國立臺中教育大學教育測驗統計研究所理學碩士論文
指導教授:郭伯臣 博士
吳慧珉 博士
不同垂直等化設計下可能值方法
估計效果之探討
研究生:葉昶成 撰
中
華
民
國
一
百
零
一
年
七
月
謝辭
兩年的時間,竟然在不知不覺中一下子就過去了。那種可以再度成為一位學 生的悸動猶縈繞心頭;猛一轉身,竟然就要畢業了! 首先,最誠摯的感谢指導教授郭伯臣博士及吳慧珉博士,在每次論文研究的 討論中悉心指導,不僅給予我的研究有了明確的方向、讓我的研究更加的嚴謹、 更引領我初窺了大型測驗的深奥。此外,也感謝口試委員柯華葳老師、廖晨惠老 師及楊裕貿老師,給予許多寶貴的建議,使本論文能夠更完整而嚴謹。 感谢各位學長姐、同學、學弟妹的加油打氣,謝謝你們的陪伴讓兩年的研究 生活變得更加有趣。 感谢筱倩及敏嫻學姊在我的論文上不厭其煩的給予指導解惑;感謝嘉玲、芷 寧、宗恩、偉民、金谷同學的加油打氣,讓我再度的回味了成為「學生」的樂趣; 也感謝婉寧、杰廷、德弘學弟妹幫忙,讓我順利的完成這份論文;尤其感謝我的 好同學兼好伙伴秀芬,謝謝你一路上的加油打氣,這份論文終於完成了! 此外,感謝我的家人,謝謝我最摯愛的妻子淑美、兒子沛言及女兒羽珊,謝 謝你們全力的支持,讓我能夠無後顧之憂的完成學業;最後,更感謝我的母親及 在天上的父親,謝謝您們無私的賜予我這一切,讓我能明瞭人生的道路並能堅定 的往前邁進,謝謝大家。 葉昶成 中華民國一百零一年七月摘要
許多國際上的大型測驗,多採用可能值方法來進行群體能力參數的估計。而 可能值的資料型態,亦可讓資料分析者進行統計特性的描述。此外,一般大型測 驗所評量的範圍都涵蓋了不同的認知向及難度,無法由單一受試者於短期間內全 部完成,測驗題目都會進行不同的等化設計以減輕受試者負擔並達成測驗的目 的。本研究係各以定錨不等組(non-equivalent groups with anchor test design, NEAT)及平衡不完全區塊(balanced incomplete block design, BIB)的垂直等化 設計,並以可能值方法、納入背景變項的期望後驗法、期望後驗法及最大概度估 計法等各種方法別進行個體能力及群體能力的平均數與標準差的估計,其主要的 目的在於探討可能值方法及其它估計法在群體參數回復的效果。 本研究結果發現在各種不同的垂直等化設計下,不管是個體能力參數的估 計,或是群體能力平均數與標準差的回復上,納入背景變項估計方法皆有較好的 估計效果。尤其在群體能力標準差的回復上,可能值方法的估計結果遠優於各種 估計方法。 關鍵詞:大型測驗、臺灣學生學習成就評量資料庫、可能值、等化設計、垂直等 化。
Abstract
The purpose of this paper is to explore the performance of plausible values method under BIB and NEAT designs for vertical equating based on simulated data. The major focus of large-scale assessments is always on the population statistics, such as means and standard deviations, and the plausible value method is usually used to estimate the population parameters. For large-scale assessments the spectrum of subject matter is usually wide, but the testing time is short. Therefore, in order to cover the proficiency domain sufficiently, multiple booklets are used. Balanced incomplete block design (BIB) and non-equivalent groups with anchor test design (NEAT) are two popular test equating methods for this condition. The experimental results show that the estimating method based on plausible values estimate better than that of other methods in vertical equating designs, and as the test length increase, population parameters (mean and standard deviation) are well estimated. In these experimental situations, the estimations of population parameters are not affected by sample size (16128 and 10920). Both linking designs, BIB and NEAT, can lead to more precision estimates by using plausible value method.
Key words:large-scale assessment, Taiwan Assessment of Student Achievement, plausible values, equating design, vertical equating.
目錄
摘要 ... I Abstract ... II 目錄 ... III 表目錄 ... V 圖目錄 ... VI 第一章 緒論 ... 1 第一節 研究動機 ... 1 第二節 研究目的與待答問題 ... 3 第三節 名詞解釋 ... 3 第二章 文獻探討 ... 7 第一節 單向度試題反應理論 ... 7 第二節 參數估計方法 ... 8 第三節 可能值方法 ... 13 第四節 測驗等化設計 ... 16 第三章 研究方法 ... 21 第一節 研究步驟 ... 21 第二節 測驗等化設計 ... 23 第三節 模擬條件與估計方法設定 ... 25 第四節 研究工具 ... 28 第五節 評估準則 ... 29 第四章 研究結果與討論 ... 31 第一節 NEAT 等化設計估計結果 ... 31 第二節 BIB 等化設計估計結果 ... 38 第三節 二種等化設計方法之比較 ... 44 第五章 結論與建議 ... 49 第一節 結論 ... 49 第二節 建議 ... 50 參考文獻 ... 53 中文部分 ... 53 英文部分 ... 54 附錄一 NEAT 設計個體能力值不同估計方法之 RMSE ... 59 附錄二 BIB 設計個體能力值不同估計方法之 RMSE ... 63 附錄三 NEAT 設計群體能力平均數不同估計方法之 RMSE ... 66 附錄四 BIB 設計群體能力平均數不同估計方法之 RMSE ... 71 附錄五 NEAT 設計群體能力標準差不同估計方法之 RMSE ... 74表目錄
表 2-1 NEAT 設計 ...18 表 2-2 BIB 設計 ...19 表 3-1 NEAT 設計表...23 表 3-2 NEAT 高低年級垂直等化連結設計表 ...24 表 3-3 BIB 等化設計 ...24 表 3-4 BIB 高低年級垂直等化連結設計表 ... 25 表 3-5 不同等化設計之變項設定 ... 25 表 3-6 試題長度設定一覽表 ... 26 表 3-7 受試者能力分布設定一覽表 ... 27 表 4-1 NEAT 設計不同情境中個體能力值估計結果之 RMSE 值 ...33 表 4-2 NEAT 設計不同情境中群體能力平均數估計結果之 RMSE 值 ...36 表 4-3 NEAT 設計不同情境中群體能力標準差估計結果之 RMSE 值 ... 37 表 4-4 BIB 設計不同情境中個體能力值估計結果之 RMSE 值 ...40 表 4-5 BIB 設計不同情境中群體能力平均數估計結果之 RMSE 值 ...43 表 4-6 BIB 設計不同情境中群體能力標準差估計結果之 RMSE 值 ...44圖目錄
圖 3-1 研究流程圖 ... 22 圖 4-1 NEAT 設計個體能力不同估計方法 RMSE ... 32 圖 4-2 NEAT 設計群體能力平均數不同估計方法 RMSE ... 35 圖 4-3 NEAT 設計群體能力標準差不同估計方法 RMSE ... 35 圖 4-4 BIB 設計個體能力不同估計方法 RMSE ... 39 圖 4-5 BIB 設計群體能力平均數不同估計方法 RMSE ... 41 圖 4-6 BIB 設計群體能力標準差不同估計方法 RMSE ... 42 圖 4-7 個體能力值各種估計方法 RMSE 比較 ... 46 圖 4-8 群體能力平均數各種估計方法 RMSE 比較 ... 47 圖 4-9 群體能力標準差各種估計方法 RMSE 比較 ... 48第一章 緒論
本研究是以試題反應理論(item response theory, IRT)中單參數 Logistic 模式, 以電腦模擬各種情境的方式,針對不同估計方法下個體能力與群體參數之估計的 效果進行探討。本章將針對研究動機、研究目的與名詞解釋逐一進行說明。
第一節 研究動機
近年來國際上陸續舉辦了數種大型測驗(large-scale assessments),諸如 Trends in International Mathematics and Science Study(TIMSS)、The Progress in
International Reading Literacy Study (PIRLS)及 The Programme for International Student Assessment(PISA)等,另外如美國實施的 National Assessment of
Educational Progress(NAEP),這些大型測驗所主要關注的焦點在於學生整體學 習情形及學習能力的評估、探索學生在各領域需具備的能力,並長時間測量教育 的發展情形等,而這些數據也將作為國家未來教育政策訂定之參考。因為這些大 型測驗主要關注焦點是放在受試母群體的整體能力展現,所以多採用可能值方法 (plausible value method)進行群體能力參數評估(OECD, 2005; Lee, Grigg & Dion, 2007)。
可能值方法(plausible value method)係在每個受試者的作答應反應中加入學 生背景變項(background variables, BV)作為輔助變數(ancillary variables, AV), 然後以潛在迴歸模式,計算出每位受試者實際能力的後驗分布,然後從後驗分布 中隨機抽取數個資料作為可能值。因為可能值方法係直接使用學生的答題反應和 背景變項資料直接估計母群參數,並未如同一般估計方法先行個別估計個體的能 力後再計算整體的參數,所以相較起來此方法所獲得之估計結果較為準確
(Mislevy & Sheehan, 1989)。可能值包含了隨機誤差成分,不適合描述個體分 數,但卻具有良好群體估計一致性,適合描述群體之特性(Mislevey, 1991; Mislevy, Beaton, Kaplan & Sheehan, 1992),因此國際上許多大型測驗都以可能值方法進行 群體統計描述(Allen, Carlson, Johnson & Mislevy, 1999; Foy, Galia & Li, 2008;
OECD, 2009),透過納入群體的背景變項進行可能值方法估計,藉以提升群體參
數估計的精確度(Adams, Wilson & Wu, 1997)。
目前國內許多大型測驗相關研究並未使用可能值方法進行分析,例如洪碧 霞、林素微、林娟如(2006)針對 TASA 數學科施測資料的研究即是一例。有學 者研究指出,利用傳統點估計方式去推論群體參數容易造成偏誤(Mislevey, 1991; Mislevy, et al., 1992; OECD, 2005; Lee, et al., 2007)。然而,即使是使用可能值方 法進行分析,沒有按照正確方式使用亦會造成估計上的偏誤。(von Davier, Gonzalez,& Mislevy, 2009)
此外,現今關於可能值方法的相關研究主要著重於單組之估計探討,包含可 能值估計方法的改善、可能值方法與點估計方法間比較、可能值方法估計不同計 分模式之比較(Adams, Wilson & Wu, 1997; von Davier, et.al., 2009 ; Wu, 2005; Glas
& Geerlings, 2009)。而在實施大型測驗時,考量測驗範圍與作答時間限制,等化 設計是一種常見的測驗實施方式,王敏嫻(2011)曾就 BIB 與 NEAT 此二種等化 設計來探討在水平等化(horizontal equating)下可能值方法及其它估計法在個體 能力值及群體參數的回復性的研究。 除了水平等化設計外,大型測驗中亦需使用垂直等化設計來進行跨年級的等 化連結,以便能描繪出學生學習成長趨勢,進行學生學習成就長期性資料庫的建 置。然而垂直等化設計下可能值方法估計效果這方面的研究卻是付之闕如,是以 本研究將針對垂直等化設計這個議題,進行可能值方法及其它估計方法的估計效 果探討。
第二節 研究目的與待答問題
本研究以模擬研究的方式探討在 NEAT 與 BIB 二種不同垂直等化設計中,在 不同人數與不同題數的情況下,探討可能值等五種不同納入或不納入背景變項的 估計方法下對於個體能力估計與群體參數估計之效果。本研究目的條列如下: 一、在不同垂直等化設計下,不同受試人數與不同測驗題數對於納入輔助變數與 否的估計方法對於個體能力估計之影響。 二、在不同垂直等化設計下,不同受試人數與不同測驗題數對於納入輔助變數與 否的估計方法對於群體能力參數估計之影響。 依據上列研究目的,設定待答問題如下: 一、在不同垂直等化設計下,施測人數多寡是否會對納入及不納入背景變項的各 種估計方法在個體能力值及群體能力參數的估計準確度上產生影響? 二、在不同垂直等化設計下,施測題數多寡是否會對納入及不納入背景變項的各 種估計方法在個體能力值及群體能力參數的估計準確度上產生影響? 三、在不同垂直等化設計下,納入及不納入背景變項的各種估計方法在個體能力 值及群體能力參數的估計上何者較為準確? 四、何種垂直等化設計有較佳的估計準確度?第三節 名詞解釋
壹、測驗等化
測驗等化是利用統計方法,將受試者在某測驗的分數轉換至另一測驗分數量 尺,使得不同的測驗的結果能夠在同一個基準上做比較的一套流程。主要分為水 平等化及垂直等化二種,本研究焦點主要聚焦在垂直等化上。貳、水平等化
水平等化係指利用測驗分數等化技術,將兩個或兩個以上測量相同特質、相 同能力的測驗,其原始分數轉換之過程,在本研究中係指同年級間不同測驗間之 等化。參、垂直等化
垂直等化(vertical equating)係指將兩組不同能力水平的受試者所獲得分數, 利用測驗分數等化之技術將之置於同一個量尺上以使能互相比較。在本研究中係 指不同年級間不同測驗間之等化。肆、定錨不等組設計
定錨不等組設計(NEAT)是將題庫試題編制成不同分測驗,各分測驗間必 須存有共同的定錨試題,通常定錨試題在每群受試者的測驗順序是一樣的,以避 免順序因素的影響(von Davier, Holland, & Thayer, 2004 ; Dorans & Holland, 2000 ; 王暄博,2006),施測時不同受試群分別以不同分測驗進行施測。伍、平衡不完全區塊設計
平衡不完全區塊設計(BIB)是由 Yates(1936)提出,並於 1992 年 Rust & Johnson 應用於測驗領域的題庫設計。此設計是指題庫中所有的試題區塊出現次 數是相同的,且成對試題區塊出現於題本中的次數也必須是相同的。所謂的「平 衡」是由於成對試題區塊出現於題本中的次數是相同的,因此在成對試題區塊平 均數間之比較有相同的精準度。各題本中的試題區塊可能部分相同或完全不同, 但是每一個試題區塊在所有題本中出現的次數是一樣的(Kuehl, 2000;曾玉琳、
王暄博、郭伯臣、許天維,2005),亦題庫中的每個試題所受測的學生約為相同 的。
陸、根均方差
本研究使用能力真值與能力估計值的根均方差( root mean square error, RMSE)作為估計的評估準則,如公式 1-2: N N i i i
1 2 ) ˆ ( ) ˆ , ( RM SE (1-2) 其中,i 表示受試者人數,i1,2,3,...,N;
1,2,3,...,N
:表示受試者能力真值;
N
ˆ ˆ, ˆ , ˆ,..., ˆ 3 2 1 :表示受試者能力估計值。第二章
文獻探討
本研究係以單向度單參數試題反應理論為基礎,使用模擬資料進行模擬實 驗。以不同垂直等化設計方式對進行模擬施測。並以可能值等數種估計法進行參 數估計,並探討不同估計方法對於個體能力與群體參數的估計效果。因此,本章 將針對單向度試題反應理論、參數估計方法、可能值方法以及測驗等化設計方法 等相關研究進行分析整理。第一節 單向度試題反應理論
試題反應理論主要是以個別試題的觀點,來解釋測驗分數的涵義。學生在某 一試題上的表現情形,與其背後的某種潛在特質(或能力)之間具有某種關係存 在,這關係可以透過一條連續性遞增的數學函數來加以表示和詮釋,這個數學函 數便稱作「試題特徵曲線」(item characteristic curve, ICC)。試題特徵曲線所代表 的涵義即為:答對某一試題的機率,是由受試者能力和試題特性所共同決定的。 (Lord, 1980)。單向度試題反應模式,主要可分成二元計分與多元化計分二大類。適用於二 元計分的單向度試題反應理論,常用的有單參數對數模式(one-parameter logistic model, 1PL)、雙參數對數模式(two-parameter logistic model, 2PL)及三參數對數 模式(three-parameter logistic model, 3PL),一般使用型試題反應論必須符合下列 四項基本的假設,才能進行測驗資料之分析:
一、單向性(unidimensionality)。 二、局部獨立性(local independence)。 三、非速度性(nonspeedence)。
本研究係使用單參數對數模式進行探討,單參數對數模式又稱為 Rasch 模 式,假設受試者 j 之能力為j,其答對試題 i 的機率為Pi(j),其數學公式如下 (Rasch, 1960): N j n i b b X P P i j i j ij j i 1,2,3,... 1,2,3,... )] ( exp[ 1 1 ) , | 1 ( ) ( (2-1) 其中,Xij為受試者 j 在試題 i 的作答反應,答對記為 1,答錯記為 0,
bi為試題 i 之試題難度參數(item difficulty parameter);
n 為試題長度;N 為受試者人數。
第二節 參數估計方法
本研究乃以傳統的點估計方法、加入輔助變數之期望後驗估計法與可能值方 法等進行探討,在傳統點估計方法中主要使用最大概似估計法、加權概似估計法 與期望後驗估計法,故以下分別介紹四種方法估計方法:最大概似估計法、加權 概似估計法、期望後驗估計法與加入輔助變數之期望後驗估計法。壹、最大概似估計法
最大概似估計法(maximum likelihood estimation, MLE)為假設測驗中共有 n 題 試題,試題間彼此獨立,則最大概似估計法之概似函數可表示為公式(2-2)所示:
ij Xij j n i i X j i n P Q X X L L
1 1 1,..., | ( ) ( ) | u (2-2) 其中,u
X ,...,1j Xnj
為所有作答反應的向量;
X1j,...,Xnj |
L 為概似函數(likelihood function); θ 為受試者的真實能力; ij X 指受試者 j 在第 i 題的作答反應,在二元計分的情況下,答對為 1,答錯為 0; ) ( j i P 指受試者 j 在第 i 題的答對機率; ) ( j i Q 指受試者 j 在第 i 題的答錯機率,Qi(j)1Pi(j)。 為了加速找到概似函數的最大值,通常是先對概似函數取對數,如公式 (2-3),再以 Newton-Raphson 法來進行迭代。
n i X i X i n i i Q P X X L L 1 1 1,..., | log[ ( ) ( )] log | u log (2-3) 使用 MLE 能力估計如公式(2-4)所示,而第 p 次的能力估計的變動量為δ( p) 如公式(2-5)所示: ) ( ) 1 -( ) (p p p δ (2-4)
[ log 2u| ]-1 log u| 2 ) ( L L δ p (2-5)貳、加權概似估計法
Lord(1983)發現,在使用 MLE 法估計個體能力值時會發生偏誤的情形,而且 對於能力值為負數的估計偏誤,會比能力值為正數的估計偏誤來得更嚴重。這種 不對稱的估計偏誤會導致用來做連結轉換的斜率值被低估,在垂直等化的情形下 會更嚴重。為了解決這個問題,Cox 與 Hinkley(1974)建議先行計算出估計值的誤 差量,然後在進行估計過程中將之減去,藉以改善估計誤差。而 Warm(1989) 提出了加權概似估計法(weighted likelihood estimation, WLE)來改善。首先,概似函數表示如下:
i ui n i i u i Q P L
1 1 ) ( ) ( | u (2-6) 其中,u
X ,...,1j Xnj
為所有作答反應的向量;θ 為受試者的真實能力;Pi()指受試者 j 在第 i 題的答對機率;Qi()指受試者 j 在第 i 題的答錯機率, ) ( 1 ) ( i i P Q 。接著對概似函數取對數後進行微分取 0 以求最大數(2-7)。
0 ' ) ( | u ln 1
PQ P P u L l n i (2-7) 其中P'P/ 假設有某個函數 f(θ)乘上概似函數(2-6)後,如公式(2-8)所示。
i ui n i i u i Q P f L f
1 1 ) ( ) ( | u (2-8) 同樣的,對公式(2-8)取對數後進行微分取 0 後,如公式(2-9)所示
0 ln ' ) ( 1
f PQ P P u n i (2-9) 假設有一組估計量 θ*能使得公式(2-9)達最大化, 當 f(θ)為一正整數時, 則 θ*為最大概似估計法的估計值,MLE(θ),而公式(2-9)會變成公式(2-7); 而當 f(θ)是個事前密度函數時,則公式(2-8)就會成為貝氏估計法,BME(θ), θ*為貝氏估計法的估計值。Lord(1983)將 MLE(θ)的偏誤以 BIAS(MLE(θ))表示,也就是 O(n-1),如公式 (2-10)所示: 2 2 )) ( ( I J MLE BIAS (2-10) 其中I P'2/PQ;J P'P"/PQ,而 2 2 / " P P
同樣的,Lord(1984)將 BME(θ) 的偏誤以 BIAS(BME(θ))表示,也同樣是 O(n-1),如公式(2-11)所示: I MLE BIAS BME BIAS( ()) ( ()) (2-11)
因為θ*為貝氏估計法的估計值,所以公式(2-11)可推導出如公式(2-12)
I f MLE BIAS BIAS ln )) ( ( ) ( * (2-12) 因為公式(2-12)的估計是不偏的,故將之設為 0。又依據公式(2-10)可求得公 式(2-13)如下:
I J f 2 ln (2-13) 將公式(2-13)代入公式(2-9),可得公式(2-14)如下,即為試題反應論中受試者 能力值的 WLE 法。 0 2 ' ) ( 1
I J PQ P P u n i (2-14) 理論上,WLE 法是 1 n 階的不偏估計式 (Warm, 1989) 。參、期望後驗估計法
期望後驗估計法(expected a-posteriori, EAP)的估計過程是依據貝氏理論,如 公式(2-15),其中公式(2-15)的分母可以表示如公式(2-16)(Baker & Kim, 2004)。 ) u ( ) ( ) , | u ( ) , u | ( j j j j j P g P g (2-15)
(u |) () ) u ( P g d P j j (2-16) 在局部獨立的假設下,受試者 j 的作答反應向量為uj
X ,...,1j Xnj
,其答對 機率如公式(2-17) ij ij X j n i i X j i j j P Q P
1 1 ) ( ) ( ) , | u ( (2-17)概似函數的條件機率是在給定個體能力值θ 的情況下,個體能力值則是從母 群的分布 g(θ)中隨機被抽取出來,因為公式(2-16)中包含了積分的運算式,因 此利用 Hermite-Gauss 分割點近似方法逼近常態分布 g(θ),Bock 和 Mislevy(1982) 提出近似點的方法,公式如(2-18):
q k k k q k k k k j j j A L A L E 1 1 ) u ( ) u ( ) u ( ) u ( u ) , u | ( (2-18) 公式(2-18)有幾個特點: 一、EAP 方法不需要 Newton-Raphson 法來進行迭代,而是直接估計能力值; 二、A(Xk)在最後被用來調整分割點的權重,透過前一步驟的概似函數進行更新; 三、EAP 的最後結果可以透過前一階段而得; 四、EAP 的能力估計是容易被獲得的。參、加入輔助變項之期望後驗估計法
加入輔助變項之期望後驗估計法(expected a-posteriori with ancillary variables, EAP_AV)主要是以 EAP 法為基礎,然後加入輔助變項進行後驗分布估計。加入 輔助變數之期望後驗估計法(EAP_AV)之公式如公式(2-15)與(2-16),因假 設抽樣的學生是來自於一個常態分布的母體,其平均數為μ,變異數為2,故公 式(2-15)之 g(θ)如下: 2 2 12 2 2 2 ) ( exp ) 2 ( ) , ; ( ) ( θ θ f θ g θ (2-19) Adams(1997)等人將平均數 μ 以迴歸模式 T j Y 取代,假設有 u 個輔助變項, 則Y 是一個 u 的向量,對於受試者 j,j Y 是固定且已知的條件變數(如性別或社j 經地位等輔助變數),β 是一個相對應的迴歸係數向量。其中,假設E ~ N( ,σ ) iid j 2 0 ,
則學生 j 的母群模式可表示為 T j j j Y β E θ 。
第三節 可能值方法
試題反應模式中,無法直接觀察到個體的能力值,亦即表示個體能力的測量 含有不確定性;而在計算群體統計量和相關連的標準誤時,應考量這些不確定性 (Allen, Donoghue, & Schoeps, 2001; Mullis, Martin, & Foy, 2008; OECD, 2009)。 而 PV 法是從後驗分布中隨機抽取學生的可能值,則能考量到上述提及的不確定 性;而且 PV 法並沒有先估計個體的能力再計算群體參數,而是直接估計母群的 參數,這樣可以使參數的估計更為精準(Mislevy & Sheehan, 1989)。PV 法是以潛在迴歸模式,加入學生答題反應和相關條件變項後計算每一位 學生的後驗機率分布,並從後驗分布中隨機抽取學生的可能值,以利於次級資料 分析者使用。當模式被正確界定時,可能值可以提供群體參數的一致性估計,但 並非個 體能 力的 不 偏估計 ,使 用可能 值的平 均並 不能代 表個別 學生 的能力 (Mislevy, et al., 1992)。 試題反應模式為條件機率的模式,它描述了以能力值θ 為條件而產生試題反 應的過程。此模式完整的定義需要界定能力值 θ 的密度函數 fθ( αθ; )。令 α 為 θ
分布的參數集。當定義單向度邊際試題反應模式(uni-dimensional marginal item
response models),常假設抽樣的受試者是來自於一個常態分布的母體,其平均數 為μ,變異數為2 。也就是: 2 2 12 2 2 2 ) ( exp ) 2 ( ) , ; ( ) ; ( θ θ f α θ fθ θ (2-20) 或者同義的式子, E (2-21) 其中,E ~ N(0,2)。
Adams(1997)等人使用迴歸模式YjT取代平均數μ,假設有 u 個輔助變項, 則Y 是一個 u 的向量,對於受試者 j,j Y 是固定且已知的條件變數(如性別或社j 經地位等學生變項),β 是一個相對應的迴歸係數向量。則受試者 j 的母群模式可 表示為 j T j j Y β E θ (2-22) 其中,假設E ~ N( ,σ ) iid j 2 0 。E 的分布應該會和j θ 相同,只是將其轉換為平j 均數為 0,利用迴歸模式 T j Y 取代平均數μ,其中Y 為 u 的向量,β 為迴歸係數,j 則母體的模式可以被替換為如下: )] ( )' ( 2 1 exp[ ) 2 ( ) , , ; ( 2 2 12 2 T j j T j n j j j Y Y Y f (2-23) 公式(2-23)為一常態分配,平均數為YTβ j ,及變異數為 2 σ ,若使用公式(2-23) 估算母體分配,則需要估算的參數為β,σ 和 ξ(試題參數),其邊際後驗機率可2 以被表示如公式(2-24),其中,X 為受試者 j 的作答反應 j ) , , , ; ( ) , , ; ( ) | ; ( ) | , , , ; ( 2 2 2 j j X j j j j j j j j Y X f Y f X f X Y h (2-24)
壹、抽取可能值
從受試者的能力值之後驗分布中抽取五個可能值,可能值的抽取步驟如下 (Foy, Galia, & Li, 2008):步驟一:從一個近似常態的分配P(, |xj,yj),固定σ 為 σˆ ,抽取一個 β。
步驟二:在β 的條件下,(且固定σ σˆ),公式(2-15)後驗分布的平均j和變異
步驟三:能力值從一個常態分布(平均j、變異數 σ)獨立抽取,此步驟重複五
次,每一位學生產生 5 個j的差補值,受試者雖然被施測較少的題數,
但是受試者的β 和 σ 是固定的,因此所有的受試者不管施測的題數都被
指定一組可能值。
貳、可能值方法之優點
Adams, Wilson & Wu (1997)指出利用 PV 法估計母群參數時,有下列四個優 勢:
一、利用學生答題反應直接估計母群體的參數,可以避免先估計個體能力,再以 估計值計算母群體參數這種兩階段步驟所衍生出來的估計誤差(Mislevy, 1984)。
二、納入學生背景變項進行參數估計,可以有效降低試題參數的估計誤差(Mislevy, 1984; Mislevy & Sheehan, 1989)。
三、納入學生背景變項進行估計,亦可以提高個別能力估計的精確度(Mislevy, 1984)。
四、若給予學生哪一題試題施測時考慮學生的背景變項,則在估計試題參數就應 該考慮這些背景變項,才能確保試題參數估計的一致性(Mislevy & Sheehan, 1989)。
參、大型測驗資料分析時未使用或誤用可能值方法造成的影響
一般而言,在大型測驗資料的分析上常遇到兩種錯誤的資料分析方式,一種 是以傳統的點估計方法進行估計,一種是錯誤的可能值使用方式,分別說明如下: 一、傳統的點估計方法進行估計產生估計偏誤目前國內許多大型測驗相關研究,大多是直接計算個別受試者能力值的平均 與變異,並未使用 PV 法進行分析,例如洪碧霞、林素微、林娟如(2006)即是 將 TASA 數學科施測資料採用上述方式進行分析研究。有學者研究指出,利用傳 統點估計方式去推論群體參數容易造成偏誤(Mislevey, 1991; Mislevy, et al., 1992; OECD, 2005; Lee, et al., 2007)。此外,von Davier, Gonzalez, & Mislevy(2009) 比較了傳統的點估計方法,最大概似估計法、期望後驗估計法以及 PV 法間的估 計效果,發現 PV 法對於回復群體參數有較好的回復性。Wu(2005)比較點估計 方法與 PV 法,在估計母群平均數時兩種方法並沒有明顯的差異,但在變異數估 計中,PV 法得到較好的結果。此外,王敏嫻(2011)的研究發現,在 BIB 與 NEAT 的水平等化連結的情境中,PV 法在群體能力平均數的估計效果上與其它點估計 方法比較起來差異不大,但是在群體能力標準差的估計上則明顯較佳。 二、錯誤的可能值使用方式導致估計偏誤 PV 正確的使用方法(PV_R)是將 5 個 PV 個別的用來計算 PV 的平均後, 再將此 5 個平均數進行估算;而 PV 錯誤的使用方法(PV_W)則是直接將針對 每個受試者所抽出的 5 個 PV 直接加以平均進行估算。以上這兩種方法雖然在估 算群體平均數時結果相當接近,但是在估算群體標準差時 PV_W 就會產生較大的 偏差(von Davier, et al., 2009)
第四節 測驗等化
測驗等化是利用統計的方法,將受試者在某一測驗的分數轉換至另一測驗分 數量尺,以比較兩測驗分數關係的過程。為了用來測量相同的特質或能力,這些 測驗的內容及難度都極為相似,因此,測驗等化的目的在調整測驗難度之差異而 非測驗內容之差異(Kolen & Brennan, 1995 )。而且測驗分數等化並不受試題內
容和受試者能力分布的影響。
一般國內外大型測驗,因題庫涵蓋不同認知程度及不同難度之試題,試題數 量無法由單一受試者於短時間內完成,因此多將欲施測之題目分別編製成數個不 同的題本分派給不同受試者進行施測,然後再將不同題本施測結果進行等化連 結,以便能計算出群體參數。其中 PISA 為採用 BIB(balanced incomplete block, BIB)(Nancy, James & John, 2001)等化設計(OECD, 2009);NAEP 則在數學與 科學使用 BIB 設計、閱讀與寫作方面則使用了 PBIB(partially balanced incomplete block, PBIB)設計(Andrew & Terry, 2001);TIMSS 則是每個題本由四個試題區 塊組合而成(每個題本均包含數學與科學各兩個試題區塊),而為了連結不同題 本,每個試題區塊在題本中出現 2 次(Graham, Christine, Alka, & Ebru, 2008);而 PIRLS 則採用 matrix sampling 設計,將 10 個 40 分鐘的試題區塊分派成 13 個題 本,每個題本包含 2 個試題區塊,每個試題區塊出現 3 次(Martin, M. O., Mullis, I. V. S. & Kennedy, A. M., 2007);國內的「臺灣學生學習成就評量資料庫」(Taiwan Assessment of Student Achievement, TASA)也於不同年度不同科目,分別採用了 BIB、PBIB 以及定錨不等組設計(non-equivalent groups with anchor test design,
NEAT)的等化設計(郭伯臣、曾建銘、吳慧珉,2012)。
測驗等化設計有許多種,諸如單組設計(single-group design)、等群組設計 (equivalent-grwoup design)、定錨不等組設計(NEAT)、平衡不完全區塊(BIB) 等。本研究主要以 BIB 與 NEAT 等化設計進行比較,故在此針對 NEAT 與 BIB 測驗等化設計做一簡要說明。
壹、定錨不等組設計
NEAT 設計包含兩個獨立的單組設計,其設計方式為在兩組受試者的母群體 中,隨機抽取 A、B 兩組受試者樣本。兩組受試者於不同的施測時間,A 組受試 者接受 Y 測驗,B 組受試者接受 Z 測驗。除此之外,A、B 受試樣本又另外須接
受同一份共同測驗 X,即為定錨試題。為避免順序因素的影響,通常定錨試題在 兩組樣本的測驗順序一樣,而測驗內容和難度必須與 Y、Z 測驗相似,其測驗長 度相當於一個分測驗(von Davier, Holland, & Thayer, 2004;Dorans & Holland, 2000;Tianyou, 2005)。NEAT 設計如表 2-1(Kolen & Brennan,1995;von Davier, et al., 2004)。 表 2-1 NEAT 設計 受試者群 定錨測驗 X Y 測驗 Z 測驗 A V V B V V 註:“V”為受試者必須受測之測驗 在 NEAT 設計中,每個受試樣本皆須施測定錨試題 X 測驗,因此,定錨試題 之試題參數好壞將會影響等化連結效果。若定錨試題挑選恰當,則可以避免練習 (practice)、疲勞(fatigue)、學習(learning)、順序因素(order effects)及需要 大樣本的問題(Klein & Jarjoura, 1985)。使用 NEAT 設計測驗等化只需要假設受 試群體是隨機抽取,不必假設兩受試群體有相同的能力值。NEAT 設計的定錨試 題內容要盡可能相似且試題難度要相同,因為定錨試題是用來調整兩個不同能力 之群體所造成的等化風險(Petersen, Kolen & Hoover,1993)。
貳、平衡不完全區塊設計
BIB 設計將試題分成若干試題皆不重複的試題區塊(block),受試者只需接 受若干試題區塊的試題,且不同受試者可能接受部分相同、完全相同、或完全不 同的試題區塊。最後,將所有受試者的作答反應資料堆疊進行等化分析,以達到 能力估計的目的,BIB 設計如表 2-2(曾玉琳、王暄博、郭伯臣、許天維,2006)。 表 2-2 是以 7 個題本之 BIB 設計為範例,在此設計範例中,有 7 個題本(S1~S7); 7 個試題區塊(M1~M7);每個題本包含 3 個試題區塊(k1~k3)。BIB 設計中試題區塊序號的組合不重複,如:S1 題本是由試題區塊 M1、M2、M4 組合而成, 則設計中其他題本(S2~S7)就不會在有相同試題區塊(M1、M2、M4)的組合。 表 2-2 BIB 設計 題本序號 M1 M2 M3 M4 M5 M6 M7 S1 V V V S2 V V V S3 V V V S4 V V V S5 V V V S6 V V V S7 V V V BIB 設計的優點為試題區塊與題本的配置方式採用螺旋(spiral)式排列方 式,此種排列方式可使每一個試題區塊的施測次數相同。此設計在無作答時間 (response time)的限制情形下,BIB 設計必須符合下列限制,求出符合的最佳 解(van der Linden, Veldkamp & Carlson, 2004;Nemhauser & Wolsey, 1999):
1. 每一個題本配置的試題區塊數目,如公式(2-25); 2. 每一個試題區塊在所有題本中出現的次數,如公式(2-26); 3. 成對試題區塊在所有題本中出現的次數,如公式(2-27); 4. 成對試題區塊與組型的一致性,如公式(2-28)。
t y yx k w 1 , x1,...,b (2-25)
b x yx r w 1 , y1,...,t (2-26)
b x ygx z 1 , yg 1,...,t (2-27) ygx gx yx w z w 2 , y g 1,...,t, x1,...,b (2-28) 其中:t指試題區塊數; x 指題本序號,x1,...,b; k指每個題本配置的試題區塊數,即區塊數目(number of blocks);r指每一試題區塊在題本中出現的次數; y 指題庫中個別試題區塊代號,y1,...,t; g 指題庫中成對區塊中第二個試題區塊代號,g 1,...,t; λ 指成對試題區塊在題本中出現的次數; yx w 指試題區塊與題本的配置組型,其中wyx
0,1 , y1,...,t, x1,...,b, 如題本 S1 出現 M1、M2、M4 三個試題區塊,則w11,w21,w41
1 ; ygx z 指成對試題區塊與題本的配置組型,zygx
0,1 ;y g1,...,t; b x1,..., 。 另外,BIB 設計必須符合三項基本限制,但實際設計情況,必須考慮試題內 容、形式及作答時間(王暄博,2006): 1. 每一個題本內的試題區塊數要相同; 2. 試題區塊作結合以求出最小題本數; 3. 每一個試題區塊在所有題本中出現的次數要相同。第三章
研究方法
本研究係以單向度單參數試題反應理論為基礎,使用模擬資料進行模擬實 驗,最後探討不同估計方法對於群體參數的估計效果。本章節共分為六個部分: 一、研究流程;二、測驗等化設計;三、模擬設計;四、研究工具;五、評估準 則。第一節 研究步驟
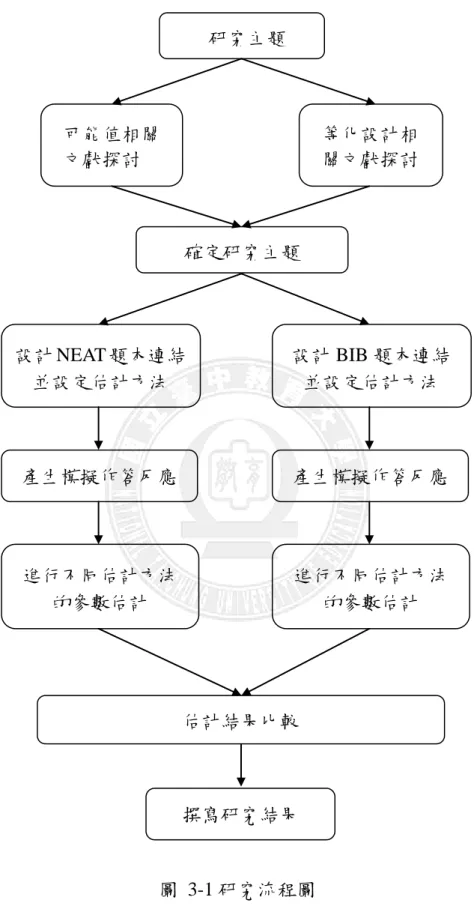
本研究首先設定研究主題,在探討相關文獻後,將關注焦點放不同垂直等化 設計下各種估計方法對個體能力與群體參數的估計準確度的比較。於是參考相關 文獻設定不同實驗情境,然後依不同實驗情境分別產生模擬資料,接著就不同的 模擬資料進行不同估計方法之參數估計,然分別就產出結果進行比較分析,最後 撰寫研究結果。研究流程圖如圖 3-1:圖 3-1 研究流程圖 研究主題 確定研究主題 設計 NEAT 題本連結 並設定估計方法 產生模擬作答反應 進行不同估計方法 的參數估計 估計結果比較 撰寫研究結果 設計 BIB 題本連結 並設定估計方法 產生模擬作答反應 進行不同估計方法 的參數估計 可能值相關 文獻探討 等化設計相 關文獻探討
第二節 測驗等化設計
本研究中探討不同等化設計對於個體能力估計之效果與群體參數的回復 性,王暄博(2006 )研究顯示,不論在 BIB 或 NEAT 設計中,隨著試題區塊 數增加,受試者能力值之風險值也跟著增加,故本研究僅針對試題區塊數為 7 的 BIB 與 NEAT 等化設計進行探討。壹、NEAT 等化設計
表 3-1 為 NEAT 設計表,共包含 7 個題本、每題本 3 個區塊、每個區塊包含 12 個試題數,其中 M1 為定錨試題區塊。 表 3-1 NEAT 設計表 題本序號 區塊(K1) 區塊(K2) 區塊(K3) S1 M1 M2 M3 S2 M1 M4 M5 S3 M1 M6 M7 題本(b)=3、區塊(t)=7、試題區塊數(k)=3、每個區塊試題數=12 關於高低年級年級間的等化連結,係由低年級的 M1 區塊中,挑選出難度參 數較高的數題做為定錨題,並將之放入高年級的 M1 區塊中,做為高年級 M1 區 塊的的試題。排列方式如表 3-2 所示表 3-2 NEAT 高低年級垂直等化連結設計表 低(L)年級 高(H)年級 L-M1(定錨區塊) H-M1(包含由 L-M1中的選出的定錨題) L-M2 H-M2 L-M3 H-M3 → L-M7 H-M7 1. H-M1 及 L-M1 分別為高低年級的定錨區塊。 2. H-M1 中包含由 L-M1 裡選出來的難度較高的題目,做為連結高低年級 間的定錨題。
貳、BIB 等化設計
表 3-3 為 BIB 設計表,共包含 7 個題本、7 個試題區塊,每個題本包含 3 個 試題區塊、每一試題區塊在題本中出現的次數為 3 次、以及成對試題區塊在題 本中出現的次數只有 1 次。根據 BIB 設計之條件,每個題本中試題區塊的組合 不重複。 表 3-3 BIB 等化設計 題本序號 區塊 (k1) 區塊 (k2) 區塊 (k3) S1 M1 M2 M4 S2 M2 M3 M5 S3 M3 M4 M6 S4 M4 M5 M7 S5 M5 M6 M1 S6 M6 M7 M2 S7 M7 M1 M3 BIB 垂直等化設計中不同兩年級的試題排列均依照 BIB 設計排列,在定錨題 部分是將 H 年級中每個試題區塊中,放入 L 年級對應試題區塊中難度較難的試 題,如表 3-4 中,H 年級的試題區塊 1(H-M1)中,包含 L 年級試題區塊 1 內試題難度較難的 g 題(L-M1-1~L-M1-g)定錨試題。 表 3-4 BIB 高低年級垂直等化連結設計表 低(L)年級 高(H)年級 L-M1 H-M1(包含由 L-M1中的選出的定錨題) L-M2 H-M2(包含由 L-M2中的選出的定錨題) L-M3 H-M3(包含由 L-M3中的選出的定錨題) → L-M7 H-M7(包含由 L-M7中的選出的定錨題) 每個高年級試題區塊中,皆包含由相對對應低年級試題區塊中選出來的 難度較高的題目,做為連結高低年級間的定錨題。
第三節 模擬條件與估計方法設定
本研究係利用電腦模擬產生作答反應,並重覆進行 50 次的資料模擬後,分 別計算在不同等化設計及不同情境下各種估計方法所估計受試者的能力值及群 體參數的根均方差。變項設定如表 3-5,並分別說明如下: 表 3-5 不同等化設計之變項設定 實驗變項 變項設定 試題長度 每個題本施測題數 18 題及 36 題 受試者群能力分布 如表3-8 每個年級施測人數 10920 人及 16128 人 試題難度參數分布(b) 截尾常態分布,高年級組:-2~4,低年級組: 2~-4 估計方法 PV、PV_W、EAP_AV、EAP、MLE、WLE 等化設計 BIB、NEAT 每一情形模擬資料集個數 50 次壹、試題長度
本次研究參考王暄博(2006)之實驗設計,模擬每個題本施測題數為 36 題, 因為試題區塊數為 3,故每個試題區塊之試題數 12 題。而依據王暄博(2006)的 研究發現,定錨題數愈多愈好;但在施測題本題數為 36 題的情形下,定錨題數 6 題和 9 題的精確度差異不大,故本次設定定錨題數為 6 題。此外,同時模擬施測 題數 18 題、定錨題 3 題之情形以做為參照比較,如表 3-6 說明。 表 3-6 試題長度設定一覽表 題本題數 試題區塊 題數 定錨題數 施測總題數 (NEAT) 施測總題數 (BIB) 36 12 6 162 154 18 6 3 81 77貳、受試者能力分布設定
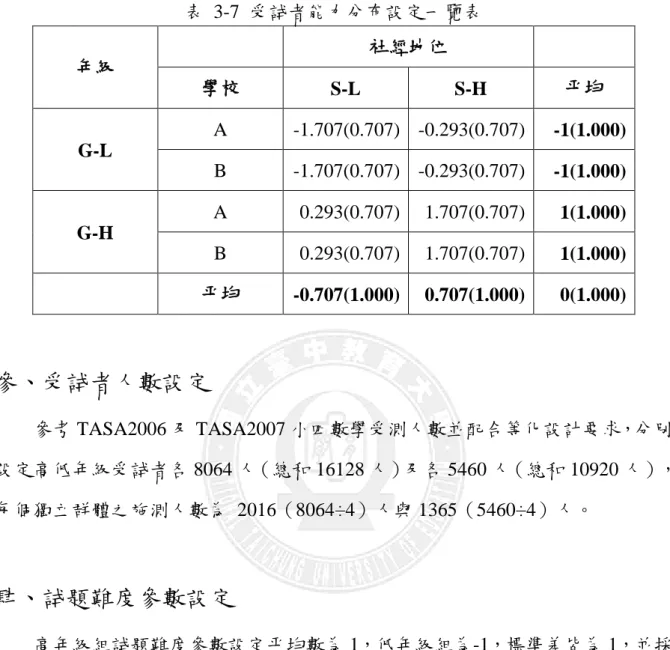
本研究參考王暄博(2006)的實驗設計,將高低年級群體能力平均數分別設 定為 1 及-1,並同時參考 von Davier、Gonzalez 和 Mislevy(2009)設計,分別將高 低年級各設定 2 組背景變項,分別是父母社經地位(Socioeconomic Status, SES)類 別(高(SH)低(SL))及學校類別((A)校及(B)校)。學校間群體能力 平均差異為 0,高底社經地位分別差距群體能力平均各正負 0.707,不同群體之標 準差皆為 0.707,而群體標準差為 1.000(0.7072+0.7072)詳如表 3-7。表 3-7 受試者能力分布設定一覽表 年級 社經地位 學校 S-L S-H 平均 G-L A -1.707(0.707) -0.293(0.707) -1(1.000) B -1.707(0.707) -0.293(0.707) -1(1.000) G-H A 0.293(0.707) 1.707(0.707) 1(1.000) B 0.293(0.707) 1.707(0.707) 1(1.000) 平均 -0.707(1.000) 0.707(1.000) 0(1.000)
參、受試者人數設定
參考 TASA2006 及 TASA2007 小四數學受測人數並配合等化設計要求,分別 設定高低年級受試者各 8064 人(總和 16128 人)及各 5460 人(總和 10920 人), 每個獨立群體之施測人數為 2016(8064÷4)人與 1365(5460÷4)人。肆、試題難度參數設定
高年級組試題難度參數設定平均數為 1,低年級組為-1,標準差皆為 1,並採 平均數上下 3 個標準差之截尾常態分布,故高年級組之範圍界定於 -2~4,記為 N(1,1);低年級組之範圍界定於 2~-4,記為 N(-1,1)。伍、估計方法
本研究主要為探討不同估計方法對於個體能力估計與群體參數估計之效 果,估計方法分計有單向度納入輔助變數之可能值方法(PV)、加入輔助變數之以及加權最大概似估計法(WLE)五種。
有關 PV 法估計個體能力的部份係用 5 個可能值平均數來表示受試者個體能 力值,此種方法於 von Davier, Gonzalez,& Mislevy(2009)的研究中以 PV_W(“W” 為 wrong)表示,這是常見的錯誤使用 PV 法,如公式 3-1: 5 PV PV PV PV PV PV i1 i2 i3 i4 i5 i (3-1) 其中,i 表示受試者人數,i1,2,3,...,N; PVi1~PVi5 為第 i 位受試者抽取的 5 個可能值。
第四節 研究工具
本研究使用的工具有 MATLAB 軟體、Acer ConQuest 2.0 軟體,茲分述如下。
壹、MATLAB 2009
MATLAB 2009 主要用來模擬產生受試者的能力、背景變項與題本、試題的 難度參數,然後進行模擬作答反應,並計算個體能力與群體參數的根均方差與估 計誤差。
貳、Acer ConQuest 2.0
Acer ConQuest 2.0 可應用於單向度、多向度 IRT 模式。本研究使用 Acer
ConQuest 2.0 軟體進行能力與試題參數估計,分別利用單向度可能值方法(PV)、
加入輔助變數之期望後驗估計法(EAP_AV)、期望後驗估計法(EAP)、最大概 似估計法(MLE)以及加權概似估計法(WLE)進行個體能力與群體參數估計。
第五節 評估準則
本研究係將模擬產生之受試者能力參數視為真值,並然後模擬 50 次,計算 不同等化設計下不同的估計方法之根均方差(RMSE),透過分別計算個體能力 與群體參數之 RMSE 來了解不同研究設計下個體能力估計與群體參數估計之效 果。 RMSE 較小即表示該情境之估計誤差小,有較好的估計結果;反之則表示 估計結果較差。壹、受試者個體能力值
受試者個體能力值之 RMSE 如公式 3-1, N N i i i
1 2 ) ˆ ( ) ˆ , ( RM SE (3-1) 其中,i 表示受試者人數;i1,2,3,...,N
1,2,3,...,N
:表示受試者能力真值 ˆ
ˆ1,ˆ2,ˆ3,...,ˆN
:表示受試者能力估計值貳、受試者群體參數
本研究中分別探討受試者之群體能力平均值與標準差兩個部分。受試者群體 能力平均值之 RMSE 如公式 3-2,受試者群體能力標準差之 RMSE 如公式 3-3。 50 ) ˆ ( ) ˆ , ( RM SE 50 1 2
m m m (3-2) 其中 m 表示每一情形模擬資料集個數,m1,2,3,...,50 ) ˆ ,..., ˆ , ˆ , ˆ ( ˆ 1 2 3 m :在第 m 個模擬資料集之群體能力平均估計值 ) ,..., , , (1 2 3 m :在第 m 個模擬資料集之群體能力平均真值50 ) ˆ ( ) ˆ , ( RM SE 50 1 2
m m m (3-3) ) ˆ ..., ˆ , ˆ , ˆ ( ˆ 1 2 3 m :在第 m 個模擬資料集之群體能力標準差估計值 ) ..., , , (1 2 3 m :在第 m 個模擬資料集之群體能力標準差真值第四章
研究結果與討論
本章中分為三節,第一節為 NEAT 等化設計各種估計結果的呈現與比較,第 二節為 BIB 等化設計各種估計結果的呈現與比較,第三節為二種等化設計間的綜 合比較。第一節 NEAT 等化設計估計結果
本研究為 NEAT 等化設計下個體能力及群體能力參數估計效果的探討,並就 不同施測人數、不同施測題數及不同估計方法等三種面向進行分析比較。壹、個體能力估結果比較
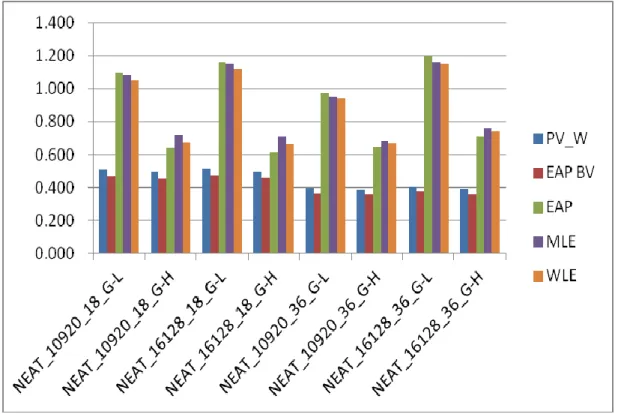
一、不同施測人數間之比較 如圖 4-1 所示。在施測題數為 18 題的情境中,就 PV_W 及 EAP_AV 此二種 估計方法而言,施測人數 10920 的個體能力估計的 RMSE 皆略低於 16128 人的情 境,但差異極小。而在 EAP、MLE、WLE 等另外三種方法在估計個體能力方面, 就低年級群組方面,此 3 種估計方法的 RMSE 亦是施測人數 10920 的個體能力估 計的 RMSE 皆略低於 16128 人的情境,但是在高年級組部份,則是 16128 人的情 境的 RMSE 略低,但差異皆不大。 而在施測題數為 36 題的部份,五種估計方法的 RMSE 皆是施測人數 10920 人的情境低於 16128 人的情境,除了在低年級群組中 EAP、MLE、WLE 此三種 方法的 RMSE 在 2 種施測人數情境間差異較大外,其餘情境差異不大。 二、不同施測題數間之比較如圖 4-1 所示,首先就 PV_W 及 EAP_AV 二種估計方法而言,不管是 10920 人的情境抑或是 16128 人的情境下,36 題的施測情境的 RMSE 皆低於 18 題的施 測情境。而對於 EAP、MLE、WLE 等三種估計方法的 RMSE 而言,除了 EAP 在 10920 人低年級群組,以及 MLE、WLE 在 10920 人高低年級群組是 36 題情境低 於 18 題情境外,其餘情境的 RMSE 則是 18 題情境低於 36 題情境。
圖 4-1 NEAT 設計個體能力不同估計方法 RMSE
三、不同估計方法間之比較
不同情境中個體能力值估計結果之 RMSE 如表 4-4 所示。其中 PV_W 及 EAP_AV 方法的 RMSE 遠優於 EAP、MLE 及 WLE 三種估計方法;而對 PV_W 及 EAP_AV 這二種方法而言,EAP_AV 又是優於 PV_W。
四、綜合討論 在 NEAT 等化設計下,個體能力值估計在本研究的不同施測人數情境中的估 計結果相差不大。與王暄博(2006)及王敏嫻(2011)結果相似。而在不同施測 數之比較下,則 PV_W 及 EAP_AV 這二種納入背景變項的估計法皆隨著受試題 數的增加而估計愈精準,此一研究果與王敏嫻(2011)結果就水平等化下之估計 結果相似。 而就不同估計方法間之比較來看,PV_W 及 EAP_AV 方法的 RMSE 遠優於 EAP、MLE 及 WLE 三種估計方法;而對 PV_W 及 EAP_AV 這二種方法而言, EAP_AV 又是優於 PV_W。
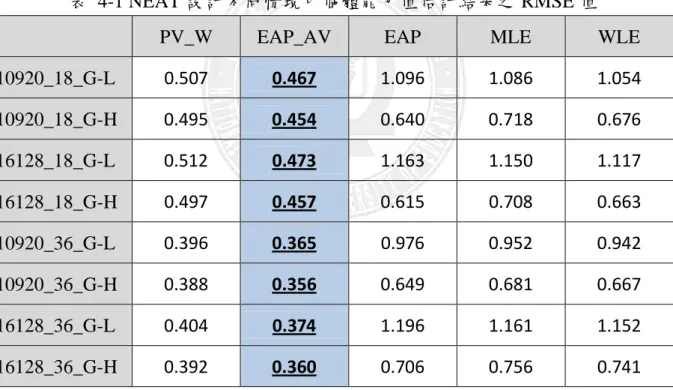
表 4-1 NEAT 設計不同情境中個體能力值估計結果之 RMSE 值
PV_W EAP_AV EAP MLE WLE
10920_18_G-L 0.507 0.467 1.096 1.086 1.054 10920_18_G-H 0.495 0.454 0.640 0.718 0.676 16128_18_G-L 0.512 0.473 1.163 1.150 1.117 16128_18_G-H 0.497 0.457 0.615 0.708 0.663 10920_36_G-L 0.396 0.365 0.976 0.952 0.942 10920_36_G-H 0.388 0.356 0.649 0.681 0.667 16128_36_G-L 0.404 0.374 1.196 1.161 1.152 16128_36_G-H 0.392 0.360 0.706 0.756 0.741 註:加底線者為 RMSE 值最低之估計方法
貳、群體能力參數估計結果比較
一、不同施測人數間之比較就群體能力平均數的估計結果而言,首先,不管是高年級還是低年級,PV、 PV_W 及 EAP_AV 方法估計群體能力平均數的 RMSE 皆遠低於 EAP、MLE、WLE 等三種估計方法(圖 4-2)。而在施測題數為 18 題的情境中,就 PV、PV_W 及 EAP_AV 此三種估計方法而言,施測人數 10920 的群體能力平均數的 RMSE 皆略 低於 16128 人的情境,但差異不大。而在 EAP、MLE、WLE 等另外三種方法在 估計群體能力平均數方面,就低年級群組方面,此 3 種估計方法的 RMSE 亦是施 測人數 10920 的群體能力平均數的 RMSE 皆略低於 16128 人的情境,但是在高年 級組部份,則是 16128 人的情境的 RMSE 略低,但差異皆不大。 而在施測題數為 36 題的部份,六種估計方法的 RMSE 皆是施測人數 10920 人的情境優於 16128 人的情境,除了在低年級群組中 EAP、MLE、WLE 此三種 方法的 RMSE 在 2 種施測人數情境間差異較大外,其餘情境差異不大。 就群體能力標準差的估計結果而言,如圖 4-3 所示,PV 的估計結果遠優於其 它五種估計方法。而不管是在題數為 18 題或是 36 題的情境中,不同施測人數間 相對之各種估計法的 RMSE 均無明顯差異。 二、不同施測題數間之比較 在群體能力平均數的 RMSE 部份,如圖 4-2 所示,就 PV、PV_W 及 EAP_AV 三種估計方法而言,不管是 10920 人的情境抑或是 16128 人的情境下,36 題的施 測情境的 RMSE 皆低於 18 題的施測情境。而對於 EAP、MLE、WLE 等三種估 計方法的 RMSE 而言,除了在 10920 人低年級群組是 36 題情境低於 18 題情境外, 其餘情境的 RMSE 則是 18 題情境低於 36 題情境。 就群體能力標準差而言,不管是在 10920 人的情境還是 16128 人的情境中, 五種估計方法的 RMSE 都是 36 題的的情境低於 18 題的情境。
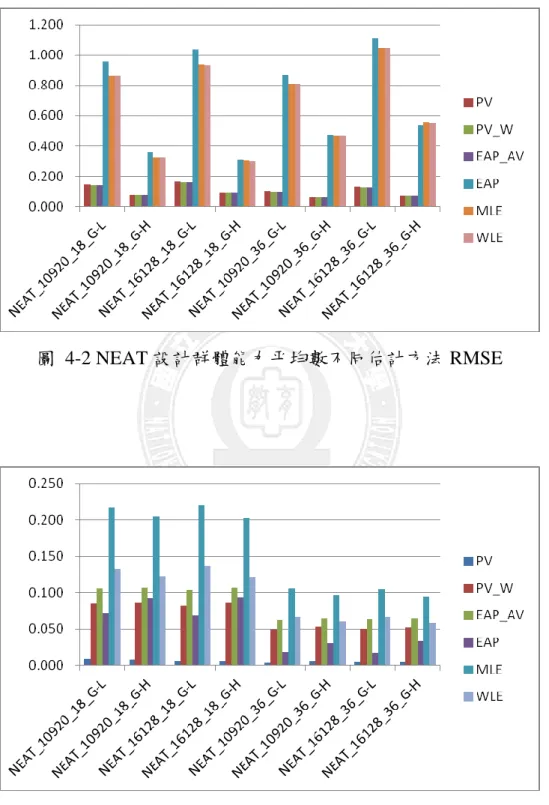
圖 4-2 NEAT 設計群體能力平均數不同估計方法 RMSE
三、不同估計方法間之比較
群體能力平均數與群體能力標準差在不同情境中估計結果之 RMSE 如表 4-2 及表 4-3 所示。就群體能力平均數的部份來說,其中 PV、PV_W 及 EAP_AV 三 種方法的 RMSE 低於 EAP、MLE 及 WLE 三種估計方法;在 PV、PV_W 及 EAP_AV 這部份而言,這三種估計法的差距非常小,最高及最低差距最多僅有 0.004 而已。 而就 EAP、MLE、WLE 這三種估計方法而言,EAP 的估計效果最差,但是整體 而言 EAP 等三種估計法的 RMSE 的差異亦不大。 而在群體能力標準差的估計情形來看,非常明顯的 PV 法的 RMSE 遠低於各 種估計法,表示 PV 的估計效果最好。而在 EAP、MLE、WLE 這三種估計方法 的部份,EAP 的估計效果最佳。此種結果與王敏嫻(2011)就水平等化研究的結 果整似。 表 4-2 NEAT 設計不同情境中群體能力平均數估計結果之 RMSE 值
PV PV_W EAP_AV EAP MLE WLE
10920_18_G-L 0.143 0.139 0.140 0.960 0.865 0.862 10920_18_G-H 0.079 0.081 0.080 0.359 0.325 0.324 16128_18_G-L 0.162 0.158 0.159 1.037 0.940 0.937 16128_18_G-H 0.092 0.095 0.095 0.311 0.307 0.299 10920_36_G-L 0.102 0.098 0.098 0.869 0.809 0.810 10920_36_G-H 0.059 0.060 0.060 0.472 0.470 0.468 16128_36_G-L 0.130 0.125 0.126 1.112 1.050 1.049 16128_36_G-H 0.073 0.075 0.075 0.536 0.559 0.554 註:加底線者為 RMSE 值最低之估計方法
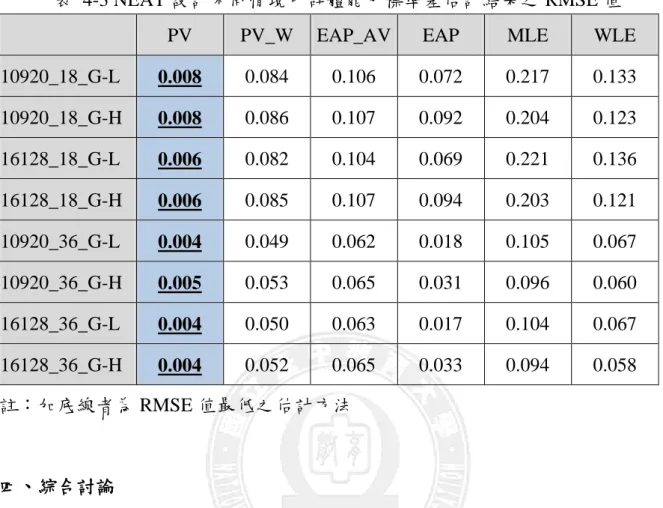
表 4-3 NEAT 設計不同情境中群體能力標準差估計結果之 RMSE 值
PV PV_W EAP_AV EAP MLE WLE
10920_18_G-L 0.008 0.084 0.106 0.072 0.217 0.133 10920_18_G-H 0.008 0.086 0.107 0.092 0.204 0.123 16128_18_G-L 0.006 0.082 0.104 0.069 0.221 0.136 16128_18_G-H 0.006 0.085 0.107 0.094 0.203 0.121 10920_36_G-L 0.004 0.049 0.062 0.018 0.105 0.067 10920_36_G-H 0.005 0.053 0.065 0.031 0.096 0.060 16128_36_G-L 0.004 0.050 0.063 0.017 0.104 0.067 16128_36_G-H 0.004 0.052 0.065 0.033 0.094 0.058 註:加底線者為 RMSE 值最低之估計方法 四、綜合討論 在 NEAT 等化設計下,群體能力平均數估計在本研究的不同施測人數情境中 的估計結果相差不大。而在不同施測數之比較下,則 PV、PV_W 及 EAP_AV 這 三種納入背景變項的估計法皆隨著受試題數的增加而估計愈精準,此一研究果與 王敏嫻(2011)就水平等化下之估計結果相似。從不同估計方法間的比較來看, PV、PV_W 及 EAP_AV 這三種納入背景變項的估計法的估計效果優於其它三種 未納入背景變項的估計法,此一研究果亦與王敏嫻(2011)就水平等化下之估計 結果相似。 就群體能力標準差而言,同樣是不同施測人數情境下的 RMSE 均無明顯差 異;隨著受試題數的增加,則估計愈精準,此一研究結果與王敏嫻(2011)就水 平等化下之估計結果相似。從不同估計方法間的比較來看,PV 的估計效果遠優 於各種估計方法,同樣的與王敏嫻(2011)就水平等化下之估計結果相似。
此外,就 PV 及 PV_W 這二種估計方法而言,在群體能力平均數的估計上, PV 及 PV_W 幾乎沒有任何差別,而在群體能力標準差的估計上,PV_W 的 RMSE 遠高於 PV,表示 PV_W 在群體能力標準差的估計上產生了偏誤,此一研究結果 與 von Davier 等人(2009)的研究結果相近。
第二節 BIB 等化設計估計結果
本研究為 BIB 等化設計下個體能力及群體能力參數估計效果的探討,並就不 同施測人數、不同施測題數及不同估計方法等三種面向進行分析比較。壹、個體能力估結果比較
一、不同施測人數間之比較 如圖 4-4 所示。在施測題數為 18 題的情境中,就 PV_W 及 EAP_AV 此二種 估計方法而言,施測人數 10920 的個體能力估計的 RMSE 皆略低於 16128 人的情 境,但差異極小。而在 EAP、MLE、WLE 等另外三種方法在估計個體能力方面, 除了 EAP 法在高年級群組是 16128 人的情境低於 10920 人情境外,其餘皆是 10920 人的情境低於 16128 人情境。但是總體而言此三種估計方法的不同人數的情境中 差異並不大。 而在施測題數為 36 題的部份,五種估計方法的 RMSE 皆是施測人數 16128 人的情境低於 10920 人的情境,但是差異皆非常小;尤其是 PV_W 和 EAP_AV 這二種估計法,相差僅 0.001 而已,甚至 PV_W 在低年級群組中完全一致。 二、不同施測題數間之比較 如圖 4-4 所示,首先就 PV_W 及 EAP_AV 二種估計方法而言,不管是 10920 人的情境抑或是 16128 人的情境下,36 題的施測情境的 RMSE 皆低於 18 題的施 測情境。而對於 EAP、MLE、WLE 等三種估計方法的 RMSE 而言,除了在 10920人低年級情境中三種估計方法是 18 題情境低於 36 題情境外,其餘皆是 36 題情 境低於 18 題情境。
圖 4-4 BIB 設計個體能力不同估計方法 RMSE
三、不同估計方法間之比較
不同情境中個體能力值估計結果之 RMSE 如表 4-4 所示。其中 PV_W 及 EAP_AV 方法的 RMSE 遠優於 EAP、MLE 及 WLE 三種估計方法;而對 PV_W 及 EAP_AV 這二種方法而言,EAP_AV 又是優於 PV_W。 四、綜合討論 在 BIB 等化設計下,個體能力值估計在本研究的不同施測人數情境中的估計 結果相差不大。與王暄博(2006)及王敏嫻(2011)結果相似。而在不同施測數 之比較下,則 PV_W 及 EAP_AV 這二種納入背景變項的估計法皆隨著受試題數 的增加而估計愈精準,此一研究果與王敏嫻(2011)結果就水平等化下之估計結 果相似。
而就不同估計方法間之比較來看,PV_W 及 EAP_AV 方法的 RMSE 遠優於 EAP、MLE 及 WLE 三種估計方法;而對 PV_W 及 EAP_AV 這二種方法而言, EAP_AV 又是優於 PV_W。
表 4-4 BIB 設計不同情境中個體能力值估計結果之 RMSE 值
PV_W EAP_AV EAP MLE WLE
10920_18_G-L 0.492 0.452 0.947 0.937 0.907 10920_18_G-H 0.482 0.441 0.661 0.721 0.678 16128_18_G-L 0.503 0.463 1.062 1.048 1.017 16128_18_G-H 0.490 0.449 0.651 0.734 0.688 10920_36_G-L 0.395 0.364 1.000 0.970 0.960 10920_36_G-H 0.385 0.353 0.629 0.672 0.655 16128_36_G-L 0.395 0.363 0.968 0.939 0.929 16128_36_G-H 0.384 0.352 0.613 0.653 0.637 註:加底線者為 RMSE 值最低之估計方法
貳、群體能力參數估計結果比較
一、不同施測人數間之比較 就群體能力平均數的估計結果而言。同樣的,不管是高年級還是低年級,PV、 PV_W 及 EAP_AV 方法估計群體能力平均數的 RMSE 皆遠低於 EAP、MLE、WLE 等三種估計方法(圖 4-5)。而不管在施測題數 18 題或是 36 題,10920 人情境的 各種估計法的 RMSE 大部份是低於 16128 人情境的相對之估計法(圖 4-5、表 4-5)。然總體觀之,不同施測人數間相對之各種估計法的 RMSE 差異並不大。遠優於其它四種估計方法。同樣的不管是在題數為 18 題或是 36 題的情境中,不 同施測人數間相對之各種估計法的 RMSE 亦均無明顯差異。 二、不同施測題數間之比較 在群體能力平均數的 RMSE 部份,如圖 4-5 所示,就 PV、PV_W 及 EAP_AV 三種估計方法而言,在 16128 人的施測情境中,36 題的施測情境的 RMSE 皆低 於 18 題的施測情境;而在 10920 人的施測情境中,則是 18 題的施測情境的 RMSE 低於 36 題的施測情境。對於 EAP、MLE、WLE 等三種估計方法的 RMSE 而言, 除了在 16128 人低年級群組是 36 題情境低於 18 題情境外,其餘情境則是 18 題 情境低於 36 題情境。 就群體能力標準差而言,如圖 4-6 所示,不管是在 10920 人的情境還是 16128 人的情境中,五種估計方法的 RMSE 都是 36 題的的情境低於 18 題的情境。 圖 4-5 BIB 設計群體能力平均數不同估計方法 RMSE
圖 4-6 BIB 設計群體能力標準差不同估計方法 RMSE
三、不同估計方法間之比較
群體能力平均數與群體能力標準差在不同情境中估計結果之 RMSE 值如表 4-5 及表 4-6 所示。就群體能力平均數的部份來說,其中 PV、PV_W 及 EAP_AV 方法的 RMSE 低於 EAP、MLE 及 WLE 三種估計方法;在 PV、PV_W 及 EAP_AV 這部份,這三種估計法的差距非常小,最多僅有 0.004,其至在部份情境中會出 現完全一致的 RMSE。而就 EAP、MLE、WLE 這三種估計方法而言,EAP 的估 計效果最差,但是整體而言這三種估計法的差異不大。 而在群體能力標準差的估計情形來看,PV 的 RMSE 遠低於各種估計方法, 此種結果亦與王敏嫻(2011)就水平等化研究的結果整似。 四、綜合討論 在 BIB 等化設計下,群體能力平均數估計在本研究的不同施測人數情境中的 估計結果相差不大。而在不同施測數之比較下,則 PV、PV_W 及 EAP_AV 這三 種納入背景變項的估計法皆隨著受試題數的增加而估計愈精準,此一研究果與王
敏嫻(2011)就水平等化下之估計結果相似。從不同估計方法間的比較來看,PV、 PV_W 及 EAP_AV 這三種納入背景變項的估計法的估計效果優於其它三種未納入 背景變項的估計法,此一研究果亦與王敏嫻(2011)就水平等化下之估計結果相 似。 就群體能力標準差而言,同樣是不同施測人數情境下的 RMSE 均無明顯差 異;隨著受試題數的增加,則估計愈精準,此一研究結果與王敏嫻(2011)就水 平等化下之估計結果相似。從不同估計方法間的比較來看,PV 的估計效果遠優 於各種估計方法,同樣的與王敏嫻(2011)就水平等化下之估計結果相似。 此外,就 PV 及 PV_W 這二種估計方法而言,在群體能力平均數的估計上, PV 及 PV_W 幾乎沒有任何差別,而在群體能力標準差的估計上,PV_W 的 RMSE 遠高於 PV,表示 PV_W 在群體能力標準差的估計上產生了偏誤,此一研究結果 與 von Davier 等人(2009)的研究結果相近。 表 4-5 BIB 設計不同情境中群體能力平均數估計結果之 RMSE 值
PV PV_W EAP_AV EAP MLE WLE
10920_18_G-L 0.099 0.095 0.095 0.799 0.696 0.700 10920_18_G-H 0.047 0.046 0.047 0.414 0.333 0.338 16128_18_G-L 0.132 0.127 0.128 0.925 0.826 0.825 16128_18_G-H 0.077 0.078 0.078 0.386 0.352 0.349 10920_36_G-L 0.101 0.096 0.097 0.893 0.832 0.832 10920_36_G-H 0.059 0.061 0.061 0.452 0.460 0.457 16128_36_G-L 0.098 0.095 0.095 0.860 0.803 0.802 16128_36_G-H 0.057 0.058 0.058 0.421 0.431 0.428 註:加底線者為 RMSE 值最低之估計方法
表 4-6 BIB 設計不同情境中群體能力標準差估計結果之 RMSE 值
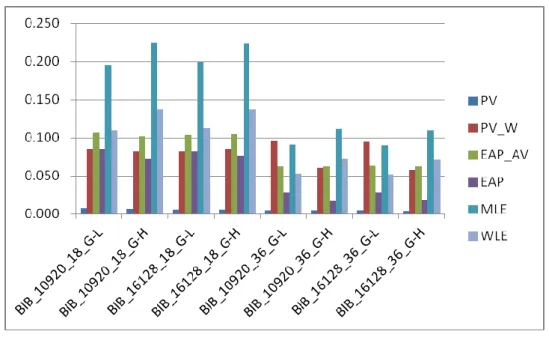
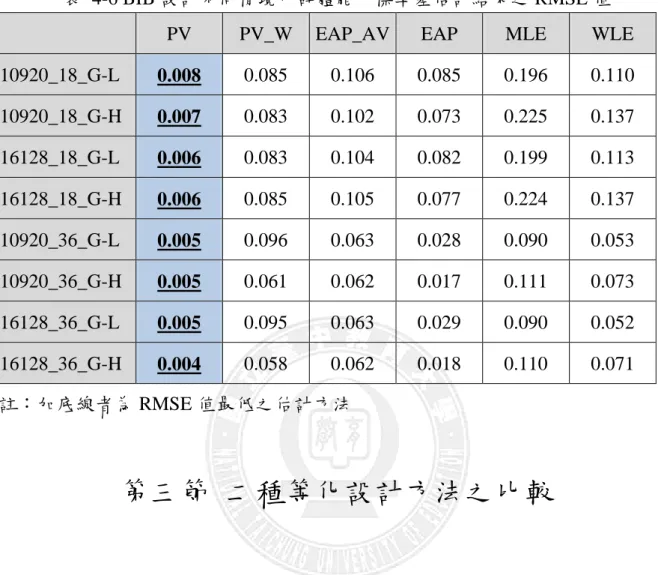
PV PV_W EAP_AV EAP MLE WLE
10920_18_G-L 0.008 0.085 0.106 0.085 0.196 0.110 10920_18_G-H 0.007 0.083 0.102 0.073 0.225 0.137 16128_18_G-L 0.006 0.083 0.104 0.082 0.199 0.113 16128_18_G-H 0.006 0.085 0.105 0.077 0.224 0.137 10920_36_G-L 0.005 0.096 0.063 0.028 0.090 0.053 10920_36_G-H 0.005 0.061 0.062 0.017 0.111 0.073 16128_36_G-L 0.005 0.095 0.063 0.029 0.090 0.052 16128_36_G-H 0.004 0.058 0.062 0.018 0.110 0.071 註:加底線者為 RMSE 值最低之估計方法
第三節 二種等化設計方法之比較
壹、個體能力值
如圖 4-7 所示,在 PV_W 及 EAP_AV 中,NEAT 設計的 RMSE 值皆比 BIB 設計的為高,但是差異不大,而在 EAP、MLE 及 WLE 三種估計方法中,則是 RMSE 值互有高下差異。
貳、群體能力平均數
如圖 4-8 所示,在 PV、PV_W 及 EAP_AV 中,NEAT 設計的 RMSE 值皆比 BIB 設計的為高,而在 EAP、MLE 及 WLE 三種估計方法中,除了 10920 人-18 題-高年級、16128 人-36 題-高年級及 10920-36 題-低年級這 3 個群組是
NEAT 設計低於 BIB 設計外,其它皆是 NEAT 設計高於 BIB 設計。
參、群體能力標準差
如圖 4-9 所示,在 PV 及 EAP_AV 中,NEAT 設計和 BIB 設計的 RMSE 值雖 然是高低互見,但兩者之間的差異非常小,可以說是非常接近。而在 EAP 法中, 所有低年級群體的情境中皆是 NEAT 設計低於 BIB 設計;而所有高年級群體則是 NEAT 設計高於 BIB 設計。在 MLE 及 WLE 中,則是所有低年級群體的情境中皆 是 NEAT 設計高於 BIB 設計;而所有高年級群體則是 NEAT 設計低於 BIB 設計。
肆、綜合討論
在個體能力估計上,在 PV_W 及 EAP_AV 這二種納入背景變項的估計法上, 是 BIB 設計的估計結果優於 NEAT 設計。同樣的,群體能力平均數估計上,在 PV、PV_W 及 EAP_AV 這三種納入背景變項的估計法上,也是 BIB 設計的估計 結果優於 NEAT 設計。而在群體能力標準差的估計上,在 PV 及 EAP_AV 中, NEAT 設計和 BIB 設計的 RMSE 的差異非常小,可說是完全一致。