റγፕЎ
Department of Computer Science and Information Engineering College of Electrical Engineering & Computer Science
National Taiwan University doctoral dissertation
ѠᇟЎೀמೌǺаᡂፓϷຒ܄ࣁٯ Processing Techniques for Written Taiwanese
-- Tone Sandhi and POS Tagging
ླྀϢق Iûnn Ún-giân
ࡰᏤ௲ȅଯԋݹറγ ഋլ଼റγ
Advisors: Gao Cheng-yan Ph.D. Chen Keh-jiann Ph.D.
ύ҇୯ 98 ԃ 1 Д January, 2009
Taiwanese is my mother tongue. I lived in Taipei for 30 years, since I was born. I spoke my mother tongue before I entered elementary school. I could also understand Mandarin, but could not speak it well. However, after entering elementary school, I gradually forgot my mother tongue. I was able to speak Mandarin fluently, and I could understand Taiwanese but found it difficult to express my thoughts in my mother tongue. In school, they told me that Taiwanese was only a dialect, and that we should not speak it in school. In fact, if we spoke Taiwanese, we could be punished. I accepted this argument until I was 20 years old.
At that time, I enrolled at National Taiwan University (NTU), during the period when Taiwan was still under martial law. A political event occurred on campus that gave me a big shock. I could not concentrate on my studies for several months. I was gradually moving out of the shadows, establishing my own independent thinking and values. I realized that cultural enlightenment is more important than political enlightenment, and that our mother tongue is a solid foundation for Taiwanese culture.
I began to relearn my mother tongue. Then, I realized that it would not be enough to just be able to understand and speak the language. The ability to read and write the Taiwanese language could contribute to its promotion.
I began to read Taiwanese material, which is difficult to find in bookstores.
including Han characters, phonetic symbols, KK phonetics, and Kana.
Afterwards, I borrowed a book from the NTU library entitled, The speech structure and transcription method of Taiwan Hokkianese ‘⎘䀋䤷⺢娙䘬婆枛䳸㥳⍲
㧁枛㱽,’ which was written by TȘϸ, Liông-úi and published in 1978 . It took me four days to learn POJ. I also founded the NTU Puppet Shows Association ‘⎘⣏
㌴ᷕ∯⛀’ with my classmate Tiuϸ, Lân-seݚk ‘⻝嗕䞛’ during my last year of university life. I strongly advocated the use of written Taiwanese to write the drama scripts, but finally failed due to a lack of time
Based on my computer science background, my study interest shifted to natural language processing during my graduate years, from 1991 to 1993. I processed Mandarin. At the same time, I was still engaged in the written Taiwanese movement. My friends and I founded the “Students Taiwanese Promotion Association,” (STAPA) ‘⬠ 䓇 ⎘ 䀋 婆 㔯 Ὣ 忚 㚫 ,’ published the
“Taiwanese Student” magazine ‘⎘婆⬠䓇’ (4 trial issues and 22 issues in total), wrote articles in Taiwanese, etc.
I entered the Dahan Institute of Technology CSIE Department as a lecturer and began to do Taiwanese processing related research work in 1999. Due to the lack of Taiwanese language related resources, I tried to establish some online written Taiwanese tools, including the Online Taiwanese-Mandarin Dictionary (OTMD), Online Taiwanese Syllable Dictionary (OTSD), and Online Taiwanese Concordancer System (OTCS), with more than 9-million-syllable written Taiwanese materials, Taiwanese word frequency reports with both
In my opinion, the computational linguistics related academic society is a minority in Taiwan. It is difficult for a researcher to master both computer science and the language itself. Obviously, Taiwanese processing related research is less popular in this minority, although I cannot understand why most researchers abandon their mother tongues. I selected Taiwanese language processing as my major field for study, tried to create this “new” field of research, and have achieved some preliminary results. I had the computer science background, and have been engaged in written Taiwanese work for more than 20 years.
I love my mother tongue and want to promote its social status. This is a difficult but, I believe, an important task.
I started reading and writing Taiwanese in 1987 when I was an undergraduate student, began written Taiwanese processing related research in 1999, and re-entered NTU CSIE as an adult student in 2004. I have always believed that working in this field is a worthwhile endeavor.
I am very grateful to my advisor, Professor Cheng-yan Kao, who encouraged me to select this topic and offered me some related research opportunities. My appreciation also goes to research fellow Keh-jiann Chen, my co-advisor, who generously provided me with many Chinese language processing resources.
Many thanks to my committee members, Professor Jason S. Chang, Hsi-Jian Lee, Hsin-hsi Chen, Chao-Lin Liu, Ming-shing Yu, Khîn-huþnn Lí, and Zhao-ming Gao, for their many constructive suggestions.
Thanks to my academic partner Haݚk-khiam Tiunn. Thanks also to Professor Yuh-dauh Lyu and Doctor Hoݚk-chû Tiunn for correcting my written English in this dissertation. Thanks to Professor Jը-hông Tiuϸ for helping me to understand some linguistic terms that confused me.
OK, I will leave space for my mother tongue. The following content will be written in Taiwanese.
Iцng ka-k̚ ê bú-gú siá, siá liáu khah kín, thang khah kín pit-giaݚp -
Ùi 1993 nî gián-kiù-só݇ pi ݚt-giaݚp liáu-þu khai-sí kóng. Hit-chըn tùi lâu t̚
haݚk-suݚt-kài si ݚt-chþi bô chhù-b̚, kám-kah chòe Tâi-gú-bûn ըn-tцng khah si ݚt-chþi.
Góa seng kè-sioݚk ku t̚ Tiong-gián-̚ϸ Sû-khò݇ sió-cho݇ chiaݚh thâu-lц݇, ná tih chòe Tâi-bûn kang-chok-chiá hóng-tâm. 1994 nî góa khì ín Tâi-tþi tiþn-sòan tiong-sim ê thâu-lц݇, kám-siþ Tân Bûn-chìn lþu-su, thiaϸ-kóng góa ùi 60 kúi ê èng-cheng-chiá hông kéng--tioݚh, lþu-su ը tàu-saϸ-kþng. T̚ hiâ chòe ê khah tiцng-iàu ê tþi-chì, tц-s̚ siá tþi-haݚk liân-khó hun-hoat thêng-sek, che s̚ Khó݇
Sùn-khim lþu-su hц݇ góa ê ki-hцe.
Góa mþ khai-sí peh-soaϸ, chham-ka Siþ Tiông-têng teng-san hцe, koh ը chòe
Tiông-têng teng-san-hцe ê pêng-iú chòe-t̚n peh Gioݚk-san, chòe chi ݚt kiþϸ tiцng-iàu ê tþi-chì, chit hþng tþi-chì, it-ti ݚt kàu 12 tang þu chiah ը mûi-thé pò-tц.1 Góa koh taݚk lé-pái kò݇-tȘng chi ݚt àm t̚ Tâi-ôan ê Tiàm chòe g̚-kang, thâu-ke A-sam-ko kah Biþu-lêng-chí tùi Tâi-ôan ê ài, s̚ góa chiok kèng-pцe ê.
In-ըi peh-soaϸ, jú lâi jú kám-kah tòa t̚ Tâi-pak si ݚt-chþi s̚ chiok kan-khó݇ ê tþi-chì, lâng chцe, chhia chцe, khong-kan oݚeh, khong-khì bái. Góa khai-sí chhȘ só݇-chþi, ը soaϸ koh l̚ to݇-chh̚ khah hnܮg ê, ը Hoa-liân, Tâi-tang kah Lâm-tâu.
1996 nî, in-ըi chhȘ-tioݚh Hoa-liân ê thâu-lц݇, t̚ lþu-pȘ lþu-bú kah Gioݚk-lêng lóng bô chi-chhî ê chêng-hêng hþ, kþ Tâi-tþi ê thâu-lц݇ sî-tiþu, cháu lâi Hoa-liân.
1996 nî, Hoa-liân iah-koh ը peݚh-sek khióng-pò݇ ê khì-hun, góa bô kþ lí phiàn!
Hó ka-chài chiݚt tang þu Gioݚk-lêng tiàu lâi Hoa-liân, só݇-í seng-oݚah thang khah ún-tȘng. Gún t̚ Hoa-liân bóe chhù, Tan-hông kah Ka-chhái mþ sio liân-sòa chhut-sì.
Seng-oݚah ún-tȘng bô piáu-s̚ thâu-lц݇ ún-tȘng, góa t̚ Hoa-liân, saϸ tang цaϸ gц݇ ê thâu-lц݇. Góa iah-s̚ hoat-kak, nþ-s̚ beh chòe Tâi-gú-bûn, t̚ haݚk-suݚt-kài iah-s̚
khah hó-sè. 1999 nî, góa jiݚp-lâi Tþi-hàn ki-suݚt haݚk-̚ϸ.
Kám-siþ Haݚk-khiam hiaϸ, i chin khòaϸ-tiцng góa, ը-sî-á hц݇ góa ki-hцe khì i ê pan ián-káng/siцng-khò, mþ ը chiap kè-eݚk, pun keng-hùi hц݇ góa tàu chòe bþng-chþm.
Góa khai-sí kiàn-liݚp Tâi-gú-bûn gián-kiù ê ki-chhó݇, Tâi-hôa sû-tián (kám-siþ TȘϸ Liông-úi kàu-siը kah chin chцe pêng-iú), Tâi-gú j̚-tián, gú-liþu-khò݇ (kám-siþ Chùn-ioݚk-hiaϸ, Pek-nî hiaϸ, Tek-hôa, LȘ-soat, … ), Sioݚk-gú (kám-siþ Siau Pêng-t̚
lþu-su), Koa-iâu (kám-siþ Gô݇ Jîn-sek lþu-su), Chhiò-khe-tþi (kám-siþ Iûϸ Chín-jը hþu-tiúϸ, Siau lþu-su, Pek-nî hiaϸ ) téng-téng.
Góa siըϸ-beh kái-tô݇, 1999 nî pat thaݚk kè Tong-hôa Choݚk-kûn só݇ chþi-chit choan-pan chiݚt haݚk-kî, 2002 nî khì khó Sêng-tþi Tâi-bûn-hȘ tȘ it kài phok-sը-pan,
chú-iàu ê gôan-in s̚ lþi-tóe chi ݚt kho݇ chiok chheh chòe Tâi-gú ê. Kám-siþ L̚
Heng-chhiong kàu-siը, i khó-lêng kám-kah ti ݚt-chiap kþ góa kóng khó phok-sը-pan bô bþng tùi góa ê táϸ-kek siuϸ tцa, só݇-í kiàn-g̚ góa ùi góa gôan-lâi ê choan-giaݚp chit-pêng lâi seng-téng khòaϸ-mþi. Kám-siþ TȘϸ Liông-úi kàu-siը, i hiòng góa iau kó, siá chiݚt phiϸ lըn-bûn tâu khì IJSL, khó-sioh þu--lâi chit pún Special Issue on Taiwanese pȘng bô chhut-pán, kám-siþ Hông-giâu (Henry), i tap-èng chòe-t̚n siá chit phiϸ lըn-bըn, i ê Eng-bûn iáu-siը chán.
In-ըi ը chit phiϸ lըn-bûn, góa tц sin-chhéng seng-téng, kám-siþ Kán Li ݚp-hong lþu-su, i siông-sòe khòaϸ góa seng-téng ê chu-liþu, hц݇ góa chin chцe kiàn-g̚, i kþ góa kóng, in-ըi chin-chцe lâng bô liáu-kái góa tih chòe ê mi ݚh-kiþϸ, só݇-í seng-téng ê chu-liþu ài lȘng-gцa siá chi ݚt hըn Proposal, kau-tài Tâi-gú-bûn chը-jiân gú-giân chhú-lí gián-kiù ê tiцng-iàu-sèng. Seng-téng sàng-sím ê sî-kan, tán chin kú chiah ը siau-sit, thiaϸ-kóng ը úi-ôan bôai sím, thòe tϹg-khì Haݚk-sím-hцe. Góa chin hó-ըn, sըn-l̚ seng-téng chòe chц݇-lí kàu-siը, mܮ-koh bú seng-téng bú kah chin thiám-thâu, khai-sí ը peݚh-thâu-mo݇ a.
Kán Liݚp-hong lþu-su koh ը kþ góa kóng chi ݚt ê chin tiцng-iàu ê koan-liþm, i kþ góa kóng, sî-kan kàu--a, tц ài chòe kai chòe ê tþi-chì, chit kù цe góa ը kþ kì t̚
sim-koaϸ tóe. Só݇-í, t̚ seng-téng kiat-kó chhut-lâi chìn-chêng, góa khai-sí sin-chhéng kok-kho-hцe kè-eݚk. LȘng-gцa, TȘϸ Liông-úi kàu-siը hit-chըn t̚ Kau-tþi, i hi-bцng góa Ș-tàng khì Chheng-hôa kè-sioݚk thaݚk phok-sը-pan.
Góa khai-sí liân-loݚk, pau-koah Tiuϸ Chùn-sȘng lþu-su, þu-lâi mþ koh liân-loݚk Lí Sek-kian lþu-su kah Tân Sìn-hi lþu-su. In piáu-s̚ hoan-gêng, mܮ-koh kám-kah chòe Tâi-gú gián-kiù beh piݚt-giaݚp ը khùn-lân. Chha-put-to t̚ chit ê sî-chըn, Ko Sêng-iþm lþu-su pþn chi ݚt tiûϸ Tâi-gú-bûn siong-koan ê gián-thó-hцe, hцe-þu chòe-t̚n chiaݚh-pnܮg ê sî, i kiò góa tϹg-lâi Tâi-tþi Chu-sìn-hȘ thaݚk, tц chòe Tâi-gú-bûn hong-b̚n. Góa tϹg-khì siըϸ chi ݚt lé-pài, che kî-kan koh ùi Hoa-liân cháu-khì Koe-lâng chhiú khan chhiú, koh kah Ko lþu-su liân-loݚk, khak-j̚m, liáu-þu chôaϸ-á koat--loݚh-lâi, khai-sí lâi chún-pí.
֓i-tioݚh Gioݚk-lêng chhцa gín-á hong-piþn, gún ùi Kiat-an poaϸ lâi Bí-lըn-á, t̚
Hù-sió þu-piah-mn۱g bóe chi ݚt keng a-phà-toh. Góa siըϸ-kóng choan-sim thaݚk khah khòai piݚt-giaݚp, só݇-í Tþi-hàn chit pêng sin-chheng liû-chit thêng-sin.
Ko lþu-su chit ê sî-chըn chhéng-tioݚh Tâi-bûn-kóan ê kè-eݚk, beh chòe Tâi-gú ê gú-im haݚk-sêng, pún-lâi chhiáϸ góa ê tông-oݚh SȘng-an tàu-t̚n chòe, khó-sioh tòng bô chiݚt kò geݚh, tц koh kþ SȘng-an tiàu khì chòe Bioinfo, Ko lþu-su ê pún-tô݇.
Pún-lâi koh chhiáϸ Hank chòe-t̚n lâi chòe Tâi-gú gú-im piþn-sek, bô gî-gц݇ i þu-lâi bô thong-kè chu-keh-khó chit koan. Kè-eݚk ը chi ݚt ê choan-j̚m ê giaݚh, chhiáϸ Kiaݚt-gaݚk hiaϸ lâi tàu-saϸ-kþng. Góa ka-k̚ ê kè-eݚk leh ? Sui-jiân sin-chhéng--tioݚh, chóng--s̚ pó݇-chц݇ kim-giaݚh siuϸ chió, só݇-í chú-chhî-jîn hùi poah chhut-lâi chhiáϸ LȘ-soat lâi Hoa-liân chòe kè-eݚk ê khang-khè.
Kám-siþ lþu-pȘ lþu-bú, ըi-tioݚh góa beh tϹg-khì Tâi-pak thaݚk-chu, in teݚk-piaݚt kþ chhù koh hoan chi ݚt piàn. Góa chi ݚt lé-pài tòa Tâi-pak gц݇-kang, mܮ-koh lþu-su kau-tài--loݚh-lâi ê khang-khè li-li khok-khok, mþ bô-hoat-tц݇ choan-sim thaݚk-chu, koh-khah hþi ê, Gioݚk-lêng ùi 11 geݚh khai-sí, khó-lêng s̚ seng-oݚah siuϸ kín-tiuϸ, liân-sòa nnܮg kò geݚh ըi-tn۱g bô sòng-khòai. Só݇-í góa liû-chit thêng-sin ûi-chhî chi ݚt haݚk-kî, liáu-þu tц koh tϹg-lâi kà-chu, thang kþ lþu-su kóng góa bцe-tàng tiþϸ-tiþϸ t̚ Tâi-pak.
Chu-keh-khó s̚ chi ݚt kiþϸ khióng-pò݇ ê tþi-chì, pêng-kun chi ݚt kài ը 1/3 ê tông-oݚh in-ըi bô thong-kè chu-keh-khó hông thòe-haݚk, chhiըϸ góa chit-khóan nî-hè khah tцa ê lþu haݚk-seng, ap-leݚk iû-kî tцa. 2005 nî 3 geݚh, tȘ it kho Complexity án-nóa kè ê ? In-ըi tè tioݚh thaݚk-chu-hцe ê kî-tiong kúi pái, kám-siþ l̚-hþi ê Ông Hông-lûn tông-oݚh. 2005 nî 10 geݚh koh khó kè Algorithm kah AI, góa kau bцe chió haݚk-hùi hioh-joݚah taݚk lé-pài cháu Tâi-pak chham-ka thaݚk-chu-hцe.
ɘ-kì-e khó-chhì chêng ê lé-pâi, Lêng-ông hong-thai lâi, Kiat-an ê chhù, chhù-téng sià chúi loݚh-lâi, Bí-lըn-á ê chhù, po-lê-thang-á phòa--khì, thêng-chúi nnܮg kang, iah bцe-hù chhú-lí, thang-á seng iцng chóa kô݇--khí-lâi, pau-hoݚk-á khóan--leh tц
ki-hцe, chóng-sϺg ôan-sêng tȘ sì kho chu-keh-khó, ná-chhiըϸ í-keng keng-leݚk chiݚt-sì-lâng hiah-n̚ kú.
Thaݚk phok-sը-pan ê kî-kan, tú-tioݚh 3 pái gin-á in-ըi hì-iþm tòa ̚ϸ, Gioݚk-lêng siцng-pan cháu bцe khui kha, só݇-í s̚ góa khì p̚ϸ-̚ϸ kò݇, Ș-kì-ê ը chi ݚt-piàn, chai-iáϸ beh tòa ̚ϸ, kín cháu-khì tô݇-su-kóan chioh chi ݚt pún “Chhèng-phàu, p̚ϸ-khún kah kϺg-thih”, l̚-iцng tòa t̚ p̚ϸ-̚ϸ ê sî-kan thaݚk ôan, che s̚ Khîn-hцaN hiaϸ kài-siþu góa thaݚk ê. Chit tцaϸ sî-kan, góa koh ը thaݚk “Tiըϸ-niû sè-kài”, “chi ݚt tháng ц-á”,
“Hun-lân keng-iþm”, “Tâi-ôan chhú-hun” … téng-téng ê chu, lâi pâi-kái sim-thâu ê ut-chut, tþi-pц݇-hըn s̚ t̚ hé-chhia téng thaݚk ôan ê. Koh ը chi ݚt tцaϸ sî-kan, chi ݚt thàu-chá khí-lâi seng sϹg chi ݚt ê Sudoku, chiþm-sî kþ chòe bцe ôan ê khang-khè khϺg chi ݚt piϸ.
Pâi-kái ut-chut, góa koh ը chòe paݚt-hþng, pau-koah khì chham-ka Google sió kang-khը pí-sài. Thiaϸ Kán Li ݚp-hong lþu-su kóng, góa ê Tâi-hôa sû-tián sió kang-khը ը ji ݚp-ûi, chóng--s̚, þu--lâi su hц݇ sϺg-miþ ê sió kang-khը. Tâi-ôan-lâng ài sϺg-miþ, khah iâϸ kè oݚh bú-gú, si ݚt-chþi chin bû-nþi. Kám-siþ Lí Chì-kiông lþu-su, i chio gún khiâ khóng-bêng-chhia, 2008 nî 3 geݚh góa ը t̚ 20 tiám-cheng í-lþi ôan-sêng 300 khí-lò, iân-lц݇ Seven bцe ê sio ê chiaݚh-mi ݚh lóng chhiúϸ bô, hit àm thiaϸ chhân-kap-á ê siaϸ thiaϸ kah pá, khiâ kah kha kiông-beh tnܮg--khì, kha-chhng oݚah-beh thiàϸ--sí, tϹg--lâi koh sûi sán 3 kong-kun, mܮ-koh tit-tioݚh chi ݚt tiuϸ chèng-su.2 Kám-siþ Tц݇ Chèng-sèng pц݇-tiúϸ, i kþ Kok-gú-bûn kȘng-sài cheng-ka Tâi-gú pheng-im pí-sài, hц݇ góa ը ki-hцe tit-tioݚh siþ-hцe-cho݇ tȘ it miâ,3 i koh sak thui-tián bú-gú kiaݚt-chhut kòng-hiàn-chióng, góa ը tioݚh-chióng, mþ in-ըi tioݚh-chióng, hц݇ góa ê siau-sit ը ki-hцe khan t̚ Chը-iû sî-pò ê tцe-hng-pán.4 Kè-eݚk ê pц݇-hըn, thaݚk phok-sը-pan ê chit tцaϸ kî-kan, chin hó-ըn, chi ݚp-hêng sì ê Kok-kho-hцe kè-eݚk, kám-siþ Kiaݚt-gaݚk hiaϸ, Tek-hôa kah Tцa-thâu-liân kþ góa tàu chòe chin chцe khang-khè. LȘng-gцa, kám-siþ L̚ Heng-chhiong lþu-su, t̚ i ê
2 http://ungian.pixnet.net/blog/post/16038270
3 http://iug.csie.dahan.edu.tw/iug/Ungian/engu/2007/phengimpisai/phengimpisai.asp
4 http://iug.csie. dahan.edu.tw/iug/Ungian/engu/2008/bugujit/bugujit.asp
chòe Tâi-gú-bûn ըn-tцng hóng-tâm, kám-siþ Bí-chhin, i thòe góa kþ siцng khùn-lân ê hóng-tâm pц݇-hըn chhú-lí hó, Kok-sú-kóan chit pún chu, 2008 nî 4 geݚh chhut-pan 800 pún, 8 geݚh tц bцe ôan a. Chòe che bô pí siá phok-sը lըn-bûn khah khin-sang, ըi-tioݚh chit ê hóng-tâm, liân-sòa kúi-lц kò-geݚh lóng òaϸ khùn, kè-nî ê sî koh mo݇h kui thaݚh ê kó-kiþϸ tih khòaϸ.5
Mþ kám-siþ Haݚk-khiam hiaϸ, Khîn-hцaϸ hiaϸ, Ûi-bûn, Gô݇ Chiau-sin i-su, Si-chong hiaϸ kah Sò݇-eng, in iau-chhiáϸ góa chòe in ê ke-eݚk ê kiцng-tông chú-chhî-jîn, só݇-í góa ê keng-leݚk Ș-tàng siá kah chiok súi-khùi -
Kám-siþ Û Bêng-heng lþu-su, i kþ góa iau-kó, hц݇ góa hoat-piáu góa ê tȘ it phiϸ kok-chè kî-khan lըn-bûn, kám-siþ Lâu Chiau-lîn kah Tân Pek-lîm lþu-su, in ê iau-kó s̚ tȘ j̚ phiϸ. Kám-siþ Tân Sìn-hi lþu-su, in-ըi i ê iau-chhiáϸ, hц݇ góa ը ki-hцe chòe Chu-sìn j̚ haݚk-mn۱g ê kui-цe úi-ôan, thê-chhut góa tùi pún-thó݇
gú-giân chu-sìn chhú-lí ê kiàn-g̚.
Kám-siþ Tþi-hàn ki-suݚt haݚk-̚ϸ, góa t̚ chiâ chiaݚh thâu-lц݇, chit-chըn s̚ tȘ 10 tang, t̚ chiâ, góa khai-sí Ș-tàng choan-sim lâi chòe Tâi-gú-bûn ê haݚk-suݚt gián-kiù, mþ t̚ chiâ seng-téng chòe chц݇-lí kàu-siը, sui-jiân chit keng haݚk-hþu í-keng put-chí-á hûi-hiám a.
Kám-siþ Tâi-tang tþi-haݚk Tâi-gú-só݇ ê haݚk-seng, sui-jiân hioh-joݚah taݚk lé-pái cháu Tâi-tang put-chí-á sin-khó݇, mܮ-koh in j̚n-chin kah chun-tiцng lþu-su ê thþi-tц݇, hц݇ góa kám-siը tioݚh chòe lþu-su ê chun-giâm. Boݚk-chiân ը 3 ê góa chí-tц ê haݚk-seng pit-giaݚp, hц݇ góa chin ը sêng-chiը-kám.
Kám-siþ Chhit-chhiϸ-thâm, Chhit-chhiϸ-thâm mܮ s̚ thâm, s̚ tцa-hái, kè-khì chit tang, góa tiþϸ-tiþϸ khiâ khóng-bêng-chhia siong-hþ-pan, khòaϸ tцa-soaϸ tцa-hái ê hó kéng-tì, koh kiam liþn sin-thé.
Khó-lêng koh ը chi ݚt kóa lâng góa bô kóng--tioݚh, mܮ-s̚ lín bô tiцng-iàu, s̚ góa kì-tì bái.
TȘ it pái ji ݚp Tâi-tþi, s̚ 1984 nî khó tioݚh Chu-sìn-hȘ, tц݇-kè jîn-seng
Tâi-ôan tцa-soaϸ ê súi, mþ ôan-sêng chiong-sin tþi-sը. TȘ saϸ pái ji ݚp Tâi-tþi, tц-s̚
chit pái thaݚk phok-sը-pan, hi-bцng Ș-tàng hц݇ góa chhȘ tioݚh khah ún-tȘng ê thâu-lц݇.
Ka-têng, khang-khè, gián-kiù, haݚk-giaݚp, … Nî-hè khah tцa, tþi-chì chцe, thaݚk-chu khí-lâi chin sϹg sin-thé, chit sì tang pòaϸ í-lâi, baݚk-chiu ը ló-hoe, koh tioݚh peݚh-lþi-chiong, chhùi-khí chhut bըn-tôe, koaϸ-kong-lêng chí-sò݇ chhèng kôan, siϸ phê-chôa, kha-tóe mþ Ș thiàϸ, kui sin-khu p̚ϸ liáu-liáu. Góa kî-si ݚt mܮ chai-iáϸ thaݚk phok-sը-pan s̚ mܮ-s̚ chèng-khak ê koat-tȘng, chóng--s̚, Tâi-gú-bûn chiâϸ-chòe góa it-seng ê chì-giaݚp, che s̚ phah sí bô thòe ê.
Chòe-þu, beh kám-siþ Tâi-gú-bûn-kài chцe-chцe ê pêng-iú, in-ըi ը taݚk-ke ê phah-piàϸ, góa chiah ը ki-hцe chòe chit ê tôe-boݚk. Tâi-gú-bûn ըn-tцng ê lц݇
iah-koh chin kú-tn۱g, lán chòe-t̚n kè-sioݚk kiâϸ loݚh-khì, Ϻg-bþng Tâi-gú-bûn chhut-thâu-thiϸ !
ps: Lըn-bûn kàu-sî Ș chiըϸ-bþng, chit phiϸ siþ-sû Ș khϺg t̚ góa ê Blog.6
ps2: Acknowledgments ê chho݇-kó ը khϺg khì Tâi-gú-bþng, kám-siþ Siau Pêng-t̚
lþu-su, Tiuϸ Hoݚk-chû i-su, Ngô ݇ Chiau-sin i-su, Tân Phek-siը bs, Lâm-hêng-hiaϸ, Kim-êng lþu-su, Jîn-sek lþu-su, Khái--ko, Siok-hըi, Tsùn-tsiu ê liaݚh-pau kah chàn-siaϸ. Chit pц݇-hըn siá liáu siцng sóng-khòai, bián chhin-chhiըϸ siá lըn-bûn an-ne, taݚk j̚ taݚk kù ài chim-chiok.
ps3: 2009/1/16 sui-jiân thong-kè kháu-chhì, mܮ -koh ài chun-chiàu kháu-chhì úi-ôan ê ì-kiàn siu-kái, in-ըi kin-nî kè-nî chá, haݚk-hþu iau-kiû siцng òaϸ 2/2 ài kau, siu-kái ê sî-kan bцe-hù, phah-sϺg iân chi ݚt haݚk-kî chiah thang pit-giaݚp, bô gî-gц݇ 1/20 siu-tioݚh haݚk-hþu ê thong-ti, kóng kau lըn-bûn ê kî-hþn kái-chòe 2/15. Che ke--chhut-lâi ê nnܮg lé-pài, ná-chhiըϸ s̚ chiam-tùi góa ê tiâu-khóaϸ. Hц݇ góa thang l̚-iцng kè-nî hioh-khùn ê sî-kan kóaϸ siu-kái ê khang-khè, kî-hþn lþi ôan-sêng siu-kái, kiám laݚp chi ݚt haݚk-kî kùi-som-som ê chù-chheh-hùi. Kám-siþ Tâi-tþi, mþ kám-siþ Gioݚk-lêng ê thé-thiap.
6 http://ungian.pixnet.net/blog/post/25236012
⎘婆㗗ᶾ䓴ᶲ慵天䘬婆妨炻⎗や㰺㚱⍿⇘ㅱ㚱䘬慵夾ˤ⛐㝸ṃ㕡朊炻⎘婆㔯 䘬䈡⿏冯厗㔯ㆾ劙㔯䚠䔞ᶵ⎴ˤ㛔婾㔯ᷣ天妶婾⎘婆㔯嗽䎮㈨埻ˤ
䘥娙⫿炷⎘婆伭楔⫿炸㗗⎘婆㔯䘬慵天㚠⮓䲣䴙ˤㆹᾹ⃰ṳ䳡䘥娙⫿䘬⫿⃫
䶐䡤炻㍸⍲䘥娙⫿㔠⫿婧嘇 䁢ᶵ⎴䘥娙⫿⫿⃫䶐䡤䘬ℏ悐堐䣢㱽ˤ憅⮵䘥娙⫿
㔯㛔㏄⮳炻ㆹᾹ㍸↢ℑ昶㭝㏄⮳䫾䔍炻᷎㍸↢䘥娙⫿枛䭨役Ụ㏄⮳䘬㕡㱽ˤㆹᾹ 怬㍷徘䘥娙⫿栗䣢㕡㱽ˣ䘥娙⫿㔯⫿嗽䎮䚠斄ㅱ䓐䦳⺷ẍ⍲㻊伭⎘婆㔯㕟娆㕡㱽ˤ
ㆹᾹ㍸↢ẍ夷⇯㕡㱽嗽䎮嬲婧⓷柴䘬㺼䬿㱽ˤ⃰⮯㭷ᾳ⎘婆娆侣ㆸ厗婆娆炻
㈦↢℞娆栆㧁姀妲〗炻ẍ娆栆㧁姀嬲婧夷⇯Ἦ㰢⭂嬲婧⼴䘬倚婧ˤㆹᾹ⮎ἄ↢
⎘婆嬲婧䲣䴙ˤ㬌䲣䴙⛐妻䶜屯㕁⍲㷔娎屯㕁↮⇍忼⇘ 97.4% 89.0%䘬嬲婧㬋 䡢䌯ˤ
㬌⢾炻ㆹᾹ㍸↢娆栆㧁姀㕡㱽ˤㆹᾹ⃰攳䘤婆娆⮵滲㩊㞍䦳⺷⮯徸㭝⮵滲䘬 ℑ䧖⎘婆㔯㛔 婆娆⮵滲炻ᷳ⼴⇑䓐 HMM 㨇䌯㧉✳㊹怠㚨怑䔞䘬厗婆⮵ㅱ娆炻 ℵ⇑䓐 MEMM ↮栆☐㊹怠↢℞娆⿏㧁姀ˤㆹᾹ䘬㕡㱽忼⇘ 91.5%䘬㬋䡢䌯ˤ
忶⍣⸦⸜炻ㆹᾹ⺢䩳Ḯᶨṃ㚱䓐䘬䶂ᶲ⎘婆㔯ⶍ℟ˤⶴ㛃忁ṃⶍ℟ẍ⍲ㆹᾹ
䘬⇅㬍䞼䨞ㆸ㝄炻傥嬻⎘婆㔯嗽䎮䚠斄䞼䨞㚜≈咔≫䘤⯽ˤ
斄挝娆 : ⎘婆㔯炻嬲婧炻娆栆㧁姀炻䘥娙⫿炻冒䃞婆妨嗽䎮ˤ
Tâi-gú s̚ sè-kài siцng chin tiцng-iàu ê gú-giân, khó-sioh soah bô hông khòaϸ-tiцng. T̚ bó݇ chi ݚt-kóa hong-b̚n, Tâi-gú-bûn ê teݚk-sèng kah Hôa-bûn iah-s̚
Eng-bûn chin bô kþng-khóan. Pún lըn-bûn chú-iàu beh thó-lըn Tâi-gú-bûn chhú-lí ki-suݚt.
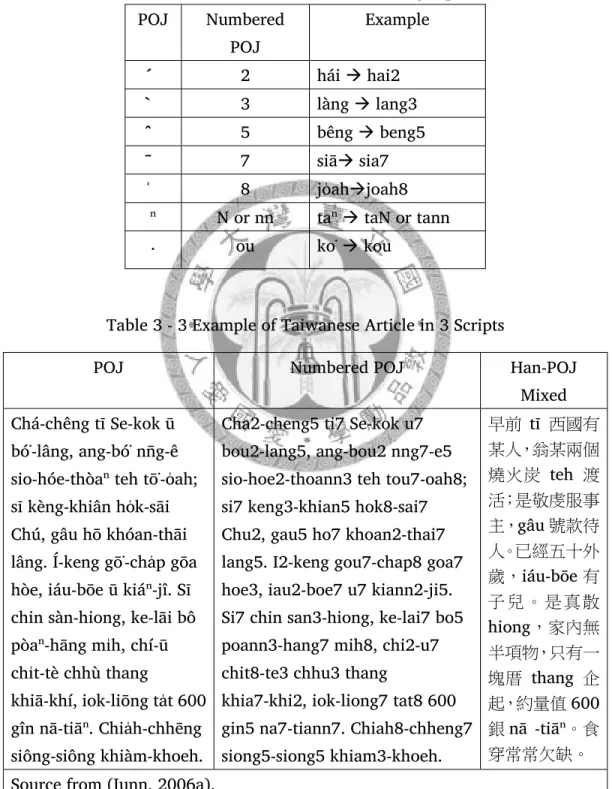
Peݚh-цe-j̚ (Tâi-gú Lô-má-j̚, POJ) s̚ Tâi-gú-bûn ê tiцng-iàu su-siá hȘ-thóng.
Gún seng kài-siþu POJ ê j̚-gôan pian-bé, thê-chhut iцng POJ sò݇-j̚ tiþu-hц chiâϸ-chòe bô kâng POJ j̚-gôan pian-bé ê lцe-pц݇ piáu-s̚-hoat. Chiam-tùi PÔJ bun-pún chhiau-chhȘ, gún thê-chhut nnܮg kai-tцaϸ chhiau-chhȘ chhek-lioݚk, koh thê-chhut POJ im-chiat lըi-sը chhiau-chhȘ ê hong-hoat. Gún koh ը kài-siþu POJ hián-s̚ ê hong-hoat, POJ ê bûn-j̚ chhú-lí siong-koan èng-iцng thêng-sek, kah Hàn-lô tnܮg-sû ê hong-hoat.
Gún thê-chhut iцng kui-chek hong-hoat chhú-lí piàn-tiþu bըn-tôe ê ián-sòan-hoat. Seng kþ múi chi ݚt ê Tâi-gú sû hoan chòe Hôa-gú sû, chhȘ chhut i ê sû-lըi piau-kì, iцng sû-lըi piau-kì kah piàn-tiþu kui-chek lâi koat-tȘng piàn-tiþu liáu-þu ê siaϸ-tiþu. Gún khai-hoat chhut Tâi-gú piàn-tiþu hȘ-thóng. Chit ê hȘ-thóng t̚ hùn-liþn chu-liþu kah chhì-giþm chu-liþu hun-piaݚt taݚt-kàu 97.4% kah 89.0% ê piàn-tiþu chèng-khak-luݚt.
LȘng-gцa, gún thê-chhut sû-lըi piau-kì hong-hoat. Gún seng khai-hoat gú-sû tùi-chôe kiám-cha thêng-sek, kþ chi ݚt tцaϸ chi ݚt tцaϸ tùi-chôe ê nnܮg-khóan Tâi-gú bûn-pún chòe gú-sû ê tùi-chôe, liáu-þu l̚-iцng HMM ki-luݚt bô݇-hêng kéng chhut siцng tàu-tah ê Hôa-gú tùi-èng-sû, koh l̚-iцng MEMM hun-lըi-khì kéng chhut sû-lըi piau-kì. Gún ê hong-hoat taݚt-kàu 91.5% ê chèng-khak-luݚt.
Kè-khì kúi-lц tang, gún kiàn-li ݚp chi ݚt-kóa chin ը lц݇-Șng ê sòaϸ-téng Tâi-gú-bûn kang-khը. Hi-bцng chiâ ê kang-khը kah gún só݇ chòe ê chho݇-pц݇
gián-kiù sêng-kó, thang hц݇ Tâi-gú-bûn chhú-lí siong-koan gián-kiù koh-khah heng.
Koan-kiþn-sû :
Tâi-gú-bûn, Piàn-tiþu, Sû-lըi piau-kì, Peݚh-цe-j̚, Chը-jiân gú-giân chhú-lí.Taiwan Southern Min (Taiwanese) is an important language that has received very little attention in the world. The characteristics of written Taiwanese are quite different from Mandarin or English in some respects. This dissertation focuses on Taiwanese processing techniques.
POJ is an important Taiwanese script. We introduce the POJ character code and mention numbered POJ as the interchange code for various POJ encodings.
Then, we propose a two-stage search strategy for a POJ text search, and propose a POJ syllable query expansion. We also describe the display method for POJ, POJ word processing utilities, and a word segmentation method for HR mixed script.
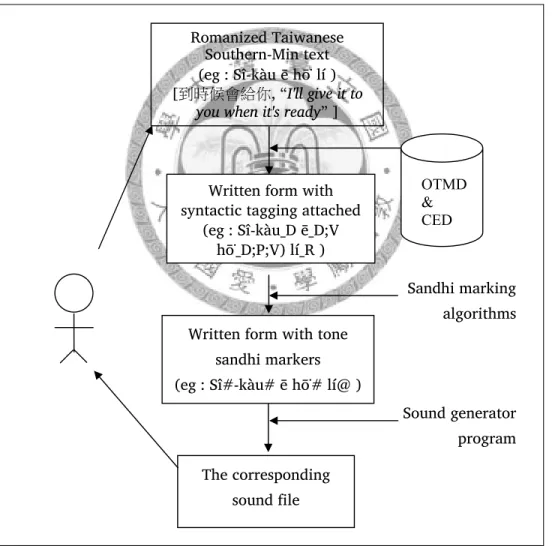
We propose a rule-based tone sandhi algorithm. We translated every word into Mandarin, and obtained the POS information. Using the POS data and tone sandhi rules, we then tagged each syllable with its post-sandhi tone marker.
Finally, we implemented a Taiwanese tone sandhi processing system. Our system achieved accuracy rates of 97.4% and 89.0% with training and test data, respectively.
Additionally, we propose a POS tagging method. We developed a word alignment checker to assist with the word alignment of the two Taiwanese scripts, selected the most adequate Mandarin word using a Hidden Markov probabilistic model, and finally tagged the word using a Maximal Entropy Markov Model classifier. We achieved an accuracy rate of 91.5% in the Taiwanese POS tagging work.
Over the past several years, we have established some useful online written Taiwanese tools. Based on these tools and our preliminary research results, we hope that written Taiwanese processing related research can be promoted.
Keywords:
Written Taiwanese, Tone Sandhi, POS Tagging, Peh-Oe-Ji, Natural Language ProcessingPreface ... i
Acknowledgments ... iv
㐀天 ... xi
Abstract ... xiii
Abbreviations ... xxiii
Chapter 1 Introduction ... 1
1.1 Background ... 1
1.1.1 Language Population in Taiwan ... 1
1.1.2 Southern Min Language Population... 2
1.1.3 Another Investigation: the Taiwan Southern Min Viewers .... 3
1.1.4 The Confusing Name of This Language... 5
1.2 Different Types of Written Taiwanese Scripts ... 6
1.2.1 The Han Characters Script ... 7
1.2.2 The Romanized Scripts ... 9
1.2.3 The Han-Romanization Mixed Script ... 10
1.2.4 Other Scripts ... 10
1.2.5 Target Scripts in This Dissertation ... 11
1.3 Issues Related to Written Taiwanese Processing ... 11
1.4 Organization of This Dissertation ... 12
Chapter 2 Resources and Survey of Written Taiwanese Processing... 19
2.1 Digital Resources for Written Taiwanese ... 19
2.1.1 Fonts ... 19
2.1.2 Dictionary ... 20
2.1.3 Text Corpora ... 23
2.1.4 Electronic Books ... 27
2.2 Survey of Written Taiwanese Processing Techniques ... 28
2.2.1 Input Method ... 28
2.2.4 Scripts Conversion ... 30
2.2.5 Text-to-Speech ... 30
2.2.6 Translation... 33
2.2.7 Parsing ... 33
2.3 Summary... 33
Chapter 3 Coding, I/O for POJ, and Text Processing ... 35
3.1 Character Code of POJ... 35
3.2 Two Kinds of POJ Representation... 39
3.3 Search Problem with POJ Text ... 41
3.3.1 Issues with POJ Text Search ... 41
3.3.2 Two-Stage Search Method: String Matching Then Filtering 42 3.3.3 Query Expansions: Toneless, Glottal Stop, Checked Syllable, and Vowel ... 44
3.3.4 Examples of Search Results... 47
3.4 POJ Text Display... 49
3.4.1 Issues with POJ Text Display ... 49
3.4.2 POJ and Numbered POJ Conversion Method ... 50
3.4.3 POJ Graph Display... 52
3.4.4 Examples of Display Results ... 53
3.5 Some Text Processing Utilities for POJ ... 55
3.5.1 POJ Phoneme Segmentation and Spelling Checker ... 55
3.5.2 POJ Syllable/Word/Sentence Count ... 57
3.6 Word Segmentation for HR Mixed Script... 58
Chapter 4 Tone Sandhi Problem and Algorithm... 63
4.1 Tone Sandhi Problem of the Taiwanese Language... 63
4.1.1 Types of the Taiwanese Language Tone Sandhi... 64
4.2.1 System Diagram ... 68
4.2.2 Observation Data and Test Data ... 70
4.2.3 POS Tagging Set ... 71
4.2.4 Tone Sandhi Marks ... 73
4.3 Rule-based Tone Sandhi Algorithm... 73
4.4 Results, Accuracy Rate and Discussion ... 78
4.4.1 Experiment Results ... 78
4.4.2 Accuracy Rate and Related Analysis ... 80
4.4.3 Discussion ... 83
4.5 Summary and Possible Direction ... 85
Chapter 5 POS Tagging Method ... 87
5.1 Problems of POS Tagging... 87
5.2 POS Tagging Methods ... 88
5.2.1 Origin of the Corpus ... 89
5.2.2 Word for Word Alignment ... 89
5.2.3 Searching for the Corresponding Mandarin Candidate Words. ... 90
5.2.4 Selecting the Best Mandarin Translation ... 91
5.2.5 Selecting the Most Appropriate POS According to the Corresponding Mandarin Word... 92
5.3 Results... 94
5.4 Error Analysis ... 99
5.4.1 Incorrect Corresponding Mandarin Word Selection... 99
5.4.2 Absence of Appropriate Mandarin Words in the OTMD .... 100
5.4.3 Unknown Words from the Viewpoint of Mandarin... 101
5.4.4 Propagation Error ... 101
5.5 Discussion ... 103 5.5.1 Is Improvement Possible ? ... 103 5.5.2 Hyphen Problems, Distinction between Taiwanese and Mandarin... 104 5.5.3 The Distinction between Different Eras or Different Genres ....
... 105 5.6 Summary... 106 Chapter 6 Conclusion and Future Work ... 109 6.1 Our Contributions to Written Taiwanese Resources and Processing ... 109 6.2 Future Work and Prospects for Written Taiwanese Processing Research ... 112 Reference... 117 Appendix ... 127 A.1 Brief Introduction to The Phoneme of Taiwanese... 127 A.1.1 Initials... 127 A.1.2 Vowels ... 128 A.1.3 Tones ... 129 A.1.4 Compared with Mandarin... 130 A.2 Examples of Written Taiwanese... 132 A.3 Terminologies ... 136 A.4 Webpages Made by Author ... 138 A.5 Differences between POJ and TL ... 139
Table 1 - 2 Southern Min Language Populations around the World... 2 Table 1 - 3 Visits to the Taiwan Southern Min Contents Website ... 4 Table 1 - 4 The Names of “Taiwan Southern Min”... 6 Table 3 - 1 POJ Unicode Encoding... 36 Table 3 - 2 POJ and Numbered POJ Synopsis ... 40 Table 3 - 3 Example of Taiwanese Article in 3 Scripts ... 40 Table 3 - 4 Toneless Search for “hoe-chhia”... 48 Table 3 - 5 Checked Syllable Search for “cha” ... 48 Table 3 - 6 Vowel Search for “uiN” ... 49 Table 4 - 1 The Taiwanese Tone Sandhi Phenomena ... 67 Table 4 - 2 Observation Data Sources ... 70 Table 4 - 3 Test Data Sources ... 71 Table 4 - 4 POS Classes ... 72 Table 4 - 5 Tone Sandhi Marks... 73 Table 4 - 6 Tone Sandhi Marking Algorithm ... 73 Table 4 - 7 Number of Errors and Accuracy Rate for Each Paragraph ... 80 Table 4 - 8 Affected and Accurately Affected Syllables of Each Rule ... 81 Table 4 - 9 Number of Dominant Rule, Accurate Dominate Rule and Accuracy
Rate ... 82 Table 4 - 10 Additional Rules to Obtain Higher Accuracy Rate ... 83 Table 4 - 11 Error Conditions and Possible Solutions... 84 Table 5 - 1 Test Data List... 95 Table 5 - 2 Tagging Accuracy Rate for the Test Data ... 96 Table 5 - 3 Example of POS Tagging Result ... 97 Table 5 - 4 The Incorrect Mandarin Words Selected and Their Respective POS
... 100
Table 5 - 6 Unknown Words from the Viewpoint of Mandarin ... 101 Table 5 - 7 The Reasons for the POS Tagging Errors... 102 Table 5 - 8 Tagging Accuracy Rates for Different Genres... 106 Table 5 - 9 Tagging Accuracy Rates for Different Eras ... 106 Table A - 1 Consonants... 127 Table A - 2 Single Vowels... 128 Table A - 3 Compound Vowels ... 128 Table A - 4 Nasal and Glottal ... 128 Table A - 5 Nasal Finals and Final Stops ... 129 Table A - 6 Syllabic Consonants ... 129 Table A - 7 Tones ... 130 Table A - 8 Terminologies ... 136 Table A - 9 Differences between POJ and TL ... 139
Fig 3 - 1 POJ Text Match Algorithm (Target: Word) ... 43 Fig 3 - 2 POJ Toneless Search Algorithm (Target: Syllable)... 45 Fig 3 - 3 POJ Checked Syllable Search Algorithm (Target: Syllable) ... 46 Fig 3 - 4 POJ Vowel Search Algorithm (Data: Syllable) ... 47 Fig 3 - 5 POJ to Numbered POJ Algorithm ... 50 Fig 3 - 6 Numbered POJ to POJ Algorithm ... 51 Fig 3 - 7 Numbered POJ to POJ Graph Algorithm ... 53 Fig 3 - 8 Unicode Display of POJ... 54 Fig 3 - 9 Graph Display of POJ... 54 Fig 3 - 10 Check If a Legal POJ Syllable Algorithm... 56 Fig 3 - 11 Result from Online Syllable/Word/Sentence Count System for POJ 58 Fig 3 - 12 Backward Maximal Matching Algorithm for HR Mixed Script ... 59 Fig 4 - 1 Taiwanese Tone Sandhi System Diagram... 69 Fig 5 - 1 Taiwanese Language POS Tagging System Architecture Diagram ... 89 Fig A - 1 Han script (Taiwanese Folk Song) ... 132 Fig A - 2 Han script (Taiwanese Textbook in Japanese-Ruled Period) ... 133 Fig A - 3 POJ script (Taiwan Prefectural City Church News) ... 134 Fig A - 4 HR Mixed Script (Taiwanese Writing Forum)... 135
Abbrev. Taiwanese (POJ) English Mandarin CCA Bûn-kiàn-hцe Council for Cultural Affairs 㔯⺢㚫
CCTPLD Tâi-ôan POJ bûn-haݚk chu-liþu so݇-chi ݚp
The Collection and
Cataloging of Taiwanese POJ Literature Data
⎘䀋䘥娙⫿㔯
⬠屯㕁吸普
CED Tiong-bûn tiþn-chú
sû-tián Chinese electronic dictionary ᷕ㔯暣⫸录℠
CKIP Tiong-bûn sû tì-sek-khò݇
sió-cho݇
Chinese Knowledge and Information Processing
ᷕ㔯娆䞍嬀⹓
⮷䳬 CWSTS Tiong-bûn tnܮg-sû kap
Sû- lըi Phiau-kì hȘ-thóng
Chinese Word Segmentation and Tagging System
ᷕ㔯㕟娆⍲娆 栆㧁姀䲣䴙 DADWT Tâi-gú-bûn sò݇-ըi
tián-chông chu-liþu-khò݇
Digital Archive Database for Written Taiwanese
⎘婆㔯㔠ỵ℠
啷屯㕁⹓
HMM Ún Markov mô݇-hêng Hidden Makov Model 晙楔⎗⣓㧉✳
LDC Gú-giân Chu-liþu Tiong-
sim Language Data Consortium 婆妨屯㕁ᷕ⽫
MEMM Siцng tцa lцan-tц݇
Markov mô݇-hêng
Maximal Entropy Markov Model
㚨⣏䅝楔⎗⣓
㧉✳
MOE Kàu-ioݚk-pц݇ Ministry of Education 㔁做悐 NMTL Tâi-ôan bûn-haݚk-kóan National Museum of Taiwan
Literature ⎘䀋㔯⬠棐
NSC Kok-kho-hцe National Science Council ⚳䥹㚫 OTCS Tâi-gú-bûn gú-sû
kiám-sek hȘ-thóng
Online Taiwanese Concordancer System
⎘婆㔯婆娆㩊 䳊䲣䴙
OTJDTT Tâi-Jiݚt tцa sû-tián Tâi-gú eݚk-pún
Online Taiwanese- Japanese
Dictionary with Taiwanese ⎘㖍⣏录℠⎘
婆嬗㛔
OTMD Tâi-hôa sòaϸ-téng sû-tián
Dictionary ⎘厗䶂ᶲ录℠
OTSD Tâi-gú sòaϸ-téng j̚-tián Online Taiwanese Syllable
Dictionary ⎘婆䶂ᶲ⫿℠
POJ Peݚh-цe-j̚ Taiwanese vernacular writing 䘥娙⫿
POS Sû-sèng Part of speech 娆⿏
SMHLA Bân-Kheh-gú tián-chông Southern Min and Hakka
Language Archive” 救⭊婆℠啷 TAICORP Tâi-ôan jî-tông gú-liþu-
khò݇
Taiwan Child Language Corpus
⎘䀋䪍婆㕁
⹓
THMLW
Tâi-gú kap Kheh-gú hiþn-tþi bûn-haݚk choan- tôe bþng-chþm
Taiwanese and Hakka Modern Literature Website
⎘婆⍲⭊婆䎦 ẋ㔯⬠⮰柴䵚 䪁!
TL
Tâi-ôan Bân-lâm-gú Lô-má-j̚ pheng-im hȘ-thóng hong-àn
Taiwan Southern Min Lц-má-j̚ phonetic scheme
冢䀋救⋿婆潝 楔⫿㊤枛㕡㟰
TVLA Tâi-ôan Peݚh-цe-j̚ bûn- hiàn chu-liþu-kóan
Taiwanese Vernacular Literature Archive
⎘䀋䘥娙⫿㔯 䌣屯㕁棐
Chapter 1 Introduction
This dissertation will focus on Taiwan Southern Min text processing. This chapter will introduce the background of this language and some related issues.
1.1 Background
1.1.1 Language Population in Taiwan
There are a total of 22 living languages in Taiwan (Gordon, 2005). The following table ranks these in descending order.
Table 1 - 1 Living Languages in Taiwan
Language Population Language Population
Min Nan 15,000,000 Taroko 4,750
Mandarin 4,323,000 Yami 3,384
Hakka 2,366,000 Tsou 2,127
Amis 137,651 Kavalan 24
Atayal 84,330 Kanakanabu 6 to 8
Taiwan Sign Language 82,558 Amis, Nataoran 5
Paiwan 66,084 Saaroa 5 to 6
Bunun 37,989 Thao 5 to 6
Rukai 10,543 Babuza 3 to 4
Puyuma 8,487 Kulon-Pazeh 1
Saisiyat 4,750 Japanese
Source: (Gordon, 2005)
As can be seen in Table 1 - 1, the Min Nan (Southern Min) population is in the majority. Six of these languages are nearly extinct because their speaking
population is less than 100. In fact, at least 10 languages, mainly aboriginal languages, have disappeared in Taiwan over the past several hundred years. In addition, some languages, like Vietnamese, Thai, etc., have migrated to Taiwan because of mixed marriages or migrant work.
1.1.2 Southern Min Language Population
Let us take another viewpoint and examine the worldwide population of Southern Min speakers (Gordon, 2005). The following table shows the populations of Southern Min speakers in different nations in descending order of percentages.
Table 1 - 2 Southern Min Language Populations around the World.
Nation Population Total Population Percentage (%)
Taiwan 15,000,000 22,057,144 68.01
Singapore 1,170,000 2,619,376 44.67
Malaysia 1,946,698 15,676,135 12.42
Brunei 12,147 341,573 3.56
China 25,725,000 1,226,606,396 2.10
Thailand 1,081,920 53,478,502 2.02
Philippines 592,200 70,556,507 0.84
Indonesia 700,000 218,607,876 0.32
Total 46,227,965
Source: (Gordon, 2005), the “Percentage” field is added by author.
As Table 1 - 2 shows, Taiwan is the most representative country for the Southern Min language.
Shuan-fan Huang estimated that the percentage of Southern Min speakers in Taiwan was over 70%, while the population was about 17 million (Huang,
1995). Therefore, Taiwan has the highest percentage of Southern Min speakers in the world.
However, according to (Grimes, 2000), the previous edition of (Gordon, 2005), there were a total of about 49 million speakers. We do not know why the number of Southern Min speakers decreased by about 3 million from 2000 to 2005. Maybe it was due to a switch in identification. In addition, these number do not consider emigration from Taiwan to the US, Japan, etc. The reasons for emigration may be political or commercial factors.
According to (Grimes, 2000), if we list languages by the sizes of their speaking populations, Southern Min is ranked 21. It is thus an important language that has received very little attention in the world!
1.1.3 Another Investigation: the Taiwan Southern Min Viewers
Ún-giân Iûnn established a Taiwanese language website in 1998. The main contents of this site are related to the written form of Taiwan Southern Min (Iunn, 1998). We used Google Analytics to view the web traffic statistics, and found that this statistical data could help us to determine where the visitors come from.
The following data came from Google Analytics. It was calculated in May 2008. The “pages” and “total time” fields were added by us. The data is sorted in descending order by total time:
Table 1 - 3 Visits to the Taiwan Southern Min Contents Website Country/Territory Visits Pages/
per Visit pages Avg Time
(sec) total time New Visits(%) 1Taiwan 15,927 44.73 712,415 1,704 27,139,608 46.00 2 United States 683 40.94 27,962 2,312 1,579,096 43.63 3 Japan 337 68.97 23,243 2,336 787,232 34.42 4China 1,105 9.37 10,354 482 532,610 75.20 5 Canada 119 113.45 13,501 2,733 325,227 52.94 6 Hong Kong 328 20.16 6,612 804 263,712 82.01 7 Netherlands 32 87.44 2,798 6,001 192,032 28.12 8 South Korea 51 107.53 5,484 3,064 156,264 47.06 9Singapore 131 24.41 3,198 1,135 148,685 59.54 10 United Kingdom 64 23.94 1,532 1,536 98,304 67.19
11 Germany 49 45.35 2,222 1,741 85,309 48.98
12Thailand 15 101.73 1,526 2,939 44,085 20.00 13Malaysia 51 28.1 1,433 729 37,179 90.20
14 Australia 33 21.73 717 1,104 36,432 87.88
15 Panama 15 22.93 344 1,546 23,190 0.00
16 Bermuda 2 117 234 10,604 21,208 100.00
17Philippines 31 6.97 216 478 14,818 41.94
18 Vietnam 19 19.05 362 729 13,851 100.00
19 Ireland 13 22.62 294 943 12,259 92.31
20 Macao 18 13.39 241 570 10,260 83.33
21 Spain 1 75 75 7,494 7,494 100.00
22 Austria 3 27 81 1,334 4,002 100.00
23 Brazil 2 39.5 79 1,950 3,900 100.00
24 Peru 7 30.57 214 543 3,801 100.00
25 Poland 5 11.6 58 580 2,900 40.00
26Indonesia 6 6 36 344 2,064 100.00
27 New Zealand 8 5.12 41 252 2,016 100.00
28 France 16 3.31 53 94 1,504 100.00
29Brunei 1 16 16 1,283 1,283 100.00
30 Belgium 3 7.33 22 377 1,131 100.00
Note: The data was counted in May 2008 by Google Analytics. The nation/
territory field is bold if it appears in Table 1 - 2.
Who are interested in websites where the contents are mainly in Taiwan Southern Min? We could not analyze the users in detail. Maybe they are:
(a) People who speak Southern Min;
(b) Taiwanese language researchers;
(c) Web robots, or someone else.
1.1.4 The Confusing Name of This Language
Khîn-huþnn Lí pointed out that this language has 17 distinct names (Li &
Ang, 2007). The divergent names reflect the status and situation of this language.
At first, foreigners called this language Amoy ‘ 攨 娙 ’ because they encountered it in the commercial harbor of Amoy. In the period of Japanese rule, the Japanese called the language Hokkienese ‘䤷⺢娙’, then Taiwanese ‘⎘䀋娙’.
In the postwar era after 1945, the Chinese called it the Southern Min language
‘救⋿婆’. On the other hand, the Hakka people called it the Hok-lo language ‘䤷 ἔ娙’.
The official name is currently “Taiwan Southern Min” ‘⎘䀋救⋿婆.’ In civil society, people often call it Taiwanese. As mentioned in Table 1 - 2, since the language population is the majority in Taiwan, and Taiwan has the highest percentage population compared with other countries, it is adequate to refer to it as “Taiwanese.”
However, someone may claim that calling it “Taiwanese” is prejudiced.
That is why the name is so confusing.
We sought suggestions via Google search in relation to this problem. We searched for the following keywords to determine the number of web pages in Taiwan.
Table 1 - 4 The Names of “Taiwan Southern Min”
Name Number of Web Pages
⎘婆 ‘Taiwanese’ 4,770,000
救⋿婆 ‘Southern Min’ 680,000
⎘䀋救⋿婆 ‘Taiwan Southern Min’ 350,000
䤷ἔ娙 ‘Hok-lo language’ 229,000
Remark: Retrieved on June 1, 2008.
As Table 1 - 4 shows, “Taiwanese” is also the term most often used on the internet. Therefore, we will call this language “Taiwanese” in this dissertation unless we wish to distinguish between it and some other native language of Taiwan, like Hakka or the Austronesian languages.
1.2 Different Types of Written Taiwanese Scripts
Taiwanese and Mandarin are different but related languages, differing in phonological, morphological, and syntactic features (H.-k. Tiunn, 1998).
Liông-úi TȘϸ (aka Robert L. Cheng) lists the following phonological and morphological characteristics of Taiwanese:
(a) Preservation of Ancient Chinese morphemes.
(b) Characters with distinct colloquial vs. literary readings.
(c) Taiwanese morphemes without standardized characters.
(d) Japanese and English loans, with most of the English loans being borrowed via Japanese.
(e) Loans that are written with Japanese characters but have Taiwanese pronunciations.
(f) Contractions (Robert L. Cheng, 1990).
The characteristics of Taiwanese, as listed above, should be taken into consideration in developing a written system for the language.
How many types of written Taiwanese systems are there? (Iunn & Tiunn, 1999) estimated that there were at least 64 systems in existence. These systems can be classified into 4 types: Han characters, phonetic symbols, Kana, and Romanized characters. In this section, we will introduce the main systems, including the Han character script, one of the Romanization scripts (Peݚh-цe-j̚, vernacular writing, abbrev. as POJ) and the Han-Romanization mixed script. In addition, other systems will be briefly described.
1.2.1 The Han Characters Script
The earliest preserved work in the Han character script was published in 1566 and found in the Southern Min area (Gou, 1995). At that time, Han characters were primarily employed in the classical language, not in the service of the written vernacular. Also, the the songbooks ‘koa-á-chheh 㫴ṼℲ’ were spread throughout Taiwan civil society in the 19th century (Klöter, 2005).
The above materials were not colloquial Taiwanese writing but only a special genre. The first complete colloquial writing in Han characters, ȾDoctrina Christianaȿȼ➢䜋天䎮,Ƚ was found in the Philippines (Iunn, 2007a, 2008).
The Han characters used for writing Taiwanese fall into four categories:
(a) Hùn-thoݚk-j̚ ‘semantic borrowing characters 妻嬨⫿’;
(b) Pún-j̚ ‘etymological characters 㛔⫿’;
(c) Chioh-im-j̚ ‘phonetic borrowing characters ῇ枛⫿’;
(d) Pún-thó݇-j̚ ‘domestic character 㛔⛇⫿’ (H.-k. Tiunn, 1998).
The first Taiwan Southern Min recommended orthographic word list, which contained 300 words ‘冢䀋救⋿婆㍐啎䓐⫿炷䫔 1 ㈡炸300 ⫿娆,’ was announced by the Ministry of Education on May 29, 2007 (MOE, 2007a). Siok-lîng Luþ used 12 Taiwanese dictionaries to investigate the usage of Han characters, and found a total of 698 different usages, with an average of 2.33 Han characters used for a common Taiwanese word (Lua, 2008).
Another problem is that a Han character usually has two or more pronunciations. For example, when readers see the word “⣏Ṣ,” it is difficult for them to know whether to say “tцa-lâng” ‘adult,’ or “tþi-jîn” ‘policeman’ without the context. Since “Ș/цe ‘can’ ‘㚫’ ” was pronounced as “kцe” in the 19th century, if you write this word using the Han character “㚫,” others cannot determine the actual pronunciation. Worse still, the Han character “㚫” has seven different sounds in total (цe/òe/kцe/kòe/hцe/hȘ/Ș), according to the Online Taiwanese Syllable Dictionary (abbrev. OTSD) (Iunn, 2003c).
There is also kau-phòa, ‘a character with two or more pronunciations, 䟜枛
⫿’ in Mandarin, but it is more ambiguous in Taiwanese. Ún-giân Iûnn examined the OTSD, and found that there are a total of 22,080 entries and 11,635 distinct Han characters, with an average of two pronunciations per Han character.
However, when he only counted the common Han character set ‘ⷠ䓐⫿普’
(5,401 characters in total), there were a total of 13,176 entries and 5,337 distinct Han characters, with an average of 2.5 pronunciations per Han character (Iunn, 2003d).
The advantage of the Han character script is that most people are educated in Han characters in Taiwan, without being formally taught the Romanized script, so they are often afraid of alphabetic writing. They are more willing to guess at the meaning when reading written Taiwanese in the Han character script than the Romanized script.
1.2.2 The Romanized Scripts
Among the dozens of Romanized scripts, three have been used as major systems in recent years. They are:
(a) POJ ‘abbrev. of Peݚh-цe-j̚, vernacular writing, 䘥娙⫿’;
(b) TLPA ‘abbrev. of Taiwanese Language Phonetic Alphabetic, ⎘䀋婆妨枛 㧁㕡㟰’;
(c) TY ‘abbrev. of Tong-yong 忂䓐’ (Iunn, 2003a).
A new system, TL ‘⎘䀋救⋿婆伭楔⫿㊤枛㕡㟰,’ which is essentially a mixture of POJ and TLPA, was announced by the Ministry of Education on October 26, 2006 (MOE, 2006).
POJ is traceable to 1832. Historically, “Taiwan Church News” (originally
“Tâi-ôan Hú-siâϸ Kàu-hцe-pò” ‘Taiwan Prefectural City Church News’ ‘⎘䀋⹄❶ 㔁㚫⟙’ ) was the first Taiwanese newspaper written in POJ. This paper was
founded in 1885. As the longest lasting newspaper in Taiwan, it is in the unique position of having documented Taiwanese society during a century of Manchurian, Japanese, and Chinese rule, and to have done so in a major language of the masses (J.-h. Tiunn, 2001).
The Han character script and Romanized script play complementary roles.
Some disadvantages of the Han character script can be solved by the Romanized script, and vice-versa (H.-k. Tiunn, 1998).
1.2.3 The Han-Romanization Mixed Script
The idea of Han-Romanization mixed script writing was first introduced to Taiwan by Liông-úi TȘϸ through publications using this system and the exposition of its theory in the late 1980s. The Han-Romanization mixed script is used in the writing of poems, novels, and prose, as well as in academic writing, Taiwanese textbooks, and religious works. It appears in newspapers, bulletins, and books. It is the writing system preferred by most of the advocates of written Taiwanese (Chhong-bi Memorial Foundation; Iunn, Tiunn, & Li, 2008).
For convenience, the “Han-Romanization mixed script” will be abbreviated as “HR mixed script” in the following sections.
1.2.4 Other Scripts
There are also other scripts that have appeared over the past several decades, most of which are oriented toward phonetic transcriptions. These scripts can be classified into four categories, including Romanized scripts, Kana
scripts ‘`⎵’, Hangul scripts ‘媢㔯’, and phonetic symbol scripts, like γδε (Iunn & Tiunn, 1999).
1.2.5 Target Scripts in This Dissertation
We intended to collect a sufficient amount of written Taiwanese material and then process it. We selected POJ and the HR mixed script as the target scripts in this dissertation. The Romanized script portion of the Han-Romanization mixed script was also POJ. In total, we have so far collected about 10 million syllables in these two scripts.
1.3 Issues Related to Written Taiwanese Processing
In order to process our two target scripts, it was necessary to understand some related issues.
(a) Written Taiwanese has not yet been standardized;
(b) Although MOE announced Taiwan Southern Min recommended orthographic word lists in May 2007 and May 2008 (MOE, 2007a, 2008b), the orthography of Han characters has not yet been standardized either;
(c) Some Han characters especially the pún-thó݇-j̚ ‘domestic characters,’ are not in the Unicode character set (The Unicode Consortium, 2006);
(d) All of the POJ characters have been in the Unicode set since 2004 (ISO/IEC JTC1/SC2 & WG2, 2004), with some of the characters being composed of two or three Unicode characters, but the characters are
separated into different zones, including basic Latin, Latin-1, Latin Extended-A, Latin Extended-B, and Latin Extended Additional (Lau, 2002);
(e) Using an internal plain text representation to record the Romanized script could be more convenient for searching;
(f) The word segmentation of the HR mixed script is more complicated than Mandarin because the usage of Han characters has not yet been standardized and this script is mixed with Romanization;
(g) Taiwanese tone sandhi is a difficult problem (M. Y. Chen, 2000; R. L Cheng, 1997), the Taiwanese corpus annotation recommends annotating the phonetic and tone sandhi markers;
(h) The technician who develops Taiwanese language related tools needs to interact with the people who are interested in the Taiwanese language in order to satisfy their needs.
1.4 Organization of This Dissertation
This dissertation is divided into six chapters.
We introduce the overall background in Chapter 1. A researcher with a background in computer science may not be familiar with the Taiwanese language, given the monolingual education in Taiwan. Therefore, we devote space to describing the background of the language, including its history, language population, different types of scripts, and abbreviations.
Chapter 2 describes the resources and our survey of written Taiwanese
processing. We omit the plentiful research results in the Mandarin and English fields for the sake of space. Written Taiwanese processing is an almost uncultivated field, and has received very little attention. Generally speaking, most journal editors are not interested in this field; therefore, we cite numerous websites rather than academic papers. In regards to the digital resources of written Taiwanese, we introduce fonts, dictionaries, corpora, electronic books, etc. We also introduce recent written Taiwanese processing techniques,
including input method, word segmentation, tagging, script conversion, text-to-speech, translation, and parsing techniques.
In Chapter 3, we introduce the coding, I/O of POJ, and text processing for written Taiwanese. English and Mandarin have their own processing problems.
For example, it is necessary to manipulate the word stemming problem and the modifier of a prepositional phrase in English processing, and the Han character encoding and word segmentation problem for Mandarin. As to POJ, it is necessary to solve some fundamental problems, including encoding, display, and search, which are not the same as English and Mandarin. We first introduce the POJ character code, and mention numbered POJ as the interchange code for various POJ encodings. Then, we propose a two-stage search strategy: perform string matching and then filter the results. In addition, we propose query expansions, including toneless, glottal stop, checked syllable, and vowel search, because it is difficult for someone with a Mandarin education to distinguish the differences. We also describe the display method for POJ, and some POJ word processing utilities, including phoneme segmentation, spelling checker, and
syllable/word/sentence count utilities. At the end of this chapter, we describe a word segmentation method for HR mixed script.
In Chapter 4, we propose a rule-based tone sandhi algorithm. We address some problems raised by the Taiwanese tone sandhi system by describing a set of computational rules to approximate this system, as well as the results obtained from our implementation. Using POJ text as the source, we took a sentence as the unit, translated every word into Mandarin via OTMD, and obtained POS information from the CED made by the CKIP group of the Academia Sinica. Using the POS data and tone sandhi rules formulated based on linguistics, we then tagged each syllable with its post-sandhi tone marker.
Finally, we implemented a Taiwanese tone sandhi processing system that takes a POJ script sentence as the input and outputs the tone markers. Our system achieved accuracy rates of 97.4% and 89.0% with the observation and test data, respectively.
For example, if a user inputs the POJ sentence:
“Chhin-chhiըϸ án-ni lâi kóng, chþi lán Tâi-ôan k̚n-k̚n chi ݚt-tiap-á-kú ê kang-hu, ài soaϸ chiը ը soaϸ, ài hái chiը ը hái, beh joݚah chiը ը joݚah, kôaϸ chiը ը kôaϸ”
Our tone sandhi algorithm adds the tone sandhi markers:
“Chhin-chhiըϸ án-ni# lâi kóng#, chþi lán Tâi-ôan# k̚n-k̚n hi ݚt-tiap&
-á-kú# ê kang-hu#, ài soaϸ# chiը ը soaϸ#, ài hái# chiը ը hái#, beh$
joݚah# chiը ը joݚah#, kôaϸ# chiը ը kôaϸ#.”
We then concatenate all of the sound files for the corresponding syllables to
an MP3 format sound file and return it to the user. The purpose of the Taiwanese tone sandhi algorithm is to implement a real-time Taiwanese tone sandhi system.
In Chapter 5, we propose a POS tagging method using the OTMD and 10 million Mandarin words as training data to tag Taiwanese. The literary written Taiwanese corpora have both POJ script and HR mixed script, with genres that include prose, novels, and drama. We followed the tagset drawn up by CKIP. We developed a word alignment checker to assist with the word alignment work for the two scripts, and then used the OTMD to find the corresponding Mandarin candidate words, selected the most adequate Mandarin word from the Mandarin training data using an HMM probabilistic model, and finally tagged the word using an MEMM (Maximal Entropy Markov Model) classifier. We achieved an accuracy rate of 91.5% in the Taiwanese POS tagging work and analyzed the errors.
For example, the original data was a paragraph by paragraph parallel corpus with POJ and HR mixed scripts, like:
góa chiong chháu-bц-á kòa t̚ piah- téng, hêng-lí khêng khêng leh, chȘ tòa sió-tiàm ê tha-tha-mì téng-kôan, …
ㆹ⮯勱ⷥṼ㍃t̚⡩枪炻埴㛶 khêng khêng leh炻⛸tòa⮷
⸿ê tha-thá-mì枪kôan炻…
First, our word alignment program rearranged the data as:
“ㆹ [góa] ⮯ [chiong] 勱 ⷥ Ṽ [chháu-bц-á] ㍃ [kòa] t̚[t̚] ⡩ 枪 [piah-téng]炻[,] 埴㛶[hêng-lí] khêng[khêng] khêng[khêng] leh[leh]炻 [,] ⛸[chȘ] tòa[tòa] ⮷ ⸿ [sió-tiàm] ê[ê] tha-thá-mì[tha-tha-mì] 枪 kôan[téng-kôan]炻[,] …”
Second, we referenced the OTMD and added the Mandarin translation(s) for every word. We called these Mandarin translation(s) candidate words. We performed this task because we intended to use the Mandarin language model:
“ㆹ [góa]{ ㆹ } ⮯ [chiong]{ ⮯ } 勱 ⷥ Ṽ [chháu-bц-á]{@ 勱 ⷥ Ṽ } ㍃ [kòa]{ⷞ;㍃;㇜} t̚[t̚]{⛐} ⡩枪[piah-téng]{䇮⡩ᶲ}炻[,]{炻} 埴㛶 [hêng-lí]{埴㛶} khêng[khêng]{㓞㊦;䚌溆} khêng[khêng]{㓞㊦;䚌溆}
leh[leh]{} 炻[,]{炻} ⛸[chȘ]{⛸} tòa[tòa]{ỷ} ⮷⸿[sió-tiàm]{@⮷
⸿} ê[ê]{䘬} tha-thá-mì[tha-tha-mì]{⟴⟴䰛} 枪 kôan[téng-kôan]{ᶲ 朊} 炻[,]{炻} …”
Note that the words “勱ⷥṼ” and “⮷⸿” are not found in OTMD, we treat the HR mixed script as the Mandarin candidate word. Third, we use Hidden Markov Model to select the most suitable Mandarin word from the candidate words:
“{ㆹ}<ㆹ> {⮯}<⮯> {@勱ⷥṼ}<勱ⷥṼ> {ⷞ;㍃;㇜}<ⷞ>
{⛐}<⛐> {䇮⡩ᶲ}<䇮⡩ᶲ> {炻}<炻> {埴㛶}<埴㛶> {㓞㊦;䚌 溆}<㓞㊦> {㓞㊦;䚌溆}<㓞㊦> {}<> {炻}<炻> {⛸}<⛸>
{ỷ}<ỷ> {@⮷⸿}<⮷⸿> {䘬}<䘬> {⟴⟴䰛}<⟴⟴䰛> {ᶲ 朊}<ᶲ朊> {炻}<炻> …”
Note that, since the words “勱ⷥṼ” and “⮷⸿” are not found in the OTMD, we treated the HR mixed script as the Mandarin candidate words. Third, we used the Hidden Markov Model to select the most suitable Mandarin word from the candidate words:
“<ㆹ>(Nh) <⮯>(D) <勱ⷥṼ>(Na) <ⷞ>(VC) <⛐>(P) <䇮⡩
ᶲ>(Nc) <炻>(COMMACATEGORY) <埴㛶>(Na) <㓞㊦>(VC) <㓞
㊦>(VC) <>(T) <炻>(COMMACATEGORY) <⛸>(VA) <ỷ
>(VCL) <⮷⸿>(Na) <䘬>(DE) <⟴⟴䰛>(Na) <ᶲ朊>(Ncd) <炻 (COMMACATEGORY)> …”
Finally, we got the Taiwanese POS tagging result:
“ㆹ[góa](Nh) ⮯[chiong](D) 勱ⷥṼ[chháu-bц-á](Na) ㍃[kòa](VC) t̚[t̚](P) ⡩ 枪 [piah-téng](Nc) 炻 [,](COMMACATEGORY) 埴 㛶 [hêng-lí](Na) khêng[khêng](VC) khêng[khêng](VC) leh[leh](T) 炻 [,](COMMACATEGORY) ⛸ [chȘ](VA) tòa[tòa](VCL) ⮷ ⸿ [sió-tiàm](Na) ê[ê](DE) tha-thá-mì [tha-tha-mì](Na) 枪 kôan[téng-kôan](Ncd) 炻[,](COMMACATEGORY) …”
We hope that this POS tagging system can assist us to develop a Taiwanese parser.
A summary of our work will be given in Chapter 6. This dissertation is not the end of our work on written Taiwanese processing tasks. Chapter 6 will also propose future directions for written Taiwanese processing research.
Chapter 2 Resources and Survey of Written Taiwanese
Processing
This chapter introduces the digital resources for written Taiwanese, including fonts, dictionaries, corpora, electronic books, etc. We also introduce recent written Taiwanese processing techniques, including input method, word segmentation, tagging, script conversion, text-to-speech, translation, and parsing techniques.
2.1 Digital Resources for Written Taiwanese
2.1.1 Fonts
The available fonts include both Han character fonts and Taiwanese Romanization fonts. As mentioned before, the orthography has not yet been standardized. If someone chooses to write Taiwanese in Han characters, it is possible to select characters that exceed the range of the Unicode character set.
Some Han characters, especially pún-thó݇-j̚ ‘domestic characters, 㛔⛇⫿’ like
“ṣ⚈ ‘they’ ‘ṾᾹ,’ ” and “㚫⊧ ‘be unable to’ ‘ᶵ㚫’ ” etc., are not included in the Unicode character set (The Unicode Consortium, 2006). If you insist on using
them, you must create your own fonts, and will encounter great difficulty when you communicate with others. This dissertation will not discuss this problem because solving it is beyond the scope of this study.
As to the POJ script, not all of the POJ character set was included in the Unicode character set before 2004. Before 2004, the POJ font makers replaced some character graphs that are unused in POJ with the specific POJ character graphs. For example, they replaced “ä” with “þ”. Some fonts, including
“HoloWin,” “Taiwanese Serif,” etc., are often attached to Taiwanese language word processing software (Lau & Iunn, 2002).
To date, most Romanization character fonts do not fully support the Unicode standard. The following fonts can support the POJ script: Taigi Unicode, Doulos SIL, Gentium, Charis SIL, DejaVu, etc. We adopted the Charis SIL font for this dissertation. These fonts can be downloaded from the Internet (Iunn, 2006b;
Laenen, Jacquerye, & Kulev, 2004; Lau, 2005; SIL).
2.1.2 Dictionary
There are three online dictionaries available on the Internet. These will be introduced in this subsection.
(a) Online Taiwanese-Mandarin Dictionary (OTMD):
This Taiwanese-Mandarin translation dictionary was announced and has been online since November 2000. The main data provider is Liông-úi TȘϸ, but many anonymous contributors also offer entries and correct the typos. This system is maintained by author. There are a
total of more than 62,000 entries. The URL is http://iug.csie.dahan.edu.tw/q .
This dictionary offers POJ, HR mixed script, and Mandarin fields, with the POJ field also offering different accents. The pronunciation function was added in 2006, and English translations were added to more than 10,000 entries in 2007 based on (Embree, 1984), which contains English, Mandarin, and POJ fields.
This data can be searched using either the Taiwanese language or Mandarin. Users can also look up entries using a toneless query expansion function. For example, if a user types “hoe-chhia,” they will find “hoe-chhia ‘vehicle decorated with flowers, 剙干,’” “hóe-chhia,
‘railway train, 䀓干,’” and “hòe-chhia, ‘truck, 屐干.’ ”
This is a popular online system; there have been a total of more than 2.4 million searches from more than 125,000 different IP addresses since December 2002, with more than 2,700 searches per day for the past year. 1
This dictionary has also been of assistance in many research works (Iunn, 2000, 2002, 2003g).
(b) Online Taiwanese Syllable Dictionary (OTSD):
This dictionary was announced and has been online since 2003. There are more than 22,000 entries, including POJ and Han character fields.
A pronunciation function was added in 2006. Its URL is
http://iug.csie.dahan.edu.tw/TG/jitian/ .
This online search system offers four kinds of query expansions, including toneless, glottal stop, checked syllable, and vowel. There have been a total of more than 290,000 searches from more than 32,000 different IP addresses since January 2003, with more than 250 searches per day for the past year.2 The POJ syllable query expansion will be discussed in Chapter 3 (Iunn, 2003c, 2003f).
(c) Online Taiwanese-Japanese Dictionary with Taiwanese Translation ‘⎘
㖍⣏录℠⎘婆嬗㛔’ (OTJDTT):
The Taiwanese-Japanese Dictionary was published in 1931 & 1932 and edited by Naoyoshi Ogawa ‘⮷ⶅ⯂佑’. There are more than 90,000 entries. In 2002, Chùn-ioݚk Lîm began re-typing some of the entries (more than 70,000) and translated the Japanese into Taiwanese. The quality of the entries is higher than the OTMD. The online search system was released in 2005 by Jer-min Tsai. Its URL is http://taigi.fhl.net/dict/ (C.-C. Cheng, Ho, Hsiao, Chiang, & Chang, 2007; Iunn & Lau, 2007; Iunn et al., 2008).
(d) MOE Taiwan Southern Min Common Word Dictionary ‘㔁做悐冢䀋救⋿
婆ⷠ䓐娆录℠’:
MOE began to edit this dictionary in 2000. There are more than 20,000 entries. This dictionary has been online since October 2008 (MOE, 2008a).
2 Retrieved on December 30, 2008.
2.1.3 Text Corpora
This subsection will omit the speech corpora since we are focusing on the written language.
(a) The Texts Database of Folk Songs in Southern Min Dialect ȼ救⋿婆
㚚ⓙ㛔ˬ㫴ṼℲ˭ℐ㔯屯㕁⹓’:
Sըn-liông Ông released “The Texts Database of Folk Songs in the Southern Min Dialect” in 1999. He hired Chinese typists to enter the data and cooperated with Academia Sinica, who offered the online search system. For some reason they discontinued the online system after a few years. At present, users need to submit an application form to Sըn-liông Ông to use this corpus (Ong, 1999).
(b) Taiwanese Wikipedia:
Taiwanese Wikipedia (aka Holopedia), which was established in 2003 and included in Wikipedia in 2004, could also be considered as a POJ corpus. There are more than 4,000 articles so far (Wikimedia Foundation, 2004).
(c) Written Taiwanese Corpus:
Ún-giân Iûnn released a POJ corpus and a HR mixed script corpus in 2003. The genres include academic papers, novels, prose, poems, drama, folk literature, interviews, lectures, dialogs, fables, reports, etc.
Afterwards he got NSC financial support from August 2004 to July 2005 to keep adding contents. He has collected more than 3.4 and 5.8
Taiwanese Concordancer System (OTCS), syllable/word frequency/
mutual information/correlation reports etc. for these two scripts. There are a total of nearly 1,900,000 times of searches from more than 56,400 different IP addresses counted from January 2003, and about 1630 times of searches per day for past one year.3 (C.-C. Cheng et al., 2007; Iunn, 2003b, 2003e, 2005a, 2005b, 2005c; Iunn & Lau, 2007).
(d) Taiwanese Bible Corpus:
Faith Hope Love Information center has offered an online Taiwanese Bible since 2006. They offered the Barclay edition version (both New and Old Testament published in 1916 and 1933, respectively) and red-cover version (only the New Testament, which was translated in the 1970s and was confiscated by the Chinese Nationalist regime) (Faith Hope Love Foundation, 2006).
(e) Digital Archive Database for Written Taiwanese (2nd stage):
“The Collection and Cataloging of Taiwanese POJ Literature Data”
(CCTPLD) ȼ⎘䀋䘥娙⫿㔯⬠屯㕁吸普Ƚproject was carried out by Heng-chhiong L̚, under the auspices of the NMTL ȼ⎘䀋㔯⬠棐,Ƚ from May 2001 to December 2004. This project collected Taiwanese literature data and entered a portion of it into a database.
The “Digital Archive Database for Written Taiwanese” project was carried out by Cheng-yan Gao from September 2004 to December 2005.
This project first recorded each syllable of the Taiwanese language,
3 Retrieved on December 30, 2008.