基於主題資訊賦予特徵不同比重之摘要系統
8
0
0
全文
(2) 3.1.2 Clustering words 演算法的數學背景介 紹 我們採用 Distributional Clustering 作為分類的 方法,所使用的演算法主要利用詞在不同主題 文章出現的分佈情況作為分類的依據,以下的 Distributional Clustering 演算法採自[1],對演 算法的說明如下:. 用作訓練資料以及評估系統的依據。. 3.特徵摘要方法描述 本節將描述本摘要系統所採用的特徵,以及取 得特徵的方式: 3.1 主題關鍵詞: 過去的研究中,許多的摘要系統使用高頻率的 詞作為文章的主題詞。此做法仍然有其缺點。 例如:若兩個詞有相同的意義或者能代表相同 的主題,但卻因為在選取高頻詞時,遺漏了其 中一個次數較少的詞,造成主題資訊獲取的偏 差。另外一個問題是究竟我們應取幾個高頻詞 作為主題的關鍵詞,選取的個數往往會影響到 最後的結果。上述的問題其原因在於:我們並 不知道究竟哪些詞代表主題,我們只能假設文 章中選出的高頻詞皆為重要的主題詞。為了改 善此一情況,我們事先將每個類別的主題詞利 用文件分類演算法挑出,以下是我們的做法:. 首 先 , c j 為 第 jth 種 文 章 類 別 , C={ c1 , c 2 ...c m } , 我 們 有 m 種 主 題 , D={ d1 , d 2 ...d n }代表文件的集合。此時,我 們可以將文件視為一連串文字的組合且彼此. (. 可視為是一串連續的詞出現機率相乘。. P(d i | c j ) 可以寫成下式:. P(d i | c j ) = ∏ P(wik | c j ) di. k =1. 3.1.1 將文章切分成單一主題的段落. wik 表示第 ith 篇文章的第 kth 個詞,. 一般文件分類的做法是將文章直接作為分類 的基本單位,若訓練資料中的文件含有多個主 題(Multi-topics)則忽略不列入考慮,因為將一 篇超過一個主題的文章直接置入文件分類的 演算法中,將會造成分類結果的偏差。我們的 資料來源皆為新聞文章,一篇新聞的內容往往 不只包含一個主題,而是許多議題的綜合。若 我們事先忽略含有多種議題的文件,對於自動 摘要的實用性會有非常嚴重的影響,將導致大 部分的新聞資料皆無法使用。因此,我們的做 法以段落作為基本的單位,每一段落會被視為 一篇文章,供文件分類的演算法使用。 I.. 表示文章. d. di. 的詞數。此時我們需要用收集的. i. 樣本去估計需要的參數。我們假設此模型的參 ∧. ∧. 數為 θ 。我們用 θ c j 表示第 j ∧. 機率估計值,也就是 θ. c. j. th. 個類別的事前. ≡ P (c j ) 。假設每. 一 篇 文 章 的 出 現 機 率 為 P(d i ) ,. P (d i ) =. 1 。其中 ∧ 的計算方式如下: θc D j. ∧. θ. 將每個類別的每篇文章的三個大寫字選 出,作為初步文件分類的關鍵詞:. c. j. ≡ . ∑. D i =1. P ( c j | d i ) D . P(c j | d i ) 將利用現有的資料取得,方法 為 : 當 di ∈ c j , 當 di 屬 於 c j 類 別 時 ,. 首先,統計每篇文章的大寫字出現次數,選擇 每篇文章中出現最多次的三個大寫字,目的是 希望能找出每一篇文章中的關鍵詞。同時我們 也假設這些關鍵詞與文章的主題是一致的,這 些選出來的詞將作為各個主題的關鍵詞,做初 步分類工作。 II.. ). 之間是獨立的。因此, P d i | c j 的條件機率. P (c j | d i ) 為一,若文章不屬於該類別時則為 零,例如: d 1 屬於 c1 類別則 P (c1. | d1 ) 為 1;. d 1 不屬於 c1 類別 P (c1 | d 1 ) 為零。將全部屬 於該類別的文章次數加總除以總文章數即可 得到該類別的文章出現的機率。 現在我們必須估計給定一類別後,每個詞. 將文章的段落分出,並為每一個段落標 上所屬類別. 出現於該類別的機率,我們使用 wt 代表詞的. 我們利用前一步驟每個類別所擁有的關鍵 詞,辨別每個段落所含的主題。我們統計每一 個段落的詞與每個類別所擁有關鍵詞的共同 出現次數;接下來選出與段落共同出現次數最 多的類別,作為該段落的主題。最後我們將每 個段落當作一篇文章並擁有一個主題。. 集合,. ∧. P (c j | d i ) 則 用 θ. t |c. 來估計,. P (wt | c j ) 表示在已知為 c j 類別的情況下, j. wt 出現的機率。 N (wt , d i ) 表示 wt 在 d i 文件 出現的次數, P (c j | d i ) 與前述相同 d i ∈ c j 則為一,反之則為零。將 wt 與屬於 c j 類別的 文章所共同出現的次數加總,除以所有詞與類 2.
(3) ∧. 別共同出現的加總來估計 θ. t |c. j. Vslot. ,其中 ws 表. P(c | wslot ) =. 示在全部文章中曾出現的詞,如下式:. 0.1 + ∑i=1 N (wt , d i )P(c j | d i ) D. ∧. θ w |c ≡ t. j. D. )P(c | wslot,t ). Vslot. ∑ P( w. slot ,t. ). wslot 表示存入某一 slot 中的詞組,共有 Vslot 個. V 表示全部文字的長度,分子的 0.1 是為了. 詞。我們將此 slot 中的每一個詞出現於 c 類別 文章的機率平均,利用每個詞的相對出現次數 作平均。此步驟必須對每一個 slot 重複作 m 次,因為每一個詞皆有出現於所有類別的機 率,同樣的每一個 slot 也必有對每一個類別的 出現機率,每一個 slot 都會有 P c j | w slot ,. 作 smoothing[9]。我們經過實驗發現,將分子 的加一改成加 0.1 效果較好,因此改成 0.1, 本節的完整式子可參考[1]。 3.1.3 Clustering Words 演算法的步驟. (. 在上述的數學模型背景下,假設我們共有 n 篇文章,有 V 個不同的詞,m 個類別。演算 法的主要目的在於將相近的詞置於同一類別 中,相近的定義為詞出現於各種主題文章的次 數分佈的接近程度。我們將詞依序置入 slot(用 來存放詞彙的空間)中,再將近似的 slot 合併 達到分類的效果。文件分類的演算法如下:. ). j=1….m。 4.. 選擇兩個相近的類別予以合併:.. 取得每個 slot 的分佈狀況後,我們將比較任兩 個 slot 的相似度,相似度的原則是:若兩個 slot 於相同類別的出現次數越相近,表示這兩 個 slot 的 詞 越 可 能 是 同 一 類 。 我 們 使 用 KL-divergence[1]衡量兩個類別的近似度,如 下面的公式所示:. 1. 將 V 個詞依據主題的分佈狀況排列,分 佈越集中,排序越前面,我們利用 Entropy 衡量詞彙在類別中的分佈狀況。. D(P(c | wslotA ) || P(c | wslotB )) =. 由於文章的分類是利用每個詞在文章之間的 分佈,若此時一個分佈很廣的詞,也就是出現 於各種主題的詞,於演算法一開始時就進入 slot 中,會造成此詞彙與大部份的詞相似度皆 類似,因此,我們需要將文字的分佈較為集中 ∧. slot ,t. t =1. t =1. 0.1* V + ∑s=1 ∑i=1 N (ws , d i )P(c j | d i ) V. ∑ P( w. ∑. c j =1. P(c j | wslotA ) P(c j | wslotA )log P(c | w ) j slotB . wslotA 表示 slotA, wslotB 表示 slotB。事實上,. P(wt ) 已 於 之 前 求 得 , 計 算 其 資 訊 含 量. 我們是希望將兩個 slot 在相同類別的出現次 數最相近者找出,因此我們必須比較兩個 slot 個 詞 對 應 類 別 的 機 率 , 我 們 採 用 KL-divergence 衡量兩個 slot 的近似度。. (Entropy)[9],公式如下:. 5.. 的詞挑出。我們利用之前得到的 θ ∧. 式定理轉換成 θ. c j |wt. j =1. 根據貝. ( ). ,其中所需的 P c j 與. (w t ) = − ∑ p (c j m. Entropy. w t |c j. | w t )log p (c j | w t ). 從 V 中取下一個詞置入空類別中,. 上一個步驟完成後會有一個 slot 的是空的,我 們便將下一個詞填入空的 slot 中。 6.. 2. 將 V 中排序在前面的 m+1 個詞置入 m+1 個 slot 中。. 處理完 2/3 的詞後,演算法停止. 在第 j 個類別出現的機率,也就是 P c j | wt 。我們將每個 slot 中詞的分佈加以. 演算法的停止條件設在全部詞數的前 3/5,原 因在於只有前 3/5 的詞的分佈較為集中,適合 將其置入一個類別。剩下的詞分佈過廣不適合 置入一個特定的類別,這種類型的詞被 Yarowsky[11] 稱 為 topic-independent distinctions。同時我們也設了一個停止條件為 V 的詞的 Entropy 值大於 0.5 時演算法停止。 在結束 clustering words 的演算法後,我 們得到每個 slot 所存放的詞代表某一個類 別。但我們仍然不知道哪一個 slot 對應到哪一 個 類 別 。 所 以 我 們 利 用 每 一 個 slot 的 c j | w slot 值,選出一個 slot 的 c j | w slot 中,. 平均,代表 slot 的分佈。平均的公式如下:. j=1….m,哪一個 c j 使 c j. 此步驟為初始化階段,每一個 slot 皆需要一個 以上的詞才能計算出 slot 本身的分佈。 計算每一個 slot 的分佈情況:. 3.. 經過 Entropy 排序過的詞依序放入 slot 後,每 一個 slot 都至少存了一個詞。我們要將兩個最 相近的類別合併,就必須知道每個 slot 的分 佈。所謂的分佈定義為:已知一個詞為 wt ,. (. ). *. | wslot 的值最大,得. 到的 c 便是該 slot 所代表的類別,如下式。 3.
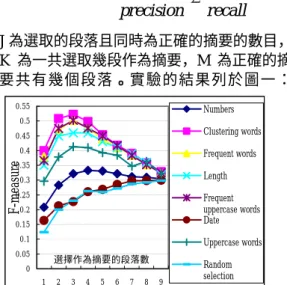
(4) c * = arg max p(c j | wslot ). 篇文章的出現次數,在計算分數的同時必須反 映其主題之間的比重,也就是區隔主題之間不 同的重要性,因此必須乘上主題的比重作為每 個詞出現的權數。權數的計算方法如下面公式 所述:. cj. 此時,每一個 slot 將會對應一個主題,而 slot 中所存的詞即為代表該主題的關鍵詞,這些關 鍵詞以下稱為 clustering words。. s j = ∑N(t j , pk ) P. 3.1.4 利用 Clustering Words 選取摘要 接下來介紹我們如何使用 clustering words 作 為選取摘要的特徵。我們希望利用 clustering words 將文章中出現的詞結合成一個較高層次 的概念(Concepts),也就是文章的主題,將純 粹只計算字數的方式轉變成對於概念的計 算。在此章中,每一個類別代表一個主題,因 此類別與主題的意義在此事共通的。以下是我 們的方法:. s. Score c. ∑. j=1. S (t . )* ∑ p. j. , p. k. N. k =1. (t. j. , p. k. ) . S (t j , p k ) 由前面的式子所得到,也就是 s j , 表示每個類別在文章中所佔的比重與類別的 權數,以反映主題之間不同的重要性。最後, 計算每一個段落的分數,依照分數將段落排 列,依序選出一定比例的段落作為選出的摘 要。. ∀j , j = 1L T. ). 出現次數。 T = {t1 , t 2 ,.....t m } 表示主題的集. 應用此方法的缺點在於:文章的主題可能判斷 錯誤。若此情形發生時將會導致將新聞文章套 用於錯誤的主題上,以致摘要擷取的方向錯 誤。為了避免這種情況發生,我們會比較高頻 率的詞與 clustering words,若出現次數最多的 高頻詞與我們選出代表主題的關鍵詞完全不 相同,我們就認為文章主題的辨認發生錯誤。 我們相信高頻詞能夠代表主題詞,但並非全部 的高頻詞。例如:選出文章中出現最多次的五 個詞,這五個詞至少一個詞包含重要的主題詞 的機會很大,這並不意味這其他四個詞皆有足 夠主題代表性,這也是我們用 clustering words 的重要原因。. 合, t j 第 jth 個主題的關鍵詞集合, T 代表總 共的類別數。通常文章可能不只擁有一個主 題,我們必須決定文章所包含的主題為哪些。 我們的方法是使用 k-means 演算法[2]將所有 的主題的比重切割成顯著的主題與不顯著的 主題,以下是我們的說明: 我們將欲區分的類別分為兩種:顯著的主 題與不顯著的主題。主題若為顯著的,其 clustering words(該主題的關鍵詞)與文章的詞 的共同出現次數(上式的 s j ),出現次數應該較 多,而不顯著的主題應該較少。我們將其視為 兩種類別,使用 k-means 區分此兩類別。我們 將 k-means 所 需 的 相 似 度 公 式 定 義 為 2. (p k ) =. Score ( p k ) 為 每 一 個 段 落 的 分 數 ,. 數, N t j , d 為第 jth 主題與該篇文章所共同. sj − m. 表示 t j 主題在文章中所佔的比重,. 同出現次數。 P 為該文章所擁有的段落數。. s j 表示該文章中第 jth 個主題所得到的分. (. j. N (t j , p k )為 t j 的關鍵詞與 p k 段落的詞的共. 我們的做法是先統計一篇文章的詞與每 個主題所包含的 clustering words 的共同出現 次數:. s j = N (t j , d ). ∀j, j =1LT. k=1. 其他的特徵包含有:高頻詞:高頻詞即為出現 次數較多的詞。日期:統計每個段落中日期相 關詞出現的次數作為分數。數字:將出現的次 數作為段落的分數加以排序。專有名詞:專有 名詞通常對於文章的主題具有著重要的意 義。為了偵測專有名詞我們採用大寫字作為代 替。段落的長短:段落的長短表示段落所含的 詞數的多寡。實驗的方法是將段落依據其長度 作為排序的依據,依序選出一定的比例作為摘 要,並檢視其結果。. ,也就是共同出現的次數與該類. 別的共同出現次數平均數的距離,m 表示 mean。最後,將被分為顯著的主題群,視為 文章所包含的主題,並利用此結果進行對摘要 的分析。 在取得文章的主題之後,接著便分析每一 個段落與文章主題的相似度。衡量相似度的方 法是:計算每個段落與文章顯著主題所擁有關 鍵詞的共同出現次數的加總,相似度同時是選 取摘要的計分方式。但若只計算單純的字數出 現次數可能造成較重要的主題被次重要的主 題所取代,因此不能只計算每個類別的詞於一. 4. 特徵分析 尋找用於選擇摘要的有效特徵是許多研究努 力的目標,目前為止有許多的特徵被用於選取 摘要也獲得了不錯的成果。我們將針對所選出 的特徵做系統性的分析,分析各項特徵的目標 4.
(5) 在於了解各別特徵對於摘要的選取能力,以及 不同主題的文章對於特徵的影響。. information gain[9]。請見下面公式說明:. j =1. Si. H (S ij ). Ak 表示第 kth 個特徵, Oi 表示未經該特徵分 類原本的分類情況。j 表示摘要與非摘要的段 落。最後我們將結果顯示於圖 2,由圖 2 所示 可以發現各項特徵對於不同主題的區分能力 有很大的差異,這表示對於不同主題的文章, 特徵對摘要的區分能力有很大的差異、甚至有 些特徵對於某些主題的摘要選取是完全不具 有鑑別能力。. 2 1 1 + precision recall. J 為選取的段落且同時為正確的摘要的數目, K 為一共選取幾段作為摘要,M 為正確的摘 要共有幾個段落。實驗的結果列於圖一:. 0.25 0.2. Information Gain. 0.55. S ij. H 表示 Entropy,S i 表示第 ith 類主題的文章,. Precision= J , Recall= J , K M F-measure =. 2. Gain ( Ak , S i ) = H (Oi ) − ∑. 4.1 使用個別特徵挑選摘要的實驗與結果 本節將利用 3.1~3.4 節所介紹的特徵與選取摘 要的方法進行摘要的選取。而評估方法如下: 依照各個特徵值選出一至九個段落作為摘 要,並使用下列的公式計算其精準度(Precision) 與召回率(Recall)。[9]. 0.15. Numbers. 0.1. 0.05. 0.5. Clustering words. 0.4. Frequent words. F-measure. 0.45. 0 Topic1. Topic2. Topic3. Topic4. Topic5. Topic6. Topic7. Topic8. Topic9. Topic10 Topic11 Topic12 Topic13. -0.05. 0.35. Length. 0.3. 0.25 0.15. Frequent uppercase words Date. 0.1. Uppercase words. 0.2. 0.05. 選擇作為摘要的段落數. 0 1. 2. 3. 4. 5. 6. 7. 8. 9. -0.1. Frequent words Numbers Uppercase. Clustering words Length Date. 圖 2 各種特徵於不同主題的文章所獲得的 Information Gain. Random selection. 例如:數字特徵值,我們發現數字對於 Topic5 、Topic6、Topic7 與 Topic9 的摘要選 取能力較高,但對於 Topic 3、 Topic 4、 Topic 8、Topic 10 是不具有選取摘要能力。因此, 對於 Topic 3、 Topic 4、 Topic 8、Topic 10 我們不應該使用數字作為選取摘要的手段。但 information gain 在某些主題中呈現共同的走 向,所有的特徵皆很高或很低,若將此因素考 慮進去的話,數字特徵真正表現最好的為 Topic 5 與 Topic 6。date 這項特徵在六個 Topics 中 呈 現 負 的 information gain 但 對 於 四 種 Topics 的摘要選擇能力是正的。其餘的特徵皆 具有一定程度的摘要選取能力,但對於不同主 題文章的選取能力仍有一定的差距。. 圖 1 利用各種特徵值選取摘要的 F-measure 圖一中的 random selection 表示隨機選取 段落作為摘要,目的在於評估摘要系統的最低 表現(Baseline Performance)。我們可以發現 clustering words 的特徵值、frequent words 與 其中 clustering words 利用主題的關鍵詞獲取 主題資訊,對於文章摘要的選取的表現較好。 4.2 利用 Information Gain 分析特徵的摘要 選取能力 接下來我們希望能獲取每個特徵對於不同主 題文章的摘要選取能力,我們將利用 information gain 作為分析的指標。我們利用每 一個特徵將區分好類別的文章加以分析,將所 有段落分為摘要段落與非摘要段落分成兩 類。我們舉一個例子,若原本有摘要段落有十 段,非摘要段落 50 段,利用 frequent words 區分摘要之後,被分為摘要與非摘要,但被分 成摘要的十個段落中有五個是正確的摘要五 個是錯誤的,而非摘要的部分有五個是真正的 摘要段落,其餘 45 個段落是正確的分類。而 後以上述的數據計算特徵所獲得的 Information,將未分類之前所獲得的資訊量扣 除分類後的資訊量即為最後該特徵所獲得的. 4.3 利用段落特徵值的排序分析 此節我們將每個摘要段落依照不同特徵值含 量所取得的分數排序,分成十等份。例如:一 篇文章有十個段落,對於高頻詞這個特徵而 言,這十個段落分別有不同的高頻詞出現次 數,此時這十個等份的段落便依照此順序排 列。排名於前百分之十的段落表示含有的高頻 詞次數最多;排名最後則表示含有該特徵的值 最少。此時記錄摘要段落排序的百分比,待全 部的文章皆完成統計後,統計排序十等份中的 每一等份,有幾個摘要段落置於其中,將每一 5.
(6) 等份的摘要段落數除上全部的摘要段落數,得 知摘要段落於每一等份的出現比例。結果列於 圖 3。. P(s )∏ P ( f j | s ) n. P (s | f 1 , f 2 , L f n ) =. j =1 n. ∏ P( f ) j. 0.41. j =1. 0.36. 在比較段落的過程中, P (s ) 為該篇文章出現 摘要段落的比例,同一篇文章中的每個段落 P (s ) 為相同的值,因此我們可以將其 P (s ) 消. 0.31 0.26 0.21 0.16. 去。. 0.11. ∏ P ( f ) 表示一段落的特徵表現排序發 n. j. j =1. 0.06. 生的機率,在不給定該段落是否為摘要時,每 個段落出現特徵值的機率是相同的,原因在於 我們將排序分成等距的十等份,例如:一段落 的特徵排序為第一,但不給定其是否為摘要段 落,此時無論其特徵的表現排名為何,其機率 與其他等份的出現機率相同。因此,在比較同 一篇文章段落的過程中,每個段落所獲得的. 0.01 -0.04. 10%. 20%. 30%. 40%. 50%. 60%. 70%. 80%. 90%. 100%. Clustering Words. Date. Frequent words. Length. Numbers. Frequent Uppercase words. Uppercase. 圖 3 摘要段落的特徵值排序 由圖 3 可以發現:除了 date、numbers 以 外的特徵,大部分的摘要段落所獲得的分數排 序較高。此外,有接近四成的摘要段落的 clustering words、frequent words 與 frequent uppercase words 三個特徵的排序為前 10%。這 個結果對於摘要的選取是有幫助的,我們認為 摘要的段落的選擇至少必須有一個段落以 上,是直接用來描述該文章的主題,而三個特 徵的目標皆是欲獲取主題的關鍵詞,並皆有一 定的主題獲取能力,因此當一個段落含有最多 的主題詞時,被選為摘要的機率也越高。. P( f j )在 ∏ P ( f ) 的值是相同的。因此,∏ j =1 j. j =1. 比較的過程中也能夠消去。我們將每個段落的 計算結果作為其得到的分數。上式可進一步簡 化為:. Score(s ) = P(s | f1 , f 2 ,L f n ) = ∏ P ( f j | s ) n. j =1. P ( f j | s ) 為我們統計摘要段落的特徵排序. 5 實驗. 值,計算的過程已經於 4.3 節說明。經過文章 分類的實驗必須先經判斷決定文章的主題,我 們採用的文章分類公式如下:. 接下來我們使用兩種方法將各種特徵方法整 合找出文章的摘要,第一種方法是統計方法, 第二種方法是決策樹:. v v v c v j ⋅d c* = arg max cos c j , d = v v cj cj d. (. 5.1 統計方法 4.3 節利用特徵值將摘要段落依次排序以獲得 不同特徵出現機率,此機率可視為當已知段落 為摘要段落時的特徵表現,我們利用此機率作 為選擇摘要的基礎。以下將說明我們的做法:. ). v v c j 表示 c j 的類別中的主題關鍵詞, d 表 示 d 文章中所出現的詞,我們希望找出一個 c. *. v v v 使 c j 的關鍵詞與 d 中的文字的 cos c j , d 值. (. P (s ) 為某一段落被列為摘要的機率,. ). 最高,使其最高的類別便是文章的主題。. f n 為第 n 個特徵值, P( f1 , f 2 ,L f n | s ) 可解 讀為已知該段落為摘要時 f1 , f 2 ,L f n 發生的 機率。. P(s | f1 , f 2 ,L f n ) =. n. n. 事實上,並非所有的特徵對於摘要的辨別 能力皆相同,因此我們需要將不同特徵的貢獻 度予以反映,以避免選取摘要時因為使用不具 有辨別摘要的特徵造成選取的偏差。我們利用 之前計算出每個特徵的 information gain 作為 每個特徵的權數。Information gain 的獲取需視 實驗而決定,當實驗為文章先經過分類時, information gain 也會經由分類過的文章所取 得,若實驗為不分類時,information gain 就會 由不經分類的方式獲取。. P( f1 , f 2 ,L f n | s)P(s) P( f1 , f 2 ,L f n ). 此時假設在已知段落是否為摘要的情況下,每 個特徵的出現為獨立的,我們可以把上式改寫 為:. 使用權數表示先將段落的計分公式取對 6.
(7) 數,將相乘轉換為相加,如下面公式所述:. ∑ log (P ( f n. Score (s ) =. j =1. j. F-measure. 0.6 0.575 0.55 0.525 0.5 0.475 0.45 0.425 0.4 0.375 0.35 0.325 0.3. | s )) ∗ w i. wi 為第 i 個特徵的 information gain。若文章 經過分類時, wi 則改寫成 wik ,k 為該篇文章. 1. 分到哪一個類別而決定。在簡單的計算過程後 可以得到每個段落的分數,依分數的高低排 序,依次選出段落作為摘要。我們將採用四種 不同計分的方法來選取摘要:. ∑ log (P ( f n. j =1. j. | s )) ∗ w i. (1). log(P( f j | s )) 最後的加總即段落所得到的分. 數。第四種方法(Method 4)為不分類且不使用 information gain,即採用第二種方法的方式計 分,但文章不經過分類。本實驗直接將 4.3 節 所作的訓練資料直接作為實驗的測試資料:四 種方法的實驗結果如圖 4 與圖 5 所示:. 此外,我們可以發現 F-measure 的值在選 取第四段後便開始下滑,這與我們的實驗資料 有關,我們的實驗資料摘要段落數最多不超過 3 段,因此在第四段之後便逐次的下滑。. Precision. 選取作為摘要的段落數 2 3 4 5 6 7 Method 1 Method 3. 5.2 決策樹 我們採用決策樹作為選取摘要的實驗方法。實 驗的系統平台採用 Weka[12]所提供的軟體, 演算法為 C4.5[10]。若實驗為文章不分類時, 總共有 6024 個段落,當實驗為文章分類時每 個類別平均有 464 個段落進行實驗。最後便利 用這些資料計算出決策樹,圖 6 為 Topic 1 文 章的訓練資料所得到的決策樹。 實驗與之前類似,將分為以下兩組:方法 一為文章依照主題類產生各自的決策樹,方法 二為文章不經過分類,所有的文章共同產生一 決 策 樹 。 評 估 的 方 式 採 用 10-fold cross-validation。分別計算 Precision、Recall 與 F-measure,最後的實驗結果如表格 1 所示:. 8 9 Method 2 Method 4. Recall 0.95 0.85 0.75 0.65 0.55 0.45 0.35 0.25 1. 9. 若比較 Method 1 與 Method 2, Method 2 並未將不同性質文章的特徵表現區分,所統計 出的機率是將全部主題的文章的特徵值表現 平均。例如:一個主題的文章有 60%的摘要 段落的 A 特徵表現在全部段落的前 10%,另 一主題有 35%的摘要段落 A 特徵表現在全部 段落的前 10%,由於每個主題的文章數一樣, 因此將兩個主題的文章合併後變成 47.5%的 摘要段落 A 特徵的表現在前 10%,這對兩個 主題的文章皆是錯誤的這也是將文章分類後 重要的好處,可能造成的選取偏差。Method 3 雖然將文章分類但並未區分不同特徵的重要 性,此舉使文章的分類受到較無鑑別力的特徵 所影響,對其正確率造成影響。. 不 採 用 權 數 ( 消 去 wi ) 的 情 形 下 , 將. 1. 4 5 6 7 8 選取作為摘要的段落數 Method 1 Method 2 Method 3 Method 4. 由實驗結果可以發現 Method 1 無論在 Recall 或 Precision 的表現皆較其他的方法表 現優異,這說明將文章依照不同性質分類對於 擷取摘要的正確率有正面的助益。. 第三種方法(Method 3)為文章經過分類,但計 分方式不使用 information gain,也就是公式(1). 0.7 0.65 0.6 0.55 0.5 0.45 0.4 0.35 0.3 0.25. 3. 圖 5 四種不同方法 F-measure 值. 第一種方法(Method 1)為使用公式(1)的計分 方式,即加入 information gain 的方法,且文 章經過主題的分類。第二種方法(Method 2)為 使用公式(1)的計分方式,但文章不經過分類。. Score (s ) =. 2. 選取作為摘要的段落數 2 3 4 5 6 7 8 9 Method 1 Method 2 Method 3 Method 4. 表格 1 決策樹的實驗結果. 圖 4 四種不同方法所得到的 Precision 值與 Recall 值. 7. Precision. Recall. F-measure. Method 1. 0.556. 0.417. 0.477. Method 2. 0.593. 0.306. 0.404.
(8) F requent w ords. F r e q u e n t > 0 .4 1 7. F r e q u e n t w o r d s < = 0 .4 1 7. No. L e n g t h < = 1 .3 0 4. L e n g t h > 1 .3 0 4. L en g th. L e n g th < = 1 .3 0 4. C o n ta in U p p e r c a s e W ord. L en g th. L e n g th > 0 .7 6 9. C o n ta in U p p e r c a s e W o r d = T r u e. C o n ta in U p p e r c a s e W o r d = F a ls e Y es. F re q u en tw o rd s. N um bers No. N u m b e r s < = 0 .4 7 6. F r e q u e n t w o r d s < = 0 .2 3 8. N u m b e r s > 0 .4 7 6 F r e q u e n t > 0 .2 3 8. D a te < = 4 .3 2. Y es. No. No. D a te. Y es. D a t e > 4 .3 2. No. 圖 6Topic 1 的決策樹 [1] L. D. Baker and A. K. McCallum, “ Distributional Clustering of Words for Text Classification,” Proc. of the 21th ACM SIGIR Conference on Research and Development in Information Retrieval, pp.96-103, 1998. [2] R. O. Duda, P. E. Hart, D. G. Stork “Pattern Classification and Scene Analysis: Pattern Classification,” Brooks/Cole Wiley, John & Sons, Incorporated Pub Co, 2000. [3] H. Edmundson. “New Methods in Automatic Abstracting,” Journal of ACM, 16(2), pp.264-285, 1969. [4] E. Hovy, and C. Y. Lin, “Automated Text Summarization in SUMMARIST, ” Advances in Automatic Text Summarization, MIT Press, pp.81-94, 1999. [5] H. Jing, R. Barzilay, K. McKeown, and M. Elhadad., “Summarization Evaluation Methods: Experiments and Analysis,” In Working Notes of the AAAI-98 Spring Symposium on Intelligent Text Summarization, pp.60-68, 1998. [6] J. Kupiec, J. Pedersen, F. Chen, “A Trainable Document Summarizer,” Proc. of the 18th ACM SIGIR, pp.68-73, 1995. [7] H. P. Luhn., “The automatic creation of literature abstracts,” IBM Journal of Research and Development, 2(2), pp.159-165, 1958. [8] T. M. Mitchell, “Machine Learning, ” The McGraw-Hill Companies, 1997. [9] S. H. Manning, “Foundations of Statistical Natural Language Processing”, MIT Press, 1999. [10] J. R. Quinlan. , “C4.5: Programs for Machine Learning, ” 1993. [11] D. Yarowsky, “Word-Sense Disambiguation Using Statistical Models of Roget's Categories Trained on Large Corpora,” Proc. of the 14th International Conf on Computational Linguistics, pp.454--460, 1992. [12] http://www.cs.waikato.ac.nz/ml/weka/. 整體而言,無論 Method1 與 Method2 的 表現皆不理想,其中 Method 2 的 F-measure 只有 0.4 左右,比起單獨使用一特徵值選取摘 要的表現要差。與 5.1 的統計方式實驗結果相 同的是經過文章分類的表現仍較未經文章分 類的部分要高出許多,雖然 Precision 的值 Method 2 較高,但只高出了 3.7 個百分點,而 Method 1 的 Recall 值卻高出了 11.1 個百分點。 對於這個實驗結果我們認為:由於決策樹 使用階層性的決定方式,在高頻詞或 Clustering words 等區分能力較一般性的特徵 區分過後,剩下特徵的區分力較低,容易造成 分類的錯誤。相對於決策樹的摘要選取方式, 統計方法的優點在於能夠將擁有越多明顯特 徵的段落分數越高,而非指依靠單一的特徵進 行摘要的區分,因此表現也較好。. 6 結論 本文主要描述利用不同的特徵找尋摘要的過 程,並對每一個特徵進行系統性的分析。此 外,我們也使用 clustering words 作為找尋摘 要的特徵之一,提出利用關鍵詞獲取主題資訊 的摘要方法,並達到了一定的效果,在加入主 題檢查的情況下,選取摘要的正確率超過了我 們所選用的其他特徵。在特徵的整合方法上, 我們利用統計方法與決策樹方法將選用的特 徵結合,並證明文章經由主題分類所達到的效 果,確實較不經主題分類的摘要方法擁有較好 的表現。未來我們希望能以特徵組合的方式, 進一步探討特徵對於摘要的選取能力。此外, 我們希望能加入文章結構的分析幫助我們對 文章摘要的掌握能力。. 致謝 感謝國科會研究計劃 NSC-91-2213-E-004-013 對本研究的部分資助。. 參考文獻 8.
(9)
數據
相關文件
Elsewhere the difference between and this plain wave is, in virtue of equation (A13), of order of .Generally the best choice for x 1 ,x 2 are the points where V(x) has
In view of this, this paper attempt to explore the impact of service quality, product involvement, perceive risk on purchase intention.. For affected consumer’s major factor in
The construction progress, quality management, security, environment, surrounding communication, traffic-maintenance and organization, which are the key points of the
Supporting Students in C++ Programming Courses with Automatic Program Style Assessment.
Finally, discriminate analysis and back-propagation neural network (BPN) are applied to compare business financial crisis detecting prediction models and the accuracies.. In
This thesis will focus on the research for the affection of trading trend to internationalization, globlization and the Acting role and influence on high tech field, the change
C., "Prediction of pollutant emission through electricity consumption by the hotel industry in Hong Kong", International Journal of Hospitality Management..
The analytic results show that image has positive effect on customer expectation and customer loyalty; customer expectation has positive effect on perceived quality; perceived
