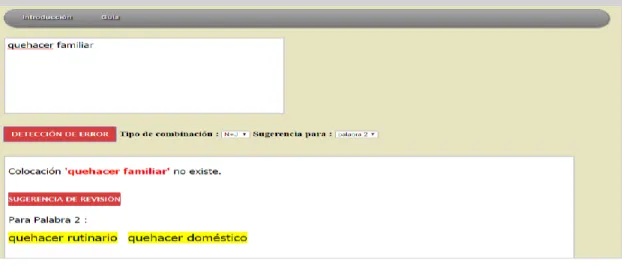
科技部補助專題研究計畫成果報告
期末報告
以西語為第三語之受詞代名詞習得研究
計 畫 類 別 : 個別型計畫
計 畫 編 號 : MOST 105-2410-H-006-071- 執 行 期 間 : 105年08月01日至106年10月31日 執 行 單 位 : 國立成功大學外國語文學系(所)
計 畫 主 持 人 : 盧慧娟 共 同 主 持 人 : 盧文祥
計畫參與人員: 碩士班研究生-兼任助理:邱國豪 大專生-兼任助理:歐宜亭
其他-兼任助理:朱玉馨 其他-兼任助理:洪聖允
報 告 附 件 : 出席國際學術會議心得報告
中 華 民 國 106 年 11 月 07 日
中 文 摘 要 : 西語受詞代名詞由於本身之型態、句法和語意的複雜性,對學習者 而言,較困難、也較晚習得;且因為針對台灣以西語做為第三語的 多語學習者之習得發展序尚未被研究過,故有探究、了解其習得程 序之必要性,以達到提升外語習得成效之目標。
本計畫所要研究的問題如下:第一、台灣學習者在西語受詞代名詞 的習得發展序為何?是否與以英語為母語者相同?第二、台灣學習 者的第一語(母語/中文)和第二語(第一外語/英文)對第三語
(目的語/西文)受詞代名詞習得的影響為何?所採取的研究方法如 下。首先,改善已建構之「台灣西語學習者語料庫」和「西英漢三 語平行語料庫」的檢索功能,以提升現有資源之可利用性。接著
,進行語料庫為本之錯誤和對比分析研究。一方面,採用正誤分析 法分析台灣西語學習者的書面語語料,以瞭解他們在習得產出之發 展序(省略、格位、人稱、單複數、陰陽性、生命性和位序特質
)。另一方面,採用對比分析法分析西英漢三語平行語料,以剖析 台灣西語學習者在習得時,第一語和第二語對第三語的影響。結合 上述兩分析法對台灣學習者在西語受詞代名詞習得的研究結果,並 與以英語為母語者比較,進而了解不同語言背景之學習者的共通性
。
針對研究問題1,我們以學習者使用的正確率來分析臺灣西語學習者 於第三語西語受詞代名詞的習得,所推論出的結果顯示:在初、中 兩階段,不同語言學屬性之代名詞的發展序為「格位」(間接>直接 )、「人稱」(第一人稱>第三人稱)、「陰陽性」(陽性>陰性)、「
單複數」(單數>複數)「生命性」(生命性>非生命性) 和「位序」習 得序(受詞代名詞+動詞>動詞+受詞代名詞)。與過去以英語為母語者 之西語學習者的文獻相比較,雖然學習者的母語、以西語為目標語 的屬性以及所使用的研究法皆不同,但所獲致的發展序相符。針對 研究問題2,我們比較平行語料在受詞代名詞的使用研究結果顯示
,西英中三語言不對應的關係反應了受詞代名詞在三語間形態與結 構上的使用差異,西語受詞代名詞對初始階段的臺灣西語學習者來 説預期會有一定的困難。以對應關係的相似度推論,臺灣西語學習 者在第三語習得初期在受詞代名詞的習得發展中,省略受詞代名詞 的現象可能同時受到兩個前語言(第一語中文、第二語英文)的影 響,而初階的學習者在第三語習得初期受到第一語的影響則多於第 二語。經由前所建構語料庫檢索功能的提升,强化搜尋結果所能覆 及的面向,透過更爲周延的變數分類與註記程序以及所屬語言學特 徵的歸納與剖析,讓研究成果對西語受詞代名詞在第三語言的習得 提供更具系統性結論的全貌。
中 文 關 鍵 詞 : 受詞代名詞、語料庫為本、西語習得、第三語
英 文 摘 要 : This study set out to investigate the following research questions: What are the developmental stages of the acquisition of the Spanish object pronouns by Taiwanese learners?, are the stages of Chinese-speaking learners the same as those of English-speaking learners? What are the influences of the first language (Mandarin Chinese/native language) and the second language (English/the first
foreign language) on the acquisition of the third language
(Spanish/target language) in contrastive studies? The data source of this study is based on a continuous improvement of a learner corpus (Taiwanese Learners’ Written Corpus of Spanish) and a trilingual parallel corpus (Parallel Corpus of Spanish, English and Chinese).
Corpus-based error analysis and contrastive analysis were employed to examine the learner productions containing the Spanish object pronouns. The error analysis on the written texts by the Taiwanese learners of Spanish enabled us to sort out the developmental stages (regarding omission, case, person, number, and gender, animacy and order).
Regarding the first research question, the acquisition of L3 Spanish objects by Taiwanese learners was defined in terms of accuracy rate of the usage of the target form. The result indicated that the developmental stages of Spanish clitic pronouns for learners at the beginning and
intermediate levels in different linguistic attributes were: case (indirect>direct), person (first person>third person), gender (masculine>feminine), number
(singular>plural), animacy (animate>inanimate), and order (object pronoun + verb>verb + object pronoun). The findings of the developmental stages presented a similar pattern as those of previous studies on English-speaking Spanish learners although the learners’ native languages and the research methods were different.
With regard to the second research question, we compared the uses of the object pronouns across three languages in the trilingual parallel corpus. The results showed the non- one-to-one corresponding relationship, which reflected different uses of object pronouns in terms of the form and structure. This differences also accounted for the
challenges that Taiwanese learners of Spanish faced as they learned the Spanish object pronouns in the beginning stage.
It is hypothesized that in the early stage of L3 Spanish Taiwanese learners, the omissions of object pronouns may be simultaneously influenced by two previously-acquired
languages (Chinese as the first language and English as the second one), and the beginners might be affected more by their first language than the second. By enhancing the search function of previously-constructed corpora,
improving the search dimensions, and adopting more thorough classification of variables, annotation process, and
induction and analysis of linguistic features, we aimed to obtain a more comprehensive conclusion systematically on the acquisition of L3 Spanish object pronouns.
英 文 關 鍵 詞 : object pronouns, corpus-based research, Spanish, third language acquisition
1
以西班牙語為第三語之受詞代名詞習得研究
計劃主持人:盧慧娟 共同主持人:盧文祥、鄭安中 一、前言
本研究以兩個自行建構語料庫為基礎,著力於台灣西班牙語學習者在目的語之形式和意 義串連的第三語習得探討,選定西語受詞代名詞作為語言分析的主題,如 Torres (2003)指出 西語受詞代名詞對第二外語學習者而言,是比較困難的。Lee & Malovrh (2009)也提到西語受 詞代名詞是較晚習得的;同時,Malovrh & Lee (2013)也表示:針對不同程度的學習者和透過 不同方式所收集之語料,其西語受詞代名詞的習得發展相當複雜。此外,在語料庫中,英國 的 SPLLOC 和西班牙的 CEDEL2 是目前世界上兩個最知名的西語學習者語料庫,這兩個語料 庫的研究團隊以其建構的成果為基礎所執行的語言分析中,皆涵蓋了西語受詞代名詞主題的 研究,也顯示此研究主題的重要性。
此研究計畫,一方面延續主持人兩個主要語料庫(「臺灣西語學習者書面語語料庫」Corpus
de Aprendices Taiwaneses de Español, CEATE 和「西英漢三語平行語料庫」Corpus Paralelo de Español, Inglés y Chino, CPEIC)的建構,增加語料量及提升檢索功能性;另一方面則以之為 本,將語料庫的建構成果結合於外語習得之分析研究。主要進行的工作包含以下四項:在語 料庫的延伸建構方面:增加三語平行語料的電影字幕語料,讓語料主題多元與生活化;以及 強化學習者語料庫和三語平行語料庫的檢索功能,以提升檢索效益。在以語料庫為本的語言 分析方面:進行西語學習者在西語受詞代名詞之使用與錯誤傾向,瞭解習得發展序;並以西 英漢平行語料對比分析三語受詞代名詞的使用異同,以解釋台灣西語學習者在目標語西語的 使用及錯誤與其第一語中文及第二語英文的關聯性。
二、研究目的
本計劃旨在結合學習者和多語平行兩類型語料庫,並進行以語料庫之為本的正誤和對比 分析法,以瞭解多語背景之學習者在西班牙語受詞代名詞習得之書寫產出發展,以及第一語 和第二語對第三語所可能造成的影響。有鑒於在台灣以西語做為第三語的學習者,涵蓋構詞、
語法和語意知識的受詞代名詞習得發展序之研究主題尚未被研究過;因此,以台灣西語學習 者語料庫為本的研究,值得針對這個主题進行分析與探討。也因研究主題之複雜性,有必要 深入探究,藉由釐清台灣西語學習者的特質,以瞭解跨語言架構下多語學習者在受詞代名詞 的習得程序、台灣西語學習者和以英語為母語的西語學習者間之異同,以及學習者第一語中 文和第二語英文對其目的語第三語西文的可能影響,以期獲致相關結論來改善教學與學習,
進而提升教學成效。
本研究所設定的研究問題如下:1.台灣學習者在西語受詞代名詞的習得發展序為何?是 否與以英語為母語者的西語學習者相同?2.學習者的第一語(中文)和第二語(英文)對第 三語(西文)受詞代名詞習得的影響為何?
三、文獻探討
2
(一)西班牙語受詞代名詞習得 A. 語言特徵
有關西語受詞代名詞之語言特徵(Harvey, 2006; Alonso et al., 2011)的研究中,西語受詞代 名詞比中文和英文的受詞代名詞複雜許多,因為它不僅有格位、人稱和單複數之別,第三人
稱代名詞還有陰陽性之分。而其中的第三人稱代名詞之一lo更是複雜,具多重功能。表一列
舉了西語受詞代名詞之構詞型式與對應之屬性,其句法位置如(1a)和(1b)所示。
表一、西語受詞代名詞之構詞型式及屬性特徵 受詞
代名詞
單數 複數
第一人稱 第二人稱 第三人稱 第一人稱 第二人稱 第三人稱
陽性 陰性 陽性 陰性
間接 me te le nos os les
直接 me te lo la nos os los las
(1) 西文受詞代名詞與動詞之詞序
(1a) 間接受詞代名詞 / 直接受詞代名詞 變化過(含,、時態等變形)之動詞1(兩/三成份分別 為獨立之個別字)
(1b) 原形動詞/現在分詞+間接受詞代名詞/+/直接受詞代名詞(兩/三成份合成為單一字)
B. 習得序
Malovrh & Lee (2013)延續了 Lee & Malovrh (2009)和 Malovrh & Lee (2010)的成果,針對 4 個不同西語程度的學習者,詳細且完整地比較了他們的中介語在 1.口語產出(production)和 2.理解處理(processing)等透過不同方式收集之語言資料的異同。所分析的受詞代名詞變數有 格位(case)、人稱(person)、單複數(number)、陰陽性(gender)等不同的構詞特性,「主-動-賓」
(SVO)和「賓-動-主」(OVS)的句法詞序,以及 [生命性]、[及物性]語意特徵等語言學分類 特質。有關西語受詞代名詞習得發展序的研究中,Klee (1989)提出:以克丘亞語(Quechua)爲 母語之西語學習者的發展階段依序是先習得格位,然後是單複數,最後才是陰陽性。Malovrh
& Lee (2013)的口語產出研究結果提出類似且更完整的發展模式:1.受詞省略、2.間接受詞>
直接受詞(>符號左方者為先習得類型,符號右方為後習得者)、3.第一人稱>第三人稱、4.單數
>複數、5.陽性>陰性。Malovrh & Lee (2013)的分析究結果顯示:整體而言,雖具系統性,但 不同西語程度的學習者間卻又展現其變異性。針對上述所提及之語言習得發展的個別特性之 相關文獻,陳述如下。
a. 省略
在以西語為第一語的研究中,Castilla & Pérez-Leroux (2010)指出以西語為母語之兒童語 言習得的產出中,直接受詞的省略出現在及物結構句法發展的初期階段;但隨著年紀的增長,
受詞使用的頻率會增加。而在以西語為第二語的研究中,Torres (2003)的研究結果也顯示較低
1 考量研究主題之聚焦性,本計劃研究西語受詞代名詞之研究範圍的界定暫不考慮命令式動詞之相關討論。
3
程度的學習者極少使用受詞代名詞,多是呈現省略的情形;其理由是因為過度使用了名詞片 語或介系詞片語,而造成少用受詞代名詞的現象。Malovrh & Lee (2013)的產出結果顯示:中 介語中,受詞代名詞的使用隨著語言程度提高而逐漸增加受詞代名詞的出現頻率,但正確率 有限;受詞代名詞和名詞片語的產出隨著語言程度之提升而增加;受詞代名詞的省略頻率則 隨之降低;相較於西語母語者,學習者使用較少的受詞代名詞,但較多的名詞片語。在文法 功能方面,me/nos/te/los/la/las 的構詞形態作為直接受詞時,西語母語者比學習者使用得頻繁。
Klee (1989)的研究則提到第三人稱直接代名詞(lo, la, los, las)常被省略。西語受詞代名詞的省 略不管是第一語或第二語的研究都顯示是出現在習得的初期,但在多語(雙語或三語)的習 得研究中,之前所習得語言(母語、第二語等)的特性是否也可能影響後習得語言的受詞代 名詞省略,這並未在省略受詞的分析中被探討,因此值得進一步探究、比較。
b. 間接與直接受詞代名詞
Andersen (1983, 1984)和 VanPatten (1990)在口語訪問以英語爲母語的西語學習者之長期 性的研究方法下,發現初階學習者是先正確說出西語間接受詞代名詞,然後才是直接受詞代 名詞。Malovrh & Lee (2013)的產出分析之發展序亦為:間接受詞>(先於)直接受詞。Zyzik (2006) 指出以英語為母語的西語學習者在第二語習得的典型影響中,學習者常把間接受詞過份概化 成直接受詞,尤其當指涉具有[+生命性]之語意特質時。有別於研究結果的習得順序,在第二 外語教材中直接受詞幾乎都比間接受詞優先被教導。因此,習得結果與可能影響因素需再進 一步釐清。
c. 人稱、單複數、陰陽性
在人稱方面,Andersen (1983, 1984)和 VanPatten (1990)的研究結果皆顯示:以英語爲母語 的西語學習者之口語表達的第一人稱比第三人稱的受詞代名詞早出現,且使用正確率也較 高。此外,Torres (2003)指出以西語為第二語的中階學習者先會使用的是第一人稱的受詞代名 詞,然後才是第三人稱的受詞代名詞。同時,Lee & Malovrh (2009)研究學習者對西語受詞代 名詞的處理,結論顯示不同程度者最一致的表現是人稱的習得,第一人稱是最先習得,之後 才是第三人稱的型態。Malovrh & Lee (2013)針對習得理解處理分析的結果顯示:第一人稱>
(先於)第二人稱>第三人稱;然而,產出結果的習得序則為:第一人稱>第三人稱,第三人 稱之受詞代名詞最少被使用。Klee (1989)的研究提到受詞代名詞以直接受詞第一和第二人稱 (me, te, nos) 的正確使用率最高,而第三人稱代名詞(lo, la, los, las)則是正確率較低的。另一方 面,在受詞代名詞單複數和陰陽性的型態中,Rossi et al. (2014)指出受詞代名詞單複數的處理 程序出現在以英文為母語之西語學習者較晚的習得階段。Malovrh & Lee (2013)對習得產出的 分析結果是單數>複數。Rossi et al. (2014)認為因為英文無陰陽性配合的文法特質,學習者對 於西語陰陽性配合的敏感度則是出現在更晚的習得階段。Lee & Malovrh (2009) 的研究顯示不 同階段的學習者間,最無規律的發展是受詞代名詞的陰陽性習得。Malovrh & Lee (2013)對習 得處理和產出的分析結果皆是:陽性>陰性。根據上述文獻的結論,西語受詞代名詞的人稱、
單複數和陰陽性中不同構詞型態有其習得先後順序之別。本研究將以中文為母語、英文為第 二語和西文為第三語的學習者為研究對象,由於這些學習者的第一語中文的人稱代名詞在主
4
格、直接受格和間接受格的型態外觀上是沒有差別的,藉此探究習得結果是否與以英文為母 語之西語學習者是否有所不同。
d. 詞序
Houston (1997), Lee (1987, 2000), LoCoco (1987), Malovrh (2006), VanPatten (1984), VanPatten & Houston (1998)等人的研究結果發現句子詞序會影響以英語為母語、西語為第二 語的學習者對句中主詞和受詞語法功能的處理與認知。如:「賓-動-主」(OVS)詞序的句型會 讓學習者將第一個名詞詮釋為主語或主事者(agent)。另外,Klee (1989)和VanPatten (1990)的研 究結果類似,他們發現:初學習者受母語的影響較大,多使用「主-動-賓」的詞序,而非「主 -賓-動」(SOV)的詞序。在本研究中,有關詞序所延伸的議題,我們涵蓋了過去文獻所沒有觸 及的面向,亦即:變化過的動詞前和原形動詞或現在分詞後之受詞代名詞的位置與呈現型態
(分開成獨立的數個字或合併組成單一字)。
e. 語意特徵
Malovrh & Lee (2013)指出[生命性]的語意特徵會影響西語學習者在受詞代名詞產出之 正確性,母語者和非母語者對此特徵皆具敏感度。Schwenter & Torres Cacoullos (2014)的結論 也顯示西語在動詞前的第三人稱直接受詞代名詞與[–生命性]語意特質相關。其它的語意特徵 討論還包括 Nishida (2012)以語料庫為本之研究指出西語在帶有 give 和 send 類型動詞的句型 結構中,以間接受詞代名詞表達接收者(recipient)語意的模式具有[+特定]的語意特質。由上述 所討論的構詞、語法和語意等個別不同觀點切入,可以掌握到西語受詞代名詞在其它母語學 習者之習得脈絡與規律性。
C. 第三語習得
過去「第二語習得」研究籠統地把所有學習外語、第二語、第三語和多語學習者及經驗全 部歸為一類,但這之間學習者的語言學習背景、學習環境和過程等因素皆會影響語言習得研 究的結果,因此有必要區分出「第三語習得」的研究,以進一步探索人類學習語言的共通特 點和語言差異所造成的習得結果。第三語相關研究中,Leung (1998, 2002, 2005, 2006)指出第 三語言學習者語言知識轉換的來源有兩種:第一語言和第二語言的中介語文法。在第二語習 得時,轉換可能來自第一語言,但習得第三語時,語言知識轉移的來源則可能同時來自第一 語和第二語。有關第三語言習得,目前主要有四大理論架構,這四個理論皆認同第一語和第 二語在第三語習得中扮演了重要的角色(García Mayo & Rothman, 2012)。其中,有假設第一語 對第三語習得之影響性最大的理論(Hermas, 2010; Na Ranong & Leung, 2009)。另外,也有理 論指出第二語學習狀態在第三語習得的過程中扮演了較重要的角色 (Bardel & Falk, 2007;
Falk & Bardel, 2011)。上述兩種理論的立場皆是從學習者的第一語知識轉移和第二語學習狀態 來預測第三語初级階段的發展。第三類的「累積精進理論」(Cumulative Enhancement Model, CEM) (Flynn, Foley & Vinnitskaya, 2004)則認為任何一種先學的語言要麼不具有任何影響性,
不然就一定會對下一個所學習的語言有正面的幫助。最後,第四個是「語言類型首因理論」
(Typological Primacy Model, TPM) (Rothman, 2010, 2011, 2015),這類裡論和「累積精進理論」
5
(CEM)類似,認為其實並不是第一語或第二語的型態句法知識轉移到第三語。「語言類型首 因理論」(TPM)假設前一種語言的影響性多半和語言類別(typology)或語言間的相似度有關。
Rothman (2015)指出中介語的發展和語言間的相似度或主觀認為的語言相似度關係密切。
De Angelis (2007)提到影響跨語言或語言知識轉移的因素包括:語言的距離(兩語言間之 關聯性和同異度)、學習者之目的語和第一語能力、最後使用該語言之時間距離、語言習得順 序等。Ringbom (2007)指出語言距離和語言能力兩因素,在多語習得時,一般都會假設最接近 目的語之語言對目的語的習得影響最大,至於該接近目的語之語言是否是學習者的母語並不 重要,學習者可能同時被多種語言所影響。跨語言影響通常發生在習得階段的初期,當學習 者對於目的語的知識粗淺或不完整時,要滿足對目的語知識不足的需求最為迫切(Odlin, 1989;
Ringbom, 1986; Williams & Hammarberg, 1998)。然而,不同語言知識的轉移也發生在較高階 程度的學習者。在習得的早期,轉移通常都是負面的,因為這是一般用來彌補語言知識不足 的策略。另一方面,正面的語言知識轉移的影響較有可能出現在進階程度的學習者,這時學 習者通常會因為具備其他語言知識而受益。透過實際語料的研究,Leung (2008)分析以粵語為 母語、英文為第二語、法文為第三語的學習者在時態和主、動詞配合的習得研究結論指出:
第二語英文有助於法文目的語的學習。Salaberry (2005)分析以英文為母語、西班牙文為第二 語、葡萄牙文為第三語的習得,以及 Chin (2009)研究以中文為母語、英文為第二語、西班牙 文為第三語的習得,皆主張第二語對第三語的影響大。Bild & Swain (1989)也指出會第二語的 學習者有助其第三語的學習。Klein (1995)也提到多語比單語的學習者有詞彙和語法上的學習 優勢。
本研究以上述的第三語理論和實證為基礎,探討研究對象習得的目的語(第三語)西文,
和他們的第一語(中文)和第二語(英文)的相關性。在語言結構上,中文和英文或西文差 異較大,英文和西班牙文則比較接近。為探究學習者的前置語言(第一語和第二語)對第三 語的可能影響,在參考相關(Li & Thompson, 1989; Greenbaum et al., 1972)文獻後,針對中、英 兩語言之受詞代名詞的型態與句法結構列出如表二及(2)-(3)所示,以利後續對比分析及習得 議題之探討。
表二、中文和英文受詞代名詞之構詞型式及屬性特徵 直 接 / 間 接
受 詞 代 名 詞
單數 複數
第一人稱 第二人稱 第三人稱 第一人稱 第二人稱 第三人稱
陽性 陰性 陽性 陰性
中文 我 你 他 她 我們 你們 他們 她們
英文 me you him her us you them
it
(2) 中文受詞代名詞與動詞之詞序 (2a) 動詞 + 直接受詞代名詞
(2b) 「把」 + 直接受詞代名詞 + 動詞
(2c) 動詞+直接受詞 + 「給」 + 間接受詞代名詞
6
(2d) 「把」 + 直接受詞+動詞 + 「給」 + 間接受詞代名詞 (3) 英文受詞代名詞與動詞之詞序
(3a) 動詞 + 直接受詞代名詞
(3b) 動詞 + 間接受詞代名詞 + 直接受詞
(3c) 動詞 + 直接受詞(代名詞) + 介詞 + 間接受詞
比較表一與表二,以及(1)、(2)和(3)之三語詞序,我們可以觀察到西英漢三個語言在型態 和結構上的不同,第一語和第二語可能對第三語的影響,將透過以下學習者和平行語料庫為 本的語言分析比較來探討其與習得產出的關聯性。此外,學習者語言能力之差異亦是值得檢 視與討論的考量因素。
(二)語料庫 A. 建構、檢索技術
檢視現有語料庫對原形動詞或現在分詞後緊接之受詞代名詞的可檢索性,結果顯示如下。
a. 西語母語語料庫
1. CREA2 (RAE: Real Academia Española): 輸入受詞代名詞,無法檢索到「原形動詞或現在分 詞+受詞代名詞」。
2. CdE3 (Birmingham Young U., Mark Davies): 輸入受詞代名詞,無法檢索到「原形動詞或現 在分詞+受詞代名詞」。
b. 西語學習者語料庫
1. CEDEL24 (Autonomous U. of Madrid, Cristóbal Lozano): 未開放檢索。
2. SPLLOC5 (Southampton U., Newcastle U., York U.): 輸入受詞代名詞,無法檢索到「原形動
詞或現在分詞+受詞代名詞」;輸入「特定原形動詞*」或「特定現在分詞*」,無法檢索到「原
形動詞+受詞代名詞」或「現在分詞+受詞代名詞」。
3. COET6 (WZ U): 未公開。
c. 西語平行語料庫
1. Europarl7 (U. of Edinburgh, Philipp Koehn): 僅可下載語料檔案。
2. P-ACTRES 2.08 (U. of León, U. of Valladolid, U. of the Basque Country): 輸入受詞代名詞,無
2 Corpus de Referencia del Español Actual. http://corpus.rae.es/creanet.html; http://corpus.rae.es/ayuda_c.htm
3 Corpus Del Español. http://www.corpusdelespanol.org/
4 Corpus Escrito del Español L2. https://www.uam.es/proyectosinv/woslac/collaborating.htm 及 Lozano, C. &
Mendikoetxea, A. (2013). https://www.uam.es/proyectosinv/woslac/collaborating.htm
5 Spanish Learner Language Oral Corpora1. http://www.splloc.soton.ac.uk/splloc1/index.html
6 COET, Corpus Oral del Español en Taiwán. Rubio Lastra, M. (2009) COET: Corpus Oral del Español en Taiwán.
Primeros textos (COET: Oral Corpus of Spanish in Taiwan). In Lingüística en la Red.
7 Europarl (European Parliament Proceedings Parallel Corpus). http://www.statmt.org/europarl/
8 P-ACTRES 2.0 (Parallel Contrastive Analysis and Translation English-Spanish.
http://actres.unileon.es/inicio.php?elementoID=12; http://contraste.unileon.es/demos/demos/p-actres2/
7
法檢索到「原形動詞或現在分詞+受詞代名詞」。
3. MLCC9 (U. of Geneva, European Commission): 可下載檔案,但非網頁檢索介面。
4. OPUS10 (Jörg Tiedemann, Lars Nygaard, Tekstlaboratoriet Hf): 輸入[word="lo"]無法檢索到
「原形動詞或現在分詞+受詞代名詞」。
針對西文相關語料庫,我們所建構的兩個語料庫「台灣西語學習者書面語語料庫」(CEATE) 和「西英漢三語平行語料庫」(CPEIC)各有其特殊之處。首先,在語料的主題上,和同質的語 料庫相比,有類似之處,也有其個別特質,如:研究需求性與獨特性。在語料量方面,雖比 不上國家型所重點補助建構的語料庫(如 CREA 或 CdE),但相較於規模大小類似的研究團隊,
我們兩個語料庫之語料量則是與之相當的。最後,在檢索功能方面,學習者語料因西語母語 者的正誤註記,透過修正文的檢索及與學習者原始文的對比即可得到學習者受詞少用(省
略)、多用和錯誤使用的情形,這是其它學習者語料庫所無法提供的檢索結果。此外,相較於
其他西語語料庫無法以詞性做為查詢目標的做法(如:搜尋出所有同詞性的詞彙),「西英漢 三語平行語料庫」可以僅設定詞類、不輸入關鍵字的條件進行檢索,對於要研究的受詞代名 詞之搜尋結果及分析皆有極大的便利性。
對於要檢索出原形動詞或現在分詞後緊鄰的受詞代名詞,以「西語語料庫」(CdE)的檢索 性較強,可以透過「正規表示法」(regular expression)的查詢語法獲得上述結構的檢索結果。
在參考該語料庫「word*.[pos*]」 (或西文版:「palabra*.[CatGram*]」)的查詢語法模式,嘗試 了多種可能性後,以設定「字根*.[VR*]」的組合模式為關鍵詞所檢索到的結果最為完整且符 合研究需求。如設定字或詞,而非字根,則查詢不到直接與間接受詞代名詞同時出現的情形。
例如:以「explic 字根*.[VR*]」的結構組合為關鍵字,是表示要檢索那些"explic"開頭且為動 詞原形的字彙,即可得到 “explicarle, explicarme, explicarlo, explicárselo 等結果,相同的模式 也可應用在搜尋現在分詞後緊鄰受詞代名詞的組合(「字根*.[VPP*])。至於其它的西語語料庫 因詞性標註系統不同的關係,檢索的方式各有不同,但包括「西語語料庫」(CdE)在內,皆受 限於需輸入特定動詞,對於要以緊鄰動詞成份的受詞代名詞為檢索目標的做法並無法透過關 鍵詞的單純設定而達到,對動詞後受詞代名詞的研究是無法進行的。有鑑於此,本研究在語 料庫建構的延續工作中,將針對受詞代名詞習得研究之「在原形動詞或現在分詞後緊接受詞 代名詞的型態」相關檢索技術進行提升,以便利研究之程序。
B. 語料庫為本
a. 學習者語料庫之正誤分析
針對學習者語料所進行的語言分析,Granger (2013)提到學習者語料庫經過錯誤註記後,
對於外語教學者是一種新興的資源。Asención-Delaney & Collentine (2011)探討以西班牙語為 第二語的初中階學習者在寫作上之中介語現象,透過多因子量化法,分析學習者在西語書面 語語料庫中詞彙與文法使用情況,以瞭解第二語習得發展。Lozano & Mendikoetxea (2010)透 過西英漢語語料庫與英語語料庫進行對比分析,探討語法知識和認知系統的相互作用關係。
9 MLCC, Multilingual Corpora for Cooperation. http://catalog.elra.info/product_info.php?products_id=764
10 Opus, Open Parallel Corpus. http://opus.lingfil.uu.se/,
http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.154.9191, http://www.lrec-conf.org/proceedings/lrec2012/pdf/463_Paper.pdf
8
Mitchell et al. (2008)透過看圖回答、敘述故事、討論等語料收集方式所建構的「西班牙語學習 者口語語料庫」(Spanish Learner Language Oral Corpora, SPLLOC),進行西語學習者動詞詞尾 變化、受詞代名詞、詞序等研究,以瞭解以西班牙為第二語之不同面向(語用、語法、構詞) 的 習得發展。
b. 平行語料庫之對比分析
Rabadán (2015)利用「英西對比分析與翻譯」P-ACTRES(Contrastive analysis and translation English-Spanish)平行語料庫,對比分析英語「still/already+動詞片語」結構在西語上不同時態 與動貌的表達方式。Xu & Li (2014)以形式暨意義理論(form and meaning),透過「英漢平行語 料庫」探討中文離合詞(splittable compounds)在英文翻譯上的構詞和語意間的差異。上述的研 究顯示,結合平行語料庫和對比分析法有助於比較語言間之型態與結構之異同,而多語平行 語料庫則可延伸至多語對比。
本研究延續過去的語料庫建構與研究成果,以語料庫為本,透過西語學習者書寫語料,
分析學習者在西語受詞代名的正誤使用;再藉由三語平行語料的西、英、漢對比分析,推論 台灣學習者的第一語(中文)和第二語(英文)對第三語(目的語西文)的可能影響。
四、研究方法與進行步驟
(一)研究方法
在語料庫延伸建構的技術層面,新增西英漢三語平行語料庫的語料以及提升「臺灣西語 學習者書面語語料庫」和「西英漢三語平行語料庫」的檢索功能,以利後續語言分析(A 與 B)之進行。
A. 採用正誤分析法分析「台灣西語學習者書面語語料庫」(CEATE)之語料,以回答第一個研 究問題,瞭解台灣西語學習者在西語受詞代名詞習得的發展序。
採用語料庫為本之正誤分析法的原因是想藉由逐年計畫的執行,進行語料庫建構成果的再 利用,透過不同學習程度來源之學習者的書面語語料,瞭解學習者語料(原始文)和目的語
(母語者修正文)間的距離,以探討習得產出在書面學習語所呈現的特性。
B. 採用對比分析法分析「西英漢三語平行語料庫」(CPEIC)之語料,以回答第二個研究問題,
探討台灣西語學習者在西語受詞代名詞習得時可能的影響因素。
採用平行語料庫為本之多語對比分析法的原因是希望透過三語的比較,瞭解不同語言間 的差異,以檢視學習者的習得情形是否和他們的母語或第一外語有關,透過分析,推論學習 者錯誤使用的可能原因。
(二)進行步驟
本研究進行以語料庫為本的西語受詞代名詞在西語學習者和西語母語者之語言使用的分 析工作,並參考三語平行語料的對比分析結果探討台灣西語學習者西語使用及錯誤與其第一 語(中文)或第二語(西文)的關係,主要執行工作所採取之進行步驟與架構如圖一所示。
9
A. 以正誤分析法分析「台灣西語學習者書面語語料庫」(CEATE)之語料 a. 「台灣西語學習者書面語語料庫」(CEATE)11檢索功能之提升
i. 舊模式:過去資料庫系統的程式設計架構是以兩字間的空格為西語斷詞的根據,其查詢方 式是系統在接收單一的關鍵字後,即至資料庫進行文字的比對,再將比對結果回報給使用者。
ii. 困難: 針對動詞(原形或現在分詞)後面無空格、緊連接的直接或間接受詞代名詞做查詢 時,以上述模式在資料庫透過比對所獲得的結果,對於本研究所包含「原型或現在分詞+受詞 代名詞」不同詞序且動詞與受詞代名詞緊鄰的結構並無法被比對、搜尋出來。這也是大部分
現有西語語料庫的共同困難點。因此,「台灣西語學習者書面語語料庫」中之檢索功能的程式
需修改與再處理。
iii. 解決方式: 因為語料庫的資料系統已經相當龐大,所以在程式的撰寫方面,是以盡量不去 變動現有的資料庫設計為原則下,進行查詢、檢索功能之提升。
b. 語料檢索
i. 來源設定: 於上述檢索功能提升後,在「台灣西語學習者書面語語料庫」中,選取 2005-2007 年所收集之自由寫作的語料為分析對象,以西語母語者的修正文和學習者原始文為語料搜尋
11 由於電腦科技的進步日新月異,在「臺灣西語學習者書面語語料庫」運作了 12 年及「西英漢三語平行語料庫」
運作 8 年後,我們對現階段建構成果進行檢視,以規劃未來之延續工作。在技術方面,兩個語料庫皆由成大資 工系盧文祥老師帶領「資料探勘實驗室」的研究生負責協助系統的開發與維護。過去 10 多年來,在研究生畢業 前皆會提早安排技術的傳承學習與交接;但因科技的進步快速,舊有系統的相關演進與細節,在交接過程有時 並無法達到完整的傳導與更新,加上時間的累積,當沿用的系統與資料庫的設計結構發生問題時,會導致無法 即時判斷可能原因的狀況,也因此造成長期維護的困難。首先,程式語言版本的更新是較大困難,因為每一個 程式語言在一段時間之後,都會進行版本更新,新版本可能會停止支援某些函式,因此當某些函式停止支援時,
程式便會發生預期之外的錯誤,而通常這類的問題是無法預知,且很難找到原因的。其次,有關系統設計架構,
在系統更新開發前,經來回討論需求與規格後,訂出了一個合適的系統架構,在可預期的更動下增加架構的彈 性,便於後續的修改以及新增系統功能時進行更動。然而,走過 10 年,對於部分規劃要新增的功能及修改,目 前語料庫系統的現行架構中是無法支援的,因此在出現問題、找到解決方法後,卻又可能衍生其他技術性的問 題,抑或需大幅度翻修原系統才能達到原來的修改目標,也因此讓系統的維護工作更加艱辛與耗時。因此,在 檢索功能強化和語料庫擴建的相關技術層面,我們嘗試盡可能在維持原有架構下,去克服現有困難;同時,也 在計畫執行過程中進一步思考日後的延續模式。
圖一、以語料庫為本之分析架圖
10
的目標來源(圖二-1 紅框#1),以獲致學習者受詞代名詞少用、誤用和多用的結果。
1. 設定條件 2. 搜尋結果
圖二、於「台灣西語學習者書面語語料庫」搜尋受詞代名詞之步驟
ii. 關鍵字:分別透過受詞代名詞的構詞形式 me, te, lo, la, le, nos, os, los, las 及 les 為十個檢索
的關鍵字搜尋(圖二-1 紅框#2)符合之語料結果(圖二-2)。本研究西語受詞代名詞與動詞組
合之研究範圍的界定考量語法同質性(詞序與動詞及物性),故未涵蓋命令式動詞以及類似 gustar 或 parecer 等動詞的相關討論。
c. 正誤對比:根據搜尋結果(圖二-2),逐一點入檢視,對照西語母語者修正文和台灣學習者 原始文之異同(圖三-1, 2 和 3),判定並註記學習者使用之正、誤(多用、少用和錯用)。並 根據搜尋結果,依照語料提供者的西文學習時數區分成 I 階(64~640 小時)和 II 階(1088~2016 小時)兩個不同語言能力階層,以分類學習者的西語程度。本研究共計分析了 749 筆來自 I 階 和 751 筆來自 II 階學習者的語料。
1. 學習者錯誤使用西語受詞代名詞 lo
2. 學習者少用西語受詞代名詞 lo
#1 #2
11
3. 學習者多用西語受詞代名詞 lo
圖三、西語母語者之修正文 vs. 台灣西語學習者之原始文
d. 根據受詞代名詞進行其屬性分類與註記:i. 格位(直接/間接受詞)、ii. 人稱(第一/二/三人 稱)、iii. 單複數(單/複數)、iv. 陰陽性(陰/陽性)、v. 位序(受詞代名詞+動詞/動詞+受詞代名詞)、
iv. 生命性(生命性/非生命性)。
e. 統計與相關性檢定
i. 使用正誤率:根據不同程度學習者之受詞代名詞使用情形,依照過去文獻所提及的類別屬 性,分別計算出與之對應的構詞語法特質之使用正確率:少用(省略)/誤用/多用、直接/間 接受詞、第一/二/三人稱、單/複數、陰/陽性、受詞代名詞+動詞/動詞+受詞代名詞、生命性/
非生命性等的使用。
ii. 關聯性分析:使用卡方檢定學習者使用正誤與受詞代名詞屬性之因果關係是否達顯著差異 的水準,分析、排序出台灣西語學習者在受詞代名詞的習得發展序,並與以英語為母語者之 發展序比較。
B. 以對比分析法分析「西英漢三語平行語料庫」(CPEIC)之語料 a. 於「西英漢三語平行語料庫」中,新增電影字幕之三語平行語料
「西英漢三語平行語料庫」在 2014 年以前已彙整了聖經、童話故事和聯合國文件的語料 類型,上述三來源主要著眼於語言和網路電子檔可取得性及格式可利用性的考量。三語平行 的電影字幕是本計畫所新增的語料類型,目的是為了讓「西英漢三語平行語料庫」中平行語 料的主題多元與生活化。
i. 語料來源
首 先, 電 影 字 幕 檔 透 過 以 下 四 個 來 源 獲 取 。 1. http://subsmax.com/ 網 站 , 2.
http://subhd.com,3. http://www.opensubtitles.org/zt 和 4. Google 引擎。透過上述方式來彙整西 文、英文和中文的三語電影字幕,當個別語言來源的電影版本不同或無法完全一致時,後續 三語平行語句對齊的工作則是透過人工檢查來修正與調整。選片的主要原則是以西語學習及 平行語料庫與相關研究為目的,故以西語系國家為發片國、西語母語為其原始語言的電影為 優先考量;同時,也考慮電影的主題及字幕的文字內容需適用於西語教學及延伸研究。設定 目標與原則後,實際收集要同時符合網路可得、兼顧西英漢三語及適合教學品質諸要素之電 影字幕來源的數量並不如原來預期得多。
12
ii. 語料匯入之前置作業
為便利字幕語料的處理,我們使用 SrtEditPortable_6.3_azo.exe 軟體來編輯所下載之電影 字幕檔,檔案包含字幕時間軸和字幕的單語語料內容(如圖四所示)。雖此軟體可提供多語字
幕整合之功能,但為了配合「西英漢三語平行語料庫」過去所撰寫的程式,我們以單語12格
式做為儲存語料的共同模式,以便順利匯入新增語料及達到後續檢索結果呈現的一致性。雖 然所收集而來的三語電影字幕可能因為電影版本間的差異,導致所下載之字幕語料中,標示 於每句最開始的時間軸在三語彼此間有所出入、無法完全配合,但時間軸的訊息對西、英、
中三語平行語意的對應(alignment)及後續處理程序仍提供了非常便利的參考依據,這是過去 在彙整童話故事或聯合國文件的語料時所未具有的優勢。下載後的文字會根據時間軸自動分 句,接著,則是透過人工手動的方式去檢查三語間句與句的對應(alignment),經由確認、調 整或修正不同語言間在語句序上不對應的問題及控管語言本身品質的正確性,以提升後續語 料訓練和檢索結果呈現的準確度。所新增的三部電影包含「Hable con ella/Talk to her/悄悄告訴 她、Truman/Truman/特魯曼和 Volver/Volver/玩美女人」13,西班牙為其發片國家,所彙整的字 幕含西文 27,033 字、英文 23,759 字和中文 21,365 字。
圖四、西英中三語字幕srt(上)及txt(下)格式文件
iii. 新增語料匯入
西文、英文和中文三個語言的電影字幕平行語料句與句對齊、檢查後,先刪除非句子文
字成份的內容(即:時間軸),進行詞性註記。接著,針對中文、西文以及英文分別斷詞,再
將結果利用 GIZA++進行語料訓練,來獲取西文與中文之間以及西文與英文之間的字詞對齊 文件。最後,再將上述文件匯入「西英漢三語平行語料庫」的後端資料庫中,除維持原來既 有之搜尋功能(單詞或詞性)與結果的呈現方式(三語語句與字詞對應)外,在本計畫中,
12 雖然從上述(a)四來源亦可獲取雙語字幕,但為配合「西英漢三語平行語料庫」原有的程式,因此,我們所下 載的字幕檔皆是以單語為主,將三個語言分別以單語格式儲存。因爲若是直接下載雙語字幕檔,則還需要其他 程序去拆分成單語。
13 三部電影的來源依序列出如下:1.西語來源:http://www.opensubtitles.org/es/subtitles/74969/talk-to-her-es,
https://www.opensubtitles.org/en/subtitles/6516419/truman-es,
https://www.opensubtitles.org/zh/subtitles/5868290/volver-es。2.英語來源:
http://www.opensubtitles.org/es/subtitles/3106260/talk-to-her-en, http://subhd.com/ar0/338333,
http://subsmax.com/subtitles-movie/volver-2006/ni。3.中文來源:http://subhd.com/a/31244,
http://subhd.com/ar0/339222, https://www.opensubtitles.org/zh/subtitles/5960301/volver-zt。
13
此三語平行語料庫也加入模糊搜尋模式的支援,以符合後續語言分析研究的搜尋目地。
b. 提升搜尋功能:和「台灣西語學習者書面語語料庫」一樣,在舊模式、困難和解決方式的 模式類似,對於「西英漢三語平行語料庫」中原形動詞或現在分詞後緊接著受詞代名詞的搜 尋功能需透過程式修改的技術及程序來改善其檢索性。
c. 三語受詞代名詞檢索:透過西文受詞代名詞的構詞形態 me, te, lo, la, le, nos, os, los, las 及 les 為西文關鍵字搜尋(圖五紅框 1)。根據搜尋結果(圖五紅框 2)逐一檢視,對照英文(圖五 紅框 3)和中文(圖五紅框 4)在受詞代名詞使用之異同並予以註記。
d. 三語受詞代名詞分類:根據西文受詞代名詞的格位(直接/間接受詞)以及所對應到英文和 中文的成分進行格位(主詞/直接受詞/間接受詞/介係詞受詞)和形態結構或外觀(省略/普通 名詞/「把/給」+受詞代名詞/普通名詞)之分類與註記。
e. 西英漢三語中兩兩雙語之對應關係:以卡方分別檢定西文受詞代名詞和所對應之英文以及 西文受詞代名詞和所對應之中文成分屬性之關係是否達顯著差異的水準,分析、排序出西文 受詞代名詞和英文及中文成分對應關係的分佈傾向。
f. 正誤分析與對比分析之整合:以對比分析結果檢視正誤分析結果。其分析結果可回答研究 問題 2:學習者的第一語(中文)和第二語(英文)對第三語(西文)受詞代名詞習得的影 響為何?
五、結果與討論
(一)檢索功能提升
為了涵蓋更廣的搜尋範圍,以提升查詢效益,我們強化了學習者語料庫和三語平行語料 庫的功能。我們使用了模糊檢索(Fuzzy Search)14的技術來達成搜尋原形動詞或現在分詞後緊 接代名詞組合的功能,藉此來快速檢索符合目標的語料以進行後續西語受詞代名詞的語言分
14 參考Ukkonen, E. (1985). “Algorithms for approximate string matching”. Information and Control. 64: 100–18.
2
3
4
1
圖五、於「西英漢三語平行語料庫」搜尋三語受詞代名詞
14
析工作。傳統的搜尋技術主要是使用精確比對(Exactly matching)為導向的搜尋演算法,透過 查詢詞彙去比對資料庫中完全符合的內容,但若是使用者無法明確表達查詢的詞彙,或是輸 入的詞彙出現了錯字或冗字,就無法查詢到結果,因此我們使用模糊檢索來作為搜尋的主要 技術。模糊檢索是在搜尋時藉由資料庫的功能協助,完成在搜尋時除了查尋詞彙外,亦能同 時搜尋包含查尋詞彙的詞彙,進而協助使用者擴展查詢範圍,以搜尋出與使用者需求相近的 資料。
在實作上,我們運用模糊檢索的技術,去對每一個單字進行字串比對,搜尋出字串相近 的資料,只要符合「原形動詞/現在分詞」字串連接「代名詞」字串的單字,便會被以不同的 顏色標註,顯示在網頁上。「臺灣西語學習者書面語語料庫」和「西英漢三語平行語料庫」
兩語料庫的進行模式類似,此處以「台灣西語學習者書面語語料庫」為例加以説明。首先,
在進入語料庫後,如圖六所示,以第三人稱單數間接受詞代名詞為例,輸入字串“le”進行搜索。
在資料庫的支援之下,可以搜索出相關單字(字尾為le的近似字)及其指標(index)結果。若透過 一般的搜索技術,也就是以精確比對為導向的搜尋演算法,則結果只會包含顯示單獨字“le”
的結果,如圖七左所示;而使用模糊搜索之後,只要單字的組成包含字串“le”,就會進一步搜 索出這些單字的指標結果,如圖七右所示。最後,再利用正規表示法(Regular Expression)將搜 索結果以紅色特別標註,如圖八所示。圖九是「台灣西語學習者書面語語料庫」和「西英漢 三語平行語料庫」兩語料庫在檢索功能提升前(左圖)與後(右圖)搜尋結果之對照。
圖六、進入「台灣西語學習者書面語語料庫」搜尋頁面,透過輸入字串“le”來搜尋結果
圖七、SQL 語法之程式範例與搜尋結果比較
圖八、搜索到的字詞以紅色標註
15
圖九 a、「台灣西語學習者書面語語料庫」檢索功能提升前後搜尋結果之對照
圖九 b、「西英漢三語平行語料庫」檢索功能提升前後搜尋結果之對照
(二)語料庫為本之使用與正誤分析 A. 使用正誤率與習得發展序
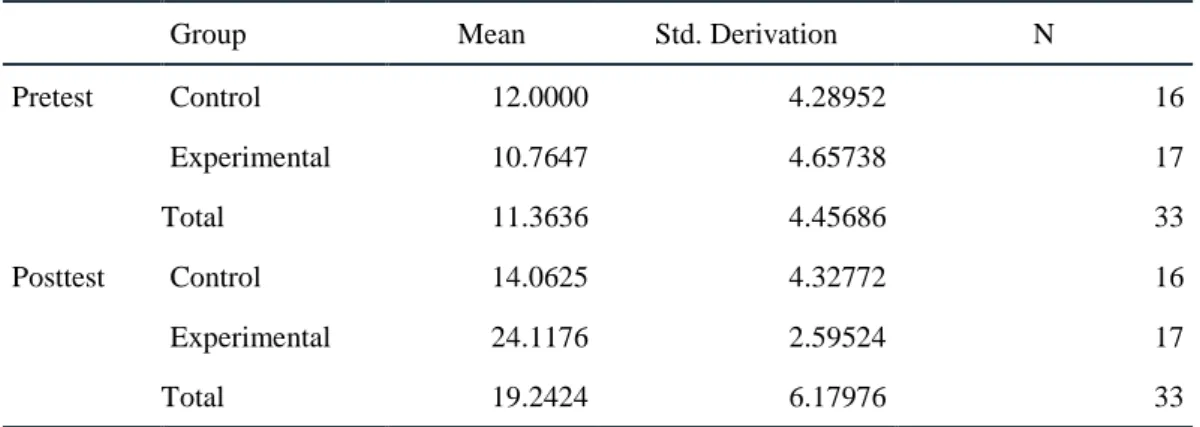
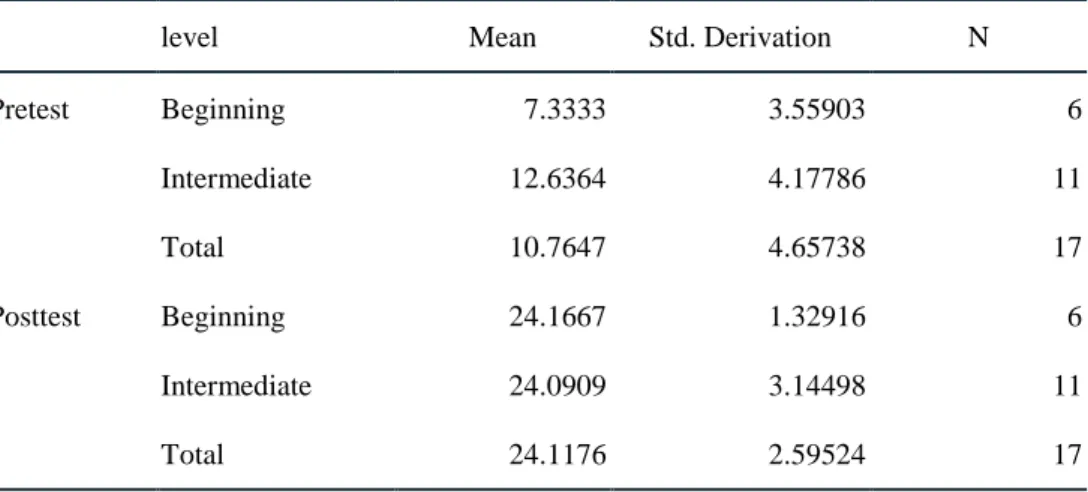
首先,在語料庫為本的正誤分析中,透過「臺灣西語學習者書面語語料庫」進行語料檢索,
針對 1500 筆資料註記、分類與計算的結果,不同階段學習者在不同受詞代名詞使用的正誤分 佈情形如表三所示。
16
表三、學習者程度與受詞代名詞使用正誤之關係 使用
總和
錯誤 正確
程度 I階 個數 298 451 749
在 程度 之內的 39.8% 60.2% 100.0%
在 使用 之內的 57.6% 45.9% 49.9%
整體的 % 19.9% 30.1% 49.9%
II階 個數 219 532 751
在 程度 之內的 29.2% 70.8% 100.0%
在 使用 之內的 42.4% 54.1% 50.1%
整體的 % 14.6% 35.5% 50.1%
總和 個數 517 983 1500
在 程度 之內的 34.5% 65.5% 100.0%
在 使用 之內的 100.0% 100.0% 100.0%
整體的 % 34.5% 65.5% 100.0%
卡方檢定,P<0.05
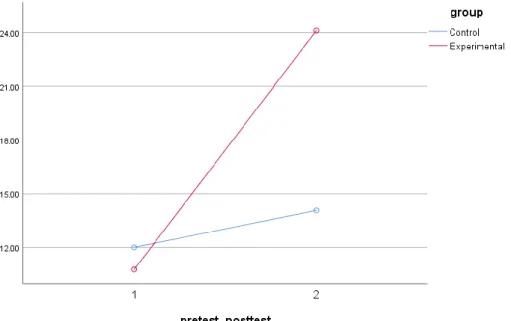
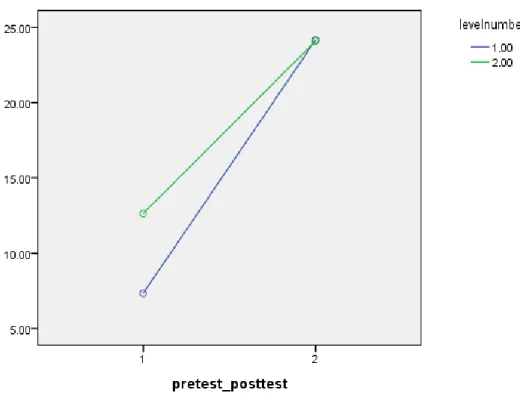
根據表三,我們觀察到 I 階和 II 階兩個不同程度之學習者間,在受詞代名詞使用的正誤 達顯著差異(P<0.05),I 階學習者在正確和錯誤使用上的差異距離較小(60.2% vs. 39.8%),II 階學習者在正誤率的差距較大(70.8% vs. 29.2%),結果顯示受詞代名詞使用的正確率隨著學習 者程度的提升而增加。
接著,我們將透過表四所呈現的 I 階和 II 階兩程度之學習者在不同變數中受詞代名詞使 用的正誤率,來比較其異同。根據正確率的呈現結果,逐一檢視過去文獻 Malovrh & Lee (2013) 對習得產出研究結果所提出的發展模式:1. 間接受詞比直接受詞早習得。2. 第一人稱較第三 人稱早習得。3.單數比複數早習得。4.陽性先於陰性的發展序。
表四、I和II階學習者在不同變數與受詞代名詞使用正誤之關係
I 階使用 總和 P 值 II 階使用 總和 P 值
錯誤 正確 錯誤 正確
格位 直
接
個數
在格位之內的 在正確率之內的 整體的 %
183 40.4%
62.2%
24.6%
270 59.6%
59.9%
36.2%
453 100.0%
60.8%
60.8%
.540 155 31.8%
72.4%
20.8%
332 68.2%
62.4%
44.5%
487 100.0%
65.3%
65.3%
.011
17 間
接
個數
在格位之內的 在正確率之內的 整體的 %
111 38.0%
37.8%
14.9%
181 62.0%
40.1%
24.3%
292 100.0%
39.2%
39.2%
59 22.8%
27.6%
7.9%
200 77.2%
37.6%
26.8%
259 100.0%
34.7%
34.7%
總 和
個數
在格位之內的 在正確率之內的 整體的 %
294 39.5%
100.0%
39.5%
451 60.5%
100.0%
60.5%
745 100.0%
100.0%
100.0%
214 28.7%
100.0%
28.7%
532 71.3%
100.0%
71.3%
746 100.0%
100.0%
100.0%
人稱 第
一
個數
在人稱之內的 在正確率之內的 整體的 %
65 27.0%
21.8%
8.7%
176 73.0%
39.0%
23.5%
241 100.0%
32.2%
32.2%
.000 28 12.2%
12.8%
3.7%
202 87.8%
38.0%
26.9%
230 100.0%
30.6%
30.6%
.000
第 二
個數
在人稱之內的 在正確率之內的 整體的 %
34 37.8%
11.4%
4.5%
56 62.2%
12.4%
7.5%
90 100.0%
12.0%
12.0%
1 3.4%
.5%
.1%
28 96.6%
5.3%
3.7%
29 100.0%
3.9%
3.9%
第 三
個數
在人稱之內的 在正確率之內的 整體的 %
199 47.6%
66.8%
26.6%
219 52.4%
48.6%
29.2%
418 100.0%
55.8%
55.8%
190 38.6%
86.8%
25.3%
302 61.4%
56.8%
40.2%
492 100.0%
65.5%
65.5%
總 和
個數
在人稱之內的 在正確率之內的 整體的 %
298 39.8%
100.0%
39.8%
451 60.2%
100.0%
60.2%
749 100.0%
100.0%
100.0%
219 29.2%
100.0%
29.2%
532 70.8%
100.0%
70.8%
751 100.0%
100.0%
100.0%
單複數 複
數
個數
在單複數之內的 在正確率之內的 整體的 %
65 34.6%
21.8%
8.7%
123 65.4%
27.3%
16.4%
188 100.0%
25.1%
25.1%
.102 47 35.1%
21.5%
6.3%
87 64.9%
16.4%
11.6%
134 100.0%
17.8%
17.8%
.115
單 數
個數
在單複數之內的 在正確率之內的 整體的 %
233 41.5%
78.2%
31.1%
328 58.5%
72.7%
43.8%
561 100.0%
74.9%
74.9%
172 27.9%
78.5%
22.9%
445 72.1%
83.6%
59.3%
617 100.0%
82.2%
82.2%
總 和
個數
在單複數之內的 在正確率之內的 整體的 %
298 39.8%
100.0%
39.8%
451 60.2%
100.0%
60.2%
749 100.0%
100.0%
100.0%
219 29.2%
100.0%
29.2%
532 70.8%
100.0%
70.8%
751 100.0%
100.0%
100.0%
18
陰陽性 陰
性
個數
在陰陽性之內的 在正確率之內的 整體的 %
35 55.6%
29.7%
13.5%
28 44.4%
19.7%
10.8%
63 100.0%
24.2%
24.2%
.081 56 40.9%
42.1%
17.1%
81 59.1%
41.5%
24.7%
137 100.0%
41.8%
41.8%
1.000
陽 性
個數
在陰陽性之內的 在正確率之內的 整體的 %
83 42.1%
70.3%
31.9%
114 57.9%
80.3%
43.8%
197 100.0%
75.8%
75.8%
77 40.3%
57.9%
23.5%
114 59.7%
58.5%
34.8%
191 100.0%
58.2%
58.2%
總 和
個數
在陰陽性之內的 在正確率之內的 整體的 %
118 45.4%
100.0%
45.4%
142 54.6%
100.0%
54.6%
260 100.0%
100.0%
100.0%
133 40.5%
100.0%
40.5%
195 59.5%
100.0%
59.5%
328 100.0%
100.0%
100.0%
位序 代
名 + 動
個數
在位序之內的 在正確率之內的 整體的 %
230 38.9%
77.2%
30.7%
362 61.1%
80.3%
48.3%
592 100.0%
79.0%
79.0%
.315 179 29.9%
81.7%
23.8%
420 70.1%
78.9%
55.9%
599 100.0%
79.8%
79.8%
.425
動 + 代 名
個數
在位序之內的 在正確率之內的 整體的 %
68 43.3%
22.8%
9.1%
89 56.7%
19.7%
11.9%
157 100.0%
21.0%
21.0%
40 26.3%
18.3%
5.3%
112 73.7%
21.1%
14.9%
152 100.0%
20.2%
20.2%
總 和
個數
在位序之內的 在正確率之內的 整體的 %
298 39.8%
100.0%
39.8%
451 60.2%
100.0%
60.2%
749 100.0%
100.0%
100.0%
219 29.2%
100.0%
29.2%
532 70.8%
100.0%
70.8%
751 100.0%
100.0%
100.0%
生命性 生
命
個數
在生命性之內的 在正確率之內的 整體的 %
209 37.3%
70.1%
27.9%
352 62.7%
78.0%
47.0%
561 100.0%
74.9%
74.9%
.016 122 23.4%
55.7%
16.2%
399 76.6%
75.0%
53.1%
521 100.0%
69.4%
69.4%
.000
非 生 命
個數
在生命性之內的 在正確率之內的 整體的 %
89 47.3%
29.9%
11.9%
99 52.7%
22.0%
13.2%
188 100.0%
25.1%
25.1%
97 42.2%
44.3%
12.9%
133 57.8%
25.0%
17.7%
230 100.0%
30.6%
30.6%
總 和
個數
在生命性之內的 在正確率之內的 整體的 %
298 39.8%
100.0%
39.8%
451 60.2%
100.0%
60.2%
749 100.0%
100.0%
100.0%
219 29.2%
100.0%
29.2%
532 70.8%
100.0%
70.8%
751 100.0%
100.0%
100.0%
卡方檢定
19
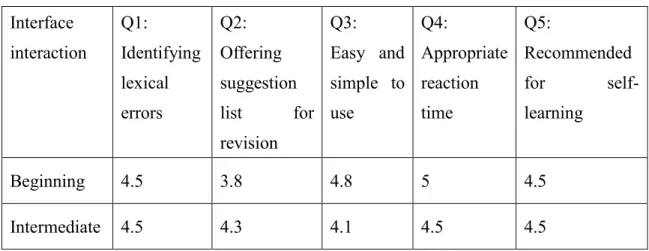
根據表四,針對不同學習程度分別檢視語言特徵的變數,達顯著差異(P<0.05)的包括II階 中的「格位」,和I、II階中的「人稱」和「生命性」。在教學上,這幾個變數如能在適當的 階段特別被提醒與注意,預期可以有較高提升學習效益的機會。
關於正確率,首先,除了「單複數」變數中的複數形態在I階的正確率幾乎和II階相等外,
其餘各變數的正確率皆是II階高於I階。再者,正確率在II階高於I階,且變數選項的正確率排 序相同者包括「格位」(間接>直接)、「陰陽性」(陽性>陰性) 和「生命性」(生命性>非生命 性)。此外,正確率也是II階高於I階,但選項的正確率排序不同者包括「人稱」(II階: 第二人 稱>第一人稱>第三人稱,I階:第一人稱>第二人稱>第三人稱) ;「位序」(II階:動詞+受詞 代名詞>受詞代名詞+動詞,I階:受詞代名詞+動詞>動詞+受詞代名詞)。最後,正確率在II階 高於I階者還包括「單複數」變數中的單數形態。
上述結果可以回答研究問題1.台灣學習者在西語受詞代名詞的習得發展序為何?是否與 以英語為母語者的西語學習者相同?以使用的正確與否為習得發展的考量點,針對以中文為 母語的西語學習者在書面表達產出之受詞代名詞的使用結果,由變數選項間正確率數據的呈 現、增加與變化,我們推論出以下的習得發展序:「格位」(間接>直接)、「人稱」(第一人 稱>第三人稱)、「陰陽性」(陽性>陰性)、「生命性」(生命性>非生命性)。上述以正確率分 析所推論出的習得發展序與以英語為母語者相同。此外,我們的研究結果還推論出「位序」(受 詞代名詞+動詞>動詞+受詞代名詞)的習得序。同時,我們也比較了第二人稱和其他人稱,結 果發現在較高階程度時第二人稱的發展超越了第一人稱。最後,就「單複數」而言,複數在I 階的發展與II階接近,但在II階時單數的使用正確率有了較大的進步;因此,我們也排序出「單 複數」(單數>複數)的發展序。整體而言,我們的研究結果對受詞代名詞的習得提供了更完整 化與系統性的全貌。
B. 平行語料庫為本之對比分析
表五是針對表三進一步將錯誤使用的類型分類為誤用(西語學習者和母語者使用不同)、
少用(西語母語者使用,而學習者卻未使用)和多用(西語母語者未使用,而學習者卻使用)
的結果。
20
表五、學習者程度與使用正誤(錯誤含誤用、少用和多用)之關係 使用
總和
正用 誤用 少用 多用
程度 I階 個數 451 121 151 26 749
在 程度 之內的 60.2% 16.2% 20.2% 3.5% 100.0%
在 使用 之內的 45.9% 56.3% 62.4% 43.3% 49.9%
整體的 % 30.1% 8.1% 10.1% 1.7% 49.9%
II階 個數 532 94 91 34 751
在 程度 之內的 70.8% 12.5% 12.1% 4.5% 100.0%
在 使用 之內的 54.1% 43.7% 37.6% 56.7% 50.1%
整體的 % 35.5% 6.3% 6.1% 2.3% 50.1%
總和 個數 983 215 242 60 1500
在 程度 之內的 65.5% 14.3% 16.1% 4.0% 100.0%
在 使用 之內的 100.0% 100.0% 100.0% 100.0% 100.0%
整體的 % 65.5% 14.3% 16.1% 4.0% 100.0%
卡方檢定,P<0.05
由表五進一步分析錯誤的類型發現 I 階的學習者在誤用和少用類型中的比例皆高於 II 階 者,但多用的比例則低於 II 階者。
一方面,較高階學習者多用比例反而高的情形可能與習得發展過程中的過分概化使用有 關。根據文法規範,直接受詞代名詞不能與普通名詞同時出現,但間接時可以(即所謂的「雙 受詞」/clitic doubling,如:la adoro a XXX);再加上 le 主義(leismo),因尊崇(culto)因 素,在原需使用直接受詞代名詞 lo/la/los/las 時,使用了間接受詞的形態 le/les 來代替。因此,
反而是較高階的學習者在後續階段習得上述兩概念後,因爲第三語過份概化造成不當多用的 情形(如:les acompaña a las niñas)。
另一方面,過去的文獻在探討有關學習者省略受詞代名詞情形時,多將之歸因於學習者 先前所習得語言的特性(受詞代名詞不存在)所造成。在平行語料庫為本的跨語對比分析中,
我們透過「西英漢三語平行語料庫」進行了語料檢索,針對所檢索出 280 筆資料註記、分類 與計算的結果如表六所示。