國立臺中教育大學教育測驗統計研究所
國民小學教師在職進修教學碩士學位班碩士論文
指 導 教 授:郭伯臣 博士
結合選擇題與建構反應題之認知診斷
模式探討
研 究 生:施學佳 撰
謝辭
能再重拾學生的生活,是一種幸福。當年從師院畢業後到小學任教服務,至 今也已二十年了,許多在學校所學的本職學能,也不敷教學所需,所以能有機會 回到學校,重新再拾起課本學習,也讓自己有新的動能繼續於教學的工作。 這四個暑假來的學生生涯,從一開始的懵懂不知,到現在逐漸摸索出興趣來, 感謝許天維老師、曾建銘老師、施淑娟老師、吳慧珉老師、鄭富森老師、胡豐榮 老師、楊志堅老師、陳桂霞老師,由於您們的認真教導,才能讓一個駑鈍的學生 逐漸有點開竅,今天如能有一點所得,都是您們辛苦教導的功勞。更感謝指導我 的指導教授郭伯臣老師,您總是很有耐心指導我們,很怕我們不懂,總不厭其煩 的說明,而且老師對問題的見解與分析能力,總讓我們受益良多,並且時時給予 我們鼓勵與關懷,讓我們有信心地完成各項功課。 感謝智為學長與俊彥學長的耐心指導與協助,不論是程式的分析與應用、或 是論文的架構與撰寫,都提供了我極大的協助。謝謝同學國禎大哥、振雄大哥的 相互支持,每次的共同討論與在江西發表論文時,有你們在一起共同的努力,在 學習的這條路上就不覺得孤單。還有班上所有的好同學們,我會記得我們曾經一 起上課、一起分享的快樂日子,我只能說,有你們這群好同學們,真棒! 最後感謝學校的同仁、好朋友的幫忙與心靈的陪伴,更感謝我的家人的支持, 可以讓我無後顧之憂地上課與學習,願以此文與你們大家一起共享。 施學佳 中華民國一 0 二年八月摘要
認知診斷評量(cognitive diagnosis assessment)是近年在測驗領域上較新興的
研究,古典測驗理論或是試題反應理論,重視測驗結果的分析,較少關注於受試 者心理的建構過程,而認知診斷評量則是研究受試者在作答反應裡,心理的知識 建構過程,提供施測者做為補救教學的依據。 本研究是結合建構反應題與選擇題的結果來模擬分析,並透過實徵資料的驗 證,希望以部分建構反應題的診斷結果,來提升診斷的正確率。 本研究結果發現: 1. 試題猜測參數相同,建構反應型之 DINA 模式比 DINA 模式的概念辨識率較 好。 2. 人數相同,建構反應型之 DINA 模式比 DINA 模式的概念辨識率較好。 3. 不同的選擇題與建構反應題的組合,建構反應型之 DINA 模式比 DINA 模式的 概念辨識率較好。 4. 實徵研究與模擬實驗數據結果相符。 關鍵字:認知診斷評量、DINA、建構反應題、概念辨識率、建構反應題型之 DINA 模式。
Abstract
Cognitive diagnosis assessment has been a prominent research in the field of testing in recent years. Classical Test Theory (CTT) or Item Response Theory (IRT) emphasizes more on the analysis of the test results and less on the subjects psychological process of construction. On the other hand, cognitive diagnosis assessment researches the psychological process of knowledge construction according to the subjects’ responses so as to provide a basis for testers as remedial teaching.
This study combines constructed-response items and multiple choice questions for simulation analysis and validates empirical data in the hope of using the diagnostic results of partial constructed responses to improve the accuracy of diagnosis.
The study has found:
1 With the same parameter of question speculation, CR-DINA(Constructed-Response DINA) model have better attribute correct classification rates than DINA model. 2. With the same number of people, CR-DINA model have better concept criterion rates than DINA model.
3 With the combination of different multiple choice questions and constructed response items, CR-DINA model have better attribute correct classification rates than DINA model.
4 The empirical data is consistent with the simulation experiment data..
Keywords: Cognitive diagnosis models, DINA model, constructed-response items, attribute correct classification rates,CR-DINA
目錄
謝辭 ... I 摘要 ... I Abstract ... II 第一章 緒論 ... 1 第一節 研究動機 ... 1 第二節 研究目的 ... 2 第三節 待答問題 ... 3 第四節 名詞解釋 ... 3 第二章 文獻探討 ... 5 第一節 認知診斷模型 ... 5 第二節 建構反應題型 ... 10 第三章 研究方法 ... 13 第一節 研究流程 ... 13 第二節 實驗設計 ... 15 第三節 評估指標 ... 28 第四節 研究工具 ... 29 第四章 研究結果 ... 31 第一節 模擬資料估計結果 ... 31 第二節 模擬資料綜合分析比較... 58 第三節 實徵資料驗證分析 ... 84 第五章 結論與未來研究建議 ... 87 第一節 結論 ... 87 第二節 未來研究建議 ... 88 參考文獻 ... 89表目錄
表 3-2-1 資料變項與估計方式彙整表 ... 15 表 3-2-2 無結構性概念試題參數分佈組型設計表 ... 16 表 3-2-3 Q 矩陣設計 ... 17 表 3-2-4 概念具有結構關係之試題參數分佈組型設計表 ... 19 表 3-2-5 概念具有線性結構關係之 Q 矩陣設計 ... 20 表 3-2-6 概念具有發散性結構關係之 Q 矩陣設計 ... 22 表 3-2-7 概念具有聚斂性結構關係之 Q 矩陣設計 ... 24 表 3-2-8 平均概念精熟人數比率表 ... 26 表 4-1-1 HO-DINA1000 人 DINA 模式的估計結果 ... 32 表 4-1-2 HO-DINA1000 人 CR-DINA 模式的估計結果 ... 33 表 4-1-3 HO-DINA500 人 DINA 模式的估計結果 ... 34 表 4-1-4 HO-DINA500 人 CR-DINA 模式的估計結果 ... 35 表 4-1-5 HO-DINA100 人 DINA 模式的估計結果 ... 36 表 4-1-6 HO-DINA100 人 CR-DINA 模式的估計結果 ... 37 表 4-1-7 概念具線性結構時,CR-DINA 模式結果(N=1000) ... 39 表 4-1-8 概念具線性結構時,DINA 模式結果(N=1000) ... 40 表 4-1-9 概念具線性結構時,CR-DINA 模式結果(N=500) ... 41 表 4-1-10 概念具線性結構時,DINA 模式結果(N=500) ... 42 表 4-1-11 概念具線性結構時,CR-DINA 模式結果(N=100) ... 43 表 4-1-12 概念具線性結構時,DINA 模式結果(N=100) ... 44 表 4-1-13 概念具發散性結構時,CR-DINA 模式結果(N=1000) ... 46 表 4-1-14 概念具發散性結構時,DINA 模式結果(N=1000) ... 47 表 4-1-15 概念具發散性結構時,CR-DINA 模式結果(N=500) ... 48 表 4-1-16 概念具發散性結構時,DINA 模式結果(N=500) ... 49 表 4-1-17 概念具發散性結構時,CR-DINA 模式結果(N=100) ... 50 表 4-1-18 概念具發散性結構時,CR-DINA 模式結果(N=100) ... 51 表 4-1-19 概念具聚斂性結構時,CR-DINA 模式結果(N=1000) ... 52 表 4-1-20 概念具聚斂性結構時,DINA 模式結果(N=1000) ... 53表 4-1-23 概念具聚斂性結構時,CR-DINA 模式結果(N=100) ... 56 表 4-1-24 概念具聚斂性結構時,DINA 模式結果(N=100) ... 57 表 4-2-1 S=0.1 1000 人之加入建構題提升結果... 59 表 4-2-2 S=0.1 500 人之加入建構題提升結果... 59 表 4-2-3 S=0.1 100 人之加入建構題提升結果... 60 表 4-2-4 S=0.25 1000 人之加入建構題提升結果... 60 表 4-2-5 S=0.25 500 人之加入建構題提升結果... 61 表 4-2-6 S=0.25 100 人之加入建構題提升結果... 61 表 4-2-7 1000 人 個別概念的辨識率估計結果 ... 62 表 4-2-8 500 人 個別概念的辨識率估計結果 ... 63 表 4-2-9 100 人 個別概念的辨識率估計結果 ... 64 表 4-2-10 1000 人 試題組合 ACCR 的估計結果 ... 65 表 4-2-11 1000 人 試題組合 PCCR 的估計結果 ... 66 表 4-2-12 500 人 試題組合 ACCR 的估計結果 ... 67 表 4-2-13 500 人 試題組合 PCCR 的估計結果 ... 68 表 4-2-14 100 人 試題組合 ACCR 的估計結果 ... 69 表 4-2-15 100 人 試題組合 PCCR 的估計結果 ... 70 表 4-2-16 1000 人 個別概念的辨識率估計結果 ... 73 表 4-2-17 500 人 個別概念的辨識率估計結果 ... 74 表 4-2-18 100 人 個別概念的辨識率估計結果 ... 75 表 4-2-19 1000 人結構概念辨識率(ACCR) ... 77 表 4-2-20 500 人結構概念辨識率(ACCR) ... 78 表 4-2-21 100 人結構概念辨識率(ACCR) ... 79 表 4-2-22 1000 人整體結構概念辨識率(PCCR) ... 81 表 4-2-23 500 人整體結構概念辨識率(PCCR) ... 82 表 4-2-24 100 人整體結構概念辨識率(PCCR) ... 83 表 4-3-1 實徵資料之 Q 矩陣 ... 84 表 4-3-2 加入建構反應題後之辨識率值比較 ... 85
圖目錄
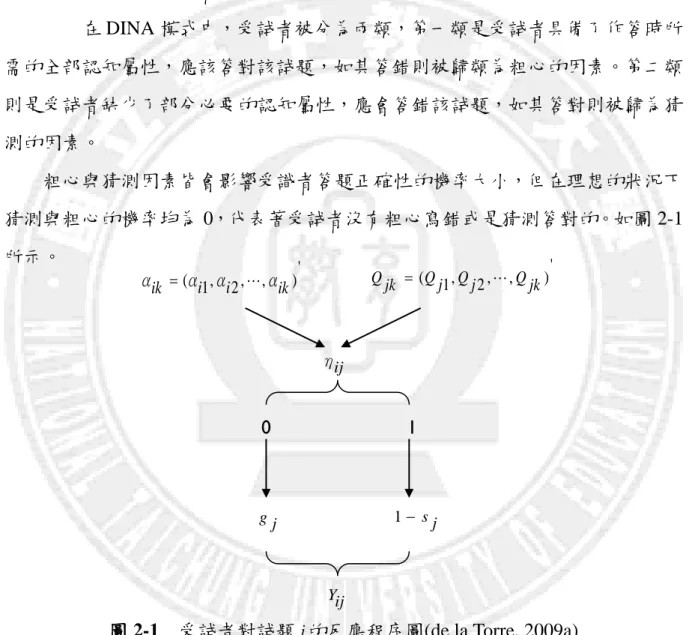
圖 2-1 受試者對試題 j 的反應程序圖(DE LA TORRE,2009A) ... 8
圖 2-2 HIGHER-ORDER DINA 模式反應程序圖 ... 9
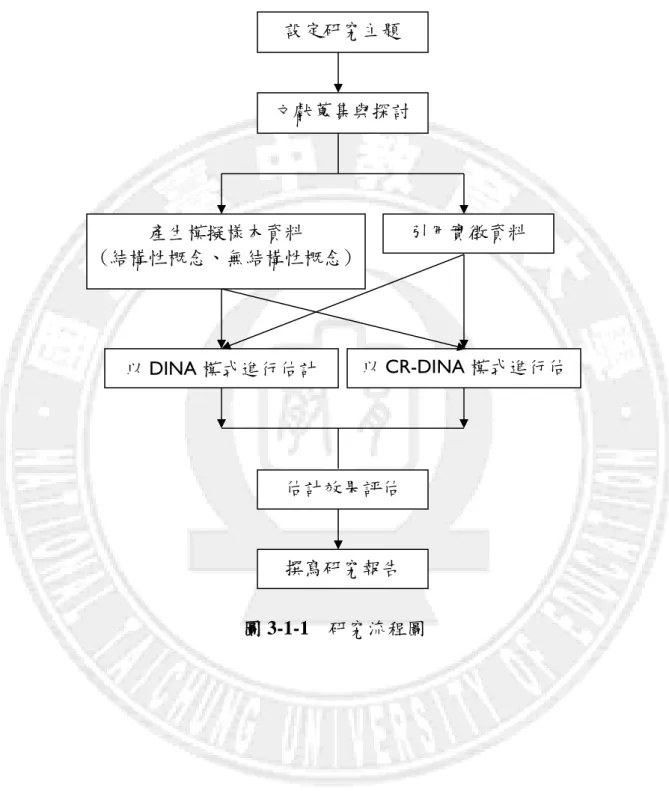
圖 3-1-1 研究流程圖 ... 14
圖 3-2-1 概念具有線性結構之結構圖 ... 21
圖 3-2-2 概念具有發散性結構之結構圖 ... 23
第一章
緒論
本研究根據認知診斷模型,以模擬樣本資料的實驗方式探討不同認知診斷模 式對學生認知屬性之診斷效果,並以實徵資料驗證模式之成效。本章將針對研究 動機、研究目的、待答問題、以及名詞解釋進行闡述。第一節 研究動機
教育的目的之一,是在於提升學生的學習成就,但學生的學習能力影響著學 生的學習成就,所以我們想了解學生的學習能力,是否因受教育之後,就能提升 學習成就,所以在學生的認知診斷上就顯得非常重要。因為認知診斷是在診斷學 生的學習認知情形,診斷其在不同學習的領域上,是否達到該領域所需的認知能 力。因此想知道學生的學習狀況,認知能力的診斷就顯得非常重要。認知診斷模型(cognitive diagnostic models, CDMs)是診斷受試者認知能力的 精熟情形或是在特定領域的表現情況,幫助教學者或受試者獲得更詳細的診斷訊 息,以達到更有效率的教學或學習。近年來專家學者們紛紛提出許多的認知診斷 模型研究,在眾多認知診斷模式中以 DINA (deterministic inputs, noisy and gate; Junker & Sijtsma, 2001)模式受到較多的運用,而許多認知診斷模型就是根據
DINA 模式發展而來,如 G-DINA(generalized deterministic inputs, noisy and gate ; de la Torre,2011)、HO-DINA(higher order Deterministic inputs,noisy and gate model ; de la Torre & Douglas,2004)、DINO(deterministic inputs, noisy or gate ; Templin &
Henson,2006)。
教學目標,而建構反應題型則可以測出較高層次的應用、分析、綜合、評鑑等教 學目標,所以建構反應題型較能夠測出學生真正的能力。 目前的研究以選擇反應題型的研究為主,探討學生在選擇反應題型上的認知 診斷,而少有結合建構反應題型與選擇題型的研究。所以本研究旨在探討結合建 構反應題型與選擇題型的認知診斷研究。 認知診斷研究,是在探討學生的認知能力是否達到測驗所需的認知狀態,而 一般測驗在概念的認知結構上可區分為結構或是無結構二種,而概念具有結構模 式又可區分為線性結構模式、發散性結構模式、聚斂性結構模式等三種結構模式。 以往的研究大都以概念間無結構的認知結構為主,少有觸及概念間具有結構的認 知結構探討,所以本研究也想了解當概念具有結構時,對於認知診斷的結果影響 如何。 使用 DINA 模式進行測驗分析時,一般而言會估計二種試題參數,猜測參數 與粗心參數,但是當使用建構反應題時,將使受試者的猜測機率降至最低,因此 本研究認為使用 DINA 分析此建構反應題時,應將猜測參數設為 0,為瞭解此一 修改之成效,本研究將模擬不同情境及考慮概念間結構之有無所造成之影響。最 後並以實徵資料來驗證模擬分析的結果,以了解 CR-DINA 的成效。
第二節 研究目的
本研究將探討認知診斷模式對不同題型的診斷辨識率,並探討在結合選擇題 與建構反應題型中,何種診斷模式的辨識率較高?並探討資料概念結構的有無, 是否也會影響診斷的成效?以作為教學的診斷依據。 根據上述,本研究的研究目的如下。 一、 探 討 當 使 用 DINA 分 析 建 構 反 應 題 時 , 將 猜 測 參 數 設 為 0 , CR-DINA(Constructed-Response DINA)模式之影響。三、 以實徵研究資料探討 CR-DINA 模式診斷成效。
第三節 待答問題
依據上述之研究目的,提出下列幾項問題 一、 CR-DINA 模式是否可提升 DINA 模式於具有建構反應題的測驗題型中的估 計精準度? 二、 概念間結構的有無,CR-DNA 模式是否都優於 DINA 模式的診斷成效? 三、 CR-DINA 模式是否提升實徵研究的認知診斷估計精準度?第四節 名詞解釋
針對本研究常用的名詞,進行釋義。壹、概念結構
概念結構是指試題本身的概念具有結構,並且具有發展順序的上下位層次結 構關係。一般分成線性、發散姓、聚斂性等三種結構模式。貳、建構反應題
測驗本身不提供選項,受試者必須自己思考解決問題。例如:填充題、簡答 題、問答題。本研究指的建構反應題是指限制反應題型的建構反應題。叁、CR-DINA 模式
屬性卻粗心答錯(slip)答錯;另一為不具該題認知屬性而猜測(guessing)答對試題。 CR-DINA 模式是依據 DINA 模式理論模型,縮減了猜測參數。因為根據建 構反應題型的答題特性,試題不提供選項,受試者如不具備該題之認知屬性,是 無法答對該題的。所以當試題是選擇題時,仍用 DINA 模式分析診斷,但如為建 構反應題時,就改用 CR-DINA 模式分析診斷,其公式如下: ij j i ij s Y P( 1|
) (1 ) :第 個受試者在第 j 個試題的反應組型。 :受試者具有回答第 j 個試題所需的認知屬性,但卻因粗心大意答錯該 題的機率。 :代表第 個受試者在第 j 個試題的認知屬性狀態。 :代表受試者是否具有答對第 j 個試題所需的所有認知屬性,若全部 具備則其值為 1,反之,受試者至少缺少 1 個答對第 𝑗個試題所需的 認知屬性,其值為 0。第二章
文獻探討
本章節乃針對本研究中所引用的認知診斷模型,包含 DINA 模式、HO-DINA 模式(Higher-Order DINA, HO-DINA; de la Torre and Douglas, 2004);及建構反應題 型上的運用,來探討相關文獻與內容。
第一節 認知診斷模型
心理計量學發展至今,不過百餘年光景,但對於測驗受試者的學習特質,隨 著科技的發展,逐漸越來越受到重視與應用。傳統的古典測驗理論,只能測出受 試者的受測分數,然後據以判斷學習的結果,但卻無法分析出受試者潛在特質的 精熟程度。 隨著現代測驗理論的試題反應理論的興起,為了改善古典測驗理論的不足之 處,在試題反應理論中,已可分析出受試者的潛在特質能力,並可推論出在不同 的測驗中可能的測驗結果。 但是人們仍不能滿足於這樣的結果,因為我們更希望能診斷出學生的所有潛 在特質的個別精熟度如何,而非只是單一的總和結果。在 2001 年美國通過一個 有教無類的法案(No Child Left Behind Act of 2001,Public Law 107-110),其 目的是要診斷出學生閱讀與數學的各項概念是否達到精熟的程度。所以新的測驗 理論應運而生,認知診斷模式即由此發展而來。近幾年來,認知診斷模型越來越盛行,逐漸超越試題反應理論而受到重視。 因為試題反應理論不能評量出受試者的個別潛在能力特質的精熟度,而認知診斷 模式可以分析出受試者的個別潛在能力特質是否精熟,進而做為學生個別補救教
認知診斷模型有潛在分類模型與潛在特質模型二種。潛在特質模型以試題反 應理論(item response theory, IRT)為例來說,只能測驗出受試者的潛在特質在測驗 結果上的表現,它是以能力值來代表受試者的潛在特質,能力值越高,答對的結 果比例就越高。 但是此診斷模式只能測出受試者的潛在特質(能力)大小及預測在測驗結果上 的表現,卻無法診斷出受試者的潛在能力缺陷及錯誤類型分類。它是以能力測驗 為主,即受試者只要達到該測驗試題所需的能力,即能達對該試題。 潛在分類模型是為改進潛在特質模型的缺陷而產生,其中 DINA 模型、 G-DINA 模型、HO-DINA 模型,都是其中較著名的模式,尤以 DINA 模式最受到
關注,許多認知診斷模式都是以 DINA 模式為基礎發展而來,容後也會加以介紹。 認知診斷模型以概念診斷為主,以(0,1)二元來代表概念的精熟度,依據概念 數的不同,會有不同的能力組型,能力組型數為 2 的概念數次方。舉例來說,以 k 代表概念數,k=3,能力組型數就有23 = 8種,即(0,0,0) (1,0,0) (0,1,0) (0,0,1) (1,0,1) (1,1,0) (0,1,1) (1,1,1)等 8 種,如果某受試者的能力組型為(1,0,1),則該受試者具有 概念 1 及概念 3。假設某試題 i 需具備概念 2 才能答對,則該受試者答對的機率 就會較低。 Q 矩陣是認知診斷很重要的判斷基準,Q 矩陣是由每題試題的概念數組合而 來,每一列代表一題的能力組型,試題有幾題,就可形成幾列的陣列 Q 矩陣。以 5 題 3 概念為例,即可形成一個5 × 3的數陣列。假設的 Q 矩陣如下: 1 1 1 0 1 0 1 0 1 1 1 0 0 0 1 Q 從上,我們可以知道試題一需要概念 1,而試題二需要概念 2 與 3,試題三
除了建立 Q 矩陣外,我們也必須判斷每個概念的精熟度對答題正確機率大小 的影響。據此,我們才能判斷受試者的認知診斷結果。而以下的將分別探討 DINA 模式與 Higher-Order DINA 模式的介紹。
壹、DINA 模式
一、 DINA 模式介紹
DINA 模式是認知診斷模型中基礎的評估方法,許多認知診斷模型都是由 DINA 模式識為基礎而發展改良而來,它是一種適用於二元計分認知診斷評量測驗的模式,是由 Junker & Sijtsma(2001)所創建並開始流行。DINA 模式的基本假 設為受試者具備或掌握試題所需的認知屬性,就能答對試題。但答對機率的大小, 會受到受試者本身的粗心(slip)與猜測(guess)這二種試題參數的影響。DINA 模式 的公式如下。 ) 1 ( ) ( ) 1 ( ) | 1 ( ij ij j j i ij s g Y P η η 其中,
K k Q ik Q k ik ij jk jk 1 : 1 α α η)
1
|
0
(
ij ij jP
Y
s
η
)
0
|
1
(
ij ij jP
Y
g
η
其中 ijY
:第i
個受試者在第j題試題的反應組型。 js
:受試者具備回答第j題試題所需要的認知屬性,但卻因粗心而答錯該題 的機率。g
:受試者不具備回答第 j題試題所需要的認知屬性,但卻因猜測而答對該則為 0。 jk
Q
:受試者答對第j題試題是否需要第 k 個認知屬性,如需要該屬性其值為 1,若無則為 0。 ijη
:受試者是否具備答對第j題試題所需要的概念,如全部具備其值為 1, 反之,若受試者缺少一個答對第j題試題所需要的概念其值則為 0。 在 DINA 模式中,受試者被分為兩類,第一類是受試者具備了作答時所 需的全部認知屬性,應該答對該試題,如其答錯則被歸類為粗心的因素。第二類 則是受試者缺少了部分必要的認知屬性,應會答錯該試題,如其答對則被歸為猜 測的因素。 粗心與猜測因素皆會影響受識者答題正確性的機率大小,但在理想的狀況下, 猜測與粗心的機率均為 0,代表著受試者沒有粗心寫錯或是猜測答對的。如圖 2-1 所示。圖 2-1 受試者對試題j的反應程序圖(de la Torre, 2009a)
因為 DINA 模式簡單且易解釋的特性,只需要粗心機率與猜測機率兩種參數, 而且也擁有非常好的模式適配(de la Torre & Douglas, 2004, 2005),所以常被應用 在許多測驗方面上的評估與診斷。 ' ) , , 2 , 1 ( i i ik ik α α α α Qjk (Qj1,Qj2,,Qjk)' ij η 0 1 j g 1 sj ij Y
貳、Higher-Order DINA 模式
在 DINA 模式中,認知屬性的關係是個別局部獨立存在的,而 HO-DINA 模 式中,是在 DINA 模式中的個別局部獨立屬性上,加上一個更高階的能力屬性, 讓屬性之間有從屬的上下階層關係,如此就可消除一些屬性之間的連結性,也減 少了許多屬性組合數量(de la Torre and Douglas, 2004)。其在認知診斷上不僅可提
供整體受試者的總體能力值(θ),也能知道受試者屬性掌握情況以及屬性與能力之 間的關係,其所提供的訊息也更為豐富(涂冬波、蔡艷、丁樹良,2012),在高階 層的公式中,給定一個高階的潛在能力值θi,而其假定元素αi為獨立條件,則其 關係可用潛在的邏輯迴歸模式來詮釋,如下式所示。
K k i k k i i i P 1 1 0 0 1 )] ( 7 . 1 exp[ 1 )] ( 7 . 1 exp[ ) | ( λ θ λ λ θ λ θ α 其中 i α:第i
人的認知屬性狀態。 i θ:第i
人的高階潛在能力值。 1 λ :鑑別度參數。 k 0 λ :難度參數,其值愈高代表難度愈難。公式與相關的參數估計方法,可參考在 de la Torre(2009a)與 de la Torre & Douglas(2008)以及 de la Torre & Douglas(2004)和 Hartz(2002)中的文獻。其圖形如
圖 2-2。 i α i θ λ ij η j q j g 1 sj
第二節 建構反應題型
建構反應題(constructed-response items)是指在測驗過程中,不提供答案選項 供受試者選擇,而是由受試者自己運用思考,解決問題,建構出答案。因此在學 生解題的過程中,可以觀察到學生的思考與解題的過程。 方便閱卷、給分標準、容易是選擇題的最大優勢(林榮煌,2006),而非選 擇題最令人擔憂與質疑的,便是給分的「公平性」。建構反應題試題的答案是藉 由參與的受試者自己思考並作答而產生,不同的受試者,在對錯間,因作答及思 考方式的不同,往往也只存些微差異,這種作答方式的可變性和多元性,雖然目 前已有研究使用電腦化自動閱卷評分的可行性,但與人工評卷一樣,也是需要耗 費大量的人力和時間,所以目前大都仍是以人工的方式來閱卷,並針對不同的解 題歷程,給予不同程度的評分。Linn & Gronlund(2000)認為,建構反應試題能測量學生運用自我思考的 能力來解決問題、透過自我批判、重新的組織後,並將最後成果統整後具體呈現 (教育部,2004)。盧雪梅(2009)的研究也指出,論文題又稱為開放式問題 (open-ended question),亦即是可以讓學生可以自由組織、歸納和表達自我的想 法。開放式問題則再依據學生作答時可以組織和表達觀念的自由度,我們可將其 分成限制反應題(restricted-response question)和擴展反應題(extended-response question)兩類(盧雪梅,2009;李烱璉,2010)。 建構反應題即非選擇題,其主要目的是在測量學生操作、思考、分析、說明、 統整和使用相關資訊科技的能力(National Assessment Governing Board, 2004;教 育部,2005)。基於此,本研究設計採用的建構反應題題型屬於限制反應題型, 並結合電腦化診斷測驗,除了避免學生在作答過程猜測答案,亦可將學生的作答 過程完整記錄下來,協助教師在事後的分析中,能得知個別學生的迷思概念,並 能給予有效的補救教學。
項次 研究名稱 研究結果 1 具 選 擇 題 與 建 構 反 應 題 之 電 腦 化 測 驗 診 斷 模 式 探 討— 以 國 小 容 量 單 元 為 例 (鄭涵,2010) 1. 自動化分析對建構反應題有良好辨識率。 2. 加 入 自 動 化 分 析 建 構 反 應 題 的 錯 誤 類 型 後,可提升貝氏網路診斷受試者能力精準 性。 2 「光」單元之電腦化 建構反應試題與診斷 模式開發初探 (莊峰魁、王文卿、劉 育隆、郭伯臣,2010) 建構反應題可以記錄並了解學生的完整解題 過程,降低了教師的閱卷時間,也能立即診斷 出受試者的錯誤類型概念。 3 數學科建構反應題診 斷系統的建置—以五 年級平行四邊形與三 角的面積單元為例 (張永鑫,2010) 加入建構反應題型的測驗信度,優於全選擇題 題型的測驗信度。 4 「空氣與燃燒」單元之 線上診斷測驗建製與 分析 (李烱璉,2010) 使用建構反應題題型結合電腦化測驗,除記錄 學生完整作答反應,避免學生投機猜測答案, 亦可協助教師了解學生在學習中常發生哪些 異於選擇題的迷思概念。 5 國小自然與生活科技 領域「天氣的變化」單 元建構題與選擇題之 電腦化測驗研發 (林玉珍,2012) 1.建構反應題可以記錄學生的完整作答反應, 並降低學生猜測作答的機率。 2.利用電腦進行診斷測驗,讓老師可以即時得 到學生認知概念狀態的回饋,減少批改所耗 費的時間。 3.在 DINA 模式診斷結果中顯示具有建構反應 題樣本的正確率高於僅具有選擇題的樣本。 根據以上的研究結果分析來看,傳統測驗的結果無法正確判斷出學生是否有
而認知診斷評量則是改進了傳統測評量的缺點,提供受試者學習概念的個別 學習診斷,讓施測者可以很清楚明瞭受試者那些概念有問題,在進行補救教學時 可以更有效率並節省時間。 一般測驗題型分成選擇題與建構反應題題型二類,根據以上的研究結果來看, 建構反應題相較於選擇題有較高的辨識率,而且建構反應題學生必須記錄完整作 答反應,所以能降低學生的猜測因素,在辨識率判斷上就較優於選擇題型的試 題。 本研究是採用電腦化診斷測驗的方式進行實徵研究,所以如果測驗採用全建 構反應題型,在診斷辨識率上的效果最好,但受試者卻必須花費更多的時間,反 而影響受試者作答的意願與答題的正確性,增加判別的困難。但如果採用全選擇 反應題型,雖然可節省作答時間,但因為多了猜測的因素,判別上就會較困難, 而且辨識率的結果也較差。 所以本研究一方面是以具有建構反應題與選擇題的測驗來做模擬診斷研究, 並探討不同的試卷組題方式,CR-DINA 模式是否都可有效提升 DINA 模式的估 計精準度,以達到節省時間的目的,最後並以實徵的研究資料來驗證所發展的模 式是否也可有效提升辨識率。 因此,本研究是依據 DINA 模式的基礎,提出一個適用於含有選擇題與建構 反應題的認知診斷模式。
第三章
研究方法
本研究探討不同認知屬性分佈的受試者與不同能力分佈的受試者在不同參 數設計下對 DINA 模式與 CR-DINA 模式估計精準度的影響。第一節 研究流程
本研究以認知診斷模型為基礎,透過 MATLAB 軟體進行模擬樣本資料的產 生,使用 DINA 模式與 CR-DINA 模式進行參數的估計,探討不同試題參數與不 同人數受試者在模擬樣本資料與實徵資料的設計情境下,對診斷辨識率之影響。 以整體辨識率 PCCR(pattern correct classification rate),代表整體概念診斷正確率; 概念辨識率 ACCR(attribute correct classification rate ),代表個別概念診斷正確率, 來作為評估受試者認知屬性狀態的依據。本研究之研究流程如下圖所示。先設定研究主題,然後進行與研究主題相關 的文獻蒐集與探討,並依據研究者設定之實驗情境,產生模擬樣本資料後,配合 實徵資料進行分析,即以 DINA 模式與 CR-DINA 模式估計不同試題參數的認知 屬性狀態的診斷辨識率之效果,最後撰寫研究報告。
圖 3-1-1 研究流程圖 文獻蒐集與探討 引用實徵資料 以DINA 模式進行估計 以CR-DINA 模式進行估 計 估計效果評估 撰寫研究報告 設定研究主題 產生模擬樣本資料 (結構性概念、無結構性概念)
第二節 實驗設計
本研究設計不同認知屬性與不同能力分佈的受試者模擬樣本資料,探討對試 題參數的估計與受試者知識結構的診斷辨識率之效果。本節將針對模擬樣本資料 中之各個變項加以說明如下。壹、變項設計
本研究模擬樣本資料變項與估計方式,如表 3-2-1 所示。 表 3-2-1 資料變項與估計方式彙整表 變項 變數 結構 無結構 樣本數 1000、500、100 試題題數 25 30 概念 7 5 試 題 參 數 選擇題 sj 0.1 ,0.25, UNIFORM(0.4,0.05) ) 0.05 , 4 . 0 ( UNIFORM gj 建構題 sj 0.1 ,0.25, UNIFORM(0.4,0.05) 0 j g資料產生方式 CONSTRUCTION HO-DINA: theta~ N(-1,1)、
N(0,1)、N(1,1)
估計模式 DINA、CR-DINA
估計方法 最大期望值演算法
(Expectation-Maximization algorithm, EM)
收斂標準 0.0001
模擬次數 100 次
本模擬研究分成兩部分,一為概念間無結構關係的資料,另一為概念間具有 結構關係的資料。
第一部分概念間無結構關係的資料是參考 de la Torre & Lee(2010)實驗設計, 先設定試題題數為 30 題、概念數為 5 個、以及試題參數分成粗心參數與猜測參 數二種。粗心參數 s 是 0.1 、0.25、隨機分布 0~0.4 等三種。當是選擇題時,猜 測參數 g 值是隨機分布於 0~0.4;當是建構反應題時,猜測參數 g 值為 0。 試題題數 30 題分成選擇題與建構反應題二種,由全建構反應題開始,到全 選擇題,每次增加 5 題選擇題來組題,共可區分成 7 種題數組合組型,最後依學 生能力產生 HO-DINA 能力組型,所以在能力參數、試題參數、題數參數交叉組 合後,可產生 28 種組型,如表 3-2-2 所示。 表 3-2-2 無結構性概念試題參數分佈組型設計表 代號 試題參數 選擇題題數/建構 反應題題數 選擇題 建構反應題 HO-DINA 1 . 0 j s ) 0.05 , 4 . 0 ( UNIFORM gj 1 . 0 j s gj 0 0/30 5/25 10/20 15/15 20/10 25/5 30/0 25 . 0 j s ) 0.05 , 4 . 0 ( UNIFORM gj sj 0.25 gj 0 5 . 0 j s ) 0.05 , 4 . 0 ( UNIFORM gj 5 . 0 j s gj 0 ) 05 . 0 , 4 . 0 ( UNIFORM sj ) 0.05 , 4 . 0 ( UNIFORM gj ) 05 . 0 , 4 . 0 ( UNIFORM sj 0 j g
並依據 de la Torre & Lee(2010)實驗設計所設定樣本資料的 Q 矩陣,來當作答 對率的對照表,如表 3-2-3 所示。
表 3-2-3 Q 矩陣設計 試題(n30) 概念(k5) Item 1 1 0 0 0 0 Item 2 0 1 0 0 0 Item 3 0 0 1 0 0 Item 4 0 0 0 1 0 Item 5 0 0 0 0 1 Item 6 1 0 0 0 0 Item 7 0 1 0 0 0 Item 8 0 0 1 0 0 Item 9 0 0 0 1 0 Item 10 0 0 0 0 1 Item 11 1 1 0 0 0 Item 12 1 0 1 0 0 Item 13 1 0 0 1 0 Item 14 1 0 0 0 1 Item 15 0 1 1 0 0 Item 16 0 1 0 1 0 Item 17 0 1 0 0 1 Item 18 0 0 1 1 0 Item 19 0 0 1 0 1 Item 20 0 0 0 1 1 Item 21 1 1 1 0 0 Item 22 1 1 0 1 0 Item 23 1 1 0 0 1 Item 24 1 0 1 1 0 Item 25 1 0 1 0 1 Item 26 1 0 0 1 1 Item 27 0 1 1 1 0 Item 28 0 1 1 0 1 Item 29 0 1 0 1 1 Item 30 0 0 1 1 1
第二部分為有概念間具有結構關係的資料,概念結構可分成三種方式:線性、 發散性、聚斂性。 設定試題題數為 25 題,概念數為 7 個、以及試題粗心參數 s 是 0.1 、0.25、 隨機分布 0~0.4 等三種。當是選擇題時,猜測參數 g 值是隨機分布於 0~0.4;當是 建構反應題時,猜測參數 g 值為 0。 然後再依最多概念數與最少概念數的題目,每題概念數不重複,依次各選擇 3 題不同最多概念數與最少概念數的試題做為建構反應題,最後依學生能力產生 能力組型,所以在能力參數、試題參數、題數參數交叉組合後,可產生 21 種組 型,如表 3-2-4 所示。
表 3-2-4 概念具有結構關係之試題參數分佈組型設計表 結構 試題參數 建構反應題題號 選擇題 建構反應題 線性 1 . 0 j s ) 0.05 , 4 . 0 ( UNIFORM gj 1 . 0 j s 0 j g 0 1 1、2 25 . 0 j s ) 0.05 , 4 . 0 ( UNIFORM gj 25 . 0 j s 0 j g 1、2、3 7 ) 05 . 0 , 4 . 0 ( UNIFORM sj ) 0.05 , 4 . 0 ( UNIFORM gj ) 05 . 0 , 4 . 0 ( UNIFORM sj 0 j g 6、7 5、6、7 聚斂性 1 . 0 j s ) 0.05 , 4 . 0 ( UNIFORM gj 1 . 0 j s 0 j g 0 1 1、3 25 . 0 j s ) 0.05 , 4 . 0 ( UNIFORM gj 25 . 0 j s 0 j g 1、3、5 25 ) 05 . 0 , 4 . 0 ( UNIFORM sj ) 0.05 , 4 . 0 ( UNIFORM gj ) 05 . 0 , 4 . 0 ( UNIFORM sj 0 j g 23、25 21、23、25 發散性 1 . 0 j s ) 0.05 , 4 . 0 ( UNIFORM gj 1 . 0 j s 0 j g 0 1 1、3 25 . 0 j s ) 0.05 , 4 . 0 ( UNIFORM gj 25 . 0 j s 0 j g 1、3、5 25 ) 05 . 0 , 4 . 0 ( UNIFORM sj ) 0.05 , 4 . 0 ( UNIFORM gj ) 05 . 0 , 4 . 0 ( UNIFORM sj 0 j g 23、25 20、23、25
表 3-2-5 概念具有線性結構關係之 Q 矩陣設計 試題(n25) 概念(k7) Item 1 1 0 0 0 0 0 0 Item 2 1 1 0 0 0 0 0 Item 3 1 1 1 0 0 0 0 Item 4 1 1 1 1 0 0 0 Item 5 1 1 1 1 1 0 0 Item 6 1 1 1 1 1 1 0 Item 7 1 1 1 1 1 1 1 Item 8 1 0 0 0 0 0 0 Item 9 1 1 0 0 0 0 0 Item 10 1 1 1 0 0 0 0 Item 11 1 1 1 1 0 0 0 Item 12 1 1 1 1 1 0 0 Item 13 1 1 1 1 1 1 0 Item 14 1 1 1 1 1 1 1 Item 15 1 0 0 0 0 0 0 Item 16 1 1 0 0 0 0 0 Item 17 1 1 1 0 0 0 0 Item 18 1 1 1 1 0 0 0 Item 19 1 1 1 1 1 0 0 Item 20 1 1 1 1 1 1 0 Item 21 1 1 1 1 1 1 1 Item 22 1 0 0 0 0 0 0 Item 23 1 1 0 0 0 0 0 Item 24 1 1 1 0 0 0 0 Item 25 1 1 1 1 0 0 0
圖 3-2-1 概念具有線性結構之結構圖 表 3-2-5 與圖 3-2-1 為概念具有線性結構資料之 Q 矩陣設計與結構關係 圖。線性結構資料設定題數為 25 題,概念數為 7。 k1 代表概念 1,為下位概念,k7 代表概念 7,為上位概念。k2 是 k1 的 上位概念,k3 又是 k1、k2 的上位概念,最後 k7 為 k1 至 k6 的上位概念。所 以概念之結構關係分布為一線性結構。 K7 K5 K2 K6 K4 K1 K3
表 3-2-6 概念具有發散性結構關係之 Q 矩陣設計 試題(n25) 概念(k7) Item 1 1 0 0 0 0 0 0 Item 2 1 1 0 0 0 0 0 Item 3 1 0 1 0 0 0 0 Item 4 1 1 1 0 0 0 0 Item 5 1 1 0 1 0 0 0 Item 6 1 1 0 0 1 0 0 Item 7 1 0 1 0 0 1 0 Item 8 1 0 1 0 0 0 1 Item 9 1 1 1 1 0 0 0 Item 10 1 1 1 0 1 0 0 Item 11 1 1 1 0 0 1 0 Item 12 1 1 1 0 0 0 1 Item 13 1 1 0 1 1 0 0 Item 14 1 0 1 0 0 1 1 Item 15 1 1 1 1 1 0 0 Item 16 1 1 1 1 0 1 0 Item 17 1 1 1 1 0 0 1 Item 18 1 1 1 0 1 1 0 Item 19 1 1 1 0 1 0 1 Item 20 1 1 1 0 0 1 1 Item 21 1 1 1 1 1 1 0 Item 22 1 1 1 1 1 0 1 Item 23 1 1 1 1 0 1 1 Item 24 1 1 1 0 1 1 1 Item 25 1 1 1 1 1 1 1
圖 3-2-2 概念具有發散性結構之結構圖 表 3-2-6 與圖 3-2-2 為概念具有發散性結構關係資料之 Q 矩陣設計與結構關 係圖。發散性結構資料設定題數為 25 題,概念數為 7。 k1 為下位概念,k2 與 k3 是 k1 的上位概念,k4、k5 是 k2 與 k1 的上位概念, k6、k7 是 k3 與 k1 的上位概念。所以概念之結構分布為一發散性的結構分布。 K1 K2 K3 K4 K5 K6 K7
表 3-2-7 概念具有聚斂性結構關係之 Q 矩陣設計 試題(n25) 概念(k7) Item 1 1 0 0 0 0 0 0 Item 2 0 1 0 0 0 0 0 Item 3 0 0 1 0 0 0 0 Item 4 0 0 0 1 0 0 0 Item 5 1 1 0 0 0 0 0 Item 6 1 0 1 0 0 0 0 Item 7 1 0 0 1 0 0 0 Item 8 0 1 1 0 0 0 0 Item 9 0 1 0 1 0 0 0 Item 10 0 0 1 1 0 0 0 Item 11 1 1 1 0 0 0 0 Item 12 1 1 0 1 0 0 0 Item 13 1 1 0 0 1 0 0 Item 14 1 0 1 1 0 0 0 Item 15 0 1 1 1 0 0 0 Item 16 0 0 1 1 0 1 0 Item 17 1 1 1 1 0 0 0 Item 18 1 1 1 0 1 0 0 Item 19 1 1 0 1 1 0 0 Item 20 1 0 1 1 0 1 0 Item 21 0 1 1 1 0 1 0 Item 22 1 1 1 1 1 0 0 Item 23 1 1 1 1 0 1 0 Item 24 1 1 1 1 1 1 0 Item 25 1 1 1 1 1 1 1
圖 3-2-3 概念具有聚斂性結構之結構圖 表 3-2-7 與圖 3-2-3 為概念具有聚斂性結構關係資料之 Q 矩陣設計與結構關 係圖。聚斂性概念結構資料設定題數為 25 題,概念數為 7。 k1,k2、k3、k4 為下位概念,k6 是 k3、k4 的上位概念,k5 是 k1、k2 的上 位概念,k7 又是 k1 到 k6 位概念。所以概念間之結構分布為一聚斂性的結構分布。 K7 ˙ K1 K2 K3 K4 K5 K6
貳、研究程序
一、 概念間無結構關係之模擬樣本資料研究
(一) 模擬樣本 以 HO-DINA 模式產生概念間無結構關係之模擬樣本資料,設定概念數k5, 高階層試題迴歸參數λ0k (1,0.5,0,0.5,1)與λ 1 1,受試者的能力分佈為 ) 1 , 1 ( ~ N θ 、θ~ N(0,1)、θ~ N(1,1)三種,以下列式子產生受試者αk的狀態。 )] ( 7 . 1 exp[ 1 )] ( 7 . 1 exp[ ) | 1 ( 0 1 0 1 k k k P λ θ λ λ θ λ θ α 在上列式子中,θ 為受試者能力值,λ1為認知屬性的鑑別度參數,λ 0k為認知 屬性的難度參數,表 3-4 為模擬樣本資料之精熟人數比率,然後以隨機均勻分配 ) 1 , 0 ( U 判定受試者答題正確與否,產生作答反應矩陣。 表 3-2-8 平均概念精熟人數比率表 概念產生分佈 K1 K2 K3 K4 K5 theta~ N(-1,1) 0.50 0.36 0.25 0.15 0.08 theta~ N(0,1) 0.76 0.64 0.50 0.36 0.24 theta~ N(1,1) 0.92 0.85 0.76 0.64 0.50 (二) 試題參數設計本研究是參考 de la Torre & Lee(2010)實驗設計,將概念數設為 5 個,題數
設為 30 題,樣本數分為 1000 人,500 人,100 人等三種,以及題數分成建構反 應題與選擇題二種組合,題數組合方式分成 7 種,並設計不同試題參數,每個實 驗重複進行 100 次。(請參考表 3-2-4)
(三) 估算
二、 概念間具有結構關係之模擬樣本資料研究
(一) 模擬樣本 以概念間具有結構關係的設計模式產生模擬資料,依三種結構模式:線性、 發散性、聚斂性來產生模擬樣本資料。 (二) 試題參數估計 本研究將線性結構模式、發散性結構模式、聚斂性結構性模式的題數均設定 為 25 題,概念數亦為 7 個。其屬性 Q 矩陣與概念結構圖,請參考表 3-2-5,3-2-6, 3-2-7 與圖 3-2-1,3-2-2,3-2-3。 樣本數設定為 1000 人,500 人,100 人三種,以及題數分成建構反應題與選 擇題二種組合,題數組合方式分成 21 種,並設計不同試題參數,每個實驗重複 進行 100 次。(請參考表 3-2-4) (三) 估算 本研究是使用 MATLAB 軟體進行參數結果分析,然後再根據分析估計的結 果來探討。第三節 評估指標
本研究使用 MATLAB 撰寫估計程式,估計方法參考 de la Torre & Douglas (2009)之 DINA 模式 EM 估計法進行撰寫。
認知診斷模型的評估是以分類正確率作為評估指標,將蒐集到的有效様本, 以專家診斷結果為效標,即可算出認知模型診斷的正確率,本研究使用二種指標, 一為整體辨識率 PCCR(pattern correct classification rate),代表整體概念診斷正確 率;另一為概念辨識率 ACCR(attribute correct classification rate ),代表個別概念 診斷正確率。 壹、整體辨識率 PCCR 公式:
𝑃𝐶𝐶𝑅 =
∑
(𝐼
(𝛼̂𝑖,𝛼𝑖))
𝑁 =1𝑁
N :樣本數 I :受試者 在概念k的真實狀態 ̂ :受試者 的所有概念估計狀態 :受試者 的所有概念狀態。 貳、概念辨識率ACCR公式:𝐴𝐶𝐶𝑅
𝑘=
∑
(𝐼
(𝛼̂𝑖𝑘,𝛼𝑖𝑘))
𝑁 =1𝑁
,
(𝑘 = 1,2, … , 𝐾)
N :樣本數 I :受試者 在概念k的真實狀態 ̂ 𝑘:受試者 的概念𝑘估計狀態 ik :受試者 的所有概念𝑘狀態。第四節 研究工具
壹、MATLAB MATLAB 是一個強大的數學程式應用軟體,在 1984 年由 MathWorks 公司 開發推出,包含了數值分析、矩陣運算、以及繪圖等功能。 本研究使用 MATLAB 來產生模擬樣本資料,根據所設定的試題參數,模擬 受試者的作答反應,並估算模擬資料與實徵資料的結果。貳、MicroSoft Office 套裝軟體(Excel)
Excel 是 MicroSoft 公司的 Office 辦公室套裝軟體其中之一,除可做資料輸 入之外,本身內建豐富的涵數與計算公式,可產生各種樣式的統計圖表。本研究 實徵資料學生線上測驗的作答資料是由 Excel 做資料的整理。
第四章
研究結果
本章分為三節,第一節為模擬樣本資料估計結果;第二節為根據模擬資料綜 合比較之分析結果,第三節為實徵資料之驗證分析。
第一節 模擬資料估計結果
本研究以實驗結果來呈現,總體呈現三種不同人數分佈、以及兩種估計模式
DINA 與 CR-DINA 之估計結果,其中試題參數部分,猜測參數g中,Uniform(0.4,
0.05)為選擇題的猜測參數,而 0 為建構反應題的猜測參數。 此實驗將分成二部分來探討,第一部分為無結構性概念資料估計結果,第二 部分為結構性概念資料估計結果。 首先探討 HO-DINA 模式產生的無結構性的模擬樣本資料。本模式將 30 題試 題以選擇題與建構反應題所占比例分成 0/30、5/25、10/20、15/15、20/10、25/5、 30/0 等七種組型來判斷,再檢視不同人數的差異,將結果分成三部分,第一部份 的為 1000 人在不同模式估計下之結果,第二部份為 500 人在不同模式估計下之 結果,第三部份為 100 人在不同模式估計下之結果,如表 4-1-1 至表 4-1-6 所示。
表 4-1-1 HO-DINA 1000 人 DINA 模式的估計結果 人數 估計 模式 試題參數 選擇 題/建 構題 各概念的辨識率 辨識率 s g K1 K2 K3 K4 K5 ACCR PCCR 1000 DINA 0.1 Uniform (0.4,0.05) / 0 0/30 0.9984 0.9991 0.9996 0.9995 0.9997 0.9992 0.9962 5/25 0.9881 0.9939 0.9970 0.9987 0.9992 0.9954 0.9774 10/20 0.9551 0.9591 0.9694 0.9837 0.9905 0.9715 0.8774 15/15 0.9530 0.9609 0.9658 0.9840 0.9905 0.9708 0.8739 20/10 0.9511 0.9543 0.9658 0.9785 0.9861 0.9671 0.8609 25/5 0.9497 0.9526 0.9612 0.9737 0.9839 0.9642 0.8481 30/0 0.9464 0.9493 0.9585 0.9697 0.9806 0.9609 0.8348 0.25 (0.4,0.05) Uniform / 0 0/30 0.9897 0.9946 0.9966 0.9981 0.9990 0.9956 0.9787 5/25 0.9646 0.9790 0.9899 0.9949 0.9977 0.9852 0.9305 10/20 0.9289 0.9507 0.9670 0.9823 0.9917 0.9641 0.8470 15/15 0.9038 0.9205 0.9376 0.9709 0.9848 0.9435 0.7723 20/10 0.9008 0.9108 0.9352 0.9592 0.9758 0.9364 0.7510 25/5 0.8928 0.8951 0.9165 0.9410 0.9665 0.9224 0.7002 30/0 0.8892 0.8935 0.9097 0.9329 0.9549 0.9160 0.6769 0.5 Uniform (0.4,0.05) / 0 0/30 0.9439 0.9638 0.9796 0.9887 0.9939 0.9740 0.8822 5/25 0.8955 0.9322 0.9614 0.9797 0.9898 0.9517 0.7955 10/20 0.8462 0.8814 0.9253 0.9610 0.9804 0.9189 0.6916 15/15 0.8015 0.8262 0.8664 0.9417 0.9716 0.8815 0.5839 20/10 0.8015 0.8105 0.8458 0.9089 0.9512 0.8636 0.5399 25/5 0.7728 0.7739 0.7991 0.8636 0.9199 0.8258 0.4395 30/0 0.7635 0.7526 0.7739 0.8182 0.8617 0.7940 0.3627 Uniform (0.4,0.05) Uniform (0.4,0.05) / 0 0/30 0.9937 0.9957 0.9978 0.9989 0.9992 0.9970 0.9855 5/25 0.9687 0.9840 0.9919 0.9964 0.9980 0.9878 0.9422 10/20 0.9378 0.9528 0.9721 0.9845 0.9921 0.9678 0.8611 15/15 0.9146 0.9281 0.9473 0.9753 0.9870 0.9505 0.7974 20/10 0.9168 0.9218 0.9391 0.9624 0.9791 0.9439 0.7761 25/5 0.9057 0.9136 0.9251 0.9513 0.9696 0.9331 0.7358
表 4-1-2 HO-DINA 1000 人 CR-DINA 模式的估計結果 人數 估計 模式 試題參數 選擇 題/建 構題 各概念的辨識率 辨識率 s g K1 K2 K3 K4 K5 ACCR PCCR 1000 CR-DINA 0.1 Uniform (0.4,0.05) / 0 0/30 0.9988 0.9995 0.9998 0.9999 1.0000 0.9996 0.9979 5/25 0.9883 0.9942 0.9973 0.9988 0.9994 0.9956 0.9783 10/20 0.9552 0.9593 0.9695 0.9839 0.9906 0.9717 0.8779 15/15 0.9531 0.9610 0.9659 0.9841 0.9908 0.9710 0.8743 20/10 0.9511 0.9544 0.9659 0.9786 0.9861 0.9672 0.8611 25/5 0.9497 0.9526 0.9612 0.9737 0.9839 0.9642 0.8482 30/0 0.9464 0.9493 0.9585 0.9697 0.9806 0.9609 0.8348 0.25 (0.4,0.05) Uniform / 0 0/30 0.9905 0.9954 0.9975 0.9988 0.9995 0.9963 0.9817 5/25 0.9654 0.9797 0.9907 0.9955 0.9981 0.9859 0.9329 10/20 0.9296 0.9516 0.9678 0.9829 0.9923 0.9648 0.8491 15/15 0.9042 0.9210 0.9382 0.9715 0.9854 0.9440 0.7734 20/10 0.9010 0.9112 0.9356 0.9597 0.9762 0.9367 0.7519 25/5 0.8928 0.8951 0.9167 0.9412 0.9668 0.9225 0.7006 30/0 0.8892 0.8935 0.9097 0.9329 0.9549 0.9160 0.6769 0.5 Uniform (0.4,0.05) / 0 0/30 0.9456 0.9660 0.9817 0.9914 0.9961 0.9761 0.8899 5/25 0.8971 0.9338 0.9642 0.9822 0.9924 0.9539 0.8025 10/20 0.8475 0.8833 0.9272 0.9633 0.9826 0.9208 0.6969 15/15 0.8023 0.8284 0.8680 0.9438 0.9738 0.8832 0.5873 20/10 0.8034 0.8116 0.8465 0.9109 0.9531 0.8651 0.5423 25/5 0.7730 0.7741 0.7998 0.8642 0.9207 0.8264 0.4404 30/0 0.7635 0.7526 0.7739 0.8182 0.8617 0.7940 0.3627 Uniform (0.4,0.05) Uniform (0.4,0.05) / 0 0/30 0.9940 0.9963 0.9983 0.9993 0.9996 0.9975 0.9877 5/25 0.9692 0.9844 0.9922 0.9969 0.9986 0.9882 0.9440 10/20 0.9383 0.9535 0.9727 0.9849 0.9925 0.9684 0.8626 15/15 0.9146 0.9285 0.9477 0.9757 0.9874 0.9508 0.7982 20/10 0.9170 0.9221 0.9395 0.9628 0.9795 0.9442 0.7770
表 4-1-3 HO-DINA 500 人 DINA 模式的估計結果 人數 估計 模式 試題參數 選擇 題/建 構題 各概念的辨識率 辨識率 s g K1 K2 K3 K4 K5 ACCR PCCR 500 DINA 0.1 Uniform (0.4,0.05) / 0 0/30 0.9974 0.9988 0.9990 0.9994 0.9994 0.9988 0.9942 5/25 0.9877 0.9936 0.9969 0.9985 0.9993 0.9952 0.9766 10/20 0.9666 0.9758 0.9832 0.9880 0.9942 0.9815 0.9172 15/15 0.9524 0.9597 0.9669 0.9830 0.9908 0.9706 0.8736 20/10 0.9501 0.9564 0.9665 0.9778 0.9863 0.9674 0.8623 25/5 0.9445 0.9541 0.9587 0.9730 0.9833 0.9627 0.8428 30/0 0.9461 0.9492 0.9529 0.9702 0.9793 0.9596 0.8316 0.25 (0.4,0.05) Uniform / 0 0/30 0.9881 0.9934 0.9959 0.9976 0.9984 0.9947 0.9743 5/25 0.9613 0.9786 0.9894 0.9948 0.9969 0.9842 0.9261 10/20 0.9256 0.9479 0.9674 0.9805 0.9906 0.9624 0.8408 15/15 0.8984 0.9165 0.9365 0.9701 0.9832 0.9410 0.7643 20/10 0.9006 0.9073 0.9342 0.9570 0.9755 0.9349 0.7458 25/5 0.8912 0.8932 0.9153 0.9403 0.9651 0.9210 0.6966 30/0 0.8905 0.8871 0.9044 0.9294 0.9466 0.9116 0.6656 0.5 Uniform (0.4,0.05) / 0 0/30 0.9417 0.9626 0.9781 0.9870 0.9919 0.9723 0.8758 5/25 0.8581 0.9262 0.9634 0.9844 0.9925 0.9449 0.7715 10/20 0.8398 0.8731 0.9220 0.9544 0.9764 0.9132 0.6757 15/15 0.7817 0.8190 0.8528 0.9380 0.9672 0.8717 0.5599 20/10 0.7921 0.8070 0.8538 0.8955 0.9407 0.8578 0.5305 25/5 0.7577 0.7574 0.7935 0.8562 0.9128 0.8155 0.4184 30/0 0.7453 0.7516 0.7590 0.7958 0.8508 0.7805 0.3396 Uniform (0.4,0.05) Uniform (0.4,0.05) / 0 0/30 0.9912 0.9936 0.9959 0.9982 0.9987 0.9955 0.9785 5/25 0.9711 0.9845 0.9912 0.9954 0.9973 0.9879 0.9425 10/20 0.9341 0.9544 0.9706 0.9831 0.9904 0.9665 0.8570 15/15 0.9168 0.9281 0.9446 0.9725 0.9861 0.9496 0.7965 20/10 0.9155 0.9246 0.9461 0.9582 0.9775 0.9444 0.7787 25/5 0.9051 0.9089 0.9284 0.9495 0.9702 0.9324 0.7350
表 4-1-4 HO-DINA 500 人 CR-DINA 模式的估計結果 人數 估計 模式 試題參數 選擇 題/建 構題 各概念的辨識率 辨識率 s g K1 K2 K3 K4 K5 ACCR PCCR 500 CR-DINA 0.1 Uniform (0.4,0.05) / 0 0/30 0.9988 0.9995 0.9997 0.9998 0.9999 0.9995 0.9977 5/25 0.9886 0.9941 0.9976 0.9989 0.9996 0.9958 0.9790 10/20 0.9671 0.9761 0.9834 0.9886 0.9945 0.9819 0.9186 15/15 0.9524 0.9600 0.9669 0.9835 0.9909 0.9707 0.8741 20/10 0.9502 0.9564 0.9667 0.9781 0.9864 0.9676 0.8628 25/5 0.9445 0.9542 0.9587 0.9731 0.9834 0.9628 0.8430 30/0 0.9461 0.9492 0.9529 0.9702 0.9793 0.9596 0.8316 0.25 (0.4,0.05) Uniform / 0 0/30 0.9896 0.9951 0.9976 0.9990 0.9993 0.9961 0.9809 5/25 0.9622 0.9800 0.9907 0.9957 0.9980 0.9853 0.9305 10/20 0.9267 0.9490 0.9688 0.9819 0.9916 0.9636 0.8449 15/15 0.8990 0.9173 0.9375 0.9712 0.9844 0.9419 0.7669 20/10 0.9007 0.9080 0.9350 0.9577 0.9760 0.9355 0.7474 25/5 0.8912 0.8934 0.9157 0.9408 0.9656 0.9213 0.6974 30/0 0.8905 0.8871 0.9044 0.9294 0.9466 0.9116 0.6656 0.5 Uniform (0.4,0.05) / 0 0/30 0.9451 0.9673 0.9821 0.9917 0.9959 0.9764 0.8910 5/25 0.8994 0.9312 0.9625 0.9825 0.9923 0.9536 0.8002 10/20 0.8447 0.8766 0.9268 0.9596 0.9804 0.9176 0.6883 15/15 0.7848 0.8204 0.8565 0.9427 0.9715 0.8752 0.5678 20/10 0.7957 0.8079 0.8573 0.8989 0.9433 0.8606 0.5364 25/5 0.7574 0.7598 0.7934 0.8573 0.9147 0.8165 0.4205 30/0 0.7453 0.7516 0.7590 0.7958 0.8508 0.7805 0.3396 Uniform (0.4,0.05) Uniform (0.4,0.05) / 0 0/30 0.9930 0.9951 0.9978 0.9992 0.9996 0.9969 0.9848 5/25 0.9718 0.9854 0.9922 0.9963 0.9979 0.9887 0.9460 10/20 0.9352 0.9556 0.9715 0.9839 0.9911 0.9675 0.8603 15/15 0.9173 0.9286 0.9452 0.9734 0.9866 0.9502 0.7981 20/10 0.9160 0.9252 0.9466 0.9590 0.9781 0.9450 0.7808
表 4-1-5 HO-DINA 100 人 DINA 模式的估計結果 人數 估計 模式 試題參數 選擇 題/建 構題 各概念的辨識率 辨識率 s g K1 K2 K3 K4 K5 ACCR PCCR 100 DINA 0.1 Uniform (0.4,0.05) / 0 0/30 0.9938 0.9951 0.9961 0.9983 0.9992 0.9965 0.9829 5/25 0.9831 0.9914 0.9949 0.9974 0.9987 0.9931 0.9665 10/20 0.9548 0.9748 0.9823 0.9874 0.9920 0.9783 0.9053 15/15 0.9442 0.9525 0.9626 0.9834 0.9849 0.9655 0.8554 20/10 0.9457 0.9510 0.9616 0.9764 0.9817 0.9633 0.8467 25/5 0.9362 0.9426 0.9544 0.9667 0.9757 0.9551 0.8155 30/0 0.9358 0.9405 0.9472 0.9608 0.9695 0.9508 0.8022 0.25 (0.4,0.05) Uniform / 0 0/30 0.9766 0.9846 0.9899 0.9939 0.9970 0.9884 0.9445 5/25 0.9538 0.9701 0.9818 0.9926 0.9959 0.9788 0.9040 10/20 0.9150 0.9355 0.9590 0.9770 0.9869 0.9547 0.8189 15/15 0.8773 0.8988 0.9250 0.9595 0.9720 0.9265 0.7242 20/10 0.8799 0.8945 0.9188 0.9416 0.9594 0.9188 0.7024 25/5 0.8695 0.8684 0.8927 0.9242 0.9391 0.8988 0.6387 30/0 0.8670 0.8765 0.8843 0.9096 0.9287 0.8932 0.6141 0.5 Uniform (0.4,0.05) / 0 0/30 0.9063 0.9359 0.9580 0.9772 0.9888 0.9532 0.8022 5/25 0.8446 0.8859 0.9414 0.9620 0.9809 0.9230 0.7061 10/20 0.7960 0.8358 0.8860 0.9159 0.9411 0.8750 0.5830 15/15 0.7280 0.7631 0.8256 0.8898 0.9124 0.8238 0.4675 20/10 0.7240 0.7530 0.7922 0.8410 0.8838 0.7988 0.4157 25/5 0.5850 0.6539 0.6780 0.7761 0.8141 0.7014 0.2554 30/0 0.4966 0.5489 0.6279 0.7057 0.7756 0.6309 0.1777 Uniform (0.4,0.05) Uniform (0.4,0.05) / 0 0/30 0.9811 0.9873 0.9917 0.9955 0.9987 0.9909 0.9557 5/25 0.9592 0.9740 0.9855 0.9955 0.9963 0.9821 0.9174 10/20 0.9215 0.9435 0.9648 0.9780 0.9876 0.9591 0.8340 15/15 0.8953 0.9157 0.9330 0.9632 0.9827 0.9380 0.7556 20/10 0.8898 0.9124 0.9344 0.9485 0.9676 0.9305 0.7412 25/5 0.8776 0.8875 0.9163 0.9344 0.9527 0.9137 0.6826
表 4-1-6 HO-DINA 100 人 CR-DINA 模式的估計結果 人數 估計 模式 試題參數 選擇 題/建 構題 各概念的辨識率 辨識率 s g K1 K2 K3 K4 K5 ACCR PCCR 100 CR-DINA 0.1 Uniform (0.4,0.05) / 0 0/30 0.9990 0.9993 0.9997 1.0000 0.9999 0.9996 0.9979 5/25 0.9864 0.9940 0.9977 0.9984 0.9995 0.9952 0.9762 10/20 0.9582 0.9765 0.9842 0.9881 0.9930 0.9800 0.9114 15/15 0.9445 0.9526 0.9638 0.9842 0.9852 0.9661 0.8576 20/10 0.9461 0.9518 0.9628 0.9767 0.9821 0.9639 0.8486 25/5 0.9363 0.9427 0.9545 0.9668 0.9753 0.9551 0.8157 30/0 0.9358 0.9405 0.9472 0.9608 0.9695 0.9508 0.8022 0.25 (0.4,0.05) Uniform / 0 0/30 0.9904 0.9948 0.9972 0.9987 0.9997 0.9962 0.9810 5/25 0.9626 0.9791 0.9891 0.9962 0.9984 0.9851 0.9302 10/20 0.9200 0.9391 0.9635 0.9795 0.9892 0.9583 0.8324 15/15 0.8809 0.9028 0.9286 0.9626 0.9740 0.9298 0.7320 20/10 0.8831 0.8973 0.9230 0.9445 0.9637 0.9223 0.7104 25/5 0.8687 0.8706 0.8936 0.9255 0.9405 0.8998 0.6410 30/0 0.8670 0.8765 0.8843 0.9096 0.9287 0.8932 0.6141 0.5 (0.4,0.05) Uniform / 0 0/30 0.9464 0.9669 0.9810 0.9916 0.9967 0.9765 0.8913 5/25 0.8868 0.9239 0.9653 0.9814 0.9907 0.9496 0.7882 10/20 0.8270 0.8645 0.9164 0.9439 0.9555 0.9015 0.6509 15/15 0.7416 0.7835 0.8471 0.9028 0.9327 0.8415 0.5075 20/10 0.7467 0.7775 0.8190 0.8609 0.9091 0.8226 0.4621 25/5 0.6377 0.7055 0.7322 0.7963 0.8338 0.7411 0.3066 30/0 0.4966 0.5489 0.6279 0.7057 0.7756 0.6309 0.1777 Uniform (0.4,0.05) Uniform (0.4,0.05) / 0 0/30 0.9921 0.9960 0.9976 0.9988 0.9998 0.9969 0.9847 5/25 0.9668 0.9798 0.9909 0.9974 0.9978 0.9865 0.9359 10/20 0.9281 0.9490 0.9684 0.9816 0.9891 0.9632 0.8488 15/15 0.8981 0.9179 0.9353 0.9663 0.9830 0.9401 0.7618 20/10 0.8905 0.9134 0.9354 0.9501 0.9688 0.9316 0.7445
以整體概念辨識率的估計來看,在不同估計模式之下可以得到相同的結論, 受試者人數越多其概念辨識率也會相對提高,估計效果也會隨著上升;而在 DINA 模式與 CR-DINA 模式的比較上,有建構反應題時,CR-DINA 模式都有較高的辨 識率,顯示 CR-DINA 的模式較優於 DINA 模式。 個別概念辨識率的估計來看,在不同估計模式之下可以得到相同的結論,當 選擇題題數越多時,其個別概念辨識率也會下降,在全選擇題時,辨識率最低, 而在全建構反應題時,辨識率最高。而粗心參數 s 越大,其個別概念辨識率也會 下降,顯見辨識率易受到試題參數與人數大小的影響。 第二部分為有概念具有結構關係的模擬樣本資料。本模式分成線性結構模式、 發散性結構模式、聚斂性結構模式等三種結構模式。並將試題分成 21 種組型來 判斷,再檢視不同人數的差異,將結果分成三部分,第一部份的為 1000 人在不 同模式估計下之結果,第二部份為 500 人在不同模式估計下之結果,第三部份為 100 人在不同模式估計下之結果,如表 4-1-7 至表 4-1-24 所示。表中灰色區塊代 表設定的建構反應題試題所包含的概念。
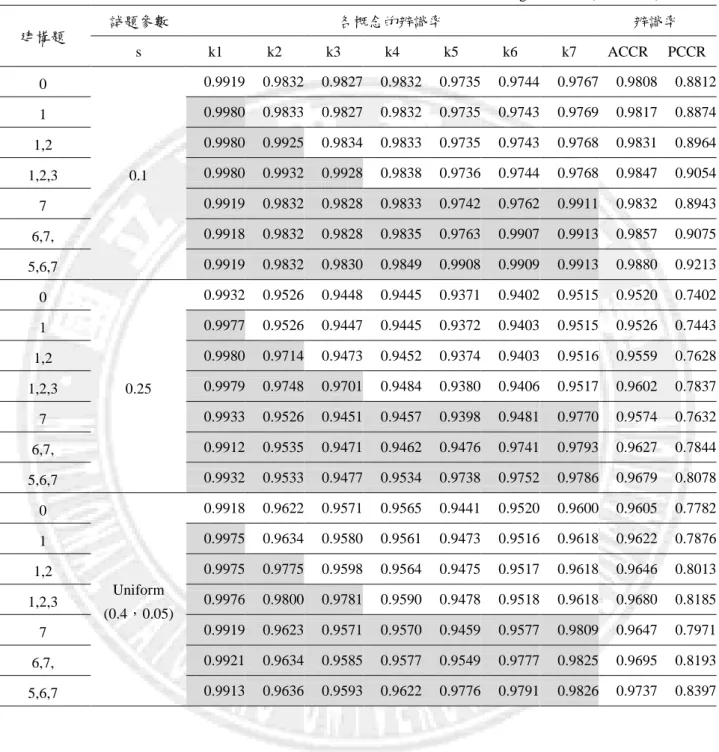
表 4-1-7 概念具線性結構時,CR-DINA 模式結果(N=1000) g= Uniform(0.4,0.05)/0 建構題 試題參數 各概念的辨識率 辨識率 s k1 k2 k3 k4 k5 k6 k7 ACCR PCCR 0 0.1 0.9919 0.9832 0.9827 0.9832 0.9735 0.9744 0.9767 0.9808 0.8812 1 0.9980 0.9833 0.9827 0.9832 0.9735 0.9743 0.9769 0.9817 0.8874 1,2 0.9980 0.9925 0.9834 0.9833 0.9735 0.9743 0.9768 0.9831 0.8964 1,2,3 0.9980 0.9932 0.9928 0.9838 0.9736 0.9744 0.9768 0.9847 0.9054 7 0.9919 0.9832 0.9828 0.9833 0.9742 0.9762 0.9911 0.9832 0.8943 6,7, 0.9918 0.9832 0.9828 0.9835 0.9763 0.9907 0.9913 0.9857 0.9075 5,6,7 0.9919 0.9832 0.9830 0.9849 0.9908 0.9909 0.9913 0.9880 0.9213 0 0.25 0.9932 0.9526 0.9448 0.9445 0.9371 0.9402 0.9515 0.9520 0.7402 1 0.9977 0.9526 0.9447 0.9445 0.9372 0.9403 0.9515 0.9526 0.7443 1,2 0.9980 0.9714 0.9473 0.9452 0.9374 0.9403 0.9516 0.9559 0.7628 1,2,3 0.9979 0.9748 0.9701 0.9484 0.9380 0.9406 0.9517 0.9602 0.7837 7 0.9933 0.9526 0.9451 0.9457 0.9398 0.9481 0.9770 0.9574 0.7632 6,7, 0.9912 0.9535 0.9471 0.9462 0.9476 0.9741 0.9793 0.9627 0.7844 5,6,7 0.9932 0.9533 0.9477 0.9534 0.9738 0.9752 0.9786 0.9679 0.8078 0 Uniform (0.4,0.05) 0.9918 0.9622 0.9571 0.9565 0.9441 0.9520 0.9600 0.9605 0.7782 1 0.9975 0.9634 0.9580 0.9561 0.9473 0.9516 0.9618 0.9622 0.7876 1,2 0.9975 0.9775 0.9598 0.9564 0.9475 0.9517 0.9618 0.9646 0.8013 1,2,3 0.9976 0.9800 0.9781 0.9590 0.9478 0.9518 0.9618 0.9680 0.8185 7 0.9919 0.9623 0.9571 0.9570 0.9459 0.9577 0.9809 0.9647 0.7971 6,7, 0.9921 0.9634 0.9585 0.9577 0.9549 0.9777 0.9825 0.9695 0.8193 5,6,7 0.9913 0.9636 0.9593 0.9622 0.9776 0.9791 0.9826 0.9737 0.8397
表 4-1-8 概念具線性結構時,DINA 模式結果(N=1000) g= Uniform(0.4,0.05)/0 建構題 試題參數 各概念的辨識率 辨識率 s k1 k2 k3 k4 k5 k6 k7 ACCR PCCR 0 0.1 0.9919 0.9832 0.9827 0.9832 0.9735 0.9744 0.9767 0.9808 0.8812 1 0.9919 0.9832 0.9827 0.9832 0.9735 0.9744 0.9767 0.9808 0.8812 1,2 0.9912 0.9924 0.9834 0.9833 0.9735 0.9744 0.9767 0.9821 0.8895 1,2,3 0.9911 0.9931 0.9928 0.9838 0.9736 0.9744 0.9768 0.9836 0.8984 7 0.9919 0.9832 0.9828 0.9833 0.9742 0.9761 0.9910 0.9832 0.8942 6,7, 0.9918 0.9832 0.9828 0.9835 0.9762 0.9906 0.9912 0.9856 0.9074 5,6,7 0.9919 0.9832 0.9830 0.9849 0.9907 0.9908 0.9912 0.9880 0.9212 0 0.25 0.9932 0.9526 0.9448 0.9445 0.9371 0.9402 0.9515 0.9520 0.7402 1 0.9932 0.9526 0.9448 0.9445 0.9371 0.9402 0.9515 0.9520 0.7402 1,2 0.9930 0.9706 0.9474 0.9452 0.9373 0.9403 0.9516 0.9551 0.7575 1,2,3 0.9931 0.9738 0.9699 0.9483 0.9381 0.9406 0.9517 0.9594 0.7784 7 0.9933 0.9525 0.9451 0.9456 0.9396 0.9481 0.9769 0.9573 0.7631 6,7, 0.9912 0.9534 0.9471 0.9461 0.9475 0.9740 0.9792 0.9627 0.7843 5,6,7 0.9933 0.9533 0.9475 0.9532 0.9735 0.9750 0.9785 0.9678 0.8077 0 Uniform (0.4,0.05) 0.9918 0.9622 0.9571 0.9565 0.9441 0.9520 0.9600 0.9605 0.7782 1 0.9921 0.9634 0.9580 0.9561 0.9473 0.9516 0.9617 0.9615 0.7822 1,2 0.9919 0.9772 0.9597 0.9565 0.9475 0.9517 0.9618 0.9638 0.7955 1,2,3 0.9917 0.9796 0.9778 0.9591 0.9478 0.9518 0.9618 0.9671 0.8124 7 0.9919 0.9623 0.9571 0.9570 0.9459 0.9576 0.9809 0.9647 0.7971 6,7, 0.9922 0.9635 0.9585 0.9576 0.9546 0.9776 0.9824 0.9695 0.8192 5,6,7 0.9914 0.9636 0.9593 0.9621 0.9774 0.9790 0.9825 0.9736 0.8395
表 4-1-9 概念具線性結構時,CR-DINA 模式結果(N=500) g= Uniform(0.4,0.05)/0 建構題 試題參數 各概念的辨識率 辨識率 s k1 k2 k3 k4 k5 k6 k7 ACCR PCCR 0 0.1 0.9773 0.9829 0.9818 0.9815 0.9719 0.9769 0.9772 0.9785 0.8657 1 0.9967 0.9832 0.9809 0.9813 0.9734 0.9757 0.9778 0.9813 0.8844 1,2 0.9966 0.9926 0.9826 0.9815 0.9717 0.9769 0.9771 0.9827 0.8939 1,2,3 0.9966 0.9933 0.9925 0.9824 0.9720 0.9769 0.9771 0.9844 0.9037 7 0.9773 0.9829 0.9818 0.9816 0.9723 0.9783 0.9912 0.9808 0.8787 6,7, 0.9773 0.9829 0.9818 0.9818 0.9741 0.9914 0.9914 0.9830 0.8900 5,6,7 0.9773 0.9829 0.9820 0.9836 0.9900 0.9918 0.9914 0.9856 0.9058 0 0.25 0.9753 0.9508 0.9425 0.9406 0.9338 0.9427 0.9516 0.9482 0.7181 1 0.9929 0.9506 0.9425 0.9407 0.9339 0.9428 0.9518 0.9507 0.7341 1,2 0.9936 0.9707 0.9461 0.9411 0.9339 0.9430 0.9520 0.9544 0.7542 1,2,3 0.9934 0.9741 0.9675 0.9443 0.9346 0.9434 0.9521 0.9585 0.7737 7 0.9751 0.9509 0.9431 0.9412 0.9365 0.9506 0.9768 0.9535 0.7413 6,7, 0.9757 0.9511 0.9439 0.9435 0.9445 0.9754 0.9781 0.9589 0.7636 5,6,7 0.9761 0.9515 0.9437 0.9512 0.9736 0.9760 0.9797 0.9646 0.7874 0 Uniform (0.4,0.05) 0.9742 0.9613 0.9576 0.9535 0.9470 0.9508 0.9605 0.9579 0.7606 1 0.9938 0.9616 0.9576 0.9535 0.9470 0.9507 0.9605 0.9607 0.7787 1,2 0.9951 0.9779 0.9578 0.9565 0.9471 0.9498 0.9588 0.9633 0.7955 1,2,3 0.9939 0.9787 0.9766 0.9559 0.9473 0.9510 0.9605 0.9663 0.8087 7 0.9741 0.9613 0.9578 0.9541 0.9488 0.9560 0.9812 0.9619 0.7793 6,7, 0.9743 0.9613 0.9580 0.9553 0.9550 0.9766 0.9822 0.9661 0.7977 5,6,7 0.9736 0.9613 0.9596 0.9596 0.9780 0.9777 0.9819 0.9702 0.8181
表 4-1-10 概念具線性結構時,DINA 模式結果(N=500) g= Uniform(0.4,0.05)/0 建構題 試題參數 各概念的辨識率 辨識率 s k1 k2 k3 k4 k5 k6 k7 ACCR PCCR 0 0.1 0.9773 0.9829 0.9818 0.9815 0.9719 0.9769 0.9772 0.9785 0.8657 1 0.9804 0.9832 0.9809 0.9812 0.9734 0.9757 0.9778 0.9789 0.8689 1,2 0.9758 0.9921 0.9826 0.9815 0.9718 0.9769 0.9772 0.9797 0.8731 1,2,3 0.9762 0.9927 0.9922 0.9824 0.9721 0.9770 0.9772 0.9814 0.8830 7 0.9773 0.9829 0.9818 0.9816 0.9723 0.9783 0.9911 0.9808 0.8786 6,7, 0.9773 0.9829 0.9818 0.9818 0.9740 0.9912 0.9914 0.9829 0.8898 5,6,7 0.9773 0.9829 0.9820 0.9835 0.9898 0.9917 0.9914 0.9855 0.9056 0 0.25 0.9753 0.9508 0.9425 0.9406 0.9338 0.9427 0.9516 0.9482 0.7181 1 0.9753 0.9508 0.9425 0.9406 0.9338 0.9427 0.9516 0.9482 0.7181 1,2 0.9738 0.9694 0.9458 0.9411 0.9341 0.9431 0.9519 0.9513 0.7346 1,2,3 0.9729 0.9724 0.9673 0.9444 0.9347 0.9434 0.9520 0.9553 0.7530 7 0.9751 0.9509 0.9431 0.9412 0.9364 0.9504 0.9766 0.9534 0.7411 6,7, 0.9757 0.9510 0.9438 0.9434 0.9442 0.9751 0.9779 0.9587 0.7633 5,6,7 0.9762 0.9515 0.9437 0.9510 0.9732 0.9758 0.9796 0.9644 0.7872 0 Uniform (0.4,0.05) 0.9742 0.9613 0.9576 0.9535 0.9470 0.9508 0.9605 0.9579 0.7606 1 0.9742 0.9613 0.9576 0.9535 0.9470 0.9508 0.9605 0.9579 0.7606 1,2 0.9705 0.9774 0.9581 0.9566 0.9471 0.9499 0.9587 0.9597 0.7718 1,2,3 0.9727 0.9776 0.9760 0.9558 0.9474 0.9510 0.9605 0.9630 0.7874 7 0.9741 0.9613 0.9578 0.9540 0.9488 0.9558 0.9810 0.9618 0.7792 6,7, 0.9743 0.9613 0.9580 0.9553 0.9548 0.9765 0.9820 0.9660 0.7976 5,6,7 0.9735 0.9613 0.9595 0.9594 0.9777 0.9775 0.9818 0.9701 0.8177
表 4-1-11 概念具線性結構時,CR-DINA 模式結果(N=100) g= Uniform(0.4,0.05)/0 建構題 試題參數 各概念的辨識率 辨識率 s k1 k2 k3 k4 k5 k6 k7 ACCR PCCR 0 0.1 0.9233 0.9798 0.9776 0.9792 0.9715 0.9699 0.9738 0.9679 0.8012 1 0.9880 0.9814 0.9776 0.9792 0.9715 0.9699 0.9739 0.9774 0.8625 1,2 0.9887 0.9918 0.9785 0.9791 0.9715 0.9700 0.9739 0.9791 0.8727 1,2,3 0.9887 0.9932 0.9910 0.9796 0.9718 0.9701 0.9739 0.9812 0.8850 7 0.9232 0.9798 0.9775 0.9790 0.9724 0.9722 0.9899 0.9706 0.8171 6,7, 0.9233 0.9797 0.9774 0.9797 0.9743 0.9901 0.9910 0.9736 0.8335 5,6,7 0.9236 0.9797 0.9785 0.9820 0.9892 0.9900 0.9911 0.9763 0.8473 0 0.25 0.9313 0.9358 0.9301 0.9292 0.9233 0.9261 0.9433 0.9313 0.6461 1 0.9719 0.9383 0.9306 0.9288 0.9239 0.9258 0.9432 0.9375 0.6802 1,2 0.9754 0.9656 0.9344 0.9294 0.9239 0.9270 0.9434 0.9427 0.7024 1,2,3 0.9747 0.9726 0.9640 0.9366 0.9268 0.9271 0.9435 0.9493 0.7281 7 0.9315 0.9350 0.9302 0.9300 0.9267 0.9345 0.9712 0.9370 0.6705 6,7, 0.9321 0.9359 0.9327 0.9353 0.9396 0.9684 0.9729 0.9453 0.7023 5,6,7 0.9305 0.9371 0.9353 0.9428 0.9672 0.9701 0.9735 0.9509 0.7234 0 Uniform (0.4,0.05) 0.9216 0.9503 0.9448 0.9482 0.9394 0.9423 0.9449 0.9416 0.6827 1 0.9792 0.9538 0.9452 0.9486 0.9395 0.9423 0.9454 0.9506 0.7329 1,2 0.9796 0.9733 0.9491 0.9489 0.9398 0.9428 0.9456 0.9542 0.7509 1,2,3 0.9802 0.9777 0.9709 0.9519 0.9406 0.9432 0.9451 0.9585 0.7707 7 0.9216 0.9509 0.9458 0.9490 0.9435 0.9528 0.9743 0.9483 0.7100 6,7, 0.9223 0.9506 0.9473 0.9515 0.9502 0.9784 0.9764 0.9538 0.7322 5,6,7 0.9219 0.9504 0.9487 0.9554 0.9740 0.9794 0.9769 0.9581 0.7525
表 4-1-12 概念具線性結構時,DINA 模式結果(N=100) 表 4-1-7 至表 4-1-12,為線性概念結構模式的模擬結果,從表中數據結果可以 發現,當加入建構反應題時,在概念的辨識率上,不論是 DINA 模式,或是 CR-DINA 模式,都能提升個別的或是整體的概念辨識率,而且 CR-DINA 的模式 g= Uniform(0.4,0.05)/0 建構題 試題參數 各概念的辨識率 辨識率 s k1 k2 k3 k4 k5 k6 k7 accr pccr 0 0.1 0.9233 0.9798 0.9776 0.9792 0.9715 0.9699 0.9738 0.9679 0.8012 1 0.9233 0.9798 0.9776 0.9792 0.9715 0.9699 0.9738 0.9679 0.8012 1,2 0.9231 0.9892 0.9781 0.9793 0.9715 0.9700 0.9739 0.9693 0.8077 1,2,3 0.9248 0.9903 0.9902 0.9797 0.9716 0.9701 0.9739 0.9715 0.8206 7 0.9232 0.9798 0.9775 0.9790 0.9724 0.9723 0.9896 0.9705 0.8170 6,7, 0.9233 0.9797 0.9774 0.9796 0.9740 0.9894 0.9908 0.9735 0.8325 5,6,7 0.9236 0.9797 0.9785 0.9816 0.9886 0.9895 0.9909 0.9761 0.8462 0 0.25 0.9313 0.9358 0.9301 0.9292 0.9233 0.9261 0.9433 0.9313 0.6461 1 0.9313 0.9358 0.9301 0.9292 0.9233 0.9261 0.9433 0.9313 0.6461 1,2 0.9276 0.9589 0.9331 0.9296 0.9239 0.9264 0.9436 0.9347 0.6584 1,2,3 0.9305 0.9669 0.9615 0.9365 0.9262 0.9275 0.9435 0.9418 0.6863 7 0.9314 0.9350 0.9299 0.9298 0.9262 0.9336 0.9702 0.9366 0.6687 6,7, 0.9321 0.9359 0.9327 0.9351 0.9384 0.9673 0.9725 0.9449 0.7017 5,6,7 0.9310 0.9361 0.9343 0.9408 0.9637 0.9686 0.9728 0.9496 0.7206 0 Uniform (0.4,0.05) 0.9216 0.9503 0.9448 0.9482 0.9394 0.9423 0.9449 0.9416 0.6827 1 0.9216 0.9503 0.9448 0.9482 0.9394 0.9423 0.9449 0.9416 0.6827 1,2 0.9250 0.9669 0.9476 0.9488 0.9395 0.9425 0.9452 0.9451 0.6981 1,2,3 0.9220 0.9708 0.9682 0.9515 0.9404 0.9430 0.9442 0.9486 0.7128 7 0.9209 0.9510 0.9459 0.9491 0.9432 0.9524 0.9741 0.9481 0.7094 6,7, 0.9216 0.9506 0.9473 0.9512 0.9498 0.9774 0.9751 0.9533 0.7298 5,6,7 0.9218 0.9505 0.9484 0.9548 0.9735 0.9784 0.9760 0.9576 0.7506