第二章 文獻探討
有關於試題方面的研究大部分都著重在試題品質的管控及建題機 制方面,如檢查試題重複性、一致性、完整性及關聯性方面作探討 (蕭 經武 民 88);藉由固定數量的題幹正確解及誘答項,來排列組合出各 種測驗題的智慧型造題機制,來達到快速豐富題目並避免因過度使 用,而造成猜題現象的問題 (侯妤青 民 89)。本研究主要在於建構一 套試題分類系統,並朝以下三方面進行探討:
1. 中文斷詞 2. 文件分類 3. 相似度分析
第一節中文斷詞
針對中文的試題而言,進行分類之前,必須先要可以對中文進行 斷詞的工作,以便於了解每一種類型的試題中所包含的關鍵字詞有哪 些。然而在斷詞方面,中文比起印歐文字要困難許多。
中文字與印歐文字的差別,主要在於斷詞的方式(Nie 1996)。以印
文字所構成的字詞。
以中文字而言,主要的特色在於:
1. 字與字之間緊密相連。
2. 有意義的詞中所包含的文字與介詞或副詞可能重複使用。
中文文件大致上有下列幾種斷詞法,分別是:詞庫式斷詞法 (Chen.K.J and S.H Kiu, 1992)、統計式斷詞法 (Fan 1988, Sproat 1990)、
混合式斷詞法 (Nie 1996)及基因演算斷詞法以下將分別對這些斷詞法 作說明:
一、 詞庫式斷詞法
為目前普遍使用的斷詞方法,其演算法相當直覺且實作容易。然 而,斷詞的品質與詞庫大小有相當的關係。所以,必須時常對詞庫的 內容加以維護,另外其他學者將詞庫斷詞法,輔以一些詞性的結構,
發展出規則式斷詞法(陳克健 民 85),提昇斷詞的品質。
二、 統計式斷詞法
互用(Nie 1996)。再者,統計式斷詞常受限於一接馬可夫模式(first-order Markov Models)(Li 1991),進一步擴充此模式會提高演算法的時間複雜 度(Nie 1996),所以大多只針對二字詞進行處理,三字詞如:「大賣場」、
四字詞如「小額投資」等就無法有效擷取。
三、 混合式斷詞法
將詞庫斷詞法及統計斷詞法整合。(Nie 1996)利用詞庫斷出不同組 合的詞彙,然後利用詞彙的統計資訊,找出最佳的斷詞組合。此法乃 需要大型的語料庫提供統計資訊。
四、 基因演算斷詞法
基因演算法(Genetic Algorithms)是在 1975 年由 John Holland 提 出,其理論是基於達爾文物競天擇、適者生存,不適者淘汰的為基礎,
所發展出來的最佳化搜尋演算法。在一個群體中,會因為環境的限制,
適應力較好的個體會存活,而延續下一代,經由數代的演化,而逐步 的得到許多可能解,甚至是最佳解。
堅決支持」七個字為例:
C1 C2 C3 C4 C5 C6 C7
強 調 將 堅 決 支 持
1 0 0 1 1 0 1 Å 染色體
斷開的關鍵詞 W1 其組成為 C1,用 W1 (C1)代表,第二組斷開的 關鍵詞 W2 其組成為 C1,C2,C3,用 W2(C1,C2,C3)代表,以此類推第三 及第四組的關鍵詞分別為,W3(C5)、W4(C6,C7),則適應函數 (Fitness function) F 為:
[ ]
∑
=×
= y
i
i
i LW
W T F
1
)2
( )
( (2-1)
式中
T(Wi):關鍵詞 Wi在詞庫中出現的機率 L(Wi):關鍵詞 Wi的長度
0<i<y, i 為正整數
IF L(Wi) > N THEN T(Wi) = -1 IF Wi can’’t find THEN T(Wi) = 1
經由數代的複製、交配、突變之後,得到最佳的斷詞如下:
C1 C2 C3 C4 C5 C6 C7 強 調 將 堅 決 支 持
0 1 1 0 1 0 1 Å 染色體 (引用自張育銘、黃國禎 民 90)
第二節 文件分類 (Text Categorization)
試題分類的概念將嘗試由文件分類的概念移植過來,因此以下將 針對文件分類作說明。
文件分類通常所指的是由一群專家,針對一類群的文件進行分類 的工作,然而隨著文件的增加,這樣的工作將會變得十分的困難,而 且無法持續的進行這類的工作,因此自動化文件分類在智慧型的資訊 系統中,是很重要的技術(M. Iwayama, 1994)。
文件分類的方法很多,大致上分成決策規則 (Decision rule)、知識 庫 (Knowledge base)及文件相識度 (Text similarity)等等。
大部分的文件分類研究,都將文件的類型鎖定新聞內容,因為新 聞內容在產生之初,都已經根據報社預先規劃進行分類,因此新聞內 容及其分類的結果,是最容易取得而且客觀的研究素材。在教育領域 中,試題也都會依據課程大綱或能力項目來出題並且分類,因此這樣 的素材也是具有客觀標準。以下將針對文件分類做介紹:
一、 最早的文件分類文獻
英文的文件分類, 是由 Maron 於 1961 年提出 (Maron 1961),其 文件分類的方法,是由文件中所萃取出一些關鍵詞當作線索。並假設 電腦可以從文件中自動萃取出這些關鍵詞,那便可以自動分類。其實 驗採用 405 篇文章的摘要當作描述樣本,並使用 206 篇當作訓練資料,
145 篇當作測試資料,結果得到 3263 個詞,去掉出現頻率最高,及只 出現過一兩次的詞,留下 1088 個詞。再藉由亂度(Entropy)公式:
M(C)=-P +log2P +- P –log2P – (2-2) 其中
C 代表所要分類的文件類別
P+ 代表文件被歸類為”+”類的機率 P –代表文件被歸類為”-”類的機率
將分佈平均者去掉,保留分佈不平均者,因為不平均者才有分類 的價值。最後只留下 90 個詞的關鍵字。其實驗結果,訓練資料有 84.6%
的回歸率,而測試資料也有 51.8%的回歸率。
二、 路透社 Reuters-21578
在 英 文 的 文 件 分 類 領 域 中 , 由 CONSTRUE 及 Hayes 採 用 Reuters-22173 為路透社建立的規則式 (rule based)的文件分類系統,這 套系統在人工與機器的分類上所得結果的一致性相當高。而在 1996 年 ACM SIGIR 研討會上,與會專家為了讓 Reuters-22173 有更高的標準。
因此 Steven Finch 與 David D. Lewis 更著手刪除重覆的文件 595 篇,並 減 少 了 拼 字 上 的 錯 誤 , 而 使 文 件 總 數 降 為 21578 篇 , 並 訂 為 Reuters-21578。此外他們也為每一份文件訂上了統一的文件格式,如 分 別 為 文 章 的 起 始 與 結 尾 標 上 <REUTERS> </REUTERS> 的 標 籤 (Tag),讓文件分類研究者有一套統一的實驗資料標準(蔡文憲 民 87)。
三、 字詞權重函數 (Term Weighting)
字詞權重在文件分類的領域十分重要,其目的是要藉由權重,來 得 知 哪 些 字 詞 可 以 成 為 分 類 的 特 徵 字 詞 (feature word) , 而 Term Frequency 及 Inverse Document Frequency 在字詞權重是最基礎的理 論,說明如下:
(一) 字詞出現頻率(Term Frequency, TF):
關鍵詞出現率指的是某一關鍵詞在某類文件中的出現次數,在 文件 d 中關鍵詞 t 的權重可定義為:
W(d,t)=TF(d,t) (2-3) 其中
TF(d,t) :文件 d 中出現關鍵詞 t 的權重
TF 值可以得到很高的回歸率(Recall Rate),但並不精密。主要 是因為關鍵詞,如果經常出現在各種文件類別的話,這些關鍵詞 作為某種文件分類的特徵並不明顯。因此最好將出現各文件類別 中頻率高的關鍵詞從關鍵詞集(Term Collection)之中移除,以提高
(二) 逆文件頻率(Inverse Document Frequency, IDF):
出現單一關鍵詞的文件數量稱之為逆文件頻率。逆文件頻率所 表達的概念是,關鍵詞是否普遍的出現在各個文件當中,如果普 遍出現的比例越高,則越無法突顯分類的特徵﹔相對的越低,最 好是集中出現在同一個分類之中,則越容易突顯。假設關鍵詞為 t,
則 IDF 定義如下:
IDF(t) = N/df(t) (2-4) 其中
N:代表文件的總數
df(t):代表含有關鍵詞 t 的文件總數
如果使用 IDF 來表達關鍵詞的特徵(term specificity),則將可 以提高回歸率(Salton and Buckley, 1988)。
(三) 同時強調字詞出現頻率及普遍性 TF × IDF
而根據 Salton 建議,如果使用 TF× IDF 當作加權數的話,則 將會有更好的執行效率。
W(d,t)=TF(d,t) .IDF(t) (2-5)
其中
W(d,t):關鍵詞 t 在 d 文件類別的權數
TF(d,t):關鍵詞出現率(Term Frequency)
IDF(t):逆文件頻率(Inverse Document Frequency)
藉由上述的公式,可以很明顯的提高回歸率及精密度。
(四) 加權式逆文件頻率 (Weighted Inverse Document Frequency, WIDF) (M. Iwayama, 1994):
依據 IDF 的定義,只論關鍵字出現的文件類別總數,不論各 類文件出現該關鍵字次數,將會出現特徵分佈不合理問題。以行 來代表文件分類 di,以列代表關鍵詞 tj,其出現頻率如下表:
表 2-1 文件集合範例
D1 D2 D3 D4
T1 0 40 3 0 T2 2 50 3 2 T3 3 2 3 2 T4 0 80 0 0 T5 0 30 20 0 (參考 M. Iwayama 1994)
以 T1、T4及 T5的關鍵字而言,其分佈在 D1~D4的頻率並不平 均,因此可以很容易的辨別其分類。T2的分佈也不平均,在 D2有 50 的權重,而 T3可以清楚的看出權重分佈平均,而計算得到:
1/df(T2)=1/(1+1+1+1)=1/4
可以改成 50/(2+50+3+2),將會更加合理。因此使用 WIDF,在文 件 d 中含有 t 關鍵詞定義如下:
∑
∈=
D i
t i TF
t d t TF
d
WIDF ( , )
) , ) (
,
( (2-6)
其中
TF(d,t):代表關鍵字在 d 文件類別中出現的頻率
∑
i∈Dt i
TF(, ):i 代表 D 的文件集合的範圍內的 各類文件。
因 為 TF(d,t)已 經 包 含 在 分 子 了 , 所 以 不 需 要 再 另 外 乘 上 TF(d,t)。因此可將 W(d,t)定義為﹔
∑
∈=
D i
t i t TF
d
WIDF ( , )
) 1 ,
( (2-7)
由 M. Iwayama 的實驗中,可以得知,其回歸率確實比 TF× IDF 提高了 4.4%,而最高的回歸率也達到 96% (該實驗以英文為主)。
(五) 採用取平方的 IDF
由上述的內容得之,使用
) log (
t df
N 會降低詞的特殊性,所以分 類效果不甚理想,為了拉大特殊詞與常用詞之間的差距,可以採
用
2
) (
t df
N 作為 IDF (林頌華 民 88)。則權重定義可調整成:
2
) ) (
, ( ) ,
(
⋅
= df t
t N d TF t d
W (2-8)
其中
TF(d,t):關鍵詞出現率(Term Frequency)
df(t):代表含有關鍵詞 t 的文件總數
N:文件類別總數
在林頌華的研究用於處理中文新聞分類,採用二、三字詞為基 本單位來處理太一新聞資料庫,在 5376 筆測試資料中對 53767 筆 資料作計算,則以原始類別來說,可得到 78.89%的正確率,而第 三高分則可高達 93.43% (該實驗以中文為主)。
以上所探討的文件分類關鍵字權重函數,可以發現大部份都是在 逆文件頻率 IDF 上作調整,以達到最佳的分類效果,主要是因為太過 於普遍出現的關鍵詞,會干擾到分類的效果;相反的關鍵詞越集中在單 一的類別之中,則其效果越好。以下就分別依各種字詞權重函數(TWF) 之優劣分析於表 2-2:
表 2-2 各種字詞權重函數 (TWF) 比較表
TWF 公式 分析
TF W(d,t)=TF(d,t)
1. 可以表現出一個關鍵字 在某文件類別上重要的 程度。
2. 無法辨識出關鍵字是否 普遍出現在各文件類別 之中
IDF IDF(t) = N/df(t)
1. 可以表現是一個關鍵字 普遍存在於各文件類別 的程度
2. 無法突顯關鍵字在單一 文件類別的重要性
TF× IDF W(d,t)=TF(d,t) .IDF(t)
1. 可以表現是一個關鍵字 普遍存在於各文件類別 的程度,也可以了解關鍵 詞是否普遍的出現在各 種文件類別的程度。
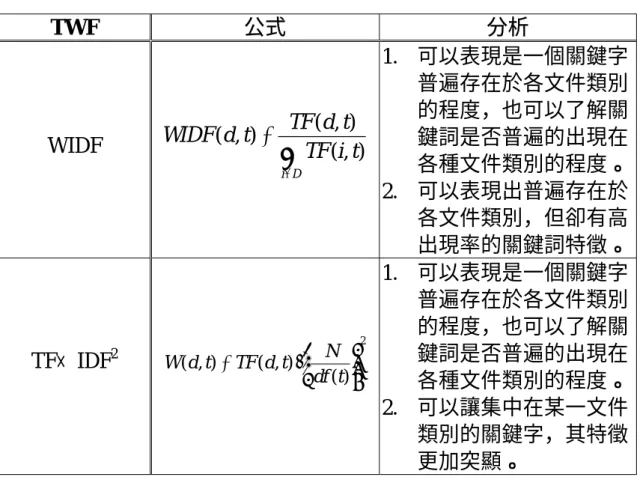
表 2-2 各種字詞權重函數 (TWF) 比較表 (續)
TWF 公式 分析
WIDF
∑
∈
=
D i
t i TF
t d t TF
d
WIDF (, )
) , ) (
, (
1. 可以表現是一個關鍵字 普遍存在於各文件類別 的程度,也可以了解關 鍵詞是否普遍的出現在 各種文件類別的程度。
2. 可以表現出普遍存在於 各文件類別,但卻有高 出現率的關鍵詞特徵。
TF× IDF2
2
) ) (
, ( ) ,
(
⋅
= df t
t N d TF t d W
1. 可以表現是一個關鍵字 普遍存在於各文件類別 的程度,也可以了解關 鍵詞是否普遍的出現在 各種文件類別的程度。
2. 可以讓集中在某一文件 類別的關鍵字,其特徵 更加突顯。
第三節 文件相似度(Text Similarity)
相 識 度 測 量 方 法 分 為 是 向 量 模 式 (Vector Model) 及 機 率 模 式 (Probabilistic Model)兩類,以下將介紹兩類的測量模式:
一、 向量模式 (Vector Model)
文件向量可以用每一個包含在文件中的關鍵詞權重來構成,以用 於區別文件之間的差別定義如下:
Vd=(w1,w2,……,wn) (2-9) 其中
wi:1<=i<=n,代表每一個關鍵字的權重 Vd:文件類別 d 的向量
衡量向量間差異的方法有很多,以 Jaccard 函數來說,其定義如下:
∑
n (wik⋅wjk)二、 機率模式 (Probabilistic Model)
藉由機率的理論所計算出文件 d 在 Ci類別出現機率為 P(Ci|d),則:
∑
=
t i
i d P C t d P t d
C
P( | ) ( | , ) ( | ) (2-11)
關鍵詞 t 的範圍超過 Ci及 d 的向量元素,假設 Ci及 d 的條件彼此 獨立,則 P(Ci|t,d)=P(Ci|t),則可以求得公式如下:
∑
=
t i
i d P C t P t d
C
P( | ) ( | ) ( | ) (2-12)
使用 Bayes rule,則最後可以得到,公式如下:
∑
=
t
i i
i P t
d t P C t C P
P d C
P ( )
)
| ( )
| ) (
( )
|
( (2-13)
關鍵詞 t 隨機於 Ci類別取出,則其機率為 P(t|Ci) ;關鍵詞 t 若隨 機於文件 d 中取出,則其機率為 P(t|d) ,P(t)及 P(Ci)分別代表關鍵詞 及文件類別的機率,而所有的機率都是由訓練資料集所評估出來的。
當一個文件 d 被歸類到類別 Ci之後,則會得到 P(Ci|d)的最高機率。