國立臺東大學資訊管理學系 碩士論文
Department of Information Science and Management Systems
National Taitung University Master Thesis
基於模糊邏輯與協同過濾之 群眾外包推薦系統
A Crowdsourcing Recommender System based on Fuzzy Logic and Collaborative Filtering
研究生:王嘉俊
Graduate Student: Gia-Tuan Vuong
指導教授:謝明哲 博士
Advisor: Ming-Che Hsieh, Ph.D.
中 華 民 國 106 年 8 月
August, 2017
I
誌 謝
大學生活結束又繼續有機會在臺東大學進修碩士學位,透過研究 結合實務發展臺東的資訊產業,對我來說是一個機會也是無比的榮 幸。
在這個過程,要感謝的人實在太多。首先感謝我的指導教授-謝 明哲老師。從題目的選擇,研究過程的討論,到研究方法與學術倫理 的指導,老師都非常熱心指導。研究過程中需要各種設備與資源,老 師都非常熱情協助,讓研究順利進行。其次要感謝臺東大學創新育成 中心-楊春桂經理及團隊,在研究過程中需要各種產學合作的資料與 領域知識,楊經理都非常熱心協助,為研究提供非常寶貴的協助。最 後,感謝臺東在地產業與鄉親給我服務的機會,希望研究成果將對未 來臺東產業的發展有所貢獻。
王嘉俊 謹致
中華民國 106 年 8 月
II
摘 要
隨著互聯網、大數據、以及物聯網的發展,產業快速升級。特別 在偏鄉的台東,資訊缺乏,交通不便,如何透過網路技術結合各個領 域的專家學者,協助產業升級,變得非常重要。本研究基於模糊邏輯 與協同過濾提出一套推薦機制,並以台東在地產業為例,實現群眾外 包推薦系統。其中,模糊邏輯應用於業者及專家對專案合作滿意度及 樂活產業成熟度評分,而協同過濾則應用於專家相似度及產業相似度 的計算。透過本研究的實現與系統的建立,讓在地業者的問題能夠找 到適合的專家學者來,經驗豐富的專家也可以找到適合的業者來發揮 所長,加速產學合作,推廣樂活產業與循環經濟。
關鍵詞:推薦系統、群眾外包、樂活產業、模糊推論、協同過濾。
III
Abstract
With the development of Internet, big data and Internet of Things, the industry is rapidly upgrading. How to use network technology to connect experts in various fields to help industrial upgrading is becoming more and more important, especially in Taitung where information is scarce and traffic is not convenient. This study proposed a recommender mechanism based on fuzzy logic and collaborative filtering, and realized the crowdsourcing recommender system for local industries in Taitung.
Fuzzy logic was used to infer the satisfaction of experts and the maturity of the LOHAS industry. The collaborative filtering was applied to the calculation of the similarity of experts and the similarity of industries. By implementing this study and establishing a system, local industries can find the right experts and scholars to tackle their problems more easily and effectively. Experienced experts can also find a suitable industry, give full play to their talents, speed up cooperation between industry and academia, and promote the development of the LOHAS industry and circular economy.
Keywords: recommender system, crowdsourcing, LOHAS, fuzzy logic,
collaborative filtering.
IV
目 錄
誌謝... I 摘要... II Abstract ... III 目錄... IV 圖目錄... VI 表目錄... VII
第一章 前言... 1
1.1 研究背景與動機... 1
1.2 研究目的... 2
1.3 研究方法... 2
1.4 章節架構... 7
第二章 文獻探討... 8
2.1 群眾外包... 8
2.2 樂活產業... 11
2.3 開放資料... 14
2.4 API 經濟 ... 17
2.5 模糊推論... 20
2.6 推薦系統... 22
第三章 群眾外包推薦系統之設計與發展... 27
3.1 方法論之設計... 27
3.2 分析前須準備的資料... 30
3.3 模糊推論之分析與設計... 33
3.4 協同過濾之分析與設計... 36
3.5 前端使用者介面之分析與設計... 37
第四章 展示與評估... 42
4.1 模糊推論之展示與評估... 42
4.2 協同過濾之展示與評估... 45
4.3 前端頁面設計之展示與評估... 48
第五章 結論與未來發展... 52
V
5.1 研究成果... 52
5.2 研究限制... 52
5.3 未來發展... 53
參考文獻... 54
VI
圖目錄
圖1.1 設計科學研究法-目標導向研究流程 ... 4
圖2.1 DDI 資料生命週期模型 ... 15
圖2.2 API 經濟價值鏈 ... 19
圖2.3 Lohas 模糊邏輯規則範例 ... 21
圖2.4 模糊邏輯系統的架構... 22
圖2.5 推薦系統架構... 24
圖2.6 協同過濾流程... 26
圖3.1 系統架構... 27
圖3.2 模糊推論機制... 28
圖3.3 協同過濾演算法... 29
圖3.4 成員函數的分配... 34
圖3.5 單頁面網路應用架構... 38
圖3.6 使用個案圖... 39
圖3.7 使用者問題評分流程... 40
圖3.8 使用者選擇答案流程... 41
圖4.1 產學合作滿意度調查... 43
圖4.2 合作滿意度模糊邏輯... 43
圖4.3 樂活成熟度模糊邏輯... 44
圖4.4 產學合作評分模糊邏輯... 44
圖4.5 推理後的模糊集合圖示化... 44
圖4.6 解模糊後的結果... 45
圖4.7 問題詳細內容... 45
圖4.8 評分矩陣... 46
圖4.9 訓練資料與測試資料分開... 47
圖4.10 專家學者相似度分析結果... 47
圖4.11 業者廠商相似度分析結果 ... 47
圖4.12 把推薦結果轉成 JSON 結果 ... 48
圖4.13 推薦結果頁面... 50
VII
表目錄
表 3.1 模糊推論規則... 29
表 3.2 問題資料表資料欄位... 30
表 3.3 解決方案資料表資料欄位... 31
表 3.4 合作專案問卷問題列表... 32
表 3.5 合作專案資料表資料欄位... 32
表 3.6 變數的分類與規劃... 33
表 3.7 模糊推論規則... 34
表 3.8 成員函數表... 35
表 3.9 廠商-專家稀疏矩陣範例 ... 36
表 3.10 以廠商為主相似矩陣範例... 37
表 3.11 以專家為主相似矩陣範例 ... 37
表 4.1 評分資料表欄位... 46
1
第一章前言
1.1 研究背景與動機
2016 年 7 月 8 號 8 點,尼伯特颱風登入台灣,登入點為台東太麻里,以 17 級風的速度破60 年來的紀錄橫掃台東。颱風離開,留下的是慘不忍睹的災區,
各個地方停水停電,農業更是受到毀滅性地破壞。人民越來越了解,要發展經濟,
首先更要尊重大自然,與自然永續發展,經濟成果才能保留下去,人民能安居樂 業,國家才會擁有真正的繁榮。這剛好是樂活產業的兩個重點,永續與健康。經 濟發展想長久一定注重永續,任何產業想永續經營,一定要注重健康,對消費者 健康,對員工健康,對大自然健康。
天災只是台東縣產業經濟因為地理位置常常遇到的問題之一。因為種種因素、
交通、環境、人口等等問題,影響到地方各個產業的生產、行銷、銷售等。比起 其它縣市,這些問題更加需要有能力,有經驗的產-官-學專家學者投入。但問題 在業者有需求卻找不到適合的專家,專家有技術但找不到適合的業者可以投入或 缺乏了解台東產業業者的狀況。這些問題發生都是因為資訊不透明與不對稱,同 時也缺乏一個媒合平台讓業者認識專家,讓專家認識業者。
國立臺東大學因此積極投入臺東地區樂活產業的分類與資料庫的建置,配合 經濟部 4G 寬頻應用軟體創新園區發展計畫,結合產官學資源,推動 TTMaker 台東創客團隊。樂活產業創新計畫鼓勵在地業者與學校師生共同參與,形成臺東 地區樂活產業產學聯盟,促進臺東在地樂活產業升級。
其中,建立一個群眾外包平台,主要使用台東樂活產業業者資料庫。目前世 界各地政府都積極推動開放政府,而在數位時代,開放政府的核心在於開放資料,
不僅讓民眾了解國家的問題,政府施政的狀況,也透過線上社群群眾外包,各地 專家學者共同建置解決國家的問題(經濟,社會福利,交通運輸等等)。開放資 料不僅是免費提供的機房或儲存控制,而是一個給自由業者與創客的生態系統。
目 前 開 放 資 料 的 最 佳 方 式 是 透 過 應 用 程 式 界 面 (Application Programming
2
Interface, 簡稱為 API)。藉由平台的建立,讓相關領域專家業者能夠認識台東產 業在地業者,能夠觸動台東樂活產業的更多合作發展,透過產-官-學三方業者與 專家的媒合與努力,為台東在地經濟增加更多利益與機會。也希望平台開發的模 式與經驗,可以用來發展其它縣市的樂活產業,讓台東產業和台灣經濟在轉型多 了一個選項,往樂活產業經濟發展。
在資訊爆炸的時代,資訊過濾與資訊推薦變得非常重要。本研究將為上述的 推薦系統建立一套推薦機制,希望藉由推薦機制與演算法的建立,能夠減少群眾 外包平台上的資訊搜尋時間,交易成本與增加媒合的成功率。
1.2 研究目的
本研究將透過設計科學研究法,結合模糊推論與協同過濾等推薦技術,為臺 東地區樂活產業群眾外包平台建立推薦模組與機制。本研究首先針對專家學者與 業者在群眾外包資訊與配對的需求(例如對過去產學合作案件的成功率與滿意度,
對樂活產業的研究、投入與貢獻等)。
對合作案的滿意度和樂活產業的認同與投入等評分項目都是難以用一般數 學邏輯來評估與呈現的,因此我們將採用模糊邏輯,透過過去相關資料結合模糊 邏輯規則計算業者對專家,業者對業者,專家對專家間的關聯,透過協同過濾推 薦技術來為使用者呈現最適合的結果。
一般的推薦系統只重視媒合成功率,但透過使用模糊推論,我們可以結合兩 個不一樣的維度,其中具有代表性的是對樂活產業的認同與貢獻。透過推薦模組 的建立,希望能加快媒合的速度與成功率,且透過廠商對專家-廠商對廠商等推 薦與媒合,協助形成樂活產業產學聯盟與樂活產業綠色供應鏈等生態系統,讓臺 東地區產業逐漸邁向樂活產業型態。
1.3 研究方法
本研究透過設計科學研究法來說明本研究的方法論。設計科學研究方法論
(DSRM)由 Peffers (2008)結合過去跟設計科系相關研究所提出的方法論。Peffers
3
認為資訊系統是一個應用研究領域,但我們常常應用來自其他領域的方法論,如 經濟,電腦科學,和社會科學來解決科技與組織的問題。但設計科學研究法是為 了創造一個明確且可應用的解決方案。在工程領域,它已被採用在少數的研究文 章來證明這個方法可以應用在研究或實務。設計科學研究方法論是創造與評估資 訊科技工具來解決已被定義的組織問題,它有一個嚴格的流程來設計與解決被觀 察的問題,提出研究貢獻,有效與使用者溝通。
Peffers 的設計科學研究法論流程包含下面這六個步驟:
1. 問題定義與動機:定義研究問題與解決方案的價值。問題定義會被拿來發展 一個有效的解決方 案。如果可以有系統地分解問題,會讓解決方案抓住問 題的複雜性。一個解決方案的價值包含兩方面:(1)激勵研究者與讀者去設 計與推行解決方案並採納他;(2)他幫助研究者的推理了解問題。這個活動 需要的資源包括對於問題的知識和方案的重要性。
2. 定義解決方案目標:從問題的定義找出解決方案的對象。對象可以被量化(如:
這個新的方案可以比舊的好)或質化。對象應該從問題的規範理性地演化出 來。這個活動需要的資源包括對問題的知識及現有的解決方案及其成效。
3. 解決方案的設計與發展:建立一個方案。這個活動包含確定方案的功能與架 構,然後設計有效的方案。需要資源有理論知識,可以把對象通過設計與開 發變成一個可以解決問題的方
案。
4. 呈現:呈現方案解決問題的效果。這個可以使用實驗,虛擬,個案學習,證 據,或其他活動等等。需要資源包括如何使用方案來解決問題的有效知識。
5. 評估:觀察與評估方案如何有效解決問題。這個活動需要比較方案原本的目 的與使用方案時觀察到的結果。它需要相關指標與分析技術的知識。在這個 活動的結束,研究者可以決定回到第三步驟來增加方案的成效或繼續到第六 步驟-溝通,把剩下的改進問題留給之後相關的專案。
6. 溝通:溝通問題與它的重要性,解決方案的效用與創新,它設計的規範,它
4
的成效對研究者及讀者的影響。在學術文章發表,研究者應該用這個流程的 架構來規範文章的結構。
Peffers 的設計科學研究法步驟與流程如圖 1.1:
圖1.1 設計科學研究法-目標導向研究流程 1.3.1 問題定義與動機:
台東縣的農場很多都是微小型農場,人力不多,大多數都是個體戶,一對夫 妻要管理整個農場的生產、耕種、收穫到銷售,甚至品牌行銷。很多農場的資料 都靠腦袋記憶來記住,靠過去經驗來處理,看天吃飯,對農場的經營管理只有基 礎的概念並沒辦法落實。在地耕耘多年的國立臺東大學及一些在地長期經營的學 術單位(如臺東區農業改良場、工業技術研究院、石材暨資源產業研究發展中心 等)擁有很多學術及技術的資源,想投入協助在地農友,但沒有系統化數據化地 了解地方產業所面臨到的問題。政府擁有很多資金及公家機關的資源,希望投入
5
協助在地中小企業及小農,特別是樂活產業,但政府系統過於僵硬,沒有符合在 地產業特色與對樂活產業做分級。
1.3.2 理論基礎:
本研究的方法論發展主要根據兩大理論。
第一是模糊推論: 與傳統一般機器的系統邏輯不太一樣,模糊推論的目標在 於模仿人類在一個不確定與不準確的環境下做理性決策的邏輯。模糊推論通常被 認為是一個多變數邏輯的延伸,但實際上模糊推論是一個只注重近似值而非準確 的模式。模糊邏輯的另外一個優點在於它不僅可以解決兩變數和多變數邏輯系統 而還可以解決機率理論和幾率性邏輯。
第二是協同過濾推薦技術:傳統的協同過濾演算法顯示使用者為 N-維度向 量的項目,而 N 是項目型錄的數量。如果使用者對項目給正面的評價,向量的 組成是正面。反過來,如果使用者給負面的評價,向量的組成會是負面。為了推 薦最適合的項目,演算法通常把向量的值乘以逆頻率(對該項目給評分的顧客數 量),增加少被看見的項目的相關性。
1.3.3 定義解決方案目標:
本研究的目標在於協助使用者-包括業者與專家學者,在媒合過程產出更好 的推薦結果。
1.3.4 解決方案的設計與發展:
本研究將提出一套方法論。設計步驟如下:
1. 模糊推論機制:根據過去產學合作的紀錄,把產學合作滿意度問卷寄給有參 加的廠商業者及相關專家學者進行評分。滿意度準則包括兩部分:計畫合作 滿意程度與該計畫執行內容對樂活產業的成熟度(本系統希望把產業往樂活 產業與循環經濟發展)。
2. 結合推薦技術增加系統媒合效果:透過相關推薦技術-模糊推論,協同過濾,
內容基礎等,為業者提出的問題快速找到對應的專家學者來協助。本研究把
6
協同過濾模型分成兩個類別:專家學者為主和廠商業者為主。從而透過餘弦 相似演算法建立相似度矩陣。在專家學者為主協同過濾機制,相似度矩陣會 計算兩個專家學者間的相似度。在廠商業者為主協同過濾機制,相似度矩陣 會計算兩個業者間的相似度。
1.3.5 展示解決方案:
本研究結合台東樂活產業資料庫開發出一套群眾外包系統。而其中,為了改 善系統配對效率與減少時間及交易成本,系統核心將結合一些推薦技術架構與演 算法,增加媒合效果,有效推薦與配對對樂活產業感興趣且對這方面有研究且有 專業知識的專家學者和希望往樂活產業方向轉型的在地業者,讓台東業者與專家 學者共同提出問題,解決產業相關問題也讓業者知道學術界在這方面有哪些知識 可以協助業者創新轉型與發展。
1.3.6 系統測試與評估:
1. 系統的有用性
系統的配對結果是否能符合專家學者與業者的需求。業者與專家學者的配對 機制與系統提供的資料,是否能讓他們感到滿意,是否促進地方樂活產業的產學 合作?我們將透過質性問卷訪問相關的專家學者與業者,改善系統的功能以及效 能。
2. 系統對樂活產業的推廣成效
系統的配對推薦機制是否能促進台東在地樂活產業的發展。業者與專家學者 是否能透過配對推薦結果找到志同道合的夥伴,有共同意願把在地產業推往樂活 產業的方向。
3. 系統分析與設計過程記錄
系統開發過程中,在分析與設計時,是否發現什麼問題,這些問題如何解決,
解決這些問題帶給業者,專家學者,開發者及未來的開發者怎麼樣的思考與啟 發。
7
1.4 章節架構
本研究一共有六章,各章內容簡述如下:
第一章 前言:說明本研究的背景與動機,定義與描述本研究將解決的問題,
即如何透過台東樂活產業資料庫資料的運用與呈現,促進樂活產業業者與專家學 者的認識與合作,以及關於本研究的目的與範圍及本研究的論文架構。第二章 文 獻探討:說明本研究使用了哪些理論基礎,過去學術界對相關議題(包括樂活產 業,開放資料,模糊推論,推薦系統等議題)有哪些研究,這些議題產生了哪些 概念與問題和方法,值得我們更深一步地探討。第三章 群眾外包推薦系統的設 計與發展:說明本研究使用了哪些研究方法及本研究的主要架構,本研究如何使 用模糊推論及協同過濾技術來解決上述的問題。說明本研究如何透過上述的文獻 探討及方法論,實現系統分析與設計,從演算法的設計,系統架構規劃與實現,
到呈現給末端使用者的介面與流程設計。第四章 展示與評估:展示系統的功能,
驗證上述系統分析與設計的可行性。第五章 結論與未來發展:呈現本研究的成 果,限制與未來的發展方向
。
8
第二章 文獻探討
2.1 群眾外包
群眾外包是一個新的商業概念,在2006 年,由 Merriam-Webster 詞典定義是 一個從大量群眾,特別是線上社群而不是從員工或供應商獲取服務,創意與內容 的過程。到2008 年,在“Crowd-sourcing: Why the Power of the Crowd Is Driving the Future of Business ”,作者認為把工作本來由特定機關執行(員工,供應商)透 過在互聯網上的公開徵求外包給不確定的大量人群。
Jeff(2012)認為,群眾外包的崛起有四大原因。第一是業餘人士的崛起,
過去要當一個業餘的工程師或攝影師非常困難,因為知識只能在學校或從老師學 到,但現在透過網路的崛起,資訊的自由分享與傳遞,知識越來越容易獲取,自 由職業者越來越多,且技能並不輸給經過正規學校培養的學員。第二是開源軟體 運動的發展,過去軟體公司為了商業利益不願意公開原始程式碼,但開源軟體運 動鼓勵開發者開放原始碼,因此慢慢形成開源群聚,大家線上共同協作,改善開 源軟體的效能與功能,也見證了線上群眾合作的可能性。第三是現有生產工具的 增加,承上題,因為開源軟體的發展,人們可以使用更多現有-便宜的軟體工具 來開發創作。人們製作一部影片或一首歌的成本,寫好一個資訊系統的成本大量 降低,同時硬體設備也不斷降價,效能缺不斷提升,使用這些軟硬體的資訊有越 來越普及且低廉。
在“群眾的智慧”(Trott, 2006)主要論述在證明在一些特定案例,大群眾做 的決策比小數精英來得有效,如何讓群眾智慧與決策影響國家,社會,經濟與企 業的運作。Trott(2006)認為過去的封建社會或西方社會非常重視個人的智慧與決 策能力,但在現代社會,很多案例證明,群體或團隊的決策與選擇比團隊中最聰 明的成員還來得正確。雖然團隊或群體裡面的每個人都是獨立思考,但當他們的 決策集合起來,我們會發現有非常大的共同點。所以,群眾的力量可以用來尋找 與解決社會經濟各領域的問題,和協助社會資源的分配與協作。我們的日常生活
9
活動,經濟與政府決策常常受群眾力量的影響,當一個環節不如預期發生通常是 因為沒有注意到一部分群眾的意見,或者這些意見沒有被清楚地表達出來。
Surowiecki 認為一個有合理結構的團體或群眾可以對特定問題提供最適合且最 好的答案,小群眾做的決策比大群眾差即使小群眾的成員都是專家,在市場上不 完美且非理智的玩家仍然可以有效分配資源,缺乏候選人資訊的選民仍然可以選 出為自己爭取權益的候選人。
群眾智慧優勢主要在於對問題提供多樣的解決方案,但這還不夠,群眾還需 要有能力分辨好與壞的答案。多樣化增加各種可能性,協作團隊能更有效解決問 題。實際上,把很多對特定領域有經驗的專家集合並不是個好方案,因為這些人 的技能與知識常常重複,反而增加一些不是該領域專家但擁有其他互補知識與技 能反而能提高團隊運作的效率。一個團隊擁有多元的技能與知識提供的決策常常 比一兩個專家更全面。單一技能或知識的團隊,特別是小團隊,常常被陷入“團 隊思維”,他們更快合作,彼此依賴且容易拒絕團隊外來的資訊。他們慢慢被自 己團隊成員的意見與想法說服和忽視其他反駁意見,他們認為不同觀點是沒有意 義且不會發生。
在學術領域,科學家通常在一個大團隊研究與協作,讓他們可以結合各種不 同的知識。它讓科學家們可以更簡單執行關於多種不同科學領域的工作,提供多 元的意見與解決方案,增加研究的效率。科學家們通常會把研究成果與知識分享 出去因為他們知道他們沒辦法徹底利用這些知識。他們公布自己的研究讓其他人 可以使用和變成新的文獻與假設。研究者依賴前輩與同事的成果與工作進度來建 立自己的基礎,從而發展自己的研究工作。科學家雖然比較關心個人的利益,但 他們找出讓他們的個人利益為別人帶來利益的作法。他們從自己的研究找出有趣 的點與其他人進行協作,透過成就自己也拉高團隊的水準。目前,對科學家社群 的挑戰在於越來越多科學研究獲得私人企業贊助。這些企業把這些研究成果商業 化比分享出去獲得更大的經濟價值。在這種環境下工作,科學家團隊成員間的默 契會因此而分裂,因為大家追求的目的不一樣(知識,名譽,經濟利益),這些
10
問題將挑戰團隊成員的獨立運作與協作成效。
Enrique Estelles Arolas - Fernando González- Ladrón de Guevara(2012)對目 前群眾外包的定義做了一些統整。首先定義誰是群眾?群眾是一群人的集合。群 眾的最佳人數會因為群眾外包的活動而有所變動,因為資訊需要過濾與評估。因 為每個群聚與成員的知識有關係,每個活動會有特定,限制數量的參與者。群聚 的異質性會由群聚活動來決定,一些會需要群眾的共識,每個人會提供個人知識;
而在一些個案,異質性不會那麼重要。總之,群聚的數量,異質性,知識會以群 聚活動的需求而有所變動。
第二,群眾需要做什麼?困難的問題會由群眾外包獲得利益。從日常單純認 知差的工作,到複雜的問題,到需要創意與創新的工作。從問題的複雜度獨立出 來,一般的群眾外包任務,會被分成更底層的工作,每一個工作可以群聚個人成 員來完成,且每一份工作要有明確的目標。透過對群聚個人工作貢獻的承諾與回 饋(金錢,知識,經驗),群聚需要提出問題的解決方法。
Jeff (2012) 認為:群眾外包發揮最大的效益,當個人或公司滿足群眾的需求。
成功的群眾外包包含滿足馬斯洛人類需求五層次金字塔理論的最上層。人民願意 合作因為一些心理,社會與感性需求得到滿足。當這些需求沒有得到滿足,他們 不會付出。如果建立群眾外包平台只為了獲取廉價勞動力,這個平台會失敗,群 眾外包平台應該鼓勵有能力與熱心工作者解決問題與分享自己的作品,金錢回饋 只是附加價值。
最後,Jeff (2012)對群眾外包做了一個總結:“群眾外包是一種線上合作活動 當一個個人、學術單位、非盈利組織、公司透過公開徵求提出工作、提案、問題 給一個群聚、包含多樣、異質的知識。任務的保證,變數複雜度與模組化,與群 聚團隊在工作,金錢,知識上的合作,為了共同利益。使用者會接受給特定需求 的滿足,為了經濟,社會認同,自尊,個人技術的發展,而外包者採納使用者所 提供的方案會獲取與優化他們的優勢。”
11
2.2 樂活產業
2016 年 7 月在國立臺東大學舉辦東大創客既樂活產業創新成果轉化工作坊,
其中的樂活產業創新論壇,引言人謝明哲(2016)在報告中認為人類正在全球暖 化的轉折點,全球暖化是危機也是轉機,我們正在LOHAS(Lifestyles of Health and Sustainability)的啟蒙期。其中的 H-Health 代表“健康的飲食,生活,身心的探 索與個人發展”,而 S-Sustainability 代表生態永續的精神。樂活 LOHAS 族在各 國各地蓬勃發展,因此也慢慢形成樂活產業來滿足這些新興消費族群的需求。謝 明哲(2016)將樂活產業定義為支持健康永續生活形態的產業,能夠滿足消費者 在做消費決策時,對自己與家人健康和環境責任的考量,並能善用綠色設計、綠 色供應鏈、清潔生產、綠色消費及綠色回收來達成循環經濟。
樂活是LOHAS 的中文翻譯,或諧音。LOHAS 這個概念是健康與永續發展 的簡寫。樂活消費者首次出現在“文化創意:5 千萬人正在改變世界” “The Cultural Creatives: How 50 Million People Are Changing the World”(2001,Paul H.Ray &
Ruth Anderson)。這些文化創意者非常注重生態系統,地球,各種連接,和平共 處與社會正義。這些消費者的需求不只在產品的品質而更重視背後的社會責任。
Ray 認為目前美國民眾消費者可以被分為三種:現代,傳統,與文化創意者。在 文化創意者部分,作者發現這個消費族群有一些共同的特質:愛大自然與對它的 破壞和毀滅有警覺心,關心地球議題和希望有實體行動來解決它,願意付更多稅 或用更高價格來購買產品,但希望剩餘的利潤可以用來解決環保議題與全球暖化,
注重發展與維持各種關係,對社區或環保志工活動感興趣,注重心理與心靈的發 展等。
文化創意者沒有一定的人口特質,他們可以是會計人員或社會工作者,餐廳 老闆或電腦工程師等。他們拒絕“左派-右派”或“進步派-保守派”等標籤。實際上,
有60%的文化創意者為女生,大多文化創意者擁有共同的價值與信仰,關於照顧 家庭,人生,關係,教育與培養下一代的議題。在個人生活,他們追求自我實現,
12
努力讓行為符合自己的理念與言論。
Ray 總結關於這股文化創意者新崛起的力量:“在二十一世紀,新的力量將 來臨。最大的挑戰在於維持與保護地球上的各種生命與找出新方法來防止現代生 活中心靈生活的壓力與現代人心理上的空虛。雖然這些議題這幾年已經被反覆研 究,但目前只有西方世界公開思考這些問題。文化創意者正在回應這些挑戰,透 過創造出一種新的文化”。透過新的商業模式,新管理模式,新科技,新型的社 會組織,新決策技巧,文化創意者正在我們日常生活中建構新的世界,即使被主 流大眾媒體忽視。
在“LOHAS mean business”(Emerich,2000)這篇文章里,作者 Monica Emerich 認為,LOHAS 將基礎建立在健康與永續。定義這些概念並不簡單。每個概念都 有很多不同的定義與看法。一般來說,“永續”與產品和服務有關,涉及產品生產,
銷售與消費的方法,這些流程重複完成是否對人,地球資源產生傷害。自然與有 機農業產品一直提倡健康,提升人體健康。作者認為樂活不僅只是一種消費與生 活方式,它還是一個非常龐大的市場,擁有可觀的商機,初步可以透過各地方的 樂活市集來運作。樂活市集有兩個大重點需要了解:
1. LOHAS 市集包含多個產業,如:建築材料,有機農業,健康照顧與個人能 力發展產品與服務。LOHAS 產業包含這下列五個區塊:
永續經濟
健康生活方式
個人發展
健康照顧
自然生態友善生活方式
2. LOHAS 市集運作根據這些產品與產業與特定客群有關係。
樂活市集注重兩大元素:健康與永續。目前的全球社會與經濟並不永續,地 球正在面臨眾多挑戰,同一時間,我們永續的經濟模式來維持全球人口與消費的
13
成長,循環經濟可能是我們在追求的答案。循環經濟不是一套開發,線性的系統,
反而它是一套封閉與循環的經濟系統。觀察這個循環流程-資源平衡模式,我們 可以看到自然環境同時擔任三個角色-資源提供者,廢物處理者與價值優化的來 源(David W. Pearce, R. Kerry Turner 1991)。
人類從大自然獲取自然資源提供生產,製造產品,在市場上銷售給消費者,
只有一個小部分回收再利用,剩下被丟棄。隨著經濟社會的發展,丟棄的垃圾量 越來越多。隨著人口增加,各種產品需求越來越增加,反而自然資源越來越少。
如目前,雖然油價還在控制範圍,但在未來,世界油儲存量全部耗盡。這不僅是 能源問題,還涉及經濟,社會,國家安全與地區穩定等問題,將是不遠未來的挑 戰。面對耗盡自然資源與環境污染的挑戰,一個新經濟模式的概念“循環經濟”
正在獲得全球各個組織與政府的關心與支持。這個新經濟發展模式優先使用再利 用的原料,減少原料消耗,增加生產效果,有效減少生產過程對環境的影響。
Pearce 和 Turner 在 1991 指出:傳統的開放式經濟的發展沒有包含再利用的趨勢,
把環境當做廢棄物掩埋場。按照熱力學的第一個定律,在一個封閉系統,熱量與 物質法的總共是不變。當考慮到使用的水與資源的產值,開放式系統應該要被轉 化成循環系統。當面臨存在的環保問題與資源缺乏,他們認為應該把地球視為一 個封閉的經濟系統,其中經濟與環境不是一個線性關聯,而是一個循環關係。
從工業革命到現在,雖然經過多次進化與多樣化,世界的工業經濟還沒離開 早期的工業化模式:一個消耗資源的線性模式按照“取得-製造-處理”的流程。公 司取得材料,使用能源與員工來生產產品,把它銷售到末端消費者-消費者會把 它丟棄,當這個產品不再擁有服務價值。雖然企業大量改進原物料與能源使用效 能,任何生產系統注重消耗而不是資源的恢復與再利用,將在價值鏈上承受大量 的損失。最近,企業們開始了解這種線性系統將增加他們面對的風險,特別對於 昂貴且稀有的資源。越來越多企業感受到這種壓力因為原物料市場上價格越來越 高且越難預測。面對這個問題,企業們希望能夠尋找新的工業模式,可以從原物 料的輸入增加利潤,這個概念成為“循環經濟”。雖然目前只在理論上的建構,“循
14
環經濟”的概念透過意圖與設計實現可恢復的工業經濟模式。在循環經濟,產品 設計為了容易再利用,拆解與翻新,或回收,透過再利用末端產品的原物料而非 抽出新材料,這是經濟成長的基礎。透過應用循環經濟,無限性的資源-如勞工 在經濟流程上有更中心的角色,而有限資源-如天然原物料只擔任協助的角色。
這個概念擁有非常可觀的願景,已經在多個產業上獲得驗證,能夠抵銷目前在自 然資源供需之間的不平衡。
過去,人們認為垃圾是丟棄物,已經使用完它的價值就不能再利用。但實際 證明生產線上與生活中大多被認為是丟棄物仍然可以再利用。一些國家開始推動 一個無丟棄物或只有安全丟棄物的社會。各國的挑戰在於重新定義垃圾,把它當 作原物料,是工業經濟的輸入原料。資源回收的本質就是把丟棄物一部分或全部 回到生產線,再組織與再利用。再利用可以是一種新的經濟活動或產業並帶來雙 重的經濟效益,第一是減少原物料,減少生產成本,第二是減少廢棄物的處理成 本,對企業本身即整體經濟社會都有正面的影響。當經濟活動與消費社會嚮往一 個無廢棄物的環境,人們越少獲取自然資源,透過再利用再使用減少廢棄物排放,
丟棄物逐漸會被減少,實現循環經濟的最終目標。
以台灣來說,樂活業者大多是中小企業,而以台東而言,企業大多為中小與 微型企業,樂活產業將有非常大的發展空間。按照中華民國中小企業發展條例,
中小企業為營業額八千萬以下,而微型企業為雇用五人以下的企業。這些業者非 常有自己的理念與獨特的產品,產品服務常結合地方特色,注重在地化,但常常 因缺乏資金,人力,人才,在經營管理上遇到很多問題。在全球化時代,面臨連 鎖餐廳與跨國大企業的到來,這些在地經營的中小和微型企業面臨更龐大的挑 戰。
2.3 開放資料
資料是指還沒經過處理的原始紀錄。一般人認為資料概念只用於科學研究領 域,實際上,資料每天都被大量收集用於各種不同的營利或非營利目的,在各個
15
學術機構與組織,企業,政府與非政府組織。對一般人而言,資料,資訊,知識,
智慧是接近且容易混淆的概念。資料是從實際被記錄與分析的原始記錄,資訊是 資料為了支援決策而按照特定方法分析,知識是某個領域的資訊和經驗的結合。
其中,資料是最具體的概念而知識是最抽象的概念。
按照資料管理協會的定義,資料資源管理是一種透過設計,政策,實作和流 程的規劃與執行來管理一個組織企業所需的資料流程(DAMA- Data Management Association)。跟一個產品一樣,資料也有自己的生命週期。不同的組織對資料 生命週期有不同的看法與規劃。
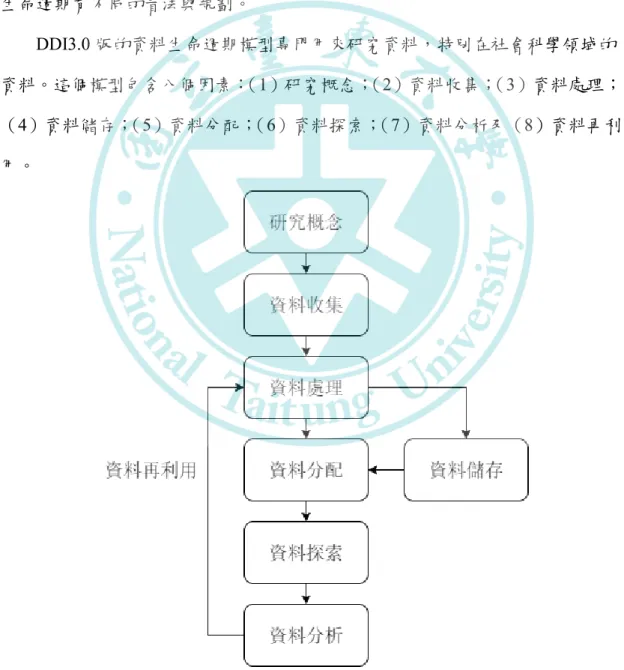
DDI3.0 版的資料生命週期模型專門用來研究資料,特別在社會科學領域的 資料。這個模型包含八個因素:(1)研究概念;(2)資料收集;(3)資料處理;
(4)資料儲存;(5)資料分配;(6)資料探索;(7)資料分析及(8)資料再利 用。
圖2.1 DDI 資料生命週期模型(DAMA- Data Management Association)
16
開放資料的想法是把資料免費開放到所有使用者使用與發佈,而沒有著作權,
專利或其他控制機制的限制(Auer 2007)。開放資料不包含政府機密資料與個人 隱私資料,這些資料提供給使用者自由利用與再利用,發布與再發布,與其他開 放資料進行整合。透過開放資料的重新利用與組合,創造出新的加值服務,為企 業,政府與社會提供新的價值。而開放資料為了容易整合必須具備相容性,相容 性讓不同的組織與系統在同一份開放資料上進行協作,甚至混合集合不同的領域 與不同來源的開放資料,協助建立龐大與複雜的資訊系統。
開放資料在美國發展一開始來自開放政府的推動,為政府實施三大原則:透 明,協作和參與(Chun, 2010)。透過讓公民知道政府在做什麼實現透明,增加 公民對政府的監督。政府機構該告訴民眾關於他們的運作與決策。參與鼓勵民眾 參加政策建立的過程,提供給政府有選擇性的想法,知識與特定領域的專業。這 種參與增加政府機構的有效與改善決策的品質。協助原則鼓勵各級政府機關,各 非盈利組織,公司與個人合作來改善政府的效率。
中華民國政府於101 年開始推動“政府資料開放平台”,提供政府各機關開放 資料,增加政府透明度,鼓勵與促進民眾參與公眾議題,監督政府。透過使用平 台上的跨領域資料,不僅滿足產業界的需求,還希望用數位科技的方法與創意協 助政府解決公共事務問題。政府機關將依據三步驟(1)「資料開放民眾與企業運 用」、(2)「以免費為原則、收費為例外」、(3)「資料大量、自動化而有系統的釋 放與交換」與四大焦點(1)「主動開放,民生優先」、(2)「制定開放資料規範」、
(3)「推動共用平臺(Data.gov.tw)」、(4)「示範宣導及服務推廣」來推動與執 行每個單位的資料開放工作。
同樣是資料開放平臺,g0v 零時政府卻從不同的角度切入,bottom-up 自下 而上,零時政府集合對公共議題有興趣的人士建立一個線上社群,目的在於推動 資訊透明化,為了鼓勵人民參與公共議題而發展相關資訊平台與工具。基於開源 的精神,零時政府更加關心自由言論與開放資料,用程式碼編寫工具讓人民更加 容易善於使用各種資訊服務。
17
不管是政府機構還是民間團體,大家越來越了解開放資料的重要性與潛力。
開放資料不只讓政府透明化,且透過資料的跨域整合,把資料分析與呈現,不僅 能夠有效了解與解決相關公共事務,且還能促進產業經濟轉型與發展。
2.4 API 經濟
API (英文全名為 Application Programming Interface)為應用程式介面。我們通 常都聽過GUI(Grapgic User Interface)圖形化介面,或 CLI(Command Line Interface)指令介面,這些都是使用者與電腦機器溝通的介面。而 API 應用程式 介面是程式與程式間的溝通介面與方式,如:應用程式與作業系統的溝通,程式 與程式的資料交換,一個企業內部不同程式模組的協助。在這個雲端時代,講到 API,大家通常會想到 Web API。整合一些 Web API 成為一個新的應用,成為 Marshup(混合網路應用)。API 的結合創造不只是跨域且有趣的 Marshup,還可 以創造出新的產品與商業模式。
開放資料可以透過API-應用程式介面的方式提供程式開發者或資料科學家 來存取。API 應用程式介面讓使用者可以擷取一部分或全部資料。API 應用程式 介面通常會連結到一個線上資料庫,這也讓API 應用程式介面提供的資料能夠 即時更新。當然,使用API 來儲存與存取開放資料會產生一些成本,比起傳統 提供一個固定的檔案,使用API 需要一個線上資料庫與伺服器設施的建置與維 護,並需要人員不斷更新與修正資料。
這些技術與管理模式結合起來,成為這個時代非常重要的API 經濟。IBM 認為,目前,頂尖企業都在轉型,數位化,投入API 經濟、轉型過程由網路與 消費者需求帶動,產生龐大的資料量。在API 經濟,應用程式界面(APIs)鏈 接各種服務,應用與系統。這讓企業可以盡可能利用他們的資料來增加顧客體驗 與開拓新收入來源。
Gartner (2016)年認為我們活在 API 經濟環境裡,而 API 經濟其實就是一 系列基於資料交換與功能存取的商業模式與溝通管道。APIs 讓企業組織更加簡
18
單整合與連接人,地點,系統,資料,物體與演算法,創造新的使用者體驗,分 享資料與資訊,驗證人與物件,提供交易與第三方演算,創造新的產品服務與商 業模式。API 經濟會把企業或組織轉化成平台。平台可以創造更多價值,因為其 允許企業生態系統內部和外部完善符合使用者與促進商品,服務,社會貨幣的創 造與交易,因此讓所有參與者可以互相創造與獲取價值。報告還指出,我們正在 邁進新的數位經濟時代,數位企業從數位資產創造價值與利潤,不管策略如何,
API 將是核心技術與資源來促進企業成長的主要動力(Gartner 2016)。
使用APIs 把企業轉成平台會包含這三大區塊:
數位商業模式:提供人,事,物的生態系統以提供價值。
商業模式平台:提供數位企業展現現有企業技術如演算法,資訊,資源與分 析。
商業生態系統:整合商業模式平台以創造新解決方案。
按照Deloitte-(一家大型會計公司)在 2015 年的報告對 API 發展史做了一 些統整:
1960-1980:基本互通讓程式間可以交換資訊,如:TCP,APRANET
1980-1990:有功能和邏輯的界面出現。物件代理人,程序呼叫,程式呼叫提供網 絡上的遠端互動,如:點對點互動,RFC,EDI 等。
1990-2000:新平台鼓勵透過中介軟體進行交換。界面改叫服務,如:訊息導向中 介軟體,企業服務匯流排,服務導向架構
2000-今天:企業建立 API 為了加速新服務的開發與提供。API 階層管理服務的整 合,如:IaaS,RESTful 服務,API 管理等等
Accenture 在 2016 裡面的報告提到,平台科技需要掌握:
基礎:雲端服務
數位鏈接:API 策略與架構
加速器:開放與再利用軟體
數位技術:行動發展平台
19
即時商業模式:物聯網導向
容器:軟體的獨立與便利性 平台經濟的三大規律:
1. 網絡效應/雙向市場:兩個使用族群(如生產者與消費者)為彼此建立彼此的 網路價值,反應在彼此在需求方面的共同經濟利益。平台的網路效應,因為 有更多使用者與交易,增加更多價值與規模。
2. 權力分配:平台商業模式透過“長尾”曲線上的利潤分配創造價值與經濟規模,
避免與傳統價值鏈模式的遞減報酬。
3. 不對稱成長與競爭:透過核心市場的需求導向,不對稱競爭存在於當兩家公 司擁有不一樣的角度與資源進入市場時。
API 經濟也擁有自己獨特的價值鏈。企業把自己的數位資產(資料,產品,
服務等等的相關資訊數位化)轉化成API,這些資產可能是企業相關的資料,資 訊或服務。API 會由公司內部或外部的程式開發工程師使用,結合其他 API 或開 放資料,來開發他們自己的應用程式,創造新的價值,為新的末端顧客提供服務,
這些服務不僅改善顧客與消費者對原來公司產品或服務的使用體驗,增加顧客滿 意度與產品價值,也讓企業在數位時代擁有新的競爭優勢。文中提及內容如圖 2-2 所示。
圖2.2 API 經濟價值鏈
API 經濟的進一步延伸是平臺經濟。人們熟悉過去的線性經濟活動。公司取 得原料,生產產品,把產品送給顧客或零售商,零售商再跟末端消費者去做交易。
20
但在互聯網時代,新一代的數位經濟正到來,平臺經濟業者大量出現,懂得開發 與經營平台來鏈接供應商的廠商,創造與媒合新的交易,從而獲利。在平台經濟 時代,人人都可以供應商,人人都是潛在顧客。平台經濟崛起的動力來自行動設 備的普及讓人人隨時上網,社群媒體的崛起讓陌生人之間產生信任,。
以台東偏鄉而言,API 經濟與平台商業模式將有效解決城鄉資訊落差與不對 稱問題。按照美國經濟部國家通訊與資訊局1995 年的定義,資訊落差是一種對 資訊與通訊科技使用,運用或受影響上的社會與經濟上的不平等。這種資訊落差 存在於國於國之間,城市與偏鄉,或個人,企業等。在不同的社經地位或地理位 置。資訊落差的距離來自各種不同的原因,但主要跟地方的人口結構與社會經濟 特性有關(當地居民的收入,教育程度,種族,性別,地理位置,年齡,政治,
文化等),其中收入與教育程度對資通訊的運用有明顯的影響。在今天的數位時 代,資訊落差會引起經濟不平等-以電子商務為例,業者不能及時更新顧客與競 爭者的資訊將被產業與市場淘汰,經濟發展停歇-資通訊科技跟不上產業的需求 往往被產業淘汰,社會移動性降低-偏鄉學生有更少機會接收到城市學生的資訊 與資源造成未來在求學求職與職涯規劃上不公平的競爭。另外,研究顯示當選民 沒有積極在網路上獲取資訊,地方或政商勢力更有能力掌控政權。
以台東為例,在各種經濟活動上,資訊落差讓交易成本大大增加。交易成本 是執行經濟交易,或參與市場所產生的成本。交易成本可分為三大類:(1)搜尋 與資訊成本-確認該商品或服務是否在市場有提供,哪一個市場會以最低的價格 提供;(2)議價成本-產生當接受或不接受對方的價格和條件,是賽局中做選擇 所產生的成本;(3)履約成本-按照合約執行所產生的成本。資訊落差讓搜尋與 交易成本變得非常高,當找不到適合的供應商,重新談判的議價成本與時間難以 估計;因交通不便,物流成本與時間高昂,履約成本又是一個大問題。
2.5 模糊推論
傳統邏輯只顧慮到兩個絕對值(0 或 1,對或錯等)。傳統邏輯遵守兩個原則。
21
第一,集合的成員性,對於任一個集合和任一項目,該項目或是集合的成員,或 是該集合補集的成員。第二是移除中間,一個項目不可能同時是某集合的成員,
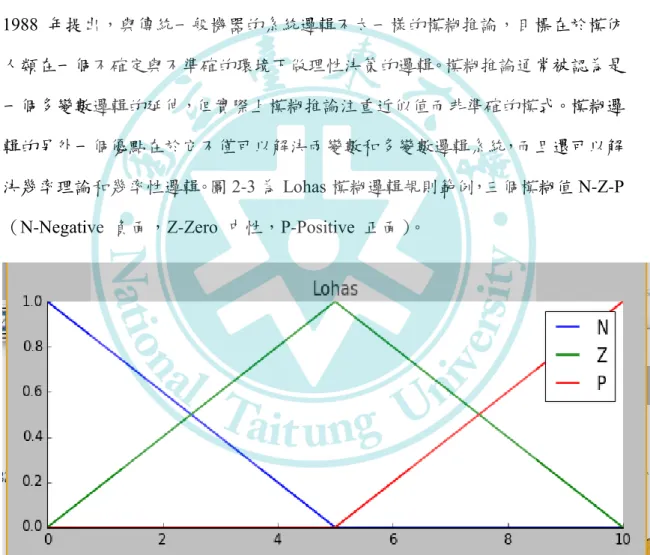
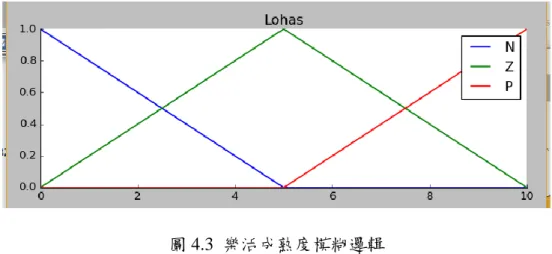
又是它補集的成員。因此,傳統邏輯的很大缺點在於很難分辨或表達模糊,不確 定性的資料,而這種資料在日常生活經常出現(如:自然語言,情緒,各種人際 關係等)。模糊邏輯是一種多值邏輯,變數真正的值可能處於0 與 1 間,是模糊 區間。相反在布林邏輯,變數的值只能是0 或 1 (Novák ,1999)。模糊邏輯通 常被應用來處理部分事實的概念即當事實處於完全對與完全錯之間。Zadeh 在 1988 年提出,與傳統一般機器的系統邏輯不太一樣的模糊推論,目標在於模仿 人類在一個不確定與不準確的環境下做理性決策的邏輯。模糊推論通常被認為是 一個多變數邏輯的延伸,但實際上模糊推論注重近似值而非準確的模式。模糊邏 輯的另外一個優點在於它不僅可以解決兩變數和多變數邏輯系統,而且還可以解 決幾率理論和幾率性邏輯。圖2-3 為 Lohas 模糊邏輯規則範例,三個模糊值 N-Z-P
(N-Negative 負面,Z-Zero 中性,P-Positive 正面)。
圖2.3 Lohas 模糊邏輯規則範例
因為可以模仿人類概念思考的模糊特性,模糊推論在一些決策支援系統擔 任特別重要的技術與角色。一般的模糊推論系統架構如圖2.4 所示,模糊化模組 接受從外在環境輸入的確定數值,處理與歸類它們到隸屬的模糊集合,推論機制 負責計算所有隸屬函數值並結合模糊規則來算出最適合的輸出結果。解模糊模組
22
在這裡負責把輸出模糊集合轉成最適合使用者決策環境與使用情況的確定數 值。
圖2.4 模糊邏輯系統的架構
雖然模糊推論提供的結果只是預估值,但它對問題解決扮演重要的角色。模 糊推論被應用在一些資訊系統,對非結構,不確定或不足的資訊提供推論與輸出 有效的結果。
2.6 推薦系統
推薦系統是為了提供對項目選擇建議的軟體工具與技術(Ricci, 2011)。推薦 主要影響決策制定過程,如需要買什麼商品,聽什麼音樂或看什麼新聞。“項目”
是一個共用的概念,用來描述系統為使用者提供的內容。一個推薦系統通常集中 在特定的項目(如音樂,新聞,商品等)並按照它的設計,使用者圖形化界面,
與核心的推薦技術提供推薦,為特定項目提供客製化且有用和有效率的建議。推 薦系統的本質在於資訊過濾(Information Filtering),這個領域主要研究如何為使 用者提供適合的資訊,防止與移除不適合的資訊。資訊過濾的應用非常廣泛,從 搜尋引擊,過濾垃圾電子郵件,到電子商務的商品推薦系統等。不同的資訊過濾 機制雖然在演算法或技術與方法論上有所差別,但它們都有共同的目標,在於為 使用提供最有意義的資訊。
在最簡單的形式,客製化的推薦系統是項目的排行。在執行排序這個動作,
推薦系統試圖找出最適合的產品與服務,根據使用者的優先背景演算出適合的推
23
薦結果。為了實現這個計算工作,推薦系統從使用者上收集他們的優先,對各樣 產品的評價,或推斷透過解釋使用者的行為。
推薦系統是一個資訊處理系統有效地收集各種資訊來建立自己的推薦模式。
資料主要描述被推薦的項目與接收推薦的使用者。但現有的資料與知識來源可以 變得更豐富,獨特不受推薦機制的限制。一般來說,推薦技術處理知識很差,他 們只使用簡單和基本的資料,如使用者對項目的評分/評估。其他技術更依賴知 識,如對使用者或項目的描述或背景,或對使用者的社會關係與活動。在一些個 案,或一般分類,推薦系統使用的個案主要有三大類:項目,使用者,交易資料, 如:項目與使用者間的關係。
其中,項目是被推薦的物件。項目的特徵來自它的複雜度和它的價值或效用。
一個項目的價值可以是正面(如果它對使用者有用),或是負面(當它不適合使 用者或使用者認為選擇它是一個錯誤的決策)。當使用者獲得一個項目,他要付 出一定的成本,這包含搜尋該項目的成本與為該項目付款真正花費的金錢成本。
使用者可以有多樣的目標與特徵。為了客製化這些建議與人-機互動,推薦 系統一定得利用使用者資料。這些資料可以透過多種方式被結構化,某些資料可 以被模組化,由推薦技術來決定。如在協同過濾技術,使用者被模組化成一個簡 單的列表關於使用者對項目評分的簡單列表。
一筆交易就是使用者與推薦系統互動的紀錄資料。交易是資料記錄儲存關於 人-機互動的重要資訊,對系統在使用的推薦產生演算法有用的資料。交易紀錄 可以儲存對特定推薦機制對使用者選擇項目的參考與描述資訊。更進一步,交易 紀錄還可以儲存使用者的回饋資料,如對項目的評分/評價。實際上,評分是推 薦系統最普遍收集的交易資料。這些評價可以很明確或有隱含性。在明確的評分 框架,使用者會被要求提供關於一個項目的評,該評價係根據一個固定的量表(如 一顆星到五顆星等)。另外一種框架集中在分類項目,如使用者幫忙分類這部電 影屬於哪一種類型:愛情,動作還是喜劇等。推薦系統架構如圖2-5 所示:
24
圖2.5 推薦系統架構
一個人口推薦系統會使用社會人口相關的欄位如年齡、性別、專業,教育背 景等資訊。使用者資料會構成使用者模組。多種使用者模型會被採用,在特定情 況,推薦系統可被視為透過建立與分析使用者模型來產生推薦的工具,因為客製 化來自使用者模型,使用者模型是系統的主角。在協同過濾技術裡,使用者透過 對項目的評分讓系統產生一個向量值,在他們的模型中透過每一個因素的權重不 同來區分使用者。協同過濾只是推薦系統技術的其中之一,下列是六種常見的推 薦技術:
(1)(Content-based)內容基礎:系統學習推薦跟過去相似的項目。項目的相似 度被計算透過衡量與被比較的項目的相關功能加以計算。例如,如果一個 使用者對一部喜劇都正面的評價,系統可以推薦其他有共同類型的電影。
(2)(Collaborative filtering) 協同過濾:推薦使用者與其他使用者有類似嗜好 的項目。兩個使用者的相似度由使用者過去歷史的評分來計算,因此協同 過濾還被稱為“人對人相關”的技術,也是最普遍且最廣應用的推薦系統技 術。
(3)(Demographic )人口統計:這種項目推薦系統根據使用者的人口背景資料。
這代表對不同人口群組該建立不同的推薦機制。一些網站透過人口統計建 立簡單且有效的個人化方案。例如,使用者被導向到適合他們國家和語言 的網頁版本,或推薦可以根據使用者的年齡進行推薦。
25
(4)(Knowledge-based)知識基礎:知識基礎系統透過特定領域知識推薦項目,
項目的屬性記錄如何滿足使用者的需求與背景,簡單來說,項目是否對使 用者有用。知識基礎推薦系統以個案為基礎。在這些系統會估算問題定義
(使用者的需求)是否符合問題的解決方式(系統推薦出來的結果)。相 似分數可以被直接顯示出來成為提供給使用者的建議。
(5)(Community-based)社群基礎:這類系統基於在使用者的朋友背景為推薦項 目。這個技術的理念就是“告訴我你的朋友是誰,我會告訴你是誰”。資料 顯示人們通常比較會聽從朋友的建議。這個觀察,隨著開放社群網路的發 展,使得推薦系統的社群基礎技術有著突破性的發展,成為社會推薦系統。
這類推薦系統獲取使用者的社交網路與朋友的背景資訊,這類推薦系統的 評分資料主要來自使用者朋友。實際上,這類的推薦系統隨著社群網路的 崛起,更容易獲取使用者社交關係的相關資料。
(6)(Hybrid recommender systems)混合推薦系統:這類推薦系統是上述技術的 整合。一個混合系統整合A 與 B 技術,使用 A 技術的優勢來解決 B 技術 的缺陷。例如,協同過濾不能對新的項目建立推薦,因為沒有過去評估,
但這對內容基礎技術並不是問題,因為內容基礎技術主要分析項目的描 述。
在本研究,我們主要使用協同過濾技術作為推薦系統的核心。協同過濾是建 立推薦系統的做法之一。協同過濾的演算法主要根據使用者的過去的交易資料或 評分資料來推薦使用者間或使用者與項目間的相似度。雖然這些演算法已經被應 用在一些推薦系統且獲得一定的成就,這些技術仍然存在一些限制需要解決。協 同過濾的主要理論基礎在於大數法則與群眾的智慧。大數法則認為當樣本越來越 多,各種統計特徵(平均數,標準差等等)會越來越接近母體的統計特徵。群眾 的智慧,上面有提到,認為多數群眾的選擇會優於少數專家,當然這裡的群眾並 非所有群眾而是以研究對象有一定關聯的群眾。
26
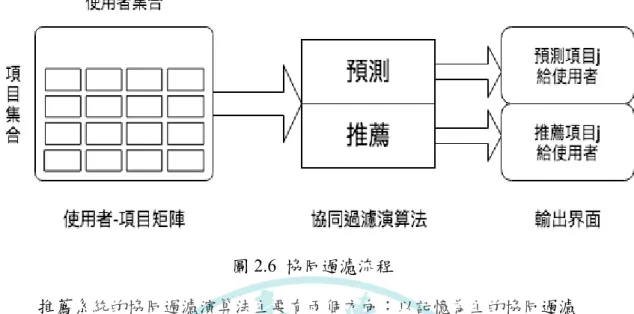
圖2.6 協同過濾流程
推薦系統的協同過濾演算法主要有兩個方向:以記憶為主的協同過濾
(Memory-Based Collaborative Filtering)和以模型為主的協同過濾(Model-Based Collaborative Filtering)。以記憶為主的協同過濾使用使用者的所有資料來預測使 用者對新產品的評價。這種方法可以直接把新資料帶進資料表所以常被應用在實 際案例,這種方法在線上資訊系統(資料一直被更新)常常提供更準確的預測。
以記憶為主的協同過濾又有兩種:使用者為主協同過濾(User-Based Collaborative Filtering)和項目為主協同過濾(Item-Based Collaborative Filtering)。這兩種方法效 果差別在於尋找使用者間的相似度或產品間的相似度。
傳統的協同過濾演算法顯示使用者為N-維度向量的項目,而 N 是項目型錄 的數量(Linden,2003)。如果使用者對項目給正面的評價向量的組成是正面,反之 則是負面。為了推薦最適合的項目,演算法通常把向量的值乘以逆頻率(對該項 目給評分的顧客數量),增加少被看見的項目的相關性。對大多使用者,這個向 量是很疏散的。演算法會透過幾個跟使用者最相似的用戶建立推薦。它可以衡量 兩個使用者間的相似度,A 和 B,透過計算兩個向量間的 cosine 值。計算方式如 方程式2.1 所示,此方法稱為餘弦相似性(Cosine Similarity)。
Sim(𝐀⃗⃗ ,𝐁⃗⃗ )=cos(𝐀⃗⃗ ,𝐁⃗⃗ )=
𝐀 ⃗⃗ 𝐱𝐁⃗⃗
‖𝐀 ⃗⃗ ‖𝐱‖𝐁⃗⃗ ‖ (2.1)
27
第三章群眾外包推薦系統之設計與發展
3.1 方法論之設計
本研究設計出一套群眾外包之推薦系統架構,研究範圍主要在業者提出問題 與媒合相關領域專家學者的過程中資訊推薦的部分。
根據過去產學合作案件的紀錄,我們邀請參與產學合作案件的業者與相關專 家學者對過去案件進行評量,得到結果再使用模糊推論,按照模糊邏輯規則的規 劃(我們系統鼓勵產業往樂活產業與循環經濟發展),得到符合系統標準與需求 的結果,再存到資料庫。
之後每次業者或專家學者在系統上提出問題或需求,系統會透過協同過濾技 術分析問題的類型,提出問題的使用者相關背景資料,然後從資料庫挖掘過去評 分資料進行分析,最後在系統界面為使用者顯示最適合的推薦結果(過去類似問 題,相關專家學者與業者等)。
圖3.1 系統架構
系統架構上有兩大技術模組:模糊推論評分模組與協同過濾推薦模組。
28
3.1.1 模糊推論機制:
根據過去產學合作的紀錄,把產學合作滿意度問卷寄給有參加的廠商業者及 相關專家學者進行評分。滿意度準則包括兩部分:本身計畫合作滿意程度與該計 畫內容對樂活產業的成熟度(本系統希望把產業往樂活產業與循環經濟發展)。 模糊推論包含四個部分,如圖 3.2。問卷評分進入模糊器之後在每一個部分會分 成三個等級:
-N-Negative:負面 -Z-Zero:中立 -P-Positive:正面
圖3.2 模糊推論機制
規則,如表 3-1 所示,儲存 IF-THEN 規則根據專家的建議。對合作滿意度 的評價,分成三種等級:N-Negative 負面(0-5 分),Zero-中立(0-10 分),P-Positive 正面(5 到 10 分)。對樂活成熟度的評價,也分成三種等級:N-Negative 負面(0-5 分),Zero-中立(0-10 分),P-Positive 正面(5 到 10 分)。綜合結果分數分成五 種等級:NB-Negative Big 大負面,NS-Negative Small 小負面,Z-Zero 中立,
PS-Positive Small 小正面,PB 大正面。推論規則如表一模糊推論規則。
29
表 3.1 模糊推論規則
樂活產業成熟程度
N Z P
產學合作 滿意程度
N NB NS Z
Z NS Z PS
P Z PS PB
推理機制,模擬人類的推理過程透過對輸入變數與 IF-THEN 規則進行模糊 推論。假設:如滿意程度是Z-Zero,樂活程度是 P-Positive,則推出結果為 PS-Positive Small,這樣設計讓專案中的樂活程度評價有更大的比重,鼓勵專家學者與廠商業 者往樂活產業與循環經濟發展。
解模糊器,轉換推理機制的模糊集合成確定的值。本演算法使用解模糊演 算法為中心法。
3.1.2 協同過濾機制
協同過濾機制流程如圖5。從資料庫把評分記錄取出來,建立評分矩陣,行 為專家,列為業者。
圖3.3 協同過濾演算法
協同過濾演算法使用餘弦相似性,通過測量兩個向量夾角間的餘弦來評量他 們的相似度。
Sim(𝐀⃗⃗ ,𝐁⃗⃗ )=cos(𝐀⃗⃗ ,𝐁⃗⃗ )=
𝐀 ⃗⃗ 𝐱𝐁⃗⃗
‖𝐀 ⃗⃗ ‖𝐱‖𝐁⃗⃗ ‖
(3.1)30
計算完成後,形成廠商對廠商相似度矩陣(如果使用者是專家學者)或專家 對專家相似度矩陣(如果使用者是廠商業者)。然而從矩陣中選出相似度最高的 N 項目作為結果顯示給使用者。
3.2 分析前須準備的資料
協同過濾是一個推薦機制透過過去項目間的評分來計算項目間的相似度,這 種推薦機制主要靠資料來提昇推薦結果的準確度,因此資料越多或系統使用時間 越久,推薦結果更加準確。透過結合樂活產業資料庫的API,我們取得台東在地 樂活產業廠商,台東在地各領域專家學者與他們過去曾經有參與的產學合作專 案。
表 3.2 問題資料表資料欄位 編號 項目 型態 內容 1 Id varchar 問題編號 2 Time datetime 提問時間 3 Question varchar 問題標題 4 Detail varchar 問題詳細內容 5 Domain varchar 問題領域 6 Tag varchar 問題標籤 7 Questioner varchar 提問者
提問者在平台上提出問題,方案提供者回復答案與提供解決方案說明。為了 讓系統更精準地推薦結果到使用者,在資料庫欄位部分,透過增加問題領域與問 題標籤的欄位,讓問題屬性更加明確。如果問題的領域是資訊,系統會優先推薦 與提問者相似度較高的資訊相關專家學者。然而,標籤-tag 讓協助系統歸類共同 主題的問題,也協助方案提供者方便快速找到自己專長解決的問題。問題會被紀
31
錄到資料庫在問題資料表的欄位。如資訊底下有很多小問題(電子商務,進銷存 等),農業底下有很多小主題(病蟲害防治,栽種技術等),專家可以透過標籤-tag 找到同時擁有進銷存與栽種技術需求的問題,提問者因此也可以找到跨領域的專 家來解決問題,讓解決方案更加全面。問題資料表設計如如表3.2 所示。
方案提供者的解決方案會被記錄到資料庫解決方案資料表的欄位,解決方案 資料表設計如表3.3 所示。
表 3.3 解決方案資料表資料欄位 編號 項目 型態 內容 1 Id varchar 方案編號 2 Time datetime 方案輸入時間 3 Question_id varchar 問題編號 4 Response varchar 方案標題 5 Detail varchar 方案詳細
5 Responder varchar 方案提供者編號 6 Tag varchar 方案標籤
7 Url varchar 方案相關連結 8 Files varchar 方案附檔
在模糊推論建構部分,主要需要資料是專家學者與廠商的過去產學合作資料。
案件結束後會要求專家學者與業者填寫合作滿意度問卷,問卷內容包含兩大議題:
合作案是否對樂活產業有幫助與雙方對合作過程是否感到滿意。
32
表 3.4 合作專案問卷問題列表
問題列表
很 不 滿 意
不 滿 意
尚 可 滿
意 很 滿 意
過 去 合 作 案 滿 意 度
您對這筆產學合作案件的整體滿意度?
計劃成果是否對您的企業有實質幫助?
此合作計劃讓我對學術研究有更深入的了 解?
我對學生老師的互動交流感到滿意?
樂 活 產 業 成 熟 度
此合作計劃有把樂活產業的理念應用到企 業上?
此合作計劃讓我了解如何推廣樂活產業及 循環經濟理念?
評分結果會被記錄到資料庫在合作案資料表的欄位,合作案資料表設計如表 3.5 所示。
表 3.5 合作專案資料表資料欄位 編號 項目 型態 內容
1 Id varchar 合作案編號 2 Time datetime 評分時間 3 Name varchar 合作案名稱 4 Vendor varchar 廠商編號 5 Expert varchar 專家學者編號 6 Domain varchar 合作領域
7 Cooperate_rate double 合作案滿意度評分 8 Lohas_rate double 樂活成熟度評分 9 Combine_rate double 綜合評分
33
3.3 模糊推論之分析與設計
第一步,我們先定義模糊推論演算法裡面的輸入與輸出變數。
在這個系統裡,輸入資料包含兩個維度:業者對樂活產業的滿意度與合作案 對樂活產業的成熟度。
樂活程度,當計算出分數在0-5 間屬於負面 N(Negative),當計算出分數在 0-10 間屬於中性 Z(Zero),當計算出分數在 5-10 間屬於正面 P(Positive):
Lohas(x)={N(Negative),Z(Zero),P(Positive)}
滿意程度,當計算出分數在0-5 件屬於負面 N(Negative),當計算出分數在 0-10 間屬於中性 Z(Zero),當計算出分數在 5-10 間屬於正面 P(Positive):
Cooporate(x)={N(Negative),Z(Zero),P(Positive)}
輸出分數為經過模糊推論得到的綜合分數Point(x)。
Point(x)={ NB(Negative Big), NS(Negative Small), Z(Zero), PS(Positive Small), PB(Positive Big) }
第二步,對輸入與輸出變數建立成員函數
以python 程式語言建立輸入與輸出變數的分類與規劃:
表 3.6 變數的分類與規劃
項目 函數
合作滿意度 C_N = fuzz.trimf(x, [0, 0, 5]) C_Z = fuzz.trimf(x, [0, 5, 10]) C_P = fuzz.trimf(x, [5, 10, 10]) 樂活成熟度 L_N = fuzz.trimf(x, [0, 0, 5])
L_Z = fuzz.trimf(x, [0, 5, 10]) L_P = fuzz.trimf(x, [0, 0, 5]) 總分數 P_NB = fuzz.trimf(x, [0, 0, 2.5])
P_NS = fuzz.trimf(x, [0, 2.5, 5]) P_Z = fuzz.trimf(x, [2.5, 5, 7.5]) P_PS = fuzz.trimf(x, [5, 7.5, 10]) P_PB = fuzz.trimf(x, [7.5, 10, 10])
34
以圖示化呈現成員函數的分配:
圖3.4 成員函數的分配
第三部,對輸入變數建立模糊知識規則,建立樂活程度對滿意程度的規則矩 陣:
表 3.7 模糊推論規則
樂活程度 L(x)
N Z P
滿 意程度
C(x)
N NB NS Z
Z NS Z PS
P Z PS PB
用IF-THEN-ELSE 結構建立模糊知識規則,以 python 程式語言為範例:
模糊規則
1 IF (L(x)是 N) AND (C(x)是 N) THEN P(x)為 NB 2 IF (L(x)是 N) AND (C(x)是 Z) THEN P(x)為 NS 3 IF (L(x)是 N) AND (C(x)是 P) THEN P(x)為 Z 4 IF (L(x)是 Z) AND (C(x)是 Z) THEN P(x)為 NS 5 IF (L(x)是 Z) AND (C(x)是 Z) THEN P(x)為 Z 6 IF (L(x)是 Z) AND (C(x)是 P) THEN P(x)為 PS
35
7 IF (L(x)是 P) AND (C(x)是 Z) THEN P(x)為 Z 8 IF (L(x)是 P) AND (C(x)是 Z) THEN P(x)為 PS 9 IF (L(x)是 P) AND (C(x)是 P) THEN P(x)為 PB 第四步,綜合每個規則產生的模糊值。
先把變數放到成員函數並計算在成員函數裡的值。其中,l 為系統提供的樂 活成熟度,l_range 為 l 的範圍(預設 0-10),c 為系統提供的合作案滿意度,c_range 為c 的範圍(預設 0-10)。
表 3.8 成員函數表
項目 函數
樂活程度 Level_L_N = fuzz.interp_membership(l_range, L_N, l ) Level_L_Z = fuzz.interp_membership(l_range, L_Z, l ) Level_L_P = fuzz.interp_membership(l_range, L_P, l ) 滿意程度 Level_C_N = fuzz.interp_membership(c_range, C_N, c )
Level_C_Z = fuzz.interp_membership(c_range, C_Z, c ) Level_C_P = fuzz.interp_membership(c_range, C_P, c )
結合上述的規則,舉例低合作滿意與低樂活程度規則產生的結果:
Rule1 = np.fmax( Level_L_N, Level_C_N ) P_NB_value = np.fmin( rule1, P_NB )
對每個規則進行這樣的動作,我們將獲取一個模糊集合。
fuzzy_set = np.fmax( P_NB_value, np.fmax( P_NS_value, np.fmax( P_Z_value, np.fmax( P_PS_value, P_PB_value ))))
第五部,進行解模糊,把模糊結果轉成非模糊答案。
經過第四步的推理,系統產生的結果是一個模糊值。這個結果應透過“解模 糊”過程來獲得一個確定的值。有多種解模糊計算方式,普遍在使用有中間法