國立屏東商業技術學院
資訊工程研究所
碩士論文
使用
WordNet 語意之拍賣商品標題自動分類
WordNet-based Semantic Classification for
Auction Commodity Titles
指導教授: 董呈煌 博士
研 究 生: 劉瑋竣
Abstract
This research aims at automatically classification merchandise in an auction website according to the Chinese titles of merchandise. Because of the shortcomings of traditional article classification, this papers proposes four methods to improve the automatic classification of merchandise titles. The first method first trains the keywords for each class of merchandise, and then exactly extracts the keywords for each testing merchandise title. The extracted feature vector is then classified by the SVM. The second method is designed to loosely extract the keywords for each testing merchandise title. The third method involves the use of machine translation from Chinese keywords to their English translations and the WordNet with semantic structures. In the training phase, the method first derives the best semantic for the English translations of each Chinese keyword. In the testing phase, by using the semantic information of the keywords and the titles, the method extracts extra keywords for the Chinese titles without matched keywords after processed by the second method. The fourth method involves the use of similar keywords, which are the keywords whose semantic distances are short. Based on the third method, the fourth method extends the matched keywords to their similar keywords, and thus each extracted feature vector may contain more keywords with similar meanings. At last, a feature vector can be transformed by a feature extraction method, such as FFT, DCT, etc., into a new feature vector to reduce the size of the feature vector. Then, the SVM can reduce the storage space and the running time while the recognition performance is still retained. Experimental results show the excellent performance of the proposed methods.
Keyword: WordNet, SVM, machine translation, automatic classification, feature
目錄
摘要 ... i Abstract ... ii 誌謝 ... iii 目錄 ... iv 圖目錄 ... vii 表目錄 ... x 第 1 章 緒論 ... 1 1.1 研究背景與動機 ... 1 1.2 研究問題與目的 ... 5 1.3 論文架構 ... 7 第 2 章 文獻探討 ... 8 2.1 特徵擷取(Feature Extraction) ... 8 2.1.1 斷詞器 ... 8 2.1.2 N-Gram 選詞法 ... 9 2.1.3 共現詞分析法(Co-occurrence Analysis) ... 10 2.2 特徵權重計算 ... 11 2.2.1 詞彙頻率(Term Frequency, TF)... 112.2.2 文件頻率倒數(Inverse Document Frequency, IDF) ... 12
2.2.3 TF-IDF ... 13
2.2.4 關鍵詞數量 ... 13
2.3 分類器(Classifier) ... 14
2.3.1 Support Vector Machine ... 14
2.3.2 Vector Space Model ... 16
2.3.3 K Nearest Neighbor ... 18
2.3.4 貝氏分類器 (Naïve Bayesian Classifier) ... 19
圖 4-31 類別「平底鍋」之 DFT 頻譜係數 ... 69
圖 4-32 類別「安全帽」之 DFT 頻譜係數 ... 69
圖 4-33 類別「耳機」之 DFT 頻譜係數 ... 70
圖 4-34 類別「吹風機」之 DFT 頻譜係數 ... 70
2.3 分類器(
Classifier
)
在自動文件分類的領域上,分類器的技術相當多種。本節大略介紹經常被使用 的分類技術。
2.3.1 Support Vector Machine
2.3.2 Vector Space Model
在相似度計算方面一般常見的計算方式如表2-6:
表 2-6 相似度計算方式[46]
Similarity Measure Sim(X,Y)
Evaluation for Binary Term Vectors
2.3.3 K Nearest Neighbor
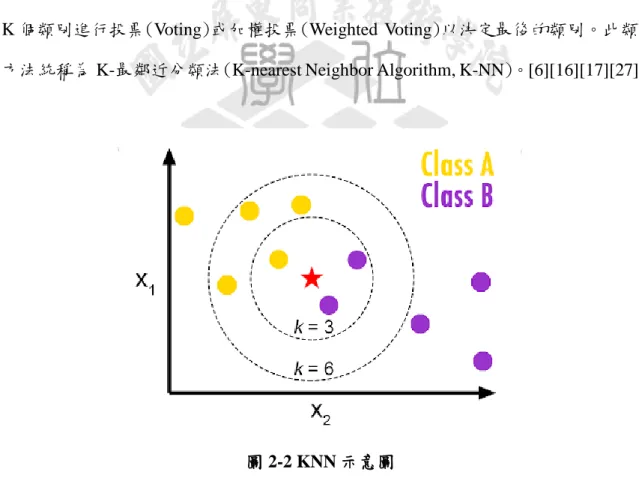
最鄰近分類法(Nearest Neighbor Algorithm, NN)[47]以空間中的點表示每筆資 料,同時假設屬於相同類別的點之間的距離會比不屬於相關類別的點之間的距離 來得接近。依此假設,對於每一筆未知類別的測試資料,只要尋找在訓練資料中和 該測試資料點距離最接近的訓練資料點,便可決定該筆測試資料和此最接近的訓 練資料屬於同一類別。 通常,在訓練資料具有很多雜訊(Noise)的情況下,若只用最靠近的資料來決 定測試資料的類別時,可能會導致分類的效果不彰。為解決這個問題,常見的做法 上如圖 2-2 所示先取與該筆測試資料最接近的 K 個訓練資料點,再依據其對應的 K 個類別進行投票(Voting)或加權投票(Weighted Voting)以決定最後的類別。此類 方法統稱為 K-最鄰近分類法(K-nearest Neighbor Algorithm, K-NN)。[6][16][17][27]
圖 2-2 KNN 示意圖
2.5 WordNet 相關應用
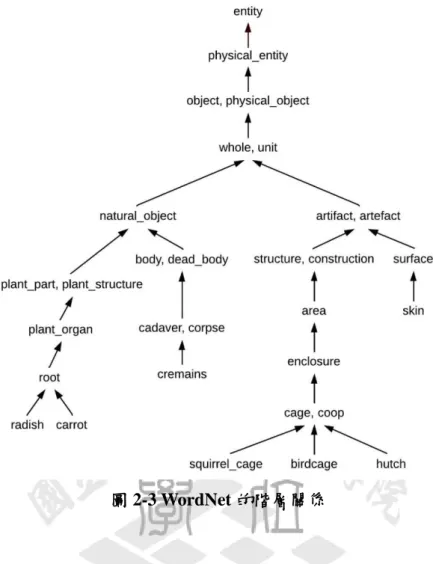
WordNet 是由普林斯頓大學教授 Miller 指導建立和維護的英文辭典[29],開發 工作從 1985 年開始。WordNet 運用認知語言學的理論,以人類語言機制中對詞彙 記憶結構的特性,將詞彙收錄至此知識庫中。這些詞彙包含英文的名詞、動詞、形 容詞以及副詞,收錄時組織成同義詞集(Synset),為語意的基本的單位,一個同義 詞集包含的資訊有:編號、同義詞、解釋、例句,如表 2-5 所示。 如果一個詞彙同時收錄於兩個以上的同義詞集中,稱此詞彙具有歧義現象,如 表 2-8 中的 club 就具有(club.3058296)、(club.3057459)、(club.3451003)三種語意 (club 在 WordNet 名詞部分中有 7 個語意﹔此處僅節錄其中 3 個)。 表 2-8 以詞「club」及「stick」為例之 WordNet 同義詞集資訊 編號 同義詞 解釋 例句 (club.3058296) clubhouse, cluba building that is occupied by a social club
"the clubhouse needed a new roof" (club.3057459) club
stout stick that is larger at one end
"he carried a club in self defense"; "he felt as if he had been hit with a club" (club.3451003)
golfclub, club
golf equipment used by a golfer to hit a golf ball
(stick.4324558) stick an implement consisting of a length of wood
"he collected dry sticks for a campfire"; "the kid had a candied apple on a stick"
圖 2-3 WordNet 的階層關係
第二階段則是藉由同議詞集「plant#n#1」之下位關係(Hyponyms)的同議詞集如 表 2-9,從這些下位同議詞集的同議詞中找出含有「plant」的詞彙,例如「bottling plant」、「assembly plant」,假設有找到則將這些詞彙依照第一階段的方法進行翻譯, 否則進入第三階段。
表 2-9 「plant#n#1」之下位關係(Hyponyms)的同議詞集
Hyponyms of noun plant plant, works, industrial_plant => bottling_plant => brewery => brewpub => microbrewery => distillery, still
=> factory, mill1, manufacturing_plant, manufactory => assembly_plant
=> maquiladora
=> automobile_factory, auto_factory, car_factory
其中朗文當代英漢字典(Longman English-Chinese Dictionary of Contemporary English)為機讀字典(Machine Readable Dictionary),主要的使用對象為以英文為第 二外語的學習者,初期字典以書的形式包含了超過 55,000 筆的資料,並有 41,000 筆資料電子化供機器處理。一筆資料包含了一個詞彙、詞性、以及所有的詞義,詞 義內容為其定義以及例句,並包含中文翻譯如表 2-12 所示。
表 2-12 以名詞「club」為例之朗文當代英漢字典資訊[33]
定義 例句 中文翻譯
1 a society of people who join together for a
certain purpose, esp. sport or amusement “a working-men's club” 俱樂部
2 a building where such a society meets 俱樂部會址
3 a heavy wooden stick, thicker at one end
than the other, suitable for use as a weapon
短棒; 棍
4 a specially shaped stick for striking a ball
in certain sports, esp. GOLF
球棒; 球桿
5 a playing card with one or more 3-leafed
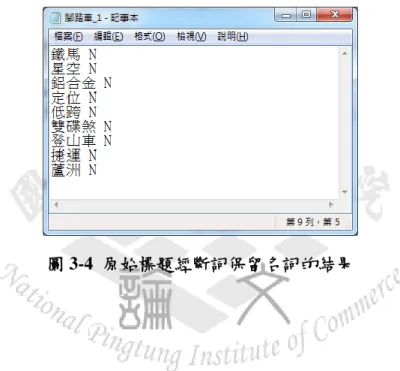
將原始標題(圖 3-2)使用 CKIP 中文斷詞系統的結果如圖 3-3 所示,接著將斷 詞結果過濾只留下詞性為名詞的詞彙如圖 3-4。
圖 3-3 原始標題經過 CKIP 斷詞的結果
在將轉換後的向量表示式格式化為 libsvm 所能支援的格式如下表 3-6 所示, 每一列代表一份文件,每一列開頭為該文件所屬類別,接著將文件所對應的特徵情 形以"向量維度:向量值"表示。 表 3-6 libsvm 所能支援的格式 1 1 : 1 2 : 0 3 : 0 4 : 0 5 : 0 6 : 0 1 1 : 1 2 : 1 3 : 0 4 : 0 5 : 0 6 : 0 2 1 : 0 2 : 0 3 : 1 4 : 0 5 : 0 6 : 0 2 1 : 0 2 : 0 3 : 1 4 : 1 5 : 0 6 : 0 3 1 : 0 2 : 0 3 : 0 4 : 0 5 : 0 6 : 1 3 1 : 0 2 : 0 3 : 0 4 : 0 5 : 1 6 : 1 將訓練特徵向量存成 train.txt 經過表 3-7 操作步驟可以得到最佳的參數以及 SVM 的訓練模型。 表 3-7 libsvm 建立 SVM 訓練模型 C:\libsvm-3.17\windows>svm-scale –s scale train.txt > train.scale C:\libsvm-3.17\windows>python grid.py train.scale
0.03125 0.0078125 100.0 C:\libsvm-3.17\windows>svm-train –c 0.03125 –g 0.0078125 train.scale
3.2.2 測試
將測試文件依照前面敘述的步驟,轉換成向量表示式在格式化成 libsvm 所能 支援的格式存成 test.txt,經過表 3-8 操作步驟可以得到分類的結果以及分類的正 確率如表 3-9 所示。 表 3-8 libsvm 預測及分類資料C:\libsvm-3.17\windows>svm-scale –r scale test.txt > test.scale
C:\libsvm-3.17\windows>svm-predict test.scale train.scale.mode test.out
表 3-9 SVM 輸出結果
3.5.2 機器翻譯
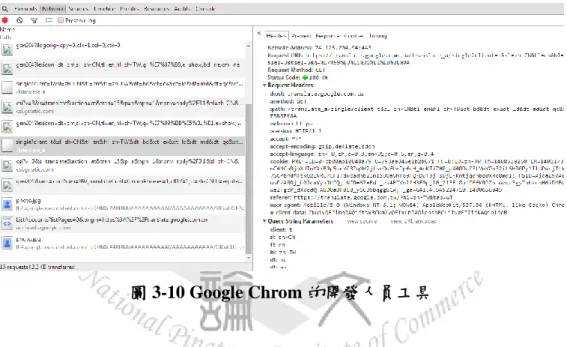
本論文使用的機器翻譯為 Google 翻譯,使用 http 協定中的 Request 及 Response 取得 Google 翻譯回傳的結果。
使用 Google Chrome 的開發人員工具可以觀察到 Google 線上翻譯的 Request 及 Response 詳細動作情形如圖 3-10
圖 3-10 Google Chrom 的開發人員工具
表 3-20 挑選翻譯流程 Step 1 將灰色區域的詞彙加入翻譯序列 Step 2 判斷是否有詳細資訊,如果有則將詳細資訊的詞彙加入候選序列, 否則將點擊後的所有詞彙加入候選序列 Step 3 將候選序列的詞彙保留原詞彙及以空白斷開的詞彙使用 WordNet 查 詢如果查詢到將其恢復原型並以不重複的方式加入翻譯序列 如表 3-20 經過 Step 1 及 Step 2 後取得中文詞可能的翻譯之後,將可能之翻譯 詞彙使用以下方法處理可能的翻譯,如果翻譯詞彙為單字則使用 WordNet 查詢是 否有該詞彙,如果查詢不到該詞彙則捨棄,反之則保留並透過 WordNet 將詞彙還 回原型,如表 3-21。 表 3-21 單字詞處理結果 colors -> color beads -> bead 如果翻譯詞彙為複合字則將該辭彙及該詞彙以空白字元斷開的詞彙,使用 WordNet 查詢是否有該詞彙,如果查詢不到該詞彙則捨棄,反之則保留並透過 WordNet 將詞彙還回原型,如表 3-22。 表 3-22 複合字處理結果
這邊我們以實例講解詳細的翻譯流程(表 3-23),第一步先將 Google 翻譯灰色 的翻譯加入翻譯序列,第二步將點擊出現的單字加入候選序列,並將候選序列的所 有詞彙以空白字元切開及保留原型使用 WordNet 查詢其結果如表 3-24,第三步將 第二步之結果以不重複的方式加入翻譯序列如表 3-25 表 3-23 「登山車」翻譯挑選實例 登山車
Step 1 翻譯序列 = {Mountain bike}
Step 2 候選序列 = {Mountain bike, MTB, Mountain bikes, Mountain bicycle} Step 3 翻譯序列 = {Mountain bike, Mountain, bike, bicycle}
表 3-24 Step 2 之處理結果 登山車
Mountain bike Mountain bike、Mountain、bike MTB
Mountain bikes Mountain bike、Mountain、bike Mountain bicycle Mountain bicycle、Mountain、bicycle
表 3-25 Step 3 之處理結果 登山車
3.5.5 關鍵詞語意
經過關鍵詞翻譯後我們藉由翻譯出來的英文詞彙在 WordNet 上找到相關的語 意,定位出中文關鍵詞可能的語意,階下來將詳細介紹定位中文關鍵詞語意的處 理流程 以下為使用類別「腳踏車」的前四個關鍵詞為範例,解說處理流程,表 3-26 為關鍵詞經過翻譯的結果。 表 3-26 「腳踏車」類別的前四個關鍵詞翻譯結果 登山車 Mountain Bike,Mountain,Bike,Bicycle 腳踏車 Bicycle 鋁合金 Aluminum,Alloy,Aluminium 自行車 Bicycle,bike 接著使用 WordNet 找到關鍵詞翻譯出來英文詞彙的語意如表 3-27,在 WordNet 中是以同議詞集所組合而成的,而每個同議詞集都代表一個獨特的概念也稱為語 意。 表 3-27 關鍵詞翻譯對應之 WordNet 語意 登山車[1] 3798315 = a bicycle with a sturdy frame and fat tires; originally designed for riding in mountainous country [2] 9382700 = a land mass that projects well above its surroundings; higher than a hill
[3] 3796045 = a motor vehicle with two wheels and a strong frame
[4] 2837983 = a wheeled vehicle that has two wheels and is moved by foot pedals 腳踏車 [1] 2837983 = a wheeled vehicle that has two wheels and is moved by foot pedals
鋁合金
[1] 14651998 = a silvery ductile metallic element found primarily in bauxite
[2] 14610949 = a mixture containing two or more metallic elements or metallic and nonmetallic elements usually fused together or dissolving into each other when molten; "brass is an alloy of zinc and copper" 自行車 [1] 2837983 = a wheeled vehicle that has two wheels and is moved by foot pedals
接著在將「登山車」的語意關聯矩陣(表 3-28)乘上自身的轉置形成方陣,如 表 3-32。 表 3-32 「登山車」語意關聯矩陣處理流程 A = 登山車語意關聯矩陣 B = A*A' 1906 1455 2063 1710 1455 1754 1603 1245 2063 1603 2276 1849 1710 1245 1849 1543 將 B 矩陣解特徵值(eigenvalues)及特徵向量(eigenvectors) 表 3-33 B 矩陣解特徵值及特徵向量 [V D] = eig(B) D(eigenvalues) = 1.6 0 0 0 0 26.4 0 0 0 0 548.8 0 0 0 0 6902.1 V(eigenvectors) = -0.7035 0.4246 0.2317 0.5206 0.0672 0.0647 -0.8949 0.4364 0.0158 -0.7921 0.2212 0.5687 0.7073 0.4338 0.3106 0.4637 接著我們找到最大特徵值對應到的特徵向量,將特徵向量中最小值所對應到 的語意做為登山車的語意,如表 3-34。 表 3-34 關鍵詞「登山車」之語意 登山車
[1] 3798315 = a bicycle with a sturdy frame and fat tires; originally designed for riding in mountainous country [2] 9382700 = a land mass that projects well above its surroundings; higher than a hill
[3] 3796045 = a motor vehicle with two wheels and a strong frame
處理完「登山車」後其他三個「腳踏車」、「鋁合金」、「自行車」,使用相同方 法處理,其中「腳踏車」只有單一個語意,所以不用處理就可以將「腳踏車」確定 下來了,表 3-35 為「腳踏車」類別的前四個關鍵詞語意選出的結果。
表 3-35 「腳踏車」類別的前四個關鍵詞語意選出的結果
登山車 2837983 a wheeled vehicle that has two wheels and is moved by foot pedals 腳踏車 2837983 a wheeled vehicle that has two wheels and is moved by foot pedals
鋁合金 14610949
a mixture containing two or more metallic elements or metallic and nonmetallic elements usually fused together or dissolving into each other when molten; "brass is an alloy of zinc and copper"
圖 4-5 ~ 4-10 為類別「手錶」、「手環」、「平底鍋」、「安全帽」、「耳機」、「吹風 機」使用方法一處理後前 5 個訓練標題的特徵向量使用公式 4-1、公式 4-2 轉換成 的頻譜係數。
圖 4-5 類別「手錶」之 DFT 頻譜係數
圖 4-7 類別「平底鍋」之 DFT 頻譜係數
圖 4-9 類別「耳機」之 DFT 頻譜係數
圖 4-17 ~ 4-22 為類別「手錶」、「手環」、「平底鍋」、「安全帽」、「耳機」、「吹 風機」使用方法一處理後前 5 個訓練標題的特徵向量使用公式 4-3、公式 4-4 轉換 成的頻譜係數。
圖 4-17 類別「手錶」之 DCT 頻譜係數
圖 4-19 類別「平底鍋」之 DCT 頻譜係數
圖 4-21 類別「耳機」之 DCT 頻譜係數
圖 4-26 奇函數xodd[ ]n 轉換後a 虛部 k
圖 4-27 偶函數xeven[ ]n 轉換後a 實部 k
圖 4-29 ~ 4-34 為類別「手錶」、「手環」、「平底鍋」、「安全帽」、「耳機」、「吹 風機」使用方法一處理後前 5 個訓練標題的特徵向量轉換成的奇偶函數頻譜係數。
圖 4-31 類別「平底鍋」之 DFT 頻譜係數
圖 4-33 類別「耳機」之 DFT 頻譜係數
5.4 方法一 單純比對關鍵詞
如表 5-3 在方法一因為完全比對不到任何特徵的標題數有 103 個,導致在「手 錶」、「平底鍋」、「安全帽」、「保溫瓶」、「紫砂壺」、「籃球鞋」,這 6 個類別 Precision 很高,但 Recall 卻不到 80%以至於 F 值表現不佳,而「平底鍋」則是 Precision 及 Recall 都不到 80%,原因則是該類分類正確數為 35 而其他類別被分為該類有 19 個 導致 Precision 只有 64.81%。 表 5-3 各類在方法一之分類成效方法一 Precision Recall F-Measure
5.5 方法二 寬鬆比對關鍵詞
如表 5-4 在方法二完全比對不到任何特徵的標題數有 91 個較方法一少了 12 個,在「手錶」、「平底鍋」、「安全帽」、「保溫瓶」、「紫砂壺」,這 5 個類別的 F 值 較方法一都有提升,「籃球鞋」這類則維持不變,而「平底鍋」則是 Recall 不變, Precision 大幅度的提升了 18.52%,其他類別被分為該類從原有的 19 個減少至 7 個 的原故,其中「保溫瓶」的 Recall 從方法一的 54%提升至 74%,其原因為在方法 一該類分類正確數為 27 而方法二的分類數為 37 以致 Recall 大幅提升了 20%。 表 5-4 各類在方法二之分類成效方法二 Precision Recall F-Measure
5.6 方法三 寬鬆比對搭配 WordNet 特徵擷取
如表 5-6 方法三完全比對不到任何特徵的標題數有 3 個較方法二少了 88 個,
除了在「手環」、「電風扇」、「聚寶盆」,這 3 個類別的 F 值較方法二有降低的情況
發生則其他類別為保持及略為提升
表 5-6 各類在方法三之分類成效
方法三 Precision Recall F-Measure
5.7 方法四 寬鬆比對搭配 WordNet 特徵擷取與擴充
如表 5-9 方法四除了在「手環」、「耳機」、「洗衣機」,這 3 個類別的 F 值較方 法三有降低的情況發生則其他類別為保持及略為提升
表 5-9 各類在方法四之分類成效
方法四 Precision Recall F-Measure
5.8 比較四種方法
本論提出之四中方法整體來看如表 5-12,從方法一到方法二加入了寬鬆條件 F 值提升了 1.71%,方法二到方法三搭配 WordNet 的操作使無特徵之標題數大幅減 少,F 值提升了 2.22%,方法三到方法四加入通義詞的擴充 F 值提升了 4.50%,與 本論之實驗比較基礎方法一來看方法二 F 值提升了 1.71%,方法三 F 值提升了 3.93%方法四 F 值提升了 8.43%,經實驗證明文件自動分類技術搭配 WordNet 可以 大幅改善對網路拍賣商品標題之分類成效。 表 5-12 比較四種方法之分類成效 _macro P macro_R macro_F 提升 累加
方法一 90.30% 79.07% 85.14% - -
方法二 92.99% 81.47% 86.85% +1.71% +1.71%
方法三 90.30% 87.87% 89.07% +2.22% +3.93%
參考文獻
[1] 電子商務經營模式, http://zh.wikipedia.org/zh-tw/電子商務經營模式.
[2] Salton, G. "Automatic text processing : the Transformation, Analysis, and Retrieval of Information by Computer." Mass. : Addison-Wesley, 1988.
[3] 杜海倫. "以標題進行新聞自動分類." 國立清華大學, 1999. [4] 吳文峰. "中文郵件分類器之設計及實作." 逢甲大學, 2002. [5] 黃嘉宏. "基於自動分類為基礎的圖書題名特徵擷取之研究-以輔助圖書分類系 統為例." 輔仁大學, 2008. [6] 吳季桓. "自動分類的實作:Knn 與 svm." 國立中正大學, 2009. [7] 廖政昱. "利用基因演算法輔助生物文件分類-以菇菌及毒蕈資料為例." 亞洲 大學, 2009. [8] 林政男. "以共現語詞為基礎的特徵選取在文件自動分類上之研究." 銘傳大學, 2004. [9] 許雅芬. "新聞文件自動分類之研究." 東吳大學, 2002. [10] 陳信源、葉鎮源、林昕潔、黃明居、柯皓仁、楊維邦. "結合支援向量機與詮 釋資料之圖書自動分類方法." (2009). [11] 簡卉伶. "中文郵件過濾系統特徵選取之效度探討." 東吳大學, 2008. [12] Cover, T. and J. "Thomas, Elements of information theory." Wiley, 1991.
[13] Hovold, J. "Naive Bayes Spam Filtering Using Word-Position-Based Attributes." Proceedings of Conference on Email and Anti-Spam, 2005.
[14] Vapnik, V. "The Nature of Statistical Learning Theory." NY Springer, 1995. [15] Salton, G. "Automatic text processing : the Transformation, Analysis, and
Retrieval of Information by Computer." Mass. : Addison-Wesley, 1988.
[17] James, M. "Classification algorithms." John Wiley & Sons Inc, 1985. [18] 梁清福. "利用多重分類器之文件自動分類." 中國文化大學, 2009. [19] 楊允言、謝清俊、陳淑美、陳克健. "中文文件自動分類之探討." 第六屆計算 語言學研討會論文集, 217-233, 1992. [20] 曾元顯. "文件主題自動分類成效因素探討." 中國圖書館學會會報, Vol.68, 62-83, 2002. [21] 林昕潔. "以 SVM 與詮釋資料設計書籍分類系統." 國立交通大學, 2005. [22] Hamill, Karen A. and Antonio Zamora. "The Use of Titles for Automatic
Document Classification." Journal of the American Society for Information Science, Vol.31, No.6, 396-402, 1980.
[23] 王稔智、張俊盛. "「適應性文件分類系統」." 第十四屆計算語言學研討會論 文集, 99-121, 2001.
[24] Tseng, Y-H. "Fast co-occurrence thesaurus construction for Chinese news." IEEE International Conference on System, Man, and Cybernetics, Vol.2, 853-858, 2001 [25] Yiming Yang, Jan O. Pedersen. "A Comparative Study on Feature Selection in Text
Categorization." Proceeding of 14th International Conference on Machine Learning, 1997.
[26] Joachims, T. "Text categorization with Support Vector Machines: Learning with many relevant features." In Proceedings of ECML-98, 137-142, 1998.
[27] Larkey, L. and Croft, W. B. "Combining Classifiers in Text Categorization" Proceedings of the 19th International Conference on Research and Development Information Retrieval (SIGIR96), Zurich, Switzerland, 289-297, 1996.
[28] 詹欣逸. "利用 wordnet 判斷字詞包含關係─應用於動態階層文件分群." 國立 中央大學, 2013.
[30] 謝靜婷. "半自動建立中文 wordnet 之研究." 國立清華大學, 2002. [31] 粘子奕. "透過階層式翻譯分類擴充雙語 wordnet." 國立清華大學, 2009. [32] 廖彥盛. "利用知識本體分類和搭配詞資訊自動翻譯 wordnet." 國立清華大學,
2010.
[33] 楊昌樺. "利用雙語詞彙資源連結詞彙網絡之研究." 東吳大學, 2002.
[34] Kolte, S. G. and S. G. Bhirud. "Word Sense Disambiguation Using Wordnet Domains." In Emerging Trends in Engineering and Technology, 2008. ICETET '08. First International Conference on, 1187-1191, 2008.
[35] Haisheng, Li, Tian Yun, Ye Ben and Cai Qiang. "Comparison of Current Semantic Similarity Methods in Wordnet." In Computer Application and System Modeling (ICCASM), 2010 International Conference on, 4, V4-408-V4-411, 2010.
[36] Ahsaee, M. G., M. Naghibzadeh and S. E. Yasrebi. "Using Wordnet to Determine Semantic Similarity of Words." In Telecommunications (IST), 2010 5th International Symposium on, 1019-1027, 2010.
[37] Peng-Yuan, Liu, Zhao Tie-Jun and Yu Xiao-Feng. "Application-Oriented Comparison and Evaluation of Six Semantic Similarity Measures Based on Wordnet." In Machine Learning and Cybernetics, 2006 International Conference on, 2605-2610, 2006.
[38] Young-Bum, Kim and Kim Yu-Seop. "Latent Semantic Kernels for Wordnet: Transforming a Tree-Like Structure into a Matrix." In Advanced Language Processing and Web Information Technology, 2008. ALPIT '08. International Conference on, 76-80, 2008.
[40] Yang, C-H. and S-J. Ker. "Considerations of Linking WordNet with MRD." In Proceedings of the 19th international conference on Computational linguistics, Vol.1, 1-7, 2002.
[41] Chen, Hsin-Hsi, Chi-Ching Lin and Wen-Cheng Lin. "Construction of a Chinese-English Wordnet and Its Application to Clir." In Proceedings of the fifth international workshop on on Information retrieval with Asian languages, 189-196. Hong Kong, China: ACM, 2000.
[42] 中央研究院中文斷詞系統, http://ckipsvr.iis.sinica.edu.tw/.
[43] 馬偉雲. 未知詞擷取作法, http://ckipsvr.iis.sinica.edu.tw/uwe.htm. 2004.
[44] Farbrizio, S. "Machine Learning in Automated Text Categorization." ACM Computing Surveys, Vol.34, No.1, 1-47, 2002.
[45] Dong, J., H. Cao, P. Liu and L. Ren "Bayesian Chinese Spam Filter Based on Crossed N-gram." Proceedings of the 6th International Conference on Intelligent Systems Design and Applications (ISDA), 103-108, 2006.
[46] Salton, G. "Automatic Text Processing ." Mass. : Addison-Wesley, 1989.
[47] Belur V. Dasarathy. "Nearest Neighbor(NN) Norms : Pattern Classification Techniques." Ieee Computer Society, 1990.
[48] Baker, L. D., and McCallum, A. K. "Distributional Clustering of Words for Text Classification." In Proceedings of SIGIR-98, 96-103, 1998.
[49] Libsvm, http://www.csie.ntu.edu.tw/~cjlin/libsvm/.
[50] 林銘達. "以影像分割和語義 WordNet 為基礎的自動圖像註解法." 國立屏東 商業技術學院, 2013.
附錄一 中研院平衡語料庫詞類標記集
精簡詞類 簡化標記 對應的CKIP詞類標記
A A A /*非謂形容詞*/
C Caa Caa /*對等連接詞,如:和、跟*/
POST Cab Cab /*連接詞,如:等等*/
POST Cba Cbab /*連接詞,如:的話*/
C Cbb Cbaa, Cbba, Cbbb, Cbca, Cbcb /*關聯連接詞*/
ADV Da Daa /*數量副詞*/
ADV Dfa Dfa /*動詞前程度副詞*/
ADV Dfb Dfb /*動詞後程度副詞*/
ASP Di Di /*時態標記*/
ADV Dk Dk /*句副詞*/
ADV D Dab, Dbaa, Dbab, Dbb, Dbc, Dc, Dd, Dg, Dh, Dj /*副詞*/ N Na Naa, Nab, Nac, Nad, Naea, Naeb /*普通名詞*/
N Nb Nba, Nbc /*專有名稱*/
N Nc Nca, Ncb, Ncc, Nce /*地方詞*/
N Ncd Ncda, Ncdb /*位置詞*/
N Nd Ndaa, Ndab, Ndc, Ndd /*時間詞*/
DET Neu Neu /*數詞定詞*/.
DET Nes Nes /*特指定詞*/
DET Nep Nep /*指代定詞*/
DET Neqa Neqa /*數量定詞*/
POST Neqb Neqb /*後置數量定詞*/
M Nf Nfa, Nfb, Nfc, Nfd, Nfe, Nfg, Nfh, Nfi /*量詞*/
POST Ng Ng /*後置詞*/
N Nh Nhaa, Nhab, Nhac, Nhb, Nhc /*代名詞*/
Nv Nv Nv1,Nv2,Nv3,Nv4 /*名物化動詞*/ T I I /*感嘆詞*/ P P P* /*介詞*/ T T Ta, Tb, Tc, Td /*語助詞*/ Vi VA VA11,12,13,VA3,VA4 /*動作不及物動詞*/ Vt VAC VA2 /*動作使動動詞*/ Vi VB VB11,12,VB2 /*動作類及物動詞*/ Vt VC VC2, VC31,32,33 /*動作及物動詞*/ Vt VCL VC1 /*動作接地方賓語動詞*/ Vt VD VD1, VD2 /*雙賓動詞*/
![表 2-6 相似度計算方式[46]](https://thumb-ap.123doks.com/thumbv2/9libinfo/9011689.297547/30.892.124.765.191.424/表26相似度計算方式46.webp)

![表 2-12 以名詞「club」為例之朗文當代英漢字典資訊[33]](https://thumb-ap.123doks.com/thumbv2/9libinfo/9011689.297547/39.892.102.794.382.764/表212以名詞club為例之朗文當代英漢字典資訊33.webp)