行政院國家科學委員會補助專題研究計畫成果報告
※※※※※※※※※※※※※※※※※※※※※※※※
※ ※
※ 可靠之基頻軌跡偵測及聲調辨認 ※
※ ※
※※※※※※※※※※※※※※※※※※※※※※※※
計畫類別:v個別型計畫
□整合型計畫
計畫編號:NSC90 - 2213 - E - 009 - 111
執行期間: 90 年 8 月 1 日至 91 年 7 月 31 日
計畫主持人:王逸如
本成果報告包括以下應繳交之附件:
□赴國外出差或研習心得報告一份
□赴大陸地區出差或研習心得報告一份
□出席國際學術會議心得報告及發表之論文各一份
□國際合作研究計畫國外研究報告書一份
執行單位:國立交通大學電信工程系
中
華
民
國
91 年
10 月
30 日
行政院國家科學委員會專題研究計畫成果報告
可靠之基頻軌跡偵測及聲調辨認
計畫編號:NSC90-2213-E-009-111
執行期限:90 年 8 月 1 日至 91 年 7 月 30 日
主持人:王逸如 國立交通大學電信工程系
計畫參與人員: 呂儲仰、鐘祥睿、魯弘茂
一、中文摘要
本計畫中針對國語連續語音提出一個利 用統計式之基週軌跡偵測方法,並製作一個國 語聲調辨認器。在統計式之基週軌跡偵測方法 中,在傳統利用語音信號之自相關係數來偵測 基頻的方法中,對每一音框產生數個基頻候選 值,適當的將語音信號中各音框為有聲/無聲 音之判別由決定值轉(deterministic)換為機率 量測值(probabilistic),並訂定音框間之機頻轉 移機率模型,則基週軌跡偵測將可視為一個尋 找 最 大 相 似 度 (Maximum Likelihood) 路 徑 問 題,可利用 Viterbi 搜尋方法來尋找一條最佳基 頻軌跡。上述方法經使用 MAT2500 語料庫實 驗證實效能較 ESPS 中之基週軌跡偵測器為 佳。其次,使用類神經網路來製作一個國語聲 調辨認器,使用上述統計式之基週軌跡偵測方 法所獲得之機頻軌跡來作連續國語語音之聲 調辨認,可獲的 77%的辨認率。關鍵詞:
基週軌跡偵測、聲調辨認、軌跡追 蹤、機率量測值Abstract
In this project, reliable pitch detection and tone recognition was studied. First, a new statistical pitch contour tracking algorithm is employed to improve the conventional auto-correlation based pitch detection method. First, several pitch candidates were leaved in each frame. Then, the voiced/unvoiced classification of frames, the inter-frame pitch transition, and the inter-segment pitch jump were model by statistical models. The pitch contour tracking problem becomes to find a pitch contour with maximum likelihood value from all possible candidates. And, the optimal pitch contour can be performed by the Viterbi search with properly
defined the probabilistic measure function. By experiments using MAT2500 speech database, the performance of proposed statistic pitch detector is proved better than the pitch detector in ESPS package. In the second part of this project, the neural network based tone recognition method proposed previously was established. The pitch contour found by the proposed pitch detector was used, in order to improve the tone recognition rate.
A tone
recognition rate of 77% was achieved.
Keywords: pitch detection, tone recognition, contour tracking, probabilistic measure 二、 緣由與目的 基週軌跡在國語是聲調辨認中所需使用 的重要參數,雖然過去有許多基週偵測方法被 提出,但其效能仍有待改善,尤其二倍頻及半 倍頻的錯誤機率頗高,所以在此計畫中將提出 更好的基週軌跡偵測方法,必進行聲調辨認器 之製作。
三、研究方法
1. 統計法之基週期偵測器 本計畫中所提出的基週期軌跡求取演算 法,主要將每個音框留下數個基頻候選值,再 將:(1)各因框之 U/V 判別,(2)基頻或區段間 基 頻 轉 移 建 立 機 率 模 式 , 再 以 maximum likelihood 的要求來尋找最佳基頻軌跡。 首 先 , 使 用 改 良 式 的 自 相 關 係 數 (autocorrelation coefficient) 作 為 特 徵 參 數 之 一,特徵參數還包括通過 BPF 的能量(E(n))以 及自相關係數的平方和( ∑ = 2 1 ) ( 2 n n n n ρ ),及自相關 係數對應的頻率值(f
i),每一個音框選擇數個自相關係數之區域最大值作為基頻候選者,給 定如下的特徵向量 6 ~ 1 , ) ( ), ( , ) ( ), ( ) ( 2 1 2 = =
∑
= i n f n i n E n x f i n n i n i ρ ρ i v 根 據 U/V 特 性 的 不 同 , 如 果 音 框 為 Unvoiced 時,為了搜尋時的方便,使用以此音 框 中 的 自 相 關 函 數 最 大 值 所 對 應 之 頻 率 值 (f (n) argmax i(n) i i = ρ ),我們將其稱為虛擬頻率。 特徵參數表示為 =∑
= ) ( ), ( , ) ( ), ( ) ( () 2 1 2 n f n i n E n x f n v n n i n unvoiced ρ ρv v voiced unvoiced unvoiced 基頻(Hz) 音框 ) | (i i−1 uu f f P ) | ( i i−1 uv f f P ) | ( i i−1 vv f f P ) | ( i i−1 vu f f P 圖 1:基頻狀態移轉機率圖。 基 於 每 個 音 框 間 的 基 頻 移 轉 為 一 階 Markov Process 的 假 設 , 我 們 總 共 要 建 立 )) 1 ( | ) ( (f n f n− Pvv i j 、 Pvu(fi(n)|fj(n−1)) 、 )) 1 ( | ) ( (f n f n− Puv i j 及Puu(fi(n)|fj(n−1))四種基頻 轉移機率模型。我們首先建立 Voiced to Voiced 的基頻轉換機率, voiced n n n f p n f n f P n f n f P j j i j i vv − ∈ − − = − ,frame 1, )) 1 ( ( )) 1 ( ), ( ( )) 1 ( | ) ( ( 我們將Pvv(fi|fi−1)假設為混和高斯機率分佈, 則可以得到 ( )∑
− − = k kf n k i n f k k i i i n f w n f P 2 ) ( , 2 ) ( , ) ( 2 1 exp 2 )) ( ( σ µ σ π(
)
( )(
)
− − − = − −∑
k k T k k k L k j i f C f C w n f n f P µ µ π v v v v 1 2 / 1 2 / 2 1 exp ) 2 ( )) 1 ( ), ( ( 其中 − = ) 1 ( ) ( n f n f f j i v 。 當起始頻率 fi(n−1)不同時,其轉移到下一 個 頻 率 fi(n)的 範 圍 與 機 率 皆 不 同 , 因 此 對 ) 1 (n− fi 作 變 數 變 換 。 令(
)
) 1 ( | ) ( ) 1 ( | ) ( ' ( ) ) ( − − − = n f n f n f n f i i n f n f σ µ ,原來的轉移機率就可 以改寫成 )) 1 ( | ) ( ( )) 1 ( | ) ( ( ()|( 1) ' − = ⋅ − − P f n f n n f n f P i j σfn fn i j 其中{
}
{
}
[
2 2]
1/2 ) 1 ( | ) (n f n− = E f(n) |f(n−1) −E f(n)|f(n−1) f σ 原來因為起始條件頻率 fi(n)不同所造成 不平均的機率分佈,在經過變數變換後將可獲 得改善。 若音框不屬於 Voiced 部分時,就沒有所謂 的『基頻值』,我們便以『虛擬頻率』作為建 立前後音框間基頻值移轉的機率模型。基頻值 移轉機率可以表示成 unvoiced , 1 frame , )) ( ( )) 1 ( ), ( ( )) 1 ( | ) ( ( − = − n− n∈ n f P n f n f P n f n f P i U j i UU j i UU 我們也使用求取 Voiced to Voiced 的基頻轉換 機率時所用的標準化因子。Pvu(fi'(n)|fj(n−1)) 與Puv(fi'(n)|fj(n−1))的 機 率 模 型 也 以 此 法 建 立。另外,定義每個基頻區段間的基頻變化機 率為 ) , ( ) , , ( ) , | ( , , , 1 , , 1 _ i end i i end i start i i end i start i jump seg D F P D F F P D F F P + = + 。 以兩個基頻區段為統計單位,第i個基頻 區段的最後一個音框基頻值為Fi,end,經過Di個 Unvoiced 音框後,下一個基頻區段的第一個音 框基頻值為Fi+1,start。對一語句中基頻值的連接 採取維特比搜尋(Viterbi Search)來尋找最佳路 徑,其最佳路徑之累積機率值為: ) , , , , ( ) , , , , ( ) 1 ( ) 2 ( ) 1 ( ,..., 1 ), ( ) 1 ( ) 2 ( ) 1 ( ) * ( ) * ( ) * ( ) ( ) ( ) ( c m i i i m n n i c m i i i f f f f P Max f f f f P K K K c c c − = ∀ − = K K 2. 中文連續語音聲調的辨認 使用前述統計方法求取一準確性較高的 基頻軌跡,對國語連續語音做聲調辨認。方法 上,採用『多層神經元』(Multi-Layer Perceptron, MLP)為主體的辨認器。 音節長度少於三個音 框之音節視為刪除型錯誤,不予辨認。考慮音 節間耦合的問題,使用前後文相關特徵參數。 基頻(Hz) 時間 Preceding Syllable Processing Syllable Following Syllable1 i vr vi2 r 3 i vr 3 , 1 − i vr vi+1,1 r i d ij ij ij s p e , , ip ip ip u e I , , Iif,uif,eif 圖 4:特徵參數抽取示意圖。 其中的元素eij,sij,pij代表第i個音節中第j 段的能量對數平均值、基頻軌跡的斜率(Slope) 以及相對應的截距(Intercept)。di代表第i個音 節內基頻軌跡的長度。Iip用來表示前面是否有 相鄰音節的二元指標,vi−1 v 表示前一個音節的 最後一段特徵向量,uip是目前音節與前一個音 節間隔的 unvoiced 區間長度,eip為此 unvoiced 區間的能量對數平均值;Iif 用來表示後面是否 有相鄰音節的二元指標,vi+1 v 表示後一個音節 的第一段特徵向量,uif 是目前音節與下一個音
節間隔的 unvoiced 區間長度,eif為此 unvoiced 區間的能量對數平均值。 3. 統計法之基週期偵測器實驗結果與分析 使用「台灣之國語語音資料庫」(MAT)。 透過電話網路,取樣頻率為 8kHz 取樣位元數 為 16 位元。以 MAT2000 語料庫第五部份作為 訓練語料;包括 1990 位語者,共 5,758,989 個 音框。另外,從 MAT2500 語料庫中第九套裡 挑選出 2893 句長句(包含 37,012 音節,其中 1512 位男生與 1381 位女生),以人工逐句檢查 的方式標示基頻值作為測試語料,同時也以 ESPS 套裝軟體求取基週期,比較彼此間的優 劣。 U/V 判別正確性的比較 基頻軌跡的比較,通常初步比較的是 U/V 判別之優劣,因此先統計兩種方法所出現刪除 型與插入型錯誤的機率,定義分別如下(1)刪除 型錯誤:在音節範圍(使用 HMM 切音範圍)內 完全沒有一個音框出現基頻的情況。(2)插入型 錯誤:在 HMM 判定為靜音部分,分為兩類。 類型 1:出現獨立的一段基頻軌跡。類型 2: 基頻軌跡延伸到 silence 部分大於等於三個 frame。結果如表 1。 由統計結果可知,統計方法出現刪除型錯 誤的機率較 ESPS 來得大,但是相對的在插入 型錯誤上卻比 ESPS 小得多,代表由 ESPS 所 求得的 Voiced 範圍較我們所提出的方法要大。 另以人工標示基頻值為準,比較統計法之 基頻軌偵測器與 ESPS,希望了解兩種基頻求 取方法在另一種 U/V 判別上的差異與正確性 如何。測試音框數為 1253775 個音框。 [實驗一] 將求得的基頻值與人工標示的基頻 值做比較,若出現的頻率值情況(Voiced or Unvoiced)與人工標示的頻率值狀況不相同,即 判定錯誤。統計結果如表 2。 若完全以參考語句基頻值來判定 U/V,兩 著的判別正確率差不多。我們所使用的統計方 法在 unvoiced 的條件下 U/V 判斷正確率較在 voiced 的條件下來的高,而 ESPS 剛好相反, 因此 ESPS 所決定的邊界也較寬。 因為在人工檢查基頻軌跡值時,對 U/V 邊 界 的 一 兩 個 音 框 也 常 會 有 不 容 易 判 斷 的 疑 慮,所以分別以不統計基頻軌跡邊界音框(Edge Frame)前後的 1 至 2 個音框來統計 U/V 判別 的錯誤比較。 [實驗二] 在第 I 個音框出現邊界音框時,第 I-1 個 frame 到第 I+1 個 frame 間,不計算 U/V 判 別辨認率。
[實驗三]:第 I 個音框出現邊界音框時,第 I-2 個 frame 到第 I+2 個 frame 間,不計算 U/V 判
別辨認率 由表 2 可以看到,當我們把基頻軌跡邊界 放寬 1~2 個音框後,統計方法的錯誤率會逐 漸的下降,但 ESPS 所得到的結果並沒有改善 的趨勢。因此統計方法的錯誤大多都是在基頻 軌跡段的邊界,對於一般基頻穩定區段的影響 並不大。 音節間基頻平均值的比較 每一音節的基頻值求其平均值,與人工標 音的部分求其比值,以瞭解基頻值的準確性為 何,可以避免因為少數音框的錯誤而造成整體 的錯誤。比值從 0.5~1 之間取其倒數作為相同 的範圍作統計,結果如表 3。 在表 3 中,統計法之測試比較音節數較少 是因為它的 Deletion 較多之故。上表 3 的結 果,我們所使用的方法相對於 ESPS 而言,有 較高的準確值。 統計式基週偵測器之重估計 以基頻軌跡偵測器重新回去求取當初建 立模型之語句的基頻軌跡,將此新得到的基頻 軌跡重新估計一新的統計模型。利用此新的基 頻軌跡偵測器再重新求取新的基頻值,將新的 基 頻 值 如 上 述 之 各 項 比 較 方 式 重 新 統 計 一 次,結果如表 2、3。 由結果之比較,可以觀察到以下兩點:(1) 由表 3 可知,經過重新估計後之基頻軌跡偵測 器所求出的基頻值更精確。(2)但由表 1 與 2 發 現,以此種方法會將基頻值較不可靠的音框判 斷成 Unvoiced,因此造成刪除型錯誤的上升。 整合以上結果,可以對於以統計模型之基 頻偵測器作一結論;由已知的基頻軌跡資訊建 立一初步的機率模型,並以此機率模型完成新 的高準確性基頻軌跡偵測器,而且此偵測器可 以藉由越來越好的基頻軌跡來重新估計建立 更新的模型,以得到準確性越來越好的基頻軌 跡偵測器。 語音信號語句中,Voiced 與 Unvoiced 出 現應不相同,因此根據 U/V 出現之事前機率(a priori prob.)作為加權值的調整,重新求取新的 基頻軌跡後,再與上一節重估機率模型所求得 的基頻值來做比較,得到結果如下表: 經由求取 P(V)與 P(U)的同時加上一偏移 量來調整機率模型,因為每個音框出現 Voiced 機率變大,加上先前在 U/V 邊界判斷的較嚴 格,因此調整後的機率模型也改善了 U/V 邊界 容易誤判的情況。 因為多出來的 Voiced 音框是較不可靠 的,所以求得的基頻值在音節的平均值與音框 的基頻值比較上,正確率有些許的下降。但整 體基頻值的正確性與 U/V 判別上都較 ESPS 來
的佳。 表 1:音節之刪除型錯誤與插入型錯誤出現機 率統計。 ESPS 統計方法 重估模型 調整模型 Deletion 0.004 0.017 0.023 0.017 Insertion(1) 0.006 0.005 0.003 0.004 Insertion(2) 0.035 0.001 0.001 0.001 總錯誤率 0.045 0.024 0.027 0.023 表 2:調整估模型前後 U/V 判別比較。 錯誤率 ESPS 統計方法 重估模型 調整模型 實驗一 11.40% 12.60% 13.00% 12.50% 實驗二 11.40% 8.20% 8.50% 7.90% 實驗三 10.80% 6.30% 6.70% 6.10% 表 3:調整模型前後音節間平均基頻值的比較。 ESPS 統計方法 重估模型 調整模型 總音節數 36,751 36,233 36,026 36,246 比值範圍 所佔比例 所佔比例 所佔比例 所佔比例 0.9~1.1 94.80% 96.20% 96.70% 96.20% 0.8~1.2 96.30% 96.90% 97.40% 97.00% 0.7~1.4 97.10% 97.40% 98.00% 97.70% 0.6~1.7 97.70% 97.80% 98.40% 98.20% 0.5~2.0 98.70% 98.90% 99.30% 99.20% 4. 連續語音聲調辨認之實驗 使用 MAT2500 語料庫第四部份,訓練語 料包含 13,219 句長句(2379 位語者);測試語料 部份,包含 2893 句長句(1473 位語者),其中 1512 位男生與 1381 位女生。扣除基頻軌跡因 為刪除型錯誤致無法使用外,總訓練音節數與 第一聲至第五聲之聲調音節數分佈如表 4。我 們也事先將語料庫裡的第三聲發成第二聲變 調(tone sandhi)的狀況依變調規則做修正。 為了避免前後連續音節耦合的問題,以前 後文相關之特徵參數做訓練與辨認,得到結果 如表 5。 以前後文相關之訊息作為特徵參數,整體 辨認率可達到 77%。除了原來一聲、二聲與四 聲的辨認正確率仍然不錯外,主要就是三聲與 五聲的明顯改進之故。在連續語音中,三聲與 五聲最容易受前後音節耦合所影響,再加上前 後文相關之特徵參數後,對辨認率有顯著的提 昇。 表 4:第一聲至第五聲之音節分佈統計。
Tone1 Tone2 Tone3 Tone4 Tone5 音節數
訓練語料 33848 43930 24368 59119 9940 171205
測試語料 7156 8904 5202 12570 2663 36495
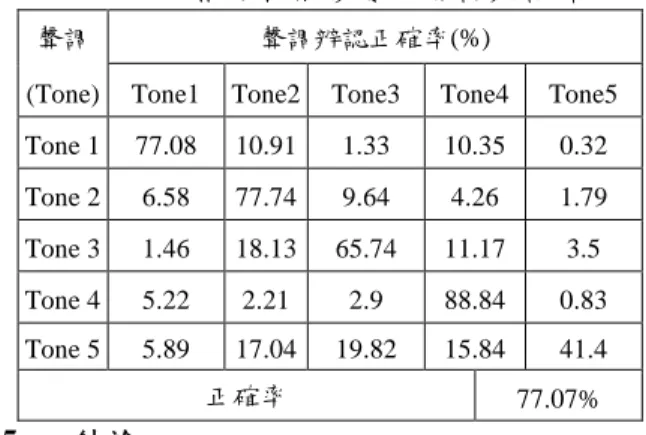
表 5:前後文相關特徵參數之聲調辨認結果。
聲調 聲調辨認正確率(%)
(Tone) Tone1 Tone2 Tone3 Tone4 Tone5
Tone 1 77.08 10.91 1.33 10.35 0.32 Tone 2 6.58 77.74 9.64 4.26 1.79 Tone 3 1.46 18.13 65.74 11.17 3.5 Tone 4 5.22 2.21 2.9 88.84 0.83 Tone 5 5.89 17.04 19.82 15.84 41.4 正確率 77.07% 5. 結論 在計畫中,以統計方法架構之基頻軌跡偵 測器,能夠有比傳統基頻求取法或者是 ESPS 所求之基頻值要準確。同時也可以由求得的基 頻值,藉由重新估計建立更新的模型,配合對 於 Voiced 出現的機率(P(V))加上一個偏移量的 調整,在刪除型與插入型錯誤以及整體基頻值 的正確率間做取捨,可以得到一良好之基頻軌 跡偵測器。在此基頻軌跡下做聲調的辨認,正 確率可以達到 77%左右。
四、計畫成果自評
在本計劃中(1)建立了一套統計式之基頻 軌跡偵測器;同時也完成了統計式 U/V 偵測 器,經比較發現其結果較 ESPS 中之基頻軌跡 偵測器為佳。(2)使用經網路製作國語聲調辨認 器,並獲得 77%之辨認率。其中統計式之基頻 軌 跡 偵 測 器 部 分 之 研 究 成 果 已 發 表 於 ICASSP-2002[7]。五、參考文獻
[1] J.D. Markel. “The SIFT Algorithm for Fundamental
Frequency Estimation,” IEEE Trans. On AE, Vol.20, pp.367-377, Dec. 1972.
[2] 翁以哲,”使用統計模式之基頻軌跡偵測器”,國立
交通大學碩士論文,民國九十年六月。
[3] Yih-Ru Wang and I-Bin Liao, “An Overwiew of
Mandarin-Speech Tone Recognition,” Journal of the Chinese Institute of Electrical Engineering, Vol.7, No.2, pp.145-155, 2000.
[4] Sin-Horng Chen, Yih-Ru Wang, “Tone Recognition
of Continuous Mandarin Speech Based on Neural Networks,” IEEE Trans. on SA, Vol.3, No2, pp.146-150, March 1995.
[5] L.R. Rabiner, “On the use of Autocorrelation
Analysis for Pitch Detection,” IEEE Trans. On ASSP, Vol. 25, pp.24-33, Feb. 1977.
[6] Hong Zhang, Taiyi Huang, Junshou Song, “A New
Method of Fundamental Frequency Extraction in Frequency Domain,” ICSP ‘98, pp.690-693.
[7] Yih-Ru Wang, I-Je Wong, and Teng-Chun Tsao, ' A
Statistical Pitch Detection Algorithm, ', Proc. of ICASSP-2002, Orlando, USA, Vol. 1, pp. 357-360,