國立臺中教育大學數學教育學系碩士班碩士論文
指導教授:許天維 博士
胡豐榮 博士
數學科試題分析之研究-以 100 學年
度四技二專商業類聯合模擬考為例
研究生:李仲瑜 撰
中華民國 102 年 5 月 31 日
I
摘要
本研究旨在探討「100 學年度四技二專第一次聯合模擬考」之「商業類」數學 科試題,選取北、中、南部各四所高職三年級學生,共 8473 筆答題情形作分析, 分別針對測驗與試題作質與量的分析,質的方面利用內容效度檢核表、雙向細目 表、試題檢核表等工具來檢驗;量的分析則探討信度、難易度、鑑別度,並利用 TestGraf 98、BILOG-MG、SPSS 等試題分析軟體,由學生答題狀況繪製選項特徵 曲線來進行正答與誘答選項之分析。 綜合本研究之分析結果與討論,歸納出以下結論: 一、測驗分析之結論: (一)質的分析方面:由雙向細目表、內容效度檢核表分析,可知此份測驗具有 良好內容效度。 (二)量的分析方面:受試者能力值與成績分布密度之關係分布圖呈現標準常態 分配,具有良好的統計特性;Cronbach α 係數為 0.888,具有不錯的信度值, 屬於理想之測驗。 二、試題分析之結論: (一)質的分析方面:由內容題幹選項要素分析表,可知僅有少數幾題試題完全 符合試題檢核表中之檢核項,其餘大部分的試題都至少有一項不符合,命 題教師在審題與編題時,應審慎做考量,如此即可提高測驗品質,並且避 免編輯與選用不當試題。 (二)量的分析方面:試題的難易度平均值為 0.53,屬於難易適中的試題;試題 的鑑別度平均值為 0.61,屬於非常優良的試題;由高低分組的選答情形來 分析,大部分均符合命題原則,為具有合理有效的試題選項。 三、學生答題情況分析之結論: 由「正答選項特徵曲線」可得知,大部份試題能清楚區分中等能力者數學 概念的理解;由「誘答選項特徵曲線」可得知,大部份之試題誘答選項, 均具有高誘答力,此測驗中的試題選項中大部分屬於優良選項,宜保留, 只有少部分選項屬於普通選項,需修改。 關鍵字:試題分析、選項特徵曲線目錄
第一章 緒論
第一節 研究動機---1 第二節 研究目的---2 第三節 待答問題---3 第四節 名詞解釋---3第二章 文獻探討
第一節 測驗理論的探討--- 6 第二節 試題分析--- 30 第三節 測驗分析--- 38 第四節 單選選擇題型分析--- 48第三章 研究方法與架構
第一節 研究架構--- 54 第二節 研究對象--- 55 第三節 研究方法--- 55 第四節 研究工具--- 55 第五節 資料處理與分析--- 57第四章 研究結果與討論
第一節 試題題本分析--- 59 第二節 個別試題分析--- 62 第三節 綜合分析--- 80第五章 結論與建議
第一節 結論---106 第二節 建議---106參考文獻
中文部份---109 英文部分---112
表次
表 2-1 試題反應理論與傳統測驗理論的比較--- 13 表 2-2 試題難易度等級表--- 32 表 2-3 鑑別度評鑑標準表--- 34 表 2-4 信度係數參考指標表--- 42 表 4-1 內容效度檢核表中不符合之檢核項--- 60 表 4-2 試題的難易度指數分析表--- 63 表 4-3 A 型之正答選項特徵曲線統計表 --- 65 表 4-4 B 型之正答選項特徵曲線統計表 --- 66 表 4-5 C 型之正答選項特徵曲線統計表 --- 67 表 4-6 D 型之正答選項特徵曲線統計表 --- 68 表 4-7 E 型之正答選項特徵曲線統計表 --- 69 表 4-8 a 型之誘答選項特徵曲線統計表 --- 70 表 4-9 b 型之誘答選項特徵曲線統計表 --- 71 表 4-10 c 型之誘答選項特徵曲線統計表--- 72 表 4-11 d 型之誘答選項特徵曲線統計表--- 73 表4-12 KMO與Bartlett檢定--- 75 表4-13 主成分分析--- 77 表 4-14 試題的選項篩選表--- 79圖次
圖 2-1 題目訊息量與測驗訊息量--- 16 圖 2-2 Rasch 模式中不同試題的特徵曲線圖--- 21 圖 2-3 二參數模式中不同試題的特徵曲線圖--- 23 圖 2-4 三參數模式中不同試題的特徵曲線圖--- 24 圖 2-5 試題特徵曲線--- 35 圖 3-1 研究架構圖--- 54 圖 4-1 受試者標準化後能力值與答題分布密度關係圖--- 61 圖 4-2 信度曲線--- 61 圖 4-3 試題 1 正答選項特徵曲線圖--- 65 圖 4-4 試題 8 正答選項特徵曲線--- 67 圖 4-5 試題 15 正答選項特徵曲線圖--- 68 圖 4-6 試題 4 正答選項特徵曲線圖--- 69 圖 4-7 試題 3 誘答選項特徵曲線圖--- 70 圖 4-8 試題 16 誘答選項特徵曲線圖--- 71 圖 4-9 試題 18 誘答選項特徵曲線圖--- 72 圖 4-10 試題 7誘答選項特徵曲線圖--- 73 圖 4-11 正答選項特徵曲線類型分類圓形圖--- 74 圖 4-12 誘答選項特徵曲線類型分類圓餅圖--- 75 圖 4-13 試題特徵曲線之矩陣圖--- 78 圖 4-14 測驗訊息曲線及測驗標準誤--- 78- 1 -
第一章 緒論
本章先從研究動機說明現行高職學制及多元升學管道,再從研究目的、待答 問題與名詞界定等方面加以陳述探討本研究重點。本章分為四個部分:第一節研 究動機、第二節研究目的、第三節待答問題與第四節名詞解釋,茲分述如下。第一節 研究動機
早期我國職業教育的目的,是以培養基層的技術人員為主,故強調終結性教 育( ending education ),目標是畢業後馬上投入就業市場,當時升學一詞對職業教 育的學生而言是遙不可及的,大學入學的管道並不暢通;另一方面技職教育一直 被視為國家競爭力的重要因素,其所培育出眾多各級的技術人才,促進國家經濟 的良性發展,受到社會各界的肯定,再加上近幾年來由於產業和經濟的轉型,對 高層級技術人力的需求也相對提高,顯示技職教育技術人力的素質必須提升,為 符合這項需求,最直接的方法便是提高技職教育的層級,使技職學生在這個體系 中可得到銜接一貫的技職教育,進修的機會和管道都必須得到適當的規劃。 近十年來,教育部積極推動教育改革,從升學管道變革、教學目標擬定、教 材內容修訂及課程綱要,積極整合多元入學之各種考試方式,提供多元入學管道, 以達技專院校自主選才之目的。然而,各校系在增進自主選才的自主性的同時, 卻也衍生出考生參加不同管道招生時,重複考試的經濟、時間、及精神負擔。為 簡化招生作業,並減輕重複應考人力物力浪費,教育部自九十學年度起技專院校 實施「考招分離制度」,將考試與招生分由不同的專責單位辦理,委由「技專校院 入學測驗中心」進行命題工作,考生僅需參加統一入學測驗一次之考試,即可持 該成績單向不同招生管道報名(教育部,1999,2003)。考招分離制度解決多年來 各技職教育體系學校及考生們之沉重負擔,其命題的謹慎及相關研究更是許多專 家學者共同努力的領域,其中「數學科」對於工業類、商業類、農業類、家政類、 商業設計類、幼保類、美容類、語文類、護理類之考生而言均為必考科目,考生 眾多影響層面甚大。 因此本研究針對「100 學年度技術校院四年制與專科學校二年制統一入學測驗 第一次聯合模擬考」的「商業類」受試者之「數學科」正答題情形作試題分析, 以期提供一套有效之試題分析方法,作為學校教師或命題專家學者改進命題的參- 2 - 考,進而瞭解技職學校商業類學生所具備的數學能力之差異性,協助教師未來改 良教學策略與方法。
第二節 研究目的
根據前述之研究動機,我們可藉由評量來瞭解學生學習之成果,一份評量試 題的優劣,常影響評量結果的準確性。因此本研究針對「100 學年度技術校院四年 制與專科學校二年制統一入學測驗第一次聯合模擬考」的「商業類」受試者之「數 學科」試題所提供之測驗資料,首先檢測作答的測驗資料是否適合用「試題反應 理論」(以下簡稱 IRT)來進行試題內容及測驗統計之分析,其次再進行試題分析 的工作,而試題分析又可分為質的分析與量的分析。質的分析方面將利用本研究 所提供之「試題檢核表」及「雙向細目表」、「內容效度檢核表」來檢核。量的分 析方面,分別為針對個別試題優劣評鑑的分析,包括了每個試題的難易度、鑑別 度、猜測度、正答力、誘答力、訊息量以及信度等,以說明個別試題的特性。經 由質與量的分析後,瞭解相關數據的意義與分析的結果,將對個別試題以及整份 測驗提出優缺點, 以期能在未來的統一入學測驗或是一般考試,能提供評鑑試題 優劣的一套有效可行之分析模式,並朝著有優良的試題才有優良的評量結果之方 向邁進。 具體而言本研究有下列目的: 一、對「100 學年度技術校院四年制與專科學校二年制統一入學測驗第一次聯合 模擬考」商業類數學科的個別試題及測驗題本作質的分析,包括試題內容、 題幹、選項等要素,利用試題分析表、內容效度分析、雙向細目表分析進行 檢核及分析。 二、對「100 學年度技術校院四年制與專科學校二年制統一入學測驗第一次聯合 模擬考」商業類數學科的個別試題及測驗題本作量的分析,包括試題的難易 度、鑑別度、猜測度、選項分析、試題特徵曲線分析及測驗題本的信度。 三、根據試題特徵曲線,對「100 學年度技術校院四年制與專科學校二年制統一 入學測驗第一次聯合模擬考」商業類數學科的題目進行相關分析。- 3 -
第三節 待答問題
一、「100 學年度技術校院四年制與專科學校二年制統一入學測驗第一次聯合模擬 考」商業類數學科試題的作答資料是否適合 IRT 模式的分析? 二、「100 學年度技術校院四年制與專科學校二年制統一入學測驗第一次聯合模擬 考商業類數學科試題」在質的分析與量的分析中,其特性為何? 三、根據試題特徵曲線,分析「100 學年度技術校院四年制與專科學校二年制統 一入學測驗第一次聯合模擬考商業類數學科試題」的試題特徵曲線有哪些類 型及特性?第四節 名詞解釋
為使讀者更清楚地瞭解本研究的用語,本節對本研究涉及的幾個特定名詞提 出定義如下:壹、考招分離制度
教育部為推動招生入學管道多元化,避免過去單一聯招管道造成學生一試定 終生以及學校各校系無法有效自主選才之缺失,規劃採行「考招分離制度」之招 生方式,並配合各校之推薦甄選、保送、直升、繁星計畫、申請入學及登記分發 等方式,共同構成技專院校多元入學方案。所謂考招分離制度,係指自九十學年 度起,技專院校入學之考試與招生工作將分由不同的專責單位辦理。由「技專校 院入學測驗中心」承辦考試相關之命題、印題與測驗工作,學生僅需參加一次測 驗,其成績可供各類多元入學管道之招生使用,減少學生重複報考各招生委員會 的考試次數與負擔;招生事務仍由各招生學校單獨或聯合組成招生委員會辦理, 各校依招生規畫提供名額參加各類不同入學管道招生的一種制度。報考時考生可 自行試興趣、能力和欲就讀校系所需採計科目,自由選擇測驗中心所提供的科目 並加以選考,以提供日後各科入學申請或推甄使用。決定考試科目後,考生須先 參加由教育部成立之「技專院校入學測驗中心」所提供的統一入學測驗,在取得 測驗成績後,才能根據測驗成績報名參加採用統一入學測驗成績之入學招生管 道。如此可避免考生為選讀各校系,在同一學年中參與由各校系所分別舉辦的多 次考試或甄選,各校亦可根據自行訂定之標準錄取各類專長考生。- 4 - 技職教育體系是我國的重要教育制度之一,也是培育國家建設人才的搖籃。 教育部為改進技職教育體系傳統聯招考試,並整合現行各類多元入學方式,進而 簡化招生作業,提升命題品質,以達技專校院自主選才的目的,自民國 87 年 11 月至 88 年 8 月,委託國立雲林科技大學進行「考招分離」專案規劃研究,於 88 年 7 月 8 日召開會議,決議委由國立台北科技大學成立「技專校院招生策進總會」, 並委由雲林科技大學協助成立「技專校院入學測驗中心」。自 90 學年度起,有關 四技二專、二技等技專校院入學測驗命題、題庫建立、考試、成績處理、資料建 立及研究改進等相關工作,均委由「財團法人技專校院入學測驗中心基金會--技專 校院入學測驗中心」此一專業的測驗機構來統籌辦理。
貳、試題反應理論
試題反應理論( item response theorem;IRT ),,又稱潛在特質論( Latent Trait Theory ),為假設受試者在相對的特質或特性的存在下,透過受試者答題的反應, 能用一個函數關係,將受試者的潛在能力和實際得分情形連結在一起。受試者的 測驗成績是由一些看不見的能力特質來決定,此能力特質可經由測驗試題表現出 來,IRT 就是依據受試者在試題上的實際反應,來分析試題的難易度、鑑別度、猜 測度,等試題的內在特性與受試者的個人能力特質的一種理論。
叁、選項特徵曲線
選項特徵函數是將受試者能力與試題選項反應結果之間的關係以數學模式表 示。如果將此模式所要表達的關係以圖形化的方式表示,則稱為選項特徵曲線, 利用圖形化的方式來記錄或比較資料及數據,相較於冗長的文字敘述或單純的數 字表現來的詳盡且清楚,選項特徵曲線具有此特性。它以受試者的能力為橫軸, 並以受試者在某一試題之選答率為縱軸,事先並無假設其服從某一特定之試題反 應模式,完全根據受試者的作答資料,再配合平滑化法之使用,得一平滑之曲線 圖( Ramsay,1991 )。肆、試題分析
是指以量化或質性的方式,對試題進行其所具備各項指標之分析,以本研究 為例,依測驗資料進行試題題本與個別試題的檢核。在個別試題檢核中,質的檢 核包含內容、題幹及選項要素的分析;量的檢核包含難易度、鑑別度及選項分析。- 5 -
在試題題本的檢核中,質的檢核包含內容效度檢核表及雙向細目表的分析;量的
- 6 -
第二章 文獻探討
美國教學評量家凱伯勒( Kibler, 1978 )在其所著「教學目標與評量」一書中, 提出「教學基本模式」( The General Model of Instruction; GMI ),把教學的歷程分 為教學目標、學前評估、教學活動、評量等四個部份。根據各個教學單元的具體 教學目標來安排整個教學活動,再用適當的評量工具與方法來了解教學成效,因 此教學活動、目標與評量是環環相扣的。在各領域的教材內容裡,具體的單元教 學目標是評量的基礎,這些基礎常被用在標準化的測驗中來命題。因此,要分析 一份測驗或試題的好壞,除了要具備強而有力的測驗理論外,還必需從測驗的本 質,即具體的教學目標來檢視。本章擬先介紹本論文主要分析的測驗試題之理論, 即試題反應理論;其次介紹個別試題分析的各種指標,包括質的分析與量的分析; 再從信度、效度來看整份測驗;最後為單選選擇題題型分析,主要探討其基本性 質、命題原則、優點與限制,作為後面章節綜觀本次試題並給予改進的依據。
第一節 測驗理論的探討
測驗理論( test theory )(或全稱叫心理測驗理論)是一種解釋測驗資料間實證 關係( empirical relationships )有系統的理論學說(余民寧,1997)。 心理與教育測驗雖是廿世紀新興的應用科學,追本溯源測驗可說是濫觴於中 國(余民寧,1997),其淵源可溯自西元一千多年前中國以六藝取士及隋唐之後建立的科舉制度( Dubois, 1970;余民寧,1997a,1997b;簡茂發,1987; Laycock, 1979; Silverman, 1995 )。 近代的心理計量學( psychometrics ),則是誕生於歐美各國,在十九世紀末葉, 當時受德、英、法三國心理學家致力於將心理特質予以量化的科學研究之影響, 對以後智力測驗的發展,是有啟發之作用。而第一套標率化心理測驗的問世,則 是在西元 1905 年編製成的;比奈( A.Binet, 1857~1911 )與另一學者西蒙( T.Simon, 1873~1961 )承法國教育部之委託所發展的智力測驗-比西量表( Binet- Simon Scale ),因而被後人尊稱為智力測驗之父。後來經美國史丹佛大學教授推孟( L.M. Terman, 1877~1956 )的修訂,是為著名的史丹佛-比奈智力量表( Stanford-Binet Intelligence Scale )(余民寧,1997;路君約,1989;張春興,1994;簡茂發,1987)。
- 7 -
測驗理論即發源於此,以提供測驗編製與評鑑的客觀標準及分析方法,來協 助施測者正確地解釋及運用施測得來的結果,是一門有系統解釋測驗資料的學 說。它的發展迄今已邁入不同的新紀元,測驗理論學者通常把它劃分成二個學派: 一為古典測驗測驗理論( classical test theory; CTT ),主要是以真實分數模式( true score model ) ( Gullikson, 1987; Lord & Novick, 1968 )為骨幹;另一為當代測驗理論 ( modern test theory ),主要是以試題反應理論( item response theory ) ( Hambleton & Swaminathan, 1985; Hambleton, Swamination & Rogers, 1991; Hulin, Drasgow & Parsons, 1983; Lord, 1980 )為架構。這兩派理論目前並行流通於測驗學界,但試題 反應理論卻有後來居上,逐漸凌駕於古典測驗理論上,甚至進而取而代之之勢。 以下分別介紹古典測驗理論與試題反應理論。
壹、古典測驗理論
比奈-賽門的第一個心理測驗問世之後,正是心理計量學誕生之始,後經諸多 學者如:Cronbach, 1951; Guilford, 1954; Gullikson, 1987; Guttman, 1944; Lord & Novick, 1968; Richardson, 1936; Terman, 1916; Thurstone, 1929; Tucker, 1946 的研究 與闡述,終於歸納形成古典測驗理論等學說。 一、誤差理論的影響 測量( measurement )是科學的開端,可以說沒有測量就沒有科學;但接受科學 訓練的科學家們在測量時都不約而同地遇上一個問題,就是在測量同一物體時會 有不同的測量結果;甚至同一位科學家測量同一物體多次,都可能得到不同的結 果。這個問題一直都是當作「誤差理論」的命題來處理,於是產生了隨機誤差 ( random error )與系統誤差( system error )的概念,如何處理因測量器具造成的系統 誤差或是測量時伴隨之隨機誤差,引起科學家的興趣並廣泛探討-若是所有的測 量都會產生些微的誤差,那麼哪一次才是測量的真值?而所謂「些微」的誤差又 是多少?若測得一個新的測量值,在無其他測量值比較之下,它的誤差又為何? 於是科學家們將單一次的測量與正確值的差異,稱為測量誤差( measurement error ) 或觀測誤差( observation error ),並進行定量分析。發現利用增加測量次數,求其 平均值最可能接近其真實測量值,而系統誤差乃因測量工具或施測者的偏差所造 成的,除非改良測量工具或是換人施測,否則很難解決系統誤差的問題。類似這 樣的想法,在以測量人的潛在特質為目標的古典測驗理論下,測量誤差可視為在
- 8 - 相同的條件下,對受試者施測同一測驗無限多次後,單一受試者在一組測驗上得 分的差異量( Osterlind, 1989 )。在現代測驗理論裡,受試者能力值必要的基本假設 是能力值適合常態分配,這種因微小隨機誤差累積而產生常態分佈的誤差理論研 究,乃是 P.S.Laplace(1749-1827) 與 C.F.Gauss (1777-1835)等人努力的研究成果, 而成為對於人類之潛在特質分佈是為常態分佈假設的主要依據所在( Bennett, 1998, 2001 )。 在測驗理論中,測驗試題是施測者用來轉化受試者心理特質成為數據的工 具,以利進行各種客觀科學研究,而 CTT 的理論基礎即是建立在受試者答對題目 的多寡上,以此建立分數與被測能力的關係,並以此分數來預測受試者的被測能 力,然而測驗有不同的誤差來源,它影響測驗的信度和確度。就邏輯上來說,瞭 解測驗分數的誤差來源,就能在設計測驗時減少誤差( Kubiszyn & Borich, 1996, l997 );就統計上來說,使用多次測驗後的平均分數,是比使用一次測驗分數來得 好,因為平均分數對被測行為的採樣較大。 二、真實分數( true score ) 早期心理學家藉由測驗工具將個人的某種心理特質數量化,發展出一套解釋 測驗分數的模式,若我們以測驗分數來代表受試者能力,那麼受試者在某一次測 驗上的得分,就可以看成測量其能力高低的觀察值;但是一份再好的試卷若僅對 受試者施測一次,就以此次分數去推估受試者能力,似乎不足以讓人信服,再加 上有許多的因素都可能會影響受試者在測驗上的表現,也就無法肯定是否就有測 得施測者原先想測的能力。因此利用統計抽樣的觀念,解決的方法是由受試者接 受測驗無數多次後,取其測驗分數的平均數,藉以推估受試者的能力;但在實際 應用上,施測無數多次後求測驗分數的平均值的辦法並不可行,不過這個想法是 可以幫助去我們估計受試者的能力。 此一模式將受試者的測驗分數分成兩部分:一為「真實分數」,代表觀察不到 的某一潛在特質( latent trait ),另一為「誤差分數」,代表(觀察不到,且不代表潛 在特質,卻是研究者想要極力去避免或設法降低的部分)因測量所造成的彼此不被 此一潛在特質所包含的部分,因此古典測驗理論又稱為「古典真實分數理論」 ( classical true-score theory )(劉湘川、許天維,1994)。
- 9 -
古典測驗理論又稱為「古典真實分數理論」( classical true-score theory ),由於 是依據弱勢假設( weak assumption )而來,故又稱為「弱真分數理論」( weak true-score theory )。其內涵主要是以真實分數模式( Gullikson, 1987; Lond & Norick, 1968 )X = T + E 為骨幹,亦即觀察分數( observed score; X )等於真實分數( true score;
T )與誤差分數( error score; E )之和為理論架構,其中觀察分數是受試者在測驗中所 得到的分數;真實分數在理論上是受試者接受無數次測驗分數的平均數或期望 值,並無法正確的被測量到;誤差分數指的是測量的誤差,也就是受試者觀察分 數和真實分數的差。 然而真分數模式雖是一種簡單線性模式,在應用時必須滿足一些基本假設, 其主要的假設有二: 1. 觀察分數的期望值等於真實分數 ( ) ( ) ( ) ( ) ( ) E X E T E E E TE E T T 2. X、T、E 互相獨立 0 TE 即真實分數與誤差分數間呈零相關 1 2 0 E E 即不同測驗的誤差分數間呈零相關 1 2 0 E T 即不同測驗的誤差分數與真實分數間呈零相關 根據以上的假設,古典測驗理論衍生出試題分析時的重要指標,如難易度、 鑑別度和信度( reliability )等,以下將分別介紹其內涵及其公式: (一)難易度 試題的難易度與測驗的效率有關,也就是指試題困難或簡單的一種指數,難 易度是以答對該試題的百分比來表示,通常以 P 代表試題難易度( difficulty ),難 易度的計算有兩種方式: 1. 2 H L P P P 2. P R 100 % N 其中P 表示高分組(全體受試者當中分數最高的 27 %) 答對該試題的百分H 比,P 表示低分組(全體受試者當中分數最低的 27 %)答對該試題的百分比,NL 為全部受試者的人數,R 為答對該題的人數。
- 10 - P 值介於 0 到 1 之間,數值愈小表示試題愈困難,反之則愈簡單,所以此試題 的難易度其實指的是試題的容易度。 (二)鑑別度 所謂鑑別度是指試題對不同能力的受試者是否能反應出其答題的差異,也就 是說鑑別度高的試題,對於能力高的受試者其答對率高;對於能力低的受試者其 答對率低。若以 D 代表鑑別指數,DPH PL,其中P 與H P 的定義如同難易度之L 所述,其值介於-1 與 1 之間,愈靠近 1 表示個別試題反應與測驗得分之間的一致 性愈高。 (三)信度 從測量誤差來看,信度就是指測驗的分數反映出真實量數( true measure )的程 度,也就是指測驗沒有誤差的程度。信度的概念即在估計測驗的誤差,測驗分數 中有多少比例是由於受試者之間能力的真實差異( 2 T )造成的,有多少比例是由於 測驗誤差( 2 E )造成的,當測驗誤差愈小,則測驗的信度愈大。根據 CTT 真分數模 式 X = T + E,X、T、E 互為獨立的假設,可推得: 2 2 2 X T E 2 2 2 2 1 T E X X 2 2 2 2 1 2 T E XT X X 一般來說,以上述公式來表示測驗信度,即 2 2 2 1 E XT X 其理論模式的發展已為時甚久,發展的相當規模,且所採用的計算公式簡單 明瞭、淺顯易懂,適用於大多數的教育與心理測驗資料,以及社會科學資料的分 析,為目前測驗學界使用與流通最廣的理論依據。但也因其模式過於簡化,於是 產生了以下幾點缺失( Guion & Ironson, 1983; Wright, 1977 ):
1. CTT 所採用的指標,諸如:難度( difficulty )、鑑別度( discrimination )和信度 ( reliability )等,都是一種樣本依賴( sample dependent )的指標;也就是說,這 些指標的獲得會因接受測驗的受試者樣本的不同而不同,因此,同一份試卷
- 11 - 很難獲得一致的難易度、鑑別度、或信度。
2. CTT 以一個相同的測量標準誤( standard error of measurement ),作為每位受 試者的測量誤差指標,這種作法並沒有考慮受試者能力的個別差異,對高、 低能力兩極端組的受試者而言,這種指標極為不合理且不準確,致使理論假 設的適當性受到懷疑。 3. CTT 對於非複本( nonparallel ),但功能相同的測驗所測得的分數間,無法提供 有意義的比較,有意義的比較僅侷限於相同測驗的前後測分數或複本測驗分 數之間。 4. CTT 對信度的假設,是建立在複本( parallel forms )測量的概念假設上,但是這 種假設往往不存在於實際測驗情境裡。道理很簡單,因為不可能要求每位受 試者接受同一份測驗無數次,而仍然假設每次測量間都彼此獨立不相關,況 且,每一種測驗並不一定同時都有製作複本,因此複本測量的理論假設是行 不通的,從方法學邏輯觀點而言,它的假設也是不合理的、矛盾的。
5.CTT 忽視受試者的試題反應組型( item response pattern ),認為原始得分相同的 受試者,其能力必定一樣;其實不然,即使原始得分相同的受試者,其反應 組型亦不見得會完全一致,因此,其能力估計值應該會有所不同。事實上, 考試的試題中每一題的難易度和鑑別度都不盡相同,因此,可能造成某一考 生能力不是很高,但是他很從容的答對了 5 題簡單的試題;而另一位考生能 力不錯,但是他也只答對了 5 題,不過這 5 題是困難度比較高的試題,若以 四技二專考試數學科來看,每一題的計分相當,因此二位考生的分數是相同 的,不過從能力上來看,如此的判別方式就有瑕疵,因此,對於受誐者能力 估計值,應該會隨著受試者的試題反應組型和題目的難易度而有所不同才合 理。 6.對偏差試題( biased item )的界定、測驗分數的等化、題庫的建立、適性測驗等, 未能提供令人滿意的解決辦法。 貳、試題反應理論
為了克服古典測驗理論的缺失,遂有「試題反應理論」( Item Response Theory; IRT )的誕生。相對於古典測驗理論,IRT 模式是依據強勢假設( strong assumptions )
- 12 - 而來,用一個函數關係,將受試者的濳在能力和實際得分情形聯結在一起,受試 者的測驗成績是由一些看不見的濳在特質來決定,經由測驗試題表現出這些特 質,每個受試者在接受測驗後,會有不同的濳力表現出來,通常用數值來表達不 同受試者濳在特質上的相對程度,亦即 IRT 中受試者的能力參數。IRT 就是以數學 式表示受試者能力與試題難易度、鑑別度及猜測度等參數間的關係,而這個數學 關係即大家所熟悉的機率,以受試者的答對機率表示縱軸,受試者的能力為橫軸 斷畫出來的曲線即為「試題特徵曲線」( Item Characteristic Curel; ICC )。ICC 能清 楚扼要地表示試題參數與能力間的關係變化,藉由模式求出受試者在試題上的表 現與對其能力之估計量的關係。不同的 ICC 就代表不同的試題參數與能力間的變 化關係,每一種關係就有其相對應的一條 ICC,亦即每一種試題反應模式都是用來 描述受試者能力與答對機率間的關係。 目前有許多測驗統計學者對測驗資料(或全體受試者的反應組型)、受試者的能力 參數與試題特徵曲線等三者之間的關係,以不同的數理統計公式加以描述進 而形 成各種不同的試題反應理論(劉湘川、許天維、鄭富森,1998)。以下將分別針對 IRT 與 CTT 的比較、常見的 IRT 模型與參數、IRT 基本假設與檢定、IRT 模式的應 用四個項目,分述如下: 一、IRT 與 CTT 的比較 IRT 的模式是針對單一試題的作答反應所提出的數學模式,在其模式中同時考 量了受試者能力與試題特性對答對機率的影響,所以它是一種直接描述作答行為 的模式。此外,IRT 其實是許多試題反應模式的總稱,這些 IRT 模式是分別依據各 種不同計分方式與不同作答方式的測驗情境所發展出來的。(陳柏熹,2008)IRT 解決了諸多 CTT 的限制,其差異與比較如下表 2-1。
- 13 - 表 2-1 試題反應理論與傳統測驗理論的比較 試題反應理論( IRT ) 傳統測驗理論( CTT ) 模式特性 1.針對單一試題的作答反應所提出的 數學模式。 1.針對測驗總分所提出的數學模式。 2.現有各種不同的 IRT 模式,適用於不 同計分方式與作答方式的測驗中。 2.各種不同計分方式與作答方式的測驗 都使用同一套模式。 試題參數 特性 題目特性(參數)的估計不會受到試者能 力所影響。 題目特性(參數)的估計會受到試者能力所 影響。 能力與分 數量尺特 性 1.對受試者的能力估計不會受到題目 特性所影響。 1.對受試者的能力估計會受到題目特性 所影響。 2.根據 IRT 模式與概似函數估計受試者 最有可能的程度值,有比較強的數學 理論基礎。 2.根據各題目的配分直接加總所得的分 數,間接推測出受試者的程度值,較缺 乏數學理論基礎。 3.可以直接參照題目的特性來解釋分 數,也可發展出一套參照標準(常模 參照或標準參照)來解釋分數。 3.通常需要額外發展出一套參照標準(常 模參照或標準參照),才能解釋測驗分 數的意義。 4.用某些 IRT 模式可算出等距量尺。 4.當群體的分數完全符合常態分布時,才 能轉換出等距量尺。 測量精準 度(信度) 測量精確度的評估是以題目為單位來 計算再加總起來,因此受試者的測量精 確度(訊息量)是隨著受試者的能力以及 所接受的題目特性而有所不同。 測量精確度的評估是以測驗為單位,因此 接受同一測驗的所有受試者其測量精確 度(信度)都相同。 應用 編製測驗(量表)、分數等化,編製題庫、 電腦化適性測驗、組合測驗 編製測驗(量表) 整體評估 優點:具有能力估計不變性、具有題目 參數估計不變性、測量精準度的 概念較合理、應用層面較廣。 優點:模式簡單易理解,能力與試題參 數容易計算。 缺點:模式不易理解、能力估計與試題 參數估計較麻煩,須仰賴電腦軟 體來分析。 缺點:不合理地假設不同人的測量精準 度相同、應用層面較狹隘,受試者 程度值會受題目特性所影響、題目 參數值會被受試者特性所影響。 (一)IRT 模式特性 IRT 針對單一試題的作答反應所提出之,適用於不同作答方式及計分方式。如 果成就測驗中都是採用是非題、選擇題等客觀測驗題型,就很適合用二元計分的 IRT 模式;如果包含計算題、簡答題、申論題等開放式題型時,就可採用部份給分
- 14 - 模式;也有專為語文類科的閱讀測驗或克漏字測驗等相依題所設計的題組反應模 式。如果是態度量表中採用 Likert 式的多點計分量表,就可以採用等級反應模式 或評定量尺模式。如果希望藉著不同向度間的相關性來提高多元性向測驗、人格 測驗或綜合能力測驗的測量精準度,還可以採用多向度 IRT 模式。 (二)試題參數特性 試題參數是指試題的難易度、鑑別度、猜對率……等用來描述試題特性的指 標。在 IRT 中,題目參數的估計不會受到試者能力所影響。這主要是因為在 IRT 中已經將試題參數與受試者能力同時納進其模式裡,因此在估計其試題參數時已 經考量了受試者能力的影響,因此所估計出來的試題參數不會受到受試者能力所 影響。所以在 IRT 中估計試題參數時,受試者是否具有代表性並不是很重要,只 要受試者的人數夠多(單參數模式至少 200 人,三參數模式至少 1000 人),程度 值不會過度集中,就能夠估計出穩定的試題參數。 在傳統測驗理論中,試題參數幾乎是完全決定於受試群體的能力。以難易度 為例,如果受試群體的能力較高,則計算出來的試題難易度值(答對率)就變高,亦 即題目變簡單;如果受試群體的能力較低,則計算出來的試題難易度值(答對率) 就變低,亦即題目變難。所以試題是難還是簡單,完全取決於抽樣時所選到的受 試群體能力高低,因此樣本的代表性對試題參數的估計有很重要的影響力。同樣 地,試題鑑別度也會明顯地受到受試群體的能力分散程度所影響。(陳柏熹,2008) (三)能力與分數量尺特性 在 IRT 中,對受試者的能力估計值也不會受到試題特性所影響,這也是因為 IRT 模式已經將試題參數與受試者能力同時納進其模式裡,因此在估計受試者能力 時已經考量了試題參數的影響,因此所估計出來的試題參數不會受到受試者能力 所影響。此外,IRT 的程度值是根據 IRT 模式與概似函數( likelihood )所估計出來 的,有比較強的數學理論基礎。而 IRT 的程度值與試題難易度值是共用同一個量 尺,也就是說一個人的能力高低可以直接參照題目的難易度以及題目的描述句來 解釋,因此不需要參照群體就能詳細地解釋受試者的能力特性。最特別的是,如 果使用 IRT 中的 Rasch 模式(單參數模式),則所估計出來的受試者能力值具有等 距量尺的特性,亦即其能力量尺的單位距離是相同的,這可以由 Rasch 模式的推 估證明出來(王文中,民 86)。
- 15 - (四)測量精準度 關於測量精準度,IRT 不是使用傳統測驗的信度,而是採用訊息量( information ) 的概念,它表示試題在不同能力點上的測量精準度。訊息量愈高表示試題對該能 力點的測量精準度愈高,其計算公式如公式(2-4)所示: 2 ' ( ) i i i i P I PQ (2-4) 其中P 為 Pi' i對 的一階微分。從另一方面來解釋,訊息量也反映出試題在不同 能力點的測量誤差( standard error, SE ),訊息量愈高表示測量誤差愈小,兩者間的 關係為: 1 ( ) ( ) SE I , (2-5)
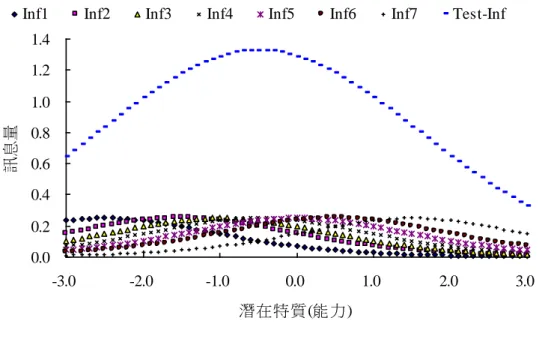
測量誤差的概念與傳統測驗理論中的測量標準誤( standard error of measurement; SEM )的概念很相似。只是測量誤差是隨著能力的不同而異的;但傳統測驗理論中 的測量標準誤對所有受試者而言都是相同的。 此外,根據 IRT 的局部獨立性的假設,各題目所提供的訊息量彼此是沒有關 聯的。因此可以將測驗中所有題目的訊息量加總得到測驗訊息量( test information )。 此測驗訊息量的概念就與傳統測驗信度的概念非常相似,只是測驗訊息量的高低 是會隨著受試者能力不同而改變的;但傳統測驗信度的概念並沒有這個特性。圖 2-1 是不同題目的訊息量與整份測驗的訊息量,從圖中可以看出這份測驗對高能力 與低能力受試者所提供的訊息量較低;但是對中等能力受試者所提供的訊息量較 高,這是因為這份測驗的題目難度大多是屬於中等難度的題目,因此對中等能力 者的測量精準度較高。
- 16 - 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 -3.0 -2.0 -1.0 0.0 1.0 2.0 3.0 潛在特質(能力) 訊息量
Inf1 Inf2 Inf3 Inf4 Inf5 Inf6 Inf7 Test-Inf
圖 2-1 題目訊息量與測驗訊息量 (五)應用 IRT 是促進現代測驗進步的重要關鍵,尤其是電腦化適性測驗。基於 IRT 的單 向度假定與受試者能力估計的不變性,接受不同題目的受試者其能力就可以比 較,因此就能讓受試者都接受適合於自己能力的題目,達到適性測驗的目的。除 此之外,IRT 的試題參數較不受樣本所影響,因此很適合用來發展題庫;而 IRT 的 能力也較不受試題參數所影響,所以也很適合用來進行能力分數的等化。另外,IRT 也明確地建構出試題與測驗之間的關係,因此可以直接根據測驗的目的(例如希 望對不同能力者的測量誤差要低於多少)來選擇測驗題目,組成各種形式的測驗。 而傳統測驗理論的應用就比較侷限在測驗編製或量表編製上,很難應用在上述各 層面中。 整體而言,IRT 是屬於理論架構較嚴謹、應用層面較廣的測驗理論,IRT 所提 來的諸多測量特性都較符合實際的測驗情況;但是由於其模式較複雜不易讓人理 解,計算過程也較繁瑣,因此尚未廣泛地被大眾所接受。不過隨著電腦科技的進 步,進行 IRT 分析時所需要的計算已經都可以用電腦來執行,因此也已經漸漸被 應用在一些著名的大型測驗中,例如國外的 TOEFL、GRE 測驗,以及國內的國中 基本學力測驗等。而傳統測驗理論由於已經被使用許久,而且其理論概念較簡單,
- 17 - 目前現有的測驗也大多以它為基礎所發展出來的,因此短期內還不太容易被 IRT 所取代;然而它在測量特性上的一些問題以及應用層面的侷限性,已經讓某些領 域的測驗(量表)編製者漸漸轉向以 IRT 為理論基礎來發展測驗。相信未來 IRT 在測驗評量領域的普及率應該會愈來愈廣。 二、IRT 基本假設及其檢定 IRT 雖然改進了 CTT 諸多缺失,但由於模式的嚴謹性,其所適用的測驗資料 種類誠屬有限。所以 IRT 在應用時是否有效,端賴理論的假設有無符合受試者應 答的實際情形,以下是 IRT 中各試題應答模式的幾個基本假設,惟有在假設成立 的前題下,試題應答模式才能被用來分析測驗資料(余民寧,1997; Weiss & Yoes, 1991):
(一)單向性( unidimensionality )
是指測驗只測一個特質或能力。在此「測驗」只表示測量同一特質或能力的 題目。如果以一小組的題目,同時測量幾個特質或能力時稱為多向度
( multi-dimentional )。Hambleton & Swaminathan(1985)認為只要測驗資料有一個「主 控」因素或成分,就可算符合單向性,而這個主控因素便是特質或能力。Crocker & Algina (l986)認為單向性就是項目間統計依賴( statistical dependence ),也就是對整 體受試而言,項目間互相關聯時才有單一特質的存在。如果測驗是單向性時對整 體受試而言,項目間為相互關聯,故應只有一條迴歸線,以表示只有一個特質存 在。而單向性的認定,當中比較常用的是 Kaiser (1970)所提出的,只有唯一的一個 因子其特徵值超過 1 ( K 標準 );Reckase (1979)建議,第一因素應能解釋百分之二 十以上的變異;或第一因素的特微值明顯大於第二因素的特徵值,且因素一與因 素二的特徵值之比值很高( Hutten, 1980 );以及( Lord, 1980 )所修正的,除了因素 一與因素二的特徵值之比值很高之外,第二因素的特徵值並不比其他的因素之特 徵值來的大多少。雖然使用試題反應理論時,必須符合單向性的假定,但是單向 性的強或弱,與試題品質的好壞不一定有關。 (二)局部獨立( local independence ) 就是對某受試能力而言,項目間無相關存在,這意味著含蓋在 IRT 模式的能 力因素,才是唯一影響受試者在測驗試題上做反應的因素。受試者對某一試題作
- 18 - 答結果,並不受其它試題影響。假設U 表示表示受試者在第i i 題上的反應,則能力 值為的受試者在某份測驗上的反應組型的機率可以下列公式表示: 1 2 1 2 1 ( , , , , , | ) ( | ) ( | ) ( | ) ( | ) ( | ) n i n i n i i P U U U U P U P U P U P U P U
這公式即說明了對某一特定能力受試者而言,他在某份測驗上的反應組型的 機率,等於他在單獨試題上的反應機率的連續乘積。 通常當單向性假設獲得成立時,局部獨立性假設也會獲得成立,因為這兩個 概念是相通的(余民寧,1992a)。但局部獨立在下列情況下無法成立,一是影響 測驗的表現能力向度不只一種時,二是連鎖性試題以及試題本身提供作答線索 等,在這種情況下 IRT 模式也就無法適用於該筆測驗資料。換言之,項目對整體 受試者是統計依賴,對某能力則是統計獨立( statistical independence )。 (三)非速度性( nonspeedness ) 由於試題反應理論模式所應用的試題均屬於難度測驗,受試者須有機會回答 所有試題才能有效測出受試者的濳在特質或能力。也就是測驗的實施不是在速度 限制下完成的,受試者在答題時沒有時間限制,即表示若受試者沒有答的題目表 示他不會答,而不是沒有時間作答。如果受試時間有限制,受試者答題的好壞, 普遍受到答題速度的影響,測驗成績會受到能力以外的因素所影響,前述的單向 性假設就會受到質疑。所以這一點常隱含在單向性的假設中,只是不常被 IRT 學 者提起,但這項假設必須要被考慮到。 (四)知道一正確假設 這個假設是指受試者只要知道某試題的正確選項便會答對該試題;換句話 說,如果受試者答錯某試題,就表示受試者不知道該試題的正確選項。當然,將 正確選項填錯,就不在本假設考慮的範圍內,因為人為的疏忽不是任何測驗理論 所能顧及到的。此外,不作答的試題和未答完的試題是有所不同的,前者是受能 力所影響,後者則是受測驗時間影響所致,即所謂的速度測驗,違反上述的非速 度性假設。此假設亦常隱含在單向性的假設中,較少被提到。 以上的假設是 IRT 模式的一般性假設,有些模式則有其它的特殊假設。以下 介紹單參數模式( Rasch model )或雙參數模式所特有的假設,即等鑑別度假設(單 參數模式適用)、最小猜測度假設(單、雙參數模式皆適用)。- 19 - (五)等鑑別力 在單參數模式中有個特殊的假定,即等鑑別力( equal discrimination )的假定。 有此假定可以省下處理資料的人力與物力。選擇鑑別力參數介於 0.8 至 1.25 之間 的題目就能大致符合等鑑別力的假定。但模式有其強韌性( robust ),亦即允許某程 度範圍的違反規定。 (六)最小猜測度 即模式的應用不能受測驗題目猜測因素影響,則稱最小猜測 ( mininal guessing ),適用於單參數及雙參數模式。但實際上測驗常用的選擇題並無法避免 猜測因素存在,而在技職體系中的考試皆為選擇題,因此使用 Rasch 模式時應注 意:(王寶慵,1995) l. 進行誤導項分析( distractor analysis )。以項目編寫的技巧及誘答選項的分 析,使測驗受到猜測因素的影響減到最少。 2. 刪除能力特低的受試者。因能力特低的受試者較可能產生猜測行為。 Bashaw( 1982 )認為 Benjamin Wright 在 AERA 研習會所提的公式可做參
考。如測驗題目有五個選項,總題數為k,刪除的臨界分數( critical scores ) 為 S,如果受試者得分低於以下公式所求出的分數,即可視為低能力而刪除。 0.2 2 (0.2)(0.8) S k k 而在技職體系中的試題規定為單選題,測驗題目有四個選項,總題數為k, 所以上述公式應修改成: 0.25 2 (0.25)(0.75) S k k 因此若以四技二專商業類數學科考試試題為 25 題來看,當受試者的分數低 於 11 分(四捨五入),即可視為低能力而刪除。 (七)模式適合度檢定 試題反應模式能否適合測驗資料,還要看受試者實際的試題表現,和由模式 預測出來的期望的試題表現之間的差距是否合理。因此試題的殘差分析便可用來 檢定測驗資料與每個試題的符合性( goodness-of-fit )。
- 20 - 三、常見的 IRT 模型與參數 IRT 其實是許多試題反應模式的總稱,當代已經有許多 IRT 模式分別適用在許 多不同的測驗情境中。常見的 IRT 模式可以根據其所包含的試題參數數目來分, 分為單參數的 Rasch 模式、二參數模式與三參數模式( Birnbaum,1968 )。也可以依 據計分型態來分,分成二元計分( dichotomous )與多元計分( polytomous )模式;或 是依據適用的作答方式來分,分成評定量尺( rating scale )模式、部分計分( partial credit )模式、名義量尺( nominal scale )模式等。故以下僅針對本研究所採用的四種 常見的 IRT 模式:單參數的 Rasch 模式、二參數模式與三參數模式、無參數模式, 分別介紹如下:
(一) Rasch 模式 ( ) ( ) ( ) 1 s i s i D b i s D b e P e i=1,2,3,…,n (2-6) 其中s:第 s 位受試者的能力參數。 ( ) i s P :表示能力參數為s的受試者 s,答對試題 i 或在試題 i 上正確反應的機率。 D:常數,在洛吉數單參數模式中通常設為 1.7。 i b :試題i 的難易度參數。 在 Rasch 模式中認為,影響受試者答對機率的試題特性主要是難易度,因此 只要了解人的能力與題目的難易度,就能知道該人在某題目上的答對機率是多 少。而在 Rasch 模式中,所有試題都被要求要具有高鑑別度(都是 1.0),而受試 者猜對題目的機率已經被納入受試者能力中,而不是試題特性,因此猜對率為 0。 該模式最大的特色是它對試題的特性與受試者的作答反應有較嚴格的要求,如果 都能符合這些要求,則所估計出來的能力值就能反映出受試者的真實能力,而且 是等距量尺。 難易度即代表試題困難的程度。從洛吉數單參數的數學模式中可看出,當第i 題的難易度參數b 落在試題特徵曲線上答對機率i pi( ) 為0.5時,試題的難易度參數 會等於受試者能力值,換句話說,當受試者能力值和試題難易度相等時,受試者
- 21 - 答對第 i 題的機率pi( ) 為0.5。若能力值小於試題難易度,受試者答對第 i 題的機 率pi( ) 低於0.5;反之,若能力值大於試題難易度,受試者答對第 i 題的機率pi( ) 高於0.5。所以難易度值愈大,受試者答對第 i 題的機率 pi( ) 要高於0.5,則必須 要有更高的能力,亦即試題的困難程度愈大,理論上,難易度值介於到之 間,但實際應用上,通常只取-2 到+2 之間的範圍。相對於古典測驗理論的難易 度指數,其所指的是試題真正的「難」度,而非古典測驗理論所指的「易」度。 並且,古典測驗理論的難易度指示是一種樣本依賴( sample dependent )的指標,其 值受到受試者樣本的影響很大(余民寧,1992a)。
根據 Rasch 模式,我們可以畫出各試題的特徵曲線( item characteristic curve; ICC ),如圖 2-2 所示。對同一試題而言,一個人的能力愈高其答對該題的機率應 該也愈高,因此這個曲線是單調遞增( monotonically increasing )曲線。由於每個試題 都被要求需要有相同的高鑑別度,因此每條曲線在中段的部分看起來都很接近平 行,整份測驗的試題特徵曲線放在一起就好像是一把尺上面有許多刻度一般。其 中以答對率為 0.5 向右劃一條橫線,與各試題特徵曲線的交叉點,對應到能力軸上 的值,被定義為該題的難易度。由此也可以看出在 IRT 中,能力與試題難易度被 視為是被放在同一個量尺上的相對概念,因為模式中兩者的數值是可以直接相減 的。 0.0 0.2 0.4 0.6 0.8 1.0 -3.0 -2.0 -1.0 0.0 1.0 2.0 3.0 潛在特質(能力) 答對機率 b1=0 b2=1 b3=-1 圖 2-2 Rasch 模式中不同試題的特徵曲線圖
- 22 - (二)雙參數模式 ( ) -1 ( ) 1 i s i i s Da b P e i1, 2,3,...,n (2-7) 其中s:第 s 位受試者的能力參數 ( ) i s P :表示能力參數為s的受試者 s,答對試題 i 或在試題 i 上正確反應的機率。 D:表示常數為 1.7。 i a :試題i的鑑別度參數。 i b :試題i的難易度參數。 此模式是由 Birnbaum (1968) 修改 Lord 所提出的常態肩型模式所擴展而成的 簡單對數模式。雙參數模式係指模式中有二個參數,即難易度、鑑別度。難易度 參數與上述的單參數模式中相同;鑑別度通常用a 表示,是指試題對不同能力的i 受試者是否能反映出其答題的差異,亦即鑑別度大的試題,對於能力高的受試者 而言,其答對率高;對於能力低的受試者而言,其答對率低。試題鑑別度參數 a i 的值,剛好與在b 點的試題特徵曲線的斜率( slope )成某種比例。試題特徵曲線愈i 陡( steeper )的試題比稍平滑的試題,具有較大的鑑別度參數值;換句話說,鑑別 度愈大的試題,其區別出不同能力水準考生的功能愈好,即分辨的效果愈好。從 ICC 來看,鑑別度是指能力變化時,受試者答對機率變化的程度,因此,ICC 愈陡 的試題,其鑑別度愈大;ICC 愈平緩的試題,其鑑別度愈小。理論上,鑑別度參數 的值介於之間,但學著們通常捨棄負的鑑別度值,因為該試題反向區別不同能 力水準的受試者,亦即從 ICC 看,能力愈高的受試者答對某試題的機率愈低,所 以在實際應用上,鑑別度值通常只取 0 到+2 之間的範圍。相對於試題的難易度, IRT 所指的試題鑑別度與古典測驗理論所指的鑑別度之意義是相同的,只不過古典 測驗理論的鑑別度是一種樣本依賴( sample dependent )的指標,其值受到受試者樣 本的影響甚大。 其中a 是試題 i 的鑑別度,其他的符號意義與公式(2-6)相同。在二參數模式i 中,與 Rasch 最大的不同點是題目可以被允許有不同的鑑別度,而這些不同的鑑 別度會對受試者答對題目的機率有不同程度的調節性影響。這種模式與實際資料
- 23 - 的分析結果較為接近,因為命題者所設計出來的試題很難都具有相同的高鑑別 度,有些題目的鑑別度總是不符合預期,但是依然能發揮部份的測量功能。 二參數模式所畫出來的試題反應曲線如圖 2-3 所示。在圖 2-3 中,有的曲線的 中段是比較陡峭的(例如 a1),有的則是比較平緩的(例如 a2),這些題目雖然具 有相同的難易度,但是隨著受試者能力的提升,他們答對這兩題的機率變化情形 卻不相同。在 a1 中段的區域,能力只要有些微的改變其答對率就有顯著的提升; 而在 a2 中,同樣的能力改變量,其答對率的提升情形明顯不如 a1。 0.0 0.2 0.4 0.6 0.8 1.0 -3.0 -2.0 -1.0 0.0 1.0 2.0 3.0 潛在特質(能力) 答對機率 b1=0,a1=1.5 b2=0,a2=0.5 圖 2-3 二參數模式中不同試題的特徵曲線圖 (三)三參數模式 ( ) 1 ( ) 1 i s i i i s i Da b c P c e i=1,2,3,…,n (2-8) 其中s:第 s 位受試者的能力參數 ( ) i s P :表示能力參數為s的受試者 s,答對試題 i 或在試題 i 上正確反應的機率。 D:表示常數為 1.7。 i a :試題鑑別度的參數。 i b :試題難易度的參數。 i c :試題猜測度的參數。 三參數模式的概念也是源自於 Lord (1952)與 Birnbaum (1968)。這種模式主要
- 24 - 是針對那些可以經由猜測來答對試題的測驗情況,例如選擇題、是非題……等。 三參數模式係指模式中有三個參數,即難易度、鑑別度、猜測度。其中難易度、 鑑別度與上述所指相同。通常用c 來表示猜測度,即指能力極低的受試者猜對該試i 題的機率。從 ICC 來看,它是位於該曲線的左下漸近線。通常猜測度參數值比受 試者在完全隨機猜測下猜答的機率稍小,亦即c 值小於試題選項數目的倒數,換句i 話說,若一個試題有四個選項,則c 應小於 0.25。猜測度參數只出現在三參數以上i 的模式中,在單參數及雙參數模式中均將其假定為 0 或接近 0 而忽略不計。c 值愈i 小,表示猜測的因素愈小,試題愈有效,最理想的c 值是i ci 0,表示答題情形完 全不受到猜測影響,但實際施測情況下,只要測驗的形式是選擇題型,通常很難 避免受試者的猜測行為(余民寧,1992a;楊明宗,2002),因此這種模式比二參 數模式更能符合實際的資料(陳柏熹,2008)。 0.0 0.2 0.4 0.6 0.8 1.0 -3.0 -2.0 -1.0 0.0 1.0 2.0 3.0 潛在特質(能力) 答對機率 b1=0,a1=1.5,c1=0.4 b2=0,a2=0.5,c2=0 1-c c 圖 2-4 三參數模式中不同試題的特徵曲線圖 參數試題選項分析模式有以下幾點不足之處,故而有無參數試題選項分析因 應而生: 1、迴歸函數主觀認定,不能適當反應資料實際情況。例如:高能力組與低能力 組選答不一定呈現反對稱情況,亦即參數試題選項分析模式無法診斷出錯誤 的命題,而發生正確選項中低能力者選答率高於高能力者之情況,或是誘答
- 25 - 選項中低能力者選答率低於高能力者之情況。 2、參數試題選項分析不具簡單直接解( closed-form solution )。因原本三參數模 式中,令N 表受試人數、 n 表測驗試題數;則須要估算的參數有N3n個, 而應答組型卻只有 n 個已知數,故須以 EM 算法遞迴估算求得近似解,故不 具公式的簡單直接解。 3、受試者人數必須夠多。IRT 的單參數模式下受試者至少須 200 人;雙參數 模式下受試者至少須 500 人;三參數模式下受試者至少須 1000 人。 4、試題參數需遞迴估計,複雜費時費力。
5、為符合最大概似法估計法( method of maximum likelihood; MLE ),參數試題 選項分析必須滿足局部獨立之限制條件。
6、無法與試題選項關聯結構分析及試題層次分析等模式進行整合分析,因違反 了局部獨立假設(劉湘川,2001)。
7、多數的研究都只是假設選項特徵函數為一簡單的參數模式,且只探討試題的 正確選項( correct option )而忽略其他誘答選項( wrong option )所帶來的資訊 (吳慧珉,2001)。
8、在 參數 估計 的過 程 中, 常會 導致 試題 參數估 計間 有很 大的 樣本共 變性 ( sampling covariation )( Lord,1980 )。如三參數洛吉數模式中的猜測參數、鑑 別度參數、和難易度參數之間就有很強的正向共變性( Ramsay,1991 )。
(四)無參數模式
試題反應理論的主要目標是在大範圍中找出一起始值來針對試題或選項特徵 函數( option characteristic function )做有效的估計。所謂的選項特徵函數是將受試者 能力與選項反應結果之間的關係以數學模式表示。如果將此模式所要表達的關係 以圖形化方式表示,則稱為選項特徵曲線( option characteristic curve )。無參數 IRT 的 ICC 不像參數型受到洛吉數函數的限制,可呈現更多樣性的特徵曲線,使得利 用 ICC 來進行概念診斷更加可行(陳怡欣,1994;簡茂發、劉湘川、許天維、郭 伯辰,1993)。
無參數迴歸估計法( nonparametric regression estimating )是一種可避免對回歸 函數主觀認定,能「讓資料自己說話( letting data speak for themselves )」的簡明估
- 26 -
計 法 。 若 以 核 函 數 ( kernal function ) 為 基 礎 , 則 稱 之 為 核 平 滑 化 法 ( kernal smoothing ) ,即拋 開 參數迴歸 的模 式,透 過試題選 項特 徵曲線 ( Item Option Characteristic Curve; IOCC )的方式真實呈現受試者作答反應情形。一般無參數試題 反應理論僅呈現正答選項之作答情形,而 IOCC 則呈現了誘答選項的作答情形。其 優點有: 找出具良好鑑別力的選項,以保留良好試題選項,刪除題意不明選項, 控制試題品質。 教學上可搭配雙向細目表,使老師了解不同能力學生的學習障礙,進而 作為改善補救教學的依據(吳慧珉,2001)。 1、Ramsay 理論
加拿大麥克基爾大學( McGill University )心理計量學教授 J.O.Ramsay(1991)首
先結合「高低鑑別度指數」和「核平滑化法無參數估算法」,發展出正確選項與誘
答選項均可分析之「核平滑化無參數試題特徵曲線估計法」( Kernal Smoothing Approaches to Nonparametric Item Characteristic Curve Estimation ) 。核平滑化 ( Kernal Smoothing )是將被估計的受試者加以排序,函數和試題選項是否被選(選 則指示為 1,否則為 0)而成為二元變數之間的關係(吳慧珉,2001)。 Ramsay 引進轉換高低鑑別指數作為受試者加權總分排序時之間加權函數所產 生之加權值,在進行非線性標準常態轉換,所得知能力值取代原始總分為橫軸, 以受試者在某一題之選答率為縱軸,畫出 OCC。此方法並無假設任何適當的模式, 完全根據受試者實際作答資料來進行分析,用以估計 OCC,是一種無參數試題反 應理論。根據此理論,Ramsay 發展一應用軟體-TestGraf98 軟體,藉助視窗化的 操作方式和圖形化的解釋說明畫出選項特徵曲線,以診斷試題和其選項的特徵, 以期了解試題編製品質的好壞。 2、點二系列相關試題鑑別指數 劉湘川(2000)在「以點二系列相關試題鑑別指數之值譜分析及其在 IRT 上 的應用」一文中,證明點二系列相關試題鑑別指數 R,除無受試者人數限制外, 當受試者之測驗得分有三個以上相異值時,點二系列相關試題鑑別指數之鑑別能 力的量化比較值恆優於任何高低鑑別指數。其優於 Ramsay 理論之特點如下(吳慧 珉,2001):
- 27 - Ramsay 理論僅考慮高分組和低分組之作答情形,忽略中間受試者的訊 息,較無充分性;而點二系列相關試題鑑別指數為考慮每位受試者作答情 形與總分之間之相關,考慮到所有的受試者,並無損失訊息。 Ramsay 理論受試者人數需為 4 的倍數,方能準確分出高分組與低分組。 而點二系列相關試題鑑別指數受試者人數則無限制,使用上較方便。 Ramsay 理論以受試者答對題數之多寡決定受試者之次序關係,並沒如點 二系列相關試題鑑別指數有考慮到誘答選項之訊息。 Ramsay 理論遇到答對題數相同之受試者,則給一極小之隨機亂數值以決 定先後次序,有欠公允;而點二系列相關試題鑑別指數則以點二系列相關 試題鑑別指數作為受試者排序加權。 Ramsay 理論中,若P ,H P 分別是 1 或 0,則試題選項無鑑別度,無L 法做加權;而點二系列相關試題鑑別指數則無此限制。
Ramsay 理論中,logit P -logit H P 並非 L P -H P 之保序變換,取 logitL
會造成較大的誤差;而點二系列相關試題鑑別指數則有保序性,能確保 次序關係之改變,是根據其作答反應訊息加權而得。 在理論上已證明點二系列相關試題鑑別指數之鑑別能力優於高低試題鑑 別指數。 吳慧珉(2001)在國內學者劉湘川教授指導下研究發展出以點二系列相關試 題 鑑 別 指 數 作 為 加 權 來 排 序 受 試 者 所 需 的 應 用 軟 體 - OCC2001 。 爰 因 軟 體 OCC2001 取得不易,故本研究使用 Ramsay 理論所發展的應用軟體 TestGraf 98 之繪圖功能,藉助視窗化的操作方式和圖形化的解釋說明畫出選項特徵曲線,以 診斷試題和其試題選項的特徵,以期了解試題編製品質的好壞。 認知測驗之記分系統,無論是二點記分或多點記分,參數型試題反應理論均 已有優美數理結構之分析模式,惟美中不足;必須滿足局部獨立之限制,只宜分 析無順序關係之試題,且僅適用於大樣本之測驗分析,無參數試題反應理論無局 部獨立之限制,可與試題順序理論結合,藉以分析個別受試之試題關聯結構,兼 可適用於班級教學小樣本之診斷評量,這是無參數試題反應理論之發展契機(施 賢文,2009)。
- 28 - 認知測驗之記分系統,無論是二點記分或多點記分,參數型試題反應理論均 已有優美數理結構之分析模式,惟美中不足;必須滿足局部獨立之限制,只宜分 析 無順序關係之試題,且僅適用於大樣本之測驗分析,無參數試題反應理論無局 部 獨立之限制,可與試題順序理論結合,藉以分析個別受試之試題關聯結構,兼 可 適用於班級教學小樣本之診斷評量,這是無參數試題反應理論之發展契機。 四、IRT 模式的優點 當代測驗理論是為改進古典測驗理論的缺失而來,它具有下列幾項特點,這 些特點正是古典測驗理論所無法具備的 ( Hambleton, 1989; Hambleton & Cook, 1977; Hambleton & Swaminathan, 1985; Hambleton, Swaminathan & Rogers, 1991; Lord, 1980 ):
1. IRT 所採用的試題參數( item parameters )(如:難易度、鑑別度、猜測度等),
是一種不受樣本影響( sample-free )的指標;即試題參數不會因受試者樣本的 不同而有所差異。 2. IRT 以試題訊息函數針對每位受試者提供個別估計標準誤,而不像 CTT 只 提供整份測驗相同的測量標準誤,因此能夠精確推估受試者的能力估計值。 3. IRT 可經由適用的同質性試題組成的測驗,測量估計出受試者個人的能力, 不受測驗的影響( test-free ),並且對於不同受試者間的分數,亦可進行有意 義的比較。
4. IRT 提出以試題訊息量( item information )及試卷訊息量( test information )的 概念,來作為評定某個試題或整份試卷的測量準確性,頗有取代古典測驗 理論的「信度」,作為評定試卷內部一致性指標之勢。 5. IRT 同時考慮受試者的反應組型與試題參數等特性,因此在估計個人能力 時,除了能夠提供一個較精確的估計值外,對於原始得分相同的受試者, 因為加入了受試者的反應組型與試題參數等特性,所以對他們能力值的估 計,也會隨受試者個人而有所差異。
6. IRT 所採用的適合度考驗值( statistic of goodness-of-fit ),可以提供檢測模式與資 料間之適合度、受試者的反應是否為非尋常( unusual )等參考指標。
五、結語
- 29 - 驗理論被採用於解決真實測驗資料者,比起古典測驗理論廣泛地被應用的情形而 言,尚屬少數,微不足道。其主要原因有下列諸點: 1. 當代測驗理論係建立在理論假設嚴謹的數理統計學機率模式上,是一種複 雜深奧、艱澀難懂的測驗理論,這對於在數學方面訓練有限的教育與心理 學界學者而言,無非是一大挑戰。閱讀有關此理論之數學方面的研究報告 與專書,已頗感困難,實在更難以深入將之發揚光大。 2. 多數當代測驗理論學者都是出身自數學界或曾是數學主修者,或至少在數 理統計學上訓練有素者,他們偏愛對理論模式的探討,遠勝於對實際應用 的推廣工作。 3. 過去,因為其所採用的計算公式非常的複雜、深奧、不容易懂,且沒有電 腦套裝軟體程式的即時配合,因此,在應用上更受限制。不過近幾十來來, 由於電腦套裝軟體程式的日新月異,減輕了使用者運算過程中的煩瑣,因 此測驗的編製和分析,逐漸以 IRT 來取代。 4. 有些古典測驗理論的擁護者,對當代測驗理論的研究與發展,所能獲致之 成效與應用性深表懷疑。為了證明與解釋疑惑,當代測驗理論學派的支持 者,便更朝理論模式的量化技術方面探討,致使當代測驗理論的發展愈趨 數學化、數量化、與電腦化。 5. 礙於嚴苛的基本假設,當代測驗理論所能適用的教育與心理測驗資料有 限,並且需要大樣本的配合,因此使得它的應用性大打折扣,未獲一般測 驗使用者的全力擁護。一般來說在大樣本的測驗資料較容易符合 IRT 的假 設,所以 IRT 較適合分析大樣本的考試。 由上述兩派測驗理論的比較可知,古典測驗理論雖然不夠嚴謹,但理論淺顯 易懂,便於在實際測驗情境(尤其是小規模資料)實施;當代測驗理論雖然嚴謹, 但理論艱深難懂, 僅適用於大樣本測驗資料的分析。所以,這兩派測驗理論各有 所長,在應用上也各有其限制,我們僅能靜觀測驗理論的發展,逐步歸納出其未 來的發展趨勢。 一般來說,有較少限制性假設的模式會比較符合測驗資料,如洛吉數三參數 模式;然而,有較少限制性假設的模式需要較大的樣本數用以估計增加的參數項 目。因此,對研究者或開發者而言,把這些有較少限制性假設的模式用於小規模
- 30 -
研究和估計的程式也許是不實際的,因此模式的選取必須基於理論和實際狀況兩 方面之互相搭配( Wayne, David, Patrick, Steve & Sasha,2001 )。
第二節 試題分析
構成一份測驗的基本單位即為試題,有良好的試題才能構成優良的測驗,學 者簡茂發(1974)指出在測驗的編製過程中,逐一檢驗個別試題的性能是重要的 步驟;而試題性能的檢核須透過邏輯與統計的分析( logical and statistical
analysis ),亦即試題分析包括兩大部分:質的分析( qualitative analysis )與量的分析 ( quantitative analsis ),且就依據之測驗理論的不同又可分為基於 CTT 的傳統試題 分析法( conventional item anaiysis method )以及基於 IRT 的現代試題分析法
( modem item analysis method )。質的分析係就試題的內容和形式,是否適切教學目 標及符合編擬試題原則加以評鑑;量的分析則是根據受試者的試題作答情形,逐 一分析試題的難度度( item difficulty )、鑑別度( item discrimination ) 和利用
Testgraf98 所產生的試題特徵曲線( item characteristic, [ICC] )進而作選項分析( item options analysis )包括正答力及誘答力,以作為修改試題或選擇試題的依據。不論基 於何種測驗理論,測驗所有試題均須經過質與量兩方面的分析,方能顯示其特性及 相對效力之高低,藉以決定試題的取捨,然後組成一份可靠又有效之測驗,以發揮 其測量及評量應有的功能。以下將詳細說明有關質的分析與量的分析。 壹、質的分析 試題內容與形式之分析主要是指試題在質的方面所作的邏輯分析而言,每一 種測驗皆有其特定的功能及適用的範圍,因此在編擬試題時,應以測驗的目的來 編製適切的試題,以學科成就測驗為例,其主要目的是在測量受試者進行某一學 科教學活動後的學習成果,故試題須符合課程之內容,依照教學目標,就受試者 行為變化的不同層面予以評量(簡茂發,1991)。此一分析可利用試題檢核表檢視 試題的品質,來檢查試題是否符合命題原則,包含一系列的檢查項目—內容、題 幹及選項要素;另利用雙向細目表來檢視試題是否符合課程內容和教學目標,並 知道各教學單元中所佔試題的比例是否適當,使命題者可以很清楚的知道試題的 缺失,以作為改進試題的依據,以達到對試題品質的要求。