IPMA-RG 在教育研究之應用
葉連
國立嘉義大學教育行政與政策發展研究所教授摘 要
重要-表現圖示分析(IPMA)可依據設定的變項間因果關係去分類變項,利 於教育領導和管理決策參考,但限制為IPMA 有賴應用特定軟體和具備高階統計 方法知能。對此,採擷IPMA 理念,提出 IPMA-RGc 和 IPMA-RGi,其應用多元 迴歸分析和一般統計軟體,堪稱簡便使用。本文說明其分析理念、相關課題和分 析流程,也提出使用IPA、IPGA、IPMA-SEM 和 IPMA-RG 的整合決策流程。另 應用教育領導研究實例資料進行分析,顯示IPMA-RGc 和 IPMA-RGi 分析品質良 好。
關鍵詞:教育領導、教育管理、重要-表現圖示分析、重要-表現矩陣分析
【通訊作者】葉連祺電子郵件:[email protected]
Using IPMA-RG in Educational Research
Lain-Chyi Yeh
Professor, Graduate Institute of Educational Administration and Policy Development, National Chiayi University
Abstract
Importance-performance map analysis (IPMA) can classify variables based on the casual relationship between variables, are useful for decision making in educational leadership and management. But its limits are rely on using specific software and need knowledge and capabilities of advance statistical methods. So the study adopted the idea of IPMA, proposed IPMA-RGc and IPMA-RGi which using multiple regression analysis and general statistical software are easy to use. This study illustrated analytic ideas, related topics, and analytic procedures about IPMA-RG, and also showed an integrated decision-making procedure for conducting IPA, IPGA, IPMA-SEM and IPMA-RG.
Moreover a practical research data of educational leadership was used to test IPMA-RG, results showed both IPMA-RGc and IPMA-RGi are good.
Keywords: educational leadership, educational management, importance-performance map analysis, importance-performance matrix analysis
Lain-Chyi Yeh’s E-mail: [email protected] (Corresponding Author)
壹、前言
重要-表現分析(importance-performance analysis, IPA)(Martilla & James, 1977)採用重要性(importance)和表現度(performance)調查資料進行事項的 分類分析,已被應用於教育領導和管理研究,有益於發現具高重要性和高表現 度、高重要性卻低表現度、低重要性但高表現度、低重要性也低表現度等性質的 四類事項,能提供決策的客觀參考資訊;若只有表現度調查資料則可運用重要-
表 現 圖 示 分 析(importance-performance map analysis, IPMA)(Ringle & Sarstedt, 2016)或稱重要-表現矩陣分析(importance-performance matrix analysis, IPMA)
(Ahmad & Afthanorhan, 2014), 其 初 始 是 採 用 PLS-SEM(partial least squares structural equation modeling, 譯為偏最小平方法結構方程模式)結果,參考 IPA 理 念 而 形 成 一 套 分 類 分 析 方 法(Martensen & Grønholdt, 2003), 係 PLS-SEM 的 進階應用(Hair Jr, Sarstedt, Ringle, & Gudergan, 2018),目前應用者漸多。進行 IPMA,需要先執行 PLS-SEM 或 SEM(Siagian & Ayuningtyas, 2019),再應用分 析結果進行類似IPA 的分類分析,又 IPMA 僅適用具連續量尺性質的變項,這些 都限制了推廣使用該方法。
據此,本研究欲突破原有IPMA 的分析限制─必須基於 PLS-SEM 和 SEM 分 析結果和變項性質,經檢視IPMA 的理念和分析實務,提出改善構想及新的 IPMA 分 析 方 法 - IPMA-RG(importance-performance map analysis based on regression analysis,譯為迴歸分析本位重要-表現圖示分析),並配合教育領導研究實例考 驗,了解其分析品質。簡言之,研究目的在提出新的IPMA 方法,即 IPMA-RG,
以增益教育研究品質,並促進領導/ 管理實務和教育研究應用 IPMA。
貳、 IPMA 理念、分析實務與限制
關於 IPMA,已有論著(葉連祺,2020;Hair Jr, Sarstedt, Ringle, & Gudergan, 2018; Martensen & Grønholdt, 2003; Ringle & Sarstedt, 2016)進行頗多闡述,以下僅 就幾項重要課題加以簡述和評論。
一、 IPMA 理念與應用
依據文獻,IPMA 由 Martensen 和 Grønholdt(2003)提出,稱為 priority map、impact-performace map(p.143),主要以 PLS 法(即 PLS-SEM)進行 IPA。
IPMA 係 importance-performance map analysis、importance-performance matrix analysis 等簡稱,另有 priority map analysis(見 Hair Jr, Sarstedt, Ringle, & Gudergan, 2018; Ringle & Sarstedt, 2016)、structural equation modeling based importance- performance analysis(譯為結構方程模式本位 IPA)(陳寬裕、巫昌陽、林永森、
高子怡,2012)、PLS-SEM based IPM method(譯為 PLS-SEM 本位 IPM)(Kim, 2019)等稱呼,但很少採用;而中譯名稱以「重要-表現圖示分析」和「重要-
表現矩陣分析」較佳(葉連祺,2020)。
何謂 IPMA,Hair Jr、Hult、Ringle 和 Sarstedt(2017, p.319)、Hair Jr、
Sarstedt、Ringle 和 Gudergan(2018, p.218) 提 出 定 義 是:「IPMA 擴 展 標 準 的 PLS-SEM 報告徑路係數分析結果,再新增考慮潛在變項分數平均值的向度,更精 確地說是將對特定目標構念(target construct)的結構模式總效果(structural model total effects)及該構念之前置變項的平均潛在變項分數(average latent variable scores)加以聯結,進行分析」。基本上,IPMA 是採擷 IPA 的理念,即使用重要 性和表現度資料,去分類待分析的項目(即原因變項/ 構念),而做法是利用既有 的表現度資料,藉助PLS-SEM 或 SEM 分析多個變項構成的因果影響關係模式,
進而轉換產生重要性資料,進行類似IPA 的分類分析。因此,IPMA 和 IPA 是分析 理念相同,但分析方法和實務卻不盡相同。
IPMA 奠基於 SEM 或 PLS-SEM 的分析結果,其提供若干功能和應用值得重視:
1. 突破 IPA 僅能分析測量變項、需要收集重要性和表現度資料等應用侷限,只採 用一般調查所得資料(視為表現度資料),就可針對特定潛在變項進行類似IPA 的分析;2. 擴展 SEM 和 PLS-SEM 分析結果,區分與特定潛在變項有關的變項為 四類,並提出不同的處理做為,增進SEM 和 PLS-SEM 分析所得變項關係模式的 應用價值;3. 強化 IPA 分類變項基於潛在變項和測量變項影響關係的數理分析依 據,更客觀辨識需優先改善的變項或事項。
二、 IPMA 分析實務
其次如何進行 IPMA,Martensen 和 Grønholdt(2003)、Ringle 和 Sarstedt
(2016)提出要件查核(requirements check)、計算表現度值、計算重要性值、繪
進 行 分 析 值 比 較( 如t-test、r、
QAP)、分類結果比較(如 χ2、 CTIPMA、CSIPMA、CRIPMA等)
進行PLS-SEM、SEM 分析 相關變項和構念關係模式成立? 關係模式品質良好具高信度和高 效度
資料符合IPMA 分析要件 ? 檢視變項資料意義和價值、資料 屬性符合
確定分析條件設定
選擇目標構念和原因變項/ 構念、
決定後續分析層級(構念和指標 項目)
計算表現度值和重要性值
進行指標項目層級IPMA?
比較跨時間、跨對象分類結果? 考驗分類表現效果?
確定分類架構和分類標準 選擇標準型(4 類)或區隔型(5 類)
進行構念層級IPMA
進 行 分 類、 繪 製 構 念 層 級 的 重 要-表現圖、解釋分類結果及意 義
修 改PLS-SEM、SEM 關 係 模 式 為適配成立,或結束IPMA 分析
轉換變項資料改變屬性、重新調 查資料,或結束IPMA 分析
進 行 分 類、 繪 製 指 標 層 級 的 重 要-表現圖、解釋分類結果及意 義
進 行 區 別 分 析 和 報 告 分 類 正 確 率、或再分析DIPMA指數,解釋 考驗結果
運作前提 否
否
否 否
是 是
是 是
要件分析
結束IPMA 基本分析
進階分析
否
是
圖 1 IPMA 分析之應用流程
註:取自“教育領導與管理研究應用IPA、IPGA 與 IPMA”by 葉連祺,2020,學校行政,125,p.172。
製重要-表現圖(importance-performance map creation)、擴展 IPMA 至指標層級
(extension of the IPMA on the indicator level)等流程,葉連祺(2020)建議加入檢 驗分類表現(classifications test)階段,形成運作前提、要件分析、基本分析和進 階分析等階段流程,各階段工作細項見圖1 所示。當變項 / 構念關係具非線性性質 時,分析流程可見Streukens、Leroi-Werelds 和 Willems(2017)或葉連祺(2020)
的說明。
前述圖1 揭示有關 IPMA 的幾項階段性關鍵工作,包括查核 IPMA 分析要件、
選擇目標構念和原因變項(casual variable)/ 構念(casual construct)、計算表現 度值和重要性值、確定分類架構和分類標準、考驗分類表現效果,目前查核IPMA 分析要件需要研究者自行處理,考驗分類表現效果可使用EXCEL、IBM SPSS Statistics 等協助,其餘工作可由 SmartPLS 3 完全處理(Hair Jr, Sarstedt, Ringle, &
Gudergan, 2018),可謂非常便利。在查核 IPMA 分析要件方面,Ringle 和 Sarstedt
(2016)提到三項要件:1. 採用的測量變項必須是可計量量尺(metric scale)和等 距離量尺(equidistant scale),變項具等距量尺(interval scale)或等比量尺(ratio scale),且採取奇數評定點數,如有兩個正向和負向類別及一個中立類別的五點 評定量尺是適用,而偶數評定點數(如2、4、6 點)和名義量尺(nominal scale)
資料都不適合。2. 評定點數應有相同量尺方向(same scale direction),如 5 點量 尺評定5 表示高感受,1 是低感受,遇到反向題(reversed item)需要重新編碼。
3. 測量變項權重值(即係數值)必須是正值,如果為負值或 p>.05,要考慮不納入 IPMA 分析。
就選擇目標構念和原因變項/ 構念部分,IPMA 是分析原因變項 / 構念(casual variable/construct)對目標變項(target variable)或目標構念(target construct)的 因果影響關係,如多個原因變項→目標變項、多個原因變項→目標構念、多個原 因構念→目標變項、多個原因構念→目標構念,進而產生重要性值和表現度值。
因此IPMA 的分析結果取決於選用的目標變項和目標構念,不同的目標變項和目 標構念將產生不同的IPMA 分類結果,此展現模式本位(model based)的特性;
相對地IPA 不必設定目標變項,分析結果取決於評定者的評定看法,屬於評定者 本位(rater based)的分析(葉連祺,2020)。故選擇目標構念 / 變項是 IPMA 的 關鍵性工作。
計算表現度值和重要性值方面,IPMA 不直接採用評定者的評定資料,透過轉
換和統計分析以產生重要性值和表現度值。其中重要性是指一些潛在變項對目標 變項(target variable)或目標構念產生影響的未標準化總效果(unstandardized total effect),數值範圍為 0 ∼ 1,而表現度是指單一潛在變項或指標的未標準化和再 量尺化(rescaled)分數平均值,數值範圍是 0 ∼ 100,計算公式可見 Ringle 和 Sarstedt(2016)的說明。
而確定分類架構和分類標準部分,關係著IPMA 的分析結果,Martensen 和 Grønholdt(2003)、Ringle 和 Sarstedt(2016) 採 取 平 均 數 為 分 類 規 準, 一 如 Martilla 和 James(1977)的構想,分成四類:給予關心(concentrate here,或譯重 點關注、集中關注)、繼續保持(keep up the good work,或譯為優勢保持)、低 優先性(low priority,或譯低優先改善、低順位)和過度表現(possible overkill,
或譯過度重視、過度努力)四類,其分類架構和分類標準見圖2a 和表 1,圖 2a 稱 為重要-表現矩陣或重要-表現圖,通常可用EXCEL、IBM SPSS Statistics 等軟 體協助繪製,SmartPLS 3 可協助計算重要性值和表現度值、繪製重要-表現矩陣。
因為Martilla 和 James(1977)構想可能遭遇到項目落在分類軸上而無法分類的問 題,故葉連祺(2020)提出修改做法,重新設定三個類別的分類標準見表 1;另 一種修改做法是增加一個類別,容納落在分類軸和分類軸附近的項目,使得原來 的四分類做法能更有效地區別,據此藉助設定區間(area),葉連祺(2020)提出 segmentation IPMA(SIPMA,譯為區隔型重要-表現矩陣分析)見圖 2b 和表 1,
其分類標準可以是四分位數(Q1和Q3)、z 值或信賴區間,新增的類別稱為「一般」
(average group),依據葉連祺(2020)建議 Z 值重要-表現分析(ZIPA)使用
±0.5z 為分類標準的研究建議,圖 2 的 S1和S2可考慮設定為-0.5z 和 0.5z。
圖 2 IPMA 的重要-表現圖架構
註:S1和S2代表分類標準,S1<S2。取自“教育領導與管理研究應用IPA、IPGA 與 IPMA”by 葉連祺,
2020,學校行政,125,p.164。
表現度
重要性 過度表現
低優先性
繼續保持 一般
給予關心 S1 S2
S2
S1
b. SIPMA 做法 表現度
重要性 過度表現 低優先性
繼續保持 給予關心
a. Ringle 和 Sarstedt (2016) 想法 IPMA 做法
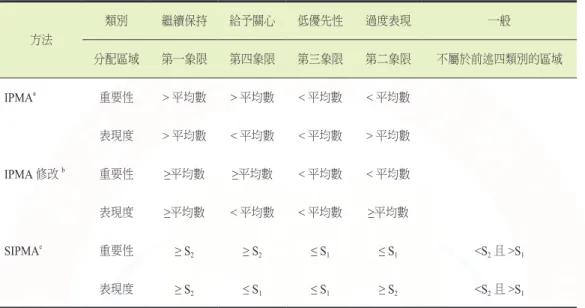
表 1 IPMA 及相關做法之分類架構和分類規準
方法
類別 繼續保持 給予關心 低優先性 過度表現 一般
分配區域 第一象限 第四象限 第三象限 第二象限 不屬於前述四類別的區域
IPMAa 重要性 > 平均數 > 平均數 < 平均數 < 平均數
表現度 > 平均數 < 平均數 < 平均數 > 平均數
IPMA 修改b 重要性 ≥平均數 ≥平均數 < 平均數 < 平均數
表現度 ≥平均數 < 平均數 < 平均數 ≥平均數
SIPMAc 重要性 ≥ S2 ≥ S2 ≤ S1 ≤ S1 <S2且>S1
表現度 ≥ S2 ≤ S1 ≤ S1 ≥ S2 <S2且>S1
註:aRingle 和 Sarstedt 所 提 做 法。b修 改Ringle 和 Sarstedt 所 提 做 法。cSIPMA 的 S1和S2代 表 分 類標準,可以是四分位數、z 值、信賴區間或其他量數,S1 < S2。改自“教育領導與管理研究應用 IPA、IPGA 與 IPMA”by 葉連祺,2020,學校行政,125,p.164。
至於考驗分類表現效果方面,未被過去IPMA 論述所重視,葉連祺(2020)
提出進行區別分析(discriminant analysis)和分析 DIPMA,區別分析是檢視區別正確 率≥ 80% 為佳。DIPMA是discrimination index for IPMA(譯為 IPMA 區別指數),係 綜合group discrimination index(Gindex)分析值而成,1 ≥ Gindex ≥ 0,Gindex值越小越
好,Gindex適用於比較各類別集群的分類效果,類別集群的Gindex值最小者最佳。而
1 ≥ DIPMA≥ 0,DIPMA值越小越好,DIPMA值≤ 0.1 表示整體 IPMA 分類效果良好,反 之則欠佳,比較多個IPMA 模式時,最小 DIPMA值者為最佳模式。如果要比較跨時 間和跨對象分析結果,能應用t-test、積差相關分析、QAP(Quadratic Assignment Procedure,譯為二次指派程序、二次方程指派程序)、Kappa coefficient(κ)、
Chi-square test(χ2)、列聯係數(contingency correlation,C)等統計方法,另有 CTIPMA、CRIPMA、CSIPMA、cCTIPMA、cCRIPMA、cCSIPMA等指數可採用,其計算公式 見葉連祺(2020),可以≤ 0.1 為判斷標準值。Gindex和DIPMA計算公式如下,可以 EXCEL 協助分析。
I:重要性值 P:表現度值 m:類別集群所有項目數 g:集群內項目數 >1 的類別集群數
三、評論 IPMA
如前所言,IPMA 有頗多優於 IPA 之處:1. 分析目標變項和原因變項可為潛 在變項,能獲取更多變項相對關係資訊,反觀IPA 只能分析測量變項;2. 分析目 標變項和原因變項彼此有因果影響關係,IPMA 結果有客觀和特定因果意義,而 IPA 分析的變項之間不必存在因果關係。至於限制則有:1. 必須先分析 PLS-SEM 或SEM 結果,再進行 IPMA,運作難度和複雜度較 IPA 高;2. 受限滿足 IPMA 的 三項分析要件,無法處理具類別量尺性質的原因變項/ 構念;3.IPMA 分析結果取 決於設定的原因變項/ 構念和目標構念關係,並以之闡釋分類結果,即兩類變項 / 構念關係的設定具關鍵性。觀察IPMA 分析的兩類變項 / 構念關係可以是單純的 多元迴歸分析(multiple regression analysis)(如圖 3 的模式 1)、路徑分析(path analysis)等關係(如圖 3 的模式 2),或是包含潛在變項的六類結構方程模式關 係(見圖3 的模式 3 ∼模式 8)。其中模式 1 可以傳統的多元迴歸分析來處理,能 將迴歸分析結果中變項的標準化係數值(其等於效果值)視為IPMA 的重要性值,
這提供了改進IPMA 分析方法的思考線索;至於模式 2 原因變項對於目標變項的 重要性,不能如同模式1 的處理方式,可能需要採取類似 IPMA 使用的總效果值 做為重要性值,不過得經過轉換程序,使得分析不同迴歸方程式所得重要性值能 夠相互比較,由於傳統的路徑分析得做多次的迴歸分析,因此適合採用的轉換方 法仍待探討和提出。
參、 IPMA-RG 理念與分析實務
前 述 提 及 的IPMA 需要奠基於 PLS-SEM、SEM 等分析結果,可說是基於 SEM 本位的 IPMA(或稱結構方程模式本位 IPMA)(importance-performance map analysis based on structural equation modeling, IPMA-SEM),雖有不少優點但有賴 SEM、PLS-SEM 分析做為基礎,反觀不少量化研究是採取 regression analysis(譯 為迴歸分析)或path analysis(譯為徑路分析),尤其採用迴歸分析佔多數,善用 該分析結果應該可以突破IPMA 限制,創建另類分析做法,因此提出 IPMA-RG,
即迴歸分析本位IPMA。又因為採用資料類型的不同:二分類別量尺資料、連續量 尺資料,能形成IPMA-RGc 和 IPMA-RGi,以下闡述其理念和分析實務。
一、 IPMA-RG 理念和相關分析課題
建 構IPMA-RG 主 要 是 改 善 IPMA-SEM 的 分 析 限 制, 擴 展 其 功 能。 因 此
圖 3 原因變項 / 構念和目標變項 / 構念之可能因果關係類型
IPMA-RG 的分析理念也類似,主要針對僅有表現度資料,無法進行 IPA 的問題,
利用原因變項對目標變項的因果影響關係(指圖3 的模式 1),即根據多元迴歸 分析結果(如下目標變項和多個原因變項形成的迴歸方程式),以利用表現度資 料形成重要性資料,便利繪製重要-表現圖,進行分類分析。進一步說,多元迴 歸分析結果的變項標準化迴歸係數值就是重要性值,此不同於IPMA-SEM 以總效 果值做為重要性值的做法,相對上分析較為簡便,而其代表意義相同,所以迴歸 分析對於IPMA-RG 非常重要。基於任何一個原因變項對於目標變項而言,都可能 具有影響力,因此規劃IPMA-RG 分析時,需要採用投入除了目標變項之外的其他 全部變項,而不論後續分析結果是否每個原因變項都具有統計的顯著性意義(指 p<.05),這將利於了解全部原因變項對於目標變項的相對重要性。
y=w1x1+w2x2+…+wk-1xk-1+wkxk Y:目標變項 Xi:原因變項 wi:原因變項 Xi的標準化加權值
至於有關的分析課題包括確認分析要件、計算表現度值、計算重要性值、分 類和繪製重要-表現圖、考驗分析品質等項。以下逐一討論:
1. 確認分析要件部份,以 IPMA-RGc 而言,需要滿足四個條件:(1) 原因變項 為二分類別量尺變項,如以0 和 1 編碼;否則需要將數值進行轉換,如以≧平均 數編碼為1,< 平均數為 0,或以使用評定量尺點數的中間值做轉換數值標準,奇 數評定點數時若≧(k+1)/2 點數值編碼為 1,否則為 0,如採用 5 點評定量尺,≧ 3 點編碼為1,<3 點編碼為 0,遇偶數評定點時若≧ (k/2)+1 點數值編碼為 1,否則 為0,如採用 4 點評定量尺,≧ 3 點編碼為 1,<3 點編碼為 0,當然亦可自訂具合 理性的轉換數值標準,如採用5 點評定量尺,≧ 4 點編碼為 1,<4 點編碼為 0。(2) 原因變項的編碼合理具意義性,且無採用負值的編碼方式,通常編碼1 表示「符合」
或「具有」的意義,編碼0 表示「不符合」或「沒有」的意思,如此才能以計算 編碼1 的樣本數比例(即百分比)做為待分析的原因變項表現度值,如原因變項 表現度值為70.5,表示對於該原因變項有 70.5% 樣本選擇為 1,另外 29.5% 樣本選 擇編碼為0,若是採用負值編碼如 -1 和 1,應重新編碼為 0 和 1。(3) 目標變項為 具連續量尺性質(即等距或等比量尺)的變項,且目標變項和多數原因變項達統 計顯著(p<.05)相關(指點二系列相關),以使後續 IPMA-RGc 分析結果有可參
考價值,此處或可設定逾60% 原因變項視為多數,低於此比例是否值得分析有待 研究者抉擇。(4) 投入原因變項和目標變項進行線性多元迴歸分析實屬合理,可考 慮若迴歸分析結果的R2<0.1 是否值得繼續 IPMA-RG 分析,又如果呈現非線性多 元迴歸分析宜考慮採取其他處理或不進行IPMA-RGc 分析,或可參考 Streukens、
Leroi-Werelds 和 Willems(2017)提議處理非線性關係(non-linear relationship)的 IPMA 做法。應注意需要符合此四項要件才能繼續進行分析。
至於IPMA-RGi,也需要滿足四個條件:(1) 原因變項為連續量尺性質的變 項,且編碼合理(如沒有負值編碼),不限奇、偶數評定點數編碼。(2) 全部原因 變項採用的評定點數宜相等,如有採取不同評定點數的情形,應先將原因變項值 進行一致性轉換,可使用(xi/Rx)×Rmax公式進行轉換,xi是樣本在某原因變項的 評定值,Rx是某原因變項採取的最大評定值,如使用5 點評定量尺則 Rx=5,Rmax 公式是全部原因變項採用評定量尺點數的最大值,如使用3 點和 5 點評定量尺,
則Rmax=5,如此則能合理比較全部原因變項的表現度值。(3) 目標變項為具連續量 尺性質的變項,且目標變項和多數原因變項達統計顯著(p<.05)相關(指積差相 關),以使後續IPMA-RGi 分析結果具參考價值,可考慮設定逾 60% 原因變項達 p<.05。(4) 投入原因變項和目標變項進行線性多元迴歸分析具合理性,亦可考慮 若迴歸分析結果的R2<0.1 是否值得繼續 IPMA-RGi 分析,如果屬於非線性關係宜 考慮採取其他處理或者不進行IPMA-RGi 分析,改採 Streukens、Leroi-Werelds 和 Willems(2017)提議處理非線性關係(non-linear relationship)的 IPMA 做法。應 該注意的是,必須符合此四項要件才能繼續進行分析。
2. 計算表現度值方面,以 IPMA-RGc 而言,是以原因變項原始數值或轉換後 數值計算編碼為1 的百分比做為表現度值,其範圍介於 0 ∼ 100 之間。而 IPMA- RGi 部份,以原因變項原始數值或轉換後數值的平均數做為表現度值,其範圍介 於0 ∼ Rmax之間,Rmax是全部原因變項採用評定量尺點數的最大值。
3. 計算重要性值方面,不論 IPMA-RGc 或 IPMA-RGi,都是採取投入全部原 因變項為自變項、目標變項為依變項進行線性多元迴歸分析的結果,以原因變項 在迴歸分析方程式中的標準化係數值為重要性值,不論該值是否達統計顯著意義
(如p<.05),或者為正、負值或 0,都全部採用。
4. 分類和繪製重要-表現圖部分,IPMA-RG 係擴展 IPMA-SEM 而成,可 援引原分類架構如表2 和圖 4,也能形成 segmentation IPMA based on regression
analysis,或簡稱 segmentation IPMA-RG(SIPMA-RG,譯為迴歸分析本位區隔型 重要-表現圖示分析),其分類標準S1和S2也可考慮設定為-0.5z 和 0.5z,後續 再考驗確認其效果。
圖 4 IPMA-RG 的重要-表現圖架構
註:S1和S2代表分類標準,S1 < S2。
表現度
重要性 過度表現
低優先性
繼續保持 一般
給予關心 S1 S2
S2
S1
b. SIPMA-RG (間隔型)
表現度
重要性 過度表現 低優先性
繼續保持 給予關心
a. IPMA-RGc 和 IPMA-RGi 標準型
表 2 IPMA-RG 及相關做法之分類架構和分類規準
方法
類別 繼續保持 給予關心 低優先性 過度表現 一般
分配區域 第一象限 第四象限 第三象限 第二象限 不屬於前述四類別的區域
IPMA-RGa 重要性 ≥平均數 ≥平均數 < 平均數 < 平均數 表現度 ≥平均數 < 平均數 < 平均數 ≥平均數
SIPMA-RGb
重要性 ≥ S2 ≥ S2 ≤ S1 ≤ S1 <S2且>S1
表現度 ≥ S2 ≤ S1 ≤ S1 ≥ S2 <S2且>S1
註:a適用IPMA-RGc 和 IPMA-RGi。b SIPMA-RG 的 S1和S2代表分類標準,可以是四分位數、z 值、
信賴區間或其他量數,S1 < S2。
5.考驗分析品質部分,進行 IPMA-RGc 時,0 ≤ I ≤ 1,0 ≤ P ≤ 100,計算 Gindex
和DIPMA的公式如下,可以≤ 0.1 做為判斷標準,能以 EXCEL 協助分析。Gindex值 越小表示集群的分類效果越佳,DIPMA值越小代表全部集群的分類效果越好。
I:重要性值 P:表現度值 m:類別集群所有項目數 g:集群內項目數 >1 的類 別集群數
至於進行IPMA-RGi 時,0 ≤ I ≤ 1,1 ≤ P ≤ Rmax,Rmax指全部變項中採用評定 點數的最大值,如採用5 點量尺,則 Rmax=5,計算 Gindex和DIPMA的公式如下,可 以≤ 0.1 做為判斷標準,能以 EXCEL 協助分析。Gindex值越小也表示集群的分類效 果越佳,DIPMA值越小代表全部集群的分類效果越好。而進行IPMA-RG 若要比較 跨時間、跨對象分類結果可進行分析值比較,如採用t-test、r、QAP,或進行分類 結果比較,如使用χ2、CTIPMA、CSIPMA、CRIPMA等,可參考IPMA-SEM 的做法。
I:重要性值 P:表現度值 m:類別集群所有項目數 g:集群內項目數 >1 的類 別集群數
二、 IPMA-RG 分析流程和報告結果
分析IPMA-RG 可援引 IPMA-SEM 的四階段流程構想,分成運作前提、要件 分析、基本分析和進階分析等階段,見圖5 所示,並可參看前已闡述的前三階段
進 行 分 析 值 比 較( 如t-test、r、
QAP)、分類結果比較(如 χ2、 CTIPMA、CSIPMA、CRIPMA等)
原因變項和目標變項具關聯性?
兩類變項的關聯性合理(如60%
的r 值達 p<.05)
資料符合IPMA-RG 分析要件 ? 目標變項和原因變項資料性質符 合要求、進行迴歸分析合理
確定分析條件設定 選擇目標變項和原因變項
計算表現度值 計算百分比值或計算轉換值 設定多個原因變項和目標變項
決定繼續IPMA-RG 分析 ? 迴歸分析結果合理具意義(如 R2≧0.1 或≧ 0.3)
比較跨時間、跨對象分類結果? 考驗分類表現效果?
計算重要性值
進行多元迴歸分析,設重要性值
確定分類架構和分類標準 選擇標準型(4類)或區隔型(5類)
進行分類和繪圖
進行分類、繪製重要-表現圖、
解釋分類結果及意義
重新選擇原因變項或目標變項,
或結束IPMA-RG 分析
轉換原因變項資料、重新調查資 料,或結束IPMA-RG 分析
進 行 區 別 分 析 和 報 告 分 類 正 確 率、或再分析DIPMA指數,解釋 考驗結果
運作前提
否
否
否 否
是 是 是
是 要件分析
結束IPMA-RG 基本分析
進階分析
是
圖 5 IPMA-RG 分析之應用流程
註:此適用IPMA-RGc 和 IPMA-RGi。
思考刪除表現不佳的原因變項再 重新分析,或繼續分析
否
若干課題內容。就運作前提部份,進行IPMA-RG 前宜確認原因變項和目標變項 之間應存在因果影響關係,或者說應存在較高的關聯性,亦即多數的原因變項和 目標變項之間的關聯性應多數達統計顯著(如p<.05),如檢視其點二系列相關
(point-biserial correlation, rpb)或積差相關(Pearson product-moment correlation, r)分析結果,是否多數相關係數值(如 60% 以上)達 p<.05。而在基本分析階段 可參考多元迴歸分析結果,決定是否繼續IPMA-RG 分析,理想上其 R2值至少應
≧0.1,若≧ 0.3 會更佳,如果 R2值過小如<0.1,表示迴歸分析品質可能欠佳,
需要思考重新選擇待分析的原因變項或目標變項。為便利進行IPMA-RG 分析,可 應用附錄一提供的IBM SPSS Statistics 命令程式協助分析。
再者IPMA-RG 分析結果應報告內容,可思考呈現目標變項和原因變項的描述 性統計資訊(如平均數、標準差)、相關係數、標準化迴歸係數及其顯著性考驗 結果、迴歸分析模式的R2、以及用於分析的重要性值和表現度值、分類結果(包 括各類別的分配項目數及百分比)和分析品質考驗結果(如區別分析的分類正確 率、DIPMA值等),以供讀者瞭解。
三、綜合比較
IPMA-RG 是以多元迴歸分析的結果為基礎,衍生出重要性資料,以進行變項 分類分析,而多元迴歸分析是一種常被採用的統計分析方法,就此IPMA-RG 可視 為一般分析的進階分析(advance analysis),亦即當一般研究若已進行多元迴歸 分析,可接續進行IPMA-RG,以增益分析成果;當然亦可視為 IPA 的進階分析,
即IPA →多元迴歸分析→ IPMA-RG。大抵上,IPMA-RG 和一般非 IPMA 的分析 差異可見表3 的比較,兩者之間能銜接應用,如先進行 IPMA-RG 再接續進行一般 非IPMA,反之也能先進行一般非 IPMA 分析,再接續進行 IPMA-RG,若是進行 IPMA-RGi 之後,甚至可重新設定目標變項和原因變項之間的影響關係模式,以進 行IPMA-SEM,進而比較其分析結果的異同。簡言之,IPMA-RG 可輔助增益一般 資料分析,更可銜接IPMA-SEM,挖掘更多隱藏於變項資料之間的豐富資訊,值 得採用。
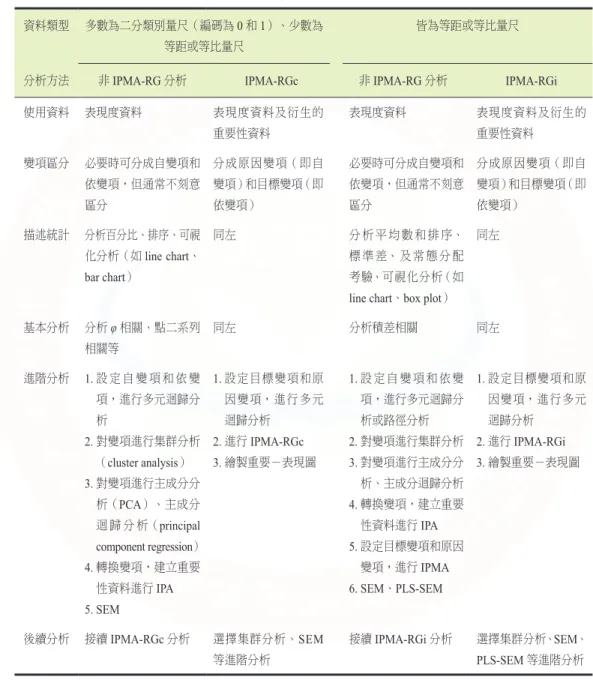
表 3 非 IPMA 和 IPMA-RG 分析變項資料之比較
資料類型 多數為二分類別量尺(編碼為0 和 1)、少數為 等距或等比量尺
皆為等距或等比量尺
分析方法 非IPMA-RG 分析 IPMA-RGc 非IPMA-RG 分析 IPMA-RGi
使用資料 表現度資料 表現度資料及衍生的
重要性資料
表現度資料 表現度資料及衍生的
重要性資料 變項區分 必要時可分成自變項和
依變項,但通常不刻意 區分
分成原因變項(即自 變項)和目標變項(即 依變項)
必要時可分成自變項和 依變項,但通常不刻意 區分
分成原因變項(即自 變項)和目標變項(即 依變項)
描述統計 分析百分比、排序、可視 化分析(如line chart、
bar chart)
同左 分 析 平 均 數 和 排 序、
標 準 差、 及 常 態 分 配 考驗、可視化分析(如 line chart、box plot)
同左
基本分析 分析φ 相關、點二系列 相關等
同左 分析積差相關 同左
進階分析 1. 設 定 自 變 項 和 依 變 項,進行多元迴歸分 析
2. 對變項進行集群分析
(cluster analysis)
3. 對變項進行主成分分 析(PCA)、主成分 迴 歸 分 析(principal component regression)
4. 轉換變項,建立重要 性資料進行IPA 5. SEM
1. 設定目標變項和原 因變項,進行多元 迴歸分析
2. 進行 IPMA-RGc 3. 繪製重要-表現圖
1. 設定自變項和依變 項,進行多元迴歸分 析或路徑分析 2. 對變項進行集群分析 3. 對變項進行主成分分 析、主成分迴歸分析 4. 轉換變項,建立重要
性資料進行IPA 5. 設定目標變項和原因
變項,進行IPMA 6. SEM、PLS-SEM
1. 設定目標變項和原 因變項,進行多元 迴歸分析
2. 進行 IPMA-RGi 3. 繪製重要-表現圖
後續分析 接續IPMA-RGc 分析 選擇集群分析、SEM 等進階分析
接續IPMA-RGi 分析 選擇集群分析、SEM、
PLS-SEM 等進階分析
再者,IPMA-RG 和 IPA、IPMA-SEM 都可供從綜合重要性和表現度的角度,
分類項目的優劣勢,能從多個方面來剖析見表4 所列。可知四類分析方法各具 特色,就分析便利性而言,IPA 最簡便,其餘依序是 IPMA-RGi、IPMA-RGc 和
IPMA-SEM;IPA 方法因為被廣泛討論,已知分析方法最為眾多和多元,形成複雜 的分析方法體系,而有關 IPMA 的論述少,其分析體系相對簡單,能分成 IPMA- SEM 和 IPMA-RG 兩類,IPMA-RG 再細分 IPMA-RGc 和 IPMA-RGi 兩類;分析時,
IPA 採用原始的重要性值和表現度值,IPMA-RG 使用原始的表現度值和轉換後的 重要性值,IPMA-SEM 都採用轉換後的重要性值和表現度值。大體而言,這四者 各有適用時機,IPA 獲得全部變項之間比較重要性和表現度的結果,而 IPMA-SEM 和IPMA-RG 則獲得在多數原因變項對單一目標變項具因果影響關係條件下,原因 變項之間比較重要性和表現度的結果。就針對特定目標的教育決策而言,IPMA- RG 應用簡便且兼具分類變項效果,是頗佳的分析工具。
表 4 IPA、IPMA-SEM 和 IPMA-RG 之比較
IPMA
IPA IPMA-SEM IPMA-RGi IPMA-RGc
分析理念 評定者本位 模式本位 模式本位 模式本位
分析基礎 無 P L S - S E M 、 S E M 、 GSCA-SEM 分析結果
multiple regression 分析 結果
multiple regression 分析 結果
分析層級 限測量變項 潛在變項層級為主,或
擴及測量變項層級
限測量變項 限測量變項
要求資料 需 要 原 始 的 重 要 性 和 表 現 度 資 料 供 分 析,
僅 有 表 現 度 資 料 時 須 經 轉 換 產 生 重 要 性 資 料供分析
需要原始表現度資料,
並 轉 換 產 生 新 的 表 現 度資料供分析,另轉換 產 生 重 要 性 資 料 供 分 析
需 要 原 始 表 現 度 供 分 析,另轉換產生重要性 資料供分析
需 要 原 始 表 現 度 資 料 供分析,另轉換產生重 要性資料供分析
分析資料 重要性和表現度資料 重要性和表現度資料 重要性和表現度資料 重要性和表現度資料
適用變項 測量變項 測量變項(為等距和等
比量尺,且是奇數的正 值評定點數)和潛在變 項
測量變項,目標變項和 原 因 變 項 皆 為 等 距 或 等比量尺
測量變項,原因變項為 二分類別量尺且編碼為 0 和 1,目標變項為等 距或等比量尺 設 定 變 項 和 關
係
不必要設定 需 設 定 目 標 構 念/ 變 項、其他原因變項和目 標/ 構念變項的因果關 係
需設定目標變項、其他 原 因 變 項 和 目 標 變 項 的因果關係
需設定目標變項、其他 原 因 變 項 和 目 標 變 項 的因果關係
(續下頁)
IPMA
IPA IPMA-SEM IPMA-RGi IPMA-RGc
分析變項性質 連續變項量尺為主 目 標 變 項 和 其 他 原 因 變 項 皆 為 連 續 變 項 量 尺
目 標 變 項 和 其 他 原 因 變 項 皆 為 連 續 變 項 量 尺
目 標 變 項 為 連 續 量 尺 變項、其他原因變項為 二分類別變項量尺
資料分析 平均數、中數及其他量
數
P L S - S E M 、 S E M 、 GSCA-SEM
multiple regression multiple regression
分類軸 重要性和表現度為主 重要性和表現度 重要性和表現度 重要性和表現度
分類類別 四類為主、五類,亦可
兩類、三類或其他
四類為主、五類 四類為主、五類 四類為主、五類
分類規準 平均數為主、中數及其
他(如GAP 值)
平均數 平均數 平均數
分析軟體 EXCEL、IBM SPSS Statistics 等
SmartPLS、LISREL 等 軟 體 為 主, 或 再 結 合 EXCEL、IBM SPSS Statistics
EXCEL、IBM SPSS Statistics 等
EXCEL、IBM SPSS Statistics 等
分 析 結 果 影 響 因素
無 設定變項因果關係、選
擇目標構念/ 變項會造 成不同分析結果
設定變項因果關係、選 擇 目 標 變 項 會 造 成 不 同分析結果
設定變項因果關係、選 擇 目 標 變 項 會 造 成 不 同分析結果
分 析 品 質 考 驗 方法
區別分析、DIPA等 區別分析、DIPMA等 區別分析、DIPMA等 區別分析、DIPMA等
進階分析 IPGA 或其他分析 通 常 做 構 念 層 次 分 析,可進階做測量變項 層次分析
無 無
教育應用 分 類 教 育 事 項 和 指 標 調查結果,區分高重要 但 低 表 現 的 事 項 和 指 標,指出決策優先作為 和增進決策品質
同IPA 應用,並擴及區 分 測 量 變 項 的 重 要 性 和表現度,指出可優先 改善的變項
同IPMA-SEM 應用 同IPMA-SEM 應用
另外,如前所述IPA、IPGA(importance-performance gap analysis, 譯為重要-
表現差距分析)、IPMA-SEM 和 IPMA-RG 四者分析有些關聯,可納入分析決策時
表 4 IPA、IPMA-SEM 和 IPMA-RG 之比較(續)
一併思考,乃提出決策參考流程如圖6 所示。至於 IPA、IPGA 詳細具體的分析流 程可見葉連祺(2018,2020)及其他論述(如 Martilla & James, 1977)的說明。
肆、 IPMA-RG 應用於教育領導研究之實例分析
一、實證分析資料性質說明
為考驗兩種IPMA-RG 分析方法的適用性和表現成效,選擇國小校長情緒 智慧領導能力調查資料(見葉連祺,2007)進行分析,該項調查資料使用依據 Goleman、Boyatzis 和 McKee(2002) 所 提 Primal leadership 理 論 編 製 的「 國 中 小校長情緒智慧領導能力量表」(採5 點量尺評定),將情緒智慧領導能力分成 自我察覺(self-awareness)、自我管理(self-management)、社會察覺(social
圖 6 進行 IPA、IPGA、IPMA-SEM 和 IPMA-RG 分析之決策流程
進行IPGA 分析測量變項層次的重
要性和表現度資料?
分析重要性和表現度資料 差異?
分析測量變項層次的表 現度資料?
分析潛在變項層次的表 現度資料?
分析測量變項層次的其 他屬性資料?
設定目標變項,分析其 他變項對目標變項影響
關係?
進行標準型、區塊型和 間隔型IPA
進行資料轉換,進行多 元迴歸分析
進行IPMA-SEM
進行IPMA-RGc、
IPMA-RGi 以表現度資料衍生其他
屬性資料,進行標準型 IPA
停 止 分 析, 或 進 行其他類型IPA 進行競爭型、
標竿型IPA
進 行SEM、PLS-SEM、
CGSA-SEM
進階分析
進階分析
是 是
是 是
是
是
否 否
否
否
否 否
awareness)、關係管理(relationship management)4 個層面、18 個向度及 55 個情 緒能力測量題項(見表5),題項內容詳見 Goleman、Boyatzis 和 McKee(2002)、
葉連祺(2007)論述。
本研究僅採用國小校長情緒智慧領導能力部分的調查資料,設定關係管理層 面為目標變項,其他三個層面的12 個向度為原因變項。表 6 顯示國小校長對於情 緒智慧領導能力自我察覺、自我管理和社會察覺層面的向度評定值(即表現度)
和關係管理層面評定值(為該層面六個向度評定值的平均數)的描述統計和關聯 性分析結果,顯示原因變項和目標變項的相關為r=.62 ∼ .81,全部皆 p<.001,以 逾越60% 的判斷值(圖 5),顯示後續進行 IPMA-RG 應有意義和參考價值。
表 5 國中、小學校長情緒智慧領導能力構念之意涵和測量結構
層面 自我察覺 自我管理 社會察覺 關係管理
意涵 能察覺自己情緒,
並精確評估情緒狀 態,展現自信做為
能自我控制情緒,
展現光明、主動、
樂觀、良好適應、
追求成就等作為
能持同理信理解他 人情緒,敏感組織 他人情緒變化,適 度提供情緒管理協 助
能良好協助他人管 理 情 緒,激 勵、正 向 影 響 和 協 助 他 人,扮演觸媒角色,
協助因應解決衝突 和促進團體合作
向度 1. 情緒自我察覺 2. 精準自我評量 3. 自信
1. 自我控制 2. 正大光明 3. 適應力 4. 成就動機 5. 主動 6. 樂觀
1. 同理心 2. 組織察覺 3. 服務
1. 激勵 2. 影響 3. 發展他人 4. 變革觸媒 5. 衝突管理 6. 團隊合作
題項 11 題 18 題 8 題 18 題
註:題項內容可見“國中小校長情緒智慧領導能力之比較”by 葉連祺,2007,當代教育研究,
15(1),pp. 39-76。
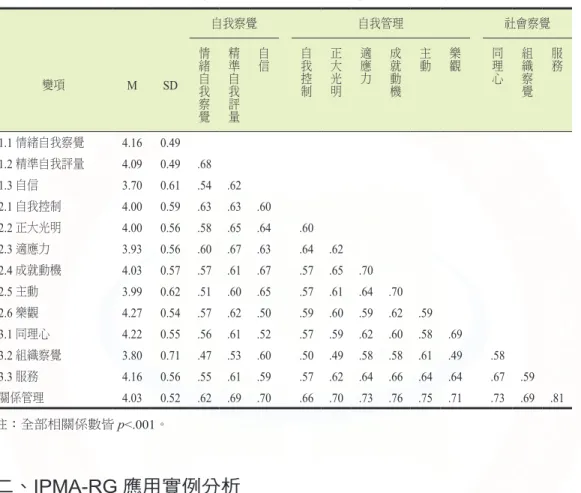
表 6 國小校長情緒智慧領導能力變項之描述統計和相關分析結果(N=782)
自我察覺 自我管理 社會察覺
變項 M SD
情緒自我察覺 精準自我評量 自信 自我控制 正大光明 適應力 成就動機 主動 樂觀 同理心 組織察覺 服務
1.1 情緒自我察覺 4.16 0.49 1.2 精準自我評量 4.09 0.49 .68 1.3 自信 3.70 0.61 .54 .62 2.1 自我控制 4.00 0.59 .63 .63 .60 2.2 正大光明 4.00 0.56 .58 .65 .64 .60 2.3 適應力 3.93 0.56 .60 .67 .63 .64 .62 2.4 成就動機 4.03 0.57 .57 .61 .67 .57 .65 .70 2.5 主動 3.99 0.62 .51 .60 .65 .57 .61 .64 .70 2.6 樂觀 4.27 0.54 .57 .62 .50 .59 .60 .59 .62 .59 3.1 同理心 4.22 0.55 .56 .61 .52 .57 .59 .62 .60 .58 .69 3.2 組織察覺 3.80 0.71 .47 .53 .60 .50 .49 .58 .58 .61 .49 .58 3.3 服務 4.16 0.56 .55 .61 .59 .57 .62 .64 .66 .64 .64 .67 .59 關係管理 4.03 0.52 .62 .69 .70 .66 .70 .73 .76 .75 .71 .73 .69 .81 註:全部相關係數皆p<.001。
二、 IPMA-RG 應用實例分析
就IPMA-RGc 分析而言,表 7 指出全部原因變項的表現值為 46.42 ∼ 81.97,
原因變項和目標變項的相關為rpb=.49 ∼ .63,皆 p<.001,顯然可繼續進行迴歸分 析。表8 顯示多元迴歸分析結果品質不錯,R2=0.693,高於建議標準值 0.3(圖 5),除了情緒自我察覺、精準自我評量和自我控制三個原因變項的標準化迴歸係 數值未達統計顯著水準(p>.05),其他 75% 的原因變項皆對目標變項有影響,
因此可將這些標準化迴歸係數值視為重要性值,進行IPMA-RGc 分析。分類結果 見表9 和圖 7a,顯示四個類別皆有原因變項,以過度表現類最多,自信、正大光 明、主動和組織察覺四項被認定為給予關心類,表示最值得關注、並應進行改善,
整體的分類正確率為91.7%,過度表現類的分類正確率為 80% 屬於最低,其餘三 個類別則達100%,而 DIPMA=0.024,此小於判斷標準值(即 0.1),整體觀之,此
分析結果品質良好。若採用未標準化迴歸係數值為重要性值,其與標準化係數值 的相關極高達r=.974,p<.001,分類結果見圖 8a,和圖 7a 比較可謂相同,這表示 IPMA-RGc 分析時採用標準化或未標準化迴歸係數值為重要性值都可以。
表 7 國小校長情緒智慧領導能力變項之描述統計和相關分析結果(N=782)
自我察覺 自我管理 社會察覺
變項 % a
情緒自我察覺 精準自我評量 自信 自我控制 正大光明 適應力 成就動機 主動 樂觀 同理心 組織察覺 服務
1.1 情緒自我察覺 74.55 1.2 精準自我評量 69.82 .50 1.3 自信 46.42 .37 .44 2.1 自我控制 72.51 .44 .53 .43 2.2 正大光明 60.10 .43 .49 .45 .40 2.3 適應力 63.94 .42 .50 .45 .48 .45 2.4 成就動機 68.41 .41 .49 .53 .48 .50 .56 2.5 主動 64.19 .37 .47 .46 .42 .46 .48 .55 2.6 樂觀 81.97 .36 .45 .31 .46 .40 .44 .44 .45 3.1 同理心 78.01 .41 .46 .34 .45 .39 .44 .46 .44 .48 3.2 組織察覺 60.10 .33 .48 .45 .42 .35 .45 .46 .45 .34 .42 3.3 服務 76.09 .40 .42 .39 .43 .43 .44 .51 .48 .52 .43 .43 關係管理 .49 .58 .57 .55 .59 .58 .63 .61 .57 .55 .58 .62 註:全部相關係數皆p<.001。a以樣本評定值≧3 轉換編碼為 1,否則為 0,而計算數值為 1 的百分比。
表 8 國小校長情緒智慧領導能力變項之迴歸分析結果(N=782)
未標準化係數 標準化係數
變項 B SE β VIF
截距 3.121*** 0.028
1.1 情緒自我察覺 0.043 0.030 .036 1.54
1.2 精準自我評量 0.048 0.032 .043 1.96
1.3 自信 0.138*** 0.027 .133*** 1.66
(續下頁)
未標準化係數 標準化係數
變項 B SE β VIF
2.1 自我控制 0.054 0.031 .047 1.74
2.2 正大光明 0.153*** 0.027 .145*** 1.67
2.3 適應力 0.075** 0.029 .070** 1.82
2.4 成就動機 0.100** 0.032 .090** 2.07
2.5 主動 0.126*** 0.029 .117*** 1.80
2.6 樂觀 0.164*** 0.035 .122*** 1.70
3.1 同理心 0.101** 0.032 .081** 1.64
3.2 組織察覺 0.157*** 0.027 .149*** 1.61
3.3 服務 0.186*** 0.032 .154*** 1.75
R2= 0.693 調整R2= 0.688
註:依變項為關係管理,採取全部變項投入法進行迴歸分析。**p<.01 ***p<.001
表 8 國小校長情緒智慧領導能力變項之迴歸分析結果(N=782)(續)
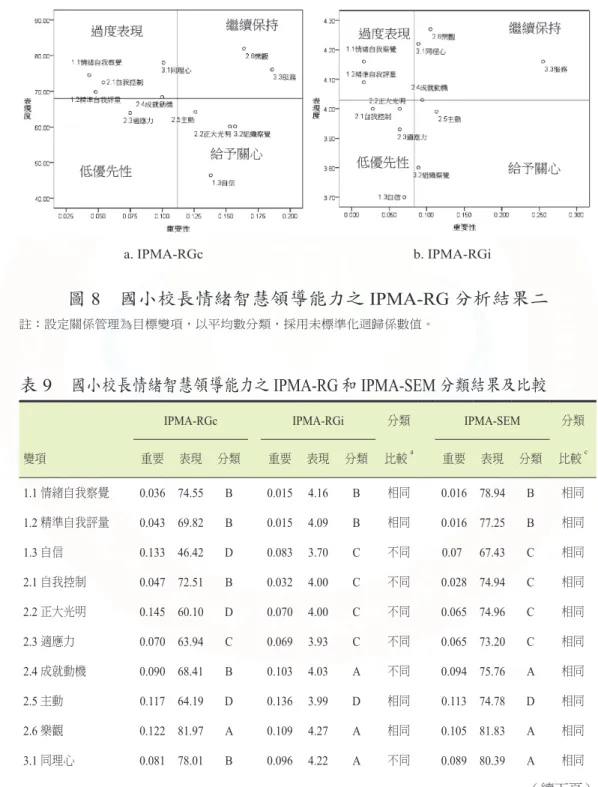
圖 7 國小校長情緒智慧領導能力之 IPMA-RG 分析結果一
註:設定關係管理為目標變項,以平均數分類,採用標準化迴歸係數值。
b. IPMA-RGi a. IPMA-RGc
表 9 國小校長情緒智慧領導能力之 IPMA-RG 和 IPMA-SEM 分類結果及比較
IPMA-RGc IPMA-RGi 分類 IPMA-SEM 分類
變項 重要 表現 分類 重要 表現 分類 比較a 重要 表現 分類 比較c
1.1 情緒自我察覺 0.036 74.55 B 0.015 4.16 B 相同 0.016 78.94 B 相同 1.2 精準自我評量 0.043 69.82 B 0.015 4.09 B 相同 0.016 77.25 B 相同 1.3 自信 0.133 46.42 D 0.083 3.70 C 不同 0.07 67.43 C 相同 2.1 自我控制 0.047 72.51 B 0.032 4.00 C 不同 0.028 74.94 C 相同 2.2 正大光明 0.145 60.10 D 0.070 4.00 C 不同 0.065 74.96 C 相同 2.3 適應力 0.070 63.94 C 0.069 3.93 C 不同 0.065 73.20 C 相同 2.4 成就動機 0.090 68.41 B 0.103 4.03 A 不同 0.094 75.76 A 相同 2.5 主動 0.117 64.19 D 0.136 3.99 D 相同 0.113 74.78 D 相同 2.6 樂觀 0.122 81.97 A 0.109 4.27 A 相同 0.105 81.83 A 相同 3.1 同理心 0.081 78.01 B 0.096 4.22 A 不同 0.089 80.39 A 相同
圖 8 國小校長情緒智慧領導能力之 IPMA-RG 分析結果二
註:設定關係管理為目標變項,以平均數分類,採用未標準化迴歸係數值。
(續下頁)
b. IPMA-RGi a. IPMA-RGc
IPMA-RGc IPMA-RGi 分類 IPMA-SEM 分類
變項 重要 表現 分類 重要 表現 分類 比較a 重要 表現 分類 比較c
3.2 組織察覺 0.149 60.10 D 0.121 3.80 D 相同 0.089 70.11 D 相同 3.3 服務 0.154 76.09 A 0.275 4.16 A 相同 0.255 79.01 A 相同
平均 0.099 68.01 0.094 4.03 0.084 75.72
類別 n % 正確% n % 正確% 相同 %b n % 正確% 相同 %d
A 繼續保持 2 16.67 100.0 4 33.33 75.0 50.0 4 33.33 75.0 100.0 B 過度表現 5 41.67 80.0 2 16.67 100.0 50.0 2 16.67 100.0 100.0 C 低優先性 1 8.33 100.0 4 33.33 100.0 25.0 4 33.33 100.0 100.0 D 給予關心 4 33.33 100.0 2 16.67 100.0 50.0 2 16.67 100.0 100.0
分類正確率 91.7 91.7 91.7
DIPMA 0.024 0.032
註:以關係管理為目標變項。A 是繼續保持類,B 是過度表現類,C 是低優先性類,D 是給予關心類。
ab比較IPMA-RGc 和 IPMA-RGi 的分類結果。cd比較IPMA-RGi 和 IPMA-SEM 的分類結果。
至於IPMA-RGi 分析部分,表 6 指出全部原因變項的表現值為 3.70 ∼ 4.27,
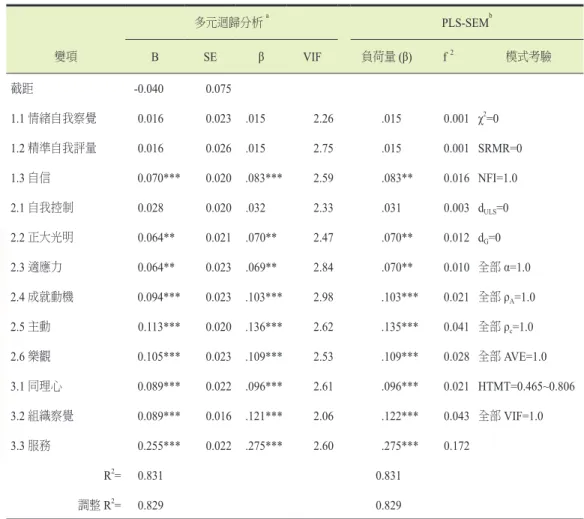
原因變項和目標變項的相關為r=.62 ∼ .81,全部皆 p<.001,表示能夠繼續進行迴 歸分析。表10 顯示多元迴歸分析結果品質頗佳,R2=0.831,高於建議標準值 0.3
(圖5),除了情緒自我察覺、精準自我評量和自我控制三者的標準化迴歸係數值 未達統計顯著水準(p>.05),其餘 75% 原因變項都影響目標變項,因此這些標準 化迴歸係數值能視為重要性值,繼續進行IPMA-RGi 分析。表 9 和圖 7b 顯示分類 結果,四個類別皆分配有原因變項,以繼續保持類和低優先性類最多,主動和組 織察覺兩項屬於給予關心類,表示其最值得關注和進行改善,整體的分類正確率 為91.7%,而 DIPMA= 0.032,此小於判斷標準值,整體觀之,此分析結果品質可謂 良好。
表 9 國小校長情緒智慧領導能力之 IPMA-RG 和 IPMA-SEM 分類結果及比較(續)
表 10 國小校長情緒智慧領導能力變項之迴歸分析和 PLS-SEM 分析結果(N=782)
多元迴歸分析a PLS-SEMb
變項 B SE β VIF 負荷量(β) f2 模式考驗
截距 -0.040 0.075
1.1 情緒自我察覺 0.016 0.023 .015 2.26 .015 0.001 χ2=0 1.2 精準自我評量 0.016 0.026 .015 2.75 .015 0.001 SRMR=0 1.3 自信 0.070*** 0.020 .083*** 2.59 .083** 0.016 NFI=1.0 2.1 自我控制 0.028 0.020 .032 2.33 .031 0.003 dULS=0 2.2 正大光明 0.064** 0.021 .070** 2.47 .070** 0.012 dG=0 2.3 適應力 0.064** 0.023 .069** 2.84 .070** 0.010 全部 α=1.0 2.4 成就動機 0.094*** 0.023 .103*** 2.98 .103*** 0.021 全部 ρA=1.0 2.5 主動 0.113*** 0.020 .136*** 2.62 .135*** 0.041 全部 ρc=1.0 2.6 樂觀 0.105*** 0.023 .109*** 2.53 .109*** 0.028 全部 AVE=1.0 3.1 同理心 0.089*** 0.022 .096*** 2.61 .096*** 0.021 HTMT=0.465~0.806 3.2 組織察覺 0.089*** 0.016 .121*** 2.06 .122*** 0.043 全部 VIF=1.0 3.3 服務 0.255*** 0.022 .275*** 2.60 .275*** 0.172
R2= 0.831 0.831
調整R2= 0.829 0.829
註:a依變項為關係管理,採取投入全部原因變項進行迴歸分析。b目標變項為關係管理,設定迭代 300 次,進行 PLS-SEM;設定 sample=5000,執行 bootstrapping。**p<.01 ***p<.001
又如果採用未標準化迴歸係數值為重要性值,其與標準化係數值的相關極高
(r=.993,p<.001),IPMA-RGi 的分類結果見圖 8,可見相同於圖 7,顯然 IPMA- RGi 分析時可以採用標準化或未標準化迴歸係數值為重要性值。
再者,前已述及IPMA-RGi 和 IPMA-SEM 兩者的分析結果應該相似性高,故 進行檢驗。設定進行多元迴歸分析的PLS-SEM 變項關係模式如圖 9a,觀察表 10 的 信 度( 指α、ρA、ρc)、 效 度(AVE 和 HTMT)、共線性(VIF)、模式適配
(指χ2、SRMR、NFI、dULS、dG)、模式R2等考驗結果,顯然此模式設定良好,