教育科學研究期刊 第五十六卷第一期 2011 年,
56 ( 1)
,
33-65
二階段分層叢集抽樣的設計效應、估計:
以 TIMSS 2007 調查研究為例
任宗浩 國立臺灣師範大學 科學教育中心 助理研究員譚克平
國立臺灣師範大學 科學教育研究所 副教授 摘要張立民
澳洲墨爾本大學 評估研究中心 副教授 大型調查研究常採用多階段分層叢集抽樣,檢視臺灣學生歷年來參與 TIMSS 研究的結果 顯示,其平均表現之標準誤常較他國稍大。應 TIMSS 專責抽樣之單位要求,本研究旨在推導 設計二階段分層叢集抽樣時即可預估標準誤的公式,以利選擇較佳分層架構,達減少標準誤 的目標,並進行三個分析檢查其有效性。分析一將 30 個參與 TIMSS 2007 的國家資料,用該 公式與 {TIMSS 技術于冊〉建議之刀切重複取樣法,分別估算各國學生平均科學成績之標準 誤,發現兩者之線性相關達 .98 0 分析二以 29 個連續參加 TIMSS 2003 和 2007 的國家資料, 論述利用該公式與現有輔助變項預估將要進行調查的誤差之實用性。分析三探討當叢集的分 層輔助變項為連續量時,不同分層數與二階段分層叢集抽樣誤差間的關係'以預估臺灣學生 在 TIMSS 2011 平均科學成績之標準誤 O 文後尚提出四階段的評估流程,供相關研究預估主要 依變項平均值之標準誤時做參考。 關鏈字:大型評量、抽樣架構計畫、降低抽樣誤差、複雜抽樣設計、變異量估計 通訊作者-任宗浩,E-mail: [email protected]
收稿日期 : 2010109/30 ; 修正日期 2011102108 、 2011/03/10 ; 接受日期 2011103115 。•
34
·減少標準誤之抽樣設計壹、前言
任宗浩、譚克平、張立民
近年來,隨著教育績效的觀念在國內外逐漸受到重視,我國一方面積極參與國際教育成 就調查,包括由國際教育學習成就調查委員會(
The International Association for the Evaluation
of Education Achievement
,
lEA) 所主持的「國際數學與科學教育成就趨勢調查 J(Trends in
International Mathematics and Science Study
,
TlMSS) 、「促進國際閱讀素養研究 J(Progress in
International Reading Literacy Study
,
PIRLS) 、「國際公民教育與素養調查計畫 J(International
Civic and Citizenship Education Study
,
ICCS) 以及由經濟合作暨發展組織 (Organisationfor
Economic Co-operation and Development
,
OECD) 所主持的「學生能力國際評估計畫 J(The
Programme for International Student Assessment
,
PISA) 等趨勢調查,希望能藉由國際比較來檢視我國教育實施之成效;另一方面,為了能夠建立國內教育相關資料庫以作為教育政策制定
之依據,也委託研究單位進行國內教育相關調查,如中央研究院主持的「臺灣教育長期追蹤 資料庫計畫 J
(Taiwan Education Panel
Surv句, TEPS) 以及國家教育研究院所主持的「臺灣學 生學習成就評量資料庫J(Taiwan Assessment of Student
Achieveme凹, TASA) 等調查。由於所有的調查都有誤差,所以愈是要求精確的調查,可以經由如較多的測驗或問卷題目,或更多 的樣本來使誤差變小 O 此外,任何一個大型調查在進行之前,應先針對主要的研究問題決定 可容許誤差的大小,再評估所擁有的資源(經費、人力、時間、事前資訊),並設法控制調查 誤差在可容訐的範圓;倘若無法將調查誤差範圍縮小到理想範圍內,則應避免輕易進行調查, 以免浪費時間與金錢 O 以樣本估計值推論母群參數時所產生的誤差來源,一般而言可以分為兩個部分:一部分 是來自於由母群抽取代表性樣本時所產生的抽樣誤差 (sampling
error)
,另一部分來自於針對 代表行為實施測量以推估整體行為的測量誤差(measurement error) 。就個人行為層級而言, 測量誤差也可視為對個人行為抽樣所產生的誤差(Adams,2005; Shavelson & Webb
,
1991)
0 以 樣本估計值推論母群參數的精確性,會和樣本大小以及抽樣方式有關,對於精確性的要求亦 隨研究或調查的目的而定。在同樣的抽樣架構下,樣本愈大,對於母群參數的推估會愈精確, 然而需要花費的人力、金錢與時間也愈多。以TlMSS 調查為例,雖然目的在調查參加國學生 的數學和科學能力,而非排序其平均能力,但為能協助各國評估其教育實施的成效,調查結 果仍需適度里現出各國學生平均能力的差異。於此,TlMSS 希望各國分數的 95%信賴區間範 圍能夠小於全球參加學生分數標準差的十分之一,相當於要求各國的標準誤小於0.05 個標準 差,因此在隨機抽樣時樣本大小至少約為400 人 (Joncas,2008)
0 可由於考量實際施測成本與 午 才票準差 在隨機抽樣的情況下,母群平均值的95%信賴區間約為士1.96 川止寺三。若要求其區間為士0.1 個標準差V
N
範圍內,則 N 至少約為 4000可行性, TIMSS 和許多大型教育成就調查測驗(如 PISA 和 TASA) 均非採用簡單隨機抽樣, 而改採二階段分層叢集抽樣設計 (two-stage
stratified cluster sample design)
:第一階段先針對 調查學生母群所在之學校分布進行分層取樣,第二階段再針對學校內部的學生進行抽樣。不 同的調查研究在第二階段抽樣時有些許不同:TIMSS (Joncas
,
2008
)和 TASA(http://tasa.naer.
edu.tw
)由抽樣各學校中隨機抽出 l 至 2 個班級作為樣本, PISA 則是由抽樣各校中隨機抽出相同學生數進行調查(
OECD
,
2009
)。然而,由於採取非隨機抽樣,對於所需樣本人數及抽樣 誤差的事前估計,就變得複雜許多 O 已有統計學者(如 Cochran,1963; Hansen
,
Hurwitz
,
&
Madow
,
1953; Kish
,
1965) 提出針對一階段分層抽樣以及叢集抽樣的誤差估計公式,但對於二階段分層叢集抽樣設計的誤差估計,似乎並無簡單的公式可用。本研究的主要目的在於導證 二階段分層叢集抽樣設計的誤差估計公式,並利用 TIMSS 2007 的資料庫檢視該公式之有效性。
TIMSS 調查會利用跨屆調查的共同試題,將跨屆間的調查量尺分數予以等化 (Fay,
Ga1ia
,
&
Li
,
2008)
,其量尺等化的方式以TlMSS 1995 為參照,將平均成績設為500 '標準差設為 1000 根據TIMSS 2007 調查結果,我國八年級學生的平均數學和科學成就分數為598 和 561'
標準誤分別為 4.5 和 3.7 '因此數學和科學成就分數的 95%信賴區間範圍均小於十分之一個標 準差而可接受。然而,如此的信賴區間範圍常使得幾個亞洲領先國家或地區(括我國、新加 坡、韓國、日本、香港)彼此之間的差異無法被區分,因此lEA 和負責進行 TIMSS 學校抽樣 的加拿大統計局(Statistics
Canada) 希望經由抽樣誤差的減少,使得我國八年級生平均成就之 標準誤能降到 3.0 量尺分數以下。而減少抽樣誤差的其中一種方法,可由事前評估以選擇較佳 的分層架構來達成。為了達到這個目標i ,本研究利用所推導出的公式,提出我國參加 TIMSS 2011 調查的學校分層架構,並針對此抽樣架構的抽樣誤差進行評估。 本文架構將包括以下幾個部分:首先,針對 TIMSS 2007 的抽樣架構及平均成就分數抽樣 誤差之估計予以介紹。其次,研究者將導證用以估計二階段分層叢集抽樣誤差的公式。第三 部分則包含三個分析:分析一,利用 30 個參與 TIMSS 2007 的國家(地區)的資料,檢驗該 公式之有效性;分析二,經由該公式分析 29 個參加 TIMSS 2003 和 TIMSS 2007 兩屆調查的國 家(地區) ,探討利用先前調查資訊以預估未來調查誤差之可行性;分析三,以我國即將進行 的 TIMSS 2011 調查之抽樣架構為實例,說明當分層輔助變項為一連續變項時,第一階段針對 叢集的分層數與抽樣誤差間之關係,並根據該公式預估八年級科學平均成就之抽樣誤差O 最 後,本研究針對二階段分層叢集抽樣之教育調查研究提出標準化的評估流程,使研究者在特 定分層抽樣架構下,應用於不同的教育調查研究,據以估計主要調查變項母群平均值之誤差。一、 TIMSS 2007 抽樣介紹
TIMSS
2007 調查針對全國學校和校內班級進行二階段分層叢集抽樣,說明抽樣方式如 後:•
36
.減少標準誤之抽樣設計 任宗浩、譚克平、張立民 (一)學校抽樣階段 在學校抽樣階段, TIMSS 採用分層抽樣方法。先依各國所提供的分類法將全國國中或國 小分為若干層 (strata) ,並依每一分類層人數占調查母群總人數之比例,估算出各分類層應抽 樣的人數不日班級數。之後,以各校每一層級學生人數占母群中該層級人數之比例,決定該校 被抽取為樣本的機率。此外, TIMSS 調查允許各參加國在學校抽樣階段,包含顯性分層( explicit
stratification) 和隱性分層(implicit
stratification) 兩種依據(Joncas
,
2008) :
1.顯性分層 目的是想藉由調查以推論不同層(子群)的特性。例如某參加國欲暸解不同學校形式(例 如:公立學校和私立學校)的教育成果是否有差異,則相關的統計量必須要能精確推估學校 形式的特性。因此,該參加國的抽樣架構,便應以涵蓋全國各種學校形式的母群為基礎,以 確保抽取出來的學校形式及學生樣本,能更準確地反映這些子群分布的比例。匈牙利
(Hungary
)便以地區發展程度為顯性分層依據,將學校分為城市學校或鄉村學校,臺灣及澳洲則單純地以行政或地理區域將學校分為不同于群(Foy
&
Olson
,
2009) 。2. 隱性分層
目的是為了減少學校層級的抽樣誤差,因此希望所抽取出來的樣本分布,能充分代表母 群的實際分布情形 O 若學校層次的隱性分層變項與該校學生在 TIMSS 調查中的平均成就相關
愈高,樣本的分布就愈能夠代表母群的分布。例如印尼( Indonesia) 等參加國 (Foy
&
Olson
,
2009
)先依據其他考試或成就調查結果將學校分為高、中、低三個不同成就層,再根據各層占整體母群之比例,估算出每層所應抽取的樣本數,然後決定各層所應抽出的學校數量。此 外,我國在 TIMSS 2007 的學校抽樣架構中,並未指定任何隱性分層變項,但由於TIMSS 考 慮到學校大小及該校被抽到的機率必須成正比(
probability proportional to school size)
,亦即學 校愈大被抽取為樣本的機率也就愈高,這種抽樣會確保隸屬不同規模學校的母群學生人數分 布能夠按比例被抽到 (Joncas,2008)
;換言之, ,-學校大小」可以視為內最於TIMSS 學校分 層架構的隱性分層變項。 因此,在 TIMSS 調查中屬同一分層的學校,亦即具有相同的的刀切變項(變項名稱 JKZONE) 的學校,是指同時具有相同的顯性分層變項(變項名稱ISATRATE) 及隱性分層變 項(變項名稱ISATRATI) ,且學校大小接近者。(二)校內班級抽樣階段
經過第一階段學校抽樣之後,第二階段的叢集抽樣(cluster
sampling) 係針對被抽到的學 校進行班級抽樣。校內班級的抽樣以每班等機率方式隨機抽出受測班級,被抽到的班級,其 整班學生均需接受調查施測 O 原則上每校抽取一班,但如果該校班級人數很少,可能會在同 一學校內抽取兩班,或是合{并其他類似背景學校的抽樣班級後,再將兩班學生合{并後,視為一個虛擬班級( pseudo-classroom) 。
二、 TIMSS 2007 調查的抽樣誤差估計
二階段分層叢集抽樣的精確性源自於兩方面所產生的效應:其一為叢集抽樣,另一方面 則來自於對叢集的分層方式,茲分別說明如後。 (一)叢集抽樣對抽樣誤差的影響 在叢集抽樣方面,因為同學校或同班級的學生共用相同的學校資源,例如,有相同的老 師、同樣的課程等等,所以同校或同班的學生會有較多相同的特質。叉如,由於人們易因社 經地位選擇居住區域,故當學生就讀於自家學區時,同一學區的學生便易來自相似的社經背 景,其成就差異也可能比來自不同學區的學生來得小 O 以下研究者舉兩個有關叢集抽樣設計 的特例加以說明: 1.假設所有的學生都是隨機地被分配到各個學校,此時,學校間同質性最高,而校內學生 的同質性最低。在此情況下,先隨機選取 150 所學校,然後從每所學校裡抽出 30 名學生去推 估母群平均值的抽樣誤差,等於從母群中簡單隨機抽樣 4, 500 名學生的抽樣誤差。 2.假設任一所學校內的每位學生是完全同質的,此時校間的異質性最高。在此情況下,由 於在任一校內所有學生的調查變項完全相同,因此只需抽出 l 位學生,就會知道同校其他所 有學生的資訊。在這種狀況下,利用二階段分層叢集抽樣先抽取 150 所學校,再從中各抽出 30 名學生,相當於從 150 所學校內各抽 1 名學生;最後有效樣本數便等同於 150 人。此時, 估計母群參數的抽樣誤差,等於隨機抽樣 150 個人的抽樣誤差。 實際上,沒有任何一個教育系統會符合這兩種極端的例子。一般而言,在相同樣本數下, 簡單隨機抽樣的抽樣誤差比叢集抽樣小。因此,利用簡單隨機抽樣抽出 4, 500 人,比起先抽出 150 所學校後,再從中各抽出 30 人的叢集抽樣方法,更能夠涵蓋母群的特質。(二)叢集的分層對抽樣誤差的影響
決定二階段分層叢集抽樣精確性的因素,除了叢集抽樣產生的效果外,還有對叢集的分 層方式。若第一階段針對對叢集的分層輔助變項(例如: TlMSS 調查中用來將學校分層的顯 性和隱性變項)和主要調查變項有高相關,以確保不同水準的叢集都能夠按比例被拍到,如 此叢集平均值的分布便較能表徵母群的實際分布。就可讓所抽出來的叢集平均值的分布比較 接近母群的分布。 至此,我們可以理解分層抽樣所具備的兩難問題 (dilemma) :如果沒有事先進行普查, 如何得到所有學校的平均成就資料?然而,如果已經得到了平均成就的普查資料,那叉何必 再進行抽樣調查?的確,各個叢集(學校或班級)在調查變項上(如TlMSS 測驗工具評量中 的數學或科學成就)的平均值不可能事先取得,但實際作法上研究者可善用過去的調查或相•
38
.減少標準誤之抽樣設計 任宗浩、譚克平、張立民 關資料庫的數據,以取得在叢集層次與調查變項相關的變項資料。以臺灣為例,利用國中九 年級生參加基本學力測驗的數學或自然科學平均成績,可為 TIMSS 調查時對學校層級的分層 依據。(三)二階段分層叢集抽樣的誤差估計
二階段分層叢集抽樣的精確性來自兩個階段的效應:在叢集的分層階段,可以讓抽樣的 結果比簡單隨機抽樣更具代表性;然而,在每一叢集層內的叢集抽樣結果,卻比簡單隨機抽 樣來得較不具代表性。由於這兩個對立的效應,使得許多大型調查無法以簡單公式用以推估 抽樣變異或統計值。但隨著資訊科技的發展,許多統計分析方法開始仰賴電腦快速運算來解 決這類問題。其中,利用現有樣本進行重複取樣便可用來推估母群參數誤差,例如平衡重複 取樣法 (balancedrepeated replications
,
BRR) (Plackett
&
Bunnan
,
1946) 、刀切重複取樣法(j
ackknife repeated replications
,
JRR) (Frankel
,
1971 )
,以及拔靴法(bootstrapping) (Efron
,
1979
)等等。除了重複取樣的技術外,有些軟體(如 SPSS) 則採用泰勒線性近似法(Taylor
linearization method) ( Demnati
&
Rao
,
2004)
,針對複雜的抽樣設計進行母群參數誤差的估計。根據 Lehtonen 和 Pahkinen
(2004
,
p.
165) 的研究結果,針對兩階段分層叢集抽樣調查的比例 統計量 (ratio estimators) 之誤差估計,無論採用線性法、平衡重複取樣法、刀切重複取樣法 以及拔靴法,所得到的誤差估計結果差異不大。在 TIMSS 國際報告中,採用 Frankel
( 1971
)針對三階段分層叢集抽樣所提之刀切重複取樣法的修訂方法來計算所有統計估計值的抽樣變異量 (Foy
et a
I.,
2008) 。根據 Frankel 的二階段抽樣刀切法,可設定重複抽樣加權值 (replicate
weights)
,在具有相同顯性分層變項的學校 中,選取隱性分層變項與學校大小最接近的2 所學校,將其定義為同一個刀切抽樣區(jackknifesampling
zone) 。因此, 150 所學校會配對成 75 組抽樣區。每一次重複抽樣,僅針對一個抽樣 區隨機去除 l 所學校的資料,與之配對的另一所學校權重則為二倍,而其他74 個抽樣區的 148 所學校權重維持不變。之後,將原始樣本之統計值。(如:平均、相關或迴歸係數等)及重複 抽樣 75 次所得之統計值。(i)(1
=1
,
2
, ...,
75) 代入式(1) ,以計算統計值。之抽樣變異量:4)= 之 (8(i)
- 8)2
、 EYl
J'E ‘、 一般而言,如果把 TIMSS 調查當作隨機抽樣,通常會低估統計量的標準誤,除非在學校 層級的分層輔助變項與調查變項有高相關。以我國八年級學生在 TIMSS 2007 的平均數學成就 估計為例,如果直接將之視為簡單隨機抽樣的結果,雖然對母群平均值( 598 分)的估計不會 產生偏誤,但是對於平均值標準誤的估計值( 2.1 分) ,卻會低於考慮複雜抽樣架構的刀切重 複取樣法所估計出來的結果( 4.6 分)。而統計量標準誤的低估,會導致統計檢定不當推論的 後果。前述幾種估計複雜抽樣調查誤差的方法,均適用於調查完成後。然而,一個大型調查若 無法在事前精準估計其誤差,待事後才發現誤差太大,已難收亡羊補牢之效。本研究所導證 的公式,可供未來的研究者,藉由該公式與可利用的輔助資訊,於調查進行前及特定分層叢 集抽樣架構下,預估主要調查變項的抽樣誤差。 三、二階段分層叢集抽樣調查的設計效果 此部分所導證的公式,可用以估計二階段分層叢集抽樣調查的抽樣誤差。首先,將設計 效果(
design
effect) “DJ定義為:在相同的樣本數下,特定抽樣架構相對於簡單隨機抽樣方 式,其抽樣變異量的比值 (Hansenet
此, 1953;Kish,1965):
D
eff =Var
SF(主)/
Var
SRS(王)(2)
其中, Var
SF
( 王)和 VarSRS
(王)分別代表特定抽樣架構與簡單隨機抽樣方式下,對母群平均值(王)的估計變異量。由式(2)可得到對王估計之標準誤SE
SF
( 主)為:風F 仙
(3)
其中正為變異量的不偏估計'n 為樣本數 o Hansen 等(
1953
)推導一階段叢集抽樣設計(
one-stage cluster sample
design) 的設計效果( Deff
山
ster) 為:D
eff cluster = [1十 ρ(b-1)] 在式(4) 中 , b 為叢集內樣本數,而 ρ 為叢集內相關,並定義 ρ 為: 2 ρ=1-
Sw州n手lustern
s"n-1
(4)
(5)
式的中, s;伽啪啪為叢集內樣本變異量的不偏估計。若各叢集樣本數不同,Donner 和 Klar(1
994
)建議可以利用加權後的平均叢集樣本大小 b'
取代式(4)中的 b 0 其數學表示如下:b'
一寸
r
_b_
iIb
=
'f.:
1b
i 2 一 )I--'-Ib=一一-frwjLlh j
tztlbf
(6)
式(6)中 'm 是所抽取的的總叢集數量,而bi
為第i 個叢集內的樣本數。 對於二階段分層叢集抽樣而言,每一分層內的叢集抽樣就相當於一階段的叢集抽樣。因 此,由式(3)和式(4)即可得到對於第h 層內平均值的估計變異量為:•
40
.減少標準誤之抽樣設計 任宗浩、譚克平、張立民Var(x
h)~
[1
+的 (b~ -l)]~
n
h(7)
其中下標 h 代表在第 h 個分層內,而舟,丸,4 , nh 則分別為第 h 層內的叢集內相關、加權
後的平均叢集內樣本數、層內變異量的不偏估計以及樣本大小。若W h 為第 h 個分層之權重, 由於
x= LhW
h丸,根據簡單的變異數運算公式(Dorofeev& Grant
,
2006
,
Eq.
3-2)以及式
(7):
V
州
=Zw;varmzZw;MJbh
lHT
(8)
如果以下三個假設可以成立,式(8)就可以被大幅簡化:
(一)假設一
跨層等抽樣比例(
equal sample fraction across
strata) 。對一個均等機率的抽樣設計(Equal
Probability of Selection Method
,
EPSEM
)而言,每一個分層內所抽出的樣本數應該與母群在該 層內的總人數呈正比。也就是: J/ν一-n-N
一一叫一凡
一-FA --一 fhu --F 力 一 fh 川(9)
其中'h
代表在第 h 個分層中,樣本數nh 與母群人數凡的比例 ,
n和N為總樣本數與母群人
數。因為每個人被抽到的機會相等,所以各層的權重(w
h ) 就會與該層的總人數成正比,因 此N
,n.
W, =-"=一主"
N
n
、‘ a/ AVl
/4. 、 (二)假設二跨層等加權平均叢集大小(
equal weighted average cluster size across strata)
,即滿足'。 一一
,
H '。 一一 一一',"
,。 一一=
'弓 b '。 一一 ,。 ' 、‘',/ •• A 咀 El i-、 (三)假設三均等分層(
equal stratum size)
,亦即各分層內所包含之母群人數均相同。這個假設配合前m
1=m
2=...=m
h=...=m
H=m
(1
2)
其中 m
h
為第
h分層抽出的叢集數。這個假設看似嚴苛,但先前提過在TIMSS 調查的抽樣設計下,同一分層(具相同的JKZONE 變項)僅抽出 2 所學校,每所學校又抽出約相同的人數卜
個班級) ,所以各分層內抽出的樣本數大約相等;又因為整個抽樣設計基本上遵守EPSEM ,各
分層內樣本之總加權值也大約相等,所以各層內包含的母群人數應很接近。實際上,只要叢 集的抽樣遵守叢集抽樣機率正比於叢集大小的原則(
Probability Proportional to Size
,
PPS )
,我 們都可以經過現有分層架構,加上叢集大小,定義出新的分層方式,將具有相同分層變項與 大小最接近的兩個叢集視為同一層。 真實的抽樣通常不符合上述三項假設,然而為了符合真實的情況,將使得所推導的公式 變得相當複雜,如此一來便失去了本研究希望能夠提供一個簡單的公式,讓研究者藉以提出 適當的抽樣架構之本意;關於違反上述各項假設所可能導致的影響,將會是未來研究的努力 方向。在許多時候,即使接受這些假設,仍然可以對抽樣誤差提供很好的近似估計,這一點 本研究的分析一將以 30 個參與 TIMSS 2007 之國家(地區)的釋出資料作為實例進行檢驗。 若接受上述三個假設,式(8)可以改寫為(導證過程請見附錄):
σ2+b'(σ2
一 σ2 ,_
.. . . L ' ) Va訂r(主)~ wit廿枷tn
(1
3)
式(13)中, σLthIn心ster 為叢集內的變異量, σ;咖恥cluster 為叢集間的變異量, σLXIII叮叫帥為被
叢集層級的分層輔助變項所解釋的叢集間變異量:茲說明其意義如後O
我們利用圖 l 說明母群參數的變異量被叢集的分層輔助變項、叢集間以及叢集內解釋之
比例 O 在一階段叢集抽樣的情況下,母群參數的變異量(σtLal) 可以被分解成叢集間的變異
量 (4tweencluster) 加上叢集內的變異量(σ;此枷
σ2 _σ2+σ2total -... between-cluster I ...within-cluster
(1
4)
在二階段分層叢集抽樣的設計下,叢集間變異量(也就是叢集平均值的變異量)的一部分 (σιl間叫able) 被叢集的分層輔助變項(例如以學校為叢集單位時,學校分層的輔助變項
可能為學校大小、學校型態或學校所在區域的發展程度等等)所解釋,如式(1日:•
42
.減少標準誤之抽樣設計 任宗浩、譚克平、張立民σiota
〈三〉
σbelwecn-c1 uster 三 pσt~)(al
' ' , 、' 、' 、' ,
σ已i州 elustcr
...~----戶句甸甸恤σbuxliiaη--variable
7 _. _7σrcsidual==
<:PP σ的tal ‘\i三 (l-<:p )pσ心
σil山in-cluster
' E
-愉喃 惆. -司 .、 d 、 ,f,',、 h 4 、 , '、 Ie 、 、' 、,σz
bcIMCcn-sIrata=σ弘肌ilia!、 -varia
H〈吋吋心圳
l刊川岫t廿仙伽伽州
h叫仙仙111叫叫1
h=l 團 l 統計估計變異量的成分分析 2 =σ+σbetween-cluster -...,auxiliary-variable I ...,residual
(15)
其中 σ;S1dual 為未被分層輔助變項所解釋的叢集間變異量。定義ψ 為叢集的分層輔助變項解釋叢
集間變異量的比例: σ2 pauxil叫 variable 2 σbetween-cluster(16)
如果對叢集的分層將同一層內各叢集之分層輔助變項控制成完全相同(通常只發生在叢集的 分層輔助變項為類別變項時),按照圖 l 的概念,則所有層內的變異量總和應為: H乞討=(卜 ψ)σLtween〈luster+σ;枷
(1
7)
式(17)中,各個分層內樣本變異量之總和2:7=1σ; 比起在式(14)中,所有樣本之總變異量σLal 少了被分層變項解釋掉的部分 ψσ;etwmclum 。同時,我們也可以化簡式(5)如下:
2 ρ:::::1 _ SWithin~c1ustern
S2 n 一 1 σ2 between -cluster ~一一 σ2 total(1
8)
在簡化式(18)的過程中,我們將(n-l)/n 和(b'-I)/b'當作卜這個近似在叢集樣本很小的時候 偏差會比較大。 進一步將式(16)和式(18)帶入式(13)式可以得到:+0, {σ2
一 σ2
T . . _ __'..L'-) within -cluster I l . / 、 between-cluster "-' auxiliarv-variableJYare主);:::; 、
n
=[-b
σWI伽-elus阻r l , σbetwe凹-dusterσ叫Ii盯 variable|σto個l〉 +(σ 一 σJ] 一
2 2 \2 ~ I 2 2
total \...,total ...,total J
;:::;
[(I一 ρ) 十 b (ρ 一 ρψ) ]﹒ VarSRS
(王)起 {[I +ρ(b
'-I)]ρ 帥,}× 34
n
-1(1
9)
最後根據式(1 9)的結果,可以獲得經由二階段分層叢集抽樣進行母群平均值估計的標準誤為: SEtwostagczd[l+ρ(b' -I) 一 ρ 帥,]×旦T
n-J 其中 一 σtotalDeft~two-stage
n
-I
(20)
D叭two-st咿 ;:::;1+ρ(b -I)ρψb(21 )
在式(20) 中, σtLal 為所有樣本的變異量, ρ 為叢集內相關 , b' 為叢集平均大小 'n 為總樣本數,
而 ψ 則是叢集平均值的變異量被叢集的分層輔助變項所解釋的比例 O 考慮以下四種情況: (一)當叢集的分層輔助變項解釋叢集平均值變異量的比例趨近於 O 時 (ψ 二o)
,就如同 我國在 TIMSS 2007 的數據一樣(這一點稍後會在分析一的結果中進一步地討論) ,式(21 )可以 簡化為 Hansen 等(1953
)針對一階段叢集抽樣所推導出的設計效應(如式 (4) )。換句話說,.
44
.減少標準誤之抽樣設計 任宗浩、譚克平、張立民 在此種情況下,叢集的分層對於降低抽樣誤差並沒有任何的幫助。 (二)如果叢集內相關和叢集的分層輔助變項解釋叢集平均變異量的比例均為O (ρ=ψ=0) ,式(20)的右方等於 1 。在這個情況下,二階段分層叢集抽樣的母群平均值之抽 樣誤差會等於以簡單隨機抽樣方式抽出相同樣本數所估計母群平均值的誤差。 (三)如果叢集內相關和叢集的分層輔助變項解釋叢集平均值變異量的比例均為l (ρ=ψ=1) ,根據式(20)可以計算出對母群平均值的估計誤差為0 。首先,叢集內相關等於 1'
代表沒有叢集內的變異量。換句話說,個人層級的變異量可以完全被叢集間的變異量所解釋; 其次,叢集間的變異量又完全可以被叢集的分層輔助變項所解釋:這表示利用這個分層抽樣 的架構所抽出的樣本可以完全反映母群的分布,所以對母群平均數的估計誤差應為 o 0 (四)如果抽樣設計效果等於 l 且叢集內相關不為 0 ,即: 1+ρ(b 一 1) 一 ρψb =1
我們可以求出一個叢集平均與叢集的分層輔助變項之相關闌值(科):
(22)
(23)
當叢集的分層輔助變項與叢集平均值問之相關大於仗時,設計效應有可能小於卜此時對於母 群平均值的估計誤差會比簡單隨機抽樣的情況來得更小。換句話說,雖然叢集抽樣的有效樣 本數不如簡單隨機抽樣,但是透過在叢集層次有效的分層,所抽出來的樣本仍然有可能比簡 單隨機抽樣的樣本更能代表母群的分布。 接下來,本研究將利用三個分析來檢驗式(20)有效性及實用性:分析一利用30 個參加TIMSS
2007 調查的國家(地區)之釋出資料,比較利用式(20)和刀切重複取樣法的誤差估計 結果;分析二利用連續參加TIMSS 2003 和 TIMSS 2007 的 29 個國家(地區)的資料,探討利 用式(20)以及現有輔助資訊預估將要進行調查的誤差之實用性;分析三探討當叢集的分層輔助 變項為連續變項時,不同分層數與三階段分層叢集抽樣調查誤差間的關係,並藉以預估我國參加 TIMSS 2011 八年級生科學平均成就之誤差。
貳、分析一
分析一的主要日的為針對二階段分層叢集抽樣設計,檢驗以式(20)估算母群平均值抽樣誤 差之有效性。本研究利用 TIMSS 2007 資料庫中 30 個參加國(地區)的釋出資料(The
International Association for the Evaluation of Education Achievement
[lE
A]
,
2009)
,計算式(20)中技術手冊〉建議之二階段刀切重複取樣法所估計出的誤差(
SE
JRR )(Martin et a
I.,
2008
)。 為了估計 SEtwo
-s
峙,研究者必須知道式(20)中變項 n' b' 、 ρ 、 σ叫和伊等數值。其中 n 為總樣本數 b' 為平均叢集內樣本數。對於大部分的國家,除了班級人數很少的學校會抽兩 個班組合成一個虛擬班級以外,每個學校只抽取一個班級,所以 b'
大致可以視為平均每個學
校所抽取的樣本數:惟在TIMSS 資料庫內認定之叢集並非完全以班級為準'而是將同時具有 相同的刀切區間 (JKZONE) 以及相同的刀切重複取樣變項 (JKREP) 之學生視為同一叢集; ρ 為叢集內相關,在這裡係指班級內學生科學成就分數之相關 ;σ叫為全國八年級生科學成就 分數之標準差;最後, ψ 為學校分層的輔助變項(包含隱性變項和顯性變項)解釋叢集問學生 科學平均成就變異量的比例。 利用 TIMSS 2007 資料庫中各國學生背景資料檔案(檔案名稱為bsg***m4.s前, ***為參 加國代碼)中的學校代碼(變項名稱 IDSHOOL) 、刀切區間變項、刀切重複取樣變項、學生總權重(變項名稱 TOTWGT) 以及每位學生的 5 個似真值 (plausible
values)
(變項名稱BSSSCIOI-BSSSC
I0
5
)可以計算得到 n 、 b' 以及 σ叫。班級內相關 ρ 是利用 HLM 6.08 軟體求 出叢集間與叢集內變異量後,依據式(1 8)計算獲得。 ψ 則是利用同一學校分層內的 2 所學校受 測學生平均成績之相關求得,就像是古典測驗中兩個平行測驗觀察分數的相關相當於任一觀 察分數與真分數相關的平方,我們很容易利用隨機誤差模型證明同一學校分層內任 2 校平均 成績之相關,其期望值會等於於學校分層輔助變項解釋層內所有學校平均成績變異量之比 例。須注意的是根據此法求出之 ψ' 在概念上應該介於 O 和 l 之間,但實際的數值是介於-∞到 l 之間 ;ψ 為負值的情況通常發生在真實的 ψ 很接近 O 的時候,主要的原因來自於取樣的誤差( Kru
s
&
Helmstad尉,1993; Solomon
,
2004)
,如表 l 中,韓國 (Korea) 、馬來西亞(Malaysia)
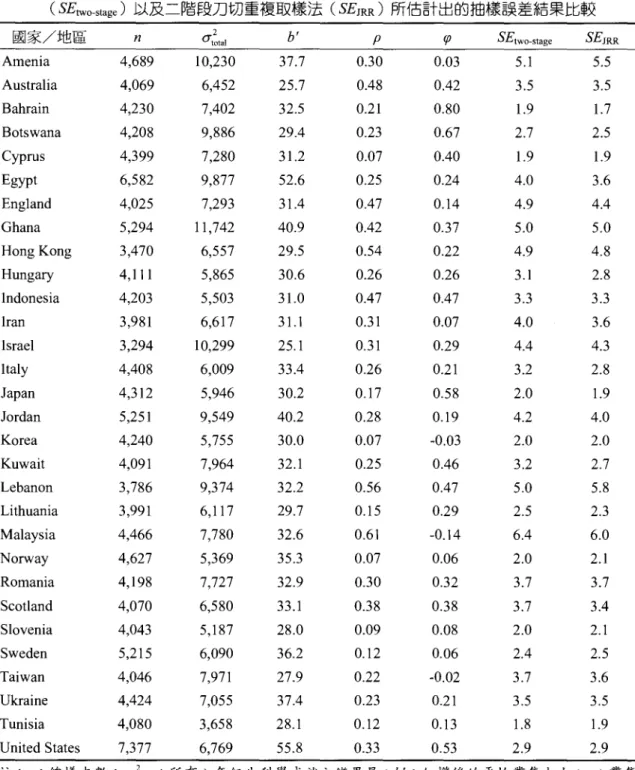
和臺灣 (Taiwan) 的情況。在 TIMSS 資料庫中,所謂同一學校分層係指具有相同刀切區間變 項而言,且 σ叫、 ρ 和伊的計算均是經過將每個學生經由學生總權重加權後,分別利用學生科 學成績的 5 組似真值求得 5 個統計量後取平均值而得。 表 l 針對參加 TIMSS 2007 的 30 個國家之八年級科學成就,呈現分別利用式(20)所計算出各國八年級平均科學成就分數之誤差(SEt削-stage) 以及利用 TIMSS 2007 技術手冊中所建議之
刀切重複取樣法所計算獲得之誤差(SEJRR
) ; 其中,各國(地區) SEJRR
會比國際報告上的各 國分數標準誤值稍小,因為後者有加進測量工具的誤差。分析結果顯示,對於各國(地區) 八年級生的科學平均成就來說,兩種方式所估計之誤差非常接近。除了對科威特( Kuwait) 和 黎巴嫩 (Lebanon) 2 個國家,兩種估計法所求出之誤差差異較大(分別為0.5 和 0.8 個量尺分 數,約為 19%和 16%) 以外,其他國家的差異大都在10%以內,有 20 個國家(地區)的差異 介於 0.0 至 0.2 量尺分數之間。兩種方式所估計出來的誤差,其相關為0.98 (如圖 2) ,這個結 果顯示,雖然式(20)的推導基於三個較嚴苛的假設,但是用來作為抽樣誤差的評估依據,仍具 有非常好的近似結果。•
46
.減少標準誤之抽樣設計 任宗浩、譚克平、張立民表 1 針對 30 個 TIMSS 2007 參加國家(地區)之八年級生的科學平均成就,利用式(l日
(
SEtwo
-s
阻
ge) 以及二階段刀切重複取樣法 (SEJRR
) 所估計出的抽樣誤差結果比較國家/地區
n
、Jt2otal
b'
ρ 伊SEtwo-stage
SE
JRRAmenia
4
,
689
10
,
230
37.7
0.30
0.03
5.1
5.5
Australia
4
,
069
6
,
452
25.7
0
.4
8
0
.4
2
3.5
3.5
Bahrain
4
,
230
7
,4
02
32.5
0.21
0.80
1.
9
1.
7
Botswana
4
,
208
9
,
886
29
.4
0.23
0.67
2.7
2.5
Cyprus
4
,
399
7
,
280
3
1.2
0.07
0
.4
0
1.
9
1.
9
Egypt
6
,
582
9
,
877
52.6
0.25
0.24
4.0
3.6
England
4
,
025
7
,
293
3
1.
4
0
.4
7
0.14
4.9
4
.4
Ghana
5
,
294
11
,
742
40.9
0
.4
2
0.37
5.0
5.0
HongKong
3
,4
70
6
,
557
29.5
0.54
0.22
4.9
4.8
Hungary
4
,
111
5
,
865
30.6
0
.2
6
0.26
3.1
2.8
Indonesia
4
,
203
5
,
503
3
1.
0
0
.4
7
0
.4
7
3.3
3.3
Ir
an
3
,
981
6
,
617
3
1.
1
0.31
0.07
4.0
3.6
Israel
3
,
294
10
,
299
25.1
0.31
0.29
4
.4
4.3
It
aly
4
,4
08
6
,
009
33
.4
0.26
0.21
3
.2
2.8
Japan
4
,
312
5
,
946
30.2
0.17
0.58
2.0
1.
9
Jordan
5
,
251
9
,
549
40.2
0.28
0.19
4.2
4.0
Korea
4
,
240
5
,
755
30.0
0.07
-0.03
2.0
2.0
Kuwait
4
,
091
7
,
964
32.1
0.25
0
.4
6
3.2
2.7
Lebanon
3
,
786
9
,
374
32.2
0.56
0
.4
7
5.0
5.8
Lithuania
3
,
991
6
,
117
29.7
0.15
0.29
2.5
2.3
Malaysia
4
,
466
7
,
780
32.6
0.61
-0.14
6
.4
6.0
Norway
4
,
627
5
,
369
35.3
0.07
0.06
2.0
2
.1
Romania
4
,
198
7
,
727
32.9
0.30
0.32
3.7
3.7
Scotland
4
,
070
6
,
580
33.1
0.38
0.38
3.7
3
.4
Slovenia
4
,
043
5
,
187
28.0
0.09
0.08
2.0
2.1
Sweden
5
,
215
6
,
090
36.2
0.12
0.06
2
.4
2.5
Taiwan
4
,
046
7
,
971
27.9
0.22
-0.02
3.7
3.6
Ukraine
4
,
424
7
,
055
37
.4
0.23
0.21
3.5
3.5
Tunisia
4
,
080
3
,
658
28.1
0.12
0.13
1.
8
1.
9
United States
7
,
377
6
,
769
55.8
0.33
0.53
2.9
2.9
註: n: 總樣本數 ;qLal: 所有八年級生科學成就之變異量 , b' 加權後的平均叢集大小 ;ρ: 叢集 內相關;伊:相同分層內(具有相同的 JKZONE 變項)叢集平均科學成就之相關SE
JRR A且可司、d(量尺分數
、、./7
6
5
2
O
0 1 2 3 4 5 6 7
SEt附 w削0叫-圖2 針對3到O個TIMSS 2007參加國(付i地也區) /八1年級生科學成就平均之抽樣誤差, 兩種估計法估計結果之分布相關參、分析二
雖然分析一的結果顯示,藉由式(20)能夠相當準確地估計二階段叢集抽樣的調查誤差。但 研究者若要利用此公式在調查進行之前先行評估調查的誤差,其中除了樣本大小(n) 以及平 均叢集大小(的可以在事前估計外,叢集內相關(ρ) 、叢集的分層輔助變項解釋叢集平均值 變異量的比例 (ψ) 以及調查變項的標準差(σ叫)均無法在事前得知,幸而在某些特定的情況(例如 TIM鈞、 PIRLS 或 PISA 調查以學校或班級為叢集調查某個年段學生的平均成就)
,
透過其他調查所提供的數據通常相當穩定。
本研究根據 TIMSS 2003 和 TIMSS 2007 的資料 (IEA, 20的, 2009) ,針對連續參加兩屆調 查之 29 個國家或地區,利用統計軟體 HLM 6.08 計算出各國(地區)八年級生科學成就的班
級內相關;且由式(20)可知班級內相關 ρ 對於誤差估計的影響小於 JP 變化的比例,表 2 的結
果顯示如果分別以 TIMSS 2003 調查的班內相關和 TIMSS 2007 調查的班內相關估計 TIMSS 2007 母群平均值的抽樣誤差,除了巴林 (Bahrain) 與瑞典( Sweden) 有較大的差異外,其他 18 個國家(地區)對抽樣誤差的估計產生之差異小於 10% 、 9 個國家小於 20% 。由此看出,將 TIMSS 2003 調查的班級內相關作為 TIMSS 2007 調查時,班級內相關的近似值,對其中
大部分國家(地區)已經可以提供很好的抽樣誤差估計。但兩屆調查畢竟間隔 4 年,如果能 利用更近期的調查資訊,或許可以提供更好的近似估計。以臺灣中小學生學科成就的校內相
•
48
.減少標準誤之抽樣設計 任宗浩、譚克平、張立民 表 2 連續參加 TIMSS 泊的與 TIMSS 2007 兩屆調查之 29 個國家(地區)的班級內相關之比較 國家(地區)0.
0030.
0070.
003/0.
007Jρ2叫 ρ2晰
Annenia
0.21
0.30
0.70
0.84
Australia
0.39
0
.4
8
0.81
0.90
Bahrain
0
.1
0
0.21
0
.4
8
0.69
Cyprus
0.09
0.07
1.
29
1.1
3
Egypt
0.28
0.25
1.1
2
1.
06
England
0
.4
8
0
.4
7
1.
02
1.
01
Ghana
0.32
0
.4
2
0.76
0.87
Hong Kong SAR
0
.4
8
0.54
0.89
0.94
Hungary
0.26
0.26
1.
00
1.
00
Indonesia
0
.4
6
0
.4
7
0.98
0.99
Iran
0.24
0.31
0.77
0.88
Israel
0.26
0.31
0.84
0.92
It
aly
。.280.26
1.
08
1.
04
Japan
0
.1
1
0
.1
7
0.65
0.80
Jordan
0.21
0.28
0.75
0.87
Korea
0.07
0.07
1.
00
1.
00
Lebanon
0
.4
4
0.56
0.79
0.89
Lithuania
0
.1
6
0
.1
5
1.
07
1.
03
Malaysia
0.50
0.61
0.82
0.91
Norway
0.08
0.07
1.1
4
1.
07
Romania
0
.4
0
0.30
1.3
3
1.1
5
Russian Federation
0.34
0.31
1.1
0
1.
05
Scotland
0
.4
5
0.38
1.1
8
1.
09
Singapore
0
.4
4
0.50
0.88
0.94
Slovenia
0.07
0.09
0.78
0.88
Sweden
0.22
0
.1
2
1.
83
1.3
5
Taiwan
0.25
0.22
1.1
4
1.
07
Tunisia
0.14
0.12
1.1
7
1.
08
United States
0.37
0.33
1.1
2
1.
06
關係數為例,利用 PIRLS 2006 的數據所估計臺灣小學四年級學生閱讀成就的班內相關為 0 .1'
而 TIMSS 2007 的數據顯示小學四年級數學和科學成就的班內相關分別為.1和 .08 。因此,若 利用 PIRLS 2006 臺灣小學四年級閱讀成就之班內相關作為 TIMSS 2007 臺灣小學四年級之數學或科學成就之班內相關,亦可提供很好的估計結果。
另一個影響估計誤差的重要變項是叢集的分層輔助變項解釋叢集平均值變異量的比例 (ψ) 。這個數值會隨著分層輔助變項與調查變項的叢集平均值之間的相關愈高而愈大。如果 在調查前能夠利用現有的資料庫,或其他的調查結果提供有利的資訊,作為學校分層的輔助
變項,就可以大幅減小調查結果的誤差。我們仔細檢視連續參加 TIMSS 2003 和 TIMSS
2007
的 29 個國家在兩屆調查的學校分層變項 (Foy
&
Olson
,
2009;
Martin
,
2005)
,發現僅有 6 個國家在兩屆調查中採用完全相同的學校分層變項;此外,臺灣在TIMSS 2003 的學校抽樣架構中 除了利用學校所在的地理區域外,比參加TIMSS 2007 時多了一個班級性別的隱性分層變項。 由於對於臺灣的學生而言,兩屆調查的結果均顯示無性別差異,所以是否加上性別作為學校 分層的隱性變項,差異應該不大。利用這7 個國家在 TIMSS 20的調查結果算出的班級內相關 (ρ) 與叢集的分層輔助變項解釋叢集平均值變異量的比例(ψ) 作為各國在TIMSS 2007 調查 的對應變項的近似用以估計各國在TIMSS 2007 的抽樣誤差,表3 的結果顯示,除了亞美尼亞 (Armenia) 和馬來西亞 (Malaysia) 的估計結果與實際調查結果差距較大(分別低估37%和
28%)
;其他幾個國家(地區),兩者的差異從低估2%至高估 19% 。但作為事前的預估,仍屬 同一個數量級,並不算太差o 表 3 利用 TIMSS 2003 相同的抽樣架構所計算的班級內相閱(ρ) 與叢集的分層輔助變頂解釋 叢集平均值變異量的比例(ψ) 估計 TIMSS 2007 調查誤差與利用刀切重複取樣法所得 到之誤差比較 國家b'
SE
(200312007JSE
JRRSE(2003/20071 / SE
JRR (地區)n
ρ。
9Armenia
4
,
689
37.65
0.21
-0.04
0.034σAnnenia 0.054σArmenia0.63
Cyprus
4
,
399
31.20
0.09
0
.4
9
0.023σCypru 0.023σCyprus0.98
Indonesia
4
,
203
3
1.
00
0
.4
6
0.35
0.047σIndonesia 0.044σIndo肘岫1.
06
Israel
3
,
294
25.10
0.26
0.34
0.034σIsrael 0.042σIsrael0.85
It
aly
4
,
408
33
.4
0
0.28
0.25
0.043σItaly 0.036σItaly1.1
9
Malaysia
4
,
466
32.64
0.50
0.13
0.049σMalaysia 0.068σMalaysia0.72
Taiwan
4
,
046
27.90
0.25
-0.04
0.039σTaiwan 0.040σTaiwan0.97
最後一個決定各種估計方法所得誤差大小的最重要因素且無法在事前得知的重要數據就
是樣本的變異量(
O"t:tal )
,或是樣本的標準差 (σte岫叫
o
時fl候|侯吏,尤其是非跨群體比較的調查,主要調查變項的標準化分數量尺都是以樣本的標準差
•
50
.減少標準誤之抽樣設計 任宗浩、譚克平、張立民來代替的情形。如果是在像TIMSS 這類跨國比較的國際調查中,換算成統一的國際量尺時,
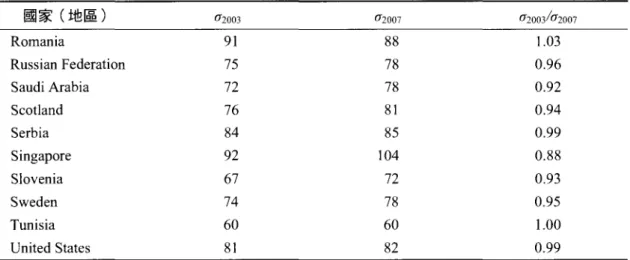
就必須知道各國學生的標準差(吼叫)相當於多少國際量尺分數。表4 列出同時參加 TIMSS
2003 與 TIMSS 2007 的各國(地區)八年級生科學平均成就之標準差,不難發現,除了亞美尼 亞 (Armenia) 、香港 (Hong Kong) 、以色列( Israel) 、馬來西亞 (Malaysia) 以及巴勒斯 坦(
Palestinian Na
t'
l
Auth.) 等 5 個國家(地區)的八年級生在兩屆調查時,科學成就標準差 的差異比較大之外,其餘有 6 個國家(地區)的差異大約都在 15%'
18 個國家(地區)的差 異在 10%以內。因此,即使有需要在事前預估調查變項的標準差,利用過去類似的研究結果 作為估計的依據通常也可以作為相當好的參考 O 表 4 比較連續參加 TIMSS 2003 與 TIMSS 2007 趨勢調查國家(地區)在兩屆調查中八年級 科學成就標準差的比較 國家(地區) σ2003 σ2007 σ'2003;4σ2007Armenia
81
101
0.80
Australia
75
80
0.94
Bahrain
74
86
0.86
Botswana
86
99
0.87
Bulgaria
93
103
0.90
Taiwan
79
89
0.89
Cyprus
79
85
0.93
Egypt
10
國499
1.
05
England
77
85
0.91
Ghana
120
108
1.
11
Hong Kong
,
SAR
66
81
0.81
Hungary
76
77
0.99
Indonesia
79
74
1.
07
Iran
,
Islamic Rep. of
73
81
0.90
Israel
85
10
0.84
It
aly
78
78
1.
00
Japan
71
77
0.92
Jordan
89
98
0.91
Korea
,
Rep. of
70
76
0.92
Lebanon
93
97
0.96
Lithuania
70
78
0.90
Malaysia
66
88
0.75
Morocco
69
79
0.87
Norway
70
73
0.96
表 4 (續)比較連續參加 TIMSS 2003 與 TIMSS 2007 趨勢調查國家(地區)在兩屆調查中 八年級科學成就標準差的比較
國家(地區)
σ2003
σ2007
σ2003;;σ20們
Romania
91
88
1.
03
Russian Federation
75
78
0.96
Saudi
Ar
abia
72
78
0.92
Scotland
76
81
0.94
Serbia
84
85
0.99
Singapore
92
104
0.88
Slovenia
67
72
0.93
Sweden
74
78
0.95
Tunisia
60
60
1
υ00
United States
81
82
0.99
肆、分析二
在分析三中,我們進一步考慮當叢集的分層輔助變項為連續變項的情形。此時,由式 (20) 可推論母群平均值的抽樣誤差下限為:S£LB
~
,/{[
1
+ρ(b' 一 1)]
-
pr勻, }XZL了
n - l(24)
其中 r 為叢集的分層輔助變項與叢集平均值的相闕, r2即為該輔助變項解釋叢集平均值 變異量的比例,相當於式(20)中的 ψ 。當在每一個針對叢集的分層內,所有叢集的分層輔助變 項完全一樣時,式(24)中的等號才會成立。因此,若叢集的分層輔助變項為連續變項時,除非 叢集的分層數為無限大,或是每個叢集自成一層,否則此一條件將無法滿足。本分析將探討 當分層輔助變項為連續變項時,分層數(H) 與母群平均值估計誤差(S£) 的關係。 當叢集的分層輔助變項(A) 為連續變項時,若假設所有叢集之分層輔助變項大小為常態分布,則在每一層內各叢集輔助變項的變異量(σ;h);之糖和 (zilσ:h) 會和分層數 (H) 有
關 O 一般而言,層內叢集輔助變項之變異量總和會隨著分層的數量增加而減少。Cochran( 1963
)證明在一階段分層隨機抽樣設計下,利用分層輔助變項進行最適配置(optimal
山ca川山分層抽樣時分層輔助變項解釋總變異量比例約為(1 前所謂最適配
置的分層抽樣係指每一層內所抽取的樣本人數應正比於分層輔助變項在該層內的標準差;也 就是說,分層輔助變項變異愈大的層內,應抽取愈多的樣本,此抽樣方式可以使得整體抽樣 誤差達到最小值。•
52
.減少標準誤之抽樣設計 任宗浩、譚克平、張立民 除了最適配置分層抽樣法之外,另一個常見的分層方法為利用分層輔助變項的均等配置 分層法 (OA) ;也就是在每一分層內抽取相同的樣本數,這種方法不考慮輔助變項的資訊,也 因為缺乏分層資訊,通常不會很精確。但我們採用的分層法是事先透過分層輔助變項,在調 查之前將各叢集依其輔助變項 (A) 的大小排序,並列出各叢集所合標的母群的人數後,依叢 集累加人數進行均等配置分層;依此法對所有叢集進行分層後,每一分層內所包含的母群人 數皆相同,而後再從各層中抽取相同的樣本。為了與一般的均等配置抽樣做區分,研究者稱 這種方法為均等分層下的等比例配置法 (ProportionalAllocation for Equal Stratification
,
PAES) 。接下來的分析將暫時把抽樣單位設定為叢集,比較利用輔助變項的 PAES 與 OA 兩種 分層方法對母群平均值估計誤差的影響。 在均等分層的等比例配置 (PAES) 叢集抽樣設計下,為了估計叢集之分層輔助變項在各 分層內的變異量,我們假設所有叢集的分層輔助變項 (A) 成常態分布 O 首先,因為每個叢集 被拍到的機率與叢集大小成正比,各層內所有叢集被抽到的機率累加後應該正比於該層內叢 集所包含調查母群人數的總和;因此在均等分層的抽樣架構下:
[P(A)odA=['P(A)odA=...=
[,
P(A)odA=...=
[,
P(A)o
“
H
(25)
式(25)中的 peA)為常態分布,為了簡化計算,我們將A 的平均值設為原點(如圖3) ,這 個假設並不會影響對於叢集的分層輔助變項A 之變異量估計: ' " 、 可 怕)=吉7.e4peA)
(26)
法)<;一 Gl...a"_1
Gha
H_1 一一〉 ∞ 圖 3 所有叢集之分層輔助變頂 (A) 大小之機率分布其中, σ; 為所有輔助變項 A 之變異量,我們根據式(25)和式(26)求出當叢集的分層數 H 分別 為 2 、 3 、 4 、...、 10 時,根據輔助變項 A 進行等人數分層的分層區間(﹒帆 Qj) 、(肉 Q2) 、...、
( Qh-
1' Qh) 、...(
QH-l' ∞)。接下來,根據式(27) 、 (28)以及附錄中的積分公式 (A-5 和 A-6)估計出每個分層內各叢集輔助變項之平均值 E(A)以及變異量 E( σ~ )。其中 E(A
I
Qh-l 三 A
<
Qh) 為
第 h 分層內各叢集的分層輔助變項 (A) 之平均值(A
h ) :fh
P(A)'A ﹒ ι4
Ah
=E(A I
Qh-I 三 A<Qh)= -"h~,I"
P(A)· dA
而第 h 分層內 , E(σ~
I
Qh-l
~
A
<
Qh) 即為分層輔助變項 (A) 之變異量為 (σ;h):
fh
peA)
.
[A-E(A)
f
·dA
σi=E(σ.~
I
Qh-I 三 A
<
Qh)
= 叫 l
肌
|叮 P(A)'dA
(27)
(28)
表 5 列出利用數值分析方法對於採用均等分層的等比例配置(PAES) 進行分層叢集抽樣 時,不同分層數的輔助變項分層區間,及對於分層輔助變項A 而言,各分層內叢集變異量之總和( 2.:=1σ~h ) 。
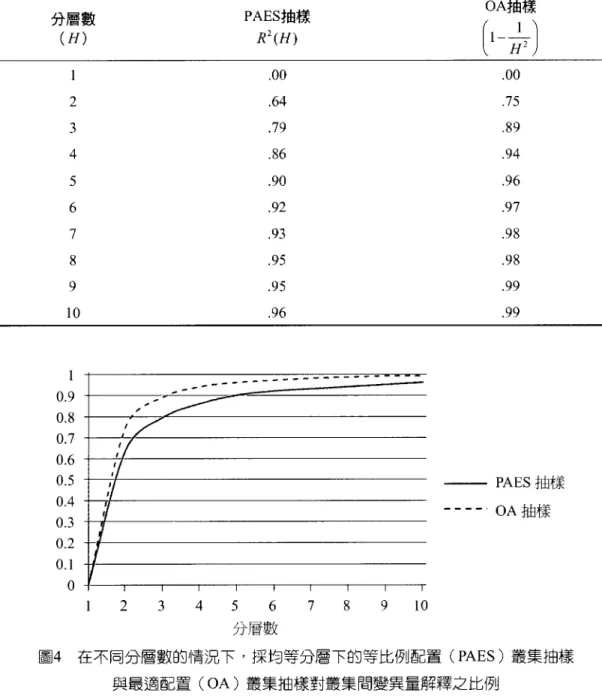
根據表 5 的數值分析結果,當分層數愈多的時候,各分層內叢集輔助變項變異量之總不日 愈小,亦即叢集輔助變項的變異量被分層解釋的部分愈大。如果分層數趨近無限大,使得各 層內叢集輔助變項之變異趨近0 ,式(24)的等號就會成立,此時母群平均值估計誤差最小。而 當分層數為有限數值時,各分層內輔助變項無法完全被控制成完全相等,此時分層解釋輔助 變項之比例R2(H) 為:2.于,σf
R"(H)=I-~二Jh σA(29)
其中 , R2(H) 為叢集的分層數 (H) 之函數。文輔助變項解釋主要調查變項的叢集間變異量之比例為 r2 ,所以式(20)中的 ψ 必須用 r
2R
2(H) 取代,改寫式(20)為:
丸 s們
(30)
•
54
·減少標準誤之抽樣設計 任宗浩、譚克平、張立民 表 5 利用數值分析法,估計對叢集探 PAES 抽樣時,不同分層數對應之輔助變項分層區間以 及各區間輔助變項變異量之總和 分層數 輔助變項分層區間(H)
( 單位:們) 變異量總和(zilσ~,
)
(-∞,∞) 1.000σ; 0.363σ; 0.207σ; 0.1 39σ;2
(-∞, 0),
(0,∞) 、、-』/ ∞'
l 令、 U A 『 AV /(\ \hd/ l 令、 ν λUT AU -令、 ν λUT AU /(\ -7 \hd/ l 令、 U A 且可 AV ∞ /(\ 令、 ν 、 1 ,/ ∞ A 且可 行/ rAU AU /',‘巴、、'
、 18/ 凡且可 行/ rAU Aυ Aυ /',\ 、、 J/ AV,
凡且可 行/ rAU AU /'t\ .歹 \hd/ A 且可 行/ rAU AV ∞ /(\ 凡且可5
(﹒∞,-0.842)
,
(-0.842
,
-0.253)
,
(-0.253
,
0.253)
,
(0
.2
53
,
0.842)
,
(0.842,∞) 0.103σ;6
(-∞,-0.96
7) ,
(-0.967
,
-0
.4
31)
,
(-0
.4
31
,
0)
,
(0
,
0
.4
31)
,
(0
.4
31
,
0.96
7),
0.081σ;(
0.967,∞)7
(品,-1.
068)
, (-1.
068
,
-0.566)
,
(-0.566
,
-0.180)
,
(-0.180
,
0.180)
,
(0.180
,
0.066σ;0.566)
,
(0.566
, 1.
068)
,
(1. 068,∞)8
(-∞,-1.1 50) ,(-1.1
50
,
-0.674)
,
(-0.674
,
-0.319)
,
(-0.319
,
0)
,
(0
,
0.319)
,
0.055σ;(0.319
,
0.674)
,
(0.674
,1.1
50)
,
(1.1 50,∞)9
(
-∞,-1.221) ,(-1.2
21
,
-0.765)
,
(-0.765
,
-0
.4
31)
,
(-0
.4
31
,
-0.140)
,
(-0
.1
40
,
0.047σ;0
.1
40)
,
(0.140
,
0
.4
31)
,
(0
.4
31
,
0.765)
,
(0.765
,1.
221)
,
(1.2剖,∞)10
(-∞,-1.
282)
, (.
1
.2
82
,
-0.842)
,
(-0.842
,
-0.524)
, (
-0.524
,
-0
.2
53
),
(-0.253
,
0)
,
0.041σ;( 0
,
0
.2
53)
,
(0.253
,
0.524)
,
(0.524
,
0.842)
,
(0.842
, 1.
282)
,
(1.282,∞)如前所述,當採最適配置 (GA) 時,叭的即為|卜上 I ;而採均等分層的等比例配置
\
H
L ) (PAES) 時,雖沒有一簡單公式可循,但根據表 5 的數值分析結果,可以比較當利用輔助變 項對所有叢集進行分層時,不同分層數的兩種配置抽樣法解釋叢集平均值變異量之比例。表 6 和圖 4 顯示比較結果,當分層數愈大時,兩種抽樣方式的誤差愈接近 O 雖然採最適配置的方 式對叢集進行分層能夠讓相同樣本下的抽樣誤差最小,但是事前的計算較 PAES 來的複雜許 多,且由於採 PAES 法抽樣時,盡可能讓每一位樣本的代表性差異最小,加權值的計算也較容 易。 最後,研究者利用分析的結果對於我國參與 TIMSS 2011 調查提出一個學校層級的抽樣架 構:由於 TIMSS 參加國必須在正式調查開始的 2 年以前,提供加拿大統計局該國學校層級的 分層抽樣架構。本研究根據我國參加 TIMSS 2007 的數據以及不違反保密原則的情況下,透過 國立臺灣師範大學基本學力測驗中心的協助,估計出我國參加 TIMSS 2007 調查之各個國中八 年級平均科學成就與該校九年級生同年參加基本學力測驗數學科平均成績之相關為 0.71 '且 同一學校每連續 2 年基測數學平均成績相關為 0.97 ;所以若由正式調查 2 年前 (2009 年)各表 6 在不同分層數的情況下,探均等分層下的等比例配置 (PAES) 叢集抽樣與最適配置 (OA) 叢集抽樣對叢集間變異量解釋之比例 分層數 PAES抽樣 OA抽樣
(H)
R\H)
(\
H
l\)、I
00
.00
2
.64
75
3
.79
.89
4
.86
94
5
.90
.96
6
.92
.97
7
.93
.98
8
.95
.98
9
95
.99
10υ.96
.99
0.9
0.8
0.7
0.6
0.5
0
.4
0.3
0
.2
0.1
O
--
一一--
戶一 -一 ---一- -
桐-"
'-
---ht三
一一一-PAES
t由千葉----
OA 抽樣2
3
4
5
6
7
8
9
10
分層數 圖4 在不同分層數的情況下,探均等分層下的等比例配置 (PAES) 叢集抽樣 與最適配置 (OA) 叢集抽樣對叢集間變異量解釋之比例 校之九年級生參加基本學力測驗之平均數學成績作為 TIMSS 2011 正式調查時, 2學校分層之 輔助變項,估計該輔助變項與我國參加 TIMSS 2011 調查之各校八年級生平均科學成就相關之 2 依據分析結果,各參與 TIMSS 2007 調查之園中,不論是 TIMSS 調查的八年級生數學或科學平均成就,和 該校同年 ft 九年級生參加基測之數學平均成績之相闕,均比與基測科學成績的相關來得高。•
56
·減少標準誤之抽樣設計 任宗浩、譚克平、張立民下限約為 0.67
(
=0.97
2X0.71
)。由於推導式 (30)時,我們假設叢集之分層輔助變項平均值成常
態分布,所以針對我國所有國中於 2009 年之第一次基測數學平均成績進行常態分布之
Ko1mogorov 品nimov 檢驗,結果,顯示該假設可以被接受 (p= .09) 。因此,我國 TIMSS 調查
中心委請基本學力測驗中心協助將所有包含八年級生之中學,按照各校在 2009 年第一次基本 學力測驗的數學平均成績,依據均等分層的方式分成八層,其中每一層所包含的學生人數大 致相同。依此架構作為我國參加 TIMSS 2011 八年級群之學校分層抽樣架構,如果我國八年級 生在 TIMSS 2011 與 TIMSS 2007 的表現情況大致相同時廿三 4,046 , ρ=0.22 , σ;個1=7 ,971 ,
b '
二27.9) ,且當叢集的分層輔助變項與叢集平均值相關 (r) 為 .67 且分層數 (H) 為 8 的情況 下,由式(30)可預估我國參加 TIMSS 2011 八年級生科學平均成績之抽樣誤差約為 2.9 量尺分 數。伍、結論
近年來,我國愈來愈重視國際與國內的大型教育調查研究,且這類調查大多採二階段分 層叢集抽樣設計。許多研究者在進行二階段分層叢集抽樣調查之前,並不清楚抽樣架構、樣 本數與抽樣誤差間的關係。本研究導證一個簡易且方便計算的公式,提供研究者在進行二階 段分層叢集抽樣調查之前,能夠藉由相關的輔助訊息,估算出主要調查變項的抽樣誤差。分 析一和分析三以 TIMSS 參加國(地區)的數據為實例,檢驗該公式之有效性和實用性。此外, 為了能夠讓我國在參加 TIMSS 2011 調查時,八年級生科學平均成就的抽樣誤差減少至 3.0 量 尺分數以下,利用各國中在基本學力測驗的平均表現作為該調查中,學校分層的輔助變項; 透過分析三,除了推論在二階段分層叢集抽樣設計下,叢集的分層數與抽樣誤差問之關係, 並據以預估我國在 TIMSS 2011 調查中,八年級生科學平均成就之抽樣誤差約為 2.9 量尺分 數。 最後,本研究嘗試提出一個四個階段的標準化評估流程,協助研究者在進行二階段分層 叢集的抽樣調查前,對主要調查變項母群平均值之抽樣誤差進行評估。分別說明各階段如下:(一)階段一
根據過去的調查和文獻,訂定合理且可以回答研究問題的誤差範圍。 舉例來說,如果想在臺灣進行一項教育調查,探討各縣市中小學生成就的差異,首先必 須根據過去的研究或是相關的資料庫研判各縣市中小學生學科成就可能的差異大小。若依據 過去的研究調查結果,如澳洲的 NAPLAN(National Assessment Program -
Literacy and
Numeracy) (Australian Curriculum
,
Assessment and Reporting Authority [ACARA
],
2010
)和芝加哥的 CARP
(Chicago Annenberg Research Project) (Newmann
,
Smith
,
Allensworth
,
&
B可k,斯 (logits) ,這也大約相當於 0.5-0.7 個學生能力的標準差;到了中學,每一年的進步甚至可 能小於 0.2-0.3 個標準差以下。我國中小學因採標準課綱,所以各縣市同一年級學生平均學科 能力的差異應該小於 0.1 個標準差。因此,若想藉由抽樣調查分辨各縣市的差異,則調查的誤 差至少應小於 0.05 個標準差,否則調查結果必然無法分辨其間差異。叉以我國將參加 TIMSS 2011 調查之八年級生科學平均成就的抽樣誤差範圍定為 3.0 量尺分數為例:由於我國參加