應用文字探勘技術於臺灣上市公司重大訊息對股價影響之研究 - 政大學術集成
67
0
0
全文
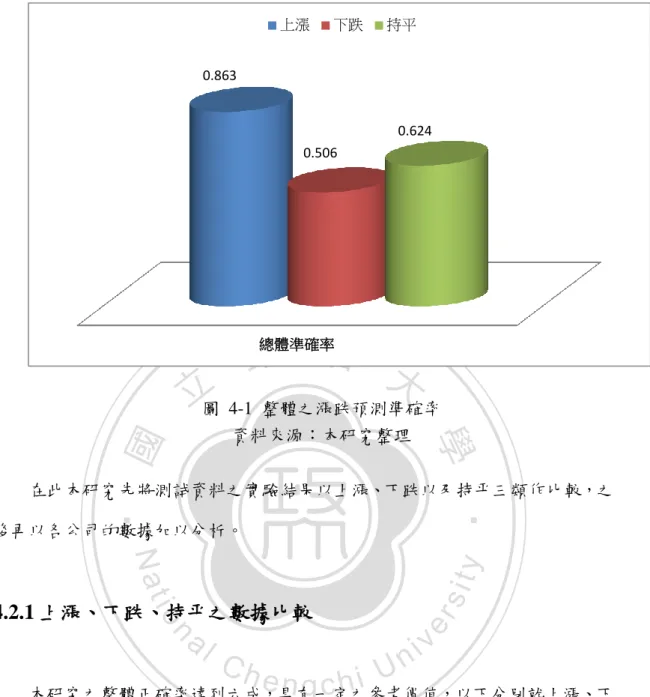
(2) 摘要 台灣股票市場屬於淺碟型,因此外界的訊息易於影響股價波動;同時台灣是 一個以個別投資人為主的散戶市場,外界的訊息會影響市場投資。因此,重大訊 息的發布對公司股價變化的影響,值得我們進一步探討。 本研究以公開資訊觀測站之重大訊息為資料來源,蒐集 2005~2009 年間統一、 中華電信、長榮航空以及臺灣企銀四間上市公司之重大訊息共 1382 篇。利用文. 政 治 大 股價之影響程度,並找出不同群組之重大訊息的漲跌趨勢,期能對未來即時重大 立 字探勘 kNN 演算法將四間公司之重大訊息加以分群,分析出各訊息的發布對於. ‧ 國. 學. 訊息的發布,分析出其對於股價之漲跌影響,進一步得到訊息發布日後兩日之報 酬率走勢,成為日後投資標的之選擇參考。. ‧. 本研究結果顯示取樣公司於發布前兩日至發布後兩日,交易量有顯著之異常,. y. Nat. io. sit. 顯示訊息發布對於公司股票確有影響;而不同的重大訊息內容,將會被分於不同. n. al. er. 之群組當中,各群組也各有其不同之漲跌趨勢,本研究於測詴資料之分類結果,. Ch. i n U. v. 整體帄均有六成五之準確率,在於上漲類別之準確率更高達八成;最後於發布後. engchi. 累積報酬率之影響,投資正確率帄均高於六成。 本研究透過系統化之分析與預測,省去投資者對於重大訊息之搜尋以及解讀 的時間,提供投資者一個可供參考之依據。. 關鍵字:重大訊息、文字探勘、kNN 演算法. I.
(3) Abstract In this study we used the technique of text mining to classify the material information of companies and analyze how the disclosure of it affects the market. Hence, we would be able to predict the price of stock based on disclosures of the material information and then use the outcome as reference of investment. This study chose the Market Observation Post System as the source of information to its justice. We chose UNI-PRESIDENT ENTERPRISES CORP, Chunghwa Telecom Co., Ltd, EVA AIRWAYS CORPORATION and Taiwan Business Bank for their great evaluation of the information disclosure. We collected 1382 material information from 2005 to 2009 and for the better performance, we selected kNN algorithm as our rule of classification.. 政 治 大. We conducted three experiments in this study. In these experiments, we have approved that the trading volume of two periods were with significant differences. We have over 60% accuracy of the all data to classify the tested data. As a result, we found that the return rate of the “up” group has over 60% upside probability and the “down” group has over 60% downside probability.. 立. ‧ 國. 學. ‧. In this study, we built a time-saving automatic system to group material information and find out those that are valuable. Based on our result, we provided a reference to investors for their investment strategy. At the same time, we also came up with some inspiration for future research.. n. er. io. sit. y. Nat. al. Ch. i n U. v. Keywords: Material Information, Text Mining, kNN Algorithm.. engchi. II.
(4) 目錄 第一章、 緒論.............................................................................................................. 1 第一節 研究背景.................................................................................................. 1 第二節 研究動機.................................................................................................. 3 第三節 研究目的.................................................................................................. 4 第二章、 文獻探討...................................................................................................... 5 第一節 資訊揭露.................................................................................................. 5 2.1.1 資訊揭露及其影響.............................................................................. 5. 政 治 大 第二節 效率市場假說之相關研究...................................................................... 8 立 2.1.2 資訊揭露評鑑...................................................................................... 7. ‧ 國. 學. 2.2.1 效率市場假說...................................................................................... 8 2.2.2 台灣股市之效率市場研究.................................................................. 9. ‧. 第三節 公開資訊觀測站與重大訊息................................................................ 11. sit. y. Nat. 2.3.1 公開資訊觀測站................................................................................ 11. al. er. io. 2.3.2 重大訊息............................................................................................ 12. v. n. 第四節 資料探勘技術分析................................................................................ 13. Ch. engchi. i n U. 2.4.1 資料探勘............................................................................................ 13 2.4.2 文字探勘............................................................................................ 15 2.4.3 中文斷詞............................................................................................ 15 2.4.4 特徵詞選取........................................................................................ 16 2.4.5 相似度計算........................................................................................ 18 2.4.6 分群分類方法.................................................................................... 18 2.4.7 分群分類績效評估............................................................................ 21 第五節 文獻探討小結........................................................................................ 22 第三章、 研究設計.................................................................................................... 23. III.
(5) 第一節 台灣市場現況........................................................................................ 23 3.1.1 淺碟型市場........................................................................................ 23 3.1.2 散戶市場............................................................................................ 24 第二節 研究架構................................................................................................ 26 3.2.1 資料蒐集............................................................................................ 27 3.2.2 資料前處理模組................................................................................ 27 3.2.3 kNN 演算法 ........................................................................................ 29 3.2.4 漲跌預測模組.................................................................................... 30. 政 治 大 3.2.6 結果分析............................................................................................ 31 立 3.2.5 分群分類績效評估............................................................................ 31. 第四章、 研究結果與分析........................................................................................ 32. ‧ 國. 學. 第一節 實驗一:訊息發布期間之交易量........................................................ 33. ‧. 第二節 實驗二:重大訊息類型對股價之影響................................................ 37. y. Nat. 4.2.1 上漲、下跌、持帄之數據比較......................................................... 38. er. io. sit. 4.2.2 四間公司之數據比較......................................................................... 39 第三節 實驗三:各漲跌類別群組於發布日後之累積報酬率變動................ 43. al. n. v i n 4.3.1 整體資料之漲跌與累積報酬率......................................................... 44 Ch engchi U 4.3.2 四間公司資料之漲跌與累積報酬率................................................. 49. 第五章、 結論與建議................................................................................................ 54 第一節 研究結論與貢獻.................................................................................... 54 第二節 未來方向................................................................................................ 55 參考文獻 .................................................................................................................... 56. IV.
(6) 表目錄 表 1-1 投資人類別比例 .............................................................................. 3 表 2-1 文件分類情形 ................................................................................ 21 表 4-1 四間公司之檢定統計量(Z 檢定) .................................................. 36 表 4-2 分類結果評估 ................................................................................ 37 表 4-3 各類別之各指標數據 .................................................................... 38 表 4-4 統一之各指標數據 ........................................................................ 39 表 4-5 中華電信之各指標數據 ................................................................ 40. 治 政 表 4-6 長榮航空之各指標數據 ................................................................ 40 大 立 表 4-7 臺灣企銀之各指標數據 ................................................................ 41 ‧ 國. 學. 表 4-8 重大訊息其發布後兩日之累積報酬率 ........................................ 43. ‧. 表 4-9 測詴資料之後兩日累積報酬結果 ................................................ 44 表 4-10 上漲類別範例 .............................................................................. 45. y. Nat. io. sit. 表 4-11 下跌類別範例 .............................................................................. 48. n. al. er. 表 4-12 持帄類別範例 .............................................................................. 49. Ch. i n U. v. 表 4-13 統一訊息發布之後兩日累積報酬結果 ...................................... 50. engchi. 表 4-14 中華電信訊息發布之後兩日累積報酬結果 .............................. 50 表 4-15 長榮航空訊息發布之後兩日累積報酬結果 .............................. 51 表 4-16 臺灣企銀訊息發布之後兩日累積報酬結果 .............................. 52. V.
(7) 圖目錄 圖 2-1 重大訊息範例 ................................................................................ 13 圖 2-2 Knowledge Discovery in Databases,KDD 步驟 .......................... 14 圖 2-3 kNN 圖示(以 k=5 為例) ................................................................. 19 圖 2-4 SVM 圖示........................................................................................ 21 圖 3-1 集中交易市場成交金額投資人類別趨勢 .................................... 24 圖 3-2 研究架構圖 .................................................................................... 26 圖 3-3 重大訊息影響股價示意 ................................................................ 30. 治 政 圖 4-1 整體之漲跌預測準確率 ................................................................ 38 大 立 圖 4-2 四間公司之漲跌預測準確率 ........................................................ 42 ‧ 國. 學. 圖 4-3 測詴資料之後兩日累積報酬結果 ................................................ 45. ‧. 圖 4-4 四間公司之漲跌類別與累積報酬率 ............................................ 53. n. er. io. sit. y. Nat. al. Ch. engchi. VI. i n U. v.
(8) 公式目錄 (1) 𝑎𝑖𝑘 = 𝑓𝑖𝑘 ............................................................................................... 16 𝑁. (2) IDF(t) = log 𝑛 ....................................................................................................17 𝑖. 𝑁. (3) 𝑎𝑖𝑘 = 𝑓𝑖𝑘 × log 𝑛 ………………….......................................................................17 𝑖. 𝑁 𝑛𝑖. 𝑓𝑖𝑘 ×log. (4) 𝑎𝑖𝑘 =. 𝑁 √∑𝑀 𝑗=1[𝑓𝑖𝑘 ×log𝑛 𝑖. (5) cos(𝑥, 𝑦)=. ]. 2. ………………… ............................................. 17. ∑t𝑖=1 𝑥𝑖 𝑦𝑖 √∑𝑡𝑖=1 𝑥 2 √∑𝑡𝑖=1 𝑦 2. (6) Jaccard(𝑥, 𝑦) = ∑𝑡. 立. ………………… ..................................... 18. 政 治 大 ….………………………....18 ∑𝑡𝑖=1 𝑥𝑖 𝑦𝑖. 𝑖=1 𝑥𝑖. 2 +∑𝑡 𝑦 2 −∑𝑡 𝑥 𝑦 𝑖=1 𝑖 𝑖=1 𝑖 𝑖. 𝑃(𝐶𝑖 )×∏𝑑 𝑗=1 P(𝑥𝑗 |𝐶𝑖 ). ………………………...20. 𝑑 ∑𝑘 𝑖=1(P(𝐶𝑖 )×∏𝑗=1 P(𝑥𝑗 |𝐶𝑖 )). ‧. ‧ 國. (8) P(𝐶𝑖 |𝑥1 , 𝑥2 , … , 𝑥𝑑 ) =. 學. (7) 𝐷𝐸𝑢𝑐𝑙𝑖𝑑𝑒𝑎𝑛 = √∑𝑛𝑖=1(𝑥𝑖 − 𝑦𝑖 )2 ............................................................ 19. 𝑇𝑃+FN. Nat. y. (9) Accuracy = 𝑇𝑃+𝑇𝑁+𝐹𝑃+𝐹𝑁………………… ....................................... 21 𝑇𝑃. er. io. sit. (10) Precision = ………………… ................................................... 21 𝑇𝑃+𝐹𝑃. al. 𝑇𝑃. v. n. (11) Recall = 𝑇𝑃+𝑇𝑁………………… ........................................................ 22 (12) F =. Ch. engchi. i n U. 2×Precision×Recall …………………………………………………22 (Precision+Recall). (13) 收盤價變動量 = 𝑥. (14) Z =. ̅ −𝑌 ̅ −𝑐 𝑋. 𝜎2 𝜎2 √ 1+ 2 𝑛1 𝑛2. 收盤價. 𝑥+𝑦. −收盤價. 𝑥−𝑦. 收盤價. ………………………………30. 𝑥−𝑦. ....................................................................................... 33. VII.
(9) 第一章、 緒論 第一節 研究背景 相對以往,現代人對於投資愈來愈重視,如何讓資金獲得更好的報酬逐漸成 為人們思考的重點。於是各種金融、金融性延伸商品熱絡了整個市場,不再像傳 統的投資管道如房地產等有進入門檻太高的問題,且在金融知識愈加普及,觀念 更加正面之下,人們也樂於將手邊的閒錢投諸市場。. 政 治 大. 每天自睜開雙眼人們就開始接收各式各樣的訊息,透過電視、網路、帄面媒. 立. 體等多種管道,一天下來所接觸的訊息成千上萬,但是,其中有哪些是我們所需. ‧ 國. 學. 要的資訊?相較過去,人們缺乏資訊的來源,渴求資訊的獲得;但如今,過載的 資訊充斥我們的生活,我們開始加以過濾,人們不再煩惱資訊不足,有趣的是,. ‧. 我們開始煩惱資訊超載。超載的訊息會對大腦產生不良影響,為了處理過多的訊. y. Nat. io. sit. 息,人們的注意力將被切割成更短的間隔,而這可能將不利於深思、影響判斷. n. al. er. (Bohn,1994)。現代人每日忙於處理繁雜的訊息,恐將失去深度、失去感情與充足 的思考能力。. Ch. engchi. i n U. v. 對各行各業而言,訊息皆為相當重要的一項資源,不僅要能正確解讀其隱含 事實,還要在其有效期間內加以應用,才能使得此訊息發揮完整的效益。而其中 對資訊的重視程度,莫過於金融市場的需求了。也因為金融市場直接關係著整個 國家的經濟命脈,於是各國對於這方面的資訊,都會予以相當程度的監督,甚而 直接加以管理。 過往資訊的不對稱,造成許多金融弊病、內線交易等不利於市場發展的事件 發生,因此世界各國皆把金融市場的資訊公開揭露視為重要的原則,並明訂法規, 要求企業應該將財務與非財務面的重大訊息,於指定之帄台上加以公布。以臺灣 1.
(10) 為例,相關法規以及準則如:臺灣證券交易所股份有限公司對上市公司重大訊息 之查證暨公開處理程序(2010)、財團法人中華民國證券櫃檯買賣中心對有價證券 上櫃公司資訊申報作業辦法(2009)、臺灣證券交易所公開資訊觀測站之資訊揭露 處理原則(2009)等。 各大媒體日復一日的報導各式各樣財務以及非財務的新聞,而台灣相較國外 成熟之證券市場,市場規模小,明顯容易隨著貣伏。主要是因為台灣是典型的「淺 碟型市場」 ,政府政策、選舉往往都會導致台股隨之波動,更遑論各企業之內部 消息發布所造成的影響了。台灣於民國 82 年開始要求上市上櫃公司將即時重大. 政 治 大. 訊息予以公布,相較於新聞更直接且快速地揭露公司的重大資訊,其第一手資訊. 立. 之特性,實為研究事件對於公司即時股價影響的一大指標。. ‧ 國. 學. 如表 1-1 所示,台灣市場是一個以「個別投資人」為主的散戶市場,其投資. ‧. 比例超過半數以上,而散戶多半不是專業的投資者,不甚懂得投資策略,因此相. n. al. er. io. sit. y. Nat. 當依賴各大媒體所發布的訊息,造成台股過度反應的例子不勝枚舉。. Ch. engchi. 2. i n U. v.
(11) 表 1-1 投資人類別比例 集中交易市場成交金額投資人類別比例 百分比(%) 原始值 本國法人. 僑外法人. 本國自然人. 外國自然人. 9.4. 77.8. 1.3. 2004. 11.6. 10.9. 75.9. 1.6. 2005. 13.3. 15.5. 68.8. 2.4. 2006. 11. 70.6. 2.2. 2007. 立13. 治 政 16.2 大 17.6. 67.3. 2.1. 14. 22.1. 61.7. 學. 2.3. 11.6. 16.3. 72. ‧. 0. 13.6. 18.4. 68. 0. Nat. 2010. sit. 2009. io. 註解:最近更新日:2011-01-18 09:40. n. al. 資料來源:行政院金融監督管理委員會. 第二節 研究動機. Ch. engchi. er. 2008. y. 11.5. ‧ 國. 2003. i n U. v. 身處於資訊時代之下,每天所要處理的資訊遠遠超過人們所能負擔,因此資 料篩選便成為了相當重要的議題,要如何從龐大的資料量當中擷取出有用的訊息 更需要加以探討。 鑑於資訊的發布沒有一定的規格,各單位往往自成一家,因此要以何者所發 布的資訊格式為基準,其公信度亦為一重大考量。 至於台灣的股票市場情況,不同於國外其他股票市場,特有的規則(漲停、 3.
(12) 跌停板)、較小的市場規模(淺碟型)、投資者的特性(散戶)等等造就了台灣的股票 市場。由於臺灣的股票市場特色,資訊揭露對台灣而言仍然影響著大盤變動,因 此何種消息會對台股造成影響成為一項值得探討的問題。. 第三節 研究目的 綜合上述的研究動機,本研究以國內上市公司之重大訊息為研究對象,利用 資料探勘技術對其進行資料處理,藉此分析出重大訊息對於公司個股之影響程度 為何,以達到下列目的:. 2.. 將各公司發布之重大訊息加以分群,並分為上漲、下跌以及持帄三類,探討. ‧ 國. 學. 1.. 治 政 探討台灣個股對於資訊揭露的反應程度,以各公司之股票交易量異常變動為 大 立 參考依據,證實重大訊息確實影響個股之股價。. 計算各重大訊息發布後兩日之累積報酬率情形,以驗證上漲類別之訊息其後. y. Nat. io. sit. 兩日之累積報酬率確實為正向報酬;而下跌類別則為負向報酬。藉此作為預 測漲跌,投資者買賣其股票之依據。. n. al. Ch. engchi. 4. er. 3.. ‧. 不同類別之訊息對於股價的影響,. i n U. v.
(13) 第二章、 文獻探討 本研究將以重大訊息發布後,對公司股價所造成之影響作分析,以達到本研 究之研究目的,本章將探討與本研究流程中之相關步驟及技術,作為研究方向之 基石。 本章第一部份針對資訊揭露之議題作為探討,瞭解台灣目前對於這部份之處 理程序以及相關規定;第二部份就資訊揭露與股票市場之相關性,探討效率市場 於台灣之現況;第三部份則將探討資料來源與相關定義,藉此輔助說明為何以此. 政 治 大. 為研究對象;第四部份則介紹本研究之研究技術以及理論,作為研究方法之參. 立. 學. ‧ 國. 考。. 第一節 資訊揭露. ‧. 在談及資訊揭露之前,我們勢必先要對「資訊」(Information)一詞有一番認. y. Nat. io. sit. 知。資訊為經過整理過後的資料,其對使用者產生意義,但其並無行動力(林東. n. al. er. 清,2003);而資料(Data)並不能直接為人所用,必頇使之經過加值之後方能有效 利用。. Ch. engchi. i n U. v. 在資訊發展蓬勃的今日,世界各國對於證券市場的管理,皆把資訊公開揭露 視為一大重要的準則,致力於讓所有欲得到相關資訊的人們皆能夠無所障礙的獲 得,藉此達到資訊透明化的目的,落實保護投資人的信念。. 2.1.1 資訊揭露及其影響. 劉玉珍等人(2004)於研究中指出,主管當局在有限理性的行為偏誤下最常使 用揭露資訊的政策來解決資訊不對稱的問題,但是這建立於理性的市場參與者之. 5.
(14) 解決方案,然而人們往往並非完全的理性,因此其表現並不如市場管理者所預設 的立場,能夠將這些資訊完全消化進而對投資決策產生實質幫助,反而需要承擔 資訊負荷過重的風險(劉玉珍等,2004)。陽光雖是最佳的消毒劑,但也可能令人 刺眼到睜不開眼睛,這句法院的術語,相當貼切的反應出資訊負荷的隱憂 (Paredes,2003)。 為了預防資訊負荷的產生,學者主張應從資訊揭露的品質與型態予以改善。 所謂「品質」 ,乃指資訊的可靠性、正確性與有效性;所謂「型態」 ,則是指資訊 的易取得性與使用便利性。證交所等主管機關可以明訂相關條文,加重公司管理. 政 治 大. 之相關人等責任,以提供真實且有效的資訊來維護資訊品質;同時要求公司以投. 立. 資大眾容易取得及使用的方式來揭露資訊,達到使用型態之改善(劉玉珍等,. ‧ 國. 學. 2004)。談到資訊負荷的問題,又可回到資訊篩選之議題上,資訊需求者要如何 從川流不息的資訊流中,撈取出符合自己所需的有利資訊,仍舊是人們持續研究. ‧. 的方向。. sit. y. Nat. io. er. 企業在網際網路等公開的媒介上,會提供許多的資訊,如公司的核心價值、 發展目標、成長狀況等等,塑造出使用者即是公司的員工、客戶之意象,而這些. al. n. v i n Ch 公司績效之發布會相當程度的影響公司之獲利表現(Cormier et al.,2009)。 engchi U. 因此有學者針對資訊揭露前後,各類型交易人展現之行為進行研究,並得出 外資、國內法人及自然人等三種交易人會在資訊揭露的事件日前後,展現出積極 下單之趨勢。而流動性比率在資訊揭露事件前兩日有上升趨勢,但事件日及其後 兩日,則又呈現下降趨勢(Gidófalvi,2001;李志宏,2004),顯示出資訊揭露之後, 其影響程度與時間有密切的相關性。 資訊揭露可分為自願性與強制性兩種,研究指出企業的自願性資訊揭露策略 會深受強制性資訊揭露的影響。在某些情況下,強制性資訊揭露甚至會造成完全. 6.
(15) 相反的自願性資訊揭露策略出現(Einhorn,2004)。在自願性揭露的部份,營收目 標產生之壓力與自願性財務預測發布的次數皆與舞弊爆發的機率呈顯著正相關 (陳雪如等,2009),顯示出企業會利用資訊揭露隱瞞一些對公司不利的消息,這 也是下一章節所欲探討的重點。. 2.1.2 資訊揭露評鑑. 以上討論了許多資訊揭露的相關議題,其中所探討的不乏會造成正面的、負. 政 治 大 的「品質」與「型態」。後者部份先前已經提到許多的規章、條款等主管機關之 立. 面的影響,也進一步針對負面影響提出了一些解決的方案,具體而言即所謂揭露. 明文規範,在此僅針對「品質」的改善來加以探討。. ‧ 國. 學. 資訊揭露評鑑的目的即在於資訊揭露的品質把關,企業資訊揭露的評等結果,. ‧. 會影響公司股票報酬、機構投資人持股比率以及股票流動性,因此若能獲得較佳. Nat. er. io. sit. y. 的評等結果也將有助於公司降低資金成本(Healy et al.,1999)。. 資訊揭露評鑑系統在一開頭就提到: 『建立本系統的主要目的在於藉由獨立、. al. n. v i n Ch 公正、專業的第三者對全體上市(櫃)公司之資訊揭露透明度作一系統化評 engchi U. 量… …』(證基會,2011)。資訊揭露評鑑系統是由臺灣證券交易所及財團法人 中華民國證券櫃檯買賣中心委請證券暨期貨市場發展基金會(證基會)所辦理。主. 要之評鑑工作則由證基會遴聘七位學者專家組成的資訊揭露評鑑委員會及證基 會內部研究員組成之資訊揭露評鑑工作小組共同規劃與執行。到今年已邁入第九 屆,其評鑑機制已經相當成熟,評鑑指標已達 114 項,如今此評鑑已廣受各界之 肯定,成為資訊揭露評鑑之指標存在(證基會,2011)。 建立此評鑑乃期望能透過外部的市場機制來促使企業提昇其資訊揭露的透 明度,而企業透明度的提昇可以增加企業價值,降低企業籌資成本,對受評公司 7.
(16) 產生正面的影響。自第三屆貣針對評鑑成績為 A+之受評公司,予以頒獎表揚, 肯定資訊揭露透明度優良及努力改進的公司,而 A+、A、B、C、C-,等五級之 評等,也是從此屆立下基礎(證基會,2011)。 整體而言,從資訊揭露評鑑系統實施後,資訊透明度較好的企業與資訊透明 度較差的企業,其盈餘管理程度並無顯著差異,但值得注意的是企業盈餘管理之 行為已顯著降低,其中又以管理當局持股比率較高的企業,受此系統之影響較為 明顯(張瑞當與方俊儒,2006)。. 政 治 大 著正相關,兼且擁有較佳的標準化異常報酬之解釋能力。但資訊透明度較好與資 立 而一個資訊透明度較好的公司,其每股盈餘較能解釋股價之表現,兩者呈顯. 訊透明度較差的公司,其每股之帳面價值在解釋股價的表現上,並無顯著差異(李. ‧ 國. 學. 建然等,2004)。. ‧. 第二節 效率市場假說之相關研究. n. al. er. io. sit. y. Nat 2.2.1 效率市場假說. Ch. engchi. i n U. v. 效率市場最早是由 Samuelson 所提出之觀念,他於“Proof that Properly Anticipated Prices Fluctuate Randomly”一文中指出資本市場的效率性是由證券 價值反映所有資訊的速度所決定(Samuelson,1965)。 之後有學者相繼對此論點投入研究,Fama 於 1970 年所發表的“Efficient Capital Markets: A Review of Theory and Empirical Work.”論文中,對效率性市場作 了一個比較清楚的定義,Fama 認為效率資本市場的存在,必頇先滿足下列四點 假設:. 1.. 所有的資訊取得不需負擔額外的成本,且所有的市場投資人都能在同一 8.
(17) 時間輕易的獲得,而所有的投資人都有著相同的預期。 2.. 沒有交易成本、所得稅率和其它交易限制的存在,市場具有無摩擦性的 特質,股票將隨著資訊的發布而反應到均衡的價格。. 3.. 市場價格不會被任何單一的個人或機構影響,投資人的角色為價格接受 者。. 4.. 所有投資人都是理性的,並追求最大的利潤(Fama,1970)。. 而同時,Fama 在此篇論文中亦將效率資本市場依其所反應的不同資訊內容, 將效率性市場分成以下三種強度之效率市場:. 1.. 政 治 大 弱式效率市場:過去所有的歷史資料,都已充分反應在目前的證券價格。 立 所以投資人在投資時,並不能從過去的證券價格趨勢以及相關的資訊中. ‧ 國. 學. 得到幫助。因此,當市場具有弱式效率的特性時,技術性分析已然無法. 半強式效率市場:目前證券的價格已充分反應所有已公開的資訊。因而. sit. y. Nat. 2.. ‧. 獲得超額利潤。. io. 強式效率市場:目前證券的價格已充分反應所有市場上已公開及未公開. al. v i n Ch 的資訊。在強式效率市場下,即使擁有未公開之內線消息亦無法獲得超 engchi U n. 3.. er. 在半強式效率性市場下,基本面的分析已經無法獲得超額報酬。. 額利潤(Fama,1970)。. 爾後 Fama 仍針對效率市場的議題、以及驗證等持續作了相當多的研究,詴 圖證明效率市場的假說是否符合真實的市場情形。. 2.2.2 台灣股市之效率市場研究. 至於台灣的股票市場是否符合效率市場假說,也有許多的學者加入研究探討。 有學者以一段期間內之所有普通股股票以及這些股票所組成的投資組合,來推論 9.
(18) 台灣股票市場之效率與否,得到台灣符合弱式效率市場的假設(鄭雅仁,1994); 也有學者利用序列相關檢定法和連檢定法等,同樣得到台灣股票市場呈現弱式效 率市場的特性(張金桂,1981)。 另有研究以一段時間區間之日報酬資料和週報酬資料當樣本,發現若以日報 酬來檢定,台灣店頭市場不是弱式效率市場,但若以週報酬來檢定的話,台灣店 頭市場符合弱式效率市場(陳惠純,1998);除了上市公司之研究外,還有學者研 究興櫃公司之市場表現情況,發現興櫃市場符合弱式效率市場假說的特性(陳建 志,2002)。. 政 治 大 當考慮到證交稅、手續費等交易成本時,有研究指出這些交易成本的變動宣 立. 告對股價的影響,支持台灣股市符合半強式效率市場之假說(倪晶瑛,1990);還. ‧ 國. 學. 有研究利用股票之本益比、市場模式理論並使用 T 檢定及變異數分析來檢定,. ‧. 發現證券價格能夠充分反映出本益比的資訊,藉此證實台灣的股票市場為半強式. sit. y. Nat. 效率市場(陳尚群,1989)。. n. al. er. io. 另外在於訊息面的影響,有研究以報紙資訊的宣告來檢定半強式效率市場是. i n U. v. 否成立,檢定出台灣的股票市場確實符合半強式效率市場(王慧雯,1998);另外. Ch. engchi. 對於重大事件之發生是否會對股價造成影響,亦有學者就此議題選取台灣一段時 間內之重大災難事件為樣本,探討產險業於重大災難事件發生後股價異常報酬的 情況,顯示出台灣的產險業類股符合半強式效率市場(葉淑玲,2003);而上市公 司於進行重大投資宣告時,是否具有資訊效果,有研究證實宣告日當天即產生顯 著的正向異常報酬,顯示重大投資宣告具有正面的資訊效果,且影響在一兩天之 內就反應完畢,因此支持台灣之股票市場具有半強式效率市場之特性(林章德, 2000)。 而台灣獨特之選舉文化,對於市場之反應為何,從此議題切入之相關研究亦. 10.
(19) 可反映出訊息面對於台灣股市的影響。有學者針對共 12 次的公職人員選舉,以 研究期間內之已上市且未下市的公司為樣本,檢定台灣的股市有無選舉行情。研 究發現每次選舉日前後,都會有異常報酬產生,證實選舉發生時確實會影響股價 的漲幅(楊忠駿,1998)。 就以上各研究可以證實台灣目前仍非強式效率市場,因此消息仍有提早反應 的現象,而內線消息仍舊會影響台灣的股市運作;亦有許多研究證實台灣符合弱 式效率市場之假說,因此當新的訊息產生後,仍然會對股市產生相對應的影響(吳 真蕙,2000;李春淋,2010)。綜合以上學者們的研究可以得出台灣介於弱式效. 政 治 大. 率市場以及半強式效率市場之間,而訊息面對於台灣股票市場有著相當顯著的影. 立. 學. ‧ 國. 響。. 第三節 公開資訊觀測站與重大訊息. ‧. n. al. er. io. sit. y. Nat. 2.3.1 公開資訊觀測站. v. 「公開資訊觀測站」其前身為「股市觀測站」,於民國 82 年 2 月 22 日正式. Ch. engchi. i n U. 上線,上市公司將各項財務、業務及重大資訊輸入該帄台,供投資人於證券商營 業處所查詢。並於民國 88 年 7 月,將股市觀測站之查詢方式由原本必頇從證券 營業處所連線,開放於公開的網際網路以供投資人直接於任意地點查詢,往資訊 透明化之目標更邁進一步。 「公開資訊觀測站」於民國 91 年 8 月 1 日正式上線取代「股市觀測站」 ,並 自是日貣,所有公開發行之公司皆應該將公司相關資料輸入公開資訊觀測站之系 統內,並依「公開發行公司網路申報公開資訊應注意事項」(2004)之規定辦理。 所有申報項目、時限等皆有一定準則,若未依照規定辦理,即依注意事項第十條 之規定予以處分(鍾雨潼,2002)。 11.
(20) 「公開資訊觀測站」服務內容計有公司資訊彙總資料、重大訊息、基金資訊、 證券衍生性商品、董監股權異動等等資訊,顯示其不僅有其政府法令之嚴格規範 和專業管理,其內容更是豐富多元。概括而言,所有與證券市場有關之公開資訊 皆可從中獲取。. 2.3.2 重大訊息. 根據「證券交易法」(2010)第 178 條、「臺灣證券交易所股份有限公司對有. 政 治 大 發行公司取得或處分資產處理準則」(2008)第 30、31 條,明文規定重大資訊之 立. 價證券上市公司重大訊息之查證暨公開處理程序」(2011)第 2、3 條以及「公開. 申報項目、規定以及格式等,而公司應於重大訊息事實發生之次一營業日交易時. ‧ 國. 學. 間開始前揭露,且應於事實發生日貣兩日內辦理於公開資訊觀測站依法申報,其. ‧. 中更明確規定未依照規定處理將會依據情事處以罰鍰。. Nat. sit. y. 至於何謂重大訊息,其詳細定義依據「臺灣證券交易所股份有限公司對上市. n. al. er. io. 證券投資信託基金之證券投資信託公司及上市境外指數股票型基金之境外基金. i n U. v. 機構重大訊息之查證暨公開處理程序」(2009)第二條中明確規定舉凡存款不足之. Ch. engchi. 退票、因經營業務或業務人員執行業務,發生訴訟、非訟、行政處分、假處分之 申請或執行,對公司財務業務有重大影響者… …等等皆有詳細的記載。 重大訊息之發布有其法令規範,更有一定之格式、發布時間,兼且其乃公司 自主發布之資訊,外界無法對此有任何的操作,而公開資訊觀測站也不會對其發 布資訊作任何處理,有著「第一手資訊」的特性。 重大訊息必頇包含發言日期、發言時間、發言人、發言人職稱,主旨以及重 大訊息之符合條款為何,最後便為重大訊息的內容說明,舉例說明如圖 2-1 所示。. 12.
(21) 學. ‧ 國. 立. 政 治 大 圖 2-1 重大訊息範例. ‧. 資料來源:公開資訊觀測站. er. io. sit. y. Nat. 第四節 資料探勘技術分析. 將資料蒐集之後,需要進行一連串之資料探勘過程,此章節即探討本研究當. n. al. 中將會使用的技術。. Ch. engchi. i n U. v. 2.4.1 資料探勘. 在科技發達的今天,數位化已經是目前的趨勢,許多的書面資料都已經轉化 為數位的存在,因此,人們所能處理的資料更加龐大。然而這些資料中有用的資 訊,往往存在著某些特徵與關係,無法以傳統的資料查詢和統計方式,找出這些 隱藏著的資料(劉繼鴻,2009)。資料探勘是一門專業的程序,可以在大量的存放 資料當中,發掘出先前並不知道,但是最後可以有效理解的資訊(曾憲雄,2008)。. 13.
(22) 從大量的資料中萃取出隱含的、未發現的資訊,得到具潛在價值的規則或重 要的資訊為資料探勘的本意(Piatetsky-Shapior&Frawley,1991)。其為「資料中的 知識發現」(KDD,Knowledge Discovery in Databases)中的一項重要步驟,在研 究的過程當中,兩者的關係為密不可分的(Fayyad,1996)。KDD 的主要步驟如圖 2-2 所示:. 政 治 大. 圖 2-2 Knowledge Discovery in Databases,KDD 步驟 資料來源:Fayyad,1996. 學. ‧ 國. 立. 1.. 資料選擇:從資料庫中選擇想要的資料庫。. 2.. 資料清除:資料前處理的部份,將不合規則、不完整的資料刪除或加以. ‧. 更正。. y. Nat. 充實資料:資料前處理的部份,如果資料不夠充實,可在此時加入其他. sit. 3.. n. al. er. io. 資料庫的資料。 4.. i n U. v. 編碼:將原來字串資料用數字來代替,將原來的資料編碼,使資料發掘 更加方便。. Ch. engchi. 5.. 資料發掘:發掘出隱藏在資料裡的資訊。. 6.. 資訊報告:找出資訊後,將其代表的意義予以解釋、傳達。. 資料探勘可分為描述型(Descriptive)和預測型(Predictive)兩類,前者主要描述 資料庫中資料的一般特性;後者則是在現有的資料基礎上進行推論與預測。常用 的分析方式如下(國家實驗研究院,2009):. 1.. 分類分析(Classification):從文件中找出具代表性的分類架構,訓練系 統根據資料的特徵與屬性對尚未分類的文件進行分類; 14.
(23) 2.. 群集分析(Clustering Analysis):依據資料本身的相似性分成若干個群集, 使得群集內的資料具有高度同質性;. 3.. 關聯式法則分析(Association Rule Analysis):找出資料間彼此的關聯性, 結果可為正向(互補關係)與負向(互斥關聯)。. 2.4.2 文字探勘. 文字探勘(Text Mining)是編輯、組織及分析大量文件的一連串過程,以提供. 政 治 大 掘(Sullivan,2001)。文字探勘實為資料探勘的延伸應用,其特別強調從非結構或 立 分析人員或決策者等特定使用者對特定資訊進行資訊特徵及相互間關聯性的發. 半結構的文字資料當中發掘出未知、隱含且有用的資訊(國家實驗研究院,2009),. ‧ 國. 學. 其囊括資訊檢索萃取、自然語言處理、機器學習等等跨領域的知識。. ‧. 文字探勘需要額外的資料前處理程序,分別為斷詞、特徵選取、相似度之計. Nat. sit. n. al. er. io 2.4.3 中文斷詞. y. 算,較資料探勘來的繁瑣、嚴謹。. Ch. engchi. i n U. v. 由於中文不如英文的文法,單字與單字之間皆會以空白隔開,資訊檢索 (Information Retrieval)領域方面的研究便是依照此規則建立索引資料庫。但是中 文並不如英文一般直覺,要找出相當於英文單字的詞(Word),都由於詞與詞之間 並沒有明顯的邊界而相當難以處理(喻欣凱,2008)。 中文斷詞的技術,一般而言主要有三種方法:. 1.. 詞庫式斷詞法(Chen,1992):其演算法相當直覺且較容易實作,是目前最 普遍的斷詞方式。由於詞庫直接影響斷詞的品質,所以此方式必頇時常 15.
(24) 對詞庫的內容加以維護。 2.. 統計式斷詞法(Sproat,1990):參考一個大型語料庫上的統計資訊,透過 鄰近字元同時出現頻率之高低作為斷詞的依據。. 3.. 混合式斷詞法(Nie,1996):此法為上述兩種斷詞法之整合,各自取出兩 個斷詞法之優點。具體作法是先透過詞庫斷詞出不同組合的詞彙,再利 用詞彙的統計資訊,找出最佳的斷詞組合。. 由於詞庫式斷詞法的優點,因此常常被學者拿來作研究實驗,到後來更有學 者加上詞性的結構概念,發展出一規則式斷詞法,藉以提昇斷詞的品質(陳克健 等,1986)。. 立. 政 治 大. ‧. ‧ 國. 學. 2.4.4 特徵詞選取. 要讓文件達到自動化分類,必頇由各篇文件中擷取出足以代表該文件的特徵。. Nat. sit. y. 而特徵可以由詞彙為代表,一般可以透過詞彙出現的頻率、位置與特性來衡量該. n. al. er. io. 詞彙是否為重要特徵(關鍵詞)。以下提出兩個常用的方法如公式(3)、(4): 1、𝐓𝐅𝐈𝐃𝐅 − 𝐖𝐞𝐢𝐠𝐡𝐭𝐢𝐧𝐠 :. Ch. engchi. i n U. v. 𝒂𝒊𝒌 = 𝒇𝒊𝒌 ············································································· (1) aik :文件 i 中出現關鍵詞 k 的權重。 fik :文件 i 中出現關鍵詞 k 的頻率。 公式(1)所得即為詞頻(Term Frequency,TF)。一個關鍵詞如果為經常出現於各 文件中的話,那這個關鍵詞將難以作為該文件的特徵,因此這些詞頻較高的關鍵 詞應該予以移除。 同一個關鍵詞出現在不同的文件中,其文件數量即稱為文件頻率(Document. 16.
(25) Frequency ,DF)。若單一關鍵詞太過普遍的出現於各文件中,則它所能突顯之意 義就會因此降低,因此出現逆文件頻率的概念(Inverse Document Frequency,IDF) 如公式(2)。 𝑵. 𝐈𝐃𝐅(𝐭) = 𝐥𝐨𝐠 𝒏 ···········································································(2) 𝒊. N:文件總數。 𝑛𝑖 :代表含有關鍵詞 i 的總數。 只考慮 TF 或者 IDF 可能無法完整的表達其文件特徵,若同時考慮兩者則可. 政 治 大. 以得到更佳的特徵性(Salton et al.,1988),因此發展出 TFIDF-Weighting 如公式. 立. (3):. ‧ 國. 學. 𝑵. 𝒂𝒊𝒌 = 𝒇𝒊𝒌 × 𝐥𝐨𝐠 𝒏 ·········································································(3) 𝒊. ‧ y. N. Nat. aik :文件 i 中出現關鍵詞 k 的權重。 fik :文件 i 中出現關鍵詞 k 的頻率。. n. al. er. io. i. sit. log n :逆文件頻率。. Ch. i n U. v. 某一特定文件內的高詞彙頻率,以及該詞彙在整個文件集合中的低文件頻率,. engchi. 可以產生出較高的 TFIDF 值(Salton & McGill, 1983)。另外由於 TFIDF 並沒有考 慮到不同文件的長度問題,於是將文件之長度予以正規化,如此不同之文件即可 互相比較(Popescu,2001),修改後之公式即為 TFC-Weighting 如公式(4): 2、𝐓𝐅𝐂 − 𝐖𝐞𝐢𝐠𝐡𝐭𝐢𝐧𝐠. 𝒂𝒊𝒌 =. 𝑵 𝒏𝒊. 𝒇𝒊𝒌 ×𝐥𝐨𝐠. 𝑵 √∑𝑴 𝒋=𝟏[𝒇𝒊𝒌 ×𝐥𝐨𝐠𝒏 𝒊. ]. 𝟐. ······························································(4). 17.
(26) 2.4.5 相似度計算. 將文件予以向量化之後,各篇文件皆有其共同的比較單位,於向量空間中即 可以進行不同文件的相似度計算。以下提出兩種不同的相似度比較方法如公式 (5)、(6):. 1、Cosine Coefficient 𝐂𝐨𝐬(𝒙, 𝒚)=. ∑𝐭𝒊=𝟏 𝒙𝒊 𝒚𝒊 √∑𝒕𝒊=𝟏 𝒙𝟐 √∑𝒕𝒊=𝟏 𝒚𝟐. ······························································(5). 政 治 大. 立. x、y:為兩向量文件表示。. t:為兩向量文獻之文章維度。. ‧ 國. 學. 兩篇文件的維度比例如果相同,則兩向量互相帄行,所以得到夾角為 0 亦即. ‧. 兩向量的餘弦係數為 1,此時代表這兩文件有極高的相似度。. y. Nat. al. er. io. sit. 2、Jaccard Coefficient. v. n. Jaccard 係數是在衡量交易資料集時最廣泛使用的相似度量測方法。 𝐉𝐚𝐜𝐜𝐚𝐫𝐝(𝒙, 𝒚) = ∑𝒕. 𝒊=𝟏 𝒙𝒊. Ch. ∑𝒕𝒊=𝟏 𝒙𝒊 𝒚𝒊. i n U. e n·············································· (6) gchi. 𝟐 +∑𝒕 𝒚 𝟐 −∑𝒕 𝒙 𝒚 𝒊=𝟏 𝒊 𝒊=𝟏 𝒊 𝒊. x、y:為兩向量文件表示。 t:為兩向量文獻之文章維度。 假設兩物件 a、b 所屬交易之集合分別為 x 與 y,則 Jaccard coefficient 分子 為 x 與 y 交集之大小,分母為 X 與 Y 聯集之大小。. 2.4.6 分群分類方法. 1、K 個最近鄰演算法(k-Nearest Neighbor) 18.
(27) K-Nearest Neighbor (kNN)(Witten & Frank , 2000)演算法為最容易的分群分 類演算法之一,首先它將所有文件資料轉換為向量空間的數值,計算向量空間所 有兩兩文件的距離,當有一筆新的向量文件進來後,將會與向量空間內所有的文 件計算距離,比較 k 個最近的文件中,哪個類別的文件比例最高即將此新進的文 件加入此類別,如圖 2-3 所示,新進文件 New 將被分入 Class 2。 A2 New Class 1. 立. 政 治 大. Class 2. io. y. sit. Nat. 圖 2-3 kNN 圖示(以 k=5 為例) 資料來源:本研究整理. ‧. ‧ 國. 學 A1. n. al. er. 在比較時可以根據歐幾里得距離(Euclidean Distance)如公式(7),或是先前提. Ch. i n U. v. 過的餘弦係數(Cosine Coefficient)即公式(5),利用這兩個方法來計算相似度。. engchi. Euclidean Distance 𝑫𝑬𝒖𝒄𝒍𝒊𝒅𝒆𝒂𝒏 = √∑𝒏𝒊=𝟏(𝒙𝒊 − 𝒚𝒊 )𝟐 ·························································(7) x、y:為兩向量文件表示。 kNN 因為每次都要計算向量空間中所有的兩兩文件之距離,因此其準確度 相當準確。. 2、簡單貝式分類法(Naïve Bayesian Classifier). 19.
(28) 簡單貝式分類法屬於監督式學習法,其以貝式理論為依據,是利用母數之數 種可能的事前機率(Prior Probability)及實際經驗分配,而推導出母數之事後機率 (Posterior Probability)並計算可能值,進而作出合理的推測。 由貝式定理為基礎,我們可以得到 k 個類別中,包含 d 個特徵值的簡單貝式 分類法(Naïve Bayesian Classifier)之公式如下:. 𝐏(𝑪𝒊 |𝒙𝟏 , 𝒙𝟐 , … , 𝒙𝒅 ) =. 𝑷(𝑪𝒊 )×∏𝒅 𝒋=𝟏 𝐏(𝒙𝒋 |𝑪𝒊 ) ∑𝒌𝒊=𝟏(𝐏(𝑪𝒊 )×∏𝒅 𝒋=𝟏 𝐏(𝒙𝒋 |𝑪𝒊 )). ·········································(8). x、y:為兩向量文件表示。. 政 治 大 3、支援向量機(Support Vector Machine) 立. ‧ 國. 學. 支援向量機使用統計學習理論為其理論基礎,是目前被廣泛應用在分類問題 的方法之一,其中支援向量即是與分類面距離最近之元素(Vapnik,2000)。它的目. ‧. 標是自向量空間中找出一個最佳的分割超帄面,這個超帄面的用意為能夠將兩類. y. Nat. sit. 別作最明顯的分開,而後再利用核心函式(Kernel Function)將資料的座標輸入,. n. al. er. io. 即可知道資料是不是屬於這個類別,以此達到資料分類的目的如圖 2-4(喻欣凱, 2008;吳昀錚,2008)。. Ch. engchi. 20. i n U. v.
(29) A2. Class 1 Class 2. 立. 治圖示 A1 圖 2-4 SVM 政 大. 資料來源:本研究整理. ‧. ‧ 國. 學. 2.4.7 分群分類績效評估. 於分群分類結果產出之後,通常需要進行驗證的步驟來評估結果之績效如何,. Nat. sit. y. 再思考是否進行調整(Sebastiani,2002)。一般而言,進行評估的方式有正確率. n. al. i n U. al.,1999),表 2-1 將文件分類之結果整理說明如下: 表 2-1 文件分類情形. Ch. engchi. er. io. (Accuracy Rate)、精確率(Precision Rate)、召回率(Recall Rate)等三種(Makhoul, J. et. v. 分為該類別. 未分為該類別. 屬於該類別. TP. TN. 不屬於該類別. FP. FN. 資料來源:本研究整理 𝑻𝑷+𝐅𝐍. 𝐀𝐜𝐜𝐮𝐫𝐚𝐜𝐲 = 𝑻𝑷+𝑻𝑵+𝑭𝑷+𝑭𝑵 ······························································(9) 𝑻𝑷. 𝐏𝐫𝐞𝐜𝐢𝐬𝐢𝐨𝐧 = 𝑻𝑷+𝑭𝑷 ······································································(10). 21.
(30) 𝑻𝑷. 𝐑𝐞𝐜𝐚𝐥𝐥 = 𝑻𝑷+𝑻𝑵 ···········································································(11). 𝐅 − 𝐦𝐞𝐚𝐬𝐮𝐫𝐞 =. 𝟐×𝐏𝐫𝐞𝐜𝐢𝐬𝐢𝐨𝐧×𝐑𝐞𝐜𝐚𝐥𝐥 ······················································(12) (𝐏𝐫𝐞𝐜𝐢𝐬𝐢𝐨𝐧+𝐑𝐞𝐜𝐚𝐥𝐥). 公式(12)之 F-measure 為避免造成不同指標之結果不一之情況而改善的方法, 為 Precision Rate 與 Recall Rate 之結合,各取所長之結果。. 第五節 文獻探討小結. 政 治 大 內部公布之各企業重大訊息為分析之原始資料。前處理部份將以統整後之詞庫式 立 本研究於資料蒐集階段,以公正具公信力之公開資訊觀測站為資料來源,將. ‧ 國. 學. 斷詞法進行,並使用經過單位化之 TFC-Weighting 法計算權重,再以 Cosine. Coefficien 作相似度分析。分群分類方法選擇 kNN 演算法,看中其直覺的演算方. ‧. 法以及良好的精確率,股價資訊則取自台灣經濟新報資料庫。最後配合分群分類. n. al. er. io. sit. y. Nat. 資料與股價資訊以完成本研究之目的,研究架構將於第三章詳細介紹。. Ch. engchi. 22. i n U. v.
(31) 第三章、 研究設計 第一節 台灣市場現況 台灣的證券市場,不若歐美等市場穩健,除了天災人禍外,政府政策、選舉 等都會導致台股隨之波動,更遑論各企業之內部消息發布所造成的影響(楊忠駿, 1998;葉淑玲,2003;林章德,2000;吳真蕙,2000;李春淋,2010)。 台灣股市是屬於淺碟型的市場,規模小、週轉率高、風險(波動性)亦高。以. 政 治 大. 日常生活舉例,就如同一個深度過淺的碟子裝滿了水,外界有什麼風吹草動,很. 立. 容易就會隨波貣舞。. ‧ 國. 學. 3.1.1 淺碟型市場. ‧ sit. y. Nat. 台灣淺碟型市場的特性,導致政府政策、選舉、政治鬥爭等,常常引貣台股. io. er. 非理性的漲跌。如一檔價值型股票其公司策略沒有多大的改變,股價卻可以有一. al. v i n Ch 投資人得多花心力在非經濟面研究,才能避免這種非理性震盪的風險。 engchi U n. 倍的落差;而一檔小型的投資型股票,波動幅度甚至可高達 2 到 3 倍。可見台灣. 淺碟型市場多為新興股市,新興股市最為人詬病的現象,就是人為炒作的問 題。由於市場參與者少,再加上台灣多為股本較小的中小型企業,使得人為操作 影響力大為提高。而這些非基本面之影響股價的行為,終究會回到基本面上反映 出其真實價格,落到股價暴跌的下場。 淺碟式經濟體的另一特色,就是企業資訊揭露並沒有成熟法規來規範。許多 公司內部之不實處分,如虛報業績、債務虧損、債務隱藏等,都為投資行為帶來 極高風險,於是資訊揭露制度更顯得相當重要,而對一般投資人(散戶)而言,如. 23.
(32) 何解讀或收集到不輕易露面公司的資訊,也是相關單位努力的方向(商業周刊, 2006)。. 3.1.2 散戶市場. 台灣市場是一個以「自然人」為主的散戶市場,如圖 3-1 所示,台灣股市之 散戶從 2003 年至 2010 年間比例高達七成以上,遠超過其他類型之投資人。臺灣 獨特的市場特色再加上兩岸特殊的政經環境,以及自由開放之政黨政治,種種的. 政 治 大. 因素導致台灣股市相當容易出現非經濟面因素的干擾,因而表現出相當不穩定的 特性。. 立. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 3-1 集中交易市場成交金額投資人類別趨勢 資料來源:行政院主計處 一般散戶取得市場資訊相對不容易,甚或不知如何獲取適切資訊,故容易受 市場之不確定消息影響而動作,甚至出現追漲殺跌(Momentum Strategy)等不理性. 24.
(33) 的投資行為發生,造成股價過度反應;另一方面,由於專業的投資機構取得市場 上相關訊息較為正確迅速,以及專業化的分析與判斷,其投資決策不易產生不理 性的行為。因此可以推斷,在股票市場中,法人或專業投資機構所佔的比例越高, 則該國市場之穩定性越高。 由淺碟型市場、散戶為大宗的特徵,不難理解台灣積極仿效歐美之資訊揭露 政策,以及迫切需要之情況(莊慶仁,2001)。同時台灣投資人亦不如 Fama(1970) 的效率市場假說中所言那般理性,「羊群效應」(The Effect of Sleep Flock)的情形 充斥整個股票市場,顯示著台灣的投資人彼此之間互相影響的事實。人們的行為. 政 治 大. 是否真為完全理性已經引發相當多的爭議,更有學者認為人們的行為實乃非理性. 立. 兼且並非隨機發生(Shleifer,2000)。. ‧ 國. 學. 由以上諸多現況可以解釋台灣的股票市場中,資訊揭露以及揭露程度如何均. n. al. er. io. sit. y. Nat. 於第二節。. ‧. 會對股價造成影響,本研究即針對此種台灣市場現況設計,詳細的研究架構介紹. Ch. engchi. 25. i n U. v.
(34) 第二節 研究架構 台 灣 經 濟 新 報 資 料 庫. 公 開 資 訊 觀 測 站. 重大訊息歷史資料. 立. ‧ 國. 學. 斷詞. kNN 分群. ‧. 向量轉換. sit. y. Nat. 分類出漲、跌、未反應 三種重大訊息. 權重計算. io. n. al. er. 資 料 前 處 理 模 組. 歷史股價資料 政 治 大. Ch. engchi. i n U. v. 預測其漲跌趨勢. 測詴資料發布. 驗證預測結果. 對應股價資料. 各重大訊息於發布後兩日之累積報酬率變動. 圖 3-2 研究架構圖 資料來源:本研究整理 26. 漲 跌 預 測 模 組.
(35) 圖 3-2 為本研究之研究架構圖,其中各個步驟之實際作法將分述如下。. 3.2.1 資料蒐集. 首先本研究從公開資訊觀測站,根據自實施資訊揭露評鑑以來之企業評價為 A+者,蒐集其五年來之重大訊息資料(2005~2009),再從台灣經濟新報資料庫取 出取樣期間內之公司股價資訊,兩者即為本研究之資料來源。共計 1382 篇重大 訊息,四間不同產業之上司公司,分別為統一、中華電信、長榮航空以及臺灣企. 政 治 大 息來源,以便瞭解重大訊息是否忠實反應其影響於股票市場。 立. 銀。之所以會選擇評價 A+的公司作為研究樣本,乃是希望能夠得到最完整的訊. ‧ 國. 學. 由於本研究主要在探討重大訊息對於發布公司有何實際的影響,而當市場上 有重大的資訊宣告時,對於股價與成交量都會有顯著的影響產生(Kim &. ‧. Verrecchia,1991;Foster & Viswanathan,1993)。因此研究一開始,將會對發布重大. Nat. sit. y. 訊息期間各公司股票之成交量與取樣全時期各公司之帄均成交量相比較,檢驗是. n. al. er. io. 否有顯著異常之交易量(Nofsinger,2001)。由先前文獻探討之結果可以得知台灣並. i n U. v. 非強效式效率市場,因此訊息會於發布日前即開始影響股市,所以本研究再參考. Ch. engchi. 過去學者之研究,將重大訊息宣告日加上其前後各兩個交易日,當作此篇重大訊 息之影響期間(李顯儀與吳幸姬,2005;李顯儀等,2006)。. 3.2.2 資料前處理模組. 資料前處理的部份首先以詞庫式斷詞法進行斷詞工作,工具為中央研究院之 中文詞知識庫小組所開發之 CKIP 中文斷詞系統,將蒐集來的重大訊息加以斷詞 後存入資料庫當中,作為進行後續步驟的詞庫使用,並為權重以及相似度的計算 基礎。 27.
(36) CKIP 中文詞知識庫,是為一個跨所合作的中文計算語言研究小組共同合作 建構中文自然語言處理的資源與研究環境,為國內外中文自然語言處理及其相關 研究提供基本的研究資料與知識架構,因此其公信度以及斷詞績效是值得信賴的 (謝佑明等,2004)。 由於 TFIDF-Weighting 並沒有考慮到不同文件的長度問題,於是本研究使用 文件正規化之 TFC-Weighting,以便將文件長度之影響降至最低,步驟說明如下: 首先計算出詞彙之 TF 值與 IDF 值,分別以下列之公式(1)(2)計算:. 政 治 大. 𝒂𝒊𝒌 = 𝒇𝒊𝒌 ·············································································(1). 立. 𝑵. ‧ 國. 𝒊. 學. 𝐢𝐝𝐟(𝐭) = 𝐥𝐨𝐠 𝒏 ············································································(2). ‧. N:文件總數。. er. io. sit. y. Nat. 𝑛𝑖 :代表含有關鍵詞 i 的總數。 aik :文件 i 中出現關鍵詞 k 的權重。 fik :文件 i 中出現關鍵詞 k 的頻率。. 將兩者乘積後得到 TFIDF 值,再使用餘弦正歸化之公式予以正規化. al. n. v i n Ch (Popescu,2001),讓資料更具比較意義、更容易解釋,如公式(4): engchi U 𝒂𝒊𝒌 =. 𝑵 𝒏𝒊. 𝒇𝒊𝒌 ×𝐥𝐨𝐠. 𝑵 √∑𝑴 𝒋=𝟏[𝒇𝒊𝒌 ×𝐥𝐨𝐠𝒏 𝒊. ]. 𝟐. ······························································(4). aik :文件 i 中出現關鍵詞 k 的權重。 fik :文件 i 中出現關鍵詞 k 的頻率。 N. log n :逆文件頻率。 i. 28.
(37) 3.2.3 kNN 演算法. 本研究之目的為找出公司發布之重大訊息對其股價之影響,因此希望能夠在 分類階段能達到最佳的精確度。k-Nearest Neighbor (kNN)(Witten & Frank,2000) 演算法一直以來皆是文字探勘領域的重要工具,由於 kNN 較為直覺的觀念,再 加上其表現的成果相當準確,與本研究一開始的出發點相契合,因此選擇 kNN 演算法。. 政 治 大 值,再將股價之漲跌資訊投入。之後開始計算向量空間所有兩兩文件的距離,距 立. 當研究作完前處理之後,所有文件資料(即重大訊息)已轉換為向量空間的數. 離即為相似度的判斷基礎,愈近者可以理解為較為相似的文件。在此如前所述,. ‧ 國. 學. 本研究以 TFC-Weighting 計算出各文件之權重,並以 Cosine Coefficien 進行文件. ∑𝐭𝒊=𝟏 𝒙𝒊 𝒚𝒊. y. Nat. io. al. n. x、y:為兩向量文件。 t:為 x、y 的維度。. ·······················································(5). sit. √∑𝒕𝒊=𝟏 𝒙𝟐 √∑𝒕𝒊=𝟏 𝒚𝟐. er. 𝐂𝐨𝐬(𝒙, 𝒚)=. ‧. 相似度的比較如公式(5):. Ch. engchi. i n U. v. 本研究即以上述的步驟進行,當有一筆新的向量文件進來後,將會與向量空 間內所有的文件計算距離,比較前 k 個最近的文件中,哪個類別的文件比例最高 即將此新進的文件加入此類別。 本研究以 1050 篇重大訊息,共四間不同產業之上市公司作為訓練資料,先 以 kNN 進行訓練動作,將這些樣本予以分群;之後再將 332 篇的重大訊息作為 測詴資料分入已分群之群組。. 29.
(38) 3.2.4 漲跌預測模組. 漲跌預測模組為對照各篇重大訊息所發布的時間,以及該時間點前後各兩日 的股價,來評斷此類重大訊息對股價的影響為何,是上升、下跌抑或持帄,如圖 3-3。. 2. 2. 重大訊息 i. 立. 2. 2. 政 治 重大訊息 大 j. ‧ 國. 學. 圖 3-3 重大訊息影響股價示意 資料來源:本研究整理. ‧. 區分漲跌的辦法本研究參考以往預測股價之相關研究,以個股收盤價之漲跌. Nat. sit. y. 變動量作為評估標準,假設某篇於 x 日所發布重大訊息之收盤價變動量 x 之計算. n. al. 收盤價變動量 = 𝒙. er. io. 公式如下,其中 y 為此訊息影響時間,即圖 3-3 中所示之前後兩日:. v i n C h ············································· (13) engchi U 收盤價. 收盤價. 𝒙+𝒚. −收盤價. 𝒙−𝒚. 𝒙−𝒚. 當收盤價變動量大於 0.03 時,將此重大訊息歸類為上漲;而當收盤價變動 量小於-0.03 時,將此重大訊息歸類為下跌;介於此範圍時則表示此訊息無顯著 影響,歸類為持帄(喻欣凱,2008)。 以此為準則將各群內之重大訊息以收盤價變動量為基礎加以分類,將各群之 漲跌類別以比例原則進行分類,因此在此步驟之結果產出即為上漲、下跌以及持 帄等三種重大訊息類別,之後再將 332 篇的重大訊息作為測詴資料予以分入這三 種類別。. 30.
(39) 3.2.5 分群分類績效評估. 最後分群分類之績效評估的部份,將使用精確率(Precision Rate)和召回率 (Recall Rate)來比較結果如何,不過為避免單獨使用兩者而造成彼消我長的情形, 本研究將使用混合兩者的 F-measure 來評估分群分類的績效如公式(12): 𝟐×𝐏𝐫𝐞𝐜𝐢𝐬𝐢𝐨𝐧. 𝐅 = (𝐏𝐫𝐞𝐜𝐢𝐬𝐢𝐨𝐧+𝐑𝐞𝐜𝐚𝐥𝐥) ·······································································(12). 政 治 大. 3.2.6 結果分析. 立. ‧ 國. 學. 透過這一系列完整的步驟之後,能夠分群出各公司之重大訊息,進而能夠分 析出各群重大訊息對於各自公司的股價影響趨勢,藉此瞭解台灣市場之發展現況. ‧. 為何;若是能夠歸納出公司對於所發布之重大訊息於股價影響,將能成為投資者. sit. y. Nat. 買賣其股票之依據;更進一步瞭解何種訊息將影響公司股價,何種類別之訊息又. n. al. er. io. 會如何影響股價波動(漲、跌)。. Ch. i n U. v. 在重大訊息分群之前,本研究會先將重大訊息之發布日及其前後各兩日之交. engchi. 易量資訊與本研究取樣之全部交易日之交易量作顯著性分析,證實重大訊息發布 時對於各公司之股票交易量確實有異常之變動,藉此結果作為本研究之支持論點, 再繼續後續分群分類之實驗,將重大訊息分群後再分成上漲、下跌與持帄三類。 最後本研究會再針對測詴的資料作進一步的解析,分別選出上漲群組以及下 跌群組內之重大訊息,計算其發布後兩日的累積報酬率加以觀察。是否上漲群組 在發布兩日後仍有正向的累積報酬率?又下跌的群組於發布兩日後是否仍有負 向的累積報酬率?最後再針對上漲群組以及下跌群組之訊息發布當日應該作出 之投資策略為何作進一步的建議。. 31.
(40) 第四章、 研究結果與分析 本研究蒐集統一、中華電信、長榮航空、臺灣企銀等四間不同產業中,自 2005 年至 2009 年資訊揭露評鑑為 A+之上市公司重大訊息,共計 1382 篇。 基於台灣之效率市場介於弱式與半強式效率市場之間(鍾雨潼,2002),因此 可以假設重大訊息對於發布公司之股價有相當程度的影響,也可藉此推測出台灣 個股對於資訊揭露的反應程度亦高。 本章之第一部份將會先作實驗一來測詴重大訊息的影響是否存在:以重大訊. 治 政 息發布影響期間之個股股票交易量帄均與取樣期間全時期之帄均成交量相比較, 大 立 檢驗是否有顯著異常之交易量(Nofsinger,2001)。股市中有句俗諺:『量是價的先 ‧ 國. 學. 行,先見天量後見天價。』,可以深入淺出的帶出交易量對於股票價格的關係如. ‧. 何。. sit. y. Nat. 第二部份則以實驗二對於資料進行分群:先利用 1050 篇的重大訊息資料作. n. al. er. io. 為訓練樣本,分別利用第三章之研究方法針對各重大訊息之型態加以分群,並判. i n U. v. 別出各群組之漲跌類別;再以 332 篇的重大訊息資料作為測詴樣本,利用分群資 料之相似度作分類的動作。. Ch. engchi. 第三部份再繼續實驗二之結果進行分析研究:探討上漲以及下跌群組中不同 性質之重大訊息發布後兩日對於股價所造成的影響,計算其累積報酬率,觀察是 否會因為其漲跌類別不同,而導致發布後兩日之累積報酬率呈現不同的發展,進 一步找出其規律為何,以作為日後投資策略之建議。. 32.
(41) 第一節 實驗一:訊息發布期間之交易量 首先將四間公司之個別股票交易量蒐集後,取出所有重大訊息發布日與其前 後各兩日之股票交易量加以帄均,與資料蒐集期間(2005~2009)所有交易日之相 對應公司股票之交易量作為比較。 樣本一:各重大訊息發布期間交易量之集合。 *𝑋1 , 𝑋2 , 𝑋3 , 𝑋4 , 𝑋5 , 𝑋6 , 𝑋7 , … , 𝑋n1 + 樣本二:全期間股票交易量之集合。. 政 治 大. *𝑌1 , 𝑌2 , 𝑌3 , 𝑌4 , 𝑌5 , 𝑌6 , 𝑌7 , … , 𝑌n2 +. 立. 當樣本數大於 30 時,根據中央極限定理,可以得知樣本之帄均數將以常態. ‧ 國. 學. 分配為極限,因此可以兩母體之假設檢定檢驗是否顯著。. ‧. 實驗假設:重大訊息發布期間與全時期之交易量有顯著差異。. Nat. sit. y. H0:假設兩樣本之帄均相等,亦即無差異。. er. io. H1:假設兩樣本之帄均不相等,亦即有所差異。. n. al. C hH0:𝜇1 − 𝜇2 = 0 U n i { engchi. v. H1:𝜇1 − 𝜇2 ≠ 0. 在顯著水準α=0.05 之下,檢定統計量公式如下: 𝐙=. ̅ −𝒀 ̅ −𝒄 𝑿. 𝝈𝟐 𝝈𝟐 √ 𝟏+ 𝟐 𝒏𝟏 𝒏𝟐. ……………………………………………………………… (14). 在信心水準 95%之下,拒絕域RR = {|𝑍| > 𝑧𝛼 },據此之決策法則為: 2. {. 如果 Z ∈ RR → 拒絕 H0 如果 Z ∉ RR → 接受 H0. 33.
(42) 表示在 Z > 1.96 和 Z < -1.96 之下,即可以拒絕 H0 假設,由此證明兩樣本之 帄均數差別顯著。以下分別就四間公司分別進行以上驗證:. 1、統一企業股份有限公司(統一) 樣本一:各重大訊息發布期間交易量之集合。 *5713.2 , 5370.4 , 4075.6 , 4075.6 , 4075.6 , 3978.2 , … , 5338.2 , 5705.2+ ̅ = 14813.49。 樣本數n1 = 352;變異數σ12 = 78365818;帄均數X 樣本二:全期間股票交易量之集合。. 政 治 大. *5898.6 , 4661.2 , 4599 , 4530.8 , 3711.4 , 3285.2 , 3159 , … , 6411,4200.8+. 立. ̅ = 13009.80013。 樣本數n2 = 1595;變異數σ22 = 60464599.98;帄均數Y. ‧ 國. 學. 將以上兩樣本之統計量代入公式(14)中,得 Z = 3.437121,屬於拒絕域,因. ‧. 此拒絕 H0。此時之 Z 值明顯大於 1.96,顯示出重大訊息發布期間與全時期之交. n. al. Ch. 樣本一:各重大訊息發布期間交易量之集合。. engchi. er. io. 2、中華電信股份有限公司(中華電信). sit. y. Nat. 易量有顯著差異,證明假設成立。. i n U. v. *8125.8 , 8125.8 , 9222.8 , 9222.8 , 8464.8 , 8005.6, … ,15954.2 , 22342.6+ ̅ = 19434.23523。 樣本數n1 = 548;變異數σ12 = 225861425.5;帄均數X 樣本二:全期間股票交易量之集合。 *8441.8 , 10211.4 , 11917.2 , 12172 , 12310.8 , 12098.8 , 10550.4 , … , 21535.4 , 11401+ ̅ = 17114.028。 樣本數n2 = 1595;變異數σ22 = 148724189;帄均數Y 將以上兩樣本的統計量代入公式(14)中,得 Z = 3.297357,屬於拒絕域,因 此拒絕 H0。此時之 Z 值明顯大於 1.96,顯示出重大訊息發布期間與全時期之交. 34.
數據

Outline
相關文件
The significant and positive abnormal returns are found on all sample in BCG Matrix quadrants.The cumulative abnormal returns of problem and cow quadrants are higher than dog and
The study explore the relation between ownership structure, board characteristics and financial distress by Logistic regression analysis.. Overall, this paper
One, the response speed of stock return for the companies with high revenue growth rate is leading to the response speed of stock return the companies with
Lessons-learned file (LLF) is commonly adopted to retain previous knowledge and experiences for future use in many construction organizations.. Current practice in capturing LLF
資料探勘 ( Data Mining )
目前 RFID 技術已列為 21 世紀十大重要技術及各大企業熱門產業投資項 目。零售業龍頭美國沃爾瑪(Wal-Mart)百貨公司在部分的零售點,已應用無線
本研究考量 Wal-mart 於 2005 年方嘗試要求百大供應商需應用 RFID 技術 於商品上(最終消費商品且非全面應用此技術,另 Wal-mart
本研究以 2.4 小節中之時程延遲分析技術相關研究成果為基礎,針對 Global Impact Technique、Net Impact Technique、As-Planned Expanded Technique、Collapsed
