國 立 交 通 大 學
外國語文學系
外國文學與語言學碩士班
碩士論文
臺灣地區國語句法歧義句之聲學線索
Acoustic Cues to Syntactic Ambiguity
in Taiwan Mandarin
指導教授:潘荷仙 博士
研究生:潘鈺楨
臺灣地區國語句法歧義句之聲學線索
Acoustic Cues to Syntactic Ambiguity
in Taiwan Mandarin
研究生: 潘鈺楨
Student: Yuh-Jen PAN
指導教授:潘荷仙 博士
Advisor: Dr. Ho-Hsien PAN
國
立
交
通
大
學
外國語文學系外國文學與語言學碩士班
碩士論文
A Thesis
Submitted to Department of Foreign Languages and Literatures
Graduate Institute of Foreign Literatures and Linguistics
National Chiao Tung University
in partial Fulfillment of the Requirements
for the Degree of Master
in
Graduate Institue of Foreign Literatures and Linguisics
June 2011
Hsinchu, Taiwan, Republic of China
Abstract
Syntactic ambiguity arises when an utterance can be represented by more than
one syntactic structure. Syntactic ambiguity may cause difficulty processing sentences,
due to the lack of speech cues. In this study, we are interested in how speakers
differentiate the competing meanings. There have been few studies on syntactic
ambiguity in tone language. This study seeks to explore how native Taiwan Mandarin
speakers use pause or acoustic features, such as intensity, f0, and duration, to
disambiguate syntactically ambiguous sentences.
Eight types of syntactically ambiguous sentence pairs with contrasting structures
were elicited by asking subjects to answer question in different scenarios. Results
showed that pauses can be observed across boundary with higher syntactic hierarchy
(stronger boundary). The intensity of the post-boundary syllable was not effective in
documenting syntactic boundaries. Greater of f0 reset ranges were observed across
stronger boundary. Duration is the most consistent cue. The stronger the boundary,
摘要
歧義現象是指語言文字的不明確,而造成句子有兩種或多種可能的解釋。然 而,歧義句的歧義現象較常出現於書面語中,在口語表達時,我們聽者很少會因 為句子潛在的歧義性而誤判句子的意思;這是因為句子所在的上下文,以及說話 者說話的方式幫助聽者判別句意。在這份研究中,我們有興趣的是後者─「說話 者說話的方式」,也就是句子由說話者的口中說出時,究竟多了什麼線索是書面 語缺乏的。雖然探討歧義句界限的相關研究不少,但大多數都是以非聲調語言為 主,有關聲調語言中的歧義句界限現象研究,相較之下就顯的匱乏許多,探討臺 灣地區語言歧義句界限現象的研究更可以說是寥寥無幾。因此此研究以誘發性語 料,針對臺灣地區國語歧義句,探討界限週圍音節的聲學現象。 在產生 (production) 實驗中設計了八種類型歧義句,每一類型歧義句皆含 兩種句意。實驗進行過程為:施測者敘述情境後並詢問一個與情境相關的問題(前 導問句),發音人聽完情境和問題後必須依據電腦螢幕上所提示之無標點符號句 子,自然地回答施測者的情境問題。實驗結果顯示,停頓現象容易出現在較強界 限之後,在感知實驗中答對率較高的句子會有較長停頓時長。音節強度受界限強 度影響甚弱,在感知實驗中錯誤的音節強度會混淆受試者。跨較強界限的基頻重 設範圍會有較大數值,且答對率較高的句子較強界限與較弱界限的數值會有較大 差距。句尾延長現象普遍出現在較強界限的界限前音節,而答對率高與低的句子 其較強界限與較弱界限的時長差距皆很大。Acknowledge
三年,真的是一段不短的時間,雖然辛苦,卻讓我成長許多。能夠完成這份 論文,要感謝潘荷仙教授的指導,讓我一次又一次地成長進步。感謝馮怡蓁教授 在擔任資考口試委員和論文口試委員時給了我許多方向和意見,讓我能及時補足 不足部分。感謝口試委員陳信宏教授的建議讓這份論文更趨臻善。感謝林若望教 授在設計語料以及分析語料時給予的協助。另外要感謝張奕華教授在生活以及人 生規劃上的關心和幫助。 能夠完成碩士學業,陪伴在身邊的親友是最大的精神支柱。感謝爸爸媽媽, 永遠以包容的心鼓勵我、支持我。感謝清大統計所的銘傳同學,百忙中抽空給予 統計方面的建議。感謝廣淳同學,總是第一時間與我分享所有喜怒哀樂。感謝藍 尹同學,因為她的陪伴使我在新竹的第一年並不孤單。感謝博任同學和筑婷學 姊,一路上不吝給予鼓勵、支持與協助。最後感謝哥哥、妹妹、小黑、胖胖、和 哈利,給我大量的熱情,讓我忘記所有疲累與氣餒。Contents
Abstract --- ⅰ Acknowledgements --- ⅲ Contents --- ⅳ List of Tables --- ⅵ List of Figures --- ⅶAcoustic Cues to Syntactic Ambiguity in Taiwan Mandarin
第一章 緒論 --- 1 1.1 前言 --- 1 1.1.1 基頻 --- 2 1.1.2 時長 --- 4 1.2 研究動機 --- 7 1.3 研究目的 --- 8 1.4 論文架構 --- 8 第二章 文獻回顧 --- 10 2.1 簡介 --- 10 2.2 停頓、基頻、時長與歧義句 --- 10 第三章 前測 (Pre-test) --- 16 3.1 簡介 --- 16 3.2 句子偏好測試--- 16 3.2.1受試者 --- 16 3.2.2 語料 --- 16 3.2.3 測試過程 --- 20 3.2.4 資料分析 --- 20 3.2.5 結果 --- 21 3.3 語境適合測試--- 23 3.3.1 受試者 --- 23 3.3.2 語料 --- 23
3.3.4 測試過程 --- 24 3.3.5 資料分析 --- 25 3.3.6 結果 --- 25 第四章 產生實驗 (Production Experiment) --- 29 4.1 簡介 --- 29 4.2 產生實驗方法 --- 29 4.2.1 發音人 --- 29 4.2.2 語料 --- 29 4.2.3 使用器材與軟體 --- 30 4.2.4 錄音過程 --- 30 4.2.5 資料分析 --- 32 4.3 產生實驗結果 --- 41 4.3.1 停頓現象 --- 41 4.3.2 界限後音節強度 --- 43 4.3.3 跨界限基頻重設範圍 --- 48 4.3.4 時長 --- 54 第五章 感知實驗 (Perception Experiment) --- 59 5.1 簡介 --- 59 5.2 感知實驗方法 --- 59 5.2.1 受試者 --- 59 5.2.2 語料 --- 59 5.2.3 實驗過程 --- 59 5.2.4 資料分析 --- 60 5.3 感知實驗結果 --- 60 第六章 討論與總結 --- 67 6.1 簡介 --- 67 6.2 研究發現 --- 67
6.2.2 強度 --- 68 6.2.3 基頻 --- 68 6.2.4 時長 --- 68 6.2.5 答對率與聲學線索 --- 69 6.2.6 小結 --- 70 6.3 討論 --- 71 6.4 結論與展望 --- 74 Reference --- 76 Appendixes --- 78
List of Tables
表 3.1 8類型歧義句解讀正確率統計表--- 26 表 4.1 8種類型歧義句在圖表中的句法結構表示名稱 --- 41 表 4.2 各句子類型標的界限後具停頓現象的百分比和平均時長 --- 42 表 4.3 發音人、句子類型、與界限強度對界限後音節強度之三因子 混和變異數分析摘要表 --- 43 表 4.4 6位發音人其8種句子類型之界限後音節強度一因子變異數分 析摘要表 --- 45 表 4.5 不同界限強度之界限後音節平均強度比較表 --- 46 表 4.6 發音人、句子類型、與界限對跨界限基頻重設範圍之三因子 混和變異數分析摘要表 --- 49 表 4.7 6位發音人其8種句子類型之跨界限基頻重設範圍一因子變異 數分析摘要表 --- 50 表 4.8 不同界限強度之跨界限基頻重設範圍平均數值比較表 --- 51 表 4.9 發音人、句子類型、與界限強度對界限前音節時長之三因子 混和變異數分析摘要表 --- 54 表 4.10 6位發音人之界限前音節時長一因子變異數分析摘要表 ---- 55 表 4.11 6位發音人之不同界限強度界限前音節平均時長比較表 ---- 55 表 5.1 答對率100%和答對率65%以下具停頓現象的句子百分比和平 62表 5.2 不同界限強度與答對率的歧義句其聲學線索統計分析表 --- 62
List of Figures
圖 1.1 歧義句「看到總統的小孩」兩種句法結構 --- 1圖 1.2 界限大小與時長關係圖 (Price, 1991) --- 5
圖 1.3 界限前音節時長與界限強度關係 (Wightman, 1992)--- 6
圖 2.1 句子(1a)的跨界限基頻曲線 (Nagel, Shapiro, Tuller, & Nawy, 1996
)
---12 圖 2.2 句子(1b)的跨界限基頻曲線 (Nagel, Shapiro, Tuller, & Nawy, 1996)
--- 12 圖 3.1 8種類型句法歧義句樹狀結構圖與音調替換設計 --- 18 圖 3.2 句子偏好測試填答單範例 --- 20 圖 3.3 8種類型歧義句的解讀偏好比較 --- 22 圖 3.4 語境適合測試填答單範例 --- 25 圖 4.1 句子提示範例 --- 31 圖 4.2 Praat軟體所呈現之聲譜圖、音節界限,以及基頻曲線之範例 33 圖 4.3 「bian」和「cheng」之間的界限無停頓之句子 --- 34 圖 4.4 「bian」和「cheng」之間的界限有停頓之句子 --- 35 圖 4.5 6位發音人在8種類型歧義句中界限前後音節強度關係 --- 47 圖 4.6 6位發音人在8種類型歧義句中跨界限基頻重設範圍大小關係 52 圖 4.7 6位發音人在8種類型歧義句中界限前後音節時長關係 --- 56 圖 5.1 不同界限強度與答對率其界限後音節強度比較 --- 63 圖 5.2 不同界限強度與答對率其跨界限基頻重設範圍比較 --- 64 圖 5.3 不同界限強度與答對率其界限前音節時長比較 --- 65第一章 緒論
1.1 前言
歧義現象是指語言文字的不明確,而造成句子有兩種或多種解釋。舉例來 說,在「看到總統的小孩」這句話中,若將「看到」視為動詞,將「總統的小孩」 視為受詞,此時這句子就可解讀為「某人看到總統的孩子」;然而,若將「看到 總統的」視為句子形容詞化並修飾名詞片語「小孩」,則此時句子就可解讀為「有 一個小孩,他看到了總統」圖1.1標示本句法歧異句之兩種不同樹狀結構。在左 邊解讀為「某人看到總統的孩子」的句子中位於「看到」與「總統的小孩」間句 法界限較右邊句型中位於「看到」與「總統」間的界線更為高階,換言之左邊界 限強度亦強過右邊句型之相對應界限強度。 圖1.1 歧義句「看到總統的小孩」兩種句法結構 然而,歧義句的歧義現象比較常出現在書面語中,在口語表達時,我們很少 會因為句子潛在的歧義性而誤判句子的意思;這是因為句子所在的上下文,以及 說話者說話的方式能夠幫助聽者判別句意。在這份研究中,我們有興趣的是後者 ─「說話者說話的方式」,也就是句子由說話者口中說出時,究竟多了什麼線索是書面語所缺乏的。為了證實聲學線索可以反映界限,Swerts(1997)設計了一個實 驗(詳細的實驗說明請見1.1.2),他讓一組人員聽到對話後在文字上標記界限,另 一組只依閱讀到的對話文字標記界限,藉此了解有語境與聲學線索輔助時所標記 的界限與無語境與聲學線索而僅依照句法知識標記的界限有無差異。結果發現, 在較強界限之處這兩組人員比較容易達到共識,因為即使只有閱讀文字,受試者 仍可以找出句子結束或段落(paragraph)交接處之界限。至於字詞與字詞間較弱的 界限,在閱讀對話文字的那一組中,不同的受試者會有不同的判斷,尤其是在句 法結構不同之處會有判斷分歧現象,但這些現象在輔以語境及聲學線索的那一組 則無。相較之下,可以聽到對話的組別不僅能夠判斷較強界限,也比較能夠判斷 較弱界限的存在,因為他們可以從聲學線索中得知句子的斷句方式。這代表母語 受試者雖然對句法有一定認知,但要判斷句子確切的界限和結構,還是必須仰賴 聲學線索。 以往探討界限的研究大多從韻律界限(prosodic boundary)的角度出發,與句法 界限相關的研究相較之下就少的許多,因此以下先介紹與韻律界限相關的聲學線 索。而此研究會比照研究韻律界限的方式,觀察這些可以反映句法界限強度的聲 學線索。
1.1.1 基頻
基頻的改變與界限有關。由於句子具有基頻下降現象(declination),所以位於句首的詞組會有較高的基頻,基頻值逐漸降低,在下一個句首開始處重新設定 (reset)新的基頻值,使基頻上升。因此界限前基頻之最低點與界限後基頻知最高 點間差距亦可作為界限之線索之一。Swerts(1997)使用德語的自發性話語,希望能 夠藉由實驗找出決定自然語流界限的方法,並了解在自發性話語中的界限與韻律 界限的關連度為何,以及是否能使用韻律結構來標示對話結構層級(hierarchical discourse structure)。Swerts使用自發性話語,內容是二位發音人敘述圖畫,而這兩 段自發性話語各有12句。他將這些話語讓兩組人員(各19位)進行界限強度標記。 第一組標記者依聽到的對話在文字上具界限處畫線作記號,第二組標記者只依閱 讀到的對話文字進行界限標記。另外,Swerts將其中一位發音人的敘述段落切成 獨立的12句,另外找了20位標記者,同樣分為兩組,在界限處給予適當的數字作 為界限強度判斷(強度為0到10)。最後將標記結果與語料的聲學分析進行對照, Swerts發現句子的聲調曲線會逐漸下降,在連接處(junctures),也就是新訊息起始 處重新設定基頻。界限強度和基頻重設值大小達顯著水準,代表重設值會隨界限 大小而呈現系統性地不同,如片語的重設值就會小於句子的重設值。Swerts認為, 說話者可以藉由逐漸下降的界限聲調(boundary tone)來標記不同的資訊結構 (information structure)。也就是說,低界限聲調傾向出現在對話結束前的音節中, 而高界限聲調通常只會在句中出現。 以上研究針對非聲調語言,但在聲調語言中,由於每一個音節都帶有聲調, 因此音節的頻率實際上會因所處環境的不同而有些微的不同,也就是音節的聲調
會與前後音節聲調產生共同發音作用,使聲調變化更為複雜。Peng(1997)想知道 台灣地區台語的聲調在不同聲調環境和韻律環境時會有甚麼變化。她找了 4位發 音人參與產生實驗。語料為變換雙音節短語的聲調:第一個音節有5種聲調([kau 5 5 ], [kau 3 3 ], [k a u 2 1 ], [k a u 5 1 ], 和[k a u 2 4 ]),第二個音節有3種聲調(55, 33, 和21),並將雙音節短語放在4種不同的韻律位置中(Phrase-initial, Phrase-medial, Phrase-final, 和Utterance-final),形成44個句子。觀察音節的基頻與時長可發現, 短語所處的韻律位置會決定句尾基頻下降(final-lowering)和句尾時長延長 (final-lengthening)的程度。在時長上,音節在句尾的長度會比在句首和句中來的 長。而在基頻方面,大致上字調型狀不會受到韻律位置的影響,但基頻會受韻律 位置而影響,也就是說音節在句尾(utterance-final)的基頻下降現象會比在短語尾 (phrase-final)還明顯。由此可知,不同的基頻值與音節延長程度的確可以作為依 據來判斷短語位於句中的位置。
1.1.2 時長
句尾延長(Final lengthening)是標記界限強度的重要線索。Price(1991)利用句法 歧義句,比較從句法結構角度和從韻律結構角度探討歧義句時會有何異同。他找 了4位專業的新聞播報人員做為發音人,設計了35組英文句法歧義句,每一組句 子皆含相同字詞,只有句法結構不同,避免音段不同而影響研究結果。每一句歧 義句(斜體字)前面皆有引導句意的語境,例子如(1a)和(1b):(1a) Mary leaves on Tuesda. She will have no problem in Europe. Mary knows many languages, you know.
(1b) Mary and you have similar backgrounds and have both learned many languages. Mary knows many languages you know.
發音人產生的句子會先讓受試者進行數字標記,判斷界限強度,接著才進行聲學 分析,測量音節時長和基頻。結果發現,聲學線索系統性地反映句法結構:句法 結構位置較高的界限其界限前音節有較長時長。圖2.1為界限大小與時長的關係 圖。 圖1.2. 界限大小與時長關係圖 (Price, 1991) 在基頻方面,雖然在界限前會有下降現象,但其與界限強度的相關性不如時長來
進一步地,Wightman(1992)想知道界限對音節聲學的影響是否僅侷限在界限
週圍音節?他沿用Price(1991)的35組英文句法歧義句,找了4位廣播新聞播報人員
作為發音人。發音人產生的句子會先讓受過訓練的受試者進行數字標記,標記的
數字範圍為0到6,以判斷界限強度,接著才進行音節時長測量。綜合聲學分析以
及界限強度判斷兩者結果,發現界限前音節延長現象可以將0到6(0: no break, 1:
word boundary, 2: accentual phrase boundary, 3: intermediate boundary, 4: intonational
phrase boundary, 5: superior major tone group boundary, 6: sentence boundary)7種不同
強度的界限再細分為四組,這四組分別是:0和1一組、2一組、3一組、以及4到6
一組,如圖2.2所示。也就是說,界限前音節延長是有階層性的:在較強界限週
圍的音節會有較長的音節時長。
圖1.3 界限前音節時長與界限強度關係 (Wightman, 1992)
線索加以區分,因為不同的聲學線索在不同強度界限上扮演著不同的重要性。
Tabain(2003 a.)使用EMA(electromagnetic articulography),想知道法文中的子音
在不同韻律界限後時發音動作是否會有所不同。他找了 3 位發音人,使用 6 種子 音/b, d, g, f, s, ʃ/,觀察當子音前的韻律界限是句子、聲調短語、句調短語、和詞 界限時,發音動作會有甚麼不同。結果證實,當韻律界限越強,界限前母音其舌 體和下顎移動的程度會越大,也就是位置會越低,且強度會越強。而母音與子音 在韻律結構越強的地方發音動作會越典型化,同時也增加所需的發音時間,而加 長音節時長。這代表界限強度的確影響發音動作,界限強度較強的地方會使發音 動作越典型化,且間接影響音節強度與音節時長。Tabain(2003 b.)進一步地將前述 探討發音動作的研究加以分析,以了解因韻律界限強度不同而造成不同的發音動 作,在聲學上會有甚麼特徵。他發現母音和子音的長度會反映韻律界限的強度: 母音在較強界限前時長會較長,在較弱界限前時長會縮減;擦音在較弱界限前, 如詞彙界限,時長會較短。
1.2 研究動機
總結上述與韻律界限有關的產生實驗可以發現,基頻與時長是能夠反映韻律 界限的線索。在基頻方面,由於界限前音節基頻數值會較低,因此跨較強界限時 基頻重設範圍(句首或短語首的基頻最大值與句末或短語末的基頻最小值之差) 較大。至於時長,由於界限前音節易有句尾延長(final lengthening)現象,所以界限前音節時長通常會大於句首音節和句中音節。 以上敘述均為韻律界限與音段之間的關係。句法界限和韻律界限一樣有階層 (hierachy)性,可區分強弱程度,因此在這份研究中我們想知道:句法界限是否如 韻律界限般,能夠透過相關聲學線索體現在界限週圍音節上?
1.3 研究目的
雖然探討界限的相關研究不少,但大多數都是以非聲調語言為主,以聲調語 言為主的研究相較之下就匱乏許多,以臺灣地區語言為主的研究更可以說是寥寥 無幾。因此此研究使用台灣地區國語句法歧義句作為語料,探討臺灣地區國語中 句法界限與相關聲學線索之間的關係;亦即界限強度的不同是否會體現在聲學線 索上。除了上述的基頻與時長,停頓(pause)與強度(intensity)也可能反映界限強 度,因此此研究也將這兩項聲學線索納入觀察的項目中。基於上述理由,此實驗 主要探討的問題是:相同字詞排列但具不同句法結構的歧義句,標的界限(target boundary)的界限後停頓現象、界限後音節強度、跨界限基頻重設範圍、和界限前 音節時長,在句法界限較強(階層高)或較弱(階層低)時有甚麼差別?1.4 論文架構
此研究一共有五個章節:第一章為「緒論」,主要敘述此研究的理論背景、 研究動機、實驗目的、與論文架構。第二章為「文獻回顧」,介紹與句法結構、界限強度、以及聲學線索相關且具代表性的實驗。第三章為前測實驗,分為「句
子偏好測試」和「語境適合測試」兩部份,分別介紹實驗設計與結果。第四章為
產生實驗,對實驗設計和結果有詳細的說明。第五章為感知實驗,介紹感知實驗
設計及觀察到的現象。最後,第六章為總結,針對整個研究做簡單的統整,並提
第二章 文獻回顧
2.1 簡介
由於此研究重點是探討句法結構界限與聲學線索之間的關係,因此以下介紹 與句法結構界限與聲學線索的相關文獻。2.2 停頓、基頻、時長與歧義句
歧義句不同的句法結構會使字詞(word)或短語(phrase)間有不同的詞組性 (constituency),而不同的詞組性會造成界限強度的不同。許多研究都證實,聽者 可以利用音節時長和基頻範圍來決定較強界限位置。Beach(1991)想探討聽者是如 何使用線索來辨認句法結構。他使用花園路徑句型(garden-path),操控句中標的 界限後的字詞時長和基頻。結果顯示,如果標的界限後字詞具有較短時長以及較 小的跨界限基頻範圍,則聽者會將該字詞判斷為動詞後的受詞。舉例來說,若受試者聽到的「Jay believed the gossip…」在動詞「believed」和名詞「the gossip」間
的基頻範圍值較小且動詞的時長較短,則受試者會認為「the gossip」是受詞而在
其後接「right away」。相對的,如果「the gossip」具有較長時長以及較大的跨界
限基頻範圍,聽者就會將其判斷為句中子句的主詞,將「wasn’t true」接在「the
gossip」之後。這代表聽者會運用時長和基頻變化來判斷界限強度,也就是句法
結構。
助,但聲學線索在真實對話中到底扮演什麼角色卻不是很明確,他們找了一位發
音人唸出12組歧義句,例句如下:
(1a) The company owner promised # the wage increase to the workers.
(1b) The company owner promised # the wage increase would be substantial.
分析產生句子的聲學線索,結果發現動詞後接子句時,如(1b),動詞「promised」
的時長會比較長,且動詞與後面名詞「the wage」的基頻曲線會有比較明顯的下
降與再上升。這兩種不同的基頻曲線如圖2.1和2.2所示。
圖2.1 句子(1a)的跨界限基頻曲線 (Nagel, Shapiro, Tuller, & Nawy, 1996)
圖2.2 句子(1b)的跨界限基頻曲線 (Nagel, Shapiro, Tuller, & Nawy, 1996)
確認了不同結構的句子具有不同聲學特徵,Nagel等人使用產生實驗中的12
組歧義句中的10組作為語料,將句子從動詞(如「promised」)與名詞(如「the wage」)
程。以句子(1)為例,他們將(1a)的前半段「The company owner promised」與(1b)的
後半段「the wage increase would be substantial」配合在一起,或是將(1b)的前半段
「The company owner promised」與(1a)的後半段「the wage increase to the workers」
配合在一起,讓聽者只聽到「The company owner promised the wage increase」,想
知道聽者聽到這樣的句子,是否會增加句子解讀的錯誤率。28位受試者參與此實
驗,得到的結果證實,這些合成的句子如「(1a)+(1b)」或「(1b)+(1a)」,的確
會增加解讀錯誤率以及解讀所需的時間。這代表聲學線索與句法結構之間有固定
關係,聲學線索是聽者辨別界限的有利工具。當此聲學線索與句法結構間的固定
關係被破壞,便會混淆聽者,而增加聽者解讀句子的難度。
Carlson, Clifton, Jr., & Frazier(2001)在其探討韻律界限位置、強度是否影響句
子解讀的文章中,找了一位受過語音訓練的發音人來唸16句歧義句與38句普通句
子,這16句歧義句是因介詞或副詞片語的修飾範圍不同而形成歧義。例子如(2),
「#」為標的界限所在位置:
(2a) Susie learned that Bill telephoned # after John visited. (high attachment)
(2b) Susie learned that Bill telephoned # after John visited. (low attachment)
在(2a)中「after John visited」修飾第一個動詞「learned」,所以介詞片語「after
John visited」是「high attachment」,與前面動詞「telephoned」間的界限較強。在
visited」是「low attachment」,與前面動詞「telephoned」間的界限較弱。分析發 音人所產生的句子發現,(2a)中的動詞「telephoned」平均時長為530毫秒,停頓時 長為402毫秒;(2b)中的動詞「telephoned」平均時長為512毫秒,停頓時長為373 毫秒。(2a)中的動詞「telephoned」最低基頻為176Hz,後面名詞「John」的最高基 頻為243Hz;(2b)中的動詞「telephoned」最低基頻為196Hz,後面名詞「John」的 最高基頻為233Hz。這表示句法結構的不同會造成界限強度的不同,而界限強度 的不同會反映在界限前音節時長、停頓現象的有無、以及界限週圍音節的基頻上。 Snedekera和Trueswell(2002)想找出說話者如何使用韻律線索來區分句法歧義 句的不同句意。他們找了32組受試者參與此實驗,一位說話者與一位聽者為一 組,使用16句因介詞修飾範圍不同而產生歧義的歧義句。實驗引導人會給說話者 看一句歧義句,並使用玩具做出示意動作,讓說話者了解該歧義句在此的句意。 說話者的任務是要對聽者說出這句歧義句,使聽者理解句意並能夠運用手邊的玩 具作出相同動作,而聽者的任務是要在聽到歧義句後使用玩具作出能夠詮釋句意
的動作。舉例來說,實驗引導者提供的歧義句為「Tap the frog with the flower」,
若實驗引導者用花輕拍青蛙,代表這句話的意思是「Tap the frog by using the
flower」,「with the flower」在此修飾的是動詞片語(VP-attachment);若實驗引導
者將一隻手拿花朵的青蛙貼在自己手上,代表這句話的意思是「Tap the frog that
has the flower」,「with the flower」在此修飾的是名詞片語(NP-attachment)。在句
強。將說話者說出的歧義句進行聲學分析,發現當介詞片語修飾動詞片語時,有 68%的句子其第一個名詞(例子的「frog」)的時長會延長,且第一個名詞與「with」 之間的停頓時長會增加。這個現象證明聲學線索可以反映句法結構:當介詞片語 修飾動詞片語時較強界限會落在第一個名詞與介詞之間(「frog」和「with」),當 介詞片語修飾名詞片語時則第一個名詞與介詞之間的界限較弱,而不會有音節時 長延長與停頓現象。
另一個相關實驗是Anderson & Carlson(2010)所設計的實驗。Anderson等人想知
道發音人是否會運用聲學線索來區分句法結構不同的歧義句,因此找了找了24
位發音人唸出20組類似(3)的歧義句,「#」為標的界限所在位置:
(3a) The jury believed # the defendant without any hesitation. (Object)
(3b) The jury believed # the defendant had committed the crime. (Clause)
(3a)中「the defendant」屬於前面動詞「believed」的受詞,但在(3b)中,「the defendant」
屬於後面動詞「had」的主詞,因此(3a)的標的界限強度會比(3b)的標的界線強度
還弱。Anderson & Carlson 想證實由於句法結構的不同,造成標的界限強度不同,
而使兩句中的「believed」和「the defendant」會有不同的聲學線索。結果發現在
時長上,(3b)的標的界限前動詞「believed」會比(3a)的動詞「believed」還長,(3b)
上,(3b)的標的界限前動詞「believed」會比(3a)的動詞「believed」還低,(3b)的標
的界限後名詞「the defendant」會比(3a)的名詞「the defendant」還高。這代表時長
和基頻可以反映不同程度的界限強度:界限強度較強,界限前音節時長會較長,
第三章 前測 (Pre-test)
3.1 簡介
此實驗之前測分為兩部分:句子偏好測試(preference test)和語境適合測試。 句子偏好測試是為了了解設計出的歧義句,在受試者解讀時是否會偏好某一句 意。語境適合測試是為了了解設計出的語境和前導問句,是否提供足夠的資訊以 誘發發音人唸出句子。此章節分別介紹這兩個測試中的受試者、語料、器材、測 試過程、資料分析、和結果。3.2 句子偏好測試
3.2.1 受試者 48 位國立交通大學外國語文學系大學部大二學生參與此測驗。受試者皆無 任何閱讀或口語障礙。參與測試的測試者皆獲得課堂回饋或酬勞。 3.2.2 語料 此實驗設計了8種中文句法歧義句,每一種歧義句皆有兩個句意,「*」標示 出此實驗欲觀察的標的界限。在圖3.1的(1)中,標的界限位於「心」和「中」之 間。(1s)(strong boundary)的「關心」為動詞,「中國的學生」是作為受詞的名詞片 語;(1w)(weak boundary)的「關心」和「中國」位於動詞關係子句「關心中國的」裡面。拿(1w)與(1s)做對照就可發現:(1w)的標的界限分枝層級為第5層,(1s)的標
的界限分枝層級為第3層,(1w)比(1s)還低階,且(1w)中的「關心」和「中國」兩
者之間的詞組性(constituency)比較強。因此,(1w)之間的界限強度比(1s)之間的界
限強度還弱。
圖3.1 8種類型句法歧義句樹狀結構圖與音調替換設計 在(2)中,標的界限位於「師」和「是」之間。(2s)的「相信律師」是句子作 為主詞,「是錯的」則是動詞片語;(2w)的「律師」是名詞,「是錯的」則是動詞 片語。拿(2w)與(2s)做對照就可發現:(2w)的標的界限分枝層級為第4層,(2s)的標 的界限分枝層級為第2層,因此(2w)比(2s)還低階,(2w)之間的界限強度比(2s)之間 的界限強度還弱。在(3)中,標的界限位於「師」和「和」之間。(3s)的「緊張的 律師」是名詞片語,「和」是連接詞;(3w)的「緊張的」是形容詞,「律師和張先
生」則是名詞片語。拿(3w)與(3s)做對照就可發現:(3w)的標的界限分枝層級為第 3層,(3s)的標的界限分枝層級為第2層,因此(3w)比(3s)還低階。在(4)中,標的界 限位於「生」和「沒」之間。(4s)的「小男生」是名詞片語,「沒有小女生會哭」 是動詞片語;(4w)的「小男生」與「沒有小女生」同在一個作為主詞的名詞片語 內。拿(4w)與(4s)做對照就可發現:(4w)的標的界限分枝層級為第3層,(4s)的標的 界限分枝層級為第2層,因此(4w)比(4s)還低階。在(5)中,標的界限位於「對」和 「家」之間。(5s)的「老師」是名詞片語,「對」是介詞;(5w)的「老師對家長的 欣賞」是一個作為主詞的句子。拿(5w)與(5s)做對照就可發現:(5w)的標的界限分 枝層級為第5層,(5s)的標的界限分枝層級為第4層,因此(5w)比(5s)還低階。在(6) 中,標的界限位於「能」和「花」之間。(6s)的「可能」是副詞片語,修飾後面 句子「花費的時間會比預期的多」;(6w)的「可能」雖然也是副詞片語但只修飾 名詞片語「花費的時間」。拿(6w)與(6s)做對照就可發現:(6w)的標的界限分枝層 級為第3層,(6s)的標的界限分枝層級為第2層,因此(6w)比(6s)還低階。 在圖3.1的類型(7)與(8),其歧義性是因結構層次的不同而使詞性改變所造成 的。(7)的標的界限位於「花」和「生」之間。在(7s)中,「生」屬於動詞的一部分, 而使名詞片語「這種花」(NP)和後面的動詞「生長」(VP)之間的詞組性比較低; 在(7w)中,「生」則是隸屬於名詞之下,因此「這種花生」裡的「花」和「生」 之間的組成詞組性比較高。在這組歧義句中,「花」和「生」之間的界限在(7w) 是層級3,在(7s)是層級2,因此強度是(7s)比(7w)強。類型8和類型7類似,其歧義
性也是由於結構層次影響詞性所致。(8)的標的界限位於「風」和「能」之間。(8s) 的「風」是名詞,「能」屬於動詞的一部分,但在(8w)中「風」和「能」共同組 成一個名詞,同在名詞片語的分支之下。在這組歧義句中,標的界限在(8w)是層 級4,在(8s)是層級3,因此強度是(8s)比(8w)強。 由於每一種類型歧義句皆有4種聲調替換設計,所以一共有32句歧義句。測 試的歧義句經隨機排列設計。 3.2.3 測試過程 此測試在國立交通大學外國語文學系教室 110 進行。每位受試者會拿到一張 雙面填答單,每面填答單上印有 16 小格,每小格裡各有一句不具標點符號的歧 義句。受試者在看到歧義句後,必須根據直覺,按想到的先後順序分別寫下歧義 句的句義。整個測試過程約持續 40 分鐘左右。圖 3.2 為填答單範例。 1. 關心中國的學生 2. 相信律師是錯的 3. 緊張的律師和張先生 4. 這種花生長在小島的南方 圖 3.2 句子偏好測試填答單範例 3.2.4 資料分析 回收填答單後,統計每句歧義句的第一個解讀句意為何。以句子類型一的一
聲─「關心中國的學生」為例,若受試者第一個解讀出的句意是「有一個人關心 著中國的學生」,符合句型結構「V*[AdjP+N]」,則記錄為具較強界限,若解讀 出的句意為「有一個學生他很關心中國」,符合句型結構「[V*NP]+N」,則記 錄為具較弱界限,若解讀出的句意在兩種句型結構之外,則記錄為「wrong」。 得到統計次數後,將每一句子分別進行卡方檢定(χ 2 -test) 統計分析,以觀察 解讀為「具較強界限時的句意」與「具較弱界限時的句意」的次數有無差異。 3.2.5 結果 以解讀次數為觀察值,進行卡方考驗。圖 3.3 呈現受試者對 8 種類型歧義句 的解讀偏好以及卡方檢定結果。
V+AdjP/NP+N
tone 1 tone 2 tone 3 tone 4
Percentage of prefer ence 0.0 0.2 0.4 0.6 0.8 1.0 1.2 V*[AdjP+N] [V*NP]+N wrong V+NP+V
tone 1 tone 2 tone 3 tone 4
Percentage of prefer ence 0.0 0.2 0.4 0.6 0.8 1.0 1.2 [V+NP]*V V+[NP*V] wrong AdjP+N+ConjP+N
tone 1 tone 2 tone 3 tone 4
Percentage of prefer ence 0.0 0.2 0.4 0.6 0.8 1.0 1.2 [AdjP+N]*ConjP+N AdjP+[N*ConjP+N] wrong NP/ +V/
tone 1 tone 2 tone 3 tone 4
Percentage of prefer ence 0.0 0.2 0.4 0.6 0.8 1.0 1.2 [NP]*V [ * ] wrong NP/ +V/ +Neg+V
tone 1 tone 2 tone 3 tone 4
Percentage of prefer ence 0.0 0.2 0.4 0.6 0.8 1.0 1.2 NP*[V+Neg+V] [ * ]+Neg+V wrong N+NegP
tone 1 tone 2 tone 3 tone 4
Percentage of prefer ence 0.0 0.2 0.4 0.6 0.8 1.0 1.2 N*[NegP] N*NegP] wrong P+N+N/V
tone 1 tone 2 tone 3 tone 4
Percentage of prefer ence 0.0 0.2 0.4 0.6 0.8 1.0 1.2 P*[N+N] P*N]+V wrong AdvP+NP+I
tone 1 tone 2 tone 3 tone 4
Percentage of prefer ence 0.0 0.2 0.4 0.6 0.8 1.0 1.2 AdvP*[NP+I] [AdvP*NP]+I wrong 圖 3.3 8 種類型歧義句的解讀偏好比較 在圖 3.3 中,橫座標的 4 種聲調是歧義句的聲調替換設計;縱座標是句子偏 好百分比。直條裡的黑色代表「具較強界限時的句意」,灰色代表「具較弱界限 時的句意」,深灰色的「wrong」代表句子被解讀為具較強界限或具較弱界限兩
者以外的意思。「具較強界限時的句意」、「具較弱界限時的句意」、和「wrong」 的次數百分比是從受試者第一個解讀出的句意而得。經由卡方檢定進行統計分 析,發現類型三的 tone 1 偏好解釋為具較強界限的句意、類型四的 tone 3 偏好解 釋為具較弱界限的句意、類型五的 tone 1 偏好解釋為具較弱界限的句意、類型七 的 tone 4 偏好解釋為具較強界限的句意、以及類型八的 tone 1 偏好解釋為具較強 界限的句意。這五句句子其兩種句意的解讀次數皆達.05 顯著水準,代表在這五 句句子中,將句子解讀為具較強界限句意或將句子解讀為具較弱界限句意,這兩 種情形是有顯著差異的。在這邊我們認為,造成差異的原因與聲調無關,應是受 到詞彙之詞頻所影響。雖然受試者在這些句子上有解讀偏好,但若這些句子在語 境的支持下能夠被辨識句意,那這些句子在此實驗中依舊可以繼續使用。
3.3 語境適合測試
3.3.1 受試者 48 位參與句子偏好測試的受試者中,15 位受試者自願繼續參加語境適合測 試。他們皆是國立交通大學外國語文學系大學部大二學生,皆無任何閱讀或口語 障礙。語境適合測試在句子偏好測試結束兩星期後才進行,參與測試的測試者皆 獲得酬勞。 3.3.2 語料在此要測試的目標是誘發歧義句的64個語境和前導問句(8種類型歧義句 x 4 種聲調替換設計 x 2種界限強度 = 64個句子)是否有效引導發音人產生不同句意 之歧義句。每一句歧義句皆包含兩種語境,以誘導發音人說出歧義句的兩種句 意。舉例來說,引出圖3.1中(1s)的一聲句子,語境為:「老校長雖然退休了,但 一直關心著教育相關新聞。自從聽到中國偏遠地區的孩子沒有足夠的師資和教育 資源後,老校長開始固定捐款,希望能夠盡一己之力來幫助他們。」,前導問句 為:「請問老校長關心著哪裡的學生?」。若目標句是圖3.1中(1w)的一聲句子,則 語境為:「小明是中國人,雖然後來移民到加拿大,但仍然天天收看中國新聞, 了解與中國相關的事。」,前導問句是:「小明是一位怎樣的學生?」。8種類型歧 義句的語境和前導問句均列於附錄中,當目標句替換不同音調的詞彙時,語境和 前導問句會隨目標句的改變而稍做變化。 3.3.3 使用器材 語境和前導問句由實驗引導人擔任發音人事先預錄好,在實驗時統一對受試
者進行撥放,撥放的音檔使用 Korg MR1000 1-bit Professional mobile recorder 和麥
克風 Shure Professional SM48 LC 進行錄製。測試的語境經過隨機排列設計。
3.3.4 測試過程
兩張雙面填答單,每面填答單上印有 16 小格,每小格裡各有一句不具標點符號 的歧義句,如圖 3.4。受試者在聆聽完事先錄好的語境敘述以及前導問句後,必 須將該題號後所列的歧義句以換句話說方式寫下該句在此語境下所代表的意 思。以填答單的第 5 題為例,實驗引導人會先讓受試者聆聽情境敘述和前導問 句:「自然老師正在介紹風,老師告訴學生們風有很大的用途,可以進行風力發 電,供應人類所需的能量。學生們聽了之後都很想知道:風是不是源源不絕的? 請問,學生們好奇的是什麼?」,受試者聽完後必須在題號 5 的格子中,根據提 供的句子「風能不能一直提供電能」,寫出該句子在此語境下的句意為何,例如 「風可不可以不斷提供電能」。相同的句子「風能不能一直提供電能」在第 37 題,針對同文字之歧義句,語境和前導問句就變為:「受到自然氣候的影響,風 不會一直吹,所以我們不可能持續地使用風來發電。請問,哪種能量不能一直提 供電能?」。受試人寫下如「風能這種能量無法不斷提供電能」之句意。整個測 試過程約持續 60 分鐘左右。 5. 風能不能一直提供電能 6. 小男生沒有小女生會哭 7. 老師對家長的欣賞是早有耳聞的 8. 可能花費的時間會比預期的多 圖 3.4 語境適合測試填答單範例
回收填答單後,統計每句歧義句被解讀的句意是否與搭配的語境相符。得到 相符的統計次數後,計算每一歧義句的解讀正確率,以觀察語境對歧義句的適合 程度。 3.3.6 結果 表3.1統計了8種類型歧義句的解讀正確率。由表可知,歧義句的解讀正確率 最低為80%,最高為100%,表示受試者聆聽語境後大都能夠正確地解讀歧義句。 這代表此實驗所設計的語境足以為歧義句提供充分的資訊,讓受試者能夠抉擇歧 義句在該語境之下代表何種意思。 而在句子偏好測試中有解讀偏好情形的句子:類型三 tone 1、類型四 tone
3、類型五 tone 1、類型七 tone 4、和類型八 tone 1,在這邊解較強界限句意與較
弱界限句意的解讀正確率分別是「100%,93%」、「100%,100%」、「100%,100%」、 「100%,100%」、和「93%,93%」,解讀正確率都算高,代表有適當語境時, 受試者可以清楚判斷歧義句在此的句意。因此這些句子在後續實驗中繼續保留使 用。 表3.1 8類型歧義句解讀正確率統計表 類型 替換詞 語境引 導句型 解答句意次數 解讀正確 率 強 弱 其他 1. 關心中/韓/美 /泰國的學生 1. 中國 強 15 0 0 100% 弱 0 14 1 93%
弱 0 14 1 93% 3. 美國 強 14 0 1 93% 弱 0 14 1 93% 4. 泰國 強 15 0 0 100% 弱 0 13 2 87% 2. 相信律師/議 員/校長/教練是 錯的 1. 律師 強 15 0 0 100% 弱 0 14 1 93% 2. 議員 強 14 0 1 93% 弱 0 13 2 87% 3. 校長 強 15 0 0 100% 弱 0 14 1 93% 4. 教練 強 15 0 0 100% 弱 0 14 1 93% 3. 緊張的律師/ 議員/校長/教練 和張先生 1. 律師 強 15 0 0 100% 弱 0 14 1 93% 2. 議員 強 15 0 0 100% 弱 0 14 1 93% 3. 校長 強 14 0 1 93% 弱 0 12 3 80% 4. 教練 強 14 0 1 93% 弱 0 14 1 93% 4. 小男生/小男 孩/小狗/百姓沒 有小女生會哭 1. 小男 生 強 15 0 0 100% 弱 0 15 0 100% 2. 小男 孩 強 15 0 0 100% 弱 0 15 0 100% 3. 小狗 強 15 0 0 100% 弱 0 15 0 100% 4. 百姓 強 15 0 0 100% 弱 0 15 0 100% 5. 老師對家長/ 員工/女僕/侍衛 的欣賞是早有 耳聞的 1. 家長 強 15 0 0 100% 弱 0 15 0 100% 2. 員工 強 15 0 0 100% 弱 0 15 0 100% 3. 女僕 強 15 0 0 100% 弱 0 15 0 100% 4. 侍衛 強 15 0 0 100%
弱 0 15 0 100% 6. 可能花費/留 下/想到/遇到 1. 花費 強 15 0 0 100% 弱 0 14 1 93% 2. 留下 強 13 0 2 87% 弱 0 14 1 93% 3. 想到 強 14 0 1 93% 弱 0 15 0 100% 4. 遇到 強 15 0 0 100% 弱 0 15 0 100% 7. 這種花生長/ 人才是/水果真/ 事變成 1. 花生 強 15 0 0 100% 弱 0 15 0 100% 2. 人才 強 15 0 0 100% 弱 0 15 0 100% 3. 水果 強 15 0 0 100% 弱 0 14 1 93% 4. 事變 強 15 0 0 100% 弱 0 15 0 100% 8. 風/太陽/水/ 沼氣能不能一 直提供電能 1. 風 強 14 0 1 93% 弱 0 14 1 93% 2. 太陽 強 15 0 0 100% 弱 0 15 0 100% 3. 水 強 15 0 0 100% 弱 0 15 0 100% 4. 沼氣 強 15 0 0 100% 弱 0 15 0 100%
第四章 產生實驗 (Production Experiment)
4.1 簡介
此章節先介紹產生實驗中的發音人、語料、器材、實驗進行流程、資料分析、 以及歧義句的界限後音節強度、停頓現象、跨界限基頻重設範圍、和界限前音節 時長所呈現的聲學現象。4.2 產生實驗方法
4.2.1 發音人 此實驗的 6 位發音人皆為女性,分別居住在台北縣、彰化縣、台南市、高雄 縣、和高雄市。6 位發音人的母語皆為國語,聽得懂閩南語但僅能以閩南語進行 簡單對話。6 位發音人在參與實驗時皆就讀於國立交通大學,其中一位發音人是 大學部學生,其餘 5 位則是研究所學生,年齡範圍在 22 至 24 歲之間。6 位發音 人皆無發音或其他生理障礙。這 6 位發音人的代號分別為:CLY、LPL、LPT、 LYJ、WDH、和 LCH。 4.2.2 語料產生實驗中使用的語境和前導問句可參考3.3.2的介紹或查閱附錄,8種歧義
句類型在3.2.2已有介紹,在此不多加贅述。語料採誘發性(elicited)方式取得,每
一位受試者皆產生192個句子 (8種句子類型 x 4種聲調 x 2種界限強度 x 重複3遍)。
4.2.3 使用器材與軟體
由於錄音期間實驗室的器材進行更新,所以此實驗使用了兩台不同的錄音儀
器和兩支不同的麥克風。使用的錄音儀器為 SONY compact disc recorder CDR-W66
或 Korg MR1000 1-bit Professional mobile recorder,使用的麥克風是 AKG HSD 200
或 Shure Professional SM48 LC。錄好的音檔先用 CDEx 軟體轉成 wav 格式,再以
Adobe Audition 1.0 軟體切割檔案。用 Praat(Boersma & Weenink, 2008) 標出每句
ortho 之後以 EasyAlign(Goldman, 2010) 切出句子中的每一個音節,以 Praat 進行微
調後,再以 VoiceSauce (SPAPL, 2010) 軟體 query 出所需聲學數值。
4.2.4 錄音過程 此實驗的錄音工作在國立交通大學外國語文學系暨研究所的語音實驗室裡 的錄音間進行,發音人和實驗引導者同時在錄音間內進行錄音工作。在實驗正 式開始之前,實驗引導人會與發音人先進行練習範例,讓發音人熟悉實驗流程 。在正式實驗中,實驗引導者會先唸一小段情境,接著唸出前導問句。 舉 例 來 說,若要引出圖3.1中(1s)的一聲句子,實驗引導者會先唸出以下情境:「老校長
雖然退休了,但一直關心著教育相關新聞。自從聽到中國偏遠地區的孩子沒有足 夠的師資和教育資源後,老校長開始固定捐款,希望能夠盡一己之力來幫助他 們 。 」, 接 著 念 出 前 導 問 句 :「 請 問 老 校 長 關 心 著 哪 裡 的 學 生 ? 」。 實驗所需要的目標句就是前導問句的答句,此答句會在實驗引導者唸完前導問 句後出現在電腦螢幕上,如圖4.1。發音人看到電腦螢幕上無標點的「關心中國 的學生」後,必須依照之前語境自然地回答:「關心中國的學生」。若目標句是圖 3.1中(1w)的一聲句子,則情境為:「小明是中國人,雖然後來移民到加拿大,但 仍然天天收看中國新聞,了解與中國相關的事。」,前導問句是:「小明是一位怎 樣的學生?」。發音人要回答的句子雖然字面上仍為「關心中國的學生」,但意義 卻有所不同。圖4.1為提供給受試者的句子提示。 圖 4.1 句子提示範例 每一次錄音過程持續 90 分鐘左右,每 30 至 40 分鐘休息 5 分鐘。發音人在 錄音工作完成後皆領取報酬。
在錄音過程中,實驗引導者會判斷發音人的回答是否符合實驗需求。若發音 人唸出的目標句有唸錯字、不順暢、發音不標準、咳嗽、中斷、或其他足以影響 句子分析的狀況時,實驗引導者會根據情況來判斷該句的錄製過程是否需重新來 過,若是則要求發音人重新回答該目標句。 4.2.5 資料分析 由於「受試者解讀句子的偏好」以及「語境的合適與否」都有可能影響發音 人在產生實驗中所產生的句子,為了了解這兩個因素是否對實驗造成影響,特別 設計了兩個前測以觀察受試者對不同句子是否有不同的解讀偏好,以及欲引導歧 義句的語境對受試者來說是否提供足夠的資訊。 在分析方面,我們知道界限的存在會反映在界限後的停頓、周圍音節的強度、 基頻、和時長上,因此在這裡要測量的聲學特徵為停頓時長、界限前後音節的平 均強度、界限前音節的最小基頻、界限後音節的最大基頻、以及界限前後音節的 時長。 由於停頓會對時長測量造成影響,若是忽略停頓的存在或是將停頓統一歸入 界限前音節時長會影響時長數據。因此在音檔製作textgrid檔之前,每位發音人所 產出的每一句子都必須經過 3 位標記者(coder)的判斷,標記者的母語皆為國語。 3 位標記者分開進行標記工作,每次標記兩位發音人,每次標記時間約為 30 分 鐘,共進行 3 次。在聽過句子後,標記者根據他們的直覺判斷有無停頓存在於句
子中,若是有,標記者會在句子清單上進行標記。根據標記者的意見,停頓的時
段會在textgrid中以「_」標示之,不納入任何一個音節的時長。3 位標記者並非
對每一句的停頓現象都持相同看法,若遇意見不同時,則採多數決方式決定該句
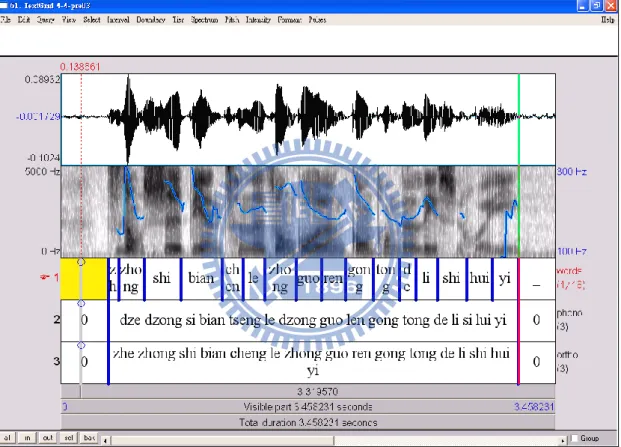
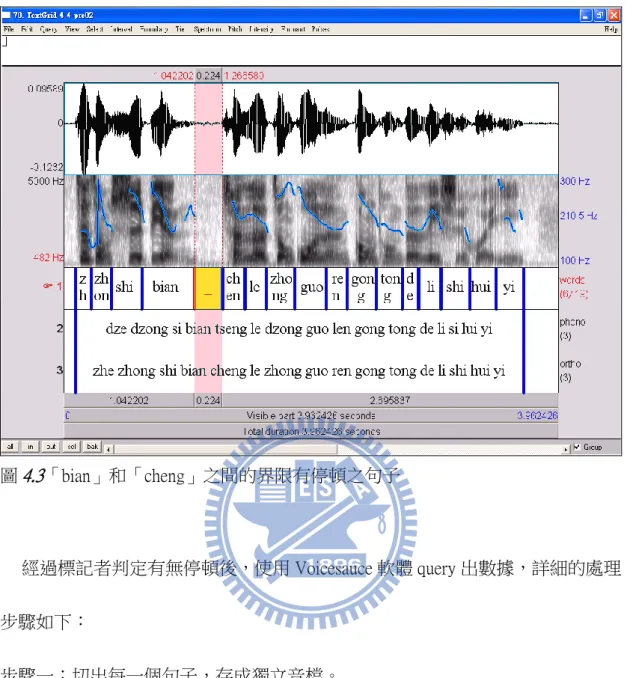
有無停頓。圖 4.2 和 4.3 分別呈現無停頓現象和有停頓現象的音檔範例。
圖4.3「bian」和「cheng」之間的界限有停頓之句子 經過標記者判定有無停頓後,使用 Voicesauce 軟體 query 出數據,詳細的處理 步驟如下: 步驟一:切出每一個句子,存成獨立音檔。 步驟二:使用Praat軟體替每一音檔製作textgrid檔。 步驟三:使用EasyAlign軟體,配合本實驗室電腦工程師所寫之程式,自動切出句 中的每一音節(syllable)。 步驟四:以人工方式檢查句子中每一音節的界限,進行界限調整。 步驟五:使用VoiceSauce軟體量出每一音節的強度、基頻數值(9 個觀察點) 、和 界限所在時間點。
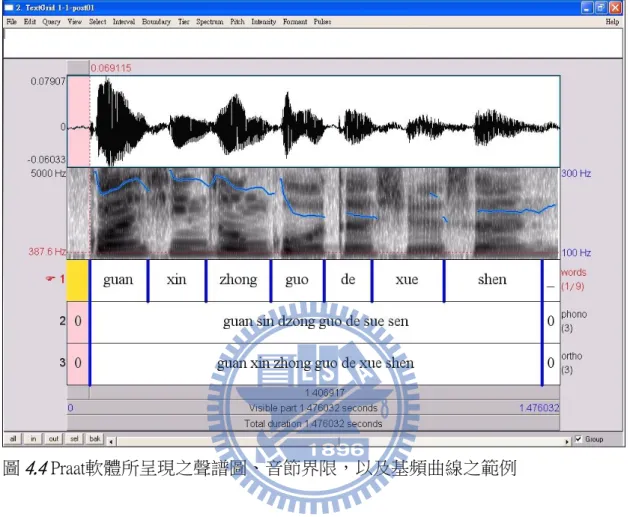
圖 4.4 為句子經上述步驟處裡後的完成型式。 圖4.4 Praat軟體所呈現之聲譜圖、音節界限,以及基頻曲線之範例 在此音節強度是指該音節的平均強度,跨界限基頻重設範圍則是指界限後音 節的最大基頻減去界限前音節最小基頻,而音節時長由音節結束時間減去起始時 間而得。 由於界限的存在會反映在停頓現象、周圍音節的強度、基頻、和時長上,因 此在這份研究中要測量的聲學特徵是停頓時長、界限前後音節強度、跨界限基頻 重設範圍、和界限前後音節時長。這些聲學特徵的算法如下:停頓時長是停頓的 起始時間與下一音節(停頓結束)的起始時間之差;界限前後音節強度是音節的均
方根(root mean square)強度;跨界限基頻重設範圍是界限前音節的最小基頻與界 限後音節的最大基頻之差;界限前後音節時長是音節的起始時間與下一音節(停 頓)的起始時間之差。 取得原始的聲學數據後,因為考量到每一位發音人的生理構造不同,表現出 的聲學特徵也不同,所以在進行統計分析之前,必須先行調整(adjust)每位發音人 的原始數據。在這裡使用公式(1)分別求出每位發音人在發同一字時該字在強度範
圍(range)中的百分段值(percentile) 。其中「Adjust intensity_X’」的「X’」指不同音 節,下標「speaker x」的「x」指不同發音人。 (1) X ker spea X ker spea X ker spea X ker spea X ker spea X ensity int MIN X ensity int MAX X ensity int MIN X ensity int X ensity int Adjust _ _ _ _ ' _ 作法是分別將每位發音人同一句中同一字的每個原始音節強度減去相同音
節中的最小強度(intensity_XspeakerX - MIN intensity_XspeakerX),求出原始音節強度與最小
強度之差,再將原始音節強度距最小強度之差除以強度範圍(range)(MAX
intensity_XspeakerX - MIN intensity_XspeakerX),所得到的數值就是該音節強度的百分段
值。也就是說,經過公式(1)換算後所得到的值,是原始音節強度在相同音節中強
最小值為 0.017,因此強度範圍為 0.319(0.336-0.017=0.319)。發音人 CLY 所唸的其 中一個「心」字強度為 0.021,將該「心」字強度減去「心」字群中的最小強度, 得到的差為 0.004(0.021-0.017=0.004)。最後將「心」字的原始強度與最小強度之 差除以「心」字的強度範圍便得到 0.013(0.004/0.319=0.013),也就是此「心」字 的百分段值。 由於在欲觀察的界限附近有聲調替換的設計,為了避免因聲調不同而造成基 頻重設範圍(f0 reset range)數值的不同,我們使用公式(2)求出每位發音人的基頻重 設範圍數值在所有相同位置的基頻重設範圍數值中的百分段值(percentile) 。其中
「Adjust f0 reset range_X’」的「X’」指不同音節,下標「speaker x」的「x」指不 同發音人。 (2) X ker spea X ker spea X ker spea X ker spea X ker spea X range reset f MIN X range reset f MAX X range reset f MIN X range reset f X range reset f Adjust _ 0 _ 0 _ 0 _ 0 ' _ 0 作法是分別將每位發音人的同一句中同一字每個原始基頻重設範圍值減去
相同位置的最小基頻重設範圍值(f0 reset range_X speakerX - MIN f0 reset range_X
speakerX),求出原始基頻重設範圍值與最小基頻重設範圍值之差,再將原始基頻重設
範圍值與最小基頻重設範圍值之差除以所有基頻重設範圍值所組成的範圍
CLY 所唸的「關心中國的學生」中的「心」和「中」字為例,在此基頻範圍值 為「中」的最大基頻與「心」的最小基頻之差。在這個位置上最大值的基頻範圍 值為 34.44Hz,最小值為 19.83 Hz,因此所組成的範圍為 14.61 Hz (34.44-19.83=14.61)。在發音人 CLY 所唸其中一句裡,「心」與「中」的基頻範 圍值為 28.06 Hz,將該基頻範圍值減去範圍中的最小基頻範圍值,得到的差為 13.45 (28.06-19.83=8.23)。最後將原始基頻範圍值與最小基頻範圍值之差除以該處 基頻範圍值所組成的範圍便得到 0.56(8.23/14.61=0.56),也就是此處基頻範圍值的 百分段值。 公式(3)是用來算出每位發音人發同一句中同一字時該字在時長範圍中的百
分段值(percentile) 。其中「Adjust Duration_X’」的「X’」指不同音節,下標「speaker x」的「x」指不同發音人。 (3) X ker spea X ker spea X ker spea X ker spea X ker spea X duration MIN X duration MAX X duration MIN X duration X duration Adjust _ _ _ _ ' _ 作法是分別將每位發音人的同一句中同一字每個原始音節時長減去相同音
節中的最小時長(duration_XspeakerX - MIN duration _XspeakerX),求出原始音節時長與最小
過的數值會介於 0 到 1 之間。以發音人 CLY 所唸的「關心中國的學生」中的「心」 字為例,在所有的「心」字中最大值為 230 毫秒,最小值為 168.18 毫秒,因此時 長範圍為 61.82 毫秒(230-168.18=61.82)。發音人 CLY 所唸的其中一個「心」字時 長為 196.54 毫秒,將該「心」字時長減去「心」字群中的最小時長,得到的差為 28.36(196.54-168.18=28.36)。最後將「心」字的原始時長與最小時長之差除以「心」 字的時長範圍便得到 0.46(28.36/61.82=0.46),也就是此「心」字的百分段值。 為控制語速對時長數值所造成影響,所以要求出每位發音人同一句中每一個 音節在該句中所佔的比例。公式(4)將時長數值標準化(normalize),目的是算出音 節在所處句子中所佔的比例。其中「Normalized duration_X’’」的「X’’」指不同音 節的調整時長,下標「speaker x」的「x」指不同發音人。 (4)
n k k X ker spea X ker spea X ker spea X duration Adjust X duration Adjust X duration Normalize 1 ' _ ' _ '' _ 作法是每一發音人,同一句中經過公式(3)調整過的音節時長百分值段相加 (方程式中以
n k 1 k X speaker ' duration_X Adjust 表示),再把欲觀察的音節之時長百分值段為 0.59,調整過的「心」時長百分值段為 0.46,調整過的「中」時長百分值 段為 0.26,調整過的「國」時長百分值段為 0.44,調整過的「的」時長百分值段 為 0.20,調整過的「學」時長百分值段為 0.38,調整過的「生」時長百分值段為 0.19,所以此句子的總百分值段為 2.52(0.59+0.46+0.26+0.44+0.20+0.38+0.19=2.52)。 若要求出「心」字的標準化時長百分值段,則將「心」字的調整時長百分值段 0.46 除以句子總百分值段 2.52,就可以得到標準化時長百分值段 0.18(0.46/2.52=0.18)。由於基頻和強度沒有語速的問題,所以不用進行標準化動 作。所有音節數據都是按發音人分開進行調整/標準化動作,再做進一步的統計 與分析比較,因此後面章節所提到的強度、基頻重設範圍、與時長均是指強度百 分值段、基頻重設範圍百分值段、和標準化時長百分值段。 為了可以更清楚地觀察歧義句的句法結構與實驗數據之間的關係,在後面圖 表中,每一句歧義句都只以詞性、界限、和結點(node)關係重新命名。舉例來說, 在「關心中國的學生」一句中,以「V」代表「關心」,「Adj」代表「中國的」, 「N」代表「學生」,此外我們使用「*」標示欲觀察的界限位置(標的界限),並 且以括弧「[ ]」將隸屬於同詞組(constituent)的詞彙放在括弧內,「+」區隔不同 片語。因此,當界限位於「關心」與「中國」之間時句子就可以寫成 V*[Adj+N], 而當界限位於「中國的」與「學生」之間時我們就以[V*NP]+N 表示之。表 4.1 為所有句型代號。
表4.1 8 種類型歧義句在圖表中的句法結構表示名稱 類型 界限強度 句子代號 1 較強 V*[AdjP+N] 較弱 [V*NP]+N 2 較強 [V+NP]*V 較弱 V+[NP*V] 3 較強 [AdjP+N]*ConjP+N 較弱 AdjP+[N*ConjP+N] 4 較強 NP*[NegP] 較弱 [NP*NegP] 5 較強 P*[N+N] 較弱 [P*N]+V 6 較強 AdvP*[NP+I] 較弱 [AdvP*NP]+I 7 較強 [NP]*V 較弱 [σ *σ ] 8 較強 NP*[V+Neg+V] 較弱 [σ *σ ] +Neg+V
4.3 產生實驗結果
在這份實驗中,雖然每一個句子都請受試者重複唸三遍,但句子重複三遍所 造成的差異性並非這裡所要了解的重點,因此在進行統計分析之前,會先將重複 三遍所得到的數據(強度、基頻、時長)進行平均,以平均過的數據進行後續的統 計分析。另外,接下來所提及的界限後音節強度、跨界限基頻重設範圍、與界限 前音節時長,「界限」都是指句子代號中「*」所標示的標的界限。 4.3.1 停頓現象在此實驗中,經標記者判斷,停頓現象只存在於較強界限之後。在產生實驗 所得到的 1152 個句子(192 句 x 6 位發音人),有 576 個句子(二分之一)屬界限較強 的句子,其中有 266 個句子在標的界限後具停頓現象,佔界限較強句子的 46.1%。 表 4.2 分別列出 8 種句子類型其標的界限後具停頓現象的句子百分比以及其停頓 時長。 表 4.2 各句子類型標的界限後具停頓現象的百分比和平均時長 句子類型 界限強度 百分比(句數) 平均時長(ms) 類型 1 強 22.2%(16) 50.98 弱 0%(0) 0 類型 2 強 33.3%(24) 84.27 弱 0%(0) 0 類型 3 強 38.8%(28) 126.09 弱 0%(0) 0 類型 4 強 55.5%(40) 105.20 弱 0%(0) 0 類型 5 強 41.6%(30) 109.97 弱 0%(0) 0 類型 6 強 44.4%(32) 128.78 弱 0%(0) 0 類型 7 強 72.2%(52) 116.32 弱 0%(0) 0 類型 8 強 61.1%(44) 101.11 弱 0%(0) 0 由表 4.2 可以發現,界限強度較弱的句子在標的界限處不具停頓現象。以下 就 8 種歧義句之標的界限之界限後音節強度、跨界限基頻重設範圍、及界限前音 節時長加以分析。
4.3.2 界限後音節強度
在這邊所測量的音節強度是指整個音節的平均強度。雖然在此實驗中主要關
心的議題是界限強度對聲學線索的影響,但由於不同受試者和不同句子類型也是
造成實驗數據不同的潛在因素,所以執行三因子混和變異數分析(Three-way mixed
factor ANOVA)(發音人 × (句子類型 × 界限強度))來判定 6 位受試者(CLY、LPL、
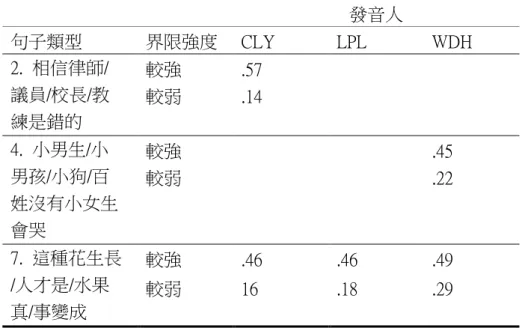
LPT、WDH、LYJ、LCH)其 8 種句子類型和強、弱界限對界限後音節強度的影響。 表 4.3 說明發音人、句子類型、與界限對界限後音節強度進行統計分析後所得到 的結果。 表4.3 發音人、句子類型、與界限強度對界限後音節強度之三因子混和變異數分 析摘要表(*:p < 0.05,**:p < 0.01,***:p < 0.001) 變異來源 SS DF MS F 值 發音人 .26 5 .05 1.96 句子類型 .92 7 .13 3.53** 界限強度 1.08 1 1.08 21.52*** 句子類型 × 發音人 1.41 35 .04 1.51* 界限強度 × 發音人 .29 5 .05 2.20 句子類型 × 界限強度 .38 7 .05 1.09 發音人 × 句子類型 × 界限強度 1.07 35 .03 1.15 誤差 6.39 240 .02 分析結果顯示,發音人、句子類型、與界限強度之間無顯著交互作用。由於 句子類型與發音人具顯著交互作用,因此接下來將界限後強度資料根據 6 位發音
分析。表 4.4 為一因子變異數分析檢定之結果,而表 4.5 則是列出表 4.4 中達顯著
表 4.4 6 位發音人其 8 種句子類型之界限後音節強度一因子變異數分析摘要表(*:p < 0.05,**:p < 0.01,***:p < 0.001) 發音人 CLY LPL LPT WDH LYJ LCH 變異來源 界限強度 1. 關心中/韓/美/泰國 的學生 F(1, 6)=.33 F(1, 6)= 2.20 F(1, 6)= 1.13 F(1, 6)= .11 F(1, 6)= 3.57 F(1, 6)= .17 2. 相信律師/議員/校 長/教練是錯的 F(1, 6)= 46.72*** F(1, 6)= 5.17 F(1, 6)= .012 F(1, 6)= 5.48 F(1, 6)= 2.87 F(1, 6)= .07 3. 緊張的律師/議員/ 校長/教練和張先生 F(1, 6)=.16 F(1, 6)= .00 F(1, 6)= .07 F(1, 6)= 4.29 F(1, 6)= .02 F(1, 6)= 2.84 4. 小男生/小男孩/小 狗/百姓沒有小女生會 哭 F(1, 6)= 5.45 F(1, 6)= 4.60 F(1, 6)= .84 F(1, 6)= 6.00* F(1, 6)= .63 F(1, 6)= 2.47 5. 老師對家長/員工/ 女僕/侍衛的欣賞是早 有耳聞的 F(1, 6)= 1.08 F(1, 6)= .26 F(1, 6)= 2.97 F(1, 6)= 1.66 F(1, 6)= .47 F(1, 6)= 2.14 6. 可能花費/留下/想 到/遇到 F(1, 6)= .03 F(1, 6)= .08 F(1, 6)= 1.32 F(1, 6)=.05 F(1, 6)= .21 F(1, 6)= .64 7. 這種花生長/人才 是/水果真/事變成 F(1, 6)= 7.44* F(1, 6)= 10.50** F(1, 6)= .29 F(1, 6)= 10.52* F(1, 6)= 8.04 F(1, 6)= .01 8. 風/太陽/水/沼氣能 不能一直提供電能 F(1, 6)= .39 F(1, 6)= .18 F(1, 6)= .99 F(1, 6)= 3.28 F(1, 6)= .09 F(1, 6)= .18
表4.5 不同界限強度之界限後音節平均強度比較表 發音人 句子類型 界限強度 CLY LPL WDH 2. 相信律師/ 議員/校長/教 練是錯的 較強 .57 較弱 .14 4. 小男生/小 男孩/小狗/百 姓沒有小女生 會哭 較強 .45 較弱 .22 7. 這種花生長 /人才是/水果 真/事變成 較強 .46 .46 .49 較弱 16 .18 .29 由表 4.4 可以發現,在句子類型方面,8 種句子類型中僅 CLY、LPL、和 WDH 3 位發音人之句型 2、4、和 7,其中 5 組強度資料 F 值達顯著水準。從圖 4.3 可 以看出,達顯著水準的組別其強界限之迴歸線會在弱界限之迴歸線上方。具顯著 界限強度之資料組之音節平均強度可從表 4.5 得知:界限強度較強的句子其界限 後音節強度會顯著地大於界限強度較弱的句子。圖 4.5 呈現 6 位發音人在 8 種不 同類型的歧義句中,界限前音節與後音節的音節強度關係。
V*[AdjP+N] V*[AdjP+N] Regr [V*NP]+N [V*NP]+N Regr V*[AdjP+N] V*[AdjP+N] Regr [V*NP]+N [V*NP]+N Regr NP*[V+Neg+V] NP*[V+Neg+V] Regr [ * ] [ * ] Regr N*[NegP] N*[NegP] Regr [N*NegP] [N*NegP] Regr P*[N+N] P*[N+N] Regr [P*N]+V [P*N]+V Regr NP*[V+Neg+V] NP*[V+Neg+V] Regr [ * ] [ * ] Regr N*[NegP] N*[NegP] Regr [N*NegP] [N*NegP] Regr P*[N+N] P*[N+N] Regr [P*N]+V [P*N]+V Regr CLY-八 種歧義句邊 界 前後音節調 整 強度 0.0 0.5 1.0 邊 界 後 音 節 調 整 強 度 百 分 值 段 0.0 0.5 1.0 0.0 0.5 1.0 邊 界 前 音節調 整 強度 百分 值段 0.0 0.5 1.0 0.0 0.5 1.0 0.0 0.5 1.0 Type 1 Type 2 Type 3 Type 4 Type 5 Type 8 Type 7 LPL-八 種歧義句邊 界 前後音節調 整 強度 0.0 0.5 1.0 0.0 0.5 1.0 0.0 0.5 1.0 邊 界 前 音節調 整 強度 百分 值段 0.0 0.5 1.0 強 強 迴歸 線 弱 弱 迴歸 線 Type 1 Type 2 Type 3 Type 4 Type 5 Type 6 Type 8 Type 7 P<.01 Type 6 strong strong Regr weak weak Regr NP*[V+Neg+V] NP*[V+Neg+V] Regr [ * ] [ * ] Regr N*[NegP] N*[NegP] Regr [N*NegP] [N*NegP] Regr P*[N+N] P*[N+N] Regr [P*N]+V [P*N]+V Regr NP*[V+Neg+V] NP*[V+Neg+V] Regr [ * ] [ * ] Regr N*[NegP] N*[NegP] Regr [N*NegP] [N*NegP] Regr P*[N+N] P*[N+N] Regr [P*N]+V [P*N]+V Regr strong strong Regr weak weak Regr strong strong Regr weak weak Regr NP*[V+Neg+V] NP*[V+Neg+V] Regr [ * ] [ * ] Regr N*[NegP] N*[NegP] Regr [N*NegP] [N*NegP] Regr P*[N+N] P*[N+N] Regr [P*N]+V [P*N]+V Regr NP*[V+Neg+V] NP*[V+Neg+V] Regr [ * ] [ * ] Regr N*[NegP] N*[NegP] Regr [N*NegP] [N*NegP] Regr P*[N+N] P*[N+N] Regr [P*N]+V [P*N]+V Regr strong strong Regr weak weak Regr strong strong Regr weak weak Regr NP*[V+Neg+V] NP*[V+Neg+V] Regr [ * ] [ * ] Regr N*[NegP] N*[NegP] Regr [N*NegP] [N*NegP] Regr P*[N+N] P*[N+N] Regr [P*N]+V [P*N]+V Regr NP*[V+Neg+V] NP*[V+Neg+V] Regr [ * ] [ * ] Regr N*[NegP] N*[NegP] Regr [N*NegP] [N*NegP] Regr P*[N+N] P*[N+N] Regr [P*N]+V [P*N]+V Regr strong strong Regr weak weak Regr NP*[V+Neg+V] NP*[V+Neg+V] Regr [ * ] [ * ] Regr N*[NegP] N*[NegP] Regr [N*NegP] [N*NegP] Regr P*[N+N] P*[N+N] Regr [P*N]+V [P*N]+V Regr NP*[V+Neg+V] NP*[V+Neg+V] Regr [ * ] [ * ] Regr N*[NegP] N*[NegP] Regr [N*NegP] [N*NegP] Regr P*[N+N] P*[N+N] Regr [P*N]+V [P*N]+V Regr LPT-八 種歧義句邊 界 前後音節調 整 強度 0.0 0.5 1.0 邊 界 後 音 節 調 整 強 度 百 分 值段 0.0 0.5 1.0 0.0 0.5 1.0 0.0 0.5 1.0 邊 界 前 音節調 整 強度 百分 值段 0.0 0.5 1.0 0.0 0.5 1.0 0.0 0.5 1.0 Type 1 Type 2 Type 3 Type 4 Type 5 Type 6 Type 8 Type 7 WDH-八 種歧義句邊 界 前後音節調 整 強度 0.0 0.5 1.0 0.0 0.5 1.0 邊 界 前 音節調 整 強度 百分 值段 強 強 迴歸 線 弱 弱 迴歸 線 Type 1 Type 2 Type 3 Type 4 Type 5 Type 6 Type 8 Type 7
LYJ-八 種歧義句邊 界 前後音節調 整 強度 0.0 0.5 1.0 邊 界 後 音 節 調 整 強 度 百 分 值段 0.0 0.5 1.0 0.0 0.5 1.0 0.0 0.5 1.0 邊 界 前 音節調 整 強度 百分 值段 0.0 0.5 1.0 0.0 0.5 1.0 0.0 0.5 1.0 Type 1 Type 2 Type 3 Type 4 Type 5 Type 6 Type 8 Type 7 LCH-八 種歧義句邊 界 前後音節調 整 強度 0.0 0.5 1.0 0.0 0.5 1.0 0.0 0.5 1.0 強 強 迴歸 線 弱 弱 迴歸 線 Type 1 Type 2 Type 3 Type 4 Type 5 Type 6 Type 8 Type 7 邊 界 前 音節調 整 強度 百分 值段 圖4.5 6 位發音人在 8 種類型歧義句中界限前後音節強度關係 圖 4.5 的橫座標是界限前音節強度,縱座標是界限後音節強度;黑點代表的 是界限強度較強句子的資料,灰點代表的是界限強度較弱句子的資料。在圖 4.5 中,黑點與灰點的分佈沒有明顯的趨勢。 4.3.3 跨界限基頻重設範圍 在這裡跨界限基頻重設範圍是指界限後音節的基頻最大值與界限前音節的 基頻最小值之差。如同界限後音節強度的分析方法,先執行三因子混和變異數分
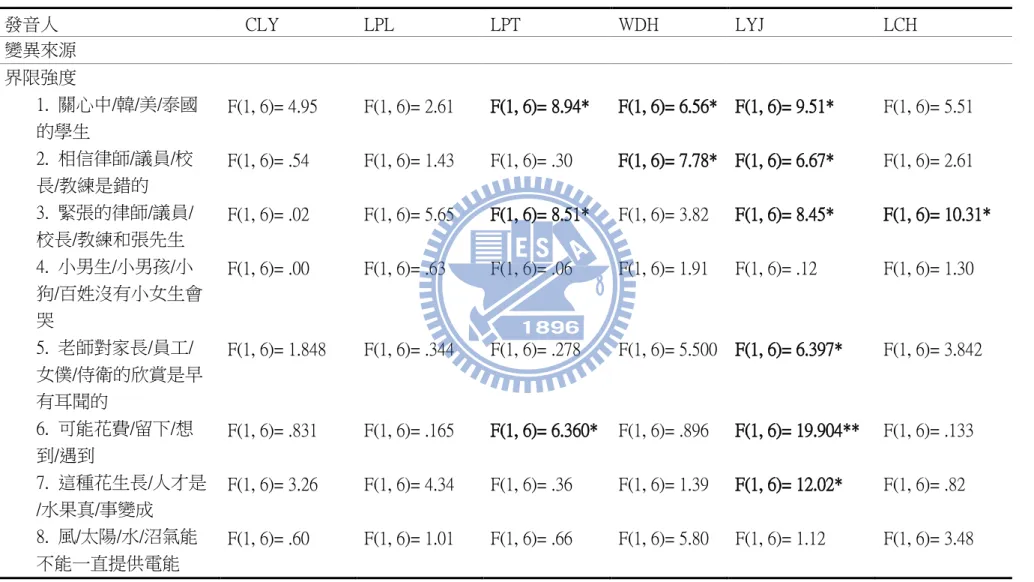
析(Three-way mixed factor ANOVA)(發音人 × (句子類型 × 界限強度))來判定 6 位
結果。 表4.6 發音人、句子類型、與界限對跨界限基頻重設範圍之三因子混和變異數分 析摘要表(*:p < 0.05,**:p < 0.01,***:p < 0.001) 變異來源 SS DF MS F 值 發音人 .17 5 .03 1.32 句子類型 .46 7 .06 .88 界限強度 3.0 1 3.01 40.39*** 句子類型 × 發音人 2.8 35 .08 3.11*** 界限強度 × 發音人 .33 5 .06 2.54* 句子類型 × 界限強度 .23 7 .03 .44 發音人 × 句子類型 ×界限強度 .53 35 .01 .58 誤差 6.32 240 .02 分析結果顯示,發音人、句子類型、與界限強度之間無顯著交互作用。由於 句子類型與發音人具顯著交互作用,因此接下來將基頻重設範圍值根據 6 位發音 人和 8 種句子類型,切割成 48 組資料,並對每組資料進行一因子界限強度變異 數分析。表 4.7 為一因子變異數分析檢定之結果,而表 4.8 則是達顯著水準之跨 界限基頻重設範圍的平均數值。
![表 4.1 8 種類型歧義句在圖表中的句法結構表示名稱 類型 界限強度 句子代號 1 較強 V*[AdjP+N] 較弱 [V*NP]+N 2 較強 [V+NP]*V 較弱 V+[NP*V] 3 較強 [AdjP+N]*ConjP+N 較弱 AdjP+[N*ConjP+N] 4 較強 NP*[NegP] 較弱 [NP*NegP] 5 較強 P*[N+N] 較弱 [P*N]+V 6 較強 AdvP*[NP+I] 較弱 [AdvP](https://thumb-ap.123doks.com/thumbv2/9libinfo/8703087.199405/50.892.128.562.134.739/較弱較強VV較強AdjP較弱AdjP較強NPNegP較弱NPNegP較強PN較弱PN較強AdvPNP較弱AdvP.webp)