國立台灣大學工學院土木工程學系 碩士論文
Department of Civil Engineering College of Engineering National Taiwan University
Master Thesis
以貝氏分析估計三度空間中的趨勢函數
Three-dimensional probabilistic site characterization by sparse Bayesian learning
黃玟翰 Wen-Han Huang
指導教授: 卿建業 博士 Advisor: Jianye Ching, Ph. D.
中華民國 108 年 7 月
July 2019
致謝
研究生兩年的生涯終於要結束了,首先非常感謝卿老師兩年的指導,這兩年間 不管是研究、課業或式做人處事的道理盡心盡力的指教,也非常感謝老師能給我機 會在課餘時間去顧問公司實習,對我來說是一個非常寶貴的經驗。
感謝撥空前來口試的王瑞斌老師與林志平老師對研究跟論文的建議與提點,讓 整個論文的架構更加完善。
感謝卿門的夥伴俊廷、元勛以及映中,一起修課討論作業與研究,感謝姿勻、
昕臻在課業上的諸多幫助,感謝一起從高大到台大的文獻、文韜、敏昀、俊廷跟荐
宇,一起準備研究所到後來課業上的幫助,也感謝一起辛苦奮鬥的R06 夥伴們不論
課業或生活上的諸多幫助,一起出遊打球嘴砲,相信這份革命情感一輩子都不會忘 記。
感謝一路上最支持我的家人與女友,支持我讀到研究所,不需要我為其他事情 操心,可以專心於課業跟研究,真的非常非常感謝。
中文摘要
本研究將以圓錐貫入試驗 (cone penetration test, CPT) 的修正之錐尖阻抗 (qt) 資料做為討論對象,探討辨識趨勢函數的可行性與方法。現地調查所獲得的空間分 布資料可以被分成兩項,趨勢函數以及沿著趨勢且平均值為零的變異性,而趨勢函 數可以讓工程師更輕易的了解土壤性質隨空間的變化,空間變異性可以透過標準差 (σ)及關聯性長度(δ)估計。除了垂直向的關聯性長度外,本研究探討三度空間問題,
所以還需要估計水平方向的關聯性長度,相比於垂直向的關聯性長度,由於土層水 平方向的變異性較小,且水平的資料數量遠少於垂直方向的資料,大大增加水平向 參數估計的難度。
當進入三維分析時,所需要的計算量將大幅提升,導致運算時間太長甚至超過 記憶體的負荷量,所以使用了 Cholesky decomposition 與克羅內克積 (Kronecker product) 等數學方法,大幅減少計算量。
本研究透過兩步驟的貝氏分析架構來辨識以及模擬空間中的趨勢函數,第一步 是透過sparse Bayesian learning 的架構來選擇真正需要的基函數 (basis function, BF),
不同種類的基函數形式在文中也會進行探討。第二步是透過漸進式馬可夫鏈蒙地卡 羅法 (transitional Markov chain Monte Carlo, TMCMC; Ching and Chen, 2007) 作為估 計隨機場參數的方法,透過上述兩個步驟就能模擬出代表現地趨勢函數,接下來則 可以利用第二步所取得的趨勢與關聯性參數進一步進行隨機場的模擬。
關鍵字: 大地工程、圓錐灌入試驗、趨勢函數、空間變異性、隨機場
Abstract
This study investigated the modified cone tip resistance (qt) data from cone penetration tests (CPT). The feasibility and method of identifying the trend function were also discussed. The vertical spatial distribution is expressed as a depth-dependent trend function and a zero-mean spatial variation. Trend function can help us catch soil properties in space. Spatial variation can be estimated by standard deviation (σ) and scale of fluctuation (δ).
In addition to the vertical scale of fluctuation, in 3D case, horizontal scale of fluctuation is also important. However, the number of horizontal data is much less than that of the vertical data. Horizontal scale of fluctuation is hard to be estimated. The estimation of the horizontal parameter is difficult. Another problem is that when analyzing multiple data at a time, the matrix becomes very huge, increasing the computation and even exceeding the load of the memory. We use Cholesky decomposition and Kronecker product to simplify the matrix. In this way, we can greatly reduce the computation.
This study uses a two-step Bayesian analysis to identify trend functions. The first step is to select the basis functions we need by sparse Bayesian learning. In this study, we also consider the effects of different kinds of basis functions. The second step is to use transitional Markov chain Monte Carlo (TMCMC; Ching and Chen, 2007) as a method for estimating the parameters of the random field. Through the above two steps, we can fit the trend function and model the random field.
Keywords: geotechnical engineering, cone penetration test, trend function, site characterizarion, spatial variability
目錄
致謝 ... I 中文摘要 ... II Abstract ... III 目錄 ... IV 圖目錄 ... VII 表目錄 ... XV
第一章 緒論 ... 1
1.1 研究動機與目的 ... 2
1.2 研究方法 ... 5
第二章 文獻回顧 ... 8
2.1 隨機場 (random field) ... 8
2.1.1 穩態隨機場 (stationary random field) ... 8
2.1.2 自關聯性函數 (auto-correlation function, ACF) ... 10
2.2 Whittle-Matérn 模型 ... 11
2.3 平滑性參數的影響 ... 12
2.4 不同型態的基函數 ... 15
2.5 一維及三維隨機場表示方式 ... 19
2.6 Sparse Bayesian Learning (SBL) ... 22
2.7 馬可夫鏈蒙地卡羅法 ... 24
第三章 研究方法 ... 29
3.1 資料模擬 ... 30
3.1.1 隨機場參數對模擬資料的影響 ... 30
3.1.2 三維空間分布資料之模擬 ... 32
3.2 Step1-選擇真正需要的基函數(BFs) ... 35
3.2.1 最大化條件證據 f(Y|S, σ, δ, ν, M) ... 35
3.2.2 三維的計算問題與新的公式推導 ... 39
3.2.3 模擬資料辨識結果 ... 41
3.3 Step2-貝氏分析 (Bayesian analysis) ... 42
3.3.1 (lnσ, lnδv, lnδh, lnνv, lnνh) 的取樣 ... 43
3.3.2 W’的取樣 ... 44
3.4 不同型態的基函數擬合成果 ... 50
3.5 Step3-建立隨機場 ... 55
第四章 現地案例討論 ... 56
4.1 Hollywood, South Carolina ... 56
4.1.1 Step1 分析結果 ... 58
4.1.2 Step2 分析結果 ... 60
4.1.3 Step3 模擬結果 ... 67
4.2 Baytown, Texas... 68
4.2.1 Step1 分析結果 ... 72
4.2.2 Step2 分析結果 ... 76
4.2.3 Step3 模擬結果 ... 89
4.3 Adelaide, South Australia ... 90
4.3.1 Step1 分析結果 ... 93
4.3.2 Step2 分析結果 ... 99
第五章 結論與建議 ... 121
參考文獻 ... 123
附錄A ... 128
圖目錄
圖 1-1 垂直方向資料較多而水平資料較少 (Stuedlein et al., 2016) ... 3
圖 1-2 相同的空間分布資料由人所判斷的趨勢不一定相同 ... 6
圖 2-1 自關聯性模型 ... 10
圖 2-2 c(ν)函數 ... 11
圖 2-3 不同 ACF 的隨機場資料 ... 12
圖 2-4 無限邊坡下 tan [ϕ’(z)]的隨機場樣本 ... 13
圖 2-5 破壞機率相對於ν的變化 (Ching and Phoon 2018)... 14
圖 2-6 Shifted Legendre polynomial ... 15
圖 2-7 Discrete cosine basis ... 16
圖 2-8 (左) σr較小時的函數形式;(右) σr較大時的函數形式 ... 17
圖 2-9 Radial basis function ... 18
圖 2-10 空間中的趨勢函數示意圖 ... 21
圖 2-11 實線為 t(z) = 500 + 200z;虛線為空間分布資料 (Ching et al., 2017) ... 22
圖 2-12 趨勢擬合結果 (Ching et al., 2017) ... 23
圖 3-1 (μ, σ) = (0, 50) 且 ACF 為 SExp 模型在不同 δ 下之模擬 ε (左) δ = 0.1 公尺; (中) δ = 1 公尺;(右) δ = 5 公尺 ... 30
圖 3-2 (μ, σ) = (0, 50) 且 SOF 為 1 時不同 ν 之模擬 ε (左) ν = 0.5;(中) ν = 1.5;(右) ν = 20 ... 31
圖 3-3 虛線為趨勢函數,實線為空間分布資料 ... 34
圖 3-4 (左) Radial basis function 基函數標準差較大;(右) Radial basis function 基函
數標準差較小 ... 37
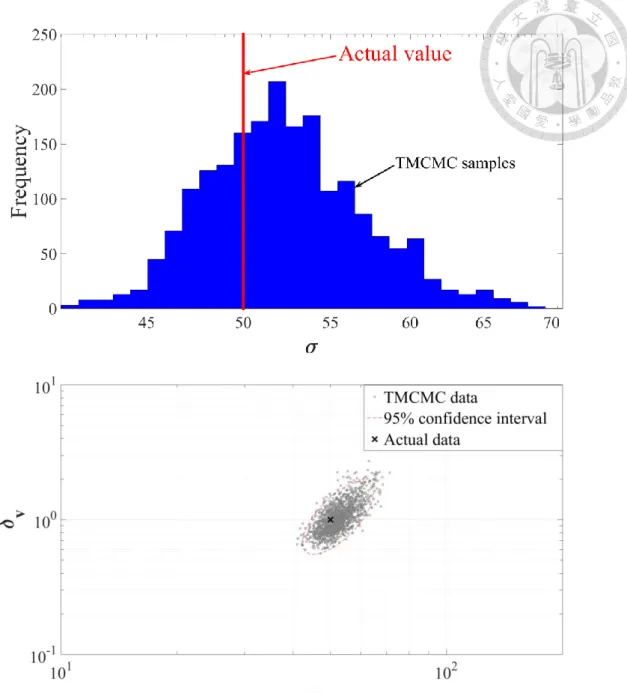
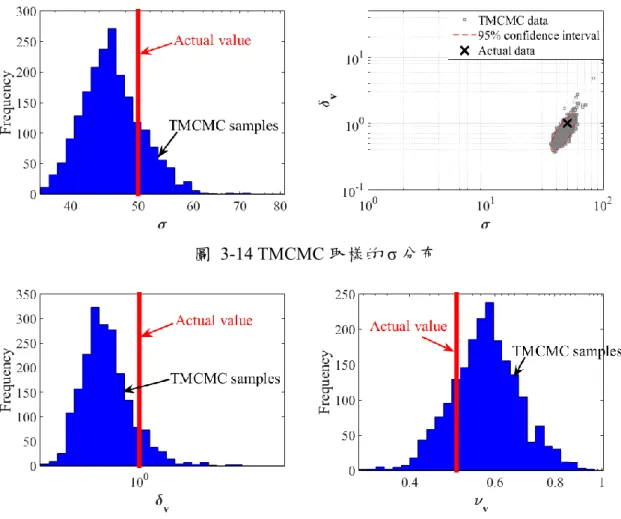
圖 3-5 TMCMC 取樣的 σ 分布 ... 45
圖 3-6 TMCMC 取樣的垂直方向關聯性長度 δv與平滑性參數νv分布 ... 46
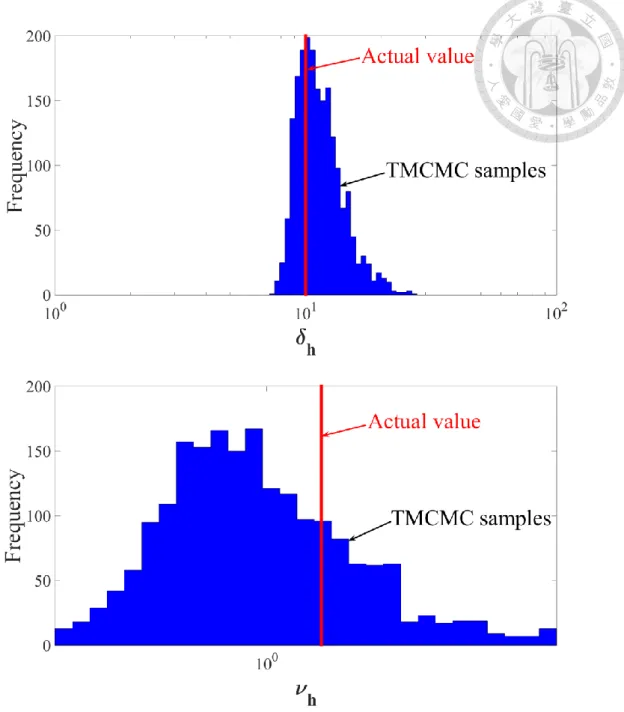
圖 3-7 TMCMC 取樣的水平方向關聯性長度 δh與平滑性參數νh分布 ... 47
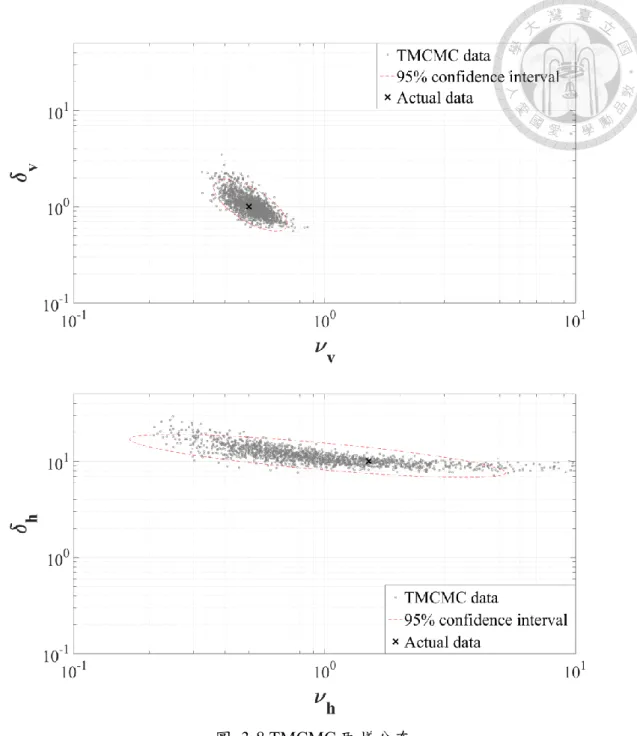
圖 3-8 TMCMC 取樣分布 ... 48
圖 3-9 黑線為真實的資料;紅線為真實的趨勢函數;灰色實線為 2000 組趨勢之中 位數;灰色虛線為95%信心區間 ... 49
圖 3-10 TMCMC 取樣的 σ 分布 ... 50
圖 3-11 TMCMC 取樣的垂直方向關聯性長度 δv與平滑性參數νv分布... 51
圖 3-12 TMCMC 取樣的垂直方向關聯性長度 δh與平滑性參數νh分布 ... 51
圖 3-13 TMCMC 取樣分布 ... 51
圖 3-14 TMCMC 取樣的 σ 分布 ... 52
圖 3-15 TMCMC 取樣的垂直方向關聯性長度 δv與平滑性參數νv分布 ... 52
圖 3-16 TMCMC 取樣的垂直方向關聯性長度 δh與平滑性參數νh分布 ... 53
圖 3-17 TMCMC 取樣分布 ... 53
圖 3-18 以 discrete cosine basis 擬合的趨勢 ... 54
圖 3-19 以 radial basis function 擬合的趨勢 ... 54
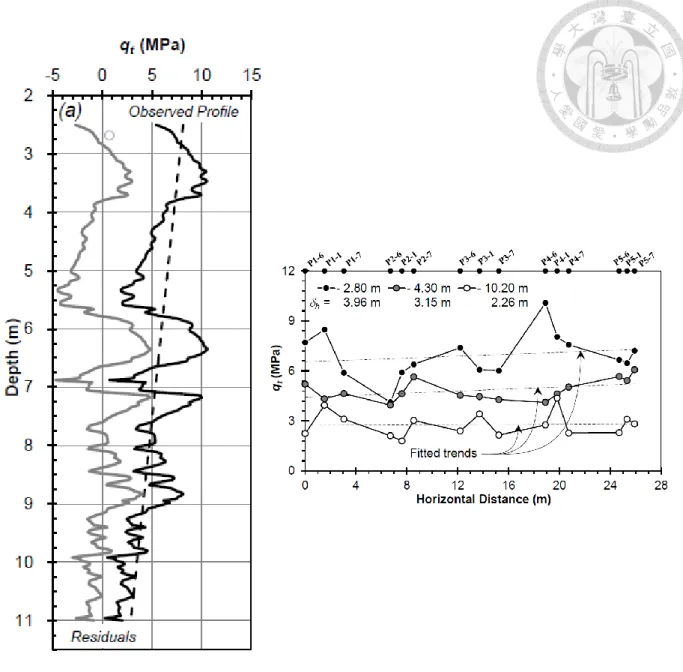
圖 4-1 案例地點之佈孔位置圖 (Stuedlein et al., 2016) ... 56
圖 4-2 案例地點沿 A-A’之剖面圖 (Stuedlein et al., 2016) ... 57
圖 4-4 TMCMC 取樣的 σ 分布 ... 61
圖 4-5 TMCMC 取樣的垂直方向關聯性長度 δv與平滑性參數νv分布 ... 61
圖 4-6 TMCMC 取樣的垂直方向關聯性長度 δh與平滑性參數νh分布 ... 61
圖 4-7 TMCMC 取樣分布 ... 62
圖 4-8 以 shifted Legendre polynomial 擬合的趨勢 ... 62
圖 4-9 TMCMC 取樣的 σ 分布 ... 63
圖 4-10 TMCMC 取樣的垂直方向關聯性長度 δv與平滑性參數νv分布 ... 63
圖 4-11 TMCMC 取樣的垂直方向關聯性長度 δh與平滑性參數νh分布... 64
圖 4-12 TMCMC 取樣分布 ... 64
圖 4-13 以 discrete cosine basis 擬合的趨勢 ... 64
圖 4-14 TMCMC 取樣的 σ 分布 ... 65
圖 4-15 TMCMC 取樣的垂直方向關聯性長度 δv與平滑性參數νv分布 ... 65
圖 4-16 TMCMC 取樣的垂直方向關聯性長度 δh與平滑性參數νh分布 ... 66
圖 4-17 TMCMC 取樣分布 ... 66
圖 4-18 以 radial basis function 擬合的趨勢 ... 66
圖4-19 A-A’剖面隨機場空間分布資料 ... 67
圖 4-20 案例地點之佈孔位置圖 (Stuedlein et al., 2012) ... 69
圖 4-21 案例地點沿 A-A’之剖面圖 (Stuedlein et al., 2012) ... 70
圖 4-22 案例地點 qt空間分布資料 ... 70
圖 4-23 上半部 qt空間分布資料 ... 71
圖 4-24 下半部 qt空間分布資料 ... 71
圖 4-25 TMCMC 取樣的 σ 分布 ... 77
圖 4-26 TMCMC 取樣的垂直方向關聯性長度 δv與平滑性參數νv分布 ... 77
圖 4-27 TMCMC 取樣的垂直方向關聯性長度 δh與平滑性參數νh分布 ... 78
圖 4-28 TMCMC 取樣分布 ... 78
圖 4-29 以 shifted Legendre polynomial 擬合的趨勢 ... 78
圖 4-30 TMCMC 取樣的 σ 分布 ... 79
圖 4-31 TMCMC 取樣的垂直方向關聯性長度 δv與平滑性參數νv分布 ... 79
圖 4-32 TMCMC 取樣的垂直方向關聯性長度 δh與平滑性參數νh分布 ... 80
圖 4-33 TMCMC 取樣分布 ... 80
圖 4-34 以 discrete cosine basis 擬合的趨勢 ... 80
圖 4-35 TMCMC 取樣的 σ 分布 ... 81
圖 4-36 TMCMC 取樣的垂直方向關聯性長度 δv與平滑性參數νv分布 ... 81
圖 4-37 TMCMC 取樣的垂直方向關聯性長度 δh與平滑性參數νh分布 ... 82
圖 4-38 TMCMC 取樣的垂直方向關聯性長度 δv與平滑性參數νv分布 ... 82
圖 4-39 以 radial basis function 擬合的趨勢 ... 82
圖 4-40 TMCMC 取樣的 σ 分布 ... 83
圖 4-41 TMCMC 取樣的垂直方向關聯性長度 δv與平滑性參數νv分布 ... 83
圖 4-42 TMCMC 取樣的垂直方向關聯性長度 δh與平滑性參數νh分布 ... 84
圖 4-43 TMCMC 取樣分布 ... 84
圖 4-44 以 shifted Legendre polynomial 擬合的趨勢 ... 84
圖 4-45 TMCMC 取樣的 σ 分布 ... 85
圖 4-46 TMCMC 取樣的垂直方向關聯性長度 δv與平滑性參數νv分布 ... 85
圖 4-47 TMCMC 取樣的垂直方向關聯性長度 δh與平滑性參數νh分布 ... 86
圖 4-48 TMCMC 取樣分布 ... 86
圖 4-49 以 discrete cosine basis 擬合的趨勢 ... 86
圖 4-50 TMCMC 取樣的 σ 分布 ... 87
圖 4-51 TMCMC 取樣的垂直方向關聯性長度 δv與平滑性參數νv分布 ... 87
圖 4-52 TMCMC 取樣的垂直方向關聯性長度 δh與平滑性參數νh分布 ... 88
圖 4-53 TMCMC 取樣分布 ... 88
圖 4-54 以 radial basis function 擬合的趨勢 ... 88
圖4-55 Baytown 下半部分隨機場空間分布資料 ... 89
圖 4-56 案例地點之佈孔位置圖 (Jaksa et al., 1999) ... 91
圖 4-57 CD 系列 qc空間分布資料 ... 91
圖 4-58 十字系列空間分布資料 ... 92
圖 4-59 A0 到 K10 空間分布資料 ... 92
圖 4-60 TMCMC 取樣的 σ 分布 ... 100
圖 4-61 TMCMC 取樣的垂直方向關聯性長度 δv與平滑性參數νv分布 ... 100
圖 4-62 TMCMC 取樣的垂直方向關聯性長度 δh與平滑性參數νh分布 ... 101
圖 4-63 TMCMC 取樣分布 ... 101
圖 4-64 以 shifted Legendre polynomial 擬合的趨勢 ... 101
圖 4-65 TMCMC 取樣的 σ 分布 ... 102
圖 4-66 TMCMC 取樣的垂直方向關聯性長度 δv與平滑性參數νv分布 ... 102
圖 4-67 TMCMC 取樣的垂直方向關聯性長度 δh與平滑性參數νh分布 ... 103
圖 4-68 TMCMC 取樣分布 ... 103
圖 4-69 以 discrete cosine basis 擬合的趨勢 ... 103
圖 4-70 TMCMC 取樣的 σ 分布 ... 104
圖 4-71 TMCMC 取樣的垂直方向關聯性長度 δv與平滑性參數νv分布 ... 104
圖 4-72 TMCMC 取樣的垂直方向關聯性長度 δh與平滑性參數νh分布 ... 105
圖 4-73 TMCMC 取樣分布 ... 105
圖 4-74 以 radial basis function 擬合的趨勢 ... 105
圖 4-75 TMCMC 取樣的 σ 分布 ... 106
圖 4-76 TMCMC 取樣的垂直方向關聯性長度 δv與平滑性參數νv分布 ... 106
圖 4-77 TMCMC 取樣的垂直方向關聯性長度 δh與平滑性參數νh分布 ... 107
圖 4-78 TMCMC 取樣分布 ... 107
圖 4-79 以 shifted Legendre polynomial 擬合的趨勢 ... 107
圖 4-80 Y 方向的趨勢 (X = 25) ... 108
圖 4-81 X 方向的趨勢 (Y = 25) ... 108
圖 4-82 TMCMC 取樣的 σ 分布 ... 109
圖 4-83 TMCMC 取樣的垂直方向關聯性長度 δ 與平滑性參數ν 分布 ... 109
圖 4-84 TMCMC 取樣的垂直方向關聯性長度 δh與平滑性參數νh分布 ... 110
圖 4-85 TMCMC 取樣分布 ... 110
圖 4-86 以 discrete cosine basis 擬合的趨勢 ... 110
圖 4-87 Y 方向的趨勢 (X = 25) ... 111
圖 4-88 X 方向的趨勢 (Y = 25) ... 111
圖 4-89 TMCMC 取樣的 σ 分布 ... 112
圖 4-90 TMCMC 取樣的垂直方向關聯性長度 δv與平滑性參數νv分布 ... 112
圖 4-91 TMCMC 取樣的垂直方向關聯性長度 δh與平滑性參數νh分布 ... 113
圖 4-92 TMCMC 取樣分布 ... 113
圖 4-93 以 radial basis function 擬合的趨勢 ... 113
圖 4-94 Y 方向的趨勢 (X = 25) ... 114
圖 4-95 X 方向的趨勢 (Y = 25) ... 114
圖 4-96 TMCMC 取樣的 σ 分布 ... 115
圖 4-97 TMCMC 取樣的垂直方向關聯性長度 δv與平滑性參數νv分布 ... 115
圖 4-98 TMCMC 取樣的垂直方向關聯性長度 δh與平滑性參數νh分布 ... 116
圖 4-99 TMCMC 取樣分布 ... 116
圖 4-100 以 shifted Legendre polynomial 擬合的趨勢 ... 116
圖 4-101 TMCMC 取樣的 σ 分布 ... 117
圖 4-102 TMCMC 取樣的垂直方向關聯性長度 δv與平滑性參數νv分布 ... 117
圖 4-103 TMCMC 取樣的垂直方向關聯性長度 δh與平滑性參數νh分布 ... 118
圖 4-104 TMCMC 取樣分布 ... 118
圖 4-105 以 discrete cosine basis 擬合的趨勢 ... 118
圖 4-106 TMCMC 取樣的 σ 分布 ... 119
圖 4-107 TMCMC 取樣的垂直方向關聯性長度 δv與平滑性參數νv分布 ... 119
圖 4-108 TMCMC 取樣的垂直方向關聯性長度 δh與平滑性參數νh分布 ... 120
圖 4-109 TMCMC 取樣分布 ... 120
圖 4-110 以 radial basis function 擬合的趨勢 ... 120
表目錄
表 4-1 Hollywood step1 基函數選擇結果 ... 59
表 4-2 土壤各層 N 值與 qt資料 (Stuedlein et al., 2012) ... 68
表 4-3 Baytown upper step1 基函數選擇結果 ... 73
表 4-4 Baytown upper step1 基函數選擇結果 ... 75
表 4-5 Adelaide CD step1 基函數選擇結果 ... 94
表 4-6 Adelaide 十字 step1 基函數選擇結果 ... 96
表 4-7 Adelaide A0 到 K10 step1 基函數選擇結果 ... 98
第一章 緒論
在大地工程現地調查中,一筆具有空間變異性的資料可以被分成趨勢函數( t )以 及平均值為零的空間變異性(ε)
Y(z) = t(z) + ε(z) 1-1
然而從現地中取得的空間分布資料並不能客觀的區分趨勢函數與空間變異性,
往往需仰賴人工判讀,尤其當土壤的空間變異性較大時,人為判斷的差異更為巨大,
為 了 解 決 這 個 問 題 ,Ching and Phoon (2017) 提 出 了 在 sparse Bayesian learning (Tipping,2001) 的架構下找出趨勢函數的方法。
空間變異性對於取得趨勢有著很大的影響,而關聯性長度 (scale of fluctuation, SOF) 是描述土壤參數隨空間變化極為重要的參數,關聯性長度可以簡單的將其想 成大約在此長度內的資料具有相關性,若兩筆資料的距離超過關聯性長度,可將這 兩點的資料視為獨立。SOF 小的資料沿著趨勢會有較高頻率的震盪,SOF 大則震盪 頻率較小,表現較接近均質,許多研究指出關聯性長度對可靠度分析有極重要的影 響 (Fenton and Griffiths, 2002, 2003; Fenton et al., 2005; Srivastava and Sivakumar Babu, 2009; Stuedlein and Bong, 2017)。根據前人的研究,以圓錐貫入試驗 (cone penetration test, CPT) 之修正錐間阻抗 (qt) 所求得的垂直方向 SOF 大約 0.3 公尺到 2.6 公尺 (Phoon and Kulhawy, 1999; Jaksa et al., 1999; Uzielli et al., 2005; Firouzianbandpey et al., 2014; Onyejekwe et al., 2016),水平方向的 SOF 大約 1.2 公尺到 80 公尺 (Phoon and Kulhawy, 1999; Jaksa et al., 1999; Firouzianbandpey et al., 2014)。
1.1 研究動機與目的
在過去的可靠度研究中,在取得隨空間變異的資料後會先將資料進行去趨勢 (detrend) 的處理,一般會以最小平方法 (ordinary least squares, OLS) 找到趨勢函 數,再利用公式1-2 得到一個平均值為零的空間變異性資料(ε)進行可靠度分析。
ε(z) = Y(z) − t(z) 1-2
然而這樣的方法也存在著一些問題,例如:在使用OLS 求取趨勢函數時必須先
決定函數的形式,所以每個人判斷出的趨勢將不相同,影響分析結果。Ching et al.
(2017) 表明如果忽略趨勢函數會增加統計不確定性且會高估可靠度,近年的研究也 開始關心趨勢對可靠度分析的影響 (e.g., Kulatilake 1991; Li 1991; Jaksa et al. 1997),
Ching et al. (2016, 2017) 分別考慮了趨勢為常數與一次函數的影響,也近一步發現 不同趨勢函數的形式也會影響分析結果。
為了取得土壤在空間中的趨勢,首先,必須先了解土壤隨空間分布的變化性,
現 在大 地工程最 常被使用的 現 地調查 方 法為 CPT 和標準貫入試驗 (standard penetration test, SPT),而 CPT 有著取樣密度極高、取樣速度快、經濟等優點,加上 電腦的普及以及資料處理速度的快速提升,CPT 所取得的大量資料也可以快速地進 行分析處理,增加其在工程應用的潛能,有助於提升大地工程設計的品質,已經是 現今大地工程中十分常見的現地調查方法。由於一般常見的鑽探試驗都以垂直方向 施作為主,水平方向鑽探往往受到重重限制且難度較高、價格昂貴,在一般工程基 本上皆無施作,然而在僅施作少數垂直孔位鑽探時,水平方向數據數量遠小於垂直 方向,且資料間距往往遠大於垂直方向,因此水平方向參數的估計也較垂直方向困 難,故過去大地工程的分析多著重探討垂直方向,水平方向多被視為均質。但在某 些現地案例中發現水平方向的土壤變異性並不能忽視,因為水平方向的調查長度往 往大於垂直方向,再加上土壤沉積後可能還會受到斷層錯動、擠壓褶皺變形等活動
圖1-1 垂直方向資料較多而水平資料較少 (Stuedlein et al., 2016)
一旦進入三維的分析,就必須面對運算量過大的問題,以CPT 為例,垂直方向
的取樣間距大約2 公分,一個 10 公尺的鑽孔就有 500 筆資料,若一次分析 20 個鑽 孔資料總共就有10000 筆資料,在做分析時需要對 10000×10000 的矩陣進行列運算 與反矩陣,而計算這個大矩陣的計算量過於龐大,需要耗費太多的時間。所以在本 研究中運用了克羅內克積 (Kronecker product) 將原本 10000×10000 的矩陣分別拆 成500×500 跟 20×20 的矩陣,大幅降低運算量,加快計算時間,進一步配合 Cholesky decomposition,將原本的方陣拆成下三角矩陣,又再一部加快了計算時間。透過這
綜合以上觀點,本研究將以 CPT 之修正錐尖阻抗 (qt) 做為主要的模擬研究資 料,以探討如何辨識出三度空間中的趨勢函數,並討論以不同函數類型作為基函數 (basis function, BF) 對分析結果的影響,進一步建立具關聯性的空間隨機場。
1.2 研究方法
圖1-2為一筆空間分布資料,這筆資料的趨勢可能判斷成一次式、二次式甚至 是更高次項的方程式,會受到人為主觀的影響,所以 Ching and Phoon在2017年發 表的Characterizing Uncertain Site-Specific Trend Function by Sparse Bayesian Learning 中提出了客觀辨識趨勢函數的方法。此篇文章將估計趨勢函數的方法分成兩個步 驟,第一步為選擇真正需要的BFs,文中以 Tipping (2001) 所提出的sparse Bayesian learning (SBL) 來做為選擇BFs的方法,其中:
t(z) = ∑ wkϕk(z)
m
k=0
1-3
ϕk為BF的第k項,wk為第k項所對應之權重 (weight)。
透過計算出wk的大小來決定ϕk是否需要,在3.2.1節會做更詳細的介紹。而本研 究進一步分析三度空間的趨勢函數,故將式1-3改寫成:
t(x, y, z) = ∑ wkϕk(x, y, z)
m
k=0
1-4
第二步就是以第一步所選定的BFs進行貝氏分析,以 Ching and Chen (2007) 提 出的 transitional Markov chain Monte Carlo (TMCMC) 進行取樣,即可求出權重 wk,進一步模擬三度空間中的趨勢函數。
第三步則可以透過第二步所擬合的趨勢與取樣的隨機場參數建立空間的隨機場 模型。
1.3 本文內容
本研究共有五章,各章之內容概述如下:
第一章簡述研究動機與目的,並簡單介紹研究過程中選用之研究方法。
第二章為文獻回顧,內容包括隨機場、自關聯性模型、Whittle-Matérn 模型、馬 可夫鏈蒙地卡羅法、TMCMC、SBL 以及介紹不同型態的 BFs。
第三章為模擬資料的隨機場參數估計,會先說明如何模擬資料,利用先前提到 的兩個步驟模擬之資料進行反算,推估隨機場的真實參數,並展示不同設計狀況所 估計的參數樣本分布與趨勢擬合的結果。
第四章為利用真實案例演示估計三維趨勢函數之過程,以及展示在不同BFs 對
趨勢函數估計的結果。
第五章為結論與建議,將針對本文之研究結果進行總結。
第二章 文獻回顧
2.1 隨機場 (random field)
工址調查為工程計畫中不可或缺的重要項目,最重要目的為取得地下土壤參數 隨空間分布的資訊。一般會將取得土壤隨空間分布的資料表示成趨勢函數與一個平 均值為零的空間變異性之和,雖然本研究主要關心對象為趨勢函數,但空間變異性 對於大地工程構造物與土壤的行為之影響在過去的許多文獻中被提及與研究,顯示 了空間變異性對於土壤行為之重要性。(Ahmed and Soubra 2014; Fan et al. 2005;
Fenton and Griffiths 2003; Haldar and Babu 2008; Hicks et al. 2014; Hu and Ching 2015;
Li et al. 2014; Srivastava and Babu 2009; Wang and Cao 2013; Wu et al. 2012)
2.1.1 穩態隨機場 (stationary random field)
空間變異性對大地工程的構造物行為有的顯著的影響,故如何透過少量的工址 調查來準確估計空間變異性的統計參數即為一個不可忽視的問題,而最常被使用來 描述空間變異性的就是隨機場模型,又以穩態隨機場最常被大家所使用。
Vanmarcke 於 1977 年提出隨機場理論應用於空間變異性的研究,而空間分布資 料為穩態是一個很關鍵的簡化假設。穩態指的是資料的統計性質不隨空間變化,
Brockwell and Davis (1987) 提出嚴謹的定義,包括:
1. 平均值 (mean) 隨距離的變化應保持常數,即資料中不存在趨勢函數或浮動項。
2. 變 異 數 (variance) 隨 距 離 的 變 化 應 保 持 常 數 , 此 即 為 變 異 性 同 質 性 (homoscedastic)。
3. 不具有周期性的變異數 (seasonal variance)。
4. 不具有不規則波動 (irregular fluctuation)。
而在實務操作上,Vanmarcke (1983) 定義較常被使用的二階穩態過程 (weak stationarity process),具備下列特徵:
1. 資料平均值為常數。
2. 變異數為常數。
3. 資料點之間的相關性 (auto-correlation) 僅和資料點與點的間距有關,和資料點 在空間上的位置無關,也就是資料點之間的相關性為資料點間距的函數。
在現實的大地工程中,資料不全然是穩態,最常見的就是資料的平均值非常數,
而對於非穩態的資料可以透過資料轉換來將其轉為穩態,資料轉換方式有分解法 (decomposition)、微分法 (differencing) 和變異數轉換法 (variance transformation),此 三種轉換方式之整理可見Jaska (1995),而在大地工程中以分解法最廣為使用 (Jaksa et al., 1997)。
分解法是將一個隨機場資料Y 可分解成趨勢函數 (t) 加上一個殘餘的項 () , 土壤隨深度的變化可以寫成:
Y(z) = t(z) +(z) 2-1
其中 Y(z)為隨深度變化土壤參數,t(z)為趨勢函數,在大地工程中最常被使用的 方法為最小平方法,本研究則以Ching and Phoon (2017) 所提出在 SBL 的架構下來 求得趨勢函數,在第三章有更深入的介紹。(z)為在趨勢函數附近跳動的震盪項,通 常會把(z)視為二階穩態狀態 (Chatfield, 2004),在(z)中則包含了不同來源的不確定 性 (uncertainty),Kulhawy 於 1992 年整理歸納出不確定性的種類來源包括:土壤本 身具有之空間變異性 (inherent soil variability),現地量測時可能出現的量測誤差 (measurement error)、統計誤差 (statistical uncertainty),若有進行量測數據與設計參 數之間的轉換,則有轉換模型不確定性 (model uncertainty),而扣除趨勢的震盪項(z) 可以透過建立適當的自關聯性函數 (auto-correlation function, ACF) 來進行模擬。
2.1.2 自關聯性函數 (auto-correlation function, ACF)
自相關函數 (auto-correlation function, ρ) 的定義為:
ρ(Δz) = CV[W(z), w(z + Δz)]
√Var[W(z)] ∙ √Var[W(z + Δz)] 2-2 其中W 為隨機場的值,z 為深度位置,Δz 為資料間距,CV[.]為共變異數函數,Var[.]
為變異數函數。
自鄉關聯性函數的種類繁多,前人的研究也提出了許多種不同的自相關聯性函 數模型 (auto-correlation models),這裡介紹以下三個在大地工程較常被使用的模型 (Vanmarcke 1977,1983; Uzielli et al. 2005):
ρ(∆z) = exp (−2|Δz|
δ ) Single exponential (SExp) model ρ(∆z) = (1 + 4Δz
δ) × exp (−4Δz
δ) Second order Markov (SMK) model ρ(∆z) = exp (−πΔz2
δ2) Square exponential (QExp) model
其中 δ 為關聯性長度 (scale of fluctuation, SOF),定義為 ACF 下的面積,如式 2-3,
Δz 為資料間距。
∫ ρ(Δz)dΔz
∞
−∞
2-3
圖 2-1 自關聯性模型
-3 -2 -1 0 1 2 3
0 0.2 0.4 0.6 0.8 1
/
()
SExp model SMK model QExp model
2.2 Whittle-Matérn 模型
Whittle-Matérn 模型 (W-M model) 為一種定義更廣泛的模型,此模型可以透過 平滑性參數ν 來控制樣本的平滑程度 (Stein 1999; Guttorp and Gneiting 2006; Liu et al. 2017),此關聯性模型表示如下:
ρ(Δz) = 21−𝜈
Γ( 𝜈 )∙ (√2𝜈 ∙ |∆z|
s )
𝜈
K𝜈(√2𝜈 ∙ |Δz|
s ) 2-4
其中 ν 為平滑性參數 (smoothness parameter),s 為尺度參數 (scale parameter),
Γ 為珈瑪函數 (Gamma function; Abramowitz and Stegun, 1970),Kν為 ν 階的第二類 修正貝索函數 (modified Bessel function of the second kind with order ν; Abramowitz and Stegue, 1970)。
在W-M 模型中,SOF 和尺度參數成正比:
s = δ
c(𝜈) 2-5
其中c(ν)之計算如下 (Hristopulos and Žukovič, 2011):
c(𝜈) =√2𝜋 ∙ Γ(𝜈 + 0.5)
√𝜈 ∙ Γ(𝜈) 2-6
圖2-2 為 c(ν)函數與 ν 的關係圖,從圖中可以發現當 ν = 0.5 時 c(ν) = 2,正好是 SExp 模型,當 ν = 1.5 和∞時正好對應 SMK 模型與 QExp 模型
10-2 10-1 100 101 102
0 0.5 1 1.5 2 2.5
c()
2.3 平滑性參數的影響
ν 值所控制的是隨機場資料的平滑程度,當 ν 值小時,關聯性隨距離下降的速 度較快,隨機場的資料分布就會有局部跳動的現象,例如:SExp 模型。而當 ν 值越 大時,隨機場資料則趨於平滑,例如:QExp 模型。圖 2-3 為不同 ν 值的隨機場資料,
以及關聯性隨距離的變化。
圖 2-3 不同 ACF 的隨機場資料
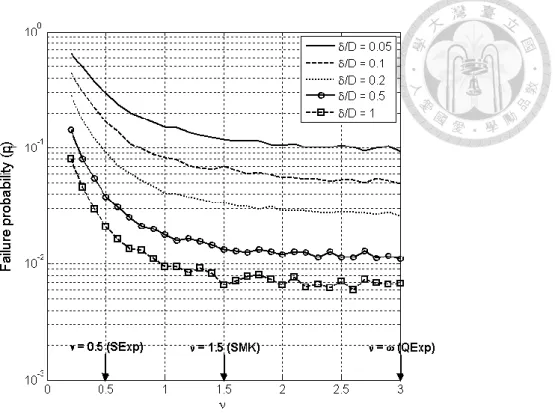
Ching and Phoon ( 2018 ) 利用大地工程中常見的工程案例說明 ν 的影響,在這
裡以淺層滑坡的案例說明ν 對破壞機率的影響。
這個案例考慮一個傾角為α = 22°的斜坡,平行於斜坡的方向用 x 表示,垂直於 斜坡用z 表示,如圖 2-4。該斜坡在 x 方向的寬度 W = 100 m 和在 z 方向的深度 D = 10 m。tan[( z )]為平均值 μ = tan(30°) 和 COV = 10%的穩態常態隨機場:
tan [ϕ′(z)] = μ + σ ∙ ε(z) 2-7 tan[( z )]表示深度 z 處摩擦角的正切值; σ = tan(30°)×10%是 tan[( z )]的標準偏
此邊坡來說,當tan[( z )] < tan(α)時,深度 z 的潛在滑動面則破壞。因此,無限邊 坡的極限狀態函數G 可寫為:
G = min
𝑧∈[0,10]tan[( z )] − tan (𝛼) = μ + σ ∙ εmin− tan (𝛼) 2-8 其中εmin表示ε(z)取樣的最小值。當 G < 0 時,此邊坡發生破壞,然而像邊坡滑動這 種由弱帶控制的案例中,ν 就會有很顯著的影響,如圖 2-4(a),當 ν 較小時 (ν = 0.5) 樣本抖動的情況較明顯,就會有比較大的機會找到較小的值,破壞機率就比較高。
當ν 較大時 (𝜈 = ∞),如圖 2-4(b),樣本較為平滑,極值出現的機率也就比較小,破 壞機率就較低。
(a)SExp 模型的 tan [( z )]的樣本
(b)QExp 模型的 tan [( z )]的樣本 圖 2-4 無限邊坡下 tan [ϕ(z)]的隨機場樣本
圖 2-5 破壞機率相對於ν的變化 (Ching and Phoon 2018)
2.4 不同型態的基函數
Ching and Phoon (2017) 之研究中發現,利用不同型態的基函數 (basis functions, BFs) 對趨勢的估計會有影響,本研究分別考慮:shifted Legendre polynomial, discrete cosine basis 以及高斯分布 (Gaussian distribution) 的 radial basis function。
Shifted Legendre polynomial 是 Legendre polynomial 的一種變形,區間再從原本 的[-1,1]變成[0,1],如圖 2-6,第零項為常數項,第一項為一次函數,第二項為二次函 數,到第m 項的 m-1 次函數。
Pk(𝑧) = 1 2𝑘𝑘!
𝑑𝑘
𝑑𝑧𝑘[(2𝑧 − 1)2− 1]𝑘 2-9
圖 2-6 Shifted Legendre polynomial
Discrete cosine basis 為離散型的 cosine 分布,如圖 2-7,第 1 項為常數,第二項 為一個半週期函數,第三項為一個全週期函數,到第N 項為(N-1)/2 個週期函數。
f(𝑧) = ∑ 𝑤(𝑘)cos [𝜋(2𝑧 − 1)(𝑘 − 1)
2𝑁 ]
𝑁
𝑘=1
2-10
𝑤(𝑘) = {
1
√𝑁, 𝑘 = 1
√2
𝑁, 2 ≤ 𝑘 ≤ 𝑁
2-11
圖 2-7 Discrete cosine basis
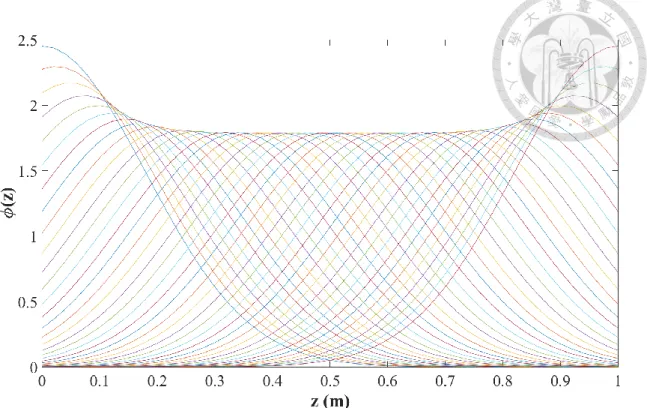
Radial basis function 是一種與到原點的距離有關的函數,在本研究選用高斯分 布 (Gaussian distribution) 作為 BFs,不同於其他兩種函數有固定的形式,radial basis
的標準差σr與每個方向個別需要幾個基函數才足以完整表現該方向的趨勢都需要自
行決定,若選擇過多的基函數會使計算量過大,且每個基函數的距離太接近,取代 性太高,若選擇的太少則有可能造成欠擬合 (poor-fit) 的問題,而本研究發現每一到
兩倍的關聯性長度以一個基函數進行擬合最為合適,舉例來說:有一個深度 10 公
尺,關聯性長度SOF 為 0.5 公尺的空間分布資料,此時需要大約 10 個基函數來進 行擬合。而高斯分布的標準差σr可以透過step1 的最佳化過程求解,若 σr較小,則 分佈較為集中,如圖 2-8(左),若 σr變大則較像均佈分布,如圖 2-8(右),整體基函 數分布形式如圖2-9。
f(z) = 1 𝜎𝑟√2𝜋𝑒−
1 2(𝑧−𝜇
𝜎𝑟 )2
2-12 μ 為平均值,σr為標準差。
圖 2-8 (左) σr較小時的函數形式;(右) σr較大時的函數形式
圖 2-9 Radial basis function
2.5 一維及三維隨機場表示方式
2.1.1 節提到為一個二階穩態的震盪項,在這裡進一步使的平均值為零,則這 個二階穩態的隨機場就可以由平均值μ 、標準差 σ 以及自相關聯性函數 ACF 來表 示:
= σ ∙ 𝐋 ∙ 𝐔 2-13
其中U 為獨立高斯隨機變數向量,L 為關聯性矩陣 R 的 Cholesky decomposition 矩 陣 (R=L×LT),R 為:
z 1 2 z 1 n
z n 1 n
1 ρ z z ρ z z
= 1 ρ z z
sym. 1
R 2-14
其中 ρz(.)為重直方向的 ACF,在本研究則採用 2.2 節提到能表現樣本平滑程度的 W- M 模型:
ρz(Δz) = 21−𝜈
Γ( 𝜈 )∙ (√2𝜈 ∙ |∆z|
s )
𝜈
K𝜈(√2𝜈 ∙ |Δz|
s ) 2-15
s 為尺度參數:
s = δ
c(𝜈) 2-16
c(ν)之計算如下 (Hristopulos and Žukovič, 2011):
c(𝜈) =√2𝜋 ∙ Γ(𝜈 + 0.5)
√𝜈 ∙ Γ(𝜈) 2-17
對於三維隨機場(x, y, z),其中 x 和 y 為水平方向 z 為垂直方向,在這裡做了兩
個假設,第一個假設是z 的深度要一致,第二個假設是垂直方向與水平方向的 ACF
可以被分開計算,也就是說:
ρ(Δx, Δy, Δz) = ρh(Δh) × ρz(Δz) 2-18 其中 ρ (.)為水平方向的 ACF,Δh = (Δx + Δy)0.5,水平方向一樣採用W-M 模型。
根據上述兩個假設,共變異數矩陣 (auto-covariance matrix) Σ 可以利用克羅內 克積 (Kronecker product) 表示成:
Σ = σ2× (Rh⊗ Rz) 2-19 而A⊗B 表示 A 和 B 的克羅內克積 (Kronecker product):
A ⊗ B = [
a11B a12B a21B a22B
⋯ a1nB
⋯ a2nB
⋮ ⋮
am1B am2B
⋱ ⋮
⋯ amnB
] 2-20
Rh為水平方向的關聯性矩陣,ns為鑽探孔個數。
h 1,2 1,2 h 1,3 1,3 h 1,ns 1,ns
h 2,3 2,3 h 2,ns 2,ns
h
h ns 1,ns ns 1,ns
1 x , y x , y x , y
1 x , y x , y
1
x , y
SYM. 1
R 2-21
Rz為垂直方向的關聯性矩陣,n 為垂直方向取樣個數。
z 1,2 z 1,3 z 1,n
z 2,3 z 2,n
z
z n 1,n
1 z z z
1 z z
1
z
SYM. 1
R 2-22
三維空間的趨勢函數可以透過將三個不同方向的基函數相乘來表示:
t(x, y, z) = ∑ ∑ ∑ wijkϕx,i(x)ϕy,j(y)ϕz,k(z)
mz
k=0 my
j=0 mx
i=0
= ∑ ∑ wijϕh,i(x, y)ϕz,j(z)
mz
j=0 mh
i=0
2-23
(ϕx, ϕy, ϕz) 分別是 x, y, z 方向一維度的基函數,(mx, my, mz) 分別為基函數的個 數,wijk跟wij為基函數所對應到的權重 (weight),ϕh(x,y) = ϕxϕy為一個二維的基函 數,mh是ϕh的個數。一個三維的趨勢函數可以被表達成:
t = Φ × w = (Φh⊗ Φz) × w 2-24
Φh = [
ϕh,0(xCPT1, yCPT1) ϕh,1(xCPT1, yCPT1) ϕh,0(xCPT2, yCPT2) ϕh,1(xCPT2, yCPT2)
⋯ ϕh,mh(xCPT1, yCPT1)
⋯ ϕh,mh(xCPT2, yCPT2)
⋮ ⋮
ϕh,0(xCPTns, yCPTns) ϕh,1(xCPTns, yCPTns)
⋮
⋯ ϕh,mh(xCPTns, yCPTns)]
2-25
Φz= [
ϕz,0(z1) ϕz,1(z1) ϕz,0(z2) ϕz,1(z2)
⋯ ϕz,mz(z1)
⋯ ϕz,mz(z2)
⋮ ⋮
ϕz,0(zn) ϕz,1(zn)
⋮
⋯ ϕz,mz(zn)]
2-26
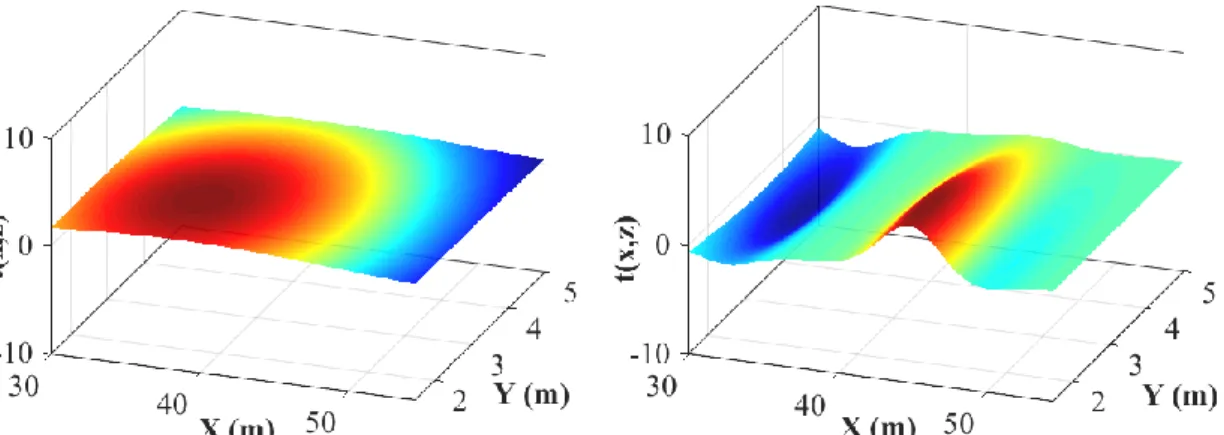
由Φh跟Φz所組合出來空間中的趨勢函數如圖2-10,圖中以 radial basis 為例,
透過不同的權重w 搭配 mxmy種Φh與mz個Φz的組合,就能模擬出空間中的趨勢 函數。
圖 2-10 空間中的趨勢函數示意圖
2.6 Sparse Bayesian Learning (SBL)
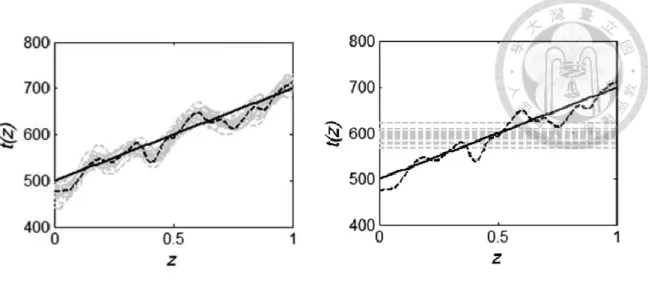
在這類趨勢函數研究中的一個重要的問題就是:到底哪些基函數是真正需要的。
以圖2-11 為例,黑色實線為真正的趨勢函數 t(z) = 500 + 200z,若以前面提到的 shefted Legendre polynomial 為基函數,趨勢函數可以表示成 t(z) = 600ϕ0(z) + 51.74ϕ1(z),所 以w0 = 600, w1 = 51.74, w2 = … wm = 0,只有常數項跟一次項是這個趨勢函數所需要 的,但如果以m = 20,也就是一個 20 次式來擬合趨勢函數,從圖 2-12 左圖中灰線 可以發現他更傾向模擬空間變異性的部分,這種情況被稱為過擬合 (overfit);相反 的如果以m = 0,也就是常數來模擬趨勢函數,從圖 2-12 右圖的灰線可以發現常數 並不足以完整表現出真實趨勢,而這種情況則被稱為欠擬合 (poor-fit)。如果能選到 一組合適的基函數就可以同時避免過擬合或欠擬合的發生。
圖 2-11 實線為 t(z) = 500 + 200z;虛線為空間分布資料 (Ching et al., 2017)
圖 2-12 趨勢擬合結果 (Ching et al., 2017)
從上面的例子可以看出是否需要第k 項的基函數 ϕk來擬合趨勢是由對應的權重 wk所決定,當wk等於0 時表示擬合趨勢不需要 ϕk這項基函數。但如果直接對權重 w 進行取樣容易造成過擬合的問題,MacKay (1992) 提出以權重 wk的標準差sk做為 判斷ϕk是否需要的標準,進一步增加 w 的變異性。在本研究中假設每一項權重 wk
的分布為平均值為0 的常態分布:
f(w𝑘|M) = 𝑁(0, sk2) 2-27 M = {ϕ0, ϕ1, …,ϕm}。當 sk很小時,wk的分布會很窄,就有很高的機率是0,也 就是說ϕk不被需要;相反的,當 sk越大,wk為 0 的機率大幅減小,ϕk需要的機率 也就越大。Tipping (2001) 進一步提出一個特殊的 sk的先驗分布 (prior PDF),f(sk)為 inverse gamma 分布:
f(sk|M) = IG(α, β) 2-28 α為形狀因子,β為尺度因子。當α與β約等於0時 f(sk) ∝ 1/sk。這個PDF有很高 的機率使sk = 0,所以除非有很強的證據表示ϕk是需要的,不然sk都會趨近於0,這個 以f(sk) ∝ 1/sk做為先驗分布的方法被稱為sparse Bayesian learning (SBL)。在SBL的 架構下一開始可以選擇較多項的基函數,不需要的基函數項可以透過貝氏定理自動 的去除,透過這個方法就能選擇真正需要的基函數。
2.7 馬可夫鏈蒙地卡羅法
在一個大地工程現地調查中往往無法取得大量有用的資訊,只能對相對稀少的 資料進行分析,然而該如何利用少量的訊息推測所關心的議題的全貌就成了大地工 程中十分重要的研究課題。馬可夫鏈蒙地卡羅法 (Markov chain Monte Carlo, MCMC) 是一套廣義的方法論,其中Metropolis-Hastings algorithm (MH; Metroplis et al., 1953;
Hastings 1970; Beck and Au, 2002) 為最常被使用的演算法,因為 MH 操作相對其他 方法容易,且不需而外計算證據機率 (evidence) 就能進行估計,透過這個方法能在 即使已知資料量較少的情況下,依然可以從所關心的機率密度分布函數取得樣本,
其估計樣本的步驟簡述如下:
1. 決定初始值 θ0。
2. 從提議分布函數 (proposal distribution) 取出候選樣本 θC,並計算r:
r =f(x1, x2, ⋯ , xn|θc)
f(x1, x2, ⋯ , xn|θ0) 2-29 其中提議分布函數可依據不同情況由使用者自行定義。
3. θC有 min(1,r)的機率被接受成為 θ1,若θc被拒絕,則 θ1=θ0。 4. 重複步驟2 到 3,直到取到足夠的樣本數量。
步驟2 中的提議分布較常採用聯合常態分布,其平均值向量為前一階段的樣本 點,共變異數矩陣Σp為:
Σ𝑝 = [
𝜎12 0 𝜎22
0 0 0 0 𝑠𝑦𝑚. ⋱ 0
𝜎𝑚2]
2-30
其中σ 值決定了現有樣本轉移至候選樣本的步階大小,當 σ 很大時,候選樣本
與現有樣本會有較大的差異,拒絕率就會變得很高使馬可夫鏈幾乎原地不動,相反
的,當σ 很小時候選樣本與現有樣本的差異極小,雖然可以降低了拒絕率,但卻造
成候選樣本與現有樣本的相關性過高,而在面對不同的取樣對象時,又會有各自較 適合的σ 值,且若取樣對象是極度峰態 (very peak)、參數之間有高相關性或多模態 (multi-model) 的事後機率分布時,提議分布的選擇將變得更加棘手,該如何選擇一
個合適的提議分布就是MH 常見的使用問題。
除了提議分布選擇的問題外,MH 還有 burn-in period 以及收斂性的問題,burn- in period 是從初始狀態到穩態的過程中會有一段不屬於目標機率分布樣本的區段,
由於此區段的樣本與目標樣本相關信極低,所以需要剔除,至於要剔除多少樣本也 都是由使用者自行決定。而要有多少馬可夫鏈樣本才足以表達目標樣本的問題則為 收斂性的問題,由於馬可夫鏈相鄰的樣本相關性往往較高,獨立樣本數較少,在樣 本數較少時難以確定這樣樣本是有有足夠的代表性。
2.8 漸進式馬可夫鏈蒙地卡羅法
為了改善MCMC 的問題,Ching and Chen (2007)在 MCMC 的架構下提出了改 良的方法:漸進式馬可夫鏈蒙地卡羅法 (transitional Markov chain Monte Carlo, TMCMC)。其概念為建立一系列漸變的機率密度分布,使事前機率分布逐漸轉為事 後機率分布,即:
fj(θ) ∝ f(θ) ∙ f(Q|θ)pj j = 0, ⋯ , m 0 = p0 < p1 < ⋯ < pm = 1 2-31 其中j 為漸變過程階段編號。
從上式可以知道當pj = p0時,fj(θ)為事前機率分布,而 pj = pm時,fj(θ)為事後機 率分布。TMCMC 所建立這一系列的漸變機率分布,可以提高了取出代表性樣本的
機率,解決MH 因為事前機率分布變化到事後機率分布過於劇烈所導致取不到代表
性樣本的困擾。
每一個階段中,將會依照不同階段中計算所得之權重進行重複取樣。若在階段 j 從 fj(θ)取出的樣本為{θj,1, θj,2, …, θj,N},N 為每一階段的樣本數,則可以在階段(j+1) 從fj+1(θ)取出樣本{θj+1,1, θj+1,2, …, θj+1,N},依照{θj,1, θj,2, …, θj,N}估算權重:
j 1 j
p p
j,k j,k
w f (Q | θ ) , k=1,...,N 2-32
如前述所提,漸變的機率分布可以解決MH 從事前機率分布變化到事後機率分
布過於劇烈的問題,指數 pj的選定就會有很重要的影響。本研究中使用的方式為:
每一階段的pj應使該階段之權重的變異係數 (covariance of variance, c.o.v.) 為 1,也 就是說:
jj
w j
w
c.o.v. w 100%
2-33
至於提議分布仍採用聯合常態分布函數,但是在TMCMC 中,共變異數矩陣會
隨著漸變階段而有所變化,這裡將不同階段的共變異數矩陣記為 Σj,這樣可以避免
樣本過度重複,且不需要使用者自行調整,Σj的計算如式(2-32):
N N N T
2 j,k j,k j,n j,n j,k j,n j,n
j
k 1 n 1 n 1
w w w
2-34其中 β 稱為尺度因子 (scaling factor),為一預先設定的數值,其作用為降低候選樣 本的拒絕率。而在本研究中會採用王俊翔 (民 105) 的研究取 β=0.5。
TMCMC 在取樣的過程中,會同時估計模型對現有資料的證據機率 (evidence, f(Q)),而為了避免計算上的數值問題,將會計算證據機率的自然對數值:
m 1 N j,kj 0 k 1
ln f ln 1 w
N
Q
2-35TMCMC 使用流程:
1. 令p0 = 0,f0(θ) = f(θ),並用蒙地卡羅法 (Monte Carlo simulation) 對事前機率分 布取出樣本。
2. 從j=1 開始,以上一階段之權重的變異係數為 100%為目標求解 pj後,重新計算 權重、提議分布以及過渡的證據機率元素:
pj 1 pjj,k j,k
w f Q| , k 1,..., N 2-36
N N N T
2 j,k j,k j,n j,n j,k j,n j,n
j
k 1 n 1 n 1
w w w
2-37N
j j,k
k 1
S 1 w
N
2-383. 以wj,k為權重進行重要性重複取樣 (importance resampling),以 Σj進行MH 對該 階段的fj(θ)進行取樣。
4. 重複步驟2 到 3,直到 pj=1。
5. 將過程中每一階段的所有樣本權重的平均值取對數後再求其和,即可得到證據
機率對數值:
m 1
j j 0ln f ln S
Q
2-39最後一階段的樣本即為TMCMC 對事後機率分布所取出的樣本。
第三章 研究方法
本研究以已知的參數分別模擬空間中的趨勢項t 以及平均值為零的震盪項,趨
勢項t 的模擬會先假設已知基函數以及其對應的權重 w,例如:以 shifted Legendred polynomial 的第 0 項與第 1 項,權重分別為 100 跟 50。這樣可以模擬出一條一次線 性的方程式。零均震盪項的模擬則先假設已知的隨機場參數來進行模擬,最後將兩 項相加即可得到一個趨勢接近一次函數的空間分布資料。
第一步先透過SBL 的方法選出所需要的基函數,並觀察所選擇的基函數是否跟
一開始假設的相同,接下來將被選到的基函數帶入第二步的貝氏分析,以TMCMC
估計隨機場的參數樣本,並檢視估計出來的參數樣本是否包含一開始假設的真實參 數。
本章節將詳細說明資料如何模擬,Step1 如何利用 SBL 來決定基函數並說明三 維空間的計算問題,Step2 的 TMCMC 取樣,以及不同型態的基函數的影響,最後 如何利用step2 取得的趨勢與參數建立隨機場模型 (3.5)。
3.1 資料模擬
此章節將說明隨機場參數關聯性長度SOF (δ) 以及平滑性參數 ν 對空間資料的 影響,以及該如何模擬三維的空間分布資料。
3.1.1 隨機場參數對模擬資料的影響
本研究模擬的深度範圍從0 公尺至 10 公尺,資料點間距為 0.1 公尺。首先針對 SOF 進行探討,先固定隨機場參數 (μ, σ) = (0, 50),並採用 SExp 的自相關函數模型,
在固定同一組隨機變數的情況下,SOF 分別為 0.1、1 和 10 公尺時所模擬出的 ε 如 圖3-1,從圖中可以看出當 SOF 小時,震盪的頻率越高,SOF 大時震盪的頻率則越 低。因此,可看出關聯性長度對資料分布的影響是資料點的震盪頻率。而在大地工 程中,當SOF 越大表示土壤越均質。
圖 3-1 (μ, σ) = (0, 50) 且 ACF 為 SExp 模型在不同 δ 下之模擬 ε (左) δ = 0.1 公尺;
(中) δ = 1 公尺;(右) δ = 5 公尺
在ACF 的選擇方面,本研究採用帶有平滑性參數 ν 的 Whittle-Matérn 模型,ν 可以反應空間變異性的粗糙度,ν 值小時,隨機場資料在小範圍內也會有產生局部 的跳動,資料曲線較為粗糙,ν 值大則隨機場資料較為平滑,如圖 3-2。ν 對於破壞 機率的影響在 2.3 節有詳細的說明。
圖 3-2 (μ, σ) = (0, 50) 且 SOF 為 1 時不同 ν 之模擬 ε (左) ν = 0.5;(中) ν = 1.5;(右) ν = 20
3.1.2 三維空間分布資料之模擬
(xCPTi, yCPTi) 表示第 i 個 CPT 的水平座標,假設第 i 個 CPT 中有 ni個資料點,
而這ni個資料點的x 座標與 y 座標完全相同,但 z 座標是不同的。假設 dCPTi為第i 個CPT 所觀察到的資料:dCPTi = [d(xCPTi,yCPTi,zCPTi,1)…d(xCPTi, yCPTi,zCPTi,ni)]T,上標T 表 示 矩 陣 的 轉 置 (transpose) 。 當 有 ns 個 CPT 鑽 探 時 , x 座 標 可 以 寫 成 (xCPT1,xCPT2,…,xCPTns),y 座 標可以寫成 (yCPT1,yCPT2,…,yCPTns),z 座標可以寫成 (zCPT1,zCPT2,…,zCPTns),d 則可以寫成 (dCPT1,dCPT2,…,dCPTns),習慣上將觀測到的資料 d 分成趨勢項t 和空間變異項:
d = t + 3-1
第 i 孔 的 的 空 間 變 異 性 資 料 可 以 寫 成i = [(xCPTi,yCPTi,zCPTi,1)…(xCPTi, yCPTi,zCPTi,ni)]T,則 = (1T2T…nsT)。假設空間變異項為二階的高斯穩態隨機場,標 準差為σ,水平和垂直向 SOF 分別為 δh和 δz。則可以表示成:
= σ ∙ 𝐋 ∙ 𝐔 3-2
其中U 為獨立高斯隨機變數向量,L 為關聯性矩陣 R 的 Cholesky decomposition 矩陣 (R=L×LT),在三維空間中 R = Rh⊗Rz,根據克羅內克積 (Kronecker product) 的運算規則L = Lh⊗Lz,其中Lh及Lz分別是Rh及Rz的Cholesky decomposition,
Rh為水平方向的關聯性矩陣。
h 1,2 1,2 h 1,3 1,3 h 1,ns 1,ns
h 2,3 2,3 h 2,ns 2,ns
h
h ns 1,ns ns 1,ns
1 x , y x , y x , y
1 x , y x , y
1
x , y
SYM. 1
R 3-3
Rz為垂直方向的關聯性矩陣。
z 1,2 z 1,3 z 1,n
z 2,3 z 2,n
z
z n 1,n
1 z z z
1 z z
1
z
SYM. 1
R 3-4
水平方向與垂直方向的ACF 則都選用 W-M 模型:
ρz(Δz) = 21−𝜈v
Γ( 𝜈v )∙ (√2𝜈v∙ |∆z|
sv )
𝜈v
K𝜈(√2𝜈v ∙ |Δz|
sv ) 3-5
ρh(Δh) = 21−𝜈h
Γ( 𝜈h )∙ (√2𝜈h∙ |∆h|
sh )
𝜈h
K𝜈(√2𝜈h∙ |Δh|
sh ) 3-6 尺度參數sv與sh為:
sv = δv
c(𝜈v) 3-7
sh = δh
c(𝜈h) 3-8
c(ν)之計算如下 (Hristopulos and Žukovič, 2011):
c(𝜈) =√2𝜋 ∙ Γ(𝜈 + 0.5)
√𝜈 ∙ Γ(𝜈) 3-9
趨勢函數的部分由基函數組成:
t(𝑥, 𝑦, 𝑧) = ∑ wkϕk(x, y, z)
m
k=0
3-10
其中ϕk(x,y,z)為第 k 個 BF,wk是第k 項對應的權重,M 為整個 BFs 的集合{ϕ0,ϕ1…ϕm},
當m 夠大時趨勢函數就能模擬多種不同的趨勢形式。
式3-10 可以表示成:
t = Φ × w = (Φh⊗ Φz) × w 3-11 其中w = (w0, w1,…, wm)T,Φ 是一個 [N×(m+1)] 的矩陣:
Φ = [
ϕ0(𝑥1, 𝑦1, 𝑧1) ϕ1(𝑥1, 𝑦1, 𝑧1) ϕ0(𝑥2, 𝑦2, 𝑧2) ϕ1(𝑥2, 𝑦2, 𝑧2)
⋯ ϕ𝑚(𝑥1, 𝑦1, 𝑧1)
⋯ ϕ𝑚(𝑥2, 𝑦2, 𝑧2)
⋮ ⋮
ϕ0(𝑥𝑁, 𝑦𝑁, 𝑧𝑁) ϕ1(𝑥𝑁, 𝑦𝑁, 𝑧𝑁)
⋮
⋯ ϕ𝑚(𝑥𝑁, 𝑦𝑁, 𝑧𝑁))
] 3-12
並進一步將每一項基函數平方的平均正規化到1,使基函數的標準差 sk與整個樣本
的標準差σ 的影響相同,以利後續步驟進行比較。
三維空間分布資料就可以寫成:
d = Φ×w + 3-13
以實際數字為例,假設有四孔深度 (D) 為 10 公尺,垂直資料點間距 (Δz) 為 0.1 公尺的 CPT 資料,鑽孔座標分別為 (x1, y1) = (0, 0)、(x2, y2) = (1, 4)、(x3, y3) = (3, 0)、(x4, y4) = (5, 5),假設水平及垂直的 ACF 都採用 W-M 模型,設定其隨機場參數 (σ, δh, δz, νv, νh) = (50, 10m, 1m, 0.5, 1.5),趨勢函數以 shifted Legendre polynomial 的 第0 項 ϕ0與第1 項 ϕ1作為基函數,權重w 分別為 100 以及 200,故趨勢 t 可以表示 成:
t = 100 × ϕ0+ 200 × ϕ1 3-14 加上空間變異性後即為模擬的完整資料如圖3-3 所示
圖 3-3 虛線為趨勢函數,實線為空間分布資料