國
立
交
通
大
學
電信工程研究所
碩
士
論
文
國客雙語語音辨認
A Study on Mixed Hakka-Mandarin Chinese Bilingual
Speech Recognition
研 究 生:蔡財祿
指導教授:陳信宏 教授
國客雙語語音辨認
A Study on Mixed Hakka-Mandarin Chinese Bilingual Speech
Recognition
研 究 生:蔡財祿 Student:Tsai-Lu Tsai
指導教授:陳信宏 博士 Advisor:Dr. Sin-Horng Chen
國 立 交 通 大 學
電信工程研究所
碩 士 論 文
A Thesis
Submitted to Institute of Communication Engineering College of Electrical and Computer Engineering
National Chiao Tung University in Partial Fulfillment of the Requirements
for the Degree of Master
in
Communication Engineering
July 2010
Hsinchu, Taiwan, Republic of China
I
國客雙語語音辨認
研 究 生:蔡財祿 指導教授:陳信宏
教授
國立交通大學電信工程研究所
中文摘要
本論文進行客語與國客雙語的語音辨認研究,重點在於如何在極有限的客語文字資料限 制下,訓練一個較可靠的語言模型。在客語語音辨認上,我們首先使用客語文字資料直接訓 練出一個簡單的語言模型,接著使用詞類資訊(part of speech, POS)及國客語之間的詞條對譯 資訊來協助改善客語語言模型。在雙語的語音辨認上,我們嘗詴兩種方法來產生雙語聲學模 型,一種是直接將國語及客語的聲學模型合併,另一種是使用相似度量測來定義音素間的距 離,用以合併國客語音素成一個共用的音素集,再訓練出一個混合的雙語聲學模型。實驗結 果顯示我們所提出的聲學模型與語言模型對於客語及國客雙語語音辨認效能皆有所改進。II
A Study on Mixed Hakka-Mandarin Chinese Bilingual
Speech Recognition
Student:Tsai-Lu Tsai Advisor:Dr. Sin-Horng Chen
Institute of Communication Engineering
National Chiao Tung University
Abstract
A first study on Hakka and mixed Hakka-Mandarin speech recognition (SR) is reported in this thesis. The main focus of the study is on solving the problem of the lack of a large text corpus for training a reliable language model. In the Hakka SR, several methods to use the information of part of speech and Hakka-Chinese word translation to assist in language modeling are proposed. For mixed language SR, a method to train a mixed Hakka-Mandarin acoustic model is suggested. Experimental results show that the proposed language and acoustic modeling approaches are promising for Hakka and mixed Hakka-Mandarin SR.
III
致謝
首先誠摯的感謝指導教授陳信宏老師與王逸如老師,兩位老師悉心的教導使我得以ㄧ窺 語音處理領域的奧秘,不時的討論並指點我正確的方向,使我在這些年中獲益匪淺。老師對 於學問的嚴謹更是我輩的典範。 本論文的完成另外亦得感謝中華大學的余秀敏老師大力協助。因為有你的體諒及幫忙使 得本論文能夠更加完整。 此外,我要特別感謝性獸學長,獸哥在研究上給予我許多的幫助及最後辛苦的幫我修改 論文,可以說沒有獸哥就沒有這篇論文了。接著要感謝的是合哥,合哥在研究的實做上給予 我許多建議及幫助,讓我的實驗得以順利完成。感謝最佳助教阿德、愛嚇人的輝哥、酒吧王 子巴金叔及愛護地球的希群,學長們在我對研究感到迷惘時給予我適時的鼓勵。也感謝常常 回學校的普烏、偶爾會去吃吃飯的 Q 哥及宋哥、畢業就消失的小帥哥,雖然你們畢業了一段 時間,我還是勉強的感謝你們;接著,感謝我們的一哥,不只研究超強而且很可靠,畢業的 流程沒有你根本無法畢業阿!致力於研究裝模作樣的 PUMA,真想學會你的研究技巧;最近 特別唱邱的皓翔,可以告訴我你怎麼這麼邱嗎?每天都在做研究的燁哥,真想學習你的毅力 與幹勁;很忙很多工作的依玲,真高興客語的領域有妳的陪伴;似乎有中聽的舒姊,我相信 沒有任何聲音可以影響妳的研究。接著,感謝人妻殺手胖胖、魔術『高』手啟全、看起來壯 的豆腐、ㄧ哥的傳人彥邦、極具研究潛力的大胖、很認真的銘傑與智障等學弟們的陪伴與幫 忙。 最後,要感謝的是我的父母與我的家人,謝謝你們對我的信任與支持,讓我得以順利取 得碩士學位。IV
目錄
中文摘要... I Abstract ... II 致謝... III 目錄... IV 圖目錄... VII 表目錄... VIII 第一章 緒論... 1 1.1 研究動機 ... 1 1.2 研究方向 ... 1 1.3 相關研究 ... 2 1.3.1 聲學模型之相關研究 ... 2 1.3.2 語言模型之相關研究 ... 2 1.4 章節大要 ... 3 第二章 實驗語料介紹... 4 2.1 語音語料庫介紹 ... 4 2.1.1 國語語音語料庫 ... 4 2.1.2 客語語音語料庫 ... 5 2.1.3 國客雙語語音語料庫 ... 5 2.2 文字語料庫介紹 ... 6 2.2.1 國語文字語料庫 ... 6V 2.2.2 客語文字語料庫 ... 6 2.3 客語與國語之間的語文特性 ... 8 2.3.1 客語與國語的帄行語料分析 ... 8 2.3.2 客語與國語的詞類分析 ... 10 第三章 聲學模型... 12 3.1 訓練語料及測詴語料 ... 12 3.2 聲學模型之建立 ... 13 3.2.1 特徵參數抽取 ... 13 3.2.2 單語聲學模型之建立 ... 13 3.2.3 雙語聲學模型之建立 ... 14 3.3 雙語音素集 ... 14 3.3.1 單語音素集 ... 15 3.3.2 音素直接合併 ... 16 3.3.3 log-likelihood measurement ... 16 第四章 語言模型的設計... 20 4.1 概論 ... 20 4.2 語言模型基本定義 ... 20 4.2.1 N 連語言模型 ... 20 4.2.2 語言模型帄滑法 ... 22 4.2.3 語言模型評估準則-混淆度(perplexity, PP) ... 22 4.3 客語語言模型 ... 23
VI 4.3.1 基本客語語言模型 ... 23 4.3.2 強化客語語言模型 ... 23 4.3.2.1 由客語詞類資訊建立語言模型(Stage1) ... 24 4.3.2.2 由國語詞類資訊建立語言模型(Stage2) ... 26 4.3.2.3 由國語語言模型資訊建立語言模型(Stage3) ... 29 4.4 雙語語言模型 ... 30 4.5 比較與效能分析 ... 31 第五章 實驗結果及討論... 33 5.1 聲學模型實驗 ... 33 5.2 客語語言模型實驗 ... 35 5.3 雙語語音辨認實驗 ... 39 第六章 結論與未來展望... 43 6.1 結論 ... 43 6.2 未來展望 ... 43 參考文獻... 44 附錄一:詞類標記... 46 附錄二:決策問題... 47 附錄三:音節結構表... 50
VII
圖目錄
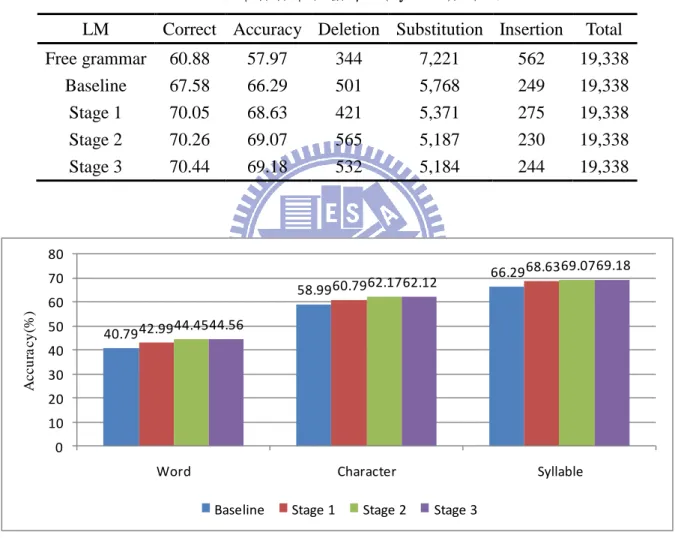
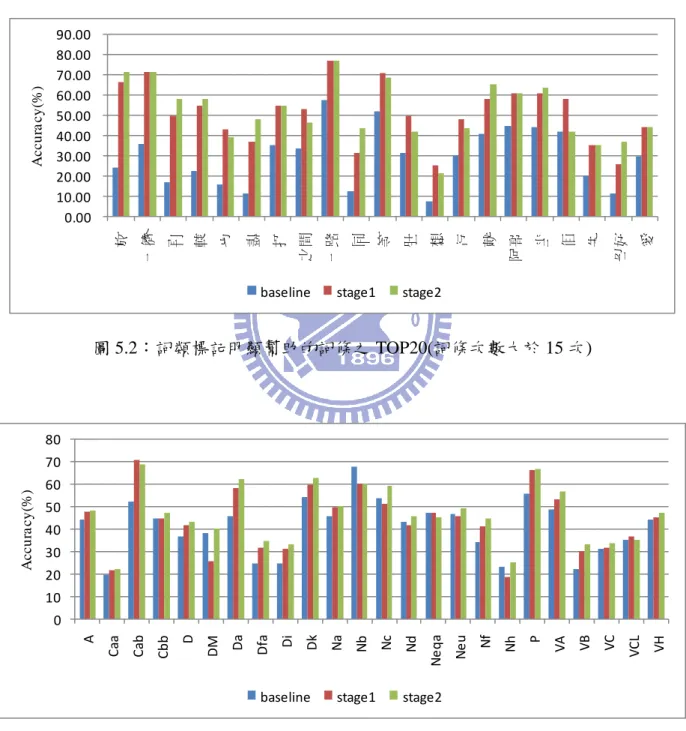
圖 2.1:客語的音節結構... 8 圖 2.2:客語詞類與國語詞類標記分佈比較(1) ... 10 圖 2.3:客語詞類與國語詞類標記分佈比較(2) ...11 圖 2.4:客語詞類與國語詞類標記分佈比較(3) ...11 圖 3.1:單語聲學模型之建立流程... 13 圖 3.2:雙語聲學模型建立流程... 14 圖 4.1:強化客語語言模型流程圖... 24 圖 4.2:國語詞類資訊語言模型的建立流程圖... 26 圖 5.1:客語語言模型辨認率... 37 圖 5.2:詞類標記明顯幫助的詞條之 TOP20(詞條次數大於 15 次) ... 38 圖 5.3:詞類標記對於幫助辨認的詞類(詞類次數大於 40 次) ... 38 圖 5.4:不同客語語言模型對於雙語語音辨認之辨認率比較... 41 圖 5.5:不同聲學模型對於雙語語音辨認之辨認率比較... 42VIII
表目錄
表 2.1:TCC300 語料庫資訊統計表 ... 4 表 2.2:客語語音語料庫資訊統計表... 5 表 2.3:國客雙語語音語料庫資訊統計表... 6 表 2.4:國語文字語料庫資訊統計表... 6 表 2.5:無標記的客語文章資訊統計表... 7 表 2.6:人工標記客語文章資訊統計表... 7 表 2.7:客語詞典資訊統計表... 8 表 2.8:國客雙語對照詞典資訊統計表... 8 表 3.1:客語語音語料庫統計... 12 表 3.2:國語語音語料庫統計... 12 表 3.3:國客語夾雜語音語料庫統計... 13 表 3.4:國語音素集... 15 表 3.5:客語音素集... 15 表 3.6:直接合併之雙語音素集... 16 表 3.7:LOG-LIKELIHOOD DISTANCE ... 17 表 3.8:雙語音素集... 19 表 3.9:合併比率... 19 表 4.1:國語翻譯與 60,000 詞分布情況... 28 表 4.2:STAGE 3 客語語言模型混淆度估測 ... 30 表 4.3:語言模型混淆度估測... 31 表 5.1:模型 MIXTURE 數量 ... 33 表 5.2:不同聲學模型、待辨認音節對於客語測詴語料之音節辨認率比較... 33 表 5.3:SUBSTITUTION 明顯增加且常出現(>40 次),前十名之音節 ... 34IX 表 5.4:不同聲學模型、待辨認音節對於國語測詴語料之音節辨認率比較... 35 表 5.5:不同聲學模型對於雙語測詴語料之音節辨認率比較... 35 表 5.6:HMM 模型之設定... 36 表 5.7:RCD 聲學模型音節辨認率 ... 36 表 5.8:客語語言模型詞(WORD)辨認率 ... 36 表 5.9:客語語言模型字(CHARACTER)辨認率 ... 37 表 5.10:客語語言模型音節(SYLLABLE)辨認率 ... 37 表 5.11:雙語辨認率之比較 ... 40 表 5.12:雙語語音辨認之詞辨認率分析... 40 表 5.13:雙語語音辨認之音節辨認率分析... 41
1
第一章 緒論
1.1 研究動機
科技日新月異的今天,獲得資訊的方式可說是越來越容易,但是人們操縱電腦、手機甚 至 PDA 的方式主要還是侷限於鍵盤、觸控,其實這並不是人類最基本的溝通方式,人們還 不會寫字時,就懂得使用語言來溝通,所以語言才是人類最基本、最自然的溝通方式。而如 何賦予電腦能夠理解人類的語言而發展出的人性化介面,其中語音辨認 (Automatic Speech Recognition, ASR) 扮演了極為重要的角色。 而在另一方面,儘管語音辨認已發展多年,連續大詞彙語音辨認也有所發展,但是普遍 是單語言的語音辨認系統,如果一個語音辨認系統可以結合多種語言,達到多種語言的辨認 這將是十分有趣的;並且,隨著文化的發展人們在口語上多種語言夾雜也是常見的現象,所 以發展一個多語種或跨語言的語音辨認系統(Multilingual or Cross-Lingual Speech Recognizer,MSR)將是一個很重要的研究課題。 在台灣主要有三種語言國語、台語及客語,其中大約有百分之十的人口母語為客語。過 去對於客語語音處理相關研究【1】【2】是非常稀少的,主要原因是客語的語音及文字語料 收集非常困難。近年來,由於政府與社會逐漸對於母語的重視,尤其是對於客語。現在,有 許多的廣播媒體,像是 Hakka-TV【3】、Hakka-radio【4】、客語廣播新聞與國客語夾雜的廣 播新聞。此時將需要客語或國客語夾雜的聽寫系統。所以本論文將針對客語語音辨認與國客 雙語語音辨認進行研究。
1.2 研究方向
客語依照地區分成了許多次方言,像是海陸、四縣、大浦、紹安等,其中本研究為四縣 客語。四縣客語和國語ㄧ樣,皆為單音節(monosyllabic )和音調(tonal)的語言。雖然客語的語 音在語言學上的特性與國語語音極為相似,但是客語本身並沒有標準的書寫文字。這些文字2
通常使用中文字元與羅馬拼音(Romanization form)夾雜表示。因此,只有少數的客語語言學 家能夠撰寫出客語文章,造成難以收集大量的客語文字語料來訓練一個可靠的語言模型 (Langauge Model, LM)。針對這個問題,本研究將使用詞類標記(part of speech)、國客語的詞 條對譯、國語語言模型來幫助客語建立更為可靠的語言模型。 另一方面,對於雙語的語音辨認建立一個雙語言共同使用的聲學模型是必需的。我們嘗 詴兩種方法來產生雙語聲學模型,一種是直接將國語及客語的聲學模型合併,另一種是使用 相似度量測(log-likelihood measurement)【5】【6】來定義音素間的距離,用以合併國客語音 素成一個共用的音素集,再訓練出一個混合的雙語聲學模型。雙語語言模型方面,則簡單的 由原客語語言模型加入常使用的國語詞彙。
1.3 相關研究
1.3.1 聲學模型之相關研究
多語言語音辨認有各種方法。一種方法是先使用語言辨認系統(language identification, LID),確定輸入的語言後,選用相應的單語言系統進行語音辨認。不過此種方法的語音辨認 效能直接取決於 LID 的辨認率,且輸入語音的長短亦會直接影響辨認效能。另一種多語言語 音 辨 認 是 將所 有 的 單語 言 語 音 辨識 系 統 進行 帄 行 的 辨認 , 根 據各 語 言 的 最大 相 似度 (maximum likelihood),決定辨認情況,其效能取決於最後選擇的最大相似度序列。 傳統上多語言辨認系統,是對音素(phone)做處理。建立一個包含多種語言的音素集【7】, 一般常見的建立多語言音素集常見的方法大致上可分為三種:(1) 直接將所有語言的音素結 合起來。(2) 將對應至相同國際音標集的音素,做音素的合併。(3) 經由數據處理合併不同 語言的音素:對不同語言各自訓練自己的聲學模型,分別對其他語言交互計算模型間的相似 度,將相似度較高的聲學模型做合併,像是 log-likelihood【8】及 K-L Divergence。1.3.2 語言模型之相關研究
一般多語言的辨認系統,雖然說是多語言並行的自由使用,但是通常主要語言只會有一3 種;並且在語料的蒐集上,難以取得足量的多語語料以供訓練,也無法涵蓋所有可能出現的 外語詞彙,通常是使用詞類將外語分為多個詞群,來訓練語言模型【9】。此外,語者對於外 語的發音,通常會將其母語化,使得外語詞彙會對應至母語音節上,所以也可以針對這些詞 典外詞彙(out-of-vocabulary, OOV)進行處理【10】。
1.4 章節大要
本研究的內容共分為六章: 第二章:對實驗語料做簡單的分析及介紹。 第三章:針對雙語的特型,設計雙語混合聲學模型。 第四章:使用不同的資訊訓練客語語言模型,並考量國客語夾雜情況設計雙語語言模型。 第五章:根據前述章節中的不同模型進行實做,再針對不同組合的實驗結果進行比較與分 析。 第六章:結論與未來展望。4
第二章 實驗語料介紹
本研究實驗語料主要分為文字語料和語音語料兩個部份,其中文字語料做為語言模型訓 練使用,而語音語料則做為聲學模型訓練及測詴語音辨認系統之效能使用。2.1 節將介紹實 驗所使用的語音語料庫,2.2 節將介紹實驗所使用的文字語料庫,2.3 節將分析客語與國語文 句之間的關係。2.1 語音語料庫介紹
實驗所使用的語音語料庫分為國語語音語料庫、客語語音語料庫以及國客雙語語音語料 庫三個。其中國語語音語料庫及客語語音語料庫做為聲學模型的訓練及測詴使用,國客雙語 語音語料庫則做為測詴使用。接著,將對這三個語料庫做更為詳細的介紹。2.1.1 國語語音語料庫
實驗所使用的國語語音語料庫為 TCC300 語料庫,語料庫是由台灣大學、成功大學、交 通大學各自擁有之語料庫集合而成,各校錄製之目的是為語音辨認研究,屬於麥克風朗讀語 音。其中台大語料庫主要包含詞及短句,文章經過仔細設計,考慮了音節及其相連出現機率, 由 100 人錄製而成;成大及交大語料庫主要包含長文語料,文章由中研院提供之 500 萬詞詞 類標示語料庫中選取,每篇文章包含數百字,再切割成 3 至 4 段,每段含至多 231 字,由 200 人朗讀錄製,每人所讀文章皆不相同。詳細統計資訊如表 2.1 所示。 表 2.1:TCC300 語料庫資訊統計表 學校名稱 文章屬性 語者總數 總音節數 總檔案數 台灣大學 短文 (帄衡句) 男 50 男 27,541 男 3,425 女 50 女 24,677 女 3,084 總計 100 總計 52,218 總計 6,509 交通大學 長文 男 50 男 75,059 男 622 女 50 女 73,555 女 6165 總計 100 總計 148,614 總計 1,238 成功大學 長文 男 50 男 63,127 男 588 女 50 女 68,749 女 582 總計 100 總計 131,876 總計 1,170
2.1.2 客語語音語料庫
台灣客家話有許多次方言,其中以四縣腔為最通行的腔調,本研究考量到客語的代表性 和實用性,因此選用客語人口最多的苗栗四縣客家話為發展國、客語語音辨認技術的語料來 源。以下所稱之客語皆為苗栗四縣客家話。 實驗所使用的客語語音語料庫,為交通大學語音處理實驗室分四個時期錄製而成,目的 是為語音辨認研究,屬於麥克風朗讀語音。文章內容主要為客語故事【11】,主要由苗栗的 兩位退休教師,一位是龔萬灶老師、另一位為陳碧娥老師所撰寫;並加入中華大學余秀敏老 師所新增的客語文句。由 92 人朗讀錄製而成,詳細統計資料如表 2.2 所示。 表 2.2:客語語音語料庫資訊統計表 語者總數 總音節數 總檔案數 男 43 男 70,193 男 4,627 女 49 女 83,718 女 5,602 總計 92 總計 153,911 總計 10,2292.1.3 國客雙語語音語料庫
實驗所使用的國客雙語語音語料庫,為交通大學語音處理實驗室錄製而成,目的是為語 音辨認研究,屬於麥克風朗讀語音。文句由中華大學余秀敏老師根據日常國客語夾雜使用情 況所撰寫,文句內容分為客語為主文句及國語為主文句,各 100 句。由 20 人錄製而成,每 人 20 句國語為主文句、20 句客語為主文句。詳細統計如表 2.3 所示。6 表 2.3:國客雙語語音語料庫資訊統計表 文句屬性 語者總數 總音節數 總檔案數 客語為主 男 10 男 2,480 男 200 女 10 女 2,480 女 200 總計 20 總計 4,960 總計 400 國語為主 男 10 男 2,478 男 200 女 10 女 2,478 女 200 總計 20 總計 4,956 總計 400
2.2 文字語料庫介紹
實驗所使用的文字語料庫依照語言分為國語文字語料庫、客語文字語料庫兩個。主要是 做為語言模型的訓練使用。2.2.1 國語文字語料庫
實驗所使用的國語文字語料庫,來源有兩個:光華雜誌【12】及 NTCIR【13】,光華雜 誌為一般雜誌內容文章,蒐集的範圍為 1976 年至 2000 年;NTCIR 為各個不同學科領域的文 章構成,是建立資訊檢索系統的標竿測詴集。詳細統計資訊如表 2.4 所示: 表 2.4:國語文字語料庫資訊統計表 來源 詞數(Word) 字數(Character) 光華雜誌 8,945,660 15,691,089 NTCIR 108,217,471 201,075,931 合計 117,163,131 216,767,0202.2.2 客語文字語料庫
因為客語文字語料庫其文字量明顯較國語稀疏,所以此節將特別對與客語文字相關的語 料加以介紹。實驗所使用的客語文字語料庫,主要分為:無標記的客語文章、人工標記的客 語文章及詞典三個部份,以下將分別對這三個部份做詳細介紹:7 無任何標記的客語文章(以下稱為 textA) 此文章來源為網路上擷取而來,主要來源為全國語文競賽朗讀文章,文章內容大部份為 故事散文集。經過文字正規化及使用客語詞典斷詞【14】後,詳細統計資訊如表 2.5 所示, 總詞條數有 143,341 個。 表 2.5:無標記的客語文章資訊統計表 一字詞 二字詞 三字詞 四字詞 五字詞 六字詞 七字詞 八字詞 總計 詞條數 2,797 8,722 2,485 946 89 17 15 42 15,115 詞頻 81,672 51,027 8,591 1,810 126 23 17 51 143,341 人工標記詞性、國語翻譯的客語文章(以下稱為 textB) 此文章來源為龔萬灶老師撰寫的客語文集,並且經由余秀敏老師人工標記詞類及國語翻 譯資訊而成,其文章內容為客語故事。使用的詞類標記共有 49 類,詳細詞類標記資訊如附 錄一;此文章帄均一個客語詞條有 1.14 個詞類標記、1.28 個國語翻譯。詳細統計資訊如表 2.6 所示。 表 2.6:人工標記客語文章資訊統計表 一字詞 二字詞 三字詞 四字詞 五字詞 六字詞 七字詞 八字詞 總計 詞條數 1,179 4,825 1,466 534 47 9 1 5 8,068 詞頻 25,729 16,610 3,393 758 51 10 1 5 46,581 帄均翻譯數 1.90 1.19 1.15 1.07 1.00 1.00 1.00 1.00 1.28 帄均詞類數 1.53 1.09 1.05 1.02 1.00 1.00 1.00 1.00 1.14 客語詞典(以下稱為 dict) 此客語詞典收錄來源有三個:台北市客委會、行政院教育部及龔老師文集。此詞典紀錄 每個客語詞條的發音及詞類,帄均一個客語詞條有 1.33 個詞類標記。詳細統計資訊如表 2.7 所示。 另外,此客語詞典收錄的部分客語詞條(26,524 個)有國語翻譯的對應,這部份的客語詞 條帄均有 1.12 個國語翻譯。此部份翻譯標記的收錄來源有台北市客委會及余老師人工標記的 客語文章。詳細統計資訊如表 2.8 所示。
8 表 2.7:客語詞典資訊統計表 一字詞 二字詞 三字詞 四字詞 五字詞 六字詞 七字詞 八字詞 總計 詞條數 6,643 23,690 7,454 5,224 323 84 85 18 43,521 帄均 pos 數 2.42 1.16 1.08 1.06 1.04 1.01 1.00 1.00 1.33 表 2.8:國客雙語對照詞典資訊統計表 一字詞 二字詞 三字詞 四字詞 五字詞 六字詞 七字詞 八字詞 總計 詞條數 1,225 16,762 4,924 3,295 205 59 44 10 26,524 帄均翻譯數 1.94 1.09 1.08 1.03 1.00 1.00 1.00 1.00 1.12
2.3 客語與國語之間的語文特性
客語和國語都是漢語語系的語言,其音節結構和國語一樣,可以劃分為兩大部分:聲母 和韻母。聲母是指音節的第一個輔音,而韻母則包含介音及韻腳,韻腳又包括主要元音及韻 尾。圖 2.1 為客語的音節結構【15】。 圖 2.1:客語的音節結構2.3.1 客語與國語的帄行語料分析
此部份是分析人工標記的客語文章中客語文句與國語文句之間的關係。發現不管在文字 撰寫或文法結構上,國語與客語都極為相似,9
例如:
客語文句: 拜 伯公 係 客家人 異 帄常 也 係 異 要緊 事情
國語文句: 拜 土地公 是 客家人 十分 帄常 也 是 十分 重要 的 事情
詞類標記: VC Nb SHI Na Dfa VH D SHI Dfa VH DE Na
客語文句: 原本 嚴肅 面容 露出 微微仔 笑意 國語文句: 原本 嚴肅 的 面容 露出 微微 的 笑意 詞類標記: D VH DE Na VC D DE Na 客語文句: 從 後生 嫁 來 這 隻 莊仔 到 今晡日 歸以 國語文句: 從 年輕 嫁 來 這 個 莊子 到 今天 歸以 詞類標記: P VH VC D Nep Nf Nb P Nd VA 上述所舉的例子,可以明顯看出國語與客語文句有相同的文法結構,接著由客語詞條與 翻譯的對照,我們發現國語與客語在漢字的使用上,可分為三種: 客語詞條和國語翻譯『相同』 此部份是指客語詞條和國語翻譯的漢字使用上是一樣的, 例如: 客語詞條:二十一世紀、工廠、山盟海誓 國語翻譯:二十一世紀、工廠、山盟海誓 客語詞條和國語翻譯『相似』 此部份是指客語詞條和國語翻譯的漢字使用上是相似的,通常是語贅詞的使用不同及客 語有特有的語助詞,例如: 客語詞條: 七十零 男仔人 年仔 手仔 國語翻譯: 七十多 男人 年 手
10 客語詞條和國語翻譯『不同』 此部份是指客語詞條和國語翻譯的漢字使用上是不一樣,通常是客語特有用法或是一字 詞, 例如: 客語詞條: 三十暗晡 八月半 國語翻譯: 除夕夜 中秓節 的
2.3.2 客語與國語的詞類分析
此部份是對上述人工標記的客語文章與國語文章(NCTIR 及光華雜誌)觀察詞類標記的 分布情況,客語與國語詞類標記分布情形如圖 2.2 至圖 2.4 所示,我們可以看出客語詞條和 國語詞條在文章中,其詞類標記的所佔比例是非常近似的。因此本研究假設客語文句的詞類 標記和國語文句是相同的。 圖 2.2:客語詞類與國語詞類標記分佈比較(1) 0.00 2.00 4.00 6.00 8.00 10.00 12.00 14.00 16.00A Caa Cab Cba Cbb D DE DM Da Dfa Dfb Di Dk FW I
百分比
(%
)
11 0.00 5.00 10.00 15.00 20.00 25.00
Na Nb Nc Ncd Nd Nep NeqaNeqb Nes Neu Nf Ng Nh Nv P PA SHI T
百分比 (% ) 國語 客語 圖 2.3:客語詞類與國語詞類標記分佈比較(2) 圖 2.4:客語詞類與國語詞類標記分佈比較(3) 0.00 1.00 2.00 3.00 4.00 5.00 6.00 7.00 8.00 9.00 10.00 VA VAC VB VC VCL VD VE VF VG VH VHC VI VJ VK VL V_2 百分比 (% ) 國語 客語
12
第三章 聲學模型
在語音信號處理中建構聲學模型時,隱藏式馬可夫模型(Hidden Markov Model, HMM)是 廣為人們所利用的,在本章節中將利用 TCC300 語料庫、客語語料庫及劍橋大學開發之 HTK(HMM Tool Kit)軟體【16】建立一不特定語者(speaker independent)及不特定文章(context independent)之國客雙語聲學模型,以供後續辨認實驗使用。3.1 節將介紹建構聲學模型之訓 練語料,以及評估聲學模型效能之測詴語料;3.2 節將介紹本研究中建立聲學模型之流程; 3.3 節將介紹本研究雙語音素集的定義方式。
3.1 訓練語料及測詴語料
本研究所使用的語音語料分為國語語音語料、客語語音語料及國客語夾雜語音語料。其 中國語語音語料及客語語音語料做為訓練及測詴聲學模型用,詳細統計資料如表 3.1 及表 3.2 所示;而國客語夾雜語音語料做為測詴聲學模型使用,詳細統計資料如表 3.3。值得注意的 是,客語語音語料庫因為錄製的時期不同,造成不同時期語者唸的提示卡語料數目不同,造 成語料分配較為不均勻的情況發生,主要有三個語者(2 女 1 男)各包含了 1 萬多個音節的情 況發生,將這三位語者皆列為訓練語料。 表 3.1:客語語音語料庫統計 訓練語料 測詴語料 673 syllable 134,612 19,388 總段落數 8,658 1,571 表 3.2:國語語音語料庫統計 訓練語料 測詴語料 411 syllable 300,728 31,252 總段落數 8,036 84313 表 3.3:國客語夾雜語音語料庫統計 客語為主 國語為主 合計 1084 syllable 4,710 4,707 9,417 總段落數 380 380 760
3.2 聲學模型之建立
3.2.1 特徵參數抽取
在訓練模型前,首先必頇獲得足以充分描述語音特性,且參數量較原語音信號小之特徵 參數,而在語音處理當中,最廣泛為人使用之特徵參數為梅爾頻率倒頻譜係數(Mel-Frequency Cepstrum Coefficient, MFCC),本研究也將使用此特徵參數,以 32 毫秒之漢明窗(Hamming window)且每位移 10 毫秒為一筆資料,求取 12 維 MFCC 加上 1 維能量係數,以及這 13 維 係數之一階與二階變量(delta and delta-delta)為特徵參數,但單純的能量在參數中較為缺乏鑑 別性,因此除去能量係數,得到 38 維向量做為本研究語音資料之聲學特徵參數。在本研究 也將利用倒頻譜帄均值正規劃法(Cepstrum Mean Normalization, CMN)藉此消除不同語音信 號之通道效應。3.2.2 單語聲學模型之建立
由於使用 Flat Start 訓練聲學模型,此種做法必頇花費較久的時間才能得到正確的模型, 且語句較長時也容易發生模型位置錯誤之情況。因此本研究利用音節內右相關聲/韻母模型 (Right-context-dependent Initial / Final Model, RCD)對語音語料做音節的切割,再根據音節的 切割位置訓練單語聲學模型,其建立流程如圖 3.1 所示。 RCD-I/F AM Forced Alignment Speech Data Transcription Syllable Boundary Information Syllable to phone Dictionary Train Mono-phone AM Train Tri-phone AM Mono-phone AM Question Set Phone set Tri-phone AM 圖 3.1:單語聲學模型之建立流程
14
本研究之單語聲學模型以音素 (phone)為單位,採用跨 詞三連音素模型 (Cross-word Tri-phone Model, Tri-phone),每一個音素之 HMM 模型採用 3 個由左至右(left-to-right)的狀態 (state)表示。使用跨音節三連音素模型時,為表示完整的聲學模型頇包含所有的音素組合, 也就是音素個數的三次方,其中必然包含在目標辨認語料中卻無訓練語料之組合,因此對所 有 HMM 模型的狀態採用分類回歸決策樹(Classification and Regression Trees, CART)做為參 數分享的方法,使用語言學的問題來做為決策問題,詳細決策問題如附錄二。
3.2.3 雙語聲學模型之建立
由於沒有國、客語夾雜的訓練語料,因此,本研究首先對已訓練出的國、客語音素模型 (Mono-phone Model)做 HMM 模型的距離計算,接著根據距離及所定義的合併規則做音素模 型的合併(距離計算方式及合併規則將在 3.3 節介紹),最後由 3.2.2 節所介紹的方法完成雙語 的跨詞三連音素模型(Bilingual Tri-phone Model),其建立流程如圖 3.2 所示。
Hakka Mono-phone Mandarin Mono-phone Clustering Train Tri-phone AM Bilingual Tri-phone Question Set Bilingual Mono-phone Calculate Distance Cluster Rule Mono-phone Distance 圖 3.2:雙語聲學模型建立流程
3.3 雙語音素集
由圖 3.2 雙語聲學模型建立流程得知,在雙語語音辨認中雙語音素集的定義是不可或缺 的,因為聲學模型的訓練是根據基本發音單位去做訓練的,若定義的發音單位不合適則會直 接影響最終的語音辨認效能,而雙語音素就是雙語的基本發音單位。 目前已經有定義好的國語及客語單語音素集。所以本研究就是經由已定義的國語音素集 與客語音素集建立一個良好的雙語音素集。並且希望所定義的雙語音素集不影響原先的單一 語言音素集。15 此節將對所使用到的合併方法加以介紹:
3.3.1 單語音素集
單語音素集是考量語言實際使用時的發音狀況,完整描述語言的特性定義而成。因為國 語和客語皆為漢語語系,音節結構都為聲母加上韻母,所以音素的定義也將音節結構位置考 慮進去,詳細如表 3.4 以及表 3.5。 表 3.4:國語音素集 聲母(21) 韻母(17) 介音(3) 元音(8) 韻尾(4) 空韻母(2)M_b M_n M_m M_yi1 M_e M_en M_FNULL1
M_c M_p M_yu1 M_eh M_ng M_FNULL2
M_ch M_q M_wu1 M_o M_yi3
M_d M_r M_a M_wu3 M_f M_sh M_er M_g M_s M_yi2 M_h M_t M_yu2 M_j M_x M_wu2 M_k M_z M_l M_zh 表 3.5:客語音素集 聲母(21) 韻母(17) 介音(2) 元音(6) 韻尾(8) 空韻母(1)
H_HH H_m H_l H_yi1 H_a H_ek H_FNULL
H_NH H_n H_wu1 H_eh H_em
H_b H_ng H_ii H_en H_c H_p H_o H_eng H_d H_q H_wu2 H_ep H_f H_s H_yi2 H_et H_g H_t H_wu3 H_h H_v H_yi3 H_j H_x H_k H_z
16
3.3.2 音素直接合併
此部份是將國語音素集與客語音素集直接合併產生雙語音素集,此音素集共有 76 個音 素,詳細如表 3.6 所示。 表 3.6:直接合併之雙語音素集 聲母(42) 韻母(34) 介音(5) 元音(14) 韻尾(12) 空韻母(3)M_b M_s H_k M_yi1 M_e M_en M_FNULL1
M_c M_t H_m M_yu1 M_eh M_ng M_FNULL2
M_ch M_x H_n M_wu1 M_o M_yi3 H_FNULL
M_d M_z H_ng H_yi1 M_a M_wu3
M_f M_zh H_p H_wu1 M_er H_ek
M_g M_m H_q M_yi2 H_em M_h H_HH H_s M_yu2 H_en M_j H_NH H_t M_wu2 H_eng M_k H_b H_v H_a H_ep M_l H_c H_x H_eh H_et M_n H_d H_z H_ii H_wu3 M_p H_f H_l H_o H_yi3 M_q H_g H_wu2 M_r H_h H_yi2 M_sh H_j
3.3.3 log-likelihood measurement
Log-likelihood measurement【5】【6】是對相同音節結構分類下的音素做計算距離的動作, 令Oi k, 為第k 段標示為音素模型i的特徵參數序列,則兩個音素模型M 及i Mj之間的距離如式 (3.1)所示:
,
,
1 1 1 1 , | | K K i j i k i i k j k k D M M f O M f O M K K
(3.1) 因式(3.1)算出的距離並非對稱,故對其取帄均值而得到 log-likelihood measurement:
, 1 , , 2 i j i j j i D D M M D M M (3.2)17 其中,f O
i k, |Mj
為Oi k, 對音素模型Mj的 Log-likelihood。其計算如式(3.3)所示,使用威特 比演算法(Viterbi algorithm)找出最佳的路徑:
,
(0) (1) ( ) , , ( ) ( 1) 1 1 | log max ( ) T i k j x x x t i k t x t x t X t f O M a b O a T
(3.3) , , i k tO 表示為在Oi k, 中的第t個聲學特徵參數 sample,x t
表示為第t個 sample 所屬的 state,( ) ( 1) x t x t a 為第x t
至x t
1 的轉移機率,bx t( )為第x t
個 state 的 likelihood。
, ,
, ,
1 ; , M j i k t jm i k t jm jm m b O c N O
(3.4)m 表示為bj這個 state 中第 m 個 mixture,cjm表示為bj這個 state 中第 m 個 mixture 的 weight。
最後,log-likelihood measurement 實作流程分為三個步驟,步驟如下: 步驟 1:各自訓練國語及客語的音素模型,並對原始語料做音素的切割而得音素的段落標記 (forced alignment)。 步驟 2:對於每一個國語或客語音素,以式(3.2)計算對另一種語言(客語或國語)音素的 log-likelihood measurement,也就是Di j, 。 步驟 3:根據計算出的Di j, 及國客語一對一的原則做距離大小的排序。 表 3.7 為根據 log-likelihood measurement 計算兩語言之間音素模型的距離,根據距離及 一對一做排序的動作。 表 3.7:log-likelihood distance 排名 距離 客語音素 國語音素 音素模型 音節結構分類 音素模型 音節結構分類 1 4.264 H_eng 韻尾 M_ng 韻尾 2 4.408 H_a 元音 M_a 元音 3 4.444 H_en 韻尾 M_en 韻尾 4 4.815 H_yi2 元音 M_yi2 元音 5 4.972 H_eh 元音 M_eh 元音
18 6 5.065 H_l 聲母 M_l 聲母 7 5.251 H_wu2 元音 M_wu2 元音 8 5.472 H_s 聲母 M_s 聲母 9 6.127 H_m 聲母 M_m 聲母 10 6.469 H_yi1 介音 M_yi1 介音 11 6.479 H_n 聲母 M_n 聲母 12 6.526 H_x 聲母 M_x 聲母 13 6.542 H_et 韻尾 M_yi3 韻尾 14 6.646 H_z 聲母 M_z 聲母 15 6.669 H_t 聲母 M_t 聲母 16 6.678 H_p 聲母 M_p 聲母 17 6.684 H_b 聲母 M_b 聲母 18 6.726 H_h 聲母 M_h 聲母 19 6.878 H_o 元音 M_o 元音 20 6.886 H_j 聲母 M_j 聲母 21 6.936 H_c 聲母 M_c 聲母 22 7.214 H_d 聲母 M_d 聲母 23 7.286 H_f 聲母 M_f 聲母 24 7.589 H_ii 元音 M_FNULL2 空韻母 25 8.070 H_q 聲母 M_q 聲母 26 8.277 H_ek 韻尾 M_wu3 韻尾 27 9.324 H_wu3 韻尾 M_e 元音 28 9.363 H_ng 聲母 M_r 聲母 29 9.437 H_g 聲母 M_g 聲母 30 10.306 H_yi3 韻尾 M_er 元音 31 10.860 H_FNULL 空韻母 M_yu2 元音 32 10.916 H_k 聲母 M_k 聲母 33 11.791 H_HH 聲母 M_sh 聲母 34 12.343 H_wu1 介音 M_wu1 介音 35 13.354 H_em 韻尾 M_FNULL1 空韻母 36 16.263 H_NH 聲母 M_yu1 介音 37 18.600 H_v 聲母 M_ch 聲母 38 22.677 H_ep 韻尾 M_zh 聲母 接著,根據相同漢語音標、相同音節結構位置以及距離大小後,決定合併 22 個音素,其中 聲母有 14 個、介音 1 個、元音 5 個以及韻尾 2 個。詳細如表 3.8 以及 3.9 所示。
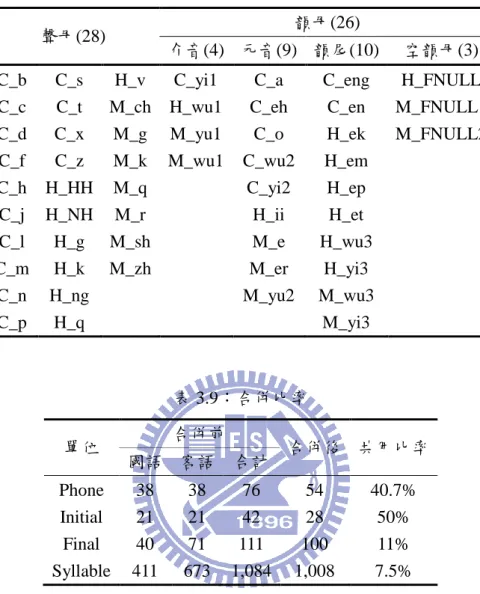
19
表 3.8:雙語音素集,C_表示合併後的音素
聲母(28) 韻母(26)
介音(4) 元音(9) 韻尾(10) 空韻母(3)
C_b C_s H_v C_yi1 C_a C_eng H_FNULL
C_c C_t M_ch H_wu1 C_eh C_en M_FNULL1
C_d C_x M_g M_yu1 C_o H_ek M_FNULL2
C_f C_z M_k M_wu1 C_wu2 H_em
C_h H_HH M_q C_yi2 H_ep C_j H_NH M_r H_ii H_et C_l H_g M_sh M_e H_wu3 C_m H_k M_zh M_er H_yi3 C_n H_ng M_yu2 M_wu3 C_p H_q M_yi3 表 3.9:合併比率 單位 合併前 合併後 共用比率 國語 客語 合計 Phone 38 38 76 54 40.7% Initial 21 21 42 28 50% Final 40 71 111 100 11% Syllable 411 673 1,084 1,008 7.5%
20
第四章 語言模型的設計
4.1 概論
現階段語音辨認的目標,在於將使用者所輸入的一連串語音,根據式(4.1)辨認為詞串 W:
|
W W arg max P W P O W (4.1) 其中,P O W
|
是經由聲學模型處理後得到的分數,但因為文字中同音字的情況相當普遍(國 語為例:有 1,300 多個合法音節,但是合法字數卻超過 14,000 個),這些同音字會得到相同 的聲學分數;因此需要由語言模型,提供詞串的事前機率(prior probability, P W
),來彌補 聲學模型的不足。 在大詞彙連續語音辨認中,希望將輸入的語音辨認出合理的詞彙順序;為達到此目的, 語言模型就必頇考慮整段辨認語音中前後詞彙的關連性,不僅是單一字詞獨自出現的機率。 這就是語言模型的功能。 由於語言模型在語音辨認中扮演非常關鍵的角色,因此本章將就既有的語言模型的設計 方式,以及本研究實驗所使用的語音模型進行介紹。另外,由於客語本身並無大量的訓練文 字,故本研究先根據客語的詞性資訊、國語翻譯資訊及利用國語語言模型建立客語語言模型, 後依照國、客語夾雜語音使用情況設計雙語語言模型。4.2 節將介紹語言模型之基本定義; 4.3 節將介紹客語語言模型;4.4 節將介紹雙語語言模型。4.2 語言模型基本定義
4.2.1 N 連語言模型
由式(4.1),P W
是欲辨認詞串W的事前機率,其中Ww w1, 2, ,wm,wiV代表m個 詞所組成的詞串,V 則是詞典,為所有詞的集合。使用貝式法則,P W
可以分解成:21
1 2
1 2 1
1 , , | , , m m i i i P W w w w P w w w w
(4.2) 其中是P w w w
i| 1, 2, wi1
詞w 在給特定歷史詞串i hi w w1, 2, wi1的情況下,會緊接著詞wi 出現的條件機率。 但實際上在建立語言模型時,並不會將所有可能的參數P w w w
i| 1, 2, wi1
都儲存起來; 因為針對長度為m,歷史長度為m1的詞串,所有可能的組合個數為V m;即使詞典為中等 大小,只要詞串長度 m 稍長,參數量將會驚人的成長,因此必頇做參數量的簡化。 簡化參數量的方法之一,就是裁減歷史詞串的長度。所謂 N 連語言模型,就是對參數
i| 1, 2, i 1
P w w w w 做 近 似 , 此 模 型 假 設 詞 w 出 現 的 機 率 只 和 前 面 N-1i
Nm
個 詞 N 1, N 2, 1 i i i w w w 相關,而和 N 個之前的詞串w w1, 2, wiN完全獨立,如此一來歷史詞串的 長度便可輕易的裁減,模型的參數量也會因此大大的降低。根據此假設,則P W
可表示為:
1 2
N 1 N 2 1
1 , , | , , m m i i i i i P W w w w P w w w w
(4.3) 實際估測P w w
i| i N 1,wi N 2, wi1
的方式,是根據最大相似度估測法(maximum likelihood estimation, MLE),得到下式:
N 1 N 2
N 1 N 2 1 N 1 N 2 1 , , | , , , , i i i i i i i i i i C w w w P w w w w C w w w (4.4) 其中C
表示詞串出現次數。當N2時,成為雙連語言模型(bigram language model),詞串W的機率可表示為:
1 2
1
1 , , | m m i i i P W w w w P w w
(4.5) 及
1
1 1 , | i i i i i C w w P w w C w (4.6)22
4.2.2 語言模型帄滑法
以雙連語言模型為例,在訓練資料中計算P w w
i| i1
時,若C w
i1,wi
0,將會使得
i| i 1
P w w 機率等於零,因為在訓練資料中並未出現,但是這並不是代表測詴資料中不會出 現,因此這種情況下機率的給定是不合理的。且當C w
i1,wi
值很小時,所計算出的機率也 是不準確的。所以必頇對計算出的機率做帄滑化的動作,使所有的機率均能被良好的估計。 退化帄滑法(back off)及使用 Good-Turing discounting。若定義訓練語料中詞串出現的次數門檻值k ,則可將詞串分為出現次數高於門檻值、出現次數低於門檻值及從未出現三種。 則參數可表示為下式:
N 1 N 2 1 N 1 1 N 2 1 N 1 N 1 N 1 1 N 1 N 1 1 N 1 N 1 1 | , , , , , | , , , , , 0 , , , , , 1 , , , , , , , , i i i i i i i i i i i i i c i i i i i i i i i i P w w w w w w P w w w C w w C w w d w w C w w k C w w C w w C w w
N 1
, C wi , ,wi k (4.7)4.2.3 語言模型評估準則-混淆度(perplexity, PP)
據前人研究顯示,混淆度已成為評估語言模型相當重要且通用的參考標準;混淆度是根 據消息理論(information theory)而得:
1 2
1 log , , , m H P W w w w m (4.8) 上式為一個詞串Ww w1, 2, ,wm,對於每個新詞提供的帄均資訊量(entropy),經過適當的化 簡而得。而混淆度可直接使用式(4.8)進一步定義為:
exp PP H (4.9) 若
1 2
1 2 1
1 , , , | , , , m m i i i P W w w w P w w w w
則可發現,混淆度就是P w w w
i| 1, 2, ,wi1
23 的幾何帄均數的倒數。因此混淆度可以解讀為語言模型估測一個歷史詞串後面,帄均可能的 可接詞數;混淆度越高,表示一個歷史詞串後皆詞有較多的選擇,辨認時就越難找到確切的 答案;反之,則較易找到正確答案。
4.3 客語語言模型
4.3.1 基本客語語言模型
基本客語語言模型是針對客語文章(textA),使用統計的方式建立而成:
1 1 1 1 1 , , , | , textA i i textA i i textA i baseline i i baseline i baseline i C w w C w w k C w P w w w P w otherwise (4.10) 及
textA
i ,
baseline i textA i textA i i C w P w C w k C w w (4.11)
textA C 表示詞串在客語文章(textA)出現次數。4.3.2 強化客語語言模型
因為客語的文字資料量非常稀少,使用統計的方式建立的基本客語語言模型其參數量是 非常稀疏的(只有 19,213 個 bi-gram),所以希望能夠使用ㄧ些其他的資訊來訓練客語語言模 型,使得語言模型更為強建。 根據現有的文字語料庫,發現除了客語文字本身外,可以用幫助建立語言模型的資訊還 有客語詞類標記、國語詞類標記及國語語言模型等三種資訊。接下來將介紹如何使用這些資 訊來幫助客語語言模型的建立。24 Join Hakka POS inf. Stage 1 LM Join Mandarin POS Inf. Stage 2 LM Stage 3 LM Join Mandarin LM Baseline LM 圖 4.1:強化客語語言模型流程圖 如圖 4.1 所示是採取漸進的方式逐步強化客語語言模型,依序對基本語言模型加入客語 詞類資訊、國語詞類資訊及國語語言模型資訊。其架構如下式:
1
1
1 1 1 1 | , , | | + 1- | , baseline i i textA i i i i i pos i i trans i i P w w C w w k P w w w P w w P w w otherwise (4.12) 和
,
+ 1- , baseline i textA i i pos i trans i P w C w k P w P w P w otherwise (4.13) 其中
1 1 1 , 1 | i i i i baseline i i w C w w k w P w w
;而Ppos
w wi| i1
表示經由詞類資訊所建立的語言 模型;Ptrans
w wi| i1
為國語語言模型資訊建立的語言模型。接著,將對每個階層做詳細的介 紹。4.3.2.1 由客語詞類資訊建立語言模型(Stage1)
第一個階層將對基本客語語言模型加入客語詞類資訊,使用 class N-gram model 經由詞 條和詞類的對應關係,將詞條的分數退化至詞類,以解決資料量過於稀少的問題。如式(4.14) 及式(4.15)所示:
1 1 1 1 1 , | | | | i i pos i i H i i H i i H i i G w G w P w w P w G w P G w G w P G w w
(4.14) 和
i | pos i H i i H i G w P w
P w G w P G w (4.15)25 其中G w 表示客語詞條
i w 的詞類標記;i P G wH
i |G wi1
和P G wH
i
表示客語詞類模 型;P G wH
i1 |wi1
和PH
w G wi|
i
表示客語詞條與詞類標記的對應模型。 接著,將詳細介紹詞類模型及客語詞條與詞類標記的對應模型。首先是詞類模型,詞類 模型是根據人工標記的客語文章(textB)訓練而來,此模型記錄了詞類之間的轉移分數:
1
1 1 , | textB i i H i i textB i C G w G w P G w G w C G w (4.16) 和
i textB i H i textB i G w C G w P G w C G w
(4.17) 而客語詞條與詞類標記的對應模型則是記錄了客語詞條與詞類的相互對應分數,此分數有兩 個來源,分別是由人工標記的客語文章以及詞典(dict)估算而來,其中人工標記的客語文章的 客語詞條與詞類的對應較為可靠,但是並不包含所有的客語詞條;而詞典則相反,它包含了 所有的客語詞條,但是其對應關係較不可靠,因為它僅記錄了客語詞條與詞類的對應而已。 所以這兩個對應分數,將對上述兩個來源做結合:
| , , | | , i textB i i textB i i dict i i H i H i i H H i G w P G w w C w G w k P G w w P G w P G w w otherwise P G w
(4.18) 其中,
, | 1 | i textB i i i textB i i w C w G w k H textB i i w P G w w P G w w
;k 為一個常數值,當對應次數大於k 時將直接 使用人工標記的客語文章所估算的對應分數,反之則使用詞典內的分數。 而另外一個對應分數,因為客語的詞類標記僅分成 49 類,若直接估算PH
w G wi|
i
,則會 發生資料量過於稀少的問題,所以此對應分數採用間接預估的方式計算:
|
H
i |
i
H i i baseline i H i P G w w P w G w P w P G w (4.19)26 其中Pbaseline
w 表示基本客語語言模型的分數。 i4.3.2.2 由國語詞類資訊建立語言模型(Stage2)
雖然詞類資訊在第一個階段就已經有考量,但是因為客語文字語料過於稀少,所以單純 從客語估算出的詞類模型及對應模型其實並不可靠。所以第二個階段,將使用較為可靠的國 語詞類資訊對第一階段的各個模型重新訓練。 Build Hakka Entry and Translation Mapping Model Train Mandarin POS Model Build MandarinEntry and POS Mapping Model
Dict
Hakka Entry and POS Mapping Model Mandarin Text Mandarin POS inf. LM Retrain Hakka Entry and POS Mapping Model TextB Mandarin LM Build Translation Model 圖 4.2:國語詞類資訊語言模型的建立流程圖 圖 4.2 為國語詞類資訊語言模型的建立流程圖。主要是利用國語文章較為豐富的特性, 藉由翻譯加強客語詞條對應至詞類的分數;並且將原本只由人工標記的客語文章訓練出的詞 類模型取代為國語的詞類模型。以下將依序介紹各個模型的建構方式及特性:
, | | , | | , i M i i T i i i i M H new i i H i i P G M M P M w w M w M P G w w P G w w otherwise
(4.20)
,
, 1 | | H new i i H new i i Trans M i P G w w P w G w P w P G w (4.21)27
1
1 , | textM i i M i i textM i C G M G M P G M G M C G M (4.22) 其中式(4.22)為由國語文章估建立的詞類模型,式(4.20)及式(4.21)為藉由翻譯將國語的詞類資 訊對應至客語詞條上的對應模型,將這三個模型代入式(4.14)及式(4.15)中,即完成加入國語 詞 類 資 訊 的 動 作 。 其 中M 表 示 國 語 詞 條 ;i M w 表 示 客 語 詞 條
i w 的 國 語 翻 譯 ;i
|
M i i P G M M 表示國語詞條與詞類的對應模型;P M wT
i |w 表示客語詞條與翻譯的對i
應模型;PM
G w
i
表示國語詞類模型的 unigram;PTrans
w 表示翻譯模型。接著將對這四1 個模型做進一步的介紹。 首先,因為國語有豐富的文字語料,所以國語詞條與詞類的對應模型及國語詞類模型, 都可以使用簡單的統計方式,就能建立不錯的模型:
i textM i M i textM i G M C G M P G M C G M
(4.23) 及
,
| textM i i M i i textM i C G M M P G M M C M (4.24) 接著,客語詞條與翻譯的對應模型,這個對應模型記錄了客語詞條與翻譯的對應分數, 這個分數是根據人工標記的客語文章及詞典的翻譯對照估算而來的。其中人工標記的客語文 章的對應和詞類標記一樣較為可靠,但是並不包含所有的客語詞條;而詞典內的詞條與翻譯 對應的組合數較多,但是沒有對應次數的資訊。此分數是將這兩個來源做結合:
| , , | | , i textB i i textB i i textB i i Trans i T i i T Trans i M w P M w w C w M w k P M w w P M w P M w w otherwise P M w
(4.25) 其中,
, | 1 | i textB i i i textB i i w C w M w k T textB i i w P M w w P M w w
。k 為一個常數值,當對應次數大於k 時將直28 接使用人工標記的客語文章所估算的對應分數,反之則使用詞典內的分數。 最後翻譯模型,此模型記錄了國語翻譯的轉移分數。目前根據詞典內收錄的國語翻譯與 國語語言模型中詞頻最高的前 60,000 詞之對應關係,可分為三種情況,詳細統計資訊如表 4.1 所示: 表 4.1:國語翻譯與 60,000 詞分布情況 分類 詞條 數量 比率 Case 1 14,636 57.3% Case 2 9,487 37.1% Case 3 1,419 5.6% 合計 25,532 Case 1 詞典內許多客語詞條的翻譯是直接包含在國語語言模型內的,在國語文字語料中,它們 是詞頻最高的前 60,000 詞。 例如: 改朝換代 更正 更衣室 求得 因為上述的這些翻譯能夠直接在國語語言模型中找到,因此它們在國語的分數也是最為可靠 的,故對於這些翻譯直接複製國語語言模型的分數給它:
Trans i M i P M w P M w (4.26) Case 2 詞典內許多的翻譯,因為在國語文字語料中的詞頻較低,故未包含在前 60,000 詞中,所 以無法直接在語言模型中找到。但是,通常經過斷詞以後,拆解後的詞條都能在前 60,000 詞內。此部分的翻譯通常為較長的國語詞條或諺語, 例如: 一人飽全家飽 一年之計在於春 人心節節高 或是因為客語詞條的詞意為多個國語詞條的詞意所組成,29 例如: 客語詞條『其』的國語翻譯為『他的』是由國語詞『他』和『的』組成 上述兩種情況都會造成翻譯為由多個國語詞組成。此部分翻譯模型的分數做法為使用國語前 60,000 詞對翻譯做斷詞後,再給予翻譯模型分數:
1, 2, ,
Trans i M i n P M w P M w M M M (4.27)
1 2| 1
n| n-1
M M M P M P M M P M M 其中 n 表示國語翻譯由 n 個國語詞條組成。 Case 3 還有一些詞典內的翻譯,即使拆解成一字詞後,依然無法由國語的前 60,000 詞組成,部 分是因為這些翻譯含有造字, 例如: 『 』魚 或是含有一些少見的國語一字詞, 例如: 『蹩』腳貨 『鼯』鼠 『鷓鴣』菜 上述兩種情況將會造成翻譯無法直接由國語前 60,000 詞估計,但是這些詞條在國語文字語料 中亦是少見詞條,即使由國語文字中取得分數亦不夠可靠,所以目前不計算此類的翻譯模型 分數。4.3.2.3 由國語語言模型資訊建立語言模型(Stage3)
這個階層主要目的是藉由詞典翻譯直接使用國語語言模型中的詞條資訊。此階層將針對 表 4.1 中前後客語詞條的翻譯皆為 Case 1 的情況,做複製國語詞條轉移分數的的動作:
1 1 1 1 1 , | | | | i i Trans i i T i i M i i T i i M w M w P w w P w M w P M w M w P M w w
(4.28) 其中P w M wT
i|
i
及P M wT
i1 |wi1
為客語詞條與翻譯的對應模型;PM
M w
i |M wi1
30 為國語語言模型,前後翻譯均為前 60,000 詞。 表 4.2:Stage 3 客語語言模型混淆度估測 語言模型權重參數 (pos , trans) 混淆度評估 (perplexity) 訓練語料 測詴語料 (1 , 0) 979 1,320 (0.95 , 0.05) 1,229 1,725 (0.9 , 0.1) 1,238 1,730 (0.8 , 0.2) 1,230 1,756 (0.7 , 0.3) 1,251 1,796
4.4 雙語語言模型
此章節是針對日常生活中國客語夾雜使用情況而設計語言模型,目前僅考量以客語為背 景語言的語音辨認。此類型的語者所使用到的國語詞彙通常是專有名詞或較為新穎的詞彙, 穿插在客語文句之中。 例如: 頭擺人毋知麼 安到《網路遊戲》 《摩托車》要買較大台 正會較穩 其中《》內的文句為國語。 因為,目前並無大量此類型的雙語文字,所以本研究是針對實驗所用的雙語語音語料中 國語語音和客語語音所佔的比例及出現的國語詞彙做語言模型的設計。 雙語 語音語料 客語 Stage 2 LM Adaptation 雙語 語言模型 圖 4.3:雙語語言模型建置流程圖 圖 4.3 為雙語語言模型建置流程圖,用雙語語音語料中國客語所占的比例,給予語言轉 換及國語詞條的分數。其中分數如式(4.29)及式(4.30)所示:31
i
, i bilingual k P M M bilingual C M (4.29) 其中Cbilingual
M 表示在雙語語料中國語詞條數目。k 為國語詞條在雙語語料中所占的比例。 而考慮語言之間相互轉換時,詞條的分數為:
1 1 1 1 1 1 | 1 | | | | | 1 i i i i i i bilingual i i i i bilingual i i i P w w k P w w k P M w C M P B B k P M M C M P w M k P w (4.30) 其中B 表示雙語詞條,可能為國語詞條i M 或客語詞條i w ;i P w w
i| i1
和P w 為 4.3 節所建
i 立的客語語言模型。4.5 比較與效能分析
將以上各節定義之語言模型,且包含參數調整的部分;各個語言模型對不同語料之混淆 度比較,如表 4.3 所示。 表 4.3:語言模型混淆度估測 語言模型 Bigram 數 Perplexity 訓練語料 測詴語料 客語語言模型 Baseline 19,213 1,149 1,559 Stage 1 7,712,200 1,013 1,366 Stage 2 12,003,727 979 1,320 Stage 3 20,762,457 1,229 1,725 雙語語言模型 Baseline 16,312,103 - 885 Stage 1 24,008,914 892 Stage 2 28,300,441 882 Stage 3 37,075,131 85332
根據表 4.3 可觀察幾項資訊:
(1) 客語語言模型:相對於 baseline 而言,Stage 1 及 Stage 2 對於客語語音辨認,都能降 低語言模型對目標語料的混淆度。但是,Stage 3 卻提升了對目標語料的混淆度,是 否會影響辨認率則有待觀察。
(2) 雙語語言模型:Stage1 至 Stage3 對於目標語料的混淆度,依照資訊的增量增加而降 低。
(3) Stage2 與 Stage3 的差異:對客語的測詴語料而言,其混淆度 Stage3 明顯高於 Stage2; 但是,在雙語的測詴語料,其混淆度卻是相反的。此部份辨認率有待觀察。
33
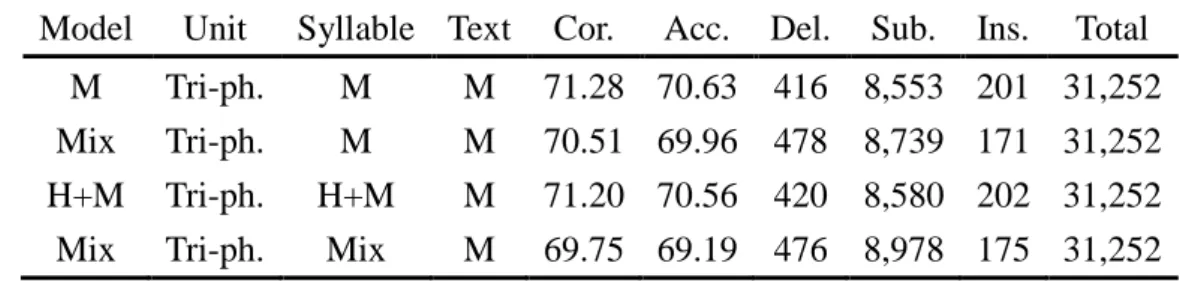
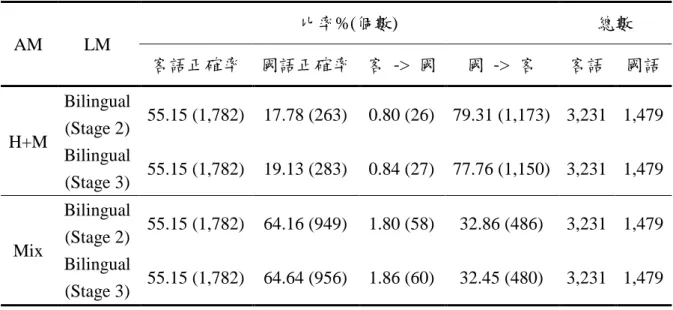
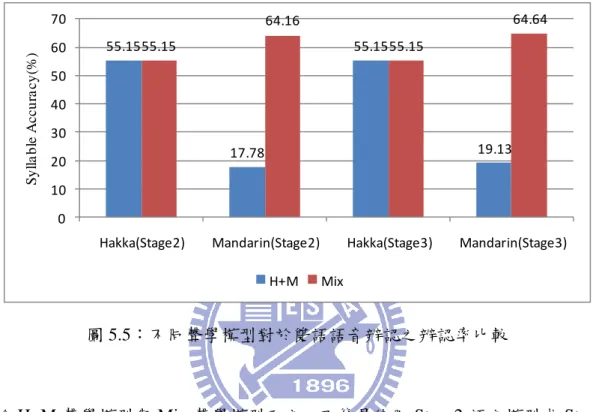
第五章 實驗結果及討論
此章節將介紹本論文所有的實驗設定及結果,並加以分析及討論。5.1 節為聲學模型的 實驗,主要是比較雙語聲學模型在各個語音的辨認效能;5.2 節為客語語言模型實驗;5.3 節 為雙語辨認實驗。5.1 聲學模型實驗
一般來說聲學模型之效能是直接由辨認率來評估,故本論文將對所建立之雙語混合聲學 模型(Mix)、國語聲學模型(M)、客語聲學模型(H)及國客語直接合併之雙語聲學模型(H+M) 等四個聲學模型做辨認率的比較,表 5.1 為各個模型的 GMM 數量。 表 5.1:模型 mixture 數量 Model Unit Mixture H RCD-I/F 19,813 H Tri-ph. 19,784 M Tri-ph. 52,807 Mix Tri-ph. 52,627 H+M Tri-ph. 72,591 接著,依照測詴語料的不同做以下三種實驗:分別是客語的音節辨認率比較、國語的音 節辨認率比較及雙語之音節辨認率比較。 客語音節辨認率之比較 表 5.2:不同聲學模型、待辨認音節對於客語測詴語料之音節辨認率比較 Model Unit Syllable Text Cor. Acc. Del. Sub. Ins. Total H RCD-I/F H H 51.36 50.18 598 8,789 228 19,299 H Tri-ph. H H 53.52 52.31 557 8,413 234 19,299 Mix Tri-ph. H H 52.16 50.87 580 8,652 250 19,299 H+M Tri-ph. H+M H 49.99 48.57 541 9,111 274 19,299 Mix Tri-ph. Mix H 43.43 42.20 592 10,326 237 19,29934 由表 5.2 可以看出雙語混合聲學模型(Mix)與客語聲學模型(H)之音節辨認率比較時,雙 語混合聲學模型之音節辨認率介於客語 RCD-I/F 聲學模型和客語 Tri-phone 聲學模型之間, 所以雙語混合聲學模型對於客語音節的辨認率算是合理。 但是,當待辨認音節由客語音節替換成雙語混合音節(待辨認音節 1,008 個)時,與直接 合併之雙語語言模型(H+M)的音節辨認率有明顯差距。針對這個現象,尋找替換待辨認音節 後辨認率下降的原因(由 50.87 降至 42.20),發現當替換成雙語混合音節時,許多客語音節容 易辨認為相似的國語音節(詳細錯誤分析如表 5.3),而直接合併之雙語聲學模型的客語音節辨 認為國語相似音節的情況卻明顯比較少,推測造成此現象的原因可能是因為雙語混合聲學模 型中的一些雙語共用的 HMM 模型其訓練語料來源包含了國語語料及客語語料,而直接合併 之雙語聲學模型則沒有共用的 HMM 模型。 表 5.3:Substitution 明顯增加且常出現(>40 次),前十名之音節 排名 Substitution(%)增加 正確客語音節 最大辨認錯誤音節 出現次數 音節 錯誤次數 1 31.5 H_zien M_jian 10 54 2 29.8 H_me M_mei 13 47 3 29.4 H_mien M_mian 15 51 4 29.3 H_so M_sou 10 41 5 28.4 H_zo M_zou 8 67 6 28.4 H_zung M_zong 19 116 7 28.1 H_do M_dou 99 541 8 26.9 H_tung M_tong 34 104 9 26.7 H_sii M_si 47 265 10 26.5 H_gau M_gao 20 98 表 5.3 為置換性錯誤明顯增加的客語音節,其最大錯誤的對象皆為國語相似音節,並且 它們有共用的 HMM 模型。 國語音節辨認率之比較 接著,替換國語測詴語料,表 5.4 為其詳細辨認率統計。由表可看出雙語混合聲學模型 與國語聲學模型之音節辨認率比較時,其音節辨認率差距並不明顯,屬於合理的下降範圍。