國 立 交 通 大 學
電控工程研究所
碩 士 論 文
利用空間域特徵空間一致性及共鳴曲線相似
度之喚醒關鍵字偵測方法
A Wake-Up-Word Detection Method Using Spatial
Eigenspace Consistency and Resonant Curve Similarity
研 究 生: 王 庭 昭
指導教授: 胡 竹 生 博士
利用空間域特徵空間一致性及共鳴曲線相似度
之喚醒關鍵字偵測方法
A Wake-Up-Word Detection Method Using Spatial
Eigenspace Consistency and Resonant Curve Similarity
研 究 生:王 庭 昭 Student:Ting-Chao Wang
指導教授:胡 竹 生 博士 Advisor:Jwu-Sheng Hu
國 立 交 通 大 學
電控工程研究所
碩 士 論 文
A ThesisSubmitted to Institute of Electrical and Control Engineering College of Electrical Engineering and Computer Science
National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Master in
Electrical and Control Engineering July 2010
Hsinchu, Taiwan, Republic of China
利用空間域特徵空間一致性及共鳴曲線相似
度之喚醒關鍵字偵測方法
研究生:王 庭 昭 指導教授:胡 竹 生 博士 國立交通大學電控工程研究所碩士班摘 要
本論文提出了一套使用麥克風陣列偵測喚醒關鍵字的方法,本方法運 用聲源於麥克風陣列在不同頻率下的特徵空間一致性(Spatial Eigenspace Consistency) , 以 及 喚 醒 關 鍵 字 語 音 共 鳴 曲 線 相 似 度 (Resonant Curve Similarity)作為判別關鍵字的特徵,並藉由貝氏風險評估與串聯式偵測器的 結合做為偵測的機制。此方法在極低訊噪比下仍保有相當強健的辨識率, 因而可以適用在遠距關鍵字語音偵測或者在吵雜的環境下作為關鍵字語音 喚醒機制。除了偵測關鍵字外,本方法還能同時估測出關鍵字的聲源方向, 並保有串接其他偵測器的能力。在有額外的語音特徵或空間特徵可以加入 時,能夠簡易的設計新的偵測器,串接到原本的架構上以持續增進辨識率。A Wake-Up-Word Detection Method Using Spatial
Eigenspace Consistency and Resonant Curve Similarity
Student: Ting-Chao Wang Advisor: Prof. Jwu-Sheng Hu
Institute of Electrical and Control Engineering
ABSTRACT
This thesis proposes a method to detect keywords using microphone array. The consistency of the spatial eigenspaces formed by the speech source at different frequencies and the resonant curve similarity of the keyword are used as the features for detection. These features are processed and detected separately and the result is determined by cascading individual outcome using Bayes risk estimate. This proposed method can keep a high recognition rate under very low SNR conditions. Therefore, it is suitable for the applications such as distant wake-up and keyword detection in noisy environments. In addition, this method can estimate the direction of arrivals of the sound source, and the proposed architecture is easy to expand by adding other feature detection methods in the cascaded manner to further improve the recognition rate.
誌謝
兩年的碩士生涯,不知不覺就結束了,這應該是學生生涯的尾端了吧。 之後也即將踏入另一個開始,另一個旅途。這兩年發生很多事情,大起大 落,很感謝很多人的陪伴跟幫忙,最後完成了碩士學業。由衷的感謝我的 指導老師,在研究上給予很多想法與建議,老師積極的態度、廣大的視野, 也讓我看到不一樣的格局跟企圖,很值得去學習的榜樣。 感謝實驗室的大家,首先是唐哥,總是不厭其煩的回答我的問題,在 研究上幫了許多忙,期待你的吉他速彈再現;還有興哥引領我進入聲音領 域,在研究上的指點,祝你博班順利畢業;計畫一直跟著的博班學長永融, 在你身上看見認真的男人最帥氣,很值得學習,希望小永融出生可以健康 的成長茁壯,並像爸爸學習;什麼都會什麼都不奇怪的阿吉,希望還能吃 到你帶來的猪腳;最近成為人妻的鏗元學姊,引領我進入三國殺的領域, 有機會再喝酒聊天,並祝妳婚姻幸福;還有業界突然轉入學術界的昌言學 長,我會永遠記住這句話"是大將,就不缺戰場",真是太會鼓勵人了, 開公司記得找我去打雜;會做小點心的阿法,新髮型真的不錯喔,總覺得 你以後的女朋友一定會很幸福;聯誼大師兄丸子學長晉源,認真覺得你的 性感小鬍子應該繼續留著,祝你博班和感情路上順遂;散打之神 JUDO,還 沒有現場看過你的比賽真是太可惜了;偶爾閒聊的得洋學長,祝你在外事 業順利。 還有已經畢業同樣是 Rocker 的 Lundy,在剛進實驗室時有你的陪伴, 祝你研替順遂;戰神 DODO,交接了讓我學到很多的居家照護計畫給我, 祝你申請國外博士順利;邊打籃球邊聊天的肉鬆,讓我了解很多業界的狀 況,可謂先驅啊;接下來是同梯的僑生戰友阿 him,看你不管做什麼都沒有 問題的啦,有空一起去衝浪吧;蛋糕社的小菜,做的蛋糕有職業級的水準 了,以後都吃不到了怎麼辦;還有一同衝刺的沛錡,我們終於要畢業了! 有空再來打打撞球吧;還有巴西同胞 Roldofol,因為你我才知道原來破碎的 英文也是可以溝通的,你踏進實驗室的一小步,是我英文成長的一大步, 希望你在台灣發展順利。 最後是碩一、碩零的學弟妹們,祝你們研究順利,從中找到興趣與成 就。直屬學弟學文,以後家聚記得要找我;幽默的 Macaca,對 3C 跟 IT 產 業的視野真是令人印象深刻;新文你該結婚了吧,看你感情很穩定;計畫 一起努力的昀軒,接下來 Wake-Up-Word 就靠你了;喜歡聊天的學妹湘筑, 穿夾腳拖不錯看啊;強大的新秀建安,希望你找到一個題目大展身手;散 打冠軍昭男,帥氣的耕維,聽說好色的建廷,還沒鬥牛的宗翰,還有不得 不說的吉他教學哲鳴,在最後都幫了許多忙,感謝你們。 更感謝我的家人和女朋友阿雅,持續給我鼓勵與支持,並陪伴我度過目 錄
摘 要 ... I
ABSTRACT ...II
誌 謝 ... III
目 錄 ... IV
表 列 ... VI
圖 列 ... VIII
第一章
緒論 ...1
1.1 研究動機 ...1 1.2 文獻回顧 ...2 1.3 研究目標 ...4 1.4 本研究創新說明 ...4 1.5 論文架構 ...5第二章
背景技術介紹 ...6
2.1 麥克風陣列訊號處理 ...62.2 MULTIPLE SIGNALS CLASSIFICATION METHOD (MUSIC) ...9
2.3 SPEECH FEATURE...14
2.4 LINEAR PREDICTIVE CODING (LPC) ...20
2.5 BAYES RISK...23
2.6 CASCADE DETECTOR...25
第三章
利用空間域特徵空間一致性 及共鳴曲線相似性之喚
醒關鍵字偵測演算法 ...26
3.2 空間域特徵空間一致性偵測 ...29 3.2.1 擷取語音特徵 ...30 3.2.2 建立空間域特徵空間一致性的特徵參數 ...31 3.3 共鳴曲線相似度偵測 ...34
第四章
實驗結果與分析 ...35
4.1 同一發聲者之實驗結果與分析 ...384.1.A 在偵測率 100%下測試最低的 False Positive Rate ...39
4.1.B 各個 SNR 下的 Equal Error Rate ...41
4.1.C 各個 SNR 下字元與字組的分析...42
4.1.D 不同 SNR 下特徵的分析...44
4.1.E 不同 SNR 下門檻值的分析...46
4.1.F 固定門檻值下不同 SNR 的整體測試結果 ...47
4.2 不同發聲者之實驗結果與分析 ...48
4.2.A 在偵測率 100%下測試最低的 False Positive Rate ...49
4.2.B 各個 SNR 下的 Equal Error Rate ...51
4.2.C 各個 SNR 下字元與字組的分析...52 4.2.D 不同 SNR 下門檻值的分析...53 4.2.E 固定門檻值下不同 SNR 的整體測試結果 ...55
第五章
結論 ...56
5.1 研究成果 ...56 5.2 未來展望 ...56REFERENCE...57
表 列
表 2.1 實際頻率跟 FFT 後頻率索引對照表(取樣頻率 8K) 表 2.2 不同決策結果的代價表 表 4.1 同一發聲者語料庫 表 4.2 不同發聲者語料庫 表 4.3 本實驗指標參數的定義表表 4.4 SNR=14.15 時偵測率為 100%時最低的 False Positive Rate 表 4.5 SNR=7.3 時偵測率為 100%時最低的 False Positive Rate 表 4.6 SNR=-0.3 時偵測率為 100%時最低的 False Positive Rate 表 4.7 SNR=-2.24 時偵測率為 100%時最低的 False Positive Rate 表 4.8 SNR=-3.82 時偵測率為 100%時最低的 False Positive Rate 表 4.9 SNR=-6.32 時偵測率為 100%時最低的 False Positive Rate 表 4.10 SNR=-8.26 時偵測率為 100%時最低的 False Positive Rate 表 4.11 SNR=-11.78 時偵測率為 100%時最低的 False Positive Rate 表 4.12 各個 SNR 下的 False Positive Rate
表 4.13 各個 SNR 下的 EER
表 4.14 SNR=14.15 時偵測率為 100%時最低的 False Positive Rate 表 4.15 SNR=-11.78 時偵測率為 100%時最低的 False Positive Rate 表 4.16 8 個不同 SNR 與其資料數
表 4.17 固定門檻值下不同 SNR 的整體測試結果
表 4.18 SNR=14.15 時偵測率為 100%時最低的 False Positive Rate 表 4.19 SNR=7.3 時偵測率為 100%時最低的 False Positive Rate 表 4.20 SNR=-0.3 時偵測率為 100%時最低的 False Positive Rate 表 4.21 SNR=-2.24 時偵測率為 100%時最低的 False Positive Rate 表 4.22 SNR=-3.82 時偵測率為 100%時最低的 False Positive Rate
表 4.23 SNR=-6.32 時偵測率為 100%時最低的 False Positive Rate 表 4.24 SNR=-8.26 時偵測率為 100%時最低的 False Positive Rate 表 4.25 SNR=-11.78 時偵測率為 100%時最低的 False Positive Rate 表 4.26 各個 SNR 下的 False Positive Rate
表 4.27 各個 SNR 下的 EER
表 4.28 排除’阿拉拉’前後 False Positive 的比較 表 4.29 8 個不同 SNR 與其資料數
圖 列
圖 2.1 均勻線性陣列架構 圖 2.2 環型陣列架構 圖 2.3 各個頻率下的 MUSIC Spectrum 圖 2.4 頻率頻譜與空間頻譜關係圖(SNR=16.14) 圖 2.5 頻率頻譜與空間頻譜關係圖 圖 2.6 Source-Filter Model 圖 2.7 聲帶震動產生的激勵訊號 ( )x t [2-7] 圖 2.8 激勵訊號的能量頻譜X(w) [2-7] 圖 2.9 共鳴濾波器的頻率響應(共鳴曲線)H(w) [2-7] 圖 2.10 合成訊號的能量頻譜Y(w) [2-7] 圖 2.11 不同音高下同字的能量頻譜與共鳴曲線 圖 2.12 同音高下不同字的能量頻譜與共鳴曲線 圖 2.13 同音高、同字但不同人的能量頻譜與共鳴曲線 圖 2.14 LPC 模型之頻率響應 圖 2.15 LPC 模型之頻率響應 (dB 表示) 圖 2.16 兩個機率分布圖 圖 2.17 串聯式偵測器架構 圖 3.1 喚醒關鍵字偵測演算法流程圖圖 3.2 Spatial Eigenspace Consistency 的整體架構圖 圖 3.3 選取的頻帶與空間頻譜示意圖 圖 3.4 兩個字的能量頻譜與共振曲線 圖 3.5 1 ( , ) MUSIC f f F D θ ω ∈
∑
S ,圖形峰值處即為角度估測量值 圖 3.6 ˆ(θ ω 的統計圖,離散程度即為角度估測變異數 f)圖 3.7 語音特徵分布圖 圖 3.8 兩條不同字的共鳴曲線 圖 3.9 語音特徵分布圖 圖 4.1 錄音環境實際照片 圖 4.2 麥克風陣列平台 圖 4.3 錄音環境平面關係的俯視圖 圖 4.4 三個字元各自的偵測結果(SNR=14.15 dB) 圖 4.5 字組的偵測結果(SNR=14.15 dB) 圖 4.6 三個字元各自的偵測結果(SNR=-11.78) 圖 4.7 字組的偵測結果(SNR=-11.78) 圖 4.8 Layer1 語音特徵分布圖 圖 4.9 Layer2 語音特徵分布圖 圖 4.10 Layer3 語音特徵分布圖 圖 4.11 不同 SNR 下使偵測率剛好為 100%時門檻值的變化 圖 4.12 排除’阿拉拉’前後字組的偵測結果(SNR=14.15 dB) 圖 4.13 不同 SNR 下使偵測率剛好為 100%時門檻值的變化
第一章 緒論
1.1 研究動機
在一般語音訊號處理上,關鍵字偵測或是擷取(Keyword Detection or Spotting)是語音辨識 (Speech Recognition)相當重要的一環,辨識步驟主要為 先擷取語音特徵參數(LPC、MFCC、PLP 等)[1-1] [1-2] [1-3]、為語音特徵建 出模型(HMM 等) [1-4] [1-5]及設定特徵參數比對方法(計算距離或相似度)。 儘管語音辨識技術已經發展多年,在訊噪比高的情形下對大型詞彙庫的辨識 率已經相當不錯,然而面對環境的雜訊干擾或是多人同時發聲的情況,即使 是單一關鍵字的辨識率,也大多很難維持一定的水準[1-6] [1-7] [1-8]。在現 實環境中,各種不同的聲音干擾是無法避免的,因此如何能在吵雜的環境中 對關鍵字仍保有極高的辨識率,仍是目前相當重要的研究課題。
在自動語音辨識系統中(Automatic Speech Recognition,ASR),何時可 以開始進行辨識是其中一項重要的功能,該功能通常稱作 push button 或是 wake-up。Wake-up 功能運用得宜可以大量降低辨識錯誤率。一般在如電腦 或手機的介面中往往以觸控或按鈕來實現,但是這個前提是所面對的裝置或 機器需要在使用者的手邊。如果與使用者有一段距離,使用者往往必須配戴 一無線裝置以提供可靠的 wake-up 訊號,在許多實際應用上這仍有其障礙。 例如要命令智慧型居家服務機器人提供服務,若使用者必須一直配戴一無線 裝置,在居家的情境中幾乎是不可行。因此,如何能夠在無需配戴任何裝置 的情形下有效的實現 wake-up 功能,就成為一個實用且富挑戰性的研究題 目。因為使用者不能配戴任何裝置,且提供語音辨識介面的機器很可能不在 視野範圍內,因此無可避免的必須回歸到以語音來執行 wake-up 的功能。簡 單來說,這即是單一關鍵字的辨識問題,但是其所面臨的問題是語者可能距 離相當遠,因此訊噪比通常很差。其次是如同按鈕或觸控,以語音關鍵字實 現 wake-up 也必須有幾乎 100%的 detection rate 以及接近於 0 的 false positive
rate,否則將產生誤動作或反應遲鈍,誠如前段所述,以目前通用的語音辨 識方法,仍無法達成這個效能。 本論文針對上述的 wake-up 問題,嘗試藉由加入相對抗雜訊能力強的空 間資訊和語音辨識器結合以保持極高的辨識率。並且在所加入的空間資訊中 考慮到語音特徵,使得判別空間資訊不僅僅考慮聲源來向的一致性,亦能區 隔非 wake-up 關鍵字的字詞。其基本想法是由預先設定的 wake-up 關鍵字(如 機器人的名字),判斷其特徵頻率的空間特性的一致性,藉以在低訊噪比的 情形下大量提升其辨識穩定度。此想法的空間特徵資訊獲取則必須使用麥克 風陣列。
1.2 文獻回顧
語音在做為人機介面(Human-Machine Interface)上擁有相當多的優點與 特性,以下先介紹人機介面的發展。在傳統上人機介面為使人去適應機器, 學習並習慣人機介面的設計與機構,以傳達控制命令。舉如圖形化使用者介 面(GUI)中的滑鼠、鍵盤等,需要適應鍵盤按鍵的位置,並於近距離與機器 互動;而在遠距中則以無線控制裝置,如遙控器、無線搖桿等裝置溝通。 近年來的人機介面趨勢已逐漸朝向機器去適應人的觀念去發展,如觸控 螢幕。但以智慧型人機介面而言,還需要更方便、更快速、更簡易使用的方 法,同時還要讓使用者能空出自己的雙手和視覺的專注力,以能夠處理其他 的事情或避免危險,例如在駕駛時與導航機溝通目的地等。多年來在許多科 幻電影或小說中早已勾勒出未來以語音方式與機器溝通的情境,其終級目標 為使人和機器間的溝通就像人和人之間的溝通同樣的簡易、方便。 在眾多人機介面技術中,語音辨識擁有以上的優點與特性[1-9][1-10]。 語音為人類的本能,不需要額外再去訓練學習,快速且有效率,可以很方便 的傳達訊息給另一方,也不需要面對著機器或為了與機器溝通必須使用雙語音具有繞射的特性,在和機器間無法直視的情況下,視覺會喪失其功能, 若要在環境中安裝多支攝影機,則又會有隱私及成本的問題。 然而以目前語音辨識的技術,仍存在著許多技術瓶頸導致其無法大量 應用於人類的生活中。其中最困難的問題是其在各種應用環境下的穩定度。 語音辨識技術已發展多年,雖然在訊噪比高的情形下對大型詞彙庫的辨識率 已經相當不錯,然而在面對環境雜訊的干擾或是多人同時發聲的情況,則很 難維持一定的水準,以致於誤動作頻繁[1-6] [1-7] [1-8]。對於穩定度的提升, 在傳統上常用的解決方法就是仰賴一個穩健的開關(Push Button or Wake-Up Button),如滑鼠、觸控螢幕等。在需要辨識時按下開關後開始辨識,減少 持續辨識產生的錯誤及誤動作,以增進語音辨識器的辨識率,如果辨識錯誤 則按下開關開起重新辨識。若使用一個穩健並獨一無二的語音關鍵字作為開 關,就為語音關鍵字喚醒機制(Wake-Up-Word)。 例如在居家機器人的應用上,預先設定一個 wake-up 關鍵字(如機器人 的名字),並只需要持續的偵測關鍵字是否有發聲。當使用者呼喚機器人時, 機器人走近使用者並可開啟語音純化與語音辨識,亦或者再開啟其他應用功 能,如人臉偵測、姿態辨識等,詢問並等待使用者發出進一步的指令。從此 應用上可以看出四個優點,第一,若語音辨識器持續運作,則在長時間運作 中可能時常辨識錯誤並產生誤動作,尤其在機器人與使用者距離過遠或者環 境吵雜下更容易發生錯誤。第二,若不使用語音關鍵字作為喚醒機制,則使 用者必須每次要走近機器人以啟動服務,不然就需要隨身攜帶遙控器,且需 擔心電池電力用磬的問題,在方便性上就大打折扣。第三,在使用者呼叫後, 機器人可以藉此得出使用者的資訊(如方位),藉由此資訊為語音辨器創造一 個更為良好的聲場環境,例如走近使用者或者開啟對使用者方向的空間純化 器等。第四,機器人平時不用開啟多項功能,節省能源並增加運作時間,減 少充電次數。
誠如以上所說,語音關鍵字喚醒有其存在的必要。在“Nonlinear Analysis:
Theory, Methods & Applications” 期 刊 中 的 一 篇 文 獻 有 一 個 完 整 的 定 義
[1-11]:語音關鍵字喚醒(Wake-Up-Word)為一個語音關鍵字或詞句的偵測機 制,藉由挑選出獨一無二的關鍵字,並只對此字做偵測,達成穩健、準確、 有效率的開關以喚醒機器平台(如機器人、電腦),並當需要喚醒機器人時擁 有將近 100%的偵測率(Detection Rate),且阻絕其他任何的字、詞句、雜訊、 音樂等任何聲音,達成將近 0 的誤報率(False Positive Rate)。此機制在語音 辨識中是一個新的範疇,並且尚未被廣泛的探討,可視為一種語音關鍵字偵 測方法(Keyword Detection or Keyword Spotting),但又和其功能與設計目的 有所不同。目前主要方法大致和關鍵字偵測相同[1-12],而後也有對語音特 徵進行多種評分並分類的方法[1-13] [1-14],然而目前都還是在純淨語音訊 號的語料庫下發展,未有見過在實際環境中可能遇到低 SNR 下的文獻探討。
1.3 研究目標
基於上述的說明,本論文以麥克風陣列訊號處理為基礎,將研究目標 分為: 1. 測試特徵頻率其空間性特徵空間一致性是否具有區別不同字的能力。 2. 抽取可運用於空間資訊鑑別之語音特徵。 3. 測試同一發聲者跟不同發聲者在所使用的特徵之差異。 4. 發展一套可於低 SNR 下運作的 wake-up 關鍵字偵測演算法。1.4 本研究創新說明
本研究的創新為相較於一般通用的語音辨識器,增加了空間判別的資 訊,用關鍵字中特徵頻率其空間性特徵空間一致性來做進一步篩選,使得可 以在低訊噪比(SNR)下有相當的辨識率,因而可以適用在遠距關鍵字語音偵 測或者在嘈雜的環境下作為關鍵字語音喚醒機制,並且還能同時估測出關鍵以達到即時的反應。基於貝氏風險(Bayes Risk)理論的門檻值(Threshold)判別 以及利用串接多個偵測器的組合,使本方法得以在極低的訊噪比之下仍保有 非常高的辨識率。經大量的語料測試,本方法可以在-3.82dB 的訊噪比之下 達成 100%的 detection rate 以及 10.32%的 false positive rate,且所測試其穩 定度的語料為與目標關鍵字相當接近的語句,在目前文獻中幾乎未見此高效 能的展現。同時,本研究串聯式偵測器保有串接其他偵測器的能力,在有額 外的語音特徵或空間特徵可以加入時,能夠簡易的設計新的偵測器,串接到 原本的架構上以持續增進辨識率。
1.5 論文架構
本篇論文架構包含了三個主要的部份,分別是麥克風陣列訊號處理與語 音辨識的背景理論、本論文提出的演算法及實驗成果與分析。以下描述各章 節的主要內容: 第二章:將介紹麥克風陣列訊號處理、Eigenspace Method 的聲源方位估算 演算法 MUSIC、語音的特性與特徵、線性預測編碼(LPC)、貝氏 風險及串聯式偵測器。 第三章:介紹本論文的演算法,如何利用空間域特徵空間一致性與共鳴曲 線一致性偵測喚醒關鍵字。 第四章:實驗的結果與分析。 第五章:研究成果及未來展望。第二章 背景技術介紹
2.1 麥克風陣列訊號處理
在傳統數位訊號處理研究中,大多著重於時域及頻域的處理技巧,通常 先將連續訊號進行取樣,接著轉換成頻域以分析訊號或者通過濾波器來區分 訊號中不同的成分。 多個麥克風排成一個固定的形狀,接收來自空間中傳遞的訊號,由於麥 克風位在空間中不同處,因而對於同一發聲源的訊號會擷取到不同的能量變 化及時間差,而對多個麥克風間擷取到的訊號差異進行處理分析的技術,稱 為麥克風陣列訊號處理。在此領域中,依照其目的不同,大致可以將其研究 領域分為兩大類: 第一類:著重於估測訊號的數量或在空間中的方位,一般稱為聲源到達方位 估測(Direction of Arrivals Estimation,DOA)。第二類:利用訊號的空間關係,能夠對不同方向的訊號作出不同的增益, 以達到空間濾波的效果,藉以分離空間中不同方向聲源的訊號, 一般稱之為波束形成理論(Beamformer),也就是一種空間濾波器 (Spatial Filter)。 當給定一個麥克風陣列及一個參考點(通常為某顆麥克風),array manifold vector 定義出每個麥克風擷取到的聲源訊號相對於此參考點的時間 關係。在波束形成理論中,array manifold vector 被用來補償入射訊號到不同 麥克風之間的相位差;而在聲源到達角度估測理論中,很多方法藉由比對 array manifold vector 跟聲源訊號 eigenspace 的相似度來求出聲源方向,此類 方法統稱為 Eigenstructure Methods DOA。
圖 2.1 均勻線性陣列架構
通常在不同的情況下會選用不同的陣列排列形狀,以下推導最常見的均 勻線性陣列(Uniform Linear Array,ULA),其架構圖如圖 2.1 所示。假設聲 源訊號為遠場平面波(Far field plane wave),s(t)為原始訊號,n(t)為雜訊,則 M個麥克風輸出可以寫成下列向量的形式: 1 1( ) ( ) 1( ) ( ) ( ) ( ) ( ) c M c x r jw c x r jw M c M x t s t e n t t x t n t s t e ⋅ ⋅ ⎡ ⎤ ⎡ ⎤ ⎢ ⎥ ⎡ ⎤ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ =⎢ ⎥= +⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎣ ⎦ ⎢ ⎥ ⎣ ⎦ ⎣ ⎦ r r r r M M M x 1 1( ) ( ) ( ) ( ) ( ) ( ) c c M jk x r jk x r M e n t s t r s t t e n t ⋅ ⋅ ⎡ ⎤ ⎡ ⎤ ⎢ ⎥ ⎢ ⎥ =⎢ ⎥ +⎢ ⎥= + ⎢ ⎥ ⎢⎣ ⎥⎦ ⎣ ⎦ r r r r r M M a n (2.1.1) c c c c w k λ π 2 = = ,k c 稱為 wavenumber,而λ 為波長,c 為波速,其中c a( )rr 稱 為 array manifold vector,包含了訊號傳遞到麥克風之間的時間關係,可以再 簡化為:
( )
sin ( 1) sin T = 1 ejk dc θ ejk Mc d θ θ ⎡ − ⎤ ⎣ L ⎦ a (2.1.2) d d sourcerv
r : unit vector
v
reference point 1x
v
x
v
2x
v
M 2x
v
⋅ v
r
θZ X Y
θ
φ
R Source Reference Point 圖 2.2 環型陣列架構 圖 2.2 是等距的環形陣列排列方式,具備有 2-D 維度的角度搜索能力, 本論文也是以此環型陣列架構為基礎。設定圖 2.2 的圓心為參考點,可推得 array manifold vector 為:
2( 1) 2
* sin cos( ) * sin cos( )
* sin cos ( ) 1 c c c M jk R jk R jk R T θ ⎡ e ι θ e φ θ− πM e φ θ− − πM ⎤ = ⎢⎣ ⎥⎦ a (2.1.3) R:圓形半徑 M :天線個數
2.2 Multiple Signals Classification Method (MUSIC)
在聲源到達方位(DOA)估測方法中,依照技術層面不同巨觀上可以分成 兩大類,第一類是利用聲音從空間中傳遞的特性所造成的時間差來作方位估 測,稱為 TDE(Time Delay Estimation)[2-1];第二類是利用不同訊號源間特 徵向量的分布關係,以互相投影或判斷相似度的方式來估測出訊號的方位, 稱為 Eigenstructure Method[2-2]。 MUSIC[2-3]是一個簡單有效率的聲源到達方位估測方法,在兩大類中 屬於 Eigenstructure Method。此方法利用不同訊號源其特徵向量的分布關 係,以訊號子空間與雜訊子空間互相正交的特性來估算聲源的方位,也因此 可以同時偵測多個聲源的方位。 使用 MUSIC 演算法必須要滿足兩個基本假設:
I. 訊號相關矩陣(Source Correlation Matrix)是滿序(Full Rank),且序等 於訊號來源的數目 D。
II. Array manifold vector ( )a iθ ,i = L1 , ,D彼此之間是線性獨立,滿 足 array manifold matrix 是滿序,且序也等於訊號來源的數目 D。
滿 足 以 上 兩 個 基 本 假 設 之 後 , 把 (2.1.1) 式 改 寫 成 多 個 訊 號 源 的 形 式 :
[
]
1 1 1 ( ) ( ) ( ) ( ) ( ) A (t) (t) , A= ( ) ( ) , ( ) = ( ) D i i i D M t s t t s t a a t s t θ θ θ = = + ⎡ ⎤ ⎢ ⎥ = + ⎢ ⎥ ⎢ ⎥ ⎣ ⎦∑
L M x a n s n s (2.2.1)經過 short time fourier transform(STFT)轉換成頻域: (ωf, )k =A(ωf) (ωf, )k + (ωf, ) k , f =1LF
X S N (2.2.2)
假設聲源和雜訊彼此不相關,則資料相關矩陣(Data Correlation Matrix) RXX 為:
(
)
( , ) ( , ) ( , ) ( ) ( , ) ( ) ( , ) H XX f f f 2 f SS f f f k E k k k σ k ω ω ω ω ω ω ω = = H R A R A + N I X , X (2.2.3) 將資料相關矩陣特徵值分解(Eigenvalue Decomposition,SVD): 1 ( ) ( ) ( ) ( ) M H XX f i f i f i f i ω λ ω ω ω = =∑
R V V (2.2.4) 雜訊相關矩陣(Noise Correlation Matrix)也可以寫成為:2 2 1 ( ) ( ) ( ) ( ) M H f f i f i f i σ ω σ ω ω ω = =
∑
I N N V V (2.2.5)則 純 訊 號 相 關 矩 陣 (Signal-Only Correlation Matrix) 就 可 以 由 方 程 式 (2.2.4)-(2.2.5)得出:
(
2)
1 ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) H XX f f SS f f M H i f f i f i f i ω ω ω ω λ ω σ ω ω ω = = =∑
− C A R A N V V (2.2.6) 因為CXX(ωf)的序為 D,可以發現其 Range space 為: 1 ( XX( f))= { ( f), , D( f)} , : Range Space Rs C ω spanV ω L V ω Rs}
{
1{
1}
( ( f)) ( , f), , ( D, f) ( f), , D( f) Rs A ω =span aθ ω L a θ ω =span V ω LV ω +1 ( ( f)) { D ( f), , M( f)} Rs A ω ⊥=spanV ω LV ω (2.2.7) 因此定義出訊號跟雜訊子空間: 1. V1(ωf),L,VD(ωf) 稱為訊號的特徵向量並且以span{ (V1 ωf),L,VD(ωf)}為訊號子空間(Signal Subspace)。
2. VD+1(ωf),L,VM(ωf)稱為雜訊的特徵向量
再來利用訊號子空間與雜訊子空間正交(Orthogonal)的特性: (ωf)Hj ( ,θ ωi f)=0 , i=1, 2,L, , D j D= +1,L,M V a (2.2.8) 建立一個投影到雜訊子空間的投影矩陣PN: 1 ( ) ( ) ( ) ( ) M H N f f i f i A f i D ω ω ω ⊥ ω = + =
∑
= P V V P (2.2.9) 而聲源到達角度 ,θi i = L ,就可利用方程式(2.2.9)得到的投影矩陣1, ,D PN去 解方程式(2.2.10)就可求得: ( ) ( , ) 0 N ωf θ ωf = P a (2.2.10) 為了更方便地可以找到θ,取方程式(2.2.10)的大小: 2 2 ( ) ( , ) H( , ) ( ) ( , ) 0 N ωf θ ωf = θ ωf N ωf θ ωf = P a a P a (2.2.11) 1 ( , ) ( , ) ( ) ( , ) MUSIC f H f N f f θ ω θ ω ω θ ω = P S a a (2.2.12) 所以最後的角度估測就為:ˆ( f) arg max MUSIC( , f)
θ
θ ω = S θ ω (2.2.13)
在方程式(2.2.12)式子中,SMUSIC( ,θ ωf)稱為 MUSIC spectrum,或者稱為
Space spectrum。另外在實際上方程式(2.2.11)因為雜訊、誤差的緣故並不會 真的等於零,所以不會看到無限高的 MUSIC spectrum。
圖 2.3 各個頻率下的 MUSIC Spectrum
MUSIC Spectrum MUSIC Spectrum
angle angle frequency frequen cy magnitude
從統計的觀點來看,MUSIC 就相當於在各個頻帶下做主要成分分析 (Principle Component Analysis,PCA)。在不考慮過低頻 space coherence 及過 高頻 space spectrum aliasing 無法使用外,比較好的訊號到達方位估測結果, 通常在某些頻域上 SNR 較高的頻帶,不過反過來卻不一定成立,因為空間 的聲場環境過於複雜。 圖 2.4 頻率頻譜與空間頻譜關係圖(SNR=16.14) 在圖 2.4 的左圖,藍線為某個字的能量頻譜(此圖已經被逆時鐘翻轉了 90 度,所以縱軸是頻率,橫軸是能量大小)。右圖紅線為把空間頻譜中估測 出正確角度的量值畫在能量頻譜上。 SNR=16.14 SNR=-2.84 SNR=-16.24 圖 2.5 頻率頻譜與空間頻譜關係圖 從圖 2.5 的三個小圖可以清楚看到,當訊號源未受到干擾時,大部分的 頻帶 SNR 都夠高,足以保存空間資訊。但當環境雜訊增加時,空間資訊只 50 10 0 150 20 0 25 0 0 2 4 6 8 10 12 14 16 18 20 fr e que nc y ma gnitud e fr equ en c y s pe c tr um M U S IC s p e c tr u m of 0 an gl e 50 100 15 0 200 250 0 2 4 6 8 10 12 14 16 18 20 fr equenc y s pe c tr um fr eque nc y mag nitude frequen cy magnitude 0 50 100 150 200 250 300 0 2 4 6 8 10 12 14 16 18 20 frequency m agni tude frequency spectrum MUSIC spectrum of 0 angle
0 50 100 150 200 250 300 0 2 4 6 8 10 12 14 16 18 20 frequency m agni tude frequency spectrum MUSIC spectrum of 0 angle
0 50 100 150 200 250 300 0 2 4 6 8 10 12 14 16 18 20 frequency m agni tude frequency spectrum MUSIC spectrum of 0 angle
另外值得一題,在對資料相關矩陣做完特徵值分解後,最大的特徵值已 經具有空間濾波器純化的效果。以下為推導:
假設雜訊的能量遠低於訊號的能量且聲源只有 1 個的情況下,根據理論則將 只會有 1 個不為 0 的特徵值,依照(2.2.7)式知道其所對應的特徵向量即是聲 源方向 array manifold vector 的估測:
{
1}
{
1}
1 1 1 ˆ( , ) ( ) ˆ( , ) '( , ) ( ) : normailzed factor f f f f f span span C C θ ω ω θ ω θ ω ω = ≡ = a V a a V (2.2.14) 在實作上以(2.2.15)式近似(2.2.3)式: 1 1 1 ( ) ( , ) ( , ) ( ) ( ) ( ) N XX f f f k M H i f i f i f i k k N ω ω ω λ ω ω ω Η = = = =∑
∑
R X X V V (2.2.15)N 代表計算 correlation matrix 的音框數(frame number),則最大的特徵值
1( f) λ ω 可以求出: 1 1 1 1 1 1 H 1 1 1 H H 1 1 ( ) ( ) ( ) ( ) 1 ( ) ( , ) ( , ) ( ) 1 ' ( , ) ( , ) ( , ) '( , ) 1 ( , ) ( , ) , ( , ) ' ( , ) ( , ) 1 H f f XX f f N H f f f f k N f f f f k N f f f f f k k k N k k N k k k k N N λ ω ω ω ω ω ω ω ω θ ω ω ω θ ω ω ω ω θ ω ω Η = Η = = = = = = ≡ =
∑
∑
∑
R y y y V V V X X V a X X a a X 2 1 ( , ) N f k k ω =∑
y (2.2.16)從(2.2.16)式看到,最大的特徵值就是依照 PCA 估測出的 array manifold vector 依照所內含的相位差去補償各個麥克風,並把各個麥克風的訊號加 總,此效果同等於 Delay and Sum Beamformer[2-4],具有空間濾波器純化語
2.3 Speech Feature
語音特徵(Speech Feature)為語音辨識鑑別出不同字的依據,每一個字、 每一個發音都有其不同的特徵,並根據這些特徵區別出不同的字。圖 2.6 Source-Filter Model 為最常描述語音發聲的模型[2-5],此模型假設激勵源和 濾波器為互相獨立的。 圖2.6 Source-Filter Model( )
y t
為環境中聽到的訊號, ( )h t 為共鳴濾波器, ( )x t 為激勵源訊號,Y(w)、 (w) X 各 為 其 能 量 頻 譜 , H(w) 為 共 鳴 濾 波 器 的 頻 率 響 應 (Frequency Response),又稱為共鳴曲線(Resonant Curve)[2-6]。圖 2.6 的關係可表示為:( )
( ) * ( )
y t
x t h t
(w)
(w) (w)
=
Y
= X
H
(2.3.1) 在語音中激勵源(excitation)為人的聲帶,在弦樂器中激勵源就為琴 弦,在管樂器中激勵源就為簧片。從激勵源出來的訊號經過了聲道、口腔、 鼻腔、胸腔、嘴型等身體器官的共鳴放大就成為了環境中被人耳所聽到的人 聲;在樂器中就是俗稱的共鳴箱。 從聲音的三要素來看,響度定義了聲音的強弱,由聲波的振幅來決定, 振幅越大,表示聲波的能量越高,聲音也就越大聲。音調定義了聲音的高低, 由振動的頻率決定,頻率越高,聲音也就越尖銳。音色定義了聲音的波形, 不同的波形聽起來的感覺就不同。 因此,可以說激勵源控制了音高,共鳴濾波器控制了音色,而不同的語 Excitation /Source y(t) x(t) h(t) Resonation /Filter圖 2.7 聲帶震動產生的激勵訊號 ( )x t 圖 2.8 激勵訊號的能量頻譜X(w) 圖 2.9 共鳴濾波器的頻率響應(共鳴曲線)H(w) 圖 2.10 合成訊號的能量頻譜Y(w) [2-7] 圖 2.7 為人的聲帶震動後所產生的訊號,通常為一個三角波。圖 2.8 則 為此波型的能量頻譜,可以看出激勵源的訊號主要為基頻與其諧波成分。此 訊號經過了共鳴濾波器的共鳴放大,最後變為環境中所傳遞的訊號,如圖 2.10。
為了進一步了解語音的特性,以下測試同一個字、不同的發音音高來作 比較,如圖 2.11(共鳴曲線為使用 LPC 所估測。藍色線為能量頻譜;紅色線為 共鳴曲線)。 可以發現不同音高使基頻跟諧波的位置不同,而共鳴曲線只有些許變 動,並注意共鳴曲線峰值處的頻率位置變異也不大。事實上共鳴曲線峰值處 的頻率位置也為語音的重要特徵,稱為共振峰(Formant)[2-8]。 圖 2.11 不同音高下同字的能量頻譜與共鳴曲線 C3 D E F G A f (Hz) 130.81 146.83 164.814 174.614 195.998 220 Freq. index 8.37 9.4 10.55 11.18 12.54 14.08 0 50 100 150 200 250 300 0 1 2 3 4 5 6 7 8 9 10x 10 5 0 50 100 150 200 250 300 0 2 4 6 8 10 12 14 16 18x 10 5 0 50 100 150 200 250 300 0 0.5 1 1.5 2 2.5 3 3.5x 10 6 0 50 100 150 200 250 300 0 0.5 1 1.5 2 2.5x 10 6 0 50 100 150 200 250 300 0 1 2 3 4 5 6 7x 10 6 0 50 100 150 200 250 300 0 0.5 1 1.5 2 2.5 3 3.5 4x 10 6 Pitch: C3 Peak indices: 9 18 26 35 43 … Formants: 45 85 Pitch: D Peak indices: 10 19 29 38 47 … Formants: 46 89 Pitch: E Peak indices: 11 22 32 43 53 63 … Formants: 52 90 Pitch: F Peak indices: 12 23 34 45 57 … Formants: 44 90 Pitch: G Peak indices: 14 26 39 52 64 … Formants: 51 87 Pitch: A Peak indices: 15 29 43 56 … Formants: 54 95
frequency frequency frequency
frequency frequency frequency
magnitude
再拿不同的字、同樣的發音音高來作比較,如圖 2.12。這時就可以發現 共鳴曲線的變異就很大了,共振峰的位置也不同,而基頻跟諧波的位置沒有 變動。在早期的語音辨識就是依照前兩個共振峰的位置來當作語音特徵,當 時可以初步區別出不同的母音[2-9]。 圖 2.12 同音高下不同字的能量頻譜與共鳴曲線 0 50 100 150 200 250 300 0 1 2 3 4 5 6 7 8 9 10x 10 5 0 50 100 150 200 250 300 0 5 10 15x 10 5 0 50 100 150 200 250 300 0 2 4 6 8 10 12 14x 10 5 0 50 100 150 200 250 300 0 1 2 3 4 5 6x 10 5 0 50 100 150 200 250 300 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2x 10 6 0 50 100 150 200 250 300 0 0.5 1 1.5 2 2.5 3 3.5x 10 6 Pitch: C3 Peak indices: 9 18 26 35 43 Formants: 45 85 Pitch: C3 Peak indices: 9 18 26 34 43 Formants: 37 120 170 Pitch: C3 Peak indices: 9 17 26 34 42 50 Formants: 34 94 Pitch: C3 Peak indices: 9 17 25 33 41 50 Formants: 20 162 Pitch: C3 Peak indices: 9 18 26 35 43 51 Formants: 35 117 Pitch: C3 Peak indices: 9 18 26 34 43 51 Formants: 34 143
Word = ‘阿’ Word = ‘甜’ Word = ‘肯’
Word = ‘基’ Word = ‘學’ Word = ‘偉’
frequency frequency frequency
frequency frequency frequency
magnitude
最後再拿同一個字、同樣的發音音高,但不同的人發音來做比較,如圖 2.13。可以發現基頻跟諧波的位置沒有變動,而共鳴曲線的變異相對於不同 字來說較小,共振峰的位置也只有稍微變動。共鳴曲線變動的差異是來自於 不同人的口音、發音方式及講話習慣的不同所造成。 圖 2.13 同音高、同字但不同人的能量頻譜與共鳴曲線 0 50 100 150 200 250 300 0 1 2 3 4 5 6 7 8 9 10x 10 5 0 50 100 150 200 250 300 0 0.5 1 1.5 2 2.5 3 3.5 4 4.5x 10 5 Pitch: C3 Peak indices: 9 18 26 35 43 Formants: 45 85 Pitch: C3 Peak indices: 9 17 26 34 42 Formants: 41.5 73 0 50 100 150 200 250 300 0 1 2 3 4 5 6 7x 10 5 0 50 100 150 200 250 300 0 2 4 6 8 10 12 14x 10 5 Pitch: C3 Peak indices: 9 18 26 35 43 52 Formants: 44 82 Pitch: C3 Peak indices: 9 18 26 35 43 Formants: 49 89 frequency frequency frequency frequency magnitude magnitude magnitude magnitude
經由以上的觀察,可以再次確定語音特徵就是整個共鳴濾波器(在人聲 中共鳴濾波器也稱為聲道濾波器),也就是此共鳴濾波器的頻率響應-共鳴 曲線,而共振峰也為其中的特徵之一。至於激勵訊號則控制了基頻跟諧波的 位置,不為語音的特徵。所以可以藉由判別共鳴曲線的相似性,或者共振峰 的位置來區別出不同的語音文字,本論文也是依據這兩個語音特徵,來作後 續的分析處理。 從語音辨識的觀點(Speech Recognition),估測出的共鳴曲線代表著不同 的發音方式,也就是不同的語音文字;從語音變換(Speech Transform)和語音 合成(Speech Synthesize)的觀點,則對共鳴濾波器係數和激勵訊號做調整, 合成出想要的語音。 而擷取語音特徵的問題,就會轉變成為估測共鳴濾波器係數的問題,或 者直接蒐集大量資料建立共鳴曲線的模型。其中常見的方法為線性預測編碼 (Linear Predictive Coding,LPC)、倒頻譜(Cepstrum)、梅爾倒頻譜係數 (Mel-scale Frequency Cepstral Coefficients,MFCC)、線性感知預測 (Perceptual Linear Predictive,PLP)幾種。
2.4 Linear Predictive Coding (LPC)
線性預測編碼(LPC)是一種最普遍被使用來描述共鳴濾波器的方法。它 的概念是,目前的取樣點可以藉由之前幾個取樣點的線性組合來加以預測, 也就是對過去的資料建立自迴歸模型(Autoregressive Mode,AR Model)來預 測目前的資料,並假設共鳴濾波器為一個全極點濾波器(All-pole Filter)。由 於 語 音 的 訊 號 在 短 時 距 內 的 變 化 緩 慢 , 取 樣 點 之 間 的 自 相 關 性 (Autocorrelation)很高,所以LPC特別適合語音的處理。 把(2.3.1)式改成離散訊號並加入雜訊項改寫Source-Filter Model: ( ) ( ) * ( ) ( ) y n = x n h n +e n (2.4.1) 假設共鳴濾波器為全極點濾波器: -=1 1 ( ) 1-p k k k z z a =
∑
H (2.4.2) 其中p為LPC 的階數(order),ak為線性預測係數,k= L1 p。再把(2.4.1)式 並轉成Z-domain並將(2.4.2)式帶入: -1 1 ( ) ( ) ( ) 1-p k k k z z z z a = = +∑
Y X E (2.4.3) 假設空間中的雜訊遠小於激勵源訊號並移項整理得出: -1 Assume ( ) ( ) , ( )(1- ) ( ) p k k k z z z z a z = >> =∑
X E Y X (2.4.4) 轉回time-domain,就可以看到AR Model的標準形式: 1 ( ) - ( ) ( ) , ( ) [ ( -1) ( - )] [ ] T T T p y n n x n n y n y n p a a = = = % % L L y a y a (2.4.5)則預測的均方誤差(Mean Square Error,MSE)為:
(
)
2 2 - ( ) ( ) - ( )T n n E ∞ x n ∞ y n n = ∞ = ∞ =∑
=∑
%y a (2.4.6) 此時的激勵訊號被看為預測誤差,解釋為此方法希望盡量用前面取樣的 資料去預測目前取樣的資料,所以當前面的資料無法預測目前的資料時也就 代表有新的激勵訊號進來。所以預測誤差代表無法預測的資料,也就是激勵 訊號。 為了得到最小均方誤差的線性預測係數,對(2.4.6)式取a的偏微分並令 為0:(
)
(
)
(
)
(
)
-- --2 ( ) ( ) 2 ( ) ( ) 0 ( ) ( )- ( ) ( ) = 0 ( ) ( ) = ( ) ( ) T n T n T n n E y n n n n y n n n n y n n n n ∞ = ∞ ∞ = ∞ ∞ ∞ = ∞ = ∞ ∂ = + = ∂∑
∑
∑
∑
% % % % % % % % % y y y a a y y y a y y y a (2.4.7) 寫成矩陣的形式: R (1) R (0) R (1) R ( -1) R (2) R (1) R (0) R ( - 2) R ( ) R ( -1) R ( - 2) R (0) yy yy yy yy yy yy yy yy yy yy yy yy p p p p p ⎡ ⎤ ⎡ ⎤ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢= ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎣ ⎦ ⎣ ⎦ L L M M M O M L a (2.4.8) 其中(
)
-R ( )=yy ( ) ( - ) n y n y n τ ∞ τ = ∞∑
,稱為自相關函數(Autocorrelation Function)。 最後定義兩個參數: R (1) R (0) R (1) R ( -1) R (2) R (1) R (0) R ( - 2) , R ( ) R ( -1) R ( - 2) R (0) yy yy yy yy yy yy yy yy yy yy yy yy yy yy p p p p p ⎡ ⎤ ⎡ ⎤ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ =⎢ ⎥ =⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎣ ⎦ ⎣ ⎦ r R L L M M M O M L (2.4.9) 就可以得出一個簡單的解: -1 yy yy = R r a (2.4.10)0 50 100 150 200 250 0 0.5 1 1.5 2 2.5x 106 frequency spectrum frequency m ag ni tude 0 50 100 150 200 250 0 1 2 3 4 5 6 7 8 9 10 frequency spectrum frequency m agni tude (dB ) 圖2.14 LPC模型之頻率響應 圖2.15 LPC模型之頻率響應(dB表示) 最後得出LPC模型的頻率響應就為共鳴曲線,也被稱為頻譜包絡線 (Spectral Envelope),如圖2.14與圖2.15。在LPC模型預測的階數,則依照取 樣頻率(Sampling Rate)的範圍,共振峰可能出現的數目而定,通常在語音訊 號中大都是在10-16 階。 另外在實作上會以(2.4.12)式去近似自相關函數,N 代表計算自相關函 數的資料數(frame size):
(
)
-1 yy 0 R ( , )= ( ) ( - ) N n N y n y nτ
τ
=∑
(2.4.12) 最後LPC模型除了使用在共鳴曲線的估測,也可以作為語音合成器的設 計方式(Speech Synthesized)或應用於語音訊號壓縮(Speech Compression)。frequency frequency
magnitude
2.5 Bayes Risk
貝氏風險(Bayes Risk)是一種總括性的決策法則。給定兩個已知的機率 分布(Probability Distribution),藉由設定各種決策結果的代價(Cost),決定出 最佳的門檻值(Threshold)以使得整體代價最小[2-10]。 0 is Ture Η Η1 is True 0 Decided as Η C00 C 01 1 Decided as Η C10 C 11 圖 2.16 兩個機率分布圖 表 2.2 不同決策結果的代價表 給定兩個機率分布如圖 2.16,定義 Hypothesis: 0 1 : =0 null hypothesis : =1 alternative hypothesis μ μ Η Η 並定義Cij為表 2.2,則總共的代價為: 00 0 0 01 0 1 10 1 0 11 1 1 00 0 0 0 01 0 1 1 10 1 0 0 11 1 1 1 E( ) ( ; ) ( ; ) ( ; ) ( ; ) ( | ) ( ) ( | ) ( ) ( | ) ( ) ( | ) ( ) C C P C P C P C P C P P C P P C P P C P P = Η Η + Η Η + Η Η + Η Η = Η Η Η + Η Η Η + Η Η Η + Η Η Η (2.5.1) 令R1為判斷成Η1的區域,R0為判斷成Η0的區域,改寫(2.5.1)式: 0 0 1 1 00 0 R 0 01 1 R 1 10 0 R 0 11 1 R 1 E( ) ( ) ( | ) ( ) ( | ) ( ) ( | ) ( ) ( | ) C C P p x dx C P p x dx C P p x dx C P p x dx = Η Η + Η Η + Η Η + Η Η∫
∫
∫
∫
(2.5.2) 根據機率的理論得知:{ }
1 0 R p x( |Ηi) 1dx= − R p x( |Ηi) dx i, 0,1∈∫
∫
(2.5.3) 0 ( ; ) p xΗ p x( ;Η1) 0 1 T y p e I e r r o r : M i s s , P(Η Η; ) T y p e II e r r o r : F o r c e A la r m , P(Η Η1; 1) D e c i s i o n B o u n d a r y把(2.5.3)式帶入(2.5.2)中整理得到: 1 1 00 0 01 1 10 0 00 0 0 R 11 1 01 1 1 R E( ) ( ) ( ) ( ( ) ( )) ( | ) ( ( ) ( )) ( | ) C C P C P C P C P p x dx C P C P p x dx = Η + Η + Η − Η Η + Η − Η Η
∫
∫
(2.5.4) 觀察(2.5.4)式,為了使E( )C 最小,可以發現: 10 00 0 0 11 01 1 1 (C −C P) (Η ) ( |p x Η =) (C −C P) (Η ) ( |p x Η ) (2.5.5) 也就是說當(2.5.6)式成立時,決策為Η1: 10 00 0 0 11 01 1 1 (C −C P) (Η ) ( |p x Η <) (C −C P) (Η ) ( |p x Η ) (2.5.6) 最後可以化簡為一個簡單的判斷式: 10 00 0 1 0 01 11 1 ( ) ( ) ( | ) ( | ) ( ) ( ) C C P p x p x C C P γ − Η Η > = Η − Η (2.5.7) 通常假設C10 >C00, C01 >C11。 所以在此方法中,只要預先設定好各種決策結果的代價,就可以簡單的 判斷兩個可能性函數(Likelihood Function)的比值是否大過 γ 值來決定為Η0 還是Η1。 值得一提,如果設定C00 =C11=0 1、C01 =C10 = ,則貝氏風險就會同等於最大化事後機率偵測(Maximum a Posteriori Probability Detector,MAP),如 (2.5.8)式。 0 1 0 1 ( ) ( | ) ( | ) ( ) P p x p x P γ Η Η < = Η Η (2.5.8) 如果再加上設定P(Η =0) P(Η1),則貝氏風險就會同等於最大化可能性偵測
(Maximum Likelihood Detector,ML),如(2.5.9)式。
1
( | ) 1
p x Η <
2.6 Cascade Detector
圖 2.17 串聯式偵測器架構 串聯式偵測器的概念,是使用多個弱偵測器(Weak Detector)的串接來完 成一個強偵測器(Strong Detector)。此方法的作法是,依據部分特徵互相獨 立、互不相關的特性,為各自獨立的特徵空間設計各自的偵測器,並串接起 來。 其優點是可以降低只有單一偵測器時的複雜度,並可以專注且獨立的針 對各自的特徵空間去簡化設計,使得各階偵測器可以很簡易並有效率的篩選 掉錯誤的情況。另外還擁有容易擴充的特性,當發現額外的特徵可以加入判 別時,不用考慮到前面原本各階的設計狀況,只需針對目前的特徵作設計。 注意到各階都是獨立的,交換排序不會有結果上的分別。 例如在人臉偵測上,第一階可能設定為擷取有膚色的地方,第二階只把 輪廓為橢圓形的部份保留,第三階為再去掉沒有偵測到眼睛的地方。可以想 像,如果要同時把上述的特徵空間全部混合在一起,並設計出一個偵測器去 檢測,則偵測器會相當複雜且難以設計。事實上目前在人臉偵測(Face Detection)中,Adaboost 和 Cascade Detector 的結合有很好的效用[2-11]。F F F
T T T
Detector Detector Detector
Reject Space
第三章 利用空間域特徵空間一致性
及共鳴曲線相似性之喚醒關鍵字偵測演算法
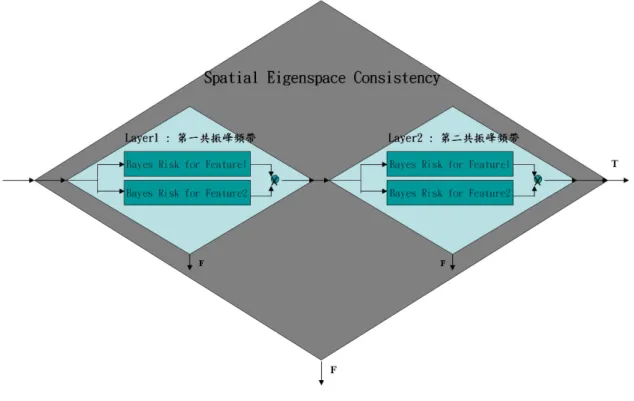
傳統在關鍵字偵測的方法上,為擷取當下語音的頻譜特徵,並對這些特 徵作辨識分析判斷是否為關鍵字,簡單來說,即為單一關鍵字的辨識問題。 而本論文所提出的方法,除了延續判斷頻譜特徵-共鳴曲線相似性之外,提 出了新的特徵-空間性特徵空間一致性,作為關鍵字偵測的依據。 所提出新的方法概念是,在不同的語音,發聲者所講的不同字,各有特 定的特徵頻率代表了這個字,並決定了這個字聽起來的樣子。當這個字在環 境中發聲的時候,聲源到達方位估測(DOA)會偵測出這些特徵的頻率共同來 自於某個方位。反過來思考,藉由預先設定偵測器一個關鍵字(如機器人的 名字),並依照語音特徵的分析,擷取出關鍵字的特徵頻率,就可以透過持 續觀測這些特徵頻率是否來自於同一方位,也就是空間性特徵空間的一致 性,來判斷這個字有沒有在這個方位發聲。而此想法的空間特徵資訊獲取則 必須使用麥克風陣列。 精確來說,先設定一個機器人喚醒關鍵字,搜集大量語料後使用 LPC 預先擷取關鍵字的共鳴曲線與共振峰,並基於貝氏風險理論作為上述兩個獨 立偵測器門檻值(Threshold)判別。運作時持續偵測共鳴曲線的相似度是否通 過偵測器門檻值,並同時用共振峰作為特徵頻率持續估測其特徵空間的一致 性是否通過門檻值,再將兩個獨立的偵測器串接作為整體偵測的機制。3.1 演算法流程架構
圖 3.1 喚醒關鍵字偵測演算法流程圖 Initialization
- Resonant Curve Model
- Formant Frequency sub-bands - Thresholds from Bayes Risk
Signal segmentation Layer1&Layer2 Spatial Eigenspace Consistency Layer3 Resonant Curve Similarity Layer4 Correctness of all letters of the Word
T T T F F F
喚醒關鍵字偵測演算法解說: 1. 根據選定好的喚醒關鍵字,蒐集大量的語音樣本,以 10 階的 LPC 估測 出每個語音樣本的共鳴曲線,並建立一個共鳴曲線的模型(Resonant Curve Model)。依照共鳴曲線模型的峰值處選定前兩個共振峰的頻帶(Formant Frequency Sub-band)。並依據收集到大量的語音樣本,使用貝氏風險決定所 有檢測器會使用到的門檻值(Threshold)。 2. 把語音訊號中每一個字元(Letter)分割出來。目前在本論文中假設語音訊 號已經做好分割,先不考慮語音分割的問題。 3. 依照選定的前兩個共振峰頻帶,判斷分割好的字元在特徵頻帶內其空間 性特徵空間的一致性是否大於事先依貝氏風險所決定的門檻值。為串聯式偵 測器的第一部份。 4. 判斷切割好的字元的共鳴曲線相似度是否大於事先依貝氏風險所決定的 門檻值。為串聯式偵測器的第二部份。 5.判斷連三個切割好的字元其空間性特徵空間一致性與共鳴曲線相似性是 否都正確,若有一個字元在串聯式偵測器中的任一階不正確,則判斷不為關 鍵字。為串聯式偵測器的第三部份。
3.2 空間域特徵空間一致性偵測
回顧章節 2.2,在各個頻率下對麥克風陣列做主要成分分析,得出各個 頻率下的空間性特徵空間,包含了訊號子空間與雜訊子空間。回顧章節 2.3, 共振峰為語音特徵之一,並且能量較大的諧波會出現共振峰頻率附近處,所 以選定共振峰及附近的頻帶為特徵頻帶。 在這章節完整的作法為,在設定完一個機器人的喚醒關鍵字,並搜集大 量語料後擷取關鍵字的共鳴曲線與共振峰,對選定的共振峰頻帶下的特徵頻 率,持續觀測其估測出的空間性特徵空間特徵的一致性,並基於貝氏風險理 論門檻值的判別,判斷目前已經分割出的字有沒有發聲。3.2.1 擷取語音特徵 蒐集大量的語音樣本,並使用 LPC 估測出共鳴曲線,再選取第一個及 第二個共振峰附近的頻帶,如圖 3.3。紅色線為共鳴曲線的模型,藍色線為 能量頻譜,黑色線為取出的共振峰頻帶。 圖 3.3 選取的頻帶與空間頻譜示意圖 從圖 3.4 可以清楚看到,如果是關鍵字,則共振峰頻帶會選擇到能量較 高的諧波成分,所以頻帶內的 Spatial Eigenspace 將比較有一致性,因為空 間資訊會保持在訊噪比較高的頻帶上。 關鍵字 非關鍵字 0 50 100 150 200 250 0 2 4 6 8 10 12 14 16 18
Frequency Spectrum and Resonant Curve
frequency
m
agni
tude
Frequency Spectrum Resonant Curve Model
0 50 100 150 200 250 0 2 4 6 8 10 12 14 16 18
Frequency Spectrum and Resonant Curve
frequency
m
agni
tude
Frequency Spectrum Resonant Curve Model 第二共振峰頻帶 令為 F2 第一共振峰頻帶 令為 F1 angle MUSIC Spectrum
3.2.2 建立空間域特徵空間一致性的特徵參數 把第一共振峰頻帶中的雜訊子空間取出,並建立一個投影到雜訊子空間 的投影矩陣PN,參考第 2.2 節: 1 ( ) ( ) ( ) ( ) , 1 M H N f f i f i A f i D f F ω ω ω ⊥ ω = + =
∑
= ∈ P V V P (3.2.1) 計算空間頻譜: 1 ( , ) , 1 ( , ) ( ) ( , ) MUSIC f H f N f f f F θ ω θ ω ω θ ω = ∈ P S a a (3.2.2) 則角度的估測為:ˆ( f) arg max MUSIC( , f) , f F1
θ
θ ω = S θ ω ∈ (3.2.3)
本論文對空間性特徵空間一致性(Spatial Eigenspace Consistency)建立兩 個特徵(第二共振峰頻帶作法也相同):
1. 角度估測量值
1 1
( , )
max , :normailed factor
MUSIC f f F x D D θ θ ω ∈ ⎛ ⎞ ⎜ ⎟ ⎜ ⎟ = ⎜ ⎟ ⎜ ⎟ ⎝ ⎠
∑
S (3.2.5) 2. 角度估測變異數 x2 =var( (θ ωˆ f)) , f ∈F1 (3.2.4) 觀察這兩個特徵的特性,當特徵空間比較有一致性的時候,角度估測量 值會比較大,相對的角度估測變異數會比較小。下圖 3.5 為第一個特徵-角 度估測量值不同字的實際結果。圖 3.6 為第二個特徵-角度估測變異數不同 字的實際結果。關鍵字 非關鍵字 圖 3.5 1 ( , ) MUSIC f f F D θ ω ∈
∑
S ,圖形峰值處即為角度估測量值 關鍵字 非關鍵字 圖 3.6 ˆ(θ ω 的統計圖,離散程度即為角度估測變異數 f) 圖 3.5 與圖 3.6 驗證出特徵頻率其空間性特徵空間一致性,的確可以當 作區別不同字的特徵之一。偵測字為關鍵字時,角度估測量值比較大,角度 - 1 0 0 0 1 0 0 0 2 4 6 8 1 0 h i s t o g r a m fr o m fo r m a n t fr e q . ( o n e - p e a k ) a n g l e - 1 0 0 0 1 0 0 0 0 . 5 1 1 . 5 2 2 . 5 3 M u s i c s p e c t r u m fr o m fo rm a n t fre q . a n g l e -1 0 0 0 1 0 0 0 0 . 5 1 1 . 5 2 2 . 5 3 M u s ic s p e c t ru m fro m fo rm a n t fre q . a n g l e - 1 0 0 0 1 0 0 0 2 4 6 8 1 0 h i s t o g r a m fr o m fo r m a n t fr e q . ( o n e - p e a k ) a n g l e0 0.002 0.004 0.006 0.008 0.01 0.012 0.014 0.016 0.018 0 1 2 3 4 5 6 7 8 9 10x 10
4 First letter, F1 freq. sub-band
mag va r WUW other word 0 0.002 0.004 0.006 0.008 0.01 0.012 0.014 0.016 0.018 0 1 2 3 4 5 6 7 8 9 10x 10
4 First letter, F2 freq. sub-band
mag va r WUW other word 圖 3.7 語音特徵分布圖 圖 3.7 為第一共振峰及第二共振峰,累積多筆資料後對兩個特徵所做出 的散佈圖(紅色為關鍵字、藍色為非關鍵字)。第一個觀察發現偵測字為關鍵 字時,角度估測量值比較大或角度估測變異數比較小。第二個觀察發現兩個 特徵算是低相關性(low correlation),因而可以各自設計各自的偵測器,再串 接起來。
3.3 共鳴曲線相似度偵測
回顧章節 2.3,共鳴曲線為語音完整的特徵。先前的論文步驟建立好了 關鍵字的共鳴曲線模型,在這章節要計算目前的偵測字其共鳴曲線和關鍵字 的共鳴曲線的相似度,並基於貝氏風險理論門檻值的判別,判斷關鍵字有沒 有發聲。如圖 3.8,比較兩條不同共鳴曲線的相似度(紅色為共鳴曲線、藍色 為能量頻譜)。 圖 3.8 兩條不同字的共鳴曲線 此論文所用的相似度定義為Bhattacharyya Distance[3-1](
,)
( ) ( ) BC p q =∫
p x q x dx (3.3.1) 圖 3.9 為累積多筆資料後對兩個特徵所做出的直方圖(紅色為關鍵字、 藍色為非關鍵字)。 0 5 10 15 20 25 30 35 40First letter, Resonant Curve correlation WUW other word 0 50 100 150 200 250 300 0 1 2 3 4 5 6x 10 5 0 50 100 150 200 250 300 0 1 2 3 4 5 6 7 8 9 10x 10 5 frequency frequency magnitude magnitude
第四章 實驗結果與分析
本章節將介紹本論文的方法於同一發聲者與不同發聲者在不同 SNR 下 的測試結果,並分析不同的 SNR 下特徵的變化及對於門檻值的設定,最後 測試固定門檻值下不同 SNR 的整體測試結果。 圖 4.1 為錄音環境的實際照片,環境中有一個喇叭作為人聲的播放,並 於麥克風陣列平台的不同方位(0 度、90 度、180、270 度)及距離(2M、4M) 錄音,如圖 4.3。另外語料庫依照同一發聲者與不同發聲者分為兩部份,細 節如表 4.1 及表 4.2。不同 SNR 的訊號則用雜訊去合成,雜訊為 Babble noise, 以喇叭播放並放置在錄音環境的 4 個角落以建立出 Diffuse noise。SNR 的估 算由於語料庫字數眾多,只能大概估出部分字的 segmental SNR,所以約有 3dB 左右的誤差。 圖 4.1 錄音環境實際照片 圖 4.2 麥克風陣列平台 圖 4.3 錄音環境平面關係的俯視圖關鍵字 ‘阿凡達’ 發聲者人數 1 人 陣列架構 環型麥克風陣列 發聲者角度 0 度 陣列半徑 17.5cm 發聲者距離 2M 取樣頻率 8K 關鍵字次數 200 次 音框大小 512 關鍵字總數 200 個字 Overlap 256 非關鍵字數目 20 個字 非關鍵字次數 10 次 非關鍵字總數 200 個字 總數 400 個字 表 4.1 同一發聲者語料庫 關鍵字 ‘阿凡達’ 發聲者人數 8 人 陣列架構 環型麥克風陣列 發聲者角度 0 度、90 度、180、 270 度 陣列半徑 17.5cm 發聲者距離 2M、4M 取樣頻率 8K 關鍵字次數 5 次 音框大小 512 關鍵字總數 320 個字 Overlap 256 非關鍵字數目 20 個字 非關鍵字次數 1 次 非關鍵字總數 1280 個字 總數 1600 個字 表 4.2 不同發聲者語料庫
本實驗指標參數的定義如下:
Wake-Up-Word Other Word Decided as
Wake-Up-Word
True Positive False Positive
Decide Other Word
False Negative True Negative
表 4.3 本實驗指標參數的定義表
1.偵測率(Detection Rate):True Positive/( True Positive+ False Negative) 在給定關鍵字下,被判斷為關鍵字的機率。
2.誤報率(False Positive Rate):False Positive/( False Positive+ True Negative) 在給定不是關鍵字下,被誤判為關鍵字的機率。
3.漏報率(False Negative Rate):1- Detection Rate 在給定關鍵字下,被誤判為不是關鍵字的機率。
4.等錯誤率(Equal Error Rate):False Negative Rate = False Positive Rate
調整偵測器的參數,使得誤報率剛好等於漏報率時的機率,作為測量偵測 器整體效能的參數。
4.1 同一發聲者之實驗結果與分析
在此章節中實驗結果與分析分為三大項,總共有六個測試。
第一項:本論文採用串聯式偵測器,設計重點需測試 Detection Rate 為 100% 下最低的 False Positive Rate,作為表示以此論文方法架構為前級的檢測器可 以初步篩選掉多少錯誤的情況。如實驗 A。
第二項:分析不同 SNR 下本論文提出方法的差異。如實驗 B、C、D、E。
第三項:在實際的聲場環境,使用者音量與環境中的吵雜程度是不可預知 的,因而需要測試在同一組門檻值下,整體條件的辨識率。如實驗 F。
總共六個測試如以下:
A. 在偵測率 100%下測試最低的 False Positive Rate B. 各個 SNR 下的 Equal Error Rate
C. 各個 SNR 下字元與字組的分析 D. 不同 SNR 下特徵的分析
E. 不同 SNR 下門檻值的分析
4.1.A 在偵測率 100%下測試最低的 False Positive Rate
WUW (200) Other word (200)
判斷為 WUW 200 0 Detection rate = 100% 判斷不為 WUW 0 200 False positive rate = 0%
表 4.4 SNR=14.15 時偵測率為 100%時最低的 False Positive Rate
WUW (200) Other word (200)
判斷為 WUW 200 0 Detection rate = 100% 判斷不為 WUW 0 200 False positive rate = 0% 表 4.5 SNR=7.3 時偵測率為 100%時最低的 False Positive Rate
WUW (200) Other word (200)
判斷為 WUW 200 0 Detection rate = 100% 判斷不為 WUW 0 200 False positive rate = 0%
表 4.6 SNR=-0.3 時偵測率為 100%時最低的 False Positive Rate
WUW (200) Other word (200)
判斷為 WUW 200 0 Detection rate = 100% 判斷不為 WUW 0 200 False positive rate = 0%
WUW (200) Other word (200)
判斷為 WUW 200 0 Detection rate = 100% 判斷不為 WUW 0 200 False positive rate = 0%
表 4.8 SNR=-3.82 時偵測率為 100%時最低的 False Positive Rate
WUW (200) Other word (200)
判斷為 WUW 200 0 Detection rate = 100% 判斷不為 WUW 0 200 False positive rate = 0%
表 4.9 SNR=-6.32 時偵測率為 100%時最低的 False Positive Rate
WUW (200) Other word (200)
判斷為 WUW 200 1 Detection rate = 100% 判斷不為 WUW 0 200 False positive rate = 0.5%
表 4.10 SNR=-8.26 時偵測率為 100%時最低的 False Positive Rate
WUW (200) Other word (200)
判斷為 WUW 200 12 Detection rate = 100% 判斷不為 WUW 0 200 False positive rate = 6%
整體測試結果如表 4.12,可以看到在同一個發聲者的偵測結果很好,因 為同一人的共鳴曲線與共振峰的位置在正常狀況下變動不大,因而會有不錯 的偵測結果。
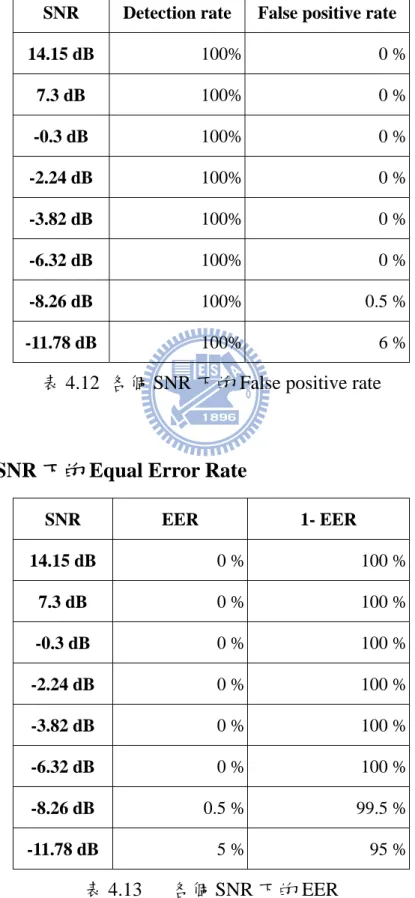
SNR Detection rate False positive rate 14.15 dB 100% 0 % 7.3 dB 100% 0 % -0.3 dB 100% 0 % -2.24 dB 100% 0 % -3.82 dB 100% 0 % -6.32 dB 100% 0 % -8.26 dB 100% 0.5 % -11.78 dB 100% 6 % 表 4.12 各個 SNR 下的 False positive rate
4.1.B 各個 SNR 下的 Equal Error Rate
SNR EER 1- EER 14.15 dB 0 % 100 % 7.3 dB 0 % 100 % -0.3 dB 0 % 100 % -2.24 dB 0 % 100 % -3.82 dB 0 % 100 % -6.32 dB 0 % 100 % -8.26 dB 0.5 % 99.5 % -11.78 dB 5 % 95 % 表 4.13 各個 SNR 下的 EER


![圖 2.7 聲帶震動產生的激勵訊號 ( ) x t 圖 2.8 激勵訊號的能量頻譜 X (w) 圖 2.9 共鳴濾波器的頻率響應(共鳴曲線) H (w) 圖 2.10 合成訊號的能量頻譜 Y (w) [2-7] 圖 2.7 為人的聲帶震動後所產生的訊號,通常為一個三角波。圖 2.8 則 為此波型的能量頻譜,可以看出激勵源的訊號主要為基頻與其諧波成分。此 訊號經過了共鳴濾波器的共鳴放大,最後變為環境中所傳遞的訊號,如圖 2.10。](https://thumb-ap.123doks.com/thumbv2/9libinfo/8250183.171662/26.892.166.737.120.241/合成訊號能量頻譜為人為此訊號主要為基頻與其諧波成分此訊號經過.webp)