台灣電力需求的研究以及預測
作者:涂宗裕、戴吟芳、吳昀珊、吳貞霖、陳碧利、劉亞函 系級:統計三乙 學號:D9420838、D9420868、D9551726、D9551136、D9420807、D9591173 開課老師: 陳婉淑 老師 課程名稱: 統計預測方法 開課系所: 統計系 開課學年: 96 學年度 第 2 學期中文摘要 對於現代人來說,能源就與空氣一樣重要。目前全世界 80%的能源供 應,來自於煤、石油、天然氣等石化燃料,根據專家估計,石化燃料在 40 年之內將面臨枯竭。台灣 97%的能源仰賴進口,能源危機正步步逼近。 本研究將回溯台灣電力發展的軌跡,值得我們尋思台灣能源的未來出路, 並以台灣近二十六年來用電量的資料,活用統計套裝軟體(SAS、SPSS、 EXCEL)為工具,並以時間序列分析中的各種分析方法,來研究這份用電 量的資料,預測未來一年的用電量變化。我們希望能夠藉由電力消耗的統 計研究分析,深入的了解「能源消耗」的議題,並分析未來的能源消耗量。 我們希望能夠藉由分析結果,以提醒我們過度消耗能源,所可能帶來的後 果。在本研究中,分析結果顯示,台灣的用電量仍有增高的趨勢,而且我 們掌握更有力的證據,預測未來一年內,台灣的用電量有大的需求量,我 們想藉此提醒人民要有節約能源的概念。減少能源的消耗,並對地球環境 的維護。能源蘊藏有限,而環境一旦遭受破壞便難以復原,地球只有一個, 我們應該要更加重視、更加珍惜。 關鍵字:
ARIMA、Box-Jenkins、Decomposition Methods、Exponential Smoothing、 Forecasting、Seasonal Time Series Regression、Time Series Regression、時間 序列、統計預測方法
目 次
第一章、緒論...3 第一節 研究動機與背景...3 第二節 研究目的...3 第三節 研究流程與架構...4 第四節 樣本描述...4 第二章、研究方法...4 研究模型之探討:...4(1)Time Series Regression...5
(2)Decomposition Method...11 (3)Exponential Smoothing...16 (4)ARIMA ...20 第三章、實證研究與分析...28 第四章、結論與建議...30 參考文獻...31
第一章、緒論
第一節 研究動機與背景
隨著科技的發展,人民對能源的依賴性越來越高,而在生活週遭中,『電 力』的需求為我們生活中不可或缺的能源,如;電燈、電器以及生活家電 的使用,使我們很難想像沒有『電力』的生活。並且隨著經濟的發展,我 們對電力的需求一年高於一年,使我們不得不擔心,這項能源的消耗,以 及未來的無止境需求。目前居住在台灣的我們,所使用的電力,主要是依 賴火力發電以及核能發電,這兩種發電法所使用的能源分別為石油與鈾 (U)。我們現在所使用的煤礦、石油、天然氣(Neutral gas)等化石燃料,都是 從遠古動物、植物的遺骸,埋在地下深處,經過變化而來的,蘊藏量有限, 遲早會枯竭。過去二、三十年間,全球石油儲存量迅速的減少,使得石油 價格快速的往上攀升,但世界能源需求量卻隨著經濟與工業技術的發展, 正在逐年增加,導致需求大過於供給的現象。另外,因消耗能源而產生出 的溫室氣體,環繞在大氣層之中,干擾了太陽對地球輻射的排放,造成地 球的平均溫度不斷在上升,即所謂的全球暖化,這也導致全球氣候異常, 帶來嚴重的自然災害。基於以上種種的理由,使得居住在地球村的我們, 不得不重視這項議題,因此我們將利用台灣用電量資料作時間序列分析來 預測未來能源的耗損與台灣人民生活的影響。第二節 研究目的
以台灣近二十六年來用電量的資料,以統計套裝軟體(SAS、SPSS、 EXCEL)為工具建構與選擇合適的時間序列之統計模式,同時預測未來一 年的用電量變化。我們預期如果分析結果顯示台灣的用電量仍然會有增高 的趨勢,那麼就可以提供我們有更充份的證據,來提醒台灣的民眾要有節 約能源的概念。第三節 研究流程與架構
第四節 樣本描述
本組以時間序列的分析方法,研究台灣地區近幾十年來的用電量,其資 料來源為 AREMOS 經濟統計資料庫系統。此份資料中的電力以千度為單位 計算,資料時間為西元 1982 年 1 月至西元 2008 年 3 月,台灣每月用電量, 總計 315 筆觀察值,平均每月用電量為 10431415.83(千度),最小用電量為 2820341(千度),最大用電量為 22029635(千度),如表 1。 表 1 基本統計量 平均數 10431415.83 範圍 19209294.00 標準誤 289375.80 最小值 2820341.00 中間值 9852614.00 最大值 22029635.00 標準差 5135910.94 總和 3285895988.00 變異數 26377581181174.30 個數 315.00第二章、研究方法
研究模型之探討:
圖 1 為原始的時間序列圖。座標 X 軸為日期,從 1982 年 1 月開始,至 2008 年 3 月為止;座標 Y 軸為用電量,以千度為單位。由此圖 2-1-1 可以 很明顯的看出,資料是呈現上升的趨勢。表示台灣地區的用電量是年年的 研究對象 台灣 用電量 研究方法 時間序列迴歸模式 分解法 指數平滑法 ARIMA 分析法 預測分析與 模式比較 結論增高。另外,也可以看出,資料含有季節的波動,且波動的程度隨時間越 來越大。由以上兩點,我們可以得知,資料的平均數與變異數都沒有保持 平衡,此資料為一份不平穩的時間序列資料,建議在後面的各種分析法中, 都要先解決資料不平穩的問題。
圖 1 台灣月平均用電量原始時間序列圖
我們將先後使用 Time Series Regression、Decomposition Method、 Exponential Smoothing、ARIMA,這四種方法來分析這份資料:
(1)Time Series Regression
從原始的時間序列圖中(圖 2),可以發現全台的用電量有隨著時間呈現 向上遞增的趨勢,在用電量方面可看出在每年夏季的用電量情形較其他季 節高,所以該時間序列圖是存在季節因子的,且季節變異波動隨著時間呈 現波動越來越大的情形,所以首先我們要先對季節變數做轉換,使得用電 量的變異要為常數。在此我們對用電量資料取平方根(yt = yt * )與自然對數 轉換( * ln( ) t t y y = )。由圖 2 可以得知,在做了平方根轉換後,季節波動變異
為常數了。圖 3 為對資料作自然對數的轉換,由圖中顯示若取自然對數的 轉換,則可能有過度轉換的現象,所以我們建議採用取平方根轉換,來對 資料作進一步的分析。
在時間序列當中,當季節變異為常數時,我們通常使用下列模型: t t t t y =TR +SN +
ε
; 其中 yt = 時間序列在時間 t 的觀察值 TRt = 時間 t 的趨勢項 SNt = 時間 t 的季節因子 εt = 時間 t 的誤差項 在資料作完平方根轉換後,我們將季節因子,以月份為虛擬變數來表 示,配適的時間序列模型如下: Model 1 • = ⎩ ⎨ ⎧ = + + + + + + + = otherwise 0, t is i period time if , 1 * 11 12 3 4 2 3 1 2 1 0 * t t i t t Y Y D D D D D t Y β β β β β β ε 首先我們要先檢查時間序列模型的誤差項是否存在自我相關,使用的 是 Durbin-Waston Test 來檢測。其檢定公式如下:表 2 為誤差項的自我相關檢測,得知 DW 值為 1.4917,其中 P 值 <0.0001,表示確實有嚴重的正自我相關現象,表示 Model 1 不適合。所以 在後面的步驟,我們對誤差項配適一階自我相關,並產生 Model 2。
表 2 誤差項的自我相關檢測表
The AUTOREG Procedure
SSE 1359504.78 DFE 290
MSE 4668 Root MSE 68.46859
SBC 3482.05145 AIC 3433.77292
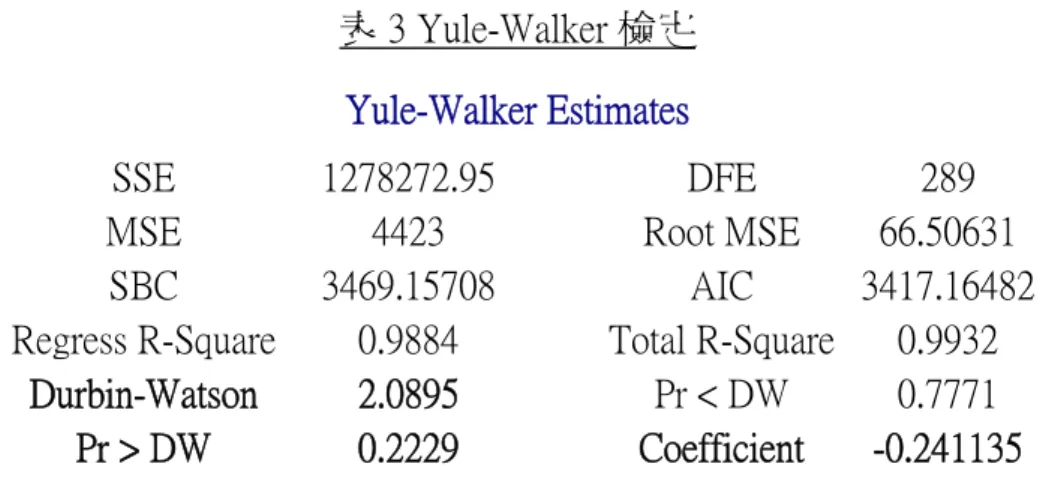
Regress R-Square 0.9928 Total R-Square 0.9928 Durbin-Watson 1.4917 Pr < DW <.0001 Pr > DW 1.0000 Model 2 • − = + = ⎩ ⎨ ⎧ = + + + + + + + = otherwise 0, t is i period time if , 1 * 1 1 11 12 3 4 2 3 1 2 1 0 * t t t t t i t t Y Y a D D D D D t Y ε φ ε ε β β β β β β 由(表 3)對殘差項配適一階自我相關之後的自我相關檢測可看出, 對殘差配適自我一階相關之後的 DW 值為 2.0895,P-value 皆大於 0.05,表 示已消除其資料自我相關的性質,也表示模型是合適的。所以我們將參數 估計帶入模型之中,表 3 為配適完模型後,我們計算出此模型的參數估計。
表 3 Yule-Walker 檢定
Yule-Walker Estimates
SSE 1278272.95 DFE 289
MSE 4423 Root MSE 66.50631
SBC 3469.15708 AIC 3417.16482
Regress R-Square 0.9884 Total R-Square 0.9932 Durbin-Watson 2.0895 Pr < DW 0.7771 Pr > DW 0.2229 Coefficient -0.241135 在時間序列迴歸模型中,我們的虛擬變數為「月份」,因為所有的月份 需為同進同出,所以只要其中一個月份的參數是顯著的,則需將所有的月 份留在模型裡。由表 4 中我們可以得知,大部分的參數皆為顯著的,即使 D1、D3、D4 的 P-value 大於 0.05 為不顯著,但我們仍將所有參數皆留在模 型中。 表 4 時間序列迴歸模型參數估計表
Variable Parameter Estimate T-value Pr > | t |
Intercept 1633 100.11 <.0001 t 8.8056 153.42 <.0001 D1 -35.288 -2.11 0.0361 D2 -167.726 -9.00 <.0001 D3 -22.0907 -1.16 0.2472 D4 8.0607 0.42 0.677 D5 106.9938 5.52 <.0001 D6 192.2867 9.93 <.0001 D7 262.2141 13.54 <.0001 D8 330.8555 17.11 <.0001 D9 272.4387 14.16 <.0001 D10 204.7908 10.89 <.0001 D11 122.816 7.28 <.0001
• = = = = − = = = 5063 . 66 ˆ 241135 . 0 ˆ 816 . 122 ˆ 288 . 35 ˆ 8056 . 8 ˆ 1633 ˆ * 1 12 2 1 0 t t Y Y σ φ β β β β … 代入時間序列 Model 2 中,得到預測方程式,如下式: • − = = + = + + + + + + + + + − − − + = 5063 . 66 ˆ 2411 . 0 8160 . 122 7908 . 204 4387 . 272 8555 . 330 2141 . 262 2867 . 192 9938 . 106 0607 . 8 0907 . 22 726 . 167 288 . 35 8056 . 8 1633 * 1 11 10 9 8 7 6 5 4 3 2 1 * σ ε ε ε t t t t t t t Y Y a D D D D D D D D D D D t Y 我們保留了 12 筆的真實值,並以程式計算出之估計式,計算出 12 筆 的預測值。我們將這預測出之 12 筆預測值與 12 筆真實值整理如表 5,且 將預測值與真實值,以及估計出之 95%信賴水準的上下界線,繪製成圖 4。 表 5 時間序列法實際值與預測表現表 日期 真實值 預測值 L95% U95% Apr-07 17319344 18410725 17272283 19585497 May-07 19502295 19529508 18325026 20772326 Jun-07 19499790 20415149 19181361 21687390 Jul-07 21116601 21143901 19887828 22438434 Aug-07 22029635 21864856 20587214 23180958 Sep-07 21159553 21404002 20140097 22706367 Oct-07 20621365 20863157 19615560 22149216 Nov-07 19307698 20200129 18972793 21465928 Dec-07 17937274 19188306 17992504 20422577 Jan-08 18605658 18957000 17768781 20183673 Feb-08 16187953 17895700 16741767 19088087 Mar-08 17913642 19226227 18029464 20461444
15000000 17000000 19000000 21000000 23000000 25000000 04/07 05/07 06/07 07/07 08/07 09/07 10/07 11/07 12/07 01/08 02/08 03/08 實際值 預測值 U95% L95% 圖 4 時間序列法實際值與預測表現圖 由圖 4 可知,我們可以看到大部分的實際值皆落在 95% 的信賴區間之 內,但是最後兩筆觀察值是落在區間之外的,分別為 2008 年 2 月及 2008 年 3 月;且還有兩筆觀測值是落在 95%信賴區間的邊界附近,分別為 2007 年 4 月及 2007 年 12 月;另外,再從整體看來,預測值較實際值為偏高。 綜合以上幾點訊息,此模式的預測能力可能還有待確認。
(2)Decomposition Method
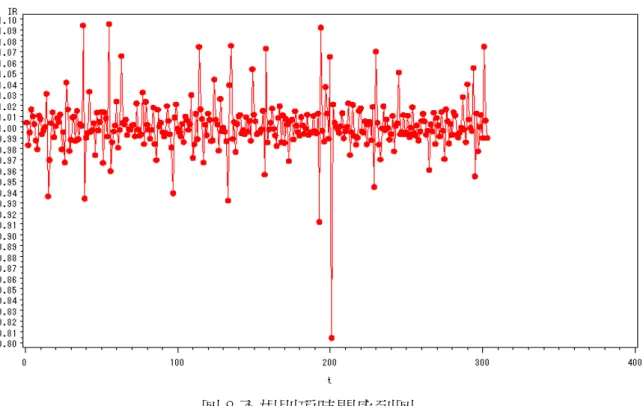
由於每月用電量的多寡會受每月天數所影響,所以在使用分解法時, 我們使用了交易日調整功能。另外,我們已經得知資料的平均數與變異數 有越來越大的趨勢,所以在分解法下,我們將使用乘法模式來討論。乘法 模式的公式為:yt =TRt ×SNt ×CLt×IRt。且趨勢預測估計式為: t t t d =β0 +β1 +ε 。表 6 為分解法中,以乘法模式來計算出之參數估計值。表 6 分解法趨勢參數估計表 Variable DF Parameter Estimate Standard Error T-Value Pr > |t| Intercept 1 1820360 71523 25.45 <.0001 t 1 54424 407.8423 133.44 <.0001 由表 6 中結果我們可以得知,此預測估計式為:dt =1820360+54424t, 圖 5 為去季節因素的時間序列圖,紅色圓點原始資料序列圖,綠色星狀為 去季節因素時間序列圖,由圖 5 可以得知去季節因素所顯現出之時間序列 有上升的趨勢;另外,參數估計值中的β0 =1820360為正值。由以上兩點訊 息可得知,原始時間序列是有上升趨勢的。趨勢-循環項的時間序列圖(圖 6)顯示資料是有上升現象的趨勢循環。圖 7 為季節項,由圖可以看出,此 份資料有明顯的季節現象,圖 8 則為不規則項。 圖 5 去季節因素的時間序列圖
圖 6 循環項時間序列圖
圖 8 不規則項時間序列圖 由殘差項的自我相關檢測表(表 7)可看出,Pr<DW 為<0.0001,表示有 嚴重的正自我相關。所以在後面的步驟,我們將會對殘差配適一階自我相 關。表 8 為對殘差配適一階自我相關之後的自我相關檢測表。由表 8 可看 出,對殘差配適自我一階相關之後的 DW 值為 2.6657,P-value 仍小於 0.0001,表示資料仍有負自我相關。 表 7 殘差項的自我相關檢測表
The AUTOREG Procedure
SSE 115692000000000 DFE 301
MSE 384358000000 Root MSE 619966
SBC 8951.774 AIC 8944.347
Regress R-Square 0.9835 Total R-Square 0.9835
Durbin-Watson 0.5548 Pr < DW <.0001 Pr > DW 1.0000
表 8 自我相關檢測表
The AUTOREG Procedure
SSE 55764900000000 DFE 300
MSE 185883000000 Root MSE 431142
SBC 8737.072 AIC 8725.93
Regress R-Square 0.9139 Total R-Square 0.9920
Durbin-Watson 2.6777 Pr < DW 1.0000 Pr > DW <.0001 我們保留了 12 筆的真實值,並以程式計算出之估計式,計算出 12 筆 的預測值。我們將這預測出之 12 筆預測值與 12 筆真實值整理如表 9,且 將預測值與真實值,以及估計出之 95%信賴水準的上下界線,繪製成圖 9。 表 9 分解法實際值與預測表現表 日期 真實值 預測值 L95% U95% Apr-07 17319344 17094883 16249472 17940294 May-07 19502295 18238471 17157561 19319381 Jun-07 19499790 19378116 18145987 20610246 Jul-07 21116601 20072483 18756070 21388896 Aug-07 22029635 21050586 19650878 22450293 Sep-07 21159553 21217525 19798753 22636296 Oct-07 20621365 20007020 18667024 21347016 Nov-07 19307698 18874701 17611038 20138363 Dec-07 17937274 17662423 16481590 18843255 Jan-08 18605658 16937226 15807060 18067391 Feb-08 16187953 15451821 14423032 16480610 Mar-08 17913642 17958980 16766044 19151916
14000000 16000000 18000000 20000000 22000000 24000000 04/07 05/07 06/07 07/07 08/07 09/07 10/07 11/07 12/07 01/08 02/08 03/08 實際值 預測值 U95% L95% 圖 9 分解法實際值與預測表現圖 由圖 9 的表現可以看出,在 12 筆的資料當中,即使使用了交易日調整 功能,仍有 2 筆的真實值都超出預測區間之外,分別為 2007 年 5 月及 2008 年 1 月;另外若從整體看來,預測值較實際值為偏低。綜合以上幾點訊息, 此模式的預測能力仍有待商確。
(3)Exponential Smoothing
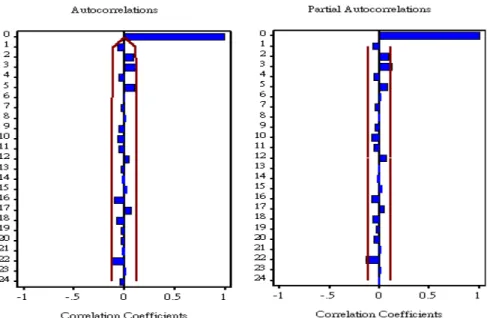
在指數平滑法當中,當季節的波動沒有變異、保持一致時,通常會對 資料配適加法季節模式;但若遇上季節波動有漸大或漸小的趨勢時,通常 會對資料配適乘法季節模式。若配適乘法季節模式,即能解決變異數不平 穩的問題,不需要再對資料作變數的轉換。 由我們的原始時間序列圖(圖 1)可以看出,此份資料的季節波動有漸大 的趨勢,為變異數不平穩的時間序列,所以我們決定不對資料作變數轉換, 直接配適乘法季節模式。經過多種試驗,我們認為配適 Multiplicative Holt -Winter Method 的表現為最佳。圖 10 為配適 Multiplicative Holt - Winter Method 後的 ACF 圖與 PACF 圖。
圖 10 ACF 圖與 PACF 圖
由圖 10 顯示配適 Multiplicative Holt - Winter Method 之後的 ACF 圖與 PACF,皆呈現了良好的 cut off 表現,表示配適這個模式是適當的。本分析 方法之預測 Multiplicative seasonality 模式如下:
表 10 為配適 Multiplicative Holt - Winter Method 之後的參數估計值表: 00 1560000000 0.179 ˆ 0.03354 ˆ 0.09276 ˆ = γ = δ = σ2 = α 表 10
Model Parameter Estimate Std. Error T Prob>|T|
LEVEL Smoothing Weight 0.09276 0.0167 5.5617 <.0001
TREND Smoothing Weight 0.03354 0.0111 3.0287 0.0027
SEASONAL Smoothing Weight 0.179 0.0237 7.5429 <.0001
Residual Variance (σ2
) 156000000000 . . .
Smoothed Level 18678212 . . .
Smoothed Trend 58489 . . .
Smoothed Seasonal Factor 1 0.92246 . . .
Smoothed Seasonal Factor 2 0.83452 . . .
Smoothed Seasonal Factor 3 0.9503 . . .
Smoothed Seasonal Factor 4 0.94169 . . .
Smoothed Seasonal Factor 5 1.0139 . . .
Smoothed Seasonal Factor 6 1.06937 . . .
Smoothed Seasonal Factor 7 1.10166 . . .
Smoothed Seasonal Factor 8 1.16022 . . .
Smoothed Seasonal Factor 9 1.13445 . . .
Smoothed Seasonal Factor 10 1.08581 . . .
Smoothed Seasonal Factor 11 1.0254 . . .
Smoothed Seasonal Factor 12 0.94792 . . .
我們保留了 12 筆的真實值,並以程式計算出之估計式,計算出 12 筆 的預測值。我們將這預測出之 12 筆預測值與 12 筆真實值整理如表 11,且 將預測值與真實值,以及估計出之 95%信賴水準的上下界線,會製成圖 11 95%預測區圖。
表 11 指數平滑法實際值與預測值表現表 日期 真實值 預測值 L95% U95% Apr-07 17319344 17644137 16870540 18417735 May-07 19502295 19056527 18278820 19834235 Jun-07 19499790 20161478 19379090 20943866 Jul-07 21116601 20834752 20047512 21621993 Aug-07 22029635 22010231 21216710 22803753 Sep-07 21159553 21587693 20790555 22384831 Oct-07 20621365 20725531 19925878 21525183 Nov-07 19307698 19632463 18831138 20433787 Dec-07 17937274 18204351 17402673 19006029 Jan-08 18605658 17769415 16964426 18574403 Feb-08 16187953 16124168 15320516 16927820 Mar-08 17913642 18416903 17598020 19235787 14000000 16000000 18000000 20000000 22000000 24000000 04/07 05/07 06/07 07/07 08/07 09/07 10/07 11/07 12/07 01/08 02/08 03/08 真實值 預測值 U95% L95% 圖 11 指數平滑法實際值與預測值表現圖
由表 11 可以看出,所有的預測值皆與真實值相去不遠,表示我們所建 立出來估計式的預測能力是良好的。再由 95%信賴水準的預測圖可以看 出,所有的預測值皆在信賴區間的範圍之內,僅有 1 筆觀測值是落在 95% 信賴區間的邊界附近,為 2008 年 1 月。若從整體看來,指數平滑法的預測 表現,較時間序列迴歸及分解法的預測表現為佳,表示該模式的預測能力 還不錯。
(4)ARIMA
由於從原始時間序列圖(圖 2)當中,我們已經得知資料的平均數與變異 數皆為不平穩的,所以首先我們要解決變異數不平穩的問題。經過多種試 驗,在此我們將利用取對數後的資料來進行 ARIMA 方法分析。圖 12 為經 過對數轉換之後的時間序列圖,其顯示經過對數轉換之後的時間序列,季 節的波動保持一致的狀態,表示變異數已經達到平穩了。但由此圖 12 仍可 以看出,資料有上升的趨勢,表示平均數仍未達到平穩。另外,我們也可 以配合資料的 ACF 與 PACF 圖,來確定資料是否平穩。由圖 13 經過對數 轉換之後的 ACF 與 PACF 圖可以發現 ACF 圖呈現的是 dies down slowly 的 狀態,更確定了此份資料在經過對數轉換之後,平均數仍是不平穩的,所 以我們要再對資料作一次的差分。圖 14 為經過 log 轉換及一次差分之後的 ACF 與 PACF 圖,由 ACF 圖可以看出,殘差在 lag 12 與 lag 24 之處皆為明 顯的不顯著,這個訊息代表資料是含有季節波動的。如果要解決季節因素 的問題,則需要對資料做季節的差分。圖 12 變數轉換之後的時間序列圖
圖 14 Log 轉換及一次差分之 ACF 圖與 PACF 圖
圖 15 為經過 log 轉換及季節差分之後的 ACF 與 PACF 圖,由 ACF 圖 可以看出,此圖所呈現的仍是 dies down 的狀態表示只經過季節差分之後, 資料仍然是不平穩的,所以我們需要對資料做一次差分與季節差分。圖 16 為經過 log 轉換、一次差分、季節差分之後的時間序列圖。由圖可以看出, 在經過這些轉換之後,時間序列的變異數與平均數皆已達到平穩的狀態, 表示資料經過這些轉換是合適的。
圖 15 季節差分後的 ACF 與 PACF 圖
圖 17 為經過 log 轉換、一次差分、季節差分之後的 ACF 與 PACF 圖。 由圖可以看出,在經過這些轉換之後,資料已呈現 cut off 的狀態,更加說 明資料已經達到平穩了。另外,我們認為 ACF 圖呈現出較好的 cut off 表現, 所以我們決定要配適 MA 模式。由 ACF 圖可以看出,殘差在 lag1 與 lag12 之處有較明顯的不顯著,且由於原始資料的變異數有變大的趨勢,所以我 們將以乘法模式來處理,對資料配適 ARIMA(0,1,1)(0,1,1)s 的模式。 圖 17 一次差分與季節差分後 ACF 與 PACF 圖 由圖 18 可以看出,資料呈現出良好的 cut off 狀態,且所有的殘差皆在 兩倍標準差之內,表示此模式的配適是適當的。另外,我們也試驗了其他 種的 ARIMA 模式,其中仍以 ARIMA(0,1,1)(0,1,1)s 的表現最優異。所以我 們決定,ARIMA 分析的最後確立模式為 ARIMA(0,1,1)(0,1,1)s。
圖 18 log 轉換 ACF 與 PACF 圖
在後面的步驟,我們還要繼續探討 ARIMA(0,1,1)(0,1,1)s 的自我相關檢 測,以及參數估計值,還有此模式的預測表現。
我們對 white noise、對單根的檢定和 Ljung-Box 檢定,用以判定殘差項 是否有自我相關。首先我們先做 white noise 檢定,並建立出虛無假設以及 對立假設為;⎩ ⎨ ⎧ noise white not H noise white H : : 1 0 ,其檢定規則為若 P-value 大於 0.01, 其可以不拒絕虛無假設,即可以檢定出殘差項無自我相關。在檢測完後, 我們發現殘差項有 White Noise 的現象,表示我們配適的 ARIMA(0,1,1)(0,1,1)s 是合適的,而此模式剛好為時間序列上很有名的 Airline Model,其模型如下: t t a B B)(1 ) 1 ( )z B -B)(1 -(1 ) ln(y Z 12 t 12 t Θ − − = = θ 。在接下來的部份, 我們再對單根做檢定,如圖 20,建立假設檢定為 ⎩ ⎨ ⎧ 時間序列平穩 時間序列不平穩 : : 1 0 H H ,其
檢定規則為若 P-value 小於值都小於 0.01,可以拒絕 H0,表示時間序列已經 達到平穩的狀態。接著進行 Ljung-Box 檢定,建立假設檢定: ⎩ ⎨ ⎧ 殘差項存在有自我相關 殘差項沒有自我相關 : : 1 0 H H ,其檢定規則為若 P-value 大於 0.05,則無法拒 絕 H0,表示殘差項沒有自我相關。由圖 21 可以看出,所有的 P-value 皆大 於 0.05,表示配適後的殘差沒有自我相關,也就是該模式的配適是合適的。 表 14 為模式的參數估計值。其套用了上列參數後,其預測方程式如下: 00137 . 0 ˆ ) 7950 . 0 1 )( 8855 . 0 1 ( y )ln B -B)(1 -(1 2 12 t 12 = − − = σ t a B B 圖 19 White Noise 檢定 圖 20 單根檢定
表 12 ARIMA 參數估計值表 Log ARIMA (0,1,1)(0,1,1)s
Model Parameter Estimate Std. Error T Prob > |T| Intercept -0.0001870 0.000063 -2.9653 0.0033 Moving Average, Lag 1 0.88546 0.0290 30.5036 <0.0001 Seasonal Moving Average, Lag 12 0.79497 0.0424 18.7417 <0.0001
Model Variance (σ ) 2 0.00137 . . . 我們保留了 12 筆的真實值,並以程式計算出之估計式,計算出 12 筆 的預測值。我們將這預測出之 12 筆預測值與 12 筆真實值整理如表 13,且 將預測值與真實及,以及估計出之 95%信賴水準的上下界線,繪製成圖 22。 表 13 ARIMA 實際值與預測值表現表 日期 真實值 預測值 L95% U95% Apr-07 17319344 17633224.3 16397454 18962126.94 May-07 19502295 19053371.6 17709662 20499034.78 Jun-07 19499790 20193562.5 18760588 21735990.88 Jul-07 21116601 20740163.9 19259369 22334812.22 Aug-07 22029635 21960856.4 20383409 23660380.98 Sep-07 21159553 21585152.0 20025417 23266371.38 Oct-07 20621365 20723123.0 19216833 22347482.10 Nov-07 19307698 19632744.7 18197385 21181321.36 Dec-07 17937274 18198296.4 16860143 19642656.15 Jan-08 18605658 17791631.1 16475933 19212395.71 Feb-08 16187953 16102922.6 14905406 17396648.82 Mar-08 17913642 18463803.8 17083084 19956118.37
14000000 16000000 18000000 20000000 22000000 24000000 26000000 04/07 05/07 06/07 07/07 08/07 09/07 10/07 11/07 12/07 01/08 02/08 03/08 真實值 預測值 L95% U95% 圖 22 ARIMA 實際值與預測值表現圖 由表 13 可以看出,所有的預測值皆與真實值相去不遠,表示我們所建 立出來的模式預測能力是良好的。再由 95%信賴水準的預測圖(圖 22)可 以看出,所有的預測值皆在信賴區間的範圍之內,也說明了模式的預測能 力是很好的。
第三章、實證研究與分析
我們利用 Time Series Regression、Decomposition Method、Exponential Smoothing 以及 ARIMA 方法以配適預測模式,其表 14 的 MAD、MSE、MPE 和 MAPE 四個準則來評估何者為殘差最小的預測模式,表示該模式為最佳。
計算出 MSE、MAD、MPE、MAPE 此四個評估值於表 15。其中 yt為真實用
表 14
表 15
分析方法 MAD MSE MPE(%) MAPE(%)
Time series Regression 685617.52 775007185040. 92 -3.6838 3.8085
Decomposition Method 667326.75 694199769745.75 3.3408 3.4449 Exponential Smoothing 637527.00 518574262280.17 -2.9091 3.3406 ARIMA 372036.43 188802832892.00 -0.3989 1.9485 由表 14 可以得知,不論是以何種評估準則來討論,皆是以 ARIMA 的預 測狀況最佳,再由四種分析方法的 95%信賴水準估計來看,亦為 ARIMA 的 預測表現最良好。由於此份資料最適合以 ARIMA 來分析,所以我們決定以 ARIMA 模式來預測為來的用電量。 分析方法 公式 判斷準則 MAD n t=1 MAD= t t y y n −
∑
越小越好 MSE(
)
n 2 t=1 MSE= n t t y −y∑
越小越好 MPE n t=1 MPE= *100 n t t t y y y −∑
越小越好 MAPE n t=1 MAPE= *100 n t t t y y y −∑
越小越好第四章、結論與建議
在這各種物價都上漲,能源價格翻騰的年代,我們若能夠控制自身對 能源的消耗量,一方面除了可以減少自我開銷,以因應物價上漲但薪水不 上漲的困境;另一方面,減少能源的消耗,是對地球環境維護的一種方式。 畢竟這些能源都是蘊藏量有限的,而環境一旦遭受破壞便難以復原,地球 只有一個,我們應該要更加重視、更加珍惜。在該研究中,我們使用了 Time Series Regression、Decomposition Method、 Exponential Smoothing、ARIMA 這四種方法來分析台灣每月用電量的資料。 而在這四個研究方法之中,使用 ARIMA 模型來預測此份資料時,其實際 值皆落在預測值的 95%信賴區間之內,且在 MSE、MAD、MPE、MAPE 四個評估準則中,皆以 ARIMA 模式為所有分析方法中為最小者,表示其 實際值與預測值相距甚小,是最合適的用來分析此份資料的模型。 根據結果顯示,國人在每年夏季的用電量有明顯增高的情形,且每年 的用電需求量也在逐年上升。這就表示,國人用電量的情況日漸增高,並 且會隨著季節變化而波動,且波動有越來越大的趨勢,這也代表我們對能 源的消耗也越來越大。 以台灣目前發電的主要類型為:核能和火力發電,這些都是需要消耗 能源才能運作的發電方式,但是這些能源都是蘊藏量有限的能源,且使用 這些發電方式會產生污染,對環境造成威脅。長久以來,低廉的電價讓大 家用電就像呼吸一樣自然,卻也是能源效率無法改進、節約能源無法落實 最關鍵的原因。台灣的能源政策,正牽涉到這一代與下一代的生存。不當
的能源結構,將會綑綁我們的現在、透支我們的未來。當我們在百年之內 迅速耗盡了幾億年的自然資源,當能源危機迫在眉睫,新能源革命,即將 發生。生存在現代的我們,如何減少能源的消耗,是我們當前應該好好思 考的問題。 在生活之中,我們可以少開冷氣、多開窗戶;或者盡量避免將電腦長 時間掛網,以減少電力的消耗。以步行、腳踏車或大眾交通工具來取代汽 機車,更減少石油的消耗,這些都是我們平常可以做得到的。 氣候變遷天氣越來越炎熱,人類越難忍受高溫,開冷氣所排放的廢氣 是造成溫室效應的氣體,然而氣溫升高,則使冷氣的使用量又再度增高, 這就是所謂的惡性循環。地球暖化不是最近的才發生,研究顯示氣溫只會 越來越高,溫室效應日漸嚴重,所以該如何減緩這樣的情形是我們現在最 需要重視的。
參考文獻
Bowerman ,O’Connell and Koehler ,Forecasting. Time series ,and Regression 4th AREMOS 經濟統計資料庫系統
經濟部能源局的網站 (http://www.moeaboe.gov.tw/) 台灣環境資訊協會 (http://e-info.org.tw/)