國立臺中教育大學教育測驗統計研究所碩士論文
指導教授:許天維 博士
資料包絡分析法在突顯國小學童
個別優勢成績分析之應用研究
研究生:柯維貞 撰
中
華
民
國
一
○
一
年
十
二
月
資料包絡分析法在突顯國小學童
個別優勢成績分析之應用研究
摘要
現代教育強調適性而教,在成績計算方面,應該找出符合學童個別差異, 對個人最優勢的成績計算方法。本研究應用資料包絡分析法(Data Envelopment Analysis, DEA)的產出導向 CCR 模型,以國語、數學、自然與社會四科目成績 為資料來源,計算出各個學童的相對分數、各科權重後,找出個別學童的學習 標、相對分數、優勢科目及成績進步方向及幅度,讓學童能找到學習的目標、 最適合自己的進步方式,以及個人的優勢科目,使其建立信心,往自身優勢能 力去努力發展。並搭配修正後交叉效能法來排序,能使此成績計算方法更為周 延,且更切合實務使用。 關鍵字 關鍵字 關鍵字 關鍵字:::個別差異、成績計算方法、資料包絡分析法、DEA、優勢能力 :An application in Data Envelopment Analysis to Salience
Individual Academic Results of Elementary School Students
Abstract
Modern education emphasizes adaptive teaching. We should find out the method confirm to the individual differences of the students and get the most advantage achievement. This paper using output-oriented CCR model in data envelopment analysis, and use mandarin, mathematics, natural simulation and society achievement as data source, calculate each student's relative mark, and every subject weight, enable student to find study goal, and relative score, personal advantage subject and the fast progressives way, make it set up confidence, go to develop hard to one's own advantage ability. Using modified cross efficiency are arranged in an order, can make the computing technology of this achievement distribution even more, and suit making sure in fact to use even more.
Keyword : Individual Differences, Academic results calculation, Data Envelopment Analysis, DEA, Advantage of the capabilities
謝辭
謝辭
謝辭
謝辭
感謝這一路走來所有幫助過我的人,有你們的協助,我才能在計劃的時間 內,完成學業、順利畢業。不論是師長、同學們、學校同事以及家人,若沒有 你們,我沒有辦法完成這項挑戰。 回首研究所短短不到兩年的時光,交織著淚水與歡笑,從再拾起書本,到 準備離校,心中有許多的感動與感謝,首先要感謝的是指導教授許天維院長, 在院長明確的引導下,我才能堅定不移的朝著目標前進,一一克服困難,完成 許多原以為不可能完成的任務,尤其是研討會論文發表兩篇的挑戰,若非老師 悉心的指導與協助,這艱難的任務絕對不可能一次成功。除此之外,也感謝老 師對我的的包容與鼓勵,給予我許多的空間,讓我能盡情的在浩瀚的知識大海 中探索,又不至於失去了方向。另外,也謝謝胡教授和辛教授,因為有你們在 口試時提出的寶貴意見,讓我的論文可以更臻於完善。 再來要感謝的是所內的課程安排及指導過我的教授們,感謝你們讓我得以 具備了充足的知識及技術來完成我的研究,不論是研究的方法、測驗與評量的 理論或是軟體的操作,在我的論文研究中都扮演著關鍵的角色。同時也感謝研 究所的同學們,每每在課業上遇到問題,你們總能熱心的給予協助。 接著是感謝我所任教的學校,無論是校長、各處室的主任、學校的同仁以 及同學年的老師們,在這個進修過程中,大家給予我許多的鼓勵與體諒,讓我 得以學業與工作兼顧;而好友蒨薇,更是擔任我的私人顧問,幫我解答許多進 修相關的問題,省卻我摸索與找尋答案的時間;而班上可愛的小朋友們,謝謝 你們的乖巧與懂事,讓我既可以快樂且開心的教書,又可以充實的進修。最後,我要感謝我最愛的家人,進修的這段時間,天天就像打仗一樣,由 於我的完美主義性格,希望學業、工作以及家庭可以兼顧,而且希望三者都可 以做得很好,所以你們也陪著我一起累,一起辛苦。兩個寶貝的獨立與貼心, 老公的包容與陪伴,是支持我,讓我堅持下去的原動力。在忙碌的生活中,為 了學校的工作以及研究所的課業,每每忙到凌晨一、兩點才能入睡,尤其是兩 篇研討會論文的發表以及口試的準備,更是天天都到凌晨兩、三點,有好幾次 甚至是看著朝陽升起,這些辛苦,到現在,都變成充滿回憶的甜美果實。 終於畢業了,這一切美好的、辛苦的過程都讓我一生珍藏,感謝所有給予 我協助的人,謝謝! 柯維貞 謹誌 2013 年 1 月
目次
目次
目次
目次
第一章 第一章 第一章 第一章 緒論緒論緒論 ... 1緒論 第一節 研究背景 ... 1 第二節 研究目的 ... 2 第三節 名詞釋義 ... 3 第四節 研究流程 ... 4 第五節 論文結構 ... 5 第二章 第二章 第二章 第二章 文獻探討文獻探討文獻探討 ... 7文獻探討 第一節 資料包絡分析法 ... 7 第二節 資料包絡分析法基本模式 ... 9 第三節 資料包絡分析結果之排序 ... 14 第四節 相關文獻探討 ... 20 第三章 第三章 第三章 第三章 研究方法研究方法研究方法 ... 21研究方法 第一節 產出效能導向 CCR 模式 ... 21 第二節 修正後的交叉效能排序法 ... 28 第三節 成績評估實施流程 ... 28第四節 研究工具 ... 30 第四章 第四章 第四章 第四章 實證分析實證分析實證分析 ... 33實證分析 第一節 受評學童各科成績 ... 33 第二節 受評學童評估結果分析 ... 34 第三節 修正後的交叉效能排序 ... 40 第五章 第五章 第五章 第五章 結論與建議結論與建議結論與建議 ... 43結論與建議 第一節 研究結論 ... 43 第二節 建議 ... 45 附錄一 附錄一 附錄一 附錄一、、、EXCEL VBA 程式碼、 程式碼程式碼 ... 51程式碼 附錄二 附錄二 附錄二 附錄二、、、實證分析、實證分析實證分析實證分析~交叉效率矩陣交叉效率矩陣交叉效率矩陣交叉效率矩陣 ... 58 附錄三 附錄三 附錄三 附錄三、、、實證分析、實證分析實證分析實證分析~超級效能矩陣超級效能矩陣超級效能矩陣超級效能矩陣 ... 62 附錄四 附錄四 附錄四 附錄四、、、實證分析、實證分析實證分析實證分析~超級與交叉效率矩陣超級與交叉效率矩陣超級與交叉效率矩陣超級與交叉效率矩陣 ... 63
表次
表次
表次
表次
表 2.1 交叉效率矩陣示意表 ... 18 表 2.2 交叉與超級效率並用示意表 ... 19 表 3.1 十位受評學童的國語及數學原始成績 ... 23 表 3.2 受評學童效能及國語、數學權重 ... 27 表 4.1 受評學童期中考成績 ... 33 表 4.2 未達滿分學童學習標竿 ... 34 表 4.3 各學童相對分數分析 ... 35 表 4.4 受評學童各科權重及相對效能 ... 36 表 4.5 原始分數與相對滿分分數對照表 ... 38 表 4.6 受評學童修正後的交叉效能排序 ... 40 表 6.1 受評學童 A~H 的交叉效能矩陣... 58 表 6.2 受評學童 I~P 的交叉效能矩陣 ... 59 表 6.3 受評學童 Q~X 的交叉效能矩陣... 60 表 6.4 受評學童 Y~AF 的交叉效能矩陣 ... 61 表 6.5 受評學童的超級效能分數 ... 62表 6.6 受評學童 A~H 的交叉與超級效能並用分數矩陣 ... 63
表 6.7 受評學童 I~P 的交叉與超級效能並用分數矩陣 ... 64
表 6.8 受評學童 Q~X 的交叉與超級效能並用分數矩陣 ... 65
圖目錄
圖目錄
圖目錄
圖目錄
圖 1.1 研究流程圖 ... 4
圖 2.1GOLANY &ROLL所提出的 DEA 模型使用程序。 ... 8
圖 3.1 學童在國語-數學平面上的相對位置 ... 23 圖 3.2 數學科目加權 100% ... 24 圖 3.3 國語科目加權 100% ... 25 圖 3.4 學童二科目平均分數示意圖 ... 26 圖 3.5 以學科成績轉換曲線衡量相對效率 ... 27 圖 3.6 簡化成績評估實施流程 ... 28 圖 3.7 學童成績輸入格式 ... 30 圖 3.8 各學童各科成績權重表 ... 31 圖 3.9 各學童超級效能數值表 ... 31 圖 3.10 交叉與超級效並用表 ... 32 圖 3.11 交叉與超級效率平均分數排序表 ... 32
第一章
第一章
第一章
第一章 緒論
緒論
緒論
緒論
第一節
第一節
第一節
第一節 研究背景
研究背景
研究背景
研究背景
傳統的教學方法,常常是填鴨式教學方式,或者是一成不變的教學模式, 對於所有的學童都是相同對待,忽視學童的個別差異,也不符合個別學童的 學習需求,在此方法下,學童無法得到良好的學習效果。故自九年一貫施行 至今,不論在教學方法或是教材內容皆強調「因材施教」,提倡適性化教育, 強調多元的教學方法以及教材內容,以學童個別差異為基礎,並配合學童身 心能力發展歷程,尊重學童個性發展,進而激發個人潛能(九年一貫課綱;游 進年 ,2009) ;而 在 測驗 與 評量 方 面, 也已 發 展出 多 項電 腦化 適 性測 驗 (Computerized Adaptive Testing, CAT),希望能針對不同能力與程度的學 童,提供最適合的測驗方式,以符合個別差異,達到適性而測,亦即希望測 驗題目能夠隨學童能力不同而調整,讓測驗的難度適合學童的能力程度,並 測到最精確的考生能力。 然而,在成績計算方面,也應考慮到學童的個別差異,依學童個別能力 優勢來計算。由於現行學童的成績計算,皆是採齊頭式的方法,即以「總分 制度」來計算成績,但是此制度中的平均數法會產生「趨中原理」的現象, 也就是當學童各科目得分越相近時,其所損失的分數就越少(余民寧,2009); 當各科目得分高低有極大差異時,在成績計算上就越不利(賴佩筠,2010)。 教學現場上,成績計算皆由主觀的自訂權重方式來計算。以國小為例, 期中評量成績採各科加總後的總分來計算,則此時各科的權重均相同,皆為 1。學年成績結算時,則先以各科分數乘以各科目授課節數,再除以總授課節 數來計算,則此時即以各科目的授課節數當作權重來計算。然而不論是以上那一種成績計算方式,皆是主觀訂定權重,對於所有的 學童都是相同的,這樣的計算方式,對於某科目相對不突出的學童而言,勢 必得到較不理想的分數,不但不能發展個人優勢,而且也會打擊個人自信心, 降低學童的學習意願,增加學習的壓力。 因此,在成績計算方面也應依照學童個別差異,找出能突顯學童個人優 勢能力,最適合每個學童的計算方式。所以,非事前人為主觀決定各科目權 重,而是在客觀環境下,將資料結果經由模型自行決定權重,找出對學童最 有利的成績計算方式的就只有資料包絡分析法( Data envelopment analysis, DEA)。
第二節
第二節
第二節
第二節 研究目的
研究目的
研究目的
研究目的
本研究目的是運用資料包絡分析法來處理多科目的成績分析,找到對學 童最有利的計算方式,得到每個學童的相對效能值,並將此效能值轉換為相 對分數,最後再對結果做分析。 本研究主要目的如下: 1. 獲得成績未達相對滿分學童的學習標竿。 2. 算出對每位學童最有利的相對效能分數。 3. 找出個別學童的優勢科目。 4. 針對未達相對滿分的學童,提出適合個別學童的成績進步方向與幅 度。 5. 以修正後交叉效能法算出學童新的分數,並以此新分數為排序的依 據,修正原資料包絡分析法無法完整排序之情形。第三節
第三節
第三節
第三節 名詞釋義
名詞釋義
名詞釋義
名詞釋義
一 一 一 一、、、決策單位、決策單位決策單位決策單位決策單位(Decision Making Unit, DMU)是指資料包絡分析法所分析的對 象,選擇決策單位時,應考慮生產過程之組織同質性。 二 二 二 二、、、效率前緣、效率前緣效率前緣效率前緣 運用數學規劃模式找出生產邊界時,此邊界即為效率前緣(Efficiency Frontier),在此前緣上決策單位的相對效率值為 1 者,即為相對有效率。不 在此線上者,即為相對無效率,其相對效率值必小於 1。 三 三 三 三、、、相對效率、相對效率相對效率相對效率 相對效率(Relative Efficiency)是指資料包絡分析法模型所得到的數值結 果,相對效率值為介於 0 到 1 之間的數值,當評估後的相對效率值為 1 時, 即代表相對有效率。 四 四 四 四、、、參考集合、參考集合參考集合參考集合 對於相對無效率之決策單位而言,可經由與有效率之參考集合(Reference Set)比較來得知被評為無效率的原因,這些被參考群體可以做為目標設定的 基準,亦即可視為無效率決策單位之學習標竿(Benchmark)。
第四節
第四節
第四節
第四節 研究
研究
研究
研究流程
流程
流程
流程
本研究的研究流程如圖 1.1,先訂出研究方向及目的,搜集相關文獻及分 析工具,再選定研究對象,依分析內容選定合適的資料包絡分析法的分析模 式。接著將模擬資料及實證資料以電腦程式分析出數據,再依數據分析模擬 及實證資料中各學童的學習標竿、相對分數、優勢科目、進步方向及幅度, 再做公正且完整的排序,最後提出相關結論及建議。 圖 1.1 研究流程圖第五節
第五節
第五節
第五節 論文結構
論文結構
論文結構
論文結構
本文共分為五章,第一章為緒論,內容為本研究的研究背景、目的及架 構。 第二章為文獻探討, 共分為三節。第一節為資料包絡分析法的相關文 獻,第二節則為資料包絡分析法分析模式的相關文獻,第三節為資料包絡分 析法排序方式的相關文獻,第四節則為資料包絡分析法在成績分析與教育上 運用的相關文獻。第三章為研究方法,第一節說明依 Charnes, Cooper and Rhodes (1978)而 命名產出導向 CCR 模式,第二節為修正後的交叉效能排序法,第三節為成績 評估實施流程,第四節則是研究工具的介紹。 第四章為模擬分析,第一節為四科目模擬成績的資料。第二節為學童成 績評估及結果分析。依此評估結果,我們可獲得個別學童的學習標竿、相對 分數、優勢科目以及成績進步的方向與幅度。第三節則為修正後的交叉效能 排序,使成績結果的排序是公正且完整。 第五章為實證分析,第一節為受評學童各科成績的資料,第二節為受評 學童評估結果分析,第三節則為修正後的交叉效能排序。 第六章為結論與建議,第一節為本研究的研究結論,第二節則為日後以 資料包絡分析法應用於成績分析的建議。
第二章
第二章
第二章
第二章 文獻探討
文獻探討
文獻探討
文獻探討
本章將探討資料包絡分析法及衡量成績表現與教育上的運用和排序方法 之相關文獻,第一節介紹資料包絡分析法,第二節說明資料包絡分析法的分 析模式,第三節整理常見的排序方法,第四節探討資料包絡分析法在教育上 運用的相關文獻。第一節
第一節
第一節
第一節 資料包絡分析法
資料包絡分析法
資料包絡分析法
資料包絡分析法
壹
壹
壹
壹、
、
、
、資料包絡分析法之探討
資料包絡分析法之探討
資料包絡分析法之探討
資料包絡分析法之探討
Charnes, Cooper and Rhodes (1978)根據 Farrell (1957)之效率模型,提出資 料包絡分析法,是一種以線性規劃(Linear Programming)來進行的績效評估的 方法。又根據三人的名字,將分析模型簡稱為 CCR 模式。資料包絡分析法 的基本原理是建立在伯瑞圖最適境界(Pareto Optimality)的效率觀念上。當達 到此最適境界時,若要再增加某個人的利益,則必會損及其他人的利益。 資料包絡分析法是利用線性規劃的方式讓決策單位找出一組能使自己效 能值極大的權重配置,同時亦不損及其他決策單位的利益。此分析方法原本 用來評估非營利事業,如各級學校、圖書館、公立醫院等的效率,後來再推 廣到評估其他營利機構的效率,如銀行、旅館等。
貳
貳
貳
貳、
、
、
、資料包絡分析法的特性
資料包絡分析法的特性
資料包絡分析法的特性
資料包絡分析法的特性
依據 Lewin and Minton (1986)的研究指出,資料包絡分析法在評估效率 有以下特性:
(一) 無需預設生產函數及參數,即可同時處理多投入及多產出的議題。 (二) 投入與產出的權重由線性規劃產出,評估過程中無人為因素影響。 (三) 能夠確認所有決策單位中,何者有效率、何者無效率。
(四) 以數值呈現決策單位的投入項以及產出項之間的關係,此數值代表 與其他決策單位之相對效率,而非絕對效率。 (五) 資料包絡分析法的評估結果,能以數值方式呈現無效率的決策單位 應如何調整投入,或增加多少產出,才能達到最有效的境界。
參
參
參
參、
、
、
、資料包絡分析法使用程序
資料包絡分析法使用程序
資料包絡分析法使用程序
資料包絡分析法使用程序
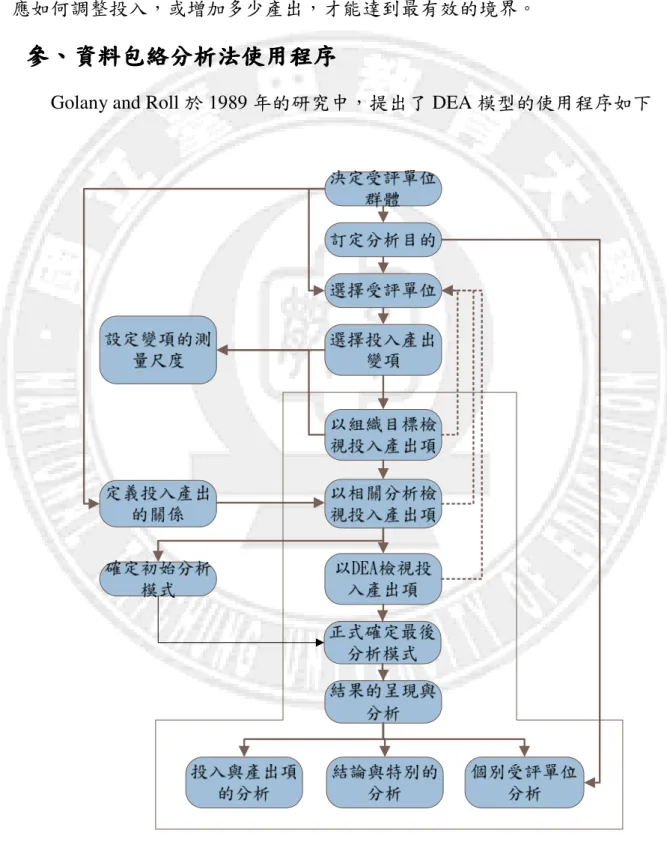
Golany and Roll 於 1989 年的研究中,提出了 DEA 模型的使用程序如下
第二節
第二節
第二節
第二節 資料包絡分析法
資料包絡分析法
資料包絡分析法基本
資料包絡分析法
基本
基本
基本模式
模式
模式
模式
關於效率的分析可以從投入面或產出面兩個角度來說明,因此以下依分 析方式的不同,分別介紹 CCR 模式的產出導向模式及投入導向模式。壹
壹
壹
壹、
、
、
、產出效率導向
產出效率導向
產出效率導向
產出效率導向 CCR 模式
模式
模式
模式
產出導向所算出的效率值,是假設決策單位具有相同的投入時,再對產 出 進行 比 較 , 因 會 得 到 投 入 與 產 出 的 相 對 效 率 , 故 稱 為 產 出 導 向 效率 (output-based efficiency)。所以,產出導向模式主要是分析在現有投入水準之 下,追求產出極大化;而投入導向的目的則是分析在現有產出水準下,追求 投入極小化。 以下分別以比率型式、原問題、對偶問題三種型式說明產出導向 CCR 模式。 一、比率型式(Ratio Form) 比率型式是能夠比較直觀的了解資料包絡分析法的一種表示方式,當我 們評估 n 個決策單位的效率時,則每一個決策單位的效率的倒數等於投入的 加權和/產出的加權和,公式如下: 1 j j i i W I W O = =∑
∑
投入的加權合 效率 產出的加權合 Wj:投入項的權重 Wi:產出項的權重 Ij:投入項 Oi:產出項 評估過程中,所評估的效率值不得大於 1,以數學規劃型式表示如下 : (一) 變數定義k g 1 (k = 1,…,n)為第 k 個決策單位的相對效率值,n 為決策單位的總數。 vi(i=1, …,m)為第 i 種投入的權重,m 為投入項的數目。 ur(r = 1,……,s)為第 r 種產出的權重,s 為產出項的數目。 Xik(i=1, 2,…,m)(k = 1,2,…,n)為第 k 個決策單位之第 i 項投入量 Yrk(r = 1,2,…,s)(k = 1,2,…,n)為第 k 個決策單位之第 r 項產出量 Xij (i=1, 2,…,m)(j = 1,2,…,n)為第 j 個決策單位之第 i 項投入量 Yrj (r = 1,2,…,s)(j = 1,2,…,n)為第 j 個決策單位之第 r 項產出量 ε是非阿基米德數(non-Archimedean number),代表一極小的正數,通常 為 10-4 ~ 10-6,代表任一因子均不可忽略不計。 (二) 目標函數 Min
∑
∑
= = = s r rk r m i ik i k uY X v g 1 1 1 (三) 限制條件 1 1 1 ≥∑
∑
= = s r rj r m i ij i Y u X v (2.1) 0 ,νi ≥ε > r u 由公式(2.1)可以看出,資料包絡分析法在分析決策單位時,將該投入/ 產出當做目標函數,所有決策單位的投入/產出則為限制條件,在效率值小於 或等於 1 的條件之下,求得可使該決策單位有最大效率值的投入/產出權重(ur / vi),所以權重 ur及 vi是由模式所決定,並非預先設定。 當評估每一個決策單位的的最佳效率時,每個決策單位都是目標函數, 均選擇對自己最有利的權重 ur及 vi,所以就算計算出的效率值小於 1,仍不 能否認此方法的客觀性。二、原問題(Primal Problem)
比率型式是個分式規劃模型,在實際求解時,會產生無窮多組解的情況, 而且不易計算,所以 Charnes and Cooper (1962)將分母設為 1,轉換成線性規 劃模式,形成產出導向的原問題。因變數定義與比率型式大致相同,故在此 只列出新增的變數。 (一) 變數定義 與比率型式變數定義相同。 (二) 目標函數 Min
∑
= = m i ik i k X v g 1 1 (三) 限制條件 1 1 =∑
= rk r s r Y u (2.2) 0 1 1 ≥ −∑
∑
= = rj r s r ij i m i Y u X v 0 , i ≥ε > r v u 三、對偶問題(Dual Problem) 公式(2.2)轉換為對偶型式如下: (一) 變數定義 θ為決策單位的擴展因素 θ 1 為產出射線效率 j λ 為第 j 個決策單位的權重 + i s 為第 i 個產出項的超額變數(surplus) − r s 為第 r 個投入項的差額變數(slack) (二) 目標函數Max 1 ( ) 1 1
∑
∑
= = − + + + = m i s r r i k s s g θ ε (三) 限制條件∑
= − = − − n j r rk rj jY Y s 1 0 θ λ (2.3)∑
= + = + n j ik i ij jX s X 1 λ 0 , , i+ r−≥ j s s λ 當 θ=1,且 + i s =0 與 − r s = 0,則該決策單位相對其他決策單位是有效率的。若 單一決策單位未達到資料包絡線,即為無效率的決策單位,其投入與產出應 做調整,以達到有效率: ) ( X = − − +* ∆ ik Xik Xik si (2.4) rk r rk rk Y s Y Y = + − ∆ (θ* −*)貳
貳
貳
貳、
、
、
、投入效率導向
投入效率導向
投入效率導向
投入效率導向 CCR 模式
模式
模式
模式
投入導向所算出的效率值,是假設產出水準相同時,對投入資源之使用 情形進行比較,因此稱為投入導向效益(input-based efficient)。 以下分別以比率型式、原問題、對偶問題三種型式說明投入導向 CCR 模式。 一、比率型式(Ratio Form) 比較公式(2.1)與(2.4),我們了解到投入導向的目標數值恰為產出導向所 取得的目標數值之倒數。 max∑
∑
= = = m i ik i s r rk r k x v y u h 1 1) 5 . 2 ,..., 1 ; 1 1 1 ( j n x v y u to Subject m i ij i s r rj r = ≤
∑
∑
= = ur, vi ≧ ε≧ 0; r = 1,...,s; i = 1,...,m以上即為 Charnes, Cooper and Rhodes(1978)所提出的分數線性規劃模 式,可求得每個決策單位的最大效率值。
二、原問題(Primal Problem)
比率型式是個分式規劃模型,公式(2.5)在實際求解時,會產生無窮多組 解的情況,而且不易計算,所以 Charnes and Cooper (1962) 將分母設為 1,
轉換成線性規劃模式,轉換後的加權權重會由(ur / vi)變成(µr / vi),此即為資 料包絡分析法的乘數型式,可使用(2.6)表示之。此模式所求出的效率值 hi* 與前式 gi * 的效率值相等(gi * = hi*)。 , 則 , , 令
∑
= − = = = m i ij i r r i i t vX t u t v v 1 1 µ∑
= = s i rj r k Y g Max 1 µ ) 6 . 2 1 1 (∑
= = m i ij iX to Subject ν n j X Y m i ij i s i rj r 0, 1,..., 1 1 = ≤ −∑
∑
= = ν µ s j m i i r,ν ≥ε >0, =1,..., ; =1,..., µ 三、對偶問題(Dual Problem) 由於原問題的限制式(n+s+m+1)轉變成對偶問題後,限制式(s+m)會減 少,而且計算上較方便。轉換為對偶型式後,可導出與原問題等同的包絡型 式,如公式(2.7)。 + − =∑
∑
= + = − s r r m i i i s s Z Minimize 1 1 ε θ m i s X X to Subject n j i ij ij j 0, 1,..., 1 = = + −∑
= − λ θ, 1,..., ( 2.7) 1 m r Y s Y rj n j r rj j − = =
∑
= + λ s j m i n j s si r j, , ≥0, =1,..., =1,..., ; =1,..., + − λ θ為決策單位的射線效率,在投入導向中,投入射線效率與縮減因素相 等, − + r i s s , 表示各項投入/產出的差額(slack)。 當θ=1, 且 − i s =0, + r s =0,則該 決策單位相對其他決策單位是有效率的。第三節
第三節
第三節
第三節 資料包絡分析結果之
資料包絡分析結果之
資料包絡分析結果之排序
資料包絡分析結果之
排序
排序
排序
資料包絡分析模型將決策單位分成兩個群組,一個為有效率群組,另一 個為無效率群組,有效率的決策單位形成伯瑞圖效率前緣,效率值皆為 1, 而無效率的決策單位其效率值皆小於 1。所以,這種方法只能將決策單位以 二分法的分類方式分成兩類。 但是,為了要完整評估決策單位的效率,我們需要能將決策單位完全排 序的方式,所以專家們致力於研究各種資料包絡分析效率值的排序方式。 Cook and Kress (1990)及 Cooper and Tone(1997)等分別提出以資料包絡分析法 中的差額變數為基礎的排序方式。Torgersen, Forsund and Kittelsen(1996)提出以測量決策單位的重要性作為 無效率決策單位基準的排序方法;Anderson and Peterson (1993)提出超級效率 (supper efficiency)模型對有效率決策單位作排序。交叉效率(Cross efficiency) 法(Sexton, Silkman and Hogan (1986), Doyle and Green (1994))則是以交叉評 估矩陣來對所有的決策單位排序。
Sinuany-Stern, Mehrez and Hadad (2000) 提 出 Analytical Hierarchical Process (AHP/DEA)排序方法。而 Hosseinzadeh (2011)則提出運用 Technique for Order Preference by Similarity to Ideal Solution (TOPISIS),來選擇最適合的
排序方法。
資料包絡分析的排序方式如上述有許多種類,Nicole, Friedman and
Sinuany-Stern(2002)將排序方式分成六大類,而 Rita(2011)則依此分類再加以 補充。以下將常使用的方式分為依被參考次數、乘數限制及效率指標三大類 (高強,2011)。
壹
壹
壹
壹、
、
、
、依被參考次數排序
依被參考次數排序
依被參考次數排序
依被參考次數排序
DEA 的效率前緣線乃由相對有效率之受評單位所構成,在此前緣上的受 評單位,其效率值皆為 1;而沒有落在效率前緣線上的受評單位,即相對無 效率。在資料包絡分析法中,相對有效率的受評單位必為其他學童的參考對 象,被參考的次數愈多,則代表其效能強度愈強。 因此要在同為相對有效率的受評單位中,比較孰優孰劣,常會採用依被 參考次數的多寡來做排序的依據。貳
貳
貳
貳、
、
、
、乘數限制排序
乘數限制排序
乘數限制排序
乘數限制排序
對乘數加以限制的方法很多種,大致可分為訂出絕對範圍、保證區域及 相同權重三類。 一、絕對範圍 絕對範圍係指各乘數有其可變動之範圍,UOr ≧ ur ≧ LOr,UIi ≧ vi ≧ LIi,只要有足夠的先驗資訊,便可決定乘數的上界及下界。公式(2.1) 可改寫 成: 1 1 1 m i ij i s i r rj r v X Min g u y = = =∑
∑
) 8 . 2 ( ,..., 1 ; 1 1 1 j n Y u X v to Subject s r rj r m i ij i = ≥
∑
∑
= = ur, vi ≧ ε≧ 0 UOr ≧ ur ≧ LOr , r = 1,...,s UIi ≧ vi ≧ LIi , i = 1,...,m 二、保證區域 實務上在衡量因子間的關係時,有時會遇到乘數間的比值具有某種關 係,此時會將對應乘數的比值限制於某範圍內,因此 Thompson, Singleton, Thrall and Smith (1986)提出保證區域(Assurance Region, AR)模式,用來減少有 效率之決策單位,範圍如下: m i U v v L Ii i Ii , 2,..., 1 = ≤ ≤ s r U u u L Or i Or , 2,..., 1 = ≤ ≤ 三、相同權重 此方法即為傳統方法,就是各決策單位均採用相同權重(Common Weight) 來衡量各投入/產出因子,再取其平均做為評比的依據,以 CCR 產出模式為 例,公式如下: 1 1 1 m i ij i s i r rj r v X Min g u y = = =∑
∑
) 9 . 2 ( ,..., 1 ; 1 1 1 j n Y u X v to Subject s r rj r m i ij i = ≥∑
∑
= = ur, vi ≧ ε , r = 1,...,s, i = 1,...,m此方法的優點是各決策單位都是用同一基準來衡量,但缺點則是忽略各 決策單位的個別優勢。
參
參
參
參、
、
、
、依效率指標排序
依效率指標排序
依效率指標排序
依效率指標排序
本分類將效率值經由計算轉換成效率指標後,再以此指標做為排序的依 據。這些計算出來的效率指標數值可能超出 1,所以這些數值不再是相對效 率,而只是一種效率指標,以下是常見的效率指標: 一、交叉效率法交叉效率法(Cross Efficiency Measure, CEM )最早由 Sexton, et al.(1986)所 提出,主要目的在鑑別出真正有效率的決策單位,其計算方法是以其他受評 決策單位的最佳乘數來評估自己的效率,再求出平均值,因為參考其他決策 單位的最佳乘數,因此又稱為同儕評估,所求出的平均值被稱為同儕評估效 率平均。 本公式中的 Yrk表示第 k 個決策單位的第 r 項產出數量;Xik表示第 k 個 決策單位的第 i 項投入數量;ur及 vi分別為產出乘數與投入乘數;Ekk為自我 評估效率, Ekl為同儕評估效率,Mk為同儕評估的效率平均。 max 1 1 s rk rk r kk m ik ik i u y E v x = = =
∑
∑
s.t 1 1 1 s rk rl r kl m ik il i u y E v x = = = ≤∑
∑
(2.10) 1 1 m ik ik i v x = =∑
, 0, , , 1,..., il ij v u ≥ ∀i r j= m l ≠ kmin 1, ( 1) m kl l l k k E M m = ≠ = −
∑
每一個受評決策單位都會估計出 m-1 個利用其他受評決策單位的乘數求 得的交叉效率,所以可以得出如表 1 的交叉效率矩陣,第 2 列中的每一個數 值代表每一個受評單位,利用第 2 位受評單位的乘數所計算出的交叉效率 值,故 E21即第 1 個受評單位,利用第 2 個受評單位的乘數所計算出的交叉 效率值,其餘以此類推。每一欄最下方為平均交叉效率。 表 2.1 交叉效率矩陣示意表 決策決策單位 乘 數 參 考 決 策 單 位 之 效 率 決策單位 1 2 … l … m1 - E12 … E1l … E1m
2 E21 - E2l … E2m
… … …
k Ek1 Ek2 … Ekl … Ekm
… … …
m Em1 Em2 … Eml … -
M1 M2 ... Ml ... Mm
二、超級效率法
原始 DEA 模型中,有效率的決策單位效率值均為 1,Anderson and Peterson (1993) 為了將有效率之決策單位加以排序,先排除有效率的決策單 位,以其他無效率的決策單位為基礎,產生新效率前緣,並以此計算出所有 決策單位距此新前緣的距離。原本為有效率的決策單位,其新的效率值會大 於 1,此方法即為超級效率法(Super Efficiency Measure),依此效率值可以將 有效率的決策單位重新排序,其對應公式如下:
Minθ , 1,..., ik j ij j J k X X i m θ λ ∈ − ≥
∑
= (2.11) , 1,..., rk j rj j J k Y λY r s ∈ − ≤∑
= 0, j j J k λ ≥ ∈ − 三、修正後的交叉效率法Jeong, Jae-won and Chang-Soo(2010)提出修正後的交叉效率法。該方法 中,交叉效率矩陣的對角線元素由超級效率值所組成,而其餘非對角線的元 素則由交叉效率值所組成。表 2.2 為修正後的交叉效率法示意表,其中 SEkk 為超級效率, CEkl 為同儕評估效率,Mk 為各決策單位的交叉與超級效率的 效率值平均。 表 2.2 交叉與超級效率並用示意表 決策單位 權 重 參 考 決 策 單 位 之 效 率 決策單位 1 2 … l … m 1 SE11 CE12 … CE1l … CE1m 2 CE21 SE22 CE2l … CE2m … … k CEk1 CEk2 … CEkl … CEkm … … … m CEm1 CEm2 … CElj … SEmm M1 M2 ... Ml ... Mm
第四節
第四節
第四節
第四節 相關文獻
相關文獻
相關文獻
相關文獻探討
探討
探討
探討
近年來研究以資料包絡分析法來衡量成績表現的相關文獻並不多,茲說 明如下:張國華、李東隆(2001)以改良後的資料包絡分析法(CCR 模式)建 立評分模式,來探討計分比重分配的問題,提出學生亦可參與成績計分方法 訂定的方法,並以學生之觀點來討論成績評量,以鼓勵的方式來評量學生成 績,學生如果部分成績表現優異,表示其具備該科基本所需之知識,所以他 可以自行訂定有利於他個人之加權比重而獲得高分。但是由學生自行訂定出 的成績,必須受到教師及班上其他同學相互制衡妥協的限制。 賴佩筠(2011)則提出以包絡分析法應用在學童成績的分析,以數學和國 語兩科成績為分析標的,然而其計算相對分數的方法有別於傳統的 DEA 模 式,是以得分基準線及垂足的概念來找出相對有效率的學童及相對分數。並 以自行研發的 Java 程式來計算相關數據,以裨益未來想應用此方法分析成績 的相關人員。 而張惠娟(2006)則以採用資料包絡分析法中的 Malmquist 生產力變動指 數,分析某校商學相關之甲系及乙系學生中,不同入學管道之學生在大學之 成績表現是否有所差異,學生背景對不同入學管道之學生之在校成績表現又 有何影響,以期可提出招生訂定方案之相關建議,以提升入學學生素質。 文獻中將資料包絡分析法應用在教育者,大多是探討學校經營績效,在 大學辦學績效與評估的研究有陳榮方(1998)、潘惠靜(2001)、何宜蒨(2004)、 孔維新(2008)、紀秀明(2010)。探討技職院校表現的有陳文琦(2007)、王民鈞 (2008)。評估高中經營效率的有吳惠櫻(2004)、何志清(2005)。第三章
第三章
第三章
第三章 研究方法
研究方法
研究方法
研究方法
第一節
第一節
第一節
第一節 產出效能導向
產出效能導向
產出效能導向 CCR 模式
產出效能導向
模式
模式
模式
傳統的資料包絡分析法包括投入及產出項,但就成績評估而言,重視的 是成績的解釋及分析,並未考慮投入的部份,亦即評估成績表現時,我們重 視的是學童的效能(effectiveness)表現而非效率(efficiency)表現。Cooper, et. al. (1999)提出效率是資源使用的情形,而效能是達成目標的能力,所以,本研 究所衡量的是各學童的在成績上的效能表現而非效率表現。當研究目的是要評估相對效能時,因為效能是目標的達成程度,此時必 須將資料包絡分析法中一般模式的投入項以 1 取代(Long Pao, Nan Shiuh and Ying Wen, 1995),其公式如下: θ Max gk = 1 s.t
∑
= ≤ n j j 1 1 λ (3.1)∑
= ≥ n j ik ij jZ Z 1 θ λ λj ≥0 Zij=(Z1j, Z2j ,…, Zsj)(i= 1,…,s; j = 1,…,k)為第 j 個受評單位第 i 項的產 出 而 Kao(1994)曾進行專科學校評鑑的研究,提出了將投入導向 CCR 模式 簡化為不具投入項的簡化 CCR 模式。因本研究將學童四科目成績視為產出 項,與此篇研究類似,故再將此簡化 CCR 模式改寫為產出導向模型:(一) 變數定義 1 gk(k = 1,2,…,n)為第 k 個學童的效能值,這裡 n 代表受評學童的總人 數。 ur(r = 1,2,…,s)為第 r 科分數的加權權重,s 為考試科目的個數。 Yrk (r = 1,2,…,s)(k = 1,2,…,n)為第 k 個受評學童之第 r 個學科分數 Yrj(r = 1,2,…,s)(j = 1,2,…,n) 為第 j 個受評學童之第 r 個學科分數。 ε 是非阿基米德數(non-Archimedean number),代表一極小的正數,通常 為 10-4 ~ 10-6。 (二) 目標函數 1 1 1 (3.7) s k r rk r M in g u y = =
∑
(三) 限制條件 1 1 1 ≥∑
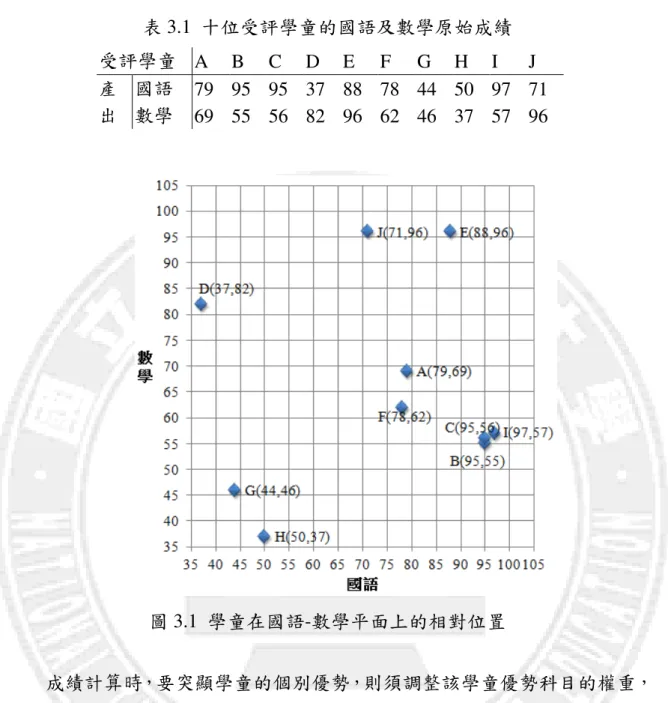
= s r rj rY u (3.2) 0 ≥ ≥ε r u 加權權重 ur需大於 ε 及 0,而且效能值大於等於 1。習慣上 ε 可為 10 -4 ~ 10-6,因本研究主要應用在成績分析上,因此 ε 訂為 10-4。 而成績仍習慣以 0 ~ 100 來分析,故本研究定義相對效能值為 1 時為相對 滿分,即為 100 分,而其餘相對效能則以無條件捨去法取到小數第二位,以 符合一般成績計算的要求。 我們以簡單二科目的模型來說明要如何以資料包絡分析法中的產出效能 導向 CCR 模式來進行學生成績分析。表 3.1 為學童 A、B、C、D、E、F、G、 H、I、J 等十個受評學童的國語、數學兩科目考試成績,圖 3.1 則為此十位學 童在國語-數學平面上的相對位置。表 3.1 十位受評學童的國語及數學原始成績 受評學童 A B C D E F G H I J 產 出 國語 79 95 95 37 88 78 44 50 97 71 數學 69 55 56 82 96 62 46 37 57 96 圖 3.1 學童在國語-數學平面上的相對位置 成績計算時,要突顯學童的個別優勢,則須調整該學童優勢科目的權重, 使其優勢科目加重計算,放大其優勢,如此成績計算的方式才能達到突顯其 優勢的目的,所以,對於數學科目優勢的學童而言,要突顯其優勢,則是將 該科目權重調高,所以,若只考慮數學成績,則數學該科加權 100%,權重 即為 1,國語加權為 0%,權重為 0,完全忽視國語科的成績,此時將學童的 成績投射到 Y 軸上,則可得到新的成績如圖 4.2。
從圖 4.2 可清楚得知,成績計算時若只採計數學單科成績時,對該科成 績表現優異的學童有利,得到的成績最理想的是學童 E 及 J,分數同為 96 分, 學童 D 的分數為 82 分次之,而表現最不理想的是學童 G,只得了 46 分。 圖 3.2 數學科目加權 100% 同樣的,對於國語科目優勢的學童而言,要突顯其優勢,則是將該科目 權重調高,所以,若只考慮國語成績,則國語該科加權 100%,數學加權為 0%,完全忽視數學科的成績,此時將學童的成績投射到 X 軸上,則可得到 新的成績如圖 4.3。從圖上可清楚得知,成績計算時若只採計國語單科成績 時,對該科成績表現優異的學童有利,得到的成績最理想的是學童 I,分數 是 97 分,次之為學童 C,分數是 95 分,而表現最不理想的是學童 D,分數 只有 37 分。
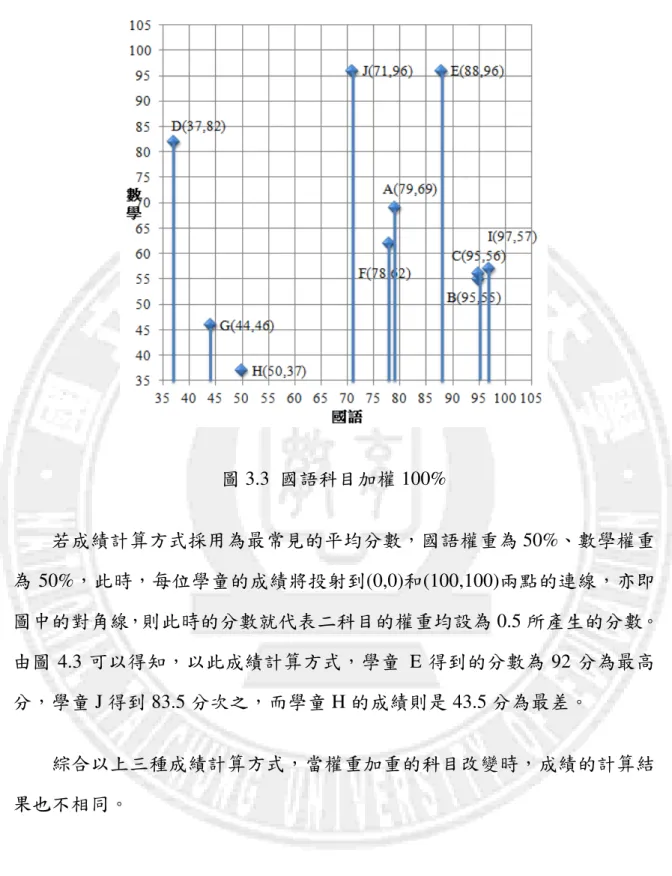
圖 3.3 國語科目加權 100% 若成績計算方式採用為最常見的平均分數,國語權重為 50%、數學權重 為 50%,此時,每位學童的成績將投射到(0,0)和(100,100)兩點的連線,亦即 圖中的對角線,則此時的分數就代表二科目的權重均設為 0.5 所產生的分數。 由圖 4.3 可以得知,以此成績計算方式,學童 E 得到的分數為 92 分為最高 分,學童 J 得到 83.5 分次之,而學童 H 的成績則是 43.5 分為最差。 綜合以上三種成績計算方式,當權重加重的科目改變時,成績的計算結 果也不相同。
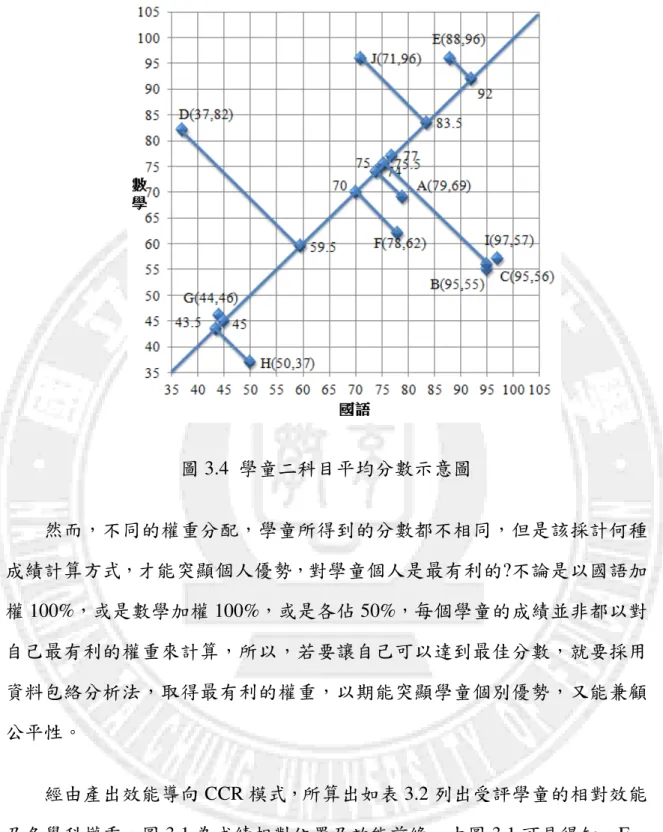
圖 3.4 學童二科目平均分數示意圖 然而,不同的權重分配,學童所得到的分數都不相同,但是該採計何種 成績計算方式,才能突顯個人優勢,對學童個人是最有利的?不論是以國語加 權 100%,或是數學加權 100%,或是各佔 50%,每個學童的成績並非都以對 自己最有利的權重來計算,所以,若要讓自己可以達到最佳分數,就要採用 資料包絡分析法,取得最有利的權重,以期能突顯學童個別優勢,又能兼顧 公平性。 經由產出效能導向 CCR 模式,所算出如表 3.2 列出受評學童的相對效能 及各學科權重,圖 3.1 為成績相對位置及效能前緣。由圖 3.1 可見得知,E、 I、J 三位學童分布在圖的最外側,也就是效能前緣,位於效能前緣線上的每 個學童定義為達到完全效能,所以其效能值為 1,也就是相對分數達到滿分, 而其餘位於效能前緣線內的受評學童即為相對無效能,其效能值小於 1,也
就是相對分數未達到滿分。 相對分數低於 100 分學童的分數計算方式,是以該受評學生到原點的距 離與效能前緣到原點距離的比值來計算,故須先找出該受評學生的評比對 象,也就是與自己射線(原點出發)距離最短之相對有效率的點。以學童 G 為 例,其評比對象是 G',所以效能值為 ' OG OG =0.496,其相對分數為 49.6 分。 表 3.2 受評學童效能及國語、數學權重 受評學童 A B C D E F G H I J 權重 國語 0.0105 0.0105 0.0092 0 0 0.0108 0.0183 0.017 0.009 0 數學 0.0024 0 0.0021 0.0121 0.0104 0.0024 0.0042 0.0039 0.002 0.0104 相對效率 0.862 0.979 0.98 0.854 1 0.838 0.496 0.531 1 1 圖 3.5 以學科成績轉換曲線衡量相對效率 G'
第二節
第二節
第二節
第二節 修正後的
修正後的
修正後的交叉效
修正後的
交叉效
交叉效
交叉效能
能
能
能排序法
排序法
排序法
排序法
本研究採用 Jeong 等所提出的修正後交叉效率法,藉由第一節所算出的 各項效能值,先算出原始交叉效能矩陣,接著算出超級效能值,並將此數值 填入交叉效能矩陣的對角線,最後再算出該學童成績的平均效能值。以此法 得到的排序結果,能完整反映出學童成績的差異,確實區分出名次。第三節
第三節
第三節
第三節 成績評估實施流程
成績評估實施流程
成績評估實施流程
成績評估實施流程
本研究使用資料包絡分析法來評估學童相對成績,成績評估實施流程依 據 Roll and Golany (1989)所提出之 DEA 方法使用程序,簡化步驟說明如下:圖 3.6 簡化成績評估實施流程 定義母體範圍 設定分析目的 選擇受評學童 列出評估科目 選擇分析模式 結論與分析 產出成績分析 個別 DMU 分析
一、決策單位(DMU)之選定 本研究的實證分析以國小班級全班 32 個學童為研究對象,決策單位即為 班級全部學童,以下本研究稱之為受評學童,分別以代號 A~AF 表示,共 計 32 個受評學童。我們在此將同班級學童視為同一母體,因為具有以下特性: (一)各受評學童間有共用的學習目標,學習的科目均相同。 (二)各受評學童的上課環境與條件相同,在課堂上的學習時間相同, 所用的教材乃至於教師群都是相同。 (三)各受評學童之投入上課時間與評分學科均相同。 二、評估項目的選取 評估項目的選取,因本研究衡量的是各學童在成績上的效能表現,而非 效率表現,所以本研究只考慮產出項目,產出項目為考試科目類別,本研究 的資料為受評學童在國語、數學、自然及社會四二科考試模擬成績,所以總 共有四二個產出項目,分別為:國語、數學、自然和社會成績。 三、分析模式的選取 依照分析目的及分析背景,本研究選擇產出效能導向 CCR 模式為分析模 式,藉以了解各學童學習標竿、相對分數、優勢科目,並提出成績進步的方 向與幅度。
第四節
第四節
第四節
第四節 研究工具
研究工具
研究工具
研究工具
資料包絡分析法發展至今已有很多擴張模式,也有相當多軟體可以產生 不同模式的分析資料,如 IDEAS、DEAP2.1-XP、Banxia Froniter Analyst、DEA Solver、DEA Solver Pro 以及 Frontier、…等各式各樣軟體,但無論使用那一 套軟體,最重要的是如何分析及解釋資料。
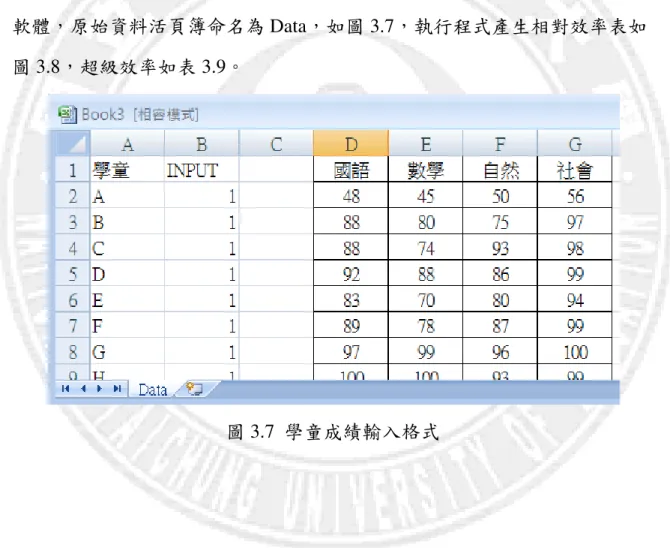
本研究採用 DEAFrontier DEA Add-In for Microsoft Excel 2007 做為分析 軟體,原始資料活頁簿命名為 Data,如圖 3.7,執行程式產生相對效率表如 圖 3.8,超級效率如表 3.9。
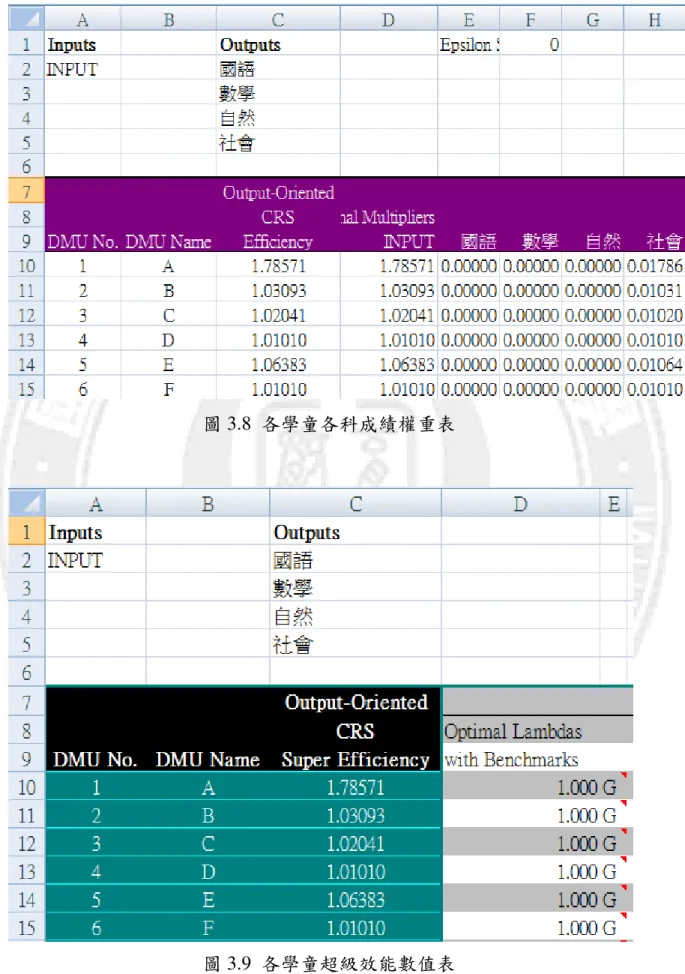
圖 3.8 各學童各科成績權重表
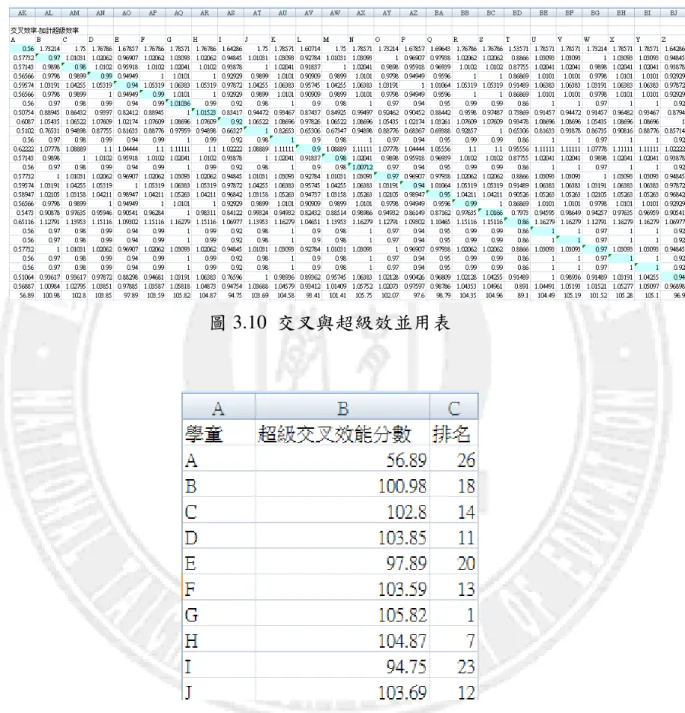
為了產生修正後的交叉效能表及學童名次排序表,我們利用圖 3.7 ~ 圖 3.10 的表,配合自行開發的 Excel VBA 巨集(程式碼如附件),產生修正後的 交叉效能表(圖 3.10)及學童名次排序表(圖 3.11)。
圖 3.10 交叉與超級效並用表
第四章
第四章
第四章
第四章 實證
實證
實證
實證分析
分析
分析
分析
第一節
第一節
第一節
第一節 受評學童各科成績
受評學童各科成績
受評學童各科成績
受評學童各科成績
本研究的實證資料來源為臺中市某國小高年級期中考成績,受評學童總 計為 32 位,評估學科為國語、數學、自然及社會四科考試成績,原始測驗成 績資料如表 4.1。 表 4.1 受評學童期中考成績 學童 A B C D E F G H 國語 48 88 88 92 83 89 97 100 數學 45 80 74 88 70 78 99 100 自然 50 75 93 86 80 87 96 93 社會 56 97 98 99 94 99 100 99 學童 I J K L M N O P 國語 72 94 93 84 90 100 96 85 數學 74 90 86 84 71 98 87 86 自然 65 98 81 64 66 93 87 67 社會 92 98 100 90 98 100 97 94 學童 Q R S T U V W X 國語 91 96 98 86 94 93 86 97 數學 81 92 95 61 82 88 85 92 自然 68 91 98 64 80 92 85 89 社會 95 99 99 86 100 100 97 100 學童 Y Z AA AB AC AD AE AF 國語 98 94 99 97 90 87 95 89 數學 86 83 86 87 86 69 68 85 自然 87 84 91 92 88 63 75 81 社會 100 92 98 100 99 86 98 100第二節
第二節
第二節
第二節 受評學童評估結果分析
受評學童評估結果分析
受評學童評估結果分析
受評學童評估結果分析
壹
壹
壹
壹、
、
、
、學習標竿分析
學習標竿分析
學習標竿分析
學習標竿分析
以往在探討各學童的學習標竿時,通常會以全班第一名的同學做為學習 標竿,出發點固然很好,但是對於各科成績表現均不好的學童,以第一名為 學習標竿的難度較高,但透過資料包絡分析法,可以找到適合每個學童的學 習標竿。 A、B、C、D、E、F、I、J、K、L、M、O、P、Q、R、T、U、V、W、 X、Y、Z、AA、AB、AC、AD、AE 和 AF 共 28 位未達相對滿分的學童, 代表各有其進步的空間及可學習的參考對象,此參考對象應用在學習中即為 學習標竿。由學習標竿如表 4.2 可看出,該班級的學習標竿大多為學童 G 及 H。 表 4.2 未達滿分學童學習標竿 學童 A B C D E F I J K L 相對分數 55.88 96.61 97.69 98.77 93.61 98.65 91.47 99.9 99.68 89.72 學習標竿 G G G G H G H S G H 學童 M O P Q R T U V W X 相對分數 97.42 96.87 93.65 94.64 98.9 85.66 99.64 99.81 96.73 99.86 學習標竿 G G G G G G G G G G 學童 Y Z AA AB AC AD AE AF 相對分數 99.79 93.85 98.86 99.84 98.75 86.68 97.53 99.63 學習標竿 G,N G H G G H H G貳
貳
貳
貳、
、
、
、相對分數分析
相對分數分析
相對分數分析
相對分數分析
從表 4.3 受評學童原平均分數與相對分數可看出,受評學童 G、H、N 和 S 共 4 位學童得到相對滿分,代表這些學童都是相對有效能的。其餘 28 位學 童則評估為相對無效能,其分數皆低於 100 分。 當我們以突顯個人優勢科目的權重來計算相對效能分數時,由表 5.3 可 以發現,與傳統的成績計算方式所得到的平均分數比較,每個學童的分數皆 向上提昇,如學童 B,傳統成績計算得到的分數是 85 分,而由本研究方法得 到的成績則達到 96.91 分。 由此可知,利用資料包絡分析法取得的相對分數,因為突顯學童個人優 勢科目,會讓每個學童分數皆有所提昇,能增加學童自信心及學習意願。 表 4.3 各學童相對分數分析 學童 A B C D E F G H I J K 原平均 49.75 85 88.25 91.25 81.75 88.25 98 98 75.75 95 90 相對效能分數 99.68 96.61 97.69 98.77 93.61 98.65 100 100 91.47 99.9 99.68 學童 L M N O P Q R S T U V 原平均 80 81.25 97.75 91.75 83 83.75 94.5 97.5 74.25 89 93.25 相對效能分數 89.72 97.42 100 96.87 93.65 94.64 98.9 100 85.66 99.64 99.81 學童 W X Y Z AA AB AC AD AE AF 原平均 88.25 94.5 92.75 88.25 93.5 94 90.75 76.25 84 88.75 相對效能分數 96.73 99.86 99.79 93.85 98.86 99.84 98.75 86.68 97.53 99.63參
參
參
參、
、
、
、優勢科目分析
優勢科目分析
優勢科目分析
優勢科目分析
在資料包絡分析的報表中,由產出項權重的數值,我們可以知道各產出 項對效率的相對貢獻。在本研究,因四科目中權重最大的科目對成績的貢獻 最大,故以權重最大的為該生的優勢科目。 在本研究中,我們不難發現,大部份的學童四科目當中,分數最高者權 重數值最大,此科目即為其優勢科目,在此計算方式下,該學童優勢科目成 績被放大,故成績結果必突顯其優勢。 由 4.4 表可得知,優勢科目為國語的學童有 H、N、Z、AA 及 AD;優勢 科目為自然的學童有 J;而優勢科目為社會的學童有 A、B、C、D、E、F、 G、I、K、L、M、O、P、Q、R、S、T、U、V、W、X、Y、AB、AC、AE 及 AF。 依據此表,各個受評學童可由此找到自己的最優勢科目,而老師也應依 其優勢科目因勢利導,讓學童能適性發展,充份發揮其優勢能力。 表 4.4 受評學童各科權重及相對效能 學童 A B C D E F G H 國語 ε ε ε ε ε ε ε ε 數學 ε ε ε ε ε ε ε ε 自然 ε ε ε ε ε ε ε ε 社會 0.0179 0.0103 0.0101 0.0101 0.0106 0.0101 0.01 0.005 學童 I J K L M N O P 國語 ε ε ε ε ε ε ε ε 數學 ε ε ε ε ε ε ε ε 自然 ε 0.0102 ε ε ε ε ε ε 社會 0.0109 ε 0.01 0.0111 0.0102 0.01 0.0103 0.0106表 4.4 受評學童各科權重及相對效能(續上頁) 學童 Q R S T U V W X 國語 ε ε ε ε ε ε ε ε 數學 ε ε ε ε ε ε ε ε 自然 ε ε 0.0034 ε ε ε ε ε 社會 0.0105 0.0101 0.0068 0.0116 0.01 0.01 0.0103 0.01 學童 Y Z AA AB AC AD AE AF 國語 ε 0.0106 0.0101 ε ε 0.0115 ε ε 數學 ε ε ε ε ε ε ε ε 自然 ε ε ε ε ε ε ε ε 社會 0.01 ε ε 0.01 0.0101 ε 0.0102 0.01 *註: ε代表最小權重限制 10-4
肆
肆
肆
肆、
、
、
、成績進步方向與幅度分析
成績進步方向與幅度分析
成績進步方向與幅度分析
成績進步方向與幅度分析
我們列出相對分數未達滿分的學童,整理成表 4.5。由表 4.5 可得知,這 28 位學童在每一科上只要進步到某個分數後,就會達到相對滿分。以學童 A 為例,要到達相對滿分點,國語需再進步 49 分即可達到相對滿分點 97 分, 數學需再進步 54 分即可達到相對滿分點 99 分,自然需再進步 46 分即可達到 相對滿分點 96 分,而社會則需進步 44 分即可達到相對滿分點 100 分。 若以傳統成績計算方式來看,各科的滿分點就是 100 分,學童 A 其國語 需進步 52 分,數學需進步 55 分,自然需進步 50 分,社會則需進步 44 分, 相較於資料包絡分析法所需進步的分數,依傳統成績計算方式,學童到達滿 分點與現有成績的差距較大,對於學童的壓力也會較大,亦可能因為差距過 大自覺無法達成而放棄努力。 而學童 B 要到達相對滿分點,國語需由 88 分進步至 97 分,數學由 80 分進步至 99 分,自然由 75 分進步至 96 分,社會由 97 分進步至 100 分,將資料包絡分析的結果與傳統成績計算方式比較,不難看出,由資料包絡分析 法的結果顯示,學生可進步的方向相當明確,而且,要達到相對滿分點的困 難度相對降低,不再像以往的成績計算方式必須達到各科 100 分才是滿分 點,每個學童在各科目都能找到適合自己的進步方向及幅度。 表 4.5 原始分數與相對滿分分數對照表 學童 原分數 相對滿分點 分數差距 國語 數學 自然 社會 國語 數學 自然 社會 國語 數學 自然 社會 A 48 45 50 56 97 99 96 100 49 54 46 44 B 88 80 75 97 97 99 96 100 9 19 21 3 C 88 74 93 98 97 99 96 100 9 25 3 2 D 92 88 86 99 97 99 96 100 5 11 10 1 E 83 70 80 94 100 100 93 99 17 30 13 5 F 89 78 87 99 97 99 96 100 8 21 9 1 I 72 74 65 92 100 100 93 99 28 26 28 7 L 84 84 64 90 100 100 93 99 16 16 29 9 M 90 71 66 98 97 99 96 100 7 28 30 2 O 96 87 87 97 97 99 96 100 1 12 9 3 P 85 86 67 94 97 99 96 100 12 13 29 6 Q 91 81 68 95 97 99 96 100 6 18 28 5 R 96 92 91 99 97 99 96 100 1 7 5 1 T 86 61 64 86 97 99 96 100 11 38 32 14 W 86 85 85 97 97 99 96 100 11 14 11 3 Z 94 83 84 92 97 99 96 100 3 16 12 8
表 4.5 原始分數與相對滿分分數對照表(續上頁) 學童 原分數 相對滿分點 分數差距 國語 數學 自然 社會 國語 數學 自然 社會 國語 數學 自然 社會 AA 99 86 91 98 100 100 93 99 1 14 2 1 AC 90 86 88 99 97 99 96 100 7 13 8 1 AD 87 69 63 86 100 100 93 99 13 31 30 13 AE 95 68 75 98 100 100 93 99 5 32 18 1
第三節
第三節
第三節
第三節 修正後的交叉
修正後的交叉
修正後的交叉效能排序
修正後的交叉
效能排序
效能排序
效能排序
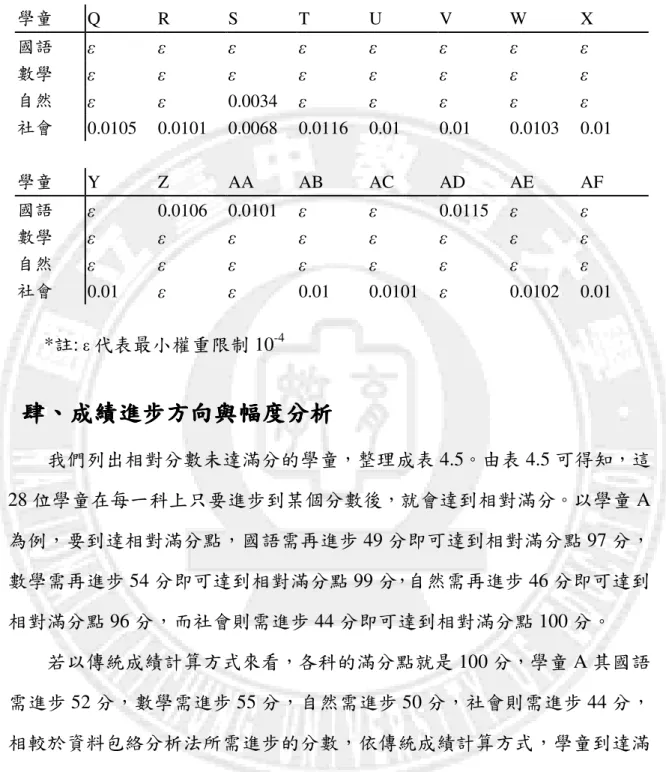
當牽涉到選拔選手或是給予獎勵時,則成績結果的排序必需是公正且完 整的,故本研究的排序方式採用修正後交叉效能排序法。 附錄二為受評學童的交叉效能矩陣,矩陣中每一格分數都是以其他學童 最有利乘數,來算出自己的分數,此即為同儕互評分數。 附錄三為受評學童的超級效能分數,由此表可以看出,原本相對有效能 的受評學童,如 G、H、N、S,相對分數都是 100 分。在使用超級效能評估 後,產生了新的分數,如此就可以針對有效能的學童做有效的區隔。不過超 效能只對相對有效能的學童適用,對原本評估為非有效能率學童的分數並沒 有改變。 本研究以原交叉效能分數為基礎,在對角線的部份補上超級效能分數, 完成了如表 4.6 的修正後的交叉效能分數矩陣。產生新的分數矩陣後,便得 到每個學童新的交叉效能分數。以此新的分數排序,能確實反映出學童成績 的差異,明顯區分出名次。但此新分數僅供排名,不作分數解釋使用。 由表 4.6 可得知此次考試成績由高至低的前五名依序為:N、G、AB、X 及 Y。 表 4.6 受評學童修正後的交叉效能排序 學童 A B C D E F G H 效能分數 56.59 100.22 101.81 103.06 96.97 102.63 105.06 104.41 排序 32 23 18 13 25 17 2 6 學童 I J K L M N O P 效能分數 93.47 102.91 103.81 92.97 100.81 105.22 101.59 96.84 排序 28 15 9 29 21 1 20 26表 4.6 受評學童修正後的交叉效能排序(續上頁) 學童 Q R S T U V W X 效能分數 98.38 103.72 104.34 89.09 103.81 104.31 100.47 104.63 排序 24 11 7 31 9 8 22 4 學童 Y Z AA AB AC AD AE AF 效能分數 104.56 96.72 103.03 104.69 102.91 89.31 101.66 103.41 排序 5 27 14 3 15 30 19 12
第五章
第五章
第五章
第五章 結論
結論
結論
結論與建議
與建議
與建議
與建議
第一節
第一節
第一節
第一節 研究
研究
研究
研究結論
結論
結論
結論
本節依據本研究資料分析的結果,歸納出五項結論,分別陳述如下: (一) 由資料包絡分析法獲得成績未達相對滿分學童的學習標竿 由此法獲得的學習標竿,其學習情形與受評學童相似,故以此標竿 為學習對象對於受評學生而言會更加適切。 (二) 算出對每位學童最有利的相對分數 本方法獲得的相對分數,對於個別學童而言是最有利的,當我們以 突顯個人優勢科目的權重來計相對效能分數時,每個學童的分數皆 比傳統成績計算分數高。使每個學童分數皆有所提昇,能增加學童 自信心及學習意願。 (三) 找出個別學童的優勢科目 依據本研究結果,每個學童皆能由各科目的權重值得知何者為其優 勢科目,在此計算方式下,學童的優勢科目成績被放大,故成績結 果必突顯其優勢,老師也應依其優勢科目因勢利導,讓學童能適性 發展,充分發揮其優勢能力。 (四) 提出適合未達滿分學童的成績進步方向與幅度 經由本法,對於每個未達滿分的學童,進步的方向相當明確,而且 達到相對滿分點的困難度降低,每個學童在各科目都能找到適合自 己的進步方向及幅度。 (五) 以修正後的交叉效能分數排序 此次法得到的排序結果是公正且完整的,能反映出學童成績的差異,確實區分出名次。
綜合上述結果,當我們使用資料包絡分析法來計算成績時,我們可以簡 單、客觀的了解學童個別能力優勢,提供老師一種可針對個別能力優勢來計 算成績的工具,再搭配修正後交叉效能法來排序,能使此成績計算方法更為 周延,且更切合實務使用。