國
立
交
通
大
學
封面
工學院聲音與音樂創意科技碩士學位學程
碩
士
論
文
時變性的音樂情緒成份分析研究
Analytic research on the time-varying ingredients of
emotion evoked by the sound of music
研 究 生:吳偉廷
指導教授:鄭泗東 教授
ii
時變性的音樂情緒成份分析研究
Analytic research on the time-varying ingredients of emotion evoked by the
sound of music
研 究 生:吳偉廷 Student:Wei-ting Wu 指導教授:鄭泗東 Advisor:Stone Cheng 國 立 交 通 大 學 工 學 院 聲 音 與 音 樂 創 意 科 技 碩 士 學 位 學 程 碩 士 論 文 A ThesisSubmitted to Master Program of Sound and Music Innovative Technologies College of Engineering
National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Master
in
Engineering
July 2011
Hsinchu, Taiwan, Republic of China 中華民國一百年七月
iii
時變性的音樂情緒成份分析研究
學生:吳偉廷 指導教授:鄭泗東 國立交通大學工學院聲音與音樂創意科技碩士學位學程摘要
人們的情緒隨著聆聽音樂的過程被牽動,以往音樂情緒檢索系統多半提出單一情緒 分類。本研究以時變性的情緒變化為基礎並嘗試結合各種心理學家提出的情緒模型,包 含二維情緒模型和類別式情緒模型,進而提出以 Content、Depression、Anxious、Exuberant 四種情緒為基礎成分並隱含二維情緒模型資訊的即時性音樂成分分析系統。系統中採用 Support Vector Machine 當作分類的演算法,針對各種特徵以 192 首訓練歌曲建立兩兩情 緒間的分類模型以此考慮二維情緒模型中的兩個維度單獨分析的情況。特徵值上採用音 樂特徵和音訊特徵兩大類,共計 11 個特徵。並依其特性以不同的音框長度作分析。最 後再以音樂情緒的問卷調查來比對程式實驗結果和實際聆聽者感受是否符合。iv
Analytic research on the time-varying ingredients of emotion
evoked by the sound of music
Student:Wei-ting Wu Advisor:Stone Cheng
National Chiao Tung University Master Program of Sound and Music Innovative Technologies
Abstract
While listening to music, people's emotions are affected. The common music emotion recognition systems used to provide only one emotion classification. This study presented a time-varying music emotion analysis, and tried to integrate several psychological emotion models, including two-dimensional emotion space and category type. And further to make a time-varying analytic system, based on four basic compositions: Content, Depression, Anxious and Exuberant, which also contains information from two-dimensional emotion space. This system uses Support Vector Machine as classified algorithm. This system uses Support Vector Machine as classified algorithm. Training in a variety of features by 192 music clips as training data to build emotional classification model between each two, in order to inspect the situations for analyzing the two dimensions separately. Feature extractions were divided into two categories: Music Features and Audio Features, total of 11 features. Each feature used different length of frame for analysis. In the end, this study performed a questionnaire survey to compare the program results with the actual listeners’ experiences.
v
誌謝
研究所的學習方式與之前求學生涯大不相同,要靠自己去摸索和尋找才能得到問題 的答案。在此首先要感謝指導教授 鄭泗東老師的帶領,在每個禮拜的進度會議上都能 激發許多新的想法並給予我許多寶貴的建議讓我的研究能順利的進行。感謝就學期間修 過的每堂課的老師,各式各樣的學門的知識讓我不被侷限在狹隘的思考中而能更廣泛地 看待自己的研究。感謝俊傑、于恬、雲凱學長姐在研究上或其他各種相助,讓我的研究 可以事半功倍。感謝我的父母、家人在就學過程中的支持。最後感謝立緯、昭成、芷伊、 俊億、思賢、舒方、志翰、哲瑋、子衡、書寰、欣諭、佳渝、宜庭、育彬、正晨、亮志、 信翰、本活、尚威、淳俊、瑋承(taco)、伊庭(小 ya)、亞雯、冠廷、兆凱、振洲、煦佳、 冀昕、哲睿、冠吾、培鈞、岱容、明運、孟亨、所有幫助過我的人、所有一起玩過的人、 我看過的所有表演。vi
目錄
封面 ... i 摘要 ... iii Abstract ... iv 誌謝 ... v 目錄 ... vi 表目錄 ... viii 圖目錄 ... ix 一、 緒論 ... 1 1-1 研究動機 ... 1 1-2 系統簡介 ... 2 1-2-1 音樂情緒模型 ... 2 1-2-2 音訊特徵值萃取 ... 4 1-2-3 Mpeg-7 規格簡介 ... 4 1-2-4 音樂內容分析 ... 5 1-2-5 情緒分類演算法介紹 ... 8 1-3 相關研究 ... 9 二、 研究方法 ... 11 2-1 研究內容探討 ... 11 2-2 研究內容構想 ... 12 2-3 系統架構及流程 ... 13 2-3-1 音訊輸入 ... 14 2-3-2 音框化分析 ... 14 2-3-3 特徵值萃取 ... 14 2-3-4 分類演算法 ... 15 2-3-5 計分方式 ... 15 2-4 音樂情緒訓練資料 ... 15 2-5 特徵值計算 ... 16 2-5-1 音樂特徵 ... 17 2-5-2 音訊特徵 ... 23 2-6 SVM 分類演算法 ... 29 2-7 情緒計分 ... 33 2-7-1 情緒分類模型建立 ... 34 2-7-2 情緒判定 ... 35 2-7-3 計分方式 ... 37 2-8 音樂情緒成分表示法 ... 38vii 三、 音樂情緒心理分析調查 ... 40 3-1 問卷調查 ... 40 3-2 問卷調查與實驗結果分析 ... 40 四、 結論 ... 44 參考文獻 ... 45 附錄一. 訓練資料曲目 ... 48 附錄二. 音樂情緒問卷 ... 54 附錄三. 問卷調查受測者資料 ... 55 附錄四. 測試音樂結果 ... 56
viii
表目錄
表 1. 一個八度間的音程表 ... 6 表 2. C 大調的順階和絃 ... 7 表 3. 各情緒成分的測試音樂數目 ... 16 表 4. 採用的特徵值 ... 16 表 5. 各特徵值採用的音框大小 ... 17 表 6. 音樂特徵辨識率 ... 34 表 7. 音訊特徵辨識率 ... 35 表 8. 情緒判定舉例 ... 36 表 9. 本研究測試音樂 ... 40表 10. Avenged Sevenfold - Dear God 結果分析 ... 41
表 11. Celine Dion - My heart will go on 結果分析 ... 42
ix
圖目錄
圖 1. 各種 MIR 系統相對應的區域圖 ... 1
圖 2. Hevner’s adjective clock 進階版本 ... 2
圖 3. 各式二維情緒模型 ... 3 圖 4. Mpeg-7 中的音頻特徵描述 ... 5 圖 5. (1)自然大調音階的組成(2)自然小調音階的組成 ... 6 圖 6. SVM 分類示意圖 ... 9 圖 7. 階級式情緒分類結構 ... 10 圖 8. 二維情緒平面模型軌跡輸入程式圖 ... 12 圖 9. 情緒成分元素示意圖 ... 13 圖 10. 系統流程方塊圖 ... 14 圖 11. MIRtoolbox 特徵萃取前流程... 17
圖 12. Over the Rainbow 藤田惠美 – audio waveform ... 18
圖 13. Over the Rainbow 藤田惠美 – 取音框 ... 18
圖 14. Over the Rainbow 藤田惠美 – 頻譜分析 ... 19
圖 15. Over the Rainbow 藤田惠美 – 音樂色譜分析 ... 19
圖 16. 主音萃取流程 ... 20
圖 17. Over the Rainbow 藤田惠美 – 調性強度分析 ... 20
圖 18. Over the Rainbow 藤田惠美 – 主音分析 ... 21
圖 19. Over the Rainbow 藤田惠美 – 主音清晰度分析 ... 21
圖 20. 調性萃取流程 ... 22
圖 21. Over the Rainbow 藤田惠美 – 調性分析 ... 22
圖 22. Over the Rainbow 藤田惠美 – 音調質心分析 ... 23
圖 23. AudioSpectrumEnvelope 分頻示意圖 ... 24
圖 24. Over the Rainbow 藤田惠美 – ASE 分析 ... 24
圖 25. Over the Rainbow 藤田惠美 – ASC 分析 ... 25
圖 26. Over the Rainbow 藤田惠美 – ASS 分析 ... 26
圖 27. Over the Rainbow 藤田惠美 – ASF 分析 ... 26
圖 28. Centroid 示意圖 ... 27
圖 29. Over the Rainbow 藤田惠美 –Centroid 分析 ... 27
圖 30. Spread 示意圖 ... 28
圖 31. Over the Rainbow 藤田惠美 –Spread 分析 ... 28
圖 32. Over the Rainbow 藤田惠美 –Flatness 分析 ... 29
圖 33. 六種情緒分類示意圖 ... 34
圖 34. 情緒判定示意圖 ... 37
x 圖 36. 實際影片結果畫面 ... 39 圖 37. 影片最後的情緒總結 ... 39
1
一、 緒論
1-1 研究動機 音樂自古以來一直是日常生活中甚至是人文藝術上不可或缺的角色。而隨著時 代的演進,科技的進步讓人們聆聽音樂的習慣也跟著改變,隨著音樂載體的不斷演 進,黑膠、唱片到卡帶乃至於 CD,不但音質越來越好、容量越來越多也更方便取 得和攜帶,但隨著 mp3 和網際網路的蓬勃發展使得音樂一口氣邁向數位化,甚至於 踏入雲端資料庫的發展。快速的網路和小容量的 mp3 衝擊傳統唱片業,改變人們的 消費習慣和聆聽習慣,線上的付費數位下載漸漸成為趨勢,類似的網站如:itunes、 KKBOX、iNDIEVOX…等,購買後可以於任何地方隨時自網站資料庫中下載聆聽。 於是當未來音樂都邁向數位化收藏時,除了現有的音樂標籤如:歌手、專輯、曲風、 年份…等,音樂情緒分類也是熱門的研究主題。而在倫敦大學有研究[1]指出對於消 費者而言,在音樂中情緒的感受是相對重要的訊息,如下圖: 圖 1. 各種 MIR 系統相對應的區域圖 資料來源:[1] 近年來針對音樂訊號內容的檢索是熱門的研究,除了哼唱檢索(QBH)外,由於音樂 內容的情緒分析的進步,更進一步的發展出情緒檢索(QBE)成了近期音樂的新型檢索方 式。在各種平台上都可見到各種不同的音樂檢索系統,尤其在新式智慧型手機上也有依2 據情緒的音樂檢索系統,但是都為將每一首歌視為單一情緒的分類,還尚未見到有針對 時間變化、隨歌曲撥放引發情緒變化的相關系統。但是在歌曲的製作和譜寫上已有起承 轉合的起伏安排,所以當在聆聽歌曲時應是有著情緒的起伏,這也是音樂之所以能感動 人心的地方。因此本研究主要針對隨時間變化的情緒成分分析做探討。 1-2 系統簡介
在這一章節中會依序對音樂情緒分析(Music Emotion Recognition,MER),相關 研究內容做個介紹,首先 1-2-1 是 MER 中常見的核心理論-音樂情緒模型;1- 2-2 則介紹關於 MER 常見的音訊特徵值;1-2-3 簡單介紹多媒體內容描述介面 的標準-Mpeg-7;1-2-4 採用音樂分析的觀點探討樂理和情緒關聯;1-2-5 則 介紹了相關研究中常見作為情緒分類的演算法。 1-2-1 音樂情緒模型 音樂與情緒間相關聯在心理學上已經有許多研究,詳細的發展文獻[2]中有詳細 介紹,文中提到關於音樂情緒分類的研究主要可分為兩種:(1)類別式(2)連續式,其 中類別式有重要影響力研究的來自 1936 年 Hevner 提出的 adjective clock,其中包含 了 8 種情緒群聚,每個群組涵蓋 6 到 11 種情緒形容詞,這個模型也在 2003 年由 Schuert 結合二維情緒模型後提出進階版,如下圖:
圖 2. Hevner’s adjective clock 進階版本 資料來源:[2]
3 在 Hevner 之後陸續有許多學者發表相關研究,最近期的研究如 Zentner(2008)提出的 階層式情緒模型 GEM-9,將四十種情緒依不同的權重彙總成九種情緒,最後再統合 成三大類。 在連續性的研究上將情緒視為是連續的,因此現今大多時變性的音樂情緒研究 大多採用這類模型。在這類型的早期研究中值得注意的是 Russell 提出的 Circumplex model(1980),將情緒表示成 Arousal 和 Valence 兩個維度的二維模型;之後陸續有許 多類似的二維情緒模型被提出,Watson 和 Tellegen 在 1985 年將 Circumplex model 旋轉 45 度同時考慮 Arousal 和 Valence,依此訂定兩個新維度 Postive Affective(PA) 和 Negative Affective(PA);Thayer 在 1989 基於分離心理生物學系統(Separate psychobiological system)將 Arousal 分成 energetic arousal(EA)和 tense arousal(TA)兩個 新維度;各情緒模型可見下圖:
圖 3. 各式二維情緒模型 資料來源:[2]
本研究嘗試結合類別式的成分表示和連續式的成分分析做為音樂情緒辨識的模型, 詳細討論可見 2-1。
4 1-2-2 音訊特徵值萃取 由於現在人們聆聽的音樂大多以 mp3 為大宗,而不是 MIDI 這種內含音樂資訊 的檔案格式,因此在分析音樂內容時大部分由兩個方面著手:(1)分析音訊波形的特 徵,常見的特徵又可分為時域空間上的波形變化和頻譜分析後在頻域空間上的頻譜 特徵。(2)逆向追蹤訊號產生的依據,在音樂訊號中即代表音樂本身的樂理分析。 音訊波形的特徵上常見的如:時域分析的過零率(Zero-crossing rate,ZCR)、波 形(Envelope)、波形質心(Temporal Centroid)、發聲時間(Log attack time)、響度 (Loudness)…等。頻域分析則有頻譜質心(Spectral Centroid)、頻譜散布度(Spectral Spread)、頻譜平坦度(Spectral flatness)、頻譜滑動(Spectral rolloff)、頻譜變遷(Spectral flux)、梅爾倒頻譜參數(Mel-frequency ceptral coefficient,MFCC)…等。
音樂內容中的特徵常見的如:音高(Pitch)、和聲(harmonicity)、和弦(Chord)、調 性(Tonality)、主音(Key)、rhythm(節奏)、節拍(Tempo)…等。 上述特徵中並非皆適用於音樂情緒辨識上,本研究針對音樂內容的分析主要分 為兩大方面:(1)樂理內容(2)音訊內容,依此分別去萃取各自類特徵為(1)音樂特徵(2) 音訊特徵。將在 1-2-3、1-2-4 中介紹本研究採用的特徵並在 2-5 詳述特徵值 計算過程。 1-2-3 Mpeg-7 規格簡介
MPEG(Moving Picture Experts Group)訂定出許多國際標準,如 Mpeg-1 和 Mpeg-2 提供了一套影音壓縮標準更在數位電視和影音光碟上實現互動式的影像,Mpeg-1 Layer3 的音訊壓縮技術也成為了現今廣泛流行的 MP3 檔案格式;Mpeg-3 原先為因 應高畫質電視(HDTV)的應用設計,但隨後發覺 Mpeg-2 已足夠應付 HDTV 的應用之 後就停止開發;Mpeg-4 提出了一套視訊的壓縮標準,其中第 10 部分的 H.264 更是 應用在現今常見的網路影片上。為了因應日益複雜且大量的多媒體資料,提出一套 多媒體內容描述介面的標準-Mpeg-7,跳過 Mpeg-5 或 6 直接發布 7 是由於
5 Mpeg-1+Mpeg-2+Mpeg4 的用意。Mpeg-7 的資料描述不在於資料的標籤而是資料的 內容,而且支援眾多聲音音訊和視覺影像的描述,以影像為例,低階的描述包含形 狀、顏色、紋理、運動、位置等。本研究主要採用 Mpeg-7 針對音訊內容方面的描 述,在音訊內容方面 Mpeg-7 的低階描述主要可以分成六類共 18 種描述,如下圖: 圖 4. Mpeg-7 中的音頻特徵描述 資料來源:Mpeg-7 Overview [3] 在本研究中只採用 Mpeg-7 作為基本的音訊內容分析,因此關於音色、旋律、和聲 等地描述皆跳過再另外由音樂理論中設計相關特徵來描述情緒成分。因此在這邊只 採用了 Basic Spectral 這個類別的描述子,相關詳細應用於 2-5-2 進行討論。 1-2-4 音樂內容分析 樂理可視為一般音樂的分析規則,其中包含節奏、調性、調式、和弦、和聲安 排…等眾多方面的分析,一般常見的音樂大多是具有調性和固定節奏的音樂,其內 容安排根據一般樂理也都是可以分析的。現今的流行音樂大多遵循西洋樂理,要由 樂理來闡述音樂內容的話,最小的單位可以由每個音來開始討論,然後再由一連串 的音組成不同的音階,這其中又包含著不同調性、調式等觀念。每個音依據不同的
6 音律下有不同的定義,古典音律如純音律是依據自然泛音列設計的音列,讓不同音 組成的和聲最接近自然,但是不方便於轉調,同一樂器彈奏不同調性音樂時需重新 調音。現今樂器大多採用十二平均律[4]的觀念設計,十二平均律中將一個雙倍頻率 的八度音(Octave)分成 12 個半音(Semitone)以中央 A 定 440Hz,其他頻率和音高換 算公式如下: semitone = 69 + 12 × log2 𝑓𝑟𝑒𝑔𝑒𝑛𝑐𝑦 440 ( 1) 由於平均律為現今廣泛使用的音律,也決定各個音高的頻率分布,本研究的音樂特 徵也是依此為基準。 決定了各個音高的定義後,接著分析由一連串的音列組成的音階,音階依照調 性、調式也有許多不同定義,分別依據不同的音程(Interval)排列而成,其中音程是 指兩個音之間的距離主要有:小、大、完全、增、減、倍增、倍減等型態,如下表: 表 1. 一個八度間的音程表 音程名稱 完 全 一 度 小 二 度 大 二 度 小 三 度 大 三 度 完 全 四 度 增 四 或 減 五 度 完 全 五 度 小 六 度 大 六 度 小 七 度 大 七 度 完 全 八 度 半音差距 0 1 2 3 4 5 6 7 8 9 10 11 12 一般大家熟識的自然大調音階和自然小調音階以 C 當主音為例的音程分布如下圖所 示: 圖 5. (1)自然大調音階的組成(2)自然小調音階的組成 在此還有兩點需要被注意的,第一點就是關係大小調(Relative Major/Minor),當圖
7 5.(2)的起始音換成 A 的話,此時音階的組成音和 C 大調將完全一樣;第二點就是平 行大小調(Parallel Major/Minor),當起始音相同,音階組成音不盡相同的兩組音階即 為平行大小調,如圖 5.中的 C 大調和 C 小調。當組成音相同時,若是由電腦來分析 將無法判別此時是 C 大調或者是 A 小調,這時就需要仰賴主音(key)來分別,一個八 度間的 12 個半音當主音的話,各大調音階將各自有其對應的 12 組自然小調音階作 為平行大小調。除了自然大小調音階外各國家也有各自發展出來的民俗音階,現代 音樂中也有更進一步分析的調式音階等。 音樂理論中除了音的橫向的流動組成的音階分析外,另一項重要的分析在於縱 向的聲音疊加,也就是同發出兩個音以上的和聲分析。和絃的組成主要在於音與音 之間音程的排列組合,但根據自然泛音列可以知道各音程間和諧度的不同,這也造 就了各種和絃聽起來會有不同的感覺進而牽動聆聽者的情緒。三個音組成的三和絃 (triads)是最常見的和絃,又可分為大和絃(major chord)、小和絃(minor chord)、減和 絃(diminished chord)、增和絃(augmented chord)。大三和絃組成音是完全一度、大三 度、完全五度,如若根音為 C 則組成音為 C、E、G;小三和絃組成音是完全一度、 小三度、完全五度,如若根音為 A 則組成音為 A、C、E;減三和絃組成音是完全一 度、小三度、減五度,如若根音為 B 則組成音為 B、D、F;增三和絃組成音是完全 一度、大三度、增五度(音程同小六度),如若根音為 Eb則組成音為 Eb、G、B。由 前述分析可看出大三和絃、小三和絃、減和絃都可以由自然音階的音階內音組成, 若將一組自然音階依序將各個音當作根音可以發覺七個順階和絃,如下表: 表 2. C 大調的順階和絃 級數 I II III IV V VI VII 和絃 C Dm Em F G Am Bdim 組成音 C E G D F A E G B F A C G B D A C E B D F 根音 C D E F G A B
8 增三和絃的和絃內音無法完全配合自然音階的音階內音,是屬於和聲小調音階的三 級和絃。本研究只針對基本的自然大小調做分析,所以在和絃方面也只考慮了自然 大小調的順階和絃,這在流行音樂中也是最常被使用到的形式。 在林金慧提出的研究[5]中也解釋了一般廣為人知的音樂和情緒間的關聯,大音 程、大和弦、大音階、大調四項觀念與正面情緒的關聯性和小音程、小音階、小調 四項觀念與負面情緒的相關性。此外,現今的當代音樂也不乏無調性和無固定節奏 的實驗性音樂,甚至於音高不在傳統音律中而是裡面採用電子合成的新音律,以打 破傳統規律為主的內容安排,這些音樂並不在本研究的考慮範疇中。 1-2-5 情緒分類演算法介紹 在上述小節的討論過程中,在選擇了音樂情緒模型後確立了音樂情緒的分類, 因此為了將音樂內容對應到音樂情緒上,音訊的特徵分析只是個媒介,而基於這些 音訊特徵將音樂訊號分群分類的演算法則是連接兩者的工具。 在資料的分群和分類上有各種不同的演算法,常見的如:k 相近(k-nearest neighbor,k-NN)、高斯混和模型(Gaussian Mixture Model,GMM)、隱藏式馬可夫模 型(Hidden Markov model,HMM)、倒傳遞類神經網路(Back-Propagation Neural Network,BPN)、支援向量機(Support Vector Machine,SVM)…等,本研究中為方便 分析高維度的特徵值,採用了 SVM 作為分類的演算法。
SVM 演算法主要的概念是找出一個平面可以將兩個不同類別的集合分開,在多 維的特徵空間下,這平面稱為超平面(hyperplane)。以二維空間為例,可見下圖:
9 圖 6. SVM 分類示意圖 在已分類過的兩個資料群組但是不知道其分類的依據,SVM 嘗試在這兩個資料群組 中找個超平面區隔開兩邊,兩邊的虛線代表的是支援用的超平面(Support hyperplane),兩個支援超平面拉開的邊界(Margin)越大也就越能分開兩個群組,故最 終目標是找出一個超平面有著最大的邊界稱之為最佳分割超平面(Optimal separating hyperplane,OSH)。 上述是可以理想分割的情況,但是資料會有誤差並不一定能夠完全的分割成兩 種類別,所以在實際運用上會有更複雜的假設,在計算上會在導入個誤差值ξ 並且 給予懲罰的權重C,讓誤差的資料在判別上會多點成本(Cost),詳細的推導見 2-6。 1-3 相關研究
現今關於音樂情緒分析(Music Emotion Recognition,MER)系統的研究有很多, 各個情緒模型都有研究採用,也衍伸出各種不同型態的系統。在文獻[6]中採用了 Hevner 的情緒分組作為情緒標籤,採用了 17 種音樂音訊特徵,以 k-NN(k 選用 5) 為分類演算法,最後比較以各種不同降低維度的方法來降低特徵維度後的辨識率, 如:FA(maximum likelihood common factor analysis)降低成 11 維、Ranker 降低成 6 維、GA(genetic algorithm of Goldberg)降低成 6 維、K-N-Match 降低成 13 維、PCA (Principal Component Analysis)降低成 10 維、Piv-Sel(local optimum selection of pivots) 降低成 10 維。而在文獻[7]採用了 Tempo、Intervals、Loudness、Note、Density、Timbre、 Chord 等七種特徵,直接對標記好的八種 Hevner 情緒類別訓練資料採用 GA-BP(back
10 propagation neural network and genetic algorithm)來建立一個音樂情緒辨識系統 (MER)。 採用二維情緒模型的如文獻[8],利用了音色(Timbre)、強度(Intensity)、節奏 (Rhythm)三種類型的特徵值以一種階層式的情緒分類結構並採取 GMM 當作分類的 演算法,如下圖: 圖 7. 階級式情緒分類結構 資料來源:[8] 隨後也有文獻[9]以相似的架構但改採用 SVM 演算法作為分類器。 除了直接分析音樂音訊內容的研究外,也有以生物學上的特徵來分析音樂情緒 對應到生理反應上的研究[10],這也證實了音樂情緒的分類的二維模型其的可靠 度。
11
二、 研究方法
2-1 研究內容探討 在音樂情緒辨識上有兩個主要的議題: (1) 音樂情緒的時變性與否:關於音樂情緒的引發是隨著歌曲播放間經由音樂事件 或音訊內容帶領變化;抑或情緒是由整首歌曲的變化所引發的單一結果,這是 一大議題。 (2) 音樂情緒的量化:現在當前的音樂情緒研究多採用二維情緒模型(2-DES)為基 底[8][9][10][11],然後再嘗試將特徵萃取的結果對應到二維平面模型的兩個維度 上去標記出當前情緒位置;但由於情緒是相當主觀的感受,要將其化作客觀的 數值化表示則是二個大議題。 針對第一點議題,部分研究[12]為單一情緒的分析,但是歌曲在編寫間就有考 慮到情緒起伏的鋪陳,故此聆聽者的感受勢必不會是整首歌都固定在一個情緒, 而是隨著歌曲的音樂事件和音訊內容的激發而有所變動,而且近期研究[13]大多開 始趨向連續變動情緒的方向發展。因此本論文主要研究主題將是在於隨時間變化 的情緒成分分析。 針對第二點議題的處理方式現在有許多不同的做法,現今研究中有依自己的 的主觀感受對各特徵值設定權重計分將各音樂片段萃取的特徵值分別對應到二維 情緒模型上兩個維度的值,以此作為量化[14],也有採用測試人員直接畫下各自聆 聽音樂的情緒感受軌跡圖,再將其量化結果和特徵值的數值計算一個數學模型做 配對,測試程式畫面如下圖。12 圖 8. 二維情緒平面模型軌跡輸入程式圖 由受測者手工繪入情緒軌跡模型。 資料來源:[15] 其中關於特徵值對應到二維模型的維度上的結果始終是令人質疑的,單一特徵是否 只對應到二維情緒模型的單一維度和每個特徵間對情緒分類的影響是否各自獨立,都是 值得研究的議題。因此,本研究將針對音樂情緒的成分來分析,而不是將音樂情緒量化 表示在單一情緒上,在此假設情緒並不是單一獨立存在,而是由多種情緒混雜堆疊而形 成。 2-2 研究內容構想 目前針對音樂情緒研究多以二維情緒模型為基礎[8][9][10][11],少數一些研究 提出的新式情緒模型也是延伸自二維情緒模型[16],在 Zentner 和 Eerola 的書中[2] 有針對二維情緒模型的演進做詳細介紹,心理學家不斷提出新的二維模型,以不同 的維度來表示情緒的分布,但是綜觀各情緒模型,雖然有不同的維度表示卻有著相 似的情緒分布,如圖 3。因此情緒模型的劃分依據各有出入,僅針對單一情緒模型 為依據做量化有失客觀性。 近年 Zentner 提出新的情緒模型 GEM-9[17]中,表示出情緒是可以階層劃分的, 將 40 個情緒形容詞加權歸類成 Sublimity、Vitality、Unease 三大類中。這也表示著 個情緒形容詞間有一定的相關性,而早期二維情緒模型平面上的單點情緒應該也 是可以歸類成簡單數個。 本研究結合上述研究提出一個對於情緒成分表示的假設,基於:
13 (1) 二維情緒模型的四個象限皆有共通相近的情緒。 (2) 各種情緒都可以簡化成簡單的情緒表示。 假設聆聽音樂所引發的情緒變化都是由四種基本情緒(Exubrant、Anxious、 Depression、Content)成分組成,如圖 9 所示。如三原色的原理,這四種情緒間將 在本研究視為組成情緒的基本要素,由這四個基本情緒依照不同比例組合進而表 現出各式各樣的情緒形容詞,取代單一情緒形容詞的描述,藉以降低不同人之間 對於情緒形容詞主觀的認知落差。 圖 9. 情緒成分元素示意圖 2-3 系統架構及流程 依據上一節中所提及的構想,本研究在 MATLAB 程式平台上設計了一套系統, 系統的流程方塊圖見圖 10。在接下來的小節中會對於程式的流程一一簡單介紹,詳 細的計算和說明則於之後 2-4 至 2-8 中探討。
14 圖 10. 系統流程方塊圖 2-3-1 音訊輸入 音樂輸入的格式採用 wav 檔案格式,取樣頻率為 44100Hz,聲音解析度為 32 bits, 雙聲道。其中測試音樂為了建立可以確實辨識連續情緒變化的分類模型,這邊選取 情緒起伏不大且單一的 30 秒音樂片段,詳細說明見 2-4。 2-3-2 音框化分析 為採用頻譜分析,並更進一步的做到即時性的情緒成分分析追蹤,在音樂片段 進入系統之前會先有音框化的前處理,將音樂片段切割成相等大小的微小片段。在 不同特徵萃取分析下會切成不同大小的音框進行分析,來增進各特徵的分析效益, 詳細的內容將在 2-5 討論。 2-3-3 特徵值萃取 採用特徵值分析音訊是目前研究普遍的方法,本研究針對音樂的音樂特徵和音 訊特徵兩個方面來選取特徵值。在音樂特徵方面選用主音(key)、主音清晰度(key clarity)、調性(mode)、音調質心(tonal centroid)。音訊特徵方面則參照 mpeg7 的標準, 採用 ASE(AudioSpectrumEnvelope)、ASS(AudioSpectrumSpread)、
15 ASF(AudioSpectrumflatness)、ASC(AudioSpectrumCentroid),含 MIRtoolbox 中採用 Spread、Centroid、flatness 共計 11 個特徵值。各特徵詳細的內容於 2-5 討論。
2-3-4 分類演算法
本系統中的分類演算法採用 Chih-Chung Chang and Chih-Jen Lin[18]統整的 SVM(Support Vector Machine)演算法,這是一個最佳化分析的演算方式,可以在已 分類好但是不知道分類依據的資料中建立一個分類模型,然後依此模型推測新進資 料會屬於哪一個分類中,詳細流程將在 2-6 討論。 2-3-5 計分方式 當各特徵對於該音框的情緒判定後會在該特徵上累計,11 種特徵不一定全指向 同一種情緒,可見得任一時刻的情緒並不是單一的。每個音框的情緒判定後也會累 計到後面 3 秒的所有音框中,因為情緒的起伏並不是瞬間的反應而是各種音樂事件 的累積,各時刻的影響會乘上一衰減加權累計進之後的音框計分,詳細計分步驟之 後 2-7 會進一步討論。 2-4 音樂情緒訓練資料 訓練資料總共 192 首,內容皆為多聲部(polyphonic)的 wav 格式。詳細曲目見附 錄-,音樂內容包含從古典到流行等各種音樂類型風格,情緒選取的方式採測試人 員主觀判斷,情緒類別包含本研究提出的四種情緒成分:Content、Depression、 Anxious、Exuberant,各情緒的歌曲數目見表 3.。這邊採用主觀的選擇也是希望未來 本系統在其他使用者的使用下可以依照各自的感受選取不同的訓練資料以建立針對 個人有更佳分辨效果的分類模型,並藉此大大的降低不同人對情緒形容詞主觀的認 知落差。
16 表 3. 各情緒成分的測試音樂數目
情緒 Content Depression Anxious Exuberant
數目 47 48 48 49
2-5 特徵值計算
特徵值的選用主要依據音樂的音樂特徵和音訊特徵兩方面,採用 Olivier Lartillot、 Petri Toiviainen 設計的 MIRtoolbox 1.3.2[19],和 MPEG-7 [20]中關於音訊內容的描述 子,詳細可見表 4.。其中各特徵值計算時對音樂片段音框化的前處理也不盡相同, 各特徵採用的音框大小可見表 5.。 表 4. 採用的特徵值 萃取工具 特徵值 特徵類別 MIRtoolbox Key 音樂特徵 Key clarity Mode Tonal centroid Spread 音訊特徵 Flatness Centroid Mpeg-7
Audio Spectrum Envelope Audio Spectrum Centroid Audio Spectrum Spread Audio Spectrum Flatness
17 表 5. 各特徵值採用的音框大小 特徵值 Key Key clarity mode Tonal centroid
spread flatness centroid ASE ASC ASS ASF
Frame
time 0.5 sec
0.075
sec 0.025 sec 0.05 sec
2-5-1 音樂特徵
本研究採用 MIRtoolbox 作為音樂特徵萃取的工具,這個 toolbox 是以 MATLAB 為平台的音訊特徵萃取套件,由芬蘭 Jyväskylä 大學的 Olivier Lartillot、Petri
Toiviainen 設計[21],其中特徵值包含音樂動態、節奏、和聲、音色…等眾多方面, 本研究採用版本為當時最新的 1.3.2, 基於 1-2-4 的討論,在研究中將採用主音 (key)、主音清晰度(key clarity)、調性(mode)、音調質心(tonal centroid)作為音樂特徵, 在擷取這些音樂特徵之前,音訊資料進到這套系統裡都會先經過一套前處理用來分 析音訊理的音樂事件,處理流程見下圖,
圖 11. MIRtoolbox 特徵萃取前流程 資料來源:MIRtoolbox user’s manual[22]
由於本研究是針對 WAV 檔案格式而非 MIDI 格式有內涵音樂事件訊息,在已經經過 複雜混音的音樂中,要回頭剖析該音樂片段的內容是非常困難的議題。
圖 11.的流程中,先以 miraudio 這程式讀入音檔,將 wav 的時域振幅波形讀入 MATLAB 中,如下圖:
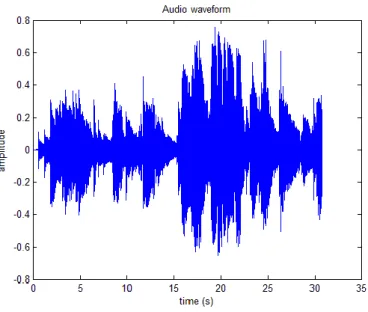
18 圖 12. Over the Rainbow 藤田惠美 – audio waveform
mirframe 是個可選用的變數,若是不經過這一環節則結果將會輸出整個音樂片段的 分析結果,在這個環節針對不同的特徵質會給予不同的音框長度,以主音為例則是 給予 500ms 的大小,取完音框後的結果如下圖:
圖 13. Over the Rainbow 藤田惠美 – 取音框
音框化的處理完後接著是採用 mirspectrum 分析頻譜,由於在十二平均律中音高是 根據頻率來定義,因此採用頻譜分析是反過來剖析樂理的重要方法,取完頻譜的結 果如下圖 :
19 圖 14. Over the Rainbow 藤田惠美 – 頻譜分析
頻譜分析之後接著的 mirchromagram 是將頻譜的資訊對應到樂理上,是一個 12 維的 特徵值,可以了解頻譜分析對應到 12 個半音上的成分多寡,如下圖:
圖 15. Over the Rainbow 藤田惠美 – 音樂色譜分析
至此已將音訊波形對應到樂理的音高資訊上,接著再進一步的繼續下面的分析。
(1) 主音(Key)
如同 1-2-4 所討論的,要以音樂理論方面切入剖析音樂內容,該音樂主 音是一個重要的特徵值。在本研究中,針對主音的分析會對輸入的音訊切割成
20 0.5 秒一個音框來處理。在 MIRtoolbox 中萃取 key 的流程圖如下:
圖 16. 主音萃取流程
資料來源:MIRtoolbox user’s manual[22]
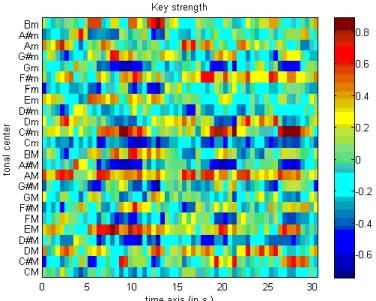
在經過音訊內容對應到音樂色譜的前處理後,在 mirkeystrength 裡會針對 12 個 主音構成的大小調做交叉相關函數(cross-correlation)來配對,最後輸出各個調性 的相關度,如下圖:
圖 17. Over the Rainbow 藤田惠美 – 調性強度分析
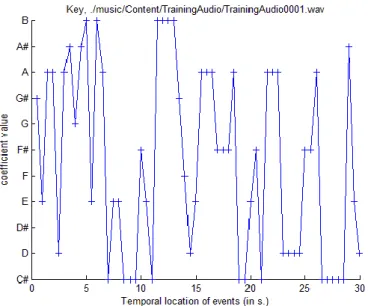
接著使用 mirpeaks 在調性強度的分布圖中找尋峰值即最有可能的調性分布,若 是在平行大小調上都有著最高的調性強度,則將這組平行大小調的主音是為該 音框的主音,最後主音的萃取結果如下圖:
21 圖 18. Over the Rainbow 藤田惠美 – 主音分析
(2) 主音清晰度(Key Clarity)
這項特徵是依據上一個特徵的內容同時計算的,在主音的特徵萃取中音樂色譜 的分析後經由對於各種可能的大小調做交叉相關函數的計算,此時若是平行大小調 皆有很強烈的峰值,則該音框有著清晰的主音也有著較高的主音清晰度的值,反之 這項特徵有較低的值,結果如下圖:
22
(3) 調性(mode)
相似於(2)中主音的萃取,對於調性的萃取流程如下圖:
圖 20. 調性萃取流程
資料來源:MIRtoolbox user’s manual[22]
調性和主音的差別在於分析完調性強度後,在 24 種不同調性結果中針對其中大調的 峰值和小調的峰值做進一步的分析,最後的輸出是一個數值,以 0 為分界若為正值 且越大的話代表是大調的強度越強,反之若為負值的話,則值越小其小調的強度越 強,結果如下圖:
圖 21. Over the Rainbow 藤田惠美 – 調性分析
(4) 音調質心(tonal centroid)
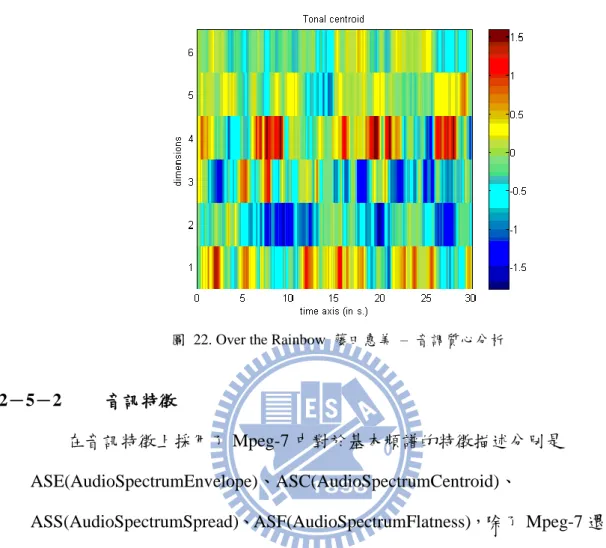
音調質心在這邊是用來表達和絃的特徵,如 1-2-4 中討論的,大和絃可以帶 給聆聽者正面的情緒,而小和絃則是會帶給聆聽者負面的情緒,這在對於音樂情緒 的分析中也是個指標性的特徵。在 MIRtoolbox 中前處理後,除了十二平均律的分析 更會加入音樂中和絃的組成推斷,包含五度圈、大三和絃、小三和絃的內容,最後
23 計算出一組 6 維的向量,其結果如下圖:
圖 22. Over the Rainbow 藤田惠美 – 音調質心分析
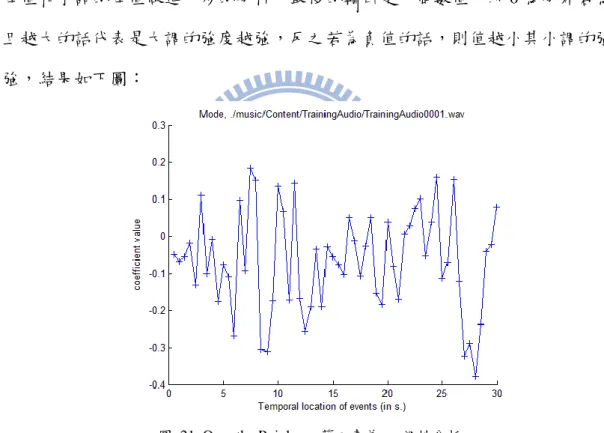
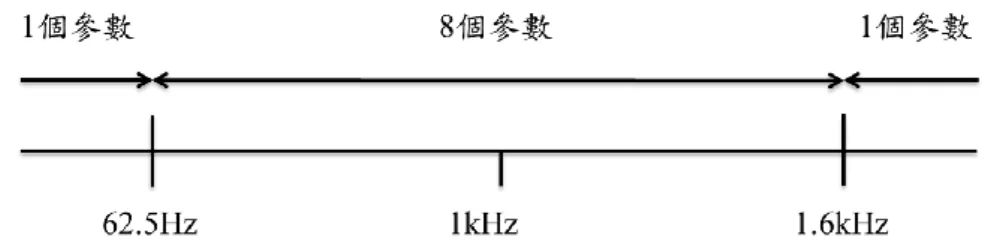
2-5-2 音訊特徵 在音訊特徵上採用了 Mpeg-7 中對於基本頻譜的特徵描述分別是 ASE(AudioSpectrumEnvelope)、ASC(AudioSpectrumCentroid)、 ASS(AudioSpectrumSpread)、ASF(AudioSpectrumFlatness),除了 Mpeg-7 還另外加入 了 MIRtoolbox 中關於音訊內容的特徵 Spread、Centroid、Flatness,這些音訊特徵在 情緒成分的辨識中都有著極高的辨識率,詳細的辨識內容可見 2-7,接著會針對各 音訊特徵萃取作詳細介紹。 (1) AudioSpectrumEnvelope 這項特徵主要描述音訊經過頻率分析後在頻域中各頻率強度的波形,可以 用來描述音訊輸入的頻譜圖,在 Mpeg-7 的描述子中會先將每個音框的分頻段計 算出 10 個參數,如下圖:
24 圖 23. AudioSpectrumEnvelope 分頻示意圖 各音框的計算公式如下: ASE = |𝑋(𝑛)| 2 𝑙𝑤 × 𝑁𝐹𝐹𝑇= P(n) (2)
其中 NFFT 表示 FFT(Fast Fourier Transform)計算的大小,𝑙𝑤則是音框大小,X 是傅立葉轉換後的各頻率強度。運算結果產生 10 維的特徵和一組對應的權重, 這 10 維的特徵可以根據對應的權重換算成頻譜,若將 10 維的結果乘上對應的 權重則結果如下圖:
圖 24. Over the Rainbow 藤田惠美 – ASE 分析
其結果相近於 MIRtoolbox 中 mirspectrum 運算出來的圖 14,在本研究中採用 10 維的頻譜特徵值作為頻譜波形的特徵做運算。
25 ASC 是計算頻譜的質心作特徵,計算公式如下: ASC =∑ log2( 𝑓(𝑛) 1000) 𝑃(𝑛) 𝑛 ∑ 𝑃(𝑛)𝑛 (3) 其中𝑃(𝑛)是頻率𝑓(𝑛)的頻譜強度。頻譜質心可以用來表達每個音框的頻率分布 趨向,可視為一個簡單的頻譜能量分布表示,每個音框會計算出一個特徵值, 其結果數值由公式中可見是以 1000Hz 為參考基準,若頻譜質心的落點大於 1000Hz 越多則為正值且越大,反之則小於 1000Hz 越多則為負值且越大,結果 如下圖:
圖 25. Over the Rainbow 藤田惠美 – ASC 分析
(3) AudioSpectrumSpread
這項特徵延續 ASC 的分析,視為 ASC 的二階中心動差(second central moment),就是所謂的變異數(Variance),計算公式如下: ASS =√ ∑ ((log2(1000) − 𝐴𝑆𝐶)𝑓(𝑛) 2 𝑃(𝑛)) 𝑛 𝑃(𝑛) (4) 其中各項變數同 ASC 中所計算的,這項特徵表現出頻譜的頻率分布是否集中, 每個音框的計算結果為單一數值,計算的結果如下圖所示:
26 圖 26. Over the Rainbow 藤田惠美 – ASS 分析
(4) AudioSpectrumFlatness 這項特徵主要用來描述頻譜的平坦程度,在這邊會分成各頻段再進一步的 計算各頻段間的頻譜平坦程度,每個頻段是 1/4 個 Octave,共計會產生 24 個頻 段,每個頻段中的 ASF 計算公式如下: ASF = √∏ 𝑐(𝑖)𝑏 𝑏 1 𝑏 ∑ 𝑐(𝑖)𝑏 (5) 其中的𝑐(𝑖)是第 b 個頻段內頻譜的參數。每個音框最後的計算結果是一組 24 維 的特徵值,代表著該音框在 24 個頻段內的平坦程度結果如下圖:
27
(5) Centroid
除了採用Mpeg-7 的音訊特徵外,本研究也採用 MIRtoolbox 中包含的音訊 特徵,這邊的 Centroid 和 Mpeg-7 的頻譜質心的差別在於輸入的音框大小不同, 計算頻域波形的一階動差(first moment)也就是期望值 (mean)、資料分布的幾何 中心可以表示頻譜的集中趨向,計算公式如下:
𝜇1= ∫ 𝑥𝑓(𝑥)𝑑𝑥 (6)
𝜇1即為幾何中心,可以見下圖表示:
圖 28. Centroid 示意圖
資料來源:MIRtoolbox user’s manual[22] 每個音框會取出單一個數值特徵,計算的結果如下圖所示:
28 (6) Spread 如同 Mpeg-7 中的 Spread 概念,進一步的計算二階中心動差,其公式如下 所示: 𝜎2= 𝜇 2= ∫(𝑥 − 𝜇1)2𝑓(𝑥)𝑑𝑥 (7) 結果以𝜎2表示,其計算的概念圖如下: 圖 30. Spread 示意圖
資料來源:MIRtoolbox user’s manual[22]
計算的結果如下圖所示:
29 (7) Flatness 這特徵表示音訊的頻域波形平坦度,可以顯示出頻譜是滑順的或者是有很 多突刺狀,計算的公式如下: flatness = √∏𝑁−1𝑛=0𝑥(𝑛) 𝑁 (∑𝑁−1𝑛=0𝑥(𝑛) 𝑁 ) (8) 計算上是該音框內的幾何平均值和算術平均值的比率,結果如下圖:
圖 32. Over the Rainbow 藤田惠美 –Flatness 分析
2-6 SVM 分類演算法
為了因應高維度的特徵值分類,本研究採用了 SVM 作為分類機制,關於 SVM 的詳細原理參考[23][24],在 SVM 中我們假設有一堆點集合
{𝑥𝑖, 𝑦𝑖},𝑖 = 1, ⋯ , 𝑛 且 𝑥𝑖 ∈ 𝑅𝑑,𝑦𝑖𝜖{+1, −1},𝑥𝑖即為測試資料,而𝑦𝑖為各筆測試資
料的類別標籤。這邊希望找到一個最佳超平面(Optimal separating hyperplane,
OSH)𝑓(𝑥) = 𝑤𝑇𝑥 − 𝑏可以剛好分隔開兩個類別,使得𝑦
𝑖 = −1的點落在𝑓(𝑥) < 0的這
一邊,且𝑦𝑖 = −1的都落在𝑓(𝑥) > 0的那一邊,如此一來即可以𝑓(𝑥)的正負來判定接
著進來的測試資料類別。
30 hyperplane),即為圖 6.裡那兩條虛線,將支援超平面寫成下面式子表示: 𝑤𝑇𝑥 = 𝑏 + 𝛿 (9) 𝑤𝑇𝑥 = 𝑏 − 𝛿 (10) 這邊形成了一個過多待解參數的問題(over-parameterized problem),假設 x、b、δ 乘 上一任意常數等式依然成立,意即 x、b、δ 有無限多組解,則為了簡化問題在等式 中皆乘上一個常數使得𝛿 = 1,藉此消去一個待解參數,在接下來的討論中 x、b 皆 已經過同樣的尺度調整。 求取 OSH 主要可以視為要找出有最大邊界(Margin)的支援超平面,這邊定義 Separating plane 到支援超平面的距離為 d 如下兩式: 𝑑 =(||𝑏 + 1| − |𝑏||) ‖𝑤‖ = 1 ‖𝑤‖ , 𝑏 ∉ (−1,0) (11) 𝑑 =(||𝑏 + 1| + |𝑏||) ‖𝑤‖ = 1 ‖𝑤‖ , 𝑏 ∈ (−1,0) (12) 則要求的邊界等於 2d, margin = 2𝑑 =‖𝑤‖2 (13) 由上式可見當‖𝑤‖越小則可以得到越大的邊界。由於之前的設計過尺度調整的,可 以知道支援超平面和 OSH 的距離在±1之內,這個限制條件可寫成下列式子: 𝑤𝑇𝑥 𝑖− 𝑏 ≤ −1 ,∀𝑦𝑖= −1 (14) 𝑤𝑇𝑥 𝑖− 𝑏 ≥ +1 ,∀𝑦𝑖= +1 (15) 上兩式可以進一步的合併如下: 𝑦𝑖(𝑤𝑇𝑥𝑖− 𝑏) − 1 ≥ 0 (16) 總和上面討論,可以得到下列的目標函式為 SVM 尋求 OSH 的主要問題(primal problem), min 𝑤 1 2‖𝑤‖2 並符合 𝑦𝑖(𝑤𝑇𝑥𝑖− 𝑏) − 1 ≥ 0 ∀𝑖 (17)
為了求解上述的最佳化問題,採用拉格朗日法(Lagrange Multiplier Method)將上述式
子轉乘對偶問題(dual problem)的二次方程式,找出可以使 L 為最小值的 w、b、αi,
31 𝐿(𝑤, 𝑏, 𝛼) =1 2‖𝑤‖2− ∑ 𝛼𝑖 𝑁 𝑖=1 [𝑦𝑖(𝑤𝑇𝑥𝑖− 𝑏) − 1] (18) 接著求解 L 的最小值分別對 w 及 b 作偏微分, ∂w𝐿𝑝= 0 → 𝑤 − ∑ 𝛼𝑖𝑦𝑖𝑥𝑖 𝑁 𝑖=1 = 0 ⇒ 𝑤∗= ∑ 𝛼 𝑖𝑦𝑖𝑥𝑖 𝑁 𝑖=1 (19) ∂b𝐿𝑝= 0 → ∑ 𝛼𝑖𝑦𝑖 𝑁 𝑖=1 = 0 (20) 將(18)、(19)代回(17)可以得到新的目標函式為, max𝐿𝐷 = ∑ 𝛼𝑖− 1 2∑ 𝛼𝑖𝛼𝑗𝑦𝑖𝑦𝑗𝑥𝑖𝑇𝑥𝑗 𝑖𝑗 𝑁 𝑖=1 並符合 ∑ 𝛼𝑖𝑦𝑖= 0 𝑁 𝑖=1 ,∀𝛼𝑖≥ 0 (21) 總合上述條件如下: ∂w𝐿𝑝= 0 → 𝑤 − ∑ 𝛼𝑖𝑦𝑖𝑥𝑖 𝑁 𝑖=1 = 0 (18) ∂b𝐿𝑝= 0 → ∑ 𝛼𝑖𝑦𝑖 𝑁 𝑖=1 = 0 (19) 𝑦𝑖(𝑤𝑇𝑥𝑖− 𝑏) − 1 ≥ 0 (15)
Largrange multiplier condition 𝛼𝑖≥ 0 (22)
complementay slackness 𝛼𝑖[𝑦𝑖(𝑤𝑇𝑥𝑖− 𝑏) − 1] = 0 (23) 上述條件被稱為 KKT 條件(Karush-Kuhn-Tucker condition),當我們將訓練資料放進 來時有些點會符合上述的 KKT 條件,由(15)和(22)可得知𝑦𝑖(𝑤𝑇𝑥𝑖− 𝑏) − 1 > 0的話, 𝛼𝑖 = 0,而當𝑦𝑖(𝑤𝑇𝑥 𝑖 − 𝑏) − 1 = 0時,𝛼𝑖 > 0,訓練用且𝛼𝑖 > 0的樣本,這些點就是 剛好落在支援超平面上的點決定了這個問題的解,一般狀況下這些點很少稱為稀疏
(sparse)解,這些點稱之為 Support vector 其𝛼𝑖 ≥ 0。
求得 Support vector 之後就可以用它們來判別新加入的測試資料是屬於哪一邊 的集合, 𝑓(𝑥) = 𝑤∗𝑇𝑥 − 𝑏∗= ∑ 𝛼 𝑖𝑦𝑖𝑥𝑖𝑇𝑥 − 𝑏∗ 𝑖 (24)
32 𝑏∗= (∑ 𝛼 𝑗𝑦𝑗𝑥𝑗𝑇𝑥𝑖−𝑦𝑖 𝑗 ) (25) 上述討論中都是假設資料都位在線性空間,非線性資料在實際情況下會把資料 映射到高維度的空間或是特徵空間中𝑥 → ∅(𝑥),∅是映射函數,透過∅將 x 映射到特 徵空間中,映射函數可能是一個非常複雜且不易求值的函數,但是內積的形式可以 使其變得簡單, ∴ 𝑥𝑖𝑇𝑥𝑗 → ∅(𝑥𝑖)𝑇∅(𝑥𝑗) (26) 映射函數做內積得到的函數在 SVM 中稱之為核化(Kernel)。 最後討論資料不可完全分割的情形,真實使用上的情況通常比假設更為複雜, 上述討論都是基於可以找到 OSH 對資料做完美分割,但在資料本身也有可能有誤差 下可能找不到一個 OSH 將資料做完美的切割,此時要再導入一個誤差項 ξ 來解決資 料在邊界地方有重疊的情形。 𝑤𝑇𝑥 𝑖− 𝑏 ≤ −1 + ξ𝑖 ,∀𝑦𝑖= −1 (27) 𝑤𝑇𝑥 𝑖− 𝑏 ≥ +1 − ξ𝑖 ,∀𝑦𝑖= +1 (28) ξ𝑖≥ 0 ∀𝑖 誤差項ξ 允許原先的限制被違反,為了使限制條件依然存在意義,會額外再給誤差 值一點懲罰性成本 C, Cost = C (∑ 𝜉𝑖 𝑖 ) 𝑘 (29) 當 k=1、2 時,這仍是一個二次規劃的問題,下面討論中選擇 k=1,c 的值將控制懲 罰跟邊緣的平衡,要將一個訓練資料放置錯誤的一邊則ξ𝑖 > 1,因此∑ 𝜉𝑖 𝑖可以解釋違 規的情形有多嚴重,同時也是違規的限制個數上限。於是新的主要問題變成, min1 2‖𝑤‖2+ 𝐶 ∑ 𝜉𝑖 𝑖 並符合 𝑦𝑖(𝑤𝑇𝑥𝑖− 𝑏) − 1 + 𝜉𝑖≥ 0 ∀𝑖 (30) 𝜉𝑖≥ 0 ∀𝑖 接著一樣使用拉格朗日法引入限制條件, 𝐿(𝑤, 𝑏, 𝜉, 𝛼, 𝜇) =1 2‖𝑤‖2+ 𝐶 ∑ 𝜉𝑖 𝑖 − ∑ 𝛼𝑖[𝑦𝑖(𝑤𝑇𝑥𝑖− 𝑏) − 1 + 𝜉𝑖] − ∑ 𝜇𝑖𝜉𝑖 𝑁 𝑖=1 𝑁 𝑖=1 (31)
33 並依此得到新的 KKT 條件, ∂w𝐿𝑝= 0 → 𝑤 − ∑ 𝛼𝑖𝑦𝑖𝑥𝑖 𝑁 𝑖=1 = 0 (32) ∂b𝐿𝑝= 0 → ∑ 𝛼𝑖𝑦𝑖 𝑁 𝑖=1 = 0 (33) ∂ξ𝐿𝑝= 0 → 𝐶 − 𝛼𝑖− 𝜇𝑖 (34) 𝑦𝑖(𝑤𝑇𝑥𝑖− 𝑏) − 1 ≥ 0 (35) 𝜉𝑖≥ 0 (36)
Largrange multiplier condition 𝛼𝑖≥ 0 (37)
Largrange multiplier condition 𝜇𝑖≥ 0 (38)
complementay slackness 𝛼𝑖[𝑦𝑖(𝑤𝑇𝑥𝑖− 𝑏) − 1 + 𝜉𝑖] = 0 (39) complementay slackness 𝜇𝑖𝜉𝑖= 0 (40) 由上述條件可見,假設𝜉𝑖 > 0則𝜇𝑖 = 0因此𝛼𝑖 = 𝐶且𝜉𝑖 = 1 − 𝑦𝑖(𝑤𝑇𝑥𝑖 − 𝑏),若當 𝜉𝑖 = 0則𝜇𝑖 >因此𝛼𝑖 < 𝐶。只有當𝜉𝑖 = 0時可以得到原先的結果: 𝑦𝑖(𝑤𝑇𝑥𝑖 − 𝑏) − 1 = 0時,𝛼𝑖 > 0,否則𝑦𝑖(𝑤𝑇𝑥𝑖− 𝑏) − 1 > 0的話,𝛼𝑖 = 0。跟原先 的結論相同,若樣本不落在支持超平面上而是在正確分類的那一邊,則𝜉𝑖 = 𝛼𝑖 = 0; 如果落在支持超平面上,則𝜉𝑖 = 0但是𝛼𝑖 > 0;但若是落在錯誤分類的那一邊,則𝛼𝑖最 大可以到 C,但是𝜉𝑖會平衡被違反的限制使得𝑦𝑖(𝑤𝑇𝑥 𝑖 − 𝑏) − 1 + 𝜉𝑖 = 0。 在眾多分類器中選用了 SVM 在於可以進行多維度特徵分類且方便使用,本研 究採用了 Chih-Jen Lin [18]統整的(lib)SVM 的 toolbox 是一套以 MATLAB 為平台統 合各種 SVM 的演算法,這邊只採用了預設的 SVM 型態-C-SVC,內容包含非線性 和誤差值的修正。 2-7 情緒計分 在萃取完特徵值和決定分類演算法後回到原先設計的情緒成分表示來討論,在 情緒成分表示的圖 9.中所示的四種情緒成分,其成分的分布依舊隱含各情緒模型的 二維觀念,在判定當前音框的情緒時,主要先將該音框萃取一特徵值,利用特徵值 在任兩情緒間做分類,產生六種分類結果最後再取眾數,採用六種情緒判定中被判 定最多的情緒作為該音框在該特徵下的情緒。
34
2-7-1 情緒分類模型建立
在四種情緒成分下,任兩個情緒間的分類共有 12 種比較,扣除重複的比較就剩 下下圖中的 6 種比較:
圖 33. 六種情緒分類示意圖
在這六種分類中除了是兩兩情緒間的分辨,對映到 Russell’s circumplex model 上更 是能表示在高 Arousal 下的比較 Valence 的情緒分布其況或者是高 Valence 下比較 Aousal 的情緒分布等。採用各特徵值採用 SVM 在六個比較下的辨識率可見下兩表: 表 6. 音樂特徵辨識率 Content Depression Content Anxious Content Exuberant Depression Anxious Depression Exuberant Anxious Exuberant Key 45.82% 50.38% 50.47% 50.21% 55.39% 51.79% Key clarity 56.86% 52.41% 58.97% 55.03% 50.57% 55.47% Mode 55.94% 51.57% 57.50% 52.27% 63.18% 58.64% Tonal centroid 52.23% 79.79% 70.93% 82.36% 73.78% 58.78%
35 表 7. 音訊特徵辨識率 Content Depression Content Anxious Content Exuberant Depression Anxious Depression Exuberant Anxious Exuberant Spread 47.23% 89.41% 77.61% 90.39% 77.14% 64.40% Flatness 64.95% 67.52% 65.76% 80.23% 77.66% 50.26% Centroid 60.09% 77.86% 71.89% 85.04% 80.26% 54.40% ASC 57.71% 63.31% 64.98% 51.96% 53.81% 51.03% ASE 54.48% 79.98% 70.29% 87.41% 73.90% 51.46% ASS 51.25% 88.37% 82.74% 88.93% 84.57% 57.57% ASF 67.91% 79.10% 69.27% 85.17% 75.82% 68.81% 上兩表是由各情緒一半的訓練歌曲當成建立 SVM 模型用的訓量資料,並拿另一半 的訓練歌曲當作測試資料去做訓練資料的內部測試,目的在於分析各個特徵值對於 該配對情緒的分類的辨識能力。 最後在事前處理的部分會將 192 訓練歌曲依照這六種分類對各情緒間的分類建 立 SVM 的分類模型,每種特徵值都會有其對應的 6 個情緒分類 SVM 模型,11 個 特徵共計 66 組分類模型。 2-7-2 情緒判定 在事前的訓練中建立了分類的模型,於是當測試資料進來時將採用這個模型進 行第一步驟的情緒判定,在第一步驟中會得到 6 個情緒判斷結果,之後再進行第二 步驟的判定由前六種情緒判定結果去投票決定出當下的情緒,下表以 Celine Dion 的 My heart will go on 的各特徵第一個音框的情緒判定結果為例:
36 表 8. 情緒判定舉例 Content Depression Content Anxious Content Exuberant Depression Anxious Depression Exuberant Anxious Exuberant result
Key Depression Anxious Exuberant Anxious Exuberant Anxious Anxious
Key
clarity Content Content Content Anxious Exuberant Anxious Content Mode Content Anxious Content Anxious Exuberant Anxious Anxious Tonal
centroid Content Anxious Content Anxious Exuberant Anxious Anxious Spread Depression Anxious Content Anxious Exuberant Anxious Anxious Flatness Content Anxious Content Anxious Exuberant Anxious Anxious
Centroid Depression Anxious Content Anxious Exuberant Anxious Anxious
ASC Depression Anxious Exuberant Anxious Exuberant Exuberant Exuberant
ASE Depression Anxious Exuberant Anxious Exuberant Exuberant Exuberant
ASS Depression Content Content Depression Depression Exuberant Depression
ASF Content Content Exuberant Anxious Exuberant Exuberant Exuberant
因此每個特徵值都會在各自的音框中決定一種情緒,若是同一時間點上不同特徵值 決定了不同的情緒,那也符合本研究的原先假設,聆聽音樂引發的情緒是由四種基 本的情緒疊加而成的結果,而不只是單一情緒可以描述的。各特徵值分析的音框長 度不同,因此情緒判定對應到時間軸上如下圖:
37 圖 34. 情緒判定示意圖
上圖中每一個圓圈代表一個音框,情緒變化時間以最小音框(0.025 秒)為基本,由於 各特徵值採用的音框大小不盡相同,並非所有時刻都有採計所有特徵的情緒判定, 如 Key、Key clarity、Mode 對情緒結果的影響每 0.5 秒累加一次;Tonal centroid 是 每 0.075 秒累加一次;Spread、Flatness、Centroid 是每 0.025 秒一次也就是基本的情 緒成分變化的時間單位;ASE、ASC、ASS、ASF 則是每 0.05 秒累加一次。 2-7-3 計分方式 情緒累積計分上將考慮人類的情緒響應並不是快速的切換,因此每個情緒的判 定後的影響不會馬上結束,而是會持續的累積到接下來的音框判斷中,但是其影響 會漸漸衰弱,因此會乘上一個衰減函數。在本研究中設定情緒的響應時間是 3 秒, 意即在當下判定的情緒會持續影響接著 3 秒內的情緒成分多寡,依此設計了 3 種情 緒的衰減加權方式:線性衰減、高斯函數衰減、自然指數衰減,如下圖: 圖 35. 各種衰減加權函數
38 計分方式以數學公式表示如下:
(linear weight − decay) 𝐸𝑖= ∑ ∑ 0.5 ∗ (
𝑥 120) 120 𝑡=1 𝑗 (41)
(Gauss’s weight − decay) 𝐸𝑖= ∑ ∑ 0.5 ∗ 𝑒
−(120−𝑐)5𝑥 2 2𝜎2 120 𝑡=1 𝑗 (42)
(Natural exponential weight − decay) 𝐸𝑖= ∑ ∑ 0.5 ∗
𝑒𝑥 𝑒120 120 𝑡=1 𝑗 (43) 𝑥 = 121 − 𝑡,𝑖 = 𝑚𝑜𝑑𝑒(𝑃1−𝑡) 其中 t 是情緒成分變化的最小音框即 0.025 秒,𝑃1−𝑡是訓練資料在各音框裡第一步驟 的六種判定結果,i 則是表示情緒成分類別,j 表示 11 種不同的特徵值,𝐸𝑖為當下的 各特徵值判定的情緒成分累積分數。由公式中可得知每個當下的情緒判定都將追朔 前 120 個基本音框(意即 3 秒)的判定結果,並乘上不同的衰減函數再累計起來。在 本研究中設定線性衰減加權函數為預設值。 2-8 音樂情緒成分表示法 在上述的的流程處理過後會產生各情緒成分的向量,其中每個元素都代表每 0.025 秒音框大小的情緒判定結果,最後的結果採用四個圓圈表示並輸出成影片,每 個時刻四個情緒的累計分數不同,因此四個圓圈也不同而是隨著時間變化的。由於 最小的時間單位為 0.025 秒,所以情緒的解析度等於 40 fps,每秒內會有 40 次情緒 判定,並隨時計算各情緒的比例,影片畫面如下:
39 圖 36. 實際影片結果畫面
在整首歌曲播畢,會統計各個情緒成分在歌曲中總佔有的比例,如下圖:
圖 37. 影片最後的情緒總結
40
三、 音樂情緒心理分析調查
3-1 問卷調查 前述章節中,本研究建立了一套視覺化即時性的情緒成分分析系統,音樂情緒 是主觀的感受,因此為了驗證系統分析的結果是否具有客觀性,在研究的最後進行 了針對音樂情緒的問卷調查。也藉此比對由數理演算分析的音樂情緒和心理學家建 立的音樂情緒模型結果是否吻合。 在此基於 Zentner 的 GEM-9 情緒模型設計了一份問卷,問卷可見附錄二,來驗 證結果的可靠度。測試音樂如下表: 表 9. 本研究測試音樂 演出者 曲名 長度Avenged Sevenfold Dear God 00:06:34
Celine Dion My heart will go on 00:04:41
Chopin Nocturne opus 9 no 2 00:04:08
Debussy Claire de lune 00:05:06
Carpenters Goodbye to love 00:03:56
Edith Piaf La Vie En Rose 00:03:05
問卷調查對象共計 66 位,一年級到四年級的大學生且來自於各系所有不同的背景, 詳細受測者資料可見附錄三。問卷調查過程為不事先告知這是一個關於音樂情緒辨 識問卷的調查,而是讓聽者在沒有預設立場下先行聆聽過歌曲後再填問卷,問卷上 針對各情緒形容詞有統一的翻譯,以降低聽者對情緒形容詞不認識或認知上落差的 情形。 3-2 問卷調查與實驗結果分析 各測試歌曲的計分統計及情緒比例圖形可見附錄四,下面針對幾首結果分析, 可以搭配觀看附錄中 DEMO 網址的影片來比較,Avenged Sevenfold - Dear God 的問
41 卷調查的結果和實驗結果比較如下表,
表 10. Avenged Sevenfold - Dear God 結果分析
問卷調查 程式結果 情緒類別 情緒比例 情緒成分 情緒比例 Wonder 9.66% Content 16.48% Transcendence 9.66% Tenderness 10.90% Depression 11.71% Nostalgia 13.39% Peacefulness 7.94% Anxious 39.57% Power 12.97% Joyful Activation 10.70% Exuberant 32.24% Tension 14.70% Sadness 10.08% 由上表中的問卷調查結果可以知道,懷舊、憂鬱(Nostalgia)和動力(Power)和激動 (Tension)這三個情緒的比例較高,在 Dear God 這首歌之中大致可以分兩個段落,主 歌觸人心弦的滑音吉他和鋪層的主唱旋律都是比較抑鬱的,在副歌激昂的歌聲中再 一口氣爆發出來,後面一段破音吉他加進來的橋段再接木吉他的平靜,最後在漸漸 進到吉他獨奏的橋段。歌曲的編曲安排非常巧妙,一般聆聽者的情緒會漸漸的被帶 領到最後的高潮,因此在問卷上會顯示這三種情緒較多。 但在程式中追蹤的是即時的變化,這首歌除了較激動的片段也不乏細膩的橋段, 不過在整個變化過程中 Anxious 和 Exuberant 的成分佔高比率的情緒結果抑是可由上 表見到的,由於這是首樂團編制的歌曲,在有鼓組編制下大多較能搧動聆聽者激昂 的情緒,這兩個情緒在能量上也都是偏高的,且 Anxious 的成分較 Exuberant 大這也 體現了問卷中負面情緒 Nostalgia 的影響。
42 表 11. Celine Dion - My heart will go on 結果分析
問卷調查 程式結果 情緒類別 情緒比例 情緒成分 情緒比例 Wonder 11.49% Content 23.76% Transcendence 13.05% Tenderness 12.40% Depression 30.93% Nostalgia 13.46% Peacefulness 10.18% Anxious 24.20% Power 8.78% Joyful Activation 7.23% Exuberant 21.10% Tension 11.33% Sadness 12.07% 這首曲中也有著主、副歌的段落安排,編曲上以笛聲為主旋律,輔以電子的氛圍長 音這也是問卷中超然(Transcendence)的分數較高的原因,當然在女主唱哀傷的腔調, 就算聽不懂歌詞也可以受到那浩瀚的悲愴情感,不外乎懷舊、憂鬱(Nostalgia)的情緒 是問卷中的最高分。這首曲子的構造和上一首不盡相同,除了音量大的時候會提高 Anxious、Exuberant 的比例外,其餘時間都表現在 Depression 上,超然的感覺也讓 Content 占有不少比例。由於這首歌是鐵達尼號(Titanic)電影主題曲,因此在問卷調 查結果是否受聆聽者喚起電影劇情的記憶的影響,也是一個值得探討的議題。 最後看到針對古典音樂 Chopin - Nocturne opus 9 no 2 的問卷結果如下,
43 表 12. Chopin - Nocturne opus 9 no 2 結果分析
問卷調查 程式結果 情緒類別 情緒比例 情緒成分 情緒比例 Wonder 10.29% Content 16.66% Transcendence 14.06% Tenderness 14.38% Depression 58.07% Nostalgia 11.33% Peacefulness 15.18% Anxious 13.16% Power 7.87% Joyful Activation 11.73% Exuberant 12.11% Tension 7.15% Sadness 8.03% 在古典音樂中的音樂內容和流行的歌曲很不相同,比如這首蕭邦的鋼琴獨奏曲,整首歌 曲中只有鋼琴的演奏,在內容上能量普遍偏低,因此情緒比例以 Depression 佔大宗,但 是可以分出 Content 和 Depression 這可以預想是音樂特徵的功用,針對這點也可以是之 後研究的議題。在問卷調查中超然(Transcendence)、溫和(Tenderness)、平靜(Peacefulness) 為最大宗,在此與程式結果最大的共通點在於低情緒能量的感受。 其餘測試歌曲問卷結果和影片 DEMO 可查看附錄四。
44
四、 結論
本研究彙整各種情緒模型提出一種新的視覺化即時性音樂情緒表示方式,有別 於一般即時性研究將音樂對只對應到單一情緒,這邊採用四種基本的情緒成分比例 來表示,在強烈單一情緒的音樂中也能瞥見細微的其他情緒成分變動。 與 Zentner 的 GEM 模型比較最大問題在於,大家對於情緒形容詞的理解不同。 這也同樣存在於受測者認知的情緒形容詞和我們預想的感覺間,也是分析結果造成 差異的主因,受測者的對音樂的學習程度也同樣是尚未考慮的變數,對於有音樂學 習經驗的人在聽音樂時候對音樂內容感受的重點可能不如一般平常人而是更具學 習經驗而有不同感受。 本研究系統較心理學家的情緒模型優勢在於測試資料可以是使用者自行定義 的歌曲庫,每個使用者可以以自己感受的情緒音樂片段輸入系統去建立屬於各自專 屬的分類模型,這也可以大大降低主觀感受的認知落差。45 參考文獻
[1] Typke, R.; Wiering, F.; Veltkamp, R.C., ”A survey of music information retrieval systems”, Proc. 6th International Conference on Music Information Retrieval, pp. 153-160, 2005
[2] Zentner, M. R. & Eerola, T. . “ch8 .Self-report measures and models.” , “Handbook of Music and Emotion”, Juslin, P. & Sloboda, J. (Eds). , pp. 187-221. Oxford University Press: Oxford, UK., 2009
[3] José M. Martínez ,”Mpeg-7 Overview”,2004 oct.
http://mpeg.chiariglione.org/standards/mpeg-7/mpeg-7.htm
[4] 劉客養, ”初探鋼琴十二平均律調音”, Jewels of the Art World, Journal of Aesthetic Education, No.131, pp.88-95
[5] 林金慧, “在蒙德里安架構下闡釋情緒的樂理”, 台南科大學報, 第 28 期, 生活藝 術類, 115-132 頁, 中華民國 98 年 10 月
[6] Maria M. Ruxanda, Bee Yong Chua, Alexandros Nanopoulos, Christian S.
Jensen, ”Emotion-based music retrieval on a well-reduced audio feature spaceg”, International Conference on Acoustics, Speech, and Signal Processing - ICASSP , pp. 181-184, 2009
[7] Bin Zhu, KejunZhang, ”Music emotion recognition system based on improved GA-BP”, International Conference On Computer Design And Appliations (ICCDA 2010), Volume 2, PP.409-412, 2010
[8] Dan Liu, Lie Lu, Hong-Jiang Zhang “Automatic Mood Detection from Acoustic Music Data”, Music Information Retrieval, pp. 13-17, 2003.
[9] Ei Ei Pe Myint, Moe Pwint, ”An approach for mulit-label music mood classification”, 2010 2nd International Conference on Signal Processing Systems, Volume 1,
PP.290-294, 2010
46 Music Listening”, Pattern Analysis and Machine Intelligence, IEEE Transactions on, VOL. 30, NO. 12, Dec 2008
[11] Sanghoon Jun, Seungmin Rho, Byeong-jun Han, Eenjun Hwang, “A fuzzy
inference-based music emotion recognition system”, 5th International Conference on In Visual Information Engineering (VIE), pp. 673-677, 2008
[12] Y.-H. Yang et al, “Mr. Emo: Music retrieval in the emotion plane,” Proc. ACM MM, 2008, accepted.
[13] Mark David Korhonen, “Modeling Continuous Emotional Appraisals of Music Using System Identification”, A thesis presented to the University of Waterloo, Canada, 2004 [14] Jun-Jie Fu, “Emotion Locus Tracking System for Automatic Mood Detection and
Classification of Music Signals” A thesis Submitted to National Chiao Tung University, Taiwan, 2010
[15] Emery Schubert , “Real Time Cognitive Response Recording”, The inaugural International Conference on Music Communication, Science 5-7, ,PP.139-142, Dec 2007
[16] 王鴻文,劉志俊, “MP3 音樂的聆賞情緒自動分類”, Journal of Information Technology and Applications, Vol. 4, No. 4, pp. 160-171, 2010
[17] Zentner, Marcel; Grandjean, Didier; Scherer, Klaus R., ”Emotions evoked by the sound of music: Characterization, classification, and measurement.” Emotion, Vol 8(4), 494-521. , Aug 2008
[18] Chih-Chung Chang,Chih-Jen Lin, ”A Library for Support Vector Machines”, ACM Transactions on Intelligent Systems and Technology, Volume 2, Issue 3, Article 27, April 2011
[19] MIR toolbox,
https://www.jyu.fi/hum/laitokset/musiikki/en/research/coe/materials/mirtoolbox
47 [21] Olivier Lartillot, Petri Toiviainen , “A Matlab Toolbox for Musical Feature Extraction
From Audio”, the 10th Int. Conference on Digital Audio Effects (DAFx-07), Bordeaux, France, September 10-15, 2007
[22] Olivier Lartillot, ”Mir toolbox1.3.2 user’s manual”, Finnish Centre of Exce!ence in Interdisciplinary Music Research, University of Jyväskylä, Finland, January, 19th, 2011 [23] 李根逸, "支持向量機教學文件(中文版)", 台灣大學通訊與多媒體實驗室
48 附錄一. 訓練資料曲目
# Title Artist EmotionType
1 Over the Rainbow 藤田惠美 Content
2 Over the Rainbow 藤田惠美 Content
3 Don't know Why Norah Jones Content
4 Don't know Why Norah Jones Content
5 Melody Fair 藤田惠美 Content
6 Melody Fair 藤田惠美 Content
7 Depois do natal 小野麗莎 Content
8 Depois do natal 小野麗莎 Content
9 All My Loving 藤田惠美 Content
10 Jingle Bell Rock 小野麗莎 Content
11 White Christmas 小野麗莎 Content
12 White Christmas 小野麗莎 Content
13 White Christmas 小野麗莎 Content
14 Paz Azul 小野麗莎 Content
15 Paz Azul 小野麗莎 Content
16 The Christmas Song 小野麗莎 Content
17 The Christmas Song 小野麗莎 Content
18 Boas Festas 小野麗莎 Content
19 Boas Festas 小野麗莎 Content
20 Um Anjo Do Ceu 小野麗莎 Content
21 Um Anjo Do Ceu 小野麗莎 Content
22 The wee small hours of the morning 小野麗莎 Content
23 The wee small hours of the morning 小野麗莎 Content
24 leaving on a jet plane 藤田惠美 Content
25 leaving on a jet plane 藤田惠美 Content
26 silent night 小野麗莎 Content
27 not going anywhere Keren Ann Content
28 not going anywhere Keren Ann Content
29 Polly Keren Ann Content
30 Polly Keren Ann Content
31 Sit on the Sun Keren Ann Content
32 Right Now and Keren Ann Content
33 Right Now and Keren Ann Content
![圖 2. Hevner’s adjective clock 進階版本 資料來源:[2]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8519423.186421/12.892.180.740.526.1085/圖2Hevnersadjectiveclock進階版本資料來源2.webp)
![圖 3. 各式二維情緒模型 資料來源:[2]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8519423.186421/13.892.248.634.520.828/圖3各式二維情緒模型資料來源2.webp)
![圖 11. MIRtoolbox 特徵萃取前流程 資料來源:MIRtoolbox user’s manual[22]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8519423.186421/27.892.117.821.115.280/圖11MIRtoolbox特徵萃取前流程資料來源MIRtoolboxusersmanual22.webp)