義守大學工業管理學系
碩士論文
運用 Savitzky-Golay 濾波法改良灰色模型預
測精度
Improvement of grey forecasting model
precision by Savitzy-Golay filter method
研 究 生:黃 桂 芳 撰
指導教授:陳 俊 益 博士
義守大學工業管理學系碩士班
研究生黃桂芳所提之論文
運用 Savitzky-Golay 濾波法改良灰色模型預
測精度
業經本委員會審議通過
召集人: 重明益 博士 哥們 .0L (簽名)委
員: 林煥章 博士 1rJ- .-x投身 (簽名)委
員: 陳俊益 博士 γ導:._ ~位必~ (簽名)委
員: 博士^
^
(簽名)所
長: 曹以明 博士、清外代,,0/
1\\
(簽名)中華民國
104 年
6 月 、I
謝誌
首先誠摯的感謝指導教授陳俊益博士,老師悉心的教導使我得以一窺灰色預 測領域的深奧,不時的討論並指點我正確的方向,使我在這些年中獲益匪淺。老 師對學問的嚴謹更是我輩學習的典範。 兩年裡的日子,實驗室裡共同的生活點滴,學術上的討論、言不及義的閒扯、 讓人又愛又怕的宵夜、趕作業的革命情感、因為睡太晚而遮遮掩掩閃進實驗 室...,感謝眾位學長姐、同學、學弟妹的共同砥礪,你/妳們的陪伴讓兩年的 研究生活變得絢麗多彩。 感謝不厭其煩的指出我研究中的缺失,且總能在我迷惘時為我解惑,也感謝 芷榕同學,琮育、勁頤、偉宏學弟,宇婷、佩芳學妹,你們的幫忙及搞笑我銘感 在心。 最後,謹以此文獻給我摯愛的雙親。 黃桂芳 2015 謹誌於 義守大學工業管理學系II
摘要
在這個瞬息萬變的科技時代中,為了因應預測未來問題,而許多預測模型陸 續被提出,但傳統的預測模型常有需要收集長期、大量的歷史資料與預測模型的 反應之能力不佳等問題。因此,灰色系統理論之提出即是針對此一需求,其中, GM(1,1)在理論中是最常廣泛應用的預測模型,其特性不需要大量的歷史資料即 可快速建構模型,但是其預測模型在預測長期、數據起伏波動劇烈或是資料數值 包含負數時,容易產生高估或是低估的情形。 因此,本研究針對此一現象進行分析且改良灰預測 GM(1,1)模型,採取結合 Savitzky-Golay 濾波法,Savitzky-Golay 濾波法是使用最小平方多項式的迴歸方式, 利用鄰近點的加權平均取代原來的資料,使原始數據更平滑、減少資料的雜訊, 能提高預測模型的精確度、降低預測誤差。 在本研究利用中華民國統計資訊網的數據作為預測資料,探討 SGGM(1,1) 的預測過程變化,如預測過程中是否採用逆 SG(ISG)、預測的數據前處理順序、 SG 平滑時的端點處理變化和當原始 GM(1,1)預測效果極佳時,採用 SGGM(1,1) 預測效果是否更佳,討論以上幾種預測變化情形,研究結果發現改良後的 GM(1,1) 確實有明顯降低預測誤差,但是有幾種情形會使預測效果明顯降低,如預測過程 採取 ISG,或是將 SGGM(1,1)預測的數據前處理順序做改變時,都會使預測效果 變差,而且發現當原始 GM(1,1)的預測誤差 MAPE<5%時,相較於 SGGM(1,1)繁複 的數據前處理計算,本研究建議採用 GM(1,1)即可達到極佳的預測能力。 關鍵詞:灰色系統理論、GM(1,1)、Savitzky-Golay 濾波法、改善灰色預測III
Abstract
In an era where technologies are rapidly changing, numerous prediction models have been sequentially developed to forecast future problems. However, conventional prediction models present a number of shortcomings, such as the long-term and extensive collection of historical data and poor forecast performance. To resolve these problems, Grey System Theory (GST) was introduced. GM (1,1) in the theory is the most widely applied prediction model. The model can be established without large historical data sets. However, it is prone to produce overestimations or underestimations when forecasting long-term data, or data that fluctuates violently or contains negative values.
Therefore, the researchers of the present study focused on such problems when reviewing the GM (1,1) model and proposed a revised grey prediction GM (1,1) model by incorporating the Savitzky-Golay (SG) filter. This filter employs a least square polynomial regression approach, where the weighted averages of neighboring points are used to substitute original data, thereby smoothing the data, reducing data noise, enhancing forecast accuracy, and alleviating forecast errors.
The researchers adopted the data published on the Taiwan National Statistics website as the forecast data to examine the changes in the forecasting process using the SGGM (1,1). Observations included (1) whether an inverse SG (ISG) model was employed; (2) pre-processing order of the forecast data; (3) the influence of end points processing during SG smoothing; and (4) forecast performance of the SGGM (1,1) when that of the original GM (1,1) was excellent. Findings confirmed that the revised GM (1,1) model significantly reduced forecast errors. However, a number of situations worsened forecast effectiveness, namely, (1) when ISG was employed during forecasting and (2) when accumulated generation was employed before SG smoothing. Moreover, the researchers found out that when the mean absolute percentage error (MAPE) was less than 5 in the original GM (1,1) model, it is unnecessary to apply SGGM(1,1) because of tedious calculation comparing to accuracy improved..
Keywords: Grey System Theory, GM (1,1), Savitzky-Golay filter, revised grey prediction
IV
目 錄
第一章 緒論
第一節 研究動機 ... 1
第二節 研究目的 ... 1
第三節 研究範圍與限制 ... 2
第四節 研究架構 ... 2
第二章 文獻探討
第一節 預測概論 ... 5
第二節 灰色系統理論 ... 6
第三節 S
AVITZKY-G
OLAY濾波法 ... 13
第三章 研究方法
第一節 灰色預測 GM(1,1)模型 ... 16
第二節 S
AVITZKY-G
OLAY濾波法 ... 21
第四章改良之 GM(1,1)-SGGM(1,1)
第一節
SGGM(1,1)預測過程 ... 24
第二節
SGGM(1,1)模型之數據端點處理方法 ... 38
第三節
SGGM(1,1)模型之 SG 變化 ... 45
第四節
SGGM(1,1)模型建議 ... 48
第五章 結果與建議
參考文獻
V
表目錄
表
2.1 改良 GM(1,1)的相關文獻 ... 10
表
2.2
S
AVITZKY-G
OLAY濾波法的文獻整理 ... 13
表
3.1MAPE 評估預測能力分類 ... 19
表
4.1 主要接單地區數據-外銷訂單 ... 26
表
4.2 消費者物價基本分類指數的數據 ... 29
表
4.3 出口貿易總值的數據 ... 32
表
4.4 進口貿易總值的數據 ... 35
表
4.5
人口數的數據 ... 49
表 4.6
失業率(%)的數據 ... 50
VI
圖目錄
圖
1.1
研究流程 ... 4
圖
3.1
原始數據與一次 AGO 曲線圖 ... 17
圖
3.2
原始灰色 GM(1,1)模型流程圖 ... 20
圖
3.3
原始數據與五筆數據五點平滑曲線圖 ... 23
圖
3.4
原始數據與五筆數據七點平滑的曲線圖 ... 24
圖
4.1
改良 GM(1,1)過程比較流程圖 ... 25
圖
4.2
主要接單地區-外銷的數據 ... 26
圖
4.3
主要接單地區-外銷之五種預測 MAPE 比較圖 ... 28
圖
4.4
消費者物價基本分類指數的數據 ... 29
圖
4.5
消費者物價基本分類指數之五種預測 MAPE 比較圖 ... 31
圖
4.6
出口貿易總值的數據 ... 32
圖
4.7
出口貿易總值之五種預測 MAPE 比較圖 ... 34
圖
4.8
進口貿易總值的數據 ... 35
圖
4.9
進口貿易總值的數據之五種預測 MAPE 比較圖 ... 37
圖
4.10
數據前處理過程 ... 38
圖
4.11
主要接單地區-外銷之四種預測 MAPE 比較圖 ... 40
圖
4.12
消費者物價基本分類指數之四種預測 MAPE 比較圖 ... 41
圖
4.13
出口貿易總值之四種預測 MAPE 比較圖 ... 43
圖
4.14
消費者物價基本分類指數之四種預測 MAPE 比較圖 ... 44
圖
4.15
主要接單地區-外銷之七種 MAPE 比較 ... 46
圖
4.16
消費者物價基本分類指數之七種 MAPE 比較 ... 47
圖
4.17
出口貿易總值之七種 MAPE 比較 ... 47
圖
4.18
進口貿易總值之七種 MAPE 比較 ... 48
圖
4.19
人口數的數據 ... 50
圖
4.20
失業率(%)的數據 ... 51
圖
4.21
人口數之三種 MAPE 比較 ... 51
圖
4.22
失業率之三種 MAPE 比較 ... 52
圖
5.1
改良 GM(1,1)流程圖 ... 54
1
第一章 緒論
第一節
研究動機
為了因應這個瞬息萬變的科技時代,許多預測模型陸續被提出,而且這些預測的方 法皆各有特色,經過整理後可以發現,常使用的預測模型有時間序列分析、迴歸分析、 類神經網路、灰色理論等,其預測模型之目的皆是希望能夠更廣泛地運用在各領域上, 並且可以達到更精確的預測結果,所以對科學家們來說,唯有不斷地提升模型的預測精 確度,才能獲得最大利潤或是防範天災,如股市預測、市場銷售預測、地震、颱風等。 在不同的預測方法中,大多需要收集長期、大量的歷史資料,而建構其預測模型, 但是其預測模型的反應之能力不佳,不能針對短期及時之預測問題提供可靠度高地預測 成效。因此,灰色系統理論之提出即是針對此一需求。 灰色系統理論是由鄧聚龍教授所提出,理論中包含了各種不同之應用的領域,其中 灰色預測極為重要之一部分。其中,GM(1,1)在理論中最常廣泛使用的預測模型,其特 性不需要大量的歷史資料即可快速建構模型,但是其預測模型在預測長期、數據起伏波 動劇烈時,容易產生高估或是低估的情形。因此,本研究即針對此一現象進行分析並提 供改善之方法。第二節
研究目的
無論是哪種預測方法或是預測模型,幾乎已經過許多修正動作,仍然無法完美地預 測各種不同趨勢型態的資料。灰色預測模型比其他預測模型較晚提出,所以灰色預測模 型的特型和各種資料型態的適性仍未清楚明確定義,僅了解其對於短期或是資料數據較 少的預測誤差較小。 近期許多學者針對灰色預測 GM(1,1)模型的改良做了不少的研究,部分文獻有提到 發現灰色預測 GM(1,1)模型運算時,因為數據變動太過劇烈或是出現含負數值而造成誤2 差增加、預測精確度大幅下降,所以近期的研究是主要為改良原有的 GM(1,1)預測模型, 提高預測精確度、預測誤差。 雖然許多研究針對灰色預測 GM(1,1)模型建構進行改良,在某程度上提高模型精確 度,但還是依然有因為數據太劇烈,而導致預測誤差提高的問題。因此,本研究針對此 問題使用可讓數值平滑化、去雜訊的 Savitzky-Golay 濾波法與灰色預測 GM(1,1)模型結 合,並加以改善預測模型的精確度、降低預測誤差。
第三節
研究範圍與限制
本研究為建立一個結合 Savitzky-Golay 濾波法的新灰色預測 GM(1,1)模型為研究目 標。說明的三項目標: 一、 以灰色預測 GM(1,1)模型結合 Savitzky-Golay 濾波法為研究主體,探討改良後的 灰色預測 GM(1,1)模型與原灰色預測 GM(1,1)模型之間的預測誤差差異。 二、 本研究利用中華民國統計資訊網上的相關資料數據,分別使用改良後的灰色預測 GM(1,1)模型與原灰色預測 GM(1,1)模型建模、預測,其比較兩模型的預測精確 度差異。 三、 灰色預測 GM(1,1)模型結合 Savitzky-Golay 濾波法後,所能改善之原灰色預測 GM(1,1)模型的預測限制。第四節
研究架構
本篇主要分為「緒論」、「文獻探討」、「研究方法與架構」、「研究進度」等四節,概 述如下: 第一章為緒論,本文緒論提出研究目的、研究方法、研究架構、研究限制及研究範 圍等。3 第二章為文獻探討,主要對於預測概論、灰色系統理論、Savitzky-Golay 濾波法做 文獻上的探討與研究參考。 第三章以灰色系統理論、Savitzky-Golay 濾波法作為本研究的方法,利用此兩種方 法做結合改善原灰色預測 GM(1,1)模型。 第四章為利用中華民國統計資訊網所公開的數據資料初步建模比較原灰色預測 GM(1,1)模型與改良後的原灰色預測 GM(1,1)模型預測精確度,以達到本篇論文之目的, 本研究流程圖如圖 1.1 所示。 第五章為本研究的結論與建議,本章節針對研究討論的改良 GM(1,1)預測提出一些 建議。
4 圖 1.1 研究流程 資料來源:本研究 確定研究方向 文獻探討 資料蒐集 選擇預測資料 建立預測模型 預測結果分析比較 結論與建議
5
第二章 文獻探討
本章節主要是將本研究所參考之各類文獻進行統整概述,首先第一節為預測概論, 第二節灰色系統理論,第三節 Savitzky-Golay 濾波法,由於是本研究改良原灰色預測 GM(1,1)模型主要的目標,所以會針對灰色系統理論與的定義與 Savitzky-Golay 濾波法 概念說明。第一節
預測概論
預測一直是計量經濟學家關注的焦點,它除了可以用來推測經濟或是金融變數未來 走勢之外,同時也是檢驗理論與判斷模型好壞的標準之一,而研究者可以藉由比較不同 計量模型的預測效果,從中挑選出合適的模型設定。欉清全等人(2005) 人們重視預測, 需要知道預測正確的機率有多高,而預測的準確與否的關鍵是有無將邏輯弄清楚。準確 的預測靠的是科學,它能反映邏輯和證據的力量,也證明破除思想與決策的迷思。(林 添貴, 2010) 預測是管理工具中的一項工具,儘管預測有一定的困難度,還是能有效幫助決策者 進行判定。 此外,一個預測模型至少要滿足以下敘述要求: (溫坤禮等人, 2002) 一、 含有顯性或是隱性時間之關係 二、 具有外延性 三、 結果具有可實證性 四、 計算數據或模型具有檢驗性 五、 具有全訊息性6 上述條件中,其中一、二、三及五稱為預測模型的基本條件。一般作為預測的模型 有兩種:一種為行為模型,是用系統行為數據建模;另一種為因子模型,不具有全訊息 性,是使用影響系統主行為的因子數列建立模型。 目前預測方法有數百種,通常採用的方法有迴歸分析、德爾菲法、統計趨勢預測法、 馬爾可夫預測法、模型法及灰色預測等,大致上可以分為四大類,本節對上述所整理說 明。(許美蓮, 2011) 一、 判斷法(judgment methods) :運用經驗、直覺、個人的價值體系、猜測與專家意 見。如德爾菲法。
二、 市場研究法(market research methods):用有效的方法建立預測,常用於新產品。 例如市場測試與市場調查。
三、 時間序列法(time-series methods):一種數學方法,利用過去相關資料來預測未來 的需求。如移動平均法、加權移動平均、指數平滑法與迴歸分析等。
四、 因果法(causal methods):根據預測的資料以外之其他資料來預測。
近年來人工智慧技術(Artificial Intelligence Technologies)的預測方法,足以解決複雜 的實務問題,其中的模糊理論(Fuzzy Theory)與類神經網路(Neural Network)更是被各行 各界使用,但都是需要繁雜的計算過程以及大量的資料量,所花費的時間成本相對較大, 而且必須具備相當程度的理論基礎才能迅速使用。(邢治宇, 2008) 在各種預測方法中,大多需要收集長期及大量的歷史資料,且建立預測模型,可是 其預測模型的及時反應能力不佳,而灰色系統理論的灰色預測可以解決針對短期且及時 反應的預測問題無法提供可靠的預測成效。(陳彥全等人, 2007)
第二節
灰色系統理論
在 1945 年控制論學者 Wiener 的 Closed Box 和 1953 年 Ashby 的 Black Box 都是用 來定義內部結構、特性及參數全部未知的系統,之後有人提出灰箱(grey box)的理論,但
7
學術上的特點不多,主要因為在大系統中,除了時間數據以外,其他訊息幾乎無從得知,
因此鄧聚龍教授在 1979 年宣讀了一文「參數不完全大系統最小信息鎮定」,之後在 1982
年出版的國際雜誌 「Systems & Control Letters」發表了「Control Problem of Grey Systems」 向國際正式宣告了灰色系統理論的誕生。(溫坤禮等人, 2009) 溫坤禮等人(2002)以顏色角度來解釋灰色系統理論,黑色代表訊息不明確,白色為 訊息明確,而灰色是介於黑色與白色之間表示訊息不完全明確;以因果關係解釋其理論, 共有四種關係:白因白果如銀行利息,存款、利息明確;白因灰果如口蹄疫發病原因明 確,但受害率不明確;灰因白果如高速公路塞車,但塞車原因不明確;灰因灰果如癌症 之產生擴散率,發病原因及擴散率不明確。趙慕芬(2003)提到環境對系統的干擾,會使 系統的特徵值-離散函數數據呈現雜亂,且不易解讀出關鍵訊息,但是系統具有整體性, 其雜亂的數據必然含某種規律,因此可透過灰色生成整理數據,弱化其隨機性並強化其 規律性,在建立模型。 灰色理論主要針對系統模型之不明確性及資訊不完整之下進行系統的關聯分析 (relational Analysis)及模型建構(model construction),透過預測(prediction)與決策(decision) 等方式,結合數學方法來探究整體系統,並能對事物的不確定(not certainty)、多變量輸 入(multi-input)、離散的數據(discrete data)以及數據的布完整性(not enough)做有效的處理。 (溫坤禮等, 2009)
其理論可以分為六大項:
壹、 灰色生成(Grey generating):
即為補充訊息之數據處理,是一種數找數的規律方法,利用灰色生成的方式降低 數據中的隨機性,並提升其規律性。常用的生成方法有:
一、 灰色關聯生成(Grey relational generating operation;GRGO):在不失真 下所做的 數據處理。
8
三、 逆累加生成(Inverse accumulated generating operation;IAGO):指的是累加生成的 逆運算。
貳、 灰色關聯分析(Grey relational analysis):
在灰色理論中用來分析離散序列間相關程度的測度方法。在傳統上的統計迴歸是處 理變數與變數之間關係的一種常用數學方法,但有以下幾點限制: 一、 變數與變數之間須有互相影響的關係 二、 需要大量的數據資料 三、 數據資料的分布要為典型的,如常態分佈等 四、 使數據變化的因素不能太多 因此傳統的統計迴歸不容易求出答案,而因灰關聯具有少數據及多因素分析的特性, 剛好可以彌補統計迴歸的缺點。
參、 灰色建模(Grey model construction):
利用生成過的數據建立一組灰差分方程與灰擬微分方程之模式。一般可以分成以下 幾種: 一、 GM(1,1):表示一階微分,而輸入變數則需要一個,一般做預測用。 二、 GM(1,N):表示一階微分,而輸入變數則為 N 個,一般做多變量關聯分析用。 三、 GM(0,N):這是 GM(1,N)的特例,表示零階微分,而輸入變數則為 N 個,一般做 多變量關聯分析用。
肆、 灰色預測(Grey decision making):
最常使用 GM(1,1)模型為基礎對現有數據所進行的預測方法,實際上是找出某一 數列中間各元素的未來動態狀況,其優點為所需的數據不用太多及使用的數學基礎相
9
當簡單。
伍、 灰色決策(Grey decision making):
因為對某一事件的考慮之對策不同,而產生不同的效果,為了解決此問題,將使 對策與模型結合做決策。
陸、 灰色控制(Grey control):
灰色控制是指通過系統行為數據,尋求行為發展的規律,以預測未來的行為,當預 測值得到後,將此一預測值迴授至系統,進行系統控制的一種法則。 在各界的學者大力推廣與努力下,已經在各領域中有相當不錯的成果,如數列預測、 災變預測、季節災變預測、拓樸預測、系統綜合預測等。例如翁士民人(2005)利用灰色 預測 GM(1,1)模型來進行土壤粒徑分布的評估,結果顯示發現均勻系數大於 300 時,相 當適合灰預測 GM(1,1)模型之評估;吳玫瑩等人(2010)透過資料分析發展印表機逆向迴 收需求預測模型,但是歷史資料不足的限制下,選擇以研究少數據不確定下的灰色預測; 許天維等人(2012)以 GM(1,1)預測方式結合灰關聯分析,改良一般傳統挑選選手的方式, 提供教師單科及多項科目選材的創新方法。 邢治宇(2008)發現許多學者利用 GM(1,1)模型具有少樣本、建模簡單的優點,結合 其他預測模型優點推導出各種適性更好、預測精確度更佳的灰修正預測模型。崔傑等人 (2008)針對 GM(1,1)預測模型進行研究改善,在某種程度下提高模型的精確度。羅傑瀛 等人(2002)認為其模型簡單而且只需要少量筆數的歷史訊息即可建模,但是其預測的精 準度在不同的情況下會有不同的效果,如預測波動劇烈的數據時,容易在趨勢曲線轉折 處產生高估或是低估的現象,無法達到更精準的預測效果。 以下為改良 GM(1,1)的整理文獻 :10 表 2.1 改良 GM(1,1)的相關文獻 作者/年份 題目 摘要 羅傑瀛等人 (2002) 應用灰色理論於時間序列轉折 點之分析與預測 灰色預測模型在趨勢曲線之 轉折處往往無法達到更精確的預 測效果,利用對造成趨勢轉折因 素進行分析,轉換成量化因素影 響權重值,使用此值將數據間的 波動予以減緩,結果顯示改良後 確實能提高 GM(1,1)的精確度。 鄒紅波等人 (2006) 無偏 GM(1,1)模型的動態特性 分析 無偏 GM(1,1)模型是在傳統 GM(1,1) 模 型 基 礎 上 的 一 種 改 進,消除了傳統 GM(1,1)模型本 身的偏差。 Tsaur, R.C. (2006)
Forecasting Analysis by Fuzzy Grey Model GM(1,1) GM(1,1)容易因為缺乏足夠 的數據,決策者從預測值上所獲 得的資訊量不足,而使決策品質 不佳。此研究將 GM(1,1)結合模 糊理論,通過模糊參數來預測, 決策者可以獲得預測的詳細訊息 曹凱等人 (2007) GM(1,1)、GM(1,N)聯合模型在 建築物沉降預測中的應用 由於 GM(1,N)模型預測精準 度高及 GM(1,1)所需統計數據數 量少的優點,並將兩者結合形成 一個聯合模型,以提高灰色模型
11 的預測精準度。 崔傑等人 (2008) 改進的新 GM(1,1)模型及其建 模精度研究 分析原 GM(1,1)建模參數固 有的缺陷,在定理中證明新的優 化建模初始值,以此建構了新優 化 GM(1,1)模型與原模型比較, 新 GM(1,1)有較高度的建模精度。 洪國禎等人 (2008) 改良式 GM(1,1)灰預測模型於 台電電量需求預測之研究 在 GM(1,1) 預 測 模 型 運 算 中,多次 IAGO 不當運算造成誤 差增加,針對以上問題改善,結 合指數平滑法修正模型,以台電 電量需求微粒進行驗證,與原灰 預測 GM(1,1)模型進行比較,結 果顯示,改良式預測模型確實能 大幅降低絕對誤差、增加精準度。 Li, W. et al. (2008)
An Improved Genetic Algorithm - GM(1,1) for Power Load Forecasting Prblem 傳統的 GM(1,1)預測模型並 不準確,提出了改良遺傳方法的 GM(1,1) , 來 建 構 灰 色 模 型 GM(1,1)的最佳α值,以提高預測 模型的精準度。
Jia, Z.Y. et al. (2008)
An Improved GM(1,1) - Genetic Algorithm to Short-term
Forecasting in Power System
GM(1,1)模型被廣泛應用許 多領域,此文結合了遺傳算法建 構最佳灰色 GM(1,1)模型,提高 預測精準度,還提出一個線性算
12 術交叉,可以大大提高遺傳算法 GM(1,1)的準確度。 陳鵬宇 (2009) 灰色 GM(1,1)模型的改進 在灰色 GM(1,1)初始值加入 擾動因子,且結合遺傳算法求 算,並實例證明了模型的改進可 以提高預測精準度。 Honglinag, H. et al. (2013) Predicting Transportation Engineering Financial Investment By An Improved GM(1,1) Model GM(1,1)模型對通用汽車的 現有研究,提出統一提高初始值 和 GM(1,1)模型優化背景值,比 較原始 GM(1,1)模型,發現新的 GM(1,1)預測較為精準。 黃守仁(2013) 灰色預測模型奇異現象產生原 因之探究與解決方法 本研究應用羅必達法則推導 的結果,當以灰控制係數 b 為其 預測值,亦即 a=0,奇異現象發 生,將灰發展係數 a 為零或不為 零的充分且必要條件,加註於 GM(1,1)原始預測模型中是有其 必要性。 王賢崙等人 (2014) 應用灰色系統模型於半導體封 裝測試之研究-以 P 公司為例 利用灰色參數校正模型,以 台灣半導體封裝測試 P 公司為 例,探討並預測其產業未來之趨 勢,結果顯示,灰色模型適用於 中期預測應用,在模型應用上,
13
非線性灰柏努力預測準確度比 GM(1,1)佳。
資料來源:本研究
第三節
Savitzky-Golay 濾波法
Savitzky-Golay 濾波法最初是由 Savitzky 和 Golay 在 1964 年提供了一種利用最小平 方法的多項式計算方法來計算濾波係數,此方法簡單易懂且計算簡易,可操作性相對於 其他方法高,之後被廣泛地使用於各種資料型態的平滑化、除雜訊,其方法是一種在某 一段時間內,透過加權移動平滑且利用最小平方法進行最佳的擬合方法。降低雜訊的方 法有很多,但大多對使用上有一定的局限性,但其方法執行過程中,只需要簡易的程式 運用,並且降低了資料處理的能力要求,因此這個方法相對更容易學習,而且相對於其 他類似平滑方法,更能夠保留相對極大值、極小值和資料寬度等分布特性,盡量維持原 始資料的不失真。 其方法有以下幾點優點:(楊鑄等人, 2011) 一、 利用最小平方法多項式擬合方法,比一般的最小平方法的操作性強。 二、 其方法沒有限制平滑資料的長度,且平滑後可以明顯降低雜訊、其研究資料訊息 不失真。 三、 所需要操作能力要求不高,容易上手學習研究。 Savitzky-Golay 濾波法是一種特殊的低通濾波法,也可以稱之為 Savitzky-Golay 平 滑法,主要之用途是用來平滑其研究的雜訊資料,觀察其資料平滑後呈現的資料型態, 並在其資料中讀取到關鍵的訊息,因為「雜訊」容易使資料訊號失真,而經常讓研究學 者誤判、誤解。其方法已經在化學、物理、生物醫學工程和其他實驗科學廣泛使用,也 有許多其方法的研究論文,主要應用於實驗收集的數據使用平滑化。(Çağatay Candan et al., 2014)
14
以下為 Savitzky-Golay 濾波法的文獻整理:
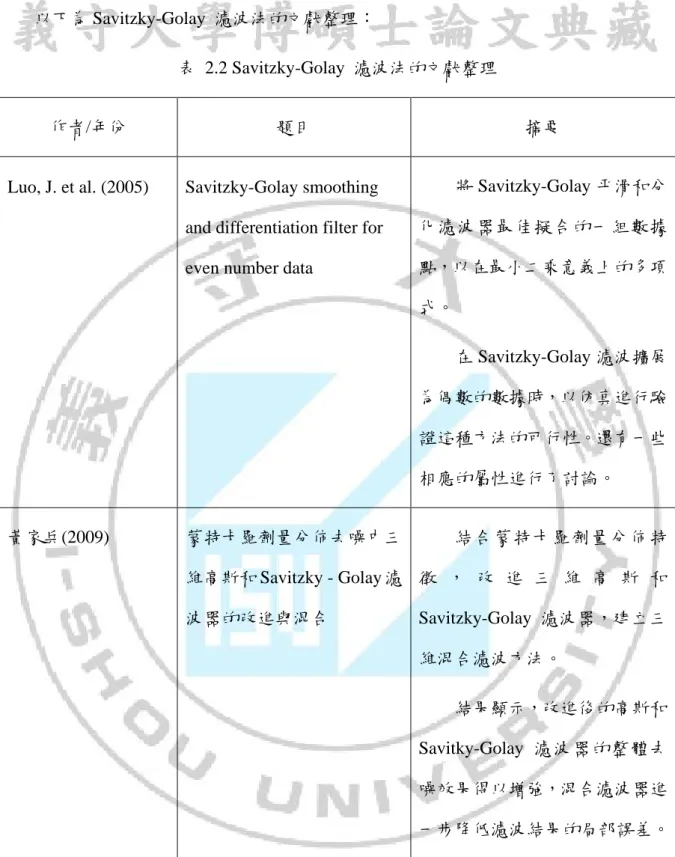
表 2.2 Savitzky-Golay 濾波法的文獻整理
作者/年份 題目 摘要
Luo, J. et al. (2005) Savitzky-Golay smoothing
and differentiation filter for even number data
將 Savitzky-Golay 平滑和分 化濾波器最佳擬合的一組數據 點,以在最小二乘意義上的多項 式。 在 Savitzky-Golay 濾波擴展 為偶數的數據時,以仿真進行驗 證這種方法的可行性。還有一些 相應的屬性進行了討論。 黃家兵(2009) 蒙特卡羅劑量分佈去噪中三 維高斯和 Savitzky - Golay 濾 波器的改進與混合 結合蒙特卡羅劑量分佈特 徵 , 改 進 三 維 高 斯 和 Savitzky-Golay 濾波器,建立三 維混合濾波方法。 結果顯示,改進後的高斯和 Savitky-Golay 濾波器的整體去 噪效果得以增強,混合濾波器進 一步降低濾波結果的局部誤差。
15
Ronald W. S. (2011) What is a Savitzky-Golay
Filter? 發現 Savitzky-Golay 濾波法 後的資料型態不失真,因此從頻 域 的 觀 點 上 , 探 討 Savitzky-Golay 濾波法量化資料 的一些頻域屬性。 楊鑄等人(2011) Savitzky-Golay 平滑濾波器 的最小二乘擬合原理綜述 對 Savitzky-Golay 濾 波 器 的 二 維 演 算 法 進 行 了 簡 單 介 紹 , 對 其 一 維 和 二 維 的 MATLAB 代 碼 進 行 了 分 析 處 理,並將與同其他低通濾波器進 行了簡單比較,簡要說明了其優 勢以及一些應用方向。
Çağatay Candan et al. (2014)
A unified framework for derivation and implementation of Savitzky-Golay filter 將 Savitzky-Golay (SG)濾 波器的設計問題提出作為一個 最低標準的解決方案,且統一的 SG 濾波器的設計框架,其中包 括幾個重要的應用,例如平滑 化、分化,整合和分數延遲顯 影。 該結構示出,以減少在所述 平滑應用的乘法器的數目。 資料來源:本研究
16
第三章 研究方法
本研究之研究方法主要可分為四節,第一節為灰色預測 GM(1,1)模型的建模流程介 紹,第二節為說明如何使用 Savitzky-Golay 濾波法平滑原始數據,第三節為改良後的灰 色預測 GM(1,1)模型建模流程,並在第四章說明改良後的預測模型。第一節
灰色預測 GM(1,1)模型
灰色預測以 GM(1,1)基本模型對現有數據所進行的預測方法,僅需要四筆或四筆以 上的數據即可建模,實際上則是找出某一數列中間各個元素之未來動態狀況,主要的優 點為所需的數據不用太多及數學基礎相當簡單,依據不同目標函數的圖形曲線,使用灰 生成、灰建模等方法擬合出相似曲線,藉此達到預測的目的。 本節將對 GM(1,1)的建模作一簡單的推導與介紹:壹、 先將所獲得的資料定義為原始序列:
x x x x n
x
k Xˆ(0) (0) 1, (0) 2, (0) 3,, (0) (0) ,k1,2,3,,n (3-1)貳、 利用累加生成(Accumulated Generating Operation;AGO)將建立原始序
列累加起來,定義
(1) x為
x(0)的一次 AGO 序列數學模式為:
n k k k k x k x k x k X k X AGO 1 ) 0 ( 1 1 2 1 ) 0 ( ) 0 ( ) 1 ( ) 0 ( , , , (3-2) GM(1,1)做累加生成的目的為降低數據的隨機性,並且使其符合單調遞增的指 數函數圖形。假設有一組數據,先形成原始序列X 0
9,3,8,5,10
,其一階累加生成
35 , 25 , 20 , 12 , 9 1 X ,如圖所示:17 圖 3.1 原始數據與一次 AGO 曲線圖 資料來源:本研究
參、 建立 GM 微分方程式與差分方程式:
一、 灰微分方程式: 0 , 1 1 aX b a dt dX (3-3) 二、 灰差分方程式:將微分方程式離散化,
t t k X k X t k X t k X dt dX 1 1 1 1 1 (3-4) ,取∆𝑡 = 1,則
k X k X k X dt dX 1 1 0 1 1 (3-5) 並令X(1) ≈ Z(1);其中Z(1)為背景值,並定義為:
t Z
k X
k
X
k
k n x11 1 1 1 1 1, 2~ (3-6) 整理後,可以得到灰差分方程式為: 9 3 8 5 10 0 5 10 15 1 2 3 4 5原始數列
9 12 20 25 35 0 10 20 30 40 1 2 3 4 5累加生成
18
b k aZ k X 0 1 ,k 2~n (3-7) 利用最小平方法以及微分和差分方程式求得參數a、b,其中
a
稱為灰發展係數, b 稱為灰控制係數,將數據分別代入差分方程式中(3-8)得
b n aZ n X b aZ X b aZ X 1 0 1 0 1 0 3 3 2 2 (3-8) 以矩陣表示為
n X X X Y 0 0 0 3 2 ,
1 1 1 2 3 2 1 1 1 Z Z Z B , b a ,整理後可得Y B 再使用最小平方法求出 b a :
b a Y B B BT 1 T
(3-9) 以灰微分方程式離散化後可求得預測方程式為:
a b e a b x k X ak 1 1 ˆ 1 0 (3-10)肆、 將上述方程式所得到的數值做反累加生成(Inverse Accumulated
Generating Operation,IAGO)後,得到預測值:
k x k x k Xˆ 0 1 1 1 0 (3-11)伍、 預測能力精確度檢驗
評估預測模型所得到的預測值與實際值之間的差異,視為預測誤差, GM(1,1)19 模型的誤差定義為:
0
100% 0 0 k x k x k x k e (3-12) 其中,x 0
k 為真實值;x 0
k 為預測值 此值可以決定預測模型成功與否的一種方法,本研究採用平均絕對誤差百分比 (Mean Absolute Percent Error;MAPE),檢測預測值的可信度,定義與分類如下:數 筆 預測 n 100, 實際值 預測值 -實際值 n 1 MAPE
(3-13) 表 3.1MAPE 評估預測能力分類 MAPE<10 預測能力極佳 MAPE=10~20 預測能力優良 MAPE=20~50 預測能力合理 MAPE>50 預測不正確 資料來源:Line, C.S., et al. (2007)20 圖 3.2 原始灰色 GM(1,1)模型流程圖 資料來源:本研究 原始數據: AGO 累加生成: 最小平方法求出 、 值,得到預測方程式 IAGO 逆累加生成,得到預測值 預測誤差檢驗 進行實際預測 計算背景值Z 1
k 1
1
1
1
1
k x a k ax k Z21
第二節
Savitzky-Golay 濾波法
Savitzky-Golay 濾波法(Savitzky-Golay digital filter;SG)是由美國化學分析學家 A. Savitzky 與瑞士數學、物理學家 M. JE Golay,在 1964 年提出,此方法係使用最小平方 多項式的迴歸方式,利用鄰近點的加權平均取代原來的資料,使數據更平滑,以減少資 料的雜訊。(曾慧怡, 2011) 假設找一個 m 次多項式來平滑,多項式如下:
m j j m m m m m m i a a i a i a i a i f j m 0 2 2 1 0 (3-14) 其中 j m a 為多項式係數 使用包含數據本身及其前後各L個點做平滑,平滑後的數據 L i L L i L L i L L L k k i k k c n c n c n c n N
1 1 (3-15) 其中N 為平滑後的數據,k nik為未平滑的數據,C 為平均權重係數 k 最小平方誤差和
2 0 2
L L k k i m j j m L L k k i i n a i n f E j (3-16) 為使誤差最小化,令 j m a E j m , , 2 , 1 , 0 , 0 0 2 0 2 0
r L L k k i j m j m L L k k i j m j m m i n i a n i a a j j j (3-17) 假設
L L k k i j m j m m r n i a a i j j 0 (3-18)22 ,其中r 0,1,2,,m,則
L L k r k i L L k r j m j m L L k r k i r j L L k m j m L L k m j r k i r j m i n i a i n i a i n i a j j j 0 0 0 0 (3-19) 定義矩陣為
m m m m m j L L L L L L L L L L L L i r j A 1 0 1 0 1 0 1 0 1 1 1 1 , 2 2 2 1 1 1 0 0 0 2 1 0 2 1 0 (3-20) 假設a a i ATA L L k r j m j mj
, ,則
ATAa ATna
ATA1ATn (3-21) 令 2 11 1 1 1 L n ,即可求出平均權重係數
12 1 1
T T L kA
A
A
c
(3-22) 在此方法中,平滑點數的多寡與多項式的項數是影響平滑效果的重要因素,而採用 此種濾波法的主要優點是,能保留原資料的特徵分布及最大值、最小值及和寬度等。在 Savitzky 與 Golay 的研究中,一個時間序列的資料,本研究選擇使用二階多項式和 5 個 數據點做平滑,即在時間 tj的資料使用過去二點(j2,j1)及未來二點(j2,j1)的資 料作加權平均,所得的平滑多項式為:
3 2 12 1 17 12 1 3 2
35 1 j j j j j j t t t t t t N N N N N N (3-23)23 假 設 有 一 組 數 據 做 平 滑 , 先 形 成 原 始 序 列 X 0
9,3,8,5,10
, 其 SG(5) =(7.0286,6.0857,5.0000,7.4857,8.4571),如圖所示: 圖 3.3 原始數據與五筆數據五點平滑曲線圖 資料來源:本研究 若同樣選擇二階多項式,改用 7 個數據點來做平滑處理,則在時間 tj的資料則,則 使用過去三點(j3,j2,j1)及未來三點(j3, j2,j1)的資料作加權平均,所得的 平滑多項式為:
2 3 3 2 6 1 7 6 1 3 2 2 3
21 1 j j j j j j j j t t t t t t t t N N N N N N N N (3-24) 假 設 有 一 組 數 據 做 平 滑 , 先 形 成 原 始 序 列 X 0
9,3,8,5,10
, 其 SG(7)=(7.5238,6.0476,5.8571,6.8571,8.9524),如圖所示: 9 3 8 5 10 0 2 4 6 8 10 12 1 2 3 4 5原始數列
7.0286 6.0857 5 7.4857 8.4571 0 2 4 6 8 10 1 2 3 4 5五筆數據五點平滑
24 圖 3.4 原始數據與五筆數據七點平滑的曲線圖 資料來源:本研究
第四章 改良之 GM(1,1)-SGGM(1,1)
此章節分成兩個階段驗證改良後的 GM(1,1)預測模型是否有提高預測精度與降低預 測誤差,第一節所討論的是在進行預測後是否執行逆 Savitzky-Golay 濾波法(Inverse Savitzky-Golay,ISG),如果執行 ISG 是否會降低預測的誤差;第二節討論的是在預測 前的數據處理順序做更動,先執行 Savitzky-Golay 濾波法(SG)再做累加生成(AGO)與先 執行累加生成(AGO)再做 Savitzky-Golay 濾波法(SG)比較之間的預測精度,討論數據前 處理更動是否有改善模型的預測精度;第三節主要探討執行濾波法時,左右兩側端點的 處理方式是否會影響預測精度。第一節 SGGM(1,1)預測過程
由於原 GM(1,1)過程做數據前處理累加生成(AGO),進行 GM(1,1)預測後,再進行 逆累加生成(IAGO)得到預測值,而本研究因為 SG 結合 GM(1,1)預測模型後,是否執行 逆 Savitzky-Golay 濾波法(Inverse Savitzky-Golay,ISG),在此節討論如果執行 ISG 會不 會影預測的精準度。 本研究在此節討論如果做 ISG 會不會影預測的精準度,利用中華民國統計資訊網數 9 3 8 5 10 0 2 4 6 8 10 12 1 2 3 4 5原始數列
7.5238 6.0476 5.8571 6.8571 8.9524 0 2 4 6 8 10 1 2 3 4 5五筆數據七點平滑
25 累加生成(AGO) GM(1,1) 逆累加生成(IAGO) 預測值 原 GM(1,1)過程 累加生成(AGO) GM(1,1) 逆累加生成(IAGO) 預測值 濾波法 (SG) 改良 GM(1,1)過程 逆 SG (ISG) 據資料,總共四種數據資料分別為「主要接單地區-外銷」、「消費者物價基本分類指數」、 「出口貿易總值」與「進口貿易總值」的年增率(%),分別比較原 GM(1,1)預測模型、 SG 五點平滑結合 GM(1,1)預測模型與 SG 七點平滑結合 GM(1,1)預測模型。 圖 4.1 改良 GM(1,1)過程比較流程圖 資料來源:本研究
壹、 實例一:主要接單地區-外銷
中華民國統計資訊網數據資料的主要接單地區-外銷,而主要接單地區有美國、大 陸、歐洲、日本、東協六國 2014 年 04 月至 2014 年 08 月的年增率(%)數據,於下表 4.1 所示26 表 4.1 主要接單地區數據-外銷訂單 主要接單地區-外銷訂單 年/月 年增率(%) 2014/04 10.26 2014/05 5.92 2014/06 10.76 2014/07 5.61 2014/08 5.28 資料來源:中華民國統計資訊網 圖 4.2 主要接單地區-外銷的數據 資料來源:中華民國統計資訊網 10.26 5.92 10.76 5.61 5.28 0 2 4 6 8 10 12 2014/4 2014/5 2014/6 2014/7 2014/8
主要接單地區-外銷
年增率(%)27 一、 原 GM(1,1) 二、 SG 五點平滑結合 GM(1,1)預測模型,不採用 ISG 三、 SG 五點平滑結合 GM(1,1)預測模型,採 ISG 四、 SG 七點平滑結合 GM(1,1)預測模型,採 ISG 原始數據 AGO GM(1,1) IAGO 誤差 預測精準度 10.2600 10.2600 10.2600 10.2600 5.9200 16.1800 18.0934 7.8334 10.7600 26.9400 25.2671 7.1737 5.6100 32.5500 31.8366 6.5695 5.2800 37.8300 37.8528 6.0162 24.1745% 75.8255% 原始數據 SG AGO GM(1,1) IAGO 誤差 預測精準度 10.2600 8.7291 8.7291 8.7291 8.7291 5.9200 8.7220 17.4511 17.7129 8.9838 10.7600 7.8474 25.2986 25.3737 7.6608 5.6100 7.2643 32.5629 31.9064 6.5327 5.2800 4.9234 37.4863 37.4771 5.5707 7.1492% 92.8508%
原始數據 SG AGO GM(1,1) IAGO ISG 誤差 預測精準度 10.2600 8.7291 8.7291 8.7291 8.7291 9.1042 5.9200 8.7220 17.4511 17.7129 8.9838 8.0442 10.7600 7.8474 25.2986 25.3737 7.6608 9.2399 5.6100 7.2643 32.5629 31.9064 6.5327 5.0452 5.2800 4.9234 37.4863 37.4771 5.5707 6.2366 17.8917% 82.1083%
原始數據 SG AGO GM(1,1) IAGO ISG 誤差 預測精準度 10.2600 9.5343 9.5343 9.5343 9.5343 -6.16E+13 5.9200 8.7662 18.3005 18.2196 8.6853 -7.08E+14 10.7600 7.6210 25.9214 25.8720 7.6525 1.23E+15 5.6100 6.5729 32.4943 32.6145 6.7425 -7.08E+14 5.2800 6.0962 38.5905 38.5552 5.9407 -6.16E+13 奇異值
-28 五、 SG 七點平滑結合 GM(1,1)預測模型,不採用 ISG 圖 4.3 主要接單地區-外銷之五種預測 MAPE 比較圖 資料來源:本研究
貳、 實例二:消費者物價基本分類指數
中華民國統計資訊網數據資料的消費者物價基本分類指數-總指數,2014 年 05 月至 2014 年 09 月的年增率(%)數據,於下表 4.2 所示 原始數據 SG AGO GM(1,1) IAGO 誤差 預測精準度 10.2600 9.5343 9.5343 9.5343 9.5343 5.9200 8.7662 18.3005 18.2196 8.6853 10.7600 7.6210 25.9214 25.8720 7.6525 5.6100 6.5729 32.4943 32.6145 6.7425 5.2800 6.0962 38.5905 38.5552 5.9407 1.6170% 98.3830% 24.1745% 17.8917% 7.1492% 1.6170% 0% 5% 10% 15% 20% 25% 30%主要接單地區-外銷 MAPE
誤差 奇 異 值29 表 4.2 消費者物價基本分類指數的數據 消費者物價基本分類指數 年/月 年增率(%) 2014/5 1.62 2014/6 1.64 2014/7 1.76 2014/8 2.06 2014/9 0.72 資料來源:中華民國統計資訊網 圖 4.4 消費者物價基本分類指數的數據 資料來源:中華民國統計資訊網 1.62 1.64 1.76 2.06 0.72 0 0.5 1 1.5 2 2.5 2014/5 2014/6 2014/7 2014/8 2014/9
消費者物價基本分類指數
年增率(%)30
原始數據
AGO
GM(1,1)
IAGO
誤差
預測精準度
1.6200
1.6200
1.6200
1.6200
1.6400
3.2600
3.4885
1.8685
1.7600
5.0200
5.1252
1.6367
2.0600
7.0800
6.5589
1.4337
0.7200
7.8000
7.8148
1.2558
31.4410%
68.5590%
原始數據
SG
AGO
GM(1,1)
IAGO
誤差
預測精準度
1.6200
1.6149
1.6149
1.6149
1.6149
1.6400
1.6400
3.2549
3.4591
1.8442
1.7600
1.9229
5.1777
5.1119
1.6528
2.0600
1.6486
6.8263
6.5930
1.4812
0.7200
1.0903
7.9166
7.9204
1.3274
85.3996%
14.6004%
原始數據
SG
AGO
GM(1,1)
IAGO
ISG
誤差
預測精準度
1.6200
1.6149
1.6149
1.6149
1.6149
1.6200
1.6400
1.6400
3.2549
3.4591
1.8442
1.6400
1.7600
1.9229
5.1777
5.1119
1.6528
1.7600
2.0600
1.6486
6.8263
6.5930
1.4812
2.0600
0.7200
1.0903
7.9166
7.9204
1.3274
0.7200
37.4797%
62.5203%
原始數據
SG
AGO
GM(1,1)
IAGO
ISG
誤差
預測精準度
1.6200
1.6038
1.6038
1.6038
1.6038
-1.072E+14
1.6400
1.8152
3.4190
3.4938
1.8900
-1.233E+15
1.7600
1.7552
5.1743
5.1445
1.6507
2.1448E+15
2.0600
1.5095
6.6838
6.5862
1.4417
-1.233E+15
0.7200
1.1638
7.8476
7.8454
1.2592
-1.072E+14
奇異值
-一、 GM(1,1)預測模型 二、 SG 五點平滑結合 GM(1,1)預測模型,不採用 ISG 三、 SG 五點平滑結合 GM(1,1)預測模型,採 ISG 四、 SG 七點平滑結合 GM(1,1)預測模型,採 ISG31
原始數據
SG
AGO
GM(1,1)
IAGO
誤差
預測精準度
1.6200
1.6038
1.6038
1.6038
1.6038
1.6400
1.8152
3.4190
3.4938
1.8900
1.7600
1.7552
5.1743
5.1445
1.6507
2.0600
1.5095
6.6838
6.5862
1.4417
0.7200
1.1638
7.8476
7.8454
1.2592
5.6901%
94.3099%
五、 SG 七點平滑結合 GM(1,1)預測模型,不採用 ISG 圖 4.5 消費者物價基本分類指數之五種預測 MAPE 比較圖 資料來源:本研究參、 實例三:出口貿易總值
中華民國統計資訊網數據資料的消費者物價基本分類指數-出口貿易總值,2014 年 05 月至 2014 年 09 月的年增率(%)數據,於下表 4.3 所示 31.4410% 37.4797% 14.6004% 5.6901% 0% 10% 20% 30% 40%消費者物價基本分類指數 MAPE
誤差 奇 異 值32 表 4.3 出口貿易總值的數據 出口貿易總值 年/月 年增率(%) 2014/5 3.22 2014/6 2 2014/7 5.65 2014/8 9.83 2014/9 5.41 資料來源:中華民國統計資訊網 圖 4.6 出口貿易總值的數據 資料來源:中華民國統計資訊網 3.22 2 5.65 9.83 5.41 0 2 4 6 8 10 12 2014/5 2014/6 2014/7 2014/8 2014/9
出口貿易總值 MAPE
年增率(%)33
原始數據
AGO
GM(1,1)
IAGO
誤差
預測精準度
3.2200
3.2200
3.2200
3.2200
2.0000
5.2200
7.5086
4.2886
5.6500
10.8700
12.6919
5.1833
9.8300
20.7000
18.9567
6.2648
5.4100
26.1100
26.5285
7.5718
49.7294%
50.2706%
原始數據
SG
AGO
GM(1,1)
IAGO
誤差
預測精準度
3.2200
2.5934
2.5934
2.5934
2.5934
2.0000
5.4874
5.4874
6.9142
4.3207
5.6500
11.5480
11.5480
12.2001
5.2859
9.8300
19.4794
19.4794
18.6667
6.4667
5.4100
26.3843
26.3843
26.5779
7.9112
23.7810%
76.2190%
原始數據
SG
AGO
GM(1,1)
IAGO
ISG
誤差
預測精準度
3.2200
2.5934
2.5934
2.5934
2.5934
3.2200
2.0000
5.4874
5.4874
6.9142
4.3207
2.0000
5.6500
11.5480
11.5480
12.2001
5.2859
5.6500
9.8300
19.4794
19.4794
18.6667
6.4667
9.8300
5.4100
26.3843
26.3843
26.5779
7.9112
5.4100
56.0085% 43.9915%
原始數據
SG
AGO
GM(1,1)
IAGO
ISG
誤差
預測精準度
3.2200
2.5890
2.5890
2.5890
2.5890
-2.652E+14
2.0000
4.2433
6.8324
7.2186
4.6296
-3.05E+15
5.6500
5.6743
12.5067
12.6092
5.3906
5.3047E+15
9.8300
6.6733
19.1800
18.8860
6.2768
-3.05E+15
5.4100
7.0319
26.2119
26.1947
7.3087
-2.652E+14
奇異值
-一、 GM(1,1)預測模型 二、 SG 五點平滑結合 GM(1,1)預測模型,不採用 ISG 三、 SG 五點平滑結合 GM(1,1)預測模型,採 ISG 四、 SG 七點平滑結合 GM(1,1)預測模型,採 ISG34
原始數據
SG
AGO
GM(1,1)
IAGO
誤差
預測精準度
3.2200
2.5890
2.5890
2.5890
2.5890
2.0000
4.2433
6.8324
7.2186
4.6296
5.6500
5.6743
12.5067
12.6092
5.3906
9.8300
6.6733
19.1800
18.8860
6.2768
5.4100
7.0319
26.2119
26.1947
7.3087
5.9947%
94.0053%
五、 SG 七點平滑結合 GM(1,1)預測模型,不採用 ISG 圖 4.7 出口貿易總值之五種預測 MAPE 比較圖 資料來源:本研究肆、 實例四:進口貿易總值
中華民國統計資訊網數據資料的消費者物價基本分類指數-進口貿易總值,2014 年 05 月至 2014 年 09 月的年增率(%)數據,於下表 4.4 所示 49.7294% 56.0085% 23.7810% 5.9947% 0% 10% 20% 30% 40% 50% 60%出口貿易總值 MAPE
誤差 奇 異 值35 表 4.4 進口貿易總值的數據 進口貿易總值 年/月 年增率(%) 2014/5 -0.82 2014/6 8.02 2014/7 9.08 2014/8 13.92 2014/9 0.49 資料來源:中華民國統計資訊網 圖 4.8 進口貿易總值的數據 資料來源:中華民國統計資訊網 -0.82 8.02 9.08 13.92 0.49 -2 0 2 4 6 8 10 12 14 16 2014/5 2014/6 2014/7 2014/8 2014/9
進口貿易總值
年增率(%)36
原始數據
AGO
GM(1,1)
IAGO
誤差
預測精準度
-0.8200
-0.8200
-0.8200
-0.8200
8.0200
7.2000
9.1127
9.9327
9.0800
16.2800
17.5799
8.4673
13.9200
30.2000
24.7980
7.2181
0.4900
30.6900
30.9512
6.1532
308.6232% -208.6232%
原始數據
SG
AGO
GM(1,1)
IAGO
誤差
預測精準度
-0.8200
1.3623
1.3623
1.3623
1.3623
8.0200
5.6046
6.9669
9.9213
8.5590
9.0800
11.9609
18.9277
17.9657
8.0444
13.9200
9.3129
28.2406
25.5264
7.5607
0.4900
4.3583
32.5989
32.6326
7.1062
41.8304%
58.1696%
原始數據
SG
AGO
GM(1,1)
IAGO
ISG
誤差
預測精準度
-0.8200
1.3623
1.3623
1.3623
1.3623
-0.8200
8.0200
5.6046
6.9669
9.9213
8.5590
8.0200
9.0800
11.9609
18.9277
17.9657
8.0444
9.0800
13.9200
9.3129
28.2406
25.5264
7.5607
13.9200
0.4900
4.3583
32.5989
32.6326
7.1062
0.4900
-471.3331%
571.3331%
原始數據
SG
AGO
GM(1,1)
IAGO
ISG
誤差
預測精準度
-0.8200
1.7162
1.7162
1.7162
1.7162
-1.4009E+15
8.0200
6.9362
8.6524
10.0507
8.3345
-1.611E+16
9.0800
9.2795
17.9319
17.7463
7.6956
2.80182E+16
13.9200
8.6214
26.5533
24.8519
7.1056
-1.611E+16
0.4900
4.8371
31.3905
31.4128
6.5609
-1.4009E+15
奇異值
-一、 GM(1,1)預測模型 二、 SG 五點平滑結合 GM(1,1)預測模型,不採用 ISG 三、 SG 五點平滑結合 GM(1,1)預測模型,採 ISG 四、 SG 七點平滑結合 GM(1,1)預測模型,採 ISG37
原始數據
SG
AGO
GM(1,1)
IAGO
誤差
預測精準度
-0.8200
1.7162
1.7162
1.7162
1.7162
8.0200
6.9362
8.6524
10.0507
8.3345
9.0800
9.2795
17.9319
17.7463
7.6956
13.9200
8.6214
26.5533
24.8519
7.1056
0.4900
4.8371
31.3905
31.4128
6.5609
22.6117%
77.3883%
五、 SG 七點平滑結合 GM(1,1)預測模型,不採用 ISG 圖 4.9 進口貿易總值的數據之五種預測 MAPE 比較圖 資料來源:本研究 從上述表圖可以發現執行改良 GM(1,1)預測過程中,原 GM(1,1)在各範例中的預 測 MAPE 不是很理想,而此節所討論是否在預測過程中執行 ISG 逆濾波法,研究結 果發現每個範例執行 ISG 逆濾波法時,都會提高研究預測誤差和降低預測精準度,甚 至在七點平滑 SG,採取 ISG 逆濾波法時,會出現奇異值,無法評斷此預測模型的精 準度。 308.6232% 571.3331% 41.8304% 22.6117% 0% 100% 200% 300% 400% 500% 600%進口貿易總值 MAPE
誤差 奇 異 值38 反之,GM(1,1)預測過程中只執行 SG 濾波法時,會發現此改良會明顯降低預測 誤差和提高預測精準度,尤其是七點平滑,不採取 ISG 逆濾波法時的預測 MAPE 比 五點平滑,不採取 ISG 逆濾波法時的預測 MAPE 還低,所以在本研究中建議在執行 GM(1,1)預測過程中不採用 ISG 逆濾波法,以降低整體的預測精度與降低誤差。
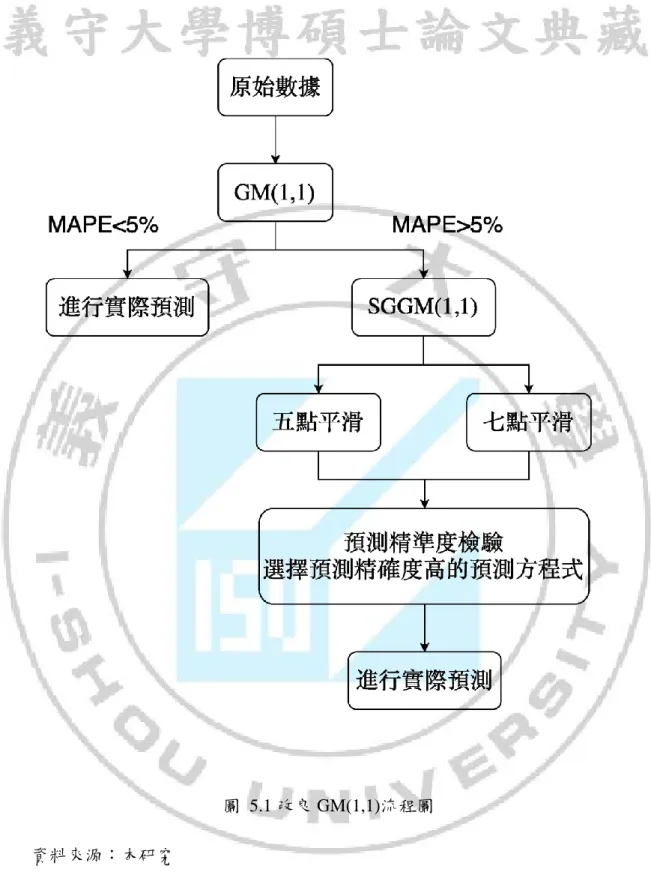
第二節 SGGM(1,1)模型之數據前處理比較
本節將預測前的數據處理順序做更動,比較先執行 Savitzky-Golay 濾波法(SG)再做 累加生成(AGO)與先執行累加生成(AGO)再做 Savitzky-Golay 濾波法(SG)之間的預測精 度差異,討論數據前處理更動後是否能提高模型的預測精度。 圖 4.10 數據前處理過程 資料來源:本研究 一、改良 GM(1,1)過程 累加生成(AGO) GM(1,1) 逆累加生成(IAGO) 預測值 濾波法(SG) 二、改良 GM(1,1)過程 累加生成(AGO) GM(1,1) 逆累加生成(IAGO) 預測值 濾波法(SG)39 原始數據 SG AGO GM(1,1) IAGO 誤差 預測精準度 10.2600 8.7291 8.7291 8.7291 8.7291 5.9200 8.7220 17.4511 17.7129 8.9838 10.7600 7.8474 25.2986 25.3737 7.6608 5.6100 7.2643 32.5629 31.9064 6.5327 5.2800 4.9234 37.4863 37.4771 5.5707 7.1492% 92.8508% 原始數據 AGO SG GM(1,1) IAGO 誤差 預測精準度 1.6200 1.6200 1.8909 1.6200 1.6200 1.6400 3.2600 3.1143 3.4921 1.8721 1.7600 5.0200 5.1760 5.1282 1.6361 2.0600 7.0800 6.8863 6.5580 1.4298 0.7200 7.8000 7.7914 7.8076 1.2495 31.3332% 68.6668% 原始數據 SG AGO GM(1,1) IAGO 誤差 預測精準度 10.2600 9.5343 9.5343 9.5343 9.5343 5.9200 8.7662 18.3005 18.2196 8.6853 10.7600 7.6210 25.9214 25.8720 7.6525 5.6100 6.5729 32.4943 32.6145 6.7425 5.2800 6.0962 38.5905 38.5552 5.9407 1.6170% 98.3830%
原始數據
AGO
SG
GM(1,1)
IAGO
誤差
預測精準度
10.2600
10.2600
12.2114
10.2600
10.2600
5.9200
5.9200
17.5576
18.3205
8.0605
10.7600
10.7600
25.1929
25.5382
7.2177
5.6100
5.6100
32.4914
32.0012
6.4630
5.2800
5.2800
36.8276
37.7885
5.7873
23.4726%
76.5274%
壹、 實例一:主要接單地區-外銷
一、 先執行 SG 五點平滑,再執行 AGO 二、 先執行 AGO,再執行 SG 五點平滑 三、 先執行 SG 七點平滑,再執行 AGO 四、 先執行 AGO,再執行 SG 七點平滑40
原始數據
SG
AGO
GM(1,1)
IAGO
誤差
預測精準度
1.6200
1.6149
1.6149
1.6149
1.6149
1.6400
1.6400
3.2549
3.4591
1.8442
1.7600
1.9229
5.1777
5.1119
1.6528
2.0600
1.6486
6.8263
6.5930
1.4812
0.7200
1.0903
7.9166
7.9204
1.3274
85.3996%
14.6004%
原始數據
AGO
SG
GM(1,1)
IAGO
誤差
預測精準度
1.6200
1.6200
1.8909
1.6200
1.6200
1.6400
3.2600
3.1143
3.4921
1.8721
1.7600
5.0200
5.1760
5.1282
1.6361
2.0600
7.0800
6.8863
6.5580
1.4298
0.7200
7.8000
7.7914
7.8076
1.2495
31.3332%
68.6668%
圖 4.11 主要接單地區-外銷之四種預測 MAPE 比較圖 資料來源:本研究貳、 實例二:消費者物價基本分類指數
一、 先執行 SG 五點平滑,再執行 AGO 二、 先執行 AGO,再執行 SG 五點平滑 7.1492% 31.3332% 1.6170% 23.4726% 0% 10% 20% 30% 40%主要接單地區-外銷 MAPE
誤差41
原始數據
SG
AGO
GM(1,1)
IAGO
誤差
預測精準度
1.6200
1.6038
1.6038
1.6038
1.6038
1.6400
1.8152
3.4190
3.4938
1.8900
1.7600
1.7552
5.1743
5.1445
1.6507
2.0600
1.5095
6.6838
6.5862
1.4417
0.7200
1.1638
7.8476
7.8454
1.2592
5.6901%
94.3099%
原始數據
AGO
SG
GM(1,1)
IAGO
誤差
預測精準度
1.6200
1.6200
2.0543
1.6200
1.6200
1.6400
3.2600
3.3295
3.5243
1.9043
1.7600
5.0200
5.0762
5.1630
1.6387
2.0600
7.0800
6.7057
6.5732
1.4102
0.7200
7.8000
7.6295
7.7868
1.2136
30.7752% 69.2248%
三、 先執行 SG 七點平滑,再執行 AGO 四、 先執行 AGO,再執行 SG 七點平滑 圖 4.12 消費者物價基本分類指數之四種預測 MAPE 比較圖 資料來源:本研究 14.6004% 31.3332% 5.6901% 30.7752% 0% 10% 20% 30% 40%消費者物價基本分類指數 MAPE
誤差42 原始數據 SG AGO GM(1,1) IAGO 誤差 預測精準度 3.2200 2.5934 2.5934 2.5934 2.5934 2.0000 5.4874 5.4874 6.9142 4.3207 5.6500 11.5480 11.5480 12.2001 5.2859 9.8300 19.4794 19.4794 18.6667 6.4667 5.4100 26.3843 26.3843 26.5779 7.9112 23.7810% 76.2190%
原始數據
AGO
SG
GM(1,1)
IAGO
誤差
預測精準度
3.2200
3.2200
3.2500
3.2200
3.2200
2.0000
5.2200
5.3160
7.3659
4.1459
5.6500
10.8700
11.6526
12.4628
5.0969
9.8300
20.7000
20.0477
18.7290
6.2662
5.4100
26.1100
25.5614
26.4328
7.7037
48.9334%
51.0666%
原始數據
SG
AGO
GM(1,1)
IAGO
誤差
預測精準度
3.2200
2.5890
2.5890
2.5890
2.5890
2.0000
4.2433
6.8324
7.2186
4.6296
5.6500
5.6743
12.5067
12.6092
5.3906
9.8300
6.6733
19.1800
18.8860
6.2768
5.4100
7.0319
26.2119
26.1947
7.3087
5.9947%
94.0053%
原始數據
AGO
SG
GM(1,1)
IAGO
誤差
預測精準度
3.2200
3.2200
3.2195
3.2200
3.2200
2.0000
5.2200
6.3895
7.0525
3.8325
5.6500
10.8700
12.4257
11.9237
4.8712
9.8300
20.7000
19.1481
18.1151
6.1915
5.4100
26.1100
24.3767
25.9847
7.8696
46.9714%
53.0286%
參、 實例三:出口貿易總值
一、 先執行 SG 五點平滑,再執行 AGO 二、 先執行 AGO,再執行 SG 五點平滑 三、 先執行 SG 七點平滑,再執行 AGO 四、 先執行 AGO,再執行 SG 七點平滑43
原始數據
SG
AGO
GM(1,1)
IAGO
誤差
預測精準度
-0.8200
1.3623
1.3623
1.3623
1.3623
8.0200
5.6046
6.9669
9.9213
8.5590
9.0800
11.9609
18.9277
17.9657
8.0444
13.9200
9.3129
28.2406
25.5264
7.5607
0.4900
4.3583
32.5989
32.6326
7.1062
41.8304%
58.1696%
原始數據 AGO SG GM(1,1) IAGO 誤差 預測精準度 -0.820 -0.820 3.250 3.220 3.220 8.020 7.200 5.316 7.366 4.146 9.080 16.280 11.653 12.463 5.097 13.920 30.200 20.048 18.729 6.266 0.490 30.690 25.561 26.433 7.704 48.9334% 51.0666% 圖 4.13 出口貿易總值之四種預測 MAPE 比較圖 資料來源:本研究肆、 實例四:進口貿易總值
一、 先執行 SG 五點平滑,再執行 AGO 二、 先執行 AGO,再執行 SG 五點平滑 23.7810% 48.9334% 5.9947% 46.9714% 0% 10% 20% 30% 40% 50% 60%出口貿易總值 MAPE
誤差44 原始數據 SG AGO GM(1,1) IAGO 誤差 預測精準度 -0.8200 1.7162 1.7162 1.7162 1.7162 8.0200 6.9362 8.6524 10.0507 8.3345 9.0800 9.2795 17.9319 17.7463 7.6956 13.9200 8.6214 26.5533 24.8519 7.1056 0.4900 4.8371 31.3905 31.4128 6.5609 22.6117% 77.3883%