行政院國家科學委員會專題研究計畫 成果報告
智慧型運輸系統之道路信息整合應用與交通控制--子計畫 一:用於路況報導之國語、閩南語、客語的整合式文句翻
語音及語言辨識(3/3) 研究成果報告(完整版)
計 畫 類 別 : 整合型
計 畫 編 號 : NSC 95-2218-E-011-006-
執 行 期 間 : 95 年 08 月 01 日至 96 年 07 月 31 日 執 行 單 位 : 國立臺灣科技大學資訊工程系
計 畫 主 持 人 : 古鴻炎
計畫參與人員: 碩士班研究生-兼任助理:蔡仲明、吳昌益、周彥佐、王如 江、曾政傑、廖皇量、陳佳新、孫世諺
臨時工:黃蕙敏
報 告 附 件 : 出席國際會議研究心得報告及發表論文
公 開 資 訊 : 本計畫可公開查詢
中 華 民 國 96 年 10 月 19 日
目錄
一、前言 2
1.1 計畫緣由
1.2 整合式 語音合成 的研究動機 1.3 整合的方式 與整合的好處 1.4 語言辨識 的研究動機
二、整合式語音合成之 資料準備 5
2.1 詞典建造和輔助輸入軟體
2.2 基本音節錄音 和 基週標記軟體
三、整合式語音合成之 系統建造 8
3.1 文句分析 3.2 韻律參數產生 3.3 信號波形合成
3.4 線上測試 與 論文發表
四、語言辨識 13
4.1 文獻回顧
4.2 系統的處理流程 4.3 特徵擷取
4.4 語言辨識之模型--GMM 4.5 語言辨識之模型--PPM 4.6 實驗語料及環境
4.7 線外測試實驗 4.8 線上測試實驗
參考文獻 24
附錄 A (期刊論文) 26
一、前言
1.1 計畫緣由
在地小人稠的台灣,研製智慧型運輸系統(ITS)以解決民眾塞車的不便,是有 其迫切性的。相對於現行的交通廣播電台的路況報導, ITS 系統可以提供更多樣、
更聰明的的服務,不只是收集、報導路況,更可以作行車路徑的規劃而讓用路人 避免塞車之苦。很明顯的,一個 ITS 系統必須要能夠同時應付許多人的路況資訊 查詢、及路程規劃之請求,再者這些描述路況及路徑規劃的文字敘述必須由電腦 軟體來自動產生(因為人工太慢、且人工費用很高)。當一個駕駛人打電話給 ITS 系統來要求服務,ITS 系統要如何把產生出的文字敘述傳達給駕駛人,很明顯地 我們必須顧慮駕駛人的安全與舒適,不能叫他一邊開車一邊看簡訊文字,所以必 須先作文字翻語音(text-to-speech, TTS)的處理,再將含有路況路徑資訊的語音播 放給駕駛人聽。由於敘述路況、路徑的文字都是以動態方式、且依駕駛人的需求 來產生的,所以不可能事先請播音員來錄製文字敘述所對應的語音訊號。因此本 計畫和另一計畫 智慧型運輸系統之信息整合與處理 的” content planning”組件互 動,由該組件來產生路況資訊的文字描述,然後由本計畫來作 文字翻語音的處理。也 就是說,我們期望能提供如目前已在使用的 1968 的路況報導專線,但是我們希 望能夠自動產生,並能即時擷取資訊及結合資料庫的使用。
1.2 整合式 語音合成 的研究動機
國內外一直有不少人在從事文字翻語音(TTS)相關問題的研究,目標是要讓
電腦接收到任意的文句時,都能輸出像人講的一樣自然、流暢的語音,因此研究
者多以自然度、流暢度、清晰度來評估一個文字翻語音系統的效能,自然度是要
評斷是否像人講的一樣自然而無機器腔(味),流暢度是要評斷整句話、整篇話是
否流暢而無斷續、或不連續的感覺,清晰度是要評斷信號是否清晰而無雜訊、迴
音(reverberation)。一般來說,一個文字翻語音系統可看成是由(a)文句分析(text
analysis),(b)韻律參數產生(prosodic parameter generation),(c)信號波形合成(signal
waveform synthesis)等三個組件所構成,其中韻律參數(pitch contour, duration,
amplitude)數值的決定,對於自然度具有關鍵性的影響,而所使用的信號波形合
成方法,是信號清晰度的一個主要決定因素。
在台灣地區,除了稱為“ 國語” 之北京話之外,另兩個被使用的主要漢語方言 是閩南語和客家語,過去由於政府錯誤的語言政策,導至許多新生的一代已不會 說自己的母語(如閩南語、客家語),因此我們認為使用於 ITS 系統中的 TTS 處理,
不能夠獨尊”北京”國語,而不顧閩南語和客家語使用者的權益,所以在本計劃 中,我們將研究一種整合式的 TTS 處理方法,以便在同一套系統中就能夠將文 字敘述轉換成三種語言的語音信號輸出。由於不同的語言之間,所使用的詞彙、
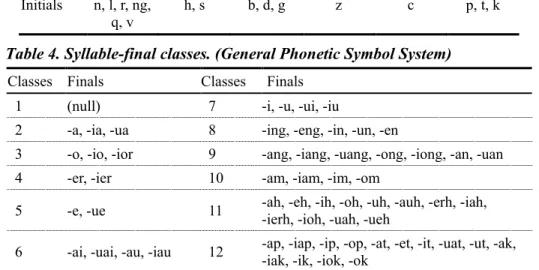
聲調、音節(syllable)結構、聲母、韻母,會有許多不一樣的地方,所以基本上無 法將一個語言的文句翻語音系統,直接移植到另一個語言裡去使用。相對於國 語,過去研究閩南語 TTS 問題的報告不多,而客語方面的則更是稀少,這表示 我們需花較多的氣力來了解、探討客家語和閩南語的特性,如音節種類、聲母和 韻母的種類,聲調種類和變調規則。
1.3 整合的方式 與整合的好處
前段提到的整合之觀念,乍看之下會覺得語言之間差異甚大,如何去整合?
要整合到什麼程度?這裡我們就以文句分析、韻律產生、信號合成等處理模組的 組合來說明可能的整合程度。圖 1-1(a)表示兩種語言獨立作語音合成之處理,
文句分析 韻律產生 信號合成
文句分析 韻律產生 信號合成
文句分析 韻律產生
信號合成 文句分析 韻律產生
文句分析
韻律產生 信號合成
文句分析 文句分析
韻律產生 信號合成
圖 1-1(a) 圖 1-1(b) 圖 1-1(c) 圖 1-1(d) 圖 1-1 不同的整合程度
也就是目前最普遍之情況;圖 1-1(b)表示兩種語言共用信號波形合成之模組,
而另二模組仍是獨立的,對以音節為語音單位的漢語方言來說,這樣的整合是可
理解的,且是明顯可行的;圖 1-1(c)表示兩種語言共用信號合成和韻律產生模
組,這樣的整合是不是可行,應不是馬上可以判斷出來,不過,這樣的整合程度
正是本計劃欲研究達成的目標;另外,圖 1-1(d)表示三個模組都是共用的,我
們覺得目前要做到連文句分析模組都共用,是非常困難的,因為對於一個輸入的
文句,要如何判斷它是屬於那一個語言的呢?不過,在 ITS 的應用裡,我們可假 設輸入的文句的詞語邊界訊息,可由 ITS 系統中產生文字敘述的模組提供,且欲 合成的語言種類,也是由文字敘述產生模組來指示,則要把簡化過的文句分析功 能作跨語言的整合,就變成是可行的。
以往的文句翻語音系統,若要作多種語言的語音合成,則必需為每一種語言 建立各自的韻律參數(基週軌跡)模型,這樣的作法有兩個缺點,第一個是訓練語 料錄製上的困難性;第二個是,每加入一個新的語言,就要耗費很大的人力、時 間成本,以建立該語言的模型。在訓練語料錄製上,需要一位精通各種語言、且 口齒清晰的人,以錄製各種語言的訓練語料,而要找一位精通各種語言且口齒清 晰者,則是很因難的。此外,當要加入新的一種語言,就必需耗費人力、時間來 錄製該語言的訓練語料,以便建立對應的韻律參數模型,這是資源的浪費。因此 本計畫研究了一種能夠整合、支援三種語言之韻律參數模型的作法,以節省研究 的資源與時間花費;此外,使用同一個軟體模組來作三種語言的語音信號合成,
即整合式的信號合成,其好處是,信號合成方面的任何改進(如流暢度或清晰度 的改進),三種語言都可同時受益,而不需花費三倍的時間、氣力,去對個別語 言的軟體模組作更改。
1.4 語言辨識 的研究動機
在許多需和人應答的自動化服務中,語言辨識亦為重要的前置處理。由於能 瞭解各種方言的人並不是相當常見,透過語言辨識,就可將撥入電話自動轉接至 熟悉該方言的人。自動化的語言辨識處理,也可以省略掉互動系統中擾人的「國 語請按 1、台語請按 2...」之類的開場說明,如此就可以節省時間,而用以服務 更多的人。
本計畫研究以整合的方式來提供國、閩南、客三種語言的 TTS 功能,那麼
相對的一個問題是,如何知道打電語給 ITS 系統的駕駛人,他正在使用那一種語
言發音?所以一個 ITS 系統也需要具備語言辨認的能力,以便依照使用者的語
言,來回應所查詢的問題。因此在本計劃裡,我們也對語言辨識的問題進行了研
究,並作了實驗測試。
二、整合式語音合成之 資料準備
本計畫第一年進行的工作是: (a)建立語詞轉換之查詢詞典;(b)三種語言之基 本音節的發音錄音,及標記基週頂點(pitch pick)。為了簡化繁瑣的人工操作,這 兩項工作,我們都發展了工具軟體,不過程式的智慧仍是有限的,還是需要人工 來作輸入和確認。
所發展的兩個工具軟體,容易操作,相當實用。所建造的詞典裡的語詞數量 不夠多,還需再增加,但是需要先找適當的紙本詞典。在隔音室作基本音節的發 音錄音是必要的,但是要找會說三種語言、且音質亮麗的,並不容易。
2.1 詞典建造和輔助輸入軟體
本計畫假設輸入文句的詞語邊界的訊息,是由 ITS 系統中產生文字敘述 的” content planning” 模組提供,如此文句分析的處理就簡化了,也不需作斷詞 的處理,因此我們只需考慮國語語詞轉換成閩南語或客語語詞的問題,這基本上 需要準備語詞對照的詞典,然後進行語詞之查詢、轉換,就可得到目的語言裡的 音標資料。
很明顯地,在 ITS 系統中,地名及街道名之語詞會經常被用到,至於其它的 語詞,可能會發生一個語詞(如專有名詞)查不到對應的閩南語或客語發音音標,
為了克服這種情況,所以對於常用的漢字,我們也都需要建造國、閩南、客家語 各自的字音詞典,以便能夠起碼地查出字為單位的發音音標。我們參考了閩南 語、客語的詞典書籍,選取其中常用者來輸入到電腦,作成國語至閩南語、及國 語至客語的語詞對照詞典。
在原始情況下,輸入一個閩南、國語的對照詞語,需使用文字編輯器來輸入
如下之資料: <前天, 昨日, zerh8_rit8>,三個欄位分別是國語詞、閩南語詞、和
閩南語通用拼音[1]。如果能夠預先建立各漢字的閩南語拼音資料,然後讓輸入者
以滑鼠來操作特製的軟體,選取適用的拼音,則拼音資料的輸入就可以節省不少
的力氣;相同道理,客語、國語的對照詞語的輸入,也可以使用特製的軟體來節
省氣力。因此,我們首先的工作是,發展、製作對照語詞輸入之輔助軟體,該軟
體執行後的一個視窗畫面如圖 2-1 所示,此軟體除了提供輸入、查詢的功能之外,
還提供了音標符號轉換的功能,可將” 台語羅馬字” 符號轉換成” 通用拼音” 符號。
圖 2-1 語詞對照輸入之輔助軟體
使用如圖 2-1 所示之輔助輸入軟體,本計畫參考吳秀麗小姐的「實用漢字台語讀音」
教材[2],已經輸入了 11,362 個閩南、國語的對照語詞,其中 6,190 個是雙字詞。 在客 家語方面,我們參考了何石松、劉醇鑫先生的「現代客語詞彙彙編」 [3],目前輸 入了 13,576 個客語、國語的對照語詞,其中 8,426 個是雙字詞。
2.2 基本音節錄音 和 基週標記軟體
由於國語、閩南語、客語都是以音節為語音單位,所以我們的整合式 TTS 系統選擇以音節作為信號合成處理的單位。雖然過去我們已成功地使用 TIPW (time-proportioned interpolation of pitch waveform)法[4]來作國語音節信號的合成 處理,但是我們知道,閩南語和客家語都有的入聲韻音節(以 p ,t ,k ,h 結尾),
是國語中所沒有的,並且在閩南語和客語裡,入聲韻音節具有高、低兩種聲調,
而其它的音節則會以 5 種聲調之一來唸。關於入聲韻音節的信號波形合成,在以
前研究客家語語音信號合成時,我們已經修正了 TIPW 法,以考慮入聲韻音節結
尾的切音波形[5],所以入聲韻音節的信號合成,我們已有經驗。
本計畫裡,我們選擇以 TIPW 法來作信號的合成處理,因此必需先準備好三 種語言的基本音節的語音信號。雖然在前幾次的計畫裡,我們曾經分別對國語、
閩南語、客語作過基本音節的錄音,但是三種語言的錄音者並非同一個人,以致 於發音音色不一致,此外先前計畫裡所錄的信號,存在有一些音節信號不夠清 晰、唸錯音等瑕疵。因此在本計畫裡,我們重新作音節信號錄製的工作,錄音時,
一次連續發數個基本音節的第一聲語音,然後作標音,把各個音節的拼音符號標 記上去,接著是切音,以切割成音節單位。錄音、標音、與切音的操作,我們使 用了一套稱為 WaveSurfer 的免費軟體,國、閩、客語分別錄了 409、782、683 個基本音節的語音信號。
得到各個基本音節的語音信號後,接著是作基週頂點標記的工作,以便能夠
使用 TIPW 法來作音節信號的合成,合成處理可用以改變原始錄音的聲調成為其
它聲調,及改變音節的時間長度成為所需的長度。本計畫裡,基週頂點的標記是
採取半自動的方式,也就是先由程式對一個音節信號作自動的基週頂點偵測,再
由人工作驗證,發現錯誤時則經由編輯(刪除、增入)頂點標記,來作更正。基週
頂點偵測與編輯的程式執行時,出現的畫面如圖 2-2 所示。
三、整合式語音合成之 系統建造
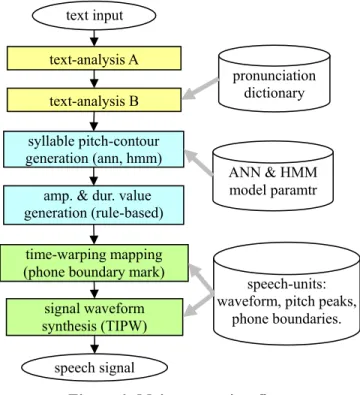
在計畫的第二個年度裡,我們完成了如下的工作項目: (a)文句分析,定義一 些標記符號,以讓產生路況報導文字的另一子計畫可以傳遞必要的資訊;剖析這 些標記符號的程式已完成。(b)韻律參數產生,我們採取 ANN 與 SPC-HMM 的混 合模型,來建立基週軌跡(pitch contour)模型,然後研究、比較閩南語模型調適後 產生出的國語基週軌跡,和原生國語模型產生出的軌跡,發現調適模型雖可產生 出聽得懂的軌跡,但是自然度會比原生模型的差一些。(c)對於 TIPW 信號波形合 成法[4],一個音節內各音素的時間分配的比例,研究使用片段線性之時間扭曲 (warping)函數,來取代原先的線性扭曲方式,結果發現可讓流暢度獲得明顯的提 升。 (d)整合各部分的軟體模組,製做成一個三種語言的文句翻語音系統,也就是 可在句子之間插入標記符號,來作動態的語言切換,而整體系統的主要處理流程 就如圖 3-1 所示。
三種語言整合的語音合成系統,已初步完成,可供作線上測試。但是仍有不 少細節的問題需要再考慮,如閩南語裡的變調問題、破音字問題。
圖 3-1 整合式語音合成系統之主要處理流程 text input
text-analysis A text-analysis B
pronunciation dictionary
syllable pitch-contour generation (ann, hmm) amp. & dur. value generation
(rule-based)
ANN & HMM model parameter
time-warping mapping (phone boundary mark)
signal waveform synthesis (TIPW)
speech signal
speech-units:
waveform, pitch peaks,
boundary location.
3.1 文句分析
由於本系統是一個國語、閩南語、客語的整合式文句翻語音系統,我們必須 考慮到閩南和客語中,有不少的發音是還未文字化的(即不知道對應的漢字),因 此我們必須接受,輸入的文句裡會有漢字夾雜拼音的情況,例如: ” cih-8 tou-7 人” 。此外,我們也需定義一些可夾雜出現於輸入文句裡的標記(tag)符號,以告 知系統,接下去要合成的是那一種語言的語音,及合成語音的說話速度,要設為 多少。本系統目前支援的標記符號的詳細情形,如表 3-1 所示。
表 3-1 已支援剖析之標記符號
標記符號 說明 標記符號 說明
@>0
合成出國語語音
@>f切換客語的海陸腔、四縣腔.
@>1
合成出閩南語語音
#0強制前一漢字的發音聲調,作變調.
@>2
合成出客語語音
#1x直接設定前一漢字的聲調調號為 x.
@>dxxx
音節音長基準值,設為 xxx 毫秒.
<, >括入語詞,如: <cih-8 tou-5>
@>txxx
音高基準值,設為 xxx Hz.
*設定呼吸停頓點
@>vxxx
聲道長度伸、縮為百分之 xxx.
|分隔語詞, 如: 水|分子.
當一個文句輸入後,首先會經由圖 3-1 裡兩個文句分析的方塊來處理。方 塊 ” text-analysis A” 負責將標記符號剖析出來,並且記錄符號所攜帶的資訊;
此外它也要將輸入的文句切割成一序列的 token,一個 token 是一個連接的漢字 串,或是一個音節的拼音字母串。方塊” text-analysis B”負責對漢字串作查詞 典的處理,以找出各漢字的音節發音,要使用那一個語言的詞典?可依據前述標 記符號所提供的資訊。當從四、三、二字詞的詞典查不到語詞發音時,接著嘗試 作構詞處理,把重複出現的漢字當作重疊詞,把接連出現的數字當作數詞。作完 斷詞處理後,接著對各別語言作不同的變調處理,例如國語裡,連續三聲前者變 二聲,及” 一” 與” 不” 的變調;閩南語裡,一個語詞的字除了詞尾字之外,都要變 調,但是當兩相鄰語詞作複合時,前一語詞的詞尾字也要變調,可是目前本系統 尚不能判斷相鄰語詞之間要不要作複合;客語的變調,則依它的變調規則來處理 [3]。
3.2 韻律參數產生
原先,國語、閩南語、客語的音節韻律參數(基週軌跡、音長、音量)數值的
產生,必需先去訓練各自的韻律模型,然後使用各自的模型去產生出參數值。但
是為了節省研究所需的資源、時間,本計畫裡我們採取一種模型調適的作法,亦
即只建造出閩南語的基週軌跡模型,再經由聲調調號的對映(mapping),就可用 以為三種語言產生出基週軌跡的參數值。另外在音長、音量方面,我們也是只建 立了一套規則,而不是分別對各語言去訂定規則。
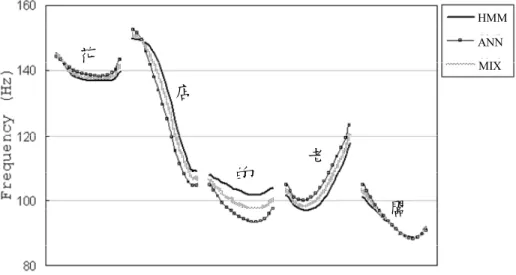
關於基週軌跡模型的建造,由於閩南語的聲調數量為 7,比國語的 5 個多,
且比客語(7 個聲調)容易找到人錄音,因此我們決定以閩南語作為工作語言,也 就是只需錄製閩南語發音的訓練語句,共錄了 643 句 3,696 字。然後使用這些語 句來分別訓練出 ANN (artificial neural network)和 SPC-HMM (syllable pitch contour hidden Markov model)的基週軌跡模型,之後當要產生基週軌跡參數時,
就讓 ANN 和 SPC-HMM 模型先各自產生出參數向量 Ca 和 Ch,再將 Ca 和 Ch 作混合 (即加權和),如此用以兼顧基週軌跡的穩定性(SPC-HMM 較穩定)和活潑性(ANN 較 活潑)[6]。
如果要合成的是客語(海陸腔)語音,如:” shit-8 bau-2 le-1” ,首先可將聲 調 8 對映至閩南語的聲調 4,聲調 2 對映至聲調 5,聲調 1 對映至聲調 2,然後 將” shit-4 bau-5 le-2”當作是閩南語語句,帶入前述的基週軌跡模型,去求得 基週軌跡參數。同理,如果要合成的是國語語音,也可先作聲調的對映,再帶入 基週軌跡模型,去求得基週軌跡參數。國語和客語的較詳細的聲調對映關係,如 表 3-2 和 3-3 所示。
表 3-2 客語聲調對映
客語(海陸)調號
1 2 3 4 5 7 8
閩南語調號2 5 3 8 1 7 4
表 3-3 國語聲調對映
國語調號
1 2 3 4 5
閩南語調號1 5 3 2 4
由於以前我們曾錄製過國語的訓練語句,用以研究、建造國語的基週軌跡模
型。因此在本計畫裡,我們便想探討調適過的和原生的國語基週軌跡模型(也是
ANN 和 SPC-HMM 混合),在所產生的基週軌跡參數上(其它因素控制為一致),是
否會造成合成語音在自然度上的明顯差異? 我們首先用調適的和原生的模型分
別合成出一段短文的語音信號,然後進行聽測,結果發現使用原生模型的合成語
音,其自然度確實是會比使用調適模型的好。所以,調適的基週軌跡模型,雖可
合成出聽得懂、可接受語音,但自然度會稍差一些。
3.3 信號波形合成
考慮到資源、人力有限,及未來系統的擴充性(如再加入其它語言),我們認 為 corpus based 的語音合成方法[7, 8],若使用於本系統,將會面臨很多困難。
因此我們決定採取 model based 的方法,首先對三種語言裡的各種基本音節,錄 製一遍語音波形,然後就可使用我們先前提出的 TIPW 合成法[4],來更改所錄的 音節的韻律特性,例如賦予新的基週軌跡,延長或縮短音節長度。
先前我們發展 TIPW 合成法時,是針對國語來考慮的,但是現在必需考慮到 閩南語和客語特有的音節特徵,例如入聲韻音節的語音波形,尾端含有一個塞音 音素(p,t,k 或 h),因此我們對 TIPW 作的一個改進是,把入聲韻音節看成是由<
無聲>、<有聲>、<無聲>等三部分所串接而成,然後以 TIPW 合成法中處理音節前 端無聲部分的方法,來處理入聲音節尾端部分的波形合成。
此外,我們對 TIPW 合成法也作了一個顯著的改進,可用以提升合成語音的 流暢度(fluency)。一般來說,韻律參數產生的模組,只是用以決定出一個欲合 成音節的時間長度 Rs,可是對於音節內部的組成音素(phoneme),如/man/是由 /m/,/a/,和/n/串成,應該如何去分配 Rs 的時間給組成的音素,則是沒有規範,
而信號波形合成方法(如 TIPW),一般也只是以線性伸、縮的方式,來分別調整 原始音節的無聲(unvoiced)、與有聲(voiced)兩部分。線性伸、縮之音長調整方 式,我們從本計畫裡的研究,發現它是一個造成流暢度不佳的重要因素。
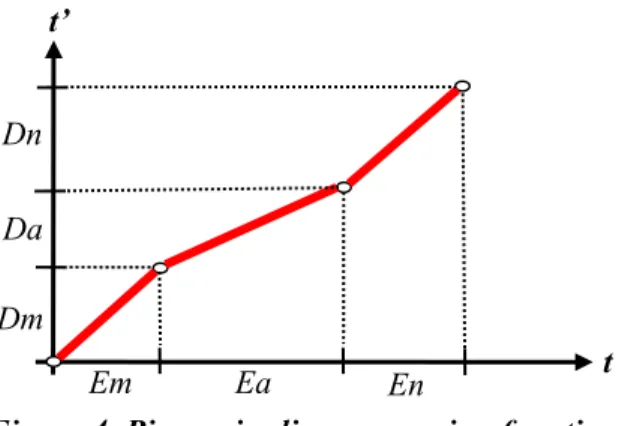
以音節/man/為例,設音素/m/的時間長度為 Dm,音素/a/的時間長度為 Da,而 /n/的時間長度為 Dn。在/man/的原始錄音裡,Dm 加上 Dn 的值會比 Da 的大很多,
即(Dm+Dn)/Da 比率很大,可是在連續的句子發音裡,(Dm+Dn)/Da 的比率值就會 變小很多。因此我們在 TIPW 合成法裡,使用了如圖 3-2 所示的片段線性時間扭 曲函數,令 Rm,Ra,Rn 分別為合成音裡/m/,/a/,和/n/等音素的長度,且 Rs = Rm + Ra + Rn,而 Dm,Da,Dn 分別為原始音裡的長度,然後以如下規則來設定合成音 裡各音素的長度:
Rm = (Dm/Ds) * 0.7 * Rs
Rn = (Dn/Ds) * 0.7 * Rs (3-1)
Ra = Rs –Rm –Rn
圖 3-2 片段線性時間扭曲函數
在使用公式(3-1)來作時間長度的分配之前,必需要先對原始音節作音素邊界 的標記處理,目前我們是以人工方式來作。對合成出的語音作聽測後,我們發現 即使只使用如公式(3-1)的簡單規則,已經可以使合成語句的流暢度獲得明顯的改 進。未來,我們將再研究比較系統化的方法,來建立原始音和合成音之間的時間 扭曲函數,期望能獲得更多的流暢度提升。
3.4 線上測試 與 論文發表
對於本計畫所製作的國、閩南、客語的整合式語音合成系統有興趣者,可瀏 覽網頁 http://guhy.csie.ntust.edu.tw/hmtts/,去試聽預先合成的語音檔案。如果要 作線上的測試,則可連至 http://guhy.csie.ntust.edu.tw/hmtts/speak.html,從網頁輸 入想要合成的文句。
目前我們已經把整合式語音合成的研究成果,寫成會議論文和期刊論文,會 議論文發表於 2006 International Symposium on Chinese Spoken Language Processing (Singapore) ; 期 刊 論 文 已 被 接 受 , 將 刊 登 於 中 華 民 國 計 算 語 言 學 會 的 期 刊 : International Journal of Computational Linguistics and Chinese Language Processing, 期刊 論文的標題是“ A System Framework for Integrated Synthesis of Mandarin, Min-nan, and Hakka Speech ” ,而全文則如附錄 A 所示。
synthetic-syllable time axis
Rm Ra Rn t
Dm Da Dn
t ’
四、語言辨識
在計畫的第三個年度裡,我們針對國語、閩南語、及客語作語言辨識的模型 研究及實作一個線上的辨識系統。在訓練階段,先從訓練語料中抽取聲學特徵和 音調特徵,對各語言建立 GMM (Gaussian mixture model)模型,此外也用 GMM 表徵器的輸出來建立各語言的 PPM (prediction by partial matching)模型。模型建 立後,依模型估計出的機率值作為測試語料的分數,然後取分數最高的語言作為 辨識結果。
在線上(on-line)測試時,由於信號經過了電話通道,並且電話卡的取樣率只 有 8KHz,對訓練語料用太多的混合數加以模式化反而造成辨識時有偏頗的現象 發生。故線上測試中,改成使用較少的 50 個混合的 GMM,並對國語進行加分,
這樣才讓平均辨識率達到 73% [9]。值得一提的是,我們回顧到的國內作者所寫 的文獻,尚沒有人製作語言辨識的線上系統,而都只是作線外(off-line)的模擬測 試而已。
國語、閩南語及客語的語言辨識,我們的線上辨識實驗,己接近實際的情況,
但是辨識率仍不夠高,而尚不能作實際應用。
4.1 文獻回顧
自動語言辨識的研究約在 70 年代興起。在 1980 年,Li 和 Edwares 就提出了 以統計方法進行自動語音辨識的研究成果 [10]。Zissman 於 1996 年整理並比較 了當時常見的四種電話語音之語言辨識方法 [11],使用 OGI-TS 語料庫來進行各 項實驗,此論文整理出的方法是,以 GMM 模式化音素特性,及以 n-gram 模式 化語言內語音發音之順序特性,這仍是現在許多語言辨識系統的根基。Reynolds 等人則是導入了 GMM 表徵化(tokenization)的處理 [12],將一連串的語音特徵 向量變成表徵(token)序列,讓 n-gram 表徵語言模型的實作變的容易。
針對台灣三種方言的研究,先前已有蔡偉和等人提出的 Gaussian Mixture
Bigram Model 方法 [13]。此方法直接結合了 GMM 和 bigram 模型,而得到很好
的辨識效果。國內碩士論文方面,林俊青[14]、張智傑[15]、郭頂益[16]等人皆以
OGI-TS 語料庫為基礎進行多國語言辨識的研究及系統實作。
4.2 系統的處理流程
我們研究的語言辨識系統,可分割成兩階段來看,亦即訓練階段和辨識階 段,而整體的流程如圖 4-1 所示。在訓練階段,訓練語料經過特徵萃取後,進行 模型訓練,得到 3 種語言各自的 4 組模型參數(共 12 組)、然後以檔案儲存。在辨 識階段,一樣先對輸入的待測語音進行特徵萃取之處理,接著讀取 12 組參數來 計算各語言的分數,最後輸出辨識的結果。
圖 4-1 語言辨識系統之主流程
我們採用高斯混合模型(GMM)來模式化各語言的聲學特性,並且以 PPM 模 型來模式化各語言之語音發音的時序關係。一開始先作語料的蒐集,然後使用各 語言分別蒐集到的訓練語料來訓練該語言的模型,模型參數可分為四個種類:聲 道 GMM 參數、聲道 PPM 參數、聲調 GMM 參數、聲調 PPM 參數。訓練階段的 處理流程如圖 4-2 所示,原始 wav 檔語料先經過特徵萃取函數轉換成 MFCC 向 量及音高軌跡向量,接著作 K-Mean 分群後建立初步的 GMM 模型,再以 MLE 或高斯機率 K-Mean 方法加以訓練,而得到較為精確的 GMM 模型。完成後再用 GMM 對各音框進行表徵化(tokenize)處理,來轉換成一序列的表徵(token)代碼,
再使用此表徵序列去訓練出一個 PPM 模型。
如圖 4-3 所示,在辨識階段裡,測試的語音信號由檔案或即時由麥克風輸入,再經 過聲道與音調各自的 GMM 和 PPM 模型作機率量測,而得到各語言的分數,分數最高
參數萃取
模型訓練
計算分數 參數萃取
訓練語料
MFCC GMM 3 MFCC GMM 2
MFCC GMM 1
Pitch GMM 3 Pitch GMM 2
Pitch GMM 1
MFCC PPM 1
Pitch PPM 1
待測語音 辨識結果
的語言,就將它輸出作為辨識的結果。
圖 4-2 訓練階段之處理流程
圖 4-3 辨識階段之處理流程 待測語音特徵向量
GMM 機率計算
音框表徵化 GMM 機率計算
PPM 機率計算
音框表徵化
PPM 機率計算
MFCC MFCC
MFCC GMM
MFCC MFCC
MFCC PPM
Pitch GMM
Pitch GMM
Pitch GMM 兼
Pitch GMM
Pitch GMM
Pitch PPM
語言分數
MFCC MFCC
MFCC 表徵器
辨識
訓練 訓練語料
抽取 MFCC 訓練 GMM
計算音高 抽取軌跡特徵
音框表徵化 訓練 GMM
建立 PPM 表 音框表徵化 建立 PPM 表
MFCC GMM
MFCC PPM
Pitch GMM
Pitch PPM
4.3 特徵擷取
由於原始語音波形的資料量太大且無穩定的特徵,故我們必須抽出對辨識有 用且易於處理的特徵參數。本研究使用了兩類的特徵參數,分別是聲學(acoustics) 特徵和音調(pitch)特徵。
聲學特徵: 一個音框的分析,最常用的方法是離散傅立葉轉換(Descrete Fourier Transform, DFT),經由傅立葉轉換,可以把本來在時域上的信號 x[n]轉換 成頻域上的信號 S[k]。轉換到頻域後,可更進一步處理頻域信號,以萃取最能代 表語音內容的特徵。倒頻譜(cepstrum)描述了人講話時的聲道形狀,它的算法如 下:將離散的頻域訊號 S[k]取絕對值後再取對數而得到 L[k],再對 L[k]作離散傅 立葉反轉換,就可得到倒頻譜係數 C[n]。這種 C[n]序列有個特性,就是激發信號 引起的係數會在較後方,所以抽取 C[n]序列的前段係數就可以將聲道響應獨立出 來作為特徵參數使用。
在此我們採用 20ms 的音框(frame),每個音框之間重疊 10ms,並且從各音框 去 求 取 12 維 度 的 梅 爾 倒 頻 譜 係 數 (Mel-Frequency Cepstrum Coefficient, MFCC),係數求取實際上是使用 HTK (HMM TooKit),也就是我們的程式內含必 要的 HTK 原始碼,並且直接呼叫 HTK 提供的外部函數。此外,由於要考慮音框 之間的關聯性,我們再取三個音框的距離來計算另外 12 維度的差分係數,即
3
k k k
C C C
,k 為音框編號。
音調特徵: 由於國、閩南、客語都是有聲調的語言,所以音高軌跡具有重要 的語言意義,我們於是把音高軌跡當作特徵參數來使用。語音的音高(pitch)代表 人在發聲時聲帶震動的頻率,也就是語音訊號的基頻(F 0 )。語音訊號可分成兩種,
一種是聲帶有週期性振動的有聲(voiced)語音,另一種是無週期性振動的無聲 (unvoiced)語音。所有的母音都是有聲,子音則分成有聲和無聲。由於無聲語音 不具有週期性而不能估計出基頻,因此我們只能球取出有聲部分的音高軌跡。
計算出所有有聲音框的音高後,再採用中值平滑法和動態規劃法來修正估計 音高時可能出現的倍頻或半頻的錯誤[17]。為了去除語者間的音高位準之差異,
我們對每個語音檔案作了 Zero Mean 處理,將各個音框的音高減去所有有聲音框
的音高平均值,而得到最終的音高序列。因為聲調語言裡的聲調是以音節為建構 單位,所以在算出原始語音訊號的音高軌跡後,我們還要把它切成以音節為單位 的片段(segment)。分段後,再採用離散餘弦轉換(Descrete Cosine Transform, DCT) 的基底,來將片段中的音高軌跡轉換為參數向量[9]。
4.4 語言辨識之模型--GMM
高斯混合模型的概念是,利用多個高斯機率分佈的組合,表達出各種語言特 性的分佈狀況。單一的高斯機率分布就是正規分布,而多個分佈混合時,第 j 個 高斯機率分布的公式如下:
2
) (
) exp (
) 2 ( ) 1 (
1
2 1 2
j j
T j
j j D
x C x
C x
D
(4-1)
其中 C j 為共變異矩陣(covariance matrix),μ
j為平均向量,D j (x)為向量 x 由此機 率分布取得的機率密度。進一步把數個高斯機率分佈用加權和(weighted sum)的 方式加總,就得到高斯混合模型:
10
) ( )
|
(
Ki
w
jD
jx
x
P (4-2)
其中λ為模型中所有參數的集合。我們採用一個高斯混合模型來模式化一種待辨 識的語言,模型訓練的目的是,使所有特徵向量在該語言的模型中的機率總和為 最大:
1 2,
arg max ( , | )
d
n d
P x x x
(4-3)
其中 x n 是所有的訓練語料,λ d 是所有有可能的參數。由於不可能窮舉出所有參 數來計算,所以我們採用 Maximum Likelihood Estimate (MLE)的迭代估計方法來 尋找最佳的參數值。
經由特徵參數擷取,各音框會得到它對應的特徵向量。收集到訓練語料的所
有特徵向量後,接著作 K-means 分群[18],將 K 群的 K 個中心向量,作為 GMM
模型的初期中心,即令一群的特徵向量屬於一個高斯分布,如此第 j 個高斯分布
的初始參數值就可計算如下:
2 ,
1 0
1 ( | ( ) )
1 (( ) | ( ) ), if 0, if
j n n
j n
n n n
m n j n
j
j
j K
k k
x g x j N
x g x j m n
C N
m n w N
N
(4-4)
為了減少計算量,我們假設特徵向量各維間互相無關,所以共變異矩陣是一 個對角矩陣。得到初始值後,就可計算訓練語料對現在模型的 Log Likelihood,
L g (λ):
1 1
0 0
( ) log ( | ) log ( | )
N N
g i i
i i
L
P x
P x
(4-5)
要求極大值,可對 L(λ)分別以μ j 、C j 和 w j 微分,分別令微分值為 0 後,就可得 到以下公式[14, 15]:
) (
) ) (
(
i i j j i
j
P x
x D x w
(4-6)
10 1
0
) (
) ( ˆ
Ni
i j N
i
i i j j
x x x
(4-7)
T j N j
i
i j N
i
T i i i j j
x D
x x x
C
ˆ ˆ )
( ) ˆ (
1
0 1
0
(4-8)
N x w
N
i
i j j
1 0) ( ˆ
(4-9) MLE 利用上述公式迭代修正λ,找出讓 L g (λ)最大的參數集合。每迭代一次,就 去計算現在的 log likelihood 值,若該值落在一定範圍以內則結束訓練。
4.5 語言辨識之模型--PPM
高斯混合模型可用來模式化聲學特性單獨的出現機率,可是無法模式化它們
之間的時間次序關係。因此我們採取 PPM 來實作 n-gram 模型,以期達到聲學特
性時間次序的模式化。
n-gram 模型的建立,必須先將一個音框的特徵向量表徵化成一個整數值,因 此我們要對各音框作表徵化(tokenize):
) ( max
arg
j tt j
D x
T (4-10)
將一個音框的特徵向量轉換成對它機率最大的高斯機率分布(的編號),然後將各 音框的表徵和它的前置表徵序列填入 PPM 表。n 階的 PPM 表共有 n+1 層,每層 存放訓練語料裡各種遇見過的前置表徵序列(context)和表徵 T t 相連出現的次數。
n-gram 有一個問題,就是辨識時若某表徵序列不存在於資料表中,也就是從 來沒出現過的話,要如何計算它的機率。PPM 使用一個想像的<Esc>脫逃表徵來 處理這種情況,當遇到最高階(比如說,4 個相連表徵形成的前置表徵序列為第 4 階)找不到該序列時,就去掉最遠的一個表徵,到下一階(第 3 階)找這個較短序列 的出現機率,並乘上前一階 Esc 表徵的出現機率。若在這階還是找不到,就再乘 上這一階的 Esc 機率並再作降階,直到 0 階為止。本論文採用 PPMc 和 PPMd 之 逃脫機率估計方法[18] 來設定 Esc 機率,其中 PPMc 設 Esc 的 count 值等於「此 層所有表徵序列的種類數」 , PPMd 則設成「此層 count 值剛好等於 1 的表徵序列 種類數」。實作上我們計算 n-gram 機率的遞迴公式如下:
Esc| ( , ) Esc | ( , )
( , ) N X t r P X t r
N X t r
(4-11)
N( | ( , ))
[1 Esc | ( , ) ] , if N( | ( , )) 0 N( ( , ))
( | ( , ))
N( | ( , 1))
Esc | ( , ) , otherwise N( ( , 1))
t
t t
t
T X t r
P X t r T X t r
X t r P T X t r
T X t r P X t r
X t r
(4-12)
其中 X(t, r)代表時間點 t 時前 r 個表徵組成的前置表徵序列,N(T t |X)代表在前置 表徵序列 X 下表徵 T t 的出現次數,N(X)代表前置表徵序列 X 的總出現次數。
4.6 實驗語料及環境
我們用數位電視棒和電視卡錄製國語、閩南語、客語的新聞語音,來源電台、
總語者數及時數如表 4-1 所示。所有檔案都是 16-bits、取樣率 22,050Hz 的 Windows
PCM 檔案,各種語言隨機選出 10 個語者的語料拿來訓練模型,並另外選出 3 個
語者的語料作為測試。表 4-1 內語者數(m/f)代表訓練用語者的男女人數。
表 4-1 語料來源及時數
語言 來源電台 語者數 時數
國語 台視、中視、華視、民視、公視 15 (6/4) 0.51hr
閩南語 民視、公視、大愛 19 (6/4) 0.63hr
客語 客家電視台、哈客廣播網 13 (5/5) 0.46hr
在測試時,我們從訓練語料中隨機抽出一定長度的語音作為 Inside 測試的測 試語料,並另外找三個語者,一樣隨機抽出一定長度的語音作為 Outside 測試的 測試語料。測試語料分為 3 秒、10 秒、45 秒,系統整體測試時,3 秒和 10 秒各 語言分別有 199 個測試檔案,45 秒則有 99 個測試檔案。
實 驗 系 統 主 要 以 Borland C++ Builder 6 開 發 , 電 腦 平 台 為 Pentium4 2.40GHz、WinXP、以及 1.5GB 的記憶體。
4.7 線外測試實驗
待測語料在抽取特徵向量後,分別由四個子系統來計算機率分數,四個子系 統分別是: (1)MFCC GMM,(2)MFCC PPM,(3)Pitch GMM,(4)Pitch PPM,其畫 分範圍如圖 4-4 所示,四個子系統算出的分數再作加權總和,即為該語言的分數。
圖 4-4 子系統範圍畫分 待測語音特徵向量
GMM 機率計算
音框表徵化 GMM 機率計算
PPM 機率計算
音框表徵化
PPM 機率計算
MFCC MFCC
MFCC GMM
MFCC MFCC
MFCC PPM
Pitch GMM
Pitch GMM
Pitch GMM 兼
Pitch GMM
Pitch GMM
Pitch PPM
語言分數
MFCC MFCC
MFCC 表徵器
β
GMM(0) β
PPM(0)
β
GMM(1) β
PPM(1)
子系統(2) 子系統(1) 子系統(3) 子系統(4)
四個子系統的加權值,分別設定為: β GMM (0:聲學特徵)=0.3,β PPM (0:聲學特 徵)=0.18,β GMM (1:音調特徵)=β PPM (1:音調特徵)=0.06。同時考量辨識速度、使用 的 記 憶 體 和 辨 識 準 確 度 後 , 這 裡 設 定 子 系 統 (1)和(2)中的 GMM 混合數為 Mg=256、Mp=32、原始 MFCC 向量和差分向量各取 12 維、MFCC 的差分間距為 3、逃脫機率估計方法為 ppmc、PPM 模型的階數為 4;子系統(3)和(4)的 GMM 混合數則設為 Mp=Mg=256,音高軌跡逼近方法為 12 維的離散餘弦函數,並且 PPM 模型採用 4 階的 ppmc 法。結果得到的辨識率如表 4-2 及圖 4-5 所示。
表 4-2 整體系統的辨識實驗
OVERALL Inside Outside
語言 3 秒 10 秒 45 秒 3 秒 10 秒 45 秒 國語 96.98% 98.99% 100.0% 95.98% 97.49% 96.97%
閩南語 94.47% 94.47% 92.93% 74.73% 66.83% 70.71%
客語 89.95% 97.49% 100.0% 63.32% 77.39% 69.70%
總平均 93.80% 96.98% 97.31% 78.01% 80.57% 79.13%
子系統 1+2 95.92% 95.24% 96.55% 83.67% 79.59% 82.76%
整體系統辨識實驗
0.00%
20.00%
40.00%
60.00%
80.00%
100.00%
In-3s In-10s In-45s Out-3s Out-10s Out-45s 測試語料
辨識率
國語 閩南語 客語 總平均
圖 4-5 整體系統辨識實驗
如表 4-2 及圖 4-5 所顯示的,使用所有的子系統來計算機率值再作加權和,
辨識正確率在內部測試時都超過 90%,而在外部測試時則可達 80%上下。外部測
試中,國語的辨識正確率遠高過另外兩種語言,如在 10 秒的外部測試裡,國語
的辨識率高達 97.49%,但閩南語只有 66.83%,客語也只有 77.39%,且另外兩種
語言的辨識錯誤也大部分是被誤判成國語。另外,和只使用子系統(1)和(2)的結 果比起來,加入音調特性對辨識率似乎沒有改進的效果,例如在外部測試裡,整 體系統對於 3 及 45 秒語料的辨識率 (78.0%和 79.1%) 都比子系統(1)和(2)的辨識 率(83.7%和 82.8%)降低了 3.5%以上,而對於 10 秒語料的辨識率也只上升 3.1%
(80.6%-79.6%)。
4.8 線上測試實驗
我們實作了一個可以自動接聽電話然後辨識發話者所用語言的線上辨識系 統,系統內安裝了亦誠科技公司的 VL4P-05O 電話卡來讓軟體可自動接聽電話並 作錄音,其實我們的 C++程式是經由呼叫電話卡提供的函式庫,來控制電話的接 聽和掛斷,作錄音及播音的處理。使用者撥號後,系統會自動接聽並播放提示音 檔,接著進入錄音模式。在錄音模式中,只要使用者停止說話 4 秒,系統就會停 止錄音並進行音檔轉換,然後辨識使用者所用的語言。
由於這張電話卡錄製的語音固定是 8-bit mu-law 8000Hz,所以我們必須另外 撰寫 mu-law 轉成 PCM 的程式。此外,由於電話卡擷取的電話語音和電視、廣播 節目錄製的訓練語料,在取樣率、通道、內容及說話方式等方面皆有差異,故在 此我們對訓練語料作增加的處理動作:(a)由於頻寬差異,先呼叫 Downsampling 模組 libsamplerate,將訓練語料的取樣率降成 8000Hz;(b)作 Cepstrum Mean Substraction,對每一個檔案求取所有音框的 MFCC 係數的平均向量,然後把該 檔案每一個 MFCC 向量減去平均向量,以除去聲音通道的影響;(c) 重新訓練模 型,得到模型參數值。
這裡準備的測試語料共 30 筆,三種語言各 10 筆,國語語料是由 6 名男性錄 音,閩南語語料是由 5 位錄音,客語語料則由 3 位錄音,每筆語料長度為 5 到 10 秒,內容則模仿電視台播報的短句。由於線外實驗結果顯示音調特徵對辨識 率無甚幫助,故為了節省運算時間,在此只使用圖 4-4 中的子系統(1)和(2)來進行 辨識。MFCC 特徵使用 12 維,差分間距設為 3。
在 MFCC GMM 的混合數方面,當訓練和測試語料特性差異太大時,過多的
混合數會導致輸出分數的偏袒,故需要重新進行混合數的實驗。不過 MFCC PPM
模型的 GMM 表徵器的混合數則只固定為 32,PPM 的階數設為 3 且使用 ppmc
之逃脫機率估計方法。依前術的模型參數設定,我們得到的實驗結果如表 4-3 所 示。在表 4-3 中,正確率代表該語言的測試語料被成功辨識的比率,平均輸分表 示誤判時正確語言分數的比誤判語言的分數低幾分,平均勝分則表示辨識正確時 正確語言的分數比分數第二高的語言高幾分。
表 4-3 線上系統之 MFCC GMM 混合數測試
混合數 正確率
Man Holo Hakka Man Holo Hakka
32 32 32 0% 10% 90%
50 50 50 0% 90% 90%
100 100 100 0% 70% 90%
100 50 50 0% 90% 90%
50 100 100 0% 70% 90%
256 256 256 0% 20% 90%
混合數 平均輸分 平均勝分
Man Holo Hakka Man Holo Hakka Man Holo Hakka
32 32 32 248 101 46 0 399 850
50 50 50 277 103 185 0 292 338
100 100 100 304 106 137 0 540 722
100 50 50 300 103 185 0 312 344
50 100 100 294 100 137 0 322 501
256 256 256 711 165 119 0 650 1228 若某語言的平均輸分小於另外兩種語言的平均勝分,則可用簡單的加分方式 來抵銷掉語言分數的偏頗現象。例如在混合數皆為 50 時,客語和閩南語間都有 90%的辨識率,國語的平均輸分 277 也低過另外二種語言的平均勝分 292 和 338,
故可對國語加分,不同加分數值的實驗結果如表 4-4 所示。在表 4-4 中,可以看 到加分太多會讓閩南語和客語誤判成國語的狀況變多,而加分太少則國語的辨識 能力又變得不好,故加上 250 分作為最終分數,此時的平均辨識率為 73%。
表 4-4 國語加分之實驗
國語加分 Man Holo Hakka Total 220 30% 80% 90% 67%
250 60% 80% 80% 73%
280 70% 70% 60% 67%
320 70% 60% 50% 60%
參考文獻
[1] 余伯泉、徐兆泉、吳長能,台灣語通用拼音,南天書局,台北,1999.
[2] 吳秀麗, 實用漢字台語讀音, 學生書局, 1997.
[3] 何石松、劉醇鑫, 現代客語詞彙彙編, 臺北市民政局, 2002.
[4] Gu, H. Y. a nd Shi u W. L. , “ A Ma nda r i n-syllable Signal Synthesis Method with Increases Flexibility in Duration, Tone a nd Ti mbr e Cont r ol ” , Proc. Natl. Sci.
Counc. ROC(A), Vol. 22, No.3, pp. 385-395, 1998.
[5] 李雪真, 客家語語音合成之初步研究, 碩士論文, 台灣科技大學資訊工程研 究所, 2002.
[6] 黃維,以混合模型產生閩南語音節基週軌跡之研究, 碩士論文, 台灣科技大 學資訊工程研究所, 2005.
[7] Chou, F. C., Corpus-based Technologies for Chinese Text-to-Speech, Doctoral dissertation, National Taiwan University, Department of Electrical Engineering, 1999.
[8] 張唐瑜,以大量詞彙作為合成單元的中文文轉音系統,碩士論文,國立中興 大學資訊科學研究所,2005。
[9] 蔡仲明,基於 GMM 及 PPM 模型的國、閩南、客語之語言辨識,碩士論文,
國立台灣科技大學資訊工程研究所,2007。
[10] Li, K. and T. Edwards, “ St a t i s t i c al mode l s f or a ut oma t i c l a ngua ge i de nt i f i c a t i on” , Proc. International Conference on Acoustics, Speech, Signal Processing, 1980.
[11] Zissman, M. A., “ Compa r i s on of f our a ppr oa c he s t o a ut oma t i c l a ngua ge i de nt i f i c a t i on” , IEEE Trans. Speech and Audio Processing, vol. 4, pp. 31-44, Jan.
1996.
[12] P. A. Torres-Carrasquillo, D. A. Reynolds, and J. R. Deller Jr., “ La nguage i de nt i f i c a t i on us i ng Ga us s i a n mi xt ur e mode l t oke ni z a t i on” , IEEE International Conference on Acoustics, Speech, Signal Processing, May 2002.
[13] Tsai, W. H. and W. W. Chang, “ Discriminative training of Gaussian mixture bigram models with application to Chinese dialect identification” , Speech Communication, Vol.
36, pp. 317-326, Mar. 2002.
[14] 林俊青,多國語言辨識系統之特徵設計研究,碩士論文,國立中山大學電機 工程研究所,2002。
[15] 張智傑,以高斯混合模型表徵器與語言模型為基礎之語言辨認研究,碩士論
文,國立清華大學電機工程研究所,2005。
[16] 郭頂益,多國語言辨識系統之設計研究,碩士論文,國立中山大學電機工程 研究所,1999。
[17] 古鴻炎、孫世諺、張小芬,「國語雙字語詞聲調評分系統」,第十八屆自然語 言與語音處理研討會(ROCLING 2006),新竹,第 77-89 頁,2006。
[18] Kaufmann, M., Data Compression, 2nd ed., Morgan Kaufmann, 2000.
附錄 A (期刊論文)
Computational Linguistics and Chinese Language Processing Vol. 12, No. 2, June 2007, pp. -
The Association for Computational Linguistics and Chinese Language Processing
A System Framework for Integrated Synthesis of Mandarin, Min-nan, and Hakka Speech
Hung-Yan Gu
, Yan-Zuo Zhou
, and Huang-Liang Liau
Abstract
In this paper, a framework for integrated synthesis of Mandarin, Min-nan, and Hakka speech is proposed. To show its feasibility, an initial integrated system has been built as well. Through integration, a model only trained with Min-nan sentences is used to generate pitch-contours for all three languages, same rules are used to generate syllable duration and amplitude values, and the same program module implementing the method, TIPW, is used to synthesize the three languages’
speech waveforms. Also, in this system, each syllable of a language has just one recorded signal waveform, i.e. no chance of unit selection. Under such a restricted situation, the synthetic speech signals still have noticeable naturalness level and signal clarity.
Keywords: Speech Synthesis, Pitch Contour Model, TIPW, Time Axis Warping.
1. Introduction
There are many languages in Taiwan, including Mandarin, Min-nan, Hakka, and others spoken by smaller population groups. Mandarin has been more extensively studied than the other languages because it is the official language. However, the successful construction of a synthesis model or system for Mandarin does not imply that the same modeling method can be directly applied to another language. Developing speech synthesis systems for other languages is strongly desired because Mandarin is not the mother tongue of most people in Taiwan, and all languages except Mandarin face the crisis of disappearance.
If systems developed or speech data collected previously can only be used for Mandarin, then further resources (effort and money) are inevitably needed to study other languages. Such a situation will become more severe if a corpus-based approach [Chou 1999; Chu et al. 2003]
is adopted. In addition, there will be inconsistency in prosody and timbre among