行政院國家科學委員會專題研究計畫成果報告
********************************************************************線上認知診斷評量模式之研究:以國小
數學科低成就學生為對象(
1/2)(2/2)
********************************************************************計畫類別:
5
個別型計畫
□整合型計畫
計畫編號:
NSC-90-2614-S-004-011(1/2)
NSC-91-2521-S-004-011(2/2)
執行期限:
90 年 8 月 1 日 至 92 年 7 月 31 日
個別型計畫:計畫主持人:余民寧
研究助理:陳新豐、林曉芳、邵俊豪、洪慧芸、
游森期、陳嘉甄、李仁豪、陳家興
整合型計畫:總計畫主持人:
子計畫主持人:
註:整合型計畫總報告與子計畫成果報告請分開編印各成一冊, 彙整一起繳送國科會。處理方式:
5
可立即對外提供參考
(請打ˇ)□一年後可對外提供參考
□兩年後可對外提供參考
(必要時,本會得展延發表時間)執行單位:國立政治大學教育學系
中華民國
九十二 年 十 月 三十一 日
謝詞
本研究之可以順利完成,本案研究主持人要特別感謝國科會補助研究經費 (補助編號:NSC-90-2614-S-004-011(1/2)和 NSC-91-2521-S-004-011(2/2)); 若沒有國科會的大力補助研究經費的話,則本案研究主持人便沒有機會去探索另 類評量的研究構想,更無法將這種改良式的紙筆測驗評量方式,落實在線上認知 診斷評量上。 其次,本案研究主持人要感謝參與本計畫的所有研究助理們:陳新豐、林曉 芳、邵俊豪、洪慧芸、游森期、陳嘉甄、李仁豪、陳家興等人;若沒有他們等人 費心地協助發展測驗、架設網站、設計網頁、發函學校上網施測、整理施測資料、 設計執行程式、和進行統計分析的話,則本研究大概也會遜色不少。 再其次,本案研究主持人要感謝台北市眾多熱心參與之小學教師和六年級學 生,若沒有他們費心上網填寫測驗卷的話,則本案也就沒有實徵資料來驗證構想 是否可行了。 最後,本案研究主持人還要感謝國立政治大學校本部及教育學系的行政同 仁,在本案執行期間所提供的行政協助與支援;更要感謝家人全心全意的支持, 讓本案研究主持人能夠專心研究和撰寫報告。故,本案研究主持人願以此份成就 與家人分享,同時並感激所有協助過本案研究主持人的人。摘要
本研究的目的,旨在發展一套線上認知診斷評量模式,用來幫助診斷國小數 學科低成就學生的知識結構,並發現學習缺陷所在,以謀求適當的補救教學措 施,進而達到改進教學評量的成效,並落實教育改革的目的。 本研究根據文獻評閱結果,設計一種用來評量知識結構的本土化工具,並以 國小數學科低成就學生為研究對象,發展出一套具有認知診斷評量功能的線上測 驗系統,作為幫助國小教師改善數學科教學評量的輔助工具。本研究過程中,先 從建立認知診斷評量的題庫著手,經由題庫建置與信效度分析後,設計適用的軟 體程式,經測試可行後,再上網轉成線上測驗系統,以完成本研究目的。 最後,本研究成果獲得下列的結論,本研究所發展的:(1)知識結構診斷評 量程式是一個有用的研究工具;(2)認知診斷評量模式是一個改良式的教學評量 模式;(3)線上認知診斷評量模式是一個有潛力的教學評量輔助工具。同時,本 研究亦提出對各學科領域知識結構評量的教學評量應用、作為實施補救教學的依 據、編擬補救教材的參考、研究學習成就差異的工具等實務性建議,以及針對未 來後續研究的建議。 關鍵詞:認知診斷評量、線上測驗、數學低成就ABSTRACT
The purpose of this study is to build a model about an on-line testing system doing the cognitively diagnostic assessment. This system will help diagnose knowledge-structures of elementary students who have low-achievement in
mathematics. It also will help find learning deficits and depict that which remedial instructions might help. And this help will improve effectiveness of instructional assessment and achieve the goals of nationwide educational reform.
According to literature review, this study designs a program for running
diagnoses of knowledge-structures of elementary students who have low-achievement in mathematics. And also, it will help develop an on-line testing system doing the cognitively diagnostic assessment that might be a big improvement for teachers' instructional assessment nationwide. On the process of this study, it begins with the development of an item bank, followed by calibration and validation of such a bank, program designing and testing, and putting it on internet for the on-line testing system, to achieve the research goals.
The conclusions of this study are as follows: (1) The knowledge structures diagnostic assessment program (KSDAP) is an useful research tool. (2) The cognitively diagnostic assessment model is an improved model of instructional assessment. (3) The on-line cognitively diagnostic assessment model is a potential tool for instructional assessment. In the meanitime, several suggestions for various applications on other subject domains, remedial instructions, construction of instructional materials, and study on differential achievements, are also proposed. Finally, suggestions for future researches are proposed, too.
Key words:cognitively diagnostic assessment, on-line testing, low-achievement in mathematics
目錄
謝詞……….. 2 中文摘要……….. 3 英文摘要……….. 4 目錄……….….. 5 表圖目次………...………..…….. 6 第一章 緒論………..………. 7 第一節 研究背景與動機 ………. 7 第二節 研究目的與問題……….. 8 第三節 研究範圍與限制……….. 8 第四節 重要名詞詮釋……….. 8 第二章 文獻探討………..10 第一節 知識的習得………..……10 第二節 知識誘發與表徵 ………11 第三節 知識結構(或結構化知識)………..15 第四節 知識結構評量………..22 第五節 路徑搜尋法………..28 第六節 認知診斷評量………..37 第七節 數學概念評量………..39 第三章 研究方法………..43 第一節 研究問題……….43 第二節 研究樣本……….43 第三節 研究工具與研究程序……….43 第四節 程式設計與資料分析……….45 第四章 結果與討論……….46 第一節 知識結構診斷評量程式……….46 第二節 數學科認知診斷測驗……… 55 第三節 認知診斷評量模式……… 56 第四節 線上認知診斷評量模式系統原型……….62 第五章 結論與建議……….…64 第一節 結論……….64 第二節 建議……….64 參考書目……….67 附錄……….89表圖目次
表目次
表1 不同知識結構表徵方法之比較分析.………..33 表2 網路一與網路二之節點距離值(假設資料值)………...………..34 表3 網路一與網路二之的 PRX 指數的相關計算值……….……….34 表4 自表 2 中所擷取的部分節點值………...35 表 5 網路 1 與網路 2 的圖形理論距離………....36 表6 PFC 試算數值………....36圖目次
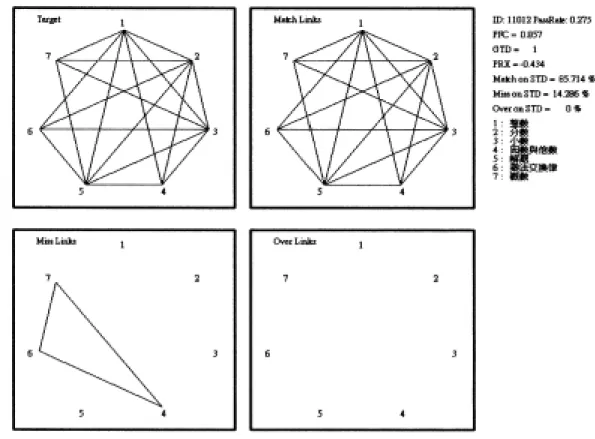
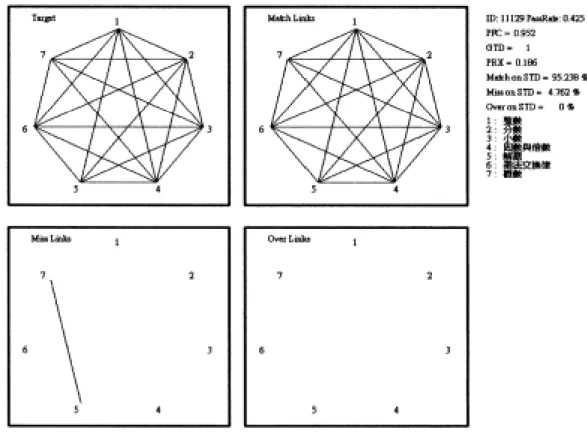
圖1 原始資料轉換為節點與鍊結線示例………...31 圖2 保留最小路徑圖示 .………33 圖3 網路 1(僅取節點 A 部分)與網路 2(僅取節點 A 部分)的 PFNET 圖………35 圖4 甲卷『數與計算』標準答案的知識結構圖………57 圖5 低成就學生(ID:11096)在甲卷作答的知識結構診斷圖………..58 圖6 低成就學生(ID:10877)在甲卷作答的知識結構診斷圖………..58 圖7 低成就學生(ID:10954)在甲卷作答的知識結構診斷圖………..59 圖8 低成就學生(ID:10256)在甲卷作答的知識結構診斷圖………..59 圖9 低成就學生(ID:11012)在甲卷作答的知識結構診斷圖………..60 圖10 低成就學生(ID:11170)在甲卷作答的知識結構診斷圖………..60 圖11 低成就學生(ID:11129)在甲卷作答的知識結構診斷圖………..61 圖12 高成就學生(ID:11104)在甲卷作答的知識結構診斷圖………..61第一章
緒論
本章的目的,旨在說明本研究的緣起與動機目的、研究問題、研究範圍和限 制、以及重要名詞的詮釋。茲分成四節陳述於后。第一節
研究背景與動機
本研究之緣起,係賡續前一專題研究案(計畫編號:NSC 88-2614-S-004-001) 的結果和筆者等人的數篇論文心得(余民寧,民91b;余民寧、林曉芳、蔡佳燕, 民90;余民寧、陳嘉成,民 87,民 90;林曉芳、余民寧,民 90)。由這些文獻 中發現,認知診斷評量(cognitively diagnostic assessment)可能是一種評量的未 來發展趨勢,它不僅比傳統的總結性評量(summative evaluation)以單一總分來 表示學生的成就更具預測效力,同時,它可以利用圖形表徵(map representation) 方式來表達學生的知識結構,讓學生"看得見"自己的知識結構和可能存在的缺 失,進而幫助學生找出缺失,對症下藥謀求補救措施。所以,它可以是一種(或 一套)具有發展潛力的評量工具(或方法)。 其次,隨著電腦化測驗(computerized testing)及網際網路(internet)的運 用日益受到重視,且為因應即將實施的國中升高中之「學科基本能力測驗」,各 大公私立機構均各自研發供練習用的電腦化模擬測驗,且透過網際網路的線上 (on-line)強大作答功能,正如火如荼地展開。這股發展趨勢告訴我們一項訊息: 結合電腦、網路、及測驗評量等領域的知識,正可以科技整合出一個新領域,即 「線上電腦化適性測驗」(on-line computerized adaptive testing)。它的功用即是透 過網際網路的線上作答功能,提供電腦化適性測驗的服務,以達到大規模、即時 化、且個別化進行的「因才施測」目標。這種發展趨勢若達成熟時,將可以幫助 各級學校教師作為輔助教學評量的工具,改善測驗評量的效能,間接提升教學品 質。 因此,考量未來的發展趨勢與需求,本研究企圖結合上述這兩種發展趨勢為 一體,擬發展出一種「線上認知診斷評量模式系統原型」(on-line prototype ofcognitively diagnostic assessment model system,簡稱 OPCDAMS),作為線上即時 診斷學生認知學習成果的一種輔助工具,並提供診斷結果的建議,以幫助教師改 善教學品質,並提高教學評量的效能。由於,目前並無這方面的中文化軟體或工 具可資使用,所以,本研究企圖發展出一套線上認知診斷評量模式系統原型,初 步選定以國小數學科低成就學生為研究對象,理由是:通常,高成就學生的作答 比較容易接近教師期望的結果(即完全答對或大部分答對),其知識結構與參照 的標準結構將會十分相近;而低成就學生的作答比較偏離教師期望的結果,其知 識結構與參照的標準結構將會差距甚遠,故可以顯現出其缺陷所在。待原型發展 確立後,其實亦可以適用全體的學生(含高成就學生),同時,還可以應用推廣 到其他學科領域,以作為一種協助教師執行教學評量的普遍化工具。
第二節
研究目的
茲根據前述的動機目的與重要文獻評閱結果,再加上筆者近年來的研究心得 與認知,擬定下列本研究案的核心目的。茲分別條述如下: 1.建立整個認知診斷評量的模式。 2.發展一套線上認知診斷評量模式系統原型。 3.探索該系統原型的應用可行性。第三節
研究範圍與限制
本研究由於時間、資源、及人力限制的關係,所研擬探討的對象暫以國民小 學生為範圍,研究題材暫訂為數學科,因此,本研究結果的推論不可過渡推論到 其他教育層級的學生和其他學科,或許,本研究的後續追蹤研究可以擴大推論和 應用的範圍,但目前仍只能侷限在國小學生的數學科為範圍。第四節
重要名詞詮釋
茲針對本研究常見的重要名詞,進行解釋或下操作型定義如后。
一、認知診斷評量
認知診斷評量是一種以認知取向的新式教育評量方法,其理論基礎是基於有 意義的學習及認知建構過程等心理學理論背景,利用統計分析模式與量尺化等技 術,進而針對學生的學習成就進行研究,以期診斷或推論出學生在學科成就表現 的認知(或知識)結構和解題過程,而所建構的一種新式評量方法,其對瞭解學 生的學習情形及協助教師進行教學規劃等方面,具有極大的實用價值與效益。二、線上測驗
將傳統的紙筆測驗,以電子檔的資料呈現方式,在網際網路上呈現、傳遞、 展示、即時施測、和即時評分,以達到快速、經濟、有效率、省資源、與個別化 實施的測驗方式,均可通稱為線上測驗。三、數學低成就
指數學科學習成就偏低者而言。本研究所指稱的數學低成就者,是指在本研 究所研發的線上測驗試卷上,得分在倒數百分之五以內者而言。這些數學低成就 者,將被特別挑選出來作為本研究的分析對象。第二章
文獻探討
本章的目的,旨在針對本研究所擬探討範圍之相關文獻,進行系統的評閱與 整理,以作為本研究之學理基礎。第一節
知識的習得
「知識」一直是許多專家學者所欲探討的主題,自古希臘柏拉圖、亞里斯多 德時代以來,哲學家便對知識的來源及相關議題提出了許多看法,「知識論」 (epistemology)因而成為哲學史上一個很重要的主題。自歐洲文藝復興運動開 始,對知識論的探討便逐漸衍生出兩個主要的傳統,其一是理性主義,其二是經 驗主義。對於知識的習得,理性主義學派的學者認為知識有其先驗的形式,強調 理性思維是獲得真實知識的依據,注重演繹推理所獲得的邏輯性知識,以康德 (Kant)、笛卡兒(Descartes)等人為代表;而經驗主義學派的學者則認為知識 是靠後天感官經驗累積的,感官經驗是一切知識的來源,強調透過經驗及實驗歸 納所獲得的知識,以洛克(Locke)、培根(Bacon)等人為代表。這兩種對知識 習得的傳統派別影響了後來心理學乃至認知心理學及教育心理學的發展。 哲學家 Ryle(1949)採用哲學思辨的方法,將知識種類區分為兩類:『知 其然』(knowing that)與『知其所以然』(knowing how)。認知心理學家根據 上述Ryle 的看法,將知識區分為『陳述性知識』(declarative knowledge)及『程 序性知識』(procedural knowledge)兩類。所謂陳述性知識是指關於事實、想法、 物體或事件的知識,例如「正方形有幾個邊?」它是一種知其然的知識,能知其 然就能對所知的事物作定義或描述。所謂程序性知識是指瞭解事情要如何做的知 識,它包括動作技能、認知技能與認知策略的知識,例如「正方形的邊長為 25 公分,則正方形的面積為多少平方公分?」,它是一種知其所以然的知識,能知 其所以然就能採取行動解決問題,所以問題解決與擬訂計畫都是含有程序性知識 的一種活動。程序性知識使基模相互關連,而成為心理運作的表徵模式。相對而 言,陳述性知識則為程序性知識提供心理運作的基礎。 陳述性知識的特徵是在需要時可將記得的知識陳述出來,所陳述出來的事實檢索的初期,必須受意識的支配,到了精熟階段,記憶的檢索會轉成自動化的歷 程(張春興,民82)。
陳述性知識與程序性知識除本質上的差異外,Gagn’e, Yekovich, & Yekovich (1993)認為就功能、動(靜)態特質、習得速度與修正速度等方面,兩種知識 都有明顯的不同。在功能方面,陳述性知識著重在引發相關想法的產生,以利反 思(reflection)的進行;而程序性知識則強調在清楚的情境下,快速的展現一連 串的行動。在動(靜)態特質方面,陳述性知識是對事物本身的理解,所以較偏 靜態性知識;程序性知識是完成某事件所需各個步驟的知識,故較偏動態性知 識。在習得速度方面,屬於事實或想法的陳述性知識,可以比較快獲得;屬於動 作技能或認知技能的程序性知識,通常需要多次練習,才能達到自動化的程度, 所以習得較慢。在修正速度方面,若欲修正已獲得的陳述性知識比較容易修改; 而程序性知識一旦達到自動化程度後,就不易修正。 陳述性知識與程序性知識是屬於兩種不同性質的知識類型,這兩種知識在人 類的認知歷程中,是如何被儲存和提取的,一直是認知心理學家亟欲瞭解的,這 也就是認知心理學與教育心理學非常重要的研究主題—「知識表徵」(knowledge representation)。
第二節
知識誘發與表徵
幾乎所有的認知心理學家都強調在人類大腦的知識是以有組織、具結構性 的,而非雜亂無章的方式來表徵儲存外界訊息。所謂「知識表徵」是指個體將各 種知識轉換成可處理的訊息,此種轉換過程,即是知識表徵的歷程,它涉及了以 概念代替實物的歷程,以及心理活動過程中產生的各種內在心像(余民寧,民 86)。對於這些知識表徵的探索工作,即是知識誘發的技術所欲探究的,所謂「知 識誘發」乃指利用某種方法讓個體表現出對某些知識的概念及概念間關係的瞭解 情形,簡單的說,知識的誘發指的即是收集人類相關知識訊息來源的過程。 Shanon(1993)分析表徵具有以下特質,1.表徵是以符號為媒介,以取替實體 的歷程,具符號的特質(symbolic);2.表徵由決定的典型編碼(determinate canonical code)來替代實體,每個典型編碼表徵一特定實體;3.典型編碼會依某種規則而呈 現,為一結構化的(structure)符號系統;4.表徵具有靜態性(static),但也會受到學習或遺忘等因素影響;5.表徵具抽象性(abstract)。
雖然認知心理學家都認為大腦的知識表徵的過程及產物是有系統及組織 的,但是認知心理學家對表徵大腦知識結構的方式仍有爭議,主要有兩個派別, 其一為序列符號模式(serial symbolic models),另一為平行分配處理模式(parallel distributed processing models)。序列符號模式主要是以電腦為參考依據,它假設 人類的訊息處理歷程就如同電腦一樣,對於訊息的處理方式是採逐步的序列處理 方式,由中央處理系統(central processing unit)來負責指揮所有的執行單位。而 平行分配處理模式主要是以人腦為依據,它假設人類的訊息處理歷程就如同人類 腦細胞的運作方式一樣,對於訊息處理方式是採同步的平行處理方式,由許多被 激發的處理單位來共同負責。以下就這兩派別的主張,分析比較如下:
一、序列符號模式的知識表徵
早期的序 列符號 模式 對於知識 表徵究 竟是 以命題式 表徵(propositional representation)的方式或類比式表徵(analogical representation)的方式,產生了 許多爭端(Anderson & Bower, 1973;Pylyshyn, 1973)。為了解決此種爭端,Paivio (1971, 1986)提出雙代碼理論(dual-coding theory),他認為影像(image)與 語言(verbal)的心理表徵可視為兩種不同的代碼,而這些代碼可以將訊息組織 成知識,以利知識的儲存與提取。影像是屬於類比代碼(analogue code),它能 表徵環境中的物理刺激,通常是以知覺為基礎的表徵方式,例如我們能根據手錶 上時針與分針的位置,而表徵成正確的時刻;語言則是屬於符號代碼(symbolic code),符號是可以任意被指定的,它通常不需保留概念的知覺訊息,是以抽象 意義為基礎的表徵方式,例如我們能依據電子錶的數字,而表徵成正確的時刻。 近年來,對於知識表徵系統類型的研究,通常是根據陳述性知識與程序性知 識的差異,而將知識表徵類型區分為屬於陳述性知識表徵的『命題式表徵』與『類 比式表徵』,以及屬於程序性知識表徵的『程序式表徵』等三種類型(Rumelhart & Norman, 1985)。McNamara(1994)將知識表徵區分為屬於陳述性的類比式 表徵與符號表徵,以及屬於程序性的程序式表徵。類比式表徵主要是關於知覺方 面的,例如:視覺、聽覺、味覺、…等;符號式表徵主要是指命題式表徵方面; 程序式表徵主要是指生產法則(production)。雖然知識表徵系統可區分為三種不同類型,但這三種知識表徵類型並非完全獨立的,在知識表徵的過程中,這三 種表徵系統是需要相互協調,才能順利完成表徵任務的。 茲就命題式表徵、類比式表徵與程序式表徵等三種不同知識表徵類型的內 涵,分析如下:
1.命題式表徵
命題式表徵系統假設知識是由一組不連續的符號所表徵,因此,每個概念將 會以形式的陳述(formal statements)方式表徵(Rumelhart & Norman, 1988)。 Quillian(1968)則主張這些不連續的符號是以樹狀圖或網路圖的方式被組織起 來的。「命題」這個用語主要是來自邏輯學和語言學(logic and linguistics),命題 通常是知識的最小單位,它大致等同於一個想法(idea),命題的功能是顯現出 概念間所具有的特殊關係(Anderson, 1990)。根據 Kintsch(1974)的看法,一 個命題總是包含兩個元素:一個關係(relation),一個或多個論點(arguments)。 論點指的是命題的主題,所以它們常是以名詞或代名詞來表現;而命題的關係則 是用來限定(constrains)這些主題,所以關係常是以動詞、形容詞或副詞來表達 (岳修平譯,民87)。
2.類比式表徵
相較於命題式表徵強調以意義基礎的表徵方式,有些認知心理學家則強調以 知覺為主的類比式表徵(Kosslyn, 1980;Shepard & Cooper, 1982),他們認為命 題式表徵是一種不連續的抽象表徵方式,通常不需要保留概念的知覺訊息,而類 比式表徵是一種連續的知覺表徵方式,通常會保留概念的知覺訊息,所以,類比 式的表徵效果並無法完全由命題式表徵來取代。 類比式表徵系統假設知識是由心像(mental image)的形式所表徵,因此, 在表徵的過程中,通常會保留概念的知覺結構(perceptual structure),亦即盡可 能的表徵出概念的物理特徵,以符合真實的表徵世界。例如當被問到:「你家裡 有幾扇窗戶?」時,你的腦海可能會很快浮現出你家裡的畫面,你可能會根據這 個類似真實情境的畫面,去算出你家裡的窗戶數量,而這個類似真實情境的畫 面,就是所謂的心像。你在回答這個問題的過程中,便是採用了類比式表徵來解 決問題的。3.程序式表徵
程序性知識是指瞭解事情要如何做的知識,而程序式表徵系統主要是用來說 明 程 序 性 知 識 是 如 何 被 表 徵 的 。 一 個 生 產 法 則 即 是 一 個 「 條 件— 行 動 」 (condition-action rule),這個條件—行動規則說明了在滿足特定的條件後,才 會導致特定的行動產生。這個生產法則的概念主要來自於對人工智慧(artificial intelligence,簡稱 AI)的研究,為了讓電腦能有效的模擬人腦的認知表現,人工 智慧的研究者(Anderson, 1983;Newell & Simon, 1972)就以生產法則來協助電 腦正確的完成任務。 一個生產法則通常包括兩個部分,其一是「若」的部分,而另一個是「則」 的部分(if…then…)。「若」的部分指出某些行動被執行時所必須存在的條件; 「則」的部分則指出當所有條件都被滿足時,哪些行動將會執行。例如若「求長 為16 公分,寬為 12 公分的長方形面積」,則「將長乘以寬即得到長方形面積」。二、平行分配處理模式的知識表徵
序列符號模式的知識表徵,不論是命題式表徵、類比式表徵或程序式表徵, 都主張知識的表徵方式是採逐步的序列處理方式,並且經處理過的知識,會分別 儲存於特定的記憶結構。對於這樣的主張,平行分配處理模式並不認同,平行分 配處理模式,又稱為連結模式(connectionism model),它主張知識的表徵方式 是採同步的平行處理方式,經處理過的知識,是被儲存在許多類似腦細胞的處理 單位。 平行分配處理模式主張所有類型的知識都會被表徵成神經網路(neural network),然而平行分配處理模式所主張的神經網路與命題式表徵的命題網路 是有所不同的。命題式表徵的命題網路是由節點所組成的,每個節點即代表一個 概念,節點與節點間的連結線,即代表概念之間的關係;而平行分配處理模式所 主張的神經網路是由類似神經細胞的處理單位所組成的,每個處理單位並不是代 表一個概念,知識是分散儲存於許多的處理單位,而不是儲存於單一節點,知識 的表徵是由藉由辨認連結的型態(pattern of connection)來進行(Sternberg, 1996)。 平行分配處理模式發展至今,雖然已獲得一些重要的研究成果,但仍有許多難題需要克服,例如平行分配處理模式主張知識並不是被儲存在特定的記憶區, 而是由一大群基本單位的激發型態所形成的,因此,若採用平行分配處理的觀 點,並不容易對知識進行任何的分析探討,因為平行分配處理模式並沒有提供分 析知識的任何工具(Ohlsson, 1988)。
第三節
知識結構(或結構化知識)
人類的大腦如何將經由表徵歷程所獲得的知識,組織成清楚顯示各概念之間 連結關係的知識結構,是知識結構理論探究的重點。關於知識結構的理論,Morton & Bekerian(1986)主張將其分成『語意網路理論』與『基模理論』兩種,其中 語意網路理論較強調知識在大腦記憶中的組織方式,而基模理論則較重視知識在 大腦記憶中的運作歷程。語意網路理論主張人類的知識是由概念節點與概念節點 的連結關係所形成的結構化網路,因此,節點間的連結關係,以及概念節點如何 促使網路的活化,是語意網路理論探討的重心;基模理論主張人類以抽象的知識 結構來表徵過去的行動或經驗,因此,訊息的儲存與提取、行動程序的組織、目 標的設定等方面,才是基模理論關注的焦點。茲進一步分析比較於下:一、語意網路理論(
semantic network theory)
語意網路是一種關於知識如何被表徵的理論,語意網路理論主張知識可透過 有指示性與標記性的圖形結構(directed, labeled graph structure)來表徵,而圖形 結構是由相互連結的節點所構成,節點代表所表徵的概念,節點與節點間的聯結 線代表概念間的關係。 Quillain(1968)從探討長期記憶表徵方式的研究中,首先提出了語意網路 的主張。自從 Quillain(1968)提出語意網路主張後,就陸續有學者提出一些語 意網路的模式,邱上真(民78)綜合 Rumelhart & Norman(1985)的看法,認 為語意網路會受重視的原因,主要具有下列幾項特徵: 1.統整性(integration):語意網路能將凡具有密切相關的概念聚集在一起, 而且關係越密切,物理距離可能就越近,或相互間的聯結線可能就越多。 2.精簡性(parsimony):同一概念盡可能只用一個節點表示。 3.抽象性(abstraction):語意網路用語意來表徵知識而非用句子中的每一
個字。 4.多樣性(versatility):影像或動作可用一系列的命題來表徵。 5.可加性(addibility):新的命題可隨時加入已存在的語意網路中。 6.可視性(visibility):語意網路能以平面圖的方式表徵知識,可使人對知 識結構一目了然,具有視覺效果。 7.自足性(self-sufficiency):每一個語意網路都可以充分表達某一群概念間 的關係。 8.直觀性(intuitivity):語意網路儘管用命題作為知識結構的最小單位,但 它仍然盡可能地配合人類使用語言的一些自然習慣。 茲就幾個主要的語意網路模式分析如下:
(一)
Collins 和 Quillian(1969)可教的語言理解者模式(teachable
language comprehender,簡稱 TLC)
1.TLC 模式的理論 這個模式是模擬電腦程式的記憶組織,主要是用電腦來模擬人類的語文理 解。TLC 模式假定每個節點有兩種聯結(Best, 1992),首先,每一節點與某些 節點有高階聯結,可決定類別的隸屬關係,此聯結顯示「是」的關係,例如魚「是」 一種動物;其次,每個節點除了顯示隸屬關係的聯結外,還有其他顯示該節點特 質的聯結,此聯結顯示「有」的關係,例如魚「有」鱗。 TLC 主張語意知識是以階層狀的網路結構來表徵的,並且遵循認知精簡原 則(cognitive economy),亦即屬於多數概念所共有的特徵,只會出現在最高階 的節點中,例如「金絲雀」和「鴕鳥」都會呼吸,但呼吸的特徵只出現在最高階 的「動物」層次上。當某概念具有與多數概念共有的特徵相異時,則需將其獨特 的特徵呈現在該概念的特徵屬性上。例如大多數的鳥類會飛,而鴕鳥不會飛,所 以就在鴕鳥的特徵屬性上表徵出鴕鳥不會飛的特質。 在 TLC 的模式中,欲搜尋概念是否具有該屬性時,可根據下列三個步驟 (Rumelhart & Norman, 1988): (1)搜尋概念的屬性時,首先尋找概念本身所具有的屬性。 (2)若無法在概念本身的屬性中找到,則沿著概念的階層關係往上一層, 從高階概念的屬性中尋找是否具有該屬性。(3)重複步驟 2,繼續往上一層的高階概念去尋找,直到確定找到或確定 不具有該屬性為止。 2.TLC 模式的評價 TLC 模式雖然能解釋某些實驗結果,卻也遭遇了一些困難: (1)無法解釋典型效果(typicality effect)。例如「知更鳥」比「鴕鳥」更 像一隻典型的鳥,根據TLC 的理論,「知更鳥」與「鴕鳥」同屬於一個階層的, 但實際的結果是,「知更鳥是鳥?」提取的時間,少於「鴕鳥是鳥?」的提取時 間(Smith, Shoben, & Rips, 1974)。
(2)無法說明某些逆轉效果(reversal effect)。例如「動物」是「哺乳動 物」的高階概念,根據 TLC 模式提取「貓是一種哺乳動物?」,應該少於「貓 是一種動物?」的時間,但實驗結果卻相反(Rips, Shoben, & Smith, 1973)。
綜合上述探討可知,TLC 模式雖然能清楚的解釋訊息是如何被提取的,同 時它呈現出知識結構是相當具有結構化的特質,然因其知識結構為單一的階層網 路,有失之簡化的缺失。
(二)
Collins 和 Loftus 的擴散激發模式(spreading activation model)
1.擴散激發模式的理論 由於TLC 模式有過度簡化的缺失,所以 Collins 和 Loftus(1975)針對 TLC 的缺點作了修正,提出了擴散激發模式。擴散激發模式不用階層組織的形式表徵 概念的階層關係,而改以非階層的網路語意距離來表徵各概念間的關係。 擴散激發模式有兩個假設(Best, 1992)。首先,兩個概念間的關聯程度端 賴聯結線段的長度,聯結線段越短,表示兩概念的連結關係越緊密;其次,概念 間的聯結,並非每個都具有隸屬性的關係,有些是屬於同階的關係。 擴散激發模式主張命題的表徵方式,猶如腦神經細胞的分佈情形,一旦一個 概念被激發後,它會沿著與此概念聯結的聯結線段,激發其他的概念,而越近的 聯結,激發的速度越快。而激發強度的大小、激發時間的長短、概念之間的距離 長度、被激發的概念是否為核心概念等因素,都會影響概念是否被激發。例如最 初被激發的是不尋常、冷僻的概念,便不會擴散到很多概念;如果被激發的是錯 綜交織的網路核心概念,那麼就會有許多相連的概念被激發(黃秀瑄、林瑞欽譯, 民80)。
2.擴散激發模式的評價 擴散激發模式雖然可以解釋TLC 所無法解釋的實驗效果,但是 Smith(1978) 認為因為擴散激發模式是為了修正 TLC 模式而產生的,所以本身並無法提出許 多清楚的實驗預測結果(clear-out predictions)。 綜合上述的探討可知,擴散激發模式認為訊息一旦被激發,便會順著聯結的 網路向四面八方擴散開來,如此的訊息提取可以較快速,並且可避免因單一階層 網路所可能導致的錯誤解釋。擴散激發模式採用類似網路神經的知識組織方式, 影響著往後測量知識結構的方法,例如路徑搜尋法即是深受擴散激發模式的影 響。
(三)
Anderson 思考的適應性控制(adaptive control of thought)
1.ACT 模式的理論 Anderson 提出 ACT 的目標是要發展一個長期記憶的理論,這個理論用來解 釋關於記憶、推理、語言理解與獲得等認知結構與認知歷程的全貌。ACT 主張 知識是以命題網路的形式被表徵在記憶結構中,命題網路中的節點代表命題,而 聯結線則代表命題之間的關係。 ACT 有七項的基本假定,其中前五項是關於陳述性知識的假定,而後兩項 則是關於程序性知識的假定(Howard, 1983): (1)陳述性知識的假定: (A)強度假定:每個聯結有特定的聯結強度,新形成的聯結強度較低, 但每次被使用後就會不斷增強。 (B)促動假定:在任何情況下,長期記憶中的節點只有小部分處在激發 狀態,其他節點則處於不激發狀態。 (C)促動擴散假定:被激發的節點會擴散到相互聯結的被動節點。兩個 節點間的聯結越強,就越可能擴散到聯結的節點。擴散是有能量限 制的,同時有越多節點被激發,就越少會擴散到其他節點。 (D)漸弱假定:激發會定期地在整個網路中逐漸減弱。 (E)促動列假定:最多有十個節點在激發列(active list)中,激發列就 是ACT 理論中工作記憶。在激發列的節點不會被減弱,只要它們 在激發列中,就處於活動狀態中。
(2)程序性知識的假定: (F)強度假定:每個生產法則有某些聯結強度,每次生產法則被執行後, 生產法則的強度就會增加。 (G)選擇假定:所有生產法則的條件會與被促動的記憶相比較,看看是 否有條件相符的生產法則。強度較強的生產法則的速度較快,一旦 某個生產法則的條件符合的話,該生產法則就會被執行。 ACT 主張永久記憶的主成分是以命題形式進行儲存的工作,此模式包括陳 述性記憶(declarative memory)、生產法則記憶(production memory)與工作記 憶(working memory)三個部分。 陳述性記憶是屬於儲存知識結構的長期記憶區,它與工作記憶進行訊息的儲 存和提取的工作;生產法則記憶是屬於負責關於程序性知識的記憶區,它與工作 記憶進行生產法則的比對和執行的工作,同時生產法則記憶本身會進行應用的工 作,以擴增生產法則的應用情境。工作記憶是屬於當下正在處理訊息的記憶區, 他必須針對外在世界所提供的訊息,進行編碼的工作,同時需立即對該訊息做出 回應的表現行為。 當外在的訊息經編碼後送至工作記憶區,相關的訊息一旦在命題網路中被激 發後,就會從陳述性記憶區提取到工作記憶區,而工作記憶區所處理的訊息,也 會被送至陳述性記憶區儲存;透過型態比對(pattern matching)的過程,選擇適 當的生產法則,當滿足特定的條件後,生產法則就會被執行,生產法則透過學習 懂得將舊經驗遷移應用至新的情境。最後,訊息經過工作記憶區的處理後,會對 外在環境表現出實際的行動。 2.ACT 模式的評價 整體而言,ACT 理論是一個整合陳述性知識與程序性知識的命題網路模 式,它對訊息的處理歷程與知識結構的形成方式,都能清楚的解釋說明,是一個 較完整的語意網路理論,它對知識結構的評量有著重大的影響力。 綜合上述的探討可知,TLC 模式、擴散激發模式與 ACT 模式等都是屬於語 意網路的知識結構類型,其中,TLC 模式與擴散激發模式等兩種語意網路模式 都主張「概念」是知識的基本單位,並且比較偏重對陳述性知識的表徵,而ACT 模式主張「命題」是知識的基本單位,ACT 模式則同時能表徵陳述性知識與程
序性知識。
二、基模理論(
schema theory)
所謂的基模是指有組織的知識結構,它是存在記憶裡用來表徵一般概念 (generic concept)的資料結構,基模可用來表徵物體、情境、事件、連續的事 件(sequences of events)、行動與連續的行動等知識(Rumelhart & Ortony, 1977), 與基模概念相似的有Minsky(1975)所提出的「架構」(frame),以及 Schank & Abelson(1977)所提出的「劇本」(script)。 基模理論是一種關於知識的理論,這種理論主要是在探討知識如何被表徵, 以及表徵如何促使知識在特定方面的使用。基模理論主張所有的知識都是被包裝 (packaged)成單位(units),這些單位就是所謂的基模群(schemata),這些 基模群是一種抽象的知識結構,它會引導個體如何使用知識。 心理學家對基模的研究,大致是從Bartlett(1932)對記憶扭曲的研究開始, 他發現當要求受試者回憶先前提供的文章內容時,受試者會傾向省略文章裡的某 些情節,而自己加入某些文章所沒有的情節,以使閱讀的文章能與自己已有的故 事基模相符。其後,Piaget 認為基模是有組織的思考模式,用來解釋人類如何透 過經驗適應生活環境,例如嬰兒會採用動作基模來探索外在的世界。 Rumelhart(1980)認為基模是認知的基石(building blocks),它是訊息處 理過程所依賴的基本元素,包括在轉譯外在的感覺資料時,在提取訊息時,在組 織行動時,在決定目標與次目標時,在分配資源時,都會應用到基模的概念。 Marshall(1987)則認為基模是包含人類如何與環境互動的訊息的一種知識 結構,它可用來說明人類如何知覺外在的環境,以及在該情境下,會採取何種行 動來因應。而人類在知覺外在環境與做出反應行動時,同時需要使用到陳述性知 識與程序性知識,因此,Marshall(1987)主張基模知識是陳述性知識與程序性 知識的綜合體。
Rumelhart & Norman(1988)綜合對基模的相關研究,提出基模具有五點特 徵:
1.基模是有變項的:任何基模都具有不可改變的部分與可以改變的部分,例 如「人」的基模,有不可改變的部分,如:「一個人有雙手及雙腳」,以及可以
改變的部分,如:「人有黑種人、白種人、黃種人」等。 2.一個基模可以包含子基模:例如「手」的基模可以包括「手指」和「手臂」 兩個子基模,而「手指」的基模又可以包括「大拇指」、「食指」、「中指」、 「無名只」和「小指」等子基模。 3.基模可以表示任何層次的知識:基模不僅可以表示大範圍的知識,例如文 化知識,也可以表示小範圍的知識,例如某個字的意義。 4.基模代表的是知識,而不是代表定義:基模代表的是個人對於外在世界所 產生的經驗,而不是對於這些經驗給予定義。 5.基模會主動的進行辨認的工作:基模會主動對新的訊息進行辨認的工作, 從辨認的過程中,選取最適合的基模來處理新的訊息。 由上述基模所具有的五點特徵可知,當個體遭遇外在環境的各種訊息時,個 體本身所擁有的基模會主動的對各種訊息進行辨認的工作,然後較能符合外在訊 息的基模就會被活化,而被活化的基模在處理外在訊息時,會先存在一些預設值 (default value),這些預設值可以協助個體快速的瞭解外在訊息的意義。 基模不但可以表徵靜態的概念知識外,也能表徵動態的行動事件,例如:當 被要求說明什麼是「房子」時,你可能會有「房子是一種建築物」、「房子裡有 房間」、「房子是由木材、磚塊或石頭所建造的」、「房子是當作人類的住處」、… 等的想法,由這些想法你就可以產生對「房子」的部分基模,有了房子的部分基 模後,你就可以很快讓別人瞭解房子的概念(Anderson, 1990)。 基模除了可以表徵像「房子」這樣靜態的概念外,也可以用來表徵動態的行 動事件。例如Schank & Abelson(1977)所提出的劇本理論,即是一套具有行動 計畫的基模。Schank & Abelson(1977)曾以「餐廳」劇本,用來說明個體對餐 廳所具有的知識表徵。一個餐廳劇本通常包括配備、角色、登場的情境、用餐的 場景與結果等部分。配備的部分有桌子、菜單、食物、帳單、錢、小費等;角色 的部分有顧客、侍者、廚師、收銀員、店主等;登場的情境是因為顧客擁有錢, 並且處於飢餓的狀態;最後的結果是顧客付了錢用餐後,就不再飢餓,店主得到 金錢的報酬,顧客和店主都皆大歡喜。至於用餐的場景部分,則是屬於動態的行 動事件,通常包括四個場景:首先是顧客進入餐廳的場景,然後是點菜的場景, 接著是開始用餐的場景,最後是顧客離開餐廳的場景。每個場景都包括了一些依 序的行動,將這些行動串連起來,就是顧客上餐廳用餐的基模知識。
第四節
知識結構評量
目前教育心理學家已發展出許多種評量知識結構的方法,而 Koubek & Mountjoy(1991)、Goldsmith, Johnson, & Acton(1991)與 Jonassen, Beissner, Yacci (1993)等人曾對這些評量知識結構的方法,加以分門別類。
Koubek & Mountjoy(1991)將知識結構的評量方法,根據評量方法的差異 而區分成三類:口語報告(verbal reports)、集群方法(clustering methodologies)、 與量尺方法(scaling methodologies)。口語報告包括晤談、問卷、放聲思考、… 等方法;量尺方法包括多向度量尺、路徑搜尋法、…等方法。
Goldsmith, Johnson, & Acton(1991)與 Jonassen, Beissner, Yacci(1993)對 於知識結構評量方法的分類,是根據評量的實施程序而分類的。他們都主張知識 的評量包括三個主要步驟:知識結構的誘發(elicitation)、知識結構的表徵與個 人知識結構表徵的評價。茲分別說明如下: 1.「知識結構的誘發」著重於評量個人是否清楚瞭解概念間所具備的關係, 此步驟可採用的評量方法包括字義聯想法、卡片分類法、相似性評定法、晤談 法、…等。 2.「知識結構的表徵」是將「知識結構的誘發」步驟所引出的知識,經由量 尺化的程序,表徵成結構性的知識組織,常用的評量方式有集群分析、多向度量 尺與徑路搜尋法、…等。 3.「個人知識結構表徵的評價」則是將個人所誘發出的知識結構表徵與參照 者的知識結構表徵相互比較,以瞭解個人的知識結構表徵與參照者的知識結構表 徵的相關程度,參照者的知識結構表徵通常是以專家的知識結構表徵為代表。 以下分別詳細介紹知識結構評量的三個步驟:
一、知識結構的誘發
目前,通用的誘發知識結構的方法,主要有下列幾種:(一)「字詞相似性聯想法」(
word association proximities)
字詞相似性聯想法是基於長期記憶理論,研究發現長期記憶中相關聯的概念 有其語意相似性(semantic proximity)的特性。語意相似性是假設相似的概念,
其關連性較強、較容易形成配對。而字詞相似性聯想法的主要目的,即在抽譯出 知識結構,亦即透過回憶所檢索出的訊息,抽譯出學習者於長期記憶中對該主題 概念的相關結構。字詞相似性聯想法所得的資料可轉成距離矩陣,用以描述概念 間的語意差異。 字詞相似性聯想法的應用,主要有二種方法: 1.自由聯想法:給予一個字詞,要求學生在一定時間內,盡可能舉出所 能聯想到的相關字詞。 2.控制聯想法:要求學生所舉出的字詞須限定在相關的領域(例如:舉 出和刺激字詞有關的「物理概念」),且須排出相關性的次序。 字詞聯想法的實施程序,為先確定所要評量的學科領域,其次就該學科領域 中的主要知識概念,選擇幾個最為重要的刺激字,請受試者在特定的時間內(通 常是一分鐘到一分半鐘之間),以該學科領域的知識為範圍,盡可能的寫出與該 刺激字相關聯的概念。 字詞聯想法的優點為實施容易且方便,受試者能主動提出與刺激字相關聯的 概念,可較客觀的誘發出受試者的知識結構;其缺點為在短暫的時間內,受試者 對刺激字所誘發出的關聯概念,可能只憑受試者對該概念的表面印象,而無法確 定該概念與刺激字是否真的有很高的關聯性。
Gesslin & Shavelson(1975)曾以字詞聯想法探討中學生學習機率的認知結 構,結果顯示字詞聯想法可以有效的評量出中學生數學的知識結構。
(二)「卡片分類法」(
card sorting)
卡片分類法指的是呈現一系列與主題相關的卡片,每一個卡片上面註明一個 概念,然後根據意義相似性把概念分類,最後給予各個類別訂一個類別標籤或分 類標題,概念間關係的準則可透過該類別的標籤或標題加以傳達。卡片分類法根 據意義的相似性或其他意義效標,例如概念的內涵、功能、特質、…等而作分類。 Miller(1969)研究發現,卡片分類技術對於以階層結構組織而成的概念而言, 是定義概念間關係距離的有效工具。 卡片分類的優點為實施容易,因為卡片分類方法簡單易懂,受試者可以很快 瞭解如何進行評量;但其限制,則為每個概念只能隸屬於一個類別,但概念常具 有多樣的意義,因此,往往無法彰顯概念的完整意義。Stein, Baxter, & Leinhardt(1990)以卡片分類法探究數學教師關於函數的知 識結構,結果發現數學老師的教學內容,與其所具有的知識結構相符合,同時也 顯示卡片分類法能有效的評量知識結構。
(三)「相似性評定法」(
similarity ratings)
相似性評定法指的是讓學生對兩兩配對的概念,以固定量尺評定概念間的相 似度或關係強度,其為評估個體認知結構中,概念相似性的最直接方法。相似性 評定法基於概念間相似性比較理論,利用空間比喻來描述認知架構,而較相關的 概念在幾何空間中的位置較接近。相似性評定法所得的評定資料,可以轉換成相 似性距離矩陣。一般相似性評定法應用在「多向度量尺法」(multidimensional scaling)、「路徑搜尋網路分析法」(pathfinder network analysis)、「集群分析 法」(cluster analysis)等評量方法上。相似性評定法所採用的量尺技術,許多調查研究指出心理量尺技術,如集群 分析、多向度量尺、網路量尺技術(network scaling technique)等,常被用來作 為誘發領域知識的技術,而且一般認為這些技術較傳統的知識誘發方法更具體、 更有效(Cooke & McDonald,1987)。
宋德忠、林世華、陳淑芬、張國恩(民 87)以相似性評定法與路徑搜尋法 評量大學生對於學習理論的知識結構,研究結果顯示徑路搜尋法所提供的知識結 構(PFC 指數),對學習成就有不錯的預測力。
(四)晤談法
晤談法是施測者提出問題由受試者來回答,受試者在回答的過程中,要將腦 中所有想到的事情大聲的說出來,當受試者陷入沈思而未能說話時,施測者應提 醒受試者說出正在想的事情,研究者即根據受試者回答的內容,分析其知識結 構。整個晤談的過程可透過錄影或錄音的方式,以便提供研究者分析資料時的參 考。 晤談法的基本假定是透過受試者將本身的知識結構以口述的方式表達出 來,研究者對於口述的內容分析,可以瞭解其知識的原貌。晤談法的優點是透過 晤談的方式,受試者可以清楚完整的表達其想法,可較深入的瞭解受試者的知識 結構,但其缺點則為對於知識結構的分析,牽涉到研究者主觀的判斷。 White(1985)認為晤談法是描述知識結構最微妙(subtle)的方法,它可以提供許多關於人類如何儲存和回憶知識的洞察力(insight)。Leinhardt & Smith (1985)曾以晤談法研究數學教學過程中所需的專家知識,研究結果顯示晤談法 可以較深入的分析教學者的教學知識。 從以上的文獻探討可以發現,知識結構誘發技術有許多種,但其中最為具 體、有效的方式是相似性評定法所採用的量尺技術。量尺技術在認知心理學中經 常被用來研究記憶中的知識概念組織。
二、知識結構的表徵
「知識表徵」(knowledge representation)是指針對被誘發的知識,以某種 表徵方式找出其結構而言。誘發的技術通常和詮釋(interpreting)或摘要資料的 方法結合在一起,而詮釋或摘要資料的內容往往是量化的或統計學上的表徵方 式。詮釋過程所輸出的結果(例如:方格(grids)、網路(networks)、集群(clusters)、 等)被視為中介表徵(mediating representation)。此一中介表徵用來表示個體所 習得的知識,在誘發的知識中,資料聚合的愈好,則表示其專家模式愈佳 (Cooke,1994)。以下將介紹三種較常使用的知識結構表徵方法:(一)集群分析法
集群分析主要是將知識誘發步驟所取得的接近性矩陣(proximity matrix), 輸入統計軟體進行統計分析,集群分析會從相似性或不相似性的資料中,抽取出 資料中的潛在結構,最後以樹狀圖(dendrogram)的形式表徵出受試者的知識結 構,樹狀圖上的分支線段代表概念,而相連的分支線段代表隸屬於同一個集群。 集群分析的基本假定,認為知識是以層級組織的方式儲存於長期記憶中,概 念間的關係越密切的,就會聚集於相同層級的組織結構中。集群分析的優點為樹 狀圖的表徵方式,可透過視覺的觀察,很清楚的知曉概念之間的隸屬關係;但其 限制則為要將樹狀圖區分為幾個集群數,目前尚未有公認的理想方法(林邦傑, 民70)。(二)多向度量尺法
多 向 度 量 尺 法 主 要 是 將 知 識 誘 發 步 驟 所 取 得 的 接 近 性 矩 陣 (proximity matrix),輸入統計軟體進行統計分析,多向度量尺法會從相似性或不相似性的 資料中,抽取出資料中的潛在結構,最後以座標圖的形式表徵出受試者的知識結 構,座標圖上的座標點代表概念,而座標的向度代表區隔概念的依據標準。多向度量尺法的基本假定,認為概念間的關聯程度可用座標圖的幾何距離表 徵出來,座標圖的幾何距離越短,即表示概念間的關係越密切。而概念之間的關 聯性,可從許多不同的向度來衡量。 多向度量尺法的優點為座標圖的表徵方式,可透過視覺的觀察,很清楚的瞭 解概念之間的關聯性;但其缺點則為每個向度代表的意義,不容易客觀的評判出 來,若超過兩個以上的向度,則更不容易解釋向度的意義。
(三)路徑搜尋法
路徑搜尋法也是需要將知識誘發步驟所取得的接近性矩陣輸入 KNOT 軟體 程式來進行統計分析,路徑搜尋法會從相似性或不相似性的資料中,抽取出資料 中的潛在結構,最後以 PFnets 網路圖的形式表徵出受試者的知識結構,PFnets 網路圖上的節點代表概念,而相連的節點代表概念間的關聯性較高。 路徑搜尋法的基本假定,認為概念間的關聯程度,可由 PFnets 網路圖中概 念之間是否存在聯結線表徵出來。若概念之間有聯結線的存在,即表示概念間的 關係越密切;若概念之間缺乏聯結線,則表示概念間的關係越疏遠,然而要特別 注意的是PFnets 網路圖中節點間聯結線的長短,並不代表聯結聯係的強度。路徑搜尋法的優點為PFnets 網路圖的表徵方式,類似 Collins & Loftus(1975) 提出擴散激發模式的語意網路形式,很容易由概念之間是否有聯結線,而瞭解概 念之間的關聯性;但其限制則為路徑搜尋法需要有特定的 KNOT 軟體程式才能 進行評量。
江淑卿(民 86)曾將上述集群分析、多向度量尺、路徑搜尋法三種知識結 構表徵的方法之相似及相異程度列表說明如下:
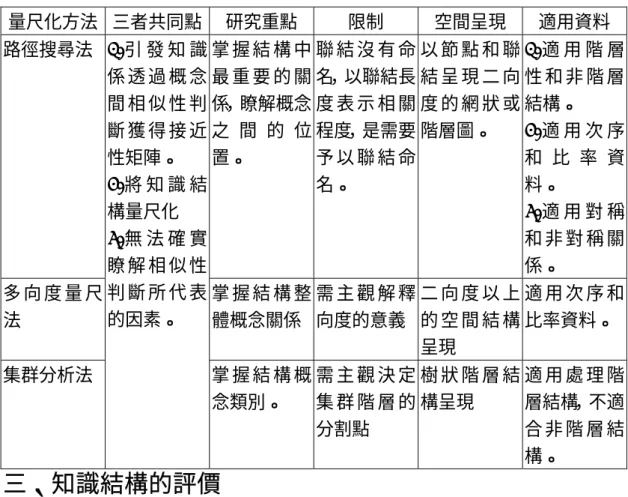
表1 不同知識結構表徵方法之比較分析 量尺化方法 三者共同點 研究重點 限制 空間呈現 適用資料 路徑搜尋法 掌 握 結 構 中 最 重 要 的 關 係,瞭解概念 之 間 的 位 置。 聯 結 沒 有 命 名,以聯結長 度 表 示 相 關 程度,是需要 予 以 聯 結 命 名。 以 節 點 和 聯 結 呈 現 二 向 度 的 網 狀 或 階層圖。 1. 適 用 階 層 性 和 非 階 層 結構。 2. 適 用 次 序 和 比 率 資 料。 3. 適 用 對 稱 和 非 對 稱 關 係。 多 向 度 量 尺 法 掌 握 結 構 整 體概念關係 需 主 觀 解 釋 向度的意義 二 向 度 以 上 的 空 間 結 構 呈現 適 用 次 序 和 比率資料。 集群分析法 1. 引 發 知 識 係 透 過 概 念 間 相 似 性 判 斷 獲 得 接 近 性矩陣。 2. 將 知 識 結 構量尺化 3. 無 法 確 實 瞭 解 相 似 性 判 斷 所 代 表 的因素。 掌 握 結 構 概 念類別。 需 主 觀 決 定 集 群 階 層 的 分割點 樹 狀 階 層 結 構呈現 適 用 處 理 階 層結構,不適 合 非 階 層 結 構。
三、知識結構的評價
個別知識結構表徵的評價,主要是將個人透過知識結構表徵的步驟所得到的 知識結構,與參照者的知識結構相互比較,以瞭解個人的知識結構與參照者知識 結構的異同點,而參照者知識結構通常都是以專家的知識結構為代表。 透過集群分析對個別知識結構與參照者知識結構的比較,從集群分析所獲得 的樹狀圖,可以瞭解個人的知識結構與參照者知識結構所產生的集群數目是否相 同,以及每個集群所包含的概念是否相同。 透過多向度量尺法對個別知識結構與參照者知識結構的比較,所獲得的座標 圖,可以瞭解個人的知識結構與參照者知識結構所產生的座標點是否在相同的位 置,以及每個向度所代表的意義是否相同。 而透過路徑搜尋法對個別知識結構與參照者知識結構的比較,所獲得的 PFnets 網路圖,可以瞭解個人的知識結構與參照者知識結構所產生的 PFnets 網 路圖是否相似,以及概念間的聯結線是否相同。另外,路徑搜尋法可以透過接近 性指數(proximity index,簡稱 PRX)、圖形理論距離指數(graphical theoretical distance,簡稱 GTD)與相似性指數(closeness index,簡稱 PFC)等三個量化的指數值來比較兩個知識結構圖之間的相似程度,這三個指數值的值域範圍都在0 與1 之間,指數值越接近 1,即顯示個人知識結構與參照者知識結構越接近。 綜合上述的分析可知,知識結構的評量方法主要包括:知識結構的誘發、知 識結構的表徵、與知識結構表徵的評價等三個步驟的評量程序,透過知識結構的 誘發,可以顯現受試者所具有的知識結構為何;透過知識結構的表徵,可以用圖 表的方式表徵出受試者的知識結構;透過個別知識結構表徵的評價,可以比較受 試者與參照者之間知識結構的異同點。
第五節
路徑搜尋法
路 徑 搜 尋 網 路 係 美 國 新 墨 西 哥 州 立 大 學 計 算 實 驗 研 究 室 的 領 導 人 Schvaneveldt 率領研究小組,根據網路模式和圖形理論,研究發展出路徑搜尋量 尺化算則(pathfinder scaling algorithm),算則運算時要設定兩個參數 r 和 q 的 數值,用來建構和分析知識結構,並設計知識網路組織工具(knowledge network organizing tool,簡稱 KNOT),用來作為協助評量知識結構的工具(江淑卿、 郭生玉,民86)。一、路徑搜尋法的圖形理論基礎
路徑搜尋法是以圖形理論為主要的理論依據,因此,本部分先介紹圖形理論 的基本觀念,再探討路徑搜尋法的圖形理論基礎。(一)圖形理論的基本觀念
圖形理論是數學知識的一個分支,主要是探討節點與聯結線段所構成的圖形 結構的知識,關於圖形理論的基本觀念如下: 1.頂點(vertices)或節點(nodes):構成圖形的點稱為圖形的頂點或節點。 2.邊(edges)或弧形(arc)或聯結鍊(links):圖形中聯結節點之間的線 段稱為邊或弧形或聯結鍊。 3.路徑(path):圖形中聯結各節點的路線(route),如果沒有重複經過某 個節點兩次,則這個路線稱為路徑。 4.循環(cycle):若某個路線的起點與終點是同一個節點時,則這個路線稱 為循環。5.連結圖形(connected graph):圖形中每個節點可藉由其它節點的聯結, 使得有路線可讓任何兩個節點相互聯結起來,則這個圖形稱為一個連結圖形。 6.樹圖(tree):沒有循環的連結圖形稱為樹圖。 7.完整圖形(complete graph):若每個節點之間都有直接的聯結鍊,則此圖 形稱為完整圖形。 8.有方向的圖形(directed graph):有方向的圖形是指圖形的聯結鍊具有方 向性,通常以箭頭來表示方向,因此節點間的配對關係必須考慮先後的關係,例 如(a, b)與(b, a)代表不同的意義。有方向的圖形,其聯結鍊通常稱為『弧形』。 9.無方向的圖形(undirected graph):無方向的圖形是指圖形的聯結鍊沒有 方向性,通常直接以線段的形式來表示,因此節點間的配對關係不用考慮先後的 關係,例如(a, b)與(b, a)代表相同的意義。無方向的圖形,其聯結鍊通常稱 為『邊』。 10.多餘的(redundant)邊:假如刪除某個邊並不會影響路徑的距離時,則 此邊就稱為多餘的邊。 當圖形的聯結鍊以正實數的權重表示時,則圖形就變成了網路的形式,網路 的節點 i 與節點 j 之間聯結鍊的權重通常以 Wij表示,一個圖形可以視為所有聯 結鍊的權重皆為1 的網路。一條路徑的權重等於此路徑所有聯結鍊的權重總和, 而圖形中兩節點間的距離,是以兩節點之間的所有可能路徑,取其權重最小的 值,作為兩節點之間的距離。 一個網路(圖形)可以表示成n×n 階的網路相鄰矩陣 A(network adjacency matrix A),若網路的節點 i 與節點 j 之間有聯結鍊的存在,且 i≠j 時,則元素 aij =1,否則 aij=∞,但節點自身的聯結則為 0,亦即 aii=0 判斷網路節點之間是否有聯結鍊的存在,可用n×n 階的距離矩陣 D(distance matrix D)來表示,若節點 i 與節點 j 之間有聯結鍊的存在,則元素的值為 dij, dij是節點i 與節點 j 的最小距離,若節點 i 與節點 j 之間沒有聯結鍊,則 dij=∞。 距離矩陣不必然是一個對稱的矩陣,但距離矩陣若是一個對稱矩陣,則該圖形就 是屬於無方向的圖形(Schvaneveldt, 1990)。
(二)路徑搜尋法的圖形理論基礎
路徑搜尋法是以圖形理論為其設計的理論依據,茲將路徑搜尋法所用到圖形理論相關定理,說明如下(Hutchinson, 1989):
一個距離矩陣D 如果可成為某個網路的距離矩陣時,則這個距離矩陣 D 稱 為當成網路是可行的(realizable),其滿足的條件為:
定理1:一個 n×n 階的距離矩陣 D 可當成網路時,若且惟若(if and only if): (a)自身:dij=0;
(b)正數:dij>0,i≠j
(c)三角形不等式:dij≦dik+dkj
路徑搜尋法將定理1 應用到 PFNET 網路上,並改以下列的形式(Schvaneveldt, Dearholt, & Durso, 1988):
令1≦r≦∞,且 n×n 階的距離矩陣 D 可當成網路時,若且惟若(if and only if): (a)自身:dij=0; (b)正數:dij>0,i≠j (c)以 r 為單位的不等式:d ij≦(d rik+d rkj)1/r, r≧1 一個網路若沒有包含多餘的邊,則該網路稱為不可刪減的網路(irreducible network),一個符合定理 1 的距離矩陣 D,若其邊為不可刪減的邊,則需滿足 的條件為: 定理2:距離矩陣D的dij邊為不可刪減的邊,若且惟若:
dij<min(dik+dkj), i≠j , k≠i , k≠j
由定理2可知,若節點i與節點j之間的直接距離小於所有透過其他節點所 得到的間接距離時,則必須保留節點i與節點j之間的聯結鍊。由定理2可以得 到一個推論,即為:
推論1:距離矩陣D的dij邊為不可刪減的邊,若且惟若:
dij≦min[max(dik , dkj)] , i≠j , k≠i , k≠j
由推論1可知,節點i與節點j之間的直接距離小於或等於所有透過其他節 點所得到的間接距離時,則必須保留節點i與節點j之間的聯結鍊。
路徑搜尋法將推論1應用到PFNET網路上,並改為求節點i與節點j之間 的直接距離dij:
dij=min(W(Pij1), W(Pij2),…W(Pijm))
為節點i與節點j之間的直接距離dij等於取連結節點i與節點j之間所有可能的 m條路徑中,最小的路徑權重值當成是節點i與節點j之間的距離。 上述圖形理論的2個定理與1個推論,便構成了路徑搜尋法相當重要的理論 依據。
二、路徑搜尋法
(PathFinder)的基本概念
路徑搜尋法會先將一個上三角(或下三角)的原始資料矩陣轉換為路徑圖(原 文稱PFNET),在一個路徑圖中包含以下元素: 1.節點:在一個路徑圖中會有n個節點,每個節點代表一個概念,可以N1, N2,N3,…,Nn表示之。 2.聯結鍊與權重:聯結鍊連結節點與節點,每條聯結鍊會有一權重值,該權 重值表示節點與節點之間的關聯性。連結節點i與節點j的聯結鍊以eij表示;而 權重值以wij表示。 3.路徑:節點與節點之間的路徑,代表從某節點到另一節點所經過的路線, 如從節點a到節點e,中間經過節點b、節點c、與節點d,則從節點a到節點e 之間的路徑就可以用Pabcde或Pae表示。 4.節點a與節點e之間的路徑通常以W(Pae)表示。 以上的繪圖概念可以從下面的例子來看,原始資料矩陣如下圖左,根據原 始資料矩陣繪出的節點如下圖右: N1 N2 N3 N4 N1 0 2 1 5 N2 2 0 4 2 N3 1 4 0 5 N4 5 2 5 0 W12=2 W14=5 W34=5 W23=4 W13=1 W24=2 N1 N2 N4 N3 圖1 原始資料轉換為節點與鍊結線示例(上圖資料的引用,改編自:Dearhotlt & Schvaneveldt (1990), Properties of pathfinder networks. In R. W. Schvaneveldt (Ed.), Pathfinder associative networks: Studies in knowledge organization (pp.
1-30). Norwood, NJ: Ablex.)
上圖僅是將節點間的關聯以圖形方式表達而已,若欲轉換為PFNET圖,並 計算得到PFNET圖,還必須經過以下的程序:
1.參數值設定:路徑搜尋法中有二個重要參數,即r及q。 (1)參數值r的設定範圍是1≦r≦∞,用以決定路徑的長度(lengths)。當 r設定為無限大時,適合用來處理次序性量數;當r不為無限大時,則適合用以 處理比率量數。R參數將與權重值的計算有關。 (2)參數q可限制網路的鍊結數目,即可以決定最大數量的鍊結。當搜 尋兩個節點間不同的路徑,q參數用來設定最大數量的搜尋節點。參數q的設定 範圍為2到n-1,n為節點數量。當q=n-1時表示能探索所有不同的路徑,若配 合參數r=無限大,q=n-1時,可以產生最少鍊結的網路,稱為『最小值的網 路』(引自江淑卿,民86,頁54-56)。 2.網路權重值的計算方法: r參數是採用Minkowski量尺來計算,用以測量多元空間 (multidimensional space)的距離。 如果向度為i(i=1,2,3,….,n),Xai表示在向度i(i=1,2,3,….,n)到向度n所構 成的多元空間的座標點a的數值;Xbi表示在向度i(i=1,2,3,….,n)到向度n所構成 的多元空間的座標點b的數值,則座標點a到座標點b之間的距離,可用以下公 式來計算, n r i r bi ai r ab X X d 1 1 ) ( (
∑
) = − = ,1≦r≦∞ (公式1) 當r=1時,即是直線距離和;當r=2時,即是歐基里德距離。 以(公式1)的距離概念應用於PFNET網路權重值的計算,整個網路 的路徑權重值來自於其個別路徑的權重值。公式可以改寫如下: K r i r i W P W 1 1 ) ( ) (∑
= = (公式2) 當r=1時,網路路徑的權重值等於每條鍊結權重的總和。亦即是: W(P) = W1 + W2 + W3 + … + Wk 以如果以圖1為例來計算,設定r=1(連續性資料數值)時,則 W(P)=(W14+W12+W13)+(W23+W24)+(W34) =(1+2+5)+(2+4)+(5) =19 3.滿足三角不等式:一個網路中若有q個三個角形,則僅存路徑m個聯結,且m≦q,這些聯結必須滿足三角形不等式。如Wae是節點Na到節點Ne的權重, 其中經過Nb,Nc,與Nd。則必須遵守以下公式: Wae≦
(
r)
r de r bc r ab w w w 1 ...+ + + (公式3) 在一個有n個節點的圖形中,如果沒有循環時,最多會有n-1個邊,將q 參數設為(n-1),可以避免違反三角不等式公式。 4.選取路徑中的最小權重值:節點Na與其本身Na的距離值為0,而節點Ni 與節點Nj的最短距離為:dij = MIN(W(Pij1),W(Pij2),…,W(Pijm)) (公式4) 以圖1為例,d13最小的路徑權重值為: d13=MIN(W(P123),W(P13),W(P1243),W(P143),W(P1423)) =MIN((2+3),1,(2+2+5),(5+5),(5+1+4)) =MIN(5,1,9,10,10) =1 5.選擇最短路徑,並僅保留該最短路徑:承前述例子,d13最小的路徑權重 值為1,為W(P13)。即決定保留最小路徑e13,並刪除其它路徑。 運用前述第5項原則,只保留所有節點間的最小路徑,可以將圖1改繪如 下所示: W12=2 W14=5 W34=5 W23=4 W13=1 W24=2 N1 N2 N4 N3 W12=2 W34=5 W13=1 W24=2 N1 N2 N4 N3 圖2 保留最小路徑圖示
(上圖資料的引用,改編自:Dearhotlt & Schvaneveldt (1990), Properties of pathfinder networks. In R. W. Schvaneveldt (Ed.), Pathfinder associative networks: Studies in knowledge organization (pp.
1-30). Norwood, NJ: Ablex.)
三、路徑搜尋法的各項評估指數
本研究所採用的資料分析方法,是由新墨西哥州立大學的 Schvaneveldt 及 其同事所共同發展出來的路徑搜尋法(PathFinder)及KNOT軟體4.2版。路徑搜尋 保留最 小路徑法以圖形表徵知識結構,同時並以圖形理論距離指數(Graph-theoretic distance index, 簡稱GTD指數)、相似性指數 (Closeness index, PFC,簡稱C指數)、及接 近性指數(Proximity index, 簡稱PRX指數)三個參數,作為量化數值的評估依據。 其計算原理如下所示(以下公式及試算資料均取自於Goldsmith et al., 1991):
(一)接近性指數(Proximity Index, PRX)
PRX 指數直接用兩個接近性資料矩陣(數值愈大表示兩兩概念的關係愈密 切的資料矩陣),以其相互對應的元素數值,求得的積差相關係數。PRX 指數的 數值介於-1至1之間,數值愈大,則表示二個網路愈接近。可用以下假設例子說 明之: 表2 網路一與網路二之節點距離值(假設資料值) 節 點 節點 A B C D E F G 網 路 一 A - 1 1 2 2 2 2 B - 2 1 1 3 3 C - 3 3 1 1 D - 2 4 4 E - 4 4 F - 2 G - 網 路 二 A - 1 2 1 1 3 3 B - 1 2 2 2 2 C - 3 3 1 1 D - 2 4 4 E - 4 4 F - 2 G - PRX 指數的計算方式,是將二矩陣中相對應位置的數值求積差相關,上述 二矩陣可分別看成二數列,數列一及數列二如下: 表3 網路一與網路二之的PRX指數的相關計算值 xab xac xad xae xaf xag xbc xbd xbe xbf xbg xcd xce xcf xcg xde xdf xdg xef xeg xfg 一 1 1 2 2 2 2 2 1 1 3 3 3 3 1 1 2 4 4 4 4 2二 1 2 1 1 3 3 1 2 2 2 2 3 3 1 1 2 4 4 4 4 2 r12 = 0.79 利用皮爾遜積差相關公式,計算數列一及數列二,可得到 r=0.79。r=0.79
即為PRX指數的數值。
(二) 圖形理論距離指數(Graph-Theoretic Distance Index, GTD)
GTD(graphical theoretical distance,圖形理論距離指數)是兩個知識結構圖各 概念節點之間的距離(以相距節點的數目多少來計算),所求得的相關係數。GTD 指數值介於0至1之間,數值愈大,則表示二個網路愈接近。其作法如下: 1.將原始資料依據前一部分「一、路徑搜尋法(PathFinder)的基本概念」所敘 述的方法,將原始資料值轉換為路徑圖(PFNET 圖)。自表 2 中僅取節點 A 與其 它節點的鍊結為例,繪出網路一(節點A部分)與網路二(節點A部分)的路徑圖如 下圖3所示(註:鍊結線段長短與權重值無關,權重值須參考原始資料表): 表4 自表2中所擷取的部分節點值 節 點 節點 A B C D E F G 網 路 一 A - 1 1 2 2 2 2 網 路 二 A - 1 2 1 1 3 3 A B C D E F G A B D C G F E 圖3 網路1(僅取節點A部分)與網路2(僅取節點A部分)的PFNET圖 (上圖資料改編引自:Goldsmith & Davenport (1990). Assessing structure similarity of graphs. In R.W. Schvaneveldt (Ed.), Pathfinder associative networks: Studies in knowledge organization (pp. 75-87). Norwood, NJ: Ablex.)