本體論架構應用於文章詞彙相似度之比對
程彥儒 中正大學電機工程學系 [email protected] 劉立頌 中正大學電機工程學系 [email protected] 黃皇賓 中正大學電機工程學系 [email protected]摘要
資訊檢索為近年來廣泛應用的技術, 為了增加檢索的準確度和效率,文章分類 和以文找文成為近年來熱門主題。其主要 方法是利用文章的詞彙做比對找出文章相 似度。若只從字面比對有同義詞和一詞多 義問題,需利用語意做比對處理。使用知 識基礎的語意比對方法,受限於知識來源 並需要大量人力成本;使用統計基礎的語 意比對方法,只能找出相關詞而非同義詞 且需收集處理大量文章。本論文利用本體 論之元素延伸建立文章語意比對演算法, 改善傳統在相似度上無法比對出文章的議 題,並提出相對應之方法流程。 關鍵詞:本體論架構、文章相似度比對。一、緒論
近年來由於網際網路的發達,許多資 訊透過網路被複製、傳播和儲存,因此造 成了資訊量的暴增。資訊使用者需耗費大 量的時間,才能從大量的資訊找到需要的 資訊,因此資訊檢索就顯得相當重要。為 了增加檢索的準確度和效率,文章分類[10] 和 以 文 找 文 [6] 成 為 了 近 年 來 熱 門 的 主 題。主要的方法是利用文章的詞彙做比對 以找出文章的相似度,但比對的方法往往 只從字面上去做比對,並沒有在語意層次 上做比對,因此無法考慮到同義詞和一詞 多義的比對問題。 針對語意問題的處理,最常見的方法 是利用 WordNet 做為知識基礎。WordNet 定 義 同 義 詞 的 集 合 和 集 合 之 間 的 關 係 [14],因此可以利用 WordNet 的知識找出 同義詞。另一種方法是利用人工對文集做 前置處理,如文章分類、語意標記,以避 免語意上發生的錯誤,但這些方法都需要 大量的人工來建立字典和做前置處理,因 此相當耗時耗力。 針對需要大量人工的問題,常見的解 決方法是統計的方法。統計方法是由大量 文集統計出詞彙出現在文章的頻率,利用 此頻率來做比對的依據,處理語意上的問 題。但統計方法需大量的文集來增加準確 度,因此需要耗費成本來處理大量額外的 文集和有可能發生收集不到相關文集的問 題。只利用詞彙在文章出現頻率的關係做 為比對的依據,只能估計出相關詞[1]的相 似度,並不能更深入的找出語意上的差異。 針對上述的問題,本論文提出一個語 意層次的比對方法,以解決同義詞和一詞 多義比對的問題。同時避免耗費大量人工 和時間以及依賴字典與收集並處理額外文 章的缺點。為了達到語意上的比對,需要 語意相關的知識做為比對的依據,但為了 不依賴字典或統計數據,因此取法於本體 論定義出了一個語意知識表示模型,以描 述文章所包含的語意結構。而且為了不花 費太多的人力收集並處理大量文章,因此 採用樣式基礎的擷取方法自動從文章中擷 取出語意結構。樣式基礎的擷取方法是事 先定義出樣式,並利用樣式比對以擷取出 文章裡詞彙和詞彙之間的關係[11]。從文 章擷取出語意結構後,就能利用語意結構 做為語意比對的依據。由於語意結構是取 法於本體論,因此利用本體論之間的語意 比對方法做為文章詞彙相似度比對的方法。
二、研究動機
文章間同義詞的比對方法可分為二 種,利用 WordNet 為知識基礎的比對方法 和潛在語意分析(Latent Semantic Analysis, LSA)[16]為統計基礎的比對方法。文章間 一詞多義的比對方法也可以分為二種,利 用人工標記文集的監督式語意歧異解析[5] 和利用統計方法的監督式語意歧異解析 [9]。 一般利用 WordNet 或一般英文字典做 為知識基礎的比對方法,最大的缺點是依 賴性,當字典中沒有欲比對的詞彙時,就 會發生無法比對的問題[3]。而現實生活中 的很多人名或專有名詞會隨著時間不斷的 被產生,且建立或更新英文字典需花費大 量的人力。潛在語意分析為統計基礎的比 對方法只利用詞彙在文集出現的頻率做為 比對知識,因此只能提供相關詞的比對。 本論文平衡這些方法的優缺點,提供 一個有效率的比對方法;此方法不需要額 外的知識基礎,可以達到語意上的比對, 而不僅是相關詞的比對。 (一) 文章語意結構 本論文參考本體論的定義,使用語意 結構來表示文章的語意。本體論包含三個 重要的元素:概念、屬性和關係[6][8][15]。 概念代表真實環境中的某個類別,屬性是 對於概念更詳細的敘述,關係表現出概念 之間組成的結構。Keet [7]指出結構可以代 表出二個本體論中的概念之間語意上的差 異,因此透過結構的比對就能找出二個本 體論中的概念之間語意上的差異。但是一 般的文章並沒有像本體論一樣的結構來表 示出語意,因此要比對文章之間詞彙語意 上的相似度就需借由額外的輔助知識,如 英文字典。 將文章轉換成類似本體論的結構,就 能透過結構來表達詞彙之間的語意,也就 不需借由額外的輔助知識,直接從文章的 語意結構中來評估詞彙之間的語意相似 度。因此可事先定義語意結構來表示文章 中的語意。在 WordNet 中定義出了詞彙的 本體論,把概念看成是名詞同義詞的集 合,概念之間用關係來組合在一起,並透 過組合出來的階層式架構來敘述這些概 念。本論文延伸 WordNet 的詞彙本體論, 利用文章中的動詞和介詞做為文章中的概 念之間的關係,對於文章的概念加以敘 述,如此一來透過動詞和介詞組織成的結 構就能表示出文章裡名詞的語意。
三、文章語意比對演算法
本論文提出的文章語意比對演算法流 程如圖 1 所示,流程中包含三大部份:文 章前處理、語意結構擷取和語意比對。文 章 p 和文章 q 分別代表不同的二篇文章。 文章前處理包括下列幾項:詞性標注、片 語標注和停字過濾。詞性標注是對文章中 的單字做詞性分析並貼上詞性標籤;片語 標注是對文章做斷字處理並做片語類型標 注;停字過濾是過濾冠詞、副詞等語意結 構擷取用不到的單字。語意結構擷取的方 法是利用樣式基礎的擷取,透過樣式比對 可以分別擷取文章 p 和文章 q 的語意結構 p 和語意結構 q。最後做語意上的比對。 (一) 文章前處理 本論文中所定義的語意結構是由名 詞、動詞和介詞所組成,因此利用詞性標 注的工具對文章進行這些詞性做標注。本 論文是使用工具 CRFTagger 進行詞性標注 [17] , 此 工 具 是 採 用 條 件 式 隨 機 域 (Conditional Random Fields)的統計模型來 處理詞性標注。 名詞可為修飾詞加上名詞後所組成的 名詞片語;動詞也可為動詞加上介詞後所 組成的動詞片語,因此可對文章進行片語 標注的處理。由於已經對文章做詞性標注 的處理,並加入了詞性資料,因此可利用 詞性資料進行片語標注。本論文利用工具CRFChunker 來處理片語標注[17]。 此外,在語意結構中利用到文章的名 詞、動詞和介詞,因此為了方便處理文章, 對文章做停字過濾的處理,如冠詞、副詞 等。 (二) 擷取文章的語意結構 經過詞性標注和片語標注等文章前處 理後,已把詞性和片語的資料加入文章 裡。接下來的問題是如何利用這些資料從 文章之中擷取語意結構。Hearst[11]利用詞 彙句法樣式基礎的擷取方法,提供簡單有 效的方法擷取 WordNet 的詞彙本體論。因 為樣式基礎的擷取方法不需要額外的知識 庫和複雜的剖析,只需要定義簡單的樣 式,並利用樣式比對方法來擷取概念和概 念之間的關係,所以不會有太多擷取成 本。本論文參考此想法,利用樣式基礎擷 取文章的語意結構,並建立詞彙句法樣式 以做為擷取的基礎。但這些樣式並不能保 證適用於所有文集,因此需針對欲比對之 文 集 作 增 加 或 修 改 樣 式 的 工 作 。 依 據 Finkelstein-Landau 和 Morin 的詞彙句法樣 式的流程[12]和本體論與本論文語意結構 之差異修改後的建立流程如下: 1. 對文集的句子做詞性標注、片語標注 和停字過濾等前處理。 2. 針對前處理完的句子,每個句子每次 只選擇一對詞彙做為擷取目標。 3. 針對步驟 2 找出的成對詞彙,選定成 對詞彙之間欲擷取的關係。 4. 把完成詞彙和關係選定的句子表示成 詞彙句法表示式。 5. 利用人工比對步驟 4 所找出的詞彙句 法表示式之間的相似度,並利用人工 對詞彙句法表示式一般化,以找出詞 彙句法樣式。 6. 透過專家對詞彙句法樣式做驗證。 7. 利用驗證過的樣式擷取文章的語意結 構。 8. 透過專家對擷取出來的語意結構做驗 證,如果發生錯誤,由專家修正錯誤 的樣式,如果擷取不完全則重覆步驟 2~8 以新增新的樣式。 透過上述的流程做樣式比對就可以找 出詞彙之間的關係。範例如下:
(S) [[NP, Chien-Ming/NNP, Wang/NNP], [VP, begin/VB], [NP, season/NN], [IN, on/IN], [NP, disabled/JJ, list/NN], [after, after/IN], [VP, pulling/VBG], [NP, right/JJ, hamstring/NN], [IN, on/IN], [NP, Friday/NNP]]
(P9) NP1 {[,] NP2 …[,] [or | and] NPm} IN NPm+1 {[,] NPm+2 …[,] [or | and] NPm+n} → R(IN, NPi, NPj), 0<i<=m, m<j<=m+n
(P11) NP1 {[,] NP2 …[,] [or | and] NPm} {’ NP | ’s NP | and other LIST | and other LIST | especially LIST | especially LIST | IN LIST | W VP LIST }* {[,]} VP NPm+1 {[,] NPm+2 …[,] [or | and] NPm+n}
→ R(VP, NPi, NPj), 0<i<=m, m<j<=m+n
(P12) NP1 {[,] NP2 …[,] [or | and] NPm} {’ NP | ’s NP | and other LIST | and other LIST | especially LIST | especially LIST | IN LIST | W VP LIST| VP LIST }+ [after | before] VP1 NPm+1 {[,] NPm+2 …[,] [or | and] NPm+n}
→ R(VP1, NPi, NPj), 0<i<=m, m<j<=m+n
句子 S 透過樣式 P9 的比對可以找出 R(on, season, disabled list)和 R(on, right hamstring, Friday)的關係;透過樣式 P11 的 比 對 可 以 找 出 R(begin, Chien-Ming Wang, season)的關係;透過樣式 P12 的比 對可以找出 R(pulling, Chien-Ming Wang, right hamstring)的關係。透過上述的方法就 能建立出文章的語意結構。 (三) 詞彙語意比對 擷取出文章的語意結構後,接下來就 是如何利用二篇文章的語意結構比對文章 之 間 詞 彙 的 語 意 。 Rodríguez 和 Egenhofer[13]利用欲比對概念之相鄰的概 念互相比較,計算本體論之間概念語意相 似度。由於本論文提出的語意結構是取法 於本體論的結構,因此可利用類似的方法 來計算語意結構之間詞彙的語意相似度。 但由於語意結構並不完全相同於詞彙本體 論,因此必需做一些修改。本論文語意結 構的知識完整性是與文章的內容相關的, 不像本體論一開始就由人工建立好完整的 知識,因此在比對時從文章裡擷取出的語 意結構,其知識完整性會影響到比對的結 果。利用權重值來調整字面、屬性和語意 相似度佔整體相似度評估的比例,而權重
值可由使用者依經驗自訂。本論文的語意 結構並不包含屬性,因此將屬性相似度的 權重值訂為零。另外,為了避免從文章擷 取出的語意結構之知識完整性影響到比對 的結果,加入相關參數來調整字面和語意 相似度的權重值,即知識完整性越高,語 意相似度佔整體相似度評估的比例越大。 整理後的公式如(1)所示。 ( ) ( ) ( ) ( ( )) ( p q) w q p q p n q p q p b wa b S a b wa b S a b a S , = , * , +1− , * , (1) (apbq) S , 代表語意結構 p 裡概念 a 和語意結構 q 裡概念 b 之間的相似度評估,Sn
(
ap,bq)
代 表語意結構 p 裡概念 a 和語意結構 q 裡概 念 b 之間語意上的相似度, ( p q) wa b S , 代表語 意結構 p 裡概念 a 和語意結構 q 裡概念 b 之間字面上的相似度,由於沒有包含屬 性,因此去掉屬性相似度的評估。w(ap,bq)代 表評估函數的權重值,其公式如(2)如示。 ( ) ⎪ ⎩ ⎪ ⎨ ⎧ > > ≤ = α α α α q n p n q n p n q n p n q p B A B A B A b a w 1 0 , , (2) 其中Anp代表本體論 p 裡 a 概念的相鄰概念 的數量,Bnq代表本體論 q 裡 b 概念的相鄰 概念的數量。α 是由使用者自定的語意信 任門檻值,α 值是代表當語意結構的語意 知識完整度超過多少時使用者才完全相信 語意評估結果,反之則由語意知識完整度 和α 值的比例做為分配的權重。語意知識 完整度是 a 概念的相鄰概念的數量和 b 概 念的相鄰概念的數量的乘積,乘積越大表 語意知識完整度越高。 評估二個本體論相似度前必需先找到 最近的父節點把二個本體論連接在一起, 之後利用概念在連接後的本體論裡與父概 念之間的距離做為評估的標準。本論文的 語意結構並沒共通的根節點,故無法利用 相同的方法評估,因此本論文使用另一種 評估的方式。文章的名詞片語是修飾詞加 上名詞所組成,而修飾詞是對於名詞做更 進一步的修飾,即對原名詞做特殊化敘 述,如果把名詞視為現實生活中實體所組 成的集合,而修飾後的名詞就代表集合中 的子集合,如球代表現實生活中所有球的 集合,而白色的球就代表球的集合裡白色 的球所組成的子集合,因此如果名詞片語 的修飾詞越多可以視為越特殊化的敘述, 換個角度即名詞片語裡單字的數量越多就 越特殊化。整理後的公式如(3)和(4)所示。 ( ) ( ) ( ( )) ( ) ( ) ( ) ( ) ( )( ) ( ) ( ) ( ) ( )( ) ⎪ ⎪ ⎩ ⎪ ⎪ ⎨ ⎧ > + − ≤ + = − + + ∩ ∩ = q p q p p q p q p p q p p w q w q p q w p w q p q w p w q w p w q p w b count word a count word b count word a count word a count word b count word a count word b count word a count word a count word b a where A B b a B A b a B A B A b a S _ _ _ _ _ 1 _ _ _ _ _ , / , 1 / , , α α α (3) ( ) ( ) ( ( )) ( ) ( ) ( ) ( ) ( ( )) ( q) j p i w q j p i q j p i n q j p i q j p i n i q j p i m j q n p n q n p n q n p n q n p n q n p n n b a S b a w b a S b a w b a S b a S max B A where A B b a B A b a B A B A b a S , * , 1 , * , , , / , 1 / , , − + = ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ = ∩ − + + ∩ ∩ = ∑ ≤ ≤ α α (4) (四) 詞彙語意比對範例 圖 3 是圖 2 文章的部份語意結構,圖 5 是圖 4 文章的部份語意結構。將語意結 構 a 的詞彙(right hander)和語意結構 b 的詞 彙(Chien-Ming Wang)做語意比對,二者字 面上的相似度利用公式(3)來評估,結果如 下: 二 者 字 面 上 的 相 似 度 利 用 公 式 (4) 來 評 估,結果如下:最後利用公式(1)把二者整合在一起,在此 α 設為 40,最後比對的結果如下: ( ) 0.875 40 7 * 5 , = = = α q n p n q pb A B a w
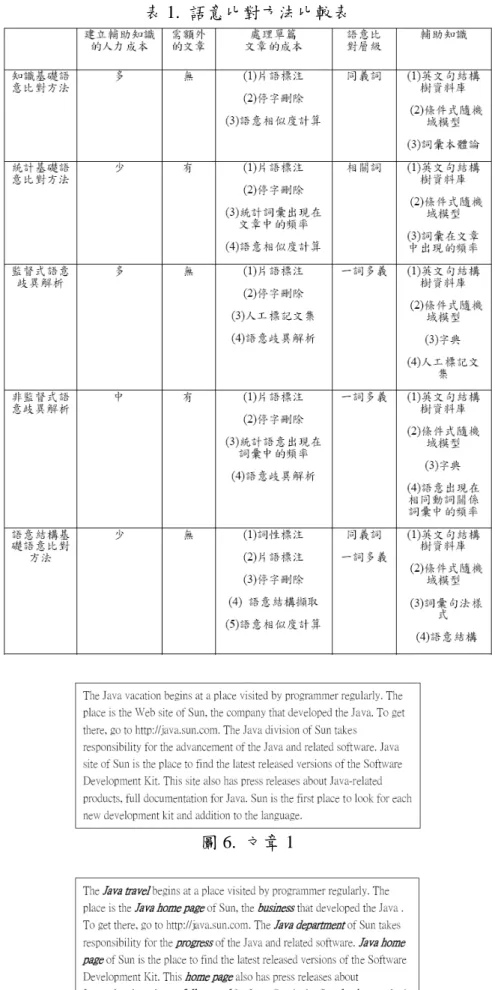
(right_hander,Chien_Ming_Wang)=0.875*0.645+0.125*0=0.564 S 計算的結果可以發現 right_hander 和 Chien_Ming_Wang 之間有 0.564 的相似 度。從計算的過程中可以發現,0.564 是代 表,語意相似度佔 87.5%和字面上的相似 度佔 12.5%的情況下,二個詞彙的相鄰概 念 有 64.5% 的 交 集 ( 語 意 上 相 似 度 為 0.645),而字面上完全不一樣(字面上相似 度為 0)。0.564 代表二個詞彙的相近程度。 二個詞彙是否能為同義字,通常需使用者 根據某個應用領域的經驗設定門檻值。二 個詞彙的相近程度大於門檻值代表二個詞 彙在應用領域很有可能是同義詞。 (五) 其他方法之比較 與其他方法的比較結果如表 1。從表 中可以看出,語意結構基礎語意比對方法 相對其它方法,只需較少的建立輔助知識 的人力成本,而且不需處理額外的文章。 雖然在處理單篇文章需要較多的成本,但 整體成本還在可接受的範圍。
四、實驗結果
本章節依據上一章所提出的方法進行 文章之間詞彙的語意比對實驗。 (一) 實驗環境 實驗範例由 www.samspublishing.com 的文章 Vacationing in Java 取其中的一些 片段組成一篇小短文。利用實驗研究方 式,驗證本論文提出的方法。利用工具 CRFTagger 和 CRFChunker 對文章進行標 注前處理[17],之後使用本論文所發展的 文章詞彙語意比對工具,對文章進行語意 結構擷取和比對的工作。CRFTagger 是利 用 WSJ 文集訓來出來的模型,經設計者測 試可達到 97%的正確率,每秒可處理 500 個句子[17]。CRFChunker 也是利用 WSJ 文集訓來出來的模型,經設計者測試 F1 的分數可以達到 95.77,每秒可處理 700 個句子[17]。文章詞彙語意比對工具是以 上一章方法所設計的工具。 (二) 實驗設計 為了驗證本論文提出的文章詞彙之間 的相似度比對的方法,因此使用了三篇文 章。文章 1,如圖 6 所示,是從網路擷取 並整理後的文章片段。文章 2,如圖 7 所 示,是將文章 1 中的大部份詞彙(斜體字加 粗體)用同義字取代。文章 3,如圖 8 所示, 是將文章 1 中的大部份詞彙保留,但修改 一些詞彙(斜體字加粗體)造成文章語意改 變。本論文採用了 Jaccard 係數[2]進行驗 證,以 p q q p B A B A ∪ ∩ 表示,其中A 代表文章 pp 裡的詞彙集合 A,B 代表文章 q 裡的詞彙q 集合 B。 為了驗證本論文提出的文章中詞彙之 間語意比對方法能成功的找出同義字和一 字多義的字,一開始利用 Jaccard 係數計算 文章 1 與文章 2 之間的相似度與文章 1 與 文章 3 之間的相似度,之後加入本論文的 方法於 Jaccard 係數的相似度計算,並觀察 是否能提高辨識度。 (三) 實驗結果 表 2 是三篇文章的詞彙,表 3 是文章 與詞彙的相關矩陣。利用 Jaccard 係數計算 文章 1 與文章 2 之間的相似度與文章 1 與 文章 3 之間的相似度的結果如表 4 所示。 圖 9、圖 10 和圖 11 分別代表文章 1、文章 2 和文章 3 的部份語意結構。利用文章的 詞彙之間語意比對方法比對出文章 1 與文 章 2 裡詞彙之間的語意相似度和文章 1 與 文章 3 裡詞彙之間的語意相似度,如表 5和表 6 所示。由於三篇文章都是短文,知 識完整性不會太高,因此將α 值(語意信任 門檻值)設為 2,代表知識完整性大於 2 就 相信語意相似度評估結果。另加上語意相 似度門檻值 0.6,只要語意相似度達到 0.6 就認為二個辭彙是相關的。最後再利用 Jaccard 係數計算經過語意比對後文章 1 與 文章 2 之間的相似度和文章 1 與文章 3 之 間相似度的結果如表 7 所示。 (四) 實驗結果分析及討論 文章 2 為將文章 1 的詞彙換成同義 字,文章 3 則是更換文章 1 少數詞彙的語 意,造成文章語意改變。基於上述的設計, 文章 1 與文章 2 是語意較相近的文章,文 章 1 與文章 3 是語意差異較大的文章。比 較表 4 和表 7 可以發現,利用傳統資訊檢 索的文章相似度計算方法,由於只利用詞 彙字面上的比對,因此文章比對結果文章 1 與文章 2 差異較大,而文章 1 與文章 3 較相近。同時也可看出傳統資訊檢索的文 章相似度計算方法並無比對出文章的語意 相似度。加入語意比對後的文章比對結 果,文章 1 與文章 2 較相近,而文章 1 與 文章 3 差異較大。所以證明本論文的方法 能比對出文章的詞彙之間語意相似度。 經由檢視表 5 和表 6 可發現,本論文 提出的語彙之間語意比對方法,在語意比 對上會還是會有誤判情形發生,如表 5 中 的 Java vacation 和 java。從圖 9 和圖 10 中 可發現,Java vacation 和 Java travel 底下只 有一個節點 place,從表 5 中可以找到文章 1 和文章 2 裡 place 的語意相似度值為 0.83,而把 α 值設為 2,計算的結果為
( )12 *0.83+(1−12)*0.5=0.66,文章 1 的 Java
vacation 和文章 2 的 Java travel 語意相似度 為 0.66。而從圖 9 和圖 10 可以發現,文章 2 的 Java 底下沒有任何節點,所以 Java vacation 和 java 只能從字面上來比對,比 對結果為 0.75。因為 0.75>0.66,所以結果 為 Java vacation 和 java 反 而 比 Java vacation 和 Java travel 來得相似。但是如果 把α 值設為 1,Java vacation 與 Java travel
的語意相似度變成( )11*0.83+(1−11)*0.5=0.83,則
Java vacation 和 Java travel 就會變得比較 相似。 由以上敘述可以發現,從文章擷取到 的知識完整度會影響語意相似度的計算結 果。知識完整度越高表示有更多的知識幫 助語意相似度的計算,知識完整度太低時 只能從字面上去比對。而α 值(語意信任門 檻值)代表知識完整度高於多少時就可完 全信任語意相似度的結果,反之則只能比 對字面上的相似度。透過α 值的調整能幫 助修正比對結果。但是α 值如果調太低表 示太容易信任語意比對,有可能兩個字彙 只因為一點點的知識交集就被誤認為是同 義字,但實際上它們只有一點點相關。 另一個值得討論的值是語意相似度門 檻值,實驗定為 0.6,如果調低到 0.2 或調 高到 0.9 都會影響到文章相似度比對結 果。而這個值代表是否能正確的辨識二篇 文章之間的差異,是屬於文章相似度比對 的需要探討的範圍。而本論文主要是針對 文章詞彙之間的語意比對,因此在此並不 深入探討。
五、結論與未來展望
一般使用知識基礎方法,受限於知識 來源需要大量人力來幫助建立。而使用統 計基礎方法,又會有只能找出相關詞和需 額外收集並處理大量文章的問題。本論文 提出的方法,只需要借助有現有的英文句 結構樹資料庫(Penn Treebank)訓練出來的 條 件 式 隨 機 域 模 型 (Conditional Random Fields Model)來進行詞性和片語標注。透 過 Phan 的實驗[17],可以知道本論文使用 的詞性和片語標注工具平圴每秒可以處理 290 句的句子。且本論文使用的詞彙句法 樣式(Lexico-syntactic Patterns)只需花費少 量人力建立的,之後透過樣式比對擷取出 文章詞彙的語意結構。最後透過簡單的語 意結構比對就能找出文章裡同義詞和一詞 多義的詞彙。 未來將更進一步探討 α 值(語意信任門檻值) 和語意相似度門檻值與語意比對 結果之間的關係。並且應用於大量文章的 相似度比對,更進一步實際驗證方法的效 果。另外,也將本論文所提出的方法真正 的應用於實際網路上的文章分類和以文找 文的問題。
六、參考文獻
[1] 石 逸 民 ,「 從 全 球 資 訊 網 擷 取 同 義 詞」,國立中正大學資訊工程研究所博 士論文,2003。 [2] 許中川,陳景揆,「探勘中文新聞文 件」,資訊管理學報,第 7 卷,第 2 期, pp. 103-122,2001. [3] 陳以理,林蘭綺,吳典松,「自然語言 處理技術於專利文件分析之應用」, 第二屆學生計算語言學研討會,2004。 [4] 黃雲龍,張佑任,「中文全文資訊檢索 之效能評量初探」,資訊管理研究,第 二期,pp37-60,2002。 [5] 賴育昇,李坤霖,吳宗憲,「網際網路 FAQ 檢索中意圖萃取與語意比對之研 究」,Proceedings of ROCLING XIII, Taipei,Taiwan,2000.[6] A. Suarez, M. Noeda and M. Palomar,
“A Method of Restricted Knowledge Acquisition from WordNet,” Proceeding of the third International Conference on
Knowledge-Based Intelligent Information Engineering System, IEEE,
pp. 38-41, 1999.
[7] B. Chandrasekaran, J. R. Josephson, and
V. R Benjamins, “What Are Ontologies, and Why Do We Need Them,” IEEE Intelligent Systems, pp.20-26, Jan.-Feb, 1999.
[8] C. Maria (Marijke) Keet, “Aspects of
Ontology Integration,” Literature research & background information for the PhD proposal, School of Computing, Napier University, Scotland, 2004.
[9] C. S. Lee, Y. H. Kuo, C. H. Liao, and Z.
W. Jian, “A Chinese Term Clustering
Mechanism for Generating Semantic Concepts of a News Ontology,” Journal of Computational Linguistics and Chinese Language Processing, vol. 10, no. 2, pp. 277-302, 2005.
[10] D. Yarowsky, “Unsupervised Word
Sense Disambiguation rivaling Supervised Method,” Proceedings of the Thirty-third Annual Meeting of the Association for Computational Linguistics, pp. 189-196, 1995.
[11] M. A. Hearst, “Automated Discovery of
WordNet Relations,” To Appear in WordNet: An Electronic Lexical Database and Some of its Applications, Christiane Fellbaum (Ed.), MIT Press, 1998.
[12] M. Finkelstein-Landau and E.
Morin, ”Extracting semantic relationships between terms: supervised vs. unsupervised methods,” Workshop on Ontologial Engineering on the Global Info. Infrastructure, 1999.
[13] M.A. Rodriguez and M.J. Egenfoher,
“Determining Semantic Similarity among Entity Classes from Different Ontologies,” IEEE Transactions on Knowledge and Data Engineering, vol. 15, no. 2, pp. 442-456, 2003.
[14] N. F. Noy and C. D. Hafner, “The State
of the Art in Ontology Design,” AI Magazine, pp. 53-74, Fall 1997.
[15] N. F. Noy and D. L. McGuinness,
“Ontology Development 101: A guide to Creating Your First Ontology,” Technical Report KSL-01-05, Stanford Medical Informatics, Stanford University, 2001.
[16] T. K. Landauer, P. W. Foltz, and D.
Laham, “An introduction to Latent Semantic Analysis,” Discourse Processes, vol. 25, pp. 259-284, 1998.
[17] Xuan-Hieu Phan, “FlexCRFs: Flexible
Conditional Random Fields,” http://flexcrfs.sourceforge.net/, 2005.
圖 1. 演算法流程圖 圖 2. 範例文章 a 圖 3. 語意結構 a 圖 4. 範例文章 b 圖 5. 語意結構 b
表 1. 語意比對方法比較表
圖 6. 文章 1
圖 8. 文章 3
表 2. 文章的詞彙
表 4. 文章的相似度
圖9. 文章1的部份語意結構
圖11. 文章3的部份語意結構
表6. 文章1,3裡詞彙語意相似度