第五章 群集式為基礎之多項式擬合統計圖等化法之 延伸
前章節敘述的群集式為基礎之多項式擬合統計圖等化法屬於較一般化(General) 的通式,若重新做一些假設後,可應用推導出不同作法。在本論文吾人延伸出二 種不同作法,第一個作法是簡化假設並只使用乾淨訓練語料(Clean Training Speech Data),應用至統計圖等化法中,吾人稱其為多項式擬合統計圖等化法 (Polynomial-Fit Histogram Equalization, PHEQ)[Lin et al. 2006a, 2006b];另一個作 法是搭配遺失特徵理論,利用多項式迴歸函數本身具有預測(Prediction)的能力,
達 到 遺 失 特 徵 的 重 建 , 吾 人 稱 其 為 (Selective Cluster-based Polynomial-Fit Histogram Equalization, SCPHEQ)。下列章節將分別詳述此二種作法及其實驗結 果。
5.1 多項式擬合統計圖等化法
在 統 計 圖 等 化 法 最 主 要 精 神 可 以 視 為 是 利 用 一 個 轉 換 函 數 (Transformation Function),此函數能將測試語句的語音特徵向量每一維的統計分布分別轉換至先 前已從訓練語句中定義好的對應參考分布,數學式關係式表示如式 2-21 與式 2-22,因此,若將群集式為基礎之多項式擬合統計圖等化法中的假設,簡化成只 使用單聲源語料(即乾淨語料),且對於訓練語料語音特徵向量的每一維只有一個 全域的(Global)多項式轉換函數表示,那麼即可將群集式為基礎之多項式擬合統 計圖等化法(CPHEQ)簡化成多項式擬合統計圖等化法(PHEQ),數學關係示表示 如下
( )
( ) ∑ ( ( ) )
=
=
= M
m
m t m t
t G CDF y a C y
y
0
~ (式 5-1)
且其均方誤差定義為:
( )
( )
∑ − ∑
= = ⎟ ⎟
⎠
⎞
⎜ ⎜
⎝
⎛ −
= 1
0
2
0 2 T
t
M
m
m t Train m
t a CDF y
y
E (式 5-2)
其中T 為訓練語料中所有音框的個數,若要使均方誤差最小,則所有多項式係數 a M
a
a 0 , 1 , K , 會滿足式 5-3 的關係,只需透過解聯立方程式,即可求得 a 0 , a 1 , K , a M 係數。
M a m
E
m
K 1 , ' 2 0
=
∀
∂ =
∂ (式 5-3)
在辨識階段,只需要將測試語句語音特徵向量中的每一維特徵值 y 的對應 t 累積密度函數值 CDF ( ) y t 代入先前已於訓練階段中求得的多項式函數(式 5-2)即 可進行等化動作,此做法不僅能有效地解決傳統統計圖等化法或分位差統計圖等 化法需耗費的大量記憶體資源與處理器運算時間的缺點,只需透過少量的多項式 係數與多項式函數的運用,便能迅速的將測試語句語音特徵向量每一維的統計分 布轉換至先前已從訓練語句中定義好的參考分布,並且能擁有和統計圖等化法相 同的補償效果。
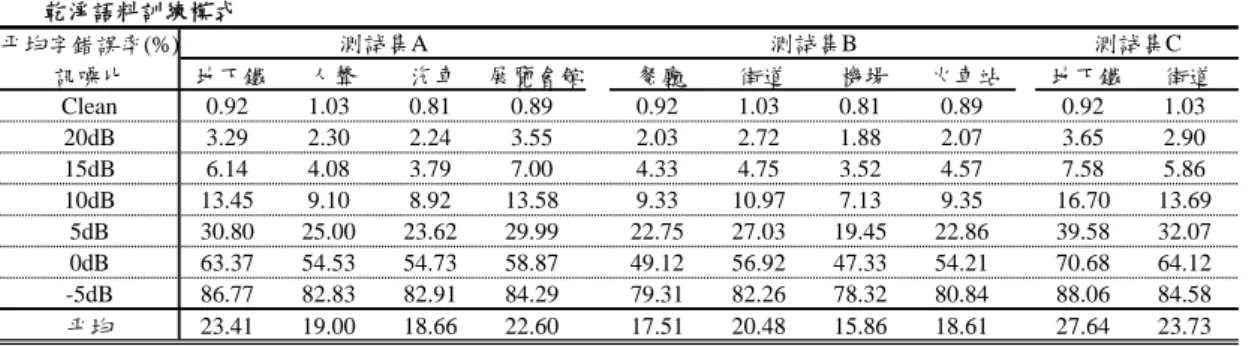
此外,雖然統計圖等化法對於補償因雜訊干擾所產生的非線性失真有顯著效 果,但值得一提的是,由非穩性噪音(Non-stationary Noise)所造成的異常尖峰 (Sharp Peak)或波谷(Valley),可能會造成統計圖等化法在等化的過程中,某些語 音特徵值被異常的放大或縮小,此異常情形可以由圖 5-1 中觀察到,最上方的圖 為尚未做統計圖等化法前,原本的乾淨語料與雜訊語料的梅爾倒譜頻係數的第二 維特徵值;中間的圖為做完統計圖等化法後的梅爾倒譜頻係數的第二維特徵值,
可清楚看見有二個區域被過度強調。因此此問題可利用語音訊號本身是屬於變化
緩慢的特性,利用移動平均法來達到音框間特徵值的平滑(Smoothing),減緩音框
間過度劇烈的快速變化。
0 10 20 30 40 50 60 70 80 90 100 -10
-5 0 5
時間點
倒頻譜特徵值
統計圖等化法前
乾淨語料 雜訊語料
0 10 20 30 40 50 60 70 80 90 100
-10 -5 0 5
統計圖等化法後
倒頻譜特徵值
時間點
0 10 20 30 40 50 60 70 80 90 100
-10 -5 0 5
統計圖等化法後 + 移動平均
倒頻譜特徵值
時間點
圖 5-1 非穩性噪音所造成的異常尖峰或波谷示意圖
移動平均的使用在語音辨識研究上,並非是一個全新的議題,例如[Chen et al.
2002]曾利用移動平均的概念,提出一種不同特徵向量正規化的方法,首先先對 語音特徵向量進行平均消去法和變異數正規化,接著再利用自動迴歸移動平均 (Auto-Regression Moving Average, ARMA)對特徵向量進行平滑的動作,實驗結果 證實移動平均的使用對於提升整體辨識率有很大的幫助。然而依照移動平均所考 慮語音特徵來源與時間軸點數不同,可以有下列數種選擇[Chen et al. 2002; Chen and Bilmes 2007]。
z 非因果關係移動平均(Non-Causal Moving Average)
( )
~
, 1
2
~ ˆ ⎪
⎩
⎪ ⎨
⎧
−
≤ + <
= ∑ = − +
otherwise y
L T t L L if
y y
t L
L
i t i
t (式 5-4)
z 因果關係自動迴歸移動平均(Causal Moving Average)
語 音 訊號
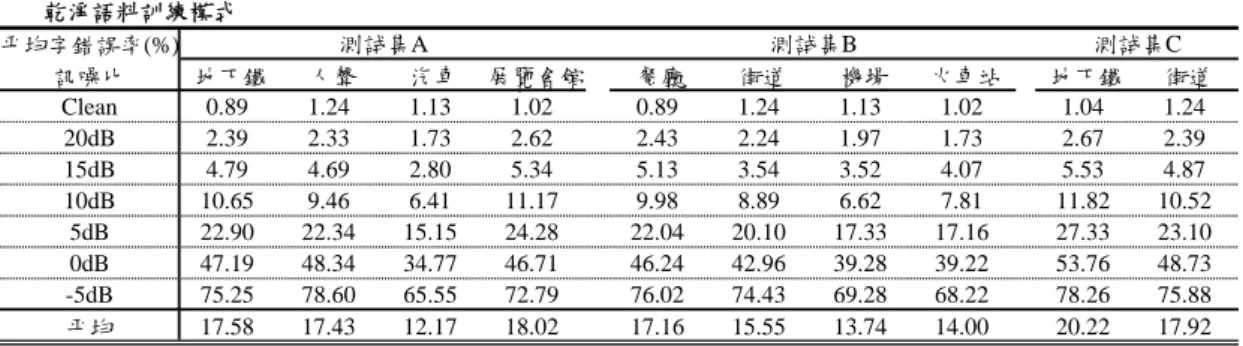
語 音 特徵 參數 擷取 梅 爾 倒頻 譜係 數
統 計 圖等 化法
特 徵 向量
訓 練 語料 累 計 密度 函 數 估測 訓 練 階段
多 項 式回 歸 參 數 估測
累 計 密度 函 數 估測 測 試 語料
多 項 式參 數
多 項 式回 歸 測 試 階段
時 間 序列 特徵 值平 均
( )
tTrain
x CDF
( ) ( CDF
Testy
t)
G
a
ma
1, L ,
y t
~
yˆ t CDF
Test( ) y
ty t
x
ty
t圖 5-2 多項式擬合統計圖等化法的流程圖
( )
~
, 1
~ ˆ
0
⎪ ⎩
⎪ ⎨
⎧
≤ + <
= ∑ = −
otherwise y
T t L L if
y y
t L
i t i
t (式 5-5)
z 非因果關係自動迴歸移動平均(Non-Causal Auto Regression Moving Average)
( ) ( )
~
, 1
2 ˆ ~
ˆ 1 0
⎪ ⎩
⎪ ⎨
⎧
−
≤ + <
= ∑ = − + ∑ = +
otherwise y
L T t L L if
y y
y
t L i
L
j t j
i t
t (式 5-6)
z 因果關係自動迴歸移動平均(Causal Auto Regression Moving Average)
( ) ( )
~
, 1
2 ˆ ~
ˆ 1 0
⎪ ⎩
⎪ ⎨
⎧
≤ + <
= ∑ = − + ∑ = −
otherwise y
T t L L if
y y
y
t L i
L
j t j
i t
t (式 5-7)
其中 y ~ 為輸入的語音特徵值, t yˆ 為經由移動平均法後所求得新的語音特徵值,L t
表示移動平均項階數(Order of Moving Average),圖 5-1 最下方的為做完統計圖等
化法加移動平均後的倒譜頻特徵向量,從圖中可清楚看到做完移動平均後,被異
常放大或縮小的語音特徵值已被平滑掉。
表 5-1 多項式擬合統計圖等化法的辨識結果
乾淨語料訓練模式
3 5 7 9
所有語料 22.39 21.54 21.08 21.30 1000組 21.80 21.46 21.13 21.16 100組 22.68 21.31 20.75 20.55 10組 23.42 22.20 22.54 23.42 訓
練 數 量
多 項 式 階 數 平均字錯誤率(%)
20.00 20.50 21.00 21.50 22.00 22.50 23.00 23.50
3 5 7 9
多項式階數 平
均 字 錯 誤 率
(
%
)
所有語料 1000組 100組 10組
訓練數量
圖 5-3 多項式擬合統計圖等化於不同設定下之實驗結果比較圖
5.1.1 多項式擬合統計圖等化法(PHEQ)相關實驗結果
在多項式擬合統計圖等化法相關實驗中,第一個實驗是利用多項式廻歸模型描述 參考分布的累積密度函數分布情形,探討使用所有訓練語料與否以及不同多項式 階數對於整體辨識效能影響結果如何。其中參考分布的資訊是由乾淨訓練語料統 計而成的,在累積密度函數的求取,除了使用所有的訓練語料外,亦嘗試將訓練 語料分成 1000 組、100 組和 10 組,每一分組是以組內所有特徵值的平均數做為 該組代表特徵值;同時也使用不同階數的多項式進行等化動作,辨識結果如表 5-1 所示。其中值得注意的是,由於多項式階數結束行為(End Behavior)的特性,
會使得使用偶數階數的多項式可能無法滿足累積密度函數結束行為的特性,所以
表 5-2 多項式擬合統計圖等化法使用 7 階的多項式廻歸以及 100 分組組數實驗的 辨識結果
平均字錯誤率(%)
訊噪比 地下鐵 人聲 汽車 展覽會館 餐廳 街道 機場 火車站 地下鐵 街道
Clean 0.92 1.03 0.81 0.89 0.92 1.03 0.81 0.89 0.92 1.03
20dB 3.29 2.30 2.24 3.55 2.03 2.72 1.88 2.07 3.65 2.90
15dB 6.14 4.08 3.79 7.00 4.33 4.75 3.52 4.57 7.58 5.86
10dB 13.45 9.10 8.92 13.58 9.33 10.97 7.13 9.35 16.70 13.69 5dB 30.80 25.00 23.62 29.99 22.75 27.03 19.45 22.86 39.58 32.07 0dB 63.37 54.53 54.73 58.87 49.12 56.92 47.33 54.21 70.68 64.12 -5dB 86.77 82.83 82.91 84.29 79.31 82.26 78.32 80.84 88.06 84.58 平均 23.41 19.00 18.66 22.60 17.51 20.48 15.86 18.61 27.64 23.73 乾淨語料訓練模式
測試集A 測試集B 測試集C
表 5-3 多項式擬合統計圖等化法結合不同移動平均法的辨識結果 乾淨語料訓練模式
0 1 2 3 4 5
20.75 17.75 16.83 17.26 18.15 19.66 20.75 19.23 18.28 17.44 17.12 17.28 20.75 17.83 16.90 16.38 16.99 17.34 20.75 17.93 16.84 19.20 17.44 19.20
移 動 平 均 項 非因果移動平均
因果自動迴歸 平均方式 平均字錯誤率(%)
因果移動平均 非因果自動迴歸
15.00 16.00 17.00 18.00 19.00 20.00 21.00
0 1 2 3 4 5
移動平均項 平
均 字 錯 誤 率
(
% )
非因果移動平均 因果移動平均 非因果自動迴歸 因果自動迴歸
圖 5-4 多項式擬合統計圖等化法結合不同移動方均方法的辨識結果比較圖
在多項式擬合統計圖等化法並不考慮偶數階數的使用。由圖 5-3 可清楚看到,辨
識效能隨著多項式階數增加有所進步,然而並非使用階數愈高愈好,因為資料的
表 5-4 多項式擬合統計圖等化法使用 7 階的多項式廻歸以及 100 分組組數搭配 3 階的非因果關係自動廻歸移動平均的辨識結果
平均字錯誤率(%)
訊噪比 地下鐵 人聲 汽車 展覽會館 餐廳 街道 機場 火車站 地下鐵 街道
Clean 0.89 1.24 1.13 1.02 0.89 1.24 1.13 1.02 1.04 1.24
20dB 2.39 2.33 1.73 2.62 2.43 2.24 1.97 1.73 2.67 2.39
15dB 4.79 4.69 2.80 5.34 5.13 3.54 3.52 4.07 5.53 4.87
10dB 10.65 9.46 6.41 11.17 9.98 8.89 6.62 7.81 11.82 10.52
5dB 22.90 22.34 15.15 24.28 22.04 20.10 17.33 17.16 27.33 23.10 0dB 47.19 48.34 34.77 46.71 46.24 42.96 39.28 39.22 53.76 48.73 -5dB 75.25 78.60 65.55 72.79 76.02 74.43 69.28 68.22 78.26 75.88 平均 17.58 17.43 12.17 18.02 17.16 15.55 13.74 14.00 20.22 17.92 乾淨語料訓練模式
測試集A 測試集B 測試集C
散布情形,可能使高階多項式為了要更符合資料分布情形,而造成過度擬合的情 形;同樣地,若使用所有訓練語料來求算多項式係數亦會有過度擬合的情形或受 異常值影響,Aurora-2 語料庫上最好的結果是利用 7 階的多項式廻歸以及 100 分 組組數的累積統計圖有較佳的辨識結果。平均字錯誤率達 20.75%,相較於查表 式統計圖等化法或是分位差統計圖等化法,辨識效能不相上下。下列所有實驗將 使用 7 階多項式廻歸,並且參考分布是利用 100 組的累積統計圖中統計而得,其 於不同雜訊與訊噪比的辨識效果如表 5-2 所示。
接下來,吾人探討移動平均的使用對於減輕由雜訊或等化過程中所造成的異 常情形,而提高辨識能的效果如何,實驗結果如表 5-3 所示,表中清楚的呈現無 論是使用哪種移動平均法,對於提升多項式擬合統計圖等化後語音特徵的辨識效 果皆有明顯的幫助,其中當移動平均項為 0 時,表示不做任何平均動作,亦即單 純使用多項式擬合統計圖等化法所得到的辨識結果。實驗結果和[Chen et al. 2002]
呈現的相同,使用非因果關係自動迴歸移動平均有較佳的辨識結果,在 Aurora-2
語料庫上以搭配 3 階非因果關係自動迴歸移動平均達最好的效果,其於不同雜訊
與訊噪比的辨識效果如表 5-4 所示,若相較於單純使用多項式擬合統計圖等化法
而言,字錯率可相對地減少約 20%左右。此外由圖 5-4 可看出若移動平均項的階
數若使用太高,可能會造成原本帶有鑑別資訊的特徵值,因此被平滑掉,使得辨
識效能下降。
5.2 群集式為基礎之選擇性多項式擬合統計圖等化法
群集式為基礎之多項式擬合統計圖等化法的另一種延伸是搭配遺失特徵理論,利 用多項式迴歸模型來預測遺失特徵的特徵值,吾人稱之為群集式為基礎之選擇性 多 項 式 擬 合 統 計 圖 等 化 法 (Selective Cluster-based Polynomial-Fit Histogram Equalization, SCPHEQ)。在遺失特徵理論中,特徵重建主要包含二個主要步驟,
第一步是決定語音特徵向量中哪些特徵參數是可靠,哪些是不可靠(或遺失)的,
因為此部份非本論文重點,所以在本論文是假設已經有一個非常好的方法可以用 來判定每個音框中每一維度的特徵值是可靠或是不可靠的。而第二步是針對不可 靠的特徵參數進行重建,此步驟乃為本小節的探討重點。
首先,吾人假設和群集式為基礎之多項式擬合統計圖等化法(CPHEQ)一樣,
假設重建的語音特徵參數可利用多項式迴歸模型,因此重建的語音特徵值可經由 如式 4-6 求得。但與群集式為基礎之多項式擬合統計圖不同的是 Y 並非倒頻譜特 t 徵值,而是頻譜特徵值(Spectral Value),主要原因是因為雜訊干擾語音訊號可能 只在某些頻段(Frequency Band)上發生,對於其他頻段並不會有所干擾,且也因 為倒頻譜係數會含蓋數個頻段的資訊,所以較難進行可靠語音特徵參數與不可靠 語音特徵參數的判定。此外,因為在頻譜特徵值的值域變化差距非常大,若利用 統計圖來求算對應的累積密度函數並不適合,因此,吾人利用高斯誤差函數 (Gaussian Error Function)求得每個音框的累積密度函數。若隨機變數的統計分布 是一高斯分布,即 Y t ~ N ( ) μ , σ 2 ,那麼累積密度函數值式求得[Abramowitz and Stegun 1965]:
( ) ( ) ( ) = ∫ −
⎟⎟ ⎠
⎜⎜ ⎞
⎝
⎛ ⎟
⎠
⎜ ⎞
⎝
⎛ − +
= Φ
=
y t t t
t t
t
dt e y
erf
erf y x
y CDF
0
2 2
2 2 1
1
π
σ μ
(式 5-8)
其中 μ 為平均數,σ 為標準差,但如同前面章節所敘述的,語音特徵參數的分布
並非是一常態分布,所以亦可將式 5-8 延伸至高斯混合模型。而在高斯混合模型 中,累積密度函數的求得可利用下式近似:
( ) ∑ ( ) ∑
=
= ⎟ ⎟
⎠
⎞
⎜ ⎜
⎝
⎛
⎟ ⎟
⎠
⎞
⎜ ⎜
⎝
⎛ − +
= Φ
×
= J
j j
j t j
J
j
t j j t
erf y c
y c
y CDF
1
1 1 2
2 1
σ
μ (式 5-9)
其中 J 為高斯混合模型中所有高斯分布的個數, c 為高斯混合模型中第 j 個高斯 j
分布的權重, μ j 和 σ j 分別為第 j 個高斯分布所對應的平均數與標準差。因此在 實作上,群集式為基礎之選擇性多項式擬合統計圖等化法需使用二組不同的高斯 混合模型,一組與群集式為基礎之多項式擬合統計圖等化法相同,即利用雙聲源 語料中的雜訊語料 Y 訓練出一組高斯混合模型: t
( ) ∑ ( ) ( ) ∑ ( )
=
=
Σ
=
= K
k
k k t k K
k
t
t P k p Y k c N Y
Y p
1 1
,
;
| μ (式 5-10)
另一組高斯混合模型則是用來近似語音特徵參數的累積密度函數,對於每一群集 k 皆有一組對應的高斯混合模型,高斯混合模型是由收集所有落至該群集的語音 特徵向量訓練而得:
( ) ( ) ( ) ( ) t k
J
j
kj kj t k kj J
j
t k k t
k Y p j p Y j c N Y Y Cluster
p = ∑ = ∑ Σ ∀ ∈
=
=
, ,
;
|
1 1
μ (式 5-11)
而參數的重建是利用迴歸模型 R ( ) y t 求得,對於每一群集的多項式迴歸模型求得 方式,與群集式為基礎之多項式擬合統計圖相同,迴歸模型的係數亦是經由最小 化下列均方錯誤求得。
( ) ∑ ∑ ( ( ) ) ( )
= = ⎟ ⎟
⎠
⎞
⎜ ⎜
⎝
⎛ ⎟ ⎟ ×
⎠
⎞
⎜ ⎜
⎝
= ⎛
= K
k
t M
m
m t km
t
t R y a CDF y k Y
y
1 0
~ δ | (式 5-12)
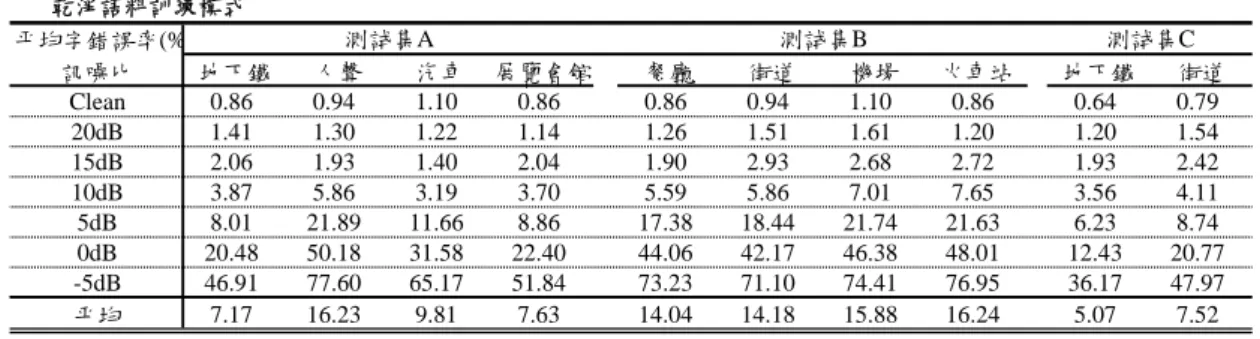
訓練高斯
混合模型 高斯混合模型 (分群)
多項式轉換 函數 尋找最相近的群集
雙聲源語音 雜訊語音 訓練階段
測試階段
( )
tk
P k Y
k = arg max
'|' ˆ
累積密度函數估測乾淨語音
X t
Y t
( ) • G
k 雜訊語音k
Yˆ t
收集每一群集的
雜訊語音 高斯混合模型
(估測累積密度函數) 累積密度 函數估測
( )
tTrain
y C
訓練高斯 混合模型 估測每一群集的 多項式轉換函數
( )
tTest
y C ˆ
多項式迴歸 音框可靠度
判定