建立醫院門診量預測模型--以地區醫院為例; Establishing a forecasting model for outpatient volume--Based on a community hospital
96
0
0
全文
(2) 由以上描述可知門診是醫院存亡的關鍵點,門診量是衡量指標, 因此如何有效的預測門診量,使醫院尋求最佳的資源分配,得以永續 經營,免於破產之命運,頓時成為重要課題。因此欲預測門診量,必 需從醫療需求利用理論及預測原理著手,綜觀所有可能之醫療利用影 響因素,再搭配最佳的預測模式,以建立最佳門診量預測模式,其分 析研究成果不僅有助於瞭解醫院特質內影響門診量之變項,亦有益於 管理者擬定經營策略因應健保政策變化。. 2.
(3) 第二節. 研究目的. 門診醫療需求可反映在門診量或費用上,從過去的研究中發現理 論部份以 Aday(1974)醫療利用理論或財務市場預測需求居多,實 證分析則是以疾病或人口特質為主的實證分析或者以費用為研究主 軸(謝啟瑞,1995;邱雅苓,2000;林小鳳,2002 等),因此從整體 因素預測門診量的主題不多,又以應用利用函數估計門診醫療為典型 代表(蘇建榮,1999)。 門診的利用是醫療利用的一部分,因此本研究內容主要是從 影響費用及醫療利用的觀點選擇變項,進而預測門診量。研究蒐 集中部某地區醫院民國 2000 年 1 月至 2004 年 12 月的門診量資料, 主要想探討醫院特質、健保政策和門診量的關連。為了具體呈現醫院 總額及自主管理之制度對門診量的變化,故涵蓋醫院總額實施前 2 年 後 3 年資料。 研究單位的選擇,係因鄰近地區為封閉性,較少出現跨區就醫及 人口遷移,因此可增加預測的準確性。至於變項的設定則是依據文獻 查證及本研究欲探討的方向而定為醫院特質及政策因素,將門診量視 為衡量結果,在門診為醫院主要收入的前提下,預測模式可實際反映 出內部特質及健保政策對門診量的影響,並作為內部決策及應變之參 考。. 3.
(4) 本篇論文的主要的即於利用歷年歷史門診量數值,搭配預測技 術,如圖 1 整體研究架構流程圖,進行以下研究目的: 一、探討門診量自身特質並建立預測模型 二、探討醫院特質與門診量之相關性並建立預測模型 三、探討健保政策與門診量之相關性並建立預測模型 四、從門診量、醫院特質、健保政策模型中,找出最適門診預測模型。. 4.
(5) 研究架構流程圖. 研究背景. 相關理論的探討. 主要研究內容. 單變量 ARIMA. 轉換函數模型. 預測結果之比較. 結論與建議. 圖 1、研究架構流程圖. 5. 介入模型.
(6) 第二章 文獻探討 在探討門診量預測之前,先瞭解近期相關政策對醫療機構的 衝擊,從醫療利用理論及相關文獻找出變項,再結合預測理論建 構基本模型,基於以上思維,本章分成以下幾節說明。第一節陳 述門診量預測的重要性。第二節透過醫療利用的觀點,整理國內 外相關文獻以找出影響門診量的因素。第三節藉由預測模式在國 內外之應用與相關文獻進行探討。. 第一節 門診量預測的重要性 門診量是非常有用的訊息,可以提供醫院及管理機構在分配資 源、安排員工休假、規劃未來擴張與否的重要參考依據(Abdel & M , 1998)。我國的醫療機構在健保制度下快速擴張,為了償付鉅額投 資及反映醫院門診診療費過低(相對於住院服務)的情況,醫療機構 紛紛以增加門診量來彌補住院的損失,加上現行論量計酬給付模式 下,使得醫師易受財務誘因影響醫療行為,在這兩種情境交錯下造成 門診量大增。 以 2003 年全民健保申報的費用為例,門診費用即占總申報費用 的 66.52%,依國民醫療保健保險部門醫療保健支出統計之門住診 比率約 6:4。從醫院資金使用項目來看,門診服務費用佔醫院總支出 高達 32.5%(蕭慶倫、盧瑞芬,1999)。然而為了控制費用的成長, 6.
(7) 健保局開始有門診合理量、藥價調整、門診部分負擔調整、總額支付 制度實施等等各項節流方案(中央健保局,2005),每項都與門診量 有關,已直接衝擊到醫院的生存。 最明顯的情況是許多以門診服務為主的中小型醫院醫院,無法承 受總額實施後點值過低的衝擊,紛紛縮小經營規模(如地區醫院改為 診所)或委託經營方式或歇業以度過難關。依據衛生署統計,2003 年醫療機構數整體較 2002 年增加 549 家(3.01%),診所增加 565 家(3.21%)為最多,醫院減少 16 家(-2.62%),醫院層級又以地區 醫院減少高達 13 家(-3.37%)為最多。. 門診收入是醫院營運資金來源,然在醫療環境政策下,醫療資源 逐漸飽和,整體費用控制、新科技的引進納入給付範圍的種種衝擊 下,已不能全然依賴費用預估收入。此外健保局在控制整體費用成長 的同時,又要求不能減少門診量,規定門住診費用比率等等,種種措 施使得醫院面臨兩難。因此如能先行預測門診量,除可預測收入外, 亦可使資金的運用更加靈活,此時門診量是最好的評估方式。. 7.
(8) 第二節. 醫療服務利用之理論模式. 醫療服務利用關注的是醫療利用者的使用原因、頻率及型態。藉 由這些訊息以作為衛生主管機關的衛生政策及計畫評價,計畫者確認 民眾潛在需要及區域需要、獲知市場佔有率等資訊決策參考。以下將 介紹關於醫療服務利用主要理論概念及衡量方式。 一、醫療服務利用概念及衡量方式 從 1950、1960 年起,開始有醫療服務利用的相關報告,當時的 研究僅限於社會學或經濟學的單一層面觀點。事實上求醫的行為非常 複雜,與人口、文化、政治、經濟、心理、社會等因素有關。醫療利 用會以數種不同特徵呈現,而經驗(實務)上可由四個主要構面:型 態(Type) 、用途(Purpose) 、地點(Site) 、間隔時間(Time interval of use)對應到最多的利用指標。 (一)型態(Type):主要是指醫療服務的提供種類,例如:西醫、 牙醫、其他開業醫、長期照護、處方、醫療設備等。 (二)目的(Purpose)主要是指照護的等級,例如:預防保健(第 一級預防) 、疾病的診斷或治療(第二級預防) 、維持或恢復長期健康 問題(第三級預防)。 (三)地點(Site) :主要是指接受醫療服務的地點,例如:住院、門 診、急診室、診所、社區健康中心或居家照護等場所。. 8.
(9) (四)間隔時間(Time interval of use):主要是指某個特定時間的利 用衡量方式,例如:某個症狀比率、服務量、偶發疾病利用。 從以上四點可得知,醫療利用構面與構面之間彼此並未互斥,描 述往往涵概多種構面及尋求醫療的階段,這也是分析多元化醫療利用 之依據。. 二、醫療服務模型分析 正因醫療服務模式主要是由多個理論模式及實務應用觀點所構 成,這樣的模式闡述了包括社會、心理、經濟、機構等廣泛可能被影 響的層面,提供實務決策者思考從個人或群體接受醫療的可能轉變。 專家學者也陸續發展各種健康信念及求醫行為模式,試圖了解民眾求 醫行為與照護利用之間的差異。 李卓倫(1987)將醫療利用行為相關理論模式,包括:Suchman (1965)疾病行為階段模式(Stages of Illness and Medical Care)、 Rosenstock(1974)健康信念模式(Health Belief Model)、Mechanic (1978)尋求協助整體理論(General Theory of Helping Seeking) 、Aday (1968)第一階段醫療服務利用模式作系統性整理分析。因此本研究 先簡述其相關理論精神,再針對最被廣泛運用的 Aday 醫療利用行為 模式從理論及實證結果深入探討。. 9.
(10) (一)Suchman(1965)疾病行為階段模式(Stages of Illness and Medical Care) 從病患尋求醫療的觀點將求醫行為分為四個因素及五個階段,提 出個人疾病行為主要受社會結構與醫療環境的影響,強調個人的之知 覺是疾病行為的關鍵,而僅適用於研究病情較嚴重且就醫的病患是此 理論被批評之處。 (二)Rosenstock(1974)健康信念模式(Health Belief Model) 是眾多社會與心理學相關理論中應用於實務上最相近的模式,包 括了健康行為的三大因素,理論假設動機或主觀的認知可透過修正因 素(如:人口學變項、社會心理變項)認知疾病威脅,進而影響行為。 事實上影響行為的因素很多,必須置入所有變項才能提高解釋力,若 只從疾病威脅尋找醫療服務的動機是無法完全說明為獲取健康的正 向健康行為。許多的實證結果顯示,察覺障礙(Perceived barrier)是 影響行為重要的預測因子,大部分研究指出易生病的體質與多種預防 性醫療行為有關,如:子宮頸抹片、感冒疫苗注射、疾病篩檢等…。 (三)Mechanic(1978)尋求協助整體理論(General Theory of Helping Seeking) 從社會心理觀點,以病患潛在有能力尋求醫療的經驗,歸納十個 影響個人對症狀反應的因素,適合所有就醫與非就醫的病患,理論僅. 10.
(11) 限於從個人察覺症狀開始至尋求醫療間的行為,因此無法擴及病患與 醫療專業間互動的關係。 (四)Aday(1968)醫療服務利用模式(Behavioral Model of Health Services Utilization) 醫療服務利用模式以 Aday 及 Andersen 為先驅代表,最初的模式 僅強調從人口學特徵、社會特徵、健康信念等個人特質探討醫療服務 利用,由於模式中缺乏社會網脈、文化等因素,因此備受批評,而後 Andersen,Aday 及其他學者陸續加入多種測量醫療可近性後,使得 應用層面大大提高。 1975 年 Anderson 發展的行為模式,係以醫療利用的個人決定因 素 , 評 估 家 庭 使 用 醫 療 的 可 近 性 , 分 為 傾 向 ( Predisposing characteristics) 、能用(Enabling resources) 、需要(Need)三個因素。 1、傾向因素(Predisposing characteristics)意指疾病發生之前, 傾向或阻礙使用醫療的人格特質,含三個層面: (1)個人特質傾向: 基本人口學(Demographic)特徵,如:年齡、性別、家庭人口、宗 教、婚姻狀況。(2)社會結構(Social structure)描述處理自身目前 存在問題的能力,如:人種、種族地位、教育程度、就業狀態及職業 類別、宗教信仰、社經地位。(3)健康信念(Health beliefs)如:健 康服務的價值與態度信念及相信醫師知識對疾病的治療。. 11.
(12) 2、能用因素(Enabling resources)表示個人有能力工作,可以獲 得醫療服務,並將服務加以使用的能力,包括兩個層面: (1)個人或 家庭的資源(personal or family resources)如:收入、存款、保險範 圍、固定就醫資源。(2)社會資源(community resources)如:使用 醫療資源之充裕度、居住區域(都市或鄉村)可近性、就醫價格、候 診時間、就醫整體花費時間。 3、需要因素(Need)對於醫療利用而言是最立即且重要的導因, 包括二個層面: (1)自覺健康與疾病狀況,如:個人自訴病徵、自訴 身體功能障礙天數、自評察知健康狀況(perceived)。(2)反映在症 狀、無能力期間之臨床評估(evaluated),藉由醫療提供者的急性診 斷或病患主訴得知,意指與個人感受與健康或疾病狀態有關,這方面 的評估並不簡單,往往需藉由有訓練的專家或學者依據理論收集第一 手資料,套用邏輯期望模式進而探究出尋求照護及依附的醫療治療種 類。 病患滿意度(Consumer satisfaction)是第二階段模型修訂時才加 入的結果評估項,在於衡量民眾接觸醫療服務系統後的經驗,即民眾 接受醫療後對服務品質的主觀評價,包括方便性、協調性、可用性、 財務、提供者的特質等等。通常以最近發生的、特定的、可識別的項 目為衡量項目,滿意度問卷調查即為常見的執行方式。. 12.
(13) LA., A.(2001)提到 Barbara Starfield 在 1973 年即預言尋求健 康服務會有新的轉變,健康狀態是健康服務系統最終結果,結構與過 程兩構面與決定健康結果是互有重要關係,並連結分析政策相關議題 以確認決定健康結果的醫療與非醫療因子。整體架構經過不斷修正, 陸續加入經濟、社會、政策變項後,產生從政策為出發點,包括結構 (如:系統、人口學特徵、環境) 、過程(如:可近性、健康風險)、 中間結果(如:公平、效益)、最終結果(如:健康)的健康服務構 面。 系統性整理與分析近 20 年環境與供給者對醫療利用之影響,並 與 Aday ( 1995 ) 模 式 比 對 , 可 獲 得 環 境 因 素 ( Environmental variables):包括健康照護系統(Health Delivery System)、外在環境 ( External Environmental)、社區階層能用因素(Community-level enabling variable)等資訊。健康照護系統有政策、資源、醫療機構、 財務安排(如:醫師供給) ;而反映經濟、健康、政治、壓力係屬於 外在環境,至於個人可就近於社區獲得服務即屬社區階層能用因素。 供給者相關變項(Provider-Related Variables) :包括個人因素(Patient factors)及提供者特質(Provider characteristics),兩者交互可影響利 用率(Phillips, M, Andersen & Aday, 1998)。. 13.
(14) 1995 年 Aday 對於整個模式的四個發展時期做回顧,最近期的發 展模式強調服務與結果間以動態(dynamic)及遞迴(recursive)的關 係彼此回饋影響(圖 2.1) 。環境因素會直接影響人口學特徵,間接影 響健康行為及健康結果;健康行為會回饋人口學特徵的需要因素,這 些都是期望增加模式的完整性及釐清醫療服務的影響因素(Anderson & Ronald, 1995)。 環境因素. Health Care System. 人口學特徵. Predis-. Enable. 健康行為. Need. posing External Environment. Personal Health Practice Use of Health Services. 健康結果. Perceived Health status Evaluated Health status Consumer Satisfaction. 圖 2.1 Aday 醫療利用理論 綜合上述理論回顧,醫療利用已不再單純的侷限僅以個人需求為 主,同時必須考慮周圍環境的變動及產生的影響。Aday 早期可近性 架構(Aday & Anderson , 1974)是以”家庭”為醫療利用單位、歷經以” 個人”為利用單位,直到最近的動態(dynamic)及遞迴(recursive) 模式,此模式與最初的模式最大差異在於增加外部環境與照顧系統的 環境變數,以及健康結果的衡量。. 14.
(15) (五)其他預估服務量方式 除了以理論為依據的評估方法外,人口特質、出院利用率、 市場大小及佔有率等市場需求為預測基礎則是另種評估方式,引 用多種動態的資訊以貼近未來預測趨勢,以預估未來醫療機構服 務量。 有別於大多數的預測方法都僅是以過去的數值,主觀的決定 調 高或 調降的 百分 比來 評估未 來需 求, 但市場 需求 預測 是以特 定、量化的方式找出需求的決定因素,因此更能客觀理性的評估。 這樣的方式需要機構服務區域、病患區域人口資料、醫療利 用率及市場大小、市場占有率及機構服務需求等訊息。服務區域 係以最多病患居住的郵遞區域來確認服務區域,分為主、次要區 域(可自行設定百分比範圍) ,即使會有服務區的變動,但一般仍 以靜止狀態作預估,除非競爭者自願或被迫開放(例如:新醫院 成立、外地病患人口增加等等)。 利用區域人口資料可規劃近期至五年,其中性別與年齡群是 主要的影響變項,市場規模估算只要將利用率(每千人有多少單 位被服務)與主要區域人口相乘之乘積即可,至於市場占有率只 要透過收集病患出院狀況即可獲得,最後將市場大小與市場佔有. 15.
(16) 率相乘所得之乘積加上外部服務區域(通常是定值)所得之值即 可視為總需求(Beech. , 2001)。 為了更有效的預測健康需求,可以依循九個步驟建立,首先評估歷史 資料(Assemble historical data),例如主要病患來源、市場佔有率、 主要就醫科別等。第二、分析歷史趨勢(Analyze historical trends), 至少三年資料確認關鍵趨勢,例如完全改變、改變的比率、年改變率。 第三、確認主要驅動原因(Identify key demand drivers) ,例如人口成 長率、老化程度、人口組成等。第四、確認有關連的基準點(Identify relevant benchmarks) ,例如國際比較、已公布的指引等。第五、現有 狀況模擬(Model existing conditions)將資料置入程式中模擬現況對 未來的適切性。第六、發展以人口需求為核心假設(Develop core assumptions for population-based demand) ,步驟一至六通常被稱為外 部因子(external factor) ,因此會隨市場變動、研究對象而不同。 第七、發展核心需求假設(Develop core assumptions for providerlevel demand)例如市場佔有率、病患組合等,通常被稱為控制因 子(Control factor)。第八、預測未來基本需求(Create a baseline forecast of future demand),此時需結合人口為基準的外部因子及 供給者市場佔有率資訊以進行最後的測試(Test sensitivity of projections to changes in core)(Finarelli, & Johnson, 2004)。. 16.
(17) 三、醫療服務利用的實證結果 (一)年齡 年齡顯著與醫療利用型態有關,主要的原因在於年齡與罹病率的 關係,一般而言,使用西醫的年齡分佈呈現 U 型,表示小孩和年老 者利用醫療資源的機率大於青壯年(蘇建榮,1999;李玉彝,1993; 李丞華,2002)。 將資源耗用橫斷面比較,分析發現 15 歲以上的民眾,年齡與實 際醫療資源耗用間呈現正相關(14 歲以下呈現負相關),縱向面比 較亦發現年齡大的人醫療資源耗用的增加幅度比年齡小的人來得 大,其主要原因是民眾為獲得更多健康資本存量,反映出年齡需要與 醫療服務的關係(陳怡心,2004)。 以 23 個縣市為觀察單位進行影響健康因素之研究,以地區的人口 結構、醫療環境、酒菸的消費、交通工具及事故、失業率、空氣污染、 檳榔、人口密度等變項,來進行 panel data 的實證分析,結果顯示與 門診量有關的是區域中 65 歲以上老年人口比率對門診次數有統計上 的正向影響,人口密度及嬰幼兒為負向影響(吳郁濬,2002)。 根據一項針對各縣市不同性別 12 歲以上 18,142 名實住民眾進行 健康訪問,調查各項醫療與預防保健服務利用情形,結果顯示 65 歲 以上的人有 6 成過去一個月曾看過西醫門診,12 至 19 歲青少年僅 17.
(18) (24.5%)約 1/4(林惠生、劉怡玟,2001),表示年齡越大接受門診 服務比例越高。. 從家戶資料深入探討年齡與醫療保健支出的關係,結果除了發現 幼年及老年時期耗用較鉅的醫療資源呈現U型的型態外,另推估未來 人口在民國 1991 年的幣值及水準下,固定年齡別的醫療保健費用支 出在未來 20 年內會使總醫療保健支出約增加 43%(李玉彝,1993)。. 由上述的資料可以得知,年齡與醫療利用間是正向關係,根據內 政部統計處最新發佈的統計資料顯示,至 2004 年 12 月底為止,我國 65 歲以上人口已達到 2,68,810 人,而該年齡層人口更已經佔總人口 數 22,689,122 人的 9.48%(台閩地區人口統計,2004),因此在預估 門診量時,年齡實為重要因素。. (二)性別 大多數的醫療利用的結果顯示一般女性比男性更常使用醫療服 務(黃瑞珍 1996;賴芳足 1996;李佳霙 1996;李曉詩 2001;李丞華 2002),可能與女性懷孕產檢、接受荷爾蒙及使用抗憂鬱劑有關 (DCD&SDA, 2001)。女性比男性醫療利用高可能與罹病率不同有 關,女性大多以輕症、急性病為主,男性以重症、慢性為主,也與男 性容易忽略身體上的不舒適有關。 18.
(19) 關於性別與醫療利用的關係,大多數的研究均支持女性醫療利用 大於男性,一般推論與懷孕、預防保健、容易察覺疾病有關,意指門 診的利用上女性多於男性,女性門診利用(38.4%)亦高於男性 (32.2%) ,也在國健局實證調查中獲得證實(林惠生、劉怡玟,2001) 。. (三)社經狀態 社經狀態傳統上被認定包括教育、收入與職業,每種都提供不同 的資源,對健康都是不同的影響,也會影響政策的制訂(Nancy & Katherine , 2002)。 為瞭解低社經地位群與容易罹患疾病而使用較多醫療之關係,調 查 25 歲 53,339 名以上的荷蘭民眾發現,經校正年齡、性別後的低社 經地位群在使用多重醫療是常人的 1.46 倍(OR=1.46),疾病盛行率 是常人的 2.47 倍(OR=2.47)(Dunlop, Coyte, & McIsaac, 2004)。 在國內研究者也有相同的實證發現,所得越高的民眾,越會往大 醫院就醫(江君毅,2002),所得與門診醫療資源利用彼此間為正向 的影響(李曉詩,2001;李丞華,2001;李玉彝,1993),該地區所 得越高越會使用門診。 社經狀況越低者,意涵在就醫時較多財務上的負擔,也意味著醫 療可近性降低,例如:低收入戶。由於社經狀況也與健康有關,因此 社經狀況較低者會利用較多的醫療是可以被預期。 19.
(20) (四)醫療資源 影響門診量的使用因素也可從整體醫療支出面或供需面(需求與 供給)觀察,以每人每年國內生產毛額及被保險人口比例為需求面因 素,每萬人口醫師數、每萬人口病床數及失業率為供給面因素,取 1954 至 1999 年國民醫療保健資料,建構總體時間序列及門檻模型, 實證結果首先發現,變數經過檢定後均為一階穩定序列,其次結果顯 示每人每年國內生產毛額為決定支出的重要因素,失業率的提高亦促 使醫療支出增加(邱雅苓,2001)。 從供給面探討影響醫療利用的因素,研究指出全民健保費用上漲 有 8 成以上來自於門診,以就診次數的增加為主要原因,且醫師密度 或病床密度較高的地區,醫療服務利用有偏高的走向,推論有供給誘 發需求的情況,使得醫療服務利用整體上漲。這樣的結果也與經濟學 的”供給誘導需求”的理論相符(陳孝平,1998)。蘇建榮(1999)卻 有每萬人醫師人數與居住地區醫療院所數對門診數無顯著影響的不 同發現。 李丞華(2002)將資源做地域性的劃分後,西醫師人力資源與西 醫門診利用率的相關性低,但考慮市場競爭因素後,則會發生供給誘 發需求(劉容華,2004)。. 20.
(21) 市場競爭與每日門住診人次有顯著相關,且主要效應發生在醫學 中心,在門住診市場內,隨著時間變化分析,顯示門診市場隨著時間 的變化越趨於競爭市場(金家玉,2002),西醫診所間的競爭結果也 是如此(楊麗雪,2002)。 另有研究指出新醫院的加入對於該區整體門診量(包括診所)呈 現正成長(鄭守夏、劉林義,2001)。若以次醫療區為觀察單位,控 制了人口結構變數、家庭經濟能力因素、時間參數與地區參數,每萬 人口增加一位醫師則平均每人每年西醫門診就診次數將增加 1.01279 次(廖凱平,2001)。 為分析地理及空間在醫療利用的效應,與鄉村居民面對面問卷調 查,詢問人口學、健康狀態、醫療區域、社經等十二類問題,發現能 用因素(是否有駕照或每週騎車;交通工具的方便性)與利用率有顯 著關係(Arcury , Gesler, Preisser, Sherman, Spencer& Perin.,2005)。 在台灣,鄭千芝(2004)報告顯示相對於鄉鎮老人,城市的老人 有較高的門診使用機率。江君毅(2002)調查台北地區民眾選擇就醫 層級因素,發現就醫距離是因素之一,兩者呈現負向關係,即距離愈 遠,就醫意願越低。醫療資源分配之研究結果也印證不同區域每人年 平均利用率存在極大差異(李丞華,2002)。 總體經濟因素、平均國民所得、經濟成長率、失業率、醫療服務. 21.
(22) 系統提供的數量也是因素之一(Newhouse, Manning, Keeler& Sloss, 1989). 由上述分析可得知,醫療資源可直接影響醫療利用,整體國家的經 濟成長、失業率亦會經由健康狀況間接影響醫療利用。. (五)政策因素 1、部分負擔 自從藍德健康保險實驗結果出爐後,部分負擔被認為是醫療需 求面上控制醫療費用的重要工具,也成為政策研究的主題、各國執行 的策略。 韓國健保制度類似我國,都是屬於民眾可自行選擇就醫地點、論 量計酬、門診大型化的國家,利用其自身 1998 年資料分析部分負擔 在門診利用效應,包括年齡、性別、婚姻狀態、教育程度、收入、醫 院等級、醫療區域等變項,發現低收入者對於部分負擔措施敏感度高 於高收入者,使用醫院的民眾對部分負擔敏感於診所(Kim, Ko, & Yang, 2005)。 林慧修(2002)以 921 災民為對象,以自然實驗方式,觀察 災民在免部分負擔措施之前後醫療利用情形,並將非災民作為對 照組,以瞭解部分負擔對不同層級及科別的影響,研究結果顯示,. 22.
(23) 增加部分負擔確實會降低醫療服務利用率,又以基層診所下降最多 (20.9%) 。部分負擔越高,民眾較不會前往就醫(江君毅,2002)。 國內部分負擔從開辦至今已調整過 7 次,且 7/15 已再次調高 部分負擔,然而此措施對於醫療利用是否達到控制成效,一直是 學者關心的重點。在所有的調整中以 1999 年上半年同時調高中 醫、復健療程、高診次、加重藥品部分負擔等措施改變幅度最大, 因而成為研究焦點。 李丞華(2002)針對調整後之結果進行效應評估,發現部分 負擔對於中、西醫整體門診利用均有抑制效應,降幅分別為-3.2% 及-0.54%。 洪明皇(2001)更細部探討部分負擔對不同社會群體影響, 結果呈現性別、就醫機率並無差異,低收入者利用率下降,老年 人與慢性病群體利用變動較大,足見部分負擔實施在不同群體間 的效果並非截然相同。 2、門診合理量 門診合理量政策是健保局管控門診量的措施之一,係參考加拿大 的高額折付方案(income threshold),對個別醫師收入超過一定臨界 點以上之收入打折支付之精神,擬藉診察費的提高,讓醫師不用靠診 察費、藥品利潤或檢查來彌補收入,增加每位病患診察時間以減少複. 23.
(24) 診次數,進而控制門診資源,其計算公式,是以前一年門診量、醫師 數及病床數等三部分加權計算而得(李玉春,2001)。 國內關於這部分的文獻探討並不多,葉淑娟(2003)實證分析次 級資料顯示診察費在實施門診合理量後明顯降低,但就診人次及部分 負擔都是增加。張虎生(2002)將 1999 年 3 月與 2001 年 3 月南區區 域醫院資料作跨年同期比較,或是吳時捷(2004)將區域級以上醫院 採用實驗及對照組研究,均呈現診察費及門診量在合理量實施後都是 增加。為瞭解區域級以上醫院對於醫院門診合理量的認知、態度與所 採取之因應策略,黃心怡(2002)採用問卷普查 80 家醫院,獲得醫 院以衝門診量為因應策略的比例(41.2%)為最高。 由上述的種種跡象看來,原先藉由門診合理量抑制門診量的成長 政策,並未達到預期成效,反而成為增加門診量的反向效應。. 3、總額支付制度 各國為了控制醫療費用的成長,試圖透過支付制度的設計, 形成由傳統的需求面成本分攤轉為供給面的成本分攤,期望增加 提供者的財務風險來降低醫療服務的誘因。 以 德 國 為 例 , 為評 估 實 施 總 額 預算 之 效 益 , 在 模式 中 置入 Gross Domestic Product(GDP) 、人口數、執業醫師數、總額預算. 24.
(25) 等變項,亦證實總額制度能抑制費用成長(Yakoboski, Paul, Ratner, Jonathan, Gross& David,1994)。 為研究健保支付制度改革對醫療支出成長率的影響,謝啟瑞 (2003)利用衛生署保健支出及健保體系支出的資料,進行時間 序列分析,報告發現總額預算實施後的醫療支出成長率明顯低於 實施前的醫療支出成長率,表示總額制度能顯著的降低部門支出 成長率。 根據莊念慈(2004)問卷調查地區以上教學醫院在總額制度 下的服務量狀況,結果顯示 56%醫院門診量呈現成長,46.6%總 營運成長,30%營運減少,表示醫院在總額下仍企圖增加門診量 以增加收入。 楊銘欽(2003)藉由問卷及訪談,深入研究鄉鎮民眾在西醫基層 總額實施後利用上的差異,發現城市民眾比鄉村民眾在就醫可近性及 交通時間上有統計上顯著差異,同時每萬人口特約診所數及醫師數均 有成長趨勢。 國內學者觀察指出,實施總額預算後之帳面上會出現醫院經 濟效益提高的假象,事實上醫院為維護經濟效益會將醫療耗用成 本轉移至其他照護機構作為因應,以致造成機構大型連鎖化,而. 25.
(26) 壓縮了中小型醫院生存空間,對未來醫療產業的可近性及地方經 濟產生影響(白裕彬,2003)。 從健康保險財務支出面探討總額支付制度的影響,為找出預測醫 療消費的變數,採 Panel Data Analysis 的方法建立計量經濟模型進行 跨國跨時間的比較研究,結果得到醫師會增加診療的病患讓自己利潤 最大化的研究應證。醫療支出模式的推導亦發現短期以每人國民所得 是影響醫療費用支出連動性最強的因素,長期來看個人醫療費用是上 一期每人醫療支出的函數(林霖,2003)。 從上述的研究可以瞭解,健保費用高漲的原因之一在於論量 計酬的支付制度潛藏不當的經濟誘因,醫師或醫院為提高自己的 收入刻意提供不必要的醫療。因此總額預算設計從供給面抑制醫 療支出,在給付的範圍下定保險費用的額度及成長率。資料亦顯 示大多數研究支持總額預算在控制費用成長上具有成效。. 4、自主管理 自主管理是健保局授與醫院自我管控的措施,最早是八十六年高 屏分局鑑於門診費用不斷攀高而推行的協商方式,但經兩年後評估發 現模式僅能控管「單價」卻無法限制「量」的成長(楊錦豐、陳淑惠, 2000),之後經過不斷修正,陸續加入門住診比例、監控指標成為目. 26.
(27) 前卓越計畫的範本,至於成效如何尚無定論,較為實證的發現在於各 機構開始出現限制門診量,減少開診數之因應措施。 依據上述文獻探討發現影響門診量的因素並不少,單以 Anderson 模式民眾的需求因素(傾向、能用、需要)評估略嫌不 足。此外門診量易受外在環境干擾,引用市場需求變項在環境的 連動上以修正此缺失。 本研究著重在以醫院為出發點,暫且忽略個人的需求考量, 藉由醫院的內部資源及健保制度的執行,量化對門診量的影響, 故將影響因素歸納為醫院特質及政策因素兩類。. 27.
(28) 第三節預測的原理與選擇. 一、預測模式理論 預測模式是預測的核心,因此如何找到正確的模型是一個關 鍵問題,有些將預測方法歸類為定性(Qualitative Method)及定 量(Quantitative Method)兩大類,前者是透過專家的意見,依 據過去經驗對未來事件做本質、特性的預測;後者以歷史資料為 依據,以數理方法模式化後再行預測(劭曰仁等,1990)。亦有 文 獻 將 預 測 分 為 時 間 序 列 ( Time Series Model )、 因 果 (Cause-and-Effect Models)及判定(Judgmental Models)三種 基本模式並進行產業分析,發現以時間序列模式被使用最多(約 佔 61.33% ), 其 次 是 因 果 模 型 ( 佔 22.65% ), 判 定 模 式 僅 (13.92%) 。即使應用在健康照護產業,也是以時間序列方法(佔 66.67%)為主(Jain.,2002) 。另有書籍分為使用過去模式的單變 數、使用多種變數之間過去關係的多變數及使用主觀判斷的定性 法三類,茲將三種方法比較如表 2.1。. 28.
(29) 表 2.1 預測方式比較表 類 別 理 論. 時間序列 因果(多變數) 定性 (單一變數) 使用過去、內部模 將 一 序 列 和 其 他 序 依據其他人對未來 型 資 料 將 過 去 值 列 之 間 的 關 係 模 式 趨勢、品味和技術 模型模式化 化 改變的觀點和判斷. 種 類. 平滑、指數平滑、 分解、傅立葉序列 分析、ARIMA、線 性趨勢、非線性成 長趨勢 短至中期的預測 具成本效益. 優 點 缺 點. 簡單及多元迴歸、經 Dephi、市場研究、 濟計量、多元方程式 小組討論、情境分 經濟計量、多變數時 析 間序列、狀況空間. 解釋因果關係最好 的方法,可以預測及 解釋行為 無 法 解釋 過去 模 需要收集和分析外 型的數學關係 部資料,比單變數昂 貴且困難. 只有少量客觀資料 就可使用 比單變數昂貴且低 精確性. (一)時間序列 時間數列亦被稱為動態數列或時間序列(Time Series),將反映 某一現象的同一指標在不同時間上的取值,依據時間的先後順序排列 所形成的一個動態。吳柏林教授則認為時間數列是指隨著時間而紀錄 的觀察值,因此時間可視為自變數,隨之紀錄的量值稱為因變數,透 過數列的分析及圖形的辨示結果,不但可提供預測與控制,更影響管 理者決策的擬訂。 至於如何選取合適的分析方法,一般建議考慮幾個因素,首先是 1、預測的形式:例如點預測、區間預測或是等級預測。 29.
(30) 2、預測期:從幾天至數年不等。 3、需預測的項目多寡:雖然許多變數與預測有關,盡可能不多於四 個以避免過多的變數混淆了預測的目標。 4、精確程度:精確度與決策品質有關,但越精確其所耗費的時間及 成本就愈大。 5、系統結構是否改變:涉及需求與供給的時間序列趨勢走向是否與 以往相似或截然不同,建構配合動態變化的模式。 此外分析時除了考慮成本效益外,也要隨時保持彈性及動態,以面對 外在的環境變化。 模式大都依循三階段建構法則:(1)階次的認定(Order identification)、(2)參數的估計(Parameters estimation)到(3)診 斷檢定(Diagnosis checking),以求取最佳的配適模型,如流程圖 (2.2)。. 階次認定. 參數估計. 診斷檢定. 判定的模式不佳 圖 2.2 三階段模式建構流程圖. 茲將步驟說明如下: (1) 階次認定(Order identification). 30. 預測.
(31) 分析走勢的型態與特性,選取幾種可能模式階次。 (2)參數估計(Parameter estimate) 藉由統計理論與計算過程,將備選的模式進行參數估計。 (3)診斷檢定(Diagnostic checking) 透過檢定程序,診斷其合適度,選取模式中最精簡且能解釋資 料結果為原則。此階段中若判定的模式不佳,則需回到最初的 階次認定重新進行流程,方可進入最後的預測。. (二)ARIMA 模式簡介 自 我 迴 歸 移 動 平 均 整 合 (Autoregressive Integrated Moving Average,ARIMA)係於 1970 年由 Box and Jenkins 所發展的一種 分析方法,包含:自我迴歸,整合與移動平均共三個部分,主要 可以藉由過去的歷史資料,檢查自相關與偏自相關的特性,建立 系統化辨識、估計、診斷和預測時間序列的實驗方法,從多個模 式中選擇最佳者,進而對未來進行預測。 ARIMA 最大的優點在於非常有彈性,使用者不用侷限在多個 單一預測模型及函數,而是依據現有可用資料搭配過去連續性資 料型態,決定最佳的模型(Newbold,1983)。. 31.
(32) (三)應用 ARIMA 模式建立預測模式的文獻 時間序列分析早已廣泛應用於財政相關領域,近年來才逐漸 推廣應用於醫療領域,經由分析時間數列資料的變動,以決定政 策方向及評估執行結果。然而以往文獻指出研究焦點多放在預估 人口成長、費用等議題,鮮少應用於預測門診量,因此應用時間 序列在門診量的預測上更具應用價值。 Bradley et al.(2003)以醫療照顧(medical care)、醫療服務 (medical care services)、醫療產品(medical care commodity)、 醫師服務(physician services)、處方藥(prescriptive drugs)及醫 療供給(medical supply)五個混合的成長率為指標,預測與醫療 淨折扣率間的關係,指標經由單根檢定後歸為非平穩型,經過一 次差分後呈現平穩,表示五種指標都具有變動性一級差分 ARIMA 特性。 楊文山(2003)以 ARIMA 方法探討台灣及日本嬰幼兒死亡率長 期移動趨勢及可能影響之變動因素,應用 Liu 與 Hanssens 提出的轉 換函數模式(Transfer Function Model) ,將日本嬰幼兒死亡率設為自 變數,台灣嬰幼兒死亡率設為依變數,解析日本嬰幼兒死亡率對台灣 嬰幼兒死亡率的影響。. 32.
(33) 楊銘欽(2004)為推估人口結構變化對未來至 2025 年健保醫療 利用與支出之影響,利用 1996 年第 1 季至 2004 年第 1 季服務量資料, 以 0 至 14 歲保險人口、老化指數、扶養比、65 歲以上保險對相及百 分比為自變項;國民所得、供給面因素、季節、政策介入為控制變項; 總醫療申報點數、門住診申報點數、門住人次及住院人日為依變項, 套用多變量時間序列模型 Multivariate ARIMA 進行分析,獲得人口數 及供給面的增加,會促進醫療利用,但與人口老化並無顯著影響之結 果,顯示人口結構對費用的影響有限,未來至 2005 年門診量若僅考 慮人口結構變化則為 0.72%成長;考慮國民生產毛額變化則有 2.07% 成長的結論。另有學者以部分負擔及門診合理量作為介入模式,投保 人口數、投保依賴人口數、老年人口數、門診人次、特約機構數、急 性病床數為相關變項,分析並探討供需成本對費用的影響,結果呈現 控制門診合理量比控制部分負擔更具費用控制效果(楊銘欽,2004) 。 以總體角度,歸納所有可能影響健保醫療支出的因素,包括「平 均每月每人實質國內生產毛額」、「65 歲以上的老人人口比例」、 「每百萬人口昂貴或高危險醫療儀器的數目的成長率」、「每萬人口 醫師數」變項,經由單根檢定確認變項具有一階差分後穩定的特質, 實證結果發現「65 歲以上的老人人口改變比率」、「每萬人口醫師數. 33.
(34) 變動率」對醫療費用有顯著影響,另外在物價波動影響下,建議納入 「國內生產毛額平減指數」為考量因素(林小鳳,2002)。 為推估總額預算下未來 15 年部分總體經濟變數數值及醫療費用 成長率,建構醫療費用成長時間序列隨機模型,研究結果呈現醫療費 用占國民所得比重成長率除了受到季節因素影響以外,與其自身前期 及人口老化指數呈正向關係,同時具有 MA(1)之時間趨勢(朱世 民,2002)。考量政策的介入是持續變動的影響,因此採用時間序列 的介入分析模式,搭配 Lorenz 曲線及 Geni 係數為指標,評估牙醫實 施總額預算後對資源分佈的影響(黃昱瞳,2002)。 利用迴歸分析與類神經網路預測模式,嘗試以某期影響因子(不 同性別人數、不同年齡分組人數、醫師人數等)與該期之下一期之服 務點數配對,建立各層級及各區域級以上醫院之點數,找出合理的總 額預算資源分配模式及建立醫院門診服務點數預測模式,結果顯示醫 院層級間影響因素不盡相同,因此有必要依不同層級或不同的醫院建 立預測模式(周宣光,2003)。. 綜合上述文獻,發現可以從醫療利用理論、市場預測觀點、 醫療資源狀況等多元角度可更完整找出門診醫療利用變項或影響 因子。醫療利用強調在基本人口學的變項,與環境因素互動探討 上較為薄弱,因此加入市場觀點的占有率、成長率等相關因素, 34.
(35) 另外因醫療市場不同於其他商業市場完全競爭的特質,必須將醫 療 資源 因素一 併考 慮, 而整體 的醫 療環 境都是 在健 保制 度下運 行,故政策面的措施也在考量因素中。 文獻探討中得知門診量本身易受上期干擾影響,即自我相關 相當高,加上與時間的因素密切相關,無法用一般的迴歸統計方 式處理,又因探究政策面介入的影響,所以採用時間序列分析處 理。 綜合上述討論的結論即是運用時間序列分析的自我迴歸移動 平均整合(ARIMA)納入選取之門診量、醫師數、醫師平均年齡、 診別數、診次數等變項建構出門診量預測模型。. 35.
(36) 第三章 研究設計與方法 本章共分為三節。第一節為研究對象與研究材料,第二節則 提出研究架構及列出操作型定義,第三節為分析方法及模型介紹。. 第一節. 研究對象與研究材料. 一、研究對象 本研究係以國內中部某地區醫院為研究對象,係因研究重點 在於探討醫院特質及政策因素對門診量的影響。由於與門診量相 關的變數相當多,且全國各地區人口特質、醫療資源及機構特質 不盡相同,為降低變異及提升預測準確性,因此予以侷限研究區 域。研究的年度涵括門診合理量,總額制度、參與自主管理前後, 2000 年 1 月至 2004 年 12 月,以月為觀察單位,共有 60 筆觀察值, 以探討政策因素對門診量的影響。. 二、研究材料 中部某地區醫院民國 2000 年 1 月至 2004 年 12 月之門診量資料, 資料中含本研究所需的醫師數、醫師平均年齡、科別數、診次數變項。. 36.
(37) 第二節. 研究架構與變項操作型定義. 一、研究架構說明 本研究主要探討影響門診量的決定因素,經由文獻探討法和 個案資料研究方式來架構基本構面,進而建立門診量預測模式。 研究中擷取 Aday-Anderson 第四修正版中的醫療照顧系統及外在 環境變數為出發點,並加以改編以期符合現況需求,探討每個變 項與門診量間之關係。其研究架構如圖 3.1。. 二、研究變項 選用的變項可歸類為兩大類,第一類為『醫院特質』變項、第二類 為『健保政策因素』變項,加上門診量變項後共有八個,其操作型 定義見表 3.1,變項均以”月”為衡量單位。. (一)『醫院內部因素』變項,包括: 1、醫師數,係指看診之主治醫師,不包括住院醫師。 2、醫師平均年齡,係指看診之主治醫師總年齡除以主治醫師數。 3、科別數,係指服務科別數加總,不包括急診、檢查診。 4、診次數,係指服務診次數加總,不包括急診、檢查診。. 37.
(38) 變項 1、門診量 2、醫師數 3、醫師平均年齡 4、科別數 5、診次數 6、門診合理量 7、自主管理 8、支付制度. ARIMA. 單變量 門診量. 轉換模型 1、醫師數 2、醫師平均年齡 3、科別數 4、診次數. 選擇最佳門診量 預測模型. 預測. 圖 3.1 研究架構圖. 38. 介入模型 1、門診合理量 2、自主管理 3、支付制度.
(39) (二)『健保政策因素』變項,包括: 1、門診合理量,係以虛擬變項衡量醫院門診合理量對門診量影響。 2、自主管理,係以虛擬變項衡量研究對象加入自主管理的門診量 影響。 3、總額支付制度,係以虛擬變項衡量醫院總額制度對門診量之影 響。. (三)變項之操作型定義 表 3.1 研究變項與操作型定義一覽表 變項. 操作型定義. 門診量. 每月門診人次(包括初複診). 醫師數. 每月實際看診之主治醫師數. 醫師平均年齡. 主治醫師年齡總計,再除以當月符合條件之醫師 數。. 科別數. 每月看診科別(不含急診、檢查診). 診次數. 每月診次數(不含急診、檢查診). 門診合理量. 將民國九十年一月醫院門診合理量制度實施前後 設虛擬變項,實施前為 0,實施後為 1。. 自主管理. 將民國九十三年七月參加自主管理的時間設虛擬 變項,非實施期間設為 0,實施期間設為 1。 將民國九十一年七月醫院總額制度實施前後設虛 擬變項,實施前為 0,實施後為 1。. 醫院總額 支付制度. 39.
(40) 第三節 分析方法與模型介紹 門診量會隨著時間經過呈現非平穩,高度自我相關特性,因此適 用於時間序列的分析方式。因此本研究將 2001 年 1 月至 2004 年 12 月時間序列資料,採用計量經濟學時間序列(Time series)分析,將 五年的門診數值及政策變項置於電腦套裝 SCA 軟體,再選擇單變 量 自 我 迴 歸 整 合 移 動 平 均 模 型 , 簡 稱 ARIMA( Autoregressive Integrated Moving Average Model)(p,d,q)、轉換函數(Transfer Function)及介入分析(Intervention Analysis model)三種模式進行 分析,以建構出在不同情境下之預測模型。 在進入時間序列模型前,首先介紹本研究模式重要的基本共 通名詞,以利於爾後各模型建構之敘述。 一、基本名詞 (一)自相關函數(Autocorrelation function,簡稱 ACF) 分析時間數列本期與前一期(或下一期)觀察值相關程度。換言 之,分析時間數列發現前一期觀察值與本期(或下期)觀察值有某種 程度關係存在,計算 ACF 值以確認相關性。 統計上一般使用相關係數(correlation coefficient) ρ (X,Y),以 表示(X,Y)兩變數間的關係: ρ(X, Y)=. Cov(X, Y) E(XY)-E(X)E(Y) = σXσY σXσY 40.
(41) E(XY)表示隨機變數的期望值 ρx , ρy 為 X,Y 的標準差. 應用在時間數列即為自相關函數(ACF),以符號 ρ k 表示。 ρ(X t , X t +k ) =. Cov(X t , X t +k ) σx t σx t + k. ρ k 表示變數 X t 與 X t 1 間的自相關係數 K 為期數. (二)偏自相關函數(Partial autorrelation function,簡稱 PACF) 分析時間數列時,單純考慮本期 X t 與 X t + k 的相關程度,X t 與 X t + k 間的所有變數影響全數除去,稱為偏自相關函數(PACF) ,以符號 ρ kk 表示。 Cov(X t , X t + k \ X t +1 , X t +2 ,...., X t +k 1 ) σ ( X t )σ ( X t + k ). (三)白干擾或稱白噪音(white noise) 隨機過程中每個觀察值均相互獨立,有相同機率隨機分配之線性 組合,變數通常假設符合常態分佈,具有相同的期望值 µ 與變異數 σ 2 ,這是最簡單穩定型時間序列,可表示為: Xt = εt ε t 為期望值 µ ,變異數 σ ε2 的分配. 41.
(42) (四)差分(difference) 差分即為取差,透過差分運算子(difference operation)將非平穩 型時間數列轉換成平穩型時間數列,差分運算子可用▽符號表示,定 義為 ▽ Z t = Zt - Z t-1 = (1- B)Zt. 由上述式子可知,▽與後移運算子 B 的關係為(▽=1-B) ,而為確認 資料平穩狀態,通常先執行一次差分來檢視數列,就一個趨勢型時間 數列而言,差分是讓期望值穩定最基本的方法。 (五)離群值(outliers) 分析時間數列的過程中,往往會發現某個觀察值受到非預期事件 的影響,產生與其他觀察值的不一致性,這些異常的觀察值即稱為離 群值(outliers),若預期事件已知,可用介入模式分析其影響程度, 但大多數情況下未知。 離群值的種類可分為相加性(AO)、創新性(IO)、水平移動 (LS)、暫時性變動(TC)四種。 1、相加性(Additive Outlier):僅影響當期,常發生於紀錄錯誤。 2、創新性(Innovational Outlier):外部原因引起,影響時點後的整 個數列。. 42.
(43) 3、水平移動(Level Shift) :反應在操作過程或設備改變,為永久性 的影響。 4、暫時性變動(Temporary Change):事件對數列的影響程度慢慢 消失。 為避免離群值所產生的偏差與干擾,偵測與除去離群值效應在整 個預測流程是相當重要的,除了相加性離群值(AO)外,其餘都會 影響預測結果。. 二、模型介紹: (一)單變量自我迴歸移動平均整合(ARIMA)模型 自 我 迴 歸 移 動 平 均 整 合 ( Autoregressive Integrated Moving Average,簡稱 ARIMA 模式)是 1970 年 Box-Jenkins 對時間序列模式 化的偉大貢獻,使用一個過程的實現(樣本)來辯識產生序列的 ARIMA(母體)的過程,建立的程序被稱為 Box-Jenkins 或 ARIMA 模式建立法(ARIMA model building methods) ,此方法主要是依據過 去的歷史資料,檢視自相關(ACF)與偏相關(PACF) 、符合白干擾 等特性找出合適的模式,再依此模式對未來進行預測。 ARIMA 包括趨勢、季節性和隨機三種模式,以自我迴歸(Auto Regression)、整合(Integrated)及移動平均(Moving Average) 來. 43.
(44) 命名,並以 ARIMA(p,d,q)表示,p 表示自我迴歸級數、d 表示整合 (差異)級數、q 表示移動平均級數。. 基本模式包括: 1、自我迴歸過程(autoregressive process):簡稱 AR 係指當期的觀察值為同一數列諸個前期觀察值的迴歸 若以 Z t 為應變數,自變數迴歸模式即是 Z t 1 , Z t 2 ,....., Z t p,係數以 φ i 代入,p 代表階數,則 AR(p)可寫成 Z t = φ1 Z t 1 + φ 2 Z t 2 + ......... + φ p Z t p + a t. 或. φ p (B) Z t = a t. 2、移動平均過程(moving average process) :簡稱 MA 如同前述之白色干擾過程,模式中負值的 θ1 , θ 2 ....., θ q 表示震動影 響或記憶函數, a t 持續震動影響 t,t+1,……,t+q 期後消失。 Zt = µ - θ1a t-1 - θ 2a t-2 - ......... - θq a t-q + a t. 或. Z t = µ + θ q (B)a t. 3、整合過程(integrated processes): 假設原始數列為無定向型時間序列,經過第 d 次差分後可轉為平 穩型數列,因此整合數列將具有固定的 d 階多項式趨勢。. 44.
(45) 4、ARIMA 模式建立過程 ARIMA 模型建立流程步驟(圖 3.2) (1)模型鑑定(identification) ,一般以圖形、統計量、ACF、PACF 以確認時間序列的類型。 (2)參數估計(estimate),以最小平方法和最大概似法決定係數。 (3)模式及殘差值診斷(diagnostics) ,模式有高的 Chi-square,殘差 值有白噪音的特徵(搭配 ACF、PACF 圖)。 (4)利用最後找出的模式進行預測. 總而言之,ARIMA 模型係透過自我相關函數(ACF) 、偏自我相 關函數(PACF) 、序列圖形進行辯識,描述性統計(Q 統計和白色干 擾)及 Schwarz 具氏資訊標準(BIC)進行估計參數及診斷模式, 直至 RSE 或 BIC 最低且僅存白色干擾時,即可算是完成模型的建立。. 45.
(46) 觀察樣本資. C. 模. 繪時序圖(time plot) 計算 ACF、ACF. 型 鑑 定. 觀察資料 是否平穩. 階 段. 不平穩. 平穩. 鑑定暫定模型 p,d,q. 資料前後期差分. 估 計 階 段. C. 估計模型參數. 診 斷 階 段. 不合適 診斷模型. 合適 預 測. 統計推論與預測. 圖 3.2 ARIMA 模型建立流程圖(摘自鄭天德,2001). 46.
(47) (二)轉換函數模型 Transfer function model 1、轉換模式 不同於從變數本身的歷史研究的單變量 ARIMA 模型或只討論產 出變數受到投入因素影響的傳統迴歸模型,轉換模式主要考慮時間數 列不單單受本身歷史影響,也與其他數列的現在、過去或未來值有 關,即整合了單變量 ARIMA 與迴歸模型及動態的解釋了投入與產出 的關係。 2、轉換函數的特性 一般假設穩定的時間序列係由 X t 與 Yt 二元隨機過程所產生,且 產出變數受到投入變數及前幾期的影響,兩者的關係可以線性關係表 示為: Yt = U t + N t. ( U t 為 Yt 的一部份,僅用來解釋 X t ; N t 為干擾項) 若以動態關係考慮 U t 與投入變數 X t 的關係,可表示為: Yt = υ(B)X t + N t. ( υ0 、 υ1 、 υ2 ,……等為各期 X t 的衝擊反應) 本研究擬探討多個(k)投入變數( X1t,X 2t, ......., X kt )與產出變數 Yt 間線 性關係,則可表示為: k. Wj (B). j=1. δ j (B). Yt = C + Σ. 47. X j,t-b +. θ(B) at φ(B).
(48) 3、轉換模型鑑定法 如同單變量以 ACF 為鑑定準則,轉換模型是以交叉相關係數 (CCF)作為鑑定的工具,不過此法不適用於分析一個以上的投入數 列,因此在 1982 年由 Liu 與 Hanssens 提出的線性轉換函數(Linear Transfer Function,LFT)修改為可應用在多個投入數列鑑定,SCA 軟 體即是使用此鑑定方式。 最後進行殘差值的偵測,如殘差值 ACF 圖在兩個標準差內,即 算完成流程,整個轉換模型如概略圖(圖 3.3)。. 隨機干擾項(at). 干擾模式. θ(B) φ(B). 干擾項( N t ) 轉換函數 投入( X t ). 模式. w(B) b B δ(B). 由 X t 解釋產 出部分( Yt ). 圖 3.3 轉換函數模式概略圖. 48. 產出( Yt ).
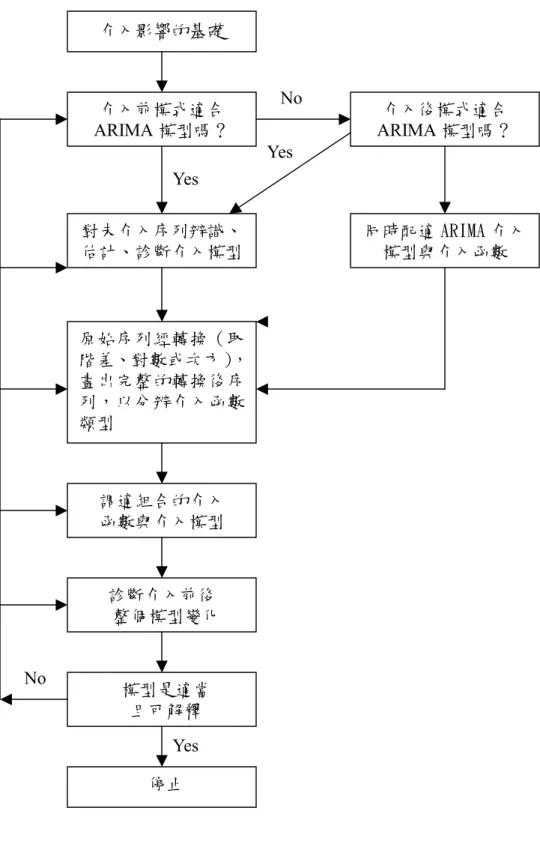
(49) (三)介入分析模型 Intervention Analysis model 1、介入分析 在時間序列的運用上,有時會因為一些外在事件的介入,劇烈影 響時間序列模式的走勢,因此降低預測的結果,這些顯著事件被稱為 介入或干涉變數(Intervention Variable) ,極可能干擾預測模式。換句 話說,為專注於事件的影響程度或消除事件對時間序列的影響,介入 模型就是最佳選擇。 模式最初由 Box 和 Tiao、Campbell 及 Stanley 發展,包括 ARIMA 模型與虛擬獨立變數(干涉函數)的組合。在實務上的案例(例如: SARS 疫情、九一一大地震)或重大的決策(例如:自主管理、總額 預算、門診合理量、部分負擔調整等)均適用介入模型分析。 2、介入分析的模型化及步驟 在進行介入模型化前需先確認以下幾點,其所建構的介入模型結 果方可作為重要的統計推論。 (1)外在因素介入的時間點(日期)。 (2)理論建議時間序列之影響類型。 (3)具有足夠的觀察值,以辨識介入前的 ARIMA 干擾模型。. 49.
(50) (4)足夠的介入和介入觀察值,以分辨介入影響的類型。如:脈動 干涉(單一事件偏離)、持續脈動(多於一期的短期影響) 、階 段函數(永久的介入)。 為了確認模型化介入的衝擊,首先必須先模型沒有衝擊的原始資 料狀態,一般採用如同 ARIMA 的模型建立法,以 ACF 及 PACF 的 圖形來判定介入事件是否曲解了序列,此時亦可稱為介入前之序列 (preintervention series)。 在確認了 ARIMA 模式後,才能以介入函數的理論基礎進行模型 辯識及估計介入函數,找出估算係數為顯著且殘差值為白噪音,即可 認為完成模型。介入發生時最好無其他介入,否則介入的強弱難以適 當分析。整個模型化介入的程序,如圖 3.4 所示。 3、介入分析的種類 介入型態(common intervention types)常以 I t 符號表示介入與 否,若 I t =1 表示介入事件發生, I t =0 表示事件未介入。依據不同的 介入時間的長短,分為脈動介入(pulse intervention)與階段函數(step function) 。階段函數係指從事件介入後開始作用且強度不變,不同於 脈動介入的短期或僅一期影響。 當介入的影響不明時,可以先從零階介入模型著手,之後再依據 時間經過影響程度增加或減少來選擇階級介入函數。表示的方式為:. 50.
(51) 0,t < T; It =. 1,t >= T;. Yt = θ 0 + w o I t …………第零階介入函數 Yt = θ 0 +. w0 I …第一階介入函數 (1-δ1B) t. ( I t 表示介入與否;θ 0 表示序列常態的中央值;w O 表示涉入影響:δ1 B 表示一階函數)。 在介入模型的應用中,大都假設介入的事件與時間是在已知的狀 態,對於某些非預期的干擾(如:突然爆發的大流行),必須偵測離 群值並予檢定,確定無離群值後才開始進行預測流程。. 51.
(52) 介入影響的基礎. No. 介入前模式適合 ARIMA 模型嗎?. 介入後模式適合 ARIMA 模型嗎?. Yes Yes 對未介入序列辨識、 估計、診斷介入模型. 原始序列經轉換(取 階差、對數或次方), 畫出完整的轉換後序 列,以分辨介入函數 類型. 調適組合的介入 函數與介入模型. 診斷介入前後 整個模型變化 No. 模型是適當 且可解釋 Yes 停止. 圖 3.4 介入模型化流程圖. 52. 同時配適 ARIMA 介入 模型與介入函數.
(53) 第四章 研究結果 本 章 依 據 第 三 章研 究 方 法 之 理 論架 構 , 建 立 門 診量 預 測模 型,本研究以中部某地區醫院 2000 年 1 月至 2004 年 12 月的月門 診量(共 60 筆)建立三類模型:第一種為單變量 ARIMA 模型, 第二種為轉換函數模型,第三種為政策介入影響的介入模型,分 別比較其結果及分析預測能力。 一、單變量 ARIMA 預測模型 ARIMA 分析的第一步是檢查數列的穩定性,沒有穩定性是 不能進行基本 ARIMA 模型化,故先將門診量原始資料繪成時序 圖(圖 4.1),檢查門診量數列( Q t )的穩定狀況,發現數列皆隨 時間緩慢上升和下降,具有高度自我相關上升和下降,逐漸攀升 的走勢,屬於非平穩型數列(non-stationary series)。. 圖 4.1. 每月門診量時序圖(89 年 1 月〜93 年 12 月). 53.
(54) 檢視 ACF 圖緩慢遞減至零,亦可判斷數列處於非平穩,需經 由一次差分(1-B) Q t 以求數列穩定性,其次由 Simplified EACF 鑑定模式,暫定 AR(1)為最佳模型(圖 4.3)。. 圖 4.2. 門診量 ACF 圖(89 年 1 月〜93 年 12 月). SIMPLIFIED EXTENDED ACF TABLE (5% LEVEL) (Q-->) 0 1 2 3 4 5 6 7 8 9 10 11 12 ---------------------------------------------------------------------------(P= 0) X X O O O O O O O O O O O (P= 1) O O O O O O O O O O O O O (P= 2) X O O O O O O O O O O O O (P= 3) X O O O O O O O O O O O O (P= 4) X O O O O O O O O O O O O (P= 5) X X O O O O O O O O O O O (P= 6) X X O O O O O O O O O O O 圖 4.3. 門診量 EACF 模型鑑定圖. 54.
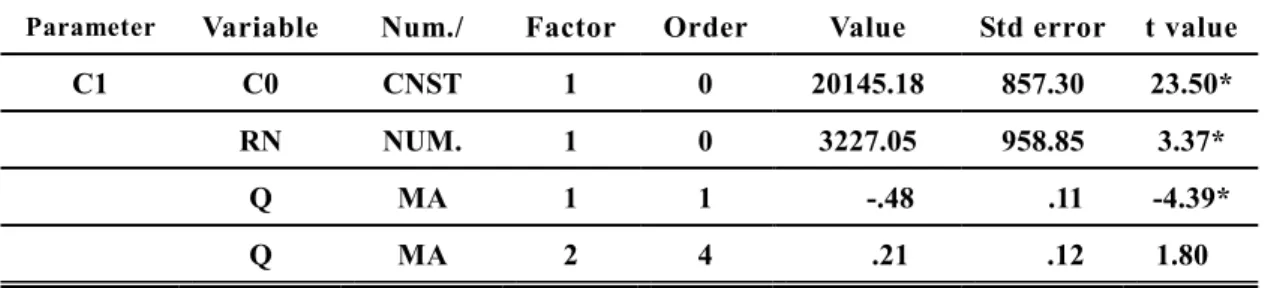
(55) 為避免離群值所產生的干擾,利用 SCA 軟體偵測分析,並未發 現,因此進行下個步驟參數之估算。估算之參數值如表 4.1,在 α=0.05 的水準下具有統計上顯著差異(t > 1.96) ,故單變量預測模. 型可寫成: Q t = 22821.40 - 0.55Q t-1 + at. 表 4.1 單變量模型參數估計表 Parameter Label. Variable. Num./. Name. Denom. 1 2. Q. Factor. Order. Value. Std error. t value. CNST. 1. 0. 22821.40. 721.80. 31.62*. D-AR. 1. 1. 0.55. 0.11. 5.15*. 註:* t-test , p<.05(t>1.96). 選定模式外,尚需檢驗殘差值以確定模式的合適性,其殘差 值需符合與統計無關、獨立、常態分佈等建構假設,具有相同的 期望值 µ 與變異數 σ ε2 ,即為白噪音(white nose)。 經由偵測殘差值的 ACF(圖 4.4)可以發現,僅在第 12 期略 為顯著,但期數較高可以忽略,整體察看殘差的 ACF 值,沒有特 別明顯的趨勢存在,因此認定已達白噪音的標準,亦表示此數列 模式應用在預測門診量是可被接受的。. 55.
(56) AUTOCORRELATIONS 1- 12 .00 -.10 .00 -.13 ST.E. .13 .13 .14 .14 Q .0 .6 .6 1.6 13- 24 -.18 -.03 .13 .14 ST.E. .17 .18 .18 .18 Q 25.3 25.4 26.8 28.4. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24. .00 -.32 .14 .14 1.6 8.3 .07 -.24 .18 .18 28.8 33.5. .06 .15 8.5 .02 .19 33.6. .06 -.03 -.21 -.06 .38 .15 .15 .15 .16 .16 8.8 8.8 12.1 12.3 22.8 -.03 .01 -.09 .07 .14 .19 .19 .19 .19 .19 33.7 33.7 34.4 34.8 36.9. -1.0 -0.8 -0.6 -0.4 -0.2 0.0 0.2 0.4 0.6 0.8 1.0 +----+----+----+----+----+----+----+----+----+----+ I 0.00 + I + -0.10 + XXXI + 0.00 + I + -0.13 + XXXI + 0.00 + I + -0.32 X+XXXXXXI + 0.06 + IXX + 0.06 + IX + -0.03 + XI + -0.21 + XXXXXI + -0.06 + XXI + 0.38 + IXXXXXXX+X -0.18 + XXXXXI + -0.03 + XI + 0.13 + IXXX + 0.14 + IXXX + 0.07 + IXX + -0.24 + XXXXXXI + 0.02 + IX + -0.03 + XI + 0.01 + I + -0.09 + XXI + 0.07 + IXX + 0.14 + IXXXX +. 圖 4.4. 單變量模型殘差項 ACF 圖. 56.
(57) 二、轉換函數模型 轉換 模式的本質 意在探討 時間數 列投入因 素與產 出變數 間 的因果關係,應用在本研究即探討門診量(產出)受到醫師數、 醫師平均年齡、科別數、診次數(投入)前幾期影響的可能性。 在建構轉換函數模型之前,必須先找出最佳的單變量 ARIMA 模型,才能達到預白化的效果。在假設產出與每個投入是二元隨 機過程,因此以下採用二元轉換函數分別建構模型,經 SCA 統計 軟體後的估算結果如下: (一)門診量與醫師數 應 用 SCA 的 轉 換 函 數 模 型 產 生 五 階 次 衝 擊 反 應 函 數 ( 表 4.2) ,偵測出門診量(Q)與醫師數(DN)之轉換函數基本 ARIMA 模型為 AR(1),且常數項與第二階次具有統計上的顯著差異。 表 4.2 門診量與醫師數之轉換函數模型初估表 Parameter. Variable. Num./. Label. Name. Denom. C1. Factor. Order. Value. Std error. t value. CNST. 1. 0. 12990.09. 3264.66. 3.98*. W0. DN. NUM.. 1. 0. -650.41. 682.65. -.95. W1. DN. NUM. 1. 1. -972.51. 796.72. -1.22. W2. DN. NUM. 1. 2. 1675.37. 842.11. 1.99*. W3. DN. NUM. 1. 3. 617.49. 838.01. .74. W4. DN. NUM. 1. 4. -360.14. 794.89. -.45. W5. DN. NUM. 1. 5. 158.60. 626.83. .25. Q. D-AR. 1. 1. .20. .14. 1.49. 註:* t-test , p<.05(t>1.96). 57.
(58) 為避免離群值所產生的干擾,利用 SCA 軟體偵測分析,發現第 26 及 41 期出現離群值,分別為春節及 SARS 所產生的效應(表 4.3) 。 表 4.3 離群值偵測及調整結果表 ---------------------------------------------------------------時點 估計值 T-值 型式 ---------------------------------------------------------------26 -6380.435 -3.57 IO 41 -5526.350 -3.66 TC -----------------------------------------------------------------. 將第 26 及 41 期剔除後重新估算(表 4.4),結果顯示常數項及 第二階次仍有統計上顯著意義(t > 1.96),因此可將模式修正為: Q t = 10516.36 + 588.65X t-2 + at. 表 4.4 修正後門診量與醫師數之轉換模型表 Parameter Label. Variable. Num./. Name. Denom. C1. Factor. Order. Value. Std error. t value. CNST. 1. 0. 10516.36. 2222.32. 4.73*. DN. NUM. 1. 2. 588.65. 100.05. 5.88*. Q. D-AR. 1. 1. .23. .13. 1.88. 註:* t-test , p<.05(t>1.96). 偵測殘差數列的 ACF(圖 4.5),顯示所有 ACF 值都在兩倍標準差 內,符合白噪音的標準,因此以上述模式除描述門診量與醫師數的關 係外,亦指門診量與落後兩期的醫師數有因果關係。. 58.
(59) AUTOCORRELATIONS 1- 12 ST.E. Q 13-24 ST.E. Q. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24. .06 -.01 .13 -.27 -.00 -.16 -.11 -.04 -.04 -.21 .01 .29 .13 .13 .13 .13 .14 .14 .15 .15 .15 .15 .15 .15 .2 .2 1.2 5.9 5.9 7.5 8.4 8.5 8.7 11.7 11.7 17.8 -.19 .06 .04 .00 .14 -.17 -.01 -.04 -.08 -.01 .14 .08 .16 .17 .17 .17 .17 .17 .17 .17 .17 .17 .17 .18 20.5 20.8 20.9 20.9 22.5 25.0 25.0 25.2 25.8 25.8 27.8 28.5 -1.0 -0.8 -0.6 -0.4 -0.2 0.0 0.2 0.4 0.6 0.8 1.0 +----+----+----+----+----+----+----+----+----+----+ I 0.06 + IX + -0.01 + I + 0.13 + IXXX + -0.27 XXXXXXXI + 0.00 + I + -0.16 + XXXXI + -0.11 + XXXI + -0.04 + XI + -0.04 + XI + -0.21 + XXXXXI + 0.01 + I + 0.29 + IXXXXXXX+ -0.19 + XXXXXI + 0.06 + IXX + 0.04 + IX + 0.00 + I + 0.14 + IXXX + -0.17 + XXXXI + -0.01 + I + -0.04 + XI + -0.08 + XXI + -0.01 + I + 0.14 + IXXXX + 0.08 + IXX +. 圖 4.5 門診量與醫師數轉換函數模型殘差項之 ACF 圖 59.
(60) (二)門診量與醫師平均年齡 應 用 SCA 的 轉 換 函 數 模 型 產 生 五 階 次 衝 擊 反 應 函 數 ( 表 4.5) ,偵測出門診量(Q)與醫師平均年齡(AGE)之轉換函數基 本 ARIMA 模型為 AR(1) ,且在僅有常數項具有統計上的顯著差 異( α = 0.05 )。 表 4.5 門診量與醫師平均年齡之轉換模型初估表 Parameter Label. Variable. Num./. Name. Denom. C1. Factor. Order. Value. Std error. t value. CNST. 1. 0. 45526.21. 23059.02. 1.97*. A0. AGE. NUM.. 1. 0. -332.41. 411.44. -.81. A1. AGE. NUM. 1. 1. -461.21. 413.72. -1.11. A2. AGE. NUM. 1. 2. 114.78. 426.55. .27. A3. AGE. NUM. 1. 3. 96.00. 426.31. .23. A4. AGE. NUM. 1. 4. -252.69. 411.82. -.61. A5. AGE. NUM. 1. 5. 248.14. 403.15. .62. Q. D-AR. 1. 1. .53. .12. 4.49*. 註:* t-test , p<.05(t>1.96). 為避免離群值所產生的干擾,利用 SCA 軟體偵測分析,發現第 26 期出現離群值,為春節所產生的效應(表 4.6)。 表 4.6 離群值偵測及調整結果表 ------------------------------------------------------------時點 估計值 T-值 型式 -------------------------------------------------------------26 -6111.227 -3.30 AO --------------------------------------------------------------. 60.
(61) 將第 26 期剔除後重新估算(表 4.7),結果顯示常數項及第一階 次有統計上顯著意義,因此可將模式表示為: Q t = 23247.49 +. 1 at (1- 0.44B). 表 4.7 修正後門診量與醫師平均年齡之轉換模型表 Parameter Label. Variable. Num./. Factor. Order. Value. Std error. t value. Name. Denom CNST. 1. 0. 23247.48. 702.49. 33.09*. Q. D-AR. 1. 1. .44. .13. 3.33*. Q. D-AR. 1. 2. .13. .14. .90. Q. D-AR. 1. 3. .16. .13. 1.27. Q. D-AR. 1. 4. -.14. .12. -1.19. C1. 註:* t-test , p<.05(t>1.96). 偵測殘差數列的 ACF(圖 4.6),顯示除第 12 期外,其餘 ACF 值都在兩倍標準差內,符合白噪音的標準,但因擬預估的變項(醫師 平均年齡)消失,因此以上述模式除描述門診量與醫師平均年齡的 關係外,亦指門診量與醫師平均年齡並無因果關係。. 61.
(62) AUTOCORRELATIONS 1- 12 ST.E. Q 13-24 ST.E. Q. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24. .04 -.09 .05 -.13 .14 -.09 .11 .06 -.05 -.20 -.01 .35 .13 .13 .13 .14 .14 .14 .14 .14 .14 .14 .15 .15 .1 .6 .7 1.8 3.1 3.6 4.4 4.6 4.8 7.5 7.5 16.7 -.17 .01 .08 .07 .12 -.20 -.00 -.06 -.09 -.05 .11 .09 .16 .17 .17 .17 .17 .17 .17 .17 .17 .17 .17 .18 18.9 18.9 19.4 19.8 21.0 24.4 24.4 24.7 25.4 25.7 27.0 27.8 -1.0 -0.8 -0.6 -0.4 -0.2 0.0 0.2 0.4 0.6 0.8 1.0 +----+----+----+----+----+----+----+----+----+----+ I 0.04 + IX + -0.09 + XXI + 0.05 + IX + -0.13 + XXXI + 0.14 + IXXX + -0.09 + XXI + 0.11 + IXXX + 0.06 + IX + -0.05 + XI + -0.20 + XXXXXI + -0.01 + I + 0.35 + IXXXXXX+XX -0.17 + XXXXI + 0.01 + I + 0.08 + IXX + 0.07 + IXX + 0.12 + IXXX + -0.20 + XXXXXI + 0.00 + I + -0.06 + XI + -0.09 + XXI + -0.05 + XI + 0.11 + IXXX + 0.09 + IXX +. 圖 4.6 門診量與醫師平均年齡轉換函數模型殘差項之 ACF 圖. 62.
(63) (三)門診量與科別數 應 用 SCA 的 轉 換 函 數 模 型 產 生 五 階 次 衝 擊 反 應 函 數 ( 表 4.8) ,偵測出門診量(Q)與科別數(SN)之轉換函數基本 ARIMA 模型為 AR(1),且常數項與第二階次衝擊反應函數在 α = 0.05 水 準下,具有統計上的顯著差異(表 4.9)。 表 4.8 門診量與科別數之轉換模型初估表 Parameter Label. Variable. Num./. Name. Denom. C1. Factor. Order. Value. Std error. t value. CNST. 1. 0. 13222.71. 4848.95. 2.73*. S0. SN. NUM.. 1. 0. -1003.70. 745.83. -1.35. S1. SN. NUM. 1. 1. -493.31. 741.07. -.67. S2. SN. NUM. 1. 2. 2295.66. 773.75. 2.97*. S3. SN. NUM. 1. 3. 311.61. 778.42. .40. S4. SN. NUM. 1. 4. 950.63. 748.44. 1.27. S5. SN. NUM. 1. 5. -1234.76. 731.20. -1.69. Q. D-AR. 1. 1. .13. 3.79*. .48. 註:* t-test , p<.05(t>1.96). 為避免離群值所產生的干擾,利用 SCA 軟體偵測分析,並未發 現出現離群值。因此可將模式表示為: Q t = 10140.94 +1076.63X t-2 + (1+ 0.46B)at. 表 4.9 門診量與科別數之轉換模型表 Parameter Label. Variable. Num./. Factor. Order. Value. Std error. t value. Name. Denom CNST. 1. 0. 10140.94. 3520.37. 2.88*. SN. NUM.. 1. 2. 1076.63. 295.01. 3.65*. Q. MA. 1. 1. -.46. .12. -3.92*. C1 S2. 註:* t-test , p<.05(t>1.96). 63.
(64) 偵測殘差數列的 ACF(圖 4.7),顯示所有 ACF 值都在兩倍標準 差內,符合白噪音的標準,因此以上述模式除描述門診量與科別數的 關係外,亦指門診量與落後兩期的科別數有因果關係。. 64.
(65) AUTOCORRELATIONS 1- 12 ST.E. Q 13-24 ST.E. Q. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24. -.01 .12 .22 -.23 .14 -.08 -.01 -.00 .02 -.11 .04 .27 .13 .13 .13 .14 .15 .15 .15 .15 .15 .15 .15 .15 .0 .9 3.9 7.4 8.7 9.2 9.2 9.2 9.2 10.1 10.2 15.9 -.25 .10 .04 -.06 .16 -.19 -.02 -.11 -.13 -.09 .05 -.07 .16 .17 .17 .17 .17 .17 .17 .17 .17 .18 .18 .18 20.5 21.3 21.4 21.7 24.0 27.2 27.2 28.2 29.8 30.6 30.9 31.3 -1.0 -0.8 -0.6 -0.4 -0.2 0.0 0.2 0.4 0.6 0.8 1.0 +----+----+----+----+----+----+----+----+----+----+ I -0.01 + I + 0.12 + IXXX + 0.22 + IXXXXX + -0.23 +XXXXXXI + 0.14 + IXXXX + -0.08 + XXI + -0.01 + I + 0.00 + I + 0.02 + IX + -0.11 + XXXI + 0.04 + IX + 0.27 + IXXXXXXX -0.25 + XXXXXXI + 0.10 + IXX + 0.04 + IX + -0.06 + XXI + 0.16 + IXXXX + -0.19 + XXXXXI + -0.02 + XI + -0.11 + XXXI + -0.13 + XXXI + -0.09 + XXI + 0.05 + IX + -0.07 + XXI +. 圖 4.7 門診量與科別數轉換函數模型殘差項之 ACF 圖. 65.
(66) (四)門診量與診次數 應 用 SCA 的 轉 換 函 數 模 型 產 生 五 階 次 衝 擊 反 應 函 數 ( 表 4.10) ,偵測出門診量(Q)與診次數(PN)之轉換函數基本 ARIMA 模型為 AR(1),且第 0 階次衝擊函數項具有統計上的顯著差異 (t > 1.96)。. 表 4.10 門診量與診次數之轉換模型初估表 Parameter Label. Variable. Num./. Name. Denom. C1. Factor. Order. Value. Std error. t value. CNST. 1. 0. 13897.90. 7315.10. 1.90. D0. PN. NUM.. 1. 0. 24.58. 8.00. 3.07*. D1. PN. NUM. 1. 1. -10.81. 8.07. -1.34. D2. PN. NUM. 1. 2. -9.37. 8.14. -1.15. D3. PN. NUM. 1. 3. 6.65. 8.18. .81. D4. PN. NUM. 1. 4. 13.59. 8.17. 1.66. D5. PN. NUM. 1. 5. -2.12. 8.14. -.26. Q. D-AR. 1. 1. .59. .11. 5.40*. 註:* t-test , p<.05(t>1.96). 為避免離群值所產生的干擾,利用 SCA 軟體偵測分析,發現第 41 期出現離群值,為 SARS 所產生的效應(表 4.11)。. 表 4.11 離群值偵測及調整結果表 ---------------------------------------------------------時點 估計值 T-值 型式 --------------------------------------------------------41 -7609.862 -3.52 IO ---------------------------------------------------------. 66.
(67) 將第 41 期剔除後重新估算(表 4.12) ,結果顯示常數項及當期有 統計上顯著意義( α = .05 ),因此可將模式修正為: Q t = 9936.93 + 32.94X +. 1 at (1- 0.66B). 表 4.12 修正後門診量與診次數之轉換模型表 Parameter Label. Variable. Num./. Name. Denom. C1 D0. Factor. Order. Value. Std error. T value. CNST. 1. 0. 9936.93. 3359.07. 2.96*. PN. NUM.. 1. 0. 32.94. 8.07. 4.08*. Q. D-AR. 1. 1. .66. .10. 6.79*. 註:* t-test , p<.05(t>1.96). 偵測殘差數列的 ACF(圖 4.8),顯示所有 ACF 值都在兩倍標準 差內,符合白噪音的標準,因此以上述模式除描述門診量與診次數的 關係外,亦指門診量與當期的診次數有因果關係。. 67.
(68) AUTOCORRELATIONS 1- 12 ST.E. Q 13-24 ST.E. Q. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24. -.18 .07 .03 -.22 .12 .02 -.06 .18 .02 -.02 -.00 .07 .13 .13 .13 .14 .14 .14 .14 .14 .15 .15 .15 .15 2.0 2.3 2.4 5.6 6.5 6.6 6.8 9.2 9.2 9.2 9.2 9.6 -.14 .08 -.05 .09 -.05 -.07 .08 -.14 .05 -.08 .06 .10 .15 .15 .15 .15 .15 .15 .15 .15 .16 .16 .16 .16 11.0 11.6 11.8 12.5 12.7 13.1 13.6 15.3 15.6 16.1 16.5 17.4 -1.0 -0.8 -0.6 -0.4 -0.2 0.0 0.2 0.4 0.6 0.8 1.0 +----+----+----+----+----+----+----+----+----+----+ I -0.18 +XXXXXI + 0.07 + IXX + 0.03 + IX + -0.22 +XXXXXXI + 0.12 + IXXX + 0.02 + I + -0.06 + XI + 0.18 + IXXXXX + 0.02 + IX + -0.02 + XI + 0.00 + I + 0.07 + IXX + -0.14 + XXXI + 0.08 + IXX + -0.05 + XI + 0.09 + IXX + -0.05 + XI + -0.07 + XXI + 0.08 + IXX + -0.14 + XXXI + 0.05 + IX + -0.08 + XXI + 0.06 + IX + 0.10 + IXX +. 圖 4.8 門診量與診次數轉換函數模型殘差項之 ACF 圖 68.
數據


相關文件
Dialogic inquiry, collaborative inquiry, community of inquiry.
蔣松原,1998,應用 應用 應用 應用模糊理論 模糊理論 模糊理論
在軟體的使用方面,使用 Simulink 來進行。Simulink 是一種分析與模擬動態
要上傳 NCBI 註解序列必須要做的流程為基因預測、rRNA 預測、跟 tRNA 預 測。做基因預測後還要做基因比對才可以上傳 NCBI,如圖 34 所示。在 NCBI
圖 2-13 顯示本天線反射損耗 Return Loss 的實際測量與模擬圖,使用安捷倫公司 E5071B 網路分析儀來測量。因為模擬時並無加入 SMA
樹、與隨機森林等三種機器學習的分析方法,比較探討模型之預測效果,並獲得以隨機森林
則巢式 Logit 模型可簡化為多項 Logit 模型。在分析時,巢式 Logit 模型及 多項 Logit 模型皆可以分析多方案指標之聯合選擇,唯巢式 Logit
二、 合院式建築以一般三合院 ,因三合院建築現在還普遍存在於一般的鄉 村中,且因規模小比較有人在使用
