線上測驗是否有可能具備與紙筆測驗相同評分
效力?
楊亨利 應鳴雄
國立政治大學資訊管理學系 親民技術學院資訊管理系摘 要
由於線上測驗系統提供填充題及問答題等題性測驗時,會產生嚴重的測驗評分等 化(Equation)問題,因此目前大部分的網路測驗系統的考試題形便以是非題、單選題 及複選題為主。 為了瞭解線上測驗是否能具備與傳統測驗相同的評分效力,本研究在第一階段發 展了一個具備模糊評分機制的線上測驗系統。該系統除了包括一般測驗系統所提供的 是非、單選、複選等題型外,也能利用智慧評分機制來進行填充題評分。在第二階段, 本研究將傳統紙筆測驗、一般型評分機制、本研究提出之智慧型評分機制進行評分效 力比較。 研究結果顯示在包含填充題型的測驗中,不同的評分機制在測驗成績的評分結果 上會有顯著差異,而智慧型評分機制運作初期雖然可以減少與紙筆評分間的差異,並 改善一般型評分機制的評分效力,但仍無法在統計上或得具有相同評分效力的結果。 但是智慧型評分機制在擴充詞彙語意後,其評分結果會比未擴充前更加提升。此外, 「已擴充語意後的智慧型評分機制」與「紙筆評分」的評分結果並無顯著差異,此結 果顯示出透過智慧型模糊評分機制,線上評分系統將有可能具有與紙筆評分相同的評 分效力來處理具有填充題型的測驗評分工作。 關鍵詞 關鍵詞 關鍵詞 關鍵詞::::測驗等化、測驗評分等化、電腦線上測驗、填充題、模糊評分機制壹、緒論
測驗是利用試題來評量學生成就的一種工 具,也是評量學習成果的有效方法。傳統紙筆 測驗,無論是出題、考試、閱卷、成績計算等 作業,皆由人工進行處理,而受測者通常也被 指定在同一時間及同一地點進行考試。如此一 來,不但測驗效率不高,且人工作業出錯的機 會亦相對較大(何榮桂,1990;周文正,1998)。 電腦輔助測驗(Computer-Based Testing [CBT]) 因為能使測驗的效率提高、測驗時間的減少、 測量誤差的降低、多元豐富的試題呈現方式、 能 夠 獲 得 測 驗 相 關 的 其 他 資 訊 ( 何 榮 桂 , 1990)。因此連托福考試也採用電腦輔助測驗方 式進行,考選部也正積極規劃國家考試採行電 腦化測驗作業,並期望能達成考試技術的重大 突破(考試院,2003)。 美 國 心 理 學 會 (American Psychological Associate [APA])在1986年,發表電腦基礎測 驗在發展、使用以及解釋上的指導原則,以使得電腦測驗能夠與傳統紙筆測驗具有同樣的效 力(Bugbee, 1996)。國內學者也指出,實施線 上電腦輔助測驗在教學活動中的確有其必要, 而且使用電腦進行測驗時,其測驗效果應該與 傳統紙筆測驗結果相同(何榮桂,2000a, 2000b;簡茂發,1999)。 目前網路測驗系統的設計經常受到傳統紙 筆測驗觀念的影響,因此測驗題型仍以單選 題、複選題及文字測驗為主。雖然目前亦有少 數系統提供填充題及其他類型的測驗,但卻都 只能做到答案的樣式(Pattern)比對,而卻未 對答案語意進行分析比對。因此在現有提供填 充題型測驗的系統中,若作答者填答之答案與 題目設定的標準答案不同,系統便判定為錯 誤。林明達(1998)認為使用電腦批閱申論題 及填充題的測驗題型並不容易,其中填充題的 答案常有不同的寫法或有許多相同意義的詞 彙,使得無法明確的指定標準答案。因此,勢 必造成電腦系統評分結果與老師的結果不同, 而產生嚴重的測驗評分效力問題。 先不管申論題,當線上測驗有填充題時, 是否真能做到Bugbee(1996)所提出「電腦測 驗需能夠達到與傳統紙筆測驗具有同樣的效 力」的觀念要求?這是本研究試圖解答的問 題?為回答此問題,本研究先探討各種不同的 測驗題型在線上測驗系統上進行施測時,影響 具備傳統紙筆測驗相同效力的因素為何,並探 討解決之方法。而後在第一階段,利用模糊函 數、相似語詞庫、集合、樣式比對、規則推論 等觀念及技術,設計一個包含填充題之智慧型 的線上測驗系統。接下來,在第二階段,透過 學生實際參與,來試圖實證一個妥善設計的線 上測驗系統應與傳統紙筆測驗評分效果相同。
貳、文獻探討
一、測驗方式的演化
由於教育的目的在於引發學生行為的改 變,因此教師必須善用測驗來評量學生學習後 行為改變的情形,所以測驗在各種學科中,均 扮演著重要的角色(林璟豐,2001)。就教學而 言,測驗的主要目的在於增進學習的效果,因 此必須將測驗納入成為整個教學過程中的一部 份(陳英豪等,1982)。 測驗題目及題型的設計,通常會考量教學 的目標,在教育測驗理論中教育目標可分成認 知領域、情意領域及動作技能等三種不同的層 次 (陳李綢,1997)。何榮桂等人(1999)則 從網路教學的角度切入,認為紙筆測驗在編撰 試題、施測、閱卷、評分等過程之中,相當耗 費人力、物力,且對遠距學習者則未必能參與 這種「會考式」的紙筆測驗。因此若透過電腦 及網路的測驗將能提供適當的支援與輔助。 所 謂 的 電 腦 輔 助 測 驗 (Computer-Based Testing [CBT])是將傳統的考試工具及考題轉 移到電腦之中,讓學生藉由電腦螢幕閱讀考 題、利用鍵盤或滑鼠來移動游標並點選答案。 Alessi 和 Trollip(1991)指出,電腦輔助測驗 在應用上,具有選擇組合試題、易於產生試題 及共享試題題庫等效用。何榮桂(1990)也認 為電腦輔助測驗,具有測驗的效率提高、試題 呈現更加豐富、減少測量的誤差、減少測驗時 間及其他測驗資訊的獲得等優點。 目前許多電腦輔助測驗均輔以試題反應理化測驗系統。此類系統又稱為電腦化適性測驗
(Computer-Adaptive Testing [CAT]),它屬於一
種智慧型的測驗方法(Van der Linden & Glas,
2000;Wainer & Dorans, 2000)。電腦輔助測驗
的 應 用 , 早 在 1992 年 美 國 著 名 的 GRE
(Graduate Record Examination)測驗便已利用
電腦進行考試,更於1993年實施電腦適性測驗 的考試形式(周倩、簡榮宏,1997)。台灣地區 托福測驗(TOEFL)自2000年10月起也由傳 統的紙筆測驗改為電腦化測驗(財團法人語言 訓練中心,2003)。 隨 著 網 際 網 路 的 普 及 , 電 子 化 學 習 (e-Learning)及網際網路遠距教學也成為目前 相當熱門的議題,以網路測驗所能夠達成的效 果而言,它不僅只是施測的工具,同時也可以 是教學的工具(周文正,1998)。目前國內外架 構在網路上的網路測驗系統題型主要包括是非 題、選擇題、填充題、配合題、問答題、模擬 表現測驗(林璟豐,2001)。 McCormack 及 Jones(1997)認為網路測 驗能夠改善評量的程序和方法,因為網路測驗 具備有節省時間、即時回饋、減少資源、保存 記錄、更加便利等特性。周倩、簡榮宏(1997) 在其針對網路測驗的優缺點進行研究時指出, 大部份的學生較信任網路測驗的結果、認為網 路測驗是比較具有效率的考試方式、大部份的 受試者喜歡網路測驗的方式、認為利用網路測 驗並不會影響考試實力。但是網路測驗的缺點 是比傳統紙筆考試的速度慢、比較容易作弊、 閱讀線上考試比閱讀紙張試題更容易感到疲 倦、面對螢幕有礙考試時的思考、以及打字速 度會影響答題表現等。
Mark(1997)及Bennett et al.(1999)則
認為,在網路測驗的試題呈現上,目前有兩種 技術的運用對網路測驗的未來有明顯的影響: (1)利用多媒體的方式來呈現更多元的測驗問 題,(2)利用人工智慧使電腦自動判斷如何去 測驗及進行評量。
二、測驗題型
Gronlund(1998)依據題型的表現方式, 將所有的題型歸納成以下四大類: (一)選擇反應(Selected Response):如選擇、 複選、是非及配合題等。 (二)供應反應(Supply Response):如填充、 簡答、申論題等。 (三)限制性實作(Restricted Performance): 乃是指高度結構化的任務,例如選擇實 驗室設備、測量濕度,或是從電腦中呼 叫資料。 (四)延伸性實作(Extended Performance): 此類型評量需要較多的理解和判斷,如 實驗的進行、利用電腦解決問題等。 本研究以認知領域為教學目標進行智慧型 線上測驗系統設計,因此僅探討認知領域中的 選擇反應及供應反應測驗題型,對於情意領 域、技能領域的實作性測驗則不進行探討。在 認知領域之中,對於學生的學習測驗,大致上 可 以 區 分 成 認 識 型 題 目 (Recognition-Type Items)及建構型題目(Constructed-Response Items),本研究所包含的測驗題型不僅包含認 識型題目外,也包含建構型題目中的填充題 型。認識型題目即Gronlund(1998)分類中的 選擇反應型題目,此類題目通常會包含一段文 字敘述的刺激,以及一些選擇或選項以提供學 生根據刺激來辨認各個選項,並選擇出適當的 答案,例如是非題、選擇題及配合題。而建構 型題目即Gronlund(1998)分類中的供應反應 型題目,此類題目包含了問題或狀況的刺激, 再要求受試者根據題目的要求,將自己對於內 容的瞭解,以文字或是語言的方式表達出來, 例如名詞解釋、填充題(Short-Answer Items)及問答題等(鼎茂,2000) 。 認識型題目的特點是它的答案不會因為 人、時、地而有所改變,亦即其答案都是固定 的,不會因為評分者的不同或情境時間不同, 而產生重閱評分結果的差異。然而,建構型題 目之答案卻經常會因評分者的不同或情境時間 不同,而產生重閱評分差異。填充題主要是要 求學生在一個未完成的敘述句之中,填上「字」 或是「句子」,而使之成為一個正確且完整的敘 述。雖然填充題在施測上,具備提供更高層次 的知識測驗、更精確的測量學生知識、降低學 生在未充分準備時的猜答機率等優點,但因為 同義詞彙太多,容易造成計分不客觀的情形(陳 英豪等,1982;李大偉,1995),因此如何使填 充題型的測驗有更客觀合理的計分方式,並使 測驗系統能辨識出與答案相關的語意詞彙,並 提供與紙筆測驗相同評分效力的評分方法,將 有其研究的重要性。 理論上,我們可以在網路環境中實施任何 型態的測驗,但由於客觀的現實環境限制、技 術上的困難及經費上不足,目前為止最常應用 在網路上的測驗題型,仍以選擇題、複選題、 是非題等選擇反應題型為主。而且由於電腦評 分上的困難,填充反應題型則比較少見,結構 性與延伸性實作之題型,更是罕見。而填充反 應題型之所以在線上測驗系統使用的不多,最 主要原因在於電腦難以自動辨識相同之詞彙, 並會造成評分效力的問題,因此若能使電腦擁 有與老師相同的專業評分準則及專業知識,那 麼對於未來線上測驗系統的發展及應用,將能 更加成熟,所以本研究將針對填充題型所造成 的評分效力問題進行研究。
三、驗評分效力
美 國 心 理 學 會 (American Psychological Associate [APA])在1986年,發表了以電腦為 基礎的測驗在發展、使用以及解釋上的指導原 則,以使電腦測驗能夠與傳統紙筆測驗具有同 樣的效力。其中包括:在解釋電腦測驗之成績 時,任何因為電腦造成的影響效果必須清除或 重新計算;電腦測驗的發展者必須證明其測驗 效度;而決定效度的方法與紙筆測驗相同;個 人在電腦測驗與紙筆測驗上的成績等級順序必 須近乎相同;平均數散佈情形也必須近似相等 (Bugbee, 1996)。因此近年來有一些學者便針 對電腦適性測驗的試題等化(Equation)等問 題進行研究,並認為電腦測驗之評量應該與傳 統測驗評量有著相同的評量效度(Tsai, et al., 2001;Han, et al., 1997)。四、人工智慧與模糊理論在測驗系統的
應用
為了使測驗系統能更具效能,許多研究也 結合人工智慧及模糊理論等技術,進行診斷系 統 的 發 展 (Langley et al., 1990;Marshall,1993;Sun, 1999;Moundridou, 2003;Hwang,
2003;林明達,1998)。若能適當結合人工智慧 技術測驗系統中,將能解決複雜的出題、評分、 解釋及回饋等問題,並使測驗系統能支援教 學,促進學生學習績效。而Devedzic(2003) 則 更 進 一 步 指 出 「 內 容 導 向 智 慧 」 (Content-Oriented Intelligence),將是下一代網 站教育系統發展的重要議題。 Zadeh(1965)提出模糊集合論,該理論將 傳統集合的特徵函數從0到1之間絕對選擇, 推展為0到1之間的任意值,此種新的特徵函 數可稱之為歸屬函數(Membership Function)。 在填充題測驗中,由於不同的填答者在填寫答 案使用的詞彙並不相同,有些詞彙與標準答案 的語意完全相同,有些則是部分相同,有些則 是完全不同,因此若使用模糊集合的觀念將能 使測驗系統不再只是具有非「對」即「錯」的
二元評分能力。因此林明達(1998)認為申論 題及填充題的測驗題型使用電腦閱卷不易,其 中填充題的答案常有不同的寫法或有許多相同 意義的詞彙,使得無法明確的指定標準答案, 這將是一個十分值得努力方向。此外,目前國 內外對於如何建立一套可以自行學習關鍵字 詞、同義字詞、具有人工智慧的閱卷系統,並 未見有特別的研究。Mark(1997)認為利用人 工智慧使電腦能自動判斷如何去測驗及進行評 量,是值得研究的方向,其對於網路測驗的未 來也有明顯的影響。
五、目前線上測驗系統及智慧型測驗系
統發展
隨著資訊科技及網路技術的發展,藉由電 腦來進行測驗已成為不可避免之趨勢,而國內 外對於線上測驗系統或智慧型測驗系統之發展 應用也相當多,例如:美國 IBM 與 Arthur Anderson公司所發展之電腦輔助測驗系統(何 榮桂等人,1996)、1992年起美國GRE測驗採 用電腦適性測驗(CAT)、1997 年美國管理會 計師協會 IMA 採用電腦測驗進行會計師認證考試(Peterson and Reider, 2002)、2000年10
月 台 灣 地 區 TOEFL 測 驗 採 用 電 腦 化 測 驗 (CBT)、2003 年 9 月考試院宣布未來國家考 試將採行電腦化測驗(財團法人語言訓練中心, 2003),由此可見採用電腦與網路技術來輔助測 驗,將成為未來測驗的必然趨勢。 然而,目前國內外對於使用電腦進行測驗 的研究,主要以Lord(1980)所介紹的項目反 映理論(IRT)及Weiss(1980)所介紹的電腦 適性測驗(CAT)為主,其中較為著名的研究 包括何榮桂等人(1996)提出一個採用遠距適 性測驗的系統架構及後續一連串 CAT 之研 究,以及游寶達(1998)對於智慧型電腦適性 測驗進行研究,並利用模糊理論及智慧選題 法 , 建 構 一 個 ICAT 系 統 (http://ical.cs.ccu.edu.tw/),以提升 CAT 對受 測者能力值的評估精確度和穩定性。另外,彰 化師範大學生物學系的研究團隊發展了一個網 際網路評量與試後分析系統WATA(Web-based
Assessment and Test Analysis System),該系統
包 含 兩 個 模 組 , 分 別 為 總 結 性 評 量 模 組
( SAM-WATA ) 與 形 成 性 評 量 模 組
( FAM-WATA )。 WATA 具 有 Triple-A
(Assembling、Administrating、Appraising)的
架構,此系統之「考試管理引擎」可讓教學者 輕易的管理考試行程、線上題庫與使用雙向細 目分析表命題;「監考引擎」可讓教學者輕易掌 握應考者的考試;「試後分析引擎」可以讓教學 者迅速取得試後分析的資訊(王子華等人, 2002)。 此外,在目前遠距教學環境中,許多教學 系統也會將測驗系統納入其中,例如 ClassNet 系統支援教師在線上編寫測驗題目、解答,測 驗題型包括是非、選擇及申論,是非及選擇由 系統批改,申論則以電子郵件寄給教師批閱
(Van Grop & Boysen, 1997)。Mallard系統提
供選擇、計算、布林運算等題型,系統會適時 進行提示、回饋及計分(Swafford and Brown, 1996)。黃國禛等人(2002)在國科會科學教育 處推動的整合計畫中,針對測驗題目進行智慧 型的線上測驗題型分析與改進研究,採用題目 語意分析,來解決相似題目重複出現的相關問 題。本研究則是針對填充題型的測驗答案語意 進行分析,以解決線上填充題測驗的效力等化 問題。
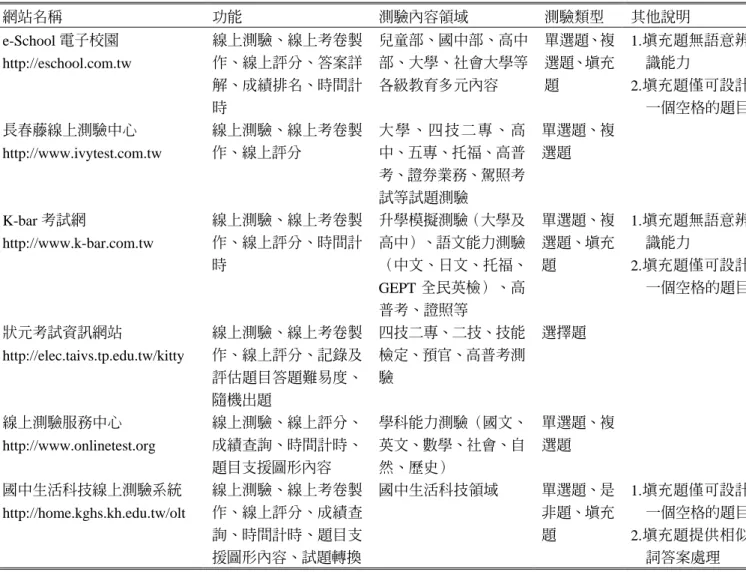
表 1 國內知名線上測驗系統功能比較表 網站名稱 功能 測驗內容領域 測驗類型 其他說明 e-School 電子校園 http://eschool.com.tw 線上測驗、線上考卷製 作、線上評分、答案詳 解、成績排名、時間計 時 兒童部、國中部、高中 部、大學、社會大學等 各級教育多元內容 單選題、複 選題、填充 題 1.填充題無語意辨 識能力 2.填充題僅可設計 一個空格的題目 長春藤線上測驗中心 http://www.ivytest.com.tw 線上測驗、線上考卷製 作、線上評分 大學、四技二專、高 中、五專、托福、高普 考、證券業務、駕照考 試等試題測驗 單選題、複 選題 K-bar 考試網 http://www.k-bar.com.tw 線上測驗、線上考卷製 作、線上評分、時間計 時 升學模擬測驗(大學及 高中)、語文能力測驗 (中文、日文、托福、 GEPT 全民英檢)、高 普考、證照等 單選題、複 選題、填充 題 1.填充題無語意辨 識能力 2.填充題僅可設計 一個空格的題目 狀元考試資訊網站 http://elec.taivs.tp.edu.tw/kitty 線上測驗、線上考卷製 作、線上評分、記錄及 評估題目答題難易度、 隨機出題 四技二專、二技、技能 檢定、預官、高普考測 驗 選擇題 線上測驗服務中心 http://www.onlinetest.org 線上測驗、線上評分、 成績查詢、時間計時、 題目支援圖形內容 學科能力測驗(國文、 英文、數學、社會、自 然、歷史) 單選題、複 選題 國中生活科技線上測驗系統 http://home.kghs.kh.edu.tw/olt 線上測驗、線上考卷製 作、線上評分、成績查 詢、時間計時、題目支 援圖形內容、試題轉換 國中生活科技領域 單選題、是 非題、填充 題 1.填充題僅可設計 一個空格的題目 2.填充題提供相似 詞答案處理
參、目前提供填充題型線上測驗系統評分效力先期研究
Bugbee(1996)認為使用電腦進行測驗必 須具有與紙筆測驗相同的測驗效力,為了確實 瞭解目前國內線上測驗系統提供之功能及填充 題評分效力,本研究針對目前國內知名的網路 線上測驗系統,從功能、測驗內容領域、測驗 題型方面進行比較。表1中顯示目前國內知名 的線上測驗系統,大多數均提供選擇題的測驗 題型,而部分的系統則提供了是非題及填充題 等題型。而比較值得注意的是,這些線上測驗 系統的填充題測驗,僅能設計一個空格的題 目,不能支援一個以上格子的題目,此外,在 答案的分析辨識上,均採用與是非及選擇相同 的字元比對。也就是說如果標準答案是「雙十 節」,受測者輸入「國慶日」、「雙十國慶」則都 算答錯,這與紙筆測驗教師批改之結果可能會 有所差異。然而,在表1中的「國中生活科技 線上測驗系統」,它的填充題型提供了相似詞的 答案分析功能,該系統允許老師在預先於答案 欄中將可以接受的答案均輸入在同一個答案欄 中(用半形逗號分開),例如老師在標準答案中輸入「國慶日,雙十國慶,雙十節」,則當學生輸 入「國慶日」、「雙十國慶」、「雙十節」時,該 系統則分析為學生答題正確,但這些語意卻無 法被其他相似題目或試題重複使用,且無法解 決相同語意答案之擴充、相似語意智慧辨識等 問題。而在回饋部分,多數系統只針對測驗結 果,給予成績評分結果查詢,並未保留當初測 驗之電子試卷及回饋內容,這些均有待加強。 此外,為了確實瞭解一般線上測驗與紙筆 測驗間的評量等化差異來源,本研究首先參考 K-bar 考試網及陽明國中官老師課程教學網之 測驗系統功能,發展一個一般型線上評分系 統,此系統之測驗題型包括是非題、單選題、 複選題及填充題,填充題可有一個以上的填充 格;此外,此雛形系統如同一般測驗系統,亦 可於線上編輯題庫及線上評分,但填充題之評 分方式則以目前坊間一般測驗系統之絕對二元 評量方式進行(需與標準答案完全相符才評量 為正確之回答)。一般型評分系統完成後,本研 究針對中部某技術學院資訊管理科修習電子商 務課程之87位學生,利用平時學習評量時間先 進行紙筆測驗,測驗題型包括是非題、單選題、 複選題及填充題各5題,當所有學生皆完成測 驗後,教師請每位同學連至線上之雛形測驗系 統,開啟完全相同題目之電子測驗卷,並將紙 筆測驗卷上所寫的答案,複製到線上電子測驗 卷中。經過事後教師對紙筆測驗卷的評分及測 驗系統的評分比較,發現學生回答相同的答案 在不同的測驗工具上卻出現明顯的分數差異, 而且線上測驗系統之分數明顯低於紙筆測驗的 分數。而其中是非題、單選題、複選題之得分 在紙筆測驗及線上測驗之結果完全相同,顯示 這些題型藉由電腦系統評分能具有相當高之評 分效力,然而在填充題部分之得分在紙筆測驗 及線上測驗上確有非常明顯的分數差異,顯示 目前線上測驗系統若提供填充題之題型,電腦 無法具備與紙筆測驗相同的評分效力。隨後本 研究將每一份試卷進行仔細的分析比對,本研 究發現填充題型在線上測驗無法擁有紙筆測驗 同樣的評分效力,其主要形成的原因歸納如下: 一、電腦科技本身造成評量效力降低:由於電 腦環境中的字有全半形、大小寫之分,因 此非關學生本身知識而是電腦環境造成的 評量效力差異便可能形成。例如答案是半 形 大 寫 的 「B2B」, 但 學 生 卻 輸 入 小 寫 「b2b」、全形的「B2B」答案,在線上 測驗中則經常被誤評為「答錯」。 二、相同語意眾多造成評量效力降低:由於相 同的答案可能有許多相同的語意字彙可替 代,因此不同的學生可能寫出不同的字彙 但有相同語意的答案,例如標準答案原本 為「B2B」,但學生可能寫出「B to B」、 「Business to Business」、「企業對企業」等 擁有相同語意的答案,在紙筆測驗中教師 一般而言會給予「答對」的評分,而線上 測驗卻因為無法辨識語意,因此給予「答 錯」的評分。 三、集合順序問題造成評量效力降低:例如某 一題目為「電子商務中常見三種的經營模 式分別是 _______、_______、_______。」 此題標準答案若為「B2B、B2C、C2C」, 但受測者填寫成「B2C、C2C、B2B」,在 紙筆測驗中教師知道本題答案屬於同一集 合,因此順序可互換,故會給予「答對」 的評分,而一般線上測驗因為只能逐一比 對,因此發現三格的內容均不相同,故三 格填充都會給予「答錯」的評分。 四、中文程度低落造成評量效力降低:由於目 前學生經常藉由手機或電腦進行人際溝 通,減少了手寫書信的機會,因而學生中 文程度普遍下降。在紙筆測驗環境中某些 學生因為某個字不會寫而有出現錯別字、
同音異字或用注音取代的情形。而在線上 測驗環境中,學生可透過輸入法選出原本 不會寫的中文字,但若因為中文程度而誤 選了同音異字的錯字,則在線上測驗系統 中只要答案有一點點不同,都會被評為「答 錯」,因而沒有真實教師「斟酌」給分的模 糊機制。 五、隨機性漏字疏忽造成評量結果差異:某些 學生在測驗中會因為不經意的疏忽而漏寫 部分答案,例如答案原本為「企業經營模 式」,學生卻因為疏忽填答成「企業經營 式」,而漏填了「模」字,在紙筆測驗中, 教師會考量學生的漏字情形,而斟酌給予 部分分數,但線上測驗系統則因答案未完 全相同,因而評為「答錯」。 為了解決並改善填充題評分產生的評分效 力問題,本研究提出「智慧型線上測驗評分機 制」,並建立雛形系統以進行實證。
肆、系統架構
本實驗所使用的線上測驗系統,採用三層 式主從遠距測驗系統架構,後端資料庫伺服器 採用Microsoft公司之SQL Server 2000,用以 執行觸發程序及存放本系統之題庫、成績、語 意 、 申 訴 記 錄 等 資 料 。Web 伺 服 器 則 使 用 Windows 2000 作 業 系 統 中 的 Internet Information Server 5.0伺服器軟體,以執行伺服 器端(Server-Side Script)的語言(本研究使用的 伺 服 器 端 語 言 為 ASP,Active Server
Pages),並藉由ASP程式與資料庫進行連結。 測驗系統主要使用 ASP 程式語言來發展各項 模組功能,另外在ASP的程式中也會依據實際 需要,結合Html、JavaScript及VBScript等網 頁相關的程式語言,以共同完成各模組的功能 需求。 本研究規劃之線上測驗系統架構如圖1所 示,各元件簡述如下: 一、題庫編修介面:此介面提供試卷及題庫發 展者(教師)能於線上新增、修改、刪除 及查詢試卷及題庫內容。 二、測驗題庫及答案資料庫:儲存測驗系統的 考題編號、語幹、選項、答案、題目配分、 題目類型、學生資料、考試時間資料、班 級資料等。 三、出題模組:產生線上測驗試題內容及試題 順序,每位受測學生所回答之試題內容都 是相同的,但試題題號順序及答案選項順 序則由電腦亂數產生。 四、知識擷取介面:提供增修知識庫內容之介 面,以持續擴充系統智慧,進而提升線上 評分的能力,以使系統具有老師的評分判 斷特徵與能力。 五、使用者介面:提供線上測驗、題目解釋、 成績查詢及答案申訴之介面。 六、評分參數資料庫:存放教師個人化評分參 數及系統內建評分參數資料。 七、模糊推論及系統內建資料運算器:模糊推 論運算器內含詞彙語意模糊歸屬函數轉換 公式及模糊規則,用以進行模糊推論過程 中的計算,並動態調整系統內建之相似詞 彙語意關係值及系統評分環境參數值,以 提供聚合教師共識的系統內建資料。關於 本系統使用模糊理論產生內建評分環境參 數及相似語意詞庫模糊相似值建構方法說 明,可參考楊亨利與應鳴雄(2006)在「具 備智慧型模糊評分機制之線上測驗系統架 構」的研究。
八、相似語意/同音異字資料庫:存放評分機制 所需要參考比較的相關資料,諸如語意詞 彙資料、詞彙間關係值、同音詞庫、全半 形對應資料等。本研究在系統運作初期依 據測驗科目的知識領域,委託該領域之教 師專家建立初期系統預設的評分參數、詞 彙語意及相似語意詞庫的相似值,以確保 系統在尚未有任何教師使用者的初期環境 中,依舊能夠提供評分參數及相似語意詞 庫相似值的預設建議資料供第一位教師或 前幾位教師使用者選用。當有多位教師同 時使用此系統時,智慧評分機制會透過模 糊推論及系統內建資料運算器,來自動產 生符合大多數教師認知的高共識相似語意 詞庫相似值及評分參數值(楊亨利、應鳴 雄,2006)。 九、測驗結果資料庫:存放學生的電子試卷結 果,包括參與考試的時間、機器位置、考 試歷程、填寫之答案、測驗成績、各題回 饋資訊等。每位學生均會產生來自一般型 評分機制及智慧型評分機制評分後的二個 成績結果。 十、申訴處理模組與申訴處理記錄:處理並記 錄學生對系統評分及答案質疑的申訴工 作。一般而言教師無法將每個答案詞彙的 相關語意全部都建立至系統中,因此仍有 可能發生受測者認為自己填答的答案語意 是正確的,但系統卻無法辨識出的狀況, 所以此模組便能協助受測者進行申訴,並 以Email 通知教師進行處理。而教師則可 利用知識擷取介面,線上處理申訴問題, 若確實因系統的語意辨識能力不足,則可 即時擴充此語意知識,使本系統之評分判 斷能力可不斷提升。 圖 1 本研究發展之線上測驗系統架構圖 評分機制 評分機制 評分機制 評分機制 使用者介面( 測驗、評分解答、答案申訴) 知識擷取 介面 線上 測驗受測者(學生) 試卷及題庫發展者(教師) 題庫 編修介面 測驗題庫及 答案資料庫 出題模組 相似語意/同 音異字資料庫 申訴 處理記錄 申訴 處理模組 測驗結果 資料庫 智慧型評分機制 智慧型評分機制 智慧型評分機制 智慧型評分機制 字元比對模組 語意分析模組 集合順序模組 英文大小寫模組 全半形模組 同音異字模組 漏字模組 訊息回饋模組 一般型評分機制 一般型評分機制 一般型評分機制 一般型評分機制 字元比對模組 評分參數 資料庫 模糊推論及系統 內建資料運算器
十一、智慧型線上評分機制:歸納前述文獻探 討中的各種題性特性及優缺點及線上測 驗系統的測驗效力問題分析,本研究認 為要解決線上測驗的評量效力問題,必 須發展一個具備智慧的線上測驗系統來 模擬實際教師之評分決策模式。因此本 研究亦將發展一個具備題庫編輯、測 驗、評分、成績查詢、出題的線上系統, 其題型則包含是非題、單擇題、複選題 及支援一個以上空格的填充題測驗題 型,而本研究實際的重心則著重於填充 題的智慧評分處理機制。智慧評分處理 機制為本研究之核心,此機制包含各種 分析及計算填充題測驗分數之相關模 組。每一個填充格的分數 S(ti)是由填答 者答案之正確率歸屬函數 P(ti)與該填充 格 之 配 分 SI(ti) 決 定 , 即 S(ti)= P(ti)*SI(ti)。以下針對各模組功能依照運 作順序簡單描述(下文中之變數 ti是指 測驗題目編號,AS(ti)表示受測者所填答 之答案,AT(ti)表示標準答案): (一)字元比對模組:此模組將AS(ti)與AT(ti) 進行字元比對,當所有字元均完全吻 合,則受測者所填答案的正確率歸屬函 數P(ti)=1。 (二)語意分析模組:此模組最主要在比較 AS(ti)與AT(ti)詞彙間是否存語意關係, 若存在關係則語意關係相似係數 RS(ti) 來決定正確率歸屬函數P(ti)。 (三)集合順序模組:此模組最主要在比較 AS(ti)與AT(ti)詞彙間是否存在集合順序 關係。例如某一題填充題的題幹為「電 子 商 務 最 主 要 的 三 種 經 營 模 式 是 _____、_____、_____。」,假設使用者 輸入次序為「B2C」、「C2C」、「B2B」, 而 測 驗 的 標 準 答 案 次 序 為 「B2B」、 「B2C」、「C2C」,則本模組開始呼叫「集 合比對副程式 SCM()」,以進行集合順 序分析,若填答者的答案存在於標準答 案集合中,則該填充格之正確率歸屬函 數P(ti)=1。 (四)英文大小寫模組:此模組最主要在比較 AS(ti)與AT(ti)詞彙間是否為英文大小寫 的關係,若此關係成立,則正確率歸屬 函數P(ti)=1。 (五)文數字全半形模組:此模組最主要在比 較 AS(ti)與 AT(ti)詞彙間是否為文數字 全半形關係,若此關係成立,則正確率 歸屬函數P(ti)=1。 (六)同音異字模組:當AS(ti)≠AT(ti)時,且 不存在語意關係、大小寫及全半形關 係,兩個詞彙間只有1個字不同時,此 模組便會啟動。此模組在檢查這個唯一 不同的字,是否為受測者使用注音輸入 法輸入時因為選字錯誤而造成的同音異 字情形,若AS(ti)與AT(ti)確實存在此種 關 係 , 則 正 確 率 歸 屬 函 數 P(ti)= P(ti)=1-PW。這裡的 PW 是教師在系統 中設定的同音異字錯誤扣分比例參數, 若 PW=0.3,則表示同音異字需扣該題 30%的 分 數 , 因 此 正 確 率 歸 屬 函 數 P(ti)=0.7。 (七)漏字模組:此模組用於AS(ti)≠AT(ti)時, 且不存在語意關係、大小寫及全半形關 係,而因為受測者填答的答案中少輸入 一個字而造成答案輸入遺漏的不完整現 象時。若AS(ti)與AT(ti)存在此種關係, 1 , RS(ti)=1 P(ti)= RS(ti) , 0<RS(ti)<1
則需檢查由教師依照自己的教學原則及 習慣自訂漏字扣分比率參數PL,以確認 在此部分的評分規則。當漏字比例低於 25%時,正確率歸屬函數P(ti)=1-PL。若 系統之PL參數設為0.6,表示漏字比例 低於25%時需扣該題60%的分數,因此 正確率歸屬函數 P(ti)=0.4。至於漏字比 例的門檻是否為25%,教師可自行修改 此參數。 (八)訊息回饋模組:訊息回饋模組之主要功 能在提供受測者正確答案之回饋,本系 統同時採用KCR及KR之回饋方式,有 別於目前線上系統大多僅使用KR回饋 的方式。因此,本系統受測者完成測驗 後,系統會根據受測所填寫之答案內 容,給予適當且具有知識傳遞的知識回 饋。本模組之回饋包括成績回饋、答案 正確性回饋、語意關係回饋、英文大小 寫關係回饋、文數字全半形關係回饋、 同音異字關係回饋、漏字關係回饋等。 十二、一般性線上評分機制:此機制僅包含一 般線上測驗系統處理填充題之字元比對 模組評分方法,此模組將使用者答案與 系統內標準答案進行比對,當所有字元 均完全吻合,則此題的正確率歸屬函數 P(ti)=1,只要有一點不符合,則正確率 歸屬函數P(ti)=0。
伍、問題陳述與假設
本研究允許教師將個人評分之規則、風格 特質,以參數設定方式建立至上述評分機制 內,期待該評分機制技術能具備與教師紙筆相 同之評分效力。不過,由於每個學生皆來自不 同的成長環境,所習慣使用的中文詞彙均可能 有差異,再加上中文詞彙間具有相似語意者眾 多,管理者或教師可能無法在系統運作初期便 在智慧型評分機制中將所有詞彙間的語意關係 都考慮周全,不過若系統評分錯誤,應有學習 功能對這些新的語意知識予以擴充,以確保在 下一次測驗評分中做出正確的判斷。因此,本 研究期待下列假設驗證成立: 一、H1:不同的評分機制在測驗成績的評分結 果上會有顯著差異。 (一)H1a:使用一般型評分機制進行包含填 充題型的測驗評分,與紙筆測驗的評分 結果會有顯著差異。 (二)H1b:使用智慧型評分機制進行包含填 充題型的測驗評分,與紙筆測驗的評分 結果沒有顯著差異。 (三)H1c:使用智慧型評分機制進行包含填 充題型的測驗評分,與一般型評分機制 的評分結果間會有顯著差異。而且智慧 型評分與紙筆測驗評分間的成績差距, 明顯會比一般型評分機制與紙筆測驗評 分間的成績差距還小。 二、H2:智慧型評分機制經過詞彙語意的知識 擴充後,其評分結果應與未擴充前有差 異,而且應更加縮小與紙筆評分間成績差 距。陸、研究方法
一、研究樣本
本研究以本研究以中部某技術學院資管系 學生3班120位修管理資訊系統課程之同學為 樣本,採實地實驗法進行,以探討線上測驗系 統環境中,評分機制對於測驗成績的影響。二、不同評分機制之評分效力實驗流程
本實驗在進行之前先根據表1的國內知名 線上測驗系統之功能,依據其評分機制概念設 計出「一般性評分機制」之評分模組,另一方 面再依據本研究提出之技術方法,設計出「智 慧型評分機制」之評分模組。為了使兩種不同 評分機制能夠進行評分效力的比較,因此這兩 種評分機制共用相同之測驗介面,受測學生在 單一測驗介面中填答問題答案後,系統會將試 卷送至這兩種不同的評分機制中進行評分,並 分別計算出評分後之成績結果。 實驗流程如圖2所示,共分成二個階段實 施。第一階段的目的是為了使受測學生能熟悉 測驗系統之操作功能,並降低受測學生因不熟 悉系統操作而產生實驗干擾。此階段刻意選擇 第三週進行正式授課後的第一次線上平時測 驗,受測學生皆於上課時透過電腦進行線上測 驗,並於線上填寫電腦網路使用之基本資料, 但是本次之成績結果則不做為本研究之分析。 第二階段則於課程第六週進行管理資訊系統課 程第二次平時測驗,教師首先在智慧型評分機 制中,依照教師批改填充題的規則完成相關參 數設定,隨後教師發給每位同學一份紙筆測驗 的試卷,內容共計17題,非填充題題型包括5 題是非題、5 題單選題及 2 題複選題,每題 5 分共計60分;填充題型有5題,共含8個填充 格,共計40分。為控制測驗時間對測驗成績的 影響,本實驗進行時並未告知學生實際考試的 時間限制,並期望每位同學均能有充分時間作 答(考題設計時以30分鐘內可填答完成為標準 進行設計)。當所有學生均完成紙筆測驗的填寫 後,此時教師則要求受測同學登入線上測驗系 統開啟線上測驗的試題,此份線上試卷之試題 與同學手上之紙筆測驗試卷內容完全相同,教 師要求同學將自己在紙筆試卷上所寫的答案, 按照題目順序將相同題目之答案照實的輸入至 線上試卷中,並當答案全部輸入完成後,則送 出試卷完成測驗。當所有學生都完成線上測驗 的程序後,教師向受測同學收回所有紙筆試 卷,並由教師親自批改,批改後的成績再輸入 至資料庫中儲存。另一方面,當測驗系統收到 學生送出之答案後,系統會自動將受測者之答 案分別送至「智慧型線上評分機制」與「一般 型線上評分機制」進行評分,不同評分機制所 產生之評分成績結果則儲存至資料庫中。因 此,每位受測者完成此實驗後,同一份試題會 出現來自三種不同評分機制所產生的成績,這 些成績資料將成為後續研究的分析資料來源。圖 2 本研究之實驗流程圖
三、研究架構與變數說明
圖3為本研究之研究架構,透過不同的評 分機制來分析對於測驗評分成績的影響,研究 架構中的變數說明如下: (一)自變數 僅有「評分機制」一項,包括三種評分機 制,分別是一般型評分機制、智慧型評分機制 及紙筆評分。 (二)依變數 Bostorm(1990)及許多探討測驗成效的研 比較紙筆測驗教師評分、智慧評分機 制測驗系統評分及一般評分機制測驗 系統評分等三種分數之比較 管理資訊系統紙筆平時測驗 (測驗後考卷暫未收回) 請求同學將紙筆試卷上所寫之答案填 入線上測驗畫面中 登入線上測驗系統 收回紙筆測驗試卷並立即批改成績 輸入紙筆測驗成績至電腦系統中 實驗結束並進行研究分析 課程第三週課程第三週課程第三週課程第三週 第一階段第一階段第一階段第一階段 :::: 登入線上測驗系統 熟習線上測驗系統功能及完成 線上測驗(測驗成績不列入本實驗) 送出受測者填答之答案,並自動送至 兩二種不同的線上評分系統進行評分 一般型線上評分機制產生 評分後之測驗分數 智慧型線上評分機制產 生評分後之測驗分數 課程第六週課程第六週課程第六週課程第六週 第二階段第二階段第二階段第二階段 ::::究中,經常會使用測驗成績來當作評量學習成 效的指標。Bugbee(1996)也認為不同的評量 工具若能具有相同的評分結果,則具有評分效 力。因此本研究直接採用線上測驗的評分成績 結果與教師親自批改評分的成績結果進行比 較,以觀察評分工具對於測驗成績的影響是否 有差異。 (三)控制變數 為使測驗時間不會去影響測驗結果及評分 效力,本研究在實驗進行時,採取寬裕測驗時 間。另外,為隔絕介面變數干擾,本研究之一 般型與智慧型評分並無自己的介面,而是由系 統統一收件後,自動分派至不同評分機制。 圖 3 研究架構
柒、資料分析
本研究採用 SPSS 作為資料分析的工具軟 體。一、樣本基本資料分析:
本研究共有120位受測者參與實驗,其中 男生63位,女生57位。但經過第一階段及第 二階段實驗後,由於有8位受測者未全程參與 實驗或錯誤操作系統導致其實驗資料未能完整 取得,因此後續資料分析將扣除此8位受測者 資料,因此全程參與之受測者共有112位,其 中男生58位,女生54位。二、研究假設檢定
本研究最終共有112個受測者,每個人會 先進行紙筆測驗,再進行線上測驗,最後會得 到三種評分工具的評分成績,此成績為包含所 有題型之成績,結果如表2所示。受測者在紙 筆測驗教師評分的平均成績為 53.31 分,而智 慧線上測驗評分機制成績為 52.21 分,一般線 上測驗評分機制成績為 48.81 分,從分數上可 看出智慧型評分成績與教師親自批改的紙筆測 驗成績差異較小。為進行本研究之第一項假設 檢定,本研究使用林清山(1990)多變項分析 統計法中的相依樣本單一組重複量數統計分析 方法,以瞭解受測者對於不同的評分機制所得 到的測驗成績評分結果是否有顯著差異。由於 使用重複量數的概念來進行,因此不能將測驗 成績直接進行分析,而需利用每位受測者在各 種評分機制所得到之成績,分別計算出其受測 者的紙筆與一般評分成績差距(使用 PG 符號 表示)、紙筆與智慧評分成績差距(使用PI符 號表示)、智慧與一般評分成績分數差距(使用 IG符號表示)等三項資料,此三項資料之平均 結果如表2所示,其中紙筆評分與一般評分成 績之分數平均差距高達 4.5 分,顯示這兩種評 分機制的評分結果差異較大;另外,紙筆評分 評分成績 評分機制 評分機制 評分機制 評分機制 - 智慧線上 - 一般線上與智慧評分成績之分數平均差距最小,但仍有 1.10分的差距。 表 2 受測樣本之測驗結果 項目 樣本數 平均分數 標準差 原始資料 一般 OLT 評分之成績 112 48.81 16.06 智慧 OLT 評分之成績 112 52.21 16.55 紙筆教師評分之成績 112 53.31 16.87 資料轉換 紙筆評分與一般評分成績之分數差距(PG) 112 4.50 4.52 紙筆評分與智慧評分成績之分數差距(PI) 112 1.10 2.40 智慧評分與一般評分成績之分數差距(IG) 112 3.40 3.57 經過 SPSS 的相依樣本單因子多變量變異 數分析(張紹勳,1997),進行不同評分機制評 分成績的多變量顯著性檢驗,結果如表 3 所 示,其中Wilks Λ值為0.490,P<0.05,表示受 測者在不同評分工具所得到的成績結果並不相 同,因此支持了本研究所提出的 H1 假設,不 同的評分機制在測驗成績的評分結果上會有顯 著差異。 表 3 評分工具假設之變異數分析表 檢驗項目 Wilks' Λ值 F 值 P 值 Eta2 顯著性α=0.05 評分工具 0.490 F(2,110)=57.293 0.000 0.510 達顯著水準 表4為評分工具間之評分成績差異檢定分 析結果,無論是「紙筆評分與一般評分(PG)」、 「紙筆評分與智慧評分(PI)」及「智慧評分與 一般評分(IG)」等工具間的成績差異檢定,P 值均小於0.05,均達到顯著水準,顯示 H1a、 H1c 假設均獲得支持:受測者在紙筆與一般評 分機制之成績有顯著差異、智慧與紙筆評分間 差距小於一般與紙筆評分間差距。但是,受測 者在紙筆與智慧評分機制之成績上也有顯著差 異,因此H1b假設並未獲得支持。 表 4 評分工具間之評分成績差異檢定分析表 相依變數 平均數 標準差 t 值 P 值 PG 4.50 4.52 10.531 0.000 PI 1.10 2.40 4.848 0.000 IG 3.40 3.57 10.098 0.000 為了確認造成評分工具間之評分成績差異 是否源自於填充題型產生的評分差異,因此本 研究另外將填充題型及非填充題型的評分成績 結果分別重新進行評分工具間之評分成績差異 檢定。 在僅包含填充題型評分成績結果中,一般 OLT評分之平均成績為17.58分(S.D=10.04), 智慧OLT的評分平均為20.81分(S.D=10.29), 紙 筆 教 師 評 分 之 平 均 成 績 為 21.82 (S.D=10.39)。在僅計算填充題型的測驗成績
時,「紙筆評分與一般評分(PG)」、「紙筆評分 與智慧評分(PI)」及「智慧評分與一般評分 (IG)」等工具間的成績差距分別是 4.41 分、 1.01分、3.40分。在不同評分機制評分成績的 多變量顯著性檢驗上,Wilks Λ值為 0.515,P 值=0.000,顯示出受測者在不同評分工具所得 到的填充題型成績結果並不相同。而評分工具 間之評分成績差異檢定分析結果,無論是「紙 筆評分與一般評分(PG)」、「紙筆評分與智慧 評分(PI)」及「智慧評分與一般評分(IG)」 等工具間的成績差異檢定,P 值均小於 0.05, 均達到顯著水準,其統計值與統計結果與計算 所有題型成績的表4結果相當類似。 在僅非填充題型評分成績結果中,一般 OLT評分與智慧OLT之平均成績均為31.31分 (S.D=8.98), 紙 筆 教 師 評 分 之 平 均 成 績 為 31.40(S.D=9.14)。在僅計算非填充題型的測 驗成績時,「紙筆評分與一般評分(PG)」、「紙 筆評分與智慧評分(PI)」及「智慧評分與一般 評分(IG)」等工具間的成績差距分別是0.089 分、0.089分、0.000分。在不同評分機制評分 成績的多變量顯著性檢驗上,Wilks Λ值為 0.991,P 值=0.319,顯示出受測者在不同評分 工具所得到的非填充題型成績結果並無顯著差 異。 由上述分析結果發現,不同的評分機制在 非填充題的評分結果上並沒有顯著差異,線上 測驗所產生的評分結果差異幾乎都來自於填充 題型的評分結果,因此使用整體分數進行評分 成績結果的差異檢定時,所得到的分析結果會 與僅考慮填充題型評分成績時的結果極為類 似,因此本研究仍以考慮各種題型的整體分數 進行分析。 本研究原先認為電腦中若使用智慧型評分 機制,由於該機制已儲存了教師的批改規則及 習慣,並藉由語意詞彙資料庫的建立,建立了 測驗知識領域的語意詞彙間關係,因此應能與 教師親自評分的結果相似。但經過上述實驗及 統計分析後,雖然使用智慧評分與紙筆評分的 成績平均只有差距1.10分,但仍舊在統計上顯 示無法有相同的評分效力。仔細分析形成原 因,可能來自於學生填答的填充題答案與教師 設定的填充題標準答案不同,雖其語意詞彙與 標準答案間存在同義或相似關係,只因為系統 語意資料庫所儲存的語意關係知識仍舊不足, 才會形成智慧評分無法與紙筆評分有相同的結 果。事實上,在第六週測驗完成後,部分學生 的確也在測驗系統中針對某些填答的答案提出 成績申訴,因此,本研究便提出了第二項假設, 認為只要智慧型評分機制經過詞彙語意的知識 擴充後,其評分結果會比未擴充前更加提升。 為了進行此項假設檢驗,本研究針對學生 所申訴的問題進行處理,並對於系統內建語意 詞彙關係不足的知識部分進行擴充。學生所申 訴的內容主要是針對答案詞彙語意的部分,例 如某填充題之題目為「從作業系統的處理方式 而言,當資料收集到一定時間或一定量才處 理,稱為 ___。而將CPU時間平均分配給每個 使用者程式的作業系統處理方式稱為 ___。」, 本題在系統內的標準答案分別是「批次處理」 與「分時處理」。以「批次處理」詞彙而言,「批 次處理」在系統中已存在的相關語意詞彙包括
「batch processing」、「Batch」、「整批處理」、「批
次」等6個詞彙,但是有一些學生所寫的答案 是當初教師及系統未想像到的,諸如「批次作 業」、「批次作業處理」及「整批處理作業」,這 些答案在教師紙筆評分時被認為是與標準答案 相同,但在智慧型線上評分機制中卻無法對這 些相同語意的詞彙進行辨識,導致評分結果產 生差異。另外,像是在另一個填充題題目為「___ 能將企業的智慧資產透過資訊科技累積起來, 並能進行有效的運用,並達到企業員工間能快
速傳遞及分享知識經驗,使企業能不斷創新。」 中,系統預設之標準答案為「知識管理」,系統 內建之不同程度之相關語意包括「知識管理系 統」、「知識庫系統」、「Knowledge Management」 等,而學生則輸入了「知識系統」答案,因為 教師在系統初期語意建立時並未將「知識系統」 的詞彙建立到語意詞彙關係資料庫中,因此系 統也無法做出正確的判斷評分,而在其他題目 中也均有類似的情形發生。由於本研究設計之 測驗系統保留了受測學生當初所填寫的電子試 卷資料,本研究在完成學生申訴的問題及擴充 所遺漏的相關語意詞彙後,將針對這些受測者 當初所填寫的電子試卷答案,重新送至智慧評 分機制重新評分,再與未擴充詞彙語意前之智 慧評分結果、紙筆評分結果進行比較。 本研究針對「未擴充詞彙語意前之智慧評 分」、「擴充詞彙語意後之智慧評分」及「紙筆 評分」進行不同評分機制評分成績的多變量顯 著性檢驗,結果如表5所示,其中Wilks Λ值 為0.821,P<0.05,表示「未擴充詞彙語意前之 智慧評分」、「擴充詞彙語意後之智慧評分」及 「紙筆評分」等不同評分工具所得到的成績結 果並不相同,因此仍支持本研究所提出的 H1 假設,不同的評分機制在測驗成績的評分結果 上會有顯著差異。 表 5 包含擴充詞彙語意後之智慧評分機制的變異數分析表 檢驗項目 Wilks' Λ值 F 值 P 值 評分工具 0.821 F(2,110)=12.023 0.000 表6為「擴充詞彙語意後之智慧評分」與 「未擴充詞彙語意前之智慧評分」及「紙筆評 分」評分工具間之評分成績差異檢定分析結 果。表中顯示「紙筆評分與已擴充語意詞彙後 的智慧評分(PI2)」間的成績差異未達顯著水 準,表示經過擴充語意後的智慧與紙筆評分的 成績並無顯著差異,具有與紙筆評分相同的評 分效力。因此,若是線上測驗系統的評分機制 經過學生實際測驗後的語意擴充,應能使得智 慧評分機制具有與紙筆測驗相同的評分效力, 先前未得到支持的H1b假設,在擴充語意詞彙 後而得到支持。 另外,表6中也顯示「已擴充語意詞彙後 的智慧評分」與「未擴充語意詞彙前的智慧評 分」間的評分結果有顯著差異,原本未擴充前 與紙筆的平均評分差異是1.03分,而已擴充後 與紙筆評分的平均評分差異則縮減為 0.071 分,顯示智慧評分機制經過不斷的擴充語意詞 彙後,將能提升其評分效力,因此假設 H2 獲 得支持。 表 6 評分工具間之評分成績差異檢定分析表 相依變數 平均數 標準差 t 值 P 值 PI2 0.071 0.07 1.02 0.312 II2 1.03 0.21 4.83 0.000 註:PI2 表示「紙筆與已擴充語意詞彙後的智慧評分」間之成績差異 II2 表示「未擴充與已擴充語意詞彙後的智慧評分」間成績差異
雖然經過語意擴充後的智慧評分機制能具 有與紙筆測驗相同的評分效力,但是這兩種評 分機制的成績結果平均仍有 0.071 分的差異, 本研究再將這些差異的受測資料進行比對發 現,這些差異是屬於實驗過程中受測者的非刻 意之隨機誤差,其中包括受測者在將紙筆測驗 上的答案抄錄至線上測驗系統時,少填答了一 題答案,或電腦輸入時拼錯字及漏字,而產生 紙筆測驗的答案與線上測驗輸入的答案並不一 致,因此導致仍出現成績差異,若排除受測者 從紙筆測驗抄寫到線上測驗過程中的人為隨機 誤差,則利用智慧型評分機制來取代紙筆測驗 時的評分效力將更能提升。
捌、結論與建議
線上測驗系統若只處理是非題、單選題、 複選題等具有固定答案的測驗題型時,並不會 產生與紙筆測驗結果不同的測驗結果。但若是 要進一步推展線上測驗系統的測驗題型應用範 圍,並於測驗中加入填充題型等具有眾多可能 的相同或相似語意詞彙答案時,則需要注意其 評分機制的評分效力問題。本研究在探討各種 評分機制的評分效力,主要是以各評量工具相 對於教師親自批改評分之成績結果差異,做為 評分效力的依據。一個完美的電腦評分機制應 該與教師親自批改的評分成績結果相同,因此 一個評分機制工具的評分結果與紙筆評分的結 果越接近,或是在統計檢定上呈現出沒有顯著 差異,則表示該評分機制具有與紙筆測驗相同 或相似的評分效力。 綜合資料分析結果,在包含填充題型的測 驗中,不同的評分機制在測驗成績的評分結果 上會有顯著差異,智慧型評分與紙筆測驗評分 間的成績差距,會明顯比一般型評分機制與紙 筆測驗評分間的成績差距還小。但「未擴充語 意前智慧評分機制」的評分效力無法與紙筆測 驗等化,若經過學生實際測驗後的語意擴充, 將能使得智慧評分機制具有與紙筆測驗相同的 評分效力。 不過,即使本研究證明智慧型評分機制經 過語意詞彙關係的知識擴充後,將可具備與紙 筆評分相同的評分效力,並不表示線上測驗系 統透過智慧型評分機制所評分後的成績結果會 與紙筆評分的結果 100%相同,這二種評分機 制的成績結果間可能只能近似 100%而已。歸 納其原因,智慧評分機制內可能永遠無法將全 世界中所有詞彙與詞彙間具有相同或相似語意 的關係知識全部建立完整,教師也無法將標準 答案相對應的所有相同或相似詞彙事先完全沒 有遺漏的建立至系統內,學生也可能因為來自 不同的背景,而有許多未預期的答案寫法。除 此之外,學生在透過線上測驗系統進行測驗 時,也可能遭受到電腦環境與技術的諸多干擾 或其他隨機性的因素,而導致線上測驗的結果 與紙筆測驗結果產生差異,其中包括對於電腦 經驗、電腦焦慮程度、中文輸入法的使用、非 刻意遺漏答案部分字元等。 根據本研究結論,對於用線上測驗系統做 為評分工具的教師及從事線上測驗系統發展工 作者而言,可以持續透過智慧評分機制、語意 詞彙關係的發展及教師評分規則參數的建立, 使得線上測驗系統提供填充題題型時,仍然可 具備與紙筆測驗相同的評分效力。然而本研究 未來仍需透過更多不同對象及測驗科目的評分 結果分析,將智慧型評分機制的成效推論至其他的對象領域及科目範圍。此外,未來對於問 答題測驗題型的評分效力研究,則還需要透過 中文詞句語法結構的分析來進一步克服。 近年來試題反應理論及電腦適性測驗對於 電腦基礎測驗領域的理論發展而言相當重要, 但由於本研究目前僅著重於電子化學習環境 中,學習過程的成就測驗,並透過測驗回饋來 輔助學生學習,因此不同於試題反應理論及電 腦適性測驗著重單一時間點的能力鑑定。但為 了深化教育測驗理論,本研究未來將針對填充 題型結合試題反應理論及電腦適性測驗的方法 進行研究,並使得網路測驗不僅在測驗時間及 內容上可以更彈性,測驗信度與效度也能獲得 保證,在結合試題反應理論及電腦適性測驗方 法的測驗題型上也可以更多元。
參考文獻
王子華、王瑋龍、王國華、黃世傑 (2002)。進階型多 功能網路評量與試後分析系統(WATA)的發展與 設計。視聽教育,43(4),21-45。 何榮桂(1990)。電腦教學系統中的測驗設計。中等教 育,41(2),29-34。 何榮桂(1999)。量身訂製的測驗-適性測驗。測驗與 輔導,157,3288-3293。 何榮桂(2000a,December)。遠距測驗與評量。載於 國立交通大學主辦之「2000 網路學習理論與實務研 討會」論文集(pp.34-43),新竹市。 何榮桂(2000b,December)。遠距測驗及相關問題之 探討。載於國立交通大學主辦之「2000 網路學習理 論與實務研討會」論文集(pp.23-33),新竹市。 何榮桂、郭再興、蘇建誠、陳麗如(1999)。在 Internet 上建構測驗環境之可行性及相關問題之探討。載於 中國測驗學會(主編),新世紀測驗學術發展趨勢 (pp.125-135)。台北:心理出版社。 何榮桂、蘇建誠、郭再興(1996)。遠距適性測驗系統 架構。資訊與教育雜誌,42,29-35。 李大偉(1995)。技職教育測量與評鑑(再版)。台北: 三民書局。 考試院(2003 年 9 月 3 日)。國家考試將規劃實施電腦 化測驗。考試院新聞稿。2004 年 2 月 10 日,取自 http://w3.moex.gov.tw/examnews/ exnews_2.asp?pgn=1。 林明達(1998)。全球資訊網線上測驗系統之設計與製 作。國立交通大學資訊科學研究所碩士論文,未出 版,新竹市。 林清山(1990)。多變項分析統計法(第五版)。台北 市:東華書局。 林璟豐(2001)。全球資訊網測驗題型之研究。國立臺 灣師範大學工業科技教育研究所碩士論文,未出 版,台北市。 周文正(1998,March)。www 上電腦輔助測驗系統之 研製。論文發表於國立高雄師範大學舉辦之中華民 國第七屆電腦輔助教學研討會,高雄市。 周倩、簡榮宏(1997)。網路評量系統之發展與研究。 遠距教育,4,12-15。 黃國禛、曾秋蓉、朱蕙君、蕭經武(2002)。智慧型線 上測驗系統題型之分析與改進。科學教育學刊,10 (4),423-439。 財團法人語言訓練中心(2003 年)。TOEFL 測驗簡介。 2004 年 11 月 10 日 , 取 自 http://www.lttc.ntu.edu.tw/Toefl.htm。 陳英豪等(1982)。測驗的編制與應用。台北:偉文出 版社。 陳李綢(1997)。教育測量與評量。台北:五南。 張紹勳(1997)。SPSS For Windows 多變量統計分析。 台北市:松崗出版社。 游寶達(1998)。ICL 心智模式取向之智慧型電腦輔助 診斷學習系統之研究。行政院國家科學委員會「電 腦 輔 助 學 習 」 專 題 研 究 計 畫 成 果 報 告 (NSC87-2511-S-194-009-ICL)。嘉義:國立中正 大學資訊工程研究所及認知科學研究中心。 楊亨利、應鳴雄(2006)。具備智慧型模糊評分機制之 線上測驗系統架構。資訊管理學報,13(1),41-73。 簡茂發(1999)。多元化評量之理念與方法。教師天地, 99,11-17。 鼎茂(2000)。教育與心理測驗。台北市:鼎茂出版社。Alessi, S.M., & Trollip, S.R. (1991).Computer-Based Instruction: Methods and Development. Englewood Cliffs. N. J.: Prentice-Hall, 2nd .
Bennett, M.G., Hessinger, J. Kahn, H., Ligget, J. Marshall, G., & Zack, J. (1999). Using Multimedia in Large-Scale Computer-Based Testing Programs. Computers in Human Behavior, 15, 283-294.
Bostorm, R.P. (1990, March). The Importance of Learning Style in End-User Training. MIS Quarterly, 14(1), 101-119.
Bugbee, A.C. (1996). The Equivalence of Paper-and-Pencil and Computer-Based Testing. Journal of Research on Computing in Education, 28(3), 282-299.
Devedzic, V.B. (2003, Aug). Key Issues in Next-Generation Web-Based Education. IEEE Transactions On Systemsm, Man, And Cybernetics-PART C: Applications And Reviews, 33(3), 339-349.
Gronlund, N.E. (1998). Assessment of Student Achievement. Needham Heights, M.A.: Allyn & Bacon.
Han, T., Kolen, M., & Poglmann, J. (1997). A Comparison Among IRT True-and Observed-Score Equatings and Traditional Equipercentile Equating. Applied Measurement in Education, 10(2), 105-121.
Hwang, G-J- (2003). A Conceptual Map Model for Developing Intelligent Tutoring Systems. Computers & Education, 40, 217-235.
Langley, P., Wogulis, J., & Ohlsson, S. (1990). Rules and Principles in Cognitive Diagnosis. In N. Frederiksen, R. Glaser, A. Lesgold, & M. G. Shafto (Eds.), Diagnostic Monitoring of Skill and Knowledge Acquisition (pp. 217-250). Hillsdale, NJ: Erlbaum. Lord, F. M. (1980). Applications of Item Response Theory
to Practical Problems. Hillsdale, N. J.: Erlbaum Publishers.
Mark, D.R. (1997). The Next Generation of Computerized Tests: Implications for Testing of Advances in Multimedia. Intelligent Tutoring Systems, and Language Processing, AEDS Journal, 19(2-3), 81-108.
Marshall, S.P. (1993), The Assessment of Schema Knowledge for Arithmetic Story Problems: A Cognitive Science Perspective. In G. Kulm (Ed.), Assessing Higher Order Thinking in Mathematics (pp. 155-168). Washington: American Association for the Advancement of Science.
McCormack, D., & Jones, D. (1997). Building a Web-Based Education System. N.Y.:Wiley.
Moundridou, M., & Virvou, M. (2003). Analysis and Design of a Web-Based Authoring Tool Generating Intelligent Tutoring Systems. Computer & Education,
40, 157-181.
Peterson, B.K., & Reider, B.P. (2002). Perceptions of Computer-Based Testing: A Focus on the CFM examination. Journal of Accounting, 20, 265-284. Sun, K. T. (1999, August). An Effective Item Selection
Method by Using AI Approaches. Paper presented at the meeting of the Advanced in Intelligent Computing and Multimedia System, Baden-Baden, Germany. Swafford, M., & Brown, D. (1996, June).
MallardTM:Asynchronous Learning on the World-Wide Web, Proceedings of the ASEE 96 Conference (Session 2632).Washington, DC.
Tsai, T. H., Hanson, B.A., Kolen, M.J., & Forsyth, R.A. (2001). A Comparison of Bootstrap Standard Errors of IRT Equating MeTHODS FOR THE Common-Item Nonequivalent Groups Design. Applied Measurement in Education, 14(1), 17-30.
Van der Linden W. J., & Glas, C.A.W. (2000). Computerized Adaptive Testing: Theory and Practice. Dordrecht, Boston: Kluwer Academic.
Van Van Gorp, M.J., & Boysen, P. (1997). ClassNet: Managing the virtual classroom. International Journal of Educational Telecommunications, 3(2), 279-292. Wainer, H. & Dorans, N.J. (2000). Computerized Adaptive
Testing: A Primer (2nd ed.). Mahwah, N. J.: Lawrence Erlbaum Association.
Weiss, D.J. (Ed.) (1980). Proceedings of the 1979 computerized adaptive testing conference. Minneapolis, MN.: University of Minnesota.
Zadeh, L. A. (1965). Fuzzy Sets. Inform. Control, 8, 338-353.
致謝
本 研 究 受 行 政 院 國 科 會 專 案 計 畫 ( NSC
93-2416-H-004-013)補助,特此致謝。
作者簡介
楊亨利,國立政治大學資訊管理學系,教授。
Heng-Li Yang is a Professor of Department of Management Information System of National Cheng-Chi University, Taipei city, Taiwan. E-mail: [email protected]
應鳴雄,親民技術學院資訊管理系,講師
Ming-Hsiung Ying is a lecturer of Department of Management Information System, Chinmin Institute of Technology, Miao-Li, Taiwan.
收稿日期:94.02.25 修正日期:94.07.07 接受日期:94.09.29
2005,50(2), 85-107
Could On-line Testing have the Same Effects on
Scoring as Paper-and-Pencil Testing?
Heng-Li Yang Ming-Hsiung Ying
Dept. of MIS, NCCU Dept. of MIS, Chinmin Institute of Technology
Abstract
With the rapid development of the Internet, computer-based or online testing has become an important issue in information education. Currently, most on-line tests only have selection-type items (single or multiple choice). Though some tests provide short-answer
(completion-type) items, they can only recognize answers as being either “all correct”
or “all wrong” given the computer’s simple binary-pattern matching system. Thus, in order to achieve the same precision of evaluation as in traditional paper-and-pencil testing, the first stage of this research project has adopted the concepts of fuzzy theory, the thesaurus, the set, and artificial intelligence to develop a “fuzzy scoring” mechanism. The proposed on-line testing system has true-false, multiple choice, and completion-type items. The latter will be graded by means of the naturally“fuzzy judgment” of human teachers.
The main purpose of this research is to evaluate the degree of equivalence of paper-and-pencil testing and on-line testing based on the fuzzy-scoring mechanism. The results demonstrate that different scoring mechanisms have a significant effect on test scores. At the beginning, though our fuzzy on-line testing system is significantly better than the usual on-line testing system, it could not achieve the same effects as paper-and-pencil testing. After we expanded our semantic vocabulary based on feedback, however, our fuzzy scoring mechanism is now equivalent, in terms of effects on scoring, to traditional paper-and-pencil testing.
Keywords: Computer On-Line Testing, Completion-Type Items, Fuzzy Scoring Mechanism, E-Learning, Test Score Equation