-1-
鏈結資料在圖書館的應用
Linked Data and Its Application in the Library
柯皓仁 Hao-Ren Ke教授兼圖書館館長、圖書資訊學研究所所長 國立臺灣師範大學
Professor and Chairperson, Graduate Institute of Library and Information Studies, University Librarian,
National Taiwan Normal University E-mail: [email protected] 陳亞寧 Ya-Ning Chen
系統分析師
中央研究院計算中心 System Analyst
Computing Center, Academia Sinica Email: [email protected]
摘要
語意網的目的是為了促成網際網路上系統間的整合與資料共享,以利各類加值應用的發 展,鏈結資料則是實踐語意網的最佳實務。本文主旨在於介紹語意網和鏈結資料的定義及相 關技術標準,舉例介紹鏈結資料的應用,繼而闡述鏈結資料對圖書館界的意涵和計畫,最後 提出結論與建議。 關鍵字:語意網;鏈結資料ABSTRACT
Semantic Web aims at facilitating system integration and data sharing on the Internet, and thus expediting the development of value-added applications. Linked Data is a set of best practice for realizing Semantic Web. This article introduces the definition of Semantic Web and Linked Data, and the related technical standards. Next, a few examples of Linked Data applications are described. Then the implication and related projects of Linked Data in libraries are explicated. Finally, conclusions and suggestions are given.
壹、緒論
隨著網際網路和全球資訊網(World Wide Web,簡稱 Web)的蓬勃發展,WEB 已然成為網 際網路的重要應用,更是人們日常取得管道的重要來源。HTML 是 WEB 文件的主要格式, 再搭配 HTTP 做為 Web 伺服器端與客戶端之間溝通與傳遞文件的機制,HTML 和 HTTP 的簡 單易實現促成了 Web 的廣為普及。 當網際網路成為人們獲取資料的重要管道時,如何有效和有效率地處理、整合和再利用 這些資料,乃成為一項重要議題。HTML 文件雖然容易被人們所閱讀,但是其語法鬆散、語 意不清的特性,卻造成了電腦化處理的困難。舉例而言,圖書館界熟知的電子資源整合查詢 系統(Federated Search Systems)利用單一查詢介面,讓使用者能夠同時檢索多個電子資源系統 (李靜宜、柯皓仁,2012),然而,除非各電子資源支援 Z39.50 等標準協定,否則電子資源整 合查詢系統必須運用 Web Scraping(Wikipedia, 2013a)的技巧,擷取並剖析電子資源系統檢索 結果的 HTML 文件,而一旦電子資源系統檢索結果的格式改變,則擷取與剖析程式必須隨之 更改,造成系統維護上的困難。又如 Web 2.0 的特色之一混搭(Mashup),乃是透過應用程式 介面(Application Programming Interface, API)達成系統間的整合與資料共享,然而各家系統的 API 皆不相同,混搭程式的開發者必須了解各家系統的 API,造成整合上的不易。
有鑑於前述問題,WEB 之父 Tim Berners-Lee 乃提出語意網(Semantic Web)的概念 (Berners-Lee, 2000),而後更進一步提出了所謂的「鏈結資料」(Linked Data),做為實現語意 網的最佳實務(Linked Data, n.d.)。本文主旨即在於介紹鏈結資料及其在圖書館界的應用。
貳、語意網與鏈結資料
本節介紹語意網與資料鏈結的基本定義及其採用的相關技術。一、 語意網
隨著大量的資料在網際網路上湧現,當個人或組織企圖取用這些資料並進一步加值運用 時,都會遭遇到以下三項關鍵問題(Linked Data, n.d.): (一) 如何提供一個優良的資料取用(access)方式,以利於資料的再利用(reuse)。 (二) 如何在大量資料集中發現(discovery)相關資料。 (三) 如何整合來自多個資料源的資料(integration)。-3- Tim Berners-Lee(Berners-Lee, 2000)指出要解決此三大關鍵問題的第一步在於以電腦能夠 了解的形式將資料發布於 Web 環境中,形成一個讓電腦能夠直接或間接處理的資料網(Web of Data),此即語意網(Semantic Web)的開端。語意網的定義如下: (一) 語意網以電腦所能理解的方式描述事物(thing)。 (二) 語意網並非是在網頁間建立超連結,而是用來描述事物的屬性(properties)和事物間 的關係(relationships)。 (三) 語意網是現有全球資訊網的擴展,在語意網賦予資訊明確的定義,促成電腦與人們 的協同工作。 (四) 語意網企圖建構一個讓電腦理解富含語意的文件和資料的基礎建設。
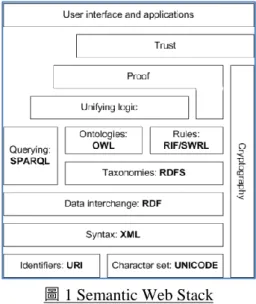
圖 1 Semantic Web Stack
資料來源:Wikipedia (2013b). Semantic Web Stack. Wikipedia. Retrieved fromhttp://en.wikipedia.org/wiki/Semantic_Web_Stack.
語意網的實現需要具備許多網路相關技術,包含:URI、UNICODE、XML、RDF、RDFS、 OWL、SPARQL 等,如圖 1 所示(Wikipedia, 2013b),並說明如下:
(一) 以統一資源識別符(Uniform Resource Identifier, URL)標示任一事物。 (二) 以萬國碼(Unicode)做為文字編碼。
(三) 以可延伸標記式語言(eXtensible Markup Language, XML)做為電腦間交換資訊的語 法。
(四) 以資源描述框架(Resource Description Framework, RDF)描述資源屬性(property)。 (五) 以 RDF 綱要(RDF Schema, RDFS)為 RDF 定義詞彙,建立種類(class)與屬性的階層架
(六) 以 Web Ontology Language (OWL)進一步擴展 RDFS,用以建構知識本體,使語意網 具備推理能力。
(七) 以 SPARQL(SPARQL Protocol and RDF Query Language)做為檢索 RDF 資料庫的檢 索語言。
二、 鏈結資料
為了具體實踐語意網,2006 年 Tim Berners-Lee 進一步提出了所謂的「鏈結資料」(Linked Data),企圖賦予全球資訊網結構化的資料,使資料得以在網際網路上自由互連,自動彙整同 一物件的相關資訊。鏈結資料乃是一組實現語意網的最佳實務(Linked Data, n.d.),用以將結構 化資料發布在 Web 上,並加以串聯。若說超連結構築了一個全域資訊空間,那麼運用鏈結資 料(以及語意網)則構築了一個全域資料空間。鏈結資料包含以下四大原則(Berners-Lee, 2006; Heath & Bizer, 2011):
(一) 利用 URI 為事物命名。 (二) 以 HTTP 做為客戶端和伺服器端之間查詢及傳送 URI 的機制,使人或電腦可以查詢 特定 URI 所代表事物的相關資訊。 (三) 伺服器端使用 RDF 與 SPARQL 等標準,提供更多的資訊。當伺服器端接獲客戶端 對於特定 URI 的請求時,伺服器端會以標準格式將該 URI 所代表事物的相關資訊傳 回給客戶端。若客戶端是「人」,則伺服器端可回傳 HTML 格式的文件;若客戶端 是「應用程式」,則伺服器端可回傳 RDF 格式的文件,以方便客戶端的應用程式再 利用這些資訊。 (四) 對於特定 URI 所代表事物的相關資訊中,應包含與其他相關事物的連結(連結到該事 物的 URI),使得事物間得以串連,以達成構築全域資料空間的目標。 除了鏈結資料此一詞彙外,另有所謂的「開放資料」(Open Data)、「鏈結開放資料」(Linked Open Data, LOD)。Paul Miller 指出鏈結資料、開放資料與鏈結開放資料等三個名詞經常混合 使用。Miller 認為鏈結開放資料同時結合了鏈結資料與開放資料等兩大名稱與概念,其中開 放資料一詞可以溯源自「語意網教育擴展」(Semantic Web Education and Outreach, SWEO)興 趣小組(Interest Group)的「鏈結開放資料社群計畫」(Linking Open Data Community Project), 主要目的在於倡導與推展自由取用與再利用資料。因而,鏈結開放資料除了強調所謂資料的 相互鏈結外,也著重在資料的法律層面,亦即資料的開放及其後續的使用授權(Miller, 2010)。 綜合上述討論,所謂的開放,除了資訊通訊暨科技外,其實也包括了法律層面的資料授權, 乃至於隱藏的潛在成本等。
-5-
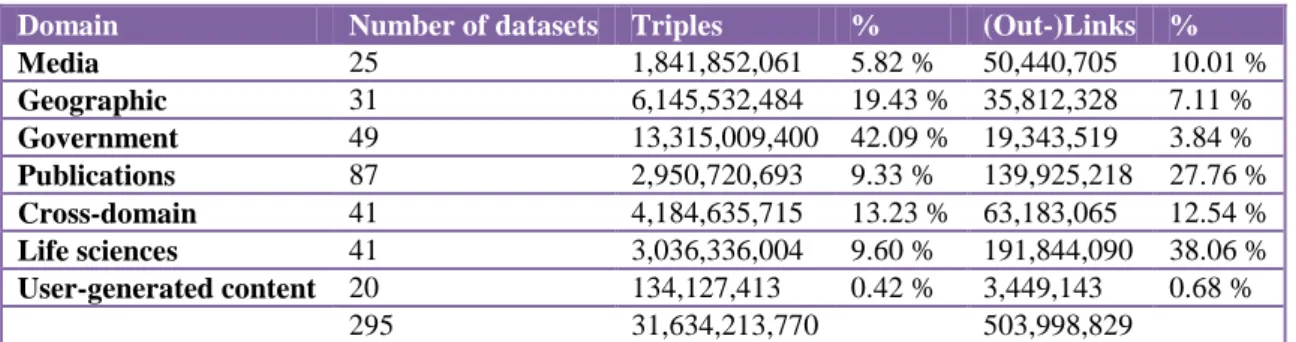
截至 2011 年 8 月為止,全球至少有 295 個以鏈結資料精神所建構的資料集,分屬於跨領 域、媒體、地理、政府、出版業/圖書館界、生物科學、使用者自建內容等範疇,所建構的 RDF Triple 已有 300 億之多,資料集彼此間的連結數則達五億個(表 1)。在這些資料集中,比 較著名的跨領域資料集包含 DBpedia、OpenCyc 等,著名的媒體業如 BBC、The New York Times 亦開始實現鏈結資料,出版業/圖書館界則有 British National Bibliography、British Museum Collection、DDC、LCSH 等資料集採用鏈結資料1。
表 1 鏈結資料資料集現況(2011/8)
Domain Number of datasets Triples % (Out-)Links %
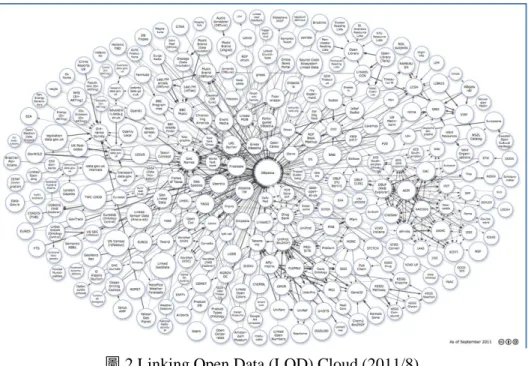
Media 25 1,841,852,061 5.82 % 50,440,705 10.01 % Geographic 31 6,145,532,484 19.43 % 35,812,328 7.11 % Government 49 13,315,009,400 42.09 % 19,343,519 3.84 % Publications 87 2,950,720,693 9.33 % 139,925,218 27.76 % Cross-domain 41 4,184,635,715 13.23 % 63,183,065 12.54 % Life sciences 41 3,036,336,004 9.60 % 191,844,090 38.06 % User-generated content 20 134,127,413 0.42 % 3,449,143 0.68 % 295 31,634,213,770 503,998,829 資料來源:http://www4.wiwiss.fu-berlin.de/lodcloud/state/#domains 當愈來愈多的組織和個人採用鏈結資料的原則將結構化資料發布到 Web 上,這些彼此串 連的資料將構築成一個全域的資料空間,亦即所謂的 Web of Data。Web of Data 可以用圖形 (graph)表示,圖 2 即為 W3C Linking Open Data (LOD)計畫所繪製的鏈結資料雲圖。
Web of Data 的特性如下(Heath & Bizer, 2011): 一、Web of Data 能夠包含各種類型的資料。 二、任何人或組織皆能發布資料至 Web of Data。
三、Web of Data 允許表達對一特定事物或實體(entity)的不同或相反見解。
四、事物或實體間以 RDF links 連接,從而建立一個跨越資料來源的全域資料圖,並使新 資料來源的發現成為可能。此意味著應用程式無須依賴固定的資料來源,應用程式 藉著追循(follow) RDF links 將可在執行時發現新的資料來源。 五、資料發布者可自由選擇語彙(vocabulary)來表徵資料。 六、資料具有自我描述(self-describing)的能力。若應用程式使用到以陌生語彙所描述的資 料時,應用程式可藉由該語彙之 URI 查找該語彙的定義。 七、運用 HTTP 做為標準化的資料取用機制,以及運用 RDF 作為標準化的資料表徵語言, 使 Web of Data 之資料取用較 Web APIs 來得容易。
圖 2 Linking Open Data (LOD) Cloud (2011/8) 資料來源:http://www4.wiwiss.fu-berlin.de/lodcloud/state/
參、鏈結資料的應用
本節以 DBpedia、OpenLibrary、SIG.MA、dblp 為例,介紹鏈結資料的應用(資料集)。
一、 DBpedia
DBpedia 位居圖 2 鏈結資料雲圖的中心位置,DBpedia 從 Wikipedia 擷取結構化內容,並 將這些結構化內容發布於 Web。DBpedia 提供使用者檢索 Wikipedia 資源屬性和關聯的功能, 並能連結到 YouTube、紐約時報(New York Times)等其他資料庫。圖 3、圖 4 分別為 DBpedia 中棒球選手王建民網頁格式文件和 RDF 格式文件的部分資料。
圖 3 DBpedia 中王建民的資料(部分) 資料來源:http://dbpedia.org/page/Chien-Ming_Wang
-7-
圖 4 DBpedia 中王建民資料的 RDF 格式(部分) 資料來源:http://dbpedia.org/page/Chien-Ming_Wang
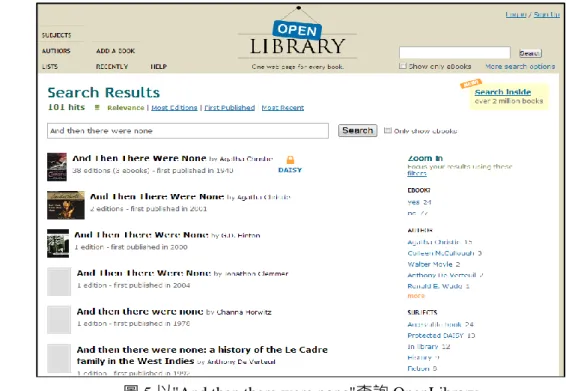
二、 Open Library
Open Library2是 Internet Archive3下的一項先導計畫(圖 5),標榜"One web page for every
book"。Open Library 已收集超過 3,000 萬筆書目紀錄,其中包含超過 100 萬筆的免費電子書 可供線上閱讀或下載(Open Library, 2012)。為了處理如此龐大的紀錄,Open Library 採用了嶄 新的資料庫架構,並運用 Wiki 介面讓熱心人士得以貢獻圖書資料。Open Library 提供了應用 程式介面 API 讓全球程式設計者得以運用其資料,使用者亦可下載每筆書目資料的 RDF 格式 檔案。
圖 5 以"And then there were none"查詢 OpenLibrary
2http://openlibrary.org 3http://archive.org/
三、 SIG.MA
SIG.MA 是鏈結資料的搜尋引擎,使用者在 SIG.MA 輸入檢索條件後,SIG.MA 會自動到 多個鏈結資料的資料來源擷取並整合資料,將整合後的結果提供給使用者。以圖 6 為例,當 使用者輸入 Spiderman 進行檢索時,SIG.MA 從 20 個資料來源擷取資料後將資料整合於畫面 左方(以[…]註明資料來源),畫面右方即為資料來源。使用者更可判斷資料正確性後給予資料 來源認可(Approve)或拒絕(Reject)的評分,SIG.MA 可進一步透過使用者的評分來衡量資料來 源的品質。 圖 6 以 Spiderman 檢索 SIG.MA
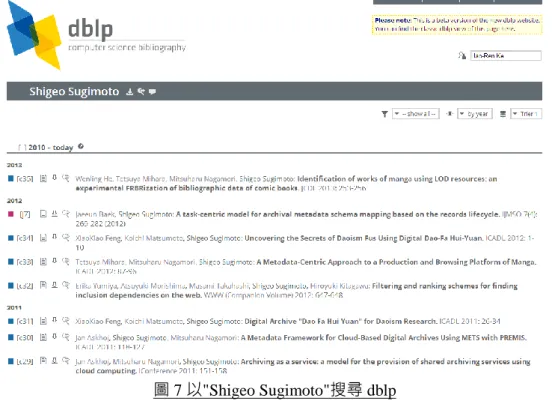
四、 dblp
dblp computer science bibliography(or dblp)是一個線上參考工具,收錄了計算機科學主要 出版品(期刊、研討會論文、專書)的書目紀錄以及該等出版品的電子版本連結。dblp 已收錄 來自 120 多萬位作者的超過 230 萬筆計算機科學出版品的書目紀錄。圖 7 為搜尋"Shigeo Sugimoto"此位作者在 dblp 中所索引的作品,除了線上檢視外,dblp 還提供使用者以 BibTex、 RDF、XML、RSS 等格式下載書目紀錄。
-9-
圖 7 以"Shigeo Sugimoto"搜尋 dblp
肆、鏈結資料對圖書館界的意涵和計畫
因應鏈結資料的趨勢發展,此一議題也引起圖書館界廣泛的討論。2011 年,美國史丹佛 大學圖書館暨學術資訊資源(Stanford University Libraries and Academic Information Resources, SULAIR)舉辦工作坊,廣邀各界人士針對鏈結資料在圖書館界的學術發展與實務應用進行討 論與意見交流。在此一工作坊報告內容中,提出鏈結資料在圖書館界的意涵有兩種,包括 (Keller, Persons,Glaser & Calter, 2011):
一、在資料語意面可用來描述資料的意義。
二、在資料語法或格式面可跳脫特定資料結構的限制。
基於上述意涵,鏈結資料可以支援資料的檢索,以及再混合(remix)(Keller, Persons,Glaser & Calter, 2011)。換言之,鏈結資料除了著重在資料相互間的連結外,也被視為資料表徵與結 構化的一種標準與方法,進而變成一種聚合資料的方式。例如,在美國國會圖書館(Library of Congress, LC)提出的「將書目框架視為資料網絡」(Bibliographic framework as a web of data) 的報告中,提出未來書目框架應重視「關聯關係」(relationships),並以此為基礎進而與鏈結 資料結合(Library of Congress, 2012)。在前述 SULAIR 舉辦工作坊時,Tim Hodson 介紹大英 圖書館進行書目紀錄的鏈結資料作業時指出,傳統書目紀錄已隱藏著許多資料的意義及其鏈 結,但並未被明確予以表徵與結構化。從鏈結資料觀點而言,書目紀錄可以從扁平式資料欄 位的紀錄轉換成(Keller, Persons,Glaser & Calter, 2011):(1) 誰寫了這本書?(2) 何時出版了這
本書?(3) 誰出版了這本書?(4) 在何處出版了這本書?(5) 這本書的內容為何?(6) 這本書 以何種語文撰寫?
在前述 SULAIR 的工作坊報告內容中,從來源、使用、保存與標準四大層面提出了多項 議題(Keller, Persons,Glaser & Calter, 2011):(1) 不同格式間的參照與調和;(2) 圖書館權威檔 的使用;(3) 富有創意的殺手級應用;(4) 資料的歸屬、來源與權威性;(5) URI 創立、衍生 與發佈,以及鏈結與發掘等訓練;(6) 資料的優使性(usability);(7) 品質控制;(8) URI 的標 準化;(9) 資料的保存;(10) 責任的分散;(11) 行銷及延展;(12) 工作流程;(13) 規模性; (14) 索引;(15) 知識本體的使用;(16) 授權;(17) 註解;(18) 識別的管理;(19) 數位學術 與數位學習的關聯;(20) 文化多樣性;(21) 搜尋引擎的最佳化;(22) 與社會媒體的結合。 因應鏈結資料的興起,圖書館界也著手進行相關計畫,將現有的紀錄轉化為鏈結,藉以 探索其可行性。主要的計畫包括虛擬國際化權威檔(Virtual International Authority File, VIAF)、 美國國會圖書館鏈結資料服務(LC Linked Data Service: Authorities and Vocabularies)、美國國 際圖書館電腦中心(Online Computer Library Center, OCLC)的全球圖書館目錄(WorldCat)、大英 圖書館(British Library, BL)的自由化資料服務(Free data service)及歐盟的 Europeana 等,分述如 下。
一、 資料值(data value)
係以權威檔或控制詞彙為對象,著名的主要計畫有:
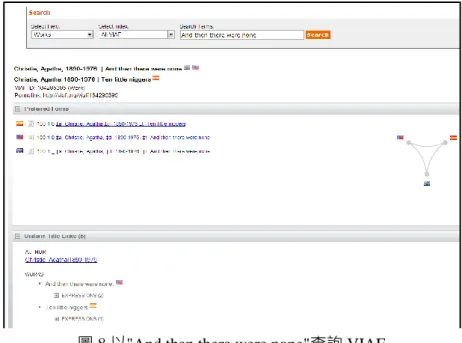
(一) VIAF(Virtual International Authority File)4
VIAF 計畫起始時,係由美國 LC、德國圖家圖書館(Deutsche Nationalbibliothek, DNB)、 法國國家圖書館(Bibliothèque nationale de France, BNF)與 OCLC 等四個單位共同合作,已有超 過 16 個國家的 20 餘個單位參與合作。主要目標在於建立國際型的名稱權威檔服務,以形成 語意網中的一部份。所謂的名稱權威檔包括:個人名稱(people)、團體名稱(corporations)、會 議名稱(conferences)、地理名稱(geographic places)、作品(work)、內容版本(expression)等。圖 8 為以阿嘉莎.克莉絲蒂(Agatha Christie)的名著《一個都不留(And then there were none)》查 詢 VIAF 的結果,除了顯示優選款目(Preferred Forms)、作者、作品及內容版本資訊外,還提 供 XML 格式的 MARC-21 紀錄、RDF 格式的紀錄下載。
-11-
圖 8 以"And then there were none"查詢 VIAF (二) LC Linked Data Service: Authorities and Vocabularies5
LC Linked Data Service 係將 LC 所擁有的各式主題詞(subject headings)、權威檔(authority file)、分類表(classification)、國家代碼(country)、語言(languages)與圖像資料索引典(Thesaurus for Graphic Materials)等不同類型的控制詞彙以鏈結資料的方式提供,使用者可以批次下載所 有資料,或者輸入關鍵詞彙進行檢索(如圖 9),檢索結果除以網頁格式呈現,亦提供使用者以 RDF/XML、JSON、N-Triples 等格式下載單一檢索結果。
圖 9 以"And then there were none"查詢 LC Linked Data Service
二、 複合式
除了資料值外,有些計畫以書目紀錄為基礎,發展書目紀錄知識本體或是導入鏈結資料, 同時融合資料元素與資料值,達成資料間的連結,包括英國的 BL6、歐盟的 Europeana7及 OCLC 的 WorldCat8等。圖 10 為大英圖書館的自由化資料服務。 圖 10 大英圖書館的自由化資料服務 資料來源:http://www.bl.uk/bibliographic/datafree.html三、 其他
除了資料值與書目紀錄知識本體外,也有些計畫試圖發展所謂的註冊中心(registry),例 如,開放型後設資料註冊中心(Open Metadata Registry, OMR)9。在 OMR 中,同時涵蓋了各式圖書館界相關的知識本體(如:FRBR、FRAD、FRSAD)、控制詞彙(如:GEM)、內容(如:RDA、 ISBD)、資料元素(如:Dublin Core、MARC21)等不同後設資料標準於一身,如圖 11 所示。 6http://www.bl.uk/bibliographic/datafree.html 7http://data.europeana.eu/ 8http://www.worldcat.org/ 9http://metadataregistry.org/
-13- 圖 11 開放型後設資料註冊中心的資料元素集列表
伍、結論與建議
網際網路已成為人們取得資訊的主要來源,如何取用與再利用、發現、整合網際網路上 的資料並予以加值乃成為一項重要議題,無論採用 Web Scraping或API等技術都有其困難點, 語意網和鏈結資料乃因運而生。尤其是鏈結資料,其為語意網的最佳實務,具有極大的可實 行性。圖書館界在鏈結資料上應可扮演資料提供者與資料接收者兩種角色,茲說明如下:一、 資料提供者
圖書館是知識的寶庫,這些知識若能運用鏈結資料的方式與大眾分享,相信能對知識傳 播與分享有更大的幫助。圖書館書目與館藏資料的鏈結資料化是一可行途徑,亦有益於 Google 等搜尋引擎將圖書館書目與館藏資料納入索引,增加圖書館書目與館藏資料的可見度。過去 幾年,許多圖書館參與了數位典藏的建置,亦可考慮將數位典藏藏品的詮釋資料(Metadata) 鏈結資料化。 另一方面,美國國會圖書館鏈結資料服務亦值得國內借鏡,我國國家圖書館日前召開的 「NBINet 臺灣書目控制工作小組(權威建置)」,其成果應可仿效美國國會圖書館的姓名權威 檔(Name Authority File)或 VIAF 予以鏈結資料化。而諸如《中文圖書分類法》、《中文主題 詞表》等亦可嘗試將其鏈結資料化,供外界以此為基礎發展加值應用。又如國家圖書館全國新書資訊網10中《全國新書資訊月刊》的書評、讀書人語,以及各
種得獎紀錄,亦是可資鏈結資料化的對象。
總之,建議各圖書館可檢視自身產出的資料是否有獨特之處,優先將該等資料鏈結資料 化,以豐富 Web of Data 的資料。
二、 資料接收者
圖書館界除了擔任資料提供者外,還可以運用網路上的鏈結資料發展各類加值運用。舉 例而言,圖書館館藏查詢系統 WebPAC 在書籍的詳目顯示時,可以在作者項連結到 DBpedia、 LC 的作者權威檔,提供讀者對於一位作者更詳實的資訊。前述的書評、讀書人語及得獎紀錄 也可以整合至圖書的詳目顯示中。在《中文圖書分類法》鏈結資料化之後,圖書館亦可利用 該資料發展圖書分類瀏覽功能。致謝
本研究為行政院國家科學委員會專題研究計畫「以 FRBR、Linked Data、Crowdsourcing 設計圖書館館藏查詢系統之研究」( NSC102-2410-H-003-121-MY3)的部分成果。-15-
參考書目
Berners-Lee, T. (2000). Weaving the Web: The original design and ultimate destiny of the World
Wide Web. HarperBusiness, 1st edition.
Berners-Lee, T. (2006). Design issues of Linked Data. Available at:
http://www.w3.org/DesignIssues/LinkedData.html.
Heath, T. & Bizer, C. (2011). Linked Data: Evolving the Web into a Global Data Space (1st edition).
Synthesis Lectures on the Semantic Web: Theory and Technology, 1:1, 1-136. Morgan &
Claypool. Available at:http://linkeddatabook.com/editions/1.0/.
Keller, M.A., Persons, J., Glaser, H. & Calter, M. (eds.) (2011). Linked data for libraries, museums,
and archive. Survey and workshop report: Report of the Stanford linked data workshop.
Available at:
http://www.clir.org/pubs/reports/pub152/reports/pub152/LinkedDataWorkshop.pdf.
Linked Data (n.d.). What is the relationship between Linked Data and the Semantic Web?
Frequently Asked Questions (FAQs). Retrieved from http://linkeddata.org/faq.
Miller, P. (2010). Linked data horizon scan. Available at:
http://cloudofdata.s3.amazonaws.com/FINAL-201001-LinkedDataHorizonScan.pdf. Open Library (2012). About Us. Retrieved from: http://openlibrary.org/about.
Wikipedia (2013a). Web Scraping. Available at: http://en.wikipedia.org/wiki/Web_scraping. Wikipedia (2013b). Semantic Web Stack. Wikipedia.
Available at: http://en.wikipedia.org/wiki/Semantic_Web_Stack. Wikipedia (2013c). DBpedia. Wikipedia.
Available at:http://en.wikipedia.org/wiki/DBpedia.
李靜宜、柯皓仁(2012)。電子資源整合查詢系統使用者接受度與使用行為之研究。教育資 料與圖書館學,49(3),369-404。