國
立
交
通
大
學
資訊科學與工程研究所
碩
士
論
文
網 路 拓 樸 的 遞 移 性:
以 流 行 性 傳 染 病 的 潛 在 感 染 風 險 為 例
The Transitivity of Network Topology: Example of Epidemic
Spreading Risk
研 究 生:陳璽文
指導教授:孫春在 教授
網路拓樸的遞移性:以流行性傳染病的潛在感染風險為例
The Transitivity of Network Topology: Example of Epidemic Spreading
Risk
研 究 生:陳璽文 Student:Hsi-Wen Chen
指導教授:孫春在 Advisor:Chuen-Tsai Sun
國 立 交 通 大 學
資 訊 科 學 與 工 程 研 究 所
碩 士 論 文
A ThesisSubmitted to Institute of Computer Science and Engineering College of Computer Science
National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Master
in
Computer and Information Science
June 2011
Hsinchu, Taiwan, Republic of China
i
網路拓樸的遞移性:以流行性傳染病的潛在感染風險為例
學生:陳璽文 指導教授:孫春在 博士國立交通大學資訊科學與工程研究所
中文摘要
分析網路拓樸動態產生的遞移性現象,儼然已成為研究網路拓樸亟需解決也 不可或缺的需求。經由分析遞移性現象找出網路各節點在動態傳播過程中的影響 力及重要性,就能控制核心節點來達到影響群體、主宰網路訊息傳遞的效果,對 於網路拓樸所反映的現實實體層面即可提供有價值的參考資訊。本研究中,將過 往探討遞移性現象的理論模型延伸擴充,依據網路拓樸架構及連結所呈現的權重 值,分析動態傳播過程中每個節點的重要性。透過重要性的排序比較,得以找出 關鍵的核心節點,解決現今研究網路拓樸的需求。 在本文以實際流行病傳播動態為案例研究來驗證演算法的正確性,並使用基 因演算法優選在流行病傳播現象中,最貼近實際傳播動態的網路拓樸結構。實驗 結果顯示經本模型分析,病原體遞移傳播對各節點的重要性造成的影響與案例研 究比對呈現正相關性,證實本研究方法能夠有效處理遞移概念並分析各節點重要 性。此外透過基因演算法搜尋結果也可顯示出實際流行病的傳播動態以及造成傳 播的影響因素。 關鍵字:網路拓樸、遞移性、馬可夫鏈模型、網頁等級排序演算法、基因演算法ii
The Transitivity of Network Topology: Example of Epidemic Spread
Student:Hsi-Wen Chen Advisor:Dr. Chuen-Tsai Sun
Institute of Computer Science and Engineering
National Chiao Tung University
Abstract
Analyzing the transitivity phenomenon influencing by network topology is among the requirements in studying network topology. Influenced by the transitive spreading, every node has different impacts in varied kinds of network topology. We can offer valuable information for the physical layer reflected by the network topology if the importance of every node can be analyzed.
In this research we propose an algorithm, based on the Markov Chain Model and the PageRank algorithm, for computing the spreading of the transitivity phenomenon of network topology and the importance of nodes. The importance of nodes in every network is determined only by considering the structure of the network topology and edge weights without taking complex dynamics of spreading into account, so the computation is rapid and easily analyzed.
We take epidemiological data as a case study to verify the correctness of our algorithm. Furthermore, a genetic algorithm can optimize the parameters to simulate an actual dynamic structure of network topology in the real epidemic spreading. Our experimental results show that the importance of nodes in network topology is correlated with epidemiological data. The algorithm can deal with the phenomenon of transitivity and analyze the importance of nodes efficiently. Besides, the solution searched by genetic algorithm can reflect the spreading dynamics of the real epidemics and the causes of spreading components.
iii
Keywords: Network Topology, Transitivity, Markov Chain Model, PageRank Algorithm, Genetic Algorithm
iv
致 謝
總算畢業了,回顧漫長的碩士生涯,不管是研究或是生活遇到什麼樣的重擔都要 咬牙扛著走下去,所幸也遇到了許多人的幫助讓我能夠順利的走到這裡,過程中 一點一滴的歡笑和淚水都會永遠烙印在我的心中。 首先要感謝的是我的指導教授孫春在老師,讓我在研究上能夠自由的探索不予限 制,教導我做研究正確的方法以及該有的態度,並且在每次的報告中直接點出我 研究的不足和正確的發展方向,令我受益良多。其次要感謝的是崇源學長,從題 目的發展到研究結果的分析,每次都能在百忙之中抽空給予細心、耐心的指導與 幫助,並且也教導我如何檢視實驗結果看到更多的研究價值,讓我萬分感激。再 者還要感謝台大地理系的溫在弘老師,不厭其煩的給予我研究報告上的建議,讓 我的研究更趨完善。 此外還要感謝實驗室的學長姐以及同學們的互相扶持。感謝博班的宇軒、聖文、 基成、昱翔、勝毅、詠宏、書豪、王豪學長,在我的論文撰寫以及報告方面給了 我許多建議,和你們相處拓展了我人生的視野,也讓我從你們身上學到了為人處 事的道理。另外還有同屆的謹譽、全榮、泰源、壯為、嘉宏、鈞凱、鵬羽、柏志, 和你們一起奮鬥過的日子很快樂,我永遠不會忘記。當然還有振濃、誌宏、偉存、 承宏、浩琮、景照、怡中,感謝你們在我碩士生涯中的陪伴以及加油打氣。 最後要感謝最重要的家人,讓我在經濟上面沒有任何的後顧之憂,也無條件的在 背後支持我、關心我的狀況,我也不斷的期許自己能夠在往後的日子好好的彌補 並照顧我的家人。 由衷的感謝大家,沒有你們也就不會有這篇研究的出現v
目 錄
中文摘要 ... i Abstract ... ii 致 謝 ... iv 圖目錄 ... vii 表目錄 ... ix 一、緒論 ... 1 1.1 研究背景與動機 ... 1 1.2 研究目標 ... 4 1.3 研究重要性 ... 5 二、文獻探討 ... 7 2.1 網路遞移性的研究 ... 7 2.2 探討遞移性的理論模型 ... 9 2.3 PageRank 演算法與遞移性 ... 10 2.4 傳染病與遞移性 ... 12 2.5 基因演算法 ... 13 三、研究資料 ... 16 3.1 交通旅運網路建構 ... 16 3.1.1 台灣短程通勤旅運網路資料 ... 16 3.1.2 台灣鐵路通勤旅運網路資料 ... 17 3.1.3 台灣航空通勤旅運網路資料 ... 19 3.1.4 台灣高鐵通勤旅運網路資料 ... 19 3.1.5 總交通通勤旅運網路建構 ... 20 3.2 真實流行病病例資料 ... 20 四、 研究方法 ... 22 4.1 流行風險指標模型 ... 22 4.2 流行病風險指標效益評估 ... 26 4.2.1 根據各行政區計算指標評估 ... 26vi 4.2.2 根據模型計算命中率評估 ... 27 4.3 基因演算法 ... 30 五、實驗結果 ... 34 5.1 模型參數敏感度分析與驗證 ... 34 5.1.1 實驗一:使用各種網路組合進行敏感度分析 ... 34 5.1.2 實驗設計與結果分析 ... 40 5.2 使用基因演算法搜尋最佳解 ... 42 5.2.1 實驗二:使用短程網路為架構搭配台鐵網路搜尋解集合 ... 42 5.2.2 實驗三:使用短程網路為架構搭配總交通網路搜尋解集合 . 60 5.2.3 實驗四:使用長程交通網路搜尋解集合... 66 5.2.4 實驗五:使用總交通旅運網路搜尋解集合 ... 71 5.2.5 實驗總結... 76 六、結論 ... 81 參考文獻 ... 83 附錄 86
vii
圖目錄
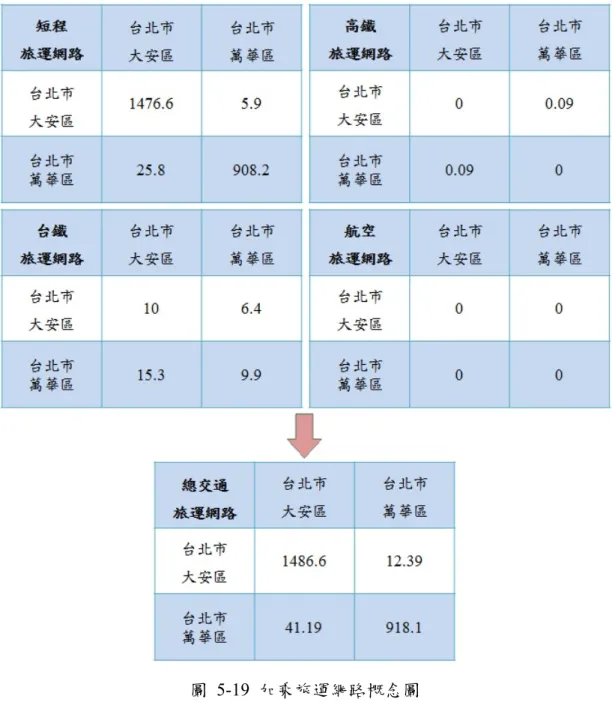
圖 1-1 網頁重要性遞移傳播圖(Page, 1998) ... 2 圖 3-1 通勤網路矩陣合併概念 ... 17 圖 3-2 台灣鐵路主要交通 49 個分區 ... 18 圖 4-1 模型整體架構圖 ... 22 圖 4-2 行政區間通勤人口範例圖... 24 圖 4-3 風險指標驗證方式 ... 27 圖 4-4 行政區命中率概念圖 ... 29 圖 4-5 基因演算法流程圖 ... 30 圖 5-1 敏感度分析結果_2009 年 H1N1-A 型流感 ... 37 圖 5-2 敏感度分析結果_2001 年 71 型腸病毒 ... 37 圖 5-3 敏感度分析簡化參數分佈結果圖_日間旅運比例為 20% ... 38 圖 5-4 敏感度分析簡化參數分佈結果_日間旅運比例為 90% ... 38 圖 5-5 2009 年 H1N1-A 型流感與 2001 年 71 型腸病毒最大檢定值比較圖 .... 39 圖 5-6 各旅運網路組成實驗結果_2009 年 H1N1-A 型流感 ... 40 圖 5-7 實驗二- ERV 與 2009 年 H1N1 對照比較圖_鄉鎮市規模 ... 46 圖 5-8 實驗二- ERV 與 2001 年 71 型腸病毒對照比較圖_鄉鎮市規模 ... 46 圖 5-9 實驗二- ERV 與 2009 年 H1N1 對照比較圖_縣市規模 ... 49 圖 5-10 實驗二- ERV 與 2001 年 71 型腸病毒對照比較圖_縣市規模 ... 49 圖 5-11 鄉鎮市與縣市規模通勤網路結構轉換概念 ... 50 圖 5-12 通勤結構與各層級檢定圖表(藍點代表行政區的百分比,紅點為平均值) ... 52 圖 5-13 H1N1-A 型流感及 71 型腸病毒各行政區染病人數與各行政區人口密度相 關係數檢定 ... 54 圖 5-14 H1N1-A 型流感及 71 型腸病毒於各行政區染病人數與各行政區人口數相viii 關係數檢定 ... 55 圖 5-15 實驗二- ERV 與 2009 年 H1N1-A 型流感對照比較圖_可縮放縣市規模58 圖 5-16 實驗二- ERV 與 2001 年 71 型腸病毒對照比較圖_可縮放縣市規模 .... 58 圖 5-17 實驗二相關係數結果比較 ... 59 圖 5-18 實驗五相關係數結果比較 ... 74 圖 5-19 加乘旅運網路概念圖 ... 75 圖 5-20 各交通旅運網路組合於各模型計算層級實驗結果圖 ... 77 圖 5-21 比較中短程交通旅運與長程交通旅運實驗結果圖 ... 77 圖 5-22 比較地理尺度實驗結果圖 ... 78
ix
表目錄
表 4-1 染病人數命中率 ... 28 表 4-2 基因演算法參數設定 ... 33 表 5-1 流行病特性比較表 ... 35 表 5-2 敏感度分析參數設定 ... 35 表 5-3 2009 年 H1N1-A 型流感與 2001 年 71 型腸病毒命中率 ... 39 表 5-4 實驗二基因演算法搜尋參數表 ... 43 表 5-5 實驗二-基因演算法搜尋參數結果_鄉鎮市規模 ... 44 表 5-6 實驗二-2009 年 H1N1-A 型流感與 2001 年 71 型腸病毒命中率_鄉鎮市規 模 ... 45 表 5-7 實驗二-基因演算法搜尋參數結果_縣市規模 ... 47 表 5-8 實驗二-2009 年 H1N1-A 型流感與 2001 年 71 型腸病毒命中率_縣市規模 ... 48 表 5-9 通勤結構與各層級對照表... 51 表 5-10 實驗二-基因演算法搜尋參數結果_可縮放縣市規模 ... 56 表 5-11 實驗二-2009 年 H1N1-A 型流感與 2001 年 71 型腸病毒命中率_可縮放縣 市規模 ... 57 表 5-12 實驗三基因演算法搜尋參數 ... 61 表 5-13 實驗三-基因演算法搜尋參數結果_鄉鎮市規模 ... 62 表 5-14 實驗三-2009 年 H1N1-A 型流感與 2001 年 71 型腸病毒命中率_鄉鎮市規 模 ... 62 表 5-15 實驗三-基因演算法搜尋參數結果_原始縣市規模 ... 63 表 5-16 實驗三-2009 年 H1N1-A 型流感與 2001 年 71 型腸病毒命中率_縣市規模 ... 64 表 5-17 實驗三-基因演算法搜尋參數結果_可縮放縣市規模 ... 65x 表 5-18 實驗三-2009 年 H1N1-A 型流感與 2001 年 71 型腸病毒命中率_可縮放縣 市規模 ... 65 表 5-19 實驗三基因演算法搜尋參數 ... 66 表 5-20 實驗四-基因演算法搜尋參數結果_鄉鎮市規模 ... 67 表 5-21 實驗四-2009 年 H1N1-A 型流感與 2001 年 71 型腸病毒 ... 67 表 5-22 實驗四-基因演算法搜尋參數結果_原始縣市規模 ... 68 表 5-23 實驗四-2009 年 H1N1-A 型流感與 2001 年 71 型腸病毒命中率_縣市規模 ... 69 表 5-24 實驗四-基因演算法搜尋參數結果_可縮放縣市規模 ... 70 表 5-25 實驗四-2009 年 H1N1-A 型流感與 2001 年 71 型腸病毒命中率_可縮放縣 市規模 ... 70 表 5-26 實驗五基因演算法搜尋參數 ... 71 表 5-27 實驗五完整實驗結果 ... 73 表 5-28 實驗五討論_基因演算法搜尋參數結果_鄉鎮市規模 ... 79 表 5-29 實驗五討論_基因演算法搜尋參數結果_原始縣市規模... 80 表 5-30 實驗五討論_基因演算法搜尋參數結果_可縮放縣市規模 ... 80
1
1
一、緒論
1.1 研究背景與動機
現今社會資訊與科技發達,無時無刻都有人透過面對面接觸或是網路交流的 方式在世界上各個角落進行頻繁的互動,產生思想、疾病、行為表現等等的傳播 交流。例如朋友之間面對面的交談產生思想上的交流、因為搭乘交通運輸工具而 位處於同一地的陌生人透過飛沫以及口鼻接觸造成病原體的傳染,還有同儕之間 使用網路通訊軟體溝通形成的謠言傳遞,在在皆為經由人際接觸而產生傳播影響 的範例。由此可知在這些每天看似頻繁且必要的人口流動以及人際間接觸交流下, 伴隨而來的是各種現象的傳播與影響。 在各種人際間互動與接觸的關係之上,能夠構成不盡相同的接觸網路,而各 類接觸網路也能夠形成許多種不同性質的現象傳遞與發展。舉例來說,我們會使 用 E-mail 或 MSN 跟來自各地的朋友進行訊息的交換,其中便隱含了謠言與思想 由 E-mail 或 MSN 所構成的接觸網路而形成傳播的現象(Moreno et al., 2003;Nekovee et al., 2007);此外還包含了愛滋病隨著性關係接觸網路傳染、流行性感 冒隨著日常人際接觸網路傳染等例。如上述所舉例子,有些現象能夠透過多種接 觸網路傳播、有些則只能在特定的網路上傳播,如果能夠考量網路的形式,利用 完整有系統的方式進而評估各種現象在接觸網路上產生的傳播影響則為重要的 一項議題。 在各種形式的網路之上不僅僅包含了許多現象的傳播,其背後更隱藏著經由 傳播而產生的遞移性。例如全球資訊網(World Wide Web)即為眾多網頁所組成 的一種網路,藉由網頁內的超鏈結可建立網頁間的連結關係進而組成一張完整的 網路架構。Page 認為在全球資訊網中就牽扯到了"重要性"此現象的遞移傳播 (圖 1-1)(Page et al., 1998),每個網頁的重要性是由所有鏈結到自身的網頁乘 上該網頁重要性而得,而自身重要性也會經由自身所連出到其他網頁的鏈結所平
2 分提供其餘網頁計算重要性,也就是說越多網頁連向我這個網頁我就越重要,或 是連向我的網頁中有重要的網頁(例如 yahoo、google 等大型入口網站)我的重 要性也受到影響而提高。 在上例中,我們不難發現網頁自身的重要性是透過整體網路連結的關係綜合 累積而得,並且自身的重要性經鏈結平分給其餘網頁運算後自身的重要性還保留 著,就如同把自身的重要性複製一份再傳遞下去,此即為各種現象傳播的背後所 包含的遞移性。網路中的節點間會受到彼此之間直接連接的節點或是有兩層以上 間接連結的節點產生互動而造成不同的重要性,此外像人際接觸網路上流行病的 傳播風險、人與人之間的影響力傳播等例也包含了遞移性,例如和我接觸的人越 多或是和我接觸的人之中有高感染風險的人,我受到感染的機率就越高。由此可 知許多現象的傳播即包含了遞移性,而這種遞移擴散的特性,恰為社會網路學中 對於節點間互動的研究重點之一。 圖 1-1 網頁重要性遞移傳播圖(Page, 1998) 社會網路學是一門研究社會上的個體之間互動關係的學問,社會網路學家利 用基礎的節點及連結所構成的網路拓樸去表達並模擬諸如人際關係網路、流行病
3 間的合作網路時,可以將每個學者都用一個節點代表,學者之間如果有一篇科學 論文以上的合作關係則用邊來連結此兩個節點,以此觀察學者之間的出版量及合 作關係;在研究流行病的擴散時可以將人及場所簡化為節點,人與人之間以及人 與場所之間的接觸皆能簡化為連結,以此觀察流行病的傳播動態(Andersen et al., 2006; Ma et al, 2008)。因此我們得以利用社會網路建構真實世界的拓樸,觀察每 種網路系統呈現的拓樸特性,進而探討人與人之間互動及交流所產生的遞移性現 象。 網路拓樸所呈現出來的特性對於各種現象的傳遞影響一向是社會網路學的 研究重點,不同的節點與連結架構所呈現的拓樸特性影響著網路中個體間的互動 行為。有許多學者研究在不同的網路拓樸結構下所形成的分隔度、群聚度及冪次
率等現象如何影響網路中個體的訊息傳遞等現象(Faust & Wasserman, 1994),例
如學者 Centola 即研究人之間行為的傳遞,在具有高群聚度或是低群聚度的網路 能夠造成較快速以及較廣泛的傳播影響(Centola, 2010),學者 Nekovee(2007) 則提出了利用馬可夫鏈(Markov chain)去計算謠言如何在人群中傳遞散播的研 究。上述研究中針對網路拓樸的群聚度及冪次率等特性做了探討,雖然觀察行為 的擴散以及計算謠言隨著個體間的互動而產生向下傳遞散播的現象包含了觀察 網路結構中遞移特性的概念,但是在研究中卻缺少對於遞移性現象的關注與清楚 的描述。 然而,以往對於社會網路中遞移性現象的研究並沒有清楚的觀察以及計算的 方法,無法明顯的觀察出各種現象於各個個體的遞移傳播影響程度,通常是由簡 單的二分法區分是否遭受到傳播影響。過去使用馬可夫鏈計算網路中遞移特性的 研究往往侷限於馬可夫鏈的特性,只能夠藉由上一次的狀態來推斷一段時間後的 狀態改變,無法得知轉變的過程,此外在計算過程也無法因應網路狀態的改變來 更改轉移矩陣計算遞移特性,並且在馬可夫鏈的機率陣列中,一般認為機率陣列 的內容於計算過程中不會有所改變,所以在機率陣列的組成方面以常數為主,並
4 未加入變數的概念;而計算遞移性的 PageRank 演算法主要則是對於網頁單項鏈 結造成重要性遞移計算的一種特例應用,在真實的實體網路中往往必須考慮到節 點間雙向鏈結的影響。若能夠清楚觀察風險於網路中個體的影響程度,以及將實 體網路中的特徵考慮進來,能隨時根據現有網路狀況調整風險傳播的計算方式並 能廣泛使用於不同網路型態,則對於觀察網路中的遞移現象有相當大的幫助。因 此在本研究中將提出一套以馬可夫鏈以及 Page Rank 演算法為基礎的演算法並加 以擴充,補足過去所缺以觀察網路中遞移傳播特性的演算法。
1.2 研究目標
本研究欲解決對於處理網絡遞移概念的問題,在此問題下發展一套演算法用 來觀察並計算網絡的遞移概念,並依據網路狀態的改變隨時更改轉移矩陣進行計 算,反映現實網路特性進而評估計算各種網路中的遞移傳播現象。此外若將各行 政區視為網路中的節點,行政區間來往的人口視為邊,則人口於各行政區流動之 際,諸如病原體及謠言等現象都能夠跟隨著宿主於各行政區四處遞移散播,恰符 合各種現象於網路中轉移的特性。因此本研究將以傳染病傳播動態為案例研究, 考量各行政區的交通旅運網路所帶來的人口流動,以各行政區間連結型態建構網 路拓樸,計算並觀察出病原體於各行政區遞移散播的染病風險程度。 為了考慮計算出來的風險程度能夠對於案例研究有實質貢獻,因此在於建構 網路拓樸的基本要素方面採取鄉鎮市層級以及縣市層級的網路拓樸建構。做出衛 生決策的單位可以分為中央層級以及地方政府層級,因此在行政區範圍的計算劃 分主要以台灣本島 22 個縣市和 353 個鄉鎮市為層級,縣市層級可提供中央政府 參考病原體在縣市規模的網路拓樸下如何進行遞移傳播,而鄉鎮市層級則提供地 方政府做參考,並且可比較鄉鎮市規模的網路拓樸與縣市規模的病原體遞移傳遞 特性。 本研究使用各行政區間交通旅運資料建構網路拓樸的邊,而經由咳嗽、打噴 嚏的飛沫傳染還有碰觸到病毒導致接觸傳染的流行病和交通旅運息息相關,傳染5 容易於交通傳輸工具的密閉空間內發生(Tang et al., 2006)。因此在本研究計算 出來的各行政區危險程度指標方面將和每年經由飛沫及接觸傳染的流行病感染 人數重症病例數做相關係數檢定,如果相關性高,則代表本模型所提出觀察病原 體經人口流動產生的遞移傳播指標通過驗證,與真實病原體傳播影響具有一定相 關性。 此外在建立風險遞移模型時,無論是構成網路拓樸特性的邊其組成結構,亦 或是各項遞移過程計算的參數皆需要透過調整,以便讓演算法的計算結果能夠完 整的考慮到影響遞移特性計算的因素,使其更為精確、更為符合真實病例資料。 因此在模型中,本研究需要藉助基因演算法來對各項參數進行優選以及計算,以 產生本研究所欲搜尋的最佳解。
1.3 研究重要性
本研究的重要性,主要可以從延伸改變、案例研究以及應用三種層面來看。從延 伸改變的層面來看,若和過去善於處理遞移特性的馬可夫鏈比較,傳統的馬可夫 鏈能夠根據網路中個體前一次的狀態來計算一段時間後經改變的個體狀態,以此 來觀察網路中的遞移特性,但卻無法得知轉變的過程也無法改變移轉矩陣進行計 算。以傳染病的散播為例,有時傳染病的傳播過程對於衛生決策者對於政策的執 行有莫大的參考價值,若無法得知遞移傳播的過程便無法提供有效資訊;同時各 行政區之間的連接狀態可能隨時因為特定情形而改變,進而影響拓樸連結特性, 若模型無法因應現實情形改變計算狀態則同樣也無法繼續計算提供有效資訊。因 此本研究欲透過流行風險指標演算法來補足過去所缺,觀察網路中遞移傳播特性 於不同的網路拓樸中具有何種傳播影響。 以案例研究層面來看,每一次的新興傳染病必須要耗費衛生單位相當多的時間來 研究病毒並研發出疫苗,這段時間可能已經造成相當重大的傷亡數及影響。因此 本研究概念能夠於流行病盛行前考慮人口流動因素進而計算傳染病因遞移傳播 造成各行政區可能的危險程度,提供衛生單位參考。無論是計算鄉鎮市或縣市地6 理尺度層級的資料,即使不知道病理的鏈結仍然可以介入最危險的地區,做出流 行病學中的初級預防來防範疾病的發生,並且對如何掌握傳染病有更深的了解。 從應用層面來看,本研究觀察網路中遞移傳播的特性不僅能使用於傳染病的 傳播動態研究,一旦能夠了解並觀察網路拓樸中的遞移現象後,針對於各種不同 架構型態的網路也能夠套用並且進行觀察提供有效參考資訊。例如經由各電腦間 網路連結狀態建立網路拓樸,觀察對於電腦病毒在網際網路間電腦的遞移散播, 提供經電腦間網路遞移傳播病毒後各電腦中毒風險程度以利防範。還有建立人際 間網路拓樸,觀察謠言或者是思想等風險於人際間的遞移傳播等,皆能夠有進一 步的探討,對於各個科學領域需觀察遞移現象影響的研究能夠有更多的幫助。
7
2
二、文獻探討
本研究將於章節 2.1 提出過去社會網路學是如何著重有關於遞移性質的研究。章 節 2.2 探討用來研究遞移性的理論模型馬可夫鏈。章節 2.3 討論 PageRank 演算法 對於遞移性質的處理方式與應用。章節 2.4 則是有關於案例研究的回顧,討論本 研究欲探討的遞移現象如何應用於流行病傳染的危險程度計算以及為什麼能夠 對應到流行病傳染的特性。章節 2.5 探討本研究為什麼使用基因演算法以及如何 應用基因演算法於模型參數的估計及優化,利用本論文文獻來探討遞移特性於各 領域理論的陳述及應用。2.1 網路遞移性的研究
猶記得當時在 2008 年因為次級房貸所發生的金融海嘯事件,美國的金融機構將 次級房貸者的貸款設計成連動債券等商品讓其他業者承接,承接的業者也不斷一 重重的轉賣給其他的投資單位。我們不難發現在金融海嘯的例子裡,連動債券一 層一層轉移到下一位投資單位,這其中就包含了投資單位間彼此對商品信任所形 成的信用轉移,以及承接連動債的風險轉移。如果我們用社會網路的觀點來看金 融海嘯的例子,投資單位間的合作就是一種點與邊的關係,透過點與邊的關係所 形成的網路就能夠造成風險與信用的轉移、遞移,承接越多連動債的投資單位其 風險就越高。 許多現象都能夠透過網路中點與邊的概念進而產生遞移傳播,近年來有一些 在社會網路上隱含關於遞移現象的研究,無論是有形的病毒、流言及謠言抑或是 無形之中受到影響的行為、思想等傳播的研究以觀察各種現象於網路中的擴散為 重點。例如學者 Pedro 探討流言如何於互相認識的朋友網路間傳遞,設定觀察不 同群聚度及分隔度的朋友網路拓樸架構下的傳播速率及傳播率(Lind et al., 2007)。 學者 Centola 則是研究朋友網路中行為的擴散,探討究竟周遭朋友數量多也就是 高群聚度的網路拓樸架構下,是否就會容易影響自身行為的改變(Centola, 2010)。8 以及學者 Viboud 探討美國各州以及各州間的交通所構成的網路拓樸中,流行病 於各州擴散時透過交通通勤於各州間擴散傳遞過程來驗證交通量與流病擴散的 相關性(Viboud et al., 2006)。 上述研究的不同點在於所探討的現象其形成擴散的本質,有些現象經由接觸 擴散後本身就不保留此特性,而有些現象則相反。例如傳染病透過一次個體間的 接觸就能夠造成病原體的傳染,重要的一點在於病原體是透過複製而形成遞移傳 播,個體 A 並不會因為傳染給個體 B 之後就減少自身的病原體數;以自身行為 為例則是需透過周遭夠多朋友的壓力才會改變,當個體影響別人的行為後自己本 身也會保留此種行為,所以也具有複製並傳播的特性。 而上述研究共同的地方在於皆建構出各自的網路拓樸,觀察各種現象在網路 拓樸中所形成的擴散,探討節點間經互動接觸後的改變,然而研究中雖然隱含了 遞移性現象,卻著重在觀察不同網路架構下各種現象的擴散,而非關注背後隱含 的遞移性現象,也沒有在研究中提及處理遞移性的方法。由這些社會網路觀察擴 散傳播的研究得知,遞移現象確實存在於各種網路拓樸結構當中,各種現象的本 質透過整體網路拓樸一層一層遞移累積並擴散所造成的影響也確實是個學者所 欲觀察的重點。 此外近來這些社會網路的研究做到了考慮節點間的連結因素所構成的網路 拓樸進而觀察某種現象如何於網路拓樸中經由各個節點的接觸產生流動擴散,但 是卻無法區分各節點受影響的程度,只能單純以二分法來模擬節點是否受到傳播 影響。以學者 Pedro 探討流言於朋友網路間的散播為例,僅能經由節點間產生互 動決定是否進行流言的散播進而觀察流言的遞移傳播現象,而無法觀察個體經由 此次互動受到整體網路的影響程度,也無法觀察此個體受整體網路遞移影響後對 於其餘有連結個體的影響程度(Lind et al., 2007)。若能夠計算各節點經每次互動 後所受整體網路遞移影響的程度,將有助於本研究對於遞移傳播的特性進行更為 精確的探討以及計算,也能夠使遞移特性更符合真實情況以應用於各方面的研
9 究。 社會網路分析學使用網路拓樸架構出欲研究的底層連結構造來研究各種現 象的擴散,不僅僅提醒了本研究遞移現象確實存在於各種網路拓樸結構當中,也 顯露出一些不足以應付真實情況、無法確實觀察背後所隱含遞移性現象的特性。 因此除了參考社會網路學如何建構網路拓樸特性以及對於底層連結構造進行群 聚度、節點中心性分析擴散現象的部分以外,如何將社會網路對於遞移性分析的 不足進行改良也為本研究欲著重的部分。
2.2 探討遞移性的理論模型
過去用來研究遞移特性中著名的理論模型即為馬可夫鏈模型,在馬可夫鏈模型 中狀態的轉移使用機率陣列來表示,並且利用前一次的狀態乘上機率陣列來計 算和預測將來的狀態改變(Meyn et al., 1993),並且藉由預測狀態改變即可得 知網路中個體經由本文所述遞移性現象影響後所受到整個網路造成的遞移性 影響。 馬可夫鏈模型中將不同個體間彼此轉移、傳播的機率用來組成機率陣列, 若和本文 2.1 節所提的流行病範例相比較,機率陣列的組成為個體間的狀態轉 移,其中即表示網路的組成以及遞移的概念,也如同掌握住一個網路的拓樸特 性及結構能夠用以計算病原體隨人際接觸遞移傳播後,每個個體狀態到最後的 改變,換句話說藉由機率陣列能夠代表整體網路拓樸的組成,也等同掌握影響 遞移特性的因素進而計算個體狀態的轉變。 因此經由掌握機率陣列,馬可夫鏈模型也能夠表示與研究網路中的遞移現 象。例如在流行病的擴散現象方面,學者 Gomez 考量在流行病傳染中每個個 體於單位時間內的隨機接觸概率等因素,利用馬可夫鏈評估各個體接觸後受感 染的機率(Gomez, 2010),而學者 Netzer 則是根據一些交易資料使用馬可夫鏈 模型來預估每個顧客間關係動態以及經由互動規則後產生的狀態改變(Netzer, 2008)。如同上述研究都能夠規劃出個體轉變的狀態利用馬可夫鏈模型的計算10 以達到觀察並推測個體狀態轉變的效果。 對於馬可夫鏈模型來說,雖然能夠藉由機率矩陣推算所有個體狀態的轉變, 模擬經單位時間後受到整體網路遞移性的影響,計算出每個個體經過可能的機 率轉移、遞移後的狀態。但是對於馬可夫鏈模型來說,機率陣列的組成內容無 法根據個體間轉移的機率改變而改變。意即如果現在網路的連結狀態有所變動, 造成遞移現象的傳播過程也有所不同,本研究便無法更改馬可夫鏈模型的機率 陣列加以運算;此外在馬可夫鏈的機率陣列中,一般認為機率陣列的內容於計 算過程中不會有所改變,所以在機率陣列的組成方面以常數為主並未加入變數 的概念,但是在真實實體網路的拓樸中,能夠影響拓樸構成的因素有很多種, 因此馬可夫鏈模型中機率陣列的連續性對於遞移特性的計算尚有稍嫌不足的 地方,也是本研究欲加以擴充補足的地方。
2.3 PageRank 演算法與遞移性
現今對於遞移性的計算應用具有高知名度的演算法實例就屬 1998 年 Google 的創辦人提出的 PageRank 演算法(Page et al., 1998),此演算法簡化馬可夫鏈模型概
念並降低馬可夫鏈模型的複雜度被用來計算每個網頁的重要性並加以排序,來應 付使用者搜尋網路資訊的需求。這套演算法考慮到網頁和網頁之間的超鏈結 (hyperlink)關係,Page 認為有越多重要網頁鏈結的網頁必定還是重要的網頁, 因此透過這些網頁間的超鏈結的組成就能夠確定每個網頁的重要性。此演算法在 將各網頁的重要性(用 PageRank 值表示)以及鏈結關係納入演算過程後,再經 由不斷的迭代計算至各網頁 PageRank 值收斂即停止計算,此計算結果即為各網 頁的重要性。在 PageRank 演算法中計算的即為網頁透過鏈結而形成的影響力遞 移,網頁的影響力遞移和傳染病相同具有複製的觀念,每個網頁的影響力並不會 被其他具有鏈結關係的網頁分享而是繼續保留著。 而在計算網頁重要性所使用到的 PageRank 演算法之中包含了網頁搜索以及 超鏈結分析,這些分析以及 PageRank 演算法的來源即為由社會網路學中節點中
11 心性(Centrality)及權威性(Prestige)的觀念演化而來。舉例來說如果我們將 整個全球資訊網看成一張社會網路圖,在這張網路圖中,每個網頁都是一個節點, 節點之間的連結即為網頁間的超鏈結,由此可觀察出每個網頁的節點中心性等屬 性,利用社會網路的角度分析此網路圖所得到的研究結果或是靈感皆能夠對應到 網頁分析之中。因此我們不難發現社會網路對於網頁分析有著息息相關,相當緊 密的關係,並且由網路圖的拓樸所呈現出來的各種特性皆能夠使用社會網路的觀 點進行分析。 以社會網路的觀點來看,在 PageRank 演算法中表達了一項相當重要的核心 概念就是 PageRank 值的移轉。學者 Hoff 認為,網站之間的鏈結所構成的有向圖 都存在著遞移性的概念(Hoff et al., 2002)。假設有 A、B、C 三個網頁,A 含鏈 結指向 B,B 含鏈結指向 C,我們可以說 A 對 C 具有一定的影響,因為瀏覽網 頁 A 的人潮可能會隨著鏈結走而瀏覽到網頁 C,同理 A 也會影響到 C 的 PageRank 值。藉由社會網路的分析也可幫助我們看出,PageRank 演算法的核心概念,即 包含了計算網路拓樸中的遞移性概念。 PageRank 演算法的概念已經不是頭一遭被拿來應用,有學者便利用 PageRank 演算法中考量個體間的鏈結關係以計算各個體數值的概念,加以修改 應用在其他方面的計算(Andersen et al., 2006; Ma et al., 2008)。以學者 Zhao 的 研究為例,將論文之間的引用設定為鏈結關係,並改良 PageRank 演算法套用於 論文間引用的模式來計算每篇論文重要性。由此可知 PageRank 演算法呈現出來 的核心概念,能夠廣泛套用且應用於各個領域的問題之上。 若將 PageRank 演算法的概念套用在傳染病的角度來看,假設在 A、B、C 三個城市中,A 和 B 之間以及 B 和 C 之間都有相當密切的人口往來流動。因為 病毒寄生在人的體內,城市之間頻繁的人口流動使得傳染病容易形成擴散,所以 當城市 A 有傳染病爆發時,病毒便容易移轉到城市 B,甚至於城市 C。但是病原 體的傳播不同於網頁的計算,因為人口的流動並非只有單向的流動而是雙向的回
12 饋,因此改良 PageRank 演算法,考慮傳染病於每個城市間移轉的概念、城市間 建立在交通網路之上的遞移性關係也是本研究在建立模型時必須考慮的重點。
2.4 傳染病與遞移性
如同本文 1.1 節所述,透過人口於各地的流動以及接觸,能夠形成如病原體等各 種風險的擴散及傳遞。以 1918 年於全球爆發大感染的流感為例,當時正逢第一 次世界大戰末期,起初病原體於歐洲戰場擴散的同時,那些從歐洲戰場各自返鄉 的士兵也將病原體帶回美國、日本等家鄉進而形成全球的大流行。顯而易見的是, 流動於世界各地之間的人口對於藉由飛沫以及接觸傳染的流行性感冒,即為背後 造成病原體擴散至世界各地的推手。 若以社會網路的角度來詮釋世界各地的人口流動,並將各地行政區及人口流 動轉化為網路的概念,那麼人口於各行政區流動之際所造成的病原體傳遞則為本 研究欲觀察並處理的網絡遞移現象。以學者 Merler 為例(Merler & Ajelli, 2010), 即利用了歐洲主要的鐵路及航空交通網路來驗證人口流動量與城市間流行病擴 散的現象,模擬出當越多人群聚集的行政區就會擁有越快速的擴散現象。學者 Keeling 則利用人的移動來建立網路連結方式並探討對於移動過的地區造成的影 響,最後得出高度移動的人口對於各行政區流行病的擴散具有雙向回饋影響的作 用。因此在由行政區以及人口流動所構成的網路之中,反覆來回流動的通勤人口 不僅僅能夠助於流行病的擴散,對於行政區之間也具有雙向的影響進而提高各行 政區危險程度,滿足本研究所欲觀察的遞移性現象,再者流行病動態複雜度足夠 資料收集方便容易做驗證,因此對於本研究而言流行病是很好的案例研究。 此外流行病隨人口流動於世界各地擴散的現象已非頭一遭被拿來討論,在流 行病學的領域早有許多學者著手探討人口流動與傳染病的關係(Grais et al., 2003;Hufnagel et al., 2004)。以學者 Grais 等人為例,在 2003 年利用了當時國際間 52
個城市的國際航空運輸資料,成功模擬出 1968 年香港流感隨著現今發達的航空 網路造成的人口流動能夠更為快速的形成擴散(Grais et al., 2004)。學者 Viboud
13 則是分析 1972 年到 2002 年間,美國各州來往通勤上班和人口數等資料,發現當 來往兩州的通勤人口流動量越多,此兩州因流感造成的疫情統計資料所計算出來 的相關係數就會更高(Viboud et al., 2006)。以上研究主要都在探討人口流動對 傳染病的影響,皆利用了交通通勤旅運資料來建構人口於各地的流動網路,因此 在本研究將傳染病當做案例研究之際也必須要考慮使用交通通勤旅運網路來模 擬人口流動構成底層的網路結構。 若將探討網絡的遞移概念套用於病原體隨人口流動造成的遞移擴散現象,則 交通旅運造成的影響則為必要考慮的條件。若以交通旅運為角度,來評估流行病 的傳播,流行病於交通旅運的傳播主要發生在諸如飛機、車廂等交通工具的密閉 空間,經由咳嗽、打噴嚏的飛沫傳染還有碰觸到病毒導致接觸傳染(Tang et al., 2006),因此本研究主要鎖定探討的流行病是以飛沫及接觸傳染為主的流行病, 其中新型流感主要以飛沫及接觸傳染為主,71 型腸病毒主要以接觸傳染為主, 皆為本研究的鎖定目標。
2.5 基因演算法
基因演算法(Genetic Algorithm)是一套根據生物演化過程的概念所建立的一種 演算法,其核心理念是仿效生物的選擇、交配、遺傳、突變等觀念建構計算模式 搜尋問題的最佳解,主要應用在解決各種領域中計算空間大、複雜度高、尋求全 域最佳解的難題(Holland, 1992)。依據核心理念,基因演算法將欲求解的問題 經過編碼的方式產生染色體,初始染色體(chromosome)母體等同於在族群中 競爭欲存活的生物,而演算法中的適應函數(fitness function)等同扮演天擇的 角色,使適合生存環境的母體留下來繁衍後代,不適生存的母體淘汰,後代的繁 衍可經由母體交配(crossover)以及一定機率的突變(mutation)來產生下一代, 模擬自然界演化特性以找尋最佳解。以上基因演算法的各項步驟往往因為探討的 內容及需求取向而有不同的設定方式,因此若能掌握基因演算法核心理念的各項 步驟所呈現出來的特性,將有助於本研究解決參數最佳化問題。14
綜合基因演算法的各項核心步驟來看,其具有搜尋空間、適應函數等等幾種 和傳統演算法不同的特性,就是這些特性使得基因演算法具有下列幾種別於傳統 的優點(Back et al., 1993; Goldberg, 1989):
(1) 基因演算法是將欲搜尋的參數先進行編碼再運算,而並非使用參數本身, 因此不需受限於過去演算法對於搜尋空間的限制,例如過去求解最佳化 演算法通常侷限在問題的目標函數、限制函數必須為連續或可微分函數 才能進行,使基因演算法不受額外的限制。 (2) 基因演算法擅長解決搜尋全域最佳解的問題,相較於過去的攀登演算法 (Hill-climbing algorithm)容易受初始值影響最後收斂在局部最佳解,基 因演算法同時對解集合進行平行搜尋使之避免陷入局部最佳解。 (3) 基因演算法不需要複雜的數學運算,只需要靠適應函數來篩選解集合, 例如傳統的梯度演算法需要根據其目標函數的導數來決定搜尋方向,基 因演算法只需要適應函數值即可進行搜尋,跳脫傳統的數學式限制,降 低處理問題的難度。 根據基因演算法幾項優於傳統的特性,其被廣泛使用在工程(模糊系統、類 神經網路)、物理(液晶及雷射技術)以及文化娛樂(動畫及視覺圖形)等領域,
解決排程順序、訊息重組、參數優選等問題(Haupt et al., 1998; Man et al., 1999;
Deepa & Sivanandam, 2007)。例如使用基因演算法來解決複雜的多項次函式,以
求達整體最佳參數解避免陷入數學函式中常見的局部最佳參數解(Michalewicz,
1992);以及應用基因演算法調整設計自動模糊系統的歸屬函數(membership
function)和模糊規則(Lee & Takagi, 2002)。目前對於使用基因演算法的研究皆
顯示出,基因演算法於工程領域的應用相當具有效率也有不錯的效果,同時也是 具有公信力被廣泛使用的求解最佳化演算法。
基於上述所列各項研究對於基因演算法所需,以及基因演算法所呈現的各項 優點,本研究在模型的進行中也有幾點問題是極需使用基因演算法所解決。對於
15 本研究所使用各項參數來說,必須要將參數分割至小數點四位以下來尋求更為細 緻的解集合提供更為有用的資訊,此作法搭配所使用的六項參數以及所使用的龐 大資料量,複雜度將隨著參數的增加呈現指數成長,此外參數的細微變動將會造 成結果的大幅變動容易造成解集合品質不一。因此若能使用基因演算法處理龐大 資料量並且對解集合進行平行搜尋,一條染色體能夠得出一組參數解的做法,對 於本研究不僅能得出各項參數對於最佳解的分佈,相較於類神經網路的搜尋方式 也是更有效率的做法。此外基因演算法適當的於染色體中加入突變基因的做法也 將有助於本研究跳脫局部最佳解,避免基因過於相近而無法突破。 本研究建構觀察遞移性的模型使用各項參數建構網路資料以此來計算風險 的遞移並且將結果與真實資料進行比對驗證,各項參數搭配計算均代表了不同實 質上的意義,有鑑於基因演算法對於本研究能夠提供的幫助,在本研究中將使用 基因演算法幫助本研究進行各項參數的最佳化搜尋以求解符合真實情況的最佳 解集合。
16
3
三、研究資料
在本文中流行風險指標使用流行病為案例研究,以台灣交通通勤旅運資料建構人 口流動網路,模擬因人口流動而產生的流行病風險遞移動態。為達到風險指標對 於案例研究的進行,研究所需資料含有用來建構人口流動網路的台灣各長短程交 通旅運資料,以及與實驗結果比對的真實流行病病例資料。因此本節將從上述研 究所需資料來源、收集到的研究資料內容、以及研究資料如何進行處理轉換來建 構本論文所需人口流動旅運網路開始進行討論。3.1 交通旅運網路建構
以傳染病而言在評估過台灣各行政區實質資源分配以及能有效影響衛生決策的 單位過後,本論文將以台灣本島現行行政劃分之直轄市、省轄市、縣所構成本島 22 縣市,以及 22 縣市依據行政區及鄉鎮市所細分之 353 鄉鎮市為規模(中華民 國交通部運輸研究所, 2008)。以上述所提及規模建構研究所需交通旅運網路資料 以模擬人口流動,進而窺探人口流動造成的病原體遞移現象。其中建構 22 縣市 及 353 鄉鎮市的交通網路資料包含了台灣短程通勤資料、台灣鐵路站起訖資料、 台灣航空站起訖資料以及台灣高鐵站起訖資料,資料內容及轉換細節則為以下所 敘。3.1.1 台灣短程通勤旅運網路資料
本研究使用台灣行政院主計處所調查 2000 年台灣人口普查資料,此資料依據民 眾戶籍地及工作地的關係建構所有鄉鎮市間每日通勤往來的人口數。此人口普查 資料包含一 409 x 409 大小的矩陣內容,代表台灣各鄉鎮市共計 409 個鄉鎮市每 日往來通勤人口數,其中列為居住地行為通勤地,矩陣中第 I 列第 J 行資料代表 編號 I 鄉鎮市每日通勤至編號 J 鄉鎮市人口數。此資料除了將台灣直轄市、省轄 市、縣所構成 22 縣市依據行政區及鄉鎮市往下細分為 353 鄉鎮市外,更將台北 市 12 行政分區再細分為 68 個部分,因此共計有 409 個鄉鎮市通勤人口資料。此17 人口普查資料不符本論文所需,所以必須將此 409 鄉鎮市通勤資料轉換為 353 鄉鎮市以及 22 縣市兩種規模,以符合本研究建構台灣短程通勤旅運網路資料的 要求。 本論文所使用的 353 鄉鎮市規模與通勤人口資料的差別在於未將台北市 12 行政分區往下細分,因此必須利用圖 3-1 概念將 409 x 409 大小的通勤人口資料 矩陣中被細分的台北市各行政分區轉換合併為 353 x 353 大小的短程通勤旅運網 路矩陣。至於 22 縣市短程通勤旅運網路的矩陣建立方式則是利用相同的處理概 念,將建構出來的 353 鄉鎮市矩陣資料依據各自所屬縣市合併為 22 縣市矩陣資 料。 圖 3-1 通勤網路矩陣合併概念
3.1.2 台灣鐵路通勤旅運網路資料
18 在鐵路通勤旅運網路資料方面,本文使用民國 95 年及 97 年台灣鐵路管理局客運 旅次起迄表建構鐵路通勤旅運網路(中華民國交通部運輸資訊組, 2009b)。台灣 鐵路管理局將台灣鐵路起訖站大致分為圖 3-2 的 49 個主要分區,如圖 3-2 每個 主要分區都涵蓋了數個鄉鎮市的起訖人數資料,資料內容為 49 x 49大小的矩陣; 矩陣內容代表了每年於此 49 個分區往來起訖的人口數,因此最後必須將資料再 除以 365 才是每日的鐵路通勤旅運人數。 圖 3-2 台灣鐵路主要交通 49 個分區 由於各鐵路交通分區涵蓋一至數個鄉鎮市,所以本論文將旅次起訖表根據下 列公式擴充至台灣 353 個鄉鎮市鐵路往來通勤旅運人數。 R = r × P P_all × P P_all (3-1) 其中R 代表每日由編號 i 之鄉鎮市搭乘鐵路往編號 j 鄉鎮市人口數,r 為每日
19 搭乘鐵路由交通分區 p 至交通分區 q 人口數,P 與P 代表編號 i 鄉鎮市與編號 j 鄉鎮市當地人口數、P_all 與P_all 代表交通分區 p 與交通分區 q 所涵蓋的鄉鎮市 總人口數,而在 22 縣市的矩陣建立則與台灣短程通勤旅運網路相同。
3.1.3 台灣航空通勤旅運網路資料
本論文使用民國 97 年台灣交通部運輸所提供國內航線班機載客率建構航空通勤 旅運網路,資料內容為 9 x 9 大小的矩陣(中華民國交通部運輸資訊組, 2009b); 以國內航班資料為主包含台灣的台東、花蓮、松山、台中、嘉義、台南、小港、 屏東及恆春共九個航空站於 97 年間往來的旅客人數,同樣的資料也必須除以 365 才是每日的航空通勤旅運人數。 本研究將航空資料的交通分區分為九大區,各個航空站代表一個交通分區, 每個交通分區的涵蓋範圍再根據各航空站位處的地理地址決定。依據航空站與鄉 鎮市的經緯度座標,本研究將各鄉鎮市分配至與其直線距離最近的航空站代表此 鄉鎮市所屬區域,接著如同 3.1.2 節台灣鐵路通勤旅運網路的還原方式,根據各 交通分區人口數比例還原便可得到 353 鄉鎮市及 22 縣市規模的航空通勤旅運網 路。3.1.4 台灣高鐵通勤旅運網路資料
台灣高速鐵路沿台灣西部一共建立了台北、板橋、桃園、新竹、台中、嘉義、台 南和左營一共八個站,本研究將根據台灣交通部高速鐵路工程局所提供民國 98 年高鐵各站起訖旅客量資料建立研究所需高鐵通勤旅運網路。資料內容為 8 x 8 大小矩陣,包含各站於 98 年間起訖旅客人數(中華民國交通部高速鐵路工程局, 2009)。 如同前述 3.1.3 節對於航空資料的處理方式,本研究將高鐵各站歸類為一共 八個交通分區,根據高鐵各站與鄉鎮市的經緯度座標來決定個高鐵站的交通分區 涵蓋多少鄉鎮市,接著同樣如本文 3.1.2 節的還原方式,根據各交通分區與鄉鎮20 市的人口數比例建構 353 鄉鎮市及 22 縣市規模的高鐵通勤旅運網路。
3.1.5 總交通通勤旅運網路建構
根據 3.1.1 節至 3.1.4 節所述,本研究利用台灣長短程通勤旅運網路資料建構出短 程通勤旅運網路、鐵路通勤旅運網路、航空通勤旅運網路及高鐵通勤旅運網路, 在本文中以下列式子代表總交通通勤旅運網路的構成: W = w × C + w × R + w × H + w × A (3-2) W 代表總交通通勤旅運網路,而W 代表每日由編號 i 之鄉鎮市通勤上班往編號 j 鄉鎮市人口數,C、R、A、H則分別代表短程通勤旅運網路、鐵路通勤旅運網路、 航空通勤旅運網路、高鐵通勤旅運網路,其中 w1、w2、w3、w4(weight1~weight4) 為由 0~1 分佈實數分別乘上 C、R、H、A 為各長短程通勤旅運網路佔有權重, 如此便為本研究用以模擬人口流動的總交通通勤旅運網路日旅運量完整組成。在 組成總交通通勤旅運網路的過程中使用權重原因在於,每種長短程交通的日旅運 量並不一定完全是通勤人口可能有部分比例為搭車遊玩的旅客,因此本研究必須 用權重的方式來調整對傳染病傳播有影響的通勤旅客人次,找出所佔權重以組成 真正有影響力的通勤旅運網路。 在調整過各長短程通勤旅運網路權重,組成真正有影影響力的通勤旅運網路 後,本研究則會將總交通通勤旅運網路進行正規化(normalize)的動作,將居住 地與通勤地的關係轉變為機率值方便本研究做出計算。正規化的方法為將總交通 通勤旅運網路的每一列元素皆除以該列總和,這樣便可獲得計算時使用的總交通 通勤旅運網路。3.2 真實流行病病例資料
根據 2.4 節所述,本研究收集經人口流動遞移傳染的兩種典範傳染病資料-2009 年 H1N1 與 71 型腸病毒傳染病,與所計算之染病風險結果做驗證。流行病病例 資料的來源為台灣行政院衛生署疾病管制局網站的傳染病統計資料查詢系統,此21 系統收集於西元 1999 年至現今的各類法定傳染病重症病例通報資料,提供本研 究收集傳染病統計資訊。 在傳染病統計資訊中有關 2009 年 H1N1 與 71 型腸病毒傳染病內容的部分, 此系統收集了民國 1999 年至 2011 年共 12 年間的重症病例數,以縣市規模及鄉 鎮市規模為統計範圍,記錄此 12 年間台灣各縣市或鄉鎮市的每周染病人數資料, 恰符合本研究欲收集流行病資料的地理規模。除 2009 年 H1N1 傳染病外,本文 收集此 12 年間 71 型腸病毒重症病例數破百的年度,包含 2000 年 291 起重症病 例、2001 年 393 起重症病例、2002 年 162 起重症病例、2005 年 142 起重症病例、 2008 年的 373 起重症病例共五年的重症病例資料。最後一共收集到各鄉鎮市及 縣市的每年每周重症病例數,同時此資料也隱含了各鄉鎮市的初始病例周數等資 訊,提供本研究進行風險程度的判斷。 根據收集到的傳染病資料,本研究先去除重症病例數為零的行政區後,再用 以下規則為順序判斷各鄉鎮市及縣市各年的實際風險程度: 1. 該年重症病例數,病例數高風險也越高 2. 初始重症病例周別,周別越早風險越高 3. 第二重症病例周別,周別越早風險越高 4. 第三重症病例周別,周別越早風險越高 如此無論行政區是鄉鎮市規模或縣市規模,本研究皆可得到每年各行政區的風險 程度排列,用來與本研究計算結果驗證。
22
4
四、 研究方法
在本章節將使用第二章節所述的文獻,與第三章研究資料建構的交通旅運網路、 驗證資料來探討模型的組成以及驗證方式。章節 4.1 針對研究目標所提,探討指 標模型的制定方式以及功能等細節。章節 4.2 討論如何驗證本模型的計算結果正 確性,提出驗證方法的目的及評估方式。章節 4.3 則解釋本模型於利用基因演算 法搜尋最佳參數解時,如何設定基因演算法的各項流程步驟以及各項設定的意義。 其中圖 4-1 為本模型整體架構組成。 圖 4-1 模型整體架構圖4.1 流行風險指標模型
本模型以流行病的傳播為案例研究,將網絡中的遞移概念套用於案例研究上,探23 討病原體隨行政區間的人口流動所造成的遞移擴散現象。模型中將使用研究資料 章節所建構的台灣長短程交通旅運網路模擬人口流動,以計算病原體隨宿主於各 行政區移動時所造成的遞移風險。 每一個人的移動都代表著一條潛在的感染路徑,如圖 4-2(a)以行政區 A 與行 政區 B 之間的每日往來通勤及原地通勤人口為例,若以行政區 A 的觀點來看, 本研究在計算染病風險時需考慮的病原體遞移擴散方式有兩種: 1. 每日從其他行政區通勤至該行政區上班的人口帶來的傳染風險。 (圖 4-2(b)) 2. 白天通勤至其他行政區受到感染後,晚上回原行政區的人口造成的傳染 風險。(圖 4-2(c)) 除了上述兩種病原體擴散方式外,原地通勤的人口數對於病原體於原行政區的擴 散也有一定的影響,因此在計算傳染病風險時原地通勤人口以及行政區間通勤人 口都是必須考量的地方。此外流行病的傳染病案例並非完全由通勤者所導致,其 他部分對傳染病的擴散所造成的影響也是本模型必須計算的重點之一。
24 圖 4-2 行政區間通勤人口範例圖 根據上述概念本研究建立風險指標模型的計算公式如下: = (1 − d) × f + d × (dayTime × W × ERV + (1 − dayTime) × W × ERV ) (4-1) :大小為N × T矩陣,N 為行政區數目、T 為迭帶計算次數,內 容為各行政區每次迭代後所計算出的風險值。 W:每日總交通通勤旅運網路,其中 W× ERV 代表計算白天通勤至其 他行政區受到感染後,晚上回原行政區的人口造成的傳染風險。 W :每日總交通通勤旅運轉置網路,其中W × ERV 代表計算每日從 其他行政區通勤至該行政區上班的人口帶來的傳染風險。 dayTime:代表通勤人口外出工作時間所佔一天的比例。 f:其餘造成傳染病傳播的因素。 d:通勤因素於該流行病所佔的影響比例 (a) (b) (c) Area A 300 people Area B 200 people Area A 300 people Area B 200 people Area B 200 people Area A 300 people 80 people 130 people 220 people 70 people 80 people 70 people
25 利用此公式能夠讓本研究考慮病原體隨人口流動以及其它因素對於傳染病 傳播的影響,進而計算出各行政區染病風險程度值。其中值得注意的地方在於流 行病的傳播具有不斷遞迴傳染的特性,因此(4-1)式經由每日總交通通勤旅運 網路量以及其它因素迭代計算一次的結果即為一日之後各行政區的風險程度;迭 代 M 次則代表 M 日後的各行政區風險程度。 為了觀察傳染病在一年內所造成的影響,本模型設定了下列兩個迭代計算的 停止條件,並以先達到為準: 1. 各行政區染病風險未變動達 100 次,表示計算趨平穩停止迭代。 2. 計算公式迭代至 365 次即停止迭代。 在計算公式停止迭代後即可獲得計算結果,同時本研究將計算結果分成下列 三種不同表示方式,每種方式都代表了不同的意義與參考價值:
1. ERV(Epidemic Risk Value):染病風險值,計算公式停止迭代後可得各
行政區的染病風險值。
2. ERR(Epidemic Risk Rank):染病風險排序,依據染病風險值將各行政
區危險程度由高到低進行排序而得,可用來提供實施公衛政策順序的參 考。
3. ERI(Epidemic Risk Index):染病風險指標,將各行政區染病風險值皆各
自除以所有行政區染病風險值總和所得的危險程度百分比比率,可比較 各行政區指標以評估危險程度的比值,具絕對及相對意義。 本模型在於計算網絡中的遞移特性功能方面與同為計算遞移特性著名的理 論模型馬可夫鏈不同點在於馬可夫鏈使用機率陣列來計算一段時間後的狀態改 變,過程中無法改變機率陣列。而本模型所建立的總交通通勤網絡矩陣,能夠隨 時於迭代過程更改結構,因應現實世界可能因防疫政策做出的交通旅運量改變而 做出計算。同理在將模型運用至其他遞移現象的計算時,也能夠因應網絡狀況更 改計算網絡矩陣的結構。
26
4.2 流行病風險指標效益評估
本文 4.1 節所述觀察遞移特性模型,在套用於案例研究計算出結果後,接著將使 用本節提出對於案例研究具有參考價值的評估方式做為驗證。由於本模型套用於 傳染病藉由人口流動傳播的遞移特性計算,因此底下將提出兩種評估方式,驗證 結果對於傳染病學研究以及公衛單位做出衛生決策的幫助。4.2.1 根據各行政區計算指標評估
對於衛生單位來說如果在一項新興流行病盛行之前,知道哪些行政區可能是具有 高度感染風險的地區,就能夠進一步實施適當的隔離與預防政策。因此本模型考 慮人口流動與傳染病遞移傳播的關係,計算出各行政區的染病風險程度,並且與 本文 3.2 節所提各行政區真實流行病病例資料做第一項驗證。若相關性高代表驗 證通過,證明本模型考量病原體隨人口流動遞移傳播的概念進而計算出各行政區 的風險程度,對於衛生單位來說具有實際參考價值。 如圖 4-3 本模型使用第一項驗證方式如下: (1) 根據本文 3.2 節所述,將各行政區傳染病病例資料根據染病人數及病例 週別做出實際風險程度的排序,得到數列 1。 (2) 將本模型所計算出來的各行政區風險程度進行排序,得到數列 2。 (3) 使用斯皮爾曼相關係數(Spearman Correlation Coefficient)將上述所得數列 1 與數列 2 進行相關程度的驗證,評估本模型計算結果的正確性。 在此使用斯皮爾曼相關係數的原因在於,相較於皮爾遜(Pearson)肯德爾(Kendall) 等其餘相關係數的檢定,斯皮爾曼相關係數不需要求兩數列的分佈形態、樣本大 小等數據條件,只需要兩個變量是兩列對等級數即可進行計算。以本研究計算結 果以及實際流行病病例資料來看,本研究只需要求得兩種資料的等級數列即可進 行相關性檢定,驗證本研究計算結果的正確性。
27 圖 4-3 風險指標驗證方式
4.2.2 根據模型計算命中率評估
每當新興流行病來臨時,如果能夠準確的預估出高風險的行政區將會更有助於預 防政策的實施,有效降低新興流行病帶來的殺傷力。因此除了知道各行政區的染 病風險程度排序能夠提供衛生單位政策實施的參考,若能夠再針對實際流行病資 料中危險程度較高的行政區,進一步分析本模型對於這些高風險地區的命中率, 也將有助於驗證本模型的計算結果。 依據標準差的組距觀念,本研究將實際資料中前 50%的高風險行政區分為前 17.5%以及 17.5%~50%兩個組距,並且觀察本模型計算結果所預估的前 50%高風 險行政區,於此兩個組距與實際資料的重疊性來計算染病人數命中率與行政區命 中率。以下將詳細介紹染病人數命中率與行政區命中率計算方式。 以表 4-1 中危險程度前 17.5%組距的行政區為例,染病人數命中率的計算方 式為:28 本模型命中之行政區染病人數總和 實際資料之行政區染病人數總和 = 30 + 26 + 20 30 + 26 + 20 + 10≅ 0.88 表 4-1 染病人數命中率 因此本模型計算結果於危險程度前 17.5%組距的染病人數命中率約為 88%,此外 參考圖 4-4,行政區命中率的計算方式為: 重疊之行政區數 實際資料之行政區數+計算結果之行政區數 − 重疊之行政區數 = 3 4 + 4 − 3= 3 5= 0.6 由此範例計算方式可得本模型於危險程度前 17.5%組距的行政區命中率為 60%,經由比較本模型計算結果於兩個組距的染病人數命中率與行政區命中率, 提供有別 4.2.1 節所述相關係數檢定的方式,進而驗證本模型計算結果的正確 性。
29
30
4.3 基因演算法
在本文中使用基因演算法來幫助模型搜尋計算遞移特性的各項參數,每條染色體 都代表一組可能的參數解,並且以 4.2 節的驗證方法為適應函數(Fitness Function) 來求解適應值最高的參數組合。以下將先以圖 4-6 的流程圖呈現概念,接著詳述 本研究於基因演算法各步驟的詳細設定方式,後再以表 4-1 的步驟設定來整理基 因演算法的各個變項設定: 圖 4-5 基因演算法流程圖 (1) 染色體編碼方式(Encoding): 根據 4.1 節所述,本模型計算公式中包含 d、dayTime、w1、w2、w3、w4六 個觀察遞移特性的參數,各參數皆從 0~1 呈實數分佈並且都使用十個二進位的數 字來編碼,因此染色體一共包含六十個二進制的數字,其內容為:31
(d d ⋯ d , dayTime dayTime ⋯ dayTime ,
w1 w1 ⋯ w1 , w2 w2 ⋯ w2 , w3 w3 ⋯ w3 , w4 w4 ⋯ w4 ) 以下列式子為例,在本文中將二進位編碼轉換為真正代表參數數值的方式為 將各個參數由二進位制轉換成十進位制之後再除以(2 − 1)以進行染色體編 碼的轉換: 1000000001 = 513 513 / (2 − 1) ≅ 0.5015 如此便可獲得各項參數實際值與染色體內表示法的轉換。 (2) 初始化與群體大小設定(Population、Initialization): 在初始值方面,本模型使用隨機亂數的方式來產生基因以構成染色體,並且 設定原始群體內的染色體數為 100 條。 (3) 適應函數(Fitness Function): 在適應值方面,使用本文 4.2.1 節所述驗證方式做為基因演算法的適應函數 (fitness function),以評估每條染色體的適應值。 (4) 挑選染色體方式(Selection):
本模型中使用競賽挑選(Truncation selection)與輪盤式挑選(Roulette Wheel selection)來從交配池中挑選欲交配的母代染色體。 在使用競賽挑選時,將從交配池(mating pool)中隨機搜尋兩條染色體以進 行下一步的演化動作,意謂每條染色體無論適應值高低,被挑選出來的機率皆相 等。而在使用輪盤式挑選時,會依據每條染色體的適應值高低決定被挑選出來的 機率,意即適應值越高其被挑選出來的機率就越高,此種作法的缺點在於適應值 高的染色體可能被大量複製,造成群體及早產生收斂的情形。
32 本模型使用兩種挑選模式進行比較,觀察就兩種挑選模式所搜尋出來的解是 否根據其挑選的特性能夠搜尋出不同的解集合,比較適應值以及染色體的演化狀 況,並且將以表現狀況較佳的模式為主。 (5) 交配方式與突變方式(Crossover、Mutation): 在經過挑選模式選出欲交配的染色體後,本模型使用兩點式交配(Two-point Crossover)來使母代交換六項參數的基因組成以期產生適應值更高的子代。在交 配過程中,隨機選擇兩個交配點將染色體分成三段,並將兩條母代染色體交換中 間段的基因產生兩條子代以達到基因交換。 接著本模型將交配後的兩條子代染色體的基因進行突變操作,突變的方式採 bit-by-bit 並設定突變率為 0.001。突變進行的方式是從子代染色體中的六十個二 進位數字,從最高位元至最低位元一個個位元根據突變率決定是否產生突變。當 完成突變操作時會將子代放入新的交配池中,一旦新的交配池中染色體數目足夠, 將捨棄舊的交配池並以新的交配池再進行下個回合的演化。 (6) 終止條件與結果篩選(Termination condition): 基因演算法演化達到 X 個世代後若染色體的適應值曲線達到平穩即停止演 化,其中 X 初始設定為 1000。 本模型設定基因演算法模擬共十回合,每回合在經過 X 個世代的演化結束 後,將保留所有染色體中適應值最高的十條染色體,如此演算法在十個回合結束 後便可獲得 100 條染色體。接著便分析所有染色體中六項參數的分佈、中位數及 平均數,觀察六項參數於各染色體的變化以及異同之處。
33
Genetic Algorithm Variables Setting
Encoding Binary
Population & Initialization 100~200、Random
Selection
Truncation Selection、 Roulette Wheel Selection
Crossover Two-point Crossover
Crossover Rate 0.8
Mutation Bit-by-bit
Mutation Rate 0.001
Simulation Round 10
Termination condition 1000 Generations
34
5
五、實驗結果
本研究以流行病在台灣 353 個鄉鎮市以及 22 個縣市間的傳播來進行網路遞移的 實驗模擬,並收集真實流行病病例資料進行驗證比對。本章節分成四個部分,第 一個部分設定總交通旅運網路的構成參數以及模型其餘參數,並以敏感度分析探 討實驗結果與真實資料驗證的正確性。第二部分使用基因演算法搜尋模型中的參 數組合,設定總交通旅運網路由短程網路以及台鐵網路所構成並以短程網路為主 體架構(短程網路權重為百分之百),觀察何種參數組合會使實驗結果與真實 H1N1-A 型流感、71 型腸病毒病例驗證相關性最高並分析參數組成及驗證結果是 否能反映現實情況。第三部分加入高鐵及航空等長程交通旅運網路探討流病經由 長程網路的傳播能力。第四部分只採取高鐵及航空兩種長程交通旅運網路與第二 及第一部分做出比較驗證。第五部分則是將總交通旅運網路去除以短程網路為主 要架構的設定,改為所有本研究所調查的旅運網路搭配而成,進行模擬並分析實 驗結果。其中基因演算法所搜尋到的各項參數在本章節將取出最佳解染色體進行 分析,而所有的染色體參數解分佈則收於附錄。5.1 模型參數敏感度分析與驗證
在使用基因演算法搜尋本模型最佳參數解之前,本研究先將總交通旅運網路的構 成參數(3-2)式以及(4-1)式其餘參數進行設定以便採取敏感度分析的做法, 來探討並驗證模型方法的正確性。5.1.1 實驗一:使用各種網路組合進行敏感度分析
如同本文 3.3 節本研究檢閱了 H1N1-A 型流感以及 71 型腸病毒的染病年齡層、 潛伏期以及傳染途徑等特性並做出資料檢定。參考表 5-1,H1N1-A 型流感在各 年齡層皆具有染病風險重症及死亡者多見於五歲以下孩童及老年人,潛伏期約 1~4 天病患在潛伏期已具有傳染力並且是經由飛沫以及接觸傳染(Chan, 2009); 71 型腸病毒染病多見於五歲以下兒童成年人具較強抵抗力受影響低,發病後一35 周具傳染力,糞口及食物接觸為主要傳染途徑(Chang et al., 1999)。經由檢視上 述流行病特性,值得本研究注意的是 H1N1-A 型流感的潛伏期以及染病族群,容 易造成病原體透過移動力較高的青壯年人口通勤上班傳播,而 71 型腸病毒與通 勤上班造成的傳播相關性則較低。意即 H1N1-A 型流感與通勤人口的相關性大過 71 型腸病毒與通勤人口的關係。 H1N1-A 型流感 71 型腸病毒 染病年齡層 1. 任何年齡層皆有染病風險 2. 重症及死亡者多見於五歲 以下兒童及老年人 1. 重症多見於五歲以下兒童 2. 成年人具較強抵抗力,較不 受影響 潛伏期 潛伏期約 1~4 天 在潛伏期病患已具有傳染力 潛伏期約 2~10 天 發病後一周傳染力最強 傳染途徑 經由飛沫 人與人直接或間接接觸 接觸傳染(糞口、食物) 表 5-1 流行病特性比較表 有鑑於此,本研究做出一項假設:將模型的計算方式設定為排除其餘與通勤 因素所不相干的影響,相較於 71 型腸病毒,計算結果與 H1N1-A 型流感的相關 性會較高,因此底下根據假設將模型中參數做出表 5-2 的設定。 參數 旅運 影響 比例 日間 旅運 影響 比例 短程 網路 權重 台鐵 網路 權重 高鐵 網路 權重 航空 網路 權重 設定 1 由 0~1 分 佈區間為 0.1 0 或 1 分佈 規模:353 鄉鎮市 流行病: 2009 年 H1N1-A 型流感 2000 年~2010 年 71 型腸 病毒 表 5-2 敏感度分析參數設定
36 本文在此實驗使用交通旅運量最大的短程通勤旅運網路以及台鐵旅運網路 來構成總交通旅運網路,設定旅運影響比例為 1 完全只看通勤對於病原體遞移傳 播所造成的影響,並且設定日間旅運影響比例參數由 0 到 1 分佈、區間為 0.1 進 行此參數的敏感度分析。計算規模以 353 鄉鎮市為準,而在流行病方面使用 2009 年 H1N1-A 型流感病例資料以及 2000 年至 2010 年間 71 型腸病毒重症病例數破 百的年度來計算,驗證方式採 4.2.1 節所述斯皮爾曼相關係數做驗證。 在圖 5-1 及 5-2 中,日間旅運影響比例參數的分佈即為本模型使用表 5-2 參 數設定後產生的敏感度分析結果,當日間旅運影響比例參數為 0 或 1 時代表沒有 圖 4-2 中另外一種影響病原體傳播的方式,比較不具意義因此選擇將把日間旅運 影響比例參數等於 0 以及 1 的結果取掉不呈現。 圖 5-1 與圖 5-2 即為本模型使用表 5-2 參數設定後產生的敏感度分析結果, 顯示模型計算結果與 2009 年 H1N1-A 型流感及各年 71 型腸病毒實際病例進行斯 皮爾曼相關係數檢定皆能夠形成正相關的檢定值。在結果方面,當日間旅運影響 比例參數的數值越高越能夠造成兩種流行病的相關係數檢定值上升,顯示影響傳 播的比重以圖 4-2(b)為主。在 H1N1-A 型流感方面當旅運網路組合越完整相關性 也上升,顯示長短程旅運網路皆為影響 H1N1-A 型流感傳播的重要因素之一,在 71 型腸病毒方面當高鐵網路加入時往往能有效提高相關性,可看出高鐵網路於 人口數高的行政區之間帶來的人口流動與 71 型腸病毒真實病例分布的重疊。