行政院國家科學委員會專題研究計畫 成果報告
數位音樂典藏之資料探勘與智慧型檢索技術
研究成果報告(完整版)
計 畫 類 別 : 個別型 計 畫 編 號 : NSC 94-2422-H-004-003- 執 行 期 間 : 94 年 03 月 01 日至 95 年 05 月 31 日 執 行 單 位 : 國立政治大學資訊科學系 計 畫 主 持 人 : 沈錳坤 計畫參與人員: 碩士班研究生-兼任助理:邱士銓、陳文婷、魏綾音、江孟 芬、彭冠誌 處 理 方 式 : 本計畫涉及專利或其他智慧財產權,2 年後可公開查詢中 華 民 國 95 年 12 月 21 日
行政院國家科學委員會補助專題研究計畫
□ 成 果 報 告
□期中進度報告
數位音樂典藏之資料探勘與智慧型檢索技術
計畫類別:; 個別型計畫 □ 整合型計畫
計畫編號: NSC 94 - 2422 - H - 004 - 003 -
執行期間:94 年 3 月 1 日 至 95 年 5 月 31 日
計畫主持人: 沈 錳 坤
共同主持人:
計畫參與人員: 邱士銓、陳文婷、江孟芬、魏綾音、彭冠誌
成果報告類型(依經費核定清單規定繳交):□精簡報告 □完整報告
本成果報告包括以下應繳交之附件:
□赴國外出差或研習心得報告一份
□赴大陸地區出差或研習心得報告一份
□出席國際學術會議心得報告及發表之論文各一份
□國際合作研究計畫國外研究報告書一份
處理方式:除產學合作研究計畫、提升產業技術及人才培育研究計畫、
列管計畫及下列情形者外,得立即公開查詢
□涉及專利或其他智慧財產權,□一年□二年後可公開查詢
執行單位:國立政治大學資訊科學系
中 華 民 國 95 年 5 月 31 日
ˇ
ˇ ˇ ˇ數位音樂典藏之資料探勘與智慧型檢索技術
摘要
本計畫的研究重點即為利用音樂探勘技術,研究數位音樂典藏中的智慧型擷取技術。 數位音樂典藏的擷取方式包括以後設資料(metadata)查詢、音樂內容擷取, 音樂曲風查詢, 相關回饋, 音樂瀏覽與個人化音樂推薦等,以有助於使用者方便地擷取典藏的數位音樂。 在本計畫中,我們主要目的將研究利用音樂探勘中的音樂樣式探勘將音樂分段,以發展音 樂瀏覽(Music Browsing)技術。 音樂分段在研究音樂分析相關的領域是很重要的研究題目。音樂的分段可以提供作音 樂結構分析、音樂瀏覽、音樂內容查詢與音樂摘要等應用。本計劃的研究目的就是對音樂 作自動分段,以幫助使用者能快速瀏覽音樂的內容。因此,我們針對音樂的主題作主題式 的分段。 音樂的主題是取決於作曲者的動機,動機是構成音樂主題的基本因素。為了能夠以主 題為基礎作音樂分段,我們必須找出決定音樂主題的因素。動機會有規則性的出現在整首 音樂當中,所以我們可以利用動機出現的規則來探勘音樂的動機。 我們提出一個以主題對音樂作分段的方法,總共分為四個主要的步驟。第一,我們從 原始的音樂資料擷取出主旋律的部分。第二,將主旋律做粗略分段。我們利用探勘Non-trivial 重複樣式的技術[17],來找出粗略段落。第三,從粗略段落中探勘動機。我們利用 Stein 所 提出來的動機變化規則,修改傳統探勘重複序列的方法,做動機的探勘。最後,我們利用 探勘出來的動機對主旋律作精細分段。我們針對 MIDI 音樂檔案利用提出來的方法,實做 出一個系統,找出音樂的主題段落。 先前研究在評估實驗結果時,多採用Precision 與 Recall 去評估實驗的結果。然而,這 樣的評估方法並不能表現出實驗結果與正確答案之間的相似程度。所以我們提出新的評估 方法,根據實驗結果與正確答案之間的相似程度來評估實驗的準確率。根據實驗結果顯示, 我們的方法準確率約65%。Data Mining and Intelligent Retrieval Techniques
for Digital Music Archives
Abstract
In this project, we investigated the data mining techniques for intelligent retrieval of digital music archive. Music browsing is one of the retrieval mechanisms for music archive. Music segmentation is one of the important design issues for music browsing. Music segmentation can be utilized for music structure analysis, music browsing, content-based music retrieval, and music summarization. In this project, we proposed a music segmentation method based on the music theme to provide users the capability to browse music segments by theme.
Motives, the concepts of the composer, are the basic elements of music themes. Music themes were constructed by motives. In order to segment music by themes, we have to discover motives. Most motives repeated in the music by some motivic treatment rules. Therefore, motives can be discovered by these rules.
We proposed the theme segmentation method. There are four steps. Firstly, we extract main melody from original music. In the second step, rough segments are generated from main melody by mining non-trivial repeating patterns. Then, motives are detected from rough segments. We modify the mining algorithm for discovering frequent patterns by applying motivic treatment rules proposed by Stein. Finally, we segment main melody based on the generated motives. Moreover, a system for segmentation of music in MIDI format was implemented.
Concerning the effectiveness evaluation of music segmentation, precision and recall are used in previous research. We proposed an effectiveness measure and corresponding algorithm to evaluate the accuracy of music segmentation. Experimental results show that our proposed music segmentation method achieves 65% accuracy.
目錄
目錄...III
圖目錄... VI
表目錄... VIII
第一章 概論 ...1
1.1 動機 ... 1
1.2 背景 ... 3
1.3 MIDI 格式 ... 5
1.4 報告架構 ... 6
第二章 相關研究 ...8
2.1 音樂分段 ... 8
2.2 主題萃取 ... 12
2.3 音樂摘要 ... 12
2.4 音樂樣式探勘 ... 14
2.4.1 探勘精確重複樣式 ...14
2.4.2 探勘趨近重複樣式 ...16
第三章 音樂分段 ...17
3.1 主旋律的萃取與表示法 ... 20
3.2 粗略分段 ... 24
3.2.1 以 Non-trivail 重複樣式作粗略分段...25
3.3 動機偵測 ... 28
3.4 精確分段 ... 37
第四章 系統實作 ...40
4.1 調性音階 ... 40
4.2 音長區間量化 ... 41
4.3 動機整合 ... 41
4.4 MIDI parser ... 42
4.5 轉換 MIDI 格式 ... 42
4.6 系統介面 ... 43
第五章 實驗 ...45
5.1 實驗資料與實驗設計 ... 45
5.2 實驗評估方法 ... 45
5.3 實驗結果 ... 49
第六章 結論與未來研究 ...51
6.1 結論 ... 51
6.2 未來研究 ... 52
圖目錄
圖1.1:自然音階的音程關係。... 4 圖 1.2:一個八度音階的鋼琴鍵分布。 ... 4 圖 1.3:音長倍數關係表示圖。 ... 4 圖 2.1:GTTM 群組範例。... 9 圖 2.2:相鄰關係與相似關係的群組。 ... 9 圖 2.3:一首音樂的重複結構分析結果,A 與 B 是重複出現的部份。... 12 圖 2.4:巴哈 C 大調二部創意曲 BWV001。... 14 圖 2.5:建立 CORRELATIVE MATRIX的範例[17]。... 15 圖 3.1:主題分段流程圖。 ... 19 圖 3.2:經過 PARSER處理後的MIDI 資料。 ... 20 圖 3.3:ALL-MONO的範例。... 22 圖 3.4:ALL-MONO主旋律擷取示意圖。... 22 圖 3.5:ALL-MONO演算法。... 24 圖 3.6:音樂中的重複樣式。 ... 25 圖 3.7:建立 CORRELATIVE MATRIX的演算法[16]。... 26 圖 3.8:修改的探勘候選 NON-TRIVIAL重複樣式演算法,與檢驗NON-TRIVIAL重複樣式規則。 ... 27 圖 3.9:CORRELATIVE MATRIX範例。... 28圖 3.10:EXACT REPEATING PATTERNS的範例。... 29
圖 3.11:INTERVAL REPEATING PATTERNS的範例。... 29
圖 3.12:SEQUENCE變化的範例。... 30
圖 3.13:CONTRARY MOTION變化的範例。... 30
圖 3.15:AUGMENTATION與DIMINUTION變化的範例。... 30
圖 3.16:EXACT REPEATING動機變化的CORRELATIVE MATRIX演算法。... 31
圖 3.17:兩種 TRANSPOSITION的範例。... 32
圖 3.18:自然音階。 ... 33
圖 3.19:針對 SEQUENCE變化所建立的CORRELATIVE MATRIX。... 33
圖 3.20:CONTRARY MOTION動機變化的CORRELATIVE MATRIX演算法。... 34
圖 3.21:針對 CONTRARY MOTION變化所建立的CORRELATIVE MATRIX。... 35
圖 3.22:RETROGRADE動機變化的CORRELATIVE MATRIX演算法。... 35
圖 3.23:針對 RETROGRADE變化所建立的CORRELATIVE MARTRIX。... 36
圖 3.24:針對 AUGMENTATION或DIMINUTION變化所建立的CORRELATIVE MARTRIX。... 37
圖 3.25:兩個音快速的交替演奏。 ... 37 圖 3.26:兩種動機在粗略段落中分佈的情形。 ... 39 圖 3.27:合併相同動機的粗略段落。 ... 39 圖 4.1;C 大調與 G 大調音階。... 41 圖 4.2:DMP2MIDI的文字格式。... 43 圖 4.3:原始 MIDI 檔案頁面。 ... 43 圖 5.1:PRECISION與RECALL誤判的第一種情形。... 46 圖 5.2:PRECISION與RECALL誤判的第二種情形。... 46 圖 5.3:兩種序列計算相似度對應的方法。 ... 47 圖 5.5:計算 S(U,V)所需的矩陣 S 範例... 49
表目錄
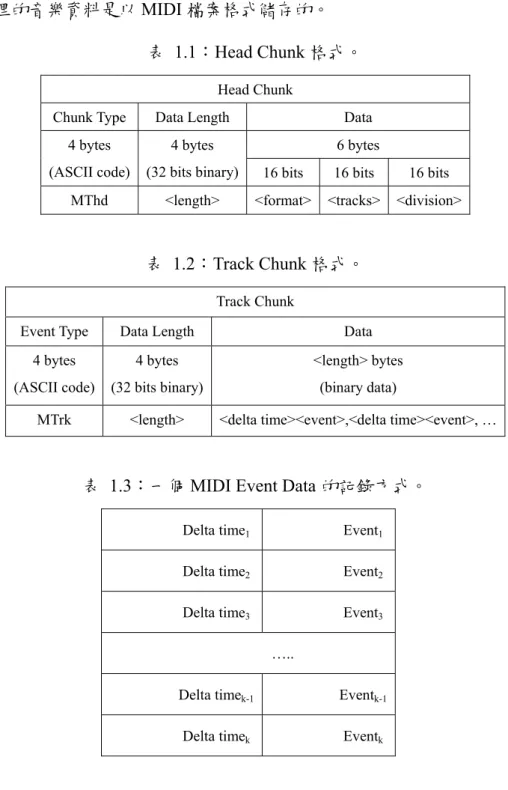
表 1.1:HEAD CHUNK格式。... 6
表 1.2:TRACK CHUNK格式。... 6
表 1.3:一個 MIDIEVENT DATA的記錄方式。... 6
表 5.1:音樂資料列表 ... 45
表 5.2:以 ORIGINAL DURATION來表示音樂節奏的實驗結果。... 50
第一章
概論
1.1 動機
「數位典藏國家型科技計畫」的目的在於妥善保存國家的文化資產,推廣精緻藝術的 流傳與品賞,強健文化的傳承與發展,並鼓勵資訊與知識的分享。在目前典藏的文物中, 常見的媒體形式多以文字、影像與視訊為主體,以音樂為主題的典藏資料庫並不多。 然而台灣在音樂方面,從國樂、南北管、原住民音樂、閩南民謠、客家民謠乃至校園 民歌都是豐富的文化資產。國樂中,由董榕森先生作曲的「陽明春曉」是耳熟能詳的梆笛 演奏曲。而 1996 年亞特蘭大奧運主題曲「反璞歸真」即源自於馬蘭地區的阿美族人郭英 男的「老人飲酒歌」。日據時期由鄧雨賢先生作曲、李臨秋先生作詞的「望春風」則為家 喻戶曉的閩南民謠。921 地震之後,旅美的大提琴家郭虔哲即在美國卡內基音樂廳演奏閩 南民謠「望春風」、「補破網」、「雨夜花」來賑災募款。60 年代陳達的恆春民謠「思想起」, 一把月琴、一生艱辛更是台灣經濟發展過程中的重要文化資產。在客家民謠方面,無論是 老山歌、山歌仔、平版調,都是質樸勤奮的客家人之寫照。而 70 年代由於時代背景而風 行一時的校園民歌,隨著時光的流逝,也逐漸進入我們的回憶中。這些音樂都伴隨著台灣 的發展,以音樂的方式訴說著我們文化發展的歷程。 與其他形式的媒體類似,數位音樂典藏的技術研究議題包括智慧財產權與隱私權管理 機制、數位典藏資料庫技術與多媒體處理技術。隨著MP3 及 P2P 的盛行,智慧財產權管 理機制在數位音樂中扮演重要的角色。與文字影像視迅等媒體不同,人類對音樂的認知是 透過聽覺的方式而非視覺的方式。因此人類在表達音樂擷取的條件時,相對地比較困難。 音樂擷取技術不僅有助於一般的使用者擷取數位音樂典藏,也有助於建置、維護與管理典 藏資料的專業使用者。例如,數位典藏加值服務的專業配樂師有搜尋音樂的需求,以方便 為以60 年代台灣鄉村風格為場景的廣告做配樂。本計畫的研究重點即為利用音樂探勘技術,研究數位音樂典藏中的智慧型擷取技術。 數位音樂典藏的擷取方式,最直接的方式是以後設資料(metadata)查詢擷取。與音樂有關 的後設資料包括曲名、作曲者、樂派、歌詞或以文字描述的曲風等。但如同其他媒體形式 的 後 設 資 料 , 後 設 資 料 必 須 透 過 專 業 人 員 的 加 註(Annotation) , 也 因 此 會 有 解 讀 (Interpretation)的問題。因此,音樂內容擷取(Content-based Retrieval), 音樂曲風查詢(Music Style Retrieval), 相關回饋(Relevance Feedback), 音樂瀏覽(Music Browsing)與個人化音樂 推薦(Personalized Music Recommendation)等功能將有助於使用者方便地擷取典藏的數位 音樂。 其中,音樂瀏覽提供音樂的分類索引,讓使用者以瀏覽的方式擷取音樂。此外,每首 音樂也可以摘要(Summarization)的方式呈現,以方便使用者不必循序的播放而直接地聆聽 音樂。這將有助於瀏覽諸如交響樂等長度長的音樂。在本計畫中,我們主要將研究利用音 樂探勘技術,發展音樂瀏覽技術。 一般作家在寫作時,會將文章依據主題利用段落的方式分開。讀者在瀏覽文章時,可 以依據章節或主題來閱讀。相較於文字資料,多媒體資料中的影片或音樂,如果在製作時 沒有明顯的段落,使用者可能必須將整個資料從頭看過或聽過,才能瀏覽到所需要的片 段。舉例來說,貝多芬第九號交響曲「合唱」,最有名的演奏版本長度為74 分鐘,愛樂人 尋找自己喜歡的片段時,可能需要花費不少時間才能找到。因此,多媒體資料的分段,有 助於使用者以分段的方式瀏覽多媒體資料。 分段的好處不止於提供使用者瀏覽的需求,我們進一步可以利用分段的結果產生出多 媒體內容的摘要(Summary 或 Thambnailing)。此外,分段的技術也可以建立查詢所需的索 引,用在以內容為基礎的多媒體查詢(Content-based multimedia retrieval)上。
一般多媒體的資料量都非常龐大,如果以人工對多媒體資料做分段,需要花費很多的 人力與時間。因此,在多媒體的研究領域,已經有許多視訊分段的相關研究[23]。相較於 視訊,音樂分段的研究在最近才興起[22]。最近幾年開始有研究學者[2][3][22][40]針對音 樂資料做分段,有一些研究做音樂分段的目的是找出比單一一個音符階層高的音樂單位, 藉此可以做高階的分析,如:合聲等。這些研究純粹找出許多分段點(Boundaries)。所以, 兩個連續的音符中間,如果特徵有很大的落差,可能就是一個分段點。這些研究並沒有針 對音樂的內容做分段。如果要達到主題式瀏覽的目的,可能要對音樂的內容做分析,如:
音樂主題的分析等。 音樂資料是具有結構性的,作曲家在作曲時會有動機,最後再由動機發展出主題,將 許多個主題串起來組成完整的音樂。因此,我們可以根據音樂的結構做主題的分段,以提 供使用者做主題的瀏覽。我們希望可以發展一套方法,對音樂內容做主題式的分段,讓使 用者可以對音樂的主題做瀏覽。
1.2 背景
音樂的特徵包含旋律(Melody)、節奏(Rhythm)、音色(Timbre)、力度(Dynamic)、和聲 (Harmonic)、織體(Texture)和曲式(Form)等元素,以特定的方式組合時,而產生獨特的效果 與特色。音樂家為了將這些訊息記錄下來,讓其他人也能夠演奏出來,開始有人發展出記 譜的方法。透過樂譜,演奏的人可以將上述音樂物理狀態,盡可能重現出來。接下來我們 簡單介紹基本音樂記譜方法所記錄的資訊。 音樂記譜的基本單位為音符,一個音符代表一個樂器所發出的一個特定聲音。幾 個音符構成一個小節,許多小節構成完整的音樂。每一個音符最基本的特徵為音高(Pitch) 與音長(Duration)。數個音高決定音樂的旋律,數個音長決定音樂的節奏。對於音高來說,Musical Scale 定義音高的連續關係,最常見的以八度音階(Octave)為 主,也就是八個音符間隔構成七個音階,這個連續的關係會循環不變。以自然音階(Diatonic)
為例,圖1.1 以五線譜(staff)表示八個音的連續關係。音樂中,有一種定音高的準則稱為十
二平均律,這是目前使用最廣泛的音高準則。這個規則會將一個八度音階切分成十二個半 音。以鋼琴鍵為例,如圖 1.2 所示,箭號所指的琴鍵為兩個相差八度音階的“do”。以每一
個琴鍵為半音,橫跨在八度音階中的黑白琴鍵共有十二個。因此,有一種稱為 Naturally
Occurring Half Step 的現象發生。Naturally Occurring Half Steps 會發生在自然音階的第三與 第四個音之間,以及第六個與第七個音之間。通常在音與音之間,會存在一個半音階 (Semitone 或 half steps),也就是兩個鋼琴白鍵中間所夾的黑鍵,兩個音的間距為兩個半音。 依據十二平均律,半音也是目前一般音樂中,最小的音程單位。然而,在Naturally occurring half steps 的地方,兩個音的距離只有半個音程。以 MIDI 記錄音高的表示法來看,圖 1.1 的“do re mi fa sol la ti do”,會表示為 <60, 62, 64, 65, 67, 69, 71, 72>。在<64, 64>與<71, 72>
自然音階的do 跟 mi 為例,兩者的 Pitch interval 為 2 個全音。 接下來,我們介紹音長的關係。每個音長與單位時間,擁有固定的倍數關係;此外, 音樂演奏時,也會分別針對不同音樂的需求,訂出不同的單位時間。圖 1.3 為樂理中,表 示音長關係的樹狀圖。每一個相鄰的階層,父節點都為子節點音長的 2 倍。在樹狀圖中的 根節點,我們稱為全音符,代表音長為四拍,由根節點分成兩個二分音符,代表的音長為
do
1 1
1/2
1
1
1
1/2
re
mi
fa sol la ti do
圖1.1:自然音階的音程關係。 圖 1.2:一個八度音階的鋼琴鍵分布。 圖 1.3:音長倍數關係表示圖。兩拍。接下來的四分音符、八分音符與十六分音符的音長也都保持相同的關係。休止符的 時間長短一樣有相同的關係。還有一種“附點”的音符,表示為原來音長的 1.5 倍。以兩拍的 二分音符為例,如果二分音符加上附點,所代表的音長為2+1 拍。 我們進一步看音樂中音符包含的資訊,每一個音符有一個開始發聲的時間與結束發聲 的時間,音長為兩者的時間差。此外,兩個連續音符的開始發聲時間間距,稱為Inter-Onset Interval(IOI);兩個連續音,第一個音的結束發聲時間到第二個音開始發聲的時間間距,稱 為Onset-Offset Interval(OOI),也就是所謂的休止符。 根據Stein[41],作曲家在譜寫一首音樂時,以動機(Motive)為基本單位。在上述音樂特 徵中,動機所含的必要元素為旋律以及節奏,動機至少包含一組特有的音程(Pitch Interval) 與一組特有的音長,音程可以構成旋律,音長構成節奏。音程是連續的音,兩兩相鄰音的 音高差;節奏是連續的音,以不同音長先後排列的關係。貝多芬第五號交響曲“命運”第一 樂章的主要動機,命運之神的敲門聲,就是最初四個音“Sol Sol Sol Mi~”,不斷在整個交響 樂中的第一樂章出現。為了不讓音樂只是單調的重複同一個動機,作曲家會安排動機以不 同的改變形式重複出現在音樂中。以交響曲“命運”第一樂章的動機來看,有時整體動機音 比較高,有時音比較低,但是動機的結構都與最初四個音一樣。動機的變化會在 4.1 詳細 的描述。 在作曲的程序中,完整的音樂作品是以動機為依據,連續不斷的變化構成音樂的主題; 多個相關的主題可以組合產生音樂的主旋律。因此,我們可以將動機探勘出來後,以音樂 的 動 機 為 線 索 切 割 音 樂 段 落 , 並 且 將 每 一 個 段 落 視 為 同 一 首 音 樂 中 的 不 同 主 題 。 Lartillot[25][26]指出,先前研究顯示,人類是因為記住音樂的“前後結構”關係,因此可以在 動機改變時辨認出來。音樂旋律也常依據某些易於讓人類記憶的規則而製作出來。
1.3 MIDI 格式
一般來說,數位音樂儲存的方式有兩種,第一種為高階的Symbolic 的儲存方法,另外 一種為低階的 Acoustic 的儲存方法。通常,Acoustic 所包含的音樂資訊是最為完整的,包 含所有人類可以感知的資訊,而Symbolic 的儲存方式,只能紀錄完整的旋律與節奏以及粗 略的音色。然而,分析動機只需要旋律與節奏兩項最主要的特徵,要從Acoustic 儲存方法 分析出旋律與節奏是很困難的;而Symbolic 儲存方式可以直接取得這兩項音樂特徵。最常見的Symbolic 儲存方法為 MIDI 檔案格式,同時也是最容易取得資料的檔案格式。因此,
本計劃所處理的音樂資料是以MIDI 檔案格式儲存的。
表 1.1:Head Chunk 格式。
Head Chunk
Chunk Type Data Length Data
6 bytes 4 bytes
(ASCII code)
4 bytes
(32 bits binary) 16 bits 16 bits 16 bits
MThd <length> <format> <tracks> <division>
表 1.2:Track Chunk 格式。
Track Chunk
Event Type Data Length Data
4 bytes (ASCII code) 4 bytes (32 bits binary) <length> bytes (binary data)
MTrk <length> <delta time><event>,<delta time><event>, …
表 1.3:一個 MIDI Event Data 的記錄方式。
Delta time1 Event1
Delta time2 Event2
Delta time3 Event3
…..
Delta timek-1 Eventk-1
Delta timek Eventk
MIDI 的全名是 Musical Instrument Digital Interface,常見的 MIDI 有三種不同的格式。 我 們 一 般 最 常 見 的 格 式 為 GM(General MIDI) , 另 外 兩 種 為 GS(General Standard) 與 XG(Extended General MIDI)。我們接下來以 GM 的 MIDI 檔案格式為主做介紹,檔案架構 由一個<Header chunk>與多個<Track chunk>所組成。如表 1.1 所示,在 Header chunk 裡包括了播放格式(format),音軌的數量(tracks),演奏的基本時間單位(division)等訊息。如 表 1.2 所示,在一個 Track chunk 內,紀錄許多 MIDI 事件(Event),每個 Track chunk 代表 一個MIDI track。每一個事件前,會記錄一個事件發生的時間(Delta-time),如表 1.3 所示。
通常,一個音符包含兩個事件的發生,第一,Onset 事件,代表音符開始發音;第二,Offset
事件,代表音符結束發音。在 Onset 與 Offset 事件中,都會記錄音符的音高與音量。根據
標準的MIDI 格式,音高的範圍是 0 到 127,我們常使用的 C 大調音階,也就是自然音階如
圖1.1 所示,在 MIDI 所記錄的音高資訊為<60, 62, 64, 65, 67, 69, 71>,每一個單位都代表半 音(Semitone)。此外,音量的範圍也是 0 到 127。Onset 與 Offset 兩個事件的時間間距,代 表該音符的音長。所以,由這兩個事件所記錄的資訊,我們可以知道一個音符開始發音的
時間、結束發音的時間、音高、音量與音長。由於MIDI 資料是以 Binary 格式儲存,我們
必須先將MIDI 透過 Parse 處理後,在分析 MIDI Event 的資料。
MIDI 的製作,通常是透過製作者以演奏的方式輸入到電腦內記錄下來。音高以半音為 單位,音長以Tick time 為單位。但是,樂譜上兩個同樣拍子的音符,實際在演奏中不會完 全相同。所以,我們在探勘音樂的資料之前,必須以 MIDI 檔案所記錄的拍子時間單位, 做音長的校正(Quantization)。
1.4 報告架構
接著我們介紹本篇報告的架構。在第二章,我們將介紹Music segmentation、Thematic extraction、Summarization 與 Mining frequent subsequence 等相關研究。第三章,我們介紹我們計畫主要的方法,包含 MIDI 資料擷取、主旋律擷取方法、兩種粗略分段方法、兩種動
機探勘方法,以及最後以主題分段的方法。第四章,介紹我們實作所需要的技術與方法。 第五章,介紹我們的實驗設計、實驗的評估方法,以及實驗結果。第六章,根據我們實驗 的方法做討論,以及未來研究可能的方向。
第二章
相關研究
2.1 音樂分段
Spevak[40]等人指出,音樂的分段是將獨立的音符以時間結構的關係結合起來。目前研 究主要的作法是從音樂的主旋律找出許多組的分段點(Boundary) ,每一個段落都是由前後 兩個分段點所決定,因此將主旋律分成許多局部的片段(Local boundary segmentations)。有 時候,音樂中有些部份是找不到完整的分段點,所以分段的結果可能不會涵蓋整段音樂。 音樂的小片段可以幫我們分析出比較高階的音樂特徵,如:對比、和聲等。通常音樂 可`以利用音長、音高資訊來決定分段點,不考慮較高階的音樂資訊[3][15]。一些研究學者 [2]針對民俗音樂(或民謠 Folksong)做分解時,考慮歌詞的押韻,因為歌曲中的歌詞與旋律 會相互影響。 另一方面來看,音樂可以依照主題分成許多的段落。比如說:古典音樂的奏鳴曲式可 以分為主題、主題發展、主題再現、終止四大段落。這種與音樂實質內容有關的段落形式, 並不能單純以分段點來決定。目前很少研究是針對音樂的段落來處理,音樂學已經有許多 相關的資訊與音樂的分段有關係,如:和弦進程 (Chord progression)可以讓我們分辨出一個 完整的段落,我們一般常聽見的民歌,在利用吉他彈唱時,都會固定的和弦進行。這樣的 方法並不能反映出音樂主題的內容,只是單純的將音樂切割開。
Generative Theory of Tonal Music
Lerdahl 與 Jackendoff[27]在 1983 年提出 “Generative Theory of Tonal Music” (GTTM), Lerdahl 等人將調性音樂(Tonal music)於人類直覺上的意義,具體的描述。GTTM 主要用於 從音樂的表面形式(Surface),找出隱含於內的結構。GTTM 主要能分析的音樂是以主音音 樂(Homophony)為主,主音音樂是由一個主旋律與外加伴奏所組成。GTTM 是目前較具體
的音樂分析理論,具有相當的參考價值。首先,這個理論將音樂以群組(Group)的方式來分 析。群組的方式指的是把主音音樂分解成一群一群的小單位,並且具有階層的關係。圖 2.1 為一個GTTM 所群組分析後的結果,所有的群組都必須符合被上層群組階層包含的關係。 GTTM 利用主音音樂在演奏或演唱時,需要換氣的部分來作為分段的依據,而這些分 段點,大都是音長較長、休止符出現或是音高的起伏改變時的部分。除此之外,GTTM 還 利用相鄰音之間的音長或休止當作距離(Proximity),以及利用各個音相似度(Similarity),來 決定群組的範圍。如圖 2.2 所示,以相同形狀來表示相似音,圖形之間的距離代表音長或 休止。因為相鄰關係與相似關係不同的考量,會改變群組的方式。舉例來說,圖 2.2 的 B 中間的部分有一個圓形與方形距離相近,我們這時候可以選擇不同的比重考量相鄰與相似 的關係。 Grouper
Temperley 等人[42]利用音樂的 Duration 資訊(Inter-Onset Interval、Offset-Onset Interval) 與Metric 資訊(Beat List),找出可能的分段點。這個方法從長度為 n 個音符的音樂中,分別
去分析2n個可能的分段方法,然後求出分段最好的結果。Temperley 利用 GTTM 的規則, 來評估分段好壞。大致來說,這些規則會讓分段點在IOI 與 OOI 間距很大,而且分段點剛 圖 2.1:GTTM 群組範例。 圖 2.2:相鄰關係與相似關係的群組。 A B C
好在Beat 上的結果得到較好的評估排序。
Local Boundary Detection Model(LBDM)
Cambouropoulos[3][4]利用 GTTM 所描述的相鄰與相似的關係,提出 Local Boundary Detection Model(LBDM)。LBDM 所能處理的音樂與 GTTM 一樣,是針對主音音樂的主旋 律。由主旋律分別計算出音程差(Pitch interval)、音長(Interonset interval, IOI)及休止(rest-計 算目前的Onset-time 到上一個 Offset-time 的間距)三個特徵序列。LBDM 計算三個序列得出 “Boundary strength value”,數值序列。數值序列中的高峰(Peak)部分,就是群組或分段的邊 界。LBDM 訂出兩個計算 Boundary strength value 的規則,“Change Rule (CR)”與“Proximity Rule(PR)”。CR 針對一個特徵序列,計算出 “Degree of change”。假設我們取用三種音樂的 特徵值k,k∈{pitch, ioi, rest},每一個特徵值序列以 Prok = [x1,x2,...,xn]表示,所有 Prok所
包含的元素都大於等於零。在x 與i xi+1的Degree of change r 計算公式如下: 1 1 1 , | | + + + + − = i i i i i i x x x x r ,iff 0xi +xi+1≠ 0 1 ,i+ = i r ,iff 0xi =xi+1 = PR 則是找出特徵序列中,可能的分界點,分界點由 Strength value 高的決定。對於一 個特徵k,可以計算出 Vk=[v1,v2,...,vn],其中vi =xi ⋅(ri−1,i +ri,i+1)。加權整合每個特徵所分 別計算出來的Vk,可以決定最後可能的邊界。 Data-Oriented Parsing
Bod[2]針對民俗音樂分段提出 Data-Oriented Parsing(DOP)的方法,利用一個已知分段 的音樂資料庫來做learning,建立一個機率分布。然後在利用 learning 的結果對其他音樂做 分段。Bod 利用 Natural Language 的方法套用到音樂的資料上,主要利用三種 Probabilistic grammar technique 做 learning,分別是 Treebank Grammar Technique,Markov Grammar Technique 與 Extended Markov Grammar Technique with DOB Technique。此外,這個方法考 慮民俗音樂歌詞押韻的方式,同樣也是以Natural Language 的技術處理。
Perceptual Analysis
Jian 等人[22]提出以人類聽覺認知對音樂訊號做分段,有別於傳統聲音訊號的分段。他 們利用Roughness、Periodicity pitch 與 Loudness 三項特徵,找出分段點。Roughness 包含有 音樂的音色與節奏的資訊;Periodicity pitch 包含音高的資訊;Loudness 包含音量的資訊。
與前面所提到的LBDM 所用的原理相同,特徵值中,如果有劇烈變化的地方,就可能是分
段點,例如:在音色變換的時候,Roughness 值會有劇烈的變化。不過,這個方法並不適用 於對主題做分段。在交響曲中,主題常常被不同樂器輪流演奏出來。舉例來說,貝多芬第 六號交響曲“田園”第一樂章的第一個主題,是由小提琴、豎笛與雙簧管三種樂器輪流演奏 出來。如果以音色變化來做分段,會將第一主題分成許多小段。
Repeating Pattern based on LBDM
Chen[8]提出一個應用 LBDM 方法的研究,對整首音樂先分解出一個個片段。然後, 以片段為單位,找出重複出現的片段。Chen 進一步修改 LBDM 的方法,使分解片段的效 果,更貼近人類的感知。
Structural Analysis
Chai[7]針對 Acoustic 音樂資料,找出音樂的重複結構。音樂結構的分析分為五個主要 的步驟,步驟如下。第一,Feature extraction,以 Frame 為單位切割音樂訊號,並且擷取每 一個Frame 的特徵值。對每一個 Frame 使用 Autocorrelation 的方法做特徵擷取,擷取出來 的音樂特徵為該Frame 所代表的音高。第二,Pattern matching,以固定的連續 Frame 個數 組合成許多有重疊(overlap)的片段,利用 Local Alignment 的方法,找出各別重疊的片段在 音樂序列中重複出現的情形。第三,Repetition detection,由前一個步驟的結果探勘出重複 序列。第四,Segment merging,將性質相近的連續數個片段合成一個。最後,結構標示 (Structure labeling),將重複出現的段落做標示。因此,一首音樂在做完結構分析後,如圖 2.3
2.2 主題萃取
Meek[32][33]提出 Thematic Extraction 的問題,從音樂的資料中,找出能夠代表音樂的 Keywords 或動機。這些 Keywords 是從 Intervallic 的旋律中,找出重複出現的樣式。Meek 提出一個Melodic Motive Extractor(MME)演算法,可以自動從音樂中找出重複出現的樣式。 由於Meek 所採用的樣式比對是以 Exact matching 的方法,重複樣式會包含許多沒有音樂意 義的樣式。因此,Meek 訂出一些可以過濾樣式的方法,用以減少樣式的數量。 MME 輸入的音樂資料是以音符的形式,每一個音符包含開始發音的時間(Onset Time),結束發音的時間(Offset Time)與音高(Pitch),以及最長樣式長度限制 W。原始音樂 的資料以長度為 W 的 Sliding Window 擷取資料,然後比對擷取出來的資料是否有重複出現 的樣式。樣式主要是依靠音高的資訊做比對,開始與結束發音的時間用來做進一步的過慮 以及最後所有Patterns 的排序。最後輸出的結果是長度 2~W 的樣式,所有的樣式會比較樣
式的Duration,Rhythmic consistency,Position 與 Register 等特徵值來做排序。
2.3 音樂摘要
Music summarization 目的是從單一的音樂資料中,擷取出具有代表性的段落,藉此可
以提供瀏覽音樂內容的功能。一些相關研究分別針對Acoustic 音樂資料與 Symbolic 音樂資
料,提出Music summarization 的作法。
Hirata[15]提出針對 Symbolic 音樂資料,透過使用者互動的 Music summarization 系統。
這個系統主要是幫助使用者能快速的製作出一首音樂的Summarization,透過電腦先篩選出
可能需要的片段,再讓使用者去做選擇。他們利用GTTM 的方法,先將音樂分段,然後將
所有分段表示成一個Time span tree。接著,利用代表各個音樂分段的 Time span tree 分枝, 作為計算相似度的依據,對所有音樂分段做分群。然後透過使用者互動的方式,去掉不符 合需求的群組。最後,利用剩下的群組產生出Music summarization。
圖 2.3:一首音樂的重複結構分析結果,A 與 B 是重複出現的部份。
Logan[29]等人提出從 Acoustic 音樂資料產生 Summary 的方法。第一,從訊號資料擷 取出Mel-cepstral 特徵序列,Mel-cepstral 是由語音辨識研究領域發展出來的特徵表示方法。 接下來,以固定長度切割特徵序列成許多 Frames。第二,對所有的 Frames 做 Buttom-up clustering 或透過 Traning Hidden Markov model 的方法,將相似的 Frames 設定成同一個標籤 (Label)。最後,從 Frames 中,挑出最常出現的標籤標示的 Frame 為 Key phrase。Xu 等人[49] 改進 Logan 等人的方法,除了 Mel-cepstral 的特徵值以外,還多考慮 Spectral power 與 Amplitude envelope 兩種特徵值。
Bartsch[1]擷取出音樂訊號的 Chroma-based 特徵值,並且利用 Similarity matrix 紀錄特
徵值比對的結果,以用來產生 Summary 的結果。方法總共分為五個步驟。第一,Frame
segmentation,Bartsch 利用 Beat tracking 的技術,先找出音樂的節拍,然後利用接拍的資訊 將音樂訊號分成許多Frames。第二,Feature calculation,計算每個 Frame 是屬於哪一個音 高種類(Pitch class)。Chroma-based 的特徵值將音高區分為 12 個種類,每個 Frame 透過計算 後,分到12 個種類裡。第三,Correlation calculation,比較任兩個 Frame 所屬的種類是否 相同,並且以一個Similarity matrix 記錄比較結果。第四,Correlation filtering,從 Similarity matrix 的資料,計算出 Time-lag matrix。最後,從 Time-lag matrix 中,找出重複出現的音樂 片段。
Chai[6]針對 Acoustic 音樂資料中,做音樂的結構分析。利用音樂結構分析的結果,在 對音樂做 Music summarization。接著,Chai 提出三種用來從結構分析結果選擇 Music summarization 的策略。第一,Section-beginning,發生在音樂一開始的片段為可能的 Music summarization。第二,Section-transition,發生在兩種重複片段中間的片段為可能的 Music summarization。最後,Multiple-phrase,選擇重複片段中,發生在音樂最前面的兩個片段, 各取一半結合起來作為Music summarization。
2.4 音樂樣式探勘
Musical Pattern Discovery (MPD)是最近興起的資訊科學研究領域,主要是對音樂做動 機分析(Motivic analyses)。音樂的動機時常會做改變,如:不同音高的動機,但是人類還是 可以知覺的出來。以前動機分析的研究大都將旋律與節奏分開處理,甚至省略節奏的資訊。 不過,依據音樂學家分析音樂動機在音樂中變化的規則,旋律與節奏是必須同時考慮的。
圖2.4 為巴哈所做的創意曲前三小節,矩形標出音樂動機出現的位置。第一聲部的 A、
B、C 分別是動機原形、動機音程重複(Pitch Interval Repeat)、動機反向進行(Contrary motion)。純粹比較音高,A、B、C 三個皆不相同,如果比較音程(Interval),A 與 B 音程相 同,C 與 A、B 不相同。然而我們可以很明顯的看到,動機的節奏在 A、B、C 三個部分都 是保持不變的。如果在探勘動機的過程,我們只考慮旋律或節奏,可能會找不到動機。音 樂動機有重複出現的特性,並且含有時間先後的關係,相似於資料庫裡的重複序列樣式 (Repeating sequence pattern)。
2.4.1 探勘精確重複樣式
Hsu[16][17]提出兩種探勘精確重複樣式(Mining Exact Repeating Pattern)演算法,找出單 聲部音樂中的重複樣式。第一種演算法是以Dynamic programming based 的方法,找出一首
音樂中精確重複樣式。主要有三個步驟,需要給定Minimum support。第一,將音樂旋律建 立出一個Correlative matrix,記錄旋律中重複的位置,以利於找出重複樣式。如圖 2.5 所示, 將音符重複出現的地方記錄下來。圖 2.5 中,Correlative matrix 第一列代表第一個音 C6 在 其他位置出現的情形;第二列代表第二個音 Ab5 在其他位置出現的情形。第二列中,Ab5 第二次出現的位置,由於前面一個音C6 也重複出現,因此記錄 2,以代表目前有一組音連 續出現的情形,2 代表這一組音目前的長度。其他列的計算依此類推,空白的部分代表沒 圖 2.4:巴哈 C 大調二部創意曲 BWV 001。
A B
C
有任何符合的音。第二,從Correlative matrix 的資訊產生所有可能的候選重複樣式。第三,
計算所有留下候選重複樣式的出現次數,保留出現次數超過Minimum support 的重複樣式。
Hsu[16]提出的第二種方法,是以 Apriori based 演算法,同樣找出精確重複樣式。主要
有兩個步驟。第一,從音樂旋律中找出所有長度為 1 的重複樣式,並且記錄個別重複樣式
的出現次數與位置。以旋律“C D E F C D E C D E F”為例,我們可以記錄長度為 1 的重複樣 式:{“C”,3,(1,5,8)}, {“D”,3,(2,6,9)}, {“E”,3,(3,7,10)}, {“F”,2,(4,11)}。第二,利用前一個步驟
產生出來長度為n 的重複樣式,利用 Join 的方式,組合產生出長度為 n+1 的重複樣式。以
前一個步驟長度為 1 的樣式,如:{“C”,3,(1,5,8)}, {“D”,3,(2,6,9)},我們可以 Join 出{“C D”,3,(1,5,8)};{“E”,3,(3,7,10)}與{“F”,2,(4,11)}可以 Join 出{“E F”,2,(3,10)}。接著不斷重複第 二個步驟,直到無法產生新的重複樣式。
Meredith 等人[34]利用空間向量的觀點,從多聲部的音樂(Polyphonic music)中,找出精
確重複樣式。Meredith 將音長忽略不計,純粹依據音高與音符開始發聲時間為空間的座標, 計算出所有點與點之間的向量。將有相同向量群組在一起,一個向量的群組群組內的點, 都可以依據此向量,同時找到對應的點,也就是重複出現的樣式。Meredith 所提出的方法 有四個主要步驟。第一,將音樂資料,依照音高與發音時間為座標,轉換到座標空間上。 第二,建立出一個矩陣計算旋律中任一點到其他點的向量。音樂旋律以空間的關係表達, 每一個點為一個單一的音符。依據空間的關係,我們可以建立一個矩陣,藉此計算出每一 個點與其他任一點的向量關係。第三,將計算出的所有向量,依序排列。同一群組的點, 圖 2.5:建立 Correlative Matrix 的範例[17]。
即為一組可能的重複樣式。最後,利用Heuristic 規則,刪除沒有意義的重複樣式。 Shih 等人[39]修改 LZ78 壓縮演算法中,建立字典(Dictionary)的原理,用以找出音樂旋 律以小節為單位的重複樣式。主要的作法有三個步驟。第一,將音樂旋律以小節為單位切 割成Bar pattern。然後,對所有的 Bar pattern 建立索引,並記錄每一個不同的 Bar pattern 的內容、重複出現的次數與一個唯一的編號。利用索引,將原來音樂旋律以索引的編號來
表示。第二,以索引編號表示的音樂旋律,透過修改過的LZ78 演算法,建立出一個字典,
而字典內的所有資料即為重複樣式。
2.4.2 探勘趨近重複樣式
Hsu 等人[16]提出 Apriori based 的探勘趨近重複樣式(Mining Approximate Repeating Patterns)方法,找出一首音樂中趨近重複樣式。首先,Hsu 定義了三種不同的 Approximate matching 的方法,分別是 Longer length matching、Shorter length matching 與 Equal length matching。
利用前述的其中一種Approximate matching 的方法探勘 Approximate 經常重複序列,主 要有三個步驟,需給定Minimum support、容許 Approximate 誤差值(Approximate degree)、
序列的長度限制。大致的做法如下,第一,從音樂旋律中找出所有長度為 1 的候選重複序
列,並檢驗是否符合Minimum support,保留符合 Minimum support 的序列。第二,利用前
一個步驟產生出來長度為n 的重複樣式,利用 Join 的方式,組合產生長度為 n+1 的候選重 複樣式。第三,利用選定的Approximate matching 方法,檢驗第二步驟所有候選重複樣式, 刪除出現次數低於最低門檻值的樣式。接著重複不斷第二與第三步驟,直到無法產生新的 重複樣式或者到達最長。舉例來說,給定一個音樂旋律音高 “A B F C D L B M A B P F C F D”,最低門檻值為 2、容許 Approximate 誤差值為 1、最長樣式長度為 4。所以我們可以從 給定的旋律找出下面的重複樣式:P1={ “A”, “B”, “C”, “D”, “F”},P2={ “AB”, “BF”, “CD”, “FC”, “FD”},P3={ “ABF”, “BFC”, “FCD”},P4={ “ABFC”}。
第三章
音樂分段
目前現有的研究中,音樂的分段大都利用人類的聽覺認知(Perceptual),並不是針對音 樂內容做主題式的分段。在一般的音樂裡面,常常包含一個以上的段落。音樂的段落如同 文章的段落,在每個段落包含一個主要的音樂主題。沒有研究對音樂做分段的目的,是希 望藉著分段後的結果,可以用來分析音樂的高階資訊。我們希望可以針對音樂做主題式的 分段,藉此可以讓使用者能夠瀏覽音樂的主題。 音樂的主題段落都包含一個主題,而音樂主題是以音樂動機(Motive)來決定的,作曲者 在作曲時,都會以音樂的動機作發展,完成一個主題的段落。因此,動機會以不同的變化 形式,重複出現在一個音樂的主題內。我們對整首音樂以探勘重複樣式技術找出動機後, 可以再利用動機將主題段落切割出來。 音樂動機序列與傳統的重複樣式特性不相同,主要差別在於樣式比對(Pattern matching) 的方法。傳統重複樣式探勘的方法,是以精確比對的方法檢查樣式在序列中重複的次數, 當樣式的重複次數超過Minimum support 時,就是經常重複樣式 (Frequent repeat pattern)。 音樂動機不是精確的重複出現,如果直接用傳統比對樣式的方法,並不完全適合。所以我 們必須針對動機的特性,設計出適合的方法。音樂的動機包含一組特有的音程與節奏,作 曲者在作曲時,利用動機處理(Motivic treatment),不斷的改變動機。音樂學中,有一種音 樂分析的方法,稱為曲式分析(Analysis of Musical Form)。針對於音樂動機的部份,音樂學 在曲式分析歸納出動機處理的規則。因此,我們可以利用動機處理的規則,對音樂的動機做重複樣式的比對,藉此探勘出音樂的動機。根據 Stein[41],常見的動機處理有六種,分
別為Repeat、Pitch Interval Repeat (Transposition)、Sequence、Contrary Motion、Retrograde 與Augmentation 或 Diminution。我們必須針對不同的動機處理,來設計探勘的方法。
我們將找出主題段落的方法分成四個步驟處理如圖 3.1 流程圖所示,並說明如下。 MIDI 檔案必須先透過 MIDI Parser 剖析檔案格式,將 Binary 格式剖析成文字格式資
取出來的主旋律會以兩種不同節奏表示法來表示,Original duration representation 與 IOI duration representation。針對兩種表示法,我們接著在下列步驟中分別找出可能的動機。 我們對音樂主旋律先做粗略分段(Rough segmentation),以利於動機探勘。粗略分段的 目的是為了幫助動機探勘時,減少誤判的動機產生。在這裡我們以探勘音樂的 Non-trivial 重複樣式,來對主旋律做粗略分段。 主旋律經過粗略分段後,從分段的結果找出動機。我們對產生出來的粗略分段結果, 做動機探勘。動機探勘針對動機重複特性修改傳統探勘重複序列的方法,我們將修改後的 方法稱為探勘 Motive Treatment 方法。 最後,利用找出來的動機對音樂做主題式的精細分段(Fine segmentation)。 第一步驟 Parser 輸出的格式與主旋律擷取的方法將在 3.1 介紹;第二步驟的粗略分段 作法,詳細的細節會在第 3.2.1 詳加敘述。在第三步驟中,兩種不同探勘動機方法的細節 會在 3.3 做進一步的說明。最後一個步驟,我們利用探勘出來的動機作精細分段,我們將 在3.4 做討論。 在進一步說明之前,我們先定義傳統重複樣式。 [ 定 義 3.1] 序 列 S = (s1,s2,…,sm) , 存 在 一 個 序 列 P=(p1,p2,…,pn) 為 S 的 部 分 序 列
(subsequence),表示成 P ⊆ S,如果∃ i, 0 ≤ i≤ m-n+1,使得 p1=si, p2=si+1…, pn = si+n-1 。反之,
我們以P⊄S 表示。
[定義 3.2]對於序列 P ⊆ S,存在 P’ ⊆ S,p1=p’1, p2=p’2, …,pn=p’n。且∃ i, j, 0 ≤ i, j≤ m-n+1,
i ≠ j,使得 p1=si, p2=si+1…, pn = si+n-1,p’1=sj, p’2=sj+1…, p’n = sj+n-1。我們稱P 為 S 中的 Exact
重複樣式。
[定義 3.3]序列 P 為 S 中一個 Exact 重複樣式,存在一個集合 PS={ ps1,ps2,…,psk },∀ps∈PS,
0 ≤ ps≤ m-n+1,使得 p1=sps,p2=sps+1,…,pn=sps+n-1。k 為 P 在 S 中的 Support,我們以 Support(P)=k 表示。
[定義 3.4]給定一 Minimum support 值 ms,如果序列 P 在 S 中的支持度 k ≥ ms,則 P 稱之
為S 的頻繁重複樣式(Frequent repeat pattern)。
[定義 3.5]當 P ⊆ S,P 為 S 的 Frequent repeat sequence pattern,∀P’ ⊆ S,P≠P’,P’為 S 的
Frequent repeat sequence pattern,P ⊄ P’。我們稱 P 為 Maximal 重複樣式。 圖 3.1:主題分段流程圖。
MIDI Files All-mono Melody
Original Duration IOI Duration Representatio Step 2: Rough segmentation IOI Parser Rough segments Step 3: Motive Detection Motive Step 2: Rough Segmentation Step 1:Melody extraction and Representation
Step 4: Fine Segmentation Fine segments Rough segments Step 3: Motive Detection Motive Step 4: Fine Segmentation Fine segments
[定義 3.6]當 P ⊆ S,P 為 S 的 Frequent repeat sequence pattern,∀P’ ⊆ S,P≠P’,P’為 S 的
Frequent repeat sequence pattern,P ⊄ P’且 Support(P)≠Support(P’)。我們稱 P 為 Non-trivial 重複樣式。
3.1 主旋律的萃取與表示法
MIDI 檔案是以 Binary 的格式儲存資料,在 1.3 中我們已經詳加介紹過 MIDI 的儲存格 式。Binary 的格式並不容易直接處理,所以我們利用 MIDI parser 將 MIDI 檔案剖析成其他 較容易使用的資料格式。如圖 3.2 所示,我們所使用的 MIDI parser 會將 MIDI 檔案的 Binary 資料轉換成文字型態的資料。
MIDI 檔案並不是直接紀錄音符的資訊,而是紀錄許多個 Events,包含 MIDI 的系統資 訊與音符的資訊等。一個音符利用兩種特定的Events,Onset event 與 Offset event 分別來表
示開始演奏與結束演奏。所以,我們將Events 的資訊,轉換成音符的資訊,以音符的序列
表達音樂。我們將MIDI 檔案轉成以音符表示的序列<note1, note2, …, notem>,每個 notei表 示一個音符,包含有(onseti, pitchi, di)。onseti表示音符開始發聲的時間;pitchi代表音高;di 代表音長。
Track 1:
tick 0: Sequence/Track Name: Right Hand tick 0: channel 2: program change 3
tick 386: channel 2: note On 60 velocity: 127 tick 435: channel 2: note Off 60 velocity: 0 tick 576: channel 2: note On 60 velocity: 127 tick 769: channel 2: note Off 60 velocity: 0 tick 770: channel 2: note On 64 velocity: 127 tick 943: channel 2: note Off 64 velocity: 0 圖 3.2:經過 Parser 處理後的 MIDI 資料。
例如圖 3.2 經過 MIDI Parser 處李後的資料,我們以音符表示的結果為<(386, 60, 49), (576, 60, 193), (770, 64, 173) >。針對(386, 60, 49),圖 3.2 中我們可以找出 tick 386 是音高
60 開始發音的時間,接著 tick 435 是音高 60 結束發音的時間,所以我們可以計算出 60 這 個音的音長為49 個 Tick time。另外兩個音符(576, 60, 193)與 (770, 64, 173)分別是由 tick 576、tick769 與 tick770、tick 943 所決定。圖 3.2 中的兩個 Tick 0 events 與音樂內容沒有直 接關係的資訊。
一般音樂包含的內容有主旋律以及伴奏。為了能夠探勘出音樂的主題,我們必須針對 主旋律的部分做擷取。因此,我們需要將主旋律從原始音樂資料中擷取出來。而且,音樂 的主旋律不完全固定在同一個MIDI track 中演奏,可能會再多個 MIDI tracks 裡輪流出現。
所以我們在轉換MIDI events 表示法成音符表式的序列時,同時對音樂做主旋律擷取。主旋
律是作曲家希望呈現的主題,而伴奏只是為了襯托或修飾主旋律的部分。通常主旋律會比 伴奏明顯,因此我們要將音樂中較明顯的音符擷取出來當作主旋律。由於大部分的音樂會 同時包含主旋律與伴奏,我們在對音樂主題資料做分析時,不需要去考慮伴奏的部分。
主旋律擷取是參考Uitdenbogerd [46] 等人擷取主旋律的方法,她們提出了 All-mono、 Entropy-channel、Entropy-part 與 Top-channel。All-mono 的方法將一首音樂的所有 MIDI tracks 資料結合成一個,此時會有許多音符有重疊在一起。然後保留同時開始發音中,音高最高 的音符作為主旋律。Entropy-channel 方法是計算各別 MIDI track 的 Entropy,保留 Entropy 最高的MIDI track 當作主旋律。Entropy-part 的方法是將每一個 MIDI track 以固定長度,如: 一個小節,切成多個部份,擷取主旋律時,選擇Entropy 最高的部份。Top-channel 的方法 與前面一個方法相似,同樣將每一個MIDI track 以固定長度切成多個部份,選擇平均音高 最高的部份當作主旋律。根據Uitdenbogerd 實驗的結果,以 All-mono 方法擷取出來主旋律 效果最好。所以,我們修改All-mono 的方法來做主旋律的擷取。 原本All-mono 的擷取方法是不考慮發聲音符音長,而我們修改成考慮發音的音長。如 圖 3.3 所示,a 的部份表示兩個聲部,以原本 All-mono 的方法從這兩個聲部擷取出主旋律, 最後會得到b 的結果。由圖 3.3 第二與第三小節我們可以觀察到,這個方法並沒有考慮一 個音符持續發音的情形。舉例來說,a 的兩個聲部中,高音的聲部在第二小節的第一個音符 為兩拍的音符,這個音符會持續發音至第二小節的第二個音開始發音為止。All-mono 的方 法並不會考慮持續發音的狀況,只考慮同一時開始發音的音符。這樣一來主旋律會被其他 伴奏的聲部影響。
我們修改原本的方法加入考慮持續發音的情形,原本 a 的兩個聲部擷取主旋律的結 果,會如圖 3.3 中 c 的結果。圖 3.4,長條代表一個音符,虛線處代表新的 Event 發生。一
個音樂序列,如果以我們修改的 All-mono 方法做主旋律擷取時,必須考慮虛線上,所有
Event 所發生的改變。經過我們修改的 All-mono 方法,最後找出的主旋律為圖 3.4 中,有 顏色的部分。
我們修改後的做法如下。首先,將一首MIDI 檔案的所有 MIDI Tracks 合成一個 MIDI Track。接著我們依時間順序處理 MIDI Track 中 Event 的資料。只要有新的 Onset event 或 Offset event 發生時,就必須重新檢查目前的最高音,並且記錄下來。如圖 3.4 所示,每一 個長條代表一個音符,虛線的地方代表Onset 或 Offset Events 發生處,最高音的改變都只
會在新的Event 發生處。如此,我們對同一時間的 Event 做處理,也將每一個發音的音長考
慮進去。最後,我們可以得到一個序列 S = <note1, note2, …, notem>表示音樂的主旋律。圖 3.5 是我們所修改的All-mono 演算法,我們依時間的順序,處理經過 MIDI parser 剖析的資料,
圖 3.3:All-mono 的範例。 圖 3.4:All-mono 主旋律擷取示意圖。 a b c Pitch Time
找出屬於主旋律的音符。我們先選擇出目前發音的音符中,最高的音。然後用目前 Onset
與Offset 的 Events 去設定發音音符的狀態。如果最高的音符已經結束發音或者最高的音符
改變,則輸出前面我們所選擇的最高音符到結果的序列中。
擷取出來的主旋律,我們又分別以兩個不同的旋律表達方法做處裡。第一種,用原始 音長表示主旋律節奏資訊的Original duration representation。第二種,用 Inter Onset Interval 的方法表示主旋律節奏資訊的IOI duration representation。在擷取主旋律的步驟之後,我們 計算主旋律中,連續兩個音發生的時間間距。以<(386, 60, 49), (576, 60, 193), (770, 64, 173) > 為例,(386, 60, 49)與(576, 60,193)兩個音的開始發生時間間距為 576 – 386 = 190。所以,我 們原本音符的資料(386, 60, 49),以 IOI duration representation 的表達方法表示為(386, 60, 190)。
3.2 粗略分段
一般傳統的作法在探勘動機時,大都是直接對整首音樂序列探勘音樂的重複樣式。但 是,大部分的重複序列可能不是音樂的動機。在一般音樂作曲中,作曲者常常會讓音樂段 落直接的重複,會讓音樂段落內的所有子序列都有重複的情形發生。為了減少這種情況, 我們可以先針對音樂做粗略的分段(Rough segmentation),產生粗略段落(Rough)再從這些段 落中探勘出音樂動機。 如圖 3.6 為例,(a)、(b)與(c)所標示的皆為重複兩次的序列。(a)所標示部分為音樂的動 機部分;(b)所標示的部分不是動機;(c)所標示的部分為由動機所構成的主題主要部分,而 且(c)為一個 Maximal 的重複樣式,也就是不被其他重複樣式所包含的樣式。由(c)的部分我Algorithm Modified All-mono Melody Extraction
Input: MIDI File E=[e1,e2,…,en] // each ei contains time, event type, pitch Output: Melody S
1. set CurrentTime to e1.time; set CurrentEventList to empty; 2. set OnsetList to empty; // store current onset notes in OnsetList 3. for each event ei of E do
4. if ei.time = CurrentTime then AddtoCurrentEventList(ei); 5. else
6. set TopPitch = the top pitch of OnsetList;
7. setOnsetList();
8. if TopPitch isn’t in OnsetList then append TopPitch to S;
9. set CurrentTime to ei.time; 10. set CurrentEventList to empty;
11. AddtoCurrentEventList(ei); 12. end
13. end
14. set TopPitch = the top pitch of OnsetList; 15. setOnsetList();
16. if TopPitch isn’t in OnsetList then append TopPitch to S; 17. return S;
Function setOnsetList
1. for each event ej of CurrentEventList do
2. if ej.type = Offset then remove ej.pitch from OnsetList; 3. else add ej.pitch to OnsetList; end
4. end
們可以觀察到,(a) 與(b)都被包含在內,此外(a)動機也在(c)裡面以 Pitch Interval Repeat 變 化的形式出現。由於作曲者會將大部分主題段落重複安排出現,加深聽眾的印象,如圖 3.6 的(c)。所以,我們可以先將這些主要部分用探勘 Maximal 重複樣式的方法先探勘出來,接 著對於每個Maximal 重複樣式再以探勘動機的方法找出動機。我們使用探勘 Non-trivial 重 複樣式的方法,來從音樂中探勘粗略段落。 3.2.1 以 Non-trivail 重複樣式作粗略分段 我們以音樂序列的Non-Trivial 重複樣式為粗略的分段,我們修改 2.4.1 中 Hsu 所提出 探勘頻繁重複樣式的Correlative matrix 方法。Correlative matrix 做法主要分成三個步驟,第 一,建立Correlative matrix,Correlative matrix 主要在標示同一個序列中,有重複出現樣式 的位置,並且紀錄序列的長度。第二,產生候選重複樣式,由於Correlative matrix 沒有辦 法針對所有可能長度的重複樣式做紀錄,所以,必須使用Correlative matrix 所記錄的資訊, 將其他候選序列也產生出來。第三,驗證每一個候選重複樣式是否超過Minimum support, 保留合乎需求的重複樣式。 我們主要修改第二個步驟與第三步驟,以符合找出粗略分段的需求。我們修改第二個 步驟中,產生所有可能長度的候選序列的部份,因為我們只需要音符數量超過一定長度的 重複樣式,比如說:只有一個音符的 Non-trivial 重複樣式不需要被產生出來,因此我們不 需要產生所有的候選重複樣式。第三個步驟,除了檢查是否符合Minimum support,我們還 圖 3.6:音樂中的重複樣式。 (a) (c) (b)
增加檢查一個重複樣式的時間長度是否符合我們的需求。以上兩個修改的部份,詳細的方 法會再下一章討論。接下來,我們以一個範例來簡單介紹使用這個方法找出音樂的粗略分 段。我們先分別介紹第二與第三個步驟原本的作法,然後再個別介紹我們所做的修改。根 據第二步驟原來的作法,所有可能長度的重複序列都必須被探勘出來。為了讓探勘出來的
重複樣式都是 Non-trivial 的重複樣式,這個方法還會標記重複樣式出現的次數以及被其他
重複序列包含的次數。因此,對Correlative matrix 的每個元素 Di,j,有四種不同的處理情形。 第一種情形,當Di,j=1 且 Di+1,j+1=0 時,表示發生一個長度為 1 的重複樣式,而且這個樣 式不會被其他樣式包含。第二種情形,當Di,j = 1 且 Di+1,j+1 ≠ 0,表示發生一個長度為 1 的重複樣式,而且這個樣式被其他樣式所包含。第三種,Di,j > 0 且 Di+1,j+1 ≠ 0,表示發 生一個長度為Di,j 的重複樣式,以及所有的 Suffix 都是重複樣式。而且 Di+1,j+1 ≠ 0,表示 所有的重複樣式都會被更長的樣式所包含。第四種,Di,j > 0 且 Di+1,j+1 = 0,表示發生一
個長度為Di,j,而且不會被其他序列所包含的重複樣式,以及所有的 Suffix 都是重複樣式。
Algorithm Construct Correlative Matrix Input: Melody S
Output: Correlative Matrix D 1. Initialize D
2. for each si of S do 3. for each sj of S do
4. if si = sj then Di,j = Di-1,j-1 + 1; end 5. end
6. end 7. return D;
圖 3.7:建立 Correlative matrix 的演算法[16]。
然而,我們所需要的是Maximal 的重複樣式。因此,我們在第二步驟的四種情形只要
考慮在Correlative matrix 中,Di,j > 0 而且 Di+1,j+1 = 0 這些位置上的重複樣式,以產生較
少的候選重複樣式。而第三個步驟,除了原本檢查重複次數是否符合 Minimum support 之 外,我們加進重複樣式的長度限制,以過濾掉沒有意義的較短序列。最後,輸出符合這兩 個條件的重複序列作為結果。 詳細的演算法如下。首先,第一個步驟,利用音樂主旋律的序列S,建立一個 Correlative Matrix D。演算法如圖 3.7 所示,對於所有的 si 屬於 S,檢查 sj(j > i)是否為重複出現的音 符,並且累計目前連續重複出現的序列長度。第二個步驟,我們只需要找出音符數量大於
一定Maximal 的重複樣式,對於 Correlative matrix 我們只需要考慮下面的一種情形。當 D 中的一個元素Di,j > 0,而且 Di+1,j+1 = 0。對應到原來的序列 S,Di,j 指的是一個重複樣式 的端點。我們就可以利用Di,j 的值,倒推出一個重複樣式 P 開始於 S 的第 i-Di,j+1 個位置
結束在第 i 個位置。演算法如圖 3.8 所示,我們先把所有符合上述條件的序列找出來,然
後找出所有可能的Maximal 重複樣式,然後再經過檢查重複樣式的長度與出現次數是否符
合Minimum support,輸出最後結果。
Algorithm Find Repeating Patterns
Input: Correlative matrix D, shortest length m of one segment Output: Repeating patterns with constrain
1. set PatternList to empty 2. for each di,j of D do
3. if di,j > 0 & di+1,j+1 != 0 then
4. add all suffix of P = <(si-di,j+1, si-di,j+2,…,si> to PatternList; 5. end
6. if di,j != 0 & di+1,j+1 = 0 then
7. add P = <(si-di,j+1, si-di,j+2,…,si> to PatternList; 8. end
9. end
10. MaximalPatternList = all maximal patterns of PatternList; 11. for each pi of MaximalPatternList do
12. if pi length less than m measures then 13. remove pi from MaximalPatternList; 14. else if frequent of pi < minimum support then 15. remove pi from MaximalPatternList; 16. end
17. end
18. return MaximalPatternList;
圖 3.8:修改的探勘候選 Non-trivial 重複樣式演算法,與檢驗 Non-trivial 重複樣式規則。
[範例 3.1] 以歌曲“小蜜蜂”為例,一個音符以(pi, di)表示,其中 pi 代表音高,di 代表音長。
在這裡音高以音樂的音名表示,音長以一拍為單位音長1。“小蜜蜂”主旋律的序列可以表示
為<(67, 1), (64, 1), (64, 2), (65, 1), (62, 1), (62, 2), (60, 1), (62, 1), (64, 1), (65, 1), (67, 1), (67, 1), (67, 2), (67, 1), (64, 1), (64, 2), (65, 1), (62, 1), (62, 2), (60, 1), (64, 1), (67, 1), (67, 1), (60, 2)>。 假設探勘重複序列參數 m 的值為 2 個小節,Minimum support 為 2。我們可以建立一個 Correlative matrix 如圖 3.9 所示。在 Di,j > 0 且 Di+1,j+1 = 0 為一個重複樣式的結尾,我們 可以找出下面幾種重複樣式,<(67, 1)>、<(64, 1)>、<(65, 1)>、<(62, 1)>、<(67, 1), (67, 1)>
與<(67, 1), (64, 1), (64, 2), (65, 1), (62, 1), (62, 2), (60, 1)>等樣式。接著,我們從這幾個樣式 中選出Maximal 的重複樣式,得到<(67, 1), (67, 1)>與<(67, 1), (64, 1), (64, 2), (65, 1), (62, 1), (62, 2), (60, 1)>。此外,我們加入長度的限制,去除總長度短於 2 小節的重複序列,<(67, 1), (67, 1)>會被去除掉。最後一個步驟,我們會檢查重複樣式是否符合 Minimum support 值。 最後我們得到一個Segment 結果<(67, 1), (64, 1), (64, 2), (65, 1), (62, 1), (62, 2), (60, 1)>。 67,1 64,1 64,2 65,1 62,1 62,2 60,1 62,1 64,1 65,1 67,1 67,1 67,2 67,1 64,1 64,2 65,1 62,1 62,2 60,1 64,1 67,1 67,1 60,2 67,1 − 1 1 1 1 1 64,1 − 1 2 1 64,2 − 3 65,1 − 1 4 62,1 − 1 5 62,2 − 6 60,1 − 7 62,1 − 1 64,1 − 1 1 65,1 − 1 67,1 − 1 1 1 1 67,1 − 1 1 2 67,2 − 67,1 − 1 1 64,1 − 1 64,2 − 65,1 − 62,1 − 62,2 − 60,1 − 64,1 − 67,1 − 1 67,1 − 60,2 − 圖 3.9:Correlative Matrix 範例。
3.3 動機偵測
我們將介紹兩種從粗略分段的結果中探勘動機的方法。第一種方法,根據 Stein[41]提 出作曲者常用的六種動機處理變化特性。我們利用這些特性修改傳統探勘重複序列的方法 來探勘動機。第二種方法,利用Local boundary detection model 的方法,對音樂中所有連續 的音符,以數種音樂的特徵值計算出Boundary strength value,代表兩個音之間落差的大小。根據計算的結果,選擇Boundary strength value 高的地方當作分段點。利用這些分段點,將 音符群組成許多小段。然後,以群組的小段為單位,找出可能的序列當作動機。
根據Stein[41]提出常用的六種動機處理變化特性,分別敘述如下。
1. Exact repeating:是動機常見的變化,如圖 3.10 所示。利用反覆的處理,作曲者可以讓 聽眾加深對主題動機的記憶。
2. Pitch interval repeating:Pitch interval 是指兩個連續音符的音高差。Pitch interval repeating 在音樂的意義是 Transposition。圖 3.11 為 Pitch interval 重複的範例,純粹看音高時,
方框所標示的地方不算重複出現。但是,我們以Pitch interval 來看,我們就可以知道方
框標示的地方是一個重複樣式。
3. Sequence(模進):模進是連續三個以上的動機 Transposition,而且每個 Transposition 不 相同,但是必須是相同的升降方向。圖 3.12 為 Sequence 變化的例子,第一個小節內是 原始的動機,接著連續兩個Transposition 變化。
4. Contrary motion(反相):反相動機處理為保持動機的節奏,但是將旋律反相進行。旋律 的反相進行指的是,將動機Pitch interval 的值,全部取負號。如圖 3.13 所示,第一小 節動機的Interval 為<1, 1, 1, -2, 1, -2>,第二小節的反相變化後的 Tonal interval 為<-1, -1, -1, 2, -1, 2>。
圖 3.10:Exact repeating patterns 的範例。
圖 3.11:Interval repeating patterns 的範例。 Pitches:|67 64 64|65 62 62|60 62 64 65|67 67 67| ……| Pitch Interval:|-3 0 1|-3 0 -2|2 2 1|2 0 0|…..|
圖 3.14:Retrograde 變化的範例。 5. Retrograde(逆行):逆行的動機處理是維持原始節奏,將音高倒過來排列。如圖 3.14 所 示,第一小節為原始動機,第二小節為逆行的動機變化。整個動機的節奏並沒有改變, 音高由原來的<65, 65, 67, 71, 72, 72>變為<72, 72, 71, 67, 65, 65>。 6. Augmentation or Diminution:作曲者在使用增值或減值的動機處理時,會保留原始的旋 律,將動機的節奏依比例加快或減慢,也就是延長或縮短動機所有音符的音長。如圖 3.15 所示,第一小節為原始動機,第二、三小節為增值的動機,第四小節為減值的動 機。 接下來,我們先介紹第一種探勘動機的方法以下我們對探勘動機方法修改的部份做介 紹。首先,我們先定義表示音樂特徵資料的符號。 圖 3.12:Sequence 變化的範例。 圖 3.13:Contrary Motion 變化的範例。 圖 3.15:Augmentation 與 Diminution 變化的範例。 Augmentation Diminution
M:代表一段單聲部的動機,記錄有 k 個音符,k ≥ 1,| M | = k;每一個音符記錄一組
(pi, di),使得 M = <(p1, d1), (p2, d2),…, (pk, dk)>。
Mint:代表動機 M 的音高部份以 Pitch interval 來表示,每一個音符記錄一組(inti, di), 使得 Mint=<(int1, d1), (int2, d2),…, (intk-1, dk-1)>,k ≥ 1,k = |M|。
i, j:代表音符在動機中的順序。
pi:代表一個音符的音高,以半音為單位,根據MIDI 所制定的規格,1≤ pi ≤128。
di:代表一個音符的音長或IOI,以 MIDI 的 Tick time 為計算時間的單位。
inti:代表前後兩個音的音程差,inti = pi+1 - pi。
Exact Repeating
給定一個 M = <(p1, d1), (p2, d2),…, (pk, dk)>,利用反覆的規則,可以產生 M’ = <(p1’, d1’), (p2’, d2’),…,(pk’, dk’)>,且 pi=pi’,di=di’,0 < i ≤ k。我們利用原始音樂的資料建立 Correlative matrix,然後利用 Correlative matrix 探勘經常重複序列。Correlative matrix 建立的演算法如 圖 3.16 所示。在第 3.2.1 節,我們利用 Correlative matrix 的方法找出音樂中 Maximal 的重 複序列。所以,我們只考慮Correlative matrix 中,Di,j > 0 且 Di+1,j+1 = 0 的情形。但是,在探 勘動機的部分,我們必須對於四種情形全部考慮。
Pitch Interval Repeating
我們直接將音樂轉換成Pitch interval 的表示方法,探勘出 Interval repeating patterns。給 Algorithm Construct Correlative Matrix for Exact repeating
Input: Melody S
Output: Correlative Matrix D 1. Initialize D
2. for each si of S do 3. for each sj of S do
4. if si = sj then Di,j = Di-1,j-1 + 1; end 5. end
6. end 7. return D;



![圖 3.7:建立 Correlative matrix 的演算法[16]。](https://thumb-ap.123doks.com/thumbv2/9libinfo/8302330.174177/36.892.85.804.566.804/圖37建立Correlativematrix的演算法16.webp)





