淺談醫療健康領域之時間序列方法應用--以類流感疫情爆發點之預測為例 副統計分析師 林怡諄 若以計量實證分析方法來區別資料型態,主要可以區分為橫斷面資料、時間 序列資料、以及追蹤型資料等三大類,根據不同資料型態所適用的實證分析方式 亦不相同。其中,就計量經濟學的分野角度而言,橫斷面資料與追蹤型資料屬於 「個體計量方法」的範疇,而時間序列資料則屬於「總體計量方法」的範疇,兩 者的差異在於是否可以定義到個體資訊。顯然地,醫療健康領域重視的每個病患 的特質差異,以及為何病患會罹患這種疾病的成因,自然地,使用橫斷面資料與 追蹤型資料是經常見到的資料,而所使用的研究方式亦以「個體計量方法」居多。 相對而言,時間序列的資料通常是加總後的人數或是門診次數,並非以個體特徵 為主,自然地,醫療健康領域非常少用時間序列資料進行分析研究。 因為資料特性的關係,時間序列的研究方法就無法應用在醫療健康領域嗎? 當然不是。以下我們就來介紹時間序列方法如何應用於醫療健康領域中的一個重 要問題,如何建立傳染病疫情爆發點的預測與模擬。 一、傳染性疾病之預警與防疫趨勢之簡介 疾病預警的重要性在於有效針對疫情爆發時間進行動態預測,使政府進行準 確的判斷,以達公共衛生資源之分配效率。為了達到這個目的,我們可以區分為 疫情資料收集與疫情異常點偵測兩大部分來討論。 首先在疫情監測方面,我國對於傳染病疫情監測體系主要透過多項監視通報 系統所建立,大致有法定傳染病監視通報系統、院內感染監視通報系統、學校傳 染病監視通報系統、人口密集機構傳染病監視通報系統、症狀監視通報系統、病 毒性合約實驗室監視、檢疫體系監視、病媒蚊監視、健保資料常規監測及死亡監 測…等(衛生福利部疾病管制署,2017)。透過前述多項監視通報系統,平時嚴密 監控國內疫情狀況,以達到早期偵測與即時防疫的目的。
動平均(moving average)」等演算法,進行時間異常點的預警,並用以偵測疫情 是否產生異常爆發,當系統偵測到常規疫情產生異常,將即時發送警示時間、症 候群、地點、流行學曲線圖、GIS 地利資訊分布圖、病例就醫紀錄等相關資訊, 提供政府部門進行疫情評估與防疫準備(莊人祥等,2007;黃兆聖等,2009)。 目前時間序列方式用於疾病偵測的學術文獻不少,但實務上用於實際預警 的模型卻是不多。然而,時間序列方式的優勢在於預測未來趨勢,如何使用時 間序列模型來建構傳染病疫情之監控與預警,應是可以努力的方向之一,以下 我們將介紹時間序列方法來進行類流感之爆發點預警方法。 二、類流感之時間序列模型之建構 本小節我們簡單介紹時間序列模型的資料分析與建構方式,從時間序列資料 的定態性質、殘差項自我相關性與常態性、遞延期間之挑選、模型選擇方式、以 及模型預測能力之鑑定方式等逐一簡介,期望讓讀者能有一個時間序列分析的簡 單概念。 由於我們將要建構類流感疫情爆發點之預警,由上節我們可知類流感的爆發 是具有週期性,通常夏季感染人數較少,而冬季感染人數較多,而類流感的種類 繁多,每年疫情大小也不一致。根據這些性質,我們可以採用季節性時間序列模 型來建構分析模型,在此使用 Box and Jenkin (1976) 所提出的 Seasonal ARIMA,並以健保資料庫 2001-2012 年的類流感週住院總量作為分析資料。以 下開始為我們分析類流感資料與模型的步驟。 (一) 時間序列的定態性質與檢定方式 所謂時間序列定態性質,簡單而言,就是數列的波動會隨著時間而逐漸集中 於某個區間之內(波動收斂),或是在很久未來會固定在某一特定數值。為何時間 序列定態性質是我們一開始關心的重點? 因為若是一個數列的波動會隨著時間 越來越大的話(波動發散),可以想像我們沒有辦法預測這個數列會在某個區間內 移動,這樣就失去我們原先預測的目的,而我們建構的模型若是在非定態數列之 下,這個模型所估計出來的結果將會不準確,甚至會產生假性迴歸(spurious regression)的情況。
時間序列定態性的檢定亦稱為「單根檢定(unit root test)」,常見的單根檢定
有 Dickey-Fuller test (DF)、Augmented Dickey-Fuller test (ADF)、Phillips-Perron test (PP)、KPSS test 等。在此,我們僅挑選 ADF test 進行定態性的檢
定,分析 2005-2007 的週資料的定態性。 (1) 直接使用週資料進行單根檢定 由以上 ADF test 結果,可以發現大部分檢定結果均不拒絕虛無檢設(H0 : 數 列具有單根(非定態)),這個結果其實在檢定前就可以猜想到,通常數列具有週期 性的變化時,此數列有極高的機率為非定態數列。如何解決非定態數列的問題, 最簡單的方式就是透過一階差分,即是當期數據減去前期數據,即可解決數據非 定態問題。 (2) 一階差分後數列進行單根檢定 【SAS Code】
procautoregdata = FLU.temp_F;
model weekly_freq = / stationarity =(adf =3); where 16053 <= DATE_TIME <= 17341;
run; 【檢定結果】
【SAS Code】
procautoregdata = FLU.temp_F;
model diff_freq = / stationarity =(adf =3); where 16053 <= DATE_TIME <= 17341;
run; 【檢定結果】
將類流感數列進行一階差分後,可以發現上面的檢定結果很明顯地呈現拒絕 數列為非定態的虛無假設。此時,我們就可以放心地使用一階差分後的數列進行 SARIMA 的估計。
(3) Seasonal ARIMA 之簡介
由於類流感疫情數列是具有很強的季節性週期,因此,我們採用 Box and Jenkin (1976) 所提出的 Seasonal ARIMA 應該較為符合類流感疫情數列的分 析,以下就 SARIMA 進行介紹,下述推導參考自「時間序列分析-單變量與多變 量方法 2 版(缪鎮宇,2012)」。 我們可以假設{Yt}包含類流感週期內部與週期之間的關係,週期內部的關 係可以表示為 … , Yt-2, Yt-1, Yt, Yt+1, Yt+2, …. 之間的相關性,而週期之間的相關 性則可表示為 … , Yt-2s, Yt-s, Yt, Yt+s, Yt+2s, ….。 若是我們無法得知{Yt}包含週期之間的季節性變化,而建構一個非季節性 的 ARIMA 模型如下: φp(B)(1-B)dYt = βq(B)bt (1) 因為上述模型不包含季節性變化,可以推論出殘差項{bt}不是 White Noise, 因此,我們再推導一個考慮週期之間的相關性的 ARIMA 模型,如下所示: Φp(Bs)(1-Bs)Dbt = θQ(Bs)εt (2)
進一步我們將(1)式與(2)式合併起來,就可以得到 Box and Jenkin 季節性 ARIMA 模型,模型如下(3)式: Φp(Bs)φp(B)(1-B)d(1-Bs)D𝑌̇𝑡 =βq(B)θQ(Bs)εt (3) where, 𝑌̇𝑡= {𝑌𝑡− 𝜇 , 𝑑 = 𝐷 = 0 𝑌𝑡 , 𝑂𝑡ℎ𝑒𝑟 而 φp(B) 與 βq(B) 為一般的自我迴歸和移動平均的落後運算因子(Lag Operator),Φp(Bs) 與 θQ(Bs) 為季節性自我迴歸與移動平均的落後運算因子, 故 SARIMA 模型通常可記為 ARIMA (p,d,q)╳(P,D,Q)s ,例如我們研究類流感週 頻率資料,其模型可記為 ARIMA (1,1,1)╳(1,1,1)52 ,因為一年有 52 週,因此, S=52。
(4) SARIMA 的落後期數決定與模型選擇之檢測
SARIMA 的落後期數的決定,我們可以藉由自我相關關係來推論,通常 AR(p) 的 p 值可以通過 PACF 來決定,而 MA(q)的 q 值則可通過 ACF 來決定,由於篇 幅關係,在此,作者不多作贅述。
我 們 就 直 接 進 入 模 型 選 擇 之 檢 測 , 檢 測 方 式 可 使 用 常 見 的 Akaike Information Criterion (AIC)與 Schwatz Bayesian Criterion (SBC)來進行分析, AIC = T ln(SSE)+2k,而 SBC = T ln(SSE) + k ln(T),其中,T 是樣本數量,ln(SSE) 是殘差平方和取自然對數,k 是待估計參數數量。SSE 是誤差總和的觀念,所以 誤差愈小,模型愈好,因此,AIC 與 SBC 的值愈小,表示 SARIMA 模型配適程 度愈好。
在此,我們採用三個 SARIMA 模型進行比較,找出最適合的模型來預測類 流感疫情,分別為 ARIMA (0,1,1)╳(0,1,1)52、ARIMA (1,1,1)╳(1,1,1)52、ARIMA
(1,1,0)╳(1,1,0)52,根據以下的 SAS 程式的估計結果,我們可以得知 ARIMA (1,1,0)╳(1,1,0)52 的 AIC 與 SBC 值最小。 比較下圖,我們可以知道 ARIMA (0,1,1)╳(0,1,1)52 與 ARIMA (1,1,0)╳ (1,1,0)52 的 AIC 與 SBC 值非常相近,但是除了這兩個判別標準之外,最重要的 是模型的預測能力的比較,所以我們在此姑且保留這兩個模型的比較結果,再進 一步分析預測能力後,再行決定較佳的 SARIMA 模型。
【SAS Code】-- ARIMA (0,1,1)╳(0,1,1)52
procarimadata=FLU.temp_F;
identifyvar=log_freq(1, 52) nlag=52; estimateq=(1)(52) noconstantmethod=ml;
forecastlead=339 id=DATE_TIME interval=week printallout=FLU.b_q; where 16053 <= DATE_TIME <= 17341;
run;quit;
【SAS Code】-- ARIMA (1,1,1)╳(1,1,1)52
procarimadata=FLU.temp_F;
identifyvar=log_freq(1, 52) nlag=52;
estimatep=(1)(52) q=(1)(52) noconstantmethod=ml;
forecastlead=339 id=DATE_TIME interval=week printallout=FLU.b_q; where 16053 <= DATE_TIME <= 17341;
run;quit;
【SAS Code】-- ARIMA (1,1,0)╳(1,1,0)52
procarimadata=FLU.temp_F;
identifyvar=log_freq(1, 52) nlag=52; estimatep=(1)(52) noconstantmethod=ml;
forecastlead=339 id=DATE_TIME interval=week printallout=FLU.b_q; where 16053 <= DATE_TIME <= 17341;
run;quit;
【分析結果】
(5) SARIMA 預測能力之比較分析 所有的時間序列模型的預測能力,均可以使用「樣本外預測力(Out of Sample Forecastability)」進行判斷。由於我們需要使用模型來預測未來趨勢, 但是我們又沒有時間等待很長的時間來驗證我們選定的模型之預測能力,因此, 我們可以將時間序列資料樣本區分為兩大區塊,分別為「樣本內區間」與「樣本 外區間」。我們使用「樣本內區間」樣本來估計模型,並且使用「樣本外區間」 樣本來驗證模型的預測值與實際值的差異,來衡量預測能力,通常而言,「樣本 外區間」樣本數量大約是整體樣本的 10%~20%。
常見的模型預測指標,有誤差均方根(Root Mean Square Error,RMSE)、 平均誤差絕對值(Mean Absolute Error,MAE)、以及平均誤差百分比值(Mean Absolute Percentage Error,MAPE)等幾種。以下我們採用 RMSE 與 MAE 來 判斷上述三個 SARIMA 模型的預測能力,由於兩者均在衡量預測誤差,所以兩 個檢測方式的值愈低,則預測能力愈強。以下為 RMSE 以及 MAE 的公式。
T N t t t Y Y 1 T 2 ) ˆ ( N 1 RMSE
T N T t t t Y Y N MAE 1 ˆ 1 我們的資料範圍從 2004 年第 51 週至 2008 年第 28 週為止,「樣本內區間」 為 2004 年第 51 週至 2007 年第 25 週,而「樣本外區間」為 2007 年第 26 週 至 2008 年第 28 週。由下表可以得知,三個 SARIMA 模型的預測能力之比較。SARIMA 模型 RMSE MAE 預測能力排名
ARIMA (0,1,1)╳(0,1,1)52 4571.96 3456.75 1 ARIMA (1,1,1)╳(1,1,1)52 5215.29 4004.32 2 ARIMA (1,1,0)╳(1,1,0)52 10010.41 7286.79 3
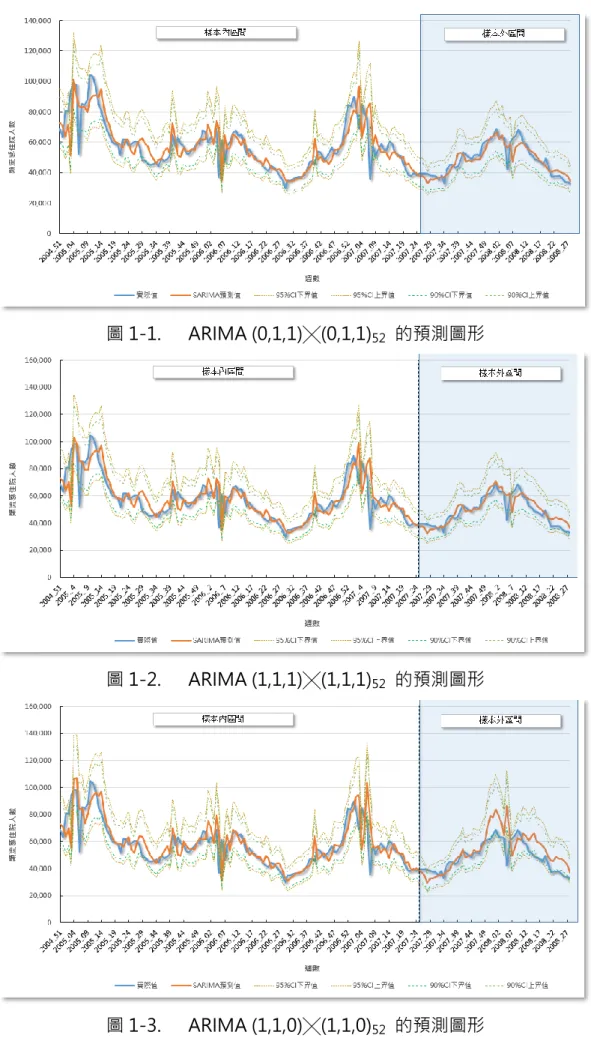
圖 1-1. ARIMA (0,1,1)╳(0,1,1)52 的預測圖形
圖 1-2. ARIMA (1,1,1)╳(1,1,1)52 的預測圖形
由上述檢測方式與圖形繪製,可以發現 ARIMA (0,1,1)╳(0,1,1)52 的預測能
力明顯優於其他兩個模型,因此,本文就採用 ARIMA (0,1,1)╳(0,1,1)52進行類
流感爆發點的預測。而 RMAE 與 MAE 的 SAS 語法如下,供讀者參考與使用。
%macro mae_rmse(
dataset /* Data set which contains the actual and predicted values */, actual /* Variable which contains the actual or observed valued */, predicted /* Variable which contains the predicted value */
);
%global mae rmse; /* Make the scope of the macro variables global */
data &dataset;
retain square_error_sum abs_error_sum; set &dataset
end=last /* Flag for the last observation */
;
error = &actual - &predicted; /* Calculate simple error */
square_error = error * error; /* error^2 */
if _n_ eq 1 then do; /* Initialize the sums */
square_error_sum = square_error; abs_error_sum = abs(error); end;
else do;
/* Add to the sum */
square_error_sum = square_error_sum + square_error; abs_error_sum = abs_error_sum + abs(error);
end; if last then do;
/* Calculate RMSE and MAE and store in SAS data set. */
mae = abs_error_sum/_n_;
rmse = sqrt(square_error_sum/_n_); /* Write to SAS log */
put 'NOTE: ' mae= rmse=; /* Store in SAS macro variables */
call symput('mae', put(mae, 20.10)); call symput('rmse', put(rmse, 20.10)); end;
run;
%mend;
/* Alternative macro that uses PROC SQL. Output is only a macro variable */ %macro mae_rmse_sql(
dataset /* Data set which contains the actual and predicted values */, actual /* Variable which contains the actual or observed valued */, predicted /* Variable which contains the predicted value */
三、類流感疫情爆發點之監控與預警
根據 Quenel and Dad (1998,European Journal of Epidemiology)對於 A 型與 B 型流感之監測方式,提供了 SARIMA 模型用於預測流感疫情之實務操 作方式。本文採用 Quenel and Dad (1998)的監測方式,用於我國類流感疫情爆 發點與結束點之監控與偵測。
我們採用 Quenel and Dad (1998)的建議,尋找一段類流感疫情相對穩定 的時期作為基準。對於時間序列分析的讀者而言,應該可瞭解使用時間序列的預 測是基於假設未來世界與過去樣本區間的的各種社會環境情況均相同的條件下, 才能精準預測未來。若是未來世界情況有所變化下,時間序列方法的預測能力則 會下降。
但是 Quenel and Dad (1998)並非把 SARIMA 的預測值作為預測之使用, 而是將其預測值作為流感疫情的動態基準值,並且採用 95%信賴區間的上界值 作為流感正常值之標準。換句話說,若是未來世界的流感疫情數量超過「預測值 的 95%信賴區間的上界值」,表示流感疫情相對過去情況嚴重,則為流感疫情失 控爆發的狀態,是一個非常聰明的監控方式。因此,本文亦採用 Quenel and Dad (1998)的作法,使用 SARIMA 作為監控我國類流感疫情爆發點之方法。
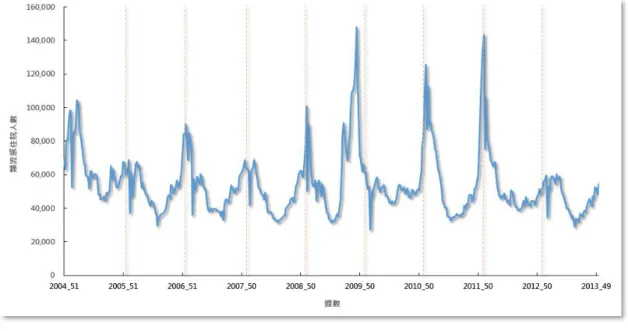
圖 2. 我國 2004~2013 年類流感住院人數之趨勢
由圖 2 可知,類流感相對平穩的時間為 2004 年 51 週至 2008 年 27 週,故 我們採用這段時間作為 SARIMA 估計的時間區間,建立估計模型,並且建構基 準值(預測值 95%信賴區間上界值),作為衡量我國類流感之爆發標準。
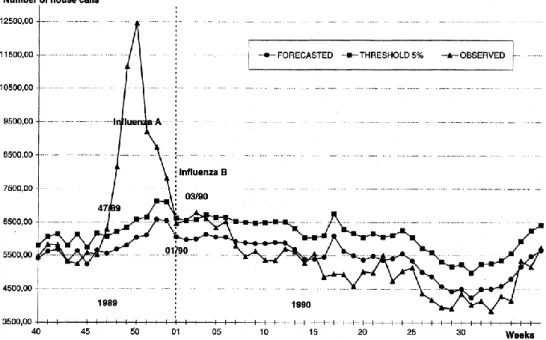
圖 3. Quenel and Dad (1998) 對於流感疫情爆發點之監控與預測 資料來源:Quenel and Dad (1998). “Influenza A and B Epidemic Criteria Based on Time-Series Analysis of
首先,比較 Quenel and Dad (1998)的流感爆發圖形(如圖 3)與我國 2009 年類流感爆發圖形(如圖 4),可以發現兩張圖形表現方式類似,表示這個時間序 列方式適用於各個國家與時間。 進一步,我們將焦點關注於我國 2009 年類流感疫情的爆發情況,這一年我 國面臨 H1N1 流感大爆發,由我們建構的 SARIMA 監控與預警模型成功地捕捉 到兩波類流感疫情爆發點,圖 4 中的淺藍色區塊表示疫情失控爆發的期間,第一 波疫情較短,時間為 2009 年第 33 周至 2009 年第 38 周,約為 1 個半月的時 間,隨後,第二波較大的疫情爆發,時間為 2009 年第 41 周至 2009 年第 50 周, 約為 2 個半月的時間。之後,類流感疫情就持續趨穩。 四、時間序列預測問題之分析 每一種監測方式均有其分析限制與缺點,當然,SARIMA 監控預警模型亦不 例外。首先,要面對的問題是每個時間序列模型都會遇到的問題,就是長期預測 不準確的問題,通常而言,隨著時間逐漸增加,未來世界的變化程度會愈大,舉 例說明,當歷經過大規模的傳染病爆發,政府衛生相關單位均會擬定預防與控制 政策,減少傳染病帶來的損失,其手段不外乎是增加傳染病疫苗的施打、學校停 課控制群聚感染之措施、強化境外移入傳染之管制措施等,這些都會影響後續傳 染病疫情的發展,就如同先前所說,時間序列模型是假設未來與過去的情況不變 下所作出的預測與預警,然而,隨著政府防疫政策日益完善的情況下,已經跟過 去情況不同,時間序列模型是否能夠作為長期的預測與預警,仍是值得商榷的事 情。 圖 5. SARIMA 之長期預測情況
由圖 5 可知,SARIMA 模型的預測在前三年(2007 年~2009 年)仍有不錯的 表現,但是在後面兩年(2010~2011 年)則開始呈現預測值明顯高於實際值的情 況,作為預警的基準線可能都無法精準地勝任。作者相信 Quenel and Dad (1998) 亦有這個問題之存在,只是在文章中沒有呈現長期預測的情況。
事實上,這個方式仍然能夠適用作為預警系統,只是需要採用滾動式估計 (rolling estimation),即為每隔一段時間在將 SARIMA 模型使用新的資料重新 估計,建立新的預測基準線,應可解決傳染病疫情結構性改變的問題,增加其疫 情預警能力的效果。 五、結論 目前傳染病疫情預警的最新發展,為即時預警系統。過去以來受限於資料特 性僅能提供週頻率資料,而且因為資料收集時間的關係,資料會有延遲反應的情 況。隨著電腦與網路科技日益進步,大數據世界已經來臨,目前資訊收集時間很 快,而且從週頻率轉化成日頻率,進一步增加了預警時間與效率。 然而,在即時與大數據的情況下,SARIMA 預警模型就顯得有些吃力,因為 所需考慮的週期性變化增加,若是轉換成日資料的情況下,估計參數預計將會增 加,對於模型估計又是一種挑戰。更何況未來的資訊在科技日益精進的情況下, 將會更加即時性,從日頻率資料轉成半日頻率資料,再從半日頻率資料變成每小 時頻率資料,這些都是挑戰著過去傳統時間序列模型的準確度的因素。 但是相信在各個學者不斷精進時間序列的理論之下,很快地能夠配合即時 性與大數據的新時間序列模型將會不斷孕育而生,配合著時代潮流,提供更加 精準的傳染病疫情預警與預測模型。
參考文獻
1. Quénel, Philippe and Willian Dad. 1998. “Influenza A and B Epidemic Criteria Based on Time-Series Analysis of Health Services Surveillance Data”. European Journal of Epidemiology. Vol. 14, No. 3, pp. 275-285.
2. Suhartono. 2011. “Time Series Forecasting by using Seasonal Autoregressive Integrated Moving Average: Subset, Multiplicative or Additive Model”. Journal of Mathematics and Statistics. Vol. 7, No. 1, pp. 20-27.
3. 莊人祥,王大為,林逸芬. 2007. “疾病流行早期即時監測系統(RODS)評估計畫”. 疾病管制局研究報告. 4. 衛生福利部疾病管制署,2017。傳染病統計暨監視年報。 5. 缪震宇. 2012. “時間序列分析-單變量與多變量方法 2 版”. 智勝文化. 臺北市. 6. 楊奕農. 2009. “時間序列分析-經濟與財務上之應用 2 版”. 雙葉書廊. 臺北市. 7. 黃兆聖等,2009。開發建置急診症候群即時監控暨偵測系統-以台北市某醫院 為例,醫療資訊雜誌 17 (3): 33-48。