以語意網建構人才推薦與信任推論機制之研究— 以某國立大學EMBA人才庫為例 - 政大學術集成
73
0
0
全文
(2) 摘要 「人」是公司中最重要的資產,而在知識密集的行業中,這樣的資產更顯得 重要。由於網路技術的出現,網路人力銀行也成為另外一種人才招募的新興管道, 但透過網路人力銀行所召募的人才素質並沒有傳統上透過公司員工推薦進來的 人才可更進一步瞭解的好處。因此本研究透過一網路人才推薦信任制度,來加強 線上人力銀行之人才篩選能力,希望透過此制度能繼續保有網路人力銀行在人才 招募速度上的優勢,並能加強其篩選的能力。. 政 治 大 立大學 EMBA 之人才庫,透過成員間的學經歷背景相似度,推薦出擁有相同顯 立. 本研究針對人才招募管道進行了文獻的探討,提出一人才推薦制度,以某國. ‧ 國. 學. 性工作能力的人才。讓人才招募單位可以得到推薦的人才,並可對其作信任評價 的推論。接著利用實驗來求出雛型系統的一些關鍵參數,讓雛型系統運作得更完. ‧. 善以及更符合使用者的需求。. y. Nat. io. sit. 本雛型系統結合了網路人力銀行人才招募方式可快速地招募到大量員工的. n. al. er. 特點,及員工推薦人才招募方式可招募到更適切員工的特點。並透過 FOAF 格式. Ch. i n U. v. 的使用,將線上社會網絡的資料格式統一,有助於縮短整個人才信任推薦系統的 建立時間。. engchi. 關鍵詞:招募管道、語意網、人才推薦系統、信任、社會網絡. i.
(3) Abstract "Human Resource" is one of the most important assets of company, especially in knowledge-intensive industries. As network technologies developed, commercial job site has also become another kind of recruitment channel. But through this kind of channel, companies don’t have better chance to know new employee than traditional way. Therefore this study filters new employees by a Recommendation & Trust Inference mechanism. Hope that commercial job site would continue to keep the advantages of high efficiency in recruitment, and enhance its filtering capability at the same time.. 立. 政 治 大. ‧ 國. 學. First, this study surveys literatures in recruitment channels. And it proposes a Recommendation & Trust Inference mechanism using a national university EMBA. ‧. program member data as an example. The Recommendation mechanism recommend. Nat. sit. y. candidates having the same specialty by comparing their similarity of education and. n. al. er. io. work experience. Furthermore, recruitment unit could use Trust Inference mechanism. i n U. v. to get suitable candidates. Third, we conduct experiments to find the key parameters. Ch. engchi. for the prototype system. Make the system able to work better and meet users’ needs.. The prototype system combines the benefit of commercial job site which can quickly recruit a large number of employees and the feature providing more appropriate candidates for the company recommended by staff. Simultaneously by taking use of the FOAF format, we can unify the data format in online social network. The way mentioned above will effectively reduce the system set-up time. Keywords:recruitment channel, semantic web, human source recommendation system, trust, social network ii.
(4) 目錄 第一章、緒論 ....................................................................................... 1 第一節、研究動機 .............................................................................................1 第二節、研究目的 ...............................................................................................3 第三節、論文章節闡述 ........................................................................................4. 第二章、文獻探討 ............................................................................... 5 第一節、招募管道 ..............................................................................................5 第二節、語意網及本體論 ...................................................................................7. 政 治 大 第四節、網際網路中的推薦與信任 ................................................................... 11 立 第三節、社會網路 ............................................................................................ 11. ‧ 國. 學. 2.4.1 網際網路中的推薦................................................................................. 11 2.4.2 網際網路中的信任................................................................................. 13. ‧. 第五節、小結 ...................................................................................................... 15. sit. y. Nat. 第三章、研究方法 ............................................................................... 15. io. er. 第一節、研究流程 .............................................................................................. 16 3.1.1 資料蒐集 ................................................................................................ 16. al. n. v i n Ch 3.1.2 資料整理 ................................................................................................ 17 engchi U 3.1.3 統計及實驗 ............................................................................................ 19 3.1.4 系統建置 ................................................................................................ 20 第二節、推薦機制 .............................................................................................. 20 3.2.1 推薦網絡的建立 .................................................................................... 20 3.2.2 顯性工作能力推論機 ............................................................................. 21 3.2.2.1 顯性工作能力相似度推論機制中的角色 ........................................... 21 3.2.2.2 顯性工作能力相似度推論架構........................................................... 22 第三節、信任推論機制 ....................................................................................... 27 3.3.1 信任推論機制中的角色 ......................................................................... 28 iii.
(5) 3.3.2 信任的種類及等級................................................................................. 28 3.3.3 信任推論機制所需要儲存的資料以及使用的變數............................... 30 3.3.4 信任推論機制之運作 ............................................................................. 31 第四節、資料模型 .............................................................................................. 33 第五節、雛型系統架構 ....................................................................................... 39 第六節、工具及語言........................................................................................... 40 3.6.1 PHP 語言的 RDF 應用程式界面(RDF API for PHP) ............................ 40. 第四章、資料統計及實驗 .................................................................... 40 第一節、資料統計分析 ....................................................................................... 40. 政 治 大 4.2.1 實驗設計 ................................................................................................ 43 立. 第二節、實驗 ...................................................................................................... 42. ‧ 國. 學. 4.2.2 實驗結果 ................................................................................................ 45. 第五章、雛型系統展示........................................................................ 54. ‧. 第六章、結論與未來研究方向 ............................................................ 61. sit. y. Nat. 第一節、結論 ...................................................................................................... 61. io. er. 第二節、未來研究方向 ....................................................................................... 61. n. 第七章、參考文獻 ............................................................................... 62 a. iv l C n hengchi U. iv.
(6) 圖目錄 圖 1、信任面向圖 ...................................................................................................2 圖 2、The Semantic Web “Layer Cake” ...................................................................8 圖 3、推薦系統工作流程 ..................................................................................... 12 圖 4、研究流程圖 ................................................................................................. 16 圖 5、舊有資料欄位圖 ......................................................................................... 17 圖 6、新增欄位後之資料欄位圖 .......................................................................... 19 圖 7、專業能力評價遞移性示意圖 ......................................................................21. 政 治 大 圖 9、顯性工作能力的推論架構圖 立 ......................................................................23. 圖 8、顯性工作能力推論機制中各個角色 ........................................................... 22. ‧ 國. 學. 圖 10、學歷、工作經歷資料權重樹 .................................................................... 24 圖 11、組織-顯性工作能力等級矩陣 ................................................................ 25. ‧. 圖 12、圖形化的範例信任資料模型 .................................................................... 39. sit. y. Nat. 圖 13、雛型系統架構 ........................................................................................... 40. n. al. er. io. 圖 14、學生擁有學歷資料的人數分配以及學生擁有工作經歷資料的人數分配圖 ................................................................................................................... 43. i n U. v. 圖 15、產業分布狀況圖 ....................................................................................... 45. Ch. engchi. 圖 16、在「電子資訊/軟體/半導體相關業」網絡覆蓋率之變化圖 .................... 50 圖 17、在「大眾傳播相關業」網絡覆蓋率之變化圖 ......................................... 51 圖 18、在「農林漁牧水電資源業」網絡覆蓋率之變化圖 .................................. 51 圖 19、網絡形成時間成本效益圖 .......................................................................... 54 圖 20、系統操作畫面-登入頁面 ........................................................................ 56 圖 21、系統操作畫面-使用者相關資訊頁面 ..................................................... 56 圖 22、系統操作畫面-顯性工作能力評價人才搜尋結果頁面 .......................... 57 圖 23、系統操作畫面-信任評價人才搜尋結果頁面 ......................................... 58 圖 24、系統操作畫面-人才搜尋結果頁面 ......................................................... 59 v.
(7) 圖 25、系統操作畫面-使用結果滿意度調查頁面 ............................................. 60. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. vi. i n U. v.
(8) 表目錄 表 1、學群分類表. ............................................................................................... 18. 表 2、產業分類表. ............................................................................................... 18. 表 3、功能別分類表. ........................................................................................... 19. 表 4、顯性工作能力評價等級 表 5、信任評價等級. ............................................................................ 23. ........................................................................................... 30. 表 6、Recommender Trust 與權重之對應表 ........................................................... 32 表 7、Inferred Trust 等級與對應分數之對應表...................................................... 32. 政 治 大 表 9、資料庫統計表 ............................................................................................... 42 立 表 8、範例人才資料模型的 triple data ................................................................... 36. ‧ 國. 學. 表 10、各產業別擁有工作經歷資料個數表........................................................... 44 表 11、網絡覆蓋率實驗結果表 .............................................................................. 46. ‧. 表 12、網絡覆蓋率時間效益實驗結果表 .............................................................. 52. n. al. er. io. sit. y. Nat. 表 13、推薦結果整理 ............................................................................................. 60. Ch. engchi. vii. i n U. v.
(9) 第一章、緒論 第一節、研究動機 「人」是公司中最重要的資產,而在知識密集的行業中,這樣的資產更顯得 重要 (Pamenter, 1999)。一項研究指出,在2000年,人力資源管理最優先考慮的 議題分別為招募 (Recruiting)、甄選 (Selecting) 與安置 (Placing)員工。而在這些 議題當中,招募新員工的質與量將會影響到人力資源之後各功能的成功與否,如 在甄選、訓練以及薪資制度。. 政 治 大 近年來,網路的出現,影響到的層面逐漸的擴大。人力銀行的興起,形成另 立. ‧ 國. 學. 外一種新興的招募管道。而且其使用狀況,從 1996 年國內並無任何企業採用此 種招募方式,到 1999 年台北市勞工局就業服務中心指出,企業運用網路招募管. ‧. 道,占所有招募方式的 10.65%,僅次於報章雜誌、同仁與親友介紹和現場徵才. sit. y. Nat. 活動,為第四大招募管道,同時網際網路也是求職者尋找工作的第三大管道。到. io. er. 了 2001 年,企業運用網路徵才管道來招募員工已取代了報章雜誌,成為第一大. al. 的管道,其招募比例成長至 18.62%。而對於大學畢業的新鮮人,網路招募已成. n. v i n C h86.52%。有鑑於以上的情況,網路招募管道已 為最熱門之應徵管道,比率高達 engchi U 經深深影響到企業在人力資源管理的後續工作,所以透過其所招募到新員工的質 與量,是極需得到企業的重視的(簡士評,2001)。下個段落會針對網路招募管. 道的一些成效不足的狀況加以討論,希望透過這樣的討論,能找出網路招募管道 的改善方向。 雖然透過網路招募可快速地招募到大量的員工,但有研究指出所招募員工的 工作表現卻不如其他召募管道(簡士評,2001)。另外一種人才招募管道-員工 推薦-也是公司常用來招募人才的方法。透過公司員工來推薦應徵者,其所招募 到之人才往往具有較好的工作表現,是一個相當有效的招募管道。其部分原因來 1.
(10) 自於具有特殊技能的員工,較有可能認識相同技能的人才;另一個原因則是因為 公司員工與該位被推薦者擁有較多的相處時間、空間,因此將更加了解該位人才 的工作態度,以及一些隱性的工作能力(簡士評,2001)。簡單來說,就是公司 員工對於該被推薦者會有一信任的評價,此信任評價包含了:一、顯性的工作能 力評價(專業的能力) ,二、隱性的公作能力評價(工作態度、團隊合作能力等…)。 進一步來看,這些擁有相同顯性工作能力的人,可能是該員工畢業於同一個學校 的同學系,或者曾經跟該位員工在同一家公司共事過。透過這樣的推斷,我們可 以說,擁有越相似的學歷以及工作經歷背景,其顯性工作能力(專業的能力)越. 政 治 大 任有兩個面向,一為對其顯性工作能力(專業能力)的評價,一為對其隱性工作 立. 相像,或者是越擁有相似的工作技能。更深入的分析,在本研究當中所提及的信. 能力(工作態度、團隊合作能力等…)的評價,如圖 1 所示,當一個人要信任另. ‧ 國. 學. 外一位人在某領域下的工作表現很好的話,除了依照其專業能力來判斷,另外一. ‧. 項判斷的指標,就是比較偏向心理層面的。因為若只有好的專業能力,工作態度. y. Nat. 不好的話,在工作上也不會有好的表現的,因此當一個人對他人作信任評價時,. n. er. io. al. sit. 同時是對顯性工作能力以及隱性工作能力做評價。. Ch. engchi. i n U. v. 圖 1、信任面向圖 資料來源:本研究整理. 透過員工推薦這樣的招募管道,雖然可招募到較優質的人力,但所花的時間 相較於網路招募管道是較長的(簡士評,2001)。現今經濟逐漸發展,廠商規模 漸增,員工推薦的招募管道無法充分滿足大量的人力需求的狀況。 2.
(11) 此外,在目前的網路招募模式當中,每個人若要加入某間網路人力銀行的招 募管道,就必頇在該網路人力銀行中維護一份履歷表;當加入越多的網路人力銀 行,其所需維護的履歷也越來越多。在這樣的狀況下,使用者為了要讓更多的求 才廠商能看到自己的履歷,往往都需要在許多的網站留下並維護自己的履歷資料; 若求才廠商沒加入該網路人力銀行,則沒辦法得到在該人力銀行中的相關人才資 訊。在上述的狀況下,求職人才及求才廠商的資訊沒有辦法很有效率地在其間流 通,因此也影響到了網路招募管道的成效。 綜合言之,網路招募管道為現今最重要且最主要企業用來招募人才的管道。. 政 治 大. 因此透過網路人力銀行的網路招募管道的招募成效,也成為各界討論的重點。本. 立. 研究主要針對網路招募管道所招募到人才的素質問題,以及求職人才與求才廠商. ‧ 國. 學. 之間的資訊流通問題加以討論,希望透過本研究所提出的方法,能改善網路招募 管道的招募成效。. ‧. io. sit. y. Nat. 第二節、研究目的. n. al. er. 為了要能解決研究動機中所提出來網路招募管道的兩項成效問題,透過文獻. Ch. 的探討,本研究期望達到以下幾項目標:. engchi. i n U. v. (1) 以 FOAF 實現一人才資料模型 語意網這項技術將會開創下一代人工智慧的發展,並讓不同系統間的資料交 換變得更為便利。透過語意網的發展,電腦開始「讀得懂」人類在網頁上所表達 的資訊,並可以幫助人類自動去處理很多事情。Finin et al. (2005) 的研究顯示, 語意網目前最大的發展方向就是人脈網絡,大量的人脈網絡的語意網頁已存在網 際網路當中,用來表達虛擬社群中個人以及與他人關係的資訊,其中以 FOAF 格式最為盛行。. 3.
(12) 透過統一描述人才相關資料的格式,我們將可以加強求職人才及求才廠商間 的資訊流通效率,並整合網路上既有資源,快速的建立並擴大人脈網絡,以支持 人才推薦及信任推論的機制。 (2) 顯性工作能力的人才推薦機制 透過可以找出相同顯性工作能力人才的推薦機制,我們可以以使用者過往評 價其他使用者的評價資料,從系統中找出與被評價者有相似工作能力(有相似學 經歷背景)的成員,來推薦給使用者。. 政 治 大. (3) 信任(隱性工作能力)推論機制. 立. 當系統找出推薦人選後,接著就需要信任推論機制的幫忙。透過這信任推論. ‧ 國. 學. 機制的支持,我們可以了解該位人選的隱性工作能力。上述「顯性工作能力的人. ‧. 才推薦機制」 、 「信任推論機制」可模擬在員工推薦招募管道中,員工會推薦其信. sit. y. Nat. 任的人給公司。在這所提之信任包含了兩個面向,一為顯性的工作能力(專業能. io. er. 。透過這樣的模擬, 力) ,二為隱性的工作能力(工作態度、團隊合作能力等…) 可改善網路招募管道中人才素質較不適切的問題,以加強網路招募管道的成效。. n. al. Ch. engchi. i n U. v. 待達到上述目標之後,我們將實際建立一線上人才推薦與信任推論系統來做概 念的可行性驗證。期望能透過以上三個目標,改善網路招募管道的成效。. 第三節、論文章節闡述 在說明本論文之動機及目的之後,在第二章便會對招募管道、語意網及本體 論、社會網絡及網際網路中的推薦與信任的相關文獻進行探討;了解這些領域中 研究的發展狀況,以發展本研究之研究目標。在文章中的第三章會說明本研究的 流程,以及如何達到本研究的三項研究目標;第四章、第五章,主要是透過對資 料庫中學員資料的分析及實驗來求出雛形系統的相關參數,並說明雛型系統的操 4.
(13) 作流程,以ㄧ實際的範例來驗證本研究所提出之推薦與信任推論機制。最後我們 將結論及未來研究方向放在第六章的地方。. 第二章、文獻探討 第一節、招募管道 首先定義「招募」到底是什麼?所謂的招募是組織為了職務空缺而吸引求職. 政 治 大. 應徵者的管道。一般而言,招募管道可分為兩種,一為正式管道,另一則為非正. 立. 式管道。正式管道的定義是雇主與應徵者的接觸,是經由外界組織或仲介機構的. ‧ 國. 學. 安排,主要包含公、私營職業介紹所、校園招募、駐校辦事處、廣播、電視及報 紙或專業雜誌的招募管道…等等;非正式管道的定義為雇主與應徵者的接觸,並. ‧. 非經由外界組織或仲介的安排,主要為員工推薦、親屬或朋友推薦、自薦、雇用. y. Nat. sit. 離職員工…等等所組成(簡士評,2001)。正式管道擁有資訊傳遞快速且廣大的. n. al. er. io. 特性,因此可以快速的招募到大量的員工;非正式管道雖然招募的速度較慢,但. i n U. v. 透過推薦者對於公司以及被推薦者的了解,可以替該職缺找到較適合的人才。. Ch. engchi. 有許多學者在其研究中針對正式管道以及非正式管道的有效性進行討論,到 底哪種招募管道會必較適合組織呢?Rees (1966) 認為傳統上經濟學者對非正式 招募管道採取較懷疑的態度,這是因為這些經濟學者認為勞動市場資訊是容易隨 著時間而消逝地,舉例如言,當A取得一公司的職缺資訊,若此職缺適合A,A 會隱藏這項資訊,以避免過多的競爭者;若此職缺並不適合他,則此項職缺的資 訊也會因此而消逝,並不會傳遞到他人。這時若此職缺資訊是由一些公私立輔導 就業機構來蒐集的話,職缺資訊對於A沒用,但或許對B或者是C是有用的。簡而 言之,此項職缺資訊不會快速的消逝而被浪費掉,因此傳統上的經濟學者會認為 5.
(14) 正式招募管道會優於非正式的招募管道(李誠、簡士評,2001)。但李誠則認為 這些管道的有效性與經濟發展的程度有相當的關聯,當經濟發展初期時,失業以 及未充分就業的人口數很多,且廠商需求的職缺數較少。透過親友或者是員工推 薦的非正式管道其成本低廉且有效,因此也成為多數企業主愛用的方式。這樣循 環的結果,讓經濟發展初期時大部分的求職者,多是透過非正式招募管道來得到 工作;但是當經濟逐漸地發展起來,廠商的規模倍增,對於職缺供給量大量的增 加,此時傳統上非正式的招募管道,已無法滿足這樣的需求。這時透過正式招募 管道大量且資料傳遞快速的特性,將可滿足需求,也因此大多數的企業便會採取. 政 治 大 與效用,例如,利用員工推薦的管道,員工較了解職缺的內容以及被推薦者是否 立. 這樣的招募管道。但是Rees (1966) 也認為非正式招募管道還是有其特殊的優點. 適合該職缺,因此提供了雇主一個很好的篩選工具。除此之外,非正式管道成本. ‧ 國. 學. 低,非正式管道也傾向找到鄰近地區的應徵者,如此會降低員工因交通因素所造. ‧. 成的遲到、曠職,甚至是離職。Taylor and Schmidt (1983) 也認為非正式招募管. y. Nat. 道較正式招募管道可以透露出更多的職缺資訊。這樣的結果降低了離職率,透過. er. io. sit. 以上的討論,簡士評 (2001) 認為就資訊傳播的角度來說,正式管道優於非正式 管道。透過正式管道可以將職缺傳播的範圍擴大、取得資訊的人更多,因而會找. al. n. v i n 到更多的應徵者,並且會有更多的應徵者經由正式管道進入公司內部;但若以工 Ch engchi U 作結果表現來說,非正式管道將會優於正式管道。. 現今,網際網路的快速發展,更出現了網路招募的這種新興招募管道,網路 招募是屬於正式招募管道的一種方式。相較其他的推薦管道而言,這樣的管道來 的更加便宜,也因此逐漸成為各企業招募人才的主流管道之一。就台灣而言,目 前最常使用的招募管道為網路人力銀行與報紙或雜誌的廣告,以帄均成本來計算, 經由網路人力銀行僱用一人的費用約為新台幣三千五百元,而經由報紙或雜誌僱 用一人的帄均費用約為新台幣一萬三千元左右。而以網路快速傳遞資料的特性, 更加快了人才招募的流程。在人才招募量已達到期望的結果之下,企業更將注意 6.
(15) 力放在,招募人才之質上面。在這樣的一個期望之下,網路招募並不能完全滿足 企業的需求。根據Kuhlen (2001) 的調查研究指出,在歐洲約有33%的受訪公司 認為經由網際網路招募的員工會有較高的離職率,有44%認為很難找到非常合適 的人才。透過以上對於網路招募管道的討論,也導出本研究的其中一項動機。. 第二節、語意網及本體論 自 1969 年網際網路的發展至今,已經有太多的資訊充斥在網際網路上。在 這資訊爆炸的時代,若只單單靠人的眼睛來篩選所需要的網路資訊,恐怕會很快. 政 治 大 人們可以自由去使用,但它並沒有辦法幫人類有效地去過濾及處理這些資訊。這 立 的就被這些資料所淹沒。目前的網際網路技術多是把文件化的資訊數位化,使得. ‧ 國. 學. 是為什麼呢?就是因為電腦沒有辦法看得懂這些資訊。. ‧. 有鑑於此,Berners-Lee and Fischetti (1999)提出新一代的網路資訊架構-「語 意網」。他主張將線上的資訊結構化,也就是將全球資訊網上的網頁,改成電腦. y. Nat. io. sit. 能夠看得懂的型態。透過這樣的方式,機器可以自動化得幫人類處理事情及分類. n. al. er. 資訊。而這樣的一個網路架構,並不是捨棄掉目前網際網路的架構,而是延伸目. Ch. 前的架構,並將意義的註解加在裡面。. engchi. i n U. v. 下圖為 Berners-Lee and Fischetti (1999) 所提出的語意網架構。透過這張圖, 我們可以發現語意網是透過好幾層的技術(語言),一層一層加上去而達成的。. 7.
(16) 治 政 圖 2、The Semantic Web “Layer大 Cake” 立 資料來源:Berners-Lee & Fischetti (1999) ‧ 國. 學. 本體論原本是哲學領域的一支,其探討的就是物體的本質,也就是說「這到. ‧. 底是什麼?」。現今在電腦科學的領域當中,本體論所代表的是一個領域中的正 式概念,也就說它描述了在一個領域中的各種物體其種類的關係。舉個例來說,. y. Nat. io. sit. 在生物這一個領域當中,各種生物可以分為各個界,每個界底下又有某些門,每. n. al. er. 個門的生物又可分為好幾個綱,每個綱又可繼續分類下去。透過這樣的一個描述,. Ch. i n U. v. 我們可以了解各種生物間的關係。現今 W3C [h]也定義了一些本體論的描述語言,. engchi. 用來描述網頁中內容,包括了 RDF 及 OWL。透過這些語言的描述,電腦可自 動化處理網頁的內容,不再受限於自然語言複雜的解析及 Relational Database 的 表達限制 (Antoniou and Harmelon, 2008; Finin et al., 2005)。豐富的知識表達方式, 讓原先透過 Relational Database 很難表達的知識都被電腦讀取且被處理,這樣一 來,電腦便可處理更複雜的事情。在何丁武等 (2006) 的文章中,作者利用本體 論來描述電子音樂的知識,其中包括了類別以及關係屬性。透過這樣的描述,我 們依照電子音樂的類別,或者是類別與類別間的關係來進行更複雜的音樂推薦。 另外楊永芳 (2002) 也利用了本體論來描述知識,透過知識節點間的關係聯結, 可以找到相關聯的知識節點,有助於一個概念的知識擴展。簡單來說,當現在有 8.
(17) 個字彙 ”eBay” 出現,透過本體論,我們可以找出與 eBay 知識節點有相關聯的 知識節點,例如:網購,並加入此知識節點,讓整個知識概念更完善。 目前語意網的發展領域相當廣泛,各行各業都有自己的本體論,例如都柏林 核心集 (Dublin Core) …等,更有本體論的搜尋引擎應運而生(Swoogle)[e]。而 為了因應整個線上社會網路的發展,有關社會網路的本體論也被提出,例:The Friend of a Friend Ontology (FOAF)。FOAF 這項計畫開始於 2000 年,由 Dan Brickley & Libby Miller 所創造,此計畫主要是希望能提供一個線上的社會網絡, 而這樣的社會網絡是由許多機器可讀的頁面所組成的。這些頁面描述了這社會網. 政 治 大. 絡中每個節點的個人資料,例如:姓名、個人網頁、曾經讀過的學校等…,除此. 立. 之外 FOAF 更可以表達出此節點認識該網絡中的哪些結點。. ‧ 國. 學. 透過 FOAF,線上社群網站的使用者不必再擔心因為其朋友使用不同網站的. ‧. 服務而斷絕的聯絡,FOAF 可以連結來自不同來源的使用者資料,讓全世界的線. sit. y. Nat. 上網絡可以串連在一起 [a]。. n. al. er. io. FOAF 是一以 RDF 為基底的模型,其透過一些已預先設定的詞彙來描述人. i n U. v. 的屬性以及與其他人之間的關係 [b],以下為一 FOAF 格式的範例。 <foaf:Person>. Ch. engchi. <foaf:name>Dan Brickley</foaf:name> <foaf:mbox_sha1sum>241021fb0e6289f92815fc210f9e9137262 c252e</foaf:mbox_sha1sum> <foaf:homepage rdf:resource="http://rdfweb.org/people/danbri/" /> <foaf:img rdf:resource="http://rdfweb.org/people/danbri/mugshot/dan bri-small.jpeg"/> </foaf:Person> 9.
(18) 以上的 FOAF 範例可以以下幾句語句來表達,「這裡有一位人,他的名字叫 Dan Brickley。他的電子郵件信箱 hash 編碼為 24102… 。他的個人網頁為 http://rdfweb.org/people/danbri/...」,除了以上這些字彙之外,FOAF 更可以利用 foaf:knows 的屬性來建立人與人之間的連結。 透過 FOAF 的使用,可以將線上社會網絡的資料格式統一,統一的格式將有 助於縮短整個人才推薦與信任推論系統的建立時間。另外,也由於 FOAF 為目前 世界上發展最為廣泛的本體論 (Finin et al., 2005),許多著名的社群網站也採用 FOAF 來描述該網站的使用者,例如:Live Journal [g]。所以若系統能讀取 FOAF. 政 治 大. 格式的資料,將可立刻利用到目前網路上已有的社會網絡資料,加速整個線上信. 立. 任網絡的形成。透過 FOAF 本體論,機器能夠自動處理、推論社會網路中個人的. ‧ 國. 學. 基本資料以及人與人之間的關係,實現了以往只有在封閉式網站才有的運算能力。 本研究中每位成員的履歷資料便是利用 FOAF 本體論來儲存。. ‧. sit. y. Nat. 除了自動化處理及推論網頁的功能之外,語意網另外一項最大的幫助就是可. io. er. 以支援整合不同來源的資訊。透過某領域下統一的本體論,該領域下各個組織可 以在語意網上共享資料,幫助該領域下知識的整合。游卓凡 (2007)提出目前國. al. n. v i n Ch 內廣告公關業界中諸多問題的源頭都是在於資訊不交流,不透明的生態,而造成 engchi U. 了一連串的惡性循環,導致整個業界每況愈下。考慮了上述的問題,該研究便為 國內廣告公關業設計了一知識本體,透過這樣的本體,廣告公關公司便可在之中, 建立、及分享相關的知識,打破同業公司間的隔閡。在本研究當中,透過 FOAF 格式的延伸,不僅可以讓這些資料是可以被分享的,不必再為了要加入不同的網 路人力銀行,而又再維護一份新的履歷資料,加強求職者以及招募單位之間的資 訊流通。更進一步地可以利用目前網際網路中已經建好的 FOAF 文件,加快整個 人脈網絡的形成。. 10.
(19) 第三節、社會網路 社會網路的發展已經有一段時間了,其中有一很著名的理論「Six degrees of Separation」,其由 Stanley Milgram 在 1960 年代所提出(Milgram, 1967),這理論 指出在這世界上的任一兩個人之前,可以透過最多不超過六個人連結得到。社會 網絡的研究範圍相當的廣泛,更包括了疾病的傳播 (Golbeck et al., 2003) 以及工 作的找尋;在 Marmaros and Sacerdote (2002) 當中也證實了不同網絡對於找工作 的結果有極大的相關,要找到好的工作跟你所位於的社群是互相連結的。到了最 近,網際網路上社群網站的蓬勃發展,更將原先在現實生活中的社會網路,移植. 治 政 到網路上。許多原本在現實生活中的社會網路功能,也都在網際網路上展現,其 大 立 中包括了,人員的招募及工作職缺的介紹 [d]。透過網路使用者之間的連結,我 ‧ 國. 學. 們可將資訊透過一條一條的人脈路徑傳遞出去,不僅加快了資訊的傳遞,也利用. ‧. 了人脈的特性,判斷資訊的可靠度。. sit. y. Nat. 在 Golbeck (2009) 的研究中更進一步地探討,目前線上社群網絡中的公共. n. al. er. io. 資料通常只包括網絡中的結構(誰是誰的朋友等…),許多使用者與使用者間的. v. 互動紀錄,以及使用者與系統間的互動紀錄都是隱密的。因此許多以此開發的應. Ch. engchi. i n U. 用受到了相當大的限制,如果在設計相關的演算法時,也應該要考量到資料現有 欄位的問題。以本研究為例,因為目前所擁有某國立大學 EMBA 學員的資料只 包含了其相關的學經歷背景,為了要能讓人才推薦機制能夠順利的運作,本研究 便利用同學及同事的關係來達到網絡的建立。接著再利用成員間學經歷背景的相 似度,來推算出其顯性工作能力相似的程度,最後再以此向招募單位推薦相關的 人才。. 第四節、網際網路中的推薦與信任 2.4.1 網際網路中的推薦 11.
(20) 在網際網路蓬勃發展的今天,網路上充斥的許多資訊,包含了商品、電影、 部落格文章、網頁等資訊。為了要在有限的時間內得到有用且符合自己需求的資 訊,網際網路中的推薦機制便扮演了相當重要的角色。推薦系統工作流程主要分 為三個步驟,第一個步驟是蒐集使用者資訊,並且加以存檔;第二個步驟是根據 使用者資訊進行資料的篩選與推薦;第三個步驟是使用者對於推薦結果進行評估 後回饋給系統(何丁武等,2006),如圖 3 所示。. 立. 政 治 大. ‧ 國. 學 ‧. 圖 3、推薦系統工作流程. 資料來源:何丁武、邱耀漢、楊建民(2006). sit. y. Nat. io. er. 進一步地我們可以將網際網路中的推薦機制進行分類,分別為內容式過濾、 協同式過濾與連結導向 (McDonald, 2003),分別說明如下:. n. al. Ch. engchi. (1) 內容式過濾 (Content-Based Filtering). i n U. v. 內容式過濾推薦方式主要比較使用者的喜好與其他資訊,或者是商品間的相 似度(相關度)。相似度(相關度)越高的資訊,商品越會被推薦給使用者。 (2) 協同式過濾 (Collaborative Filtering) 協同式過濾推薦的方式,主要是比較使用者本身對商品或是資訊評價的相似 度。在這裡我們可以稱使用者對商品或資訊的評價資訊為「使用者輪廓」,使用 協同式過濾的推薦系統,會推薦使用者輪廓與使用者相似的系統中其他成員所評 12.
(21) 價的資訊,或者是商品,給該使用者。 (3) 連結導向 (Link-Based) 此種方式主要是利用圖論演算法,找尋整個圖中,最多人參照到的節點,並 將此節點推薦給使用者。 本研究中的人才推薦,主要是採用 Content-Based Filtering 的推薦方式,此 種方式主要是透過商品或資訊本身間的相似度,來推薦相似的物品給使用者。在 本研究中,首先會請使用者對數個認識的成員作顯性工作能力評價,透過計算成. 政 治 大. 員與成員間學經歷背景的相似度,來找出擁有相似顯性工作能力的成員,並把這. 立. 些成員們推薦給使用者。. ‧ 國. 學. 2.4.2 網際網路中的信任. ‧. 除了上節所述的那些傳統的推薦方式,有學者便將現實生活中,朋友對朋友. y. Nat. sit. 的推薦方式,引用至網際網路當中。現今所發展的網際網路中的信任應用相當廣. n. al. er. io. 泛,其應用像是電影的推薦、電子郵件的篩選、部落格推薦等等(李永銘等,2007;. i n U. v. 李永銘等,2006;Golbeck et al., 2003;Golbeck, 2006)。信任的發展在目前這種. Ch. engchi. 資訊爆炸的狀況之下,尤其重要。最近,許多信任相關地研究大多著重在「信任 推論」上面,這種信任值預測的模型,多在利用信任值在信任網絡(利用信任關 係所串起的人脈網絡)中的傳播,來預測對於一未曾碰面過網絡中成員的信任度 (Abdul-Rahman and Hailes, 2000;Golbeck, 2003),透過這樣的推論,便可對一未 曾謀面的人得到信任的評價。Sinha and Sewaringen (2001) 發現使用者較喜歡從 他們認識,或是信任的人那裡收到推薦,例:朋友、家人等…,勝過於從線上推 薦系統那收到相關推薦資訊。於是有研究便開始利用”信任”來支援或者是取代傳 統上的推薦方式。在 Papagelis et al. (2005) 中便利用兩使用者間評價物品的紀錄 來計算其中的品味相似度,當相似度越高時,便可以說兩使用者間存在越大的信 13.
(22) 任。透過這些信任值的建立,雖然兩使用者之間並沒有相同的商品評價記錄,但 透過信任的推論,系統便可利用推論的結果來支援 Collaborative Filtering 的推薦 方式,擴大 Collaborative Filtering 的推薦範圍。Kim et al. (2008) 便利用信任來取 代傳統的 Collaborative Filtering 推薦方式,直接利用 Global Trust 來做推薦;Cosley (2003)、Ziegler and Golbeck (2005)、Bonhard et al. (2006)、Golbeck (2009) 等人 也透過實驗的方式,來找出傳統上 filtering 中的相似度跟信任是否有關係。實驗 發現當使用者越相似的時候,其越信任對方或者其間的合作也越愉快。不過在上 述研究中的相似度,多半侷限在商品評價的紀錄,或者是使用者的基本資料(年. 政 治 大 音樂及部落格文章等,跟本研究所論及之學經歷背景相似度及在某產業別中的工 立 齡、性別等),而且其所探討信任的領域多半是某種品味上的信任,例:電影、. 作表現信任有相當大的差別。因為在上述研究中,實驗顯示當使用者越相似的話,. ‧ 國. 學. 其對對方的在品味的信任度越高,這是合理的,因為當你跟其他使用者越相似的. ‧. 話,同時也代表你與他的品味越雷同,因此合理的推斷你會越信任其品味。但是. y. Nat. 若此信任是指在某產業別下工作表現的信任,當使用者之間學經歷背景越相似時,. n. al. er. io. 作表現會一致。. sit. 並不代表其越相信其工作能力,我們只能推斷說使用者們在該產業別下的顯性工. Ch. engchi. i n U. v. 更進一步的來討論信任的種類,有研究提出信任可分成兩種 (Kim et al., 2008),一為 Global Trust(信譽) ,另一為 Local Trust(信任推論) 。在 Global Trust 信任度計算方式之下,因為信任度的值是綜合網路整體的意見而來,因此每項資 訊都有一固定的信任度,而不會因為之於不同的人而有所改變。這樣的狀況,與 現實生活中的狀況不是那麼的相同。就現實而言,每個人對於同樣的資訊都有不 同的信任度,所以這樣的機制實在不足以反映現實。這樣看起來 Local Trust 似乎 是比較滿足現實的狀況,但 Local Trust 信任度計算方式,有一缺點,那就是每個 人都必頇要維護一份朋友的信任清單。以現今的狀況之下,這樣的信任資訊是缺 少的,必頇要重頭建立,所以透過 Global 以及 Local Trust 的結合,將是一較可 14.
(23) 行的方式。. 第五節、小結 由文獻中我們可以看出,在目前網路招募管道上也存有人才推薦以及信任推 論的需求。而為了能結合員工推薦招募管道中的好處,本研究採用了 Content-Based Filtering 之人才推薦模型,找出擁有相同顯性工作能力的人才,接 著再進一步地透過信任推論模型,推論出該人才的信任度,以解決網路招募管道 缺乏推薦以及信任評價的現況。另外透過語意網的技術,我們將 FOAF 格式作延. 政 治 大 人力銀行,而又再維護一份新的履歷資料,加強求職者以及招募單位之間的資訊 立. 伸,可以讓這些成員的履歷資料是可以被分享的,不必再為了要加入不同的網路. ‧ 國. 學. 流通。更進一步,可以利用目前網際網路中已經建好的 FOAF 文件,加快整個人 脈網絡的形成。希望能透過以上的作法,讓網路招募管道可擁有原先資料傳遞上. ‧. 的優勢,更能擁有非正式管道中的種種好處。. er. io. sit. y. Nat. n. a l第三章、研究方法 i v n Ch U engchi. 本研究探討了社會網路上之信任機制以及人才招募之相關文獻,期望能夠找 出: (1) 以 FOAF 實現的人才資料模型 (2) 顯性工作能力的人才推薦機制 (3) 信任(隱性工作能力)推論機制 最後利用某國立大學 EMBA 學員資料,將其轉換為本研究所設計出之人才 資料模型。透過實驗來找出推薦系統的相關參數,並利用這些參數實做一線上人 15.
(24) 才推薦與信任推論系統來做驗證。. 第一節、研究流程 整個研究的流程包括了以下幾個步驟如:資料蒐集、資料整理、統計及實驗、 系統建置。如圖 4 所示,在文章後面會對各個步驟加以描述。. 治 政 資料來源:本研究整理大 圖 4、研究流程圖. 立. ‧ 國. 學. 3.1.1 資料蒐集. 本研究針對的是網路人力銀行人才的招募,因此資料蒐集的目標為具有個人. ‧. 基本資料、最高學歷以及過往工作經歷等欄位的資料。考量資料需求屬性,最後. y. Nat. sit. 決定以某國立大學 EMBA 學程的學員資料,當作本研究的資料來源。因為國內. n. al. er. io. EMBA 學程的錄取要求需要多年的工作經驗,因此這類學程中學員的資料擁有. i n U. v. 基本資料、最高學歷以及豐富過往工作經歷等資料,正好符合本研究的需求。. Ch. engchi. 本研究整理該學程內 87 至 99 學年入學之學員資料,擷取出與本研究相關的 資料欄位,並對資料作保密處理(修改學員姓名、畢業學校名稱、工作經歷公司 名稱),資料筆數共計 2354 筆,資料欄位顯示如下:. 16.
(25) 學員資料. 基本資料. 學歷資料. 工作經歷資 料. 學號. 學校. 公司. 姓名. 系所. 部門. 學位 政 治 大. 立 圖 5、舊有資料欄位圖. ‧ 國. 學. 資料來源:本研究整理. 3.1.2 資料整理. ‧. sit. y. Nat. 為了要讓這些資料更符合研究的需求,首先對學歷資料內的學校做校名的統. io. er. 一。校名的統一包括將校名簡稱改為全名,如:臺大→臺灣大學,以及將改制前 的校名改成改制後的校名,如:台北工專→台北科技大學。原來資料庫中的學校. al. n. v i n Ch 筆數為 232 筆,經過整合後的學校筆數變為 筆。接著在對工作經歷資料內的 e n g c220 hi U. 公司名稱作統一。公司名稱的統一包括將公司的簡稱改為全名,如:台積電→台 灣積體電路股份有限公司,以及將公司的英文名稱改成中文名稱,如:HTC→宏 達國際電子股份有限公司。透過這樣的整合,公司名稱由原來的 3434 筆減為 2542 筆。 除了作上述學校、公司名稱的統一,本研究也對這些資料做了欄位上的新增。 新增的欄位包括了學群(系所的分類)、產業別(公司的分類)以及部門別(部 門的分類)。學群分類考量到與工作的相關性,因此是以國內最大的網路人力銀 行-104 網路人力銀行裡對系所的分類而定,總計分為 18 類,如表 1 所示。 17.
(26) 表 1、學群分類表. 語文及人文. 經濟社會及心. 法律. 學科類. 理學科類. 學科類. 自然科學. 數學及電算機. 醫藥衛生. 工業技藝及機. 學科類. 學科類. 科學學科類. 學科類. 械學科類. 工程. 建築及都市. 農林漁牧. 家政相關. 運輸通信. 學科類. 規劃學科類. 學科類. 學科類. 學科類. 觀光服務. 大眾傳播. 軍警體育及其. 學科類. 學科類. 他學科類. 教育學科類. 藝術學科類. 商業及管理. 資料來源:(104 網路人力銀行). 學. 表 2、產業分類表. 法律/會計/顧問/ 研發/設計業. 住宿/餐飲服務 業. 其他. n. al. 農林漁牧水電 資源業. 運輸物流及倉 儲. 建築營造及不 動產相關業. i n U. Ch. engchi. y. 金融投顧及保 險業. io. 一般製造業. 旅遊/休閒/運動 業. sit. Nat. 電子資訊/軟體/ 半導體相關業. 大眾傳播相關 業. er. 文教相關業. ‧. 批發/零售/傳直 銷業. ‧ 國. 治 政 考量到業界對於產業別的分類,本研究中的產業別分類以國內最大的網路人 大 立 力銀行-104 網路銀行裡對產業的分類而定,總計分為 17 類,如表 2 所示。. v. 醫療保健及環 境衛生業. 一般服務業. 政治宗教及社 福相關業 礦業及土石採 取業. 資料來源:(104 網路人力銀行). 另外參考呂等人 (2009) 文中所提之功能別分類定義,將部門分類成 12 類, 如表 3 所示。. 18.
(27) 表 3、功能別分類表. 生產. 行銷. 人力資源管理. 資訊管理. 研發. 法政服務. 經營管理. 教育. 專案管理. 財務管理. 傳播. 醫療服務 資料來源: 104 網路人力銀行. 新增後的資料欄位,顯示如下(新增的欄位以紅框表示)。. 學員資料. 政 治 工作經歷 大 學歷資料. 立. 資料. 學. 學校. 產業. 姓名. 學群. 公司. 系所. 部門別. n. er. io. al. sit. y. Nat. 學號. ‧. ‧ 國. 基本資料. Ch. 學位. engchi. i n U. v. 部門. 圖 6、新增欄位後之資料欄位圖 資料來源:本研究整理. 3.1.3 統計及實驗 在本研究的推薦模型當中,有兩項重要的參數分別為「向外尋訪階層數」 、 「初 始所需輸入顯性工作能力評價人數」。為了要找出相關系統參數,首先統計出各 項學員資料的資訊,並設計了一項實驗,以找出在哪些參數下可以建構出一較完 整的推薦網絡。. 19.
(28) 3.1.4 系統建置 在研究的最後,將建立一線上人才推薦與信任推論系統,透過此系統的建置, 以驗證在一分散式資料架構下,實行推薦以及信任推論的可行性。. 第二節、推薦機制 3.2.1 推薦網絡的建立 在網路招募管道當中,其組成的成員包含了兩種角色:一為工作需求者,二. 政 治 大. 為工作供應者,每個工作需求者都擁有一份應徵工作的履歷表。一份最基本的履. 立. 歷表,內容包含了個人資料、工作經歷、學歷資料以及自傳。有研究指出,人對. ‧ 國. 學. 於人的評價,部分來自於人對於該人所在系統的評價而來 (Huang and FOX, 2006)。這裡所指的系統包括某個組織或者是團體,舉例而言,A 對政治大學商. ‧. 學院有極高的顯性工作能力評價,而 B 為畢業於政大商學院的校友,因此 A 也. sit. y. Nat. 會相信 B 在某領域下的顯性工作能力。這裡所指的顯性工作能力指的是對於專. n. al. er. io. 業的能力,進一步分析這樣「專業能力評價遞移」,大家對於組織的顯性工作能. v. 力評價來自於組織中所有成員表現的累積。也就是說當大家評價該組織中某成員. Ch. engchi. i n U. 的表現很好的話,也會對於該組織產生相同的印象,間接的也對於該組織中其他 的成員產生相似的顯性工作能力評價。透過這樣的「專業能力評價遞移性」,便 可建立起一推薦網絡,如圖 7 所示。. 20.
(29) 圖 7、專業能力評價遞移性示意圖 資料來源:本研究整理. 政 治 大 做人與人之間的聯結,透過學歷資料中的學校、學群,工作經歷資料中的產業、 立 以這樣的概念作出發,本研究利用網絡中成員的學歷以及工作經歷等資料來. ‧ 國. 學. 公司來做人於人的關係聯結。舉例而言,假設 B 畢業於政治大學的商業及管理 學科類,且曾經在兆豐銀行工作過,當 A 評價 B 在金融投顧及保險業中的表現. ‧. 是很好的,間接著也可假設 A 認同 B 在政大的同學以及 B 在兆豐銀行同事的顯. io. sit. y. Nat. 性工作能力(專業能力)表現。. er. 3.2.2 顯性工作能力推論機制. al. n. v i n Ch 整個推薦推論的機制的基礎是來自於「顯性工作能力相似度」的一個特性- engchi U 遞移性,本研究所提出的顯性工作能力推論機制主要是基於 Huang and FOX (2006) 所提出之人對於系統的信任加以延伸而成,透過相似度的遞移,更可以 人才的推薦擴及整個網絡。 3.2.2.1 顯性工作能力相似度推論機制中的角色 在本研究的顯性工作能力推論機制當中,所參與的角色有三種,分述如下:. (1) Source:在此推論機制中,要求進行顯性工作能力相似度推論的節點,即稱 之為 Source 節點。 21.
(30) (2) Sink:在此推論機制中,被進行顯性工作能力相似度推論的目標節點,即稱 之為 Sink 節點。 (3) Recommender:在此推論機制中,Source 節點與 Sink 節點之間所有人脈推薦 路徑中的節點,即稱之為 Recommender 節點。 圖 8 為各角色在顯性工作能力推論機制中的示意圖,在圖中的 Source 節點 到 Sink 節點之間有兩條人脈路徑,而在這兩條路徑上則有三個 Recommender 節 點分別為 R1、R2、R3。在本研究的顯性工作能力推論機制當中,Source 節點與 Sink 節 點 之 間 並 沒 有 直 接 的 連 結 , 因 此 需 要 透 過 第 一 條 人 脈 路 徑. 政 治 大. (Sink→R1→R2→Source),將 R1 對 Sink 的顯性工作能力相似度透過 R2 傳回,. 立. 並與第二條人脈路徑 (Sink→R3→Source) 中,R3 對 Sink 的顯性工作能力相似. ‧. ‧ 國. 學. 度作結合,得到最後推論出 Source 到 Sink 的顯性工作能力相似度。. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 8、顯性工作能力推論機制中各個角色 資料來源:本研究整理. 3.2.2.2 顯性工作能力相似度推論架構 進一步繼續解釋本顯性工作能力相似度的推論架構,圖 9 為本研究所提之顯 性工作能力的推論架構圖。 22.
(31) 圖 9、顯性工作能力的推論架構圖 資料來源:本研究整理. Step A 填寫顯性工作能力評價資料 推論機制開始於這個步驟,一開始推薦與信任推論系統會要求使用者為數個 網絡中的成員來作領域下的顯性工作能力評價。在此所提出之領域即為產業別,. 政 治 大. 這項評價將會作為推薦機制,判別該被評價成員在某產業別下的顯性工作能力。. 立. 這項步驟除了對被評價成員評價其顯性工作能力,而此評價也會被延伸至對該位. ‧ 國. 學. 被評價成員曾經待過組織(畢業學校學群、工作經歷公司)在某產業別下的顯性 工作能力評價,評價等級如下表所示。. ‧. io. sit. 顯性工作能力評價等級. er. Nat. y. 表 4、顯性工作能力評價等級. VG (Very Good). n. al. Ch. G (Good) B (Bad). engchi. i n U. v. VB (Very Bad) 資料來源:本研究整理. Step B 推薦路徑搜尋 Step B 開始於推薦網絡中搜尋所有 Source 節點至 Sink 節點的推薦路徑,並 將此路徑儲存下來,以利後續成員顯性工作能力相似度的計算與推論。 Step C 成員顯性工作能力相似度計算 23.
(32) 在這步驟當中,推薦機制便會對所有推薦路徑當中的相鄰成員,倆倆來作顯 性工作能力相似度 (WAS) 的計算。關於 A、B 兩位成員間的顯性工作能力相似 度主要是由兩部分所組成,一為成員 A 對成員 B 的學經歷相似度 (BS),一為成 員 A 對自己和成員 B 所待過組織的顯性工作能力等級信賴度 (WLCO)。首先對 學經歷相似度 (BS) 作描述,在相似度上的計算本研究首先將成員的每筆學歷、 工作經歷資料轉換為樹狀結構,每筆學歷或者是工作經歷資料都會被轉換成一顆 樹,接著在對每棵樹的節點加上權重,如圖 10 所示。. 立. 政 治 大. y. ‧. io. sit. 資料來源:本研究整理. er. ‧ 國. 學. Nat. 圖 10、學歷、工作經歷資料權重樹. 參考 Bhavsar et al. (2003) 中對於加權樹的相似度計算演算法,接著開始對. al. n. v i n Ch 學歷資料中的每筆學歷資料兩兩比對計算其相似度,如以下式子所示。 engchi U weightes Tree Similarity =. si wi + w ′ i /2 wi + w ′ i 2. si :節點間資料的相似度,若兩節點值一樣的話則為 1,反之為 0 wi 、w ′ i :相同名稱弧線的權重值 計算完兩兩的相似度過後,將其作帄均,接著對工作經歷資料作一樣的操作, 最後將兩筆帄均值再去作帄均,所得到之值稱為學經歷相似度 (BS)。 接下來繼續說明成員 A 對自己和成員 B 所待過組織的顯性工作能力等級信 24.
(33) 賴度 (WLSO) 計算方式。在 Step A 中有提到,當成員 A 對成員 B 作評價時,同 時該評價也會被延伸至成員 B 曾經待過的組織(畢業學校學群、工作經歷公司)。 在本研究當中,組織(畢業學校學群、工作經歷公司)和每個顯性工作能力評價 等級在每個產業別當中會組成一"組織-顯性工作能力等級矩陣",如下圖所示。 矩陣中的值即為該組織所累積的顯性工作能力等級評比次數,每當使用者對某位 成員作信任評價時,系統便會記錄在相對應的欄位。. 立. 政 治 大. ‧. ‧ 國. 學 sit. y. Nat. io. al. 資料來源:本研究整理. er. 圖 11、組織-顯性工作能力等級矩陣. n. v i n C h「金融投顧及保險業」 舉例來說,當 A 給 B 一個在 e n g c h i U 顯性工作能力評價-Very. Good 時,這時系統就會自動修改該產業別的組織-顯性工作能力等級矩陣, 將 B 所有待過的組織在相對應欄位中的值加上 1。透過這樣的矩陣我們可以求 出在某產業下各個顯性工作能力等級的組織的顯性工作能力等級信賴度。首先 我們先求出該產業下某等級評比次數的百分位數,而該組織在該產業下某顯性 工作能力等級信賴度的計算公式如下。. WLSO =. r/100 當該組織的評比累積次數之位置正好位於百分位 r 上 2r + 1 2 00 當該組織的評比累積次數之位置介於百分位 r 及 r + 1 間. 25.
(34) 當計算完 BS 及 WLSO 之後,則可求出 WAS,式子如下。. WAS =. 1 1 × WLSO + × BS 2 2. Step D 成員顯性工作能力相似度推論 當推薦路徑中,相鄰成員間的顯性工作能力相似度得到之後,便需要透過推 薦路徑上成員間 WAS 的傳遞,來得到被使用者評價的成員 (Source 節點) 至 Sink 節點間的顯性工作能力相似度 (WAS)。另外當使用者節點與 Sink 節點間存在有 多條路徑時,也需要整合每條推薦路徑以得到最後的 WAS。本論文參考了. 治 政 Golbeck (2006) 裡所提出之信任推論公式,來計算最後整合的顯性工作能力相似 大 立 度,節點 i 至節點 s 的 WAS 計算請見下式。 WASis =. WAS js × WAS ij. ,if WAS ij ≥WAS. TC ij × TC ij ,if WAS ij <𝑊𝐴𝑆 n j=0 WASij. Nat. y. ‧. ‧ 國. 學. n j=0. n. al. Step E 依相似度決定顯性工作能力評價. Ch. engchi. er. io. sit. n:與i節點在推薦路徑中相鄰節點的個數. i n U. v. 當被使用者評價後的節點 (Source 節點) 到 Sink 節點之間的顯性工作能力 相似度都算好之後,最後一個步驟就是觀察哪一個信任等級的信賴度最高,選出 擁有最高相似度的顯性工作能力等級即為使用者節點對 Sink 節點的顯性工作能 力評價推論值,公式如下:. WASa = WAS1→sink , WAS2→sink , WAS, … … . WASmax = max (WASa ) 26.
(35) 顯性工作能力評價推論值 = 擁有WASmax 的顯性工作能力等級 WASa :被使用者信任評價的節點至 Sink 節點的 WAS 集合向量 綜合以上對於人才推薦的討論,我們可以看出,本研究所提出的推薦機制包 含了以下幾個特性: (1) 顯性工作能力是分領域的 (2) 當 A、B 兩成員學歷或者是工作經歷背景越相似者,系統有越大的信心(越 高的相似度)說 B 的顯性工作能力近似於 A. 政 治 大 (4) 顯性工作能力評價會隨著使用者對於系統中其他成員的評價資料的增加而 立. (3) 顯性工作能力評價決定於擁有最高 WAS 的顯性工作能力評價等級. 有所改變. ‧ 國. 學. 第三節、信任推論機制. ‧ sit. y. Nat. 在人才被推薦出來之後,我們只能說該位人才具備有某領域下某等級的顯性. n. al. er. io. 工作能力(專業能力)。為了要得知該位人才在該領域下的工作表現是否值得信. v. 任,這時我們就必頇要對其作信任推論。透過推論出來的信任值,我們不僅能確. Ch. engchi. i n U. 定該位人才擁有該職缺所需要的專業技能,更能確信該人才在整體的表現上會是 值得信任的。整個信任推論的機制的基礎是來自於信任的一個特性-遞移性,在 Huang and FOX (2006) 的研究中,便指出不同種類的信任,其遞移的特性也不同; 因此本研究也針對這樣的問題來設計出不同種類的信任 (Direct Trust 以及 Recommender Trust),透過這些信任的結合才能有效的來做信任的推論。本研究 所提出的信任推論機制主要是基於 Abdul-Rahmanand and Hailes (2000)、Golbeck and Hendler (2003) 所提出之 Trust Model 加以改良而成。透過本研究的修改,讓 這樣的信任推論機制更符合信任在現實生活中所扮演的角色,所提出的信任推論 機制包含了以下幾個特性: 27.
(36) (1) 信任是分領域的 (2) 信任是基於以往與該人才的合作經驗 (3) 該合作經驗可以來自於自己或者是透過推薦來得知別人與該人才的合作經 驗 (4) 每個人對於同樣人才的信任是不一樣的,端看其與該人才之間的合作經驗而 定 (5) 信任會依經驗的增加而有所改變 在討論本研究所設計之信任推論機制之前,先來討論在信任推論中的一些概 念。. 立. 政 治 大. 3.3.1 信任推論機制中的角色. ‧ 國. 學. 在本研究的信任推論機制當中,所參與的角色以及其間的互動關係跟推薦機. ‧. 制相似,只是其推論傳遞的值由顯性工作能力相似度轉換成信任度而已。詳細的. Nat. sit. n. al. er. io. 3.3.2 信任的種類及等級. y. 說明請參考 3.2.2.1。. Ch. engchi. i n U. v. 在本研究中參考 Abdul-Rahman and Hailes (2000) 中所提出了信任的分類, 將信任分為兩種,分別為 Direct Trust 以及 Recommender Trust。Direct Trust 所代 表的是在某個領域之下,Source 節點對一曾經合作過之 Sink 節點(也就是說, 在某個領域之下,Source 節點對於 Sink 節點有一直接的連結)表現之信任度。 而 Recommender Trust 所代表的則是在某領域之下,Source 節點對於一曾經 推薦過他之 Recommender 節點(也就是說,在某個領域之下,與 Source 節點有 直接連結的 Recommender 節點)推薦結果之信任度。 舉個例子來說明上述信任的種類,對於 Direct Trust 我們可以說 Mary 對於 28.
(37) Andy 在修車領域中擁有一個非常高的 Direct Trust;這句話也可以說成 Mary 對 於 Andy 在修車這領域的表現十分的信任。另外對於 Recommender Trust 我們可 以說 Mary 對於 Andy 在推薦修車領域的人才擁有非常高的 Recommender Trust; 這句話也可以說成 Mary 對於 Andy 在推薦修車領域中人才的評價非常的信任。 另外為了要能達到信任的推論,我們要能先區分出何種信任是能夠遞移的。 用 Huang and FOX (2006)的研究對應到本研究所提出的信任種類,Direct Trust 是 不具遞移性,而 Recommender Trust 是具有遞移性的,因此透過 Recommender Trust 的幫忙,我們將可以推論出 Source 節點對於 Sink 節點的信任度。. 政 治 大 對於信任評價的等級有許多的研究有提出不同的看法,Golbeck et al. (2003) 立. 在研究中所提出的信任模型包含了有 1~9 ,九個等級的信任等級;而 Ding 在其. ‧ 國. 學. 論文當中比較了布林值(boolean)等級與數值(numerical)等級的優劣,其指出布林. ‧. 值等級在信任度的處理上較為方便,而數值等級的優點則是可以充分表現出信任. sit. y. Nat. 度模糊的概念(李永銘等,2007)。. n. al. er. io. 下表為本研究中所提出的信任評價等級,因為考量到使用者對於信任的感覺. i n U. v. 通常並不是那麼的敏感,如果利用 numerical 的表達方式的話,會造成使用者衡. Ch. engchi. 量的困擾。而 Golbeck 所提出的九個信任等級也略顯精細,因此本研究直接將信 任評價分為四個等級,分別為 VT、T、U、VU,讓使用者可以以更直覺的方式 去衡量信任的程度,其評價等級如表 5 所示。. 29.
(38) 表 5、信任評價等級. 信任評價等級 VT (Very Trustworthy) T (Trustworthy) U (Untrustworthy) VU (Very Untrustworthy) 資料來源:本研究整理. 3.3.3 信任推論機制所需要儲存的資料以及使用的變數. 治 政 本研究所提出的信任推論機制,會隨著使用者的使用經驗增加而不斷的去做 大 立 校正。所以在研究中必頇要儲存以下幾項資料,分別為 Direct Trust、推薦校正值 ‧ 國. 學. 集合向量。另外在信任度 (Inferred Trust) 推算的同時,本研究所提出之機制會. ‧. 自動產生以下幾項變數,分別為推薦校正值集中度向量、語意距離、Recommender Trust,以下便對這些資料以及變數分別表述。. n. al. er. io. sit. y. Nat. (1) Direct Trust. Ch. i n U. v. 每個 Source 節點對於每個合作過之 Sink 節點在該合作領域下有一 Direct. engchi. Trust 值。此值是在 Source 節點與 Sink 節點實際合作過後,由 Source 節點給 Sink 節 點 之 信 任 評 價 。 在 本 研 究 中 以 DT 來 表 示 該 值 , 則 DT 的 定 義 域 為 {VT,T,U,VU}。 (2) 推薦校正值集合向量 每個 Source 節點對於每個推薦過他之 Recommender 節點在該推薦領域有一 推 薦 校正值集合向量 。 此集合向量是由系 統自動記錄 Source 節點對於該 Recommender 在該領域下每次推薦結果的校正值,在本研究中以 RA 來表示該向 量,則 RA 的定義域為{-3,-2,-1,0,1,2,3}。 30.
(39) (3) 推薦校正值集中度向量 每個 Source 節點對於每個推薦過他之 Recommender 節點在該推薦領域下有 一推薦校正值集中度向量,以 ND 來表示該向量,則 ND(nd−3 , nd−2 , nd−1 , nd0 , nd1 , nd2 , nd3 ) 1. ndi =. N (x −i)2 n =1 n. (4) 語意距離. 立. , N = num RA , xn ∈ RA N. 政 治 大. 每個 Source 節點對於每個推薦過他之 Recommender 節點在該推薦領域有語. ‧ 國. 學. 意距離值。語意距離的涵意指的是,該 Source 節點對於某個 Recommender 結點 在該推薦領域下的推薦結果與親身體驗後之落差值,在本研究以 SD 變數來表示,. ‧. io. sit. y. Nat. nde = max (ND). n. al. er. 則. Ch. SD = e. engchi. i n U. v. (5) Recommender Trust 每個 Source 節點對於每個推薦過他之 Recommender 節點在該推薦領域有一 Recommender Trust 值,在本研究中以 RT 變數來表示,則 RT = mod( ∀x ∈ RA |x|}) 3.3.4 信任推論機制之運作 整個信任推算機制運作之後的結果會對該 Source 節點產生一對該 Sink 節點 31.
(40) 在某領域下的 Inferred Trust。其值域為{VT,T,U,VU},在本研究中以 IT 變數來表 示,則. IT = RD ⊕ SD RD 為 recomender 推薦 Sink 之信任等級, IT 為推論後的信任等級 ※ ⊕運算代表依等級增加 若 Source 節點與 Sink 節點之間同時存在著至少兩條以上之人脈路徑,這時. 政 治 大 所產生之結果即為 Source 節點在該領域下對 Sink 節點之 IT,表 6、表 7 分別為 立. 就必頇要將各路徑上所得到 IT 依不同 Recommender Trust 所代表的權重進行合併。. ‧ 國. 學. Recommender Trust 與權重的對應表以及 IT 等級與對應分數之對應表格。. 3. 5. 3. 1. io. 資料來源:本研究整理. n. al. Unknow 0. sit. 9. 2. er. Weight. 1. ‧. 0. Nat. RT. y. 表 6 、Recommender Trust 與權重之對應表. i n U. v. 表 7 、Inferred Trust 等級與對應分數之對應表. IT. VT. Corresponding Degree. 4. Ch. e n Tg c h i 3. U. VU. 2. 1. 資料來源:本研究整理 n. IT = ROUND(. n. wi × CDi i=1. wi ) i=1. wi 為推薦者 i 之推薦權重, CDi 為推薦者 i 之推薦等級對應分數, n為推薦者的個數 32.
(41) 第四節、資料模型 由文章第三章第二節的部分,我們可以得知,要讓人才推薦機制運作得非常 順利的話,需要的是網絡中每位成員的學歷以及工作經歷等資料,才有辦法達到 的最完善的狀況。所以為了要讓整個人才推薦機制能夠以最快的速度正常地運作, 最好的方法就是利用現今已有的檔案規格加以延伸來設計出本研究任資料模型。 透過現今已廣泛發展的檔案規格有以下兩點好處: (1) 目前已有大量的人採用該統一規格,因此若我們採用這樣的規格的話,將可. 政 治 大 (2) 若採用一已廣泛發展之規格,有更大的機會,此規格會成為主流標準,因此 立 以利用目前眾多已發展的人脈資料,以快速的拓展整個線上社會網絡。. ‧ 國. 學. 也可以確保後續節點資料加入的速度。. ‧. 本研究中所設計的人才資料模型,參考了 Golbeck et al. (2003) 中所提出的 信任模型,加以變化而成。此資料模型主要是以 FOAF 為基底延伸而成,主要可. y. Nat. n. al. er. io (1) 個人資料區塊. sit. 以分為三個部分:. Ch. engchi. i n U. v. 利用 FOAF 所提供的字彙來描述個人的一些基本資料,包括:姓名、綽號、 電子郵件地址…等等 [b]。 (2) 學歷資料區塊 本資料區塊利用本研究所創造的字彙來描述該節點的學歷資料。 (3) 工作經歷資料區塊 此資料區塊則記錄著此節點曾經工作過的工作經歷資料。 下列程式碼即為本研究所提出之人才資料模型的範例。透過資料裡面學歷資 料區塊、工作經歷資料區塊,經過本研究所提出之推薦機制,將可迅速地建立起 推薦網絡。透過這樣的一個人才資料模型,讓本研究可以完全支持在本文章中 33.
(42) 3.2 所提之推薦機制。. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#" xmlns:foaf="http://xmlns.com/foaf/0.1/" xmlns:admin="http://webns.net/mvcb/" xmlns:tt="http://140.119.19.130/trust/"> <foaf:PersonalProfileDocument rdf:about=""> <foaf:maker rdf:resource="#me"/>. 政 治 大 <admin:generatorAgent rdf:resource="http://www.ldodds.com/foaf/foaf-a-matic"/> 立 <foaf:primaryTopic rdf:resource="#me"/>. ‧ 國. 學. <admin:errorReportsTo rdf:resource="mailto:[email protected]"/> </foaf:PersonalProfileDocument>. ‧. <foaf:Person rdf:ID="me">. y. Nat. io. <foaf:name>Todd Tsai</foaf:name>. al. er. sit. <!-- 個人資料區塊的開始-->. v. n. <foaf:mbox_sha1sum>151704d6433d8e7cd515de77e8c9a8dcf81 7f5cc</foaf:mbox_sha1sum>. Ch. <!-- 個人資料區塊的結束-->. engchi. i n U. <!—學歷資料區塊的開始--> <tt:hasEducationExperience> <foaf:schoolHomepage rdf:resource="www.nccu.edu.tw"> <foaf:schoolName>NCCU</foaf: schoolName> <foaf:schoolDepartmentType> 商業及管理學科類 </foaf:schoolDepartmentType> nt>. <foaf:schoolDepartment>MIS</foaf:schoolDepartme <foaf:schoolDegree>碩士</foaf:schoolDegree> 34.
(43) </ foaf:schoolHomepage> </tt: hasEducationExperience> <!—學歷資料區塊的結束--> <!—工作經歷資料區塊的開始--> <tt:hasWorkExperience> <foaf: workplaceHomepage rdf:resource="www.datasystem.com.tw"> <foaf:industry> 電子資訊/軟體/半導體相關業 </foaf:industry>. 政 治 大 <foaf:companyDepartmentType> 立. <foaf:companyName>鼎新電腦股份有限公司 </foaf:companyName>. 研發. ‧ 國. 學. </foaf:companyDepartmentType>. <foaf:companyDepartment>MIS</foaf:companyDepart. ‧. ment>. </ foaf:schoolHomepage>. Nat. sit. y. </tt:hasWorkExperience>. al. n. </rdf:RDF>. io. </foaf:Person>. er. <!—工作經歷資料區塊的結束-->. Ch. engchi. i n U. v. 表 8 為本人才資料模型,經過 RDF parser 所產生出來 triple data。從下面的 表格,我們可以很清楚地看到人才資料模型中所描述的各個語句。. 35.
(44) 表 8、範例人才資料模型的 triple data. Number. Subject. Predicate. Object. 1. http://www.w3.org/. http://www.w3.org/1999/02/22. http://xmlns.com/f. RDF/Validator/run/ 1277138256559. -rdf-syntax-ns#type. oaf/0.1/PersonalPr ofileDocument. http://www.w3.org/ RDF/Validator/run/ 1277138256559. http://xmlns.com/foaf/0.1/make http://www.w3.org r /RDF/Validator/ru n/1277138256559. 2. #me. http://www.ldodds .com/foaf/foaf-amatic. http://webns.net/mvcb/errorRe. mailto:leigh@ldod. RDF/Validator/run/ 1277138256559. portsTo. ds.com. http://www.w3.org/ RDF/Validator/run/ 1277138256559#m. http://www.w3.org/1999/02/22 -rdf-syntax-ns#type. io. n. al. http://www.w3.org/ RDF/Validator/run/ 1277138256559#m e. y. http://xmlns.com/f oaf/0.1/Person. sit. Nat. http://www.w3.org/. e 7. rAgent. http://www.w3.org /RDF/Validator/ru n/1277138256559 #me. ‧. 6. 立. 治 政 http://webns.net/mvcb/generato 大 學. 5. http://www.w3.org/ RDF/Validator/run/ 1277138256559. http://xmlns.com/foaf/0.1/prim aryTopic. er. 4. http://www.w3.org/ RDF/Validator/run/ 1277138256559. ‧ 國. 3. i n U. v. http://xmlns.com/foaf/0.1/name "Todd Tsai". Ch. engchi. 8. http://www.w3.org/ RDF/Validator/run/ 1277138256559#m e. http://xmlns.com/foaf/0.1/mbo x_sha1sum. "151704d6433d8e 7cd515de77e8c9a 8dcf817f5cc". 9. genid:A23919. http://www.w3.org/1999/02/22. http://140.119.19.. -rdf-syntax-ns#type. 130/trust/educatio n. http://www.w3.org/. http://140.119.19.130/trust/has. genid:A23919. RDF/Validator/run/. EducationExperience. 10. 1277138256559#m 36.
(45) e 11. genid:A23919. http://xmlns.com/foaf/0.1/scho olHomepage. http://www.w3.org /RDF/Validator/ru n/www.nccu.edu.t w. 12. genid:A23919. http://140.119.19.130/trust/sch oolName. "NCCU". 13. genid:A23919. http://140.119.19.130/trust/sch. "商業及管理學科. oolDepartmentType/trust/trust Degree. 類". 14. genid:A23919. http://140.119.19.130/trust/sch oolDepartment. "MIS". 15. genid:A23919. http://140.119.19.130/trust/sch. "碩士". 16. genid:A23920. 政 治 大 oolDegree http://www.w3.org/1999/02/22 -rdf-syntax-ns#type. http://140.119.19. 130/trust/work. 17. http://www.w3.org/ RDF/Validator/run/. 學. ‧ 國. 立. http://140.119.19.130/trust/has WorkExperience. genid:A23920. http://xmlns.com/foaf/0.1/work placeHomepage. sit. v ni. n. al. er. io. http://www.w3.org /RDF/Validator/ru n/www.datasystem. y. Nat. 18. ‧. 1277138256559#m e. genid:A23920. Chttp://140.119.19.130/trust/ind hengchi U ustry. .com.tw "電子資訊/軟體/ 半導體相關業". 19. genid:A23920. 20. genid:A23920. http://140.119.19.130/trust/com "鼎新電腦股份有 限公司" panyName. 21. genid:A23920. http://140.119.19.130/trust/com "研發" panyDepartmentType. 22. genid:A23920. http://140.119.19.130/trust/com "MIS" panyDepartment 資料來源:本研究整理. 透過圖 12 我們更可以視覺化的圖形來了解本人才資料模型範本裡所描述的 內容。. 37.
(46) 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 12、圖形化的範例信任資料模型 資料來源:本研究整理. 38.
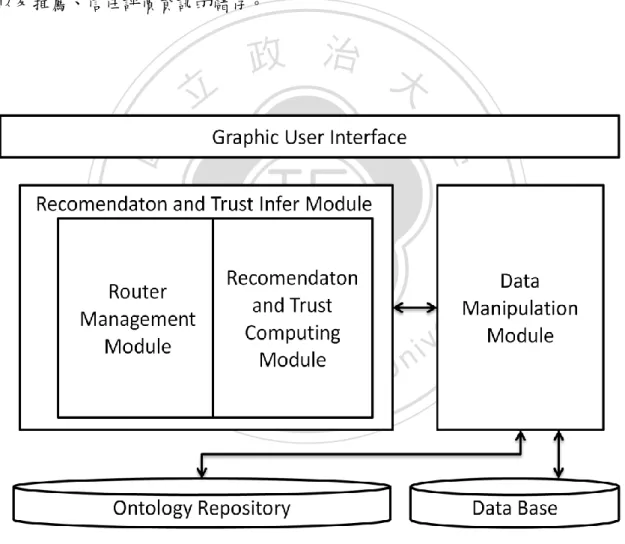
(47) 第五節、雛型系統架構 圖 13 為雛形系統之架構。包括了圖型化的使用者介面 (Graphic User Interface) 提供使用者簡單友善的操作介面,推薦及信任推論模組 (Recommendation and Trust Infer module) 其功能為人脈路徑規劃、顯性工作能力評價等級推論及信任 推論的計算,資料操作模組 (Data Manipulation module) 主要用來讀取且截取 RDF 文件中的資訊,最後一塊即是我們資料的儲存,包括了成員履歷表 (FOAF) 以及推薦、信任評價資訊的儲存。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. 圖 13、雛型系統架構 資料來源:本研究整理. 39. v.
數據

Outline
相關文件
這類文章,不以阿彌陀佛所創建之西方極樂世界淨土,為信
為配合政府推動六大新興產業及十大重點服務業之發展與開拓就業
分類法,以此分類法評價高中數學教師的數學教學知識,探討其所展現的 SOTO 認知層次及其 發展的主要特徵。本研究採用質為主、量為輔的個案研究法,並參照自 Learning
傳統上市場上所採取集群分析方法,多 為「硬分類(Crisp partition)」,本研 究採用模糊集群鋰論來解決傳統的分群
全國人民代表大會常務委員會在徵詢其所屬的香港特別行政區基本法委
• 將已收集的 LPF 有效顯證,加入為校本的 學生表現 示例 ,以建立資源庫作為數學科同工日後的參照,成 為學校數學科組知識管理
港大學中文系哲學碩士、博士,現 任香港中文大學人間佛教研究中心
電機工程學系暨研究所( EE ) 光電工程學研究所(GIPO) 電信工程學研究所(GICE) 電子工程學研究所(GIEE) 資訊工程學系暨研究所(CS IE )
