學習表現的知識結構評量研究:
以「教育統計學」學科知識為例
摘 要
本研究目的,旨在利用路徑搜尋網路分析評量選修相關教育統計學的 教育學程學生,對教育統計學概念間所形成的知識結構。具體而言,本研 究檢視三項問題:(1)學習穩定型和學習異常型兩組學生與教師的知識結 構圖為何?(2)學習穩定型和學習異常型兩組學生的知識結構圖與教師知 識結構圖相似程度是否有顯著差異?(3)三種相似性指數對學生的學習表 現是否有顯著的預測效果?研究結果發現:(1)兩種不同學習類型的學生 對於知識結構不僅有「量」的差異,其概念連結亦呈現「質」不同;(2)
三種知識結構指數與學習表現具有顯著的正相關;(3)知識結構指數對學 習表現具有顯著的預測效果,以PRX指數最具預測力,其解釋變異量為 34.20%。最後,本研究亦針對研究結果提出相關建議,以作為未來研究之 參考。
關鍵詞:學科知識、知識結構、路徑搜尋網路分析 李敦仁
國立政治大㈻教育㈻系博士班研究生
余民寧
國立政治大㈻教育㈻系教授兼系主任
Abstract
The main purpose of this study is to explore how to use the Pathfinder network analysis to assess knowledge structures in Educational Statistics courses taken by students in teacher training programs. Specifically, this paper examines (1) How to present knowledge structures in stable learning students, abnormal learning students, and experienced teachers? (2) In knowledge structure graphs, are the two types of students similar to experienced teachers? and (3) Do the three proximity indices predict learning performance? Research results are as follows: (1) In knowledge structure graphs and three proximity indices, there is a significant difference between two types of students and experienced teachers. (2) The proximity indices are all significantly positively correlated with learning performance. (3) The PRX index is the best predictor of knowledge structure on learning performance, and could explain 34.20% of the variance. Finally, some implications and suggestions are proposed.
Keywords: content knowledge, knowledge structures, pathfinder network analysis
Duen R. Lee
Ph. D. Graduate Student, Department of Education, National Chengchi University
The Assessment of Knowledge Structures of Learning Performance in Educational Statistics
Min-Ning Yu
Professor & Chair, Department of Education, National Chengchi University
壹、緒論
教學(instruction)是教師和學生共同參與的一種活動歷程。教師在預 定的教學目標指引下,運用各種方法,循序漸近進行教學,以期學生的學習 行為能夠隨著教學的進展而有所改變,以達成既定的教學目標。而要知道教 學結果是否達成預期目標,就必須針對教學效果實施客觀又正確的評量(余 民寧,2002a)。因此,教學與評量,猶如一種互為鏡像的關係;在評量的 鏡像可以反映出教學目標是否達成,在教學實況中則反映出評量的目標(謝 祥宏、段曉林,2001)。Glaser(1962)所提出的一般教學模式,認為「教 學評量」在整個教學歷程中所扮演的角色,不僅可以提供回饋訊息給教師,
更能使整個教學歷程統整在一起,發揮最大的教學與學習效果。
Wiggins(1998)明白指出評量有二個基本意涵:第一,評量是改進教 學,讓學生確認自己是否達到標準。因為一個友善、好的評量系統應該是激 勵學習動機,而不是藉由秘密考試、簡短答案,腐蝕學生的學習熱情和毅 力;第二,提供豐富詳盡且富有意義的回饋訊息給學生、老師、家長和政策 制訂者,因為清楚豐富的資料及評論,能讓學生進行正確的自我評量和自我 修正學習表現的機會。在心理計量學(psychometric)的評量典範下,傳統 式的紙筆測驗執行至今,已出現諸多問題並有其限制,例如:「考試領導教 學」、「標籤化」、「強調能力與排名」等,無法確實對教學與學習形成正 確的引導與幫助。此種強調常模參照與總結性評量的方式,往往只能測量到 受試者目前的表現程度,而無法探究深藏在實際操作表現之下的心智運作歷 程,僅能提供受試者目前表現情形的教學評量,而無法對教師教學、學生學 習提供充分且有效的訊息。有鑑於傳統紙筆測驗的限制,近年來,隨著建構 論的興起及認知心理學的蓬勃發展,結合認知心理學和心理計量學兩大領域 所形成的認知診斷評量(cognitively diagnostic assessment),期望藉由學生 模式(student model)、概念網路(conceptual network)與心理計量屬性(
psychometric attribution)等三大方面,以對學生的知識建構做更進一步的了 解,並透過生手與專家的知識結構差異比較,找出學生的錯誤概念,以便因
材施教及進一步做補救教學(Nichols, Chipman, & Brennan, 1995)。
教育統計學是師範(教育)大學或教育學程規定必修的教育專業科目 之一,許多修課同學初次接觸統計學科目,必須面對大量數理符號,心生焦 慮結果,排斥感油然而升;再加上教育統計學科所隱含的學科知識內容,有 如積木般的堆積工程,其概念與概念間的附屬階層非常明顯、聯結關係非常 強,學生的學習需建立在先備知識的聯結上,如果其中某一概念不清楚或一 知半解,往往會影響未來的學習,而瞭解學生在教育統計學學科知識的表徵 形式,將有助於教師分析學生在教育統計學學習方面的知識結構差異,並以 適當的教學策略與課程設計來幫助學生學習。因此,找出學生在教育統計學 學科的知識結構,將對教育統計學的學習成效影響深遠。
基於上述理由,本研究試圖採用路徑搜尋網路分析(pathfinder network analysis),去分析教育學程學生在修習教育統計學課程後,對教育統計學 概念所形成的知識結構,並分析教師的知識結構與學生知識結構的異同,藉 由教師與學生知識結構圖的相似性比較,試圖瞭解學生對教育統計學的學習 成果,並評估此種方法是否適用於教育統計學領域知識的測量。
貳、文獻探討
認知心理學對學習的基本觀點,認為學習乃是個人建構外在世界意義 的結果,而知識乃是學習後產出的結果;因此,認知心理學家莫不積極致力 於探索人類的知識結構、瞭解人類的學習機制和開發更有效的學習方法,以 幫助人類的學習成效。為了方便知識研究的進行,認知心理學家對於知識類 型的區分,大致可分為陳述性知識(declarative knowledge)與程序性知識(
procedure knowledge)兩種,個體在從事各項認知活動時,需要這兩種知識 相互的支援協助,才能使個體順利完成各項認知活動。結構性知識則是一種 中介型態的知識,其功能在於調節陳述性知識以轉換成程序性知識,且促進 程序性知識的應用(Jonassen, Beissner, & Yacci, 1993)。
一、知識結構的理論基礎
根據Morton與Bekerian(1986)對於知識結構的主張,本研究將知識結 構的理論區分為語意網路理論與基模理論兩類,茲就兩種理論的內涵分析如 下:
(一)語意網路理論
語意網路理論是一種關於知識如何被表徵的理論,語意網路理論主張 知識可透過有指示性與標示性的圖形結構來表徵,而圖形結構是由相互連 結的節點所構成,節點代表所表徵的是概念,節點與節點的連結線代表概念 的關係。一般較常被學者提及的語意網路模式有:Collins與Quillian的可教 導的語言理解者模式(Teachable Language Comprehender, TLC)、Collins與 Loftus的蔓延激發模式(Spreading Activation Model, SAM)及Anderson的思 考調控模式(Adaptive Control of Thought, ACT)等三種(江淑卿,1997;
鄭昭明,2001;Rumelhart & Norman, 1983)。
Collins與Quillian的TLC模式認為,人的知識系統是一個階層狀的 網路結 構 , 貯 存 在 知 識 系 統 裡 面 的 訊 息 , 是 由 單 位 (units)、特徵(
properities)與指向連結(pointers)所組成。此網路結構是由圖形中節點間 的關係所連接起來,節點就是記憶系統中的概念,包括單位和特徵兩大類。
一個「單位」是一個節點,對應於一個物件、事件、或想法;相對地,一個
「特徵」是用來描述或說明一個「單位」的結構,它等同於一個語句的述詞
(predicate)或形容詞、副詞的概念。單位與特徵彼此之間,可用具有方向 性的指向連結連接起來,當受試者在核對句子時,會從主詞與述詞之間的概 念節點開始進行交會搜尋(intersection search),介於兩者間的指向連結愈 多,則搜尋的時間也愈長,代表兩者的語意距離愈大。由於TLC模式有過度 簡化的缺失,Collins與Loftus針對TLC的缺點提出SAM模式,認為人類的長 期記憶中,是以概念節點及其交互連結所構成的非階層語意網路距離,來表 徵概念間的結構關係,其命題的表徵方式,猶如腦神經細胞的分佈情形,一
旦一個概念被激發後,它會沿著與此概念連結的連結線段,激發其他概念,
而越近的連結關係,其激發的速度越快。Anderson的ACT模式,則以命題(
proposition)做為知識結構的單位,並認為知識是以命題網路的形式被表徵 在記憶結構中。
雖然不同的學者,對於人類知識表徵的方式有不同的解釋,但大扺均 有一個共識,即在特定的知識領域內,概念與概念之間,都具有某種交互連 結的關係,因而形成一種組織上的特性,此種概念與概念間的組織特性,即 可稱之為「知識結構」。從知識結構的組織特性中,可以看出不同的專技程 度,例如:專家在某特定領域的知識結構,可能比一個生手更為一貫、更為 抽象(Chi, Glaser, & Rees, 1982)。Larkin等人(1980)比較物理專家與物 理生手在解決動力學問題上的研究,就發現專家與生手在知識組織方面和解 題策略方面有所差異;Shavelson 與Stanton(1975)觀察學生與教授在物理 學名詞類聚結構上的異同,發現隨著練習的逐漸增加,學生的名詞類聚結構 逐漸接近老師的類聚結構;Thro(1978)亦有類似的發現。由於知識結構的 特性可以反應出不同的專技程度或學習狀態,因此,如何瞭解或評量個體的 知識結構,便成為值得深入探討的問題。
(二)基模理論
基模理論是一種關於知識的理論,這種理論在探討知識如何被表徵,
以及表徵如何促使知識在特定領域方面的使用。基模理論主張所有的知識 都是被包裝(packaged)成單位(units),這些單位就是所謂的基模群(
schemata),這些基模群是一種抽象的知識結構,它會引導個體如何使用知 識。
基模的概念最早是由Barlett(1932)所提出,他認為個人能理解和記住 傳遞中的訊息,主要在於過去經驗和先備知識的脈絡下產生,並界定「基模」
為一個人用以同化新訊息以及產生訊息回憶的現存知識,但他並未詳細說明 此種心智結構的本質。直到1970~1980年代,隨著電腦科學的精進及人工智 慧的研究,基模理論才慢慢被發展成為解釋個人知識運作和組織的理論架構
(Nassaji, 2002)。Rumelhart與Ortony(1977)認為基模是指有組織的知識
結構,它是存在記憶裡用來表徵一般概念的資料結構,基模可用來表徵物 體、情境、事件、連續的事件、行動與連續的行動等知識,與基模概念相 似的有Minsky(1975)所提出的「架構(frame)」及Schank與Abelson(
1977)則所提出的「腳本(scripts)」。雖然每一個心理學家對基模的定義 各有不同,但一般而言,皆包括以下幾點(林清山譯, 1990):(1)普遍性
(general):基模可廣泛被運用在許多不同的情境,以做為瞭解輸入進來的 訊息的基本架構;(2)知識(knowledge):基模就如同我們所知道的事物 一樣是存在於記憶之中的;(3)結構(structure):基模圍繞著某些主題而 被加以組織;(4)包含(comprehension):基模中包含有一些要用短文的 特殊訊息來加以填補的空間。
二、路徑搜尋網路分析
知識結構是當代認知心理學的關心主題,而測量知識結構的方法很 多,如晤談法、分類法、圖解法和量尺法,皆各有其特色和限制,本研究 基於實徵分析的需要,選擇量尺法作為工具。「量尺法」又可分為多向度 量尺法(multidimensional scaling)、集群分析(cluster analysis)和路徑 搜尋網路分析(pathfinder network analysis)等三種。路徑搜尋網路分析係 Schvaneveldt(1994)及其研究小組,參考網路模式和圖解理論所發展而成 的一種量尺化算則方法。它能將近似值矩陣(proximity matrix, PRX),經 過分析後,獲得一個網路結構,在這個網路結構中,每一個概念是一個節 點,而節點之間則用一條直線來連結,以表示兩兩概念之間的關係,並且 在鍊結的線上有一個加權值,以表示節點之間的連結強度。相關文獻已發現 它可用來做為:(1)表徵概念之間的關聯性及結構特徵,(2)能預測記憶 搜尋及記憶組織,(3)分析生手與專家的不同表徵及轉換方式(Gonzalvo, Canas, & Bajo, 1994),其測量知識結構的過程,大至可以分成下列三個 步驟(江淑卿,1997;Goldsmith & Davenport, 1990; Schvaneveldt, 1990;
Dearholt & Schvaneveldt, 1990):
(一)知識結構的引出
由受試者判斷某個領域知識之概念兩兩配對間的相似性、關聯性或心 理距離值,以獲得相似值矩陣,作為資料分析的輸入值。理論上,每對節點 間都有鍊結,則為完全網路,亦即若有n個節點,則有n(n-1)∕2個鍊結,
每個鍊結相當於一個相似值。
(二)知識結構的表徵
透過路徑搜尋量尺化算則,將相似值矩陣轉換成路徑搜尋網路、圖解 理論距離和路徑搜尋網路圖解。其中,(1)路徑搜尋網路(PFNets)是由 一組概念,以節點(nodes)和鍊結(links)所連接而成的網路結構,鍊結 可以是非直接鍊(indirect link)和直接鍊(direct link),鍊結上沒有命名,但 是有鍊值(weights),保留了完全網路的「最接近的非直接徑路」(closest indirect path)。(2)圖解理論距離(graph-theoretic distance, GTD)係指最 小鍊結數或最短路徑之節點距離,透過算則,可將路徑搜尋網路的鍊值,轉 換為圖解理論距離,以節點間的距離代表網路的特質。(3)路徑搜尋圖解
(pathfinder graph)係結合路徑搜尋網路的鍊值和節點位置,所構成的知識 結構圖解,運用算則時,需設定參數r和q的數值,不同的r和q值,會產生異 種同形(isomorphic)的網路。參數r的數值是用來決定路徑的長度,係根據 Minkowsky距離的計算方法,計算非直接路徑的鍊值,r值的範圍是1到∞,
當r=1時,路徑的值等於路徑內鍊值之和;當r=∞時,路徑的值等於路徑中任 何一個鍊之最大值。參數q的數值則能限制網路的鍊結數目,q值的範圍是2 到n-1,n表示節點數量,當q=n-1時,表示搜尋所有不同的路徑,因此對路 徑長度沒有限制,若配合參數r便可獲得限制;當r=∞,q=n-1,則可產生最 少路徑的網路。
(三)知識結構的評價
將相似值矩陣、圖解理論距離、路徑搜尋網路,與參照結構比較,分 別計算出PRX指數、GTD指數與PFC指數等相似性指數,藉此比較個別受 試者和參照者的相似程度。三種指數的計算方式如下:(1)相似性指數(
PRX指數):係計算兩個網路的相似值矩陣之相關,以相關係數表示兩個網
路之間的相似程度。(2)圖解理論距離指數(GTD指數):係指根據圖解 理論的算則,計算兩個網路的圖解理論距離之相關,以相關係數表示兩個 網路之間的相似程度。(3)相近性指數(closeness index,簡稱C值或PFC 指數):係根據集合理論(set-theoretic)的方法,計算兩個網路所共有的節 點組,其臨近節點的交集和聯集之平均比率。這三種相似性指數的範圍值,
皆介於0到1之間,指數值愈大,即表示受試者的知識結構和參照者的知識 結構愈相似;在參照結構方面,可採用個人或團體的參照結構,其中,尤 其以專家的團體參照結構,所計算出的相似性指數之測量效果最佳(Acton, Johnson, & Goldsmith, 1994)。對於PRX指數、PFC指數、GTD指數三種相 似性指數的關係為何?Knoebel、Dearholt及Schvanevedlt(1988)認為PFC指 數重視鍊值,能掌握知識結構的接近性特質;GTD指數重視結構特質,能 掌握知識結構的空間型態;相較之下,PRX指數則屬於完全網路模式,較不 易精確掌握鍊結的重要訊息。總而言之,這三種指數皆有其特色。(4)正 確連結、缺失連結及過度連結:根據KNOT的分析結果,本研究另增三種新 指數的計算。其中,正確連結是指受試者的知識結構與專家參照結構比較之 後,與專家參照結構相符合的連結關係總數,即稱為「正確連結」(correct links);缺失連結是指受試者的知識結構與專家參照結構比較之後,專家參 照結構中具有的連接關係,但受試者的知識結構中卻不具有的連結關係總 數,即稱為「缺失連結」(missing links);而過度連結是指受試者的知識 結構與專家參照結構比較之後,專家參照結構中未具有的連接關係,但受試 者的知識結構中卻具有的連結關係總數,即稱為「過度連結」(over links)。
KNOT程式最後以連結總數當分母,正確連結、缺失連結、過度連結當分 子,分別計算正確連結、缺失連結、過度連結的百分比數值。
三、知識網路組織工具
知識網路組織工具(Knowledge Network Organizing Tool, KNOT)是由 New Mexico State University 的Schvaneveldt 等人以路徑搜尋網路算則為理論 基礎所發展的程式,主要用於建構、分析和評量路徑搜尋網路。KNOT 程式
進行徑路搜尋法分析的步驟如下(江淑卿,1997):
(一)評定概念配對的相似性:首先確定學習領域的概念,兩兩配對呈 現給學習者評定其相關性,可得到相似性資料矩陣,亦即相似性 數值(PRX)。輸入PRX 時可採similarities(得分越高,距離越 近),或採dissimilarities(得分越高,距離越遠)兩種方式來表 示資料屬性。
(二)結合相似性資料檔:根據研究需要而定,若分析團體資料,可用 AVE結合不同個人的相似性資料檔。
(三)計算路徑搜尋網路:設定參數r為∞,參數q為n-1,利用PF或 KNOT將相似性矩陣轉換成PFNETs,包括加權值,亦即路徑搜尋 網路。
(四)計算圖解距離:利用DIS或KNOT計算PFNETs的圖解距離。
(五)計算節點距離:利用SPRING或KNOT計算節點距離SPR。
(六)計算C值或PFC指數:利用NETSIM或KNOT計算兩個PFNETs的 PFC指數,可用來比較不同PFNETs的差異。
(七)計算相關:利用CORR或KNOT計算兩組相似性資料的相關,若 包含參照結構,則此相關係數為PRX指數;若以CORR或KNOT 計算兩組圖解距離的相關,如果包含參照結構,則此相關係數為 GTD指數。
(八)呈現路徑搜尋網路圖解:結合PFNETs與SPR,利用LAYOUT可以 呈現路徑搜尋網路圖解。
四、相關實徵研究
有關知識結構的相關研究,大致可區分為專家與生手知識結構的差異 研究,以及知識結構與學習表現的關聯性研究兩大類。首先,就專家與生手 知識結構的差異研究,知識結構理論基本假設專家與生手的知識結構組織和 關係有所不同,專家傾向以抽象向度組織知識,比較容易接觸知識,而生手 組織知識則缺乏理論、組織架構與基模(江淑卿,1997;Gonzalvo, Canas,
& Bajo, 1994)。相關研究結果也確實發現認知程度表現不同,其內在的知 識結構也有所不同,例如:Azzarello(2007)以pathfinder進行分析,發現在 實驗教學結束後學習表現最優和最差的兩組學生,在社區健康護理學的知 識結構有明顯差異;Boldt(2001)探討7位教師、11位碩士學生與8位大學 生在會計學知識結構的差異,發現碩士生所形成的知識結構圖與教師的知識 結構圖相類似,而大學生的知識結構圖與教師的知識結構圖則有明顯不同;
William、Craig與David(1997)發現四類不同吸毒經驗者,對16種毒品概念 其知識結構也有明顯有所不同。國內學者,如林曉芳(1999)、方慧君(
2003)、丁碧莉(2004)及余民寧教授所領導的一系列研究(林曉芳、余民 寧,2001;余民寧、林曉芳、蔡佳燕,2001;余民寧、陳嘉成,2001;余民 寧,2002b;涂金堂,2002;陳新豐,2002;陳嘉甄,2001;游森期、余民 寧,2006;葉倩亨,2001;塗振洋,2001),亦有類似的研究發現。綜合上 述有關知識結構的差異性研究結果,發現不同特定領域的專家與生手在知識 結構有明顯的差異存在;不同能力者在知識結構也有顯著的差異。這些研究 顯示路徑搜尋網路法具有區別專家與生手及不同能力者的知識結構之差異。
本研究基於上述文獻分析,試著探討路徑搜尋網路法的區別效度。
另外,就知識結構與學習表現的關聯性研究,大部份研究均發現應用 路徑搜尋網路所產生的知識結構指數與受試者的學習表現有顯著正向關聯,
如Azzarello(2007)以102位選修社區健康護理學的大學生為研究對象,結 果發現教學後學生知識結構與教師愈相似者,則期末成績表現就愈好;
Day、Arthur與Gettman(2001)以86位電動玩具受訓者為研究對象,發現受 訓者的知識結構與專家的知識結構相似度程度愈高,其複雜的電動遊戲技 能表現就愈好,並對電動遊戲技能保留及遷移具有顯著的預測效果。江淑 卿(1997)以266位國小六年級學生為對象,發現PFC、GTD及PRX對於科 學文章理解及自然科學期末成績有良好的預測效果,並且PFC在其他兩個指 數的影響力排除後,仍可以有效預測文章理解及學期成績;只有Hoole
(2005)發現知識結構PFC指數對數學學習表現具有負向預測效果。由於 不同的知識結構指數對學習表現有不同的預測效果,Johnson、Goldsmith與
Teague(1994)、江淑卿(2000)、宋德忠等人(1998)、林曉芳(1999)、
余民寧(2002b)發現PFC 指數對學習最具預測力;而方慧君(2003)、涂 金堂(2002)、塗振洋(2001)則發現PRX 指數對學習成就的預測力最 好;但游森期與余民寧(2006)卻指出GTD指數對學習表現,則有最高的 預測力。基於上述文獻分析,本研究以三種相似性指數為預測變項,分別與 學習成就進行逐步多元迴歸分析(stepwise regression analysis),以找出具 有顯著水準的預測指數,作為預測學習表現之用。
五、
S-P表分析與判定類別S-P表(Student-Problem Chart, S-P Chart)是由日本學者佐藤隆博(
Takahiro Sato)於1970年代所創,是一種將學生的作答反應情形「圖形化」
分析的方法,其目的在獲得每位學生的學習診斷資料,當作學習輔導之參 考。S-P表所使用的指標,計有:差異係數(disparity index)、同質性係數
(homogeneity index)、試題注意係數(item caution index)及學生注意係 數(student caution index)等四種指標。
假設教師蒐集到一筆N個學生在n個試題上的反應資料,經過評分(答 對者給1,答錯者給0)之後,得到一個未經任何處理的原始得分N×n階矩陣 資料,稱為「S-P原始資料表」。接下來,按照每位學生總分之高低,將學 生的整個反應組型及總分,由上(總分最高者排在最上面)往下(總分最低 者排在最下面)依序排列;接著,按照每道試題答對學生人數之多寡,由左 往右(答對人數最多的試題排在最左端)排列;最後,依據每位學生所得總 分(即1個數),從左端往右端,數出和其總分相同的試題個數,並且在其 右邊畫一條直線(分界線),如此一來形成的階梯狀曲線,稱作「S曲線」。
依照同樣的方法,依據每道試題之答對學生人數(即1的個數),從上往下 開始數,數出和其答對學生人數相同的學生個數,並且在其下邊畫一條直線
(即分界線),如此一來所形成的階梯狀曲線,稱作「P曲線」(余民寧,
2002a)。圖1即是依據期末成就測驗前30位受試者之作答情形所繪製的S-P 表。
圖1 期末成就測驗前30位受試者之作答情形所繪製的S-P表
S曲線是指學生得分之累加分布曲線,它是用來區分學生答對答錯的分 界線,S曲線以左的區域,大多數的數值都是1,因此這個區域範圍內學生的 反應大多數是答對的試題;同理,P曲線以上的部分,大多數的數值都是1,
因此這個區域範圍內學生的反應大多數是答對的試題。當S曲線以左或P曲 線以上全部出現為1時,這種情況稱為「完美量尺」的反應組型,但是在實 際的作答反應組型中,這種狀況不太可能出現,反而容易出現S曲線以左或 P曲線以上的部分有學生答錯的情形,這種不完美量尺組型會呈現S曲線和P 曲線分離的狀態,S曲線和P曲線分離的程度,可以用差異係數來表示(余 民寧,2002a)。
注意係數是異常反應組型指標,注意係數是指S-P表資料中的實際反應 組型與完美反應組型之間的差異,占完美反應組型是最大差異的一種比值,
其數學意涵可以用下列的公式來表示:
注意係數 =(實際反應組型與完美反應組型間的差異)/(完美反應組 型的最大差異)
亦可改寫為:1-(實際反應組型與基準變量之共變異)/(完美反應
組型與基準變量之共變異)
因此,當作答為完美反應組型時,注意係數等於 0;當作答為隨機反應 組型時,注意係數會接近於1,實際的反應組型之注意係數,通常介於0與1 之間。0≦注意係數<.50時,表示試題或學生異常反應組型不嚴重;.50≦注 意係數<.75時,表示試題或學生異常反應組型嚴重;注意係數 ≥ .75時,表 示試題或學生異常反應組型非常嚴重(余民寧,2002a)。
根據S-P表分析的結果,我們可根據學生的注意係數當作橫軸,以學生 得分之百分比當作縱軸,繪製學生診斷分析圖。學生診斷分析圖依據學生注 意係數將學生的學習狀況分為六大類(如圖2所示):學習穩定型(A區)、粗 心大意型(A'區)、努力不足型(B區)、欠缺充分型(B'區)、學力不足 型(C區)與學習異常型(C'區)。這六種學習類型有下列幾項特性(余民 寧,2002a)
圖2 學生診斷分析圖 75%
�
�
�
�
�
�
� 100%
50%
0 .50 1.00
������
A
����
����
A'
������
������
B
�������
�������
B'
��������
��������
C
����������
����������
C'
��������������
��������������
(一)學習穩定型(A區):
學習穩定型的學生學習狀況穩定良好,學業成績優良、能快速熟悉教 材達到精熟程度。這一類型學生,教師只需予以持續的鼓勵和勉勵,即可維 持他們持續穩定的學習狀況。
(二)粗心大意型(A'區)
粗心大意型的學生學習狀況稍欠穩定,雖然仍是班上程度較好的學 生,但是考試粗心大意,造成許多不經意的錯誤。
(三)努力不足型(B區)
努力不足型的學生學習狀況尚稱良好,只是表現不如「學習穩定型」
學生,這類型的學生多半屬班上中上程度的學生,他們的學習尚稱穩定,但 是可能因為努力用功不足,而導致考試成績不夠理想。
(四)欠缺充分型(B'區)
此類型學生學習準備不夠充分,偶爾也會粗心犯錯,學習狀況漸趨不 穩定,努力也不足。他們兼具用功不足與粗心大意兩種特性。
(五)學力不足型(C區)
此類型學生基本學力不足,學習不夠充分,努力用功程度亦不足。他 們的基本問題在於過去並沒有奠定良好的學習基礎和背景知識,以致在學習 新知識時倍感吃力。
(六)學習異常型(C'區)
此類型的學生學習極不穩定,對考試內容沒有充分準備,且隨便作 答、盲目猜題或有作弊之行為,導致作答反應組型異常。
傳統上認知心理學家在探討知識結構與專家技能的關係時,常會認為 專家與生手在知識結構的組織架構關係之連結、抽象程度及可獲取程度等向 度都有所不同(Chi, Glaser, & Rees, 1982)。因此,透過專家-生手之研究 典範(expert-novice paradigm)來研究領域的專業知能,對於認知心理學家 是一項重要的研究主題。本研究利用S-P表分析的判定類別,我們從中挑選 出得分百分比大於75%,注意係數小於.50的「學習穩定型」學生,視同為 專家;而得分百分比小於50%,注意係數大於.50的「學習異常型」學生,
則視同生手,透過專家-生手之比較,以探討此兩種類別之學生其知識結構 是否有所差異。
參、研究方法
一、待答問題與研究假設
經文獻探討後,本研究以路徑搜尋網路分析方法,針對修習過「教育 統計學」課程的學生知識網路結構進行評量,以比較「學習穩定型」和「學 習異常型」兩類學生與教師知識結構間的差異情形,並對知識結構與學習表 現間的關聯性做深入的探討。因此,本研究具體的待答問題與研究假設,可 以羅列如下:
1.學習穩定型和學習異常型兩組學生與教師的知識結構圖為何?
2.學習穩定型和學習異常型兩組學生,在學習教育統計學後的知識結構 圖與教師知識結構圖間的相似程度是否有差異?亦即,路徑搜尋網路 分析方法的區別效度為何?
3.三種用來判斷學習表現的知識結構相似性程度的相似性指數,其對學 生學習表現的預測效果為何?
所以,本研究提出的虛無假設可以表示如下:
1.學習穩定型和學習異常型兩組學生的知識結構圖與教師的知識結構圖 之間的相似程度,並無顯著差異存在。
2.三種相似性指數對學生的學習表現,並不具有顯著的預測效果存在。
二、研究對象
本研究的受試者為58名國立新竹教育大學選修「教育統計學」的大學 部學生及24名國立政治大學選修「實驗設計與統計推理」的英國語文學系英 語教學碩士在職專班(ETMA)的學生,合計82名學生,男生25名,女生57 名。他們係因修習相關「教育統計學」課程,應課程要求而參加本研究。
三、研究工具
(一)S-P表分析
利用TESTER for Windows 2.0版程式進行S-P表分析,計算注意係數與 判定類別。根據學生的注意係數當作橫軸,學生得分之百分比當作縱軸,繪 製學生診斷分析圖,並將學生的學習狀況分為六大類:學習穩定型(A)、
粗心大意型(A')、努力不足型(B)、欠缺充分型(B')、學力不足型
(C)與學習異常型(C'),這六種種學習類型各有不同的學習特性(余民 寧,2002a)。
(二)知識網路組織程式(KNOT)
本 研 究 藉 由 路 徑 搜 尋 網 路 分 析 法 來 測 量 學 生 知 識 結 構 的 工 具 為 Schvaneveldt(1994)所研發的KNOT軟體第4.3版。該軟體可由受試者直接 在螢幕上輸入概念間的近似性評定資料,或者經由紙筆評定後再輸入。輸入 的概念近似性評定資料矩陣可以轉換成概念構圖,再與專家結構圖加以比 較,求得PFC、GTD及PRX等知識結構指數。
(三)期末成就測驗
本研究者以余民寧(2005)所著「心理與教育統計學」(修訂二版)
第一章「導論」至第八章「推論統計學導論」做為授課教材內容,並依據測 驗的編製原理(余民寧,2002a),編擬了一份含有50題單選題的期末成就 測驗,整份測驗的內部一致性信度係數為.78,該項測驗成績,即作為受試 者的效標分數。
(四)概念相似性判斷測驗
本研究所使用的概念取自「心理與教育統計學」內容中有關「描述統 計」(包含集中量數、變異量數、相對地位量數、相關與迴歸)與「推論統 計」(包括機率、抽樣分析、估計、假設考驗)的重要概念。概念的來源是 依據授課教材內容,而概念選取則是根據下列三項規準:(1)必須是授課 的教材內容,(2)必須是對理解教育統計學的領域知識是很重要的,(3)
必須是在教育統計學的主題下具有代表性;總共挑選20個基本概念(參見附
錄1),編擬成一份概念相似性判斷測驗。然後,要求受試者針對兩兩配對 的概念組合進行李克特式五點評定量表(Likert-type five-point rating scale)
之評定;受試者若評定認為每一配對概念間最相似的話,則給予5分;若評 定的相似程度依序遞減的話,則依序分別給予4、3、2分;若評定為最不相 似的話,則給予1分,本項參照知識結構圖的內部一致性測量係數.75。
四、研究程序
本研究的研究程序,大致可分為下列幾個步驟:
(一)編製研究工具:依據研究之需,編製「教育統計學」期末成就 測驗及概念相似性判斷測驗。
(二)完成相似性評定作業及成就測驗施測:受試者在課程結束後,
以班級為單位進行期末考試,該期末考包括兩個部分:50題單選題的成就測 驗及20個重要概念的概念相似性判斷測驗(參見附錄1)。
(三)進行路徑搜尋網路分析:將學生在概念相似性判斷測驗所獲得 的相似性資料,經KNOT軟體轉換成知識構圖,再與教師個人的知識結構圖 比較,求出每一位受試者的PFC、GTD及PRX指數,以作為本研究的預測變 項資料。
(四)取得效標分數:以受試者的期末成就測驗成績作為效標分數。
(五)以S-P表分析找出不同學習類型學生:應用TESTER for Windows 2.0版程式,繪製學生診斷分析圖,找出「學習穩定型」的學生作為學習精 熟型(視同專家型)代表,「學習異常型」的學生作為學習未精熟型(視同 生手型)代表,比較該兩類學生在此三種相似性指數的差異,並且呈現這兩 類學生的知識結構圖,以供輔助解釋研究結果之參考。
五、資料處理與分析
首先,將評量後所獲得的資料,以KNOT程式中的PF、NETSIM、
CORR、DIST等副程式,分別計算出PFC、GTD與PRX等三種知識結構指 數。接著,應用TESTER for Windows 2.0版程式進行S-P表分析,找出「學習
穩定型」與「學習異常型」兩類學生,並進行獨立樣本t考驗,以比較該兩 類學生在此三種相似性指數的差異情形。最後以 SPSS 15.0版統計套裝軟體 程式求取Pearson積差相關係數矩陣,並進行逐步多元迴歸分析,以找出最 佳預測變項。
肆、結果與討論
在受試者期末考試完畢後,隨即進行資料的登錄、轉檔及統計分析,
並進行TESTER for Windows2.0程式的S-P表分析(余民寧,2002a)及路徑 搜尋網路分析,茲將82名受試者的三種相似性指數、期末成就測驗成績及其 學習類型資料,陳列於表1。
表1 82名受試學生的三種相似性指數和期末成就測驗成績
學生 PFC GTD PRX 期末成績
(類型) 學生 PFC GTD PRX 期末成績
(類型)
Stu01 .292 .392 .556 88(A') Stu42 .236 .206 .469 48(C')
Stu02 .255 .195 .347 46(C) Stu43 .310 .351 .428 48(C)
Stu03 .333 .273 .464 60(B) Stu44 .185 .151 .252 62(B)
Stu04 .246 .362 .467 92(A) Stu45 .231 .225 .282 60(B)
Stu05 .167 .000 .051 62(B) Stu46 .333 .359 .519 86(A)
Stu06 .243 .216 .418 52(B') Stu47 .200 .231 .243 62(B')
Stu07 .125 .123 .086 60(B) Stu48 .357 .449 .532 72(B)
Stu08 .255 .339 .365 66(B) Stu49 .313 .462 .405 70(B)
Stu09 .125 .091 .075 36(C) Stu50 .282 .330 .454 88(A)
Stu10 .242 .383 .489 54(B) Stu51 .211 .261 .317 70(B)
Stu11 .159 -.071 .227 54(B) Stu52 .134 .171 .193 64(B)
Stu12 .105 .089 .055 40(C) Stu53 .254 .215 .321 72(B)
Stu13 .182 .136 .150 52(B) Stu54 .233 .308 .448 68(B)
Stu14 .127 .109 .028 40(C) Stu55 .313 .414 .486 58(B')
Stu15 .246 .268 .209 58(B) Stu56 .258 .347 .514 66(B)
Stu16 .133 -.142 .094 52(B') Stu57 .194 .217 .290 56(B)
Stu17 .271 .127 .411 56(B) Stu58 .291 .230 .444 70(B)
Stu18 .297 .445 .580 66(B) Stu59 .268 .293 .408 80(A')
Stu19 .304 .284 .446 66(B) Stu60 .219 .104 .292 68(B)
Stu20 .169 .154 .238 62(B) Stu61 .271 .210 .439 80(A)
Stu21 .303 .225 .415 62(B') Stu62 .321 .372 .461 82(A')
Stu22 .083 -.054 -.107 48(C) Stu63 .397 .396 .576 76(A)
Stu23 .280 .494 .530 72(B) Stu64 .309 .331 .445 70(B)
Stu24 .339 .443 .534 80(A') Stu65 .202 .137 .220 70(B)
Stu25 .345 .522 .561 74(B) Stu66 .299 .351 .462 84(A)
Stu26 .218 .160 .379 66(B) Stu67 .218 .322 .279 70(B)
Stu27 .352 .492 .469 58(B) Stu68 .281 .279 .439 62(B)
Stu28 .327 .308 .537 68(B) Stu69 .183 .149 .306 70(B)
Stu29 .183 .148 .121 44(C') Stu70 .262 .154 .394 70(B)
Stu30 .191 .006 .304 46(C') Stu71 .429 .430 .521 80(A)
Stu31 .188 .093 .291 42(C) Stu72 .255 .151 .454 54(B)
Stu32 .186 .231 .273 48(C) Stu73 .255 .096 .274 56(B)
Stu33 .286 .328 .560 54(B) Stu74 .348 .402 .596 62(B)
Stu34 .150 .219 .195 46(C') Stu75 .190 .156 .187 42(C)
Stu35 .253 .127 .282 64(B) Stu76 .279 .339 .362 62(B)
Stu36 .241 .176 .165 42(C) Stu77 .308 .421 .476 62(B)
Stu37 .276 .336 .492 72(B) Stu78 .169 .059 .225 64(B)
Stu38 .143 .101 .152 64(B) Stu79 .233 .173 .259 54(B)
Stu39 .207 .225 .528 74(B') Stu80 .236 .149 .331 72(B')
Stu40 .222 .117 .450 74(B') Stu81 .194 .178 .255 52(B)
Stu41 .270 .336 .464 76(A) Stu82 .211 .283 .236 60(B)
一、教師知識結構圖與學習穩定型及學習異常型學生知識結構圖 之比較
圖3所示,是教師的教育統計學知識結構圖,可做為評量用的標準參照 結構圖。從教師的知識結構圖來看,KNOT程式所產生的連結線總數共33 條,其主要核心概念大致可以區分三群:第一群核心概念是位在結構圖上方 的「假設考驗」,與其連結者有7條,分別與「自由度」、「常態分配」、
「z分數」、「機率」、「中央極限定理」、「統計考驗力」、「第一類型 錯誤」等七個概念之間有直接連結關係,此部份的連結關係可用「推論統計 的重要概念」加以解釋;第二群核心概念是位在結構圖右下方的「相關係 數」,與其連結者有6條,分別與「標準差」、「共變數」、「簡單迴歸」、
「離均差平方和」、「z分數」、「決定係數」等六個概念之間有直接關聯 性,此關聯性可用「相關與迴歸」的概念來加以解釋;第三群核心概念是位 在結構圖左下方的「標準差」,與其連結者有6條,分別與「平均數」、「
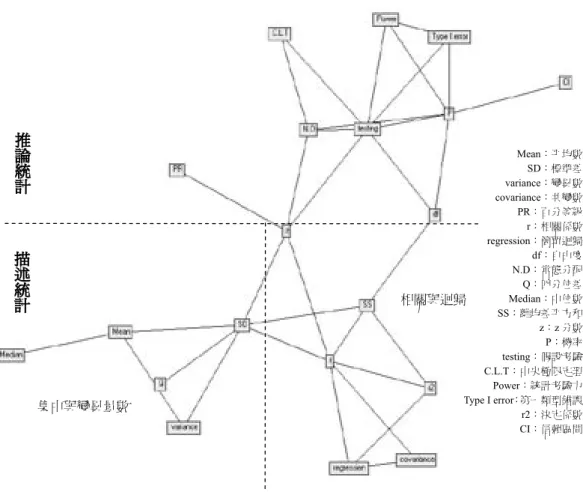
變異數」、「相關係數」、「四分差」、「離均差平方和」、「z分數」等 六個概念有直接關聯性,此關聯性可用「集中量數與變異量數」的概念加以 解釋。最後,觀察教師的教育統計學概念結構圖,我們可以發現教師的教育 統計學概念大致呈現階層性隸屬關係,並且每個概念群組內的概念彼此有高 密度連結,在「自由度」及「z分數」兩個概念之下,大致屬於「描述統計 學」範圍,其「描述統計學」又可進一步含攝「相關與迴歸」及「集中量數 與變異量數」兩個次範疇;之上,則大致屬於「推論統計學」範圍。此「教 育統計學」學科知識的概念結構圖,至為清晰明確,並能充分反映出本課程 的授課核心內容。
圖3 教師的教育統計學知識結構參照圖
接著,我們將Stu04、Stu41、Stu46、Stu50、Stu61、Stu63、Stu66、
Stu77等8位學習穩定型學生及Stu29、Stu30、Stu34、Stu42等4位學習異常型 學生,以KNOT中AVE副程式進行團體平均,分別求出學習穩定型學生的教 育統計學知識結構圖(如圖4所示)以及學習異常型學生的教育統計學知識 結構圖(如圖5所示)。
Mean����
SD����
variance����
covariance����
PR�����
r�����
regression�����
df����
N.D�����
Q�����
Median����
SS�������
z�z ��
P���
testing�����
C.L.T�������
Power������
Type I error�������
r2�����
CI�����
�
��
�
�
�
��
�������
�����
圖4 學習穩定型學生的團體平均知識結構圖
與圖3相較,學習穩定型學生的團體平均知識結構圖連結總數有20條,
概念群組也大致可分成三群:相關與迴歸、集中與變異量數、推論統計的重 要概念,每個概念群組所包含的概念與教師的群組分類方式大同小異,只是 概念群組內的概念彼此之間的連結密度較低。同樣地,與圖3相較,學習異 常型學生的團體平均知識結構圖連結總數也有20條,概念群組也大致與學習 穩定型學生的分類相似,但每個概念群組所包含的概念與教師的群組分類差
PFC=.205 GTD=.340 PRX=.638
����=45%
����=65%
����=55%
Mean����
SD����
variance����
covariance����
PR�����
r�����
regression�����
df����
N.D�����
Q�����
Median����
SS�������
z�z ��
P���
testing�����
C.L.T�������
Power������
Type I error�������
r2�����
CI�����
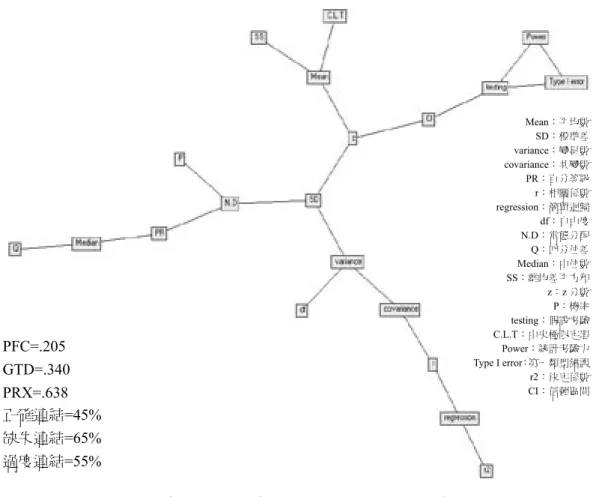
異甚大,並且概念群組內的概念彼此之間的連結密度更低,例如:以「相關 與迴歸」這個概念群組為例,老師概念群組包含「共變數」、「相關係 數」、「簡單迴歸」、「離均差平方和」、「決定係數」等5個概念;學習 穩定型學生則包含「共變數」、「相關係數」、「簡單迴歸」、「決定 係數」等4個概念;而學習異常型則包含「共變數」、「相關係數」、「簡 單迴歸」、「自由度」等4個概念。因此,兩類學生與教師概念分群相較之 下,我們可以發現教師概念分群是比較有意義的,同類屬性的概念大都群聚 在一起,並且緊密相互連結;而學習穩定型學生的概念分群與老師的分類相 似,所包含的概念數及概念較相近;但學習異常型學生的概念分群,雖然仍 與老師的分類相似,但每群包含的概念數及概念則差異甚大,且部分概念的 屬性歸類,呈現比較沒有意義及連結的現象。
圖5 學習異常型學生的團體平均知識結構圖 PFC=.178
GTD=.209 PRX=.421
����=40%
����=125%
����=60%
Mean����
SD����
variance����
covariance����
PR�����
r�����
regression�����
df����
N.D�����
Q�����
Median����
SS�������
z�z ��
P���
testing�����
C.L.T�������
Power������
Type I error�������
r2�����
CI�����
二、知識結構指數的區別效果
為了進一步驗證三種知識結構相似性指數,是否對於生手與專家兩種 不同學習類型學生具有良好的區別效果,本研究根據S-P表的運算法則,將 82名學生的學習狀況分為六大類型:即學習穩定型、粗心大意型、努力不足 型、欠缺充分型、學力不足型與學習異常型,並且從中挑選出屬於「學習穩 定型」的學生作為學習精熟型(視同專家型)的代表,而屬於「學習異常 型」的學生作為學習未精熟型(視同生手型)的代表。由於過去研究文獻大 致發現(余民寧、陳嘉成,2001;余民寧,2002b),不論針對學業成就、
考試成績、或與教師間知識結構的相似性指數而言,學習穩定型學生的表現 皆比學習異常型學生的表現為優。因此,本研究擬進一步比較這兩類學生在 這三種相似性指數上的差異情形,資料分析結果如表2所示。
表2 學習穩定型與學習異常型學生在三種相似性指數之差異考驗分析摘要表
指數 類型 平均數 標準差 人數 自由度 t值
PFC指數 學習穩定型(A) .3159 .0656 8
10 3.53**
學習異常型(C') .1900 .0354 4
GTD指數 學習穩定型(A) .3468 .0642 8
10 4.36***
學習異常型(C') .1448 .0975 4
PRX指數 學習穩定型(A) .4878 .0464 8
10 3.85**
學習異常型(C') .2723 .1512 4
註:** p<.01 *** p<.001
由表2的差異考驗分析摘要表得知,在三種相似性指數方面,PFC指數、
GTD指數與PRX指數均達到顯著性差異,換言之,即學習穩定型學生在PFC 指數、GTD指數及PRX指數上,均優於學習異常型學生,顯示這三種相似性 指數具有區別專家與生手兩種不同學習類型學生的作用。由這三種相似性指 數的涵義中亦可顯示,學習穩定型學生的知識結構比學習異常型學生的知識 結構更接近教師的知識結構,兩者間達到顯著的差異。由此可見,這三種相 似性指數皆具有區別力。
為了能夠進一步說明專家與生手兩種不同學習類型學生的知識結構概 況,以AVE副程式將學習穩定型與學習異常型的近似性資料矩陣之各元素加 以平均(average),以獲得新的平均資料矩陣。茲將教師的知識結構參照 圖、學習穩定型的團體平均知識結構圖與學習異常型的團體平均知識結構 圖,此三種知識結構圖中節點與節點間的連結關係,呈現於表3,以供參考 判斷。
表3 三種知識結構圖的節點連結關係
項目
知識結構 連結總數 正確連結 缺失連結 過度連結
參照結構
Teacher 33 學習穩定型(A)
Stu04 48 16(33.33%) 17(35.42%) 32(66.67%)
Stu41 47 17(36.17%) 16(34.04%) 30(63.83%)
Stu46 67 25(37.31%) 8(11.94%) 42(62.69%)
Stu50 58 20(34.48%) 13(22.41%) 38(65.52%)
Stu61 56 19(33.93%) 14(25%) 37(66.07%)
Stu63 48 23(47.92%) 10(20.83%) 25(52.08%)
Stu66 67 23(34.33%) 10(14.93%) 44(65.67%)
Stu77 52 20(38.46%) 13(25.00%) 32(61.54%)
團體平均 20 9(45%) 13(65%) 11(55%)
學習異常型(C')
Stu29 38 11(28.95%) 22(57.89%) 27(71.05%)
Stu30 73 17(23.29%) 16(21.92%) 56(76.71%)
Stu34 36 9(25%) 24(66.67%) 27(75%)
Stu42 35 13(37.14%) 20(57.14%) 22(62.86%)
團體平均 20 8(40%) 25(125%) 12(60%)
註:括號內的數字為百分比
由圖3至圖5及表3所示可知,依據點對點之間的集合理論方法所計算出 的PFC指數,可以顯示學習穩定型學生的團體平均知識結構圖,比學習異常 型學生更接近教師的知識結構;因為,從表中的百分比數據亦可得知,學習 穩定型學生比學習異常型學生具有較多與教師相同的點對點之間的「正確連 結」(correct links)關係,較少的「缺失連結」(missing links)關係 (即 教師具有,但學生不具有的連結關係)和較少的「過度連結」(over links)
關係 (即教師不具有,反而是學生具有的連結關係)。其中,正確的連結 關係顯示出兩個結構之間有一致性的程度,缺失的連結關係反應出學生的 學習未達精熟的程度,而過度的連結關係則顯示出學生的學習產生錯誤的程 度(游森期、余民寧,2006)。然而,單從由連結次數來看,會因為缺乏比 較的基準點,而有失客觀。因此,若改用百分比值來看,不論是正確連結、
缺失連結及過度連結的百分比值,學習穩定型學生的平均該三項指數分別 為45%、65%、55%,而學習異常型學生的平均該三項指數則各為40%、
125%、60%;由此可見,相較之下,學習穩定型學生比學習異常型學生更 具有接近教師知識結構的一致性(45%>40%)、較少的不精熟程度(65%
<125%)和較少的錯誤程度(55%<60%)。這也就是為什麼看起來,圖4 會比圖5更接近圖3的理由所在;同時,這也可以說明學習穩定型學生會比學 習異常型學生,在一般正常學習之後,會比較接近教師教學期望的原因所在。
綜合上述的說明可知,傳統的紙筆測驗雖然有它的方便性和優點,但 是,本研究所使用的知識結構評量模式,亦具有其優點及發展潛力。如果評 量的目的只是在了解個別概念已經學會的總數量的話,則傳統的紙筆測驗就 已經夠用了;但是,如果評量的目的不僅止於此的話,那麼,搭配路徑搜尋 網路分析方法學的使用,以圖形表徵及網路分析技術所建構的知識結構評量 模式,正可以用來彰顯看不見的個別概念之間的結構關係,以補充詮釋紙筆 測驗結果所得資訊不夠充分的缺失。
三、知識結構指數對於學習表現的預測效果
根據認知學習理論,個人內在知識結構會影響外在的學習表現(Pines,
1985),許多相關實證研究也證實了知識結構與受試者的學習表現之間具 有關聯性。為了比較不同的知識結構指數對於學習成就的預測效果及找出最 佳預測變項以建立預測模式。本研究一開始即以全體受試者的PFC、GTD及 PRX等三種相似性指數為預測變項,期末成就測驗成績為效標變項,進行逐 步多元迴歸分析。茲將這三種指數與期末成就測驗成績間的相關係數矩陣與 逐步多元迴歸分析結果,陳列於表4與表5。
從表4資料分析結果顯示可知,受試者的三種相似性指數與期末成就測 驗成績均達顯著正相關(r=.502~.585, p<.001);此外,三種相似性指數間 的相關亦達顯著性水準(r=.771~.857, p<.001)。
表4 三種相似性指數與期末成就測驗成績的相關係數矩陣(N=82)
期末成績 PFC指數 GTD指數 PRX指數
期末成績 --
PFC指數 .529*** --
GTD指數 .502*** .792*** --
PRX指數 .585*** .857*** .771*** --
註:***表示 p<.001
從表5資料分析結果可知,當以逐步多元迴歸分析來探討三種相似性指 數對於學習成就的預測效果,其變異數波動因素(variance inflation factor;
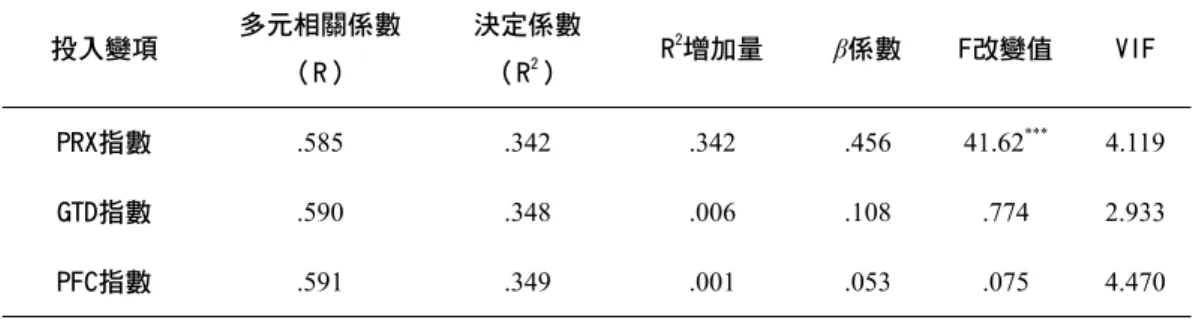
VIF)並未大於10以上,表示預測變項間並無多元共線性問題,真正具有預 測力的變項僅剩PRX指數(F=41.62, p<.001),而GTD指數(F=.774, p>
.05)及PFC指數(F=.075, p>.05)則幾乎不具預測力。由於PRX指數與期 末成就測驗成績兩者間的多元相關係數R=.585,所以PRX指數對於學習表 現的解釋變異量(R2)為34.20%,加入GTD指數的解釋力後,則解釋變異 量增加0.6%,再加入PFC指數的解釋力後,則解釋變異量僅增加0.1%而已。
這表示根據「路徑搜尋量尺化算則」所算出的三種相似性指數,僅有其中的 PRX指數在本例中可以有效預測受試者的期末成就測驗成績,其餘兩者都不 行。
表5. 三種相似性指數預測期末成就測驗成績之逐步多元迴歸分析結果
投入變項 多元相關係數
(R)
決定係數
(R2) R2增加量 β係數 F改變值 VIF
PRX指數 .585 .342 .342 .456 41.62*** 4.119
GTD指數 .590 .348 .006 .108 .774 2.933
PFC指數 .591 .349 .001 .053 .075 4.470
註:***表示 p<.001
由上述的積差相關分析結果得知,82名受試者在教育統計學概念相似 性判斷測驗上的PRX指數、PFC指數及GTD指數之得分與期末成就測驗成 績,都具有顯著的正相關。此種結果顯示PRX指數、PFC指數及GTD指數 得分愈高的學生,則期末成就測驗成績也就愈好;此研究結果與江淑卿(
1997)、宋德忠等人(1998)、涂金堂(2002)、余民寧(2002b)、陳新 豐(2002)、方慧君(2003)與游森期與余民寧(2006)等人的研究結果相 類似,均支持三種知識結構指數與學習成就有顯著的相關。對於三種知識結 構指數,何者對學習成就最具預測效果,則上述的相關研究結果並未具有一 致性,方慧君(2003)、涂金堂(2002)、塗振洋(2001)等人的研究結果 發現PRX指數最具預測效果;而江淑卿(1997)及游森期與余民寧(2006)
則發現GTD指數最具預測效果;但江淑卿(2000)、宋德忠等人(1998)及 林曉芳(1999)卻發現PFC指數最具預測效果;而本研究的研究結果與方慧 君(2003)、涂金堂(2002)、塗振洋(2001)等人的研究結果相符,此結 果支持本研究假設(二),即「知識結構」對學生學習表現具有顯著的預測 效果。本研究認為,PRX指數屬於完全模式,較能充份考量了所有概念間連 結的訊息;不像PFC指數,僅能掌握概念的關係特質,而GTD指數,僅能掌 握概念的空間型態,因而不易瞭解那些鍊結的訊息比較重要,故其預測效果 不如PRX指數。
伍、結論與建議
本研究以知識結構為建構,網路模式為理論基礎,教育統計學為特定 領域,在實際教育情境中,利用路徑搜尋網路分析呈現教師和兩類學生的團 體平均知識結構圖,並探討知識結構的區別效果及預測效果。綜合上述的發 現,本研究獲致下列結論,並據此提出相關建議供教育實務工作者及後續研 究者參考。
一、結論
(一)兩種不同學習類型的學生對於知識結構不僅有「量」的差異,
其概念連結亦呈現「質」不同
研究發現學習穩定型與學習異常型兩種不同學習類型的學生,不僅其 在PFC、GTD及PRX三種知識結構指數上,有明顯「量」的差異存在。從 KNOT程式所繪製的路徑搜尋網路圖及節點的連結關係中,亦可明顯看出兩 種不同學習類型的學生在其所呈現的知識結構圖的有「質」的不同-學習穩 定型的知識結構圖其統計概念其階層架構十分明顯,各概念間的關係也大致 可以清楚地握;相對地,學習異常型對於統計概念知識,不僅在知識組織架 構上混沌不明,在各概念關係上亦是雜亂無章。因此,路徑搜尋網路分析可 以反應出學科知識專技不同者的知識結構之差異,此點也支持路徑搜尋網路 分析作為評量方法,有其區別效果存在。
(二)三種知識結構指數與學習表現具有顯著的正相關
以路徑搜尋網路分析法求得的知識結構指數與學習表現的關聯性,以 Pearson積差相關分析的結果發現,知識結構的三種相似性指數(PFC、
GTD、PRX)與期末成就測驗成績都有顯著的正相關,表示三種相似性指 數得分愈高的學生,則期末成績表現也愈好。
(三)知識結構指數對學習表現有顯著的預測效果,其中以PRX指數最 具預測力
就知識結構的預測效果而言,逐步多元回歸分析結果顯示只有PRX指數
對期末成就測驗成績有顯著預測力,其餘兩種相似性指數則無顯著預測力。
PRX指數與期末成就測驗成績多元相關係數為.585;因此,PRX指數可解釋 期末成就測驗成績總變異量的34.20%。
二、建議
(一)教學上的建議
1.透過階層性概念構圖方式表徵教育統計學的知識結構,以促進學生 學習表現
由於教師的知識結構圖中的概念具有階層從屬關係及群組內的概念緊 密相連結。因此,首先教學者可以以教師的知識結構圖做為課程授課大網,
並以階層性概念構圖的結構化方式呈現統計學的核心概念及概念的從屬關 係;接著以概念圖中的關係和交叉連結,幫助學生瞭解描述統計與推論統計 的階層連結關係及相同階層內核心群組概念的關係及意義。
2.利用路徑搜尋網路分析的認知診斷功能,找出錯誤統計概念以進行 補救教學
從學生知識結構圖中的節點間之連結關係,不管是學習穩定型學生或 學習異常型學生,均有缺失連結和過度連結的現象產生;因此,在正確連結 部分,老師可給予概念強化教學,以增強概念間的連結強度;在缺失連結和 過度連結部分,則可透過概念比對方式,以找出未精熟的概念及錯誤概念連 結之處,直接予以補救教學及概念澄清,以促使錯誤的統計概念能夠獲得即 時有效的補正。
3.開發視窗界面的人性化電腦執行軟體,擴展路徑搜尋網路分析方法 學的使用
本研究所使用的電腦執行軟體為KNOT,是Schvaneveldt(1994)為「
路徑搜尋量尺化算則」網路分析所發展出來的電腦程式,由於該軟體年代久 遠,僅能在DOS作業系統下運用,在使用上,非常不具人性化、親和性,因 此對於習慣使用Windows視窗界面的操作者而言,其實是一項極大的挑戰及 考驗。為了改善該軟體使用上的限制,建議未來的研究人員,能開發出以視
窗為界面的簡單、易學、易用的電腦執行軟體,並增加計分、診斷訊息及補 救教學等功能,相信在擴展路徑搜尋網路分析方法學的使用上,必定有莫大 的效益和助益。
4.採用質與量多元並進的研究方法,以增進深層瞭解知識結構圖的涵義 本研究僅以量化研究的方式,來針對學生的知識結構圖進行分析與探 討,至於深層知識結構的涵義,若能輔以質性研究的方式,來針對學生實施 晤談、文件分析等,將有助於瞭解學生的學習進展情形。因為知識網路模式 非常容易受到脈絡的影響,若能透過質性研究,或許可以釐清學生知識結構 的脈絡,發現學生的另類思考架構,因而突破連結關係未命名的限制及增進 瞭解概念相似性的意義。
(二)未來研究建議
1.增加研究樣本數及其他學習類型之研究
就研究樣本數而言,本研究僅以兩所國立大學82名修習「教育統計學
」相關課程的學生為研究對象,缺乏大樣本施測的外部效度;因此,未來相 關研究,若能增加選修「教育統計學」的學生數,將可擴大研究結果的推論 效果。就學習類型而言,本研究僅限於學習穩定型(視同專家型)及學習異 常型(視同生手型)兩種類型學生之差異比較,末來類似相關研究,若有足 夠的樣本數,或許可以再納入粗心大意型、努力不足型、欠缺充分型、學力 不足型等其他四種類型學生;或以得分百分比75%和50%作為分類標準,比 較三種不同能力其知識結構差異情形;或以注意係數.50作為分類標準,比 較兩種注意係數不同的學生其知識結構的差異情形,相信不管以何種分類方 式或標準區分不同學習類型學生,所得到的研究結果會更加多樣和細緻。
2.採取多位專家平均所得的團體知識結構圖,做為參照標準
本研究是以評定法來測量概念間的相似性,由於評定法並不是一種非 常客觀的測量方式,常因研究情境或研究對象而有所不同。未來的研究或許 可以採用多位專家評定後的平均團體知識結構圖,作為參照標準,如此所測 量到的相似性指標會更具客觀性。
參考文獻
丁碧莉(2004)。語文知識結構之評量研究-以國小英語科為例。國立雲林科技大
學資訊管理研究所碩士論文,未出版。
方慧君(2003)。知識結構診斷分析:以四技二專入學考試數學科為例。國立雲林
科技大學資訊管理研究所碩士論文,未出版。
江淑卿(1997)。知識結構的重要特性之分析暨促進知識結構教學策略之實驗研
究。國立臺灣師範大學教育心理與輔導研究所博士論文,未出版。
江淑卿(2000)。徑路探測法在測量知識結構的效度研究。測驗年刊,47(1),
73-94。
宋德忠、林世華、陳淑芬、張國恩(1998)。知識結構的測量:徑路搜尋法與概念
構圖法的比較。教育心理學報,30(2),123-142.
余民寧(2002a)。教育測驗與評量:成就測驗與教學評量(二版)。台北:心理。
余民寧(2002b)。學科知識結構之評量研究—以「教育測驗與評量」學科知識為
例。教育與心理研究,25(中),341-367。
余民寧(2005)。心理與教育統計學(修訂二版)。台北:三民。
余民寧、林曉芳、蔡佳燕(2001)。國小學生數學知識結構認知診斷評量之研究。
教育與心理研究,24(下),263-302。
余民寧、陳嘉成(2001)。領域知識結構之評量研究:以「垃圾分類處理」知識領
域為例。教育與心理研究,24(下),393-420。
林清山(譯)(1990)。教育心理學-認知取向。台北:遠流。
林曉芳(1999)。數學低成就國中生在代數概念學習之評量研究。國立政治大學教
育研究所碩士論文,未出版。
林曉芳、余民寧(2001)。國中學生在數學代數概念學習之評量研究:以二元一次
方程式為例。教育與心理研究,24(下),303-326。
涂金堂(2002)。國小學生數學文字題知識結構之評量。教育與心理研究,25(
中),369-399。
陳新豐(2002)。國小學生知識結構的評量分析-以國小自然學習成就為例。教育
與心理研究,25(下),657-680。
陳嘉甄(2001)。國小學生自然科知識結構之測量。教育與心理研究,24(下),
327-344。
游森期、余民寧(2006)。知識結構診斷評量與S-P表之關性研究。教育與心理研
究,29(1),183-201。
葉倩亨(2001)。路徑搜尋網路分析應用於大一心理學學習效果評量之研究。教育
與心理研究,24(下),421-446。
塗振洋(2001)。路徑搜尋網路分析在教學評量上的應用-以國小六年級學生在天
文概念上的學習為例。教育與心理研究,24(下),367-392。
鄭昭明(2001)。認知心理學:理論與實踐。台北:桂冠。
謝祥宏、段曉林(2001)。教學與評量:一種互為鏡像(mirror image)的關係。
科學教育月刊,241,2-13.
Acton, W. H., Johnson, P. J., & Goldsmith, T. E. (1994). Structural knowledge assessment:
Comparison of referent structures. Journal of Educational Psychology, 86, 303-311.
Azzarello, J. (2007). Use of the pathfinder scaling algorithm to measure student’s structural knowledge of community health nursing. Journal of Nursing Education, 46(7), 313-318.
Barlett, F. C. (1932). Remembering: A study in experiment and social psychology.
Cambridge: Cambridge University Press.
Boldt, M. N. (2001). Assessing students’ accounting knowledge: A structural approach.
Journal of Education for Business, 76(5), 262-269.
Chi, M. T. H., Glaser, R., & Rees, E. (1982). Expertise in problem solving. In R. Sternberg (Ed.), Advance in the psychology of human intelligence. Hillsdale, NJ: Erlbaum.
Day, E. A., Arthur, W., Jr., & Gettman, D. (2001). Knowledge structures and the acquisition of a complex skill. Journal of Applied Psychology, 86(5), 1022-1033.
Dearholt, D. W., & Schvaneveldt, R. W. (1990). Properties of pathfinder networks. In R. W. Schvaneveldt(Ed.), Pathfinder associative networks: Studies in knowledge organization. Norwood, NJ: Alex.
Glaser, R. (1962). Psychology and instructional technology. In R. Glaser (Ed.), Training, research, and education. University of Pittsburgh Press.
Goldsmith, T. E., & Davenport, D. M. (1990). Assessing structural similarity of graphs.
In R. W. Schvaneveldt(Ed.), Pathfinder associative networks: Studies in knowledge organization. Norwood, NJ: Alex.
Gonzalvo, P., Canas, J., & Bajo, M. T. (1994). Structural representations in knowledge acquisition. Journal of Educational psychology, 86, 601-616.
Hoole, E. R. (2005). Integrating and evaluating mathematical models of assessing
structural knowledge: Comparing associative network methodologies. James Madison University Disseration.
Johnson, P. J., Goldsmith, T. E., & Teague, K. W. (1994). Locus of the predictive advantage in pathfinder-based representations of classroom knowledge. Journal of Educational Psychology, 86, 617-626.
Jonassen, D. H., Beissner, B., Yacci, M.(1993). Structure knowledge: Techniques for representing, conveying, and acquiring structural knowledge. Hillsdale, NJ : Erlbaum.
Knoebel, A., Dearholt, D., & Schvaneveldt, R. (1988). Empty nexus graphs. Paper presented at the American mathematical Society meeting, Las Cruces, NM.
Larkin, J., McDermott, J., Simon, D. P., & Simon, H. A. (1980). Expert and novice performance in solving physics problems. Science, 208, 1335-1342.
Minsky, M. F. (1975). A framework for representing knowledge. In P. H. Winston(Ed.), The psychology of computer vision(pp. 211-277). New York: McGraw-Hill.
Morton, J., & Bekerian, D. (1986). Three ways of looking at memory. In N. E.
Sharkdy(Ed.), Advances in cognition science 1. ChichESTER: Ellis Horwood.
Nassaji, H. (2002). Schema theory and knowledge-based processes in second language reading comprehension: A need for alternative perspectives. Language Learning, 52(2), 439-481.
Nichols, P. D., Chipman, S. F., & Brennan, R. L. (1995). Cognitively diagnostics assessment. Hillsdale, NJ: Erlbaum.
Pines, A. L. (1985). Toward a taxonomy of conceptual relations and the implications for the evaluation of cognitive structures. In L. H. T. West & A. L. Pines (Ed.), Cognitive structure and conceptual change, (pp. 101-105). Orlando: Academic Press, Inc.
Rumelhart, D. E, & Ortony, A. (1977). The representation of knowledge in memory. In R.
C. Anderson, R. J. Spiro, & W. E. Montague (Eds.), Schooling and the acquisition of knowledge. Hillsdale, NJ: Lawrence Erlbaum.
Rumelhart, D. E, & Norman, D. A. (1983). Representation in memory. In R. C. Atkinson, R. J. Herrnstein, G. Lindzey, & R. D. Luce (Eds.), Handbook of Experimental psychology. New York, NY: Wiley.
Schank, R. C., & Abelson, R. P. (1977). Scripts, plans, goals, and understanding.
Hillsdale, HJ: Erlbaum.
Schvaneveldt, R. W. (1990). Proximities, networks, and schemata. In R. W.
Schvanevldt(Ed.), Pathfinder associative networks: Studies in knowledge organization. Norwood, NJ: Alex.
- (1994). Knowledge network organizing tool (PCKNOT version: 4.3). Las Cruces, NM: Interlink, Inc.
Shavelson, R. J., & Stanton, G. C. (1975). Construct validation: Methodology and application to three measures of cognitive structure. Journal of Educational