國立臺灣大學公共衛生學院流行病與預防醫學研究所 碩士論文
Institute of Epidemiology and Preventive Medicine College of Public Health
National Taiwan University Master Thesis
網絡統合分析中偏差的傳導模式
Bias propagation in network meta-analysis models
李 驊 Hua Li
指導教授:杜裕康 博士 Advisor: Yu-Kang Tu, DDS, Ph.D.
中華民國 107 年 7 月
July 2018
口試委員會審定書
中文摘要
研究目的
研究偏差的治療效果,在不同網絡結構與不同的模型中會如何影響估計值的 結果。
研究方法
以頻率學派的架構執行Lu & Ades model、Baseline model 和 Arm-based model。Arm-based model 的相關係數矩陣設定為治療彼此之間互相獨立,每個治 療允許有各自的隨機效應。三種模型皆以二階段分析處理。第一階段先以固定效 應模型估計,以其結果估計隨機效應變異數的值。第二階段將前面估計出的變異 數作為隨機效應模型的權重參數,再估計(相對或絕對)治療效果。Arm-based model 的絕對治療效果將被轉換成相對治療效果後,與其他兩個模型做比較。透 過模擬不同的網絡結構下七種偏差情境,來探討偏差在不同模型下傳遞的模式。
研究結果
Lu & Ades model 執行前需將治療做排序,一組成對比較中不論偏差的治療是 哪一個,偏差的影響會往兩個治療中排序靠後的治療的估計值傳遞。當兩個治療 偏差的方向與大小相同時,偏差影響會互相抵消使估計結果不受影響。偏差在 Baseline model 裡主要影響偏差的治療的相對效果估計值,因此偏差的影響較能 如實呈現在對應治療的估計值上。但部分偏差的影響會透過基底治療傳遞到整個 網絡,這部分對治療效果評估的影響類似Lu & Ades model,傾向傳遞給排序靠後 的治療的估計值。Arm-based model 的偏差會如實地在偏差的治療的相對效果估 計值上觀察到,其他完全不會受到影響。
結論
三種模型的偏差情況各有特色,區別在於要由哪些估計值去吸收偏差的效 果,因此不存在最好的模型。研究者可以根據資料有疑慮、可能存在偏差的部 分,評估使用何種模型最有利,或是較能預期估計值偏差的大小與方向。
關鍵字:網絡統合分析、contrast-based model、arm-based model、二階段模 式、偏差
Abstract
Aims: To investigate how bias contained in direct evidence of one treatment contrast within a network meta-analysis will impact on the estimation of other treatment contrasts under the Lu & Ades model, baseline model, and arm-based model.
Methods: Simulations of the three statistical models for network meta-analysis within the frequentist framework were undertaken to evaluate the impact of bias in evidence on one treatment contrast. The within-study correlation structure in the arm-based model was assumed to be independent and heterogeneous. The analyses of the three models used two-step methods by first pooling together all pairwise comparisons for each treatment contrast and then undertaking a fixed effect network meta-analysis. This result was used to calculate a variance by the sum square of Pearson residual, and then in the second step we estimated the relative or absolute treatment effect with the variance becoming weighted parameter in random effect model. We simulated seven scenarios to evaluate how different geometrical structures of a network affect the impact of the bias in the evidence of a treatment contrast on the estimates of other treatment contrasts.
Results: In Lu & Ades model, treatments were arranged in an order that started with the global baseline treatment. The bias in one treatment affected the estimate of treatments that were farther in the order. When the biases in the two treatments of a contrast had the same direction and magnitude, the estimated bias in this treatment contrast was cancelled out. In the baseline model, the bias in one treatments partially affected the estimate of this treatment, while some of the bias was propagated through the baseline treatment, yielding small bias in the other relative effects. Under the arm-based model, the effect of the biases did not spread to other treatment contrasts unrelated to the biased
treatment.
Conclusions: Bias propagation in three different models has various patterns which are also affected by the geometry of the network. When evidence of some treatments may contain biases, researchers could then evaluate which estimates may be affected by these biases and how much the potential impact is.
Keywords: network meta-analysis, contrast-based model, arm-based model, two-
stage model, bias目錄
口試委員會審定書 ... i
中文摘要 ... ii
Abstract ... iv
目錄 ... vi
表格目錄 ... viii
圖片目錄 ... ix
第一章 介紹 ... 1
1.1 研究背景 ... 1
1.2 研究目的 ... 2
第二章 文獻回顧 ... 3
2.1 基本假設 ... 3
2.1.1 相似性(similarity) ... 3
2.1.2 不一致性(inconsistency) ... 4
2.2 兩種隨機效應假設 ... 5
2.3 試驗的偏差 ... 5
第三章 研究方法 ... 8
3.1 名詞定義 ... 8
3.2 Lu & Ades model ... 10
3.2.1 兩階段分析 ... 10
3.2.2 相關係數矩陣 ... 13
3.2.3 帽子矩陣(hat matrix)與貢獻圖(contribution plot) ... 14
3.3 Baseline model ... 16
3.3.1 分離式模型(separate model)與補值 ... 17
3.4 Arm-based model ... 18
3.4.1 兩階段分析 ... 18
3.5 模型比較 ... 19
第四章 模擬 ... 23
4.1 模擬情境 ... 23
4.2 模擬結果 ... 25
4.2.1 Lu & Ades model ... 31
4.2.2 Baseline model ... 32
4.2.3 Arm-based model ... 35
第五章 討論與結論 ... 36
5.1 Lu & Ades model 傳遞模式 ... 36
5.2 Baseline model 傳遞模式 ... 39
5.3 Arm-based model 傳遞模式 ... 41
5.4 研究限制 ... 42
5.4.1 建構在頻率學派下 ... 42
5.4.2 實際偏差狀況 ... 44
5.5 實際應用 ... 44
5.6 結論 ... 45
參考文獻 ... 47
附錄 ... 49
R code ... 49
A. Lu & Ades model 和貢獻圖 ... 49
B. Baseline model ... 56
C. Arm-based model ... 61
表格目錄
表3.1 分組範例 ... 9
表3.2 虛擬變數生成模式 ... 11
表3.3 表 3.1 第 4、5 個試驗的資料 ... 18
表3.4 補值後的參考治療 ... 18
表4.1 基本參數設定 ... 24
表4.2 偏差設定 ... 24
圖片目錄
圖3.1 網絡統合分析假設 ... 21
圖3.2 簡易模型示意圖 ... 22
圖4.1 網絡結構圖 ... 23
圖4.2 Network 1 估計值偏差程度 ... 26
圖4.3 Network 2 估計值偏差程度 ... 27
圖4.4 Network 3 估計值偏差程度 ... 28
圖4.5 Network 4 估計值偏差程度 ... 29
圖4.6 Network 5 估計值偏差程度 ... 30
圖4.7 Network 1 帽子矩陣 ... 33
圖4.8 Network 1 貢獻圖 ... 33
圖4.9 Network 2 帽子矩陣 ... 34
圖4.10 Network 2 貢獻圖 ... 34
圖4.11 Network 3 帽子矩陣 ... 34
圖4.12 Network 3 貢獻圖 ... 34
圖4.13 Network 4 帽子矩陣 ... 34
圖4.14 Network 4 貢獻圖 ... 34
圖4.15 Network 5 帽子矩陣 ... 35
圖4.16 Network 5 貢獻圖 ... 35
圖5.1 以不同 Contrast-based 模型的角度看網絡結構圖 ... 40
第一章 介紹 1.1 研究背景
目前社會上講究實證醫學1,各個醫學期刊湧現大量的論文。這使我們無法 閱讀完特定藥物或特定疾病治療的相關文獻,且不同研究的結果可能有所差異。
為此發展出了統合分析來幫助我們整合文獻的結果2。然而,隨著越來越多新穎 的藥物被開發與治療技術的演進,傳統統合分析受到一個嚴重的限制。它僅能整 合兩種治療的相對效果,無法有效的利用文獻中的其他治療證據。例如,要比較 的治療有N 種,研究者最多要做 N(N-1)/2 個傳統統合分析才能得到所有治療彼 此之間的相對效果。此外,個別執行傳統統合分析的結果並非同步,可能分別做 完A 治療比較 C 治療和 B 治療比較 C 治療的結果,得到 A 優於 C 和 B 優於 C,
但因為文獻中沒有直接比較A 和 B 治療,還是無法得知 A、B 治療哪個較優。這 對於醫師在決定給予病人何種治療時會有困難3; 4,因此近年發展出網絡統合分析 來同步比較多種治療效果。
網絡統合分析是延伸傳統統合分析發展出的統計方法5; 6。當許多治療同步做 比較時,某些治療彼此之間可能缺乏直接比較的證據。儘管沒有文獻有直接比較 這些治療,亦可透過與其他治療的比較來間接獲得,因此原本無法直接比較的治 療變得能相互比較。例如說,蒐集來的文獻有A 治療和 B 治療的比較,以及 A 治療和C 治療的比較。儘管缺乏 B 和 C 治療的直接比較,但依舊能透過 A、B 治 療和A、C 治療的相對效果來間接獲得 B 和 C 治療之間的相對效果。若 B 和 C 治療之間有直接證據,網絡統合分析亦能合併治療的直接證據(直接比較 B、C 治 療的結果)與間接證據(透過 A、B 比較和 A、C 比較間接獲得的結果),來加強統 計檢定力。
網絡統合分析所使用的資料,都是透過文獻搜尋、粹取出臨床試驗研究結果 來獲得。因此,研究者必須了解,在執行臨床試驗的過程中,每一個環節都可能 導致偏差7。包含執行試驗前的實驗設計、樣本選擇;執行試驗中缺乏盲性;試
驗結束後,分析結果受到干擾因子影響。因此,文獻中蒐集來的資料,可能會因 為某些原因而產生偏差。有的可以從文獻當中看出來,而有的看起來每個環節都 沒有問題,然而得到的結果看起來就是與其他的試驗結果不同。這些或許是潛在 地具有偏差的試驗,它們符合研究者納入的標準,而被留在研究中。
由於間接證據是透過合併其他直接證據獲得。因此,當執行網絡統合分析 時,納入的試驗若存在偏差,偏差的這些治療做為直接證據時,無可避免地會影 響到與其治療相關的估計值。與此同時,做為其他治療之間的間接證據,亦有可 能使偏差影響到其他估計值。在不同的網絡結構下,一個估計值的間接證據來源 不盡相同,受偏差影響的估計值亦有所不同。間接證據對估計值的影響,會根據 網絡結構與治療在網絡中的距離而有差異,估計值受到的影響也會根據治療在網 絡中的位置而有方向與程度上的差異。當網絡複雜度低時,有經驗的的研究者可 以自行判斷出偏差對整個網絡的影響,但複雜度提高,很難僅靠經驗去推論出受 到的影響,因此,本研究希望能釐清,並總結出偏差影響的模式與規則以供參 考。
1.2 研究目的
探討偏差在不同網絡結構與不同網絡統合分析模型中,對於估計結果的影響 與偏差在網絡模型中傳播的途徑,模擬使用的方法為頻率學派架構(frequentist framework)下的三種模型:
1. 最常使用的Contrast-based 模型:Lu & Ades model
2. Contrast-based 模型加上基底治療效果估計:Baseline model 3. 標準的Arm-based 模型:Arm-based model
第二章會回顧網絡統合分析中的基本假設,以及過去的文獻對於偏差的討 論;第三章將針對研究中使用的三種模型做詳細的介紹;第四章呈現模擬的設定 與結果;第五章整理模擬結果,討論偏差如何影響估計值,並歸納出一些簡單的 規則以供參考。使用的軟體以R 為主,詳細的 code 附在附錄中。
第二章 文獻回顧 2.1 基本假設
模型若違反基本假設,容易使研究者得到錯誤的結果,因此釐清模型假設相 當重要。網絡統合分析是由傳統統合分析拓展而來的,因此在傳統統合分析中存 在的假設同樣的會延伸到網絡統合分析中。
傳統統合分析中,最重要的是同質性(homogeneity)假設,在不同的試驗下,
兩個相同治療的效果差值變異(variance)不能太大。傳統評估同質性的方法有 Cochran’s Q 檢定和I2判斷8,但兩種方法的檢力不高,樣本數不多時精準度會很 差9。實做時,要判斷是否具備同質性,通常直接以τ2大小判斷。在統合分析 中,我們觀察到的變異分成試驗內變異(within-study variance)和試驗間的變異 (between-study variance),而試驗間的變異就稱為異質性(heterogeneity),也就是所 謂的τ2。若是在研究結果顯示τ2很大,則會違反同質性的假設,不處理這個問題 可能會導致研究者得到錯誤的結論。處理的方法可以考慮使用敏感度分析
(sensitivity analysis)和 meta-regression 找出有問題的試驗和潛在的干擾因子 (confounding factor)10。
2.1.1 相似性(similarity)
延伸到網絡統合分析中,一樣有類似同質性(homogeneity)假設。因為納入模 型中的治療超過兩個,同質性假設不足以支持,在網絡統合分析中,則以相似性 代替11。研究者需要確認每個試驗的病人都具有可比性,不同試驗下的病人組 成、研究設計是否相似。若是治療本來就針對不同的族群而使用,或研究方法差 太多,那這些試驗就不應放在一起比較。目前現有的統計方法中,並無用來檢定 相似性的方法3,需要研究者依據自身的經驗與研究目的去篩選出相似的試驗。
因此納入的試驗的挑選比實際分析資料還要重要,良好的資料品質得到的結果才 令人信服12。
根據相似性假設,模型得以運用可交換性(exchangeability)和傳遞性
(transitivity)性質3; 13。相似性可延伸解釋,同一個試驗內的每個組別,病人特性 要相似(包含人口學分布、疾病嚴重程度等等)。因此,理論上不同組別的病人 使用相同的治療要能得到類似的結果。而由於具備可比性,相對治療效果在不同 的試驗下,同樣兩種治療的差值要差不多。換句話說,每個試驗可以有各自的治 療效果,但治療的相對效果要相似,因此治療相對效果可以在不同的試驗彼此交 換,這樣的特性稱為可交換性。再將結果進一步解釋,可將直接比較的結果組合 成間接比較,而得到傳遞性。以三種治療的網絡來舉例說明,比較A、B 和 C 三 種治療時,則每個包含A 和 B 治療的試驗,觀察到的 A 和 B 的治療效果可以不 同,但效果差值(dAB𝑑𝑖𝑟)理論上要相似;而每個每個包含 A 和 C 治療的試驗,A 和 C 治療效果的差值(dAC𝑑𝑖𝑟)也要相似。因此 B 和 C 治療效果的差值(dBC𝑖𝑛𝑑),可以透過 dAB𝑑𝑖𝑟和dAC𝑑𝑖𝑟來間接獲得,這種特性稱為傳遞性。此時的dAB𝑑𝑖𝑟為A 和 B 的相對治療 效果直接證據,而dAC𝑑𝑖𝑟為A 和 C 的相對治療效果直接證據。同時,dAB𝑑𝑖𝑟和dAC𝑑𝑖𝑟亦 是B 和 C 的相對治療效果間接證據。
2.1.2 不一致性(inconsistency)
網絡統合分析能夠整合網絡中的直接證據與間接證據,直接和間接證據可基 於相似性假設獲得。然而,研究中所蒐集來的試驗,就算都是隨機分派試驗 (randomize control trials),也並非每個都會詳細報告所有可能影響結果的潛在因 子,這會導致無法準確的判斷相似性是否成立,而可能使研究者得到偏差的結 果。在傳統統合分析中,只存在直接證據,討論異質性的問題即可。但在網絡統 合分析中因涉及間接證據,此時變成討論不一致性的問題。
網絡統合分析的模型有一致性(consistency/coherence)假設,即直接證據和間 接證劇的結果要一致11。延續前面的例子,若在研究中,有試驗是直接比較B 和 C 治療的,那麼 B 和 C 治療效果的差值(dBC𝑑𝑖𝑟)可以直接從觀測值獲得。在一致性 假設下,直接和間接證據要相同dBC𝑑𝑖𝑟 = dBC𝑖𝑛𝑑(= dAC𝑑𝑖𝑟− dAB𝑑𝑖𝑟)。若是違反相似性假 設,可能會出現dBC𝑑𝑖𝑟 ≠ dBC𝑖𝑛𝑑的情況,稱之為不一致性14。
目前網絡統合分析中,主要將不一致性分成design inconsistency、loop inconsistency、side-splitting inconsistency 三種,它們分別對應三種檢定方法15;
16。檢定沒檢查出不一致性,不代表相似性假設必然成立,可能只是無法檢測到 而已。
2.2 兩種隨機效應假設
統合分析中的模型分為固定效應(fixed-effect)與隨機效應(random-effect)模 型,兩者在於理論假設上有些許差別。一般來說,納入的試驗都來自不同的母群 體,才會考慮使用固定效應模型。實作時,較少碰到這種案例,因此較常使用隨 機效應模型將試驗之間的差異納入考慮。針對隨機效應的假設,根據相似的解讀 不同,有兩派說法17; 18。
第一種,效果隨機(effect at random)是以傳統統合分析的角度做延伸,以傳統 的角度去解讀相似性。此假設下的可交換性與傳遞性皆針對相對效果,因此效果 隨機也是針對相對效果做假設。相似性允許一個治療,在不同試驗可以有不同的 治療效果,在效果隨機的假設下,將其歸咎到試驗本身的效果,而試驗本身的效 果是不可忽略的,會對試驗內的所有治療效果造成固定影響,為了消除試驗的效 果,將治療效果相減,達到消去試驗效果的目的,因此相對治療效果理論上要相 似,才具備可交換性。
第二種,研究隨機(study at random)是較為新穎的假設,以異於傳統的角度切 入。假設隨機分派在試驗的層級(study-level or trial-level)中執行,因此病人是被隨 機分派到所有的試驗內,而非在一個試驗內被隨機分派每個治療。在這樣的假設 下,治療效果差異都是由隨機誤差造成。因此不具有試驗效果(study effect),絕對 治療效果具有可交換性,能在不同試驗之間交換。而隨機效應也是針對絕對治療 效果。
2.3 試驗的偏差
統合分析幫助研究者整合期刊上各個文獻結果。然而,在蒐集的試驗中,可
能某些結果會異於其他試驗,這樣的試驗可能會導致估計結果出現偏差,不適合 納入研究中。
一個試驗可能出現偏差的地方有很多。按照執行的先後順序,可以分為試驗 前、試驗中、試驗後三部分7。試驗前主要指研究設計與樣本選擇的問題。文獻 一般來說都需要報告這些訊息,因此在訂立試驗納入標準時,可排除掉較多問 題。比較困難的問題是訂立的條件文獻上沒有報告到,解決方法可以考慮直接寄 信詢問該篇文獻的作者。試驗中指資料測量過程中產生的偏差。例如醫生對於治 療效果有預期、期待心理,並在已知受試者被分到哪種治療的情況下,對不同治 療組的病人測量的細緻程度不同,或是態度影響到受試者心理,而對結果造成影 響。或試資料的測量是由不同人測得,測量手法不一致而導致。文獻當中有的會 概略提到執行過程是如何排除這些問題,以證明資料的可靠度,然而有些研究本 身無可避免地無法處理這些問題,此時需要評估結果高(低)估或無法預期。前兩 種可以在篩選文獻的過程中,盡可能的排除有問題或干擾研究目的的試驗結果。
最後,試驗後指資料分析的過程與結果發表時的問題,分析過程中可能用碰 到研究無法處理得干擾因子。較為著名的例子是卡介疫苗得效果受到緯度影響,
不同緯度得到的結果有差異性。若納入的研究,有搜集到干擾因子的訊息,可以 使用meta-regression 去調整結果。而發表上的問題指研究結果因為某些理由而沒 有被發表,從而導致無法被研究納入,原因大致上可分兩種,一種是結果並非研 究者希望看到的結果,特別是贊助者不希望看到、會阻礙產品推廣的結果不可能 被公開。另一種是結果與其他研究者有差異,甚至可能結論與其他人相反。有此 結果的研究若不是大型研究不易被期刊接受,也容易使研究者自行放棄發表。儘 管這種偏差有統計方法(例如 Egger’s test)可以檢定,但檢力(power)不足19。結果 通常會搭配漏斗圖(funnel plot)解釋。若是觀察到有這類型的偏差,研究者需要對 結果得解讀更為小心謹慎,以免被誤導。
過去,在執行網絡統合分析的過程中,經驗較為豐富的研究者可以從蒐集的
資料中判斷哪些試驗得結果可能有潛在的問題。當回顧這些資料來源的試驗時,
或許能夠找到原因而排除部分的資料。但亦可能從試驗的研究設計到分析結果,
都無法從文獻上找出問題,沒有合理的理由去解釋。這樣的資料研究者需要注意 其對於結果的影響,以往僅能知道有影響。但由於網絡統合分析本身較為複雜,
無法明確預估偏差對於其他估計值的影響有多大。因此這個問題還尚待釐清。
第三章 研究方法
網絡統合分析中,模型依據估計尺度不同被分為Contrast-based 和 Arm-based 模型。在Contrast-based 模型中,較常被使用的模型為 Lu & Ades model。另一種 較少用為Contrast-based 模型混合基底治療的模型。而 Arm-based 模型稱為 Arm- based model。本章將介紹研究中所使用的此三類模型。
第一個是目前做網絡統合分析最常被使用的模型,由Lu 和 Ades 在 2006 年 提出14,因此被稱為Lu & Ades model。其方法是將他們 2004 年提出的 k-
comparison version of Smith-Spiegelhalter-Thomas (SST) model 進一步更新而成20。 模型主要有兩個特色:估計相對治療效果、基底治療為固定效應。
第二個模型是由Dias 等人在 2013 年提出的模型13; 21,是根據常使用在成本 效益分析(cost-effectiveness analysis)的 history natural baseline model 的角度切入,
將傳統Contrast-based 模型以絕對治療效果的方式(Arm-based approach)呈現後,
針對基底治療做不同的假設而成。模型有三個特色:估計相對治療效果、基底治 療為隨機效應、基底治療和相對治療效果結合,可以推出每種治療對母群體的絕 對治療效果。此模型並未有特定名稱,較常使用Contrast-based plus baseline 模型 來稱呼。因此本篇研究中,將此模型簡稱為Baseline model。
第三個模型是Zhang 等人在 2013 年首次提出22,並於2015 年更新的 Arm- based model18。其模型架構有別與前兩者,主要特色為:估計絕對治療效果、每 個試驗的治療效果都具備可交換性。
以上三種模型將在頻率學派架構下(frequentist framework)執行,由於固定效 應模型較少被使用,本研究皆假設隨機效應存在,並以兩階段分析(two-stage analysis)進行估計。
3.1 名詞定義
在介紹模型前,我們先清楚定義在Contrast-based 模型所使用的名詞。
分組
納入研究的試驗,比較的治療不完全相同,因此根據試驗內的治療將每個試 驗分組23。同一組內的試驗比較的治療要完全相同。以一個簡單的例子來說明分 組如何執行。假設A1、A2和A3一個研究納入的治療。只比較A1和A2的試驗與只比 較A1、A2和A3的試驗分為不同組
S1 = {只比較A1和A2的2-arm試驗}
S2 = {只比較A1、A2和A3的3-arm試驗}
S1和S2為互不交集的兩個集合。| ∙ |為計算集合內元素數的函數,因此|S𝑔|為第𝑔 組的試驗數目,而∑ |S𝑔 𝑔|為研究納入的試驗總數。若此時納入的試驗如表3.1 所 示,則分為S1 = {試驗 1, 試驗 2}、S2 = {試驗 3}、S3 = {試驗 4}和S3 = {試驗 5}
四組。
表3.1 分組範例
試驗 治療 組別
1 A1, A2 1 2 A1, A2 1 3 A1, A2, A3 2 4 A2, A3 3 5 A2, A4 4 參考治療(reference treatment)
我們所使用的Contrast-based 模型估計的為相對治療效果,需要選擇一個治 療做為估計相對效果的參考物件。模型中作為參考的治療稱為參考治療16。
基礎參數(basic parameter)與功能參數(functional parameter)
以表3.1 作為例子說明,若選擇以A1治療作為參考治療,估計的𝑑1𝑥, 𝑥 = 2,3,4稱為基礎參數。而透過基礎參數間互相加減的線性關係表示的參數,則稱為 功能參數14
𝑑23 = 𝑑13− 𝑑12 基底治療(baseline treatment)
一個試驗做為參考物件的治療,稱為基底治療16。原則上,參考治療是基底
治療的最佳選擇。但一個研究中納入的試驗,不見得會有參考治療。此時勢必要 另外選擇一個參考物件,再透過功能參數表示成基礎參數。
給予選擇參考物件的標準,有助於模型的表達與程式的運算。因此先將所有 的治療進行排序,再根據排列的順序選擇該試驗中排序最靠前的做為基底治療。
需注意參考治療的排序為第一。以表3.1 為例,若選擇以A1治療作為參考治療,
則試驗4 和 5 的的相對治療效果將無法直接以一個基礎參數表示。此時我們將治 療以A1, A2, A3, A4的順序排序,則試驗4 和 5 的基底治療皆為A2。
3.2 Lu & Ades model
假設納入I個試驗比較A1, A2, … , AK共K種治療方式,並以A1, A2, … , AK的順序 排序,Ti為在第i個試驗中被比較的治療的集合,將A1指定為參考治療,A𝑏(𝑖) = { 第 i 個治療中,排序最前面的治療}為第i個試驗的基底治療23; 24:
𝑔(𝑦̂i∙k) = θi∙k= 𝛽𝑏(𝑖)+ 𝑈𝑖∙𝑘δ𝑖∙𝑏(𝑖)𝑘 (3.1) 𝑈𝑖∙𝑘 = {1, 𝑘 ≠ 𝑏(𝑖)
0, 𝑘 = 𝑏(𝑖) (3.2)
𝛿𝑖∙𝑏(𝑖)𝑘~𝑁(𝑑𝑏(𝑖)𝑘, 𝜏2), 𝑑𝑏(𝑖)𝑘 = 𝑑1𝑘− 𝑑1𝑏(𝑖) , 𝑑11= 0 (3.3) 其中𝑔(∙)為鍊結函數(link function),根據不同的資料型態給予適合的函數。
𝛽0𝑖為第i個試驗的基底治療效果。δ𝑖∙𝑏(𝑖)𝑘為第i個試驗中,A𝑘治療與基底治療(A𝑏(𝑖)) 的相對治療效果。𝑈𝑖∙𝑘為第i個試驗的指示函數(indicator function)。
3.2.1 兩階段分析
以依變項(dependent variable)的資料型態為連續型作說明,假設第i個試驗比 較Ax、Ay和Az三種治療(three-arm trial),且Ab(i) = Ax。第一階段以固定效應模型 的結果估計隨機效應23。首先將絕對治療效果轉換成相對治療效果
∆𝑖= (∆𝑖∙𝑥𝑦
∆𝑖∙𝑥𝑧) = (y𝑖∙𝑦− y𝑖∙𝑥
y𝑖∙𝑧− y𝑖∙𝑥) (3.4) 三種以上的治療(multi-arm)算出來的∆𝒊會是長度為|Ti| − 1的向量,若試驗只 比較兩種治療(two-arm trial),則∆𝒊將會是純量。∆𝑖∙𝑦𝑧不需要計算,可以透過另外
兩者組合而來
∆𝑖∙𝑦𝑧= (−1 1)∆𝒊
一個∆𝒊對應的𝐗i則為(|Ti| − 1) × (K − 1)的矩陣或向量(K = 2) 𝐗i = (𝑿𝑖∙𝑥𝑦
𝑿𝑖∙𝑥𝑧) 生成的模式如表3.2 所示
表3.2 虛擬變數生成模式
試驗 治療 X𝑖∙12 X𝑖∙13 … X𝑖∙1𝑥 … X𝑖∙1𝑦 … X𝑖∙1𝑧 … X𝑖∙1𝐾 𝑖 Ax 𝑣𝑠 Ay 𝑿𝑖∙𝑥𝑦 0 0 0 -1 0 1 0 0 0 0
Ax 𝑣𝑠 Az 𝑿𝑖∙𝑥𝑧 0 0 0 -1 0 0 0 1 0 0 模型假設同一試驗內的治療效果彼此獨立,因此推導出下列式子
𝑉𝑎𝑟(∆𝑖∙𝑥𝑦) = 𝑉𝑎𝑟(y𝑖∙𝑦 − y𝑖∙𝑥) = 𝑉𝑎𝑟(y𝑖∙𝑦) + 𝑉𝑎𝑟(y𝑖∙𝑥) = 𝑠𝑒𝑖∙𝑦2 + 𝑠𝑒𝑖∙𝑥2 𝑉𝑎𝑟(∆𝑖∙𝑥𝑧) = 𝑉𝑎𝑟(y𝑖∙𝑧− y𝑖∙𝑥) = 𝑉𝑎𝑟(y𝑖∙𝑧) + 𝑉𝑎𝑟(y𝑖∙𝑥) = 𝑠𝑒𝑖∙𝑧2 + 𝑠𝑒𝑖∙𝑥2 𝐶𝑜𝑣(∆𝑖∙𝑥𝑦, ∆𝑖∙𝑥𝑧) = 𝑉𝑎𝑟(y𝑖∙𝑥) − 𝐶𝑜𝑣(y𝑖∙𝑥, y𝑖∙𝑧) − 𝐶𝑜𝑣(y𝑖∙𝑦, y𝑖∙𝑥) + 𝐶𝑜𝑣(y𝑖∙𝑦, y𝑖∙𝑧)
= 𝑠𝑒𝑖∙𝑥2
𝑠𝑒𝑖∙𝑘2 為第i個試驗所報告的Ak治療的標準誤(standard error)。組合起來得到共變異 矩陣(covariance matrix)
𝑾𝑖−1 = 𝑉𝑎𝑟(∆𝑖) = (𝑠𝑒𝑖∙𝑥2 + 𝑠𝑒𝑖∙𝑦2 𝑠𝑒𝑖∙𝑥2
𝑠𝑒𝑖∙𝑥2 𝑠𝑒𝑖∙𝑥2 + 𝑠𝑒𝑖∙𝑧2 ) (3.5) 同樣地,三種以上的治療會算出的𝑾𝑖−1矩陣維度為(|Ti| − 1) × (|Ti| − 1)。若試驗 只比較兩種治療,則𝑾𝑖−1將會是一個純量。𝑾𝑖−1取反矩陣(純量取倒數)則為權重 𝑾𝑖。
將所有試驗的∆𝑖、𝐗i和𝑾𝑖−1分別合併成∑𝐼𝑖=1(|𝑇𝑖| − 1)× 1、∑𝐼𝑖=1(|𝑇𝑖| − 1)× (𝐾 − 1)和∑𝐼𝑖=1(|𝑇𝑖| − 1)× ∑𝐼𝑖=1(|𝑇𝑖| − 1)的向量和矩陣
∆= (∆1′, … , ∆𝐼′)′, 𝑿 = ( 𝑿1
⋮ 𝑿𝐼
) , 𝐖−1= diag(𝑾1−1, … , 𝑾𝐼−1)
從固定效應模型獲得參數𝜷𝑭
∆= 𝑿𝜷𝑭+ 𝛜, 𝐜𝐨𝐯(𝛜) = 𝐖−𝟏 (3.6) 𝜷̂𝑭 = (𝑿′𝑾𝑿)−𝟏𝑿′𝑾∆ (3.7) 根據(3.6)和(3.7)的結果將皮爾森殘差的平方加總,以及計算自由度
Q = (∆ − 𝑿𝜷̂𝑭)′𝑾(∆ − 𝑿𝜷̂𝑭) = ∑(∆𝑖− 𝐗i𝜷̂𝑭)′𝑾𝑖(∆𝑖 − 𝐗i𝜷̂𝑭)
𝐼
𝑖=1
(3.8)
𝑑𝑓 = (∑ (|𝑇𝑖| − 1)
𝐼 𝑖=1
) − (𝐾 − 1) (3.9) 異質性的部分,模仿傳統統合分析的估計方式,利用(3.8)和(3.9)估計。由於 分母的部分不再是純量,要使用矩陣的方式運算,此外,根據比較的治療不同,
矩陣的維度也不相同,因此先將試驗以3.1 名詞定義節的分組方法,根據比較的 治療分成S1, S2, … , 𝑆𝐺組,每組各有𝑁𝑔 = |𝑆𝑔|個試驗。根據組別計算各自的比重
𝜏2 = max {0,𝑄 − 𝑑𝑓
∑𝐺𝑔=1𝐶𝑔} (3.10)
𝐶𝑔 = tr {∑ 𝑾𝑔∙𝑗
𝑁𝑔 𝑗=1
− ∑ 𝑾𝑔∙𝑗2
𝑁𝑔 𝑗=1
(∑ 𝑾𝑔∙𝑗
𝑁𝑔 𝑗=1
)
−1
} (3.11)
其中𝑾𝑔∙𝑗為第𝑔組第𝑗個試驗的權重,計算方式同(3.5)。若𝑁𝑔 = 1,則𝐶𝑔 = 0。若 𝑔 = 1,2, … , 𝐺時𝑁𝑔 = 1,則𝜏2 = 0。
將𝜏2和𝑾𝑖−1根據隨機效應模型的變異數矩陣的結構結合
𝑾∗𝑖−1= 𝜏2𝑽𝑖 + 𝑾𝑖−1 (3.12) 𝑽𝑖為Lu & Ades model 中的相關係數矩陣,其中𝑽𝑖為維度與𝑾𝑖−1相同、對角線為 1、非對角線為 0.5 的矩陣,設定成這種結構的原因將於 3.2.2 相關係數矩陣小節 說明。將全部的𝑾∗𝑖−1合併可以得到
𝐖∗−1= diag(𝑾∗1−1, … , 𝑾∗𝐼−1)
接下來第二步驟23,從固定效應模型獲得參數𝜷𝑹和其共變異數矩陣
∆= 𝑿𝒅𝑹+ 𝛜, 𝐜𝐨𝐯(𝛜) = 𝐖∗−𝟏 (3.13) 𝒅̂𝑹 = (𝑿′𝑾∗𝑿)−𝟏𝑿′𝑾∗∆ 和 𝐶𝑜𝑣(𝒅̂𝑹) = (𝑿′𝑾∗𝑿)−𝟏 (3.14) 參數只估計以A1作為參考治療的基礎參數,無法直接取得Ax和Ay(x, y ≠ 1)的 相對效果,因此需要透過一個大小為𝐾(𝐾−1)
2 × (𝐾 − 1)的矩陣去轉換。首先先定義 𝟎𝑛 = (0, … ,0)′和−𝟏n= (−1, … , −1)′為n × 1的矩陣,將兩者以下面的方式與單位 矩陣(𝑰𝑛)結合後,合併成一個轉換矩陣
𝐇K−1 = 𝐼𝐾−1, 𝐇K−2= (−𝟏K−2 𝑰𝐾−2)和
𝐇K−j = (𝟎⏟ 𝐾−𝑗, . . , 𝟎𝐾−𝑗
𝒋−𝟐
, −𝟏K−j, 𝑰𝐾−𝑗),當2 < j < K時
𝐇 = (𝐇K−1′ 𝐇K−2′ … 𝐇2′ 𝐇1′)′ (3.15) 以表3.1 為例,轉換矩陣為
(
1 0 0 0 1 0 0 0 1
−1 1 0
−1 0 1 0 −1 1)
透過(3.15)的結果轉換,可以得到包含功能參數在內的所有參數
𝒅̂𝑎𝑙𝑙 = 𝐇𝒅̂𝑹 (3.16) 𝐶𝑜𝑣(𝒅̂𝑎𝑙𝑙) = 𝐶𝑜𝑣(𝐇𝒅̂𝑹) = 𝐇𝐶𝑜𝑣(𝒅̂𝑹)𝐇′ (3.17)
3.2.2 相關係數矩陣
儘管在模型中並未特別說明𝐶𝑜𝑣(𝛿𝑖∙𝑏(𝑖)𝑘, 𝛿𝑖∙𝑏(𝑖)𝑙)的關係,但由於 𝛿𝑖∙𝑏(𝑖)𝑘~𝑁(𝑑𝑏(𝑖)𝑘, 𝜏2)的假設,以模型的角度考慮隨機效應
𝑉𝑎𝑟(𝛿𝑖∙𝑥𝑦) = 𝜏2 和 𝑉𝑎𝑟(𝛿𝑖∙𝑥𝑧) = 𝜏2 同時對𝑉𝑎𝑟(𝛿𝑖∙𝑦𝑧)來說,下列運算成立
𝑉𝑎𝑟(𝛿𝑖∙𝑦𝑧)
= 𝑉𝑎𝑟(y𝑖∙𝑧− y𝑖∙𝑦) = 𝑉𝑎𝑟 (y𝑖∙𝑧− 𝑦𝑖∙𝑥− (y𝑖∙𝑦− y𝑖∙𝑥))
= 𝑉𝑎𝑟(y𝑖∙𝑧− y𝑖∙𝑥) + 𝑉𝑎𝑟(y𝑖∙𝑦 − y𝑖∙𝑥) − 2𝐶𝑜𝑣(y𝑖∙𝑧− y𝑖∙𝑥, y𝑖∙𝑦− y𝑖∙𝑥)
= 𝑉𝑎𝑟(𝛿𝑖∙𝑥𝑧) + 𝑉𝑎𝑟(𝛿𝑖∙𝑥𝑦) − 2𝐶𝑜𝑣(𝛿𝑖∙𝑥𝑧, 𝛿𝑖∙𝑥𝑦)
⇒ 𝜏2 = 𝜏2 + 𝜏2 − 2𝐶𝑜𝑣(𝛿𝑖∙𝑥𝑧, 𝛿𝑖∙𝑥𝑦) 故𝐶𝑜𝑣(𝛿𝑖∙𝑥𝑧, 𝛿𝑖∙𝑥𝑦) =1
2𝜏2得證,因此在(3.12)中的𝑽𝑖為此結構
(
1 1/2 ⋯ 1/2 1/2 1 1/2
⋮ ⋱
1/2 1/2 1 )
3.2.3 帽子矩陣(hat matrix)與貢獻圖(contribution plot)
為了能觀察一個網絡中,每個直接比較的相對治療效果是如何影響模型結 果,我們將網絡中所有的兩兩比較都做傳統統合分析(pairwise meta-analysis)。模 型都假設為隨機效應模型(詳見(3.13)),計算過程使用與 3.2.1 兩階段分析小節的 兩段式分析一樣的手法。由於傳統統合分析只做兩個治療的比較,因此實際計算 過程更為簡化25。為了便於說明,假設研究僅納入A𝑤、A𝑥、A𝑦和A𝑧四種治療,
研究中最多有6 個(= 4(4 − 1) 2⁄ )成對比較。定義T𝑖為第i 個試驗所包含的治療的 集合。以一個3-arm 試驗為例計算,若第i個試驗比較A𝑤、A𝑥和A𝑦三種治療,以 和(3.4)同樣的方式計算此試驗的所有相對治療效果
(
∆𝑖∙𝑤𝑥𝑑𝑖𝑟
∆𝑖∙𝑤𝑦𝑑𝑖𝑟
∆𝑖∙𝑥𝑦𝑑𝑖𝑟 ) = (
y𝑖∙𝑥− y𝑖∙𝑤 y𝑖∙𝑦− y𝑖∙𝑤 y𝑖∙𝑦 − y𝑖∙𝑧) 一個試驗能夠計算的相對治療效果數量為|𝑇𝑖|(|𝑇𝑖|−1)
2 。
在傳統統合分析不需要考慮共變異數,因此分別計算每個直接比較的變異 數,計算方式與(3.5)變異數的部分相同
( 𝑊𝑖∙𝑤𝑥−1 𝑊𝑖∙𝑤𝑦−1 𝑊𝑖∙𝑥𝑦−1
) = (
𝑉𝑎𝑟(∆𝑖∙𝑤𝑥𝑑𝑖𝑟 ) 𝑉𝑎𝑟(∆𝑖∙𝑤𝑦𝑑𝑖𝑟 ) 𝑉𝑎𝑟(∆𝑖∙𝑥𝑦𝑑𝑖𝑟 )
) = (
𝑠𝑒𝑖∙𝑤2 + 𝑠𝑒𝑖∙𝑥2 𝑠𝑒𝑖∙𝑤2 + 𝑠𝑒𝑖∙𝑦2 𝑠𝑒𝑖∙𝑥2 + 𝑠𝑒𝑖∙𝑦2
)
取倒數後,𝑊𝑖∙𝑤𝑥、𝑊𝑖∙𝑤𝑦、𝑊𝑖∙𝑥𝑦即為各自的權重。
A𝑤和A𝑥治療以傳統統合分析,在固定效應模型(詳見(3.6)和(3.7))下得到的估 計值,可以表示成
S = {同時包含𝐴𝑥治療和𝐴𝑤治療的所有試驗}
𝑑̂𝐹𝑑𝑖𝑟𝑤𝑥 = ∑ 𝑊𝑖∙𝑤𝑥
𝑖,𝑇𝑖∈S
∆𝑖∙𝑤𝑥𝑑𝑖𝑟 ∑ 𝑊𝑖∙𝑤𝑥
𝑖,T𝑖∈S
⁄ , 𝑓𝑜𝑟 S ≠ ∅ 而皮爾森殘差(詳見(3.8))與自由度(詳見(3.9))則可以表示成
𝑄𝑤𝑥 = ∑ 𝑊𝑖∙𝑤𝑥
𝑖,T𝑖∈S
(∆𝑖∙𝑤𝑥𝑑𝑖𝑟 − 𝑑̂𝐹𝑑𝑖𝑟𝑤𝑥)2和𝑑𝑓𝑤𝑥 = ∑ 𝐼(T𝑖 ∈ S)
𝑖
利用皮爾森殘差平方總和、權重與自由度,計算出相對治療效果估計值的隨 機效應(詳見(3.10))
𝜏𝑤𝑥2 = max (
0, 𝑄𝑤𝑥 − 𝑑𝑓𝑤𝑥
∑𝑖,T𝑖∈S𝑊𝑖∙𝑤𝑥−∑𝑖,T𝑖∈S𝑊𝑖∙𝑤𝑥2
∑𝑖,T𝑖∈S𝑊𝑖∙𝑤𝑥)
, 𝑖𝑓 |S| > 1
若|S| = 1,異質性不存在,因此𝜏𝑤𝑥2 = 0。最後將計算估的隨機效應,做為傳統統 合分析下的隨機效應模型的參數(詳見(3.12))
𝑊𝑖∙𝑤𝑥∗−1 = 𝜏𝑤𝑥2 + 𝑊𝑖∙𝑤𝑥−1 如此一來,就能根據(3.13)和(3.14)估計出
𝑊𝑤𝑥∗ = ∑ 𝑊𝑖∙𝑤𝑥∗
𝑖,T𝑖∈S
𝑑̂𝑅𝑑𝑖𝑟𝑤𝑥 = ∑ 𝑊𝑖∙𝑤𝑥∗
𝑖,T𝑖∈S
∆𝑖∙𝑤𝑥𝑑𝑖𝑟 ⁄𝑊𝑤𝑥∗
以上是將3.2.1 兩階段分析的過程簡化為兩個治療的相對治療效果,重複同 樣的過程可以得到所有直接比較的相對治療效果。最後將所有直接比較的結果,
透過𝐙映射到網絡中所有可能存在的成對比較治療中
𝒅̂𝑅 = 𝒁(𝒁𝑑𝑖𝑟′ 𝑾𝑑𝑖𝑟∗ 𝒁𝑑𝑖𝑟)−1𝒁𝑑𝑖𝑟′ 𝑾𝑑𝑖𝑟∗ 𝒅̂𝑅𝑑𝑖𝑟
𝒅̂𝑅𝑑𝑖𝑟為所有直接比較的相對治療效果估計值。𝑾𝑑𝑖𝑟∗ 為與𝒅̂𝑅𝑑𝑖𝑟的位置相對應的相對 治療效果估計值變異數矩陣,非對角線皆為0。𝐙矩陣為類似(3.15),但排列順序
略有不同,以表3.1 為例
𝒅̂𝑅𝑑𝑖𝑟 = (
𝛽̂𝑅𝑑𝑖𝑟12 𝛽̂𝑅𝑑𝑖𝑟13 𝛽̂𝑅𝑑𝑖𝑟23 𝛽̂𝑅𝑑𝑖𝑟24)
, 𝑾𝑑𝑖𝑟∗ = (
𝑊12∗ 0 0 0 0 𝑊13∗ 0 0 0 0 𝑊23∗ 0 0 0 0 𝑊24∗
)
𝐙 = 1𝑣𝑠2 1𝑣𝑠3 2𝑣𝑠3 2𝑣𝑠4 1𝑣𝑠4 3𝑣𝑠4(
1 0 0 0 1 0
−1 1 0
−1 0 1 0 0 1 0 −1 1
⏞
1𝑣𝑠2 1𝑣𝑠3 1𝑣𝑠4
)
, 𝒁𝑑𝑖𝑟 = 1𝑣𝑠2 1𝑣𝑠3 2𝑣𝑠3 2𝑣𝑠4(
1 0 0 0 1 0
−1 1 0
−1 0 1
⏞
1𝑣𝑠2 1𝑣𝑠3 1𝑣𝑠4
)
而帽子矩陣則為
𝐡𝐚𝐭 = 𝒁(𝒁𝑑𝑖𝑟′ 𝑾𝑑𝑖𝑟∗ 𝒁𝑑𝑖𝑟)−1𝒁𝑑𝑖𝑟′ 𝑾𝑑𝑖𝑟∗ = (ℎ𝑎𝑡𝑖,𝑗)|𝑇𝑖|(|𝑇𝑖|−1)
2 ×(|𝑇𝑖|−1)
而將帽子矩陣每列數值取絕對值後,再換算成列百分比,即為貢獻圖矩陣 𝐜𝐨𝐧 = (con𝑖,𝑗)|𝑇𝑖|(|𝑇𝑖|−1)
2 ×(|𝑇𝑖|−1), con𝑖,𝑗 = |ℎ𝑎𝑡𝑖,𝑗|
∑|𝑇𝑗=1𝑖|−1|ℎ𝑎𝑡𝑖,𝑗|× 100%
3.3 Baseline model
假設納入I個試驗比較A1, A2, … , AK共K種治療方式,並以A1, A2, … , AK的順序 排序,Ti為在第i個試驗中被比較的治療的集合,將A1指定為參考治療21:
𝑔(𝑦̂i∙k) = θi∙k = 𝛽𝑖+ 𝑈𝑖∙𝑘δ𝑖∙1𝑘 (3.18) 𝛽𝑖~𝑁(𝜇1, 𝜎12) (3.19) 𝑈𝑖∙𝑘 = {1, 𝑘 ≠ 1
0, 𝑘 = 1, 𝛿𝑖∙1𝑘~𝑁(𝑑1𝑘, 𝜏2)
其中𝑔(∙)為鍊結函數(link function),根據不同的資料型態給予適合的函數。𝛽𝑖 為第i個試驗的基底治療效果。δ𝑖∙1𝑘為第i個試驗中,A𝑘治療與參考治療的相對治 療效果。𝑈𝑖∙𝑘為第i個試驗的指示函數。
3.3.1 分離式模型(separate model)與補值
不同於Lu & Ades model,模型假設參考治療服從常態分布。本研究分離式模 型採取將(3.18)中的參考治療的分布先行估計的方式,也就是先估計如下的模型
𝑔(𝑦̂i∙1) = θi∙1= 𝛽𝑖 (3.20) 𝛽𝑖~𝑁(𝜇1, 𝜎12) (3.21) 參數的估計方法,模仿自傳統統合分析估計參數的方式。參考治療效果的平 均值以加權平均的方式估計,而變異數以類似τ2的方式估計。
𝜇̂1′ = ∑ 𝑤𝑖 𝑖𝑦𝑖∙1
∑ 𝑤𝑖 𝑖 若Ti ∋ 𝐴1 (3.22)
𝜎̂12 = max {
0,∑ 𝑤𝑖 𝑖(𝑦𝑖∙1− 𝜇̂1′)2− 𝑑𝑓
∑ 𝑤𝑖 𝑖− (∑ 𝑤𝑖 𝑖2
∑ 𝑤𝑖 𝑖) }
若Ti ∋ 𝐴1 (3.23)
其中𝑤𝑖 = 1
𝑠𝑒𝑖∙12 為試驗𝑖的權重。𝑠𝑒𝑖∙𝑘2 為第i個試驗所報告的Ak治療的標準誤。自由度 (𝑑𝑓)為∑ 𝐼(T𝐼𝑖 i∋ 𝐴1)− 1。最後在考慮𝜎̂12的情況下,重新估計參考治療效果的平均 值
𝜇̂1 = ∑ 𝑤𝑖 𝑖′𝑦𝑖∙1
∑ 𝑤𝑖 𝑖′ 若Ti ∋ 𝐴1 (3.24) 其中𝑤𝑖′= 1
𝑠𝑒𝑖∙12 +𝜎̂12為試驗𝑖的權重。
估計好參考治療的分布後,以表3.1 第 4、5 個試驗的資料為範例來說明補植 方式,分析需要的治療效果、標準差和樣本數如表3.3 所示。
表3.3 表 3.1 第 4、5 個試驗的資料
試驗 A2治療 𝐬𝐭𝐝𝟐 𝐧𝟐 A3治療 𝐬𝐭𝐝𝟑 𝐧𝟑 A4治療 𝐬𝐭𝐝𝟒 𝐧𝟒 4 y4∙2 std4∙2 n4∙2 y4∙3 std4∙3 n4∙3 - - - 5 y5∙2 std5∙2 n5∙2 - - - y5∙4 std5∙4 n5∙4 參考治療效果以平均值補入。標準差的部分直接以其他治療的標準誤,以樣 本數為權重作加權平均標準誤補入。由於標準差的部分以標準誤補入,因此樣本 數直接補入1 即可。結果如表 3.4 所示。
表3.4 補值後的參考治療
試驗 A1治療 𝐬𝐭𝐝𝟏 𝐧𝟏
4 y4∙1= 𝜇̂1
std4∙1 = se4∙1 = 𝑠𝑡𝑑4∙2
√𝑛4∙2
𝑛2∙2+𝑠𝑡𝑑4∙3
√𝑛4∙3
𝑛4∙3 𝑛4∙2+ 𝑛4∙3
n4∙1= 1
5 y5∙1= 𝜇̂1
std5∙1 = se5∙1 = 𝑠𝑡𝑑5∙2
√𝑛5∙2
𝑛5∙2+𝑠𝑡𝑑5∙4
√𝑛5∙4
𝑛5∙4 𝑛5∙2+ 𝑛5∙4
n5∙1= 1
使用(3.20)和(3.21)補完值後,將結果代回(3.18)和(3.19)中,再以 3.2.1 兩階段 分析的方法進行相對治療效果的估計,最終得到所有參數。
3.4 Arm-based model
假設納入I個試驗比較A1, A2, … , AK共K種治療方式,並以A1, A2, … , AK的順序 排序,Ti為在第i個試驗中被比較的治療的集合,將A1指定為參考治療18; 22:
𝑔(𝑦̂i∙k) = θi∙k = 𝛽𝑘(𝑖) (3.25) 𝛽𝑘(𝑖)~𝑁(𝜇𝑘, 𝜎𝑘2)且𝑐𝑜𝑣(𝛽𝑘(𝑖), 𝛽𝑙(𝑖)) = 0 若𝑘 ≠ 𝑙 (3.26) 其中𝑔(∙)為鍊結函數(link function),根據不同的資料型態給予適合的函數。
𝛽𝑘(𝑖)為第i個試驗的Ak治療效果。相關係數的估計在頻率學派的架構下,不容易在 每個網絡結構中都使用相同設定去估計。因此我們選擇將相關係數限制為0,也 就是假設治療彼此相互獨立。
3.4.1 兩階段分析
Arm-based model 估計絕對治療效果,且根據(3.26)的假設,治療彼此之間互
相獨立,因此採取(3.22)、(3.23)和(3.24)相同的估計方式獲得 𝜇̂𝑘′ = ∑ 𝑤𝑖 𝑖∙𝑘𝑦𝑖∙𝑘
∑ 𝑤𝑖 𝑖∙𝑘 且𝑤𝑖∙𝑘 = 1
𝑠𝑒𝑖∙𝑘2 若Ti ∋ 𝐴𝑘
𝜎̂𝑘2 = max {
0,∑ 𝑤𝑖 𝑖∙𝑘(𝑦𝑖∙𝑘− 𝜇̂𝑘′)2− 𝑑𝑓𝑘
∑ 𝑤𝑖 𝑖∙𝑘− (∑ 𝑤𝑖 𝑖∙𝑘2
∑ 𝑤𝑖 𝑖∙𝑘) }
若Ti ∋ 𝐴𝑘
𝑑𝑓𝑘 = ∑ 𝐼(Ti ∋ 𝐴𝑘)
𝐼
𝑖
− 1
𝜇̂𝑘 =∑ 𝑤𝑖 𝑖∙𝑘′ 𝑦𝑖∙𝑘
∑ 𝑤𝑖 𝑖∙𝑘′ 且𝑤𝑖∙𝑘′ = 1
𝑠𝑒𝑖∙𝑘2 + 𝜎̂𝑘2 若Ti ∋ 𝐴𝑘
𝑠𝑒𝑖∙𝑘2 為第i個試驗所報告的Ak治療的標準誤。估算完的絕對治療效果,最後相減為 相對治療效果
𝑑̂kl= 𝜇̂𝑙− 𝜇̂𝑘, 𝑘 ≠ 𝑙 𝑉𝑎𝑟̂ (𝑑̂kl) = 𝜎̂𝑘2+ 𝜎̂𝑙2, 𝑘 ≠ 𝑙
3.5 模型比較
在2.2 兩種隨機效應假設小節中有介紹過兩種隨機效應的假設方式,
Contrast-based 模型以效果隨機為主要的假設,而 Arm-based 模型以研究隨機為主 要假設。
如圖3.1 所示,Lu & Ades model 做為標準的 Contrast-based 模型,假設為效 果隨機。而Baseline model 在效果隨機的基礎上,針對參考治療假設研究隨機,
因此可以估計參考治療的隨機效應。一般在隨機效應的假設上,會使用較強的同 質性(homogenous)的假設去簡化模型,也就是假設所有相對治療效果的變異成度 相同。雖然異質性(heterogeneity)的假設較弱、較有彈性,但需要估計較多參數
20,且不容易解釋。此外,實際執行也不容意,幾乎沒有人會使用。
而Arm-based model 的所有治療都假設研究隨機,那些沒有被我們觀察到的 治療效果為隨機缺失(Missing at random)18。也就是說,若比較K 種治療,理論上 每一個試驗都有全部K 種治療效果,但因為某些原因,部分試驗中的某些治療效
果遺失了,因此我們只能觀察到目前的資料。
Arm-based model 中,不同治療的隨機效應和不同治療之間的相關性可根據 資料狀況做假設18,以一個比較三種治療的變異數矩陣來舉例:
(
𝜎12 𝜌12𝜎1𝜎2 𝜌13𝜎1𝜎3 𝜌12𝜎1𝜎2 𝜎22 𝜌23𝜎2𝜎3 𝜌13𝜎1𝜎3 𝜌23𝜎2𝜎3 𝜎32
)
假設由強到弱,可分成五種程度。Homogenous perfect: 𝜎1 = 𝜎2 = 𝜎3, 𝜌12= 𝜌13= 𝜌23 = 0;Heterogeneity uncorrelated: 𝜎1 ≠ 𝜎2≠ 𝜎3, 𝜌12 = 𝜌13 = 𝜌23 = 0;
Homogenous exchangeable: 𝜎1 = 𝜎2 = 𝜎3, 𝜌12= 𝜌13= 𝜌23 ≠ 0;Heterogeneity exchangeable:𝜎1 ≠ 𝜎2≠ 𝜎3, 𝜌12 = 𝜌13 = 𝜌23 ≠ 0;Heterogeneity unstructured:𝜎1 ≠ 𝜎2 ≠ 𝜎3, 𝜌12≠ 𝜌13≠ 𝜌23。
部分的學者認為研究隨機的假設會破壞隨機分派試驗的隨機性26,因為每個 試驗納入的受試者的族群不完全相同,直接假設它們可交換,顯然有問題。因此 Baseline model 和 Arm-based model 都會破壞隨機性,只有 Lu & Ades model 被認 為能夠完整的保存這個性質。
在圖3.2 視覺化三種模型的假設,Lu & Ades model 和 Baseline model 可明顯 看出區別。前者的參考治療(A 治療)是固定效應,根據不同的試驗有不同的參考 治療效果,因此真正的治療效果不會維持一個水平線;後者參考治療為隨機效 應,不同試驗的差異都被當作抽樣誤差,因此真正的治療效果不管在哪個試驗中 都一樣。
而圖3.2 中 Arm-based model 與 Baseline model 有些相似。但所有個估計都針 對估計絕對治療效果,而非相對治療效果。相關性主要在呈現不同治療間的關 係。若為正值代表同一試驗內的A 治療效果越好,B 治療效果也傾向越好;負值 代表同一試驗內的A 治療效果越好,B 治療效果傾向越差;0 代表 A 和 B 的治療 效果無關。
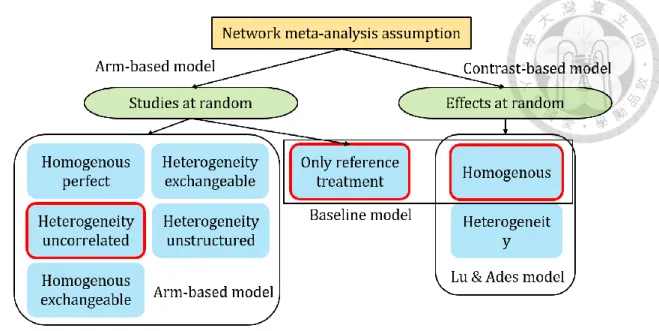
圖3.1 網絡統合分析假設
呈現三種不同的模型,假設上的異同之處。Arm-based model 針對治療彼此之間 的關係,有五種假設方式。Homogenous perfect 假設治療彼此獨立,且不同治 療的隨機效應相同;Heterogeneity uncorrelated 同樣假設治療彼此獨立,但不同 治療的隨機效應不同;Homogenous exchangeable 假設治療彼此不獨立、相關係 數相同,且不同治療的隨機效應相同;Heterogeneity exchangeable 假設治療彼 此不獨立、相關係數相同,但不同治療的隨機效應不同;Heterogeneity
unstructured 假設治療彼此不獨立、相關係數各不相同,而不同治療的隨機效應 亦不相同。Contrast-based model 中,Homogenous 假設所有相對治療效果的隨 機效應相同;Heterogeneity 假設不同相對治療效果的隨機效應不同。其中以紅 色框起來的是本研究中所使用的假設。
(a) Lu & Ades model (b) Baseline model
(c) Arm-based model 圖3.2 簡易模型示意圖
呈現三種不同的模型的假設。橫軸代表不同的試驗;縱軸代表絕對治療效果;
兩條紅色虛線分別為兩個治療的真正的治療效果;每個點代表一個絕對治療效 果,藍色為A 治療,綠色為 B 治療,在同一垂直線上的治療代表來自同一個試 驗;右側的分布為模型有估計的隨機效應。其中Lu & Ades model 中的試驗根 據A 治療的絕對治療效果重排過。
第四章 模擬
為了模擬在不同的網絡結構下,治療的偏差是如何在影響模型估計,需要設 定網絡結構與偏差的位置。考慮到設定納入的治療只有三、四個會過於簡化網絡 結構,因此模擬中設定研究納入五種治療。
4.1 模擬情境
在此基礎下,我們篩選出具備代表性的五種網絡結構(詳見圖 4.1)。
(a)Network 1 (b)Network 2
(c)Network 3 (d)Network 4 (e)Network 5 圖4.1 網絡結構圖
每個網絡皆納入5 種治療,點的大小代表使用該種治療的總人數;每條線代表 4 個試驗;紅線代表存在偏差的 4 個試驗。(a)Network 1 為所有治療都僅與治療 C 有直接比較的星狀網絡,共 16 個試驗;(b)Network 2 為結構完整的網絡,共 40 個試驗;(c)Network 3 為一個迴圈與一分支組成的網絡,共 20 個試驗;
(d)Network 4 以 Network 3 為基礎,分支與 B 治療相連,形成第二個迴圈,共 24 個試驗;(e)Network 5 為所有治療形成一個大型迴圈,共 20 個試驗。