM界 面还可查看相关的日志和告警。
函数工作流服务
函数工作流服务(FunctionGraph)是华为云提供的一款无服务器(Serverless)计算 服务,无服务器计算是一种托管服务,服务提供商会实时为你分配充足的资源,而不 需要预留专用的服务器或容量,真正按实际使用付费。
通过AOM界面您可监控FunctionGraph的基础资源和运行在其上的应用,同时在AOM 界面还可查看相关的日志和告警。
智能边缘平台
智能边缘平台(Intelligent EdgeFabric,简称IEF)通过纳管您的边缘节点,提供将云 上应用延伸到边缘的能力,联动边缘和云端的数据,满足客户对边缘计算资源的远程 管控、数据处理、分析决策、智能化的诉求,同时,在云端提供统一的设备/应用监 控、日志采集等运维能力,为企业提供完整的边缘和云协同的一体化服务的边缘计算 解决方案。
AOM提供对IEF资源的运维能力,无需额外安装其他插件,通过AOM您可监控IEF的资 源(例如:边缘节点、应用、函数),同时在AOM还可以查看IEF资源的日志和告警
弹性云服务器
弹性云服务器Elastic Cloud Server,简称ECS)是由CPU、内存、镜像、云硬盘组成的 一种可随时获取、弹性可扩展的计算服务器,同时它结合虚拟私有云、虚拟防火墙、
数据多副本保存等能力,为您打造一个高效、可靠、安全的计算环境,确保您的服务 持久稳定运行。弹性云服务器创建成功后,您就可以像使用自己的本地PC或物理服务 器一样,在云上使用弹性云服务器。
您购买了弹性云服务器(弹性云服务器操作系统需满足表1 AOM支持的操作系统及版 本中的使用限制,且购买后需要给弹性云服务器安装ICAgent,否则无法使用AOM监 控)后,在AOM界面可对弹性云服务器的基础资源和运行在其上的应用进行监控,同 时在AOM界面还可查看相关的日志和告警。
裸金属服务器
裸金属服务器(Bare Metal Server,简称BMS)为您和您的企业提供专属的云上物理 服务器,为核心数据库、关键应用系统、高性能计算、大数据等业务提供卓越的计算 性能以及数据安全,结合云中资源的弹性优势,租户可灵活申请,按需使用。
您购买了裸金属服务器(裸金属服务器操作系统需满足表1 AOM支持的操作系统及版 本中的使用限制,且购买后需要给裸金属服务器安装ICAgent,否则无法使用AOM监 控)后,在AOM界面可对裸金属服务器的基础资源和运行在其上的应用进行监控,同 时在AOM界面还可查看相关的日志和告警。
9 基本概念
指标
指标是对资源性能的数据描述或状态描述,指标由命名空间、维度、指标名称和单位 组成。
其中,命名空间特指指标的命名空间,可将其理解为存放指标的容器,不同命名空间 中的指标彼此独立,因此来自不同应用程序的指标不会被错误地聚合到相同的统计信 息中。维度是指标的分类,每个指标都包含用于描述该指标的特定特征,可以将维度 理解为这些特征的类别。图9-1以集群指标为例,介绍了命名空间、维度和指标的关 系。
图9-1 集群指标
AOM的基础版和按需版所对应的指标存储时长及计费方式不同,详见收费详情。
主机
AOM的每一台主机对应一台虚拟机或物理机。主机可以是您自己的虚拟机或物理机,
也可以是您通过华为云购买的虚拟机(例如:弹性云服务器,简称ECS)或物理机(例 如:裸金属服务器,简称BMS)。只要主机的操作系统满足AOM支持的操作系统
(AOM支持的操作系统详见操作系统使用限制)且主机已安装ICAgent,即可将主机 接入到AOM中进行监控。