發展軟體無線電技術(II):
智慧型天線系統/技術之研發
期末報告
整合型總計畫主持人: 彭松村教授
子計畫主持人: 黃家齊教授
本子計畫中文名稱:
以垂直正交分頻分碼多工調變為基礎之基地台接
收機架構之設計
本子計畫英文名稱:
A Study on Base Station Receiver Design for
OFDM/CDMA-based Cellular Mobile Communications
Systems
申請機關:國立交通大學電信工程學系
目錄
第一章、簡介 ………..1 第二章、渦輪碼 ………..4 2.1 編碼器 ………... 5 2.2 解碼器 ………... 6 2.2.1 MAP 演算法 ……….6 2.2.2 循環式 MAP 解碼 ………9 2.2.3 渦輪解碼器的虛擬碼 ………..11 第三章、訊息傳遞演算法 ………..15 3.1 MPA 的介紹 ………..15 3.1.1 正規圖 ………...16 3.1.2 在正規圖上的訊息傳遞 ………17 3.1.2.1 一個節點 ……….17 3.1.2.2 兩個節點 ……….19 3.1.2.3 兩個模組 ……….23 3.1.3 應用 ………24 3.1.3.1 同等節點 ……….24 3.1.3.2 白色高斯雜訊的外質機率………...25 3.2 MPA 在渦輪解碼上的應用 ...26 3.2.1 籬笆狀圖及其相對的正規圖………..26 3.2.2 利用 MPA 推導渦輪解碼 ………..28 3.2.3 與最大後置機率渦輪解碼的比較 ……….32 3.2.4 利用 MPA 推導渦輪碼同位位元的軟資訊………33 3.3 模擬結果與探討 ………35第四章、多載波分碼多重進接系統傳送機架構和通道模型………37 4.1 傳送機架構 ………...37 4.2 展頻碼 ………...37 4.3 通道模型 ………...43 4.4 上鏈多用戶環境 ………...44 第五章、多載波分碼多重進接系統接收機與渦輪多用戶偵測技術之結 合 ………..46 5.1 符號定義 ………...46 5.2 接收機架構 ………...47 5.3 領航訊號干擾消除 ………...48 5.4 應用於頻域之渦輪多用戶偵測 ………...50 5.4.1 使用者u的第l級偵測器 ………...50 5.4.2 碼匹配、通道匹配及渦輪解碼 ………..53 5.4.2.1 不經過渦輪解碼器的軟位元計算………...55 5.4.2.2 經過渦輪解碼器的軟位元計算………...57 第六章、通道估計架構 ………...63 6.1 解展頻 ………...63 6.2 通道估計 ………...65 6.2.1 路徑選擇 ………68 6.2.2 路徑解相關 ………...69 第七章、電腦模擬 ………...70 7.1 模擬環境 ………70 7.2 模擬結果與討論 ………73 第八章、結論與未來發展的方向 ………...80
附錄 A、結合多載波分碼多重進接及渦輪多用戶偵測之下鏈基頻接收
機的模擬與討論 ………82
A.1 模擬環境 ………...82
A.2 模擬結果與討論 ………...84
第一章
簡介
目前第四代行動通訊系統還處於研究的階段,其中呼聲還滿高的 系 統 之 一 為 多 載 波 分 碼 多 重 進 接 系 統 (Multicarrier CDMA , MC-CDMA),它所使用的多載波調變技術─正交分頻多工(Orthogonal Frequency Division Multiplexing,OFDM)調變可以有效的利用頻寬; 又 多 重 路 徑 下 , 傳 輸 速 率 高 意 味 著 容 易 產 生 ISI(Inter symbol interference),在頻率上即容易遇到頻率選擇性衰減通道,而 OFDM 調變則可以克服這一點;結合 CDMA 和 OFDM 可以看成是在頻率上 作展頻,也就是賦予這個系統有多重進接,可以提供多個使用者使用。 目前的行動通訊系統皆會包含通道編碼,而渦輪碼則是近年來通 道編碼領域上的一大突破,它不管在傳送端的編碼器和接收端的解碼 器,都是巧妙地結合了一些已存在的觀念,使這個碼可以很接近夏隆 通道容量(Shannon channel capacity),換句話說,當要讓接收端的錯誤 率很低時,在一定的頻寬下,渦輪碼所需的訊號雜訊比不需很高,且 渦輪碼的設計亦可以讓它對於通道發生叢錯(Burst error)時有很高的 抵抗力,我們將會在第二章介紹渦輪碼。
但渦輪碼一直被看作是一種工程上的發明,它的解碼器並非由數 學一步步推演而來,在第三章中,我們將介紹一種近年提出的演算 法,資訊傳遞演算法(Message passing algorithm,MPA)[1],在參 考資料[1]中,MPA 可用來推演出 LDPC(Low density parity check code) 的解碼器,而本報告將會利用此演算法推導出渦輪解碼器以及在渦輪
多用戶偵測中所需的同位位元的軟資訊。 本報告將 MC-CDMA 和渦輪碼結合在一起,在上鏈傳輸系統中, 每個使用者皆會經過不同的通道到達接收機,因此每個使用者使用的 正交碼的正交特性便會變得不完美,使得使用者的干擾成為系統表現 的最大絆腳石,為了移除這個絆腳石,便有了使用多用戶偵測的 MC-CDMA 系統[2];多用戶偵測系統中有一種是平行干擾消除法, 亦即把前一級中其它使用者偵測出的資料重建成干擾消除掉,經過幾 級後,重建的干擾愈來愈準確,因此在消除重建的干擾後,使用者的 干擾便愈來愈少,其資料偵測的準確度也會愈來愈好,但是這樣的改 善會趨於飽和。只使用多用戶偵測並沒有利用到接收訊號全部的資 訊,既然訊號有經過渦輪編碼,何不利用渦輪解碼器所得到的資訊去 重建干擾呢,因此渦輪多用戶偵測的做法便是將干擾重建的地方從解 碼器前移到解碼器後[3][4]。 在第四章中我們將介紹使用渦輪編碼器的 MC-CDMA 傳送器的架 構;在第五章中我們將介紹使用渦輪多用戶偵測的 MC-CDMA 接收器的 架構,其中多用戶偵測器和渦輪解碼器互相傳遞的軟資訊會是這一章 的重點。 我們知道,在作干擾重建時,必須將訊號和通道響應作相乘的動 作,因此即使解碼後的訊號很準確,但估計的通道不準確,最後重建 的干擾也不會太準確,因此通道估計不管是在多用戶偵測還是渦輪多 用戶偵測中都是決定系統表現的關鍵,我們特別把通道估計獨立成一 章,在第六章中介紹,這一章所介紹的通道估計只是基本的方法,尚 有改進的空間。最後,第七章為電腦模擬和討論,第八章為結論及未 來發展的方向。
第二章
渦輪碼
渦輪碼在 1993 年第一次被提出來[5],渦輪碼的發明是結合了已 經存在的演算法[6]和一些概念,並很有技巧地將它們結合在一起, 使得渦輪碼有十分接近夏隆限制(Shannon limit)的表現。在本章中, 我們將分別針對渦輪碼的編碼器和解碼器去討論渦輪碼的優點,最後 並列出渦輪解碼器的虛擬碼(Pseudo-code)[7]。 我們首先定義以下的符號: c E 為編碼後每個位元傳送到通道的能量 0 N 為白色高斯雜訊的功率頻譜密度 E1表示第一個成分編碼器(Constituent encoder) E2表示第二個成分編碼器 D1表示第一個成分解碼器 D2表示第二個成分解碼器( )
IT 表示經過交錯器的動作( )
DIT 表示經過解交錯器的動作 m表示成分編碼器的記憶體大小 S表示成分編碼器所有 2m種狀態的集合(
1, 2, ,)
(
1, 2, ,)
s s s s N N x x x u u u = = x K K 為輸入成分編碼器的資訊位 元,也是成分編碼器所產生的系統位元(Systematic bits)(
1 , 2, ,)
p p p p N x x x = x K 為成分編碼器所產生的同位位元(Parity bits)(
s, p)
k k k y = y y 為(
x xks, kp)
加上白色高斯雜訊(AWGN)的資料(
, 1, ,)
b a a a b y = y y + K y(
)
1 1, 2, , N N y y y = = y y K 為所收到的字元2.1 編碼器
渦輪編碼器由兩個成分編碼器及一個交錯器所組成,如圖2.1 所 示。其中每個成分編碼器為遞迴系統式迴旋編碼器(Recursive
systematic convolutional code)。
由於是系統式編碼,因此上下兩個成分編碼器會輸出相同但順序 不同的系統位元,故我們只需傳送第一個成分編碼器產生的系統位元 s k x , 令一個 用虛線表 示的系 統位元則 可不送 ,也就是 被穿孔 掉 (Punctured),在解碼時被穿孔掉的資訊則利用經過通道的 s k x (也就是 s k y )經過交錯器後取得,以替供第二個成分解碼器解碼之用,因此系 統編碼配合穿孔可節省傳送所需的頻寬。 RSC Encoder 1 N-bit Interleaver k
u
x
ks 1 k px
2 k px
RSC Encoder 1 圖2.1 碼率為1/3的渦輪編碼器架構圖由於當迴旋編碼器的輸入權術(Input weight)小時,輸出權術也會 比較小,而一個編碼器的表現好壞,其中一個就是看它產生的最小輸 出權術,最小輸出權術愈大愈好,因此迴旋編碼器的表現會被輸入權 術小的輸入給侷限住;但是若是遞迴式迴旋編碼器則不會如此,對遞 迴式迴旋編碼器而言,輸入權術小,輸出權術不一定就會小,要看輸 入權術的分佈為何,因此若配合交錯器打散輸入權術的分佈,則兩個 成分編碼器同時產生輸出權術小的機率便會變小,使等效的最小輸出 權術變大;此外交錯器愈大,則可以打得愈散,使兩個成分編碼器愈 不容易產生相同數目的輸出權術,因此交錯器愈大則表現愈好。 因此渦輪編碼器使用了兩個遞迴系統式迴旋編碼器配合交錯器 以節省傳送頻寬及提升等效的最小輸出權術。下一節裡我們將介紹渦 輪碼在解碼器方面如何利用循環式解碼(Iterative decoding)提升表現。
2.2 解碼器(Decoder)
在Berrou 等人所提出的渦輪碼的解碼器中,使用到了Bahl 等人 在約20年前所提出的最大後置機率(MAP)演算法,(又稱為 BCJR演 算法),因此在2.2.1節中我們首先介紹 MAP 演算法,並指出此演算 法在實際使用電腦處理時所造成在數值上的不穩定性,進而提出修改 的版本[7];接著在 2.2.2節中我們將介紹 Berrou如何把MAP 演算法 應用在循環式解碼(Iterative decoding)中;最後在 2.2.3節中我們將列 出渦輪解碼器的虛擬碼,使得讀者對於渦輪解碼的流程更加清楚。2.2.1 MAP 演算法
在MAP 解碼器中,如果P u
(
k = +1|y)
>P u(
k = −1|y)
,解碼器便 決定uk = +1,否則便決定uk = −1。若以數學式簡潔的來表示,則為:( )
ˆk sign k u = L u 其中 L u( )
k 稱作對數可能性比例(Log-likelihood ratio),並被定義為:( )
(
(
1|)
)
log 1| k k k P u L u P u = + = − y y 若將上式利用編碼器狀態與輸入輸出的關係去分解,我們可以得到下 式:( )
(
)
( )
(
)
( )
1 1 ', , log ', , k k S k k k S p s s s s p L u p s s s s p + − − − = = = = ∑
∑
y y y y (2-1) 其中sk ∈S為編碼器在時間 k 時的狀態,S+為uk = +1時所造成的編碼 器狀態轉移(
sk−1=s') (
→ sk =s)
中所有的( )
s s 集合,同樣的,S', −則為 1 k u = − 情況下的集合。 在(2-1)式中,我們可以把p y 消掉,並由[6]可知:( )
(
', ,)
k 1( ) ( ) ( )
' k ', k p s s y =α
− s ⋅γ
s s ⋅β
s (2-2) 其中 1.( )
(
1)
1( ) ( )
' , k ' ', k k k k s S s p s s y s s sα
α
−γ
∈ = =∑
(2-3) 且α
0( )
0 =1、α
0(
s≠0)
=0 2.( )
(
)
(
) (
)
( ) (
)
1 ', , | ' | ' | ', | k k k k k k k k s s p s s y s s p s s p y s s p u p y uγ
= − = = = (2-4) 3.β
k( )
s p y(
kN+1|sk =s)
( )
( ) ( )
1 ' ', k k k s S s s s sβ
−β
γ
∈ =∑
(2-5) 且 (0) 1β
N = 、β
N(
s ≠0)
=0從以上的定義,我們可以重寫(2-1)式成(2-6)式:
( )
1( ) ( ) ( )
( ) ( ) ( )
1 ' ', log ' ', k k k S k k k k S s s s s L u s s s sα
γ
β
α
γ
β
+ − − − ⋅ ⋅ ⋅ ⋅ ∑
∑
(2-6) 從上述的定義我們發現,α
k( )
s 的值會隨著k變大而愈來愈小,( )
k sβ
的值則會隨著k變小而愈來愈小,其例子如參考書籍[8]的表 5.1。由於實際上硬體表示數字的精確度有限,當k值很大時將會造成 可觀的誤差,為了降低這樣數值上的不穩定性,我們將上述的定義作 以下的修正[7]:( )
( )
( )
1 k k k s s p y α α% =( )
( )
(
)
1| 1 k k N k k s s p y y β β + = % 經由以上的定義,則我們可以推導出如下的式子:( )
' 1( ) ( )
( ) (
)
1 '' ' ', ', '' k k s S k k k s S s S s s s s s s s α γ α α γ − ∈ − ∈ ∈ =∑
∑ ∑
% % % (2-7)( )
( ) ( )
( ) (
)
1 1 '' ', ' '' '', k k s S k k k s S s S s s s s s s s β γ β α γ ∈ − − ∈ ∈ =∑
∑ ∑
% % % (2-8)( )
1( ) ( ) ( )
( ) ( ) ( )
1 ' ', log ' ', k k k S k k k k S s s s s L u s s s sα
γ
β
α
γ
β
+ − − − ⋅ ⋅ ⋅ ⋅ ∑
∑
% % % % (2-9) 注意α%k( )
s 和β%k( )
s 與(2-3)及(2-5)式具有相同的邊界條件。且使用 新的定義去計算L u( )
k 與舊的定義的差別只在α
k( )
s 及β
k( )
s 計算時 的不同,因此為方便起見,本報告之後皆採用(2-3)及(2-5)的定義,僅 在使用電腦模擬時換成(2-7)及(2-8)的定義。2.2.2 循環氏 MAP 解碼
上一節所介紹的 MAP 演算法,在計算
γ
k( )
s s', 時必須知道事前 機率p u( )
k ,若無法得知 p u( )
k 的值,只能將之設成 0.5,如此一來, 此演算法相對於使用 Viterbi 演算法去解碼的表現便無太大的改進, 且 MAP 相對於 Viterbi 演算法的複雜度又較高,因此單只使用一個 MAP 解碼器作解碼並不划算。Berrou 等人所提出的渦輪碼在編碼器 使用平行的兩個成分編碼器,如 2.1 節所介紹;而解碼器便是使用兩 個 MAP 成分解碼器,互相去估計對方所需的事前機率p u( )
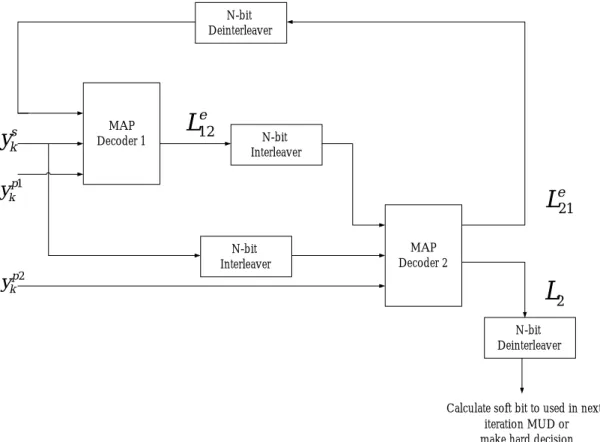
k ,進而 大幅改善解碼的表現。這一節裡我們將介紹如何將 MAP 演算法應用 在渦輪解碼裡,圖 2.2 為渦輪解碼器的架構圖: MAP Decoder 1 MAP Decoder 2 N-bit Interleaver N-bit Interleaver N-bit Deinterleaver N-bit Deinterleaver s k y 1 p k y 2 p k y 2L
12 eL
21 eL
Calculate soft bit to used in next iteration MUD or make hard decision
首先我們要改寫(2-4)式,我們令
( )
(
)
(
)
1 log 1 k a k k P u L u P u = + = − ,因為此式中 的P u(
k = − = −1)
1 P u(
k = +1)
,因此我們可以算出:(
)
(
(
( )
( )
)
)
(
( )
)
(
( )
(
)
( )
)
(
)
(
( )
)
(
( )
)
(
( )
(
)
( )
)
exp exp 2 exp 2
1 1 exp 1 exp exp 2 exp 2 1 1 1 exp 1 exp a a a k k k k a a k k a a k k k a a k k L u L u L u P u L u L u L u L u P u L u L u ⋅ = + = = + + ⋅ − = − = = + + 根據以上兩式,我們可以把P u
( )
k 寫成:( )
(
(
( )
( )
)
)
(
( )
)
( )
(
)
exp 2 exp 2 1 exp exp 2 a k a k a k k k a k k k L u P u u L u L u A u L u = ⋅ ⋅ + = ⋅ (2-10) 此外,(
)
(
) (
)
2 2 2 2 2 2 2 2 2 2 2 | exp 2 2 exp exp 2 2 exp 2 s p p k k k k k k s p p s p p k k k k k k k k s p p k k k k k y u y x p y u y u y x u y y x u y y x B σ σ σ σ σ − − ∝ − − + + + + = − ⋅ + = (2-11) 其中 c 2 0 E 1 N 2 σ = ;因此(2-4)可以寫成( )
', exp(
( )
2 exp)
2 2 s p p a k k k k k k k u y y x s s u L uγ
σ
+ ∝ ⋅ ⋅ (2-12) 在(2-12)式中,我們之所以把常數項都去掉,是因為這些項在最 後計算對數可能性比例時,皆會分子分母對消掉。接著我們把(2-12) 式代入(2-6)式可得:( )
( ) (
) (
) ( )
( ) (
) (
) ( )
( )
(
( )
)
( )
( )
(
( )
)
( )
1 1 1 2 1 2 ' 1 | log ' 1 | ' exp 2 exp 2 log ' exp 2 exp 2 k k k k k S k k k k k k S s p p a k k k k k k S s p p a k k k k k k S s p u p y u s L u s p u p y u s y y x s L u s y y x s L u s α β α β α β σ α β σ + − + − − − − − ⋅ = + ⋅ ⋅ = − ⋅ + ⋅ ⋅ ⋅ = − + ⋅ − ⋅ ⋅ ∑
∑
∑
∑
經過化簡,上式又可寫成:( )
( )
( )
( )
( )
( )
( )
( )
2 1 2 1 2 2 ' exp =log ' exp s a k e k k k p p k k k k e S k p p k k k k S y L u L u L u y x s s L u y x s s σ α β σ α β σ + − − − = + + ⋅ − × ⋅ × ⋅ − ⋅ ∑
∑
其中 (2-13) (2-13)式的第一項為事前機率的對數可能性比例,此值可由另一 個 MAP 解碼器估計出來;第二項為系統位元的資訊;第三項為同位 位元的資訊,稱為外質資訊(Extrinsic information)。因此對於第一個 MAP 解碼器 D1 而言,(2-13)可以寫成(2-14)式:( )
(
(
( )
)
)
12( )
1 21 2 2 DIT IT s e k e k k k y L u L u L u σ = + + (2-14) 其中DIT(
21(
IT( )
)
)
e k L u 表示 D2 傳給 D1 的外質資訊,也就是(2-13)式中 的 a( )
k L u 項; 12( )
e k L u 表示 D1 欲傳給 D2 的外質資訊。2.2.3 渦輪解碼器的虛擬碼(Pseudo-code)
因為編碼器的做法比較直觀,因此這裡我們只列出解碼器的虛擬 碼,但必須注意的是,因為編碼器使用了平行的兩個成分編碼器,因 此無法同時滿足此兩個碼具有(2-5)式的邊界條件,因此我們只針對其中一個成分編碼器去設計終結位元(Termination bits),方法請詳閱參 考書籍[8]的第 4.2.3 節。 首先解碼器必須知道編碼器的架構及白色高斯雜訊的功率頻譜 密度。 設定初始值: D1: Δ (1) 0 ( ) 1 for 0 0 for 0 s s s α = = = ≠ Δ (1) ( ) 1 for 0 0 for 0 N s s s β = = = ≠ Δ 21
( )
0 for 1, 2, , e k L u = k = K N D2: Δ (2) 0 ( ) 1 for 0 0 for 0 s s s α = = = ≠ Δ 於第一個迴圈計算出 (2) ( ) N s α 後,設定 (2) (2) ( ) ( ) for all s N s N s β =α 第 th n 迴圈 D1: for =1:Nk Δ 取得(
1)
, s p k k k y = y y ;其中y1 pk 為 E1 產生的同位位元經過 AWGN 通道後的值。 Δ 利用(2-12)式計算所有可能的s'→s的γ
k( )
s s', ,其中的 a( )
k L u 為DIT(
21(
IT( )
)
)
e k L u 。Δ 對所有的 s,利用(2-3)式計算 (1)
( )
k s α 。 end for =N:-1:2k Δ 對所有的 s,利用(2-5)式計算 (1)( )
1 k s β − 。 End for =1:Nk Δ 計算( )
( )
( )
( )
( )
1 1 1 1 (1) (1) 2 12 1 1 (1) (1) 2 ' exp =log ' exp k k k k p p k k e S k p p k k S y x s s L u y x s s α β σ α β σ − + − − ⋅ − × ⋅ × ⋅ − ⋅ ∑
∑
end D2: for =1:Nk Δ 取得(
2)
, s p k k k y = y y ;其中ykp1為 E1 產生的同位位元經過 AWGN 通道後的值。 Δ 利用(2-12)式計算所有可能的s'→s的γ
k( )
s s', ,將式中的 s k y 換成經過交錯器的值IT( )
yks ,其中的( )
a k L u 為IT(
L12e( )
uk)
。 Δ 對所有的 s,利用(2-3)式計算 (2)( )
k s α 。 end for =N:-1:2k Δ 對所有的 s,利用(2-5)式計算 (2)( )
1 k s β − 。 endfor =1:Nk Δ 計算
(
( )
)
( )
( )
( )
( )
1 1 2 2 (2) (2) 2 21 2 2 (2) (2) 2 ' exp IT =log ' exp k k k k p p k k e S k p p k k S y x s s L u y x s s α σ β α β σ − + − − ⋅ − × ⋅ × ⋅ − ⋅ ∑
∑
end 做完最後一個迴圈之後 for =1:Nk Δ 計算 2(
( )
)
(
12( )
)
2 21(
( )
)
2 IT IT IT IT s e k e k k k y L u L u L u σ = + + Δ( )
(
)
(
2)
if DIT IT 0 decide 1 else decide 1 k k k L u u u > = + = − end第三章
訊息傳遞演算法
(Message Passing Algorithm,簡稱 MPA)
由 於 在 渦 輪 多 用 戶 偵 測 中 , 渦 輪 解 碼 器 必 須 輸 出 系 統 位 元 ( Systematic Bit )及同位位元( Parity Bits )的軟資訊回傳給多 用戶偵測器,但是傳統渦輪解碼器只能得出系統位元的軟資訊,因此 一般渦輪多用戶偵測為部份軟性( Partial Soft )多用戶偵測,亦即 在同位位元部份使用渦輪解碼器得出系統位元軟資訊後,經硬性決策 後再經過渦輪編碼器得出,因此同位位元在此處為一硬資訊。 在本章中,我們將介紹訊息傳遞演算法[1],並提出使用此種演 算法導出渦輪碼同位位元軟資訊的方法,以提升傳統渦輪多用戶偵測 的表現。
3.1 MPA 的介紹
MPA 的主要目的是將一個複雜的問題分解成許多簡單的問題。它 的做法是將問題先表示成正規圖,並利用正規圖的結構及本質機率去 推導局部的外質機率,然後再將此訊息傳遞給別處,作為別處問題的 本質機率,然後最後便可算出整體的外質機率及後置機率。3.1.1 正規圖(Normal Graph)
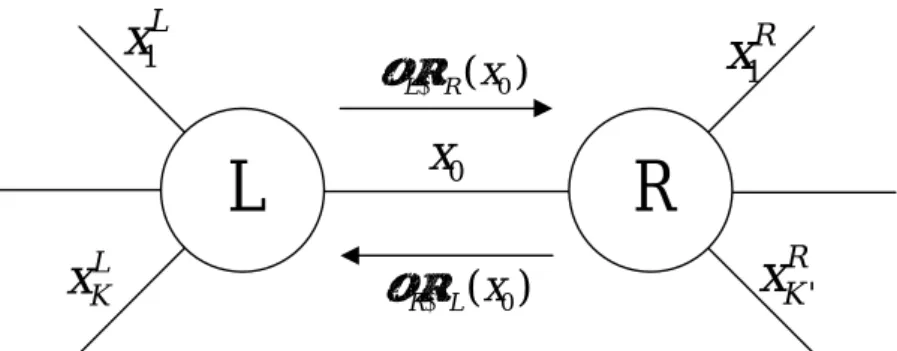
正規圖[9]由一群邊及節點所組成,圖 3.1 為一個節點及兩個節 點的例子。我們將正規圖的物理意義整理成表 3.1。其中,節點所代 表的意義為局部約束,而邊所代表的意義為變數,所謂的約束指的便 是連結至此節點的變數必須符合某特定的關係,例如連結至此節點的 變數皆必須相等,因此圖 3.1 中,N 所代表的為一特定的集合;A 代i 表的是一組x 可能的值,i A0× ×A1 A2則代表x 、0 x 及1 x 的完整集合,因2 此 N 包含於A0× ×A1 A2。µ
A→B( ) 指連結節點 A 的邊變數 x 的外質機率,x 對節點 B 而言則為與 B 節點連結的邊變數 x 的內質機率,因此µ
A→B( )x 為節點 A 傳給節點 B 的訊息。 圖 3.1 正規圖的例子 1x
2x
0x
N
邊變數
外部邊
約束集合
0 1 2N
⊂
A
× ×
A
A
L
x
0R
內部邊
節點
訊息
0 ( ) L R x µ → 0 ( ) R L xµ
→關係 目的 外部邊 (External edge) 符號變數 輸入輸出 內部邊 (Internal edge) 狀態變數 訊息傳遞 節點 (Node) 局部約束 (Local Constraint ) 計算 表 3.1 正規圖的組成元件
3.1.2 在正規圖上的訊息傳遞
定義: 3.1.2.1 一個節點 首先我們先考慮一個節點的情況,如圖 3.2 所示,假設每個邊變 數為獨立,且每個邊變數的本質機率為已知,則我們可以分別計算出 每個邊變數的外質機率及後置機率,以邊變數 X0 為例,其外質機率 及後置機率可分別由(3-1)及(3-2)式計算出: int ( ) ( ) ( ) ( | ) ( ) ( | ) 1 ( | ) E post E ext E x a A P x a P x a P x a P x a E P x a c P E x a P E x a ∈ = = = = = = = = = = =∑
x 1. 本質機率: 2. 後置機率: 3. 外質機率: 其中 c圖 3.2 一個節點 外質機率: 0 0 1 1 0 1 int 0 0 0 0 , ,..., 1 ( , ,..., ) ( ) ( | ) ( ) k k x K ext x i i N N i N P x c P N x c P x α α α α α α α α α = ∈ = = = =
∑
∏
= (3-1) 利用貝氏定理(Bayes’ Theorem), 我們可以將後置機率拆解成如下 的式子: 後置機率: 1 2 0 1 0 0 0 0 0 0 0 0 int , ,..., 0 ( , ,..., ) 1 ( ) ( | ) ( | ) ( ) ( ) 1 ( ) ( ) k k post N K i i N i N P x P x N P N x P x P N P x P N α α α α α α α α α α α = ∈ = = = = = = =∑
∏
= (3-2) 以下為(3-1)式的證明:N
1x
2x
kx
0x
int ( ) N i P x 0 ( ) ext N P x(
)
0 1 0 0 1 1 1 : , , , , , , , , K K K K N N A A A x x x N ⊂ × × × = α = α = α α α α ∈ L K K 0 1. 連結至約束節點 的可能集合為 也就是說 當 時 事件N為真的條件是{
}
{
}
1 1 1 ( , , ) 1 ( , , ) 2. ( ) 1 ( ) ( , ) K K K K K i i i A A K i i i A A P x P N P N x = α α ∈ × × = α α ∈ × × = α = ∴ = = α∑
∑
K L K L Q 1 1 3.1.2.2 兩個節點 接下來我們考慮兩個節點的情況,如圖 3.3 所示,如果我們把 L 及 R 兩個局部約束集合看成一個大約束集合 g,則套用(3-1)式,我 們可以計算出每一個外部邊變數的外質機率,如(3-3)式所示。{
}
{
}
{
}
{
}
{
}
1 1 0 0 0 0 1 0 0 ( , , ) 0 0 0 1 ( , , ) 0 0 1 ( , , ) ~ 1 ( | ) ( , | ) ( | ) ( | ) ( | ) ( ) K K K K K K K i i i A A K K i i i i i i A A K i i i A A K i i i P N x P N x x P N x P x x P x x P x α α α α α α αα
α
α
α
α
α
α
α
α
= ∈ × × = = ∈ × × = ∈ × × = = = = = = = = = = = = = =∑
∑
∑
K L K L K L 1 1 0 3. 由2的結果, 則條件機率 0 0 0 0 ( , , ) ~ ( , , ) 1 ~ ( ) K K K K A A K i i A A i P x α α α α α αα
∈ × × ∈ × × = = =∑
∑
∏
K L K L Q 0 0 變數間為獨立圖 3.3 兩個節點 由於整體的變數增加,所以可能發生的邊變數集合也變多,使得 (3-3)式的複雜度很高。接下來我們將會介紹如何分開處理 L 和 R 的 局部約束以使複雜度降低。
(
)
(
)
0 1 ' 0 1 2 ' 0 1 1 ' ' int ( , ,..., ) 0 { }, ,
,
,
,
,...,
,
,...,
( )
'
( )
i k k i i L L R R K K K K K K ext g i x g l x x x g l l i xx x x
x
x x
x
x
x
x
P
x
c
P
x
+ + + ∈ = ≠=
=
∑
∏
K
的假設我們將3.3圖的邊變數重新取名:
則 外質機率
(i
介於0到K+K'):
(3-3)
L
R
1 Lx
L Kx
1 Rx
' R Kx
0x
0 ( ) L R x µ → 0 ( ) R L x µ →{ }
(
)
{ }
{ }
(
)
(
{ }
)
{ }
{ }
(
)
(
{ }
)
{ }
0 ' 2 0 ' 2 0 ' 2 ' 1 0 2 1 , ' ' 0 1 0 2 1 , ' ' 0 1 0 2 1 , ( , | ) , , , | | , , , , | | , , , | K R i i K R i i K R i i K R R R i i x x K K R R R i i i i x x K K R R R i i i i x x P L R x P L R x x x P R L x x P L x x x P R x x P L x x x = = = = = = = = = = =∑
∑
∑
Q Q 貝式定理 馬可夫定理{ }
(
)
(
{ }
)
(
{ }
)
{ }
{ }
(
)
{ }
0 ' 2 0 ' 2 ' ' ' 0 1 0 1 0 2 1 , ' int int 0 1 0 0 , | , | , , | | , ( | ) ( ) K R i i K R i i K K K R R R R i i i i i i x x K R R i i g g i x x P R x x P L x x P x x x P R x x P L x P x P x = = = = = =∑
∑
∏
Q Q K' i=2 = 貝式定理 = ( ) 變數獨立 以上的證明簡言之,就是當有兩個節點 L、R 以一內部邊變數相 連時,將其中一節點 L 在此內部邊變數的外質機率,看作是另一節點 R 的內質機率時,對 R 節點去算出的外部邊變數的外質機率,等於同 時對 L 及 R 節點去算出的 R 那邊的外部邊變數的外質機率;將 L 及 R 反過來看也是一樣。因此我們由 L 節點的局部約束去算出 R 節點需要 的內質機率後,再由 R 節點的局部約束去算出 R 節點其中一外部邊變 數的外質機率,這樣個別去計算的複雜度會比對整體 g 的局部約束去 計算其中一外部邊變數的外質機率的複雜度低很多。我們將兩個節點 的 MPA 步驟整理如下:{ }
(
)
{ }
(
)
{ }
1 1 0 ' 2 1 0 1 2 ' 1 int 0 0 1 1 ' int 0 1 0 , int 0 , , , ,1
( )
(
)
( , |
)
|
,
( |
)
(
)
( |
)
(
R R K R i i R R R R K R g ext R R g x K R R i g i x i x x R g i x x x x x R xP
x
A
p
x
c P L R x
c
P R x
x
P L x
P
x
c
P L x
P
x
= = ∈=
=
∑
∏
∑
K K' i=2假設
為均勻分布, 則
=
'
=
'
(
)
{ }
1 0 1 2 ' 1 int 0 , , , , int 0 0)
( |
)
(
)
( |
)
( )
R R R R K R R R i x x x x x R x Rc
P L x
P
x
P L x
P
x
∈∏
∑
∏
K K' i=2 K' i=2=
'
(3-4)
此處
可看成
(
)
{ } 0 0 1 2 0 int 0 int int int 0 , , , , 0 0 : ( ) 1, 2 , ( ) L L L K g L L L i g i ext L L x L i x x x x L x ext L R L P x P x P x i K P x c P x x P xµ
∈ → ← = ←∑
∏
K K 0 K i=1 步驟 1 設定初始值 1 將內部邊邊數設為均勻分佈: ( )= A 步驟 2(a): 計算從L節點傳至R節點的訊息 輸入 : ( ) , 計算 : ( )= ' 輸出 : ( ) ( ) 步驟 2(b)(
)
{ } 0 0 1 2 ' 0 int int int 0 ' , , , , 0 0 int 0 0 ( ) ' 1, 2 , ' ( ) ( ) ( ) R R R K R R R i g i ext R R x R i x x x x R x ext R L R L R L P x P x i K P x c P x x P x P x xµ
µ
∈ → → ← = ← ←∑
∏
K K K' i'=1 : 計算從R節點傳至L節點的訊息 輸入 : ( ) , 計算 : ( )= ' 輸出 : ( ) ( ) 步驟 3(a): 計算L節點的外質機率輸出 輸入 : 及(
)
{ }
0 1 2 int int int int 0 , , , , int 0 ( ) 1, 2 , ( ) ( ) 1, 2 , ( ) 1, 2 , ( ) L i L L L K L i L L L i g i ext L L L i x L L l x x x x L x ext L ext L g i L i R P x P x i K P x c P x P x i K P x P x i K P x ∈ ≠ ← = = ← =∑
∏
K K K K K l=1 l i ( ) , 計算 : ( )= ' , 輸出 : ( ) , 步驟 3(b): 計算R節點的外質機率輸出 輸入 :(
)
{ }
' 0 1 2 ' ' int int 0 ' ' int int ' 0 , , , , ' ' ( ) ( ) ' 1, 2 , ' ( ) ( ) ' 1, 2 , ' ( ) ' 1, 2 , ' R i R R R K R i R R L R R i g i ext R R R i x R R l x x x x L x ext R ext R g i R i x P x P x i K P x c P x P x i K P x P x i Kµ
→ ∈ ≠ ← ← = = ← =∑
∏
K K K K K' l=1 l i' 及 ( ) , 計算 : ( )= ' , 輸出 : ( ) ,3.1.2.3 兩個模組 當有兩個以上的節點時,我們可以將這些節點先分成兩個模組, 如圖 3.4 所示,分成 L 及 R 模組,此時 L 和 R 間的訊息傳遞就可以使 用上一節中所介紹的兩個節點訊息傳遞的方法,而 L 或 R 中若還包含 兩個以上的節點時,則又可以繼續分解下去,直到分解成一個模組為 一個節點。
L
R
N1 N2 N3 N4 N5 N6 N7 N8 圖 3.4 以一個邊相連的兩個模組3.1.3 應用
3.1.3.1 同等節點(Equality Node) 同等節點指的是與節點相連的變數被約束成必須相等,我們將同 等節點表示成圖 3.5。在這種情形下外質機率的公式(3-1)可被簡化 成如(3-5)式: 圖 3.5 同等節點 (3-5) 在二位元系統中, (3-5)式又可以用對數可能性比例(LLR)的方 法來表示:(為了方便起見,這章裡的二位元指的是 1 和-1) 0 0 int 0 0 0 0 0 ( ) ( | ) ( ) ext N x x N i P x =α
=c ⋅P N x =α
=c ⋅∏
P x =α
K i 外質機率 :=
1x
2x
kx
0x
int ( ) N i P x 0 ( ) ext N P xN
0 int 0 1 0 int 0 1 1 ( 1) ( 1) ( ) log log ( 1) ( 1) ( ) (3-6) i K ext N i N i N x ext K N N i i K x N i i P x P x LLR x P x P x LLR x = → = → = = = = = = − = − =∏
∏
∑
3.1.3.2 白色高斯雜訊的外質機率 假設我們傳送 x 訊號經過白色高斯雜訊通道後收到 y: y=x+n 且白色雜訊具有如下的機率分布: 則我們可以寫出 x 的後置機率為: 2 2 1 ( ) exp( ) 2 2 n a P a
σ
πσ
= −(
)
(
)
2 2 2 2( | ) ( )
( )
( | )
( )
1
exp(
) ( )
2
2
( )
1
exp(
)
2
2
post AWGNP y x P x
P
x
P x y
P y
y
x
P x
P y
y
x
x
σ
πσ
σ
πσ
=
=
−
=
−
−
−
(3-7)
其中 的外質機率為
.
3.2 MPA 在渦輪解碼上的應用
接下來我們將介紹如何把 MPA 應用至渦輪解碼上。由於渦輪編碼 是由兩個編碼器加上一個交錯器所組成的,每一個編碼器皆可由一籬 笆狀圖(Trellis diagram)來代表,因此我們首先會介紹籬笆狀圖的 正規圖表示法,然後由此正規圖去推導我們所要的後置機率,此即為 一個編碼器下的解碼方法;然後我們將把此正規圖擴展成渦輪編碼的 正規圖,去推導渦輪碼系統位元和同位位元的後置機率,並將之與傳 統渦輪解碼的方法作一比較。3.2.1 籬笆狀圖及其相對的正規圖
圖 3.6 籬笆狀圖及其相對的正規圖 2 t S− St−1 St St+1 St+2 狀態: ( ) t st β αt( )st βt+1(st+1)αt+1(st+1) 2 t N− 籬笆狀 節點 2 t z− 2 t x− 2 t s− Nt−1 1 t z− 1 t x− 1 t s− Nt t z t x t s Nt+1 1 t z+ 1 t x+ 1 t s+ Nt+2 2 t z+ 2 t x+ 2 t s+ ( ) t st α ( ) t st β βt+1(st+1) 1( 1) t st α+ +在圖 3.6 中,我們以狀態數為四,碼率為 1/2 的編碼器為例,上 方的圖為此編碼器的籬笆狀圖,而下方的圖則為等效的正規圖。其中 t S 為在時間 t 時編碼器的狀態;x 及t z 則為在時間 t 時的編碼器輸出t 位元;N 則為時間 t 時所可能的t
(
S St, t+1, ,x zt t)
集合,此集合與編碼器 的結構有關。 此外定義: 由圖 3.6 的正規圖,及(3-1)式計算外質機率的公式可知,α及β可 以遞回的方式算出: 假設此編碼器為一系統性編碼器(Systematic encoder),而x 為t 系統位元,z 為同位位元,此時我們可以經由 MPA 算出系統位元t x 的t 外質機率及後置機率如下所示: 1 1 ( ) ( ) ( ) ( ) ( , ) ( ) ( ) t t t t t t t t t t N N t t t N N t t t t X N t Z N t s s s s x z x zα
µ
β
µ
γ
µ
µ
− − → → → → = = = 1 1 1 1 1 1 ( , , , ) { } 1 ( , , , ) { } ( ) ( ) ( , ) ( ) ( ) ( , ) t t t t t t t t t t t t t t t t s t t t t t s s x z N s t t s t t t t t s s x z N s s c s x z s c s x zα
α
γ
β
β
γ
+ + + + + + ∈ + ∈ = =∑
∑
1 1 1 1 ( , , , ) { } 1 1 ( , , , ) { } ( ) ( ) ( ) ( ) : ( ) ( ) ( ) ( ) ( , ) ( ) t t t t t t t t t t t t t t t t t t t t t t t N X t x t t t t Z N t s s x z N x post N t x N X t X N t x t t t t t t t s s x z N x x c s s z P x c x x c s x z sµ
α
β
µ
µ
µ
α
γ
β
+ + → + + → ∈ → → + + ∈ = = =∑
∑
外質機率: 後置機率若訊號所經過的通道為白色高斯雜訊,由(3-7)式,則我們可以 寫出x 的對數可能性比例如(3-8)式所示: t
3.2.2 利用 MPA 推導渦輪解碼
上一節中我們介紹了傳送端一個編碼器的正規圖畫法及其系統 位元的對數可能性比例表示法,由於渦輪編碼器為兩個編碼器及一個 交錯器所形成,因此我們可以將圖 3.6 擴展至圖 3.7 以表示渦輪碼的 正規圖。 圖 3.7 中,我們以 1 t x 表示在時間 t 時的第一個編碼器同位位元, 以 2 t x 表示時間 t 時的第二個編碼器同位位元;以z 表示時間 t 時的第t 一個編碼器系統位元,以p 表示時間 t’時的第二個編碼器系統位t' 元;在碼率為 1/3 的渦輪碼中,第一個編碼器在時間 t 時的系統位元 會等於第二編碼器在時間 t’時的系統位元(t’和 t 的關係取決於交 錯器的設計),又等於最後出輸出的值 0 t x ,因此正規圖中我們用一同 等節點將這三個邊變數連結在一起。(
)
(
)
(
)
(
)
2 1 , , 0 2 2 1 , , 0 2 1 2 2 ,0 ,1 1 1 2 ( , , 1, ) { } 1 ( , ) ( ) ( ) exp 2 , , : ( ) exp ( ) : ( ) log ( ) exp t j t j j t t t t t j t j j t t t t t t r v t t t X N t Z N t t t t t t r v t t t t s s x z N x t t t x z x z v v x z x s s LLR x s σ σγ
µ
µ
πσ
α
β
α
= = + − → → − + + = ∈ ∑ = = − = −∑ Λ =∑
由圖3.6 : 其中 則 的對數可能性比例(
)
2 1 , , 0 2 1 1 1 2 ( , , 1, ) { } ( ) t j t j j t t t t t t r v t t s s x z N x s σβ
= + − + + =− ∈ ∑ − ∑
(3-8)In te rl ea ve r
=
=
=
=
T re llis 2 T re lli s 1W
P
圖
3.7
碼
率
1/3的
渦
輪
碼
正
規
圖
N
接下來我們利用圖 3.7 推導出 0 t x 的後置機率: 1. 首先因為一開始不曉得
µ
Nt'→Wt( )zt 的值,因此先設為 0.5,然後利用系 統位元的本質機率計算出µ
Wt→Pt( )zt 。 2. 接著使用上一節的方法去計算第一個成份編碼器的α
t( )st 和β
t( )st 。 3. 以時間 t=1 時為例,假設通道為白色高斯雜訊,則由圖 3.7 可知: { }(
)
1 1 0 1 1 1 1 2 1 1 1 1 1 1 1 0 0 2 1 1 ( , , , ) ( ) ( ) exp ( ) 2 P W z S S z x P z r x z c s sµ
α
β
σ
πσ
→ ∈ − = − ∑
1 2 以傳統渦輪碼的觀點來看,µ
Pt→Wt( )z1 即為第一個編碼器產生給 第二個編碼器的事前機率(Priori probability)。 4.(
)
0 1 1 1 0 1 0 1 4 1 1 1 1 1 1 2 0 0 1 1 1 1 2 1 1 ( ) ( ) ( ) exp ( ) 2 W N y x W P W y P W x y c x z z r x c zµ
µ
µ
µ
σ
πσ
→ → → → = = = − = − ∴ Q 同等節點 : y1 1 2 同時其它時間 W 節點傳給 N 節點的外質機率亦可算出,有了這些 機率,我們便可以較準確的算出第二個編碼器α
t'( )st 和β
t'( )st 的質。 計算完α
t'( )st 和β
t'( )st 的質後,我們又可算出第二個編碼器傳給第一 個編碼器的事前機率,如此經過幾個迴圈後,這些機率將會愈來愈準 確。5. 經過幾個迴圈後,則 0 t x 的後置機率以時間 t=1 為例:
(
)
{ }
(
)
0 0 1 1 0 0 1 1 0 1 0 1 0 1 1 1 0 1 0 1 1 1 0 1 1 0 0 0 1 4 1 1 1 1 1 1 0 int 0 0 1 1 1 1 1 1 1 2 2 0 0 1 1 1 1 int 0 1 1 1 1 0 0 1 2 2 2 ( , , , ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) exp ( ) ( ) exp ( 2 2 2 post W N W P W x x W W P W x x W x W S S x x P x x y z P x c x x x c x P x x c r x r x P x sµ
µ
µ
µ
µ
α
β
πσ
σ
σ
→ → → → → ∈ = = = = − − = − − ∑
Q 1) s 其中 int 0 1( 1) W P x =µ
N4→W1(x10) 6. 將上式推廣至一般形式:(
)
{ }
(
)
0 0 1 1 0 0 2 2 0 0 1 1 int 0 1 1 2 2 2 ( , , , ) ( ) exp ( ) ( ) exp ( ) 2 2 2 t t t t t t post Wt t t t t t x Wt t t t t t S S x x P x P x c r x r x P xα
sβ
sπσ
σ
− − −σ
∈ − − = − − ∑
7. 在二位元系統中,則上式又可以對數可能性比例來表示:(
)
{ }(
)
(
)
{ } 0 0 1 1 0 0 0 1 1 0 0 2 2 0 1 1 int 0 1 1 2 2 2 ( , , 1, ) 2 0 int 0 1 1 2 2 ( , , 1, ) ( ) 1 exp ( 1) ( ) exp ( ) 2 2 2 log 1 exp ( 1) ( ) exp 2 2 t t t t t t t t t t t t t t t t x Wt t t t t t S S x x P x t x Wt t t t S S x x P x x c r r x P x s s c r P x s α β πσ σ σ α πσ σ − − − − = ∈ − − =− ∈ Λ − − − = − = + − = − ∑
∑
(
)
2 1 1 2 int 0 0 0 int 0 2 ( ) 2 ( 1) 2 log ( ) ( 1) t t t t Wt t t e t Wt t r x s P x r x P x β σ σ − − = = + + Λ = − (3-10){ }
(
)
{ }
(
)
0 1 0 0 1 0 2 1 1 2 ( , , 1, ) 0 2 1 1 2 ( , , 1, ) ( ) exp ( ) 2 ( ) log ( )exp ( ) 2 t t t t t t t t t t i i t t t t t t S S x x P x e t i i t t t t t t S S x x P x r x s s x r x s sα
β
σ
α
β
σ
− − = ∈ − − =− ∈ − − Λ = − − ∑
∑
其中3.2.3 與最大後置機率(MAP)渦輪解碼的比較
這一節裡我們將比較使用 MPA 與 MAP 的渦輪解碼所推導出的系統 位元後置機率有什麼不同。 MAP 演算法中: 對於一碼率為 1/2 的系統迴旋編碼,它的系統位元x 的對數可能性比t 例為[8]: 在(3-11)式中, 1 t B 代表ct =1時可能的(St−1,St)集合;B 代表t0 0 t = c 時可能的(St−1,St)集合; 1 , ( ) t i t x S 代表狀態為S ,輸入t x =1 時的t 第 i 個輸出; 0 , ( ) t i t x S 代表狀態為S ,輸入t x =-1 時的第 i 個輸出;又t 因為是系統性編碼,所以 1 ,0( ) t t x S =1,xt0,0( )S =-1。 t 1 1 1 ( ) ( , ) ( ) ( | ) ( ', ) ( , , | ) ; 0,1 t t t t t t t t t t t t t s P S r s P r S l l P q k S r S k τα
β
γ
+ − = = = = =(
)
(
)
2 1 1 , , 0 2 1 1 2 1 0 , , 0 2 0 1 ( ) 1 1 2 ( , ) ( ) 1 1 2 ( , ) ,0 1 2 ( ) ( 1)exp ( ) ( ) log ( ) ( 1) exp ( ) ( 1) 2 log ( ) ( 1) t i t i t i t t t t i t i t i t t t r x S t t t t t t S S B t r x S t t t t t t S S B t t t e t t t s p x s x s p x s P x r x P x σ σα
β
α
β
σ
= − = − − − − ∈ − − − ∈ ∑ = − Λ = ∑ = − − = = + + Λ = −∑
∑
(3-11)首先我們注意到 MPA 及 MAP 的 α、β、γ 的定義不同,但物理 意義是相同的,故我們可以把 MPA 及 MAP 中的 α、β、γ 看成是等 效的。 比較(3-8)及(3-11)式,可以發現 MAP 推導的 LLR 比 MPA 推導的 LLR 多了本質機率p xt( t ),但比較(3-10)式及(3-11)式又可發現 MAP 及 MPA 推導出的 LLR 相同。若不是在渦輪碼的情況下,MPA 的本質機 率都設為 1/2,為一常數,此常數在分子分母會互相除掉,因此(3-8) 式與(3-11)式在這種情況下是相同的。又在渦輪碼的情況下,由於 (3-10)與(3-11)式相同,因此我們可以說渦輪解碼中,由 MPA 所推導 出的系統位元的 LLR 與由 MAP 推導出的系統位元的 LLR 是相同的。 傳統渦輪碼中,並無以數學來說明,為何接收端渦輪解碼器中所 傳遞的事前機率必須不包括系統位元的資訊,如果以 MPA 來看渦輪解 碼,便能用數學的推演結果來證明。
3.2.4 利用 MPA 推導渦輪碼同位位元(Parity bits)的軟資
訊
由於 MAP 及 MPA 所推導出的對數可能性比例具有等效性,因此我 們可以利用 MPA 去推導渦輪碼同位位元的對數可能性比例,以作為渦 輪多用戶偵測裡重建訊號之用。由圖 3.7,在計算系統位元的對數可 能性比例時,我們已經得到 α、β、γ 及 Pt 的值: 0 0 1 21 2 1 ( 1) 2 log ( ) ( 1) e Wt Pt t t Wt Pt z r Pt L x zµ
µ
→→σ
= = + = − ( 1) ( 1) 1 exp( ) ( 1) 1 exp( ) 1 ( 1) 1 exp( ) Wt Pt t Wt Pt t Wt Pt t Wt Pt t z z Pt z Pt z Pt
µ
µ
µ
µ
→ → → → = + = − = ∴ = = + = − = + Q 利用 MPA 及圖 3.7,我們可以寫出同位位元x
t1的對數可能性比例:( )
0 1 1 0 1 1 0 1 1 1 ( , , , 1) 1 2 0 1 1 ( , , , 0) ( ) ( ) ( ) 2 ( ) ( ) ( ) t t t t t t t t t t t t t s s x x P t t t t t t t s s x x P s P x s r L x s P x sα
β
σ
−α
β
− − − = ∈ − − = ∈ ⋅ ⋅ = + ⋅ ⋅ ∑
∑
log (3-12)( )
2 t L x 其中 A1+ 代表輸入系統位元為 1 而輸出同位位元為 1 的集合; A1- 代表輸入系統位元為 -1 而輸出同位位元為 1 的集合; B1+ 代表輸入系統位元為 1 而輸出同位位元為 -1 的集合; B1- 代表輸入系統位元為 -1 而輸出同位位元為 -1 的集合; 同理我們可得 . 在計算同位位元的對數可能性比例時,不需要重新計算 α 和 β 的值,因此複雜度並不高。 1 1 1 1 1 1 1 1 1 ( , ) 1 ( , ) 1 2 1 1 1 1 ( , ) 1 ( , ) 1 ( ) ( 1) ( ) ( ) ( 1) ( ) 2 ( ) ( 1) ( ) ( ) ( 1) ( ) t t t t t t t t t t Wt Pt t t t t t Wt Pt t t t s s A s s A t t t Wt Pt t t t t t Wt Pt t t t s s B s s B s z s s z s r s z s s z s α µ β α µ β σ − α µ β − α µ β − − − − → − − → ∈ + ∈ − − − → − − → ∈ + ∈ − ⋅ = ⋅ + ⋅ = − ⋅ = + ⋅ = ⋅ + ⋅ = − ⋅ ∑
∑
∑
∑
log 3.3 模擬結果與探討
以下我們以電腦來模擬渦輪解碼的系統位元錯誤率,及使用 MPA 渦輪解碼的同位位元的錯率,以驗證(3-12)式的正確性。 編碼器記憶體個數 3 碼率 1/3 2 個遞迴式迴旋編碼器之八進位表示式 (17,15) 通道形式 白色高斯雜訊 交錯器形式 隨機 交錯器長度 100 迴圈數目 5 取樣數目 1e7 位元 表 3.2 渦輪碼模擬參數表 由圖 3.8 的模擬結果可以看出,兩個同位位元的錯誤率只比系統 位元(即資訊位元)的錯誤率高了一些,這表示系統位元受到的保護較 好,這是合理的。而經由 MPA 推導出的同位位元的解碼方法也的確與 系統位元一樣具有低錯誤率的表現。0 0.5 1 1.5 2 2.5 SNR (dB) 0.0001 0.001 0.01 0.1 BER message bit parity bit 1 parity bit 2 圖 3.8 渦輪碼系統位元及同位位元的錯誤率
第四章
多載波分碼多重進接(MC-CDMA)系
統傳送機架構和通道模型
本章將建構一使用渦輪編碼的 MC-CDMA 系統上鏈傳送機架 構,並對系統所使用之展頻碼、通道模型和上鏈多用戶環境做詳細的 介紹。本報告中假設其它蜂巢的干擾為零,故架構中不包含攪亂碼。
4.1 傳送機架構
圖 4.1 為 MC-CDMA 系統的傳送機架構圖。每個用戶要傳送的訊 號分為資料訊號(Data signal)與領航訊號(Pilot signal)。頻域的資料訊 號依序經過碼率為 1/3 的渦輪編碼、外部交錯器、QPSK 調變、展頻, 也就是說原先的資料經過渦輪編碼後得到一個系統位元和兩個同位 位元,之後再將它們經過外部交錯器,目的是為了減少因衰減通道所 造成資料在時間上有衰減的相關性,(相對於在渦輪編碼器中的內部 交錯器,因此稱為外部交錯器);編碼後的資料經並列變串列轉換器 後傳至 QPSK 作調變的動作;調變後的資料先複製成N組資料(N為 FFT 或展頻碼的長度),每一組資料再分別乘上展頻碼的各個切片 (chip),可視為將N組資料放在不同的次載波上傳送。QP S K Mo d u la ti o n Co p ie r IF F T P/ S . . . . . . . . . . Spr ea di ng P ilo t s ig n al Gu a r d In te rval In se rt io n us er Tu rb o E nc od er P/ S Ex te rn al Int erl ea ve r 圖 4. 1 M C -CD MA 上鏈傳送 機 架構圖 (第u個用戶 ) BP SK M o d u la tio n R andom bi t ge ne ra to r fo r us er u
為了降低 MAI 的影響,採用彼此正交的華氏碼(Walsh code)區分 每個用戶的資料訊號,而有良好相關性的金氏碼(Gold code)則用來區 分不同用戶的領航訊號。接著做 IFFT 運算轉換成時域訊號,再加入 時域上的領航訊號。領航訊號的目的是在接收端作為估計每個用戶的 通道之用,其產生方法是利用隨機位元產生器產生隨機的位元後再經 BPSK 調變,然後再由金氏碼展頻而得。在傳送訊號前,每個資料框 要加上護衛間隔。圖 4.1 中的符號說明如下: , s u n b :第u個用戶的第n個資訊位元(或稱作系統位元)。 p u1, n b :第u個用戶的第n個資訊位元所產生的第一個同位位元。 p2,u n b :第u個用戶的第n個資訊位元所產生的第二個同位位元。 u w δ : s u, n b 、bnp u1, 及bnp2,u經過並列變串列轉換器後的第w個位元。 u m v : 對δwu作 QPSK 調變後的第m個符元。 依照上述的傳送機架構,則第u個用戶欲傳給基地台的第m個傳 送資料符元的第τ 個切片可表示成如下: -1 0 ( ) cd ( ) exp( 2 / ) N u u m m u k D τ v k j π τk N = = ×
∑
(4-1) 其中 u( ) m D τ :第u個用戶的第m個傳送資料符元的第τ 個切片。 u m v :第u個用戶的第m個傳送資料符元(Data symbol)。 ( ) u cd k :第u個用戶資料訊號展頻碼的第k個切片。 N :IFFT 的長度。假設第u個用戶領航訊號其展頻碼為cpu