國
立
交
通
大
學
資訊科學與工程研究所
碩
士
論
文
影音媒體之建築物圖像偵測
Building Detection in Image and Video
研 究 生:曾坤隆
指導教授:傅心家 教授
影音媒體之建築物圖像偵測
Building Detection in Image and Video
研 究 生:曾坤隆 Student:Kun-Lung Tseng
指導教授:傅心家 Advisor:Hsin-Chia Fu
國 立 交 通 大 學
資 訊 科 學 與 工 程 研 究 所
碩 士 論 文
A ThesisSubmitted to Institute of Computer Science and Engineering College of Computer Science
National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Master
in
Computer Science July 2009
Hsinchu, Taiwan, Republic of China
影音媒體之建築物圖像偵測
研究生:曾坤隆 指導教授: 傅心家 教授 國立交通大學資訊科學與工程研究所摘要
從圖像本身的內容偵測出兩張圖像間是否含有相同的建築物是個困難且極 富挑戰性的工作。如果能夠藉由圖像內容進行檢索,就可避免使用關鍵字檢索引 起的各種問題。本篇論文中提出一個以紋理特徵為基礎的建築物匹配方式。首先 從圖像中截取出特徵,並找出兩張圖像之間相同的特徵。然後,將結果中不合理 的部分刪除並使用此結果找出兩張圖像中是否含有相同建築物。因為並未使用建 築物模型,所以任何類型的建築物偵測皆可使用,不需做其他調整。我們以 4 支介紹景點的影片中所擷取出來的圖像及 16 張在影片中出現的建築物之圖像, 驗證所提的方法能正確的找出圖像中相同的建築物。論文最後更進一步將所提的 方法整合至一個已有的影音網站中並成功應用在影片中景點的定位上。Building Detection in Image and Video
Student:Kun-Lung Tseng Advisor:Prof. Hsin-Chia Fu
Institute of Computer Science and Engineering National Chiao Tung University
Abstract
Detecting the same building between two images by their content is an important and challenging task. If we can query images by the content getting from an image, then we avoid all problems which keyword-search causes. In this paper, we propose a method for building mapping based on texture feature. First, we get the features from two images and find same features between two images. Then, we discard some of the results in unreasonable and use the result to find out whether the two images contain the same building. Because we don’t use any building models, so the algorithm can detect any type of building and does not need to adjust model for different buildings. The efficacy of the proposed method is tested on the images getting from 4 videos and 16 building images which are appeared in the videos. Moreover, we integrate the proposed method to an existed video web site and locating the attractions in the video successfully.
誌謝
謝謝傅老師在我研究所兩年的生涯給予我的指導和照顧,並幫助我的論文找 到研究方向,學習到做研究的方法與態度,才得以完成此篇論文。同時,感謝實 驗室博士後研究以及博士班學長,永煜、岳宏、柏伸、政龍、士賢,同學威人, 還有學弟祐楷平常在生活上及學業上的建議與指教。特別感謝永煜學長與政龍學 長在論文上的極大幫助,讓我認識影像方面的知識也幫助我解決困難並修改論 文,讓論文更為完美。感謝大學同學以及每一個朋友在生活上的鼓勵。最後,感 謝爸爸、媽媽、哥哥一直在背後支持我,給我無憂無慮的生活,讓我可以專注在 學業上,才得以順利完成學業。目錄
中文摘要 ...i 英文摘要 ...ii 誌謝 ...iii 目錄 ...iv 表目錄 ...vi 圖目錄 ...vii 第 1 章 緒論 ...1 1.1 研究背景 ...1 1.2 研究動機...2 1.3 研究目的...2 第 2 章 相關研究探討 ...3 2.1 分群法...3 2.2 圖像匹配...4 第 3 章 研究方法 ...6 3.1 特徵擷取的方法...6 3.1.1 簡介SIFT...6 3.1.2 SIFT的概念及實施細節...8 3.1.3 擷取色彩特徵...19 3.2 特定建築物偵測...19 3.2.1 關鍵點匹配 ...20 3.2.2 圖像切割...21 3.2.3 關鍵點相對位置檢測...24 3.2.4 計算相似值...28 3.2.5 匹配特定建築物...30 3.3 系統實作...34 第 4 章 實驗 ...36 4.1 色彩特徵的實驗結果與分析...36 4.1.1 資料來源與評比方式...36 4.1.2 實驗結果與分析...36 4.2 加入關鍵點相對位置檢測所造成的影響...404.2.1 資料來源與評比方式...40 4.2.2 實驗結果與分析...40 4.3 建物圖像偵測結果與分析...42 4.3.1 資料來源與評比方式...42 4.3.2 實驗結果與分析...42 4.4 考慮影音連續性時的建物圖像偵測結果與分析...44 4.4.1 資料來源與評比方式...44 4.4.2 實驗結果與分析...45 4.5 場景偵測結果與分析...46 4.5.1 資料來源與評比方式...46 4.5.2 實驗結果與分析...46 4.6 影片景點自動定位應用實驗...49 4.6.1 資料來源與評比方式...49 4.6.2 實驗結果...50 第 5 章 結論與未來工作 ...51 5.1 結論...51 5.2 未來展望...51 參考文獻 ...53 附錄一 ...56
表目錄
表 4-1 有色彩特徵時的特定建築物偵測結果 ...37 表 4-2 無色彩特徵時的特定建築物偵測結果 ...38 表 4-3 無關鍵點相對位置檢測的特定建築物偵測結果 ...41 表 4-4 建物圖像偵測結果 ...43 表 4-5 考慮影音連續性時的建物圖像偵測結果 ...45 表 4-6 雕像圖像偵測結果 ...47 表 4-7 考慮影音連續性時的雕像圖像偵測結果 ...48 表 4-8 影片中之景點定位結果 ...50圖目錄
圖 3-1 SIFT流程圖 ...8 圖 3-2 尺度空間的圖片 ...11 圖 3-3 高斯差濾波器示意圖 ...12 圖 3-4 取極值的示意圖 ...12 圖 3-5 關鍵點在直線上受雜訊影響之示意圖 ...15 圖 3-6 從原圖至決定關鍵點的方向的差異 ...15 圖 3-7 擷取特徵的示意圖 ...18 圖 3-8 特定建築物偵測的流程圖 ...20 圖 3-9 關鍵點匹配流程圖 ...21 圖 3-10 圖像切割結果 ...22 圖 3-11 JSEG的流程圖 ...23 圖 3-12 同一分割區域中總數最多的平行線群 ...25 圖 3-13 當圖上下顛倒時關鍵點相對位置檢測的情況 ...26 圖 3-14 關鍵點對應關係矩陣(a)的結果 ...26 圖 3-15 關鍵點對應關係矩陣(b)的結果 ...27 圖 3-16 關鍵點相對位置檢測流程圖 ...27 圖 3-17 計算相似值的流程圖 ...30 圖 3-18 欲偵測之建築物在兩張圖像中內容與大小皆大致相同 ...31 圖 3-19 欲偵測之建築物在兩張圖像中內容相同但大小差異過大 ...31 圖 3-20 欲偵測之建築物在範例圖像中的內容超過測試圖像的內容 ...32 圖 3-21 欲偵測之建築物在兩張圖像中部分的內容相同但其餘皆不同 ...32 圖 3-22 影片景點自動定位流程圖 ...35 圖 4-1 建築物範例圖像 ...39 圖 4-2 建物圖像偵測之正確率、召回率與f評估曲線圖 ...43 圖 4-3 考慮影音連續性時的建物圖像偵測之正確率、召回率與f評估曲線圖 .45 圖 4-4 雕像圖像偵測之正確率、召回率與f評估曲線圖 ...47 圖 4-5 考慮影音連續性時的雕像圖像偵測之正確率、召回率與f評估曲線圖 .48 圖 4-6 雕像範例圖像 ...49第 1 章
緒論
1.1研究背景
隨著網路技術的進步,圖像檢索的重要性被突顯了出來。如何讓使用者從網 路的眾多圖像中找出需要的圖像,是一個非常急迫待解決的問題。早期是靠著人 工建立索引的方式來達到將圖像分類,以便於日後要用時可以依照索引標記查 找,並藉由資料庫的建立,可以方便地將圖像(image)依照檔案輔助資訊做分類 標記,並可依照關鍵字檢索,然而,此種方式的檢索效能常與分享者所提供的資 訊有關,但不同的人看同一張圖像卻常會有不同的解讀,因此,此種方法缺乏客 觀性,當檔案輔助資訊與內容無關時降低檢索效能,於是便有了以內容為基礎的 圖像檢索(Content-based image retrieval, CBIR)方式,利用圖像本身所提供 的資訊,如色彩、紋理(texture)、外型(shape)等等來做出比較判斷,進而在圖 像中正確的判斷出某處有個特定物件,來達到圖像檢索的目的。1.2 研究動機
雖然目前圖像偵測技術不停有新的進步,除了物件偵測還有車子偵測等等, 而前人大都利用物件固定的形狀或者是物件中的紋理等資訊來偵測,但鮮少有人 會針對特定單一的建築物來進行比對。因偵測特定建築物比人更困難,照相的角 度、光線的改變,使圖像中的建築物產生外型、色彩、亮度(illumination)的變 化。但單一建築物不但可供搜尋者搜尋出他真正想要的建築物,也可用來進行圖 像的定位。所以,本研究想經由圖像匹配(Image Matching)來偵測範例圖像中 (sample image)的建築物是否存在於測試圖像(testing image)中。1.3 研究目的
偵測的目的是在圖像中,搜尋出使用者所感興趣的目標物。本研究可偵測圖 像中特定建築物是否存在。讓使用者在搜尋圖像時,可利用本研究提高搜尋的準 確度。假設圖像中存在很多物件,本研究可對特定建築物利用其邊界(edge)和紋 理及色彩的資訊,經處理後即可判斷圖像中是否有相同的建築物,讓使用者所選 取的任意圖像,都可經本研究來判斷此特定建築物是否存在於圖像中。第 2 章
相關研究探討
隨著網路傳輸速度不斷的進步,越來越多的圖像可以透過網路搜尋而得到。 但是,關鍵字搜尋所引發的種種問題,卻極大的影響了搜尋的結果,對於以內容 為基礎的圖像搜尋技術的需要也日益迫切。 因為建築物的圖像偵測應用十分廣泛,可以應用於圖像檢索、場景偵測 (scene detection)…等,所以有許多論文提出偵測建築物的方法來完成上訴的 應用,而這些方法大致上分成兩類,將分別在 2.1 及 2.2 中詳述。2.1 分群法
這類的方法中,為了區分建築物與非建築物,所以需要準備一些訓練範本
(training image),由人工挑選出想偵測的區域,將這些區域的特徵擷取出來, 再利用這些特徵訓練出一個模型(model)。在偵測圖像中的建築物時,先從圖像 中找出可能的候選區域,然後再將這些候選區域的特徵擷取出來,並利用之前的模型偵測這些特徵,去判斷出哪些為建築物而哪些為非建築物。
例如[4]中為了區分天空與建築物的區域,以提升之後判斷的準確率,所以 利用小波轉換,對水平與垂直邊緣的訊號作強化,將天空與建築物的區域分開, 再找出人眼覺得明顯的區域作為候選區域,取出特徵,並使用支持向量機分類器 (Support Vector Machine, SVM) 訓練模型。當偵測圖像中是否有建築物時,只 要將候選區域的特徵取出,放入模型中,判斷此區域是否為建築物。 在[10]中,為了取得最能代表建築物圖像的區塊特徵來訓練模型,所以必須 先將含有建築物的圖像分割成數個區塊(block),利用賈柏過濾器(Gabor filter) 取出這些區塊的特徵,並將這些特徵互相比較,得出一個最能代表這張圖像的特 徵。將每張圖像的代表特徵收集起來,利用支持向量機分類器訓練模型。測試時, 利用賈柏過濾器取出測試圖像(testing image)的特徵放入事先訓練好的模型中 判斷即可知圖像中是否含有建築物。
在很多的論文中皆使用支持向量機(Support Vector Machine, SVM)[ 2, 5 ] 分類器將特徵分群,訓練模型。此方法的觀念在於找出一分割線使得兩個不同類 別(class)的資料以最大距離分開,且支持向量機亦有針對超過兩種類別的所提 出的分群方法,使得其適用範圍大大增加。
2.2 圖像匹配
這類的方法是用來判斷兩張圖像上的內容是否相似,而判斷的依據則是圖
像上的特徵,例如邊緣(edge)或者是角(corner)等關鍵點(significant point 、 interest point or keypoint)的特徵。藉由找出兩張圖像中相同的關鍵點,進 而得到兩張圖像之間的轉換矩陣(transform matrix),再透過轉換矩陣判斷兩張圖像是否相似。所以,這個方法的第一步是先找出兩張要比對的圖像中的關鍵 點,再透過特徵比對的方式匹配兩張圖像中的關鍵點,建立兩張圖像中關鍵點的 關係。之後,透過這些關係將建築物的區域給強化出來。 如[11]中,論文所使用的關鍵點是邊和角。所以必須先使用邊角 偵 測 (edge-corner detect)找到關鍵點後並得到特徵後,再找到兩張圖像中特徵的對 應關係。利用特徵的對應關係與極線(epipolar line)得到兩張圖像之間的轉換 矩陣。最後,再使用轉換矩陣判斷這兩張圖像是否相似。
第 3 章
研究方法
本章內容主要是介紹從範例圖像(sample image)及測試圖像(testing image) 中找出相同的建築的方式。3.1 節是介紹方法中所用到的特徵及擷取方式。3.2 節是介紹如何用特徵得到範例圖像及測試圖像中是否有相同的建築。
3.1 特徵擷取的方法
本節內容主要是介紹本論文中所使用的特徵,主要是針對 SIFT(Scale Invariant Feature Transform)[ 1 , 3 ]做完整的介紹。使用 SIFT 來取出圖像 特徵是因為本論文的主要目的是為了比對兩張圖像中是否有相同的建築物存 在,但建築物的造型千變萬化,要透過分群法來達成此事的難度非常高,所以才 選擇了圖像匹配的方式。但是 SIFT 只處理灰階(gray level)圖像,彩色影像中 的顏色特徵完全被拋棄,但這些特徵對於判斷建築物是否相同有一定的幫助,所 以在論文中也擷取了顏色的特徵來提升判斷的準確率。
3.1.1 簡介 SIFT
SIFT 的主要目的是從灰階的圖像中取出一種不受到圖像的尺度,旋轉,視 角(viewpoint)轉變,雜訊(noise),亮度(illumination)等影響的特徵,並將這 種特徵提供給圖形識別(Pattern Recognition)及 3D 圖像重建等應用使用。SIFT 的主要流程分為四個部份:
(1) 偵測尺度空間的極值:
偵測尺度空間的極值(scale-space extrema detection)的目標是得到具有尺 度不變性(scale invariant)的點的位置。為了得到這個目標,必須先做出各 個尺度的圖像,再將兩個相鄰的尺度像素與像素(pixel by pixel)直接相減 並取出區域的最大值或最小值(local maxima or minima)。取區域的最大值 或最小值是因為這個位置是兩個相鄰的尺度中區域變化最為劇烈的地方,如 果圖像本身有受到雜訊(noise)干擾,這些地方會因為受到雜訊干擾而找不到 的可能最低。如此,就可以得到各種尺度中最不容易受雜訊干擾的點的位置 及其所在之尺度,並稱這種點為關鍵點。 (2) 關鍵點所在位置精確化: 關鍵點所在位置精確化(keypoint localization)的目標是從(1)的關鍵點結 果中排除掉不穩定的關鍵點,確立真正的關鍵點。 (3) 決定關鍵點的方向: 決定關鍵點的方向(orientation assignment)是為了在擷取關鍵點的特徵 時,可以運用關鍵點的方向讓特徵具有不受圖像旋轉影響的性質。得到關鍵 點方向的方法是在當初得到該關鍵點的尺度中,針對關鍵點及周圍的像素, 取 出 這 些 像 素 的 梯 度 (gradient) 。 建 立 一 個 方 向 直 方 圖 (orientation histogram),將各個像素的強度(magnitude)依各個像素的方向加入方向直方 圖中的合適的箱(bin)。將方向直方圖中擁有最高值的箱的方向指定給關鍵 點,此方向代表的就是以關鍵點及周圍的各個像素為中心,像素值增加最快 的方向。之後取特徵時,只需將關鍵點及周圍區域依方向把關鍵點及周圍區 域旋轉使其方向轉至 90 度的狀態。如此,就可以保證擷取特徵時,關鍵點的
方向皆保持在 90 度,也就得到不受旋轉影響的性質。 (4) 關鍵點描述子: 關鍵點描述子(keypoint descriptor)的目標就是為了取得該關鍵點的特 徵。方法是在當初得到該關鍵點的尺度中,擷取出關鍵點周圍區域(遠大於(3) 中的區域)的梯度的方向及強度,並將關鍵點周圍區域分割成若干個 4*4 的區 塊。針對每個區塊分別建立方向直方圖,將區塊中各個像素的強度依各個像 素的方向加入該區塊的方向直方圖中的合適的箱。將各個區塊中方向直方圖 的箱的值拿出來當特徵,接著,將特徵正規化(normalized)至單位長度(unit length)。 偵測尺度空間的極值 決定關鍵點的方向 關鍵點描述子 關鍵點所在位置精確化 圖 3-1 SIFT 流程圖
3.1.2 SIFT 的概念及實施細節
本節的目的是詳細介紹如何運用 SIFT 取出圖像中的特徵及這些特徵所代表 的意義。 3.1.2.1 偵測尺度空間的極值 SIFT 所取出的特徵有一個主要特性為特徵在圖像的各種尺度皆不變,不會 因為圖像尺度改變導致特徵失效,而本節的目標,就是要得到圖像在各種尺度中
的關鍵點。為了達成這個目的,必須先將圖像的尺寸縮小(downsize),再從各種 尺寸的圖像中取出高頻並找出極值(extrema)的位置,當作關鍵點。為此,SIFT 採用了高斯差(Different of Gaussian ( DOG ))濾波器(filter)。先用高斯函 數(Gaussian function),G(x, y,σ),以及不同的σ(尺度)將圖像( I(x, y) ) 做不同程度的糢糊化,這麼做就相當於把圖像的寬和高分別乘上 1/σ,也就是 圖像解析度縮小但是圖像尺寸不變。另外,也可以過濾一些細微的雜訊去除雜訊 影響。這部份,就是標題中的尺度空間(圖像結構在不同的尺度下所表達出來的 一組單變數平滑化圖像),如圖 3-2。 接下來,將鄰近的σ及 kσ所做出的模糊影像 L(x, y,σ)及 L(x, y, kσ) 像 素與像素直接相減,其中 k 為一個常數,代表兩鄰近σ之間的間隔,得到 DOG 的結果,D(x, y,σ),代表σ中的高頻部份。 DOG 實施方式如下: G(x, y,σ) = 12e-(x +y )/22 2 2 2 σ πσ
L(x, y,σ) = G(x, y,σ) ∗ I(x, y) (*為迴旋積(convolution)) L(x, y, kσ) = G(x, y, kσ) ∗ I(x, y)
D(x, y,σ)= (G(x, y, kσ)−G(x, y,σ)) ∗ I(x, y)=L(x, y, kσ)−L(x, y,σ)
(1) 至於為何要選用高斯差濾波器,第一點是因為它的執行過程只做了一次迴旋 積(convolution)及一次減法,所以高斯差濾波器的執行效率十分好,花的時間 相對也較少。其次,高斯差濾波器的執行結果與拉普拉斯差(Laplacian of Gaussian( LOG )) 濾波器的結果十分相近,而在其他論文[ 18 ]的實驗中已發 現拉普拉斯差濾波器的區域最大值及最小值所產生的特徵相對於其他方法較為 穩定。拉普拉斯差濾波器的第一步與高斯差濾波器相同,都是先用高斯函數以及
不同的σ將圖像做不同程度的糢糊化,將一些細微的雜訊率掉,但之後卻是用拉 普拉斯濾波器處理模糊化後的影像,如此,所偵測出來的部份就是圖像中的高頻 部份,而其中的區域最大值及最小值就是區域變化最劇烈的地方。所以,拉普拉 斯差濾波器的處理過程中必須先做一次迴旋積,再做一次拉普拉斯,使用的時間 較高斯差濾波器多,這就是 SIFT 採用高斯差濾波器而不是拉普拉斯差濾波器的 理由。 高斯差濾波器相似拉普拉斯差濾波器的推導過程: 2 2 2 2 2 G G(x, y, k ) - G(x, y, ) LOG= G= * G= * k G G(x, y, k ) - G(x, y, )=DOG σ σ σ σ σ σ σ σ σ σ σ σ ∂ ∇ ∇ ≈ ∂ ⇒ ∇ ≈ (2) 接著要決定 k 的值,我們可以參考建立高斯金字塔(Gaussian Pyramid)的方 式,如果σ的值加倍的時候,也就是代表圖像解析度已經減半,為了加速計算, 就將圖像尺寸減半(ex:1024*768→512*384),再將σ還原成開始的值繼續做下 去。但在高斯金字塔的方式中,σ值每次皆加倍,導致中間的間隔太大。要解決 這個問題,可以在σ至 2σ之間,插入 s-1 張平滑化圖像來縮小間隔,也就是令 k=21/s ,並將一次σ至 2σ的過程稱之為一個 octave,如圖 3-3。 因為高斯差濾波器相似於拉普拉斯差濾波器,且拉普拉斯差濾波器的極值所 產生的特徵是較為穩定,所以我們從高斯差濾波器的結果中取出極值,也就是區 域變化最為劇烈的地方,所得到的特徵也較為穩定。 實施方式如下: 將像素(x, y)跟 26 個鄰近的像素 (本身尺度的 8 個+上一個尺度的 9 個+下一 個尺度的 9 個),如果該像素(x, y)為最大值或最小值則將該像素選為關鍵點
的候選者,若不是,則繼續做下一個像素,直到做完為止,如圖 3-4。 為了達到每一個尺度都能取得極值的目的,每個 octave 中應該包含σ*k-1 、 σ、σ至 2σ之間的 s-1 張、2σ以及 2σ*k 這些尺度的平滑化圖像(共有 s+3 張 平滑化圖像),如此才能取得σ和 2σ尺度的極值。 原本應該每個尺度都要執行一次,但如此執行時間就會被大幅度的延長,很 沒有執行效率。經過一系列的實驗後,發現在 s=3 及σ=1.6 時,執行效果及使 用時間的效果較佳,所以 s 及σ就用這組設定值,但為了避免因σ=1.6 而失去 原圖(未模糊化)的資訊,所以第一個 octave 是以原圖的 2 倍尺寸(ex:400*300 →800*600)開始執行。 圖 3-2 尺度空間的圖片 圖(a)為原圖(σ=0),圖(b)的σ=1, 圖(c)的σ=2,圖(d)的σ=4
圖 3-3 高斯差濾波器示意圖
3.1.2.2 關鍵點所在位置精確化 當關鍵點候選人擷取出來之後,必須更進一步的將一些不穩定的關鍵點去除 掉,這些不穩定關鍵點就是對比度低(low contrast)的關鍵點及在邊(edge)上的 關鍵點。 首先,為了得到更好的執行結果,需要更加精確的關鍵點位置,所以要用次 像素(sub-pixel)及次尺度(sub-scale)的概念來偵測關鍵點。將先前求出來的 D(x, y,σ)利用泰勒展開式(Taylor expansion)展開至到二次方,表示成D( )χ , 其中χ =(a, b,σ),代表此關鍵點,並將 χ 當成座標軸的原點,方便計算之後極 值的位置。 將泰勒展開式微分並令D( )χ 等於 0 解 χ ,即可得到極值, ,如果 中任 一維度(dimention)超過 0.5,則代表極值應該更靠近另外一個點,將此關鍵點 刪除並移至( +原關鍵點)所在的位置,將其當成關鍵點再做一次,以求出真正 的極值 ,最後再將 加上原本的關鍵點數值,就是極值的所在位置了。
ˆX
ˆX
ˆX
ˆX'
ˆX'
實施方式如下: T 2 D 1 T D D( )=D+ x'+ x' x' x'=(x- ) =(a, b, ) keypoint 2 x 2 x χ D -1 2D D ˆ X= - 2 代表的是 , 透過這種變數變換的方式將 當成原點,而 則是將此數值帶入運算後所得 到的常數 χ χ χ σ χ χ ∂ ∂ ∂ ∂ ∂ ∂ ∂ ∂ ,其中 , 。 (3) 接下來,要判斷所得之極值是否為不穩定。將極值令為 並把 帶入 D( ) 中。如果 <0.03,代表產生這個極值的兩個尺度在此像素的差異並不大, 很容易受到雜訊影響或者是受到這個極值為雜訊影響所產生的結果,並不穩定, l Y Yl Yl l |D(Y)|所以要把此關鍵點刪除(圖像像素的值在[0,1])。 實施方式如下: l T l lT 2 l l 2 D 1 D 1 D D(Y)=D+ Y+ Y Y=D+ Y x 2 x 2 x ∂ ∂ ∂ ∂ ∂ ∂ T 其中 Dxx Dxx Dx y Dyx Dyy ⎢ ⎥ ⎣ ⎦ (4) 高斯差濾波器對偵測位於邊上的關鍵點的能力很強(因為邊屬於高頻部 份),如果關鍵點位於邊的交界處,其中有一些邊為直線(或近似直線)。這種位 於直線上的關鍵點很容易受到因為一點雜訊的影響,導致關鍵點的位置改變至直 線上受雜訊影響的地方,如圖 3-5,所以這種關鍵點不穩定。要去除位於直線段 上的關鍵點,可以用角偵測(Harris Corner Detector)[ 13 ]的方式偵測關鍵點
是否位於直線段。令 H 為 代表對 x 方向偏微分兩次(x 方向 的變化量),Dxy、Dyx代表對 x、y 方向各偏微分一次,Dyy代表對 y 方向偏微分兩 次(y 方向的變化量),則 Dxy=Dyx。令 H 的 eigenvalue 為λ1、λ2,λ1>=λ2,則可 能有下列四種情形(如圖 2-5): ⎡ ⎤ ⎢ ,⎥ (1)如果 Dxx>>Dyy,則 Dxx =λ1、Dyy =λ2。代表 x 方向變化劇烈,y 方向變化相對 平緩,此為一條直線。 (2)如果 Dyy>>Dxx,則 Dxx =λ2、Dyy =λ1。代表 y 方向變化劇烈,x 方向變化相對 平緩,此為一條橫線。 (3)如果 Dxx、Dyy十分相近遠大於零,代表 x 及 y 方向變化劇烈,為一個角。 (4)如果 Dxx、Dyy十分接近零,代表 x 及 y 方向變化平緩,為其他情況。 實施方式如下:
利用 Tr(H)=λ1+λ2、det(H)=λ1*λ2,令λ1=r*λ2, 2 2 2 2 1 2 2 2 1 2 2 ( + ) ((r+1)* ) Tr(H) (r+1) T= = = = 令門檻值 r’=10,若 T > (112 /10) = (121/10)=12.1,則此極值為直線,將其 刪除。 圖 3-5 關鍵點在直線上受雜訊影響之示意圖 圖 3-6 從原圖至決定關鍵點的方向的差異,(a)233*189 像素的原圖 (b)做完偵測尺度空間的極值,共有 832keypoints(向量代表強度,方向及位置) (c)去除對比度低的關鍵點,共有 729keypoints (d)去除在邊上的關鍵點,共有 536keypoints 原關鍵點 新關鍵點 雜訊 det(H) λ λ r*λ r λ λ λ (5)
3.1.2.3 決定關鍵點的方向 這一節的目標是要找出每個關鍵點的方向,讓之後取出的特徵具有不受圖像 旋轉影響的特性。 為了取出關鍵點的方向,必須在先將圖像的尺度轉變到當初得到該關鍵點的 尺度,求出在此尺度下的 L(x, y),並藉由 L(x, y)得到環繞在關鍵點周圍各點 的梯度的強度, m(x, y),及方向,θ(x, y)。將這些梯度的強度依該點與關鍵 點的距離加權,並建立一個方向直方圖,將加權後的強度的值加入包含此梯度的 方向的值的箱中。將統計表中統計值最高的及接近最高值的箱的方向皆指定給關 鍵點(也就是可能會有兩個關鍵點有相同的位置及尺度但不同的方向),這個方向 也就是該關鍵點的方向。 當我們要取特徵時,只要在取特徵之前將要擷取特徵的區域(region)旋轉使 得關鍵點的方向為 90 度後再擷取特徵,就可以具有不受圖像旋轉影響的特性。 實施方式如下: 先計算出梯度的強度,m(x, y),及方向,θ(x, y): 2 2 -1
( , )
( (
1, ) - ( -1, ))
( ( ,
1) - ( , -1))
( , ) tan (( ( ,
1) - ( , -1)) /( (
1, ) - ( -1, )))
m x y
L x
y
L x
y
L x y
L x y
x y
L x y
L x y
L x
y
L x
y
θ
=
+
+
+
=
+
+
(6) 接著,創造一個 36 個箱的方向直方圖,其中每個箱各佔了 10 度的區間(range)。 將之前梯度強度的值乘上高斯分佈(Gaussian distribution)(其σ為尺度值 的 1.5 倍)依此梯度的方向的值加入方向直方圖的適當的箱中。方向直方圖中最高的值及高度在最高值*0.8 以上的方向,皆會被當作關鍵點的方向,所以 一個關鍵點可能有兩個以上的方向。最後,利用最高值及其左右的箱,求出一 條拋物線,再利用此拋物線求出其極值的位置,以這個值來表示關鍵點的方向。 3.1.2.4 關鍵點描述子 這節的目標是取出不受圖像旋轉、視角(viewpoint)及亮度(illumination) 的具鑑別力的特徵。在這裡採取的方法依然是方向直方圖。確定關鍵點的尺度 後,求出在此尺度下的 L(x, y),將圖像旋轉使得關鍵點的方向為 90 度,並把 關鍵點及週遭的區域分割成若干個 4*4 大小的 block,依第三節的方式將區塊中 的方向統計成方向直方圖,將這些方向直方圖稱為關鍵點描述子(keypoint descriptor),如圖 3-7。因為是以關鍵點為中心,考慮其周圍各點,所以利用 這種描述子,就可以不管關鍵點是否大幅度的平移,皆可以偵測出來。但是,將 關鍵點週遭的區域分隔成 4*4 大小的區塊以及在方向直方圖中將 360 度分割成數 個箱,這些方式皆會產生邊緣效應(boundary effect)。為解決這個問題,使用 了三線性內插(trilinear interpolation)的方式。 接著,為了不受亮度影響,必須先將特徵正規化至單位長度,此步驟的作用 是如果圖像中的對比度(contrast)改變導致像素值之間差乘上某常數,那麼梯度 也會有相同倍數的改變,將特徵正規化至單位長度後,這種倍數改變即可解除。 若是圖像中的明亮度(brightness)改變,導致每個像素直加上了一個常數,但是 先前所做的特徵擷取過程皆為像素值相減,所以不受明亮度改變的影響。若特徵 正規化後還有特徵中某個值大過常數 h(就是某一個區塊中的方向直方圖的某個 箱的值,超過一定程度),代表可能因為照相角度改變或受到亮度影響而在物體 表面形成如同鏡子的反光區域(Specular Surfaces),導致強度的值大幅度上 升,不具參考價值,必須先把這些值歸零,再次將特徵正規化至單位長度。 實施方式如下:
雖然說一樣是使用方向直方圖的方式,但因為和第三節的情況不同,所以參數 必須改變。依實驗所得,σ為關鍵點區域寬度的0.5 倍,關鍵點週遭的區域大 小最好為16*16,也就是會有 4*4 個區塊,方向直方圖要分為 8 個箱,所以得 到的特徵維度為4*4*8=128 維度。另外,上述的常數 h 則定為 0.2。 圖 3-7 擷取特徵的示意圖 先將關鍵點週遭的區域分割成若干個4*4 大小的區塊,如圖(a)所示。 再乘上高斯分佈將梯度的強度加權後(藍色圓圈), 將每個區塊中的梯度統計成方向直方圖,如圖(b)所示。 在圖(a)中的區域為 8*8,所以產生了 2*2 的描述子, 且每個方向直方圖有8 個箱。 但依照後來的實驗結果所示,區域的大小最好為16*16, 每個方向直方圖最好有8 個箱, 也就是會產生4*4 個描述子,每個特徵應該有 4*4*8=128 維度。
3.1.3 擷取色彩特徵
因為 SIFT 只處理灰階圖像,並未使用圖像中的色彩特徵,但是色彩特徵對 於提高結果的準確率是有所助益的,所以本節中將敘述如何取得論文中所使用的 色彩特徵。 在擷取顏色特徵時,如果直接使用 RGB 色彩空間(color space),十分容易 受到照度 (Luminance)的影響,導致人眼判斷相似的兩種顏色電腦卻判斷這兩種 顏色完全不同。為了解決此問題,本論文中所採用的色彩空間為 Lab 色彩空間, 特徵的擷取方式為以關鍵點為中心,取 15*15 的區塊大小,再分別求出此區塊的 L、a、b 的平均值(mean)當作特徵。 要比較兩個區塊顏色是否相近時,就使用 International Commission on Illumination (CIE)所提供的 Delta E2000[ 17 ]來判斷兩種顏色是否相近。 Delta E2000 是專門用來計算兩種顏色之間的差距,所算出的顏色差距較接近人 眼觀看所得出的結果,所以可避免上述的問題。只要將算出的數值與之前所設定 的門檻值(threshold)做比較,不超過門檻值 c 則認為兩個區塊的顏色相近;反 之,則代表兩區塊的顏色差距極遠。
3.2 特定建築物偵測
在這個部份,要介紹的是如何運用 3.1 所得到的特徵,判斷範例圖像及測試 圖像中是否有相同的建築物。3.2.1 節是先找到範例圖像與測試圖像中相同的關 鍵點。3.2.2 節是將範例圖像與測試圖像做圖像切割(segmentation)。3.2.3 節 是對 3.2.1 節的結果中,位於同一切割區域的關鍵點做相對位置檢測。3.2.4 節 是算出範例圖像與測試圖像中各切割區域的相似度。3.2.5 節是判斷範例圖像與 測試圖像中的切割區域是否為相同建築物。計算相似值 匹配特定建築物 關鍵點相對位置檢測 圖像切割 關鍵點匹配 圖 3-8 特定建築物偵測的流程圖
3.2.1 關鍵點匹配
SIFT 將關鍵點及其特徵擷取出來後,為了得到兩張圖像之間的轉換矩陣進 而求得兩張圖像中是否有相似的建築物,必須先找出兩張圖像中相同的關鍵點。 首先,利用特徵判斷範例圖像中的各個關鍵點是否存在測試圖像中。若存在,則 必須決定範例圖像中的關鍵點與測試圖像中的哪個關鍵點相同。此動作稱之為關 鍵點匹配(keypoint matching)。(為了區別從範例圖像及測試圖像中取得的關鍵 點,在之後的論文中,從範例圖像中取得的關鍵點稱為範例關鍵點,從測試圖像 中取得的關鍵點稱為測試關鍵點) 在本論文中所採用的關鍵點匹配方式是先計算範例關鍵點的特徵與各個測 試關鍵點的特徵之間的歐幾里德距離(Euclidean distance)。接著,為了避免範 例關鍵點是從圖像中的背景所取出,所以將所得到的最近距離除以次近距離,如 果此值大於之前所訂立的門檻值 t,代表此關鍵點特徵與最近距離及次近距離的關鍵點特徵都很相近,有可能是背景所擷取出來的,所以不與任何一個測試關鍵 點特別相近,判定此範例關鍵點與任何測試關鍵點皆不相同;反之,則需再用 Delta E2000 判斷這兩個關鍵點的顏色特徵是否超過門檻值 c。不超過門檻值 c, 則判定此範例關鍵點與最近距離之測試關鍵點相同;超過門檻值,則此範例關鍵 點不與任何一個測試關鍵點相同。最後,可得到範例圖像與測試圖像中關鍵點的 匹配關係,將此匹配關係整理成矩陣儲存。其中,門檻值 c 為經過數次實驗後, 經由觀測結果所得出之最佳數值。 依序計算每個範例關鍵點的特徵與各個測試關鍵點的特徵之間的歐幾 里德距離(Euclidean distance) 此值超過門檻值t 將所得之最近的距離除以次近的距離 否 運用Delta E2000計算出該範例關鍵點與最近距離 之測試關鍵點的顏色差距 此值超過門檻值c 該範例關鍵點與最近距離之測試關鍵點為一組匹配關鍵點,並將此紀 錄於匹配關鍵點矩陣中 否 是 是 圖 3-9 關鍵點匹配流程圖
3.2.2 圖像切割
在範例圖像及測試圖像中,除了欲偵測之建築物,可能也包含了一些背景或是其他不相干的物件(object),例如;天空、草地、道路及只存在於範例圖像或 者是測試圖像中的其餘建築物。為了使偵測結果不受到這些物件的干擾,所以必 須先對圖像切割,並將一塊切割區域(segmentation region)視為一個物件。在 本論文中所採用的圖像切割方法為 JSEG[ 12 ]。 圖 3-10 圖像切割結果,每一個白線分割的區域為同一群 JSEG 圖像切割技術介紹: JSEG 是一種區域擴張與融合的影像切割方式,利用顏色為特徵來分割圖 像,第一階段為色彩空間量化(color space quantization),第二階段為空間切 割(spatial segmentation),其中空間切割又可細分為計算 J 值、區域成長與區 域合併等三個步驟。。
色彩空間分割 J 值計算 區域擴張 圖像分割結果 彩色圖像 圖 3-11 JSEG 的流程圖 3.2.2.1 色彩空間量化 將圖像中的各像素的值量化成某幾個特定的值。量化後的圖像將被稱為色彩 等級分配圖(class map)並儲存。 3.2.2.2 計算 J 值 將色彩等級分配圖進行分群的動作,若圖中相鄰區域的像素值越接近,則越 容易被分為同一群,J 值也會越大。 3.2.2.3 區域成長 區域成長(region growing)包含種子決定與種子成長兩個步驟。首先,須先 決定區域圖像中種子的個數及分布情況,再經由種子的成長來產生新的區域分 布。其中,種子的個數會影響區域的個數。
3.2.2.4 區域合併 區域成長會生成初步的圖像切割結果,區域合併(region merging)是將此結 果中破碎的區塊加以合併。每個區域以顏色直方圖(color histogram)當特徵, 若相鄰區域的顏色特徵差距不超過門檻值,則將區域合併並重新計算特徵,直到 所有相鄰區域的顏色特徵差距大於門檻值為止。此合併結果即為圖像切割的最終 結果。
3.2.3
關鍵點相對位置檢測
在執行關鍵點匹配後,得到了範例圖像與測試圖像中關鍵點的匹配關係矩 陣。執行圖像切割後,得到了每個物件的區域。之後,為了使最後得到的結果更 佳的準確,必須將匹配關係矩陣中錯誤的結果去除,讓之後得到的轉換矩陣更加 的準確。首先,考慮匹配關係矩陣,將其中的範例關鍵點依範例圖像的切割區域 作分類,把位於相同分割區域的範例關鍵點視為同一群,也就是將相同物件中的 範例關鍵點視為同一群。 如果照相機的拍攝方式不改變(天空是在圖像的正上方,地面是在圖像的正 下方),同一棟建築物中關鍵點的相對位置也不應該改變。依此想法,照相機的 拍攝方式不改變的情況下,在匹配關係矩陣中,測試圖像內被匹配的測試關鍵點 的相對位置,應同於範例圖像內範例關鍵點的相對位置。為了檢測此項性質,本 論文中所用的方法為將範例圖像與測試圖像並排且假設每一組匹配的關鍵點之 間有一條連線,如果符合上述性質,線與線之間應為平行的狀態,所以只要將同 一群中總數最多的平行線群找出來即可,如圖 3-12。圖 3-12 同一分割區域中總數最多的平行線群 但是,為了能夠在範例圖像及測試圖像的拍攝方式不同的情況下,依然能夠 使用此性質,可以使用 SIFT 中得到的關鍵點的方向。先將匹配關係矩陣中每一 組關鍵點中範例關鍵點與測試關鍵點之間方向的差值算出來,再針對各組關鍵 點,先將測試圖像依之前算出之差值旋轉後,再做關鍵點相對位置檢測,就能得 到在該物件中哪幾組關鍵點所構成之線與此組關鍵點所構成的線互相平行,如圖 3-13。 但是,每組關鍵點在執行關鍵點相對位置檢測之前,都必須依範例關鍵點與 測試關鍵點之間方向的差值旋轉測試圖像,因而耗費了大量的執行時間。為了要 減少執行時間,可以先利用統計的方式決定測試圖像的旋轉角度。方法為先建立 一個方向直方圖,其中每一個 bin 的範圍為 10 度角,共 36 個 bin。利用關鍵點 的方向資訊,算出每組匹配關鍵點之間的角度的差額並用方向直方圖統計,再挑 選出統計值最高的 bin 當作測試圖像旋轉的角度。在此方式下,只需旋轉測試圖 像一次,即可完成每一組關鍵點的關鍵點相對位置檢測,進而節省了大量的執行 時間。
圖 3-13 當圖上下顛倒時關鍵點相對位置檢測的情況 此外,為了預防圖像切割錯誤,關鍵點匹配的對象除了同群的關鍵點外,也 包含該關鍵點周圍一定範圍內的其餘匹配關係矩陣中的關鍵點並將各組關鍵點 所得結果分別整理成該組關鍵點的關鍵點對應關係矩陣(a),如圖 3-14。最後, 因為要由一個物件匹配至另一個物件,所以我們也要從各組關鍵點的關鍵點對應 關係矩陣(a)中,挑選出與該組的測試關鍵點相同物件中的測試關鍵點並分別整 理成關鍵點對應關係矩陣(b),如圖 3-15。 圖 3-14 關鍵點對應關係矩陣(a)的結果,其中共有 22 組的關鍵點匹配結果
圖 3-15 關鍵點對應關係矩陣(b)的結果,其中共有 18 組的關鍵點匹配結果 找出與該組的範例關鍵點位於同群或彼此 距離小於門檻值 d 的關鍵點組並將此紀錄 成該組關鍵點的關鍵點對應關係矩陣(a) 執行關鍵點相對位置檢測 依序對匹配關係矩陣中每一組關鍵點,將 測試圖像旋轉範例關鍵點與測試關鍵點方 向值的差距角度 挑選出與該組的測試關鍵點位於相同分割 區域內的關鍵點組並整理成該組關鍵點的 關鍵點對應關係矩陣(b) 將位於範例圖像中相同分割區域內的關鍵 點視為同一群 圖 3-16 關鍵點相對位置檢測流程圖
3.2.4 計算相似值
為了得到範例圖像上欲偵測建築物及測試圖像上欲偵測建築物之間的轉換 矩陣(transform matrix),進而得到兩個物件的相似值,本論文的方法為針對匹 配關係矩陣中的各組關鍵點,若是其關鍵點對應關係矩陣(b)中關鍵點組數大於 等於 3,則利用關鍵點對應關係矩陣(b)及最小平方法(minimum least square solution)得到從範例圖像仿射(affine)至測試圖像的最佳仿射參數;若關鍵點 對應關係矩陣(b)中關鍵點組數小於 3,則代表此物件不存在於測試圖像中。 i i i i i i x 1 2 y 3 4 u x u , , (ratation v y v t m m
matrix) , (translation matrix) t m m ⎡ ⎤ ⎡ ⎤ ⎡ ⎤ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎣ ⎦ ⎣ ⎦ ⎣ ⎦ ⎡ ⎤ ⎡ ⎤ ⎢ ⎥ ⎢ ⎥ ⎣ ⎦ ⎣ ⎦ 令 為任一組轉換完的座標 為 轉換前的座標 旋轉矩陣 為 轉移矩陣 為 ,則 x i i y i i t u m1 m2 x = + t v m3 m4 y ⎡ ⎤ ⎡ ⎤ ⎡ ⎤⎡ ⎤ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥⎢ ⎥ ⎣ ⎦ ⎣ ⎦ ⎣ ⎦ ⎣ ⎦ (8) x 1 2 i i y 3 4 i i t m m u x t m m v y 已知⎡ ⎤⎢ ⎥與⎡ ⎤⎢ ⎥求⎡⎢ ⎤⎥與⎡ ⎤⎢ ⎥,則 ⎣ ⎦ ⎣ ⎦ ⎣ ⎦ ⎣ ⎦ 1 1 2 1 1 1 3 1 1 4 x y m u m x y 0 0 1 0 v m 0 0 x y 0 1 = . m ... . t ... . t ⎡ ⎤ ⎡ ⎤ ⎢ ⎥ ⎡ ⎤⎢ ⎥ ⎢ ⎥ ⎢ ⎥⎢ ⎥ ⎢ ⎥ ⎢ ⎥⎢ ⎥ ⎢ ⎥ ⎢ ⎥⎢ ⎥ ⎢ ⎥ ⎢ ⎥⎢ ⎥ ⎢ ⎥ ⎣ ⎦⎢ ⎥ ⎣ ⎦⎢ ⎥ ⎢ ⎥ ⎣ ⎦ (9) 1 i 2 i i i 3 i i 4 x y m u m x y 0 0 1 0 v m 0 0 x y 0 1 A= x= b= . Ax=b x m ... . t ... . t 令 , , ,則 ,解 ⎡ ⎤ ⎡ ⎤ ⎢ ⎥ ⎡ ⎤ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎣ ⎦ ⎢ ⎥ ⎢ ⎥ ⎣ ⎦ ⎢ ⎥ ⎣ ⎦
T -1 T
x=[A A] A b (10)
如果使用其他的方式,例如基本解矩陣(fundamental matrix solution) [ 14, 15 ],來獲得轉換矩陣會有更穩定的正確率,但這些方法對轉換矩陣中關鍵點的 總數要求卻遠大於本論文的方法,但是,關鍵點相對位置檢測所得出結果,其總 數通常都不足以支持這些方法的運用。 將範例圖像上與此組的範例關鍵點位於同一群之範例關鍵點透過轉換矩陣 後,每個關鍵點都可以得到一個新的座標。在測試圖像中,使用 kd 樹(kd-tree) 演算法[ 16 ]得到與此座標之間距離小於門檻值 d 的關鍵點,再查看其中是否有 尺度、方向和顏色皆與其相似的關鍵點,並紀錄共有幾個範例關鍵點可在測試圖 像中找到與其相似的關鍵點。之後,將紀錄的數目除以此群中關鍵點的總點數即 可得到這兩個物件的相似度。但是,為了解決兩邊關鍵點多寡不一而影響相似度 的判斷,所以也要從測試圖像上與此組測試關鍵點位於同一群之測試關鍵點透過 轉換矩陣的反矩陣再做一次,再從兩次結果中取出相似度高的當成最終結果。
檢查各組關鍵點的關鍵點對應矩陣(b)中 關鍵點的總組數 否 將範例圖像中該組範例關鍵點 所在之群內的其餘關鍵點透過 轉換矩陣得到新座標 查看在測試圖像內此座標附近 是否有相似之關鍵點。 紀錄共有幾成的關鍵點可在測 試圖像內找到相似之關鍵點 查看在範例圖像內此座標附近 是否有相似之關鍵點 紀錄共有幾成的關鍵點可在範 例圖像內找到相似之關鍵點 得到範例圖像與測試圖像中該組關鍵點所 在切割區域的相似度 將測試圖像中該組測試關鍵點 所在之群內的其餘關鍵點透過 轉換矩陣得到新座標 解轉換矩陣的參數 是 總組數 >=3 圖 3-17 計算相似值的流程圖
3.2.5 匹配特定建築物
本節的目的是找出範例圖像與測試圖像中相似的物件。當範例圖像與測試圖 像要進行圖像匹配時,假設範例圖像中所拍攝到的欲偵測之建築物為 A,測試圖像中所拍攝到的欲偵測之建築物為 B,則 A 與 B 的內容可能會有下列 4 種狀況: (1)A 和 B 的大小與內容皆大致相同,如圖 3-18。
圖 3-18 欲偵測之建築物在兩張圖像中內容與大小皆大致相同
(2)A 和 B 的內容皆大致相同但大小差異過大,如圖 3-19。
(3)A 的內容超過 B 的內容或 B 的內容超過 A 的內容,如圖 3-20。
圖 3-20 欲偵測之建築物在範例圖像中的內容超過測試圖像的內容
(4)兩者的內容僅有部份相同,如圖 3-21。
本論文中提出兩個方法來解決以上 4 種狀況: (1)利用 3.2.4 中所得到的相似度 只要相似度的值大於門檻值就認定 A 與 B 為相同之建築物。 (2)利用關鍵點對應關係矩陣(a)與關鍵點對應關係矩陣(b) 相似度可以解決前 3 種狀況,但在第四種狀況中,由於 A 與 B 僅有部份相同, 相似度必然不會太高,也就無法使用相似度成功的匹配 A 與 B。所以,本論文中 使用除了使用相似度來判定 A 與 B 是否為相同建築物之外,也使用了另外一種方 式,就是利用之前所得到的關鍵點對應關係矩陣(a)與關鍵點對應關係矩陣(b) 來判斷 A 與 B 是否相同。如果在關鍵點對應關係矩陣(b)中關鍵點的總組數很多, 代表著 A 和 B 中有許多相同的關鍵點,但相似度卻不高,可能是因為第 4 種情況 發生或是 A 與 B 兩者拍攝角度相差太大導致這樣的結果,所以,可以參考關鍵點 對應關係矩陣(b)中關鍵點的總組數,如果大於門檻值 b,就代表 A 與 B 是相同 的建築物。 考慮關鍵點對應關係矩陣(a)是因為如果矩陣內總組數大於超過門檻值 a, 但關鍵點對應關係矩陣(b)卻低於門檻值 b,可能是圖像切割錯誤導致此結果, 所以還是要將認定 A 與 B 為相同之建築物,而 a 與 b 的值則是按照圖像的大小來 決定。 3.2.5.1 門檻值之訂定 經過了數種不同尺寸的圖像測試並觀察其偵測結果,發現當 a 與 b 滿足下列 關係時結果為最佳: 如果圖像的寬*高小於 100000,則 a=7、b=5,否則
a=⎡⎢(圖像的寬 高* )/100000 +6⎤⎥ b=⎢⎣(圖像的寬 高* )/200000 +6⎥⎦
3.3 系統實作
在 此 節 中 , 要 將 本 論 文 所 提 到 的 方 法 實 際 運 用 在 影 音 園 地 的 系 統 中 ( http://140.113.216.55/videomap )。實作的方式為運用本論文所提出之方 法,在使用者給予影片起始地點的情況下,來進行影片中景點的定位。但是如果 影片中有場景變更(scene change)的情形發生,則希望使用者可以提供場景變更 後的大致地點,縮短景點定位所需時間。 為了減少相同景點的重複偵測,必須先將範例圖像利用顏色特徵將圖像做分 群。將圖像轉成 Lab 色彩空間後,分別取 L、a、b 的平均值當特徵,再用 Delta E2000 計算任兩張圖像的顏色差距並將差距由小至大排序。依排序結果將圖像進 行分群,同一群中的圖像之顏色差距皆小於門檻值。 除此之外,當影片發生場景變更時,該畫面(frame)會編碼成 I 畫面(I frame),如果影片未發生場景變更時,則編碼成 B 畫面或 P 畫面。在考慮每支影 片的執行時間與執行效果後,決定只針對影片中 I 畫面進行偵測。 操作流程如下: (1) 複製影片及影片資訊 (2) 依照影片資訊蒐集網路圖像 (3) 網路圖像分群 (4) 抽取影片 I 畫面(5) 將影片 I 畫面與分群後的網路圖像作建築物偵測 (6) 將偵測到的景點資訊寫回資料庫 Database 影音園地 影片 複製影片 景點偵測機器 網路圖像 抽取影片的 I frame 影片資訊 網路圖像 分群 景點資訊 景點偵測 圖 3-22 影片景點自動定位流程圖
第 4 章 實驗
4.1 色彩特徵的實驗結果與分析
本節實驗的目的是分辨出不使用色彩特徵(color feature)及使用色彩特徵 所得之正確率(precision)與召回率(recall)的差異。4.1.1 資料來源與評比方式
從 Google 蒐集的 4 支介紹景點的影片中所抽取出來的圖像(1 張/秒)及 16 張在影片中出現的建築物之圖像。 評量的標準是用偵測結果的正確率與召回率來評估,正確率與召回率的算法 如下: = = 偵測正確的建築物的數量 正確率 程式所偵測出建築物的數量 偵測正確的建築物的數量 召回率 欲偵測之建築物出現的張數4.1.2 實驗結果與分析
實驗結果如表 4-1、4-2。當加入色彩特徵時,可以看到正確率很明顯的提 升,雖然召回率有所下降,但有色彩特徵的執行時間較無色彩特徵的執行時間快 上 10%,這是因為利用色彩特徵可以將某些顏色明顯不同的關鍵點在匹配時過濾 掉,節省了後面所花費的計算時間。所以,在考量執行速度與正確率後,還是加入色彩方面的特徵。 表 4-1 有色彩特徵時的特定建築物偵測結果 圖 像 編 號 (Image ID) 影 音 編 號 (Video ID) 欲 偵 測 之 建 築 物 出 現的張數 程 式 所 偵 測 出 建 築 物的數量 偵 測 正 確 的 建 築 物 的數量 正確率 召回率 1 1 80 38 34 0.894737 0.425000 2 1 62 0 0 Nan 0 3 1 62 49 39 0.795918 0.629032 4 1 69 22 22 1 0.318841 5 2 12 12 12 1 1 6 2 8 14 8 0.571429 1 7 2 8 1 0 0 0 8 2 8 3 0 0 0 9 2 8 9 8 0.888889 1 10 2 12 2 2 1 0.166667 11 3 38 1 1 1 0.026316 12 3 38 1 1 1 0.026316 13 3 333 155 155 1 0.465465 14 3 333 236 236 1 0.708709 15 4 53 29 28 0.965517 0.528302 16 4 53 44 44 1 0.830189 總和 1177 616 590 平均值 0.957792 0.501274
表 4-2 無色彩特徵時的特定建築物偵測結果 圖 像 編 號 (Image ID) 影 音 編 號 (Video ID) 欲 偵 測 之 建 築 物 出 現的張數 程 式 所 偵 測 出 建 築 物的數量 偵 測 正 確 的 建 築 物 的數量 正確率 召回率 1 1 80 85 52 0.611765 0.65000 2 1 62 0 0 Nan 0 3 1 62 67 50 0.746269 0.806452 4 1 69 44 43 0.977273 0.623188 5 2 12 17 12 0.705882 1 6 2 8 25 8 0.320000 1 7 2 8 5 2 0.400000 0.25 8 2 8 9 1 0.111111 0.125 9 2 8 11 8 0.727273 1 10 2 12 4 4 1 0.333333 11 3 38 5 2 0.41 0.052632 12 3 38 3 2 0.666667 0.052632 13 3 333 208 208 1 0.624625 14 3 333 251 251 1 0.753754 15 4 53 36 35 0.972222 0.660377 16 4 53 57 52 0.912281 0.981132 總和 1177 827 730 平均值 0.882709 0.620221
在表 4-1 中圖像編號 2 的實驗結果中,發現雖然有 62 張欲偵測之建築物的 圖像,但是卻沒有偵測到任何一張圖像中有相似的建築物,其原因是因為圖像中 欲偵測之建築物的拍攝角度除了因左右旋轉所造成的角度改變外,也包含了仰角 部分的改變,而導致建築物變形,使得關鍵點匹配結果不佳。(建築物範例圖像 與 62 張欲偵測之建築物的圖像經整理後放在 http://picasaweb.google.com/nnmeeting/ 網頁中) 圖 4-1 建築物範例圖像
4.2 加入關鍵點相對位置檢測所造成的影響
本節內容是比較建立關鍵點的對應矩陣之假設中是否含有關鍵點相對位置 檢測所造成的影響。4.2.1 資料來源與評比方式
從 Google 中所蒐集的 4 支介紹景點的影片中所抽取出來的圖像(1 張/秒)及 16 張在影片中出現的建築物之圖像。 評量的標準是用偵測結果的正確率與召回率來評估,正確率與召回率的算法 如 4.1.1。4.2.2 實驗結果與分析
有關鍵點相對位置檢測,特定建築物偵測結果如同表 4-1,無關鍵點相對位 置檢測,特定建築物偵測結果如表 4-3。從實驗結果中可以很明顯的看出使用關 鍵點相對位置檢測的正確率與召回率皆高過未用關鍵點相對位置檢測,這說明了 關鍵點相對位置檢測能確實提高圖像匹配的正確率與召回率。表 4-3 無關鍵點相對位置檢測的特定建築物偵測結果 圖 像 編 號 (Image ID) 影 音 編 號 (Video ID) 欲 偵 測 之 建 築 物 出 現的張數 程 式 所 偵 測 出 建 築 物的數量 偵 測 正 確 的 建 築 物 的數量 正確率 召回率 1 1 80 0 0 Nan 0 2 1 62 2 1 0.5 0.016129 3 1 62 13 9 0.692308 0.145161 4 1 69 12 12 1 0.173913 5 2 12 6 5 0.833333 0.416667 6 2 8 26 8 0.307692 1 7 2 8 0 0 Nan 0 8 2 8 6 2 0.333333 0.25 9 2 8 3 3 1 0.375 10 2 12 1 1 1 0.083333 11 3 38 6 1 0.166667 0.026316 12 3 38 0 0 Nan 0 13 3 333 63 63 1 0.189189 14 3 333 154 154 1 0.462462 15 4 53 0 0 Nan 0 16 4 53 14 14 1 0.264151 總和 1177 306 273 平均值 0.892157 0.231946
4.3 建物圖像偵測結果與分析
本節內容是比較關鍵點匹配條件中的門檻值大小,對正確率、召回率及執行 時間造成的影響。在判斷範例圖像中的建築物是否有出現在測試圖像中時,不考 慮影音的連續性,也就是不考慮前後圖像的偵測結果。4.3.1 資料來源與評比方式
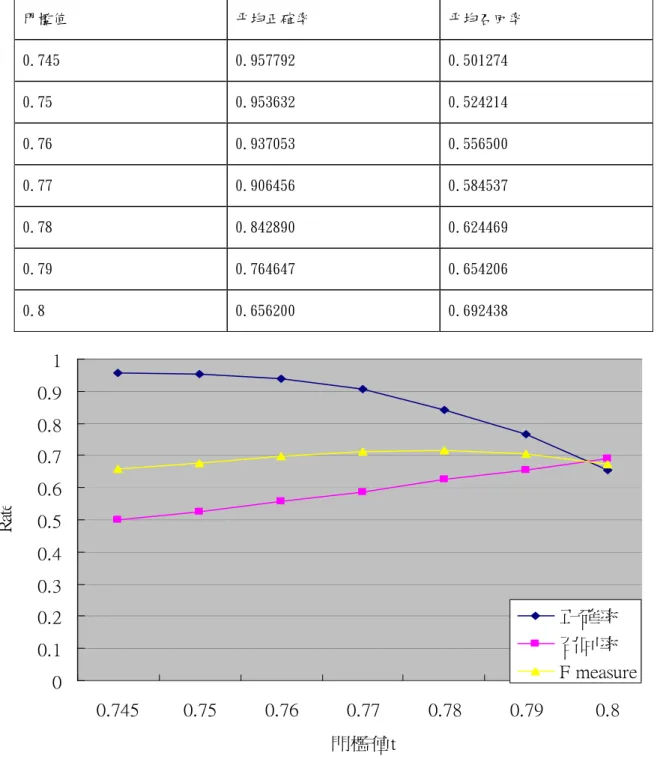
從 Google 中所蒐集的 4 支介紹景點的影片中所抽取出來的圖像(1 張/秒)及 16 張在影片中出現的建築物之圖像。 評量的標準是用偵測結果的正確率與召回率來評估,正確率與召回率的算法 如 4.1.1。4.3.2 實驗結果與分析
結果如表 4-4。從結果中可以很明顯的看出在門檻值不超過 0.77 時,正確 率皆在 90%以上,但當門檻值超過 0.77,正確率就快速下滑。這應該是門檻值超 過 0.77 後,失去了辨識背景中的關鍵點的能力,使得背景中的關鍵點影響了正 確率。表 4-4 建物圖像偵測結果 門檻值 平均正確率 平均召回率 0.745 0.957792 0.501274 0.75 0.953632 0.524214 0.76 0.937053 0.556500 0.77 0.906456 0.584537 0.78 0.842890 0.624469 0.79 0.764647 0.654206 0.8 0.656200 0.692438 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.745 0.75 0.76 0.77 0.78 0.79 0.8 門檻值t Ra te 正確率 召回率 F measure 圖 4-2 建物圖像偵測之正確率、召回率與 f 評估曲線圖
4.4 考慮影音連續性時的建物圖像偵測結果與分析
本節內容是比較程式判斷範例圖像與測試圖像中是否有相同建築物時,有考 慮影音連續性與不考慮影音連續性(4.3 節),所得出的正確率、召回率之間的差 異。在此節中,判斷的方式與 4.3 節有所不同,因為考慮影音連續性,所以在決 定是範例圖像與測試圖像是否有相同建築物時必須考慮前後數秒的匹配特定建 築物結果,但是在 3.2.5 節中所提到的門檻值 a 和 b 也因為影音連續性的關係, 導致單張影像的匹配結果錯誤不會對最後結果不會產生太大影響,所以 a 與 b 的數值有所下降。 另外,由於影片具有連續性,所以為了縮短執行時間,可使用上一張測試圖 像的偵測結果來幫助偵測此張測試圖像與範例圖像是否擁有相同建築物。在完成 範例圖像與測試圖像的關鍵點匹配的動作後,先針對範例圖像中與上一張測試圖 像所偵測出來最相似的建築物區塊,依序對此區塊內的範例關鍵點實施關鍵點相 對位置檢測及計算相似度,查看其中結果是否可通過相似度的門檻值或是門檻值 a 與 b,若通過,則代表範例圖像與此張測試圖像有相似建築物;若皆不通過, 則對範例圖像中其餘區塊的關鍵點進行關鍵點相對位置檢測及計算相似度,偵測 是否有相似建築物。如此,即可節省部份的執行時間。4.4.1 資料來源與評比方式
從 Google 中所蒐集的 4 支介紹景點的影片中所抽取出來的圖像(1 張/秒)及 16 張在影片中出現的建築物之圖像。 評量的標準是用偵測結果的正確率與召回率來評估,正確率與召回率的算法 如 4.1.1。4.4.2 實驗結果與分析
結果如表 4-5。與未考慮影音連續性相比,考慮影音連續性時,在門檻值不 超過 0.78 之前,正確率與召回率皆有明顯的上昇。這是因為有了影音連續性後, 單張影像的匹配結果錯誤不會對最後結果不會產生太大影響,所以可將 3.2.5 節中所提到的門檻值 a 和 b 的數值下降,使得原先錯誤的判斷得以糾正回來。 表 4-5 考慮影音連續性時的建物圖像偵測結果 門檻值 平均正確率 平均召回率 0.745 0.988796 0.599830 0.75 0.989262 0.626168 0.76 0.980916 0.655055 0.77 0.946163 0.701784 0.78 0.902163 0.744265 0.79 0.756956 0.785896 0.8 0.593220 0.820889 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.745 0.75 0.76 0.77 0.78 0.79 0.8 門檻值t Ra te 正確率 召回率 F measure 圖 4-3 考慮影音連續性時的建物圖像偵測之正確率、召回率與 f 評估曲線圖4.5 場景偵測結果與分析
進行場景偵測時,除了偵測兩張圖像中是否含有相同的建築物之外,通常也 會偵測圖像中是否有相同的雕像。因為雕像通常被當成地標,完全相同的雕像很 少見,所以可用雕像來當作場景偵測的目標物。在此節中,將要測試本論文所提 出之方法對於偵測雕像的效能。4.5.1 資料來源與評比方式
從 Google 中所蒐集的 3 支影片中所抽取出來的圖像(1 張/秒)及 6 張在影片 中出現的建築物之圖像。 評量的標準是用偵測結果的正確率與召回率來評估,正確率與召回率的算法 如下: = = 偵測正確的雕像的數量 正確率 程式所偵測出雕像的數量 偵測正確的雕像的數量 召回率 欲偵測之雕像出現的張數4.5.2 實驗結果與分析
表 4-6 為雕像圖像偵測結果,表 4-7 為考慮影音連續性時,雕像圖像偵測結 果。從結果來看,雕像圖像的偵測結果雖然比建物圖像的偵測結果差,但是在門 檻值不超過 0.76 的情況下,正確率依然高於 85%,所以依然可以用來偵測雕像。 至於召回率較差的原因,是因為在偵測雕像時,由於雕像外表的線條較為柔 和,所以關鍵點的數量較少,造成雕像中的各組關鍵點,僅有少量組別的關鍵點 對應關係矩陣(b)的總組數大於等於 3,得以計算物件的相似度。所以,導致偵 測雕像時會有如此低召回率的結果。(雕像範例圖像經整理後放在http://picasaweb.google.com/nnmeeting/ 網頁中) 表 4-6 雕像圖像偵測結果 門檻值 平均正確率 平均召回率 0.745 0.909091 0.147059 0.75 0.872340 0.150735 0.76 0.863636 0.209559 0.77 0.744186 0.235294 0.78 0.688073 0.275735 0.79 0.647482 0.330882 0.8 0.647799 0.378676 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.745 0.75 0.76 0.77 0.78 0.79 0.8 門檻值t Ra te 正確率 召回率 F measure 圖 4-4 雕像圖像偵測之正確率、召回率與 f 評估曲線圖
表 4-7 考慮影音連續性時的雕像圖像偵測結果 門檻值 平均正確率 平均召回率 0.745 1 0.125 0.75 1 0.139706 0.76 0.979167 0.172794 0.77 0.932203 0.202206 0.78 0.869565 0.294118 0.79 0.820513 0.352941 0.8 0.774648 0.404412 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.745 0.75 0.76 0.77 0.78 0.79 0.8 門檻值t Ra te 正確率 召回率 F measure 圖 4-5 考慮影音連續性時的雕像圖像偵測之正確率、召回率與 f 評估曲線圖
圖 4-6 雕像範例圖像
4.6 影片景點自動定位應用實驗
將本論文中所題之方法實作於影音園地中,並且上傳數支影片至影音園地檢 測本論文所提方法是否能偵測影片中所出現之景點。4.6.1 資料來源與評比方式
從 Google 中所蒐集的 12 支介紹各地景點的影片(其中有 5 支影片介紹中國 景點,5 支影片介紹歐洲景點,2 支影片介紹日本景點)中所抽取出來的圖像(I Frame)及影片拍攝地點的建築物圖像。 評量的標準是用偵測結果的正確率與召回率來評估,正確率與召回率的算法 如下:= = 偵測正確的景點數 正確率 程式所偵測出景點數 偵測正確的景點數 召回率 欲偵測之景點數
4.6.2 實驗結果
影片中之景點定位結果如表 4-8。 表 4-8 影片中之景點定位結果 影 音 編 號 (Video ID) 欲 偵 測 之 景 點數 程 式 所 偵 測 出的景點數 偵 測 正 確 的 景點數 正確率 召回率 1 4 2 2 1 0.5 2 5 6 4 0.666667 0.8 3 2 1 1 1 0.5 4 6 5 4 0.8 0.666667 5 2 1 1 1 0.5 6 3 3 3 1 1 7 4 5 4 0.8 1 8 1 2 1 0.5 1 9 5 5 3 0.6 0.6 10 1 1 1 1 1 11 6 4 2 0.5 0.333333 12 2 1 1 1 0.5 總和 41 36 27 0.75 0.658537第 5 章 結論與未來工作
5.1 結論
本文提出以圖像匹配(image matching)的方式將圖像中的關鍵點找出,再配 合圖像切割(image segmentation)將圖像中的各物件(object)分隔。之後,使用 “若關鍵點位於同一建築物中,則範例圖像與測試圖像中的匹配之關鍵點所形成 的直線段,應為互相平行"此假設,將錯誤的關鍵點匹配排除,並用建立關鍵點 對應關係的矩陣與最小平方法得到變換矩陣。利用變換矩陣和關鍵點對應關係的 矩陣得到範例圖像與測試圖像中最相近的物件。5.2 未來展望
在本論文的研究與實驗和應用中,發現有數個主題是我們可以繼續改進的重 點,在此說明如下: 1. 本論文實作於系統上是只針對I畫面做圖像匹配,但若能以每秒一張的速率抽 取圖像作圖像匹配的話,就能提高判斷景點出現時間的精確度與正確率。 2. 本論文實作的圖形匹配方法所花的時間較多,原因是在關鍵點匹配的過程中 需要將範例圖像與測試圖像中的所有關鍵點做匹配,此步驟會花許多時間, 若能在不失精確度的情形下減少時間的花費,則1.中所提的建議就能實現。3. 本論文中關於建築物匹配的正確率有不錯的效能,但召回率方面則有些差強 人意,希望將來能夠增加其他的特徵,在不影響正確率的情況下提升召回率。
參考文獻
1. D.G. Lowe, “Distinctive image features from scale-invariant
keypoints," International Journal of Computer Vision, vol. 60, pp. 91 – 110, Nov 2004
2. J. C. Platt, N. Cristianini, and J. Shawe-Taylor, “Large Margin DAGs
for Multiclass Classification," Proceedings of Neural Information Processing Systems, 2000
3. P. Quelhas, J. Odobez “Natural Scene Image Modeling Using Color and
Texture Visterms," Conference on Image and Video Retrieval CIVR, vol. 4071, pp.411 - 421, 2006
4. Q. Yanyun, Z. nanning, “Salient building detection in natural image
using SVM," IEEE Intl Conf. Vehicular Electronics and Safety, pp. 126 – 130, Oct 2005
5. Christopher J. C. Burges, “A Tutorial on Support Vector Machines for
Pattern Recognition," Data Mining and Knowledge Discovery, vol. 2, pp. 121 - 167, June 1998
6. D. Comaniciu, P. Meer, “Mean shift: a robust approachtoward feature space analysis," IEEE Trans. PAMI, vol. 24, no. 5,
pp. 603-619, 2002.
7. S. Se, D.G. Lowe, J. Little, “Global localization using distinctive
visual features," In International Conf. Intelligent Robots and Systems, Lausanne, Switzerland, pp. 226 - 231 2002
8. S. Se, D. Lowe, J. Little, “Local and global localization for mobile robots using visual landmarks," In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems,
pp. 414 – 420, Maui, Hawaii, Oct 2001.
9. D.G. Lowe, “Local feature view clustering for 3D object
recognition," IEEE Conf. Computer Vision and Pattern Recognition, Kauai, Hawaii, pp. 682 - 688. 2001
10. Joo-Hwee Lim, Jean-Pierre Chevallet, Sheng Gao, “Scene
Identification using Discriminative Patterns," In Proceedings Of ICPR 2006 pp. 642-645 Aug 20-24, 2006,
11. Jiangjian Xiao, Mubarak Shah, “Two-FrameWide Baseline Matching,".
Proceedings. Ninth IEEE International Conference on Computer Vision, 2003
12. Y. Deng, B. S. Manjunath, “Unsupervised segmentation of
color-texture regions in images and video," IEEE Trans. PAMI, vol. 23, no. 8, pp. 800-810, 2001
13. Harris, C. and Stephens, M.“A combined corner and edge detector,"
In Fourth Alvey Vision Conference, Manchester, UK, pp. 147-151, 1988 14. Luong, Q.T., and Faugeras, O.D.“The fundamental matrix: Theory,
algorithms, and stability analysis," International Journal of Computer Vision, 17(1):43-76, 1996
15. Hartley, R. and Zisserman, A, “Multiple view geometry in computer
vision," Cambridge University Press: Cambridge, UK, 2000
16. Friedman, J.H., Bentley, J.L. and Finkel, R.A. “An algorithm for
finding best matches in logarithmic expected time," ACM Transactions on Mathematical Software, 3(3):209-226, 1977
17. http://www.brucelindbloom.com/index.html?Eqn_DeltaE_CIE2000.html, 2009 年
transformations," Ph.D. thesis, Institut National Polytechnique de Grenoble, France, 2002
附錄一: 實驗資料原始檔連結
建築物景點影片連結:
1. http://lltv.libsyn.com/index.php?post_id=356602# 2. http://lltv.libsyn.com/index.php?post_id=362399# 3. http://lltv.libsyn.com/index.php?post_id=321107# 4. http://tv.liontravel.com/world_media/show_media.asp?index_id=1033&Smedia=1 &selected_img=1#網路圖像連結--建築物
1. http://eo.wikipedia.org/wiki/Dosiero:Threadneedle_street.jpghttp://www.panorami o.com/photo/238843 2. http://www.panoramio.com/photo/238843 3. http://www.travelstripe.com/images/fleet-street-london1.JPG 4. http://commons.wikimedia.org/wiki/File:17_Fleet_Street_London.jpg 5. http://www.flickr.com/photos/tkeator/2506356476/ 6. http://www.pepysdiary.com/indepth/images/2005/09/19/17_fleet_street.jpg 7. http://www.ship-of-fools.com/mystery/specials/london_05/reports/media/city/st_b rides_1.jpg 8. http://farm2.static.flickr.com/1134/1195001928_e0833f7b58_o.jpg 9. http://farm1.static.flickr.com/99/257074269_6490cef961_o.jpg 10. http://www.essential-architecture.com/LO/026-StPaulsCathedralSouth.jpg 11. http://www.richard-seaman.com/Travel/UK/London/Highlights/StPaulsFromSideS treet.jpg 12. http://www.londonpass.com/images/sections/attractions/StPaulsCathedral.jpg雕像景點影片連結:
1. http://www.youtube.com/watch?v=nR9Vxw9o5ao 2. http://www.youtube.com/watch?v=SNUaUrugU1I&feature=PlayList&p=21BA98 1999686D6B&playnext=1&playnext_from=PL&index=9 3. http://www.youtube.com/watch?v=DIRgVrOeklk網路圖像連結--雕像
1. http://www.panoramio.com/photo/7884688 2. http://www.panoramio.com/photo/14040255 3. http://images3.ctrip.com/wri/images/200806/13763395A5D5F5F25222833734.jp g 4. https://vcmvua.blu.livefilestore.com/y1mnPMzUC_DVEWfVUy3_YssE4poUp3 HMXk2ez4hOxwimpqvzvDsn0yarwHc-_Zza84sXKIOex2JHvrIqv3SCQ67OKQ9 VyrzspnjZT9IiUDdrjnukRtLj7VLGqHeGAdJ9OU1U6tN2m7jS78E9ksHSMEmi Q/DSCF20012.jpg 5. http://static.panoramio.com/photos/original/40504.jpg影片景點自動定位應用實驗之影片
1. http://140.113.216.55:8080/videomap/playerdistribute.php?name=f34dfd71c3e1eb 5d2e88373f695ec73b 2. http://140.113.216.55:8080/videomap/playerdistribute.php?name=f5f896676b21e 9a54dcd2a4799c855ec 3. http://140.113.216.55:8080/videomap/playerdistribute.php?name=b98cbecc234e4 8be642211e0ac7d9efb 4. http://140.113.216.55:8080/videomap/playerdistribute.php?name=be8e119a0897c613abb6a18b5cdbcb9a 5. http://140.113.216.55:8080/videomap/playerdistribute.php?name=ebd55b8ed34e4 26ddfa428d4adb87fc6 6. http://140.113.216.55:8080/videomap/playerdistribute.php?name=65470220d904e 821a91f023b6bb5d74f 7. http://140.113.216.55:8080/videomap/playerdistribute.php?name=9ef4de20e0d43 b0cbff1a908ceacbf0a 8. http://140.113.216.55:8080/videomap/playerdistribute.php?name=d865d41142be1 4643c35c96d09ee3ebf 9. http://140.113.216.55:8080/videomap/playerdistribute.php?name=10d82c8a05158 4b7a68d8c73c2698f85 10. http://140.113.216.55:8080/videomap/playerdistribute.php?name=829b0a433c448 861e35a598ee20e92f1 11. http://140.113.216.55:8080/videomap/playerdistribute.php?name=7327a0260ba4b 622313357bef6eaeefd 12. http://140.113.216.55:8080/videomap/playerdistribute.php?name=200809261432 RomanHoliday