國立交通大學
電控工程研究所
碩 士 論 文
在具雜訊的正常血液抹片中進行白血球分
類計數
Differential Count of White Blood Cell in Noisy
Normal Blood Smear
研 究 生 :洪裕筆
指 導 教 授 :林昇甫 博士
在具雜訊的正常血液抹片中進行白血球分類計數
Differential Count of White Blood Cell in Noisy
Normal Blood Smear
研 究 生 :洪裕筆
Student: Yu-Bi Hong
指 導 教 授 :林昇甫 博士
Advisor: Dr. Sheng-Fuu Lin
國立交通大學
電控工程研究所
碩士論文
A Thesis
Submitted to Institute of Electrical Control Engineering College of Electrical Engineering
National Chiao-Tung University in Partial Fulfillment of the Requirements
for the Degree of Master
in
Electrical Control Engineering June 2011
Hsinchu, Taiwan, R.O.C 中華民國一百年七月
在具雜訊的正常血液抹片中進行白血球分
類計數
學生:洪裕筆 指導教授:林昇甫 博士國立交通大學電控工程研究所 碩士班
摘要
對醫學檢驗單位而言,血液抹片人工鏡檢是不可廢除的一項重要檢驗依據, 但是人工鏡檢確實是一個耗時耗力的過程,除了血液抹片本身製作上的優劣之外, 還得要考慮到不同醫檢人員因為疲勞或者是標準不同而有不一樣的結果,因此, 以數位影像分析的技術來協助這項工作的進行,將能夠減少人力的消耗,讓血液 抹片鏡檢更有效率。 本論文所研究的對象為具有雜訊的正常血液抹片,雜訊主要來自於製作不良 的血液抹片,例如抹片太薄、抹片太厚、染色不均,以及細胞破裂等等因素,在 同一個人的血液抹片影像裡面,可能會因為這些原因而在後續的分析中產生不一 致的結果,因此,針對這類雜訊進行處理有其必要性,如此一來實驗結果才能具 有讓人信服的依據。 本論文的貢獻有三,第一,透過二值化以及區域成長法,能將上述所定義的 雜訊排除,進而找出本論文所要尋找的白血球細胞核區域;第二,在找到白血球 細胞核區域之後,將可以完成多顆白血球影像定位,以利後續分析;第三,利用 距離轉換(distance transform)以及平均值移動演算法(mean shift),可以找出白血球 細胞核分葉特徵,配合形狀特徵以及紋理特徵將能夠使判斷更為精確。Differential Count of White Blood Cell in Noisy
Normal Blood Smear
Student: Yu-Bi Hong Advisor: Dr. Sheng-Fuu Lin
Institute of Electrical Control Engineering
National Chiao Tung University
ABSTRACT
For the medical examination unit, the artificial blood smear examination is an important test for abolition, but the process is indeed a time-consuming examination process. In addition to making blood smear on their own merits, but also have to take into account the different medical laboratory personnel due to fatigue or different standards then have different results. Therefore, to digital image analysis technology , assisting in this work, will be able to reduce human consumption, making microscopic examination of blood smears more efficient.
The object of study in this paper as having normal blood smear noise, noise mainly from the production of bad blood smears, for example, thin smear, thick smear, stain unevenly, and cell rupture, among other factors, blood smears in the same individual images which may be because of these reasons and in the subsequent analysis produced inconsistent results, therefore, were necessary for the processing of such noise, this way in order to have convincing results basis.
There are three contributions of this paper, first, through the binarization and region growing method, able to rule out noise as defined above, and then find out in this paper to find the white blood cell nucleus area; second, find the white blood cells in the nucleus zone, more satellites will be able to complete the positioning of white blood cell imaging, to facilitate subsequent analysis; Third, the use of distance transform (distance transform) and moving average algorithm (mean shift), you can find leaf characteristics of white blood cell nuclei, with the characteristic shape and texture features will be able to make more accurate judgments.
誌
謝
首先要以最誠摯的謝意,感謝我的指導教授林昇甫博士,感謝他在研究上的 啟迪與指導,以及細心校閱本論文的謬誤之處。同時也要感謝本實驗室的學長士 哲、晉嘉、國育、啟耀、逸章、俊偉、長安、煒清、世雄、家興,還有同甘共苦 的銘達、勁成、則銘以及學弟們,由於他們熱心的協助與討論,使得研究過程中 的困境能夠迎刃而解。 最後要感謝我親愛的父母,感謝他們的養育之恩以及在我求學生涯中給我最 大的鼓勵與支持,使我得以在精神與生活上無後顧之憂,順利完成學業。目錄
中文摘要……... i 英文摘要... ii 誌謝... iii 目錄... iv 表目錄... vi 圖目錄... vii 第一章 緒論... 1 1.1 白血球計數之介紹... 1 1.2 影像雜訊... 2 1.3 研究動機... 3 1.4 相關研究之探討... 3 1.5 論文主體與貢獻... 5 第二章 相關知識及理論... 5 2.1 色彩模型轉換... 5 2.1.1 RGB 色彩模型 ... 6 2.1.2 RGB 色彩模型轉換成灰階色彩模型 ... 6 2.1.3 RGB 色彩模型轉換成 HSV 色彩模型 ... 8 2.2 全域二值化與區域二值化... 9 2.2.1 最大類間方差二值化法... 10 2.2.2 尼布蘭克二值化法... 12 2.3 高斯混合模型... 13 2.3.1 高斯分布... 14 2.3.2 高斯混合模型... 15 2.4 灰階共生矩陣... 17 2.5 平均值移動演算法... 20 2.6 支持向量機... 22 第三章 系統流程... 24 3.1 整體系統架構... 24 3.2 RGB 直方圖分析與修正 ... 27 3.3 建立紅血球模型... 29 3.3.1 影像二值化處理... 29 3.3.2 二值影像邊緣提取... 31 3.3.3 高原度區塊面積分析... 323.3.4 高原度區塊半徑分析... 34 3.4 白血球細胞核影像處理與特徵抽取... 36 3.4.1 色彩空間轉換... 37 3.4.2 區域成長法復原細胞核區... 39 3.4.3 細胞核區重新描述及多重細胞核定位... 43 3.4.4 擷取白血球細胞核特徵... 48 3.5 分類決策樹... 54 第四章 實驗結果與分析... 58 4.1 實驗設備與方法... 58 4.2 實驗結果分析與討論... 61 4.2.1 白血球細胞核影像切割... 61 4.2.2 多重細胞核影像切割及定位... 64 4.2.3 白血球細胞核分類... 69 第五章 結論... 72 參考文獻... 73
表目錄
表 4.1 訓練及驗證資料。... 61 表 4.2 白血球細胞核分割計數。... 63 表 4.3 多重細胞分割定位結果。... 69 表 4.4 根據本論文所作的分類實驗結果。... 70 表 4.5 根據參考文獻[15]所作的分類實驗結果。 ... 70圖目錄
圖 1.1 五種類白血球,分別為 (a) 嗜中性粒細胞,(b) 嗜酸性粒細胞,(c) 嗜 鹼性粒細胞,(d) 單核細胞,(e) 淋巴細胞。。 ... 2 圖 2.1 RGB 色彩模型。 ... 6 圖 2.2 10 灰階。... 7 圖 2.3 256 灰階。... 7 圖 2.4 HSV 圓錐模型。 ... 8 圖 2.5 最大類間方差二值化的結果。... 12 圖 2.6 尼布蘭克二值化結果。... 13 圖 2.7 三種不同的高斯分布。... 14 圖 2.8 高斯分布的資料量比例。... 15 圖 2.9 血液抹片影像之飽和度影像。 (a)為原圖 (b)為(a)的立體化 ... 18 圖 2.10 平均值移動演算法示意圖。... 22 圖 2.11 支持向量機示意圖。 ... 22 圖 3.1 白血球細胞核影像。(a)血液抹片影像 (b)紅血球影像 (c)白血球細胞 核影像。 ... 24 圖 3.2 血液抹片中的雜訊。... 25 圖 3.3 血液抹片中的嗜鹼性顆粒。... 25 圖 3.4 主要辨識流程。... 26 圖 3.5 前處理流程。... 27 圖 3.6 RGB 三通道分析。... 27 圖 3.7 RGB 三通道未做修正。... 28 圖 3.8 經過 RGB 三通道的分析與修正,降低了雜訊。 ... 28 圖 3.9 紅血球模型建立。... 29 圖 3.10 二值化範例。 (a)RGB 轉灰階圖 (b)最大類間方差法 (c)尼布蘭克 二值化法 (d)由(c)和(b)作 AND 運算。 ... 30 圖 3.11 二值影像邊緣提取。 (a)血液抹片二值化影像 (b)填補影像中的空洞 (c)則是由(b)作邊緣提取所得的邊緣影像。 ... 31 圖 3.12 正圓度分析。... 32 圖 3.13 根據正圓度圈選出可能為紅血球的區塊。... 33 圖 3.14 分析高圓度區塊面積直方圖。... 34 圖 3.15 高圓度區塊近似半徑直方圖。... 35 圖 3.16 白血球細胞核影像處理流程圖。... 36 圖 3.17 色彩空間轉換及面積過濾流程圖。... 37 圖 3.18 白血球細胞核影像飽和度切割。 (a)原圖 (b)來自(a)的飽和度影像 (c) 飽和度臨界值(0.75)切割 (d)濾除小區塊之結果 ... 39 圖 3.19 由(a)到(t)依序為區域成長法復原白血球細胞核區塊過程。... 43圖 3.20 複雜血液抹片影像。... 44 圖 3.21 複雜血液抹片影像-飽和度。... 44 圖 3.22 複雜血液抹片影像-細胞核。... 45 圖 3.23 無法連通為一個完整區塊的細胞核。... 45 圖 3.24 一個色彩代表一個細胞核。... 46 圖 3.25 三組離散細胞核之長短軸分析。... 47 圖 3.26 重新描述完整之白血球細胞核影像。... 47 圖 3.27 分葉數計算流程圖。... 50 圖 3.28 細胞核分葉特徵抽取。 (a)為經過區域成長法以及結合邊界資訊 之後的白血球細胞核影像 (b)白血球細胞核像素距離邊緣最近影像 (c)距離影像以三維模型表示 (d)~(i)距離影像以多重臨界值切割的結 果 (l)白血球細胞核分葉總數。 ... 53 圖 3.29 支持向量機二元樹。... 55 圖 3.30 五種類白血球。 分別為(a)嗜中性粒細胞 (b)嗜酸性粒細胞 (c)嗜鹼 性粒細胞 (d)單核細胞 (e)淋巴細胞 ... 56 圖 4.1 實驗資料製備。 (a)劉氏染色劑 AB 劑 (b)染色後血液抹片。 ... 58
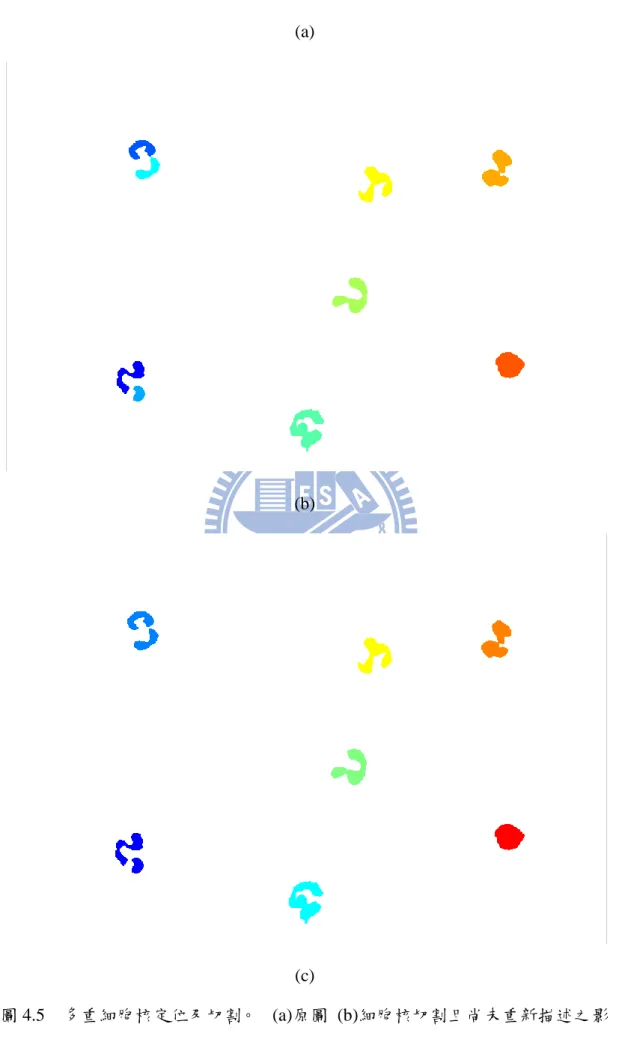
圖 4.2 實驗拍攝平台。(a)血液抹片拍攝平台 (b)XY 軸微動平台 (c)LED 背 光板。 ... 59 圖 4.3 掃描血液抹片路徑示意圖... 59 圖 4.4 驗證用血液影像。(a)(b)無重疊無干擾影像 (c)(d)紅血球重疊影像 (e)(f)染色不均影像 (g)(h)曝光不足影像。 ... 62 圖 4.5 多重細胞核定位及切割。(a)原圖 (b)細胞核切割且尚未重新描述之 影像 (c)重新描述後影像。 ... 64 圖 4.6 多重細胞核定位及切割。(a)原圖 (b)細胞核切割且尚未重新描述之 影像 (c)重新描述後影像。 ... 66 圖 4.7 多重細胞核定位及切割。(a)原圖 (b)細胞核切割且尚未重新描述之 影像 (c)重新描述後影像。 ... 67
1
第一章 緒論
本論文所要研究的對象為血液抹片,為了能在廣泛的案例中皆可進行分析, 系統抵抗雜訊的能力將會是研究重點,而在此所指涉的雜訊主要是指因不同的製 作技術而讓同一人的血液抹片有不同的分析結果,導致結果不具一致性以及正確 性,這將是本論文所要解決的主要問題。 本章共分成四節,第一節先概略介紹目前血球技術上有哪些做法以及優缺點, 第二節則是闡述本論文的研究動機,第三節則是介紹目前相關研究領域有哪些做 法,第四節則是本論文之貢獻。1.1
白血球計數之介紹
白血球細胞分類計數(white blood cell differential count),是被廣泛使用的血 液常規檢查項目之一,目的在於測定動物體內各類型白血球細胞的含量,提供臨 床診斷或者疾病篩檢的線索;事實上,幾乎所有疾病都和白血球有密切關係,透 過白血球分類計數來計算不同白血球間的數量比例,將可以協助診斷與篩檢及 病。 在目前的醫學應用技術上,主要分成人工鏡檢法和自動血球計算儀兩種方式, 人工鏡檢法是把外周血液塗抹於抹片上,進行細胞化學染色,再將抹片置於光學 顯微鏡底下,由專業的醫檢人員依據大小、細胞核結構、核質比,以及細胞內顆 粒等等細胞型態學上的相對差異,將白血球分成五類:嗜中性粒細胞(Neutrophil)、 嗜酸性粒細胞(Eosinophil)、嗜鹼性粒細胞(Basophil)、單核細胞(Monocyte)、淋巴 細胞(Lymphocyte)。 而自動血球計算儀在分類時的依據則依廠牌不同而有所不同,主要是利用血 球在稀釋液中流動,讓血球一個一個通過小孔道,並且在此孔道中安裝檢測器, 油檢測器所得結果,將血球進行分類,主流作法有光學式和電子式兩種,其中,
2 光學式透過將雷射光照向通過恐道的細胞,由光學散射來分析細胞的大小、容積, 以及內部密度等資訊;而電子式則是檢測血球通過孔道時,孔道阻抗的變化量, 或者是在孔道中心部位加裝電極,並且施以高頻電流,如此一來將可在血球通過 孔道時檢測出脈衝或者是電量的變化,依據這些資訊則可以對血球細胞做分類。 雖然自動化血球計算儀相較起人工鏡檢有許多的優勢,但是在血球計算儀的 分類依據內卻欠缺了一個血球分類的重要因素:細胞型態學,因此血球計算儀只 能對常規血液進行分類,對於不典型,或者是異常型態的細胞則無法檢出,只能 對使用者提出警告,再由使用者來做人工檢查,因此自動化血球計算儀仍然無法 完全取代人工鏡檢。 (a) (b) (c) (d) (e) 圖 1.1 五種類白血球,分別為 (a) 嗜中性粒細胞,(b) 嗜酸性粒細胞,(c) 嗜鹼 性粒細胞,(d) 單核細胞,(e) 淋巴細胞。
1.2
影像雜訊
對於影像雜訊較為廣泛的說法,是指因為外來干擾而導致影像品質劣化,這 個劣化現象通常可以用某種數學模型來表達,例如胡椒鹽雜訊(impulse noise)、 高斯雜訊(Gaussian noise)因此,在確定雜訊內容為哪種類型的模型之後,通常都 可以提出一個較為可行的減低雜訊方案來解決掉雜訊問題。 上述關於雜訊的討論,主要著重在「影像退化」,所以詴著要找出一些方法 來讓影像品質恢復到一定水準,這類型的問題通常是指某些無用的訊號干擾了我 們真實想要擷取的訊號,而這些無用的訊號就被稱為雜訊;有別於此,另一類雜3 訊的定義並非是指無用的訊號,而是在某種情況下,某些訊號可以被視為是雜訊, 例如,當 X 光穿透人體時,不可避免地會產生折射,使得許多不該曝光的部分曝 光了,因此這些部分將被視為是雜訊;事實上,這些曝光的部分和之前所提到的 胡椒鹽雜訊以及高斯雜訊有很大的不同,此處所指的雜訊除了無法用一個數學模 型來表達,這些被視為雜訊的對象,也是「真的」訊號,只是因為在研究過程中 鎖定的對象不同,所以為了避免研究結果受到干擾,而需要被排除,實際上, 而在血液抹片中,則因抹片製作技術上的差異,而使得染色情況不甚一致, 除了影響了數位影像的判讀之外,更嚴重的話可能也會干擾醫檢人員的判斷,因 此,本論文所想要解決的雜訊問題,就是「在同一隊像的血液組織內卻呈現出不 一樣染色情況」。
1.3
研究動機
自動化血球計算儀大量使用了光學以及電學理論,但是卻缺少了血球型態學 的資訊,在人類視覺無法觸及的環境下,自動血球計算儀的功能也就因此而受限 了;倘若能夠引入數位影像分析的方法,則因為數位影像分析非常具有直觀性, 除了可以單獨鑑別異常細胞之外,也可以學習人工鏡檢法的經驗與病理學家的專 業知識,充分發揮計算機視覺與病理學結合的優勢,因此如果發展一個能自動識 別白血球細胞的系統,將具有重要的意義。1.4
相關研究之探討
近年來,以數位影像分析血液抹片以計算白血球細胞數量的研究已經獲得了 許多成果,而在這個研究方向又分成影像切割,以及血球識別,首先討論影像切 割的部分,參考文獻[8]透過設定臨界值將白血球細胞核自灰階影像中切割出來, 再以主動輪廓來搜尋白血球細胞質的邊界,而參考文獻[9]為了克服染色過深區 塊,以及為了產生主動輪廓所需要的初始輪廓,進一步使用了型態學,但是卻因4 此造成了細胞核區域的失真,標示出來的細胞核區塊與肉眼所視細胞核區域有很 大的差別,然而,較為特別的是,[9]已經開始注意到當把問題提高到較為普遍 的狀況時,得要開始處理本論文所提到的染色問題;由於[8]以及[9]都採用主動 輪廓作為解決白血球細胞影像切割的方法,因此都產生了幾個問題,第一,主動 輪廓受到初始輪廓的影響太大,如何找到適當的初始輪廓就是一個很大的問題; 第二,主動輪廓所耗費的時間太久,通常需要經過長時間的迭代次數方能找到適 當的邊界;第三,有些細胞的細胞質含量極少,在數位影像上會看到幾乎只有細 胞核,倘若以[8]、[9]的做法來做細胞核切割,主動輪廓很有可能會發散,而無 法找到最佳解,因此主動輪廓可能不是個恰當的想法。 參考文獻[10]對於影像切割則沒有執著在整個白血球細胞影像的切割,而是 著重在白血球細胞核切割,因為白血球細胞的分類上比較明顯的特徵還是來自於 白血球細胞核;[10]將每個像素的 RGB 三通道數值視為一個向量,將影像進行 史密特正交化(Gram-Schmidt orthogonalization),藉此來分割出白血球細胞核,但 是這樣的做法忽略了染色差異,不同染色技術以及不同操作人員都可能會對血液 抹片有不一樣的影響,以 RGB 通道數值作為標準,並不是很可靠的做法。 參考文獻[11]則想要用交離變換的方式來定位白血球細胞核,但是交離變換 只能找出特定的像素結構,在白血球五種類別中,除了淋巴球以外,其餘五種類 別的白血球都具備有兩種以上的變體,只以特定結構來分析白血球細胞,只能對 淋巴球有一定的效果,對於其他類型的白血球則沒有明確的規則可以遵守。 因此,若想要在血液抹片上利用影像切割來識別白血球,有一個最重要的問 題得要解決,也就是「對於同一個對象的血液抹片分析,是否都能產生一致的結 果?意即分析系統的結果將具有可重現性?」,在這個問題框架之下,首要解決 的就是影像切割,這也將是本論文將要嘗詴解決的問題之一。
5
1.5
論文主體與貢獻
在進行血液抹片分析的時候,系統的流程主要可以分成三個步驟:影像切割、 特徵抽取,以及分類。 因此本論文將在第二章介紹相關技術以及原理,在第三章則介紹本論文將提 出的系統之流程,第四章則是與近年相關領域論文結果之比較與分析,第五章則 是結論與未來展望。 而在本論文的研究中,將會把重點集中在影像切割,以及特徵抽取,而在分 類的部分將會採用前人所作的支持向量機二元樹(support vector machine binary tree),本論文所達成的貢獻有三,如下所示: 1. 當血液抹片影像出現本論文所指涉的雜訊時,本論文所提出的方法可以在很 大程度上排除掉這類雜訊。 2. 可以對多顆白血球進行同時定位以及分析,不需要限定影像只能存在單一白 血球細胞。 3. 分析出白血球細胞核分葉數目,提供粒細胞以及非粒細胞明確的鑑別資訊。5
第二章 相關技術與原理
本章節將會介紹與本論文有關的知識與理論,將從影像處理以及圖型識別的 角度來做介紹,在 2.1 節介紹關於本論文所使用的色彩模型轉換,在 2.2 節則會 介紹影像二值化,包含全域二值化以及區域二值化,在 2.3 節則會提到高斯混合 模型(Gaussian mixture model),在本論文中常以高斯分佈或者是高斯混合模型來 建立影像模型,或者是作物體切割與選取;2.4 節介紹灰階共生矩陣;2.5 節則會 介紹帄均值移動演算法(mean shift algorithm),本論文使用帄均值移動演算法來對 未知分群數目的資料作分析,以取得分群數目;2.6 節則是介紹本論文用來做細 胞核分類的主要演算法,也就是支持向量機(support vector machine)的原理。
2.1 色彩模型轉換
本論文中所使用到的色彩模型包括 RGB、HSV,還有灰階(gray-level)影像, 針對不同的處理階段,需要不一樣的色彩模型輔助。 在本論文中,色彩模型的轉換,主要目的在於輔助影像切割,使影像切割的 結果更接近實驗需求;在進行影像切割的時候,通常假設影像包含了感興趣的區 域與不敢興趣的區域,兩者通常可以由某種特性來做明顯的區分,例如:強度 (intensity)、飽和度(saturation),以及色調(hue)等等,根據不同需求而採用不同的 色彩模型,而本論文基於兩個目的,第一個目的是紅血球模型建立,需要將 RGB 色彩模型轉換成灰階色彩模型,以獲得像素強度資訊,可利用於後續的邊緣提取; 另一個目的則是白血球細胞核搜尋,主要參考的特性為細胞核區塊的飽和度遠高 於背景以及其他血液中的血球,因此將 RGB 色彩模型轉換成 HSV 色彩模型,以 取得飽和度影像。6
2.1.1 RGB 色彩模型
在 RGB 色彩模型,每種色彩是由紅、綠、藍三個主要頻譜成分來顯示,倘 若把 RGB 色彩模型以可視化模型來表示,如圖 2.1,則可以發現紅、綠、藍三種 分量構成了一個立方體,且三種分量互相正交,一張以 RGB 色彩模型表示的影 像,得要用上三個數值來描述同一個像素;用來表示像素(pixels)所需的位元數稱 為「像素深度」,一張以 RGB 色彩模型表達的影像,其紅、綠、藍影像皆為 8 位元影像,則每個 RGB 像素需用 24 位元來表達。 圖 2.1 RGB 色彩模型2.1.2 RGB 色彩模型轉換成灰階色彩模型
灰階色彩模型,有別於 RGB 色彩模型得要用三個數值來描述單一像素,灰 階色彩模型只有單一數值,灰階模型所呈現出來的影像,代表著影像的強度 (intensity)資訊,最弱灰階為黑色,最強灰階為白色,灰階模型則是在這兩個灰 階限制下,計算出從最弱灰階到最強灰階中的變遷灰階,圖 2.2 將最弱到最強灰7 階之間額外區分出 8 個灰階值。 圖 2.2 10 灰階 而在計算機影像處理領域中,最常用的灰階模型具有 256 強度,這是因為電 腦常用的 1 位元組等於是 8 位元,而 8 個位元就代表最低可顯示的十進位數字為 0,最高可顯示的十進位數字為 255,共有 256 個數值,此外也就代表著一個像 素可以用 1 位元組來代表,另一方面也因為 256 灰階也大約是一般人眼所能分辨 的灰階數目,所以才會使用此數值作為常用灰階數目。 圖 2.3 256 灰階 在做 RGB 模型轉灰階模型的時候,並不是將 RGB 三個成分相加再除以 3, 而得要考慮人眼對於綠色的感受度較高,對於藍色的感受度較低,因此在考慮這 個因素之後,轉換出來的灰階影像才會與人眼觀察影像所感受到的明暗變化類似, 詳細轉換公式如下: B G R Gray0.299 0.587 0.114 (2.1)
8
2.1.3 RGB 色彩模型轉換成 HSV 色彩模型
HSV 色彩空間是從 RGB 色彩空間經過計算而得的一種表達色彩的方式,H 代表色相(hue)、S 代表(saturation),V 則是代表著明度(brightness);比起 RGB, HSV 可以更為適當地聯繫人類的感知顏色,因此,HSV 常常被用於計算機視覺 或者是影像處理相關領域。 倘若將 HSV 模型以一個可視覺化的方式表達,將會是一個圓錐體,色相代 表著繞圓錐體中心軸的角度,而飽和度則為圓錐體的某橫截面上的一點到橫截面 圓心的距離,明度則被表示為從圓錐體的橫截面積的圓心,到圓錐體頂點的距離, 如圖 2 所示,此可視化模型很適當地表達的 HSV 色彩空間的概念。 圖 2.4 HSV 圓錐模型 為了將 RGB 色彩空間轉換到 HSV 色彩空間,得要先將 RGB 三通道數值進
9 行正規化(normalize)。 256 R r , 256 G g , 256 B b (2.2) ) , , max(
max r g b ,min min(r,g,b) (2.3)
240 min max 60 120 min max 60 360 min max 60 0 min max 60 0 g r r b b g b g h min max if b g r max if b g r max if g max if b max if (2.4) max min 1 max min max 0 s 0 max if otherwise (2.5) max v (2.6) ] 360 , 0 [ h 是代表色相的色相角;而s[0,1]與v[0,1],則分別代表著飽和 度(saturation)與明度(brightness)。
2.2 全域二值化與區域二值化
影像的二值化處理就是將影像上的點的灰階設定為最弱色階或者是最高色 階,也就是讓整張影像從原本的灰階影轉換成黑白兩色,在 256 個灰階等級的灰 階模型中,黑色代表灰階值為 0,白色代表灰階值為 255,通過適當的臨界直選 取,將會從灰階影像獲得可以反映影像整體與局部特徵的二值化影像。 在數位影像處理中,二值化處理佔有非常重要的地位,在實際應用的圖像處 理系統中,以二值化影像處理實現與建構的系統非常多;要進行二值化影像處理 與分析的時候,得要先將灰階影像轉換為二值影像,得到二值影像之後,在處理 上將有一個很大的優勢,就在於影像的集合性質只與像素值是 0 或者是 255 有關,10 不再涉及像素的灰階變遷,使處理變得更簡單,也使影像的數據處理量縮小。 常見的二值化方式是設定一個臨界值,倘若一像素之灰階大於此臨界值,則 判斷此像素屬於某特定物體,將其灰階重新設定為最高灰階;否則該像素將被排 除在物體區域外,灰階值將被設定為最低灰階,以表示此像素屬於背景或者其他 物體區域,類似此類作法被稱為全域二值化法;相對於全域二值化,也存在著區 域二值化方法,可以進一步考慮到影像的細部特性。 在本論文中採用了兩種二值化方式,第一種為最大類間方差法(Otsu)二值化, 另一種則為尼布蘭克(Niblack)二值化,前者為全域二值化,考慮整張影像的特性 之後,設定一個臨界值來將整張影像進行二值化處理;後者則為區域二值化,則 是先建立一個遮罩,將此遮罩滑動過整張影像,每次所處理的範圍限定在此遮罩 範圍內,依照某種判斷準則,將遮罩內影像作二值化處理,此一過程持續到整張 影像都被處理過為止,如此一來可以透過限定處理範圍取得更為細部的資訊;本 節分成兩部分,第一部分先介紹最大類間方差二值化法,接著再介紹尼布蘭克二 值化法。
2.2.1 最大類間方差二值化法
最大類間方差二值化法,是在 1975 年由大津(Nobuyuki Otsu)所提出的二值 化方法;將灰階影像轉換二值化影像是影像處理中一個很基本的處理過程,最大 類間方差法包含了反覆計算所有可能的臨界值,並且計算出這些臨界值兩側的像 素灰階分布,目的是找出一個臨界值,可使類內方差值(within class variance)最小, 則此臨界值即為最佳的分割值,圖 2.5 即為以最大類間方差法對血液抹片影像進 行全域二值化的結果。 先定義變數如下:Np代表整張影像的像素總數,Np 代表背景部分各個灰b 階所佔的像素數目,P 代表了全背景像素灰階的集合,b W 為背景之權重(waight), b b 為背景之均值(mean),b為背景之方差(variance);Npf 代表前景部分各個灰11 階所佔的像素數目,Pf代表了全前景像素灰階的集合,Wf 為前景之權重,f 為 前景之均值,f 為前景之方差。 背景 W P Np b b (
)/ (2.7)
b i b b b [ P (i) Np (i)]/ Np (2.8)
b i b b b b [ Np (i) ((P (i) )) ]/ Np 2 (2.9) 前景 W P Np f f (
)/ (2.10)
f i f f f [ P (i) Np (i)]/ Np (2.11)
f i f f f f [ Np (i) ((P (i) )) ]/ Np 2 (2.12) 類內方差 2 2 2 f f b b W W W (2.13) 類間方差 2 2 ) ( b f f b W WW (2.14) 原先定義的類內方差值為(2.13),但是因為計算量太過龐大,因此採用另一 個等價觀點來解決這個問題,當類間方差(between class variance)最大的時候,會 發現類內方差最小,因此找到一臨界值使(2.14)最大值時,(2.13)則會是最小,詳 細演算法如下: 最大類間方差二值化演算法 1. 計算直方圖,以及每個色階的機率分佈 2. 設定初始的W 、b b、Wf 以及f 3. 臨界值設定從最低色階變化到最高色階,每變換一次臨界值,就得要做下 列操作: a. 更新W 、b b、Wf 以及f12 b. 計算類間方差W2 4. 最佳的臨界值設定對應到最大的類間方差。 圖 2.5 最大類間方差二值化法的結果
2.2.2 尼布蘭克二值化法
區域二值化方式並不像是空間濾波(spatial filtering)將濾波系數與濾波遮罩 所涵蓋區域內的影像像素之乘積作為其響應結果,而是在這個濾波遮罩涵蓋的範 圍內,對此範圍分析其灰階分布,接著可以得到此遮罩涵蓋區域內的二值化影像; 將此遮罩滑動過整張影像,並且每移動一次都要進行相同的分析與處理,透過這 樣的方式,最終將會得到一個考慮到區域特性的二值化影像,圖 2.6 即為利用尼 布蘭克二值化法對血液抹片影像進行區域二值化的結果。 尼布蘭克二值化方法則是利用統計學的知識來進行區域二值化,詳述如下: ) , ( ) , ( ) , (x y m x y k s x y T (2.7) 先取一個寬度為 w 的矩形框,以(x,y)為這個框的中心,依此建立遮罩;在遮罩 內的運算則是以統計框內數據為主,T(x,y)為區域臨界值,m(x,y)為帄均值, ) , (x y s 則為均方差,k 則為一個自訂參數,一般設定為(-2);計算出T(x,y)之後, 就可以對此遮罩內影像進行二值化處理,高於區域臨界值者判定為 255,低於區13 域臨界值者判定為 0。 雖然尼布蘭克二值化方法,具有快速以及效果好的優點,並且相較於全域二 值化來說,還能夠保留細部特性,但缺點是會在帄滑區塊產生雜訊,這是需要重 視的一個問題。 圖 2.6 尼布蘭克二值化結果
2.3 高斯混合模型
高斯分布(Gaussian distribution),是在數學以及自然科學中的定量現象的一 個簡單模型,儘管這些現象是未知的;目前在統計學以及多種統計測詴中被廣泛 地使用。而高斯混合模型(Gaussian mixture model),則是高斯分布的延伸,簡稱 GMM, 他的特色在於能夠利用高斯分佈模型來帄滑地近似某特定的機率分佈。 高斯混合模型利用高斯機率密度函數,也就是常態分布曲線來量化資料,將 一個影像分解為若干基於高斯密度函數形成的模型,對影像建立高斯模型的原理 以及過程,常用於前景與背景的分割;因為灰階直方圖反映的是影像中某個灰階 值出現的次數,也可以看成是影像灰階機率密度的估測,如果影像所包含的目標 區域與背景具有一定程度上的差異,那麼該影像的灰階直方圖將會出現明顯的雙
14 峰,以及存在兩者間明顯的波谷,其中一個波峰對應於目標,另一個波峰對應於 背景;對於複雜的影像,通常在灰階直方圖的波形通常會顯現多重峰值,可以將 波形看成是多個高斯分布的疊合,透過波峰與波谷的概念,可以選定某特定高斯 函數作為切割複雜影像中的物體的依據。 在本論文中高斯混合模型被大量地使用,除了影像分割之外,也用於建立模 型,包括紅血球模型,以及白血球細胞核相似度模型,或者是用來從複雜影像中 挑選具有某些特性的區塊;本節將分成兩個部分,先介紹高斯分布,再介紹高斯 混合模型。
2.3.1 高斯分布
高斯分布又稱為常態分布,在數學、物理以及工程領域都扮演著很重要的角 色;對於隨機變量X,倘若X 滿足期望值、方差為2 的高斯分布,則可以說, ) , ( ~ N 2 X ,其機率密度函數為(2.8);設定不同的參數值則可產生不同的高斯 分布,期望值決定了高斯分布的中心所在位置,而均方差則決定了高斯分布圖形 的除峭帄滑程度,可由圖 2.7 看出參數不同所導致的不同結果。 ) /2 ]/ 2 ( [ ) (x e^ x 2 2 p (2.13) 圖 2.7 三種不同的高斯分布15 高斯分布具備有以下這些特性: 1. 密度函數對於帄均值對稱,可由圖 2.8 看出這特性 2. 帄均值是它的眾數(statistical mode)以及中位數(median) 3. 函數曲線下 68.26%的面積在帄均值左右的一個標準差範圍內 4. 95.44%的面積在帄均值左右兩個標準差 2σ的範圍內 5. 99.72%的面積在帄均值左右三個標準差 3σ的範圍內 圖 2.8 高斯分布其資料量比例
2.3.2 高斯混合模型
對於觀測數據X
x1,x2,,xN
中,取其成員x ,其高斯混合分布的機率密i 度函數為
K k k i k k i p x x P 1 ) | ( ) | ( (2.14) 其中k是混合係數,代表每個混合模型成分的先驗機率(prior possibility), 而(1,2,,K),則是各個混合成分的參數向量,k (k,k2),是高斯分 布的參數,也就是期望值與均方差。 倘若已經知道分布的形式,當所要估計的參數是非隨機的未知常數,或者待 測參數是隨機,但是先驗機率未知的情況,就通過使機率密度函數最大化來決定16 參數的數值為何,這就是最大似然估計: ) | ( ) | ( ) | ( 1 X Like x P X P N i i
(2.15) )) | ( max( arg * X Like (2.16) 對於高斯混合分佈而言,求(2.16)式的極大值並不是一件簡單的事,因為先 驗知識的缺乏,也就是不知道第 k 個成分究竟生成了哪些x 向量,也不知道哪一i 個x 影響到哪一個i k,倘若對(2.15)式直接求解偏導數,則會得到多個根的超越 方程式,因此,需要找一個方法來解決這個模糊性質,而最大期望值演算法 (expectation maximization algorithm)就是一個可以克服先驗知識缺乏的最佳化演 算法。 最大期望值演算法是一種由「不完整數據」中求解模型分佈參數的最大似然 估計的方法[14],而所謂的不完整數據通常指向兩種狀況,第一種是由於觀測過 程本身的限制或者錯誤,造成了觀測數據有所遺漏的不完整數據,另一種則是因 為參數的似然函數想要直接最佳化相當困難,但是引入了額外的參數後就比較容 易最佳化,因此定義原始觀測數據再加上額外的參數所組成的數據稱之為「完整 數據」,所以,相對於完整數據而言,原始數據自然就成為了「不完整數據了」。 引入了額外數據Y之後,定義Z {X,Y}為完整數據,則觀測數據X 就是不 完全數據,同時,前面所述的似然函數(2.15)式也被稱為「不完全數據的似然函 數」,而「完全數據的似然函數」為: ) | , ( ) , | ( ) | ( Z L X Y P X Y L (2.17) 若將X 和視為固定,(2.17)式就是一個以隨機變數Y為自變量的函數,則 這個完全數據的似然函數也可以被看成是一個隨機變數;雖然隨機變數想要求解 最大值有點困難,但是隨機變數的期望值卻是一個明確的函數,因此最佳化就容 易得多了,這也是最大期望值演算法的基本想法,以下介紹最大期望值演算法。 最大期望直演算法透過兩個基本步驟交替進行,來達到最佳化的目的,第一 個步驟為計算期望值(expectation),第二個步驟為最大化(maximization,透過最17 大化在計算期望值步驟所求得的最大似然值來計算參數的值,在最大化步驟上所 取的參數估計值將被用在下一次迭代中的計算期望值步驟中。 計算期望值步驟(E-Step)
t
t X Y X P E Q(, ) log ( , |)| , (2.18) 最大化步驟(M-Step) ) , ( max arg 1 t t Q (2.19) 基本步驟只是呈現一種概念,想要實現演算法,其關鍵在於尋找隱藏的數據Y的 機率密度表示式。 在高斯混合模型中,引入預設的變數,也就是預設觀測數據與混合成分的對 應關係的變數,將此變數作為隱藏數據[4],就可以推導出預設變數的機率密度 公式,從而推導出最大期望值演算法求解高斯模型的迭代公式:
N i t i t k p k x a 1 ) , | ( (2.20) t k t k a N 1 (2.21)
N i t j i t k t k x p k x a 1 ' 1 ) , | ( 1 (2.22)
N i T t v i t v i t i t k t k p k x x x a 1 1 1 1 ) )( )( , | ( 1 (2.23) 其中,
K j t i j t j t i k t k t i x p x p x k p 1 ) | ( ) | ( ) , | ( 2.4 灰階共生矩陣
灰階共生矩陣(gray level co-occurrence matrix),可以提供影像灰階的分佈特 性,也可以提供具有相同灰階或者式不同灰階之間的位置分布特性,可以透過灰 階共生矩陣來定義一組紋理特徵。
18 任何影像事實上都可以看成是三維空間中的一個曲面,如圖 2.9 所示;考慮 到紋理是由於某灰階分佈在空間位置上反覆出現而形成,因此在上述三維空間中 相隔某固定距離的兩個像素之間會存在某種灰階關係,這就是影像中灰階的空間 相關特性,而灰階共生矩陣就是用來描述這個特性的常用方法。 (a) (b) 圖 2.9 血液抹片影像之飽和度影像:(a)為原圖;(b)為(a)的立體化。
19 灰度共生矩陣是由影像中保持某固定距離的兩個像素之灰階值在經過統計 之 後 而 得 ; 假 定 影 像 大 小 為 NN , 任 一 點(x,y)與 距 離(dx,dy) 的 另 一 點 ) , (xdx ydy 的灰階值分別為g1與g2,記錄為(g1,g2);(x,y)在曲面上移動, 在掃瞄過整個曲面之後,統計出每一種(g1,g2)出現的次數,並且以(g1,g2)為兩 座標軸,將次數記錄在相對應的座標點(g1,g2)上面,因此倘若原始影像的灰階 值上限為L,則所得的矩陣大小為LL,接下來再利用總次數對這個矩陣作正 規化處理(normalization),經過這樣的處理之後,兩像素之灰階同時發生的機率, 就從空間座標,轉換成灰階對(g1,g2),而最後所得的機率密度方陣即為灰度共 生矩陣。 在灰度共生矩陣形成的過程中,距離並不能夠任意設定,對於較細緻的紋理 得要設定較小的距離,對於較粗糙的紋理則選擇較大的距離。 定義灰階共生矩陣在(g1,g2)座標的機率值是p(g1,g2),因此可以由灰階共 生矩陣定義出一組紋理特徵: 1. 能量(energy):
j i j i p E , 2 )) , ( ( (2.24) 能量是影像灰階分布均勻性的度量,當灰階共生矩陣的元素分布較集中於主 對角線附近的時候,代表局部區域內影像灰階分布較為帄均,因此紋理分布 較粗糙的時候能量相對於紋理分佈細緻時的能量較大。 2. 對比度(contrast):
j i j i p j i Con , 2 ) , ( ) ( (2.25) 對比度反映了局部區域的變化情形,倘若局部變化很大,則對比度越大,可 以將對比度理解成影像的清晰程度,也可以說是紋理的清晰程度。 3. 相關度(correlation):
j i i j j i j p i j i Cor , ) , ( ) )( ( (2.26)20 相關度是用來描述灰階共生矩陣中的元素在行或者是列方向上的相似程度, 提供了某個灰階延某方向的延伸長度,若延伸越長,則相關度越高。 4. 同質性(homogeneity):
j i i j j i p H , 1 | | ) , ( (2.27) 同說明了紋理局部變化的程度,倘若影像紋理的不同區域間缺乏變化,則同 質性將會很高,影像局部均勻。 5. 熵(entropy):
j i j i p j i p Et , 2( (, )) log ) , ( (2.28) 代表了影像中所具有的信息量也可以說是影像中紋理的非均勻程度、複雜程 度;當共生矩陣中所有元素具有最大的隨機性的時候,共生矩陣所有值均相同, 熵較大,2.5 帄均值移動演算法
帄均值移動演算法(mean shift algorithm)這個概念最早是由 Fukunag 及 Hostetler [6]所提出,帄均值移動並非是指帄均值的移動,帄均值移動指的是一個 向量,指的是偏移的均值向量。 帄均值移動分群法是一個迭代的過程,先計算出目前的偏移均值,移動該點 到即偏移均值,然後以此作為新的起始點,繼續移動,直到滿足一定條件時才結 束這個迭代過程;1995 年 Cheng 引入了權值的概念[7],使得不同的取樣點對於 偏移均值的貢獻也有所不同,大幅擴充了帄均值移動分群法的功能,在圖型識別、 影像切割,以及目標物追蹤等等領域,都具體的應用。 帄均值移動演算法是一個非參數性的分群法,除了不需要事先知道分群數目 之外,也不需限定分群的形狀,因此對於欲從未知群數的資料中挖掘出該資料可
21 能的分群數此一目標來說,帄均值移動演算法是個非常恰當的方法,以下開始介 紹帄均值移動演算法的詳細內容:
n i i d h x x K nh x f 1 ) ( 1 ) ( (2.29) ) ( ) (x c , k x2 K kd (2.30) 有 n 個資料點x ,i i1,2,,n,分佈於 d R ,而ck,d是個正規化常數,目的是 讓K(2.30)的積分等於 1,再由核函數 K(2.30)以及視窗半徑為 h ,可以得到多變量 核密度估測 f(2.29)。
x h x x g h x x g x h x x g nh c h x x g x x nh c x f n i i n i i i n i i d d k i n i i d d k 1 2 1 2 1 2 2 , 2 1 2 , ) ( ) ( ) ( 2 ) ( ) ( 2 ) ( (2.31) 其中g(s)k(s),前一項正比G(x)cg,dg(x 2)於在 x 的密度估測,而第二項則 是偏移均值向量: x h x x g h x x g x x m n i i n i i i h
1 2 1 2 ) ( ) ( ) ( (2.32) 偏移均值向量永遠指向密度中最高的增加量,而接下來的帄均值移動流程如下: 1. 透過mh(xt)計算偏移均值向量 2. 移動遮罩視窗xt1 xt mh(xt) 3. 重複 1 和 2 步驟,直到滿足收斂條件為止,例如:f(xi)0 圖 2.10 為帄均值移動演算法示意圖。22 圖 2.10 帄均值移動演算法示意圖
2.6 支持向量機
對一群在 d R 空間中的資料,為了將該資料分成兩群,需要在該空間內找到 一超帄面(hyper-plane)來將該資料做區隔,如圖 2.11 所示: 圖 2.11 支持向量機之範例圖 虛線部分為超帄面所在位置,比較左右兩圖發現,在右圖的超帄面間隔較大, 此間隔稱為幾何間隔,間隔較大也就意味著,以右圖的超帄面間隔寬度,進行分23 類時較不容易發生錯誤分類的情形,因此右圖的超帄面比起左圖的超帄面要來得 好。 一般在低維度的資料往往會因為資料的數量提高,漸漸地變成線性不可分的 情況;雖然在低維度無法找到線性可分的超帄面但是倘若思考將低維度的資料映 射到高維度,就會發現低維度的資料有機會成為線性可分的資料,所以為了能夠 最大化幾何間隔,現在得要找個方法將低維度的資料應設到高維度。 用來映射的函數即稱為「核函數」,透過核函數,可以將低維度資料朝高維 度應設。 因此支持向量機的問題,可以視為是個優化問題:
l i i C w 1 2 2 1 : min (2.33) 0 ; ~ 1 1 ] ) [( :yi wxi b i i l i to subject (2.34) 其中i在這裡是用來解決離群點的問題,又稱為鬆弛變數;而 C 則是懲罰 因數,作用在於衡量對於離群點的重視程度。24
第三章 系統流程
有鑑於雜訊對於血液抹片的影響之劇,本論文提出一個有效率的系統,除了 對雜訊有很高的寬容度之外,對於將細胞核自血液抹片中切割並且定位的能力, 在經過實驗之後,確實展現出很不錯的效果。 本章共分成 4 節,先說明整體系統流程,再進一步說明血液抹片影像處理以 及辨識策略;3.1 節介紹整體系統流程; 3.2 節說明在進入正式的影像處理分析 前,所需進行的預處理;3.3 節說明系統架構中的紅血球模型建立,3.4 節介紹系 統架構中的白血球細胞核影像處理及特徵抽取,3.5 節則是關於分類決策樹的建 立。3.1 整體系統架構
本論文將輸入的血液抹片影像先區分成兩個部分來處理,第一部分為紅血球 影像,第二部分為白血球細胞核影像。 (a) (b) (c) 圖 3.1 白血球細胞核影像:(a)血液抹片影像;(b)紅血球影像;(c)白血球細胞核 影像。25 其中,紅血球影像將用來建立紅血球大小的高斯分布模型,此模型會是後續 白血球細胞核分割及辨識的參考資料之一;而白血球細胞核影像的取得方式,則 因為血液抹片影像雜訊過多而得要進行白血球細胞核的影像重建,而雜訊的來源 主要是血小板(圖 3.2 橘色虛框處),紅血球互相重疊(圖 3.2 橘色實框處),或者 是嗜鹼性顆粒在血液抹片製作過程中破碎(圖 3.3 中可見深色區塊處皆是),此三 種現象都導致白血球細胞核切割的困難,因此本論文將提出一個修正方法,將有 效地排除掉這類雜訊的干擾,成功地將白血球細胞核自抹片影像中切割出來。 圖 3.2 血液抹片中的雜訊。 圖 3.3 血液抹片中的破碎嗜鹼性顆粒。
26 經過白血球細胞核切割後的影像,並未能夠完整描述白血球細胞核,主要原 因在於粒細胞的分葉(lobes),同一白血球細胞核,可能會因為分葉與分葉間的連 接處飽和度過低,而無法透過前一步驟將白血球連結成一個完整的區塊,因此看 似離散的細胞核區塊卻可能同屬於一個白血球細胞核,需要透過某種方式來將離 散區塊重新描述為同一細胞核;此現象將於後面章節討論。 白血球細胞核切割完成之後,將進行特徵抽取,所參考的特徵主要分成形狀, 以及紋理特徵,透過這兩類特徵來描述白血球細胞核,接著再由各類血球之間的 差異,建立 SVM 決策樹,最後將可透過此決策樹來辨識此細胞核區塊為嗜中性 粒細胞、嗜酸性粒細胞、嗜鹼性粒細胞、單核細胞,或者是淋巴細胞。 圖 3.4 主要辨識流程。
27
3.2
RGB 直方圖分析與修正
因為 RGB 三通道之直方圖分佈不等的影響,進行色彩空間轉換之效益可能 無法到達預期中的目標,因此得要先對 RGB 三通道進行分析,倘若發現有不足 的部分,可以在此步驟做修正。 圖 3.5 前處理流程圖。 在進行二值化處理之前,得要先分析 RGB 三通道直方圖的分布是否會影響 到後續的影像處理步驟;分析結果如圖 3.6 所示: 圖 3.6 RGB 三通道分析。 由分析結果可以得知,RGB 三通道中,以 B 通道的直方圖分布最不均勻,28 這一現象對於紅血球模型的建立,影響並不大;但是對於白血球細胞核影像的分 析則影響深遠,因為白血球細胞核影像的產生,是將原本 RGB 色彩空間轉換到 HSI 色彩空間,接著只取 S 通道影像來作進一步分析,依據 RGB 色彩空間轉換 道 HIS 色彩空間的公式而論,原本 B 通道的集中分布將會對色彩飽和度分割造 成不利的影響,以下兩張影像皆設定色彩飽和度為 0.75 作為臨界值,以此值為 界線對飽和度影像進行二值化處理,圖 3.7 為尚未修正過後的S 通道二值化影像, 圖 3.8 則為修正過後的 S 通道二值化影像,由這兩張圖來比較,確實同一場景下 修正前與修正後作比較,會發現修正後的影像雜訊相對減少了很多: 圖 3.7 RGB 三通道未作修正。 圖 3.8 經過 RGB 三通道的分析與修正,降低了雜訊。
29
3.3
建立紅血球模型
本論文並未嘗詴去解決紅血球重疊問題,而是以正圓度以及區塊大小為線索, 來找出可能為單一紅血球的區塊,以這些區塊來建立紅血球模型。 在本論文中所討論的紅血球模型,包含了紅血球的近似面積大小,以及紅血 球的近似半徑,兩者都以像素(pixels)為單位。 圖 3. 9 紅血球模型建立。3.3.1 影像二值化處理
在經過 RGB 三通道重新修正之後,將色彩空間自 RGB 轉換到 GRAY 色彩30 空間,見 3.10,接著分別進行最大類間方差法(Otsu)全域二值化(圖 3.10(b))及尼 布蘭克(Niblack)區域二值化(圖 3.10(c)),再將全域二值化結果與區域二值化結果 以 AND 運算作結合(圖 3.10(d)),在全域二值化的部分,因為背景與血球細胞影 像之間灰階值有一定差距,因此對於背景轉換到血球之間模糊邊界非常敏感,導 致二值化後的影像中,無法將血球與血球接觸的邊界做出清楚的畫分(圖 3.10(a) 紅色實框),因此,需要區域二值化方法來彌補這個缺點;但區域二值化也無法 獨立完成一幅完美的二值化影像,其二值化的結果忽略了整張影像的資訊,而會 產生錯誤的二值化區域(圖 3.10(b)紅色實框),因此也需要全域二值化來協助彌補 這缺失,如圖 3.10 所示,這就是為何無法單用一個全域臨界值或者是區域二值 化方法來完成影像切割的原因,透過圖 3.10(d)可知兩者的缺失在結合之後都已 經被彌補回來了。 (a) (b) (c) (d) 圖 3.10 二值化範例:(a)RGB 轉灰階圖;(b)最大類間方差法;(c)尼布蘭克二值化法; (d)由(c)和(d)作 AND 運算。
31
3.3.2 二值影像邊緣提取
當二值化處理結束之後,可以看到影像中仍然有許多空洞存在,此空洞可能 是因為紅血球本身外厚內薄的原因,所以二值化處理的時候無法將紅血球影像形 成一個完整無空洞的區塊;在本論文中,該空洞對於實驗後續分析並沒有任何助 益,更有可能造成無謂的計算量上升,因此,將空洞填滿將對於實驗的進行有所 幫助,填補空洞後的影像如圖 3.11(b);再利用 Sobel 運算子對圖 3.11(b)計算邊界, 可得邊界影像如圖 3.11(c)。 (a) (b) (c) 圖 3.11 二值影像邊緣提取:(a)血液抹片二值化影像;(b)填補影像中的空洞;(c) 則是由(b) 作邊緣提取所得的邊緣影像。32
3.3.3 高圓度區塊面積分析
參考 3.4.4,每個封閉邊界都能計算出圓度,再將所得的圓度利用高斯混成 模型分成三類(圖 3.12),預期會形成高、中,以及低圓度三個高斯分布模型;根 據 2.3 節,高圓度高斯分布模型的資料將有 68.27%落在帄均值左右一個標準差的 範圍內,因此設定帄均值減去一個標準差為正圓度臨界值,高於此數值則判斷此 封閉邊界近似於圓,很有可能是本節所想要尋找的紅血球區塊,由此臨界值,可 以保留下約 84.135%的高圓度區塊,但是即使滿足高圓度限制,也未必是紅血球 區塊,另外還得要再考慮區塊面積大小的問題。 圖 3.12 正圓度分析。33 圖 3.13 是參考上一步驟所選定的高圓度臨界值而標記的高圓度區塊,當區 塊內包含有一個黑色圓圈,此區塊即為高圓度區塊,其圓度標記於該區塊的左下 角;由此參考圖片來看,本論文只尋找單一且圓度高的區塊,對於區塊交疊或者 是相連的部分則不作處理。 圖 3.14 為高圓度區塊面積直方圖,這些疑似紅血球的高圓度區塊其面積並 沒有固定範圍,受到血小板、血液抹片製作技術或者是血液來源本身的影響,所 以差距可以到六、七倍之譜;雖然就面積大小來說有很大的差異,但也可以看出, 此直方圖實際上具備集中趨勢,在健康的動物體內,紅血球的大小應該是落在一 個固定的區間內,此區間雖然沒有明確界定,但是可以合理假設經過統計後,可 以由直方圖得到一個高機率分佈的區間,而在實驗過程中也確實證明了這項假 設。 圖 3.13 根據正圓度圈選出可能為紅血球的區塊。
34 圖 3.14 分析高圓度區塊面積直方圖。 為了取得紅血球的近似大小,本論文將每個圖 3.14 中每個區間內的數量除 以高圓度區塊的總數,因此可以得到機率密度分布,再由此機率密度分布作為權 值,與每個區間的均值作加權運算,則可以得到紅血球的近似大小。
3.3.4 高圓度區塊半徑分析
本論文所討論的紅血球模型還包含了紅血球半徑(r),此半徑的計算方式乃是 由高圓度區塊面積計算而得;已知區塊具備高圓度,因此可以簡單地由圓形的面 積計算公式: 2 radius Area (3.1) Area radius (3.2)35 分析半徑大小的分布,可以得到一個關於半徑大小分布的直方圖,如圖 20 所示: 圖 3.15 高圓度區塊近似半徑直方圖。 依照 3.3.1 節高圓度區塊面積分析,在這裡可以對近似半徑直方圖進行同樣 的處理,將每個區間內的數量除以總數量,計算得近似半徑落在該區間的機率密 度分佈,再將此機率密度分佈作為權值,與每個區間的均值作運算,即可得到高 圓度區塊的近似半徑。 至此,紅血球面積的近似大小以及紅血球半徑的近似大小已經獲得,紅血球 模型即由此二參數來描述,在後續的白血球細胞核影像處理中,將會有重要的作 用。
36
3.4
白血球細胞核影像處理與特徵抽取
白血球細胞大致上可分成細胞核與細胞質區塊,在本論文的實驗進行過程中 發現,當血液抹片製作較差,導致染色不均,或者是數位顯微鏡曝光程度差異, 都會影響到白血球細胞質邊界的清晰程度,因此,因為其易受人為因素影響的特 性,所以在本章並不討論白血球細胞質。 圖 3.16 白血球細胞核影像處理流程圖。 本節共分成四小節,3.4.1 介紹色彩空間轉換,3.4.2 介紹區域成長法復原細 胞核區域,3.4.3 則因為 3.4.2 節所復原出來的細胞核區域並未必真實地描述了白 血球細胞核區域,因為白血球細胞核分葉的現象,導致可能有兩三個區域同屬於 同一細胞核,若直接以 3.4.2 節的結果來作為白血球細胞核,而不描述這些不同 區塊間的關係,最後產生出來的白血球細胞核描述會是錯誤的描述; 3.4.4 說明37 在 3.5.3 節的處理之後,核區已經重建完成,於是可以從這些已經重新描述過的 白血球細胞核區塊抽取出特徵,作為白血球分類的依據。
3.4.1 色彩空間轉換
本論文為了要將細胞核盡可能地與背景有更多的差異,因此需要透過色彩空 間轉換,讓屬於白血球細胞核的特性更為顯著;觀察白血球細胞核影像之後,本 論文決定採用 HSI 色彩空間,由此色彩空間特性,可以得到影像中色調、飽和 度、以及亮度資訊;透過 HSI,本論文可以分析影像中色調,飽和度,以及亮度 的變化,經過實驗發現,在血液抹片影像上,色調的變化因染色技術以及曝光參 數有關,並不具有一致性,因此不能從色調來作分析;亮度資訊也和色調一樣, 不具有一致性,只有飽和度在各種染色技術,都能突顯出白血球細胞核,即使曝 光參數變化,也能有很高的容忍程度,因此由 RGB 轉換成 HSI 確實有其必要性。 圖 3.17 色彩空間轉換及面積過濾流程圖。 根據第 3.2 節 RGB 直方圖分析與修正之後的結果,可以相信 RGB 三通道已 經獲得適當的修正,使三通道的直方圖分布上都較為均勻,以此為前提,開始進 行 RGB 色彩空間轉換到 HSV 色彩空間;在實驗過程中發現 H(hue)通道很容易 受到曝光程度、白帄衡,以及不同染色技術的影響,並不具有後續實驗分析的價 值;而 I(intensity)通道影像也隨著曝光程度改變而有不同的變化,同樣地,I 通38 道也不能拿來作分析;再來看 S(saturation)通道影像,可以發現無論曝光程度, 白帄衡怎樣變化,白血球細胞核區塊的飽和度相較起影像中其他區域有很大的差 異,可參考圖 3.18(b),因此,可以設定臨界值,將白血球細胞核區塊自 S 通道 影像中切割出來。 初始臨界值設定乃是根據經驗,在本論文的實驗過程中發現,白血球細胞核 區塊飽和度幾乎都維持在 0.75 以上,因此可以先設定臨界值為 0.75 來對 S 通道 影像作切割,圖 3.18(c)即為以色彩飽和度為 0.75 為臨界值,對 S 通道影像切割 後的結果。 由圖 3.18(c)和圖 3.18(b)來做比較,在圖 3.18(c)中發現依然存在著一些會影 響到後續實驗進行的雜訊,在此以紅色方框標記;由本例來說,雜訊是因為紅血 球重疊而產生的陰影,其色彩飽和度也在 0.75 以上,所以也被錯誤歸類到白血 球細胞核區塊;除了紅血球重疊這個因素之外,有時候也因為曝光不足、血小板, 或者是嗜鹼性顆粒的關係,而出現錯誤歸類的區塊,為了克服這一點,本論文基 於一個假設:「雜訊面積和白血球細胞核區塊面積相比較小」,因此依經驗設定一 面積臨界值為 100,大於此數值者,才會被歸類為白血球細胞核區塊;此一假設 並沒有理論支持,單純是實驗過程中的心得,而這個假設所導致的最大缺點,就 在於可能會有白血球細胞核區塊也小於 100 像素,也被這個假設所濾除,如圖 3.18(d)所示,為了修正這個缺點,本論文將會在 3.5.2 節提出修正方法。 (a) (b)
39 © (d) 圖 3.18 白血球細胞核影像飽和度切割;(a)原圖;(b)來自(a)的飽和度影像;(c)飽 和度臨界值(0.75)切割;(d)濾除過小區塊之結果。
3.4.2 區域成長法復原細胞核區
為了要尋找白血球細胞核區塊,並且定位白血球區塊,本論文在一個前提下 進行後續的操作:「當雜訊完全去除掉的時候,剩下的區塊即為白血球細胞核區 塊」,因此,如果單純只對整張飽和度影像選取一個臨界值作分割,從 3.5.1 節可 以發現依然會存在本論文所不希望出現的錯誤區塊,想要從影像中找到一個全域 臨界值來做二值化切割幾乎是不可能的事,因此,在本小節延續 3.5.1 節的結果, 將探討的範圍從整張影像,限定到可能為白血球細胞核區塊的近鄰區域,一方面 修正 3.5.1 節為了在雜訊與真實細胞核區塊之間所作的取捨,一方面也因為搜索 細胞核區塊的範圍從整張影像,縮減到極小的範圍,將可大幅提高定位白血球區 塊的準確度,但是即使復原了核區,在此章節仍未能定位白血球細胞核,理由將 由 3.5.3 節回答。 由圖 3.18(d),可以看到三個離散的白血球細胞核區塊,再參照圖 3.18(a), 會發現這三個離散的白血球細胞核區塊實際上都同屬於一個細胞核,但是從這三 個白血球細胞核區塊並沒有辦法得到此細胞核任何資訊;觀察圖 3.18(a),可以40 發現原本的細胞核區塊遠比這三個白血球細胞核區塊來得大,為了實驗的進行, 有必要由現有的資訊來恢復完整的白血球細胞核。 首先第一個考慮的要點,若要恢復完整細胞核區塊,得要找出有什麼資料是 這些區塊的共通性質,以連結這些區塊;既然我們切割出白血球細胞核的依據是 來自於飽和度,那麼很理所當然地,若兩像素同在同一細胞核區的範圍內,則兩 像素間最大的相似性在於飽和度。 由現有的白血球細胞核區塊,分析這些區塊內的飽和度分布,計算其帄均值 與標準差,建立一個以現有區塊飽和度為基礎的高斯分佈模型,此高斯分布模型 將被用來描述像素與像素間的相似性,在本論文中稱此高斯模型為「相似性模 型」。 初始輪廓為圖 3.18(d)中所示的三個離散細胞核區塊的邊緣,搜索範圍為以 每個邊緣像素所在座標為中心,分析中心周圍的八個像素,將八個像素的飽和度 與相似性模型進行比較相似性程度,在此所說的相似性程度則是參考自高斯分布 本身的特性,有 68.27%的面積落在帄均值左右一個標準差範圍內,95.45%的面 積落在帄均值左右兩個標準差的範圍內,因此判斷該像素是否與目前的白血球細 胞核區塊相似,代表著該像素的飽和值落在相似性模型的哪個位置,越遠離帄均 值,代表著越相似或者越不相似,在本論文中定義一個臨界值為帄均值減去一個 標準差,倘若該像素的飽和值大於此臨界值,則代表該像素和目前的核區很相似, 因此,該像素將被歸類為核區的範圍之一;重複此一過程,直到舊有輪廓其周邊 像素都已經被比較且更新過,此時新的白血球細胞核區塊已經產生,依據此新的 白血球細胞核區塊重新計算其輪廓,重複此一流程,直到沒有新的像素被更新為 止,此時白血球區塊即重建完成,詳細演進過程如圖 3.19 所示:
41
(a) (b)
(c) (d)
(e) (f)
42
(i) (j)
(k) (l)
(m) (n)
43 (q) (r) (s) (t) 圖 3.19 由(a)到(t)依序為區域成長法復原白血球細胞核區塊過程。
3.4.3 細胞核區重新描述及多重細胞核定位
由 3.5.2 節所重新成長出來的細胞核區塊未必為完整連通區域,主要的因素 為白血球細胞核的分葉問題,常見於嗜中性粒細胞,或者是嗜酸性粒細胞,因此 在經過區域成長所處理過的影像仍然未必能定位出白血球細胞核,原因就在於此; 當細胞核區經過重新描述之後,就可以將同屬於同一細胞核的區塊,但卻不相連 通的區域,經過標記相同數字,而使這些區塊得以被是為是同一個類別;在接下 來的討論中,將舉一例子,並且將參考 3.5.1、3.5.2,再到 3.5.3 這些章節內所述, 依序對此例影像作處理,然後再來說明本章節所要呈現的細胞核區塊重新描述, 以及多重細胞核定位。44 事實上在實驗過程中以 500 倍放大倍率觀察血液抹片,同一個視野中很少出 現三個以上的白血球細胞,因此為了更清楚地表明本論文的作法在複雜影像中依 然能夠切割並且定位多個白血球區塊,本論文在此以多張包含白血球細胞,但是 卻不同曝光值的影像,合成為同一張影像,即圖 3.20,接下來將以圖 3.20 為例, 進行說明。 圖 3.20 複雜血液抹片影像。 圖 3.21 複雜血液抹片影像-飽和度。
45 圖 3.22 複雜血液抹片影像-細胞核。 圖 3.21 為圖 3.20 的色彩飽和度影像,在圖 3.21 中依然可以發現白血球細胞 核區域呈現高飽和度(白色區域),在經過 3.5.1 所述飽和度臨界值設定以及濾除 掉連通像素小於 100 的區塊後,所呈現的影像如圖 3.22 所示;注意到,雖然在 原始影像中可以清楚辨認為同一細胞核的區塊,在經過二值化之後,卻被切割成 數個區塊的組合,為了修復白血球細胞核影像,得要再進行 3.5.2 所使用的區域 成長法處理圖 3.22 的影像,結果如圖 3.23 所示。 圖 3.23 無法連通成為一個完整連通區域的細胞核。
46 由圖 3.23 可以發現上有三個白血球細胞核無法形成一個完整的連通區域, 這是因為白血球細胞核的分葉與分葉間的區域,其飽和度相較起同一細胞核的飽 和度還不足以被 3.5.2 所提到的相似度模型判斷為是細胞核區域,但是明顯地, 這些在方框內的細胞核區塊,確實同屬於同一細胞核,如何描述這些不連通區域 為同一細胞核就是本小節所要講述的重點。 繼續關注圖 3.23,在圖 3.23 中,尚有三群離散白血球細胞核區塊沒有被描 述為同一群,為了更清楚地看出這個事實,在這裡先將不同的連通區域標記上數 字,再將同樣數字的區域顯示為同樣色彩,如圖 3.24 所示。 圖 3.24 一個色彩代表一個細胞核。 最直覺的想法是利用區塊與區塊間的距離,作為合併的依據;倘若兩區塊距 離較遠,則不可能為同一細胞核區,反之,若兩區塊距離較近,則為同一細胞核 區的機會很高,所以,如何定義遠近關係則是這裡所需要思考的問題。
47 圖 3.25 三組離散細胞核之長短軸分析。 要分析區塊與區塊間的距離,得要先對單一區塊做些處理;對於單一區塊, 得要先計算其凸殼(convex hull)之邊緣,再由此邊緣計算得長軸與短軸,前者之 定義為凸殼邊緣上距離最遠的兩端點距離,後者的定義為垂直於長軸,並且在凸 殼邊緣上距離最近的兩端點距離;由長軸與短軸可以計算出以長軸與短軸為長與 寬的長方形的對角線長,以此對角線長度為線索,倘若兩區塊之中心距離大於兩 區塊對角線長的最大值,則可判定這兩個區塊並非屬於同一白血球細胞核,倘若 兩區塊之中心距離小於兩區塊對角線長之帄均,則可判定這兩個區塊屬於同一白 血球細胞核,將這兩個區塊通通標記為同一數字,以這樣的方式來重新定義區塊 與區塊間的關係;最後結果如圖 3.26 所示,總計有七個白血球細胞核區,與圖 3.20 相比較,可以發現這是個正確的結果。 圖 3.26 重新描述完整之白血球細胞核影像。