電路設計中電流值之罕見事件的統計估計探討 - 政大學術集成
56
0
0
全文
(2) 謝辭 隨著論文的完成,求學生涯也正式告一段落,歡呼著「終於畢業了!」的同 時,卻也得揮手向快樂、單純又自由的學生生活告別,心中的確萬般不捨…。論 文的完成首要感謝余清祥老師,老余是個博學多聞、很有想法和創意,且親切和 藹、幽默風趣的老師,在論文研究時指點了我許多方向,同時也不厭其煩的聆聽 並與我討論,雖然過程中遇到許多挫折,常常覺得自己很笨跟不上老師的思緒, 就像貝珊學姐說的:「余老師的魔力就是不著痕跡的在笑容跟關懷下,盡其可能 的折磨妳,讓妳感到驚慌失措,面對老師潸然淚下,在夜深人靜時想崩潰逃走,. 政 治 大 老師的付出,妳也會驚訝自己怎麼能做到這些?」,這些話真是完全說到了心坎 立. 妳會沒有自信覺得自己是笨蛋白癡,但當黑暗期過去後,妳會感念自己的成長與. ‧ 國. 學. 裡,現在很驕傲自己做到了,謝謝學長姐們的鼓勵和分享,真的很感激余老師的 砥礪和教導,也謝謝李隆安老師、蔡紋琦老師、林麗芬老師在口詴時給我許多寶. ‧. 貴的意見,特別感謝提供研究計畫的科技公司,給予我珍貴的機會能夠應用所學. sit. y. Nat. 解決實際的問題。這趟苦楚卻美麗的旅程我相信未來絕對會是我生命中的基石。. n. al. er. io. 碩班兩年很感謝有你們陪我一起走過-99 級的政統同學們,一起在研討室. i Un. v. 裡念書與玩樂,熬夜趕工、唱歌慶生、打 Bang 拱豬、看電影、欺負同學、打最. Ch. engchi. 愛的排球、喝啤酒打籃球、出遊…好多好多回憶好像昨天才發生似的,一轉眼大 家就得各奔東西了,謝謝你們讓我的碩班生活多采多姿,每天都充滿歡樂與笑聲, 沒想到念到碩士班也會有「每天都想到學校和同學玩」的感覺,真的很開心。 謝謝師大附中語萱手語社的夥伴們,從高中到現在仍保持聯絡,一路從不知天高 地厚的輕狂少年一起成長,一起分享各自後來的故事,讓我覺得在不順心時永遠 都可以有一個避風港能依靠,每次聚會完就能補充能量重新出發。 最後也最重要的是,感謝我的父母,總是全心全意支持我、鼓勵我,分享我 的喜悅,卻也無條件的分擔我的悲傷,你們的辛苦和付出我看在眼裡記在心裡, 謝謝你們,我愛你們,傴以此文獻給你們。 i.
(3) 摘要 距離期望值 4 至 6 倍標準差以外的罕見機率電流值,是當前積體電路設計品 質的關鍵之一,但隨著精確度的標準提升,實務上以蒙地卡羅方法模擬電路資料, 因曠日廢時愈發不可行,而過去透過參數模型外插估計或迴歸分析方法,也因變 數蒐集不易、操作電壓減小使得電流值尾端估計產生偏差,上述原因使得尾端電 流值估計困難。因此本文引進統計方法改善罕見機率電流值的估計:先以 Box-Cox 轉換觀察值為近似常態,改善尾端分配值的估計,再以加權迴歸方法估 計罕見電流值,其中迴歸解釋變數為 Log 或 Z 分數轉換的經驗累積機率,而加. 治 政 權方法採用 Down-weight 加重極值樣本資訊的重要性,此外,本研究也考慮能蒐 大 立 集完整變數的情況,改以電路資料作為解釋變數進行加權迴歸。另一方面,本研 ‧ 國. 學. 究也採用極值理論作為估計方法。. ‧. 本文先以電腦模擬評估各方法的優劣,假設母體分配為常態、T 分配、Gamma. sit. y. Nat. 分配,以均方誤差作為衡量指標,模擬結果驗證了加權迴歸方法的可行性。而後. io. er. 參考模擬結果決定篩選樣本方式進行實證研究,資料來源為新竹某科技公司,實 證結果顯示加權迴歸配合 Box-Cox 轉換能以十萬筆樣本數(. iv. n. al. 右尾機率. 、. 、. ),準確估計左、. n C h 極端電流值。其中右尾部分的加權迴歸解釋 engchi U. 、. 變數採用對數轉換,而左尾部分的加權迴歸解釋變數採用 Z 分數轉換,估計結 果較為準確,又若能蒐集電路資訊作為解釋變數,在左尾部份可以有最準確的估 計結果;而篩選樣本尾端 1%和整筆資料的方式對於不同方法的估計準確度各有 利弊,皆可考慮。另外,1%門檻值比例的極值理論能穩定且中等程度的估計不 同電壓下的電流值,且有短程估計最準的趨勢。. 關鍵詞:罕見事件、電流估計、加權迴歸、變數轉換、極值理論. ii.
(4) Abstract To obtain the tail distribution of current beyond 4 to 6 sigma is nowadays a key issue in integrated circuit (IC) design and computer simulation is a popular tool to estimate the tail values. Since creating rare events via simulation is time-consuming, often the linear extrapolation methods (such as regression analysis) are applied to enhance efficiency. However, it is shown from past work that the tail values is likely to behave differently if the operating voltage is getting lower. In this study, a statistical method is introduced to deal with the lower voltage case. The data are evaluated via the Box-Cox (or power) transformation and see if they need to be transformed into normally distributed data, following by weighted regression to. 政 治 大. extrapolate the tail values. In specific, the independent variable is the empirical CDF. 立. with logarithm or z-score transformation, and the weight is down-weight in order to. ‧ 國. 學. emphasize the information of extreme values observations. In addition to regression analysis, Extreme Value Theory (EVT) is also adopted in the research.. ‧. The computer simulation and data sets from a famous IC manufacturer in Hsinchu are used to evaluate the proposed method, with respect to mean squared error.. y. Nat. sit. In computer simulation, the data are assumed to be generated from normal, student t,. al. n. with probabilities. Ch. observations and tail values. er. io. or Gamma distribution. For empirical data, there are. i Un. v. are set to be the study goal given that only. engchi. observations are available. Comparing to the traditional methods and EVT, the proposed method has the best performance in estimating the tail probabilities. If the IC current is produced from regression equation and the information of independent variables can be provided, using the weighted regression can reach the best estimation for the left-tailed rare events. Also, using EVT can also produce accurate estimates provided that the tail probabilities to be estimated and the observations available are on the similar scale, e.g., probabilities. vs.. observations.. Keywords: Rare Event, Estimating Current, Weighted Least Squares, Data Transformation, Extreme Value Theory iii.
(5) 目 第一章. 錄. 緒論 ........................................................................................................... 1. 第一節. 研究動機 ................................................................................................ 1. 第二節. 研究目的 ................................................................................................ 2. 第二章. 文獻探討 ................................................................................................... 4. 第一節. 背景文獻探討 ........................................................................................ 4. 第二節. 統計方法探討 ........................................................................................ 6. 第三節. 極值理論 ................................................................................................ 9. 第三章. 政 治 大. 研究方法與模擬 ..................................................................................... 12. 立. 研究方法 .............................................................................................. 12. 第二節. 模擬設定 .............................................................................................. 17. 第三節. 模擬結果 .............................................................................................. 20. ‧ 國. ‧. 實證研究 ................................................................................................. 25. Nat. y. 第四章. 學. 第一節. 第二節. 實證結果-無解釋變數 ...................................................................... 26. 第三節. 實證結果-有解釋變數 ...................................................................... 34. 第四節. 實證結論 .............................................................................................. 36. n. al. er. sit. 資料來源與目標 .................................................................................. 25. io. 第一節. 第五章. Ch. engchi. i Un. v. 結論與建議 ............................................................................................. 37. 第一節. 結論 ...................................................................................................... 37. 第二節. 討論與建議 .......................................................................................... 39. 參考文獻 ..…………………………………………………………………………..41 附錄………….............................................................................................................. 44. iv.
(6) 圖 目 錄 圖 1-1 積體電路促進科技發展 .................................................................................. 1 圖 2-1 罕見機率電流值估計探討 .............................................................................. 6 圖 2-2 兩種極值選擇方法示意圖:BMM(左)和 POT(右)....................................... 9 圖 3-1 經驗累積機率對應樣本值 ............................................................................ 14 圖 3-2 加權迴歸方法(上為 Z 分數轉換,下為 Log 轉換) ............................... 15 圖 3-3 樣本篩選圖示 ................................................................................................ 16 圖 3-4 罕見機率電流值估計方法 ............................................................................ 16. 政 治 大. 圖 3-5 模擬流程圖 .................................................................................................... 19. 立. 圖 3-6 常態(左上)、T 分配(右上)和 Gamma(下)執行 Box-Cox 轉換 ... 21. ‧ 國. 學. 圖 3-7. 之 10 萬筆樣本轉換前(左)和轉換後(右)Q-Q Plot ......... 22. 圖 3-8 Gamma(2,1)之 10 萬筆樣本轉換前(左)和轉換後(右)Q-Q Plot ........ 23. ‧. 圖 3-9 實證分析流程圖 ............................................................................................ 24. y. Nat. io. sit. 圖 4-1 三種電壓(1.0、0.8、0.6)下,電流值的 Q-Q Plot ....................................... 27. n. al. er. 圖 4-2 三種電壓的電流值進行 Box-Cox 轉換(無解釋變數)............................ 27. Ch. i Un. v. 圖 4-3 三種電壓(1.0、0.8、0.6)下,轉換後電流值的 Q-Q Plot ........................... 27. engchi. 圖 4-4 電壓 1.0 左尾(左)與右尾(右)不同樣本數的 MSE(無解釋變數) 28 圖 4-5 三種電壓的電流值進行 Box-Cox 轉換(有解釋變數)............................ 34. v.
(7) 表 目 錄 表 2-1 SRAM 實測電流值文獻整理 ........................................................................... 4 表 3-1 以 T 分配為例,以. 估計. (Moment 法) .................................... 13. 表 3-2 模擬結果的均方誤差(MSE) ......................................................................... 20 表 4-1 右尾實證結果均方誤差 ................................................................................ 29 表 4-2 左尾實證結果均方誤差 ................................................................................ 32 表 4-3 實證結果均方誤差整理表 ............................................................................ 35. 附 錄. 政 治 大. 附表 1 模擬研究結果................................................................................................ 44. 立. 附表 2 右尾實證結果(抽樣 100 次平均)............................................................ 45. ‧ 國. 學. 附表 3 左尾實證結果(抽樣 100 次平均)............................................................ 46. ‧. 附圖 1 常態(左)、T 分配(中)、Gamma(右)的 100 次抽樣估計值平均 ... 47 附圖 2 左尾(左)與右尾(右)各電壓的 100 次抽樣估計值平均.................... 48. y. Nat. n. al. er. io. sit. 附圖 3 左尾(左)與右尾(右)各電壓的 100 次抽樣估計值平均總整理........ 49. Ch. engchi. vi. i Un. v.
(8) 第一章. 緒論. 第一節 研究動機 積體電路(Integrated Circuit, IC)利用專業技術將大量電晶體集結在晶片中, 透過一顆小小的晶片便能處理機器的運作,就此成就了電子、資訊與網路等科技 產業的蓬勃發展,開啟了第三波工業革命,如圖 1-1 所示。而其進步的原動力之 一,在於電晶體(Transistor)的微型化,尺寸的縮小提升了切換速度和功能性,並. 政 治 大 提出著名的摩爾定律(Moore's Low)後,積體電路的生產技術便遵循著摩爾定律的 立 降低了單位成本和功率消耗,大幅提升效能與產能。自 1965 年 Gordon Moore. 米)邁入奈米(. 米)時代,至今已突破至 28 奈米製. ‧. ‧ 國. 寸也由數十微米(. 學. 預測發展,IC 晶片內的電晶體數目由個位數成長至現在的數十億,電晶體的尺. 程並持續向更小的尺寸發展,這象徵了一個技術的新紀元,也代表著將面臨更多. n. al. er. io. sit. y. Nat. 新的挑戰與衝擊(參考資料:維基百科1)。. Ch. i Un. v. 積體電路(Integrated Circuit). engchi. 電晶體(Transistor). 晶片(Chip). 圖 1-1 積體電路促進科技發展. 1. 網址 http://zh.wikipedia.org/zh-tw/Wiki 1.
(9) 新挑戰多來自於尺度縮小,越來越小的電晶體元件帶來過去不曾出現的物理 效應,電流於低電壓下的分配變異便是其中之一。微型電晶體可採用較低的操作 電壓供應,低電壓能有效降低功率消耗,提升製程效能,然而當電壓越低,在某 些微型電路架構中如 SRAM2,其電流尾端分配被測量出有偏離常態分配的趨勢 (Abu-Rahma et al., 2011),代表過去假設常態分配的電流設計方法,尾端將產生 錯誤估計的疑慮。 此外,現代半導體製程工序複雜而繁多,當電路設計越趨精細,就算是單一 元件的極微小變異,整合起來就有可能影響電路的運作,因此電路設計中對於電 流穩定性的要求也較從前高度提升,舉例來說,假設一顆電晶體良率為 99.9%,. 治 政 當晶片內電晶體數量增至十億個,良率將會趨近於零,代表從前穩定性需求常態 大 立 分配 3 倍σ已不足夠,現今電路設計要求穩定性達 6 倍σ,機率約 ,實為相 ‧ 國. 學. 當罕見之機率。. ‧. 因此,對於估計距離期望值 4 至 6 倍標準差以外的罕見機率電流值,成為決. sit. y. Nat. 定電路設計品質的關鍵之一,不管是極小的電流值(即電流分配左尾)或是過大. io. er. 的電流值(即電流分配右尾),皆為關心的重點所在。這種具備有「發生機率極 小,但一旦發生影響力極大」的罕見事件(Rare Event)估計實為現今多種領域的. al. n. iv n C 重要問題,不管是巨災、金融海嘯、風險危機等等,皆為具有此特質的罕見事件, hengchi U 如何處理罕見事件問題將為未來各產業的重要議題。. 第二節 研究目的 關於電路元件參數,包括電流、良率、臨界電壓等等,過去雖有不少實際測 量的實驗,結果精確但實驗成本昂貴,故大多以蒙地卡羅方法(Monte-Carlo Simulation)進行理論動態模擬。 2. 全名為靜態隨機存取存儲器(Static Random Access Memory, SRAM) 2.
(10) 但對於距離期望值 4 至 6 倍標準差以外的罕見事件(即電流值),當資料服 從常態分配,距離期望值六倍標準差觀察值的發生機率大約為 ,也就是說平均隨機產生每十億筆資料,才會出現一筆罕見事件,加上要有 足夠罕見事件(例如:5 件)方足以得到穩定估計。若以蒙地卡羅模擬方法,在 給定電壓下模擬電晶體元件運作並記錄電流值,則需要模擬相當龐大數量的觀察 值,所需時間動輒數月,結果固然準確卻十分耗時,若能從相對少筆的觀察值中 推論罕見事件,將能改善模擬效率。 因此,本研究期望能以較少的資料數量,建立可信的統計方法,估計電路設 計上的罕見事件,即距離期望值 4 至 6 倍標準差以外的電流值,希冀提高電路設. 治 政 計效率,並提供各領域對於罕見事件估計的參考。大 立. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 3. i Un. v.
(11) 第二章. 文獻探討. 本文結合幾種統計方法和極值理論,估計電路設計上罕見機率的電流值,因 此文獻探討從三方面著手:第一節先介紹在電路設計領域中,過去實務上對於電 流值的操作和處理方式,以及目前遭遇到的問題和挑戰;而後第二節說明本文為 了解決罕見電流值問題,所應用的幾種統計方法文獻探討;最後第三節說明極值 理論。. 第一節 背景文獻探討. 立. 政 治 大. ‧ 國. 學. 電流、良率、臨界電壓…等電晶體元件參數的表現一直都是電路設計探討重 心所在,欲了解電路中的電流表現,實際測量電路觀測值為最直接且精確的方法,. ‧. 但基於成本和便利性考量,大多使用積體電路模擬程式(例如:Simulation Program. sit. y. Nat. with Integrated Circuit Emphasis, SPICE) ,以蒙地卡羅方法模擬積體電路的運作,. er. io. 以得到元件參數相關資料。. al. n. iv n C 2-1 SRAM h e實測電流值文獻整理 ngchi U. 表. Chiao et al. (2000). Amirante et al. (2007). Abu-Rahma et al. (2011). 製程尺寸. 0.18 微米. 90 與 65 奈米. 28 奈米. 操作電壓. 1.1 至 1.8 電壓. 0.9、1.2 電壓. 0.7 電壓. 電流分配. 常態分配. 常態分配. 偏離常態分配. 以 SRAM 電 路 設 計 的 互 補 式 金 屬 氧 化 物 半 導 體 製 程 (Complementary Metal-Oxide-Semiconductor, CMOS)為例,許多測量資料皆指出其電流值為常態 分配,例如 Chiao et al. (2000)測量出 0.18 微米製程電流在 1.1 至 1.8 電壓近似常 4.
(12) 態分配,而 Amirante et al. (2007)測量 90 奈米與 65 奈米製程電流值,認為在 0.9、 1.2 電壓下的電流呈常態分配,並驗證蒙地卡羅模擬結果的一致性。 (參考表 2-1) 因此過去在許多電路設計上,欲估計距離期望值 4 至 6 倍標準差的罕見機率 電流值,大多以蒙地卡羅方法模擬千萬筆以上資料,或將電流視為常態分配,模 擬較為少筆的資料,而後以參數模型(常態分配)外插方式,即「平均數. 倍. 標準差」(k = 4~6)的常態分配外插方式估計電流值(Hsiao et al., 2005)。 然而兩種方法皆面臨了挑戰,即使假設資料遵循某種已知分配,但模擬罕見 事件卻需要很長的時間,對於時間即是金錢的業界難以接受;而電流為常態分配 的假設隨著電晶體的尺寸縮小,以及電壓的降低越趨違背。Abu-Rahma et al.. 治 政 (2011)首次在 28 奈米製程下,實際測量 0.7 電壓時大 SRAM 於 6 倍標準差內的電 立 流值,證實 SRAM 在低電壓時的尾端電流分配呈現非常態分配(non-Gaussian ‧ 國. 學. distribution),代表以常態假設外插將產生嚴重的錯誤估計問題。若以常態分配(假. ,而 T 分配尾端機率卻為. ,相差了 40 倍之遠。. sit. y. Nat. 率傴為. ‧. 設模型)和自由度 10 的 T 分配(真實模型)為例,4 倍標準差下的常態尾端機. io. er. 面對未來微型電路的罕見事件估計,簡單的常態假設已不可行,而蒙地卡羅 方法完整模擬又需龐大資料以得到估計值,統計方法在這時發揮了作用,許多縮. al. n. iv n C 減變異數方法,如:重點抽樣(Important (Latin h e n g c Sampling)、拉丁超立方設計 hi U Hypercube)等等,改善了蒙地卡羅模擬的效率,例如 Doorn (2008)以重點抽樣方 法取代傳統蒙地卡羅方法估計 SRAM 良率。然而重點抽樣的關鍵在於找到適當 的抽樣分配,但隨著電晶體尺寸縮小,電流分配會有更大的變異,對其尾端分配 更加難以掌握,找尋適當的抽樣分配會是一個難題,且由於積體電路設計複雜又 精細,同時控制多種電路元件重複產生目標電流值有操作上的困難,因此本研究 不考慮變異數縮減,主要探討重心為利用統計方法從觀察值估計本身尾端分配。. 5.
(13) 第二節 統計方法探討 對於罕見機率電流值估計,若以蒙地卡羅模擬方法需時過久,但參考過去實 測資料將電流視為常態分配,從較少樣本以參數模型(常態)外插估計罕見電流 值,愈遠離中心點偏誤愈明顯,因為隨著製程尺寸與電壓下降,電流被測量出尾 端偏離了常態分配。本研究提出一套統計方法估計程序,希望能以少量樣本估計 罕見電流值,取代蒙地卡羅完整模擬效率,並改善常態外插估計,以下解釋本研 究提出的估計方法其想法依據。 首先,參數模型外插方式開始不管用,來自於電流值的偏離常態,因此若能. 治 政 將電流值轉回常態,就能夠以同樣方式估計電流值,在此本研究採用 Box-Cox 大 立 轉換方法在第一步先將觀察值轉換成近似常態;但若電流值無法完全轉換成常態 ‧ 國. 學. 分配,本研究提出加權迴歸方法配合樣本篩選估計罕見電流值,其完整想法請參. ‧. 考第三章第一節。此外,本研究也考慮了針對處理極大值(或極小值)發展出的. sit. y. Nat. 「極值理論」(Extreme Value Theory),將其應用在本研究的罕見機率電流值估計. io. n. al. er. 上,研究想法如圖 2-1 所示。. 蒙地卡羅模擬. C. hengchi 過於費時. U. v ni. 轉換回常態. 過去測量資料顯. 加權迴歸. Box-Cox. 示電流呈常態. 參數模型外插 尺寸與電壓降低. 極值理論. 電流尾端偏離常態. 圖 2-1 罕見機率電流值估計探討. 6. 篩選樣本.
(14) 以下對於上述幾種方法進行說明與文獻探討,包括 Box-Cox 變數轉換方法、 加權迴歸法所使用的加權最小平方法,而第三節介紹極值理論。. (一) Box-Cox 轉換 給定一個迴歸模型(Regression Model): ,其中 考慮轉換反應變數,Box and Cox (1964)提出乘幕轉換(Power Transformation):. 立. 政 治 大. ‧. ‧ 國. 學. 其中 y 為 n 筆樣本觀察值,轉換之後的概似函數為:. Nat. sit. io. 估計量如下:. y. ,給定一轉換參數 ,則 的最大概似估計量亦即最小平方. n. al. er. 其中. ,. 而殘差平方和. 為:. Ch. engchi. i Un. v. 的最大概似估計量為:. 將. 與. 代入概似函數. 可得最大值為:. Box-Cox 變數轉換方法即是以轉換後的概似函數. 為目標,找到使其最大. 值,即為最佳轉換次方 ,此方法可將資料轉換為近似常態,也能改善變異數 異質性。 7.
(15) (二) 加權最小平方 給定迴歸模型. ,其中. ,利用讓殘差平方和 ,其中殘. (Residual Sum of Squares, RSS)最小,得到參數估計值 差平方和為:. 此為最小平方估計(Ordinary Least Squares Estimation , OLS),將每一個觀察 值視為同等重要,給予同樣的權重。而加權最小平方估計(Weighted Least Squares. 政 治 大. ,i={1,2,…,n},亦. Estimation, WLS)考慮觀察值重要性差異,給予不同的權重. 立. 即加權殘差平方和為. ‧ 國. 學 ‧ y. 。. sit. Nat. 其中. ,. n. al. er. io. WLS 讓估計多了靈活度,可以依據對資料的倚賴程度給予相對的權重設定,. i Un. v. 而對於估計尾端極值而言,本研究認為越是靠近尾端的樣本,其代表性應越高,. Ch. engchi. 所含資訊應越為重要,因此參考 Donald (2004)提出區塊拔靴法(Block-Bootstrap) 加權方式,給予樣本 Down-weight 權重設定的方法,其想法為越靠近估計目標的 樣本值越能反應近期的變動資訊,而越為早期的資料相對較無法解釋最近趨勢, 故由近而遠給予權重高至低為 1、1/2、1/3、…1/n (Down-weight)。 由此想法出發,本研究使用 WLS,並設定權重為 Down-weight,想法為: 尾端極值為估計目標,因此越是尾端的樣本值重要性越高,應給予較高的權重, 而越遠離尾端的樣本值重要性越低,應給予較低的權重,由近至遠權重由高至低 為 1、1/2、1/3、…1/n (Down-weight)。. 8.
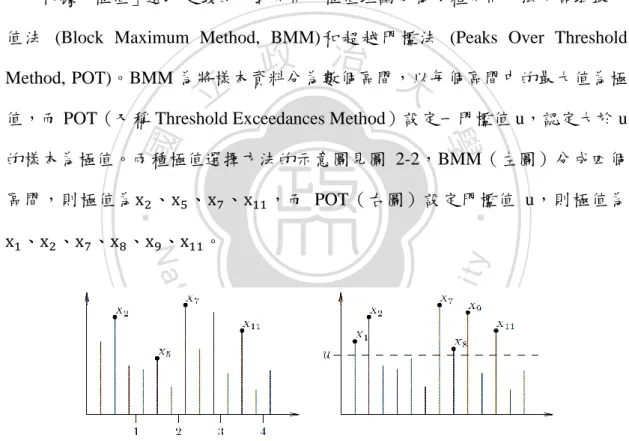
(16) 第三節 極值理論 極值理論(Extreme Value Theory, EVT)主要探討最大值(或最小值)的極限分 配,亦即描述尾端極值分配的方法,其應用發展可追溯至 1953 年荷蘭因海嘯潰 堤造成國家重大損失,而利用極值理論計算海堤所需之高度與厚度,而如今極值 理論已被廣泛地應用於各領域,包含有風險管理、保險、財務、水文、環境科學、 工程…等等。 根據「極值」選取定義的方式不同,極值理論分為兩種不同方法:區域最大 值法 (Block Maximum Method, BMM)和超越門檻法 (Peaks Over Threshold. 學. ‧ 國. 治 政 Method, POT)。BMM 為將樣本資料分為數個區間,以每個區間中的最大值為極 大 立 值,而 POT(又稱 Threshold Exceedances Method)設定一門檻值 u,認定大於 u 的樣本為極值。兩種極值選擇方法的示意圖見圖 2-2,BMM(左圖)分成四個 、. ,而 POT(右圖)設定門檻值 u,則極值為. y. 。. io. sit. Nat. 、 、 、 、 、. 、. n. al. er. 、. ‧. 區間,則極值為. Ch. engchi. i Un. v. 圖 2-2 兩種極值選擇方法示意圖3:BMM(左)和 POT(右). (一) 區域最大值法 Fisher and Tippet (1928) 和 Gnedenko (1943) 指 出 獨 立 且 具 有 相 同 分 配 (Independent and Identically Distributed, i.i.d.)的隨機變數序列. 3. 摘自 Gilli and Këllezi (2006) 9. ,令.
(17) ,若實數序列. 、. 存在且. ,則. 會收斂至. 三種非退化型分配 H,包含 Gumbel、Fréchet 和 Weibull 分配(Fisher-Tippet and Gnedenko Theorem),稱之為極值分配(Extreme Value Distributions);Jenkinson (1955)將其表達成一般化極值分配(Generalized Extreme Value Distributions, GEV) 如下. 政 治 大. 其中 為形狀參數(shape parameter)、 為位置參數(location)、 為尺度參數. 學. 等分配;. 立. 為厚尾型態的 Fréchet family,如 Student t、log-gamma、Pareto. ‧ 國. (scale)。當. 為尾部指數衰退(exponentially decaying tail)型態的 Gumbel family,. 例如 normal、log-normal、gamma、chi-squared、Gumbel 等分配;. ‧. 態的 Weibull family,如 beta 等分配。. n. al. er. io. sit. y. Nat (二) 超越門檻值法. 為短尾型. Ch. i Un. v. 根據 Balkema and de Haan (1974)和 Pickands (1975)的推導,對於隨機變數 和 門檻值 u,超過門檻值 u 的餘額 Distribution ). engchi. ),其餘額累積函數(Excess. 為. 當門檻值 u 越大,. 會近似於廣義柏拉圖分配(Generalized Pareto. Distribution, GPD),其中 為形狀參數、 為尺度參數:. 10.
(18) 使用 GPD 配適尾端極值分配時,如何權衡估計不偏性(Bias)和估計變異 (Variance)以選擇適當的門檻值是問題之一,因為過低的門檻值,會使得許多普 通的樣本被視為極端樣本,而導致估計偏誤,又若門檻值設定過高,則會選取過 少的極端樣本數,使得估計值變異過大。關於門檻值的選擇過去有許多的討論與 研究,但仍沒有一致性的準則,主要分成以下四種方法:. 治 政 (1) 根據常識或背景知識,簡單的選擇某尾端比例為極值 大 ,大部分建議不超過 10% 立 至 15%,而 5%至 10%為經驗法則。 ‧ 國. 學. (2) 以圖形方法判斷,例如以 Q-Q plot 或 平均餘額圖(Mean Excess Plot)判斷圖形. ‧. 呈直線關係或形狀改變時的門檻值,作為門檻值選擇依據。. sit. y. Nat. (3) 以蒙地卡羅模擬方法,找到令均方誤差(Mean Squared Error, MSE)最小的門檻. io. er. 值,例如 NcNeil and Frey (2000)與 Marimoutou, Raggad and Trabelsi (2006) 模 擬自由度 4 的 Student t 分配 1000 筆樣本資料,建議以第十分位數為門檻值,. n. al. 因其 MSE 為最小。. Ch. engchi. i Un. v. (4) 以其他運算方法,如:拔靴法(Bootstrap)、迴歸法(Regression)計算使資料 MSE 最小的門檻值,以取代蒙地卡羅模型假設。. 超越門檻方法的想法為:高過某門檻後會成為某個分配,將此想法連結至電 流值分配,低電壓下的電流值分配變異,即是過了尾端某部分比例的門檻電流值 後開始偏離常態,成為另一種分配型態,因此本文將極值理論中的超越門檻法應 用至罕見機率電流值的估計上,又因門檻值選擇並非本文重點,故門檻值參考經 驗法則,直接選擇特定比例的門檻值進行比較。 11.
(19) 第三章. 研究方法與模擬. 對於罕見機率電流值的估計,本文將之視為某分配尾端百分位數的估計,提 出加權迴歸方法,配合變數轉換與樣本篩選,建立尾端百分位數估計的流程與方 法,並比較常態外插方法和極值理論結果,第一節先說明本研究提出的估計方法 其想法與操作,而後第二節進行電腦模擬,將上述方法套用在幾種已知分配上, 包括常態、T 分配、Gamma 分配,以驗證估計效果,並確認實證資料估計時的 操作程序。. 政 治 大. 立. 第一節 研究方法. ‧ 國. 學. 在電流分配未知的情況下,欲估計尾端罕見機率電流值,此問題相當於:假 服從某分配 F,. ,. ,目標為估計百分位數 ,使. ,其中 即可視為電流隨機樣本,而. 為欲估計之. sit. y. Nat. 得. ‧. 設隨機樣本 為. al. 作為罕見事件的總稱,將目標轉化為估計. 若 F 為常態分配 差(Moment)即 和. v ni. n. 的罕見電流值,而以. er. io. 尾端 機率電流值,F 則為電流分配,因此,以下先不將問題局限於電路設計中. 來估計. Ch. ,. 。. U e n g c h i ,則可以透過估計一階、二階動. ,亦即. ,也就是文獻回顧中所敘. 述的常態外插方法,本文稱此為「Moment 法」。 但若 F 並非常態分配,此方法將會產生偏誤,且越尾端的估計值錯估程度 越大,以 T 分配為例,假設 服從自由度 10 的 T 分配, 估計. 、. 、. 次模擬結果見表 3-1,結果顯示. 、. 、. 錯估. 達 65 倍標準差之多。. 12. ,欲. ,以 Moment 法估計 達 3 倍標準差,又. 的 1000. 錯估. 高.
(20) 表 3-1 以 T 分配為例,以. 1000 次模擬. 估計. (Moment 法). 1.3722. 4.1437. 7.5269. 1.4317. 3.4527. 4.7653. 0.0169. 0.0318. 0.0425. Moment 法雖可以較少的樣本數取代完整蒙地卡羅模擬,但當分配偏離常態 時便會出現問題,因此,本文提出先以 Box-Cox 法轉換觀察值,再以加權迴歸 或 Moment 法配合樣本篩選的估計程序,改善 Moment 法對於尾端非常態分配時 的估計偏誤,另外亦應用極值理論中的超越門檻法估計 。以下說明本研究對於 上述方法的操作。. 立. 政 治 大. ‧ 國. 學. (一) Box-Cox 轉換. ,以常態檢定配合 Q-Q plot 觀察並檢定樣本. ‧. 對於隨機樣本 ,. 常態性,若樣本服從常態分配,則可以利用 Moment 法,即. ,. Nat. y. 估計. io. sit. 若樣本不服從常態分配,則利用 Box-Cox 轉換將樣本轉換為近似常態分配,而. n. al. er. 後再以 Moment 法或以下提出的加權迴歸方法估計 ,可以得到較好的估計值。. Ch. i Un. v. 另外,因 Box-Cox 轉換法只能處理非負的數值,故對於包含負數的樣本,先將. engchi. 整筆資料位移再執行轉換,便可解決此問題。. (二) 加權迴歸方法 資料經過 Box-Cox 轉換後,雖大部分都近似常態,但很常出現尾端仍有偏 離常態的趨勢,無法以. 估計. ,需要別種方法對於罕見機率值的尾端. 極值進行估計,本研究提出以經驗累積機率為解釋變數,配合 Down-weight 權重 的加權迴歸方法估計極值,其想法如下:. 13.
(21) 假設有 1000 個樣本,將其排序後便可以找到每一個樣本對應的經驗累積機 率,反過來說,也就是可以找到經驗累積機率 0.001 至 0.999 所對應之樣本值, 但對於經驗累積機率 0.999 至 1 所對應之數值,亦即需要超過 1000 個樣本才能 知道的經驗累積機率部分,為未知且欲估計的部分,如圖 3-1 問號部分。. 政 治 大. 立. 圖 3-1 經驗累積機率對應樣本值. ‧ 國. 學. 欲利用這 1000 個樣本估計尾端未知的經驗累積機率數值,本質上為一種外. ‧. 插估計問題,本研究提出以經驗累積機率作為解釋變數的迴歸方法,也就是把樣. sit. y. Nat. 本的經驗累積機率當成解釋變數(Independent Variable),其對應的樣本電流值當. n. al. er. io. 成反應變數(Dependent Variable),進行簡單迴歸,而後外插估計至更為尾端(即 經驗累積機率更大)的電流值。. Ch. engchi. i Un. v. 其中由於機率值最大為 1,亦即有範圍限制問題,因此本研究將樣本值的經 驗累積機率進行適當的轉換,作為解釋變數樣本值,轉換方法為「取 Log」 、 「轉 換成常態 Z 值(z-score)」 ,讓機率值範圍從原本的 0 至 1,變成 0 至無限大,以符 合對於極值無上限範圍的想法。 另外,由於欲估計的部分為尾端極值,本研究認為樣本各自的重要性應有所 差異,因此考慮加權最小平方(WLS)估計迴歸參數,根據觀察值代表性差異給定 不同權重(Weight),想法為越尾端的樣本值較能反映極值趨勢,參考 Donald (2004) 給予最極端的樣本值最大權重 1、次極端的樣本值次大權重 、 、 、. 14. 、 ,.
(22) 而後執行以 Log 或 Z 分數轉換的經驗累積機率作為解釋變數的迴歸,見圖 3-2。 其中,以 Log 轉換經驗累積機率值的 Down-weight 加權迴歸方法,本文稱為 「WLS(log)」 ,而以常態 z 值轉換經驗累積機率值的 Down-weight 加權迴歸方法, 本文稱為「WLS(z)」。. 立. 政 治 大. ‧. ‧ 國. 學 sit. y. Nat. n. al. er. io. 圖 3-2 加權迴歸方法(上為 Z 分數轉換,下為 Log 轉換). (三) 樣本篩選 對於隨機樣本 ,欲估計. Ch. engchi. 使得. i Un. v. ,當 極小即. 為尾端極值時,. 若採用全部的樣本估計 ,則可能會納入太多普通樣本的資訊干擾,而影響極值 估計,產生低估(右尾而言)或高估(左尾而言),因此,一種作法為只採用樣 本的尾端資訊,認為尾端的樣本較能代表分配極端的表現,而捨去普通樣本,篩 選樣本尾端部分進行估計,如圖 3-3 所示。 樣本的全選或篩選代表了估計偏誤和變異的取捨,類似極值理論門檻值的想 法,因此本研究考慮兩種篩選樣本情況:選用整筆樣本,或是只篩選尾端部分比 例(m%)的樣本。 15.
(23) 圖 3-3 樣本篩選圖示 (四) 極值理論 對於本研究而言,欲探究的目標為分配尾端罕見機率值的電流極值,其於低 電壓下的有分配變異情形,亦即過了尾端某門檻電流值後會開始偏離常態,成為. 政 治 大 的餘額分配,並以最大概似估計法(Maximum Likelihood Estimation, MLE)估計形 立 另一種分配型態,故選擇極值理論中的超越門檻法,由 GPD 配適超過門檻值 u. ‧ 國. 學. 狀參數 和尺度參數 ,其中因門檻值的選擇並非本文重點,故門檻值參考經驗法 則,直接選擇特定比例作為門檻值進行比較,本文以「EVT」簡稱此方法。. ‧. sit. y. Nat. 總言之,本研究對於罕見機率電流值估計整理出以下方法,分別是以參數模. io. er. 型(常態分配)外插的「Moment 法」 、解釋變數為經驗累積機率取 Z 分數或 Log 的加權迴歸「WLS(z)」或「WLS(log)」 、以及極值理論「EVT」 ,如圖 3-4 所示。. n. al. Ch. engchi. i Un. v. 常態 「Moment 法」. 觀察值 非常態. Box-Cox 轉換. 加權迴歸. 篩選樣本. 「WLS(z)」、WLS(log)」 極值理論:超越門檻法. 「EVT」. 圖 3-4 罕見機率電流值估計方法 16.
(24) 第二節 模擬設定 假設隨機樣本 為. 服從某分配,. ,為估計. ,其中. ,本研究提出四種方法:Moment 法、WLS(z)、WLS(log)、EVT, 對於近似常態的樣本(即經過轉換後的樣本)估計其極值,為了確認估計效率和 程序,而先進行模擬研究。. (一) 模擬參數設定 過去以 Moment 法可處理分配為常態的情況,但當尾端逐漸偏離常態,例如:. 治 政 中間仍近似常態但尾端機率增加-即厚尾分配,或是變成不對稱的分配-即左或 大 立 右偏分配,則 Moment 法逐漸產生偏誤,因此本模擬考慮三種分配:常態分配、 ‧ 國. 學. 厚尾型態的 T 分配、右偏型態的 Gamma 分配,測詴四種方法的估計效果與使用. 筆,約只需數小時即. sit. y. Nat. 考慮電路模擬資料所需時間,亂數個數選擇十萬(. ‧. 極限。. io. er. 可模擬完成,先保守期望能縮減樣本數量達 1%效率,亦即估計至尾端機率為 的分配數值,同時亦考慮尾端樣本篩選以減少偏誤,因此設定兩種樣本篩選方式:. al. n. iv n C 使用整筆樣本(即十萬筆),或傴篩選部分 h e n g c1%、5%、10%尾端比例的樣本。其 hi U. 中部分樣本的篩選方式,對於 WLS(z)、WLS(log)、EVT 皆為篩選樣本尾端 1%、 5%、10%的部分,而對於 moment 方法為隨機抽樣 1%、5%、10%。 另外,分配的極值雖包含左右兩尾部分,但其實將最小值取倒數即為最大值, 因此在此模擬研究中,以估計右尾極值為主要目標,左尾部分只需取倒數便可用 同樣的估計方法處理。. 17.
(25) 模擬設定整理如下: 假設隨機樣本 為. 服從某分配,. ,. 、. 、. ,目標為估計. 、. . 估計目標(右尾):. . 分配假設:. . 樣本篩選:整筆樣本、尾端部分樣本(1%、5%、10%). . 估計方法:Moment 法、WLS(z) 、WLS(log)、EVT. 、. 、. 、. 、. 、. 立. (二) 模擬流程. ,其中. 政 治 大. ‧ 國. 學. 對於各分配隨機模擬 10 萬筆亂數樣本值,首先進行 Box-Cox 轉換,決定適 當的轉換次方值 ,將樣本轉換成近似常態,而後以整筆和部分的兩種篩選樣本. ‧. 方式,分別使用上述四種方法計算轉換後估計值,再以次方倒數 、. 估計值。. y. 、. sit. 、. Nat. 得到各分配的. 轉換回來,. n. al. er. io. 其中 10 萬筆資料整筆篩選方式傴進行 Moment、WLS(log)、WLS(z),而部. i Un. v. 分篩選方式(1%、5%、10%)進行 Moment、WLS(log)、WLS(z)、EVT,又 Moment. Ch. engchi. 為隨機抽樣,其他三種為篩選右尾樣本。. 上述轉換後步驟重覆進行一百次模擬,得到. 、. 計值平均和標準差,完整模擬研究流程圖如圖 3-5 所示。. 18. 、. 、. 的估.
(26) 模擬 10 萬筆樣本 Box-Cox 轉換 決定適當的次方轉換. 模擬 10 萬筆樣本並以 次方轉換. 10 萬筆資料取 m%,m=1、5、10. 10 萬筆資料. 立. Moment. 右尾 m% 政 治 大. 隨機 m%. WLS(log). ‧ 國. 學. WLS(log). WLS(z). WLS(z). Nat. y. ‧. EVT. Moment. 、. sit. io. n. al. 、. 估計值,. 、. er. 得到轉換後的. Ch. 估計值 次方轉換回去. 得到各分配的. engchi 、. i Un. 、. v. 、. 上述步驟重覆進行 100 次. 得到. 、. 、. 、. 的平均值和標準差. 圖 3-5 模擬流程圖. 19.
(27) 第三節 模擬結果 本文以統計上常見的估計評量指標:均方誤差(Mean Square Error, MSE)作為 衡量四種估計方法的依據,MSE 同時考慮了估計值的偏誤(Bias)和變異(Variance), 其值越小代表估計結果越好。. 100 次模擬結果估計值的 MSE 如表 3-2 所示,由左而右分三區塊:左為常 態分配(Normal)、中為 T 分配、右為 Gamma 分配;由上而下分兩區塊:. 筆-. 包含 3 種估計方法、部分篩選(1%、5%、10%)-包含 4 種估計方法。. 學. ‧ 國. 治 政 每一種分配下,MSE 平均最佳的估計結果(即大 MSE 最小者)以粗體表示, 立 次佳者(即 MSE 次小者)以粗斜體表示。又各分配詳細的估計值平均和標準差 見附表 1,以圖形呈現估計值平均見附圖 1,以下分別探討各分配的模擬結果。. gamma(2,1). sit. alpha. y. T(df=10). Nat. Normal. ‧. 表 3-2 模擬結果的均方誤差(MSE). 1%. WLS(Z). Ch. v. 0.075 1.309 6.562 20.889 0.084 0.191 0.481 1.095. i Un. 0.127. 0.546. 1.359. moment 0.006. 0.008. 0.010. 0.012. WLS(Z). 0.006. 0.015. 0.028. 0.044. 0.075 0.447 2.818 11.125 0.142 0.453 0.973 1.748. WLS(log) 0.008. 0.016. 0.052. 0.148. 0.069 0.360 1.673 6.283 0.191 0.467 1.900 7.069. 0.003. 0.014. 0.046. 0.116. 0.029 0.228 1.107 3.986 0.041 0.260 1.068 3.187. moment 0.001. 0.002. 0.002. 0.003. 2.374 7.640 19.742 44.694 0.693 1.841 3.965 7.437. WLS(Z). 0.007. 0.013. 0.022. 0.031. 0.090 0.541 3.437 13.038 0.145 0.332 0.607 1.009. WLS(log) 0.011. 0.011. 0.052. 0.177. 0.086 0.346 1.632 6.270 0.225 0.407 2.793 11.675. 0.004. 0.028. 0.104. 0.268. 0.038 0.356 1.872 6.896 0.070 0.587 2.678 8.007. moment 0.001. 0.001. 0.001. 0.002. 2.360 7.613 19.696 44.611 0.669 1.794 3.886 7.313. WLS(Z). 0.007. 0.013. 0.021. 0.029. 0.069 0.593 3.835 14.220 0.123 0.264 0.498 0.886. WLS(log) 0.010. 0.019. 0.098. 0.300. 0.070 0.303 1.578 6.261 0.183 0.606 4.683 18.484. 0.052. 0.184. 0.445. 0.079 0.773 3.705 12.506 0.134 1.282 5.288 14.352. EVT. 10%. 0.004 0.005 0.007 0.009. WLS(log) 0.005. EVT. 5%. al. n. 筆. er. io. moment 0.0001 0.0001 0.0001 0.0001 2.362 7.616 19.701 44.623 0.643 1.745 3.799 7.173. EVT. 0.007. 0.062 0.223 1.267 5.411 0.113 4.711 27.966 92.969. engchi. 2.369 7.624 19.711 44.634 0.775 1.942 4.073 7.528. 20.
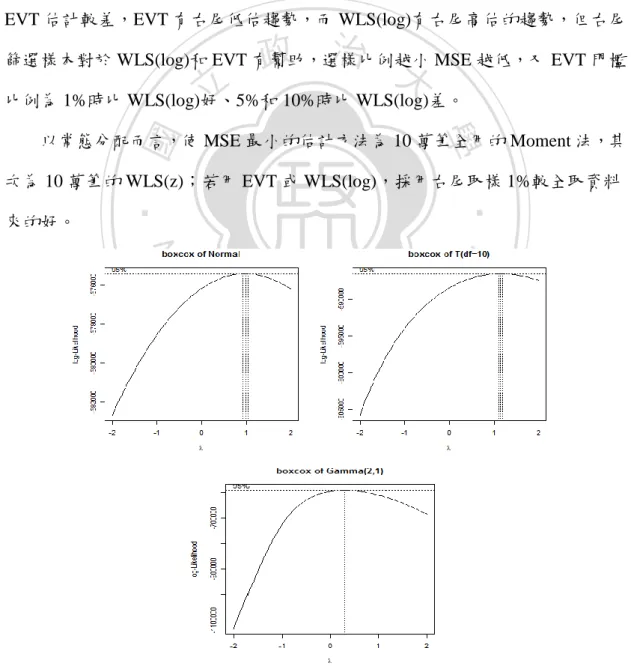
(28) (一) 模擬結果 1. 常態分配 模擬常態分配 10 萬筆樣本,Box-Cox 轉換(圖 3-6 左上)顯示最佳轉換次 方約為 1,亦即不需要轉換已是常態分配。 以 MSE 評量四種方法模擬 100 次的估計結果,MSE 越小表示估計越好: Moment 法估計效果最好,誤差及變異皆最小;WLS(z)估計次佳,又樣本數 越多 MSE 越小,即右尾篩選樣本的方式對於 WLS(z)沒有幫助;而 WLS(log)和 EVT 估計較差,EVT 有右尾低估趨勢,而 WLS(log)有右尾高估的趨勢,但右尾. 政 治 大. 篩選樣本對於 WLS(log)和 EVT 有幫助,選樣比例越小 MSE 越低,又 EVT 門檻. 立. 比例為 1%時比 WLS(log)好、5%和 10%時比 WLS(log)差。. ‧ 國. 學. 以常態分配而言,使 MSE 最小的估計方法為 10 萬筆全用的 Moment 法,其 次為 10 萬筆的 WLS(z);若用 EVT 或 WLS(log),採用右尾取樣 1%較全取資料. ‧. 來的好。. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. 圖 3-6 常態(左上)、T 分配(右上)和 Gamma(下)執行 Box-Cox 轉換 21.
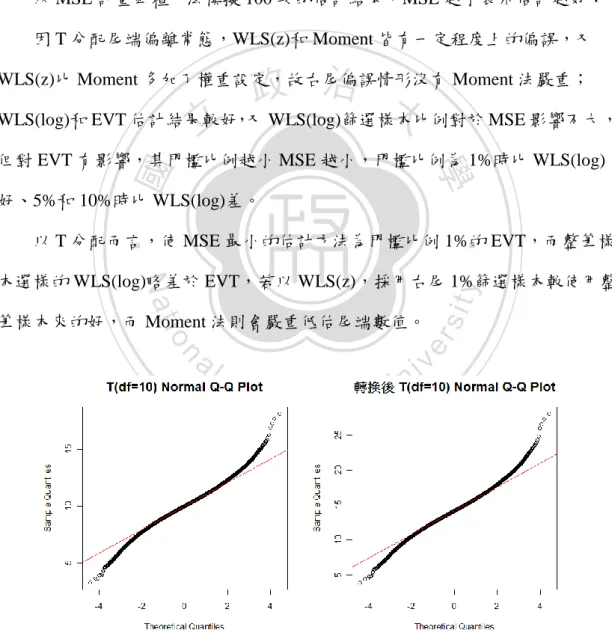
(29) 2. T 分配(自由度 10) 模擬自由度 10 的 T 分配 10 萬筆樣本,Box-Cox 轉換(圖 3-6 右上)顯示 最佳轉換次方接近 1,約為 1.15,近似於常態分配,但由圖 3-7 的 Q-Q Plot(圖 中斜直線表示常態)顯示出原始樣本(左圖)尾端明顯偏離常態分配,1.15 次方 轉換後(右圖)尾端仍舊偏離常態,對此樣本而言,中心似常態但尾端偏離, Box-Cox 轉換效果不佳。 以 MSE 評量四種方法模擬 100 次的估計結果,MSE 越小表示估計越好: 因 T 分配尾端偏離常態,WLS(z)和 Moment 皆有一定程度上的偏誤,又. 政 治 大 WLS(log)和 EVT 估計結果較好,又 WLS(log)篩選樣本比例對於 MSE 影響不大, 立 WLS(z)比 Moment 多加了權重設定,故右尾偏誤情形沒有 Moment 法嚴重;. ‧ 國. 學. 但對 EVT 有影響,其門檻比例越小 MSE 越小,門檻比例為 1%時比 WLS(log) 好、5%和 10%時比 WLS(log)差。. ‧. 以 T 分配而言,使 MSE 最小的估計方法為門檻比例 1%的 EVT,而整筆樣. n. al. er. io. 筆樣本來的好,而 Moment 法則會嚴重低估尾端數值。. 圖 3-7. sit. y. Nat. 本選樣的 WLS(log)略差於 EVT,若以 WLS(z),採用右尾 1%篩選樣本較使用整. Ch. engchi. i Un. v. 之 10 萬筆樣本轉換前(左)和轉換後(右)Q-Q Plot. 22.
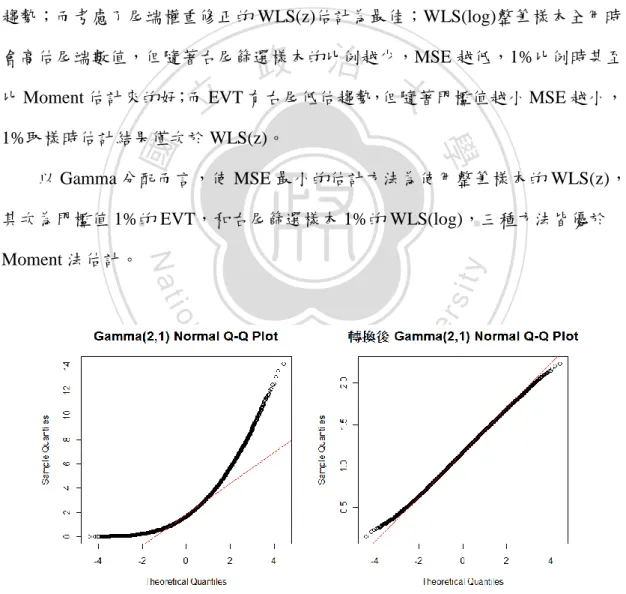
(30) 3. Gamma 分配(. 2,. 1). 模擬 Gamma 分配(. 2,. 1)10 萬筆樣本,Box-Cox 轉換(圖 3-6 下)顯. 示最佳轉換次方約為 0.303,由圖 3-8 的 Q-Q Plot(圖中斜直線表示常態)顯示 出原始樣本(左圖)尾端明顯偏離常態分配,0.303 次方轉換後(右圖)近似常 態,唯有最尾端稍微偏離常態,Box-Cox 轉換效果佳。 以 MSE 評量四種方法模擬 100 次的估計結果,MSE 越小表示估計越好: 因轉換後 Gamma 分配近似常態但尾端稍微偏離,故 Moment 法尾端有低估 趨勢;而考慮了尾端權重修正的 WLS(z)估計為最佳;WLS(log)整筆樣本全用時. 政 治 大 比 Moment 估計來的好;而 EVT 有右尾低估趨勢,但隨著門檻值越小 MSE 越小, 立 會高估尾端數值,但隨著右尾篩選樣本的比例越少,MSE 越低,1%比例時甚至. ‧ 國. 學. 1%取樣時估計結果傴次於 WLS(z)。. 以 Gamma 分配而言,使 MSE 最小的估計方法為使用整筆樣本的 WLS(z),. ‧. 其次為門檻值 1%的 EVT,和右尾篩選樣本 1%的 WLS(log),三種方法皆優於. n. al. er. io. sit. y. Nat. Moment 法估計。. Ch. engchi. i Un. v. 圖 3-8 Gamma(2,1)之 10 萬筆樣本轉換前(左)和轉換後(右)Q-Q Plot. 23.
(31) (二) 模擬結論 綜合上述各分配模擬結果得知,當分配為常態,Moment 法估計的偏誤最小 (且變異最小) ,但一旦分配稍微偏離常態,Moment 法馬上反應偏誤。相反的, 考慮了加權的 WLS(z)或 WLS(log)為較穩健的方法,在偏離常態的情形下得到偏 誤較小的估計,又偏離情形越嚴重,WLS(log)較 WLS(z)估計結果佳。然而,雖 然分配為常態時,Moment 法的 MSE 比 WLS(z)小,但若只考慮不偏性,由附圖 1 及附表 1 可以看出,兩者的估計值平均相當接近。 而 EVT 為較中庸的方法,不論尾端分配偏離情形皆有一定估計效果,值得 時 MSE 都 政 治 大 MSE 較大。而關於樣本篩選方式,不論哪種方法,. 一提的是,EVT 大致有「短程估計最準」趨勢,即估計尾端機率 較其他方法小,但. 至. 立. ‧ 國. 學. 皆以使用整筆樣本或 1%右尾篩選樣本(1%門檻)的 MSE 最小,估計結果最好。 因此,本文對於實證研究之電流極值估計,整理出以下程序:首先以 Box-Cox. ‧. 轉換將資料轉換成近似常態,而後以使用整筆樣本或 1%篩選樣本兩種方式,分. sit. y. Nat. 別採用 Moment 法、WLS(Z)、WLS(log)估計電流極值,其中 Moment 法為隨機. io. al. er. 抽樣,而 WLS(Z)、WLS(log)為右尾取樣,並比較門檻值 1%的 EVT 估計方法,. v. n. 以 MSE 為評量指標衡量四種方法的估計結果,流程如圖 3-9 所示。. Ch. i Un. e電流值隨機樣本 ngchi. Box-Cox 轉換 全部取樣 moment WLS(z) WLS(log). EVT 門檻 1%. 取樣 1% moment WLS(z) WLS(log) 圖 3-9 實證分析流程圖 24.
(32) 第四章. 實證研究. 根據模擬研究所建立的分配尾端估計流程與方法(圖 3-9) ,本研究將之應用 至電路設計上的罕見機率電流值估計,方法包括 Moment 法、WLS(log)、WLS(z)、 EVT,同時也配合篩選樣本的兩種方式,進行實證研究。本章第一節先介紹電路 資料來源與實證研究目標,並說明兩種解釋變數情況,其一為無其他解釋變數情 況,以電流值之經驗累積機率作為解釋變數,本章第二節為此情況之實證研究結 果;其二為有解釋變數情況,以其他電路資料作為解釋變數,本章第三節為此情. 政 治 大 另外,為了簡單區分,本章稱呼以經驗累積機率作為解釋變數的情況為「無 立. 況之實證研究結果,最後本章第四節為實證結論與討論。. ‧. ‧ 國. 學. 解釋變數」情況,以其他電路資料作為解釋變數的情況為「有解釋變數」。. 第一節 資料來源與目標. sit. y. Nat. n. al. er. io. 資料來源為新竹某科技公司之積體電路長時間模擬資料,分為三種電壓設定:. i Un. v. 1.0 電壓、0.8 電壓、0.6 電壓,每種電壓下各別模擬一千萬筆電路資料,而資料. Ch. engchi. 包含七項變數,其中之一為目標變數「電流值」,而另外六項變數為十多種其他 電路資訊之主成份( Principle Component)。 由於積體電路設計複雜且精細,很難同時控制多種電路資訊以達成目標電流 值,亦即將其他電路變數當成電流值的解釋變數,會有實際操作上的困難,因此 本實證研究首先探討重心為:從觀察值估計本身尾端分配,即在沒有解釋變數情 況下,期望能以較少的資料數量,估計距離期望值 4 至 6 倍標準差以外的電流值, 包含左尾與右尾兩端電流值,此為本章第二節部分;但若能夠有解釋變數的資料, 例如本實證資料中的其他六項電路資訊主成分,亦可作為解釋變數進行加權迴歸, 利用解釋變數提供更多的資訊估計電流值,此為本章第三節部分。 25.
(33) 若電流為常態分配,則距離期望值 6 倍標準差的尾端機率約為 以千萬筆(. ,若直接. 筆)的樣本數量估計至 6 倍標準差數值,因缺乏真實資料值對照,. 估計結果無所依據,故本實證研究將目標縮小為估計至尾端機率. (約為 5.2. 標準差)的電流值。 總言之,本實證研究目標為以較少的資料數量(少於 、. 筆) ,估計右尾機率. 、. 、. (約為標準常態值 3.7、4.3、4.8、5.2)的極端電流值,. 以及左尾機率. 、. 、. 、. (約為標準常態值-5.2、-4.8、-4.3、. 估計目標:左右尾機率. 、. 、. -3.7)的罕見電流值。 . 、. 的電流值. . 估計方法:有解釋變數、無解釋變數(Moment 法、WLS(z) 、WLS(log)、EVT). . 衡量指標:均方誤差 MSE. ‧. ‧ 國. . 學. . 治 政 電壓設定:電壓 1.0、電壓 0.8、電壓 0.6 大 立 樣本篩選:整筆樣本、尾端 1%樣本. sit. y. Nat. n. al. er. io. 第二節 實證結果-無解釋變數 (一) Box-Cox 轉換資料. Ch. engchi. i Un. v. 首先以 Q-Q Plot 了解三種電壓(1.0、0.8、0.6)下電流左右尾端分配情形。從 一千萬筆資料中,各隨機抽出 1%即十萬筆電流值,繪製 Q-Q Plot 如圖 4-1 所示 (圖中斜直線表示常態分配),由圖中可以看出不管是左尾還是右尾,電壓越小 其電流尾端數值越偏離常態分配,亦即電壓 0.6 時的電流左右尾偏離情形都較電 壓 0.8 與電壓 1.0 嚴重;另一方面,不管是哪一種電壓,電流右尾分配都比左尾 更為偏離常態。 接著以 Box-Cox 轉換方法嘗詴將三種電流值轉換成較為接近常態分配,見 圖 4-2,取其概似函數最大時的 值為最佳轉換次方值,電壓 1.0 時的電流最佳轉 26.
(34) 換次方值約為 0,即為 log 轉換,而電壓 0.8 時的最佳轉換次方約為 1/3,又電壓 0.6 時的最佳轉換次方約為 1/7,故以取 log、1/3 次方、1/7 次方轉換資料。轉換 後的電流值 Q-Q Plot 如圖 4-3 所示,三種電壓尾端電流值都變成較為近似常態, 其中又以電壓 0.6 轉換效果最好,樣本多在 Q-Q Plot 的對角線上,而電壓 0.8 次 之,電壓 1.0 轉換效果較差,左右尾兩端皆仍有偏離常態現象。. 立. 政 治 大. ‧ 國. 學. 圖 4-1 三種電壓(1.0、0.8、0.6)下,電流值的 Q-Q Plot. ‧. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. 圖 4-2 三種電壓的電流值進行 Box-Cox 轉換(無解釋變數). 圖 4-3 三種電壓(1.0、0.8、0.6)下,轉換後電流值的 Q-Q Plot 27.
(35) (二) 樣本數決定 本研究希望能以較少的樣本數估計至千萬筆機率值(. ),因此需要先決定. 樣本數,考慮樣本數量為千萬筆的 10%、1%、0.1%、0.01%四種情況,亦即隨機 抽樣百萬筆、十萬筆、一萬筆、一千筆樣本,而後採用上述加權迴歸方法(WLS(z) 與 WLS(log))估計尾端罕見機率電流值,反覆執行 10 次抽樣,計算估計值的均 方誤差(MSE)。 以電壓 1.0 資料為例,圖 4-4 為左尾(左圖)與右尾(右圖)的均方誤差, 當樣本數從一千筆增加至一萬筆、一萬筆增加至十萬筆、十萬筆增加至百萬筆時, MSE 會逐漸減少,但減少幅度有略減趨勢,其中左尾 WLS(z)和右尾 WLS(log). 治 政 方法,樣本為十萬筆時的 MSE 已和百萬筆的 MSE大 相當接近,而電壓 0.8 和電壓 立 0.6 皆有類似情況。 ‧ 國. 學. 因此本實證研究決定以千萬筆資料的百分之一(即十萬筆)作為樣本數量。. ‧. 從千萬筆電流值中隨機抽取十萬筆作為樣本進行估計,重覆 100 次抽樣,便得到. sit. y. Nat. 估計值平均與標準差,最後將此結果與千萬筆觀察值比較,以下先討論右尾各個. io. n. al. er. 電壓的估計結果,再討論左尾各電壓的估計結果。. Ch. engchi. i Un. v. 圖 4-4 電壓 1.0 左尾(左)與右尾(右)不同樣本數的 MSE(無解釋變數). 28.
(36) (三) 右尾部分實證結果 從千萬筆觀察值中重覆 100 次隨機抽樣十萬筆樣本值, 估計右尾罕見機率 電流值的均方誤差如表 4-1 所示,表中由左而右分兩區塊:左為使用全部十萬筆 樣本、右為只篩選 1%的樣本資料;由上而下分三區塊:電壓 1.0、電壓 0.8、電 壓 0.6。 每一種電壓下,MSE 平均而言最佳的估計結果(即 MSE 最小者)以粗體表 示,次佳者(即 MSE 次小者)以粗斜體表示。又各電壓下詳細的估計值平均和 標準差見附表 2,以圖形呈現估計值平均見附圖 2 右半部,以下分別探討各電 壓的右尾估計結果。. 立. 政 治 大 10 萬筆篩選 1%. 右尾 alpha. 10.56. 27.13. 109.9. 0.264. 3.365. 12.19. 71.72. 0.323. 2.236. 7.696. 52.34. 0.276. 0.674. 1.73. 4.559. 0.344. 1.790. 4.169. 26.86. 0.138. 1.269. 4.772. 33.82. 13.41 22.81 0.576 3.059 a2.824 l C 7.851 14.22 0.178n i v0.799 0.121 1.038 U 0.681 e n g3.338 0.165 0.699 h0.835 c h i 0.172. 13.87. 23.46. 5.409. 9.551. 2.863. 3.676. io. EVT. 2.144. 壓 0.8. n. Moment 法 0.457 電. WLS(z) WLS(log) EVT. Moment 法 0.008 電 壓 0.6. y. WLS(log). 107.5. sit. 1.0. WLS(z). 25.97. Nat. 壓. 9.885. er. Moment 法 1.836 電. ‧. ‧ 國. 10 萬筆全用. 學. 表 4-1 右尾實證結果均方誤差. 0.063. 0.550. 4.240. 7.602. 0.087. 0.297. 0.093. 0.033. 0.128. 0.359. 0.171. WLS(z). 0.021. 0.097. 0.295. 0.136. 0.030. 0.145. 0.405. 0.409. WLS(log). 0.024. 0.343. 1.850. 8.779. 0.038. 0.124. 0.293. 1.221. 0.010. 0.075. 0.288. 0.554. EVT 註:單位為. ,篩選 1%在 Moment 法為隨機抽樣,其他方法為篩選右尾 1%樣本. (1) 電壓 1.0 右尾 兩種選樣方式下,WLS(z)、WLS(log)、EVT 估計結果皆優於 Moment 法, 其中以使用全部樣本的 WLS(log)其 MSE 最小為最佳估計方式,其次為 EVT,又 29.
(37) EVT 在較高右尾機率值( 至. )的估計較 WLS(log)佳,但於較低右尾機率值(. )的估計較 WLS(log)差;而 WLS(z)的 MSE 較 WLS(z)和 EVT 大,而其. 右尾 1%篩選樣本方式比使用整筆好。若單看偏誤情形,使用 Moment 法估計右 尾. 至. 電流值,其偏誤皆為使用整筆資料 WLS(log)的 6 倍以上、篩選 1%. 右尾樣本 WLS(z)的 1.5 倍以上、EVT 的 2 倍以上;而 WLS(log)和 EVT 估計值 平均偏誤皆小於 2 倍估計值標準差。 表示電壓 1.0 下,以 WLS(z)、WLS(log)、EVT 能取代 Moment 法改善右尾 電流值估計,且使用整筆資料的 WLS(z)和門檻值 1%的 EVT,能夠有效估計至 右尾機率. 電流值。. 立. 政 治 大. ‧ 國. 學. (2) 電壓 0.8 右尾. ‧. 電壓 0.8 結果和電壓 1.0 類似,兩種選樣方式下,WLS(z)、WLS(log)、EVT. sit. y. Nat. 估計結果皆優於 Moment 法,其中以使用全部樣本的 WLS(log)其 MSE 最小為最. io. 與. al. WLS(log)佳,但於較低右尾機率值(. 與. )的估計較. er. 佳估計方式,其次為 EVT,又 EVT 在較高右尾機率值(. )的估計較 WLS(log)差;而. n. iv n C WLS(z)的 MSE 較 WLS(z)和 EVTh大,而其右尾 1%篩選樣本方式比使用整筆好。 engchi U 若單看偏誤情形,使用 Moment 法估計右尾. 至. 電流值,其偏誤皆為使用. 整筆資料 WLS(log)的 2.8 倍以上、篩選 1%右尾樣本 WLS(z)的 1.7 倍以上、EVT 的 2 倍以上;而 WLS(log)和 EVT 估計值平均偏誤皆小於 2 倍估計值標準差。 表示電壓 0.8 下,以 WLS(z)、WLS(log)、EVT 能取代 Moment 法改善右尾 電流值估計,且使用整筆資料的 WLS(z)和門檻值 1%的 EVT,能夠有效估計至 右尾機率. 電流值。. 30.
(38) (3) 電壓 0.6 右尾 以 MSE 最小為衡量準則,則 Moment 法估計最佳,其次為使用整筆的 WLS(z) 和 EVT,其中 EVT 在較高右尾機率值( 佳,但於較低右尾機率值(. 、. 與. )的估計較 WLS(z). )的估計較 WLS(z)差;而 WLS(log)所得 MSE 較. WLS(z)和 EVT 大,但其右尾 1%篩選樣本方式比使用整筆好。若單看偏誤情形, 使用 Moment 法估計右尾. 至. 電流值,其偏誤皆為 WLS(z)的 1.3 倍以上、. EVT 的 2 倍以上;而 WLS(z)和 EVT 估計值平均偏誤皆小於 2 倍估計值標準差。 表示電壓 0.6 下,若以不偏性為考量重點,WLS(z)和 EVT 能取代 Moment 法改善右尾電流值估計,且使用整筆資料的 WLS(z)和門檻值 1%的 EVT,能夠. 治 政 電流值;但若要同時考量不偏與變異小,採用 Moment 大 立. 有效估計至右尾機率 法估計表現較佳。. ‧ 國. 學 ‧. (四) 左尾部分實證結果. sit. y. Nat. 從千萬筆觀察值中重覆 100 次隨機抽樣十萬筆樣本值, 估計左尾罕見機率. io. er. 電流值的均方誤差如表 4-2 所示。. 表中由左而右分兩區塊:左為使用全部十萬筆樣本、右為只篩選 1%的樣本. al. n. iv n C 資料;由上而下分三區塊:電壓h 1.0、電壓 0.8、電壓 e n g c h i U 0.6。. 每一種電壓下,MSE 平均而言最佳的估計結果(即 MSE 最小者)以粗體表 示,次佳者(即 MSE 次小者)以粗斜體表示。又各電壓下詳細的估計值平均和 標準差見附表 3,以圖形呈現估計值平均見附圖 2 左半部,以下分別探討各電 壓的左尾估計結果。. 31.
(39) 表 4-2 左尾實證結果均方誤差 10 萬全用. 10 萬筆篩選 1%. 左尾 alpha 電 壓 1.0. 電 壓 0.8. Moment 法 2.911 WLS(z). 1.737. 2.440. 0.833. 4.077. 2.875. 3.339. 1.536. 1.093. 0.772. 0.691. 7.459. 5.480. 2.559. 1.196. 84.640 42.520 10.690. 1.363. 27.330 13.410. 3.623. 0.905. 7.551. 3.385. 1.408. 0.268. 1.177. WLS(log) EVT. Moment 法 1.404 WLS(z). 2.286. 0.559. 0.408. 1.968. 2.828. 1.013. 0.800. 0.494. 0.398. 0.308. 2.709. 1.504. 1.365. 0.524. 38.570 15.440. 6.949. 0.644. 11.250. 3.779. 2.066. 0.376. 3.338. 2.091. 0.651. 0.159. 0.034. 0.042. 0.019. 0.018. 0.055. 0.050. 0.025. 0.113. 0.072. 0.019. 0.067. 0.020. 0.006. 0.432. WLS(log) EVT. Moment 法 0.018 電 壓 0.6. 0.025. WLS(z). 0.016. 0.018. WLS(log). 0.903. 立0.478. EVT. 0.001. 治 0.070 0.017 0.016 政 大 0.253 0.031 0.237 0.099. ‧ 國. 學. 註:單位為. 0.002. ,篩選 1%在 Moment 法為隨機抽樣,其他方法為篩選左尾 1%樣本. ‧. (1) 電壓 1.0 左尾. y. Nat. )的估計較 Moment 佳,但於較. n. al. 與. 低機率值(. 與. er. io. EVT,又 EVT 在較高左尾機率值(. sit. 使用全部樣本的 WLS(z)其 MSE 最小為最佳估計方式,其次為 Moment 法和. i Un. v. )的估計較 Moment 差;而 WLS(log)的 MSE 為最大,有. Ch. engchi. 低估左尾電流值的趨勢,而其左尾 1%篩選樣本方式比使用整筆好。 若單看偏誤情形,使用 Moment 法估計左尾. 至. 電流值,其偏誤皆為. 使用整筆資料 WLS(z)的 2.4 倍以上、EVT 的 1.9 倍以上;而 WLS(z)和 EVT 估計 值平均偏誤皆小於 1 倍估計值標準差。 表示電壓 1.0 下,以 WLS(z)、EVT 能取代 Moment 法改善左尾電流值估計, 且使用整筆資料的 WLS(z)和門檻值 1%的 EVT,能夠有效估計至左尾機率 流值。. 32. 電.
(40) (2) 電壓 0.8 左尾 電壓 0.8 估計結果與電壓 1.0 結果相似,使用全部樣本的 WLS(z)其 MSE 最 小為最佳估計方式,其次為 Moment 法和 EVT,又 EVT 在較高左尾機率值( 與. )的估計較 Moment 佳,但於較低機率值(. 、. )的估計較 Moment 差;. 而 WLS(log)的 MSE 為最大,有低估左尾電流值的趨勢,而其左尾 1%篩選樣本 方式比使用整筆好。 若單看偏誤情形,使用 Moment 法估計左尾. 至. 電流值,其偏誤皆為. 使用整筆資料 WLS(z)的 2.2 倍以上、EVT 的 2.3 倍以上;而 WLS(z)和 EVT 估計 值平均偏誤皆小於 1 倍估計值標準差。. 治 政 表示電壓 0.8 下,以 WLS(z)、EVT 能取代 Moment 大 法改善左尾電流值估計, 立 且使用整筆資料的 WLS(z)和門檻值 1%的 EVT,能夠有效估計至左尾機率 電. sit. y. Nat. (3) 電壓 0.6 左尾. ‧. ‧ 國. 學. 流值。. io. er. 以 MSE 最小為衡量準則,則 Moment 法估計最佳,其次為使用整筆的 WLS(z) 和 EVT,其中 EVT 在較高左尾機率值(. n. al. 機率值(. 、. 與. )的估計較 WLS(z)佳,但於較低左尾. iv n C )的估計較 WLS(log)的 MSE 較大, h e n gWLS(z)差;而 chi U. 而其右尾 1%篩選樣本方式比使用整筆好。若單看偏誤情形,Moment 法在左尾 較高機率值(. 與. )的偏誤比 WLS(z)大,且在較高機率值(. 、. 與. )的偏誤比 EVT 大;而 Moment、WLS(z)和 EVT 估計值平均偏誤皆小於 1 倍估計值標準差。 表示電壓 0.6 下,若以不偏性為考量重點,WLS(z)和 EVT 能階段式的改善 Moment 法左尾電流值估計,且使用整筆資料的 WLS(z)和門檻值 1%的 EVT 能 有效估計至左尾機率. 電流值;但若要同時考量不偏與變異小,採用 Moment. 法估計較佳。 33.
(41) 第三節 實證結果-有解釋變數 由於實證資料除了目標變數電流值之外,尚包含其他電路資訊,因此本研究 考慮另外一種情況:若能獲得適當的解釋變數,如何利用解釋變數資訊估計罕見 電流值。本研究提出類似上述的加權迴歸方法,同樣先以 Box-Cox 轉換電流值, 後改以六項電路資訊主成分作為解釋變數(取代以經驗累積機率做解釋變數), 而電流值為反應變數,進行加權迴歸,加權仍採 Down-weight 加權方法,估計方 法為:加權迴歸估計值平均±k 倍估計值標準差(k= 3.7、4.3、4.8、5.2),外插估 計左、右尾電流值,因為是平均數加減 k 倍外插方式,故不考慮篩選樣本方式。. 「WLS」簡稱此有解釋變數的加權迴歸方法。. 學. ‧ 國. 治 政 此節先討論 Box-Cox 轉換結果,接著比較有無解釋變數的加權迴歸估計結 大 立 果,在此傴與無解釋變數估計結果中(上一節)較好的估計方法做比較,且以 ‧ sit. y. Nat. (一) Box-Cox 轉換資料. io. er. 對於有解釋變數的迴歸模型,Box-Cox 轉換結果見圖 4-5,取其概似函數最 大時的 值為最佳轉換次方值,電壓 1.0 時的電流最佳轉換次方值約為 0,即為 log. al. n. iv n C 轉換,而電壓 0.8 時的最佳轉換次方約為 0.6 時的最佳轉換次方約為 h e n g1/3,又電壓 chi U 1/7,故以取 log、1/3 次方、1/7 次方轉換資料,同無解釋變數的轉換方式。. 圖 4-5 三種電壓的電流值進行 Box-Cox 轉換(有解釋變數) 34.
(42) (二) 有解釋變數實證結果 同樣採用十萬筆樣本數量以進行比較,從千萬筆觀察值中重覆 100 次隨機抽 樣十萬筆樣本值, 以有解釋變數方式估計左右尾罕見機率電流值,均方誤差如 表 4-3 所示,表中除了包含有解釋變數加權迴歸(以 WLS 代表),另外摘要出 各電壓下無解釋變數的較佳估計結果,每一種電壓下,MSE 平均而言最佳的估 計結果(即 MSE 最小者)以粗體表示,次佳者(即 MSE 次小者)以粗斜體表 示,而 100 次抽樣之估計平均值作圖見附圖 3。 右尾部份,電壓 1.0 與電壓 0.8 類似,WLS 的均方誤差比 Moment 法的均方 誤差小,但比 WLS(log)和 EVT 的均方誤差大;而電壓 0.6,WLS 的均方誤差比. 治 政 Moment 法要小。也就是說,右尾部份,電壓 1.0 與電壓 大 0.8 下納入解釋變數的 立 資訊能改善 Moment 法的估計效果,但仍以無解釋變數的加權迴歸方法最佳;但 ‧ 國. 學. 電壓 0.6 下,有解釋變數加權迴歸是最好的估計方法,比 Moment 法或是無解釋. 0.252 0.155 0.222 0.142. 電. Moment. 2.911. 壓. WLS(z). 1.177. WLS. sit er. 右尾 alpha. 0.183 2.159 9.645 65.217. a1.737 v l C2.440 0.833 Moment n i1.836 1.093 0.772 h e n0.691 h i U 0.323 g cWLS(z)_1%. n. WLS. io. 左尾 alpha. Nat. 表 4-3 實證結果均方誤差整理表. y. ‧. 變數方法佳。但左尾部份三種電壓都以有解釋變數的加權迴歸方法 MSE 最小。. 1.0 WLS(log) _1% 27.330 13.41 3.623 0.905. 9.885 25.97 107.5 2.236 7.696 52.34. WLS(log). 0.276 0.674 1.73 4.559. EVT. 7.551. 3.385 1.408 0.268. EVT. 0.138 1.269 4.772 33.82. WLS. 0.094 0.432 0.022 0.022. WLS. 0.119 0.616 6.572 12.493. 電. Moment. 1.404. 2.286 0.559 0.408. Moment. 0.457 2.824 13.41 22.81. 壓. WLS(z). 0.432. 0.494 0.398 0.308. WLS(z)_1%. 0.178 0.799 5.409 9.551. WLS(log). 0.165 0.699 0.835 3.338. 0.8 WLS(log) _1% 11.250 3.779 2.066 0.376 EVT. 3.338. 2.091 0.651 0.159. EVT. 0.063 0.550 4.240 7.602. WLS. 0.007 0.011 0.001 0.001. WLS. 0.027 0.039 0.138 0.066. 電. Moment. 0.018. 0.025 0.002 0.001. Moment. 0.008 0.087 0.297 0.093. 壓. WLS(z). 0.016. 0.018 0.017 0.016. WLS(z). 0.021 0.097 0.295 0.136. 0.237. 0.113 0.072 0.019 WLS(log)_1% 0.038 0.124 0.293 1.221. 0.099. 0.067 0.020 0.006. 0.6 WLS(log)_1% EVT. EVT. 0.010 0.075 0.288 0.554. 註:WLS 為有解釋變數的加權迴歸,_1%表示篩選 1%樣本,單位為. 35.
(43) 第四節 實證結論 實證結果顯示,三種電壓下的電流值經過 Box-Cox 轉換後皆變成較為接近 常態分配,但電壓 1.0 與電壓 0.8 的左、右尾皆仍有偏離常態趨勢,故相較於給 予每一個觀察值同樣權重的 Moment 法,電壓 1.0 和電壓 0.8 時採用加權迴歸方 法加重極值影響力,不管是有無考慮解釋變數,均方誤差皆較 Moment 法小,且 偏誤情形不顯著;而電壓 0.6 轉換後較電壓 1.0 與電壓 0.8 更為近似常態分配, 故 Moment 法可以達到均方誤差較小的估計結果,但若以不偏性為單一考量,則 加權迴歸方法在左、右尾的偏誤皆較 Moment 法小。另外,左尾的估計結果較右. 治 政 尾更為準確,推測可能因為左尾電流值不會小於 0,具有範圍限制故估計結果較 大 立 好,且有解釋變數的加權迴歸方法對於左尾估計效果最佳 。 ‧ 國. 學. 而關於篩選樣本的方式,篩選右尾 1%比例的選樣方法,對於估計結果較好. ‧. 的方法而言沒有增加準確性只使得變異增加,但對於估計結果較不好的方法而言,. sit. y. Nat. 捨去普通樣本的干擾,只納入較極端樣本的資訊對於估計結果的準確度有改善。. io. er. 另外,1%門檻比例的 EVT 亦為不錯的替代估計方法,於三種電壓下都有中間程 度的估計準確性,但有短程估計較長程估計準的現象,即前段尾端機率值的估計. n. al. ni Ch 準確度較佳,但後段尾端機率值的估計準確度下降。 U engchi. v. 總言之,本研究證實由十萬筆電流樣本值,以 Box-Cox 方法轉換資料為近 似常態後,再配合加權迴歸方法,能有效估計左尾和右尾機率 的極端電流值,並改善直接以. 、. 、. 、. 估計電流極值結果,電壓大者改善. 效果較好,其中右尾部分的加權迴歸解釋變數-經驗累積機率值採用 Log 轉換, 而左尾部分的加權迴歸解釋變數-經驗累積機率值則採用 Z 分數轉換,估計結 果較為準確。若能夠獲得適當的解釋變數,則在左尾部份以解釋變數進行加權迴 歸後,外插估計左尾罕見電流值結果最為準確。另外,極值理論亦可用於估計極 端電流值,採用 1%門檻值能穩定程度的估計不同電壓下的電流值。 36.
(44) 第五章. 結論與建議. 第一節 結論 隨著積體電路製程越趨精細且複雜,電路設計中對於電流穩定性的要求提高, 特別是距離期望值 4 至 6 倍標準差以外的罕見機率電流值,成為當前電路設計的 重要考量。實務上多以蒙地卡羅方法,以理論模型或實務模擬,產生數量龐大的 電路資料或實驗,獲得完整的罕見機率電流值資料,但這種方法隨著精確度的標. 政 治 大 過參數模型外插,由於過去在電晶體較大尺寸的模擬電流值大多接近常態分配, 立 準提高,因為曠日廢時而愈來愈不可行。另一種獲得罕見機率觀察值的方式是透. 倍標準差,k = 4~6)估計罕見機率電. ‧ 國. 學. 故以相對少量資料常態外插(即平均數. 流,或是抽樣方法(例如:Importance Sampling 及 Latin Hypercube)皆為可行之. ‧. 替代方案。. sit. y. Nat. 然而隨著電晶體的尺寸縮小,積體電路的操作電壓也隨之降低,發現電流值. n. al. er. io. 的兩尾端分配經常偏離常態分配,因為尾端電流的變異,使得以常態外插或縮減. i Un. v. 變異數方法估計罕見機率電流值愈形困難。例如:Abu-Rahma et al. (2011)在 28. Ch. engchi. 奈米製程下測量 0.7 電壓時 SRAM 於 6 倍標準差內的電流值,證實 SRAM 在低 電壓時的尾端電流分配呈現非常態分配。因此,引進統計方法改善罕見機率電流 值的估計成為本文面對之挑戰。 延續工程上依賴常態分配作為估計基礎,本文首先以 Box-Cox 轉換觀察值 為近似常態,改善常態分配外插估計,接著再以加權迴歸方法或常態外插法估計 罕見電流值,其中迴歸方法的解釋變數為 Log 或 Z 分數轉換的經驗累積機率, 使其無上限範圍,而加權方法採用 Down-weight 加重極值樣本資訊的重要性,認 為越尾端的樣本越具代表性而給予權重 1,次尾端的樣本權重 、 、 、. 37. 、 。.
(45) 此外,考慮此電路罕見事件為電流極大或極小情形,故本研究也採用了針對 處理極大值(或極小值)而發展出的極值理論,應用其中的超越門檻方法於罕見 機率電流值估計上,以最大概似估計法估計其形狀和尺度參數。 為確認估計效果和操作程序,本文先以模擬方式,假設母體分配為標準常態 分配、T 分配(自由度 10) 、Gamma 分配(. ,. ,由均方誤差(Mean Square. Error, MSE)作為衡量指標,模擬結果驗證了加權迴歸方法的可行性。當母體為常 態分配,常態外插方法能準確的估計尾端分配值;但當母體為厚尾 T 分配時, Box-Cox 轉換效果不佳,取 Log 轉換的加權迴歸方法可以得到最小的均方誤差; 當母體為 Gamma 分配時,Box-Cox 轉換能將樣本轉換成較為近似常態,取 Z 分. 治 政 數轉換的加權迴歸方法可以得到最小的均方誤差。極值理論的表現居中,大致上 大 立 有「短程估計最準」的趨勢,即估計尾端機率 與 時均方誤差較小,但 ‧ 國. 學. 估計尾端機率. 與. 時的均方誤差較大。關於樣本篩選方式,各方法皆以. ‧. 使用整筆樣本或是 1%右尾篩選樣本的估計結果最好。. sit. y. Nat. 參考模擬所得結果,本文選用整筆樣本或 1%篩選樣本兩種方式,以此估計. io. 的樣本數量(即十萬筆)估計至左右尾機率. al. er. 方法對於電流值進行實證研究,資料來源為新竹某科技公司,實證目標為以 1% (約為標準常態 5.2 標準差)的. n. iv n C 電流值。實證結果顯示,由十萬筆電流樣本值,以 h e n g c h i UBox-Cox 方法轉換資料為近 似常態後,再配合加權迴歸方法,能有效估計左尾和右尾機率. 、. 、. 、. 的極端電流值。其中右尾部分的加權迴歸解釋變數-經驗累積機率值採用 Log 轉換,而左尾部分的加權迴歸解釋變數-經驗累積機率值則採用 Z 分數轉換, 估計結果較最為準確。關於篩選樣本的方式,篩選尾端 1%比例的取樣方法,和 整筆資料全用的方式對於不同方法的估計準確度提升各有利弊,兩種樣本使用方 法皆可考慮。 實證研究部分另外考慮了納入其他電流資訊做為解釋變數的加權迴歸方法, 此方式在左尾部份能達到最佳的估計效果,因此本研究建議左尾部份若能獲得完 38.
(46) 整的解釋變數,可採用有解釋變數的加權迴歸方法。另外,實證研究結果顯示, 極值理論亦可用於估計極端電流值,採用 1%門檻值能穩定程度的估計不同電壓 下的電流值,有短程估計最準的趨勢。. 第二節 討論與建議 對於電路設計上距離期望值 4 至 6 倍標準差以外的罕見機率電流值,本文由 十萬筆樣本值以加權迴歸方法配合 Box-Cox 轉換,估計罕見機率至 5.3 倍標準差 的電流值,改善過去完整蒙地卡羅需模擬一千萬筆的效率,以及常態外插估計準. 治 政 確度,建立罕見事件估計流程的參考。上述方法已經取得提供本研究資料的高科 大 立 技公司認同,經過他們反覆測詴,發現比現行方法更加簡單有效,未來將作為該 ‧ 國. 學. 公司研發、製造的方法之一。這個產學合作的成功經驗,可以作為學校執行統計. ‧. 諮詢的參考交流,提升統計研究的附加價值和影響力。. sit. y. Nat. 然而本研究也發現,電流值在較低電壓時(0.6 電壓)的分配較為偏離常態. io. er. 分配,經過 Box-Cox 轉換後,以常態分配外插的效果不錯;但在較高電壓時(1.0 電壓) ,電流經過 Box-Cox 轉換的結果反而不如低電壓。因為本研究傴使用常用. al. n. iv n C 於工程的 Box-Cox 轉換,傴包含目標變數的次方(Power)變換,如果能結合應用 hengchi U. 領域的專業知識,選取範圍更廣的函數轉換方式,像是三角函數(例如:類神經 網路中的 Sigmoid Function、Hyperbolic Tangent) 、多項式(類似 Taylor Expansion 的想法)等。 另外對於解釋變數(即經驗累積機率)的轉換方式,本文採用 Log 與 Z 分 數轉換,而加權方法採用 Down-weight 加權(1、1/2、1/3、…),本研究也詴過其 他權重,其效果各有不同,因此未來研究可考慮其他不同的轉換方式和加權方法, 例如根號或平方的 Down-weight,以加重或減輕權重的影響。. 39.
數據
相關文件
z 在使用分壓器時有某些情況必須考慮,以右圖 的分壓器為例,總電壓亦即V CO 為+90V,若三 個電阻均相等,則理論上V AO =V BA =V CB =
,外側再覆上防刮塗膜,且塗膜上佈滿 低壓電流形成電容狀態,玻璃板周圍的
附表 1-1:高低壓電力設備維護檢查表 附表 1-2:高低壓電力設備維護檢查表 附表 1-3:高低壓電力設備(1/13) 附表 2:發電機檢查紀錄表. 附表
表 6.3.2 為不同電壓下,驅動整個系統運作所需電流。圖 6.3.2 為 測試情形。其中紅燈代表正常工作。結果證明只要太陽能板能夠提供
使我們初步掌握了電壓、電流和電阻三者之間的關係。我
進而能自行分析、設計與裝配各 種控制電路,並能應用本班已符 合機電整合術科技能檢定的實習 設備進行實務上的實習。本課程 可習得習得氣壓-機構連結控制
油壓開關之動作原理是(A)油壓 油壓與低壓之和 油壓與低 壓之差 高壓與低壓之差 低於設定值時,
請繪出交流三相感應電動機AC 220V 15HP,額定電流為40安,正逆轉兼Y-△啟動控制電路之主
