考慮固定效果的隨機邊界模型概似函數之推導: Copula Functions之應用 - 政大學術集成
150
0
0
全文
(2) 謝辭 研究所兩年的生活終於劃上一個休止符,撰寫這篇論文讓我學到了很多,雖 然過程中經歷了不少辛苦,但獲得的我相信不僅僅是這個碩士學位而已,包括同 學、學長姐、助教、師長們都是讓我學習及反思的來源;特別要感謝鼎堯,求學 過程中能與你互相的討論想法、共同努力,讓我的思維及眼界都開闊了不少,還 有在我論文推導過程中貢獻良多的楙然,如果不是你的幫助及指點,我也無法踏 出那最初的一步,另外還有淑芳助教,以及在研究室陪我度過許多日子的大家, 感謝你們帶給我的歡笑以及幫助;感謝我的指導教授黃台心老師,老師對我而言. 政 治 大. 不僅僅是指導論文,更讓我深刻的看到了做學問的態度及該有的精神。. 立. ‧. ‧ 國. 奕淙 謹誌於. Nat. io. sit. y. 政治大學金融系碩士班 中華民國一○一年七月. n. al. er. 向前的動力。. 學. 謝謝盈竹以及我所愛的家人們,謝謝你們在我踟躕煩躁的時候,給了我繼續. Ch. engchi. I. i Un. v.
(3) 摘要 Greene (2005) 在縱橫資料型態下提出真實固定效果隨機邊界模型 (true fixed effect stochastic frontier analysis, TFESFA),該模型保留了傳統隨機邊界法之 架構並考量到廠商間之異質性問題,同時設定廠商之無效率項可隨時間改變。但 此模型假定不同廠商皆有特定之固定效果參數,當廠商家數多而資料觀察期間較 少時,會因待估參數過多而導致模型存在擾攘參數問題,產生估計偏誤 。 本研究利用 Tsay et al. (2009) 提出之方法,以錯誤函數 (error function) 之非 線性近似函數以及關聯結構函數 (copula function) 推導得到 TFESFA 模型經一. 政 治 大. 階差分轉換後組合誤差項之近似概似函數,成為本研究提出之差分隨機邊界模型. 立. (difference stochastic frontier model, DSFA) 模型,透過模擬過程生成平衡縱橫樣. ‧ 國. 學. 本及不平衡縱橫樣本,發現本研究提出之 DSFA 模型的確能在觀察期間較少時消. ‧. 除擾攘參數問題之影響。最後,本研究使用 TFESFA 模型及 DSFA 模型,配合投 入面距離函數來衡量俄羅斯銀行之技術效率,而 DSFA 模型亦能達到更良好之估. n. al. er. io. sit. y. Nat. 計效果。. Ch. engchi. i Un. v. 關鍵詞:隨機邊界法;固定效果模型;關聯結構函數;距離函數. II.
(4) 目錄 第一章 緒論 ............................................................................................................... 1 1.1 研究動機與目的 ......................................................................................... 1 1.2 研究架構 ..................................................................................................... 2 第二章 文獻回顧 ....................................................................................................... 3 2.1 效率之定義 .................................................................................................. 3 2.2 隨機邊界模型相關文獻 .............................................................................. 5 2.3 關聯結構函數相關文獻 ............................................................................ 10 2.4 距離函數相關文獻 .................................................................................... 11 2.5 文獻統整 .................................................................................................... 13. 政 治 大 3.1 研究模型介紹 ............................................................................................ 17 立 3.2 差分隨機邊界模型 .................................................................................... 19. 第三章 研究方法 ..................................................................................................... 17. ‧ 國. 學. 3.2.1 模型定義 ............................................................................................. 19 3.2.2 一階差分模型推導 ............................................................................. 20. ‧. 3.2.3 關聯結構函數之應用 ......................................................................... 27 3.3 考慮環境變數之固定效果模型 ................................................................ 30. y. Nat. sit. 第四章 模擬分析 ...................................................................................... .............. 38. al. er. io. 4.1 平衡縱橫資料模擬 .................................................................................... 38. n. 4.2 不平衡縱橫資料模擬 ................................................................................ 49. Ch. i Un. v. 4.3 考慮環境變數之模擬分析.......................................................................... 53. engchi. 第五章 實證分析 ..................................................................................................... 56 5.1 實證模型介紹 ............................................................................................ 56 5.2 資料處理及變數定義 ................................................................................ 58 5.3 實證估計結果 ............................................................................................ 59 5.4 穩健度分析 ……….................................................................................... 66 第六章 結論及建議 ................................................................................................. 72 6.1 結論 ............................................................................................................ 72 6.2 未來研究方向 ............................................................................................ 73 參考文獻 ................................................................................................................... 74. III.
(5) 表目錄 表 2-1 隨機邊界模型演進文獻整理 ......................................................................... 13 表 2-2 關聯結構函數於隨機邊界模型應用文獻整理 ............................................. 15 表 2-3 隨機邊界模型演進文獻整理 ......................................................................... 15 表 3-1 差分組合誤差項之近似封閉解及原始公式之誤差值 ................................. 22 表 3-2 差分組合誤差項之機率密度函數及累積分配函數之近似封閉解誤差值....26 表 3-3 考慮環境變數之差分組合誤差項近似解及原始公式之誤差值 ................ 34 表 4-1 DSFA 模型模擬結果. ........................................................... 40. 表 4-2 DSFA 模型模擬結果. ........................................................ 43. 表 4-3 DSFA 模型模擬結果. ........................................................ 46. 政 治 大 ............................. 51 表 4-5 不平衡縱橫資料 DSFA 模型模擬結果 ............................. 52 立 表 4-6 考慮環境變數之差分模型模擬結果 ............................................................ 54 表 4-4 不平衡縱橫資料 DSFA 模型模擬結果. ‧ 國. 學. 表 5-1 變數定義 ......................................................................................................... 58 表 5-2 變數敘述統計量 ............................................................................................. 58. ‧. 表 5-3 樣本觀察值個數 ............................................................................................. 59 表 5-4 TFESFA 模型係數估計結果 ......................................................................... 60. y. Nat. sit. 表 5-5 DSFA 模型係數估計結果 ............................................................................. 61. al. er. io. 表 5-6 效率值估計結果 ............................................................................................. 62. n. 表 5-7 效率值估計結果-以規模分組......................................................................... 65. Ch. i Un. v. 表 5-8 縮減資料下 TFESFA 模型係數估計結果 ................................................... 66. engchi. 表 5-9 縮減資料下 DSFA 模型係數估計結果 ....................................................... 67 表 5-10 縮減資料下效率值估計結果 ....................................................................... 68 表 5-11 縮減資料下效率值估計結果-以規模分組................................................... 70. IV.
(6) 圖目錄 圖 2-1 從投入面衡量效率 .......................................................................................... 4 圖 2-2 投入面距離函數衡量 .................................................................................... 11 圖 3-1 差分組合誤差機率密度近似函數圖. .................................... 23. 圖 3-2 考慮環境變數之差分組合誤差機率密度近似函數圖 ........................................................................ 35 圖 3-3 考慮環境變數之差分組合誤差機率密度近似函數圖 .............................................................. 36 圖 5-1 TFESFA 模型效率平均值歷年趨勢圖 .......................................................... 63 圖 5-2 DSFA 模型效率平均值歷年趨勢圖 .............................................................. 63. 政 治 大 圖 5-4 DSFA 模型效率平均值歷年趨勢圖-以股權結構分組 ................................ 64 立 圖 5-5 效率值估計趨勢圖-以規模分組 ................................................................... 65 圖 5-3 TFESFA 模型效率平均值歷年趨勢圖-以股權結構分組 ............................ 64. ‧ 國. 學. 圖 5-6 縮減資料下 TFESFA 模型效率平均值歷年趨勢圖 ................................... 68 圖 5-7 縮減資料下 DSFA 模型效率平均值歷年趨勢圖 ....................................... 69. ‧. 圖 5-8 縮減資料下 TFESFA 模型效率平均值歷年趨勢圖-以股權結構分組 ...... 69 圖 5-9 縮減資料下 DSFA 模型效率平均值歷年趨勢圖-以股權結構分組 ........... 70. y. Nat. n. al. er. io. sit. 圖 5-10 縮減資料下效率值估計趨勢圖-以規模分組 ............................................. 71. Ch. engchi. V. i Un. v.
(7) 第一章 緒論 1.1 研究動機與目的 Greene (2005) 在縱橫資料型態下提出真實固定效果隨機邊界模型 (true fixed effect stochastic frontier analysis, TFESFA),該模型保留了傳統隨機邊界法之 架構並考量到廠商間之異質性問題,同時設定廠商之無效率項可隨時間改變。由 於此模型假定不同廠商皆有特定之固定效果參數,當廠商家數多而資料觀察期間 較少時,會因模型待估參數 (固定效果參數) 過多而導致估計存在偏誤,此即. 政 治 大. Neyman and Scott (1948) 所提出之擾攘參數問題 (incidental parameter. 立. problem)。. ‧ 國. 學. 為避免擾攘參數問題,可採用一階差分法或組內估計法等轉換方式消去固定 效果項,進而得到具備一致性的係數估計量;但在隨機邊界模型具有組合誤差之. ‧. 架構下,我們無法導得 TFESFA 模型經過轉換後組合誤差項機率密度函數之封閉. sit. y. Nat. 解,因而無法使用最大概似法進行估計。Wang and Ho (2010) 透過將 TFESFA 模. io. er. 型內無效率項之假設為特定之函數型式,可導出此模型一階差分法及組內估計法. al. iv n C hengchi U 之非線性近似函數以及關聯結構函數. n. 兩種模型轉換後誤差項之概似函數。本研究則利用 Tsay et al. (2009) 提出之方法, 以錯誤函數 (error function). (copula. function) 推導得到 TFESFA 模型經一階差分轉換後組合誤差項之近似概似函數, 成為本研究提出之 difference stochastic frontier model (DSFA) 模型,同時參考 Battese and Coelli (1995) 之模型設計,推導求得考慮環境變數下之近似概似函 數。 透過模擬過程生成平衡縱橫樣本及不平衡縱橫樣本,發現本研究提出之 DSFA 模型的確能在觀察期間較少時消除擾攘參數問題之影響。最後,本研究使 用 TFESFA 模型及 DSFA 模型,配合投入面距離函數來衡量俄羅斯銀行之技術效 率,而 DSFA 模型亦能達到更良好之估計效果。 1.
(8) 1.2 研究架構 本論文共分六章;第一章為緒論,說明研究動機、目的,第二章介紹隨機邊 界模型之相關文獻,第三章介紹主要使用之研究模型及轉換方法,第四章則透過 模擬來驗證與比較原始模型及轉換模型之估計效果,第五章進行實證分析,利用 俄羅斯銀行業資產負債表和損益表中的資料,分析與比較兩種模型估計結果之異 同,第六章為結論並提出後續研究之建議。茲將本研究流程圖繪製如下:. 緒論. 立. 政 治 大. Nat. y. ‧. ‧ 國. 學. 文獻回顧. n. er. io. al. sit. 研究方法. Ch. engchi. i Un. 模型模擬. 實證資料及結果分析. 結論. 2. v.
(9) 第二章 文獻回顧 本研究之目的在於透過近似錯誤函數以及關聯結構函數 (copula function), 推導一階差分轉換後 TFESFA 模型之概似函數,成為本文提出之 DSFA 模型,並 進行模擬分析,最後使用投入面距離函數與俄羅斯銀行業資料,估計和比較 TFESFA 模型以及 DSFA 模型在技術效率方面之差異。本章首先介紹生產效率之 定義以及衡量方法;其次回顧衡量生產效率之隨機邊界模型相關文獻;接著介紹 本研究使用之關聯結構函數及投入面距離函數應用於隨機邊界模型相關文獻。. 2.1 效率之定義. 政 治 大 Farrel (1957) 提出之生產效率概念為:在投入要素的不同水準組合下,可找 立. ‧ 國. 學. 出一最大產出邊界,即生產邊界 (production frontier),若廠商之產出水準落在此 生產邊界上,廠商即具有生產效率。由於生產邊界代表在既定的技術水準下,不. ‧. 同產出對應之最小投入或是不同投入對應之最大產出所形成之邊界,Farrel 建議. sit. y. Nat. 以此生產邊界來進行效率之衡量,可從投入面 (input-oriented) 及產出面. io. er. (output-oriented) 兩種角度來進行。固定產出水準,最少要素投入與實際投入之. al. iv n C hengchi U 值,即為產出面技術效率值,無論投入面或產出面技術效率值,皆介於 0與1 n. 比值,即為投入面技術效率值;而固定要素投入水準,實際產出與最大產出之比. 之間。Farrel 進一步將生產效率分解為技術效率 (technical efficiency) 及配置效 率 (allocative efficiency) 等兩種,技術效率可從上述投入面及產出面兩種角度進 行衡量,而當要素之邊際替代率等於投入要素之價格比時,即滿足配置效率。 圖 2-1 以投入面效率為例說明,橫軸與縱軸分別為. 及. 的要素投入量 ,I. 代表某產出水準的等產量曲線,為所有滿足技術效率之要素組合連線,假設 A 點為實際要素使用量,將原點 O 與 A 點做射線連接,交等產量曲線於 B 點,技 術效率值. 即為. ,當實際要素使用量 A 點就在等產量線 I 上時,技術效. 率值為 1,代表要素投入達到技術效率。若要素投入價格已知時,便可進一步分 3.
(10) 析配置效率;與等產量線 I 相切於 C 點之直線 格比,而配置效率值. 即為. 為等成本線,其斜率為要素價. ,當等成本線與等產量線相切之點為 B 點時,. 配置效率值為 1,代表滿足配置效率;整體經濟效率值 EE 則為. 。. 政 治 大 圖 2-1 從投入面衡量效率 立. O. ‧ 國. 學. 為衡量生產效率,首先需估計邊界函數如成本函數、利潤函數、生產函數或 距離函數等。估計邊界函數之方法,從函數型式設定之角度可分為參數法. ‧. (parametric approach) 及非參數法 (non-Parametric approach) 等兩種,參數法需對. Nat. sit. y. 邊界函數之型式予以設定,並藉由經濟計量方法估計此邊界函數之參數,進而得. n. al. er. io. 以求算各樣本廠商的技術效率值;非參數法則不需預設函數之型式,利用數理規. i Un. v. 劃法估計各樣本廠商的技術效率值。從是否有隨機誤差項之設定,可分為確定性. Ch. engchi. 邊界及隨機性邊界,隨機性邊界中的隨機誤差項即代表非人為可控制之干擾因素, 如天災、戰爭、政治因素等等。換言之,確定性邊界是建立在生產條件均處於最 佳狀態之假設,而隨機性邊界則將生產條件之不確定性納入模型當中。 前在衡量效率之方法中,主要以 Aigner et al. (1977) 和 Meeusen and Van Den Broeck (1977) 提出之隨機邊界法 (stochastic frontier analysis, SFA) 以及 Charnes et al. (1978) 提出之資料包絡法 (data envelopment analysis, DEA) 最為常見,後 續模型演伸及發展也最為成熟。本研究即針對隨機邊界模型中,Greene (2005) 提 出之 TFESFA 模型進行討論,下節以生產函數為例,介紹隨機邊界法之模型發展 及演進。 4.
(11) 2.2 隨機邊界模型相關文獻 Aigner et al. (1977) 和 Meeusen and Van Den Broeck (1977) 首先從橫斷面資 料架構下,提出隨機邊界模型之概念,模型設定如下:. 其中. 為產出,. 含有隨機誤差項. 為投入要素向量, 即為隨機邊界模型特有之組合誤差項, 及無效率項. 假設為雙邊常態分配,而. 立則為生產過程中發生之技術無效率,導致產出減少。. 必須假設為非負值,例如半常態分配。. ‧ 國. 學. 因此. 政 治 大. , 代表生產過程中非人為可控制之干擾因素,. 而隨著計量模型的發展,後續出現縱橫資料 (panel data) 模型,此資料包括. ‧. 多個廠商多個觀察期間的樣本觀察值,比起早期橫斷面資料,蘊含較多訊息。Pitt. Nat. sit. y. and Lee (1981) 提出了隨機效果模型,將 Aigner et al. (1977) 之隨機邊界模型擴. n. al. er. io. 展至縱橫資料架構下,此模型設定為:. Ch. engchi. i Un. v. 假定廠商之無效率項為非時變性 (time-invariant),亦即同一廠商之無效率表現是 不隨時間變動的,僅在個別廠商間有所區別;Schmidt and Sickles (1984) 則提出 了固定效果模型,相對於隨機效果模型將 視為待估計參數,其設定為:. 5. 設定為隨機變數,固定效果模型將.
(12) 無效率項估計式. 則為. ,在此模型中,由於無效率項是透過. 各廠商之截距項相互比較得出,因此必存在一最小截距項 ,即相對最有效率之 廠商,其效率值為. ,其餘各廠商的效率值介於 0 與一之間。. 上述之隨機效果模型及固定效果模型,皆設定廠商之效率不隨時間改變,但理論 上隨著經營期間的增加,有可能會產生技術變化或學習效果而使經營效率改變,. 政 治 大. 如此一來非時變性之無效率項假設顯得不甚合理。. 立. 為了將廠商之學習效果或技術變化之現象納入模型考量,Cornwell et al.(1990). ‧ 國. 數,即. 重新設定為時間趨勢之二次函. 學. 將 Schmidt and Sickles (1984) 模型內之截距項. ,意即隨著時間趨勢二次項係數. 正負號的不同,. ‧. 廠商之技術變化可能有先增後減或先減後增之差異。. Nat. sit. n. al. er. io. 時變性:. y. Battese and Coelli (1992) 則提出下述隨機效果模型之延伸,考慮無效率項之. 此模型中,無效率項. Ch. engchi. i Un. v. 為一包含時間趨勢項之函數; 為待估參數,當. 時,. 代表無效率表現會逐年遞減,技術效率隨時間經過逐年上升,存在正面學習效果; 當. 時,代表無效率表現會逐年遞增,技術效率隨時間經過逐年退步。. Kumbhakar (1990) 則建議可將無效率項. 6. 設計為.
(13) ,Lee and Schmidt (1993) 則建議將無效率項 之函數,即. ,而. 設定為時間虛擬變數. ,但相較於前兩模型之設計,在此. 模型中當觀察期間 T 越多時,模型待估參數. 也會跟著增加。. 上述之隨機邊界模型,皆隱含了廠商條件為同質性 (Homogeneous) 之假設, 但實際上,各廠商卻是處於異質性 (Heterogeneous) 的營運環境,即便是在相同 生產條件、相同規模、相同投入水準的兩廠商,最終產出仍可能不同。此生產水 準之不一致並不能完全歸因於經營效率之表現差異,往往是由於外部環境因素或 其他異質性條件之影響。Battese and Coelli (1995) 根據此概念,將無效率項設計 為環境變數之函數,藉此將異質性影響納入隨機邊界模型中,模型設定為:. 立. 政 治 大. ‧ 國. ‧ sit. y. Nat. 即為外部之環境變數向量,代表廠商之無效率表現. 會受到環境變數. io. er. 其中. 學. 故. al. iv n C hengchi U 不同之處在於,此模型並未對無效率項之時變趨勢做出假設, n. 之影響;此模型除了考量廠商異質性,同時也考慮了無效率項之時變性,與 Battese and Coelli (1992). 廠商在觀察期間內之無效率變動並非一定為遞增或遞減之型式。 Caudill et al. (1995) 提出另一種廠商異質性之考量方式,認為廠商之無效率 項可能存在異質之變異數,成為:. 其中. 通常設定為與廠商規模有關之環境變數向量,並進而影響廠商之無效率 7.
(14) 項變異數;Hadri et al. (2003) 則認為不僅無效率項 誤差項. 會存在異質變異數,對稱. 也會存在異質異質變異數,模型修改為:. 除了將對稱誤差項加上異質變異數假設外,Hadri et al.(2003)也認為對稱誤差項 是受到規模環境變數. 影響,無效率項. 則是受到管理面環境變數. 之影. 政 治 大 Tsionas (2002) 認為將廠商之異質性會影響投入要素的係數值,即: 立. 響,而與 Caudill et al. (1995) 之模型有所區別。. ‧. ‧ 國. 學 sit. n. al. er. 的係數向量,並假設為多維常態分配,因此在投入資料. io. 即為投入要素. y. Nat. 其中. 個數上升時,多元常態變異數矩陣. Ch. i Un. v. 之維度會上升,而使. engchi. 之分配結構難以估. 計。根據此模型,Huang (2004) 假設僅有部分投入要素的係數值會受到廠商異質 性影響,模型設定須改為:. 代表會受廠商異質性影響之投入要素,其對應之參數向量. 則假設平均數為. 0 之多元常態分配。另外,Tsionas (2002) 及 Huang (2004) 分別假設無效率項之. 8.
(15) 分配為指數分配及伽瑪分配下進行模型模擬。 Greene (2005) 有別於以往之隨機邊界模型,將廠商之異質性直接納入截距 項參數,容許模型同時包含固定效果與技術無效率項,稱為"真實"固定效果隨機 邊界模型 (true fixed effect stochastic frontier analysis, TFESFA),其模型設定為:. 政 治 大 時變趨勢做假設,由於此模型所需假設較少,因此能對各廠商做出較為客觀及合 立. 此模型同時考量了廠商之異質性以及無效率項之時變性,且並不需對無效率項之. ‧ 國. 學. 理之效率評估。. 然而,實證上 Greene (2005) 之 TFESFA 模型若使用虛擬變數代表固定效果,. ‧. 往往在觀察期間過少時易受到擾攘參數問題之影響,而使估計式存在偏誤。Wang. y. sit. io. n. al. er. 加以修改,成為:. Nat. and Ho (2010) 將環境變數之影響納入 TFESFA 模型中,並將無效率項分配假設. Ch. engchi. i Un. v. 透過此一修改後,上述之模型便能利用一階差分法或組內估計法等模型轉換來解 決擾攘參數問題,並導得其模型概似函數。 綜觀隨機邊界文獻之演進,可以發現各種考量廠商異質性以及無效率項隨時 間變異性之模型逐漸發展完備,目前以 Greene (2005) 之 TFESFA 模型較受實證 研究者的注意。 9.
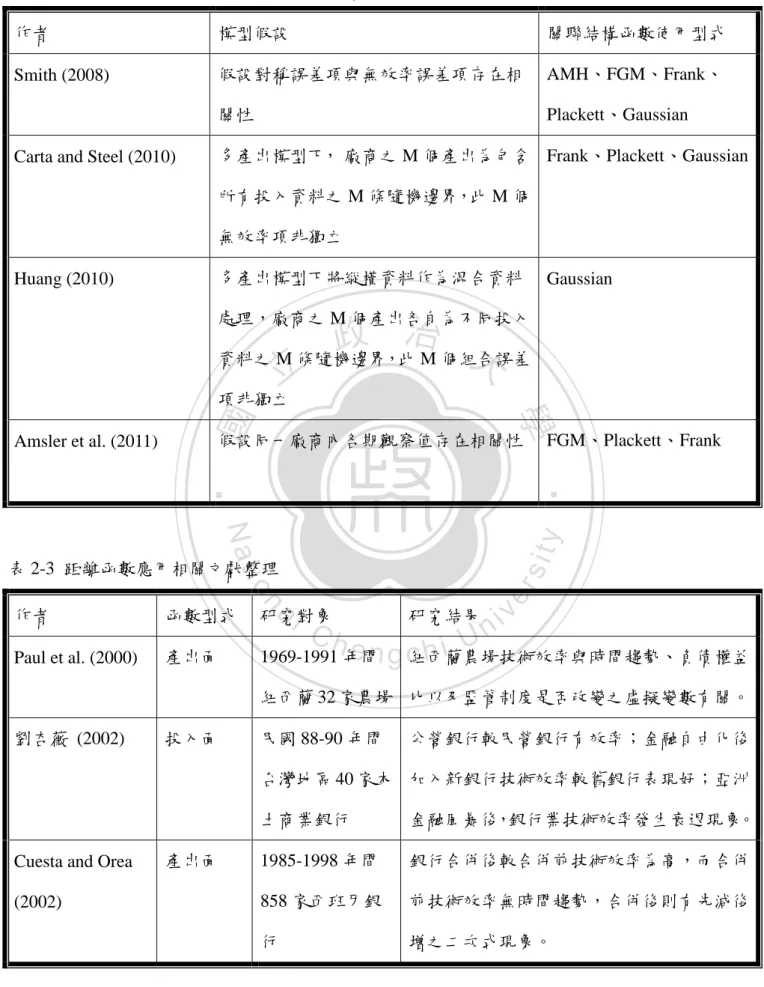
(16) 2.3 關聯結構函數相關文獻 由於本研究需利用關聯結構函數來衡量一階差分組合誤差之相關性,本節介 紹過去將關聯結構函數應用於隨機邊界模型之相關文獻。在傳統隨機邊界模型中 存在許多獨立性假設,如 (1) 對稱誤差項與無效率誤差項為獨立;(2) 第 i 廠商 各期觀察值為獨立;(3) 廠商間彼此獨立。在上述之獨立性假設成立下,便能直 接用連乘之方式得到概似函數。當獨立性假設不成立時,過去文獻曾利用不同之 關聯結構函數來描述其相關性,進一步求得概似函數。 Smith (2008) 將對稱誤差項. 與效率誤差項. 設定為羅吉斯分配. 政 治 大 AMH、FGM、Frank、Plackett、Gaussian 等關聯結構函數來比較衡量橫斷面資料 立 (logistic) 與指數分配,在假設對稱誤差項與無效率誤差項存在相關性時,使用. ‧ 國. 學. 下美國電力產業之成本效率值。Amsler et al. (2011) 考慮廠商各期觀察值存在相 關性之隨機邊界模型,並假設當廠商兩期觀察值相關性存在時,模擬比較使用. ‧. FGM、Plackett、Frank 等三種關聯結構函數與兩期獨立時之最大概似法估計值,. sit. y. Nat. 發現在大樣本下,使用關聯結構函數之估計值存在一致性。. io. er. 傳統隨機邊界模型通常為單一產出模型,Carta and Steel (2010) 則在多產出. al. v. n. 模型下做非獨立性之假設,在多產出模型架構時,Carta and Steel (2010) 設定 M. i n C U hengchi 個產出各自包含所有投入資料之隨機邊界,即為:. 此多產出模型假設第 i 個廠商在生產 M 個產出時各自之無效率項. 並非獨立,. 進而利用多種關聯結構函數實證應用於荷蘭農場之雙產出縱橫資料。 Huang (2010) 則設定另一種多產出模型型式,假設廠商有 M 個產出,各自 由廠商內不同部門所生產,則不同產出各自為不同投入資料之隨機邊界函數,並 將縱橫資料當做混合資料 (poolling data) 處理,模型設定為: 10.
(17) 此模型假設 M 個產出間各自之組合誤差項. 彼此相關,因同一廠商內不同部門. 雖然投入產出不同,但仍存在某種生產相關性。Huang (2010) 以 Gaussian 關聯 結構函數來衡量此一相關性,透過模擬後發現當存在相關性時,傳統最大概似估 計式會偏誤,而關聯結構概似函數則能得到一致性之估計結果。. 2.4 距離函數相關文獻. 立. 政 治 大. 學. ‧ 國. 本文的實證分析,將利用投入面距離函數配合 TFESFA 模型及 DSFA 模型, 衡量俄羅斯銀行之經營效率。本節以圖 2-2 介紹投入面距離函數之基本概念,圖 及. 要素的投入量,I 代表產量等於 y 的等產量曲線,等. ‧. 中橫軸與縱軸分別為. 產量線 I 右上方區域代表固定產出量為 y 時所有可行之要素投入集合. Nat. y. ; 點. ,投入面距離函數表示為. n. al. Ch. ,與投入面效率值. i Un. 呈倒數關係。. engchi. O 圖 2-2 投入面距離函數衡量. 11. er. io. 素投入組合. sit. 為實際要素投入,將實際要素使用量等比例減少 倍後,可得滿足技術效率之要. v. ,且.
(18) Paul et al. (2000) 使用產出面距離函數分析監管制度改變對 1969-1991 年間 紐西蘭 32 家農場效率及生產力的影響,結果發現紐西蘭農場之技術效率與時間 趨勢、財務面變數(負債權益比)以及監管制度是否改變之虛擬變數有關;另外監 管制度的改變也使得農場之生產組合在這段期間從羊毛及羊肉轉向牛肉與鹿肉, 而與技術無效率關連性較低。 Cuesta and Orea (2002) 用產出面距離函數及 Battese and Coelli (1992) 隨機 邊界模型分析 1985-1998 間 858 家(包含合併前 726 家及合併後 132 家)西班牙銀 行資料,觀察銀行合併對技術效率之影響;但模型容許無效率項可以有非單調 (non-monotonicity) 之趨勢,結果發現銀行合併後較合併前技術效率為高,而合. 政 治 大. 併前技術效率無時間趨勢,合併後則有先減後增之二次式現象。. 立. 劉杏薇 (2002) 利用投入面距離函數分析民國 88-90 年間台灣地區的 40 家本. ‧ 國. 學. 土商業銀行,探討公民營組織特性、金融自由化、亞洲金融風暴等因素對銀行技. ‧. 術效率的影響。結果發現公營銀行較民營或營運未成熟之銀行有效率,金融自由 化後加入之新銀行技術效率較舊銀行表現好,且亞洲金融風暴後,銀行業之技術. y. Nat. er. io. sit. 效率發生衰退之現象。. Karagiannis et al. (2004) 利用 Bauer (1990) 以成本函數之總要素生產力分解. n. al. Ch. i Un. v. 及成本函數和距離函數之對偶關係,將投入面距離函數之總要素生產力拆解為規. engchi. 模效果、技術改變、技術效率改變、配置效率改變;並利用自然對數(translog) 型式之投入面距離函數,分析 1983-1992 年間 121 間英國畜牧場資料。 李明宗 (2005) 以民國 85-93 年間 34 家台灣地區上市櫃銀行為研究對象,探 討造成銀行無效率的主要因素,分析樣本銀行歷年來效率走勢及技術變動,並納 入風險與放款品質變數,探討成立金控公司對銀行在效率與風險水準的表現,是 否有顯著不同。結果發現系統風險與放款品質變數是造成無效率的主要因素,而 在成立金控前後,銀行效率與風險水準皆有顯著差異。 Kumbhakar and Wang (2007) 以 1993-2002 年間 14 家中國銀行,研究銀行所. 12.
(19) 有權、資本適足率、銀行規模及其他環境因子是否會對銀行效率造成影響。藉由 拆解總要素生產力為規模效果、技術改變、技術效率改變以及其他環境變數因子 造成的改變,分析總要素生產力變動的走勢。結果發現公營銀行效率較差,生產 力成長主要來自於規模效果;而民營銀行效率與規模呈反向關係,生產力成長來 自於技術改變以及技術效率改變。 張佩茹 (2008) 配合 Battese and Coelli (1995) 之模型衡量 2004 年第一季至 2008 年第三季 17 家台灣上市櫃證券商的技術效率,並以投入導向一般化 Malmquist 生產力指數來分析生產力變動情形。結果顯示小型券商之經營效率平 均而言比大型券商之經營效率高。而股價愈高的證券商經營效率較高,可能是由. 政 治 大. 於在相同的投入之下有較多的產出表現,且較有能力調整生產規模至規模報酬較. 立. 佳的生產狀況。. ‧. ‧ 國. 學. 2.5 文獻統整. sit. y. Nat. 本節以表格型式,將本章回顧之文獻做統整如下列表 2-1 ~ 表 2-3。. io Aigner et al. (1977),Meeusen. al. n. 作者. er. 表 2-1 隨機邊界模型演進文獻整理 模型型式. Ch. engchi. and Van Den Broeck (1977) Pitt and Lee (1981) Schmidt and Sickles (1984). Cornwell et al.(1990). Battese and Coelli (1992). 13. i Un. v. 模型備註.
(20) 表 2-1 隨機邊界模型演進文獻整理(續) 作者. 模型型式. 模型備註. Kumbhakar (1990). Lee and Schmidt (1993). 為時間之虛擬變數. Battese and Coelli (1995). 為環境變數向量. Caudill et al. (1995). 立. 為與廠商規模相關之. ‧ 國. 為與管理. ‧. 面相關之變數向量. y. sit. n. al. er. io. Huang (2004). 變數向量. 變數向量,. Nat. Tsionas (2002). 為與廠商規模相關之. 學. Hadri et al. (2003). 政 治 大. Ch. engchi. i Un. v. 為多維常態分配, 假設為指數分配 為會受廠商異質性影 響之投入要素,. 假設. 為伽瑪分配 Greene (2005) 為環境變數向量. Wang and Ho (2010). 14.
(21) 表 2-2 關聯結構函數於隨機邊界模型應用文獻整理 作者. 模型假設. 關聯結構函數使用型式. Smith (2008). 假設對稱誤差項與無效率誤差項存在相. AMH、FGM、Frank、. 關性. Plackett、Gaussian. Carta and Steel (2010). 多產出模型下, 廠商之 M 個產出為包含 Frank、Plackett、Gaussian 所有投入資料之 M 條隨機邊界,此 M 個 無效率項非獨立. Huang (2010). 多產出模型下將縱橫資料作為混合資料. Gaussian. 處理,廠商之 M 個產出各自為不同投入. 治 政 大 資料之 M 條隨機邊界,此 M 個組合誤差 立 項非獨立. ‧ 國. 學. Amsler et al. (2011). 假設同一廠商內各期觀察值存在相關性. FGM、Plackett、Frank. ‧ sit. y. Nat. 作者. 函數型式. n. al. er. io. 表 2-3 距離函數應用相關文獻整理. Paul et al. (2000). 產出面. 1969-1991 年間. 研究對象. Ch. i Un. 研究結果. v. e n g c紐西蘭農場技術效率與時間趨勢、負債權益 hi. 紐西蘭 32 家農場 比以及監管制度是否改變之虛擬變數有關。 劉杏薇 (2002). 投入面. 民國 88-90 年間. 公營銀行較民營銀行有效率;金融自由化後. 台灣地區 40 家本 加入新銀行技術效率較舊銀行表現好;亞洲. Cuesta and Orea (2002). 產出面. 土商業銀行. 金融風暴後,銀行業技術效率發生衰退現象。. 1985-1998 年間. 銀行合併後較合併前技術效率為高,而合併. 858 家西班牙銀. 前技術效率無時間趨勢,合併後則有先減後. 行. 增之二次式現象。. 15.
(22) 表 2-3 距離函數應用相關文獻整理(續) 作者. 函數型式. 研究對象. 研究結果. Karagiannis et al.. 投入面. 1983-1992 年間. 總要素生產力增加顯著來自於規模效果、技. 121 家英國畜牧. 術進步、技術效率改變、配置效率改變,而. 場. 技術效率改變為主要因子。. 民國 85-93 年間. 系統風險與放款品質變數是造成無效率的主. 34 家台灣地區上. 要因素,而在銀行成立金控前後,銀行效率. 市櫃銀行. 與風險水準皆有顯著差異。. (2004). 李明宗 (2005). Kumbhakar and. 投入面. 投入面. 1993-2002 年間. 公營銀行效率較差,生產力成長主要來自於 治 政 規模效果;民營銀行效率與規模呈反向關 大 14 家中國銀行 立. Wang (2007). 率改變。 2004 年第一季至. 小型券商之經營效率平均而言比大型券商之. ‧. 家台灣上市櫃證. io. al. sit. y. Nat. 2008 年第三季 17 經營效率高。股價愈高的證券商經營效率較 高。. er. 投入面. 學. 張佩茹 (2008). ‧ 國. 係,生產力成長來自於技術改變以及技術效. n. 券商. Ch. engchi. 16. i Un. v.
(23) 第三章 研究方法 3.1 研究模型介紹 Greene (2005) 在縱橫資料架構下提出真實固定效果隨機邊界模型 (true fixed effect stochastic frontier analysis, TFESFA),假設廠商家數為 N,觀察期數為 T 之 TFESFA 模型架構如下:. (3-1). 政 治 大. 立. ‧ 國. 學. 其中. 為未知常數,代表不同廠商之異質性固定效果, 為待估參數向量,. ‧. 為具常態分配之隨機誤差項,. 代表第 i 家廠商在第 t 年之技術無效率,為. Nat. sit. y. 一半常態之隨機變數,當估計模型為生產函數或利潤函數時, 設定為 1;若為. n. al. 即為隨機邊界模型特有之組合誤差項,以. er. io. 成本函數時, 則設定為-1, 代表。此模型之特點為: (1) 考量廠商間之異質性, (2) 容許廠商之固定效果. Ch. engchi. 與解釋變數. i Un. v. 間具有相關性,. (3) 容許廠商之無效率項可隨時間改變。 由 Aigner et al. (1977) 可知此模型組合誤差. 之機率密度函數如下:. (3-2). 其中. 及. 為標準常態分配之機率密度函數以及累積分配函數,由於模型假設 17.
(24) 每個樣本觀察值在各期與各廠商間皆是獨立的,將式 (3-2) 連乘後可得全部樣本 期間的聯合機率密度函數:. (3-3). 對應之對數概似函數表為:. (3-4). 政 治 大 極大化概似函數後可得各參數之估計值,對於無效率項 立. 的條件期望值,作為估計值:. ‧. ‧ 國. 下. 學. et al. (1982) 建議使用給定組合誤差項. 之估計,Jondrow. Nat. al. n. 以上述公式得到無效率項之估計值. Ch. er. io. sit. y. (3-5). v. 後,技術效率估計值即為. engchi. i Un. 然而,Greene (2005) 也指出 TFESFA 模型會受到參數擾攘問題 (incidental parameter problem) 之影響;其意涵為,當資料涵括之期數 間廠商固定效果. 過少時,會導致每. 之估計樣本過少,而使最大概似法之參數估計存在偏誤。為. 了解決此參數擾攘問題,應對模型做轉換以減少待估參數,或是增加資料期數 使固定效果之估計更為準確。但是,實證分析的資料蒐集不易,資料期數往往不 長,因此必須以其他方法對 TFESFA 模型做轉換。 在縱橫資料的固定效果模型中,通常可使用一階差分方法或組內估計法消去 18.
(25) 模型之固定效果減少待估參數。本研究即透過一階差分方法消除固定效果項,並 推導此差分模型之誤差項概似函數,期能在減少待估參數後,即便在較短的資料 期間下亦能得到精準之參數估計值。. 3.2 差分隨機邊界模型 3.2.1 模型定義 本節介紹本研究提出之差分隨機邊界模型定義及推導過程(difference stochastic frontier model , DSFA),首先將式 (3-1) 之 TFESFA 模型透過一階差分 轉換後,可得到如下之差分模型:. 政 治 大. 立. (3-6). ‧. ‧ 國. 學 er. io. sit. y. Nat. 經由上述之轉換後,即可消除固定效果項,因而可解決原先模型之參數擾攘問題;. n. al. Ch. i Un. v. 然而,在使用最大概似法估計式 (3-6) 時,卻會遇到兩個問題: (1). 之機率分配為何?. engchi. 之機率密度函數雖然已知為式 (3-2),但經由一階差分轉換後,. 之機率. 分配卻為未知,必須重新推導得到封閉解後,才能進一步利用最大概似法進 行估計。 (2) 差分組合誤差項. 之相關性問題. 在原始之 SFA 模型中,我們假設各個廠商在各個時間點的觀察值為獨立,因 此在. 獨立的假設下,概似函數只需透過各個誤差項概似函數連乘即可求得. (如式 (3-4))。然而,在得到. 之機率分配後,由於差分後之組合誤差項間. 19.
(26) 會存在相關性,無法單純透過連乘之方式得到概似函數,因此本研究將透過 關聯結構函數 (copula function) 求得第 i 家廠商之差分組合誤差項概似函數. 3.2.2 一階差分模型推導 本節推導差分組合誤差項. 之概似函數,首先根據式 (3-6),差分後之. TFESFA 模型如下:. (3-7). 根據式 (3-2),可求得. 及. 立. 政 治 大. 之聯合機率密度函數為:. ,則. 及 之聯合機率密度函數為. ‧. ‧ 國. 學. 定義差分組合誤差項. n. er. io. sit. y. Nat. al. i Un. v. 上式對 積分後,即可得到差分組合誤差 之邊際機率密度函數. Ch. engchi. (3-8). 由於. 為標準常態分配之累積分配函數,無封閉型式,故無法對式(3-8)直接進. 行積分,本研究使用 Tsay et al. (2009) 之方法進行推導,該研究以非線性函數來 近似錯誤函數 (error function),進而推導切齊應變數隨機邊界模型之概似函數。 錯誤函數之定義如下:. (3-9) 20.
(27) Tsay et al. (2009) 用以下函數來近似此錯誤函數 (3-10). 透過式 (3-9) 及 (3-10),可得到標準常態累積分配函數之近似函數為. (3-11) 將式 (3-11) 代回式 (3-8),推導後可求得式 (3-8) 差分組合誤差之機率密度函數 的近似函數如下,詳細推導過程見附錄一:. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. 式中. –. Ch. engchi. i Un. v. (3-12). 表 3-1 為利用 R 軟體中數值積分之指令,觀察經過推導後之數值近似封閉解 式 (3-12) 以及原始公式 (3-8) 在給定不同差分誤差值 以及不同模型參數設計 下之誤差值,可以發現在不同的參數組合下,誤差值都能在正負 0.0001 以內, 顯示本研究使用錯誤函數近似公式推導之近似函數與原始機率密度函數誤差不 大。圖 3-1 為在參數設計. 下之差分組合誤差機率密度近似函數圖,. 顯示差分組合誤差項為一類似常態分配之對稱分配1。. 1. 此分配其實為 CSN (closed skew-normal) 分配之特例,可參考 Armando et al. (2007). 21.
(28) 表 3-1 差分組合誤差項之近似封閉解及原始公式之誤差值. 2. 0.08933878. 0.2312037. 0.3176674. 0.2312037. 0.08933878. 0.08934631. 0.2312371. 0.3176213. 0.2312371. 0.08934631. 7.53E-06. 3.34E-05. -4.6E-05. 3.34E-05. 7.53E-06. -2. -1. 0. 1. 2. 0.07817393. 0.2364349. 0.07814212. 0.2364476. 0.3431499. 0.2364476. 1.27E-05. 2.48E-05. 1.27E-05. -1. 0. 1. 0.3822877. 0.2392478. 0.06190138. n0.2391999 U engchi. 0.06191341. 立. -3.181E-05. 0.2392478. al. n. 誤差值. 0.07817393 0.07814212 -3.2E-05. y. io. 0.06190138. 治 政 0.3431251 大0.2364349. ‧. -2. Nat. 值. 1. 學. 誤差值. 0. Ch. 0.06191341. 0.2391999. 1.203E-05. -4.8E-05. 0.3822989 1.12E-05. 22. sit. 值. -1. er. 誤差值. -2. ‧ 國. 值. iv. -4.8E-05. 2. 1.2E-05.
(29) 立. 政 治 大. ‧. ‧ 國. 學. 圖 3-1 差分組合誤差機率密度近似函數圖. y. Nat. er. io. sit. 得到差分組合誤差 之機率密度近似函數後,我們可同樣利用錯誤函數近似 公式 (3-10) 來進一步推導出差分組合誤差 之累積分配近似函數. n. al. Ch. i Un. v. ,做為. 後續在關聯結構函數上所用。將式 (3-12) 積分後,即可得到差分組合誤差之累. engchi. 積分配函數如下,由於推導過程較為冗長,故置於附錄二:. 23.
(30) 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 24. i Un. v.
(31) 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. (3-13) 表 3-2 為差分組合誤差項機率密度函數近似封閉解式 (3-12),利用 R 之數值積分 指令計算之結果以及差分組合誤差項之累積機率密度函數近似封閉解式 (3-13) 兩者在給定不同. 值下之誤差;我們可以發現誤差值比表 3-1 稍微放大,但最大. 仍約在 0.001 左右,代表本研究所推導之近似封閉解應皆屬可以接受之誤差範圍 內。. 25.
(32) 表 3-2 差分組合誤差項之機率密度函數及累積分配函數之近似封閉解誤差值. -1. 1. 2. 0.05581314 0.2130154. 0.5. 0.7869846. 0.9441869. 0.05581937 0.2127657. 0.5006287. 0.7884917. 0.945438. -6.23E-06. -0.00063. -0.00151. -0.00125. 0. 1. 2. 0.04337368 0.1951178. 0.5. 0.8048822. 0.9566263. 0.04339693 0.1947043. 0.5008935. 0.8070826. 0.00025. 立 -1. -2. 政 治 大. ‧. ‧ 國. 值. -2. -0.0022. v. -0.00176. 0. 1. 2. 0.02975973 0.1701362. 0.5. 0.8298638. 0.9702403. 0.02980052 0.1697507. 0.5009961. 0.8322415. 0.9721917. -4.079E-05. -0.001. -0.00238. -0.00195. n. 誤差值. al. er. io. 值. 0.95839. sit. Nat. 誤差值. y. 誤差值. 0. 學. 值. -2.325E-05. -2. 0.000414. Ch. engchi. -1. 0.000385. 26. i Un. -0.00089.
(33) 3.2.3 關聯結構函數之應用 原始 TFESFA 模型由於組合誤差項在各廠商及各期之間獨立,且各組合誤差 項服從同一分配,因此只要有組合誤差項之機率密度函數,即可透過連乘求得全 體樣本之概似函數。然而,經過一次差分後之組合誤差 在各期之間並不獨立, 因此即便得到個別差分組合誤差之機率密度函數,我們仍無法透過連乘的方式得 到概似函數。舉例而言,假設有一期數為四,廠商數為二之縱橫面資料,存在一 誤差向量. ,透過一次差分後可得到差分誤差. 向量為. ,而由於 ,顯然相鄰期變數. 與. 且. 皆含有. 之成份而存在相關性,. 政 治 大. 且透過推導後可得到此相鄰差分誤差之線性相關係數為-0.5 (相關係數推導過程. 立. 見附錄三)。. ‧ 國. 學. 本研究即利用關聯結構函數來建立具有相關性誤差向量之概似函數。關聯結. ,透過變. io. er. 之邊際分配函數為. sit. Nat. 假設隨機變數向量. y. 此一多維隨機變數之聯合機率分配之函數 (Nelsen,1999)。. ‧. 構函數可透過將多維隨機變數向量變數轉換至邊際分配為均勻分配之後,來描述. 數變換可將此隨機變數向量轉換為邊際分配為均勻分配之變數向量. n. al. Ch. 2,根據. 數,則存在唯一的關聯結構函數. v i, n U. Sklar’s 定理,若. engchi. ,. ,. 為連續函. 使得:. 其中 為此隨機變數向量之聯合累積機率分配函數,我們透過上式,進一步推導 出聯合機率密度函數如下:. 2. 任意隨機變數 透過此隨機變數累積分配 (.)轉換為 後 即. 從均勻分配 (0,1) 27. ,此一隨機變數 必服.
(34) ,. , ,. (3-14). 式 (3-14) 顯示一組隨機變數之聯合機率密度函數可拆解為兩個部分: 1. 關聯結構”密度”函數. ,用以描述變數向量. 間的相關性結構,當隨機變數向量 時,. 為相互獨立. 。. 政 治 大. 2. 隨機變數向量. 之邊際密度函數的連乘積. 立. 本研究使用 Gaussian copula 函數來描述差分誤差項之相關性結構3,一組隨 透過 Gaussian copula 轉換之聯合機率密度函數公式如下:. ‧. ‧ 國. 學. 機向量. n. er. io. sit. y. Nat. al. 式中. Ch. engchi. 為多維常態之累積分配函數, 為. 之單位矩陣,. 為向量. i Un. (3-15). v. 為標準常態累積分配函數之反函數,. 之相關係數矩陣,由於一般採用之線性相關. 係數往往無法描述經過標準常態累積機率分配反函數轉換後隨機變數之相關性, 因此本研究採用 spearman 等級相關係數. ,此相關係數之優點為兩隨機變數同. 時透過相同之遞增函數轉換後,等級相關係數與該兩隨機變數原先之等級相關係 數相同,故可更正確的描述函數轉換後的相關程度,其公式為: 3. 常用以描述相關性結構之 copula 函數包括本文所使用且最為常見之 Gaussian copula、t copula 等 等 28.
(35) (3-16). 其中. 為向量. 內第 i 個及第 j 個元素之線性相關係數。. 透過式 (3-15) 之 Gaussian copula 函數,我們可求出第 i 廠商在樣本期間 T 年內之一次差分誤差聯合機率密度函數。如前所述,相鄰差分誤差之線性相關係 數. 為-0.5,透過式 (3-16) 可得到 spearman 等級相關係數. 約為-0.48258,代. 入式 (3-12) 及式 (3-13) 導出之差分組合誤差邊際機率密度近似函數及邊際累 積分配近似函數,並將所有廠商差分誤差項聯合機率密度函數連乘後,所有 N 間廠商在樣本期間 T 年內,差分組合誤差之聯合機率密度函數為:. 立. 政 治 大. ‧. ‧ 國. 學. io. y. sit. 即為式 (3-12) 及式 (3-13) 所導出之差分組合誤差邊際機率. er. 及. Nat. 上式中. (3-17). 密度近似函數及邊際累積分配近似函數,透過式 (3-17) 取自然對數後,可進一. n. al. Ch. i Un. v. 步得到全體樣本之對數概似函數如下,即為 DSFA 模型之概似函數:. engchi. (3-18). 3.3 考慮環境變數之固定效果模型 Battese and Coelli (1995) 考慮將環境變數對無效率的影響納入隨機邊界模 型中,模型架構如下: 29.
(36) 故. 此模型假設無效率項. 為環境變數向量. 之函數, 為對應之待估參數向量。. 接下來,本研究亦嘗試將上述模型設定納入 Greene (2005) 之 TFESFA 模型中, 成為:. 學. ‧ 國. 立. 故 政 治 大. 根據 Battese and Coelli (1995),此模型組合誤差項. ‧. 數為:. 之機率密度函. y. Nat. n. al. (3-19). er. io. sit. ,. Ch. engchi. i Un. v. 式 (3-19) 對所有 i 及 t 連乘後,可得全樣本期間的誤差項聯合機率密度函數及對 數概似函數為:. (3-20). 30.
(37) 此模型之無效率項. 分為兩部份,分別為受環境變數影響之無效率項. 以及非受環境變數影響之無效率項 而無效率項. ,極大化概似函數可求得各參數之估計值,. 之估計,則與式 (3-5) 相同,使用給定組合誤差項. 下. 的條. 件期望值為其估計值,公式為:. (3-21). 政 治 大. 根據上式得到無效率項估計值. 後,技術效率估計值即為. 立. ‧ 國. 學. (3-22). 階差分方法來求得模型差分組合誤差項. ‧. 為消除模型之固定效果項以解決參數擾攘問題,我們同樣利用 3.2.2 節之一 之近似機率密度函數. y. Nat. n. er. io. al. sit. 如下(詳細推導過程見附錄四):. Ch. engchi. 31. i Un. v.
(38) 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. (3-23). 32.
(39) 式中. ,. ,. ,. ,. , ,. , 及. ,. ,. 為兩組合誤差. 及. ,. ,. ,. ,. ,. 內含之環境變數向量. 表 3-3 為利用 R 軟體中數值積分之指令,觀察考慮環境變數時差分誤差項之 近似封閉解式 (3-23) 以及原始函數在給定不同差分誤差項 以及不同模型參數 設計下之誤差值,在此簡化假設模型只存在一項環境變數,斜率項. 政 治 大. 項需差分之誤差項各自內含之環境變數假設只有一項,並表示為. 立. 分別為相同. 及相異. 及. ,假設. 兩種情況;可以發現. 學. ‧ 國. 及. 為 1,而兩. 在不同的參數組合下,誤差值皆能在可接受之範圍內。圖 3-2 及圖 3-3 為參數設 以及. ‧. 計. 差分組合誤差機率密度近似函數圖,可以發現當. sit. 時,由於環境變數值會影響無. er. io. 之下界,因此差分組合誤差會形成非對稱之分配。. al. n. 效率項. 時,差分組合誤差. y. Nat. 函數同樣接近一對稱之分配;而當. Ch. 兩種情況下,. engchi. 33. i Un. v.
(40) 表 3-3 考慮環境變數之差分組合誤差項近似解及原始公式之誤差值. 2. 0.1009568. 0.2227248. 0.2897841. 0.2227248. 0.1009568. 0.1009219. 0.2225596. 0.2895186. 0.2225596. 0.1009219. 3.49E-05. 0.000165. 0.000265. 0.000165. 3.49E-05. -2. -1. 0. 1. 2. 0.09734543. 0.2163368. 0.09734671. 0.2162778. 0.2856556. 0.2258696. 5.9E-05. 0.000135. 0.00012. -1. 0. 1. 0.3009697. 0.2266663. 0.09653422. n0.2265551 U engchi. 0.09651306. -1.3E-06. 值. 誤差值. 0.2266663. al. n. 誤差值. 0.1074605 5.38E-05. y. io. 0.09653422. 0.1075143. ‧. -2. 治 政 0.285791 大0.2259892. 立. Nat. 值. 1. 學. 誤差值. 0. Ch. sit. 值. -1. er. 誤差值. -2. ‧ 國. 值. iv. 0.3007803. 2. 0.09651306. 0.2265551. 2.12E-05. 0.000111. 0.000189. 0.000111. 2.12E-05. -2. -1. 0. 1. 2. 0.0895166. 0.2126242. 0.2910547. 0.2336473. 0.1113282. 0.08952021. 0.2125975. 0.2909489. 0.2335225. 0.1112627. -3.61E-06. 2.67E-05. 0.000106. 0.000125. 6.55E-05. 34.
(41) 表 3-3 考慮環境變數之差分組合誤差項近似解及原始公式之誤差值(續). 誤差值. 值. -1. 0. 1. 2. 0.0894729. 0.2315316. 0.317826. 0.2315316. 0.0894729. 0.08946161. 0.2314435. 0.3176664. 0.2314435. 0.08946161. 1.13E-05. 8.81E-05. 0.00016. 8.81E-05. 1.13E-05. -2. -1. 0. 1. 2. 0.07994073. 0.2087673. 0.07993788. 0.2087373. 0.2989287. 0.2431224. 3E-05. 8.81E-05. 9.9E-05. 治 政 0.2990168 大0.2432214. 立. 2.85E-06. 學. 誤差值. -2. ‧ 國. 值. ‧. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. 圖 3-2 考慮環境變數之差分組合誤差機率密度近似函數圖(一) 35. 0.1146203 0.1145745 4.58E-05.
(42) 立. 政 治 大. ‧ 國. 學 ‧. 圖 3-3 考慮環境變數之差分組合誤差機率密度近似函數圖(二). sit. y. Nat. io. al. er. 為能使用關聯結構函數求得此模型之概似函數,我們仍須推導出差分組合誤差 h. v. n. 之累積分配函數,由於推導過程過於繁雜,本研究尚未得出結果,僅提出此方向 供後續研究發展所用。. Ch. engchi. i Un. 而在僅有差分組合誤差 h 之機率密度函數下,我們仍可將式 (3-6) 之一階差 分模型做修改,以使用最大概似法來估計考慮環境變數之 TFESFA 模型,修正之 模型如下:. (3-24). 故. 36.
(43) 式 (3-6) 之一階差分模型是將第 i 家廠商組合誤差的 T 筆樣本資料,透過差 分後縮減為 T-1 筆差分樣本資料,因此相鄰期之差分組合誤差會存在相關性;而 式 (3-24) 之一階差分模型則將 T 筆樣本資料減半為 T/2 筆樣本資料。此模型在 同一廠商內各個差分組合誤差間則為獨立;舉例而言,第 i 間廠商的第一筆差分 組合誤差為. ,第二筆差分組合誤差為 ,因此相鄰之差分組合誤差並沒有相. 同的隨機誤差項. 或無效率項. 成份存在。在各期以及各廠商之差分組合誤差. 項獨立下,使用最大概似法估計模型 (3-24) 所對應之對數概似函數,即只需將 式 (3-23) 連乘取對數,成為:. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 37. i Un. v. (3-25).
(44) 第四章 模擬分析 4.1 平衡縱橫資料模擬 本章打算透過模擬方式,驗證本研究提出之 DSFA 模型是否能夠消除擾攘參 數問題,並得到較原始 TFESFA 模型更有效之估計式。做法為給定相同的參數值, 透過模擬產生平衡縱橫資料 (balanced panel data),並分別觀察利用最大概似法估 計 TFESFA 模型及 DSFA 模型之參數估計結果的偏誤值 (Bias) 和均方差 (mean square error, MSE)。Bias 代表重複模擬一定次數時,得到之參數真值與估計值的. 政 治 大 近 0,代表參數估計結果越佳。一般而言,小樣本時注重估計值是否為不偏 (偏 立 平均數之差;MSE 代表估計值偏離參數真值之平均距離,偏誤量與均方差越接. ‧ 國. 學. 誤值是否趨近 0),大樣本時則注重估計值是否有一致性 (均方差是否趨近 0)。 模型設計及資料生成過程 (data generating process) 如下:. ‧. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. 生產函數設定為簡單迴歸方程式,即單一投入 估計參數包括. v. 和單一產出. 。投入變數產生自常態分配. ,廠商之固定效果產生自均勻分配 誤差項變異數. ,模型中待. 及. 之部份固定. 三種比例;樣本觀察期數 結果如表 4-1 至表 4-3,其中 代表所有固定效果. ;斜率項設定 ,. 等. ,廠商家數. 。模擬. 為所有固定效果估計結果的平均值,即. 的平均估計表現,並與給定之參數值. ,. ,. 比較;. 則為給定估計殘差後使用公式 (3-5) 求出之每一廠商每一期無效率項估計之平 38.
(45) 均值,即. ,並與母數. 比較。. 根據表 4-1 至表 4-3 之模擬結果,按不同觀察期數. 及不同參數 分類後繪. 製折線圖,即可觀察兩種估計模型得到的參數估計量,在偏誤值以及均方差之表 現(見附錄五)4。 本研究模擬之最小觀察期數 T =5 時,無論是偏誤值或均方差, DSFA 模型的參數估計量皆明顯的較 TFESFA 模型為佳;另在整體固定效果 及 無效率項之變異數. 的估計上,DSFA 模型估計量不管在偏誤值或均方差上亦. 遠較 TFESFA 模型為優。此外,在固定 T=5 時,TFESFA 模型之參數估計量隨廠 商家數 N 放大,參數估計量的偏誤值亦有放大的情形,顯示在觀察期間不長 (例. 政 治 大 parameter) 問題,使模型估計結果存在偏誤;但是 MSE 則有些下降,有些上升。 立 如 T=5) 的情況下,TFESFA 模型之參數估計的確存在擾攘參數 (incidental. ‧ 國. 學. 若將觀察期間放大至 T=10,可發現 TFESFA 模型及 DSFA 模型在不同參數 估計量的表現上,互有優劣;當廠商家數 N 較小時 (例如 N=100 或 200),DSFA. ‧. 模型的某些參數估計量之表現雖比 TFESFA 模型差,但當 N 放大至 500 時,DSFA. sit. y. Nat. 模型之參數估計量的偏誤值及均方差都有快速收斂的情形,且與 TFESFA 模型的. io. al. er. 表現相差不大或更佳,顯示在 T=10 時若廠商家數夠大,DSFA 模型之參數估計. iv n C h e n g c模型之參數估計量,無論在偏誤值 若將觀察期間再放大至 T=20,TFESFA hi U n. 量的收斂速度可能會比 TFESFA 模型快。. 及均方差方面,皆可達到相當低的水準 (約在 0.03 以下),顯示此時擾攘參數問 題已甚輕微。而 DSFA 模型在 T=20 時之估計偏誤值及均方差,均較 TFESFA 模 型稍高,可能的原因是,本研究採用近似解推導差分模型之最大概似函數,近似 誤差的存在略為影響 DSFA 模型的表現,唯整體而言,該模型的估計效果與 TFESFA 模型並無太大差異。 此外,從 T=5 逐漸增加至 T=20 時,TFESFA 模型及 DSFA 模型之參數估計 偏誤值與均方差皆逐漸收斂,顯示隨著每家廠商觀察期間 T 的放大,兩種模型. 4. 偏誤值部分取絕對值做折線圖,以直接觀察偏誤值之絕對距離 39.
(46) 之參數估計值都存在一致性。. 表 4-1 DSFA 模型模擬結果 , MSE 0.149920894 0.001994857 0.124433295 0.691707455. Bias 0.082906488 -0.001903307 -0.270241354 0.438210207. MSE 0.03250080 0.03466241 0.07436164 0.08419586. Bias -0.020752869 -0.004074314 -0.159030647 -0.009229596. 0.1429073. 0.0572805. 0.0188994. 0.007381411. 政 治, 大. 立. MSE 0.03024460 0.03087677 0.07263931 0.09375755. Bias -0.009890970 0.005449362 -0.162952621 0.018907915. 0.1278009. 0.0839427. 0.01883842. 0.01876421. Nat. n. al. Ch. MSE 0.1152763557 0.0009884066 0.1329975771 0.7622863238 0.08727894. Bias 0.227576541 -0.008457612 -0.316958644 0.620384980 0.1628493. engchi. 40. er. io. ,. sit. y. ‧. ‧ 國. Bias 0.122914483 -0.007843835 -0.279803448 0.478427828. 學. MSE 0.137695630 0.001320838 0.125304298 0.697754167. v iMSE n U. 0.02311002 0.02453907 0.06033272 0.06595701 0.01396702. Bias -0.004985585 -0.001460043 -0.134812104 0.015938613 0.01762007.
(47) 表 4-1 DSFA 模型模擬結果. (續) ,. MSE 0.030762176 0.000760225 0.011667845 0.056856005 0.0294405. Bias -0.0256969238 -0.0013529648 -0.0666778930 0.0001254162 -0.01718673. MSE 0.02492335 0.02753721 0.06773202 0.08264987 0.01551715. Bias 0.007878375 -0.011019666 -0.150637587 0.035779567 0.02877693. MSE 0.01896188 0.01954050 0.04495873 0.05823333 0.01200589. Bias 0.0085480674 -0.0003732676 -0.0918802297 0.0376720152 0.02304853. , MSE Bias 0.0132546089 -0.0106030014 0.0003828972 -0.0005786474 0.0087593003 -0.0701957511 0.0297893048 0.0024015578 0.01277378 -0.004026964. 學. ‧. ‧ 國. 立. 政 治 大. n. Ch. engchi. 41. sit. io. al. MSE 0.01116427 0.01640508 0.03752050 0.02728396 0.005922418. er. Nat. MSE Bias 0.0037782412 0.0084155934 0.0001590404 -0.0008306563 0.0069646658 -0.0747790918 0.0113381370 0.0193735213 0.003673167 0.009522964. y. ,. i Un. v. Bias 0.005579663 0.001181234 -0.070989857 0.021240175 0.01900597.
(48) 表 4-1 DSFA 模型模擬結果. (續) ,. MSE Bias 0.0114579618 -0.0105273204 0.0003089444 0.0002212078 0.0043233155 -0.0332435878 0.0243020878 -0.0019634358 0.01081118 -0.006551556. MSE 0.01516421 0.01465903 0.04099147 0.03673618 0.008829932. Bias 0.001390519 0.002006186 -0.066588311 0.021695424 0.01808091. ,. 0.001374382 -0.032271603 -0.004471846 -0.003465698. 0.01128577 0.03951021 0.03921520 0.007693313. Bias 0.014422958 0.004899461 -0.067276034 0.041610747 0.02659835. ‧. ‧ 國. 立. Bias治 MSE 政 -0.007195861 大 0.01206239. 學. MSE 0.005660514 0.000192473 0.002626842 0.012769090 0.005027841. n. al. Bias 0.0016781818 0.0004137932 -0.0359779818 0.0051917496 0.003167076. Ch. engchi. 42. MSE 0.00571325 0.01331422 0.04238434 0.00884579 0.002027837. er. io. MSE 1.708262e-03 6.912574e-05 1.875891e-03 4.408189e-03 0.001439195. sit. y. Nat. ,. i Un. v. Bias 0.002999562 0.003178330 -0.071063102 0.012173595 0.02145293.
(49) 表 4-2 DSFA 模型模擬結果 , MSE 0.060431945 0.001920615 0.079747131 0.386513133 0.04402129. Bias 0.146092281 -0.001155233 -0.256500329 0.488554605 0.08135519. MSE 0.04741476 0.05083756 0.02966734 0.12124313 0.03021689. Bias -0.028441329 0.005218507 -0.041234383 -0.004266715 -0.003241069. ,. -0.002926824 -0.275464906 0.564499901 0.1063063. 0.04082415 0.02329249 0.10183881 0.02274356. Bias -0.0003203246 0.0027679316 -0.0502699296 0.0437089242 0.01094479. ‧. ‧ 國. 立. Bias治 MSE 政 大 0.190384085 0.03520271. 學. MSE 0.052547128 0.001032555 0.083516558 0.407643126 0.02620383. n. al. Bias 0.237004916 -0.008126767 -0.303441437 0.672662484 0.1301145. Ch. engchi. 43. MSE 0.02330823 0.03125003 0.01635677 0.05785363 0.01459513. er. io. MSE 0.0589840102 0.0008968627 0.0928699636 0.4658544541 0.01885207. sit. y. Nat. ,. i Un. v. Bias -0.012396888 0.009247255 -0.027403138 0.009479520 0.00299765.
(50) 表 4-2 DSFA 模型模擬結果. (續) ,. MSE 0.0086544875 0.0005870276 0.0068736616 0.0308313244 0.007629422. Bias 0.008303099 -0.001038185 -0.061203338 0.025325482 0.00900913. MSE 0.02915002 0.02875725 0.01865936 0.08816019 0.02040482. Bias -0.003362560 -0.001839321 -0.016037133 0.021921549 0.002080789. ,. 2.828044e-06 -6.013687e-02 2.275967e-02 0.01060557. 0.02128241 0.01334835 0.05585133 0.01201029. Bias 0.003235773 -0.001547717 -0.011043602 0.025311748 0.005339346. ‧. ‧ 國. 立. Bias治 MSE 政 8.958631e-03 大 0.01840762. 學. MSE 0.0037298493 0.0002971205 0.0049999503 0.0130586391 0.00308056. n. al. Bias 0.012146735 0.002339145 -0.064908429 0.021307474 0.01182833. Ch. engchi. 44. MSE 0.011304216 0.014943439 0.009510721 0.032356853 0.007526404. er. io. MSE 0.0017519557 0.0001323609 0.0046971478 0.0048709726 0.001126029. sit. y. Nat. ,. i Un. v. Bias -0.005246717 -0.005565616 0.003338538 -0.003335685 -0.001716676.
(51) 表 4-2 DSFA 模型模擬結果. (續) ,. MSE Bias 0.0036477890 -0.0011961613 0.0002825337 -0.0007375892 0.0017901130 -0.0275332120 0.0103604185 0.0011523711 0.00247082 0.00207632. MSE 0.01878908 0.01668033 0.01320878 0.05866347 0.01350872. Bias -0.0118209034 -0.0005718047 0.0108127756 -0.0027895400 -0.004802931. , MSE 政 治 0.006152126 大 0.008107823 0.006639090 0.015218683 0.003451199. Bias -0.013667327 0.003129954 0.028505508 -0.018796976 -0.007031393. ‧. ‧ 國. 立. 學. MSE Bias 0.0017661459 0.0011462479 0.0001226176 0.0001876668 0.0012911228 -0.0274522061 0.0052050003 0.0032612283 0.00121124 0.003221333. n. al. Bias 0.003286745 0.003787536 -0.028349740 0.007931855 0.004865569. Ch. engchi. 45. MSE 0.005842836 0.012608693 0.006493595 0.009449933 0.001830827. er. io. MSE 0.0008095110 0.0000448077 0.0009364279 0.0016446143 0.0003844466. sit. y. Nat. ,. i Un. v. Bias -0.005324430 -0.001589071 0.011812474 -0.009528125 -0.00175978.
(52) 表 4-3 DSFA 模型模擬結果 , MSE 0.193610929 0.002251737 0.163097820 0.916009169 0.1901491. Bias 0.081130809 -0.001538065 -0.305140517 0.473171224 0.06637776. MSE 0.04353204 0.01879138 0.07812132 0.14648853 0.03427096. Bias 0.019683718 -0.001122174 -0.169846208 0.083521226 0.02148477. ,. -0.004416918 -0.276132580 0.382955782 0.05857848. 0.01600270 0.07523256 0.13527204 0.03123857. Bias 0.03537145 -0.01050237 -0.16602843 0.09506416 0.03117254. ‧. ‧ 國. 立. Bias治 MSE 政 大 0.073263267 0.03860881. 學. MSE 0.1620696 0.0012662 0.1332357 0.7079734 0.1566226. n. al. Bias 0.087543648 0.001979534 -0.258987204 0.363178855 0.08016535. Ch. engchi. 46. MSE 0.01922842 0.01014674 0.05016093 0.05501871 0.01510262. er. io. MSE 0.1388099268 0.0003551492 0.1162004362 0.6750315039 0.13362. sit. y. Nat. ,. i Un. v. Bias 0.012608539 -0.003842544 -0.102106158 0.040836576 0.01423385.
(53) 表 4-3 DSFA 模型模擬結果. (續) ,. MSE Bias 0.0759731671 -0.08366210 0.0009517776 0.00003117901 0.0179046121 -0.07890196 0.0873746566 -0.0002933852 0.07494625 -0.07146697. MSE 0.03933548 0.01379654 0.06347459 0.13470960 0.03156671. Bias 0.055028599 0.001461924 -0.136203953 0.130255725 0.05167521. ,. -0.0006672572 -0.0745281371 -0.0104174942 -0.05123176. 0.009608422 0.041198047 0.065393354 0.01733273. Bias 0.044051014 0.004996426 -0.080476791 0.095016721 0.04312066. ‧. ‧ 國. 立. Bias治 MSE 政 -0.0591336441 大 0.021202340. 學. MSE 0.0509356171 0.0004020664 0.0125959684 0.0523077370 0.0482782. n. al. Bias 0.014233614 -0.004486814 -0.080718177 0.029520069 0.01097357. Ch. engchi. 47. MSE 0.010111110 0.006345236 0.033622849 0.026564533 0.00771191. er. io. MSE 0.0100225512 0.0001958371 0.0107686032 0.0198926954 0.009070038. sit. y. Nat. ,. i Un. v. Bias 0.031706104 0.002083559 -0.056716601 0.059237476 0.03237167.
(54) 表 4-3 DSFA 模型模擬結果. (續) ,. MSE 0.0432080532 0.0003973092 0.0073411388 0.0445315348 0.04151732. Bias -0.0539615659 -0.0008718896 -0.0380884874 -0.0113852498 -0.04602797. MSE 0.026632102 0.007560964 0.038674289 0.081498191 0.02115705. Bias 0.065705168 -0.001920532 -0.070608442 0.096897844 0.05790506. , MSE 政 治 大 0.012487031 0.005558671 0.028097651 0.034374575 0.00997569. Bias 0.045880636 0.002908752 -0.039053501 0.083667615 0.04308234. ‧. ‧ 國. 立. 學. MSE Bias 0.0250285996 -0.0384557090 0.0001920742 0.0003025452 0.0046732318 -0.0335479589 0.0268552847 -0.0172237482 0.02420521 -0.03265473. n. al. Bias 0.009031179 0.001286941 -0.050870534 0.024997928 0.01036164. Ch. engchi. 48. MSE 0.007188025 0.007967704 0.028094728 0.013182273 0.004535489. er. io. MSE 0.0057064147 0.0001256589 0.0042739057 0.0121357926 0.00580498. sit. y. Nat. ,. i Un. v. Bias 0.039313991 -0.003315893 -0.036574255 0.060896010 0.03628253.
(55) 4.2 不平衡縱橫資料模擬 前節已針對. 及. 之平衡縱橫資料,進行參. 數模擬。然而,實務上之資料往往存在缺失值,導致所有廠商之觀察期數並不相 同,稱為不平衡縱橫資料 (unbalanced panel data),本節即希望能在更貼近實務面 設計的資料假設下,研究在資料觀察期間不一致時,擾攘參數問題對模型估計之 影響。 此時由於各廠商之觀察期數不完全同,因此模擬時在觀察期數之設定上較為 困難,實證研究者所蒐集之縱橫資料,平均觀察期數大約介於 4~8 年左右。從. 政 治 大 而在 T 上升至 10 之後,估計量的表現能大幅提升。因此,為了能較貼近實證且 立 4.1 節之模擬結果可看出,當 T=5 時,TFESFA 模型存在明顯的擾攘參數問題,. ‧ 國. 學. 與前節平衡縱橫資料之模擬結果比較,本研究設定整組樣本之觀察間 T 包含為 及. 等兩種組合,各期間廠商數的比重比例 (ratio) 設定為 等兩種。舉例而言,若觀察期間設定為. ,代表 100 間廠商有. y. 時,假設廠商數. ,權重比. sit. Nat. 例設定為. ‧. 及. io. al. er. 100*1/4=25 間廠商的觀察期數 T 為 3,100*2/4=50 間廠商的觀察期數 T 為 5,. v. n. 100*1/4=25 間廠商的觀察期數 T 為 7,再以此準則模擬生成不平衡縱橫資料。其 他參數設定一律簡化為. Ch. i Un. e n,廠商家數 gchi. ,模型設計及. 資料生成過程與 4.1 節相同,模擬結果如表 4-4 及表 4-5。 在. 且. 時,在. 的估計上,DSFA 模型之參數均. 方差及偏誤值較 TFESFA 模型略高,其他參數之估計效果則無太大差異。在 且. 時,由於 TFESFA 模型在. 值皆顯著放大,間接導致 及. 之估計效果變差。在. 的估計均方差及偏誤 且. 兩種模型設計下,可以發現每個參數的估計結果,TFESFA. 模型的估計均方差及偏誤值都明顯的較 DSFA 模型為高,. 估計結果的差異也. 隨著資料觀察期間的降低而更加放大(模擬結果之趨勢折線圖見附錄六)。 49.
(56) 在 4-1 節我們使用平衡縱橫資料架構,研究資料觀察期間為 等三種情況之模擬結果,發現在 T=5 時,TFESFA 模型之估計量顯著的受到擾攘 參數問題之影響,導致參數之估計存在偏誤且不具一致性;T=10 時 TFESFA 模 型之估計效果整體而言較 T=5 時顯著提升。本節則給定資料為不平衡縱橫資料 架構下進行模擬,並設計四種資料型態: 、. 且. 且. 和. 和. ,四種設計下. 之資料平均觀察期間分別為 7、6.5、5 和 4.5。從模擬結果來看,可以發現隨著 平均觀察期間的減少,TFESFA 模型之參數估計效果越來越差,且在. 的部份. 最為明顯;而 DSFA 模型未受太大的影響,即便在較少的資料觀察期間下,估計 量之表現仍然不錯。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 50. i Un. v.
(57) 表 4-4 不平衡縱橫資料 DSFA 模型模擬結果 , MSE 0.08011274 0.01424182 0.02287313 0.10734598 0.05274839. Bias -0.004750719 -0.009719067 -0.110687888 0.041966204 -0.01440272. MSE 0.10967355 0.03496557 0.08486853 0.06825333 0.0138164. Bias -0.041619171 0.007193213 -0.162955575 -0.030072381 0.008592821. ,. -0.02413166 -0.08276658 -0.04217866 -0.03461662. 0.02020761 0.08820697 0.10520256 0.01898413. Bias 0.009022184 -0.003128496 -0.181547208 0.038335175 0.03471636. ‧. ‧ 國. 立. Bias治 MSE 政 大 -0.02444154 0.07228020. 學. MSE 0.028782424 0.005951142 0.015163780 0.058832404 0.03066114. n. al. Ch. Bias 0.12710072 0.01166772 -0.32705271 0.66840101 0.1137363. engchi. MSE 0.12413796 0.05817810 0.10356242 0.03534776 0.007507773. er. io. MSE 0.20920404 0.04240416 0.16481749 0.98858764 0.1137363. sit. y. Nat. ,. i Un. v. Bias -0.08731129 0.02494994 -0.21477458 -0.07341447 0.002133803. , MSE 0.20024137 0.02302818 0.12106575 0.72606243 0.07170962. Bias 0.22965544 -0.02190134 -0.30522736 0.58240953 0.1512283. 51. MSE 0.07939226 0.03091175 0.13853414 0.05845953 0.008651414. Bias -0.02022642 -0.01811037 -0.30629571 -0.06761880 0.01947996.
(58) 表 4-5 不平衡縱橫資料 DSFA 模型模擬結果 , MSE 0.11561843 0.01284447 0.04256088 0.26330685 0.07682115. Bias 0.02170076 -0.01866158 -0.13597349 0.12507856 0.0008096262. MSE 0.08840533 0.03490834 0.11385455 0.06167455 0.01235981. Bias -0.08316019 0.02641698 -0.23267399 -0.05685898 0.01280277. ,. -0.03845598 -0.10777355 0.10614634 -0.02349079. 0.02682928 0.08386093 0.07468456 0.0157047. Bias 0.0537273339 -0.0485261405 -0.1698588720 0.0004541942 0.02016346. ‧. ‧ 國. 立. Bias 治 MSE 政 大 0.02520007 0.07370335. 學. MSE 0.09447176 0.00714555 0.02967191 0.22833391 0.06754395. n. al. Bias 0.28800881 -0.04293129 -0.41640385 0.86417774 0.1866728. Ch. engchi. MSE 0.1437906 0.0319215 0.1479066 0.1250698 0.02385328. er. io. MSE 0.26047506 0.04165964 0.20418623 1.07639621 0.1190643. sit. y. Nat. ,. i Un. v. Bias -0.08454324 0.01729499 -0.30187678 -0.04970988 0.01705957. , MSE 0.1226185 0.0253487 0.1412689 0.8550814 0.1299147. Bias 0.05632211 0.02914004 -0.30637513 0.56869098 0.09596622. 52. MSE 0.10814733 0.03442761 0.09437625 0.10843532 0.02229075. Bias -0.035033557 0.009090223 -0.180662543 0.003395199 0.01778175.
(59) 4.3 考慮環境變數之模擬分析 本研究尚未推導出考慮環境變數下 TFESFA 模型之差分組合誤差項累積分 配函數,因此本節使用 (3-24) 之一階差分模型進行模擬,該模型假設第 i 家廠 商各期之差分組合誤差項相互獨立,因此不需透過關聯結構函數即能得到概似函 數,但也由於該模型會將. 筆樣本資料減半為. 筆,因此估計量之表現易. 較 (3-6) 之一階差分模型差。 模型設計及資料生成過程與 4.1 節未考慮環境變數時相同,即為單一投入與 單一產出模型,環境變數個數設定為一個,其他參數簡化設定為 ,其中. 政 治 大. 2= v2+ w2 , = w v , 為對應該環境變數之待估參數,廠. 立. 商家數. ,而在 (3-24) 之模型架構下,觀察期間 T 若為偶數比較. ‧ 國. ,模擬結果如表 4-6。. 學. 容易操作,故設定為. 攘參數問題而使. ‧. 從模擬結果可以發現在 T=6 時,考慮環境變數之 TFESFA 模型同樣會因擾 之估計均方差及偏誤值過高,雖然其他參數部份在均方差. y. Nat. er. io. sit. 的表現上兩模型大致相當,但偏誤值卻明顯的較一階差分模型為高,且多在 0.1 ~ 0.2 以上,顯示在觀察期間較低時,TFESFA 之模型估計存在較大的偏誤。當 T=12. n. al. Ch. i Un. v. 時,TFESFA 模型之估計偏誤值及均方差皆能有效的降至 0.1 以下,估計量之表. engchi. 現與差分模型無異甚至更佳,而差分模型量之表現未隨觀察期間上升而有較為顯 著的提升,表現與 T=6 時相去不遠,這可能是因為本研究是使用 (3-24) 之樣本 資料減半差分模型,因樣本資訊大幅減少而使估計效果不易快速收斂。未來期能 在推導得出考慮環境變數之差分組合誤差累積機率分配近似函數後,加入關聯結 構函數之概念而使估計效果有更為顯著的提升(模擬結果折線圖見附錄七)。. 53.
(60) 表 4-6 考慮環境變數之差分模型模擬結果 , MSE 0.104537234 0.001489168 0.107743627 0.486492141 0.133521259 0.1143273. Bias 0.11979870 0.01235376 -0.24157873 0.39409233 -0.21705357 0.1663817. MSE 0.09479068 0.02980612 0.09242192 0.12764710 0.04574091 0.04801808. Bias -0.103045814 0.003757811 -0.175188881 -0.047410609 -0.058906279 0.04476283. ,. 0.184773059 0.005507724 -0.257785629 0.433367682 -0.137444446. 0.10070520 0.02417014 0.07724451 0.15637743 0.03809816. Bias -0.0748509495 0.0169220123 -0.1375772799 0.0009320994 -0.0682071889. 0.1637502. 0.06051592. 0.05465665. n. al. Ch. MSE 0.0802889919 0.0007907307 0.1015944128 0.4262218314 0.0188285934. Bias 0.22457375 -0.00785556 -0.27750058 0.43042133 -0.04761364. 0.08443389. 0.1560957. engchi. 54. er. io. ,. sit. y. Nat. 0.124582. ‧. ‧ 國. 立. 學. MSE 0.065585345 0.001087336 0.100659960 0.542259687 0.066052581. 政 Bias治 大MSE. iv MSE n U. 0.07686645 0.01884456 0.06845084 0.11244544 0.01391452. Bias -0.09474233 0.01015547 -0.12873500 -0.01190847 -0.05299809. 0.04372238. 0.04289358.
(61) 表 4-6 考慮環境變數之差分模型模擬結果(續) , MSE 0.0218789029 0.0006733454 0.0158111349 0.0412440962 0.0258142018 0.009243886. Bias 0.078023378 0.003701434 -0.095780840 0.066687141 -0.052229192 0.03628869. MSE 0.09129927 0.02858630 0.07309630 0.12770259 0.03120392 0.04766284. Bias -0.08095449 -0.01926340 -0.12542754 -0.03341738 -0.07264328 0.04329511. ,. 0.069830769 0.000122148 -0.082148964 0.047357700 -0.073512868. 0.07236112 0.02066143 0.06934610 0.09640287 0.02933868. Bias -0.10816768 0.01359288 -0.12391068 -0.04607070 -0.07174284. 0.02606124. 0.02906736. 0.03554357. n. al. Ch. MSE 0.0083098242 0.0001913113 0.0079080578 0.0085058246 0.0060563977. Bias 0.078213343 -0.002211382 -0.083029997 0.050291700 -0.050566267. 0.002026432. 0.02431121. engchi. 55. er. io. ,. sit. y. Nat. 0.005423286. ‧. ‧ 國. 立. 學. MSE 0.0106307108 0.0003185885 0.0095800975 0.0207804116 0.0147885130. 政 Bias治 大MSE. iv MSE n U. 0.06582140 0.01813126 0.06261579 0.08026246 0.01512072. Bias -0.1240698825 -0.0009799055 -0.11130635 -0.05851334 -0.07524975. 0.02284588. 0.02720835.
數據

Outline
相關文件
表 2.1 停車場經營管理模型之之實證應用相關文獻整理 學者 內容 研究方法 結論
住宅選擇模型一般較長應用 Probit 和多項 Logit 兩種模型來估計,其中以 後者最常被使用,因其理論完善且模型參數之估計較為簡便。不過,多項
樹、與隨機森林等三種機器學習的分析方法,比較探討模型之預測效果,並獲得以隨機森林
則巢式 Logit 模型可簡化為多項 Logit 模型。在分析時,巢式 Logit 模型及 多項 Logit 模型皆可以分析多方案指標之聯合選擇,唯巢式 Logit
而此時,對於相對成長率為 k 的族群,其滿足族群成長模型 的解為指數函數 Ce kt ,此時的 k 便是指數中時間 t
自從 Engle(1982)提出 ARCH 模型以來,已經超過 20 年,實證上也有相當多的文獻 探討關於 ARCH 族模型的應用,Chou(2002)將 GARCH
The empirical results indicate that there are four results of causality relationship between Investor Sentiment and Stock Returns, such as (1) Investor
• 數學上有一個很類似的定義叫做凸函數 (convex function). • 上下顛倒後就叫凹函數
