以單因子拉普拉斯關聯結構模型評價合成型抵押擔保債券憑證 - 政大學術集成
55
0
0
全文
(2) 謝辭 在統計所兩年的學習中,除了學到很多與統計相關的理論與知識外,也認識 了很多幫助過我的老師和同學。 首先要感謝的是我的論文指導教授劉惠美老師,老師的教導讓我對衍生性金 融商品有更進一步的了解。除了課業知識的傳授外,老師也會跟我們分享以前一 些學長姊的發展狀況,讓我對畢業後的就業有了方向。此外,感謝洪明欽教授與 劉家頤教授在論文口試時給我的意見,讓我的論文更加完善。. 政 治 大 一起討論、寫論文,謝謝你們每次在我沒有靈感或與到困難時都會跟我開玩笑, 立 感謝我的好夥伴義欣跟煒融,一年級的時候就認識你們了,很高興我們可以. ‧ 國. 學. 讓我本來緊張的心情可以放鬆下來。. 感謝我的父母,謝謝你們願意支持我讀研究所。最後,以此文獻給你們。. ‧. n. er. io. sit. y. Nat. al. Ch. engchi. i. i Un. v.
(3) 摘要 以往在評價合成型抵押擔保債券時,最常使用的方法為應用大樣本一致性資 產組合(large homogeneous portfolio, LHP)假設的單因子常態關聯結構,但會造成 評價與市場報價間差異過大的問題,且會造成相關性微笑曲線現象。單因子常態 關聯結構模型會有上述的問題是因為其缺少厚尾度或偏斜性,因此若能在單因子 關聯結構模型中加入具厚尾度或偏斜性的分配,就能改善以上的問題,像是 Kalemanova et al.(2007)提出應用 LHP 假設之單因子 NIG 關聯結構模型來對合成. 政 治 大 用單因子拉普拉斯關聯結構模型對合成型抵押擔保債券作評價,並與其它單因子 立. 型 CDO 進行評價,該模型的評價結果遠優於單因子常態關聯結構模型。本文使. ‧ 國. 學. 關聯結構模型的配適結果做比較,探討在評價上單因子拉普拉斯(Laplace)關聯 結構模型是否能有其特有的優點與更好的配適效果。由最後的實證分析結果可得. ‧. 到幾個結論,第一,高斯(Gaussian)及拉普拉斯(Laplace)關聯結構模型皆能反應. sit. y. Nat. 負報價。第二,單因子 NIG(2)關聯結構模型是本文使用的關聯模型中配適結果. n. al. er. io. 最好的,其在各年度合成型抵押擔保債券商品的絕對誤差和都是最小。第三,對. i Un. v. 於本文所使用的全部模型,它們在各分券的隱含相關震盪幅度很大,因此這些模 型都不符合 LHP 假設。. Ch. engchi. 關鍵字 : 合成型抵押擔保債券、單因子關聯結構模型、NIG 分配、拉普拉斯分 配. ii.
(4) 目錄 謝辭................................................................................................................................. i 摘要................................................................................................................................ ii 表目錄............................................................................................................................ v 圖目錄............................................................................................................................ v 第一章. 緒論............................................................................................................ 1. 第一節. 前言........................................................................................................ 1. 第二節. 研究目的................................................................................................ 1. 第三節. 抵押擔保債券(Collateralized Debt Obligation ,CDO) ........................ 2. 第四節. 政 治 大 合成型抵押擔保債券(Synthetic CDOs) ............................................. 3 立 信用違約交換(Credit Default Swaps ,CDS) ....................................... 4. 第六節. 信用違約指數(Credit Default Indexes) ............................................... 5. ‧. ‧ 國. 學. 第五節. 第二章 文獻回顧.......................................................................................................... 8 關聯結構模型(Copula Model)............................................................. 8. 第二節. 單因子關聯結構模型(One Factor Copula Model) .............................. 9. n. al. er. io. sit. y. Nat. 第一節. i Un. v. 第三節 Normal Inverse Gaussian Distribution (NIG) ........................................ 14. Ch. engchi. 第三章 以單因子關聯結構模型評價合成型抵押擔保債券.................................. 15 第一節. 評價合成型抵押擔保債券 ............................................................. 15. 第二節. LHP 假設下之單因子高斯關聯結構模型 ...................................... 18. 第三節. NIG 分配性質 .................................................................................. 23. 第四節. LHP 假設下之單因子 NIG 關聯結構模型........................................... 24. 第四章 單因子拉普拉斯分配之關聯結構模型........................................................ 27 第一節. 拉普拉斯(Laplace)分配 ................................................................ 27. 第二節. LHP 假設下之單因子拉普拉斯關聯結構模型 .............................. 28. 第三節 應用 LHP 假設之單因子雙指數與標準常態關聯結構模型................ 31 iii.
(5) 第五章. 實證分析...................................................................................................... 33. 第一節. 比較在不同時期各模型對 DJ iTraxx 之分券的評價........................ 34. 第二節. 觀察不同時期各模型在 DJ iTraxx 的隱含相關性.......................... 39. 第六章. 結論與建議.................................................................................................. 45. 參考文獻...................................................................................................................... 48. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. iv. i Un. v.
(6) 表目錄 表 1. 1 表 1. 2 表 5. 1 表 5. 2 表 5. 3 表 5. 4. 全世界主要的信用違約指數名稱 信用違約指數及分券市場報價(2004.8.4) 2009 年 3 月 31 日之市場報價及不同模型的配適結果 2010 年 3 月 31 日之市場報價及不同模型的配適結果 2011 年 9 月 30 日之市場報價及不同模型的配適結果 2012 年 1 月 31 日之市場報價及不同模型的配適結果. 6 7 36 37 37 38. 表 5. 5 表 5. 6 表 5. 7. 2013 年 1 月 31 日之市場報價及不同模型的配適結果 不同模型在 2009 年 3 月 31 日之各分券隱含相關值 不同模型在 2010 年 3 月 31 日之各分券隱含相關值. 38 40 41. 表 5. 8 不同模型在 2011 年 9 月 30 日之各分券隱含相關值 表 5. 9 不同模型在 2012 年 1 月 31 日之各分券隱含相關值 表 5. 10 不同模型在 2013 年 1 月 31 日之各分券隱含相關值. 42 43 44. 政 治 大. 立. y. ‧. ‧ 國. 學. Nat. n. er. io. al. sit. 圖目錄 i Un. 圖 1. 1 抵押擔保債券流程 圖 1. 2 合成型抵押擔保債券流程 圖 1. 3 信用違約交換流程 圖 4. 1 圖 5. 1 不同模型在 2009 年 3 月 31 日之隱含相關曲線 圖 5. 2 不同模型在 2010 年 3 月 31 日之隱含相關曲線 圖 5. 3 不同模型在 2011 年 9 月 30 日之隱含相關曲線 圖 5. 4 不同模型在 2012 年 1 月 31 日之隱含相關曲線 圖 5. 5 不同模型在 2013 年 1 月 31 日之隱含相關曲線. Ch. engchi. 圖 6. 1 資產報酬 的模擬分配. v. 3 4 5 28 40 41 42 43 44 47. v.
(7) 第一章 緒論 本章首先說明前言以及研究目的,接著介紹本文中的主要評價商品(合成型 抵押擔保債券)與其相關商品。. 第一節 前言 近年來,信用衍生性商品(credit derivatives)的市場快速地成長,主要的原因 是金融機構為了避免交易對手的違約風險,希望藉由該商品將此違約風險轉移到. 政 治 大 產的信用違約風險轉變成多個標的資產的組合信用違約風險,因此提供了組合信 立 金融市場。但是隨著金融市場的演變,金融機構所面臨的風險已經從單一標的資. ‧ 國. 學. 用衍生性商品發展的契機,組合信用衍生性商品如抵押擔保債券(Collateralized Debt Obligation ,CDO)與合成型抵押擔保債券(Synthetic CDOs)等皆能管理組合. ‧. 信用風險。本文將對不同年度的合成型抵押擔保債券(Synthetic CDOs)商品,以. n. al. er. io. sit. y. Nat. 不同的單因子關聯結構模型進行評價。. 第二節 研究目的. Ch. engchi. i Un. v. 對於合成型抵押擔保債券的評價,目前最常用的方法是單因子關聯結構模型 (One Factor Copula Model),此模型最早是由 O'Kane and Schloegl(2001)所提出, 作者將常態分配引進單因子關聯結構中,形成單因子常態關聯結構模型,而該模 型在進行各分券的評價時,只有在權益分券會得到好的配適結果,而且會造成相 關性微笑曲線的問題。Kalemanova et al.(2007)提出應用 LHP 假設之單因子 NIG 關聯結構模型來對合成型 CDO 進行評價,該模型的評價結果遠優於單因子常態 關聯結構模型,但缺點是其會高估中間順位層級以上的分券。邱嬿燁(2007)使用 單因子 CSN 關聯結構模型對合成型 CDO 進行評價,但該模型仍然無法估計得很 1.
(8) 準確,只有在最高層級分券(senior tranche)的評價有明顯的改善。除了提出單因 子 CSN 關聯結構模型之外,邱嬿燁(2007)亦使用 NIG 及 CSN 混合分配之單因 子關聯結構模型對合成型 CDO 進行評價,該模型在實證分析中得到極佳的評價結 果。本文的研究目的是使用單因子拉普拉斯關聯結構模型對合成型抵押擔保債券 作評價,並與其它單因子關聯結構模型的配適結果做比較,探討在評價上單因子 拉普拉斯關聯結構模型是否能有其特有的優點與更好的配適效果。. 第三節 抵押擔保債券(Collateralized Debt Obligation ,CDO). 治 政 抵押擔保債券(CDO)是資產擔保證券(asset-backed 大 securities)的衍生性商品。 立 其證券化的流程如圖 1.1,假設有一個創始機構(如:某一金融機構)持有多筆債 ‧ 國. 學. 權的資產群組(Asset Pool),該創始機構將其所擁有的資產群組轉售給特殊目的. ‧. 機構(Special purpose vehicle ,SPV),而特殊目的機構再將其切割並重新包裝,最. er. io. sit. y. Nat. 後賣出固定收益證券給投資人。. 值得注意的是,CDO 是將收益證券分為好幾個層級(Tranche),以吸引不同. al. n. iv n C 風險偏好的投資人購買。CDO 運作的方式是債務人每月償還本金及利息給擁有 hengchi U. 其債權的服務機構,服務機構收取其應得的服務費用後,將剩下的錢轉移給特殊 目的機構,特殊目的機構收取信託費用後交給投資人,而投資人收取利息的方式 為,由優先順位層級(Senior Tranche)投資人先收取利息,等優先順位層級投資人 收取足額的利息後,中間順位層級(Mezzanine Tranche)投資人才開始收到利息, 同樣地,等到中間順位層級投資人收取足額的利息後,次順位(Junior Tranche) 投資人才開始收到利息,付清三個層級後,剩餘現金才會支付給權益層級(Equity Tranche)的投資人。. 2.
(9) 發生損失時,則由權益層級的投資人先承擔損失,之後由次順位層級的投資 人承擔損失,依此類推,最後由優先順位的投資人承擔損失。因此權益層級投資 人所承擔的風險最大,但其報酬率最高,而優先順位投資人所承擔的風險最小, 其報酬率也是最小。. 現金(cash) 創始機構. 現金(Cash) 特殊目的機構(SPV). 投資人. 出售. 發行收益證券. 資產群組. 立. 資產 1 資產 2. 中間順位. ‧ 國. 權益層級. sit. io. er. 圖 1. 1 抵押擔保債券流程. 次 順 位. y. ‧. Nat. al. iv n C U h e n g c h i CDOs) 合成型抵押擔保債券(Synthetic n. 第四節. 優先順位. 學. 資產 N. 政 治 大. 合成型抵押擔保債券的商品結構大致與抵押擔保債券相同,最大的差異在於, 在合成型抵押擔保債券中,創始機構與特殊目的機構(SPV)會簽訂信用違約交換 合約,將債權群組可能會發生違約的風險移轉給特殊目的機構,由特殊目的機構 承擔風險,而創始機構會定期地給予特殊目的機構權利金,作為其承擔風險的代 價。 合成型抵押擔保債券的運作流程如圖 1.2,在期初,特殊目的機構會收到投 資人因購買合成型抵押擔保債券所投入的資金,且其不需要付給創始機構任何費 用,因此特殊目的機構可用此筆費用購買穩定的收益商品(如:政府公債),以作 3.
(10) 為違約事件發生時,可支付給創始機構的現金。. 違約事件發生時 支付的現金 創始機構. 現金(Cash) 特殊目的機構(SPV). 投資人. 定期支付. 發行收益證券. 的權利金. 優先順位. 政府公債. 資產群組 資產 1 資產 2. 中間順位. 立. 次 順 位 權益層級. 學. 圖 1. 2 合成型抵押擔保債券流程. ‧. ‧ 國. 資產 N. 政 治 大. 第五節 信用違約交換(Credit Default Swaps ,CDS). sit. y. Nat. n. al. i Un. 或無能力承受因持有標的資產違約而帶來的風險。. Ch. engchi. er. io. 信用違約交換是信用衍生性商品的一種,主要是因為持有資產方不願意承受. v. 信用違約交換的運作流程如圖 1.3,保護買方與保護賣方簽訂合約,以規避 其資產的信用風險,在約定的期間內,持有標的資產的信用違約風險將由保護買 方移轉至保護賣方,而保護買方也將定期支付權利金給保護賣方,作為其承擔信 用風險的代價,當標的資產發生違約時,保護賣方須給予保護買方一筆金額,以 彌補因其資產違約而帶來的損失。. 4.
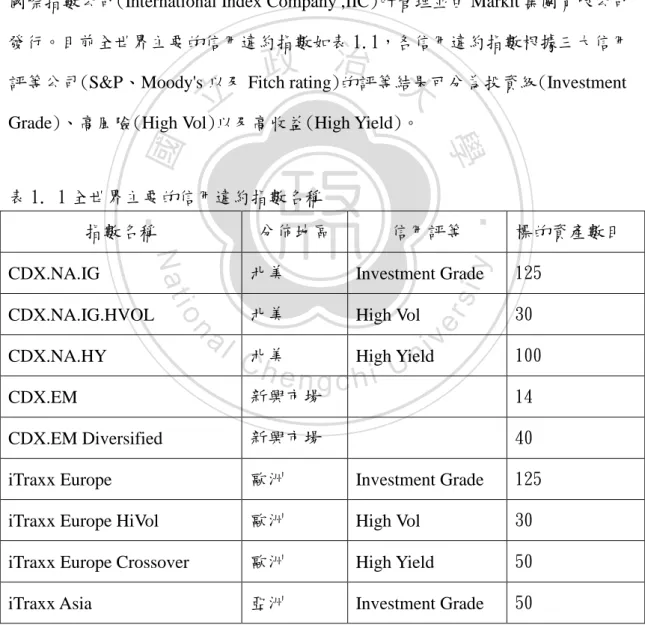
(11) 定期支付權利金 保護買方. 保護賣方 方. 違約事件發生時 補償保護買方的損失 標的資產 圖 1. 3 信用違約交換流程. 在信用違約交換中,若保護買方考慮的是多個標的資產,則該類型的信用違. 政 治 大. 約交換合約稱為一籃子信用違約交換。最常見的一籃子信用違約交換為第 N 個違. 立. 約交換,即買賣雙方約定當所參考的資產組合中,有 N 個或 N 個以上發生違約時,. ‧ 國. 學. 保護賣方必須立即支付保護買方因資產違約而造成的損失。但是如果違約事件未 達 N 個時,保護買方需要定期地支付費用給保護賣方。. ‧. n. er. io. al. sit. y. Nat. 第六節 信用違約指數(Credit Default Indexes). Ch. i Un. v. 信用違約指數是用來規避信用風險的另一種衍生性商品,該指數增加了信用. engchi. 商品的流動性及減少買賣價差。信用違約指數的運作方式為選擇市場上流動性較 高公司的信用違約交換作為一籃子資產,然後將這群資產以平均加權(Equal Weight)的方式計算其權利金,每隔六個月信用違約指數會定期地依照標準調整 其指數成員,若指數的標的資產都沒有發生違約情況,則該指數的成員維持不變, 而發生違約或信用等級下降的標的資產則從指數成員中移出。 信用違約指數的權利金由保護買方在合約期間內(如:3、5、7 或 10 年)定期 支付,付費日期訂在每一年的三月、六月、九月與十二月的二十號。因為在合約 期間發生數個標的的公司違約情況,使需要被保護的資產個數減少,連帶地降低 了本金金額,因此保護買方定期支付的權利金金額會與剩餘的本金金額成比例。 5.
(12) 信用違約指數等同於購買許多單一的信用違約交換合約,且其能減少交易成本, 但在權利金支付方面則有些許不同,以信用違約指數來說,發生違約事件時,保 護買方立即停止支付權利金給保護賣方。. CDX 指數與 iTraxx 指數是目前市場的兩個主要信用違約指數。前者的涵蓋 範圍為北美和新興市場的企業,由 CDS 指數公司(CDS Index Company)所管理並 由 Markit 集團有限公司(Markit Group Limited)發行;後者則涵蓋了其他地區,由 國際指數公司(International Index Company ,IIC)所管理並由 Markit 集團有限公司 發行。目前全世界主要的信用違約指數如表 1.1,各信用違約指數根據三大信用. 治 政 評等公司(S&P、Moody's 以及 Fitch rating)的評等結果可分為投資級(Investment 大 立 Grade)、高風險(High Vol)以及高收益(High Yield)。 ‧ 國. 學. io. CDX.NA.IG.HVOL. al. n. CDX.NA.HY. y. 信用評等. 標的資產數目. 北美. Investment Grade. 125. 北美. High Vol. 30. sit. Nat. CDX.NA.IG. 分佈地區. er. 指數名稱. ‧. 表 1. 1 全世界主要的信用違約指數名稱. iv High Yield n C北美 hengchi U. 100. 新興市場. 14. CDX.EM Diversified. 新興市場. 40. iTraxx Europe. 歐洲. Investment Grade. 125. iTraxx Europe HiVol. 歐洲. High Vol. 30. iTraxx Europe Crossover. 歐洲. High Yield. 50. iTraxx Asia. 亞洲. Investment Grade. 50. CDX.EM. 6.
(13) 隨著信用違約指數的發展,合成型抵押擔保債券商品的概念也被導入信用違 約指數中,亦即將指數分割成不同層級的標準化分券型式以吸引不同風險偏好的 投資者。而之前提到的兩大信用違約指數 CDX 指數和 iTraxx 指數被分為五個 分券,分別是權益分券、次順位分券、中間層級分券、優先層級分券和最高層級 分券。CDX 指數的標準化分券架構為 0-3%、3-7%、7-10%、10-15%以及 15-30%;iTraxx 指數的標準化分券架構為 0-3%、3-6%、6-9%、9-12%以及 12-22%。 投資人在各分券中可得到的投資報酬分為兩大類,第一類的投資人在訂立契約的 期初,會收到一筆等同市場報價的預付費用(upfront payment),並可在每一期拿 到信用價差(running spread),而第二類的投資人只會定期地在每一期拿到信用價. 治 政 差。在 2008 年以前,只有權益分券為第一類報酬方式,其餘分券則為第二類報 大 立 酬方式,如表 1.2。本文將評價以 iTraxx 指數為標的之不同商品結構的合成型抵 ‧ 國. ‧. 信用違約指數及分券市場報價(2004.8.4). y. Nat. iTraxx Europe(5 年) 42bp. n. al. 信用違約指數. er. io. 信用違約指數. CDX.NA.IG(5 年). Ch. 分券. 市場報價. 0-3%. 27.6%. 3-6% 6-9%. sit. 表 1. 2. 學. 押擔保債券。. i Un. 分券. engchi. v. 63.25bp 市場報價. 0-3%. 48.1%. 168 bp. 3-7%. 347 bp. 70 bp. 7-10%. 135.5 bp. 9-12%. 43 bp. 10-15%. 47.5 bp. 12-22%. 20 bp. 15-30%. 14.5 bp. 7.
(14) 第二章 文獻回顧 評價合成型抵押擔保債券時,必須考慮各資產間的違約相關性,最早能捕捉 該違約相關性(default correlation)的模型為 Li(2000)所提出的關聯結構模型 (Copula Model),該模型後來更演變成單因子關聯結構模型(One Factor Copula Model),本文將以單因子關聯結構模型來做實證分析,因此本章將回顧與單因 子關聯結構相關之文獻,以了解各文獻對此模型的觀點與應用方法。. 政 治 大. 第一節 關聯結構模型(Copula Model). 立. ‧ 國. 學. Li(2000)使用隨機變數「time-until-default」來表示各個金融標的資產從合約 開始到發生違約的總時間,即各資產的違約時點,並定義不同金融標的資產間會. ‧. 存在違約相關性。. sit. y. Nat. n. al. er. io. Li(2000)使用關聯結構函數將上述各隨機變數的邊際機率分配做連結,形成. i Un. v. 資產組合違約時點的聯合分配函數。此外,Li(2000)透過高斯關聯結構模型. Ch. engchi. (Gaussian copula)及 Sklar's 定理得到資產組合違約時點的聯合分配函數,如下:. 其中, 為第 i 個標的資產的違約時點, 為其相關係數矩陣, 酬設定為. 為一個 n 維度的多變量常態分配,. 為第 i 個標的資產的違約機率。此模型將各資產的報 ,如此便能以標的資產報酬的相關性取代. 違約時點的相關性,而且也能以蒙地卡羅(Monte Carlo)模擬方法來模擬各資產的 8.
(15) 違約時點. 。. 但是蒙地卡羅法需要透過大量的模擬來得到各個標的資產的違約時點,在標 的資產數目為大樣本下,勢必會提高運算過程的複雜性。此外,標的資產間的相 關係數矩陣必須為正定矩陣。. 第二節 單因子關聯結構模型(One Factor Copula Model) Li(2000)提出的關聯結構模型的優點為能夠以標的資產報酬的相關性取代. 治 政 違約時點的相關性,而其缺點為當資產數目過多時,會增加蒙地卡羅模擬方法的 大 立 計算複雜度及增加計算時間。單因子關聯結構模型就是在這樣的環境下產生,該 ‧ 國. 學. 模型的精神為對於不同的標的資產給定相同的因子(市場因子)條件。相對於. ‧. Li(2000)的關聯結構模型,單因子關聯結構模型可以快速地計算在不同時點下的. y. sit. io. er. 間。. Nat. 違約損失分配,且可避免如蒙地卡羅模擬方法的計算費時性,因此可縮短計算時. al. n. iv n C 單因子關聯結構模型的概念最早是由 and Schloegl(2001)所提出,文 h e n g cO'Kane hi U 中介紹對於持有不同數量的標的資產應該如何建立信用模型(credit model),而該 模型必須在無套利(arbitrage-free)的情況下,保證評價的一致性及擁有可以洞察 些許違約過程(default process)的價值。以單一標的資產的信用模型來說,其可分 為結構式模型(Structural model)與縮減式模型(Reduced-form Model)。前者是 利用 Merton(1974)模型原理,以公司本身的資產價值來衡量其信用風險,若該 公司的資產價值低於某個門檻值時將認定該公司為違約,因此結構式模型又稱為 公司價值模型(Firm value model),而此模型的缺點為其假設過於簡化,假設違 約事件只會發生在到期日而已,且不考慮除了公司本身資產價值外的可能違約事. 9.
(16) 件。Black and Cox(1976)放寬了 Merton 模型中的違約條件,假設在到期日前任 意時點,若公司資產價值達到某個邊界(boundary),則視為該公司違約,因此又 可稱之為通過時點模型(Passage time model)。結構式模型的優點為其對於風險事 件的定義與財務上對於公司違約的定義非常類似,但困難處在於要確實地掌握公 司的資本結構資訊是一件很不容易的事,若無法準確地估計公司的資產價值與負 債總額,在計算信用價差的時候,很有可能會出現不合理的價格。與結構式模型 不同,縮減式模型不解釋違約事件的發生原因(如:公司的資產價值達到某個資產 邊界則視為違約),而是以統計方法去捕捉違約事件發生的時間點。縮減式模型 是利用卜瓦松(poisson)過程來建立違約過程,且隨機違約行為會被違約率函數. 治 政 所決定,並得到資產的存活時間為指數分配。縮減式模型的評價方法與結構 大 立 式模型是相同的,不同的是,縮減式模型的違約機率、回復率、市場利率都是由 ‧ 國. 學. 外生所決定,而結構式模型則必須確實地知道公司的資產價值與負債總額,才能. ‧. 做風險評估。. sit. y. Nat. O'Kane and Schloegl(2001)首次提出單因子關聯結構模型,該模型假定標的資產. io. al. n. 為. er. 組合擁有共同的市場因子 M(t),且各標的資產從契約開始到第 t 時間的總報酬. Ch. 其中 M(t)為市場共同因子,. engchi. v. 為資產本身因子,. 立的隨機變數,且假設它們皆服從標準常態分配。 由常態分配的封閉性可知. i Un. 和 為. 為相同且互相獨 和. 的線性組合,. 亦為一服從標準常態分配的隨機變數。在標的資產. 組合中,若資產數目夠多的話,則增加大樣本一致性資產組合 LHP(Large homogeneous portfolio)的額外假設條件 視各個標的資產為同質性資產 (homogeneous assets),有了這個額外假設條件,就可快速地算出資產組合的損 失分配函數。因為單因子關聯結構模型有上述的優點,因此此模型成為了市場上 評價擔保債權憑證的主要方法。. 10.
(17) Laurent and Gregory(2003)建議以 semi-analytic 方法來評價一籃子違約交換 (basket default swaps)和合成型抵押擔保債券分券。雖然同樣使用單因子關聯結 構模型,但文中介紹的評價方法與 O'Kane and Schloegl(2001)的評價方法兩者最 大的差異是標的資產發生違約時的損失分配,後者使用 LHP 假設方法來計算,而 前者是使用快速傅立葉轉換法(Fast Fourier Transforms, FFT)來計算,即由資產組 合損失的特徵函數來求得資產組合的損失分配。與蒙地卡羅法比較,此方法具有 大量減少計算時間的優點,但是其缺點為數學運算過程複雜。. Hull and White (2004)發展了兩種評價 CDO 分券的方法,這兩種方法都是. 治 政 採用因子關聯結構模型且能取代 Laurent, J-P and J.gregory(2003)所提出的快速 大 立 傅立葉轉換法。這兩種方法的主要差異為損失分配的計算,第一種方法是假設在 ‧ 國. 學. 投資組合中各標的資產的權重比例相等且回復率為固定值之下,利用遞迴關係. ‧. (recurrence relationship)求出在特定時點下 K 個資產違約的機率,其中資產的總. sit. y. Nat. 損失可以看成是二項式分配。第二種方法是機率杓斗法(probability bucketing. io. er. method),此法沒有限制各標的資產的權重比例必須相等且假設回覆率可以是隨 機的情況之下,去計算到期日前特定時點的總損失分配。Hull and White (2004). al. n. iv n C 除了提出兩種評價方法外,對於單因子關聯結構模型他也提出了一個新的觀點, hengchi U. 即在模型中除了可使用常態分配外,如果在給定分配的期望值為零且變異數為一 下,任何分配都可以套用在單因子關聯結構模型裡,而不同的分配選擇代表不同 的關聯結構模型。文中使用單因子常態關聯結構模型與雙 t 分配關聯結構 (Double t-distribution)模型來評價 iTraxx 與 CDX 指數的分券市場資料,由實證 結果顯示具有厚尾(heavy tails)性質的雙 t 分配關聯結構模型會有較好的配適結 果。此外,文中亦提出單因子常態關聯結構模型的缺點,即在該模型下計算各分 券的隱含相關(Implied correlations)及基底隱含相關(Base implied correlations)時, 會出現相關性微笑曲線(correlation smile)與隱含相關偏斜(Implied correlations. 11.
(18) skew)的現象,該現象的發生主要是因為常態關聯結構模型缺少厚尾性質。文中 介紹的雙 t 分配關聯結構模型雖然具有改善此現象的優點,但由於 t 分配沒有穩 定摺積性(convolution),也沒有如常態分配的封閉性,所以計算損失分配時,必 須透過數值積分分法來求解,所以該模型具有計算過程較為耗時的缺點。. Andersen,L. and J.Sidenius(2005)提出了兩個拓展高斯關聯結構的新模型,新 模型仍有原本模型的易處理性與計算的效率性,第一個模型是回復率隨機化模型, 該模型是將回復率隨機化(randomized recovery),且能允許資產違約頻率與回復 率之間呈現負相關的影響。第二個模型是因子負荷項隨機化模型,該模型是將因. 治 政 子負荷項隨機化(randomized factor loadings),使得在總體經濟衰退時得到的違約 大 立 相關會比總體經濟成長時要來得高。作者認為這兩個模型可以產生類似厚尾性質 ‧ 國. 學. 所擁有之較好的評價效果。當使用新模型求取隱含相關時,回復率隨機化模型的. ‧. 偏斜影響是相當小的,而因子負荷項隨機化模型會產生如高斯關聯結構模型的相. io. er. 的模型,如:Marshall-Olkin 關聯結構。. sit. y. Nat. 關偏斜現象。除了上述的兩個修正模型外,作者也介紹可使用具有偏斜性質(skew). al. n. iv n C Dezhong(2006)延續了 Hull and (2004)的想法,藉由使用具厚尾特性 h eWhite ngchi U 的函數來改善單因子關聯結構模型。作者建議可用四種單因子高斯關聯結構延伸 模型:. (1) 高斯混合關聯結構(a double mixture Gaussian copula.) (2) 自由度為非整數的雙 t 關聯結構(a double t distribution with fractional copula.) (3) t 與高斯分配混合關聯結構(a double mixture distribution of t and Gaussian distributions copula.). 12.
(19) (4) 雙平滑截斷 穩定分配關聯結構(a double smoothly truncated. stable copula.). (1)~(4)延伸模型都是藉由調整一個參數來控制整體關聯結構函數的厚尾度 (tail-fatness)。其中(1)與(3)模型所使用的分配函數都是以兩個分配混合而成, 假設有一個隨機變數 Y 為. 與. 的混合分配,則 Y 可以表示成 機率為 機率為. 在使用混合分配時,必須滿足一個條件,即不論. 和. 的分配為何,最後 Y 的期. 望值與變異數必須為零與一,若不滿足該條件,可將其標準化以符合條件。在單. 治 政 因子混合分配關聯結構模型裡,資產因子與市場因子的厚尾度是由 、 大 立 配各自的參數與 p 三者共同決定。作者建議使用此模型時,可以先固定. 兩個分 和. 的. ‧ 國. 學. 參數,使得 p 成為唯一能控制關聯結構函數之厚尾度的參數。. ‧. sit. y. Nat. 雖然可從文獻上知道以雙 t 關聯結構來做 CDO 商品的評價,其結果很接近. io. er. 市場報價,但是該模型在運算上有其缺點,因為 Student t 分配有摺積(convolution) 的不穩定性,所以對於違約門檻值的計算必須透過尋找極值的數值分析技巧,但. n. al. Ch 這也使得計算時間增加了很多。. engchi. i Un. v. Kalemanova et al. (2007) 在大樣本一致性資產組合(Large Homogeneous Portfolio)假設下,提出以 NIG 分配取代 t 分配作為擔保債券憑證分券的評價。 NIG 分配擁有許多良好的性質。首先,相較單因子高斯關聯結構,NIG 分配具有 尾點相依性(tail dependence)的性質;其次,NIG 分配具有穩定的摺積性 (convolution);再者,單因子 NIG 關聯結構模型能夠簡單且快速地計算各資產的違 約門檻值;並且,因為其擁有多個參數可以在建立投資組合的相關性結構上有更 多的彈性。文末進行實證分析,和雙 t 分配關聯結構類似,兩者皆在前兩個分券. 13.
(20) 0~3%及 3~6%得到好的配適結果,但卻高估了 6~9%以上的分券。此外,文中將 NIG 模型分成 NIG(1)與 NIG(2),兩者的差別在於使用的參數數目,在 NIG(1)模 型中,固定 參數為 0,而在 NIG(2)模型中, 參數為變動的,且由實證分析發現 NIG 分配的 參數並沒有帶來改善的評價效果。 邱嬿燁(2007)使用 CSN 分配(Closed skew normal)來做擔保債權憑證分券的 評價,其動機在於 CSN 分配具有常態分配的性質且具有封閉性,同時具有較多 的參數可控制分配的峰態與偏態。但與單因子常態關聯結構模型相同,單因子 CSN 關聯結構模型仍無法估計的很準確,只有在最高等級分券(senior tranche)的 評價上有明顯的改進。. 立. 政 治 大. ‧ 國. 學. 第三節 Normal Inverse Gaussian Distribution (NIG). ‧. Barndorff-Nielsen (1978)提出 NIG 分配,該分配為廣義雙曲分配(the. sit. y. Nat. generalized hyperbolic distributions)的特殊例子。因為該分配擁有的特定性質,使. io. er. 得其漸漸應用在金融及經濟方面。如:Dimitris Karlis(2000)使用 EM 演算法得到 NIG 分配參數的最大概似估計值,且發現以 NIG 分配配適希臘雅典指數(Athens. al. n. iv n C Stock Exchange index)的資料,其結果是相當好的;Kalemanova et al.(2007)應用 hengchi U NIG 分配評價擔保債權憑證分券。NIG 分配為一個具有四個參數的分配,能夠同 時產生厚尾性及偏斜性。. 14.
(21) 第三章. 以單因子關聯結構模型評價合成型抵押擔保債券. 本章分成兩個部分,首先先說明合成型抵押擔保債券的評價方法,再說明如 何使用 LHP 假設下之單因子高斯與 NIG 關聯結構模型來計算合成型抵押擔保債券 的分券價格。. 第一節 評價合成型抵押擔保債券 考慮一個合成型抵押擔保債券,其只包含信用違約交換(credit default swap). 政 治 大. 契約之標的資產組合,該合成型 CDO 分券的持有者(保護賣方, protection seller). 立. 每季都會收到該分券的發行者(保護買方, protection buyer)所支付的信用價差費. ‧ 國. 學. 用(credit spread payments)。如果標的資產組合的違約總損失超過分券的面額 (notionals),保護賣方將付給保護買方一筆補償分券損失的費用。. ‧. 基本上,合成型 CDO 的. 分券. 的評價方法與評價信. y. Nat. n. al. er. io. 號:. sit. 用違約交換(credit default swap)的方法相同。我們先定義評價過程會用到的符. 1.. 為評價日。 2. 3. 4. 5.. Ch. i Un. v. :為信用價差的付費日, 為合成型 CDO 的到期日,而. engchi. : 每期的信用價差。 : 合成型 CDO 的. 分券在時間 的損失百分比。. : 無風險短期利率,且假設此利率與分券損失獨立。 : 合成型 CDO 的. 分券的期望損失,假設整個評價過程. 都是在風險中立測度 Q 下進行,因此. 也可以表示為. 。 6.. : 折現因子,在 時間的 1 元以每期無風險短期利 15.
(22) 率. 折現到評價日 的現值。. 要評價合成型抵押擔保債券各分券之公平信用價差之前,須先求得此分券的 違約給付金額(Protection leg)與保護收入(Premium leg) ,並且在風險中立測度下 假設這兩筆現值金額為相等來計算信用價差價格。. 違約給付金額是當未來發生違約事件時,保護買方可從保護賣方收到的一筆 補償金額現值:. 立. 政 治 大. ‧. ‧ 國. 學 y. sit. n. al. er. 時間內的總違約金額僅在時間 付費。. io. 示,假設在. Nat. 必須注意的是此筆違約給付金額應該在違約事件發生時立即給付,但為了簡化表. Ch. engchi. i Un. v. 而分券的保護收入是分券的持有者在未來預期可收到來自分券的發行者的 所有信用價差的現值,且分為兩種類型,第一種類型為保護賣方僅在每一期會收 到來自保護買方的信用價差,如下:. 16.
(23) 其中,. 。. 假設在時間 的信用價差費用s會與在此時間的剩餘本金百分比成比例,且該 信用價差費用只在 時付費,因此必須乘上折現因子. 。此外,. 分券的保護收入還有另一種可能型式,即保護賣方除了在每一期收到來自保護買 方的信用價差,並且在契約訂立期初時會收到一筆等同於. 分券市場報價. (market quote)的預付費用。此類型的分券其保護收入可表示成:. 政 治 大 其中,mq是期初由保護買方給予保護賣方的一筆預付費用。 立. ‧ 國. 學. 假設分券的違約給付金額(Protection leg)等於保護收入(Premium leg)以求得. ‧. 合成型CDO分券的公平信用價差。. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. 當分券的保護收入為第二類時,每一期的信用價差會是一個固定的金額,需要計 算的是期初保護賣方收到的一筆等同於. 分券市場報價(market quote)的預. 付費用,與第一類一樣,同樣是令分券的違約給付金額與保護收入相等,以得到 該筆預付費用:. 17.
(24) 假設標的資產組合在時間 之損失為. ,則可將. 分券之損失百分. 比表示為. 假設已知一個連續型標的資產損失分配函數. ,則. 分券在第t時點的. 期望損失百分比可以寫成:. 立. 政 治 大. ‧. ‧ 國. 學 sit. y. Nat. ,即可計算合成型. io. er. 由(3.4)式可知,只要得到分券的期望損失. 抵押擔保債券的公平信用價差,而在計算該期望損失前,必須先計算標的資產組. al. n. iv n C 。後面的小節將介紹單因子關聯結構以導出資產組合的損失 hengchi U. 合的損失函數 函數. 與期望分券損失. 。. 第二節 LHP 假設下之單因子高斯關聯結構模型 對於一個信用資產組合而言,若其標的資產個數夠多的話,則我們可以假設 此信用資產組合為大樣本一致性資產組合(large homogeneous portfolio portfolio ; LHP),亦即假定資產組合中的各資產具有同質性(有相同的權重比例、違約機率、 復原率以及對共同因子的相關性),經由此假設,我們去預測真實信用資產組合 的市場報價。 18.
(25) 假設各資產的違約時間都服從相同的分配 參數為 的指數分配,其中 為資產的信用違約強度. ,本文將使用市場上的信用資產組合. 的平均CDS價差與固定的復原率(recovery rate)來估計違約強度,由上述定義可知 第i個資產在t時點前違約的機率為. 。. 考慮一個標的資產個數為 的信用資產組合,並假設其具有共同的市場因子. M(t),則第 個資產從契約開始到第t時間的資產報酬. 其中,. 為共同市場因子,. 為:. 為資產本身因子,假設為. 與. 為獨立. 的線性組合,由常態分配的封閉性性質可知. 亦服從. 治 政 且相同的隨機變數,並假定它們都服從標準常態分配,即 大 立 與. 標準常態分配,且在給定共同市場因子. 之下,因為. y. sit. n. al. er. io 總資產報酬. 彼此互相獨立,所. 也彼此互相獨立,即. Nat. 以資產報酬. ‧. ‧ 國. 是. 學. 因為. Ch. engchi. i Un. v. 對於第 個標的資產的違約時間 ,則可運用百分比轉換. (percentile-to-percentile transformation):. 定義第i標的資產在時間 之前違約的機率為. 假設各個資產的違約時間為指數分配,此違約機率為 則能夠求得違約門檻值. 為. 19. 。.
(26) 為標準常態分配的累積密度函數。 由(3.9式)知,第 標的資產在 時點之前發生違約事件的條件為. 則給定共同因子. 之下,第 個標的資產在時間 之前發生違約事件的條件機. 率為. 立. 政 治 大 ,以及相. 同的本金及復原率,且資產之間的相關係數會是相同的. ,因此(3.10)式. ‧ 國. ‧. 可改寫成. 學. 在給定LHP的假設下,所有標的資產擁有相同的違約門檻值. n. er. io. sit. y. Nat. al. 發生k個標的資產違約之資產組合損失百分比 配. Ch. engchi. v i 的違約機率為二項式分 n U. ,為了求得非條件下的資產組合損失百分比,必須要對. 共同因子M(t)積分. 然後就能夠計算資產組合損失百分比的累積機率,考慮其不會大於 ,則. 20.
(27) 其中. (3.11). 從(3.11)式可以發現要得到期望分券損失. 的結果是非常複雜的,. 但因為我們已經假設在LHP條件下,所以可利用Vasicek (2002)提出的Large portfolio limit approximation來計算資產損失百分比的累積分配函數. 。在資. 產個數夠多的情況下, 則(3.11)式二項式分配可用常態分配來近似,並令 替換(3.11)式:. 立. 政 治 大. ‧ 國. 學. 接著考慮標的資產個數為無限多個,則資產組合損失百分比的累積機率 如下:. ‧. n. er. io. sit. y. Nat. al. 其中. Ch. engchi. ,因為. 則資產組合損失百分比的累積分配函數為. 21. i Un. v. (3.12).
(28) 為了計算. 的期望分券損失,我們使用(3.7)式,並將它改寫成. 立. 政 治 大. ‧ 國. 學. 要計算此積分前,必須先求得該資產組合損失百分比的機率密度函數. ‧. n. al. er. io. sit. y. Nat 代入(3.13)式. Ch. engchi. i Un. v. 以上為假設復原率為零之. 期望分券損失推導過程及結果,若我們假設資. 產的復原率並不為零,則. 的期望分券損失可以寫成:. 即為假設復原率不為零的分券損失百分比,而以上的關係式在接下來不同 22.
(29) 模型的關聯結構中一樣適用。. 第三節 NIG 分配性質 NIG 分配為一個混合了反高斯分配(inverse Gaussian distribution, IG)與常態 分配的分配。反高斯分配有兩個正參數 、 ,定義一個非負隨機變數 X,令 X~IG(. ,則 X 的機率密度函數如下:. 立. 政 治 大. ,且參數滿足:. io. y. 與. al. er. ,且將 Y 的機率密度與機率分配函數表示為. n. 及. sit. ‧ 國. ,其中. ‧. Nat. 則 Y 服從. 學. 假設有另一隨機變數 Y,且假設 Y 符合以下條件:. Ch. 。Y 的機率密度函數為:. 其中. engchi. i Un. v. 是 the modified Bessel function of the third kind。. 再來介紹 NIG 分配的幾個定理。假設一隨機變數 Y 服從 1. Y 的動差母函數. 2. Y 的中央動差(平均數、變異數、偏態、峰態)分別為 23. ,.
(30) (1) (2) (3) (4) 3. NIG 分配具有尺度與摺積性質(scaling and convolution property)。 給定一隨機變數 c,且設兩隨機變數. 和. ,. 且 X 和 Y 互相獨立,則. 政 治 大. (1). 立. (2). ‧ 國. 學. Nat. y. ‧. 第四節 LHP 假設下之單因子 NIG 關聯結構模型. n. al. 其中,. Ch. 為共同市場因子,. engchi. er. io. 個標的資產,則第 i 個標的資產報酬可表示為:. sit. 本節將在單因子關聯結構模型裡導入 NIG 分配,假設信用資產組合具有 N. i Un. v. 為資產本身因子,假設為. 與. 為獨立. 且相同的隨機變數,並假定它們都服從 NIG 分配。為了使資產報酬標準化,將兩 因子的參數設定如下:. 利用 NIG 分配的封閉性可以得到第 i 個標的資產報酬. 在這裡,我們定義分配函數. 為 24. 的分配為. ,因此共同市場.
(31) 因子 M 的分配函數可定義為. ,而資產因子 X 的分配函數可定義為. 。 與單因子高斯關聯結構模型一樣,定義第i標的資產在時間 之前違約的機率 為. 因此可得到違約門檻值. ). 同的市場因子 M(t)下,第 i 個標的資產報酬. 會小於違約門檻值 C(t)的條件. ‧. 違約機率為. 學. ‧ 國. 治 政 在給定LHP的假設下,所有標的資產擁有相同的違約門檻值 ,以及相 大 立 同的本金及復原率,且資產之間的相關係數會是相同的 ,因此在給定共. n. er. io. sit. y. Nat. al. Ch. engchi. 發生k個標的資產違約之資產組合損失百分比 配. i Un. v. 的違約機率為二項式分. ,為了求得非條件下的資產組合損失百分比,. 必須要對共同因子M(t)積分,如下:. 25.
(32) 接著跟(3.8)~(3.12)的步驟一樣,再利用 Vasicek (2002)提出的 Large portfolio limit approximation 來計算資產損失百分比的累積分配函數:. 其中. 。. 為了計算. 的期望分券損失,我們使用(3.7)式,並將它改寫成. 要計算此積分前,必須先求得該資產組合損失百分比的機率密度函數. 立. ‧. ‧ 國. 學. n. al. er. io. sit. y. Nat. 代入(3.15)式. 政 治 大. Ch. engchi. i Un. v. 藉由 R 軟體中的 fabsics 套件的 dnig、pnig 與 qnig 函數函數可以快速地計算 此積分,且因為 NIG 分配具摺積性質與封閉性,所以也能快速求得違約門檻值 C(t)。. 26.
(33) 第四章 單因子拉普拉斯分配之關聯結構模型 本章會先介紹拉普拉斯(Laplace)分配,該分配又稱為雙指數分配。因為拉 普拉斯分配沒有如高斯分配與 NIG 分配的摺積性質與封閉性,因此考慮使用模 擬方法,模擬的方法會在第二節介紹。接下來再介紹如何使用 LHP 假設下之單 因子拉普拉斯分配關聯結構模型來計算合成型抵押擔保債券分券價格。. 第一節 拉普拉斯(Laplace)分配. 政 治 大. 拉普拉斯分配可以看作是兩個不同位置的指數分配背靠背接在一起,所以它. 立. 也稱為雙指數分配。. ‧ 國. 學. 給定一個隨機變數 X,假設其為兩個參數 和 的拉普拉斯分配,則 X 的機 率密度函數如下:. ‧. n. er. io. sit. y. Nat. al. 其中,. Ch. engchi. i Un. 是位置參數,b > 0 是尺度參數,如果. v. 0,那麼,正半部分恰好是. 尺度為 1/2 的指數分佈。為了方便之後的公式推導,我們將隨機變數 X 表示為. Laplace(. ,並將 X 的機率密度及分配函數表示為. 與. 。 而拉普拉斯分配的兩個參數對於機率密度函數的影響分別以圖形呈現:. 27.
(34) 圖 4. 1. 政 治 大. 參數與 參數對拉普拉斯分配的密度函數影響. 立. 從圖 4.1 中來看,我們先固定某一個參數,然後觀察單一參數對於密度函數的影. ‧ 國. 學. 響,可以發現拉普拉斯分配可藉由改變尺度參數 b 來產生厚尾性,而當位置參數. ‧. 時,拉普拉斯分配會呈現對稱分配。. sit. y. Nat. io. n. al. er. 第二節 LHP 假設下之單因子拉普拉斯關聯結構模型. i Un. v. 本節將在單因子關聯結構模型裡導入拉普拉斯分配,假設信用資產組合具有. Ch. engchi. N 個標的資產,則第 i 個標的資產報酬可表示為:. 其中,. 為共同市場因子,. 為資產本身因子,假設. 與. 為獨立且. 相同的隨機變數,並假定它們都服從拉普拉斯分配。為了使資產報酬標準化,將 兩因子的參數設定如下:. 與高斯分配與 NIG 分配相比,拉普拉斯分配不具有封閉性,所以單因子拉普拉斯 關聯結構模型對於違約門檻值. 無法將其表示為某個機率分配函數的反函數, 28.
(35) 因此必須使用模擬的方法來求取各時點的違約門檻值 1. 對. 與. 各模擬 50000 個. ,步驟如下:. 的值,令這兩個模擬出來的序. 列為 M 與 X,然後將 M 與 X 代入(4.1)式,得到一個 A 的序列。 2. 因為. 所以對於每個時點 ,都可得到 3. 對 1.步驟得到的 A 做排序,然後依照 2.步驟算出來的每期 累積機率的 做為每期的違約門檻值. 立. ,取相對應. 。. 政 治 大. 在給定LHP的假設下,所有標的資產擁有相同的違約門檻值. ‧ 國. 學. 同的本金及復原率,且資產之間的相關係數會是相同的. y. sit. n. er. io. al. Ch. engchi. 發生 k 個標的資產違約之資產組合損失百分比 配. 會小於違約門檻值 C(t)的條件. Nat. 違約機率為. ,因此在給定共. ‧. 同的市場因子 M(t)下,第 i 個標的資產報酬. ,以及相. i Un. v. 的違約機率為二項式分. ,為了求得非條件下的資產組合損失百分比,. 必須要對共同因子 M(t)積分,如下:. 29.
(36) (4.3). 接著跟(3.8)~(3.12)的步驟一樣,再利用 Vasicek (2002)提出的 Large portfolio limit approximation 來計算資產損失百分比的累積分配函數:. 其中 為了計算. 。 的期望分券損失,我們使用(3.7)式,並將它改寫成. 立. 政 治 大. 要計算此積分前,必須先求得該資產組合損失百分比的機率密度函數. ‧. ‧ 國. 學. n. al. er. io. sit. y. Nat. 代入(4.4)式. Ch. engchi. i Un. v. 將(4.5)式代入(3.4)式與(3.5)式,即可求得公平信用價差與市場報價預付費 用。. 30.
(37) 第三節 應用 LHP 假設之單因子雙指數與標準常態關聯結構模型 與第二節一樣,但本節將資產本身因子. 的機率分配函數由雙指數分配改. 為標準常態分配,假設信用資產組合具有 N 個標的資產,則第 i 個標的資產報酬 可表示為:. 其中,. 為共同市場因子,. 並假定. 為資產本身因子,假設. 與. 為獨立,. 。. 治 政 在這裡, 並不是一個特定的分配,所以應用 大 LHP 假設之單因子雙指數 立 與標準常態關聯結構模型(?)對於違約門檻值 無法將其表示為某個機率分配 ‧ 國. 學. 函數的反函數,因此同第二節一樣必須使用模擬的方法來求取各時點的違約門檻 ,進行步驟則相同。. ‧. 值. sit. y. Nat. io. er. 在給定LHP的假設下,所有標的資產擁有相同的違約門檻值 同的本金及復原率,且資產之間的相關係數會是相同的. n. al. Ch. iv. ,以及相. ,因此在給定共. C(t)的條件 Un e n g c h i 會小於違約門檻值. 同的市場因子 M(t)下,第 i 個標的資產報酬 違約機率為. 發生 k 個標的資產違約之資產組合損失百分比 配. 的違約機率為二項式分. ,為了求得非條件下的資產組合損失百分比,必須要對 31.
(38) 共同因子 M(t)積分,如下:. 接著跟(3.8)~(3.12)的步驟一樣,再利用 Vasicek (2002)提出的 Large portfolio limit approximation 來計算資產損失百分比的累積分配函數:. 其中. 立. 的期望分券損失,我們使用(3.7)式,並將它改寫成. 學 ‧. ‧ 國. 為了計算. 。. 政 治 大. 要計算此積分前,必須先求得該資產組合損失百分比的機率密度函數. n. er. io. sit. y. Nat. al. 代入(4.6)式. Ch. engchi. i Un. v. 將(4.7)式代入(3.4)式與(3.5)式,即可求得公平信用價差與市場報價預付費 用。. 32.
(39) 第五章. 實證分析. 本章以五年為到期日的 DJ iTraxx Europe 信用違約交換指數為標的之合成型 抵押擔保債券分券進行實證分析,且會以 Gaussian、拉普拉斯(Laplace)、NIG 三種單因子關聯結構模型去評價不同時期的合成型抵押擔保債券,並做不同關聯 結構模型間的數值比較分析。. DJ iTraxx Europe 包含了 125 種信用交換契約標的資產,這些標的資產具有. 政 治 大 0~3%、3~6%、6~9%、9~12%、12~22%。本文選擇不同時期的 DJ iTraxx Europe series 立 相同的權重比例,以 DJ iTraxx Europe 為標的的合成型抵押擔保債券分券分為. ‧ 國. 學. 來進行分析,分別為 series 5、series 9 及 series 15,並在這些 series 中得到各分券 的市場報價日期是在 2006.4.12(series 5)、2009.3.31(series 9)、2010.3.31(series. ‧. 9)、2011.9.30(series 15)、2012.1.31(series 15)及 2013.1.31(series 9)。. sit. y. Nat. n. al. er. io. 使用單因子關聯結構模型評價合成型抵押擔保債券分券需要幾個參數,第一. i Un. v. 個是平均 CDS 價差,其是由訂立契約開始到發佈市場報價當天每天的 CDS 指數. Ch. engchi. 平均而得到,五個時期的平均 CDS 價差分別為 127.67bp、115.42 bp、124.913 bp、 144.35bp、122.983 bp,第二個重要參數是資產復原率,皆假定其為固定 的 40%,第三個是無風險利率,其選擇三個月 Euro LIBOR 拆款利率為基準利率。 使用以上的參數就能利用固定違約強度 導出不同時點的邊際機率分配。除此之 外,在各關聯結構模型的參數估計上,除了各資產間的相關係數 以外,還必須 估計如 NIG 分配的 與 。各關聯結構模型的參數估計可以使用 Kalemanova et al.(2007)所介紹的方法,即極小化絕對誤差(absolute errors)和來估計各參數,其 中絕對誤差和為將各模型所產生的評價結果與實際市場報價間的差異取絕對值, 再將這些絕對值加總。 33.
(40) 第一節 比較在不同時期各模型對 DJ iTraxx 之分券的評價 本節將對不同時期之 DJ iTraxx 的分券進行評價,按照市場報價的發布時間 先後順序逐一地進行分析評價並且解釋各模型的配適結果,其中各時期的 DJ iTraxx 之分券市場報價與不同模型所產生的分券評價結果列在表 5.1 到表 5.5。 在各模型的參數估計方面,Gaussian 模型和拉普拉斯模型只需要估計相關係數 ;NIG(1)模型的限制為參數 等於 0,由各分券的最小絕對誤差和來估計參數 與 ;比起 NIG(1)模型,NIG(2)模型必須多估計一個參數 。. 治 政 由表 5.1 來看,Laplace-N 模型在 0~3%分券的評價比在其他分券的評價要來 大 立 得準確,僅跟市場報價差 0.01%,而在 3~6%與 6~9%分券出現嚴重低估的情形, ‧ 國. 學. 分別低估了 7.8%(相當於 780 bp)與 10.41%(相當於 1041 bp)。Double Laplace 模型. ‧. 在 0~3%分券為嚴重高估,使得絕對誤差和多了約 13.5%(相當於 1350 bp),而在. sit. y. Nat. 3~6%分券則是使用的模型中估計得最準確的,僅與市場報價相差 0.02%(相當於. io. er. 2 bp)。Gaussian 模型與 NIG(1)模型在各分券的配適結果都很類似,其在 0~3%分 券的評價較為準確,而在其他分券則呈現評價低估的情形。NIG(2)模型在 0~3%. al. n. iv n C 分券的評價結果與市場報價完全相同,但是在 Double h e n g c h 3~6%的配適結果則不如 i U Laplace。而在 6~9%與 9~12%分券該模型則是配適效果最好的。. 由表 5.2 來看,Laplace-N 模型與 Double Laplace 模型在各分券的的配適結 果非常類似,只有在 0~3%分券的評價較為準確,其它分券則與市場報價有相當 大的差異,且在該年度這兩個模型都無法在 3~6%與 6~9%分券反應出負報價。 Gaussian 模型與前面兩個模型一樣,只有在 0~3%分券的評價較為準確,在其他 分券則是嚴重高估市場報價,且在 2010 年該模型亦無法在 3~6%與 6~9%分券反 應出負報價,使得其絕對誤差和增加很多。NIG(1)與 NIG(2)模型則可在 3~6%與. 34.
(41) 6~9%分券反應出負報價,整體的絕對誤差和為 Laplace-N 模型與 Double Laplace 模型的三分之一。. 由表 5.3 來看,Laplace-N 模型只有在 0~3%與 12~22%分券的評價較為準確, 其餘分券則與市場報價有相當大的差距,在 3~6%與 6~9%分券,該模型嚴重低 估市場報價,而在 9~12%分券,該模型則是高估市場報價。Double Laplace 模型 與 Laplace-N 模型在 6~9%、9~12%及 12~22%分券的評價效果類似,皆為高估, 但該模型在 0~3%分券則是嚴重高估,其幅度大於 Laplace-N 模型對 3~6%分券的 高估幅度,因此造成該模型的絕對誤差和大於 Laplace-N 的絕對誤差和,在 3~6%. 治 政 分券,該模型的配適效果是非常好的,僅與市場報價相差 大 0.02%(相當於 2 bp)。 立 Gaussian 模型與 NIG(1)模型在各分券的的配適結果非常類似,且 Gaussian 模型 ‧ 國. 學. 在 0~3%分券的評價是所有模型中最好的,僅與市場報價相差 0.02%(相當於 2 bp). ‧. 。NIG(2)模型在 0~3%與 3~6%分券的評價效果相當不錯,都與市場報價符合。. sit. y. Nat. io. er. 由表 5.4 來看,Laplace-N 模型、NIG(1)模型、NIG(2)模型在 0~3%、3~6%與 6~9%的配適效果都不錯。Double Laplace 模型只有在 0~3%與 6~9%的評價較為準. al. n. iv n C 確,在 3~6%分券的評價為低估市場報價,而在 12~22%分券則為嚴重 U h e n g c h i 9~12%與. 高估。Gaussian 模型只有對 0~3%分券的評價比較準確,在其他分券的評價則與 市場報價差異甚大,尤其是在 3~6%與 6~9%分券,該模型的絕對誤差比其他模型 在這兩個分券的絕對誤差要來得大。NIG(1)與 NIG(2)模型在 0~3%分券的評價非 常準確,前者與市場報價完全相同,後者則與市場報價僅差 0.01%(相當於 1 bp)。 而五個模型皆有相同的問題,即嚴重高估 9~12%分券,以配適效果最好的 NIG(2) 模型來說,其絕對誤差和為 1522.133 bp,但該模型在 9~12%分券的絕對誤差就 高達 975 bp(占了該模型整體絕對誤差的 64%)。. 35.
(42) 由表 5.5 來看,Laplace-N 與 Double Laplace 模型在 0~3%、9~12%與 12~22% 分券的配適結果是非常類似的,不同於 2010 年的配適結果,在 3~6%分券兩模 型皆可反應負報價,且兩模型都是低估市場報價,但 Double Laplace 模型低估的 幅度較大,而在 6~9%分券兩者皆無法反應負報價,且兩模型都是高估市場報價, 但 Laplace-N 模型高估的幅度較大,綜合以上的討論,因此兩模型的絕對誤差和 相當接近。Gaussian 模型在 0~3%分券的配適結果相當準確,僅與市場報價相差 0.01%(相當於 1 bp),與 Laplace-N 與 Double Laplace 模型一樣,在 3~6%分券該 模型亦能反應負報價,且在所有模型中與市場報價最接近,而在 6~9%分券該模 型也無法反應負報價。NIG(1)模型與 NIG(2)模型在各分券的的配適結果非常類. 6-9%. 11.53%(500bp). 9-12%. 418.8 bp. 12-22%. 155 bp. 絕對誤差. y. 31.23%(500bp). 80.26%. sit. 3-6%. 66.82%. Gaussian 66.85%. er. 66.83%(500bp). Double Laplace. 31.25% 27.50% a23.43% v l C 1.12% 3.84% n i 6.65% U h 315.1264 bp e n g363.41 379.07 c h i bp. n. 0-3%. Laplace-N. io. 市場報價. 2009 年 3 月 31 日之市場報價及不同模型的配適結果. Nat. 分券. ‧. 表 5. 1. 學. ‧ 國. 治 政 似,而 NIG(2)模型在 0~3%分券的評價與市場報價完全一樣,皆為 3.14%。 大 立. NIG(1). NIG(2). 66.89%. 66.83%. 27.52%. 32.42%. 6.65%. 10.00%. 378.9 bp. 393.35 bp. 147.2802 bp. 196.11 bp. 137.83. 137.64 bp. 105.92 bp. 1932.736 bp. 2211.122 bp. 919.810 bp. 921.30 bp. 346.95 bp. 0.3036. 0.3819. 0.2569. 0.2567. 0.224. 246.907. 3.21. 0. 1.9. 36.
(43) 表 5. 2. 2010 年 3 月 31 日之市場報價及不同模型的配適結果. 分券. 市場報價. 0-3%. 27.03%(500bp). 26.75%. 26.77%. 26.95%. 26.83%. 27.10%. 3-6%. -4.18bp(300bp). 1132.05 bp. 959.73 bp. 1525.81bp. -12.99 bp. -1.95 bp. 6-9%. -3.99bp(300bp). 447.74 bp. 388.58 bp. 778.68bp. -350.16 bp. -349.28 bp. 9-12%. 94.01bp(100bp). 972.61 bp. 1000.24 bp. 1207.02bp. 459.00 bp. 454.35 bp. 12-22%. 37.13bp(100bp). 533.29 bp. 688.64 bp. 627.58bp. 344.11 bp. 334.72 bp. 2991.177 bp. 2939.923 bp. 4008.243bp 1047.186 bp. 1004.59 bp. 0.6561. 0.7974. Laplace-N. 絕對誤差. 立. Double Laplace. NIG(2). 0.7881. 0.788. 0.4952. 0.654. 0. -0.165. ‧. ‧ 國. 學 y. sit. 0-3%. 61.65%(500bp). 3-6%. 27.60%(500bp). 19.59%. 6-9%. 19.17%(300bp). 9-12% 12-22%. er. al. Laplace-N. C 62.34%h. 絕對誤差. NIG(1). 2011 年 9 月 30 日之市場報價及不同模型的配適結果. n. 市場報價. io. 分券. 0.6438. 政 治 大. Nat 表 5. 3. Gaussian. Gaussian iv n U. Double Laplace. NIG(1). NIG(2). e n g c77.61% hi. 61.67%. 61.75%. 61.65%. 27.58%. 24.13%. 24.17%. 27.60%. 8.93%. 11.46%. 14.03%. 14.03%. 16.44%. 491.5bp(100bp). 977.219 bp. 1156.18 bp. 1263.12 bp. 1262.09 bp. 1348.73 bp. 243.17bp(100bp). 284.50bp. 465.55 bp. 253.38 bp. 251.68 bp. 170.59 bp. 3255.37 bp 1645.644 bp. 1646.07 bp. 1202.42 bp. 0.2989. 0.2726. 386.481. 3.6. 0. 1.8967. 2407.095 bp 0.3446. 0.4096. 37. 0.2996.
(44) 表 5. 4 分券. 2012 年 1 月 31 日之市場報價及不同模型的配適結果. 市場報價. Laplace-N. Gaussian. Double Laplace. NIG(1). NIG(2). 0-3%. 56.71%(500bp). 56.38%. 56.84%. 56.64%. 56.71%. 56.72%. 3-6%. 18.98%(500bp). 19.70%. 16.16%. 24.73%. 18.55%. 18.18%. 6-9%. 11.44%(300bp). 12.38%. 11.65%. 17.62%. 12.16%. 11.62%. 9-12%. 345.25 bp(100bp). 1371.13 bp. 1461.85 bp. 1721.51 bp. 1357.93 bp. 1319.18 bp. 12-22%. 160 bp(100bp). 625.53 bp. 908.01 bp. 685.54 bp. 617.22 bp. 609.42 bp. 1689.987 bp. 2180.395 bp. 0.4733. 0.6561. 絕對誤差. 立. 0.4871. 0.4937. 1.3587. 1.0672. 0. 0.164. ‧. ‧ 國. 學 y. 0-3%. 3.14%(500bp). 3-6%. -1.75%(500bp). 6-9%. -0.96%(300bp). 9-12%. 5.25%(100bp). 9.18%. 12-22%. 3.25%(100bp). io. Laplace-N. a3.20% l C -4.65% h. Double Laplace. v ni. NIG(1). NIG(2). 3.13%. 3.15%. 3.14%. -3.78%. -7.84%. -7.86%. 2.46%. -0.95%. -0.94%. 8.55%. 9.83%. 7.18%. 7.20%. 6.87%. 6.98%. 7.31%. 5.83%. 5.87%. 1315.546 bp. 1303.672 bp. 1410.48 bp 1062.243 bp. 1069.015 bp. 0.8874. 0.9351. n. 3.11%. Gaussian. er. 市場報價. sit. 2013 年 1 月 31 日之市場報價及不同模型的配適結果. 分券. 絕對誤差. 0.4031. 政 治 大. Nat. 表 5. 5. 3101.65 bp 1584.534 bp 1522.133 bp. 1.68%. -6.13%U e n g c0.63% hi. 38. 0.9052. 0.936. 0.9349. 2.1868. 2.0622. 0. 0.1262.
(45) 第二節. 觀察不同時期各模型在 DJ iTraxx 的隱含相關性. 本文在給定 LHP 的假設下使用各單因子關聯結構模型對合成型抵押擔保債 券作評價,假設各分券與市場的相關性皆相同,但是 Hull and White(2004)發 現單因子常態關聯結構模型會造成中間層級分券的隱含相關性(implied compound correlation)較低,而低順位與優先順位層級分券的隱含相關性較高 的情形,此現象即是相關性微笑曲線(correlation smile),違反了在做評價前 即給定的 LHP 假設。各分券隱含相關的計算方法為在給定單因子關聯結構模型下, 將相關係數值以外的模型參數固定以使得各分券絕對誤差和最小的相關係數值. 治 政 代入,然後找到一個最適相關係數值讓各分券的估計價格必須與其所對應的市場 大 立 報價相等,此相關係數值即為該分券的隱含相關 ‧ 國. 學 ‧. 不同時期各模型在 DJ iTraxx 的隱含相關結果在表 5.6~到表 5.10,每張表. sit. y. Nat. 下面都有附各模型的隱含相關曲線。觀察圖 5.1 到圖 5.5 可以發現本文所使用的. io. er. 五種單因子關聯結構模型,其在各分券的隱含相關值皆會呈現大幅度的震盪,圖 5.1 呈現了 9~12%具較高相關性,而其餘分券相關性較低的反微笑曲線現象;圖. al. n. iv n C 5.2 則呈現了隱含相關值震盪幅度最大的現象,最高的隱含相關值與最低的隱含 hengchi U 相關值差了快 90%。圖 5.3 說明以五種關聯結構模型來對合成型 CDO 做評價時, 皆會產生相關性微笑曲線現象,Laplace-N、Double Laplace、Gaussian 、NIG(1) 及 NIG(2)模型的隱含相關係數值都是先下降後上升,但只有 Laplace-N 模型在 3~6%分券時其隱含相關係數就開始上升,其餘模型的隱含相關則是從 9~12%分 券才開始上升。. 39.
(46) 表 5. 6. 不同模型在 2009 年 3 月 31 日之各分券隱含相關值. 分券. Laplace-N. 0-3%. 30.19%. 52.66%. 25.72%. 25.72%. 22.39%. 3-6%. 20.45%. 38.21%. 20.08%. 20.08%. 24.11%. 6-9%. 23.53%. 37.12%. 21.31%. 21.31%. 20.89%. 9-12%. 47.51%. 50.27%. 40.14%. 57.91%. 62.99%. 12-22%. 32.80%. 27.97%. 28.88%. 28.87%. 18.86%. Double. 立. Laplace. Gaussian. NIG(1). 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. 圖 5. 1 不同模型在 2009 年 3 月 31 日之隱含相關曲線. 40. NIG(2).
(47) 表 5. 7 分券. 不同模型在 2010 年 3 月 31 日之各分券隱含相關值. Laplace-N. Double. Laplace. Gaussian. NIG(1). NIG(2). 0-3%. 63.91%. 79.61%. 64.29%. 78.67%. 78.85%. 3-6%. 93.91%. 96.37%. 96.81%. 78.49%. 78.88%. 6-9%. 88.37%. 93.12%. 94.43%. 28.55%. 27.38%. 9-12%. 8.51%. 7.94%. 7.27%. 12.72%. 11.99%. 12-22%. 26.19%. 21.58%. 24.73%. 35.17%. 35.52%. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. 圖 5. 2 不同模型在 2010 年 3 月 31 日之隱含相關曲線. 41.
(48) 表 5. 8 分券. 不同模型在 2011 年 9 月 30 日之各分券隱含相關值. Laplace-N. Double Laplace. Gaussian. NIG(1). NIG(2). 0-3%. 24.37%. 56.62%. 29.99%. 29.99%. 27.26%. 3-6%. 11.49%. 39.95%. 23.91%. 23.91%. 27.26%. 6-9%. 33.00%. 23.03%. 21.70%. 21.69%. 21.42%. 9-12%. 39.25%. 12.46%. 9.50%. 9.50%. 9.93%. 12-22%. 84.34%. 29.16%. 26.10%. 29.52%. 29.78%. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. 圖 5. 3 不同模型在 2011 年 9 月 30 日之隱含相關曲線. 42.
(49) 表 5. 9 分券. 不同模型在 2012 年 1 月 31 日之各分券隱含相關值. Laplace-N. Double. Laplace. Gaussian. NIG(1). NIG(2). 0-3%. 47.06%. 56.62%. 40.24%. 48.72%. 49.38%. 3-6%. 48.44%. 39.95%. 51.53%. 47.99%. 48.10%. 6-9%. 52.74%. 23.03%. 69.21%. 51.79%. 50.10%. 9-12%. 5.17%. 12.46%. 4.32%. 4.97%. 5.39%. 12-22%. 20.92%. 29.16%. 19.27%. 21.13%. 21.9. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. 圖 5. 4 不同模型在 2012 年 1 月 31 日之隱含相關曲線. 43.
(50) 表 5. 10 不同模型在 2013 年 1 月 31 日之各分券隱含相關值 分券. Laplace-N. Double Laplace. Gaussian. NIG(1). NIG(2). 0-3%. 88.78%. 93.49%. 90.51%. 93.61%. 93.49%. 3-6%. 82.16%. 86.51%. 86.97%. 83.11%. 82.96%. 6-9%. 96.56%. 96.91%. 97.49%. 93.62%. 93.53%. 9-12%. 14.41%. 13.24%. 10.02%. 10.97%. 11.01%. 12-22%. 39.53%. 33.61%. 33.39%. 36.04%. 35.88%. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. 圖 5. 5 不同模型在 2013 年 1 月 31 日之隱含相關曲線. 44.
(51) 第六章 結論與建議 本文使用不同單因子關聯結構模型來評價不同年度的 DJ iTraxx 分券,並且 比較分析各模型的評價結果。. 對於合成型抵押擔保債券的評價,目前最常用的方法是單因子關聯結構模型 (One Factor Copula Model),此模型最早是由 O'Kane and Schloegl(2001)所提出, 作者將常態分配引進單因子關聯結構中,形成單因子常態關聯結構模型,而該模. 政 治 大 關性微笑曲線的問題。Kalemanova et al.(2007)提出應用 LHP 假設之單因子 NIG 立. 型在進行各分券的評價時,只有在權益分券會得到好的配適結果,而且會造成相. ‧ 國. 學. 關聯結構模型來對合成型 CDO 進行評價,該模型的評價結果遠優於單因子常態 關聯結構模型,但缺點是其會高估中間順位層級以上的分券。邱嬿燁(2007)使用. ‧. 單因子 CSN 關聯結構模型對合成型 CDO 進行評價,但該模型仍然無法估計得很. sit. y. Nat. 準確,只有在最高層級分券(senior tranche)的評價有明顯的改善。除了提出單因. n. al. er. io. 子 CSN 關聯結構模型之外,邱嬿燁(2007)亦使用 NIG 及 CSN 混合分配之單因. i Un. v. 子關聯結構模型對合成型 CDO 進行評價,該模型在實證分析中得到極佳的評價結. Ch. engchi. 果。以上為各學者針對合成型抵押擔保債券的評價所提出來的方法。. 而本文的研究目的是使用單因子拉普拉斯關聯結構模型對合成型抵押擔保 債券作評價,並與其它單因子關聯結構模型的配適結果做比較,探討在評價上單 因子拉普拉斯關聯結構模型是否能有其特有的優點與更好的配適效果。此外,本 文也對各關聯結構模型進行分析以驗證其是否符合 LHP 假設。根據實證分析的結 果,提出本研究的結論如下:. 由表 5.5 可發現,Laplace-N、Double Laplace、Gaussian、NIG(1)及 NIG(2) 45.
(52) 關聯結構模型皆可反應負報價,但前三者並不是在每次市場出現負報價時都能反 應出來,例如,在 2010 年 3 月 31 日報價的合成型抵押擔保債券中,3~6%與 6~9% 分券的市場報價皆為負值,但前三個模型對這兩個分券的配適結果卻是正值,也 間接地增加了它們的絕對誤差和。而在 2013 年 1 月 31 日報價的合成型抵押擔保 債券中,3~6%與 6~9%分券的市場報價亦為負值,前三個模型無法在 6~9%分券中 反應出負報價,但是它們可以在 3~6%分券中反應出負報價,使得前三個模型與 NIG 分配的絕對誤差和差距不像 2010 年時來得大。. NIG(1)與 NIG(2)模型具有在 0~3%與 3~6%分券配適佳的優點,且能反應負報. 治 政 價。在 2010 年與 2013 年的合成型 CDO 中,3~6%與大 6~9%分券的市場報價皆為負 立 值,且 NIG(1)與 NIG(2)模型皆能反應出來。比較五個模型的配適結果,NIG(2) ‧ 國. 學. 模型仍然是最好的模型,特別是在 2009 年,該模型在中間順位層級分券得到極. ‧. 好的配適效果。. sit. y. Nat. io. er. Gaussian 模型的評價結果與之前文獻的研究相同,只有在權益層級分券得 到極好的配適結果。反應負報價能力方面,本研究發現 Gaussian 亦有反應負報. al. n. iv n C 價的能力,在 2010 年與 2013 年的合成型 6~9%分券的市場報價 h e n g cCDOh中,3~6%與 i U. 皆為負值,但是 Gaussian 模型僅能反應出 2013 年商品 3~6%分券的負報價,說 明了 NIG(1)與 NIG(2)模型反應負報價的能力優於 Gaussian 模型。. Laplace-N 與 Double Laplace 模型雖然配適效果不如 NIG(1)與 NIG(2)模型, 但優於 Gaussian 模型。Laplace-N 模型優於 Gaussian 模型的原因可能是因為在 Laplace-N 模型中,資產報酬 的分配具有厚尾度,圖 6.1 為 Laplace-N 模型中, 資產報酬 的模擬分配。Laplace-N 與 Gaussian 模型比較,前者在 2010 年、2012 年與 2013 年的絕對誤差和小於後者,主要是因為前者在較高層級(9~12%與. 46.
(53) 12~22%)分券的評價效果較好。Laplace-N 模型具有反應負報價能力,但與 Gaussian 模型一樣僅能反應出 2013 年商品 3~6%分券的負報價,說明了 NIG(1) 與 NIG(2)模型反應負報價的能力優於 Laplace-N 模型。. 立. 政 治 大. er. io. sit. y. ‧. ‧ 國. 學. Nat. 圖 6.1 資產報酬 的模擬分配. 本文在給定 LHP 的假設下使用各單因子關聯結構模型對合成型抵押擔保債. al. n. iv n C 券作評價,假設各分券與市場的相關性皆相同,而在本文的研究中,各關聯結構 hengchi U 模型在各分券的隱含相關震盪幅度很大,因此這些模型都不符合 LHP 假設。. 本文使用的拉普拉斯模型是位置參數. 為 0、尺度參數. 為. 的單因子. 拉普拉斯關聯結構模型,因此無法控制分配的位移與厚尾度,只能藉由違約相關 性 來最小化絕對誤差和,在此本文建議可以使用位置參數 可調整的單因子拉普拉斯關聯結構模型來做評價。. 47. 與尺度參數. 為.
(54) 參考文獻 1. Dezhong, W. Rachev S.T., Fabozzi F.J. (October 2006). Pricing Tranches of a CDO and a CDS Index: Resent Advances and Future Research. Working paper. 2. Dezhong W., Rachev S.T., Fabozzi F.J. (November 2006). Pricing of Credit Default Index Swap Tranches with One-Factor Heavy-Tailed Copula Models. Working paper. 3. Kalemanove, A., Schmid, B., and Werner, R. (spring 2007). “The Normal Inverse. 政 治 大. Gaussian Distribution for Synthetic CDO pricing.” The Journal of Derivatives, Vol.. 立. 14, pp. 80-93.. ‧ 國. 學. 4. Karlis, D. and Papadimitriou, A. (2004). Inference for the Multivariate Normal Inverse Gaussian Model. Working paper. ‧. 5. Hull, J. and White, A. (winter 2004) “Valuation of a CDO and an n-th to Default. y. sit. n. al. er. io. 8-23.. Nat. CDS without Monte Carlo Simulation.” The Journal of Derivatives, Vol. 12, pp.. i Un. v. 6. Li, D.X. (April 2000). On Default Correlation: A Copula Function Approach. Working Paper.. Ch. engchi. 7. D. O’Kane and L. Schloegl., M. (2001). Modeling Credit: Theory and Practice. Quantitative Credit Research, Lehman Brothers. 8. Black, Fischer and John C. Cox, "Valuing Corporate Securities: Some Effects of Bond Indenture Provisions", Journal of Finance, Vol. 31, No. 2, (May 1976), pp. 351-367. 9. Merton, R. C (1974) . On the Pricing of Corporate Debt: The Risk Structure of Interest Rates, Journal of Finance, 29, pp. 449-470.. 48.
(55) 10. O.E. Barndor® -Nielsen. (1978). Hyperbolic distributions and distributions on hyperbolae. Scandinavian. Journal of statistics, 5, 151-157. 11. Karlis. D. (2000). An EM type algorithm for maximum likelihood estimation of the normal–inverse Gaussian distribution. Statistic & Probability Letters , 57, 43-52. 12.林聖航(民 101)。探討合成型抵押擔保債券憑證之評價。國立政治大學統計 學系碩士論文,台北市。 13.邱嬿燁 (民 97) 。探討單因子複合分配關聯結構模型之擔保債權憑證之評 價 。國立政治大學統計學系碩士論文,台北市。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 49. i Un. v.
(56)
數據
相關文件
科技教育 設計 模型 製作.
自從 Engle(1982)提出 ARCH 模型以來,已經超過 20 年,實證上也有相當多的文獻 探討關於 ARCH 族模型的應用,Chou(2002)將 GARCH
Red, white and brown 是典型 Mark Rothko
The empirical results indicate that there are four results of causality relationship between Investor Sentiment and Stock Returns, such as (1) Investor
若股票標的公司的財務體質不健全,或公 司管理階層刻意隱瞞經營危機事實,導致
[7] C-K Lin, and L-S Lee, “Improved spontaneous Mandarin speech recognition by disfluency interruption point (IP) detection using prosodic features,” in Proc. “ Speech
住宅選擇模型一般較長應用 Probit 和多項 Logit 兩種模型來估計,其中以 後者最常被使用,因其理論完善且模型參數之估計較為簡便。不過,多項
樹、與隨機森林等三種機器學習的分析方法,比較探討模型之預測效果,並獲得以隨機森林
