小區域死亡率模型的探討 - 政大學術集成
54
0
0
全文
(2) 謝詞 感謝余清祥老師對我的指導,除了在專業領域的指導之外,也教導我許多關 於做研究的態度及想法,另外,也感謝黃泓智老師、李隆安老師、王信忠老師在 我口試時提供了諸多寶貴建議。除此之外,我也要感謝研究所的同學們,在碩士 班的二年當中,無論是課業、生活方面,都提供我許多幫助。而帶我們處理健保 資料庫的小馬學長,不僅教我們在資料庫方面和程式撰寫的部份,也在課業上提 供許多範例給我們參考。而在我做論文遇到瓶頸時,願意聽我訴苦、給我支持與 鼓勵的女朋友,也在此感謝妳。. 政 治 大 最後,感謝我的父母,在我求學的過程中給我的支持與鼓勵,讓我能夠無後 立. 顧之憂地完成學生生涯。. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. I. i n U. v.
(3) 摘要 壽命延長及生育率下降使得人口老化日益明顯,成為全球多數國家在 21 世 紀必須面對的議題,由於各區域人口老化的速度不同,必須根據各地特性而調整 因應對策。其中研究死亡率變化為面對人口老化的必備課題,尤其是高齡族群的 死亡率,這也是近年高齡死亡模型廣受重視的主因之一。因為樣本數與變異數成 反比,人口較少的區域或是高齡人口,死亡率的觀察值通常會有較大震盪,為了 降低震盪多半會經過修勻,以取得較為穩定的死亡率推估值(王信忠等人,2012) 。 此外,Li and Lee (2005)的 Coherent Lee-Carter 模型也是另一種可行方法,透過參. 政 治 大. 考大區域的資訊降低小區域的估計誤差。. 立. 本文探討結合上述修勻、死亡率模型的可能,希冀能綜合兩者的優點,提高. ‧ 國. 學. 小區域死亡率推估的精確性。因為 Coherent Lee-Carter 模型的想法類似增加小區 域的人數(加入大區域的人數),本文探討人口數與 Lee-Carter 模型參數估計值. ‧. 的關係,再以修勻調整大小區域的差異,透過電腦模擬及資料分析,驗證本文提. y. Nat. sit. 出方法是否有效。其中,仿造王信忠等人的作法,假設小區域與大區域死亡率間. n. al. er. io. 的七種可能情境,以平均絕對百分誤差(Mean Absolute Percentage Error)為衡量標. i n U. v. 準,找出調整修勻、相關模型的方法。另外,本文也以臺灣縣市為研究區域,驗. Ch. engchi. 證本文方法的估計結果。研究發現適當地使用修勻方法,可降低小區域的死亡率 估計值,其效果優於 Coherent Lee-Carter 模型。. 關鍵詞:小區域人口推估、修勻、標準死亡比、Lee-Carter 模型、電腦模擬 II.
(4) Abstract Reducing mortality rates and declining fertility rates speed up the population aging in the world. The study of elderly population and its mortality rates thus becomes a popular research topic. However, the life expectancy has increased rapidly and many countries (especially for those with small population and rapid increase in longevity) do not have enough of elderly data (including the size and the period), which makes modeling the elderly mortality rates difficult. The traditional graduation methods can be used to handle the problem of insufficient data, and if there are (larger). 政 治 大 standard mortality ratio (SMR) methods are recommended. In addition, the coherent 立 reference populations, Wang et al. (2012) showed that the Whittaker and partial. ‧ 國. 學. Lee-Carter model by Li and Lee (2005) can reduce the estimation errors by referencing larger populations.. ‧. In a sense, the coherent Lee-Carter model and graduation methods increase the. sit. y. Nat. sample size of small areas and thus in this study we explore the possibility of. io. er. combining graduation methods and coherent Lee-Carter model, provide that the. al. mortality rates of small areas satisfy the Lee-Carter model. In particular, we use. n. v i n graduation methods to modify C thehparameter estimation e n g c h i U of Lee-Carter model for the small areas. Similar to the setting in Wang et al., under certain mortality scenarios, we use computer simulation to evaluate whether the modification via graduation is valid with respect to MAPE (Mean Absolute Percentage Error). Also, we use the empirical data from Taiwan and Taipei city to check the proposed method. The results show that the Whittaker and partial SMR can improve the parameter estimation of Lee-Carter model for small areas. Key Words: Small Area Estimation; Standard Mortality Ratio; Graduation methods; Computer Simulation; Lee-Carter model III.
(5) 目錄 第一章 緒論 ............................................................................................................... 1 第一節 研究動機 ...................................................................................................... 1 第二節 研究目的 ...................................................................................................... 4 第二章 文獻探討 ....................................................................................................... 6 第一節 修勻方法 ...................................................................................................... 6 第二節 死亡率模型 ................................................................................................ 12. 政 治 大. 第三章 資料介紹與研究方法 ................................................................................. 16. 立. 第一節 資料介紹 .................................................................................................... 16. ‧ 國. 學. 第二節 研究方法 .................................................................................................... 17. ‧. 第四章 電腦模擬分析 ............................................................................................... 26. sit. y. Nat. 第一節 模擬方法對於死亡率估計的影響 ............................................................ 26. io. er. 第二節 修勻方法探討 ............................................................................................ 28 第三節 修勻方法及死亡率模型探討 .................................................................... 32. al. n. v i n Ch 第四節 死亡率模型探討 ........................................................................................ 36 engchi U 第五章 結論與建議 ................................................................................................. 39 第一節 結論 ............................................................................................................ 39 第二節 後續研究建議 ............................................................................................ 40 參考文獻 ..................................................................................................................... 42 附錄………………………………………………………………………………… . 45. IV.
(6) 表目錄 表 3-1、台灣女性人口資料 ...................................................................................... 16 表 3-2、台北市女性人口資料 .................................................................................. 16 表 3-3、衡量估計誤差標準(MAPE) ........................................................................ 18 表 4-1、小區域人數 10 萬、大區域人數 200 萬時之誤差 .................................... 30 表 4-2、小區域人數 10 萬、大區域人數 400 萬時之誤差 .................................... 31 表 4-3、小區域人數 20 萬、大區域人數 200 萬時之誤差 .................................... 31 表 4-4、小區域人數 20 萬、大區域人數 400 萬時之誤差 .................................... 31. 政 治 大. 表 4-5、αx 不同的七種情境之誤差 .......................................................................... 34. 立. 表 4-6、βx 不同的七種情境之誤差……….……………..……………..…………..35. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. V. i n U. v.
(7) 圖目錄 圖 1-1、台灣三階段人口年齡變動趨勢(2010-2060 年人口推估、中推計) ...... 1 圖 1-2、2010 年及 2060 年人口金字塔(2010-2060 年人口推估、中推計) ....... 2 圖 1-3、Lee-Carter 各年齡層參數估計值(人數 10 萬) ............................................. 3 圖 1-4、Lee-Carter 各年齡層參數估計值(人數 200 萬) ........................................... 3 圖 3-1、Whittaker 修勻後調整值對 MSE 的影響 ................................................... 19 圖 3-2、比較 Whittaker 修勻在不同 h 值的表現 .................................................... 19 圖 3-3、死亡率比值上限對 Whittaker Ratio 修勻的影響....................................... 20. 政 治 大. 圖 3-4、死亡率比值下限對 Whittaker Ratio 修勻的影響....................................... 21. 立. 圖 3-5、比較獨特性參數的重要性 .......................................................................... 23. ‧ 國. 學. 圖 3-6、修勻與死亡率模型 ...................................................................................... 24. ‧. 圖 4-1、Lee-Carter 各年齡層參數估計值 Bias 比例(假設死亡率服從常態分配) 26 圖 4-2、10000 次檢定中 P 值<0.05 的次數 ............................................................. 28. y. Nat. io. sit. 圖 4-3、死亡率比值Sx的七種情境 .......................................................................... 29. n. al. er. 圖 4-4、Lee-Carter 各年齡層參數估計值 Bias 比例 ............................................... 37. Ch. i n U. v. 圖 4-5、Li and Lee 方法之參數估計值 .................................................................... 38. engchi. 附圖 1、Lee-Carter 方法使用近似法估計參數的參數估計值(人數 10 萬)……….45 附圖 2、Lee-Carter 方法使用近似法估計參數的參數估計值(人數 50 萬)………45 附圖 3、Lee-Carter 方法使用近似法估計參數的參數估計值(人數 200 萬)……..46 附圖 4、Li and Lee 方法參數估計值βx、k t ……………………………………….46 附圖 5、Li and Lee 方法,資料合併方式改為幾何平均之參數估計值βx、k t ….47. VI.
(8) 第一章. 緒論. 第一節 研究動機 隨著醫療的進步等因素,平均壽命逐漸延長,加上少子化的影響,台灣人口 老化的趨勢愈加明顯。根據國家發展委員會所公布之「2010 年至 2060 年臺灣人 口推計」報告的中推計(圖 1-1) ,預計 2025 年台灣的老年人口(65 歲以上人口, 以下也記為 65+)占總人口數的比例超過 20%,邁入世界衛生組織定義的超高齡 社會(Super Aged Society);2060 年老年人口比例更高達 42%,總人數接近 800 萬。. 政 治 大. 其中,在 2010 年占多數的工作年齡人口(15 到 64 歲),因為近年生育率偏低,. 立. 未來隨著年齡增長仍將居於多數,使得 2060 年的人口結構產生失衡的現象(圖. ‧ 國. 學. 1-2) ;除了勞動人口不足,因為老年人所需的社會資源也將大幅上升,包括醫療. Nat. n. al. er. io. sit. y. ‧. 保健、照護需求、以及老人年金等社會保險及福利支出。. Ch. engchi. i n U. v. 圖 1-1、台灣三階段人口年齡變動趨勢(2010-2060 年人口推估、中推計) (資料來源:國家發展委員會). 為瞭解人口老化的速度與趨勢,死亡率變化的研究不可或缺,尤其是高齡族 群的死亡率,這也是近年高齡死亡模型廣受重視的主因之一。高齡死亡率過去大 1.
(9) 多採用 Gompertz 法則之類的關係模型(Relational Model),這系列的死亡模型具 有不錯的實質詮釋,估計值與觀察結果頗為吻合(Yue, 2002),且其估計方法也 相對簡單,像是 Gompertz 法則可透過瞬間死亡率的對數值是年齡的線性函數。 但這些模型因為參數估計值震盪幅度較大,用於預測時多半有較大誤差,不如現 在常用的隨機死亡模型(Yue et al., 2001)。. 立. 政 治 大. ‧. ‧ 國. 學. n. al. er. io. sit. y. Nat. 圖 1-2、2010 年及 2060 年人口金字塔(2010-2060 年人口推估、中推計) (資料來源:國家發展委員會). Ch. i n U. v. Lee-Carter 模型(Lee and Carter, 1992)大概是隨機死亡模型中使用比例最多者,. engchi. 然而因為樣本數與變異數成反比,小區域死亡率數值通常因人數較少而有較大震 盪。解決震盪過大的問題,傳統上會使用修勻(Graduation),以取得較為穩定的 死亡率推估值(王信忠等人,2012)。此外,Li and Lee (2005)的 Lee-Carter 死亡 率相關模型也是另一種可行方法,透過參考大區域的資訊降低小區域的估計誤差。 上述兩種方法或多或少假設小區域的死亡率特性與大區域接近,以取得較佳的調 整效果。 根據王信忠等人(2012)的研究,因為誤差和人口數成反比,小區域死亡率估 計值的誤差會較大,我們以 Lee-Carter 模型為例說明。圖 1-3 和圖 1-4 分別 10 2.
(10) 萬人口、200 萬人口的 Lee-Carter 參數估計值αx 及βx,圖形為 10,000 次模擬的結 果。由圖形不難看出在人口數 10 萬的區域,除了變異數較大外,Lee-Carter 模型 參數估計值會明顯偏差(大多數為低估),而隨著人數的增加,偏差的情形也會 跟著改善。. 立. 政 治 大. ‧. ‧ 國. 學. n. al. er. io. sit. y. Nat. 圖 1-3、Lee-Carter 各年齡層參數估計值(人數 10 萬). Ch. engchi. i n U. v. 圖 1-4、Lee-Carter 各年齡層參數估計值(人數 200 萬). 至於造成參數估計偏差的原因,可能因為人口數較少的地方,死亡率觀察值 3.
(11) 上、下震盪較大,使得代入 Lee-Carter 模型時產生不穩定的估計值。另一可能原 因是 Lee-Carter 模型的誤差分配,原始的估計方法是在常態分配假設下得出,但 實際的死亡人數(及死亡率)並不服從常態分配,而是假設為二項分配或布阿松 分配,不過對於人口數較少的小區域,死亡率以常態分配代入並不適宜,因此導 致參數估計值的偏差。 然而,雖然增加樣本數可減少參數估計偏差,但直接將大地區的死亡特性套 到小區域,可能會引起另一種偏差。像是台灣各縣市的各年齡死亡率及平均餘命 差異甚大,以 2011 年台灣地區簡易生命表為例,臺北市及臺東縣的零歲平均餘. 政 治 大 小區域的死亡率估計方法,減少因為人數不足引起的估計偏差。 立. 命差異大約 8 歲,兩者合併考慮會有問題。綜合以上所述,我們認為有必要發展. ‧ 國. 學. 第二節 研究目的. ‧. 小區域死亡率推估遭遇到的問題之一為人口數過少,造成推估數值有較大震. y. Nat. io. sit. 盪,本文試圖透過不同方法降低因人口數不足所造成的估計誤差。王信忠等人. n. al. er. (2012)的研究發現,小區域若參考大區域之訊息有穩定推估的效果,且修勻有助. Ch. i n U. v. 於降低推估之誤差。而修勻方法包含根據資料可靠度加權的 Whittaker 修勻法. engchi. (Whittaker, 1923)、大小區域間比值的 Whittaker Ratio 修勻法、或是套用標準死亡 比的 Partial SMR 修勻法(Lee, 2003)。本研究評估所使用之修勻方法,建議其適 用情況、限制條件以及設定的參數,使其提升估計的穩定性。 除了研究修勻方法對於死亡率的改善效果,本文也考慮貝氏相關的模型,探 討 Li and Lee (2005)的 Lee-Carter Coherence 模型,因為其為大、小區域的關聯性 模型,概念如同加入大區域的人數來補足小區域因為人口數不足所造成的問題。 另外,本文也欲驗證修勻方法對死亡率模型的估計值影響,亦即比較先修勻後再 配適模型,或是直接使用死亡率模型再修勻,何者較能降低因為小區域人數較少 引起的震盪。 4.
(12) 本文後續章節安排:第二章介紹修勻方法及死亡率模型的相關文獻。第三章 利用電腦模擬分析修勻方法的優劣,以及探討不同參數設定的所造成的影響,並 且探討死亡率模型的應用。第四章以台灣縣市的資料去模擬分析,第五章則是結 論與建議。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 5. i n U. v.
(13) 第二章. 文獻探討. 對於死亡率的估計方法,一般來說可以透過修勻方法或是死亡率模型,改善 其震盪的情況,修勻是生命表(Life table)中常見的方法,尤其在於人口數較少的 地區,死亡率觀察值震盪的情形更為嚴重,使用修勻方法可以改善此情形,得到 較為平滑的死亡率曲線。除了修勻之外,死亡率模型也常被用來估計死亡率, Lee and Carter 在 1992 年提出估計死亡率的方法,就是一個常見的死亡率模型, 在大部份人口數較多的地區,Lee-Carter 模型往往可以有較好的估計效果,本文 會探討 Lee-Carter 模型在人口數較少的小區域配適情形,並嘗試改善之,尋求較. 政 治 大. 佳的估計結果。本文使用修勻方法和死亡率模型來改善小區域死亡率的震盪,因. 立. 此以下將介紹所使用的修勻方法的概念,以及死亡率相關性模型。. ‧ 國. 學. 第一節 修勻方法. ‧. y. Nat. 生命表(Life table)之編算可以了解國家人民平均壽命的水準,在於政府施政. er. io. sit. 或是保險業之保費訂定時,都是重要的參考依據。由於各個年齡組別的死亡人數 和人數觀察值會有所不同,常會造成死亡率的上、下震盪,所以在編算生命表的. al. n. v i n 過程,常會使用修勻的方法,使得死亡率符合一般人的預期,即愈高年齡組別的 Ch engchi U 死亡率愈高,以及死亡率為一平滑的曲線。以下介紹幾種修勻方法: (一)移動加權平均法 (Moving Weighted Average Method). 保險業使用移動加權平均(MWA),最早可追溯至 19 世紀,又稱為線性合成 法(Linear Compound Formula),也經常用於時間數列(Time Series)中。因為計算簡 易,只需要考量各年齡死亡率的加權平均,加上樣本數較大時有不錯的效果,至 今仍有不少國家仍然使用 MWA 修勻方法編算生命表。MWA 的修勻公式一般表 示如下:. 6.
(14) ∞. 𝑣𝑥 = ∑𝑟=−∞ 𝑎𝑟 𝑢𝑥+𝑟. (2.1). 其中,𝑣𝑥 :x 歲的修勻值。 𝑢𝑥 :x 歲原始估計值。 𝑎𝑟 :第 r 項的權數。 通常又會假設以下兩個條件: (1)有限性(Boundedness):𝑎𝑟 =0,如果 r > n 或 r <− n,其中 2n+1 為範圍(Range)。 (2)對稱性(Symmetry):𝑎𝑟 =a-r,r=1,2,3,…,n。. 政 治 大. 代入上述條件,MWA 的公式可改為. vx = ∑nr=−n ar ux+r. 學. ‧ 國. 立. (2.2). MWA 兩個常見的要求:. ‧. (1)還原性(Reproduce):E(𝑉𝑥 ) = 𝑡𝑥 ;. Nat. n. al. (二) Whittaker 修勻法. Ch. engchi. er. io. 其中,𝑡𝑥 :x 歲理論值(真實的死亡率)。. sit. y. (2)縮小變異(Reducing Variations):Variance(𝑉𝑥 ) ≤Variance(𝑈𝑥 ). i n U. v. Whittaker 修勻法最初由 Whittaker (1923)首創,Henderson (1924, 1925)改良, 因此也稱為 Whittaker-Henderson 修勻法。與 MWA 不同,Whittaker 修勻兼顧適 度性(Fit)及平滑性(Smoothness),不單單要求各年齡死亡率間的平滑,也考慮各 年齡死亡率的適度性。適度性代表修勻值與觀察值間的差異,即修勻的程度;平 滑性代表修勻值是否平滑,即修勻後的死亡率是否符合過去經驗。其模型如下所 示: z. 2 M = F + hS = ∑nx=1 wx (vx −ux )2 + h ∑n−z x=1(Δ vx ). 7. (2.3).
(15) 其中,F :適度性函數。 S :平滑性函數。 ux :x 歲的死亡率,原始待修勻的觀察值。 𝑣𝑥 :調整後的 x 歲死亡率,即𝑢𝑥 經過修勻後的值。 𝑤𝑥 :x 歲的加權數,一般定為 x 歲的人口數。 n :樣本數,通常為修勻的年齡組別。 h :參數之一,用來決定平滑性和適度性的權重,當參數值 h→0 時,幾 乎不考慮修勻;而 h→∞時,修勻幾乎只考慮平滑性。 𝑧. 政 治 大. z :參數之一,Δ 為第 Z 次的差分(Difference),通常選擇為 2、3、4,. 立. 本文選擇 z = 3。. ‧. ⃑ =(W + hk z ′k z )−1 Wu v ⃑. (2.4). er. io. sit. y. Nat. 其中. ‧ 國. 修勻值為:. 學. 找出使(2.3)式最小化的vx ,即為 Whittaker 修勻值。而經由矩陣的運算可以得到. n. a l k =D …D D v i n−1 n z n−z+1 n Ch engchi U. −1 1 0 0 −1 1 D=[ ⋮ ⋮ ⋮ 0 ⋯ ⋯. 0 ⋯ 0 ⋯ ⋮ ⋱ ⋯ ⋯. ⋯ 0 ⋯ 0 ] ⋱ ⋮ −1 1. (2.5). (2.6). 因為 Whittaker 修勻法並未參考大區域的資料,對於人口數較少的小區域來 說,後續介紹的 Whittaker Ratio 修勻法,是一個較適合的方法。 (三) Partial SMR 修勻法 在流行病學中,標準死亡比(Standard Mortality Ratio, SMR)為一種常見的比 較標準,其定義為: 8.
(16) ∑x dx. SMR =. (2.7). ∑x ex. 其中,𝑑𝑥 :x 歲觀察死亡人數 𝑒𝑥 :x 歲期望死亡人數 SMR 代表觀察死亡人數和期望死亡人數的比值,當 SMR=1 時,代表二者相同, 當 SMR 大於 1 時,表示觀察死亡人數大於期望死亡人數,當 SMR 小於 1 時, 則表示觀察死亡人數小於期望死亡人數。 當我們預期小區域的死亡率可以參考大區域的死亡率時,可將上式改寫為:. 政 治 大. SMR =. 立. ∑x dx ∑x nx ∙u∗x. (2.8). 其中,n𝑥 :小區域 x 歲人口數. ‧ 國. 學. 𝑢𝑥∗ :大區域 x 歲死亡率. ‧. 當小區域的死亡率在各年齡層之間的變動和大區域相似時,上述之 SMR 將會是. y. Nat. 一個可靠的參考數值。Lee (2003)考慮小區域和大區域間各年齡層的死亡率比值,. er. io. al. n. 為. sit. 再加上 SMR,提出 Partial SMR 的方法修勻小區域的死亡率,令調整過的死亡率. vx =u∗x. C d ×h ĥe×log( nd ×h c+(1−h i ĝ)+(1− ×exp{ x. 2. dx ex. dx ∑ dx dx ) ∑ dx. 2. x. iv n U (SMR) )×log. }. (2.9). 在修勻小區域的死亡率之前,先選擇一個死亡率和小區域有相似性質的大區域, 而 x 歲的修勻值v𝑥 是在 x 歲的死亡率比值與 SMR 之間取得加權幾何平均所得之 ̂2 是異質性參數ℎ2 的估計值,是在一些假設之下使誤差最小的估計 數值,式中的ℎ 值,詳細推導過程可以參考 Lee (2003), 2. ̂2 =max{∑((dx −ex ×SMR) −∑ dx ) , 0} h 2 2 SMR ×∑ ex. (2.10). ̂2 越大代表小區域和大區域死亡率存在越大的異質性(Heterogeneity)。當死亡人 ℎ 9.
(17) 數越少時,修勻值參考大區域的比例越高,當死亡數為 0 時,修勻值會完全參考 大區域,也就是 SMR× 𝑢𝑥∗ ,可以視為大區域死亡率的平移。 又因為 Partial SMR 修勻法參考 SMR 的訊息較多,所以當 SMR 是一個可靠 的參考標準時,修勻值就越合理,而當各年齡層死亡率比值變化較大時,SMR 就不再是一個可靠的參考值,因此,可以嘗試對死亡率比值作 Whittaker 修勻, 詳細過程稍後介紹。 (四) Whittaker Ratio 修勻法 Whittaker Ratio 修勻的作法為仍使用 Whittaker 修勻法,只是修勻的對象不. 治 政 是直接修勻死亡率,而是先將小區域和大區域的死亡率做比值,並且將死亡率比 大 立 值套入 Whittaker 修勻法,去修勻死亡率比值,所得到之修勻完後的比值,再乘 ‧ 國. 學. 上大區域的死亡率,即可得到 Whittaker Ratio 法之修勻值(死亡率)。. ‧. 當小區域和大區域之間各年齡層死亡率比值較大時,則可使用此修勻法,在 修勻前先將死亡率比值異常的點以 SMR 取代,令 x 歲死亡率比值rx =u𝑥 /𝑢𝑥∗ ,金. y. Nat. io. sit. 碩 (2011)提出異常的點之處理方法,採取以下標準: 「若rx =0 或rx >2× SMR 異常,. n. al. er. 則該年齡層的死亡率比值用 SMR 取代」 。這麼做不只參考了 SMR 的訊息,因為. Ch. i n U. v. 加入 Whittaker 修勻,更考慮了死亡率在年齡間的變化,因為此法主要修勻死亡. engchi. 率比值,因此稱為 Whittaker Ratio 法。本文也嘗試尋找當死亡率比值異常時,死 亡率比值該用何者取代,在文中會詳細說明。 (五) 貝氏(Bayesian) 修勻法 貝氏理論(Bayesian Theory)是統計學中重要的領域,由 Thomas Bayes 於 1763 年發表的貝氏定理而得名。由於貝氏理論可合併過去經驗,近年愈受重視,在精 算 保 險 的 應 用 更 為 廣 泛 。 貝 氏 方 法 是 將 過 去 的 經 驗 作 為 先 驗 資 訊 (Prior Information),結合本次蒐集的資料(Data),綜合起來可得新的經驗,一般稱為後 驗結果(Posterior),概念如同以下: 10.
(18) 先驗資訊+實驗結果→後驗結果 若將貝氏理論用於修勻,可以將大區域的資料視為先驗資訊,再結合小區域的資 料,得到的修勻結果即為後驗結果。最早由 Kimeldorf-Jones 在 1967 年提出,假 設先驗分配滿足t~N(m ⃑⃑⃑ , A),而死亡率觀察值為u ⃑⃑⃑ |⃑t~N(t, B),貝氏修勻的死亡率修 勻值為: 𝑣=𝑚 ⃑⃑ + (I + B𝐴−1 )−1 (u ⃑⃑⃑ − m ⃑⃑⃑ ). (2.11). 其中,I:單位矩陣. 政 治 大 ⃑⃑⃑ :小區域的死亡率觀察值。 u 立. 𝑚 ⃑⃑ :參考地區的死亡率,也就是大區域死亡率。. ‧ 國. 學. A:參考地區的各年齡層死亡率的共變異數矩陣。 B:小區域各年齡層死亡率的共變異數矩陣。. ‧. 一般建議 A 可選取. (2.12). er. io. al. sit. y. Nat. A𝑥𝑦 = √A𝑥𝑥 √A𝑦𝑦 𝑟 |𝑥−𝑦| , 0≦r≦1. n. v i n 貝氏修勻在大、小區域死亡率相近似,通常可以提供不錯的估計效果,因為貝氏 Ch engchi U. 修勻的效果相當於用樣本數去加權大、小區域的死亡率,所以可以得到較為穩定 的估計效果。 (六) Gompertz 法則 Gompertz 在 1825 年提出此法則。認為 30 歲以後,人類的瞬間死亡率(Force of Mortality)會隨著年齡增加而呈現幾何級數的成長,並用一個簡易的公式來描 述高齡人口的死亡率: μx = BCx , B > 0 , C > 1 11. (2.13).
(19) 其中,μx 為 x 歲人的瞬間死亡率。 根據 Gompertz 的假設,可以推得: x+1. 𝑝x = e− ∫x. μx dt. x+1. = e− ∫x. BCx dt. =e−BC. x (C−1)/logC. (2.14). 對𝑝x 取對數可以得到: log(− log px )=log B + log( C + 1)- log(log C)+xlog C=α+β𝑥. (2.15). 其中,𝑝x 為 x 歲的人在未來一年存活的機率。 α = logB+ log(C+1)+ log(logC). 立. 學. ‧ 國. β𝑥 = log C. 政 治 大. 經由加權最小平方法(WLS)可以估計死亡率,即利用. ‧. minα,β ∑𝑥 𝑤𝑥 (ln(−ln 𝑝𝑥 )−α − β𝑥)2. (2.16). Nat. sit. y. 計算α和β的估計值,而加權的權數為各年齡層總人口數,帶回原式就可以得到𝑝x,. n. al. er. io. 再由𝑞x = 1 - 𝑝x 計算出 x 歲的人在未來一年中死亡的機率。. 第二節 死亡率模型. Ch. engchi. i n U. v. (一) Lee-Carter 模型 Lee and Carter 於 1992 年提出一個預測美國死亡率的模型,也可以用來估 計死亡率,除了在死亡率的應用外,曹郁欣 (2013)將此模型應用在預測生育率。 近年來被廣泛的應用與討論,其模型為下: log(m𝑥,𝑡 )=α𝑥 +β𝑥 κ𝑡 +𝜀𝑥,t 其中,m𝑥,𝑡 :x 歲在 t 年的中央死亡率。 α𝑥 :x 歲年齡組死亡率的平均曲線。 12. (2.17).
(20) β𝑥 :x 歲年齡組相對死亡率的變化率。 κ𝑡 :t 年死亡率強度的變化量。 𝜀𝑥,t :誤差,服從常態分配。 此模型假設在不同年度中,死亡率在同一年齡層會有相同的改善輻度;在不 同年齡層中,死亡率在同一年度中有相同之改善輻度,一般認為各年齡死亡率隨 著時間會有不同的改善,亦即預期κ𝑡 是一條遞減的曲線,代表死亡率隨著時間逐 漸下降,也就是說,隨著年代的演進,預期死亡率會逐漸下降;而β𝑥 會是大於 0 的數,數值愈大代表改年齡死亡率改善輻度愈大。. 政 治 大. 在求解參數時,為避免有無限多解的情況,會假設∑𝑥 β𝑥 =1,∑𝑡 κ𝑡 =0。估計. 立. 參數的方式有許多種,Lee and Carter 提到可以利用死亡人數和人口數找出κ𝑡,而. ‧ 國. 學. Koissi et al. (2006) 整理了幾種估計方法,包括 Lawson and Hanson (1974) 提出的 奇異值分解法 (Singular Value Decomposition, SVD)、主成份分析法(Principle. ‧. Component Analysis, PCA) 、最大概似估計法 (Maximum Likelihood Estimation,. Nat. sit. y. MLE),除了上述幾種方法,亦有近似法 (曾奕翔, 2005)和 加權最小平方法. n. al. er. io. (Weighted Least Squares, WLS)。而對於未來的預測(亦即對於時間參數κ𝑡 的預測),. i n U. v. 一般為假設κ𝑡 具有飄移項的隨機漫步(Random Walk with Drift, RWD),簡而言之,. Ch. engchi. 假設κ𝑡 為時間的線性函數,再以κ𝑡 數值代入求得未來的死亡率(Li et al., 2004)。 關於 SVD 的具體做法,先對中央死亡率取對數之後,先根據最小平方法估 計α𝑥 , min ∑𝑇𝑡=1[log(m𝑥,𝑡 ) − α𝑥 − β𝑥 κ𝑡 ]2. (2.18). 由於β𝑥 κ𝑡 加總為 0,所以求得α𝑥 為 α𝑥 =. ∑𝑇 𝑡=1 log(m𝑥,𝑡 ) 𝑇. 13. (2.19).
(21) 再對[log(mx,t ) − α𝑥 ]做 SVD,可以得到β𝑥 和κ𝑡 。將死亡率矩陣分解為 UΣV 𝑇 三個 矩陣相乘,其中 U 和V 𝑇 是正交的單位向量矩陣,Σ 是奇異值的對角矩陣,奇異 值代表每組向量可解釋的共變異數之量。 而關於近似法做法,為了有相同的解,採用相同的限制式,即∑𝑥 β𝑥 =1,∑𝑡 κ𝑡 =0。 利用∑𝑥 β𝑥 =1 可得: ∑𝑇 𝑡=1 log(m𝑥,𝑡 ). α𝑥 =. (2.20). 𝑇. 而利用∑𝑡 κ𝑡 =0 可得:. 政 治 大. κ𝑡 = ∑𝑥 [log(m𝑥,𝑡 ) − α𝑥 ]. 立. (2.21). ‧ 國. 距項的迴歸配適,得到的係數即為參數β𝑥 估計值。. 學. 接著令log(m𝑥,𝑡 ) − α𝑥 為應變數,參數κ𝑡 估計值為自變數,分別對各年齡層作無截. ‧. (二) Coherent Lee-Carter 模型. y. Nat. er. io. sit. Li and Lee (2005) 提供了一個小區域結合大區域的模型,利用大區域人口數 較多,降低估計死亡率的誤差,透過樣本數和變異數成反比的概念,希望提供一. al. n. v i n 個大區域給小區域做參考。他們以 Database)中 15 個較低 C h HMD(Human Mortality engchi U 死亡率的國家,將這 15 個國家的資料合併視為一個大區域,大區域的變化視為. 小區域的連貫(Coherent),在大區域的共通 Lee-Carter 模型中加入小區域資料的 波動,此模型的小區域死亡率預測值會因為加入參數和大區域的預測值有所不同。 又因為以此方法估計死亡率時,會先估計大區域和小區域的共通參數,再估計出 小區域的獨特性參數,可視為「Two Stages」估計方式。 具體的做法如下:先將大區域和小區域合併後共通的死亡率資料代入 Lee-Carter 模型中,取其估計出的參數β𝑥 、κ𝑡 ,當作共通性參數β𝑥 、κ𝑡 ,分別稱 為B𝑥、K 𝑡,接著再根據小區域的死亡率資料,代入 Lee-Carter 模型中,取其估計 14.
(22) 出的參數α𝑥,作法等同將小區域的死亡率取對數後,估計出各年齡層的平均死亡 率,當作獨特性參數α𝑥 ,稱為a𝑥 ,此時得到殘差為 log(m𝑥,𝑡 ) − a𝑥 − B𝑥 K 𝑡. (2.22). 並且再以 SVD 分解殘差,將小區域變化的獨特性萃取出來,得到b𝑥 、k 𝑡 。最終 Li and Lee 的模型為 log(m𝑥,𝑡 ) = a𝑥 + B𝑥 K 𝑡 + b𝑥 k 𝑡 + εx,𝑡. (2.23). 此模型在小區域和大區域人口結構相似時,可以提供相當不錯的死亡率估計值,. 政 治 大. 本文中會比較此模型及其他修勻與模型結合的估計方法。而 Li and Lee 建議若是. 立. 要預測未來K 𝑡、k 𝑡 時,可以令K 𝑡 為具有飄移項的隨機漫步(Random Walk with Drift,. ‧ 國. 學. RWD),並且令k 𝑡 為一階自我迴歸 (First Order Auto correlation)進行預測,再推算. ‧. io. sit. y. Nat. n. al. er. 出死亡率。. Ch. engchi. 15. i n U. v.
(23) 第三章. 資料介紹與研究方法. 研究以電腦模擬為主,根據小區域資料的特性,先前文獻探討中發現修勻及 死亡率模型都能夠改善小區域因為人口數過少造成的震盪,先根據不同的修勻方 法研究其參數設定,尋找修勻時較佳的參數值,期望可以將誤差降至最低。. 第一節 資料介紹 使用資料分別為台灣女性及台北市女性的人口資料,以內政部戶政司及內政. 政 治 大 性自 1970 年至 2010 年共 41 年的資料,台北市女性 1990 至 2010 年共 21 年資料, 立 部統計處提供的人口資料來分析,人口數與死亡人數皆使用五齡組資料,台灣女. 部份年份的資料高齡人數記錄較為不足,各年份記錄的年齡分別可以參考表 3-1. ‧ 國. 學. io. n. al. 0~85+ 0~90+ 0~95+ 0~95+ 0~100+. Ch. 死亡人數記錄年齡(歲). y. Nat. 1970~1974 1975~1990 1991~1994 1995~1997 1998~2010. 人口數記錄年齡(歲). 0~85+ 0~85+ 0~90+ 0~95+ 0~100+. sit. 資料年份(年). ‧. 表 3-1、台灣女性人口資料. er. 及表 3-2。. engchi. i n U. v. 表 3-2、台北市女性人口資料 資料年份(年). 人口數記錄年齡(歲). 死亡人數記錄年齡(歲). 1991~1997 1998~2010. 0~100+ 0~100+. 0~95+ 0~100+. 研究小區域死亡率修勻時,以台灣 2010 年女性五齡組死亡率,0 歲獨立成 一組,最高年齡組至 85-89 歲 (0 歲、1-4 歲、5-9 歲、…、85-89 歲),並且將此 20 年 19 個年齡層的資料代入 Lee-Carter 模型中,並且以 Lee-Carter 模型估計出 16.
(24) 的死亡率當作大區域理論死亡率,小區域理論死亡率則照各情境設定和大區域死 亡率之關係,大區域和小區域的人口結構則分別以台灣女性人口結構及台北市女 性人口結構作設定,人口數的設定則依情境做設定,大區域人數為 100 萬、200 萬、400 萬,小區域人數為 10 萬及 20 萬,不同分析時的人數不同,詳細人數會 在分析時說明。 同時考慮修勻以及死亡率模型時,所使用的資料則為台灣 1991-2010 年共 20 年的女性五齡組死亡率,0 歲獨立成一組,最高年齡組一樣至 85-89 歲 (0 歲、 1-4 歲、5-9 歲、…、85-89 歲),當作大區域死亡率,人口結構則分別以台灣女性. 政 治 大. 人口結構及台北市女性人口結構做設定,大區域人數為 200 萬,小區域人數為 10 萬。. 立. ‧ 國. 學. 第二節 研究方法. ‧. 近年來為了修勻資料較為缺乏的小區域,與其他大區域比較的方法如. sit. y. Nat. Bayesian、Partial SMR 等越來越受到重視(金碩 2011),以及修勻大、小區域死亡. io. al. n. 料的修勻。. er. 率比值的 Whittaker Ratio 方法,因此,本文主要使用這些修勻方法探討小區域資. Ch. 一、死亡率估計誤差比較標準. engchi. i n U. v. 估計誤差的選擇標準,一般可由 MAPE(Mean Absolute Percentage Error)或 MSE(Mean Square Error)作為判斷標準,其中 MAPE 以數學式表示為:. MAPE =. 1 𝑛. ∑𝑛𝑖=1. |𝑌̂i −𝑌𝑖 | 𝑌𝑖. ̂𝑖 :估計值。 其中,𝑌 𝑌𝑖 :理論值或真實值。. 17. × 100%. (3.1).
(25) 而 MAPE 多半分為四個等級 (Lewis 1982),在人口推估上 20%為良好,50%為合 理的推估界線。 表 3-3、衡量估計誤差標準(MAPE) MAPE. 準確度. <10% 10%~20%. 高 良好. 20%~50% >50%. 合理 低. 而 MSE 以數學式表示:. 政 治 大. 立. ‧ 國. 學. ̂𝑖 )+[Bias(𝑌 ̂𝑖 − 𝑌𝑖 )2]=Variance(𝑌 ̂𝑖 )]2 MSE=E[(𝑌. ‧. ̂𝑖 :估計值。 其中,𝑌. (3.2). 𝑌𝑖 :理論值或真實值。. Nat. sit. y. ̂𝑖 ) = E(𝑌 ̂𝑖 )-𝑌𝑖 Bias(𝑌. n. al. er. io. ̂𝑖 )則為𝑌 ̂𝑖 的變異數。 Variance(𝑌 二、修勻方法與參數選擇. Ch. engchi. i n U. v. 接下來介紹不同修勻方法,並且同時探討修勻時參數的設定,驗證一般建議 的參數值是否正確,以及提供修勻時參數可以調整的建議: (一) Whittaker 修勻法 由於使用 Whittaker 修勻法時,因為小區域人口數較少導致資料震盪較大, 會發生修勻完後死亡率小於或等於 0 的情況,因此,必須對此情況調整。考慮到 通常是在原始死亡率較低的情況會發生此情形,需要找一個數值取代,如圖 3-1 可知,研究發現取值10−5、10−4、10−3、10−2 在不同的情境下皆有不錯的效果, 18.
(26) 考慮到一般最小年齡層的死亡率接近10−4,因此選擇10−4作為取代的數值。. 政 治 大 圖 3-1、Whittaker 立 修勻後調整值對 MSE 的影響. ‧ 國. 學. 而在 Whittaker 修勻法中,參數 h 值的選擇中,一般建議 h 值為各年齡層平. ‧. 均人數,由圖 3-2 可知,因為各年齡層平均人數約為 5000 人,當 h 值選取 5000. y. Nat. 及其他值時,對於估計結果的影響不大,只有在 h 值選取過大時,修勻完全考慮. n. al. er. io. sit. 平滑性,會造成估計誤差的增加,因此,h 值可以選擇為各年齡層平均人數。. Ch. engchi. i n U. v. 圖 3-2、比較 Whittaker 修勻在不同 h 值的表現 (二) Whittaker Ratio 修勻法 19.
(27) 在參考大區域資料的修勻方法中,Whittaker Ratio 是一個不錯的方法,但若 遇到小區域資料震盪過大時,會造成死亡率比值為 0 或是太大的可能,假設小區 域 x 歲死亡率為ux ,參考之大區域死亡率為ux ∗ ,而死亡率比值為rx =ux /ux ∗ ,金 碩(2011)建議當rx =0 或是rx >2×SMR 時,x 歲死亡率比值以 SMR 的值取代,但 考慮到若極端值皆以 SMR 的數值取代時,會過度調整,建議若rx >死亡率比值上 限時,以上限值取代,若rx <死亡率比值下限時,以下限值取代,根據圖 3-3 知, 若上限值取 1.6-2.5 時,其實並沒有太大的差異,因此建議rx >2 時,將rx 以 2 取 代。而根據圖 3-4,死亡率比值下限的選取,對於估計的誤差並沒有太大的影響, 因此,為了避免過度調整,選取10−5當作死亡率比值下限的調整值。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 3-3、死亡率比值上限對 Whittaker Ratio 修勻的影響. 20.
(28) 政 治 大. 圖 3-4、死亡率比值下限對 Whittaker Ratio 修勻的影響. 立. (三) Bayesian 修勻法. ‧ 國. 學. 貝氏(Bayesian)修勻法和 Whittaker Ratio 修勻法同樣參考大區域的資料,修. ‧. 勻時參數 r 一般選擇 0.9,本文也嘗試選擇 r=0.5 比較,而當小區域 x 歲死亡率為 0 時,共變異矩陣 A 的元素𝐴𝑥𝑥 為 0,會導致 x 歲死亡率修勻時完全沒有參考大. y. Nat. io. sit. 區域的死亡率,而是直接以小區域的原始死亡率當作修勻值,也就是修勻完的死. n. al. er. 亡率數值仍然是 0,金碩 (2011)提出若遇到此情形,可以先將小區域死亡率以. Ch. i n U. v. SMR 取代,再代入貝氏修勻法修勻,可以得到較為合理的數值,本文也採用此 修正方法進行修勻。. engchi. 三、死亡率模型 估計死亡率的模型,最常見的是 Lee and Carter 在 1992 年提出的 Lee-Carter 模型,而 Li and Lee (2005)提出的 Coherent Lee-Carter 模型,是一個結合大、小 區域資料再估計的方法,屬於「Two-Stage」的估計方法,以下分別介紹之。 (一) Lee-Carter 模型 使用 Lee-Carter 模型估計死亡率時,參數α𝑥 、β𝑥 、κ𝑡 的估計有不同的方法, 21.
(29) Lee and Carter 建議使用 SVD(Singular Value Decomposition)估計死亡率改善幅度, 而曾奕翔 (2005)使用近似法求解,是一個較為簡便的方法,本文比較 Lee-Carter 採用以上方法估計參數對於小區域死亡率的估計結果。 (二) Coherent Lee-Carter 模型 如第二章所提到,Li and Lee 的模型為: log(m𝑥,𝑡 ) = a𝑥 + B𝑥 K 𝑡 + b𝑥 k 𝑡 + εx,𝑡. (3.3). 對於小區域的死亡率取 Logarithm 後,直接利用log(m𝑥,𝑡 )計算各年齡組死亡率的. 政 治 大. 平均數,而結合大、小區域資料後,代入 Lee-Carter 模型,使用 SVD 的方法求. 立. 學. ‧ 國. 得大、小區域共通的死亡率改善參數B𝑥 、K 𝑡 ,之後再計算出殘差: log(m𝑥,𝑡 ) − a𝑥 − B𝑥 K 𝑡. (3.4). ‧. 對殘差做 SVD 取出小區域獨特的參數b𝑥 、k 𝑡 ,但因為大、小區域合併的資料可. y. Nat. sit. 以解釋大部份死亡率的改善率,小區域獨特的改善率b𝑥 、k 𝑡 就不見得如此有效。. n. al. er. io. 因此本文比較獨特性參數放入模型與否。具體做法為下:. Ch. (a)分別檢定:H0 :bx =0、H0 :k t =0. engchi. i n U. v. (b)若該 x 歲年齡組的獨特性參數b𝑥 顯著異於 0,則在計算 x 歲年齡組之死亡 率時,將獨特性參數放入模型中計算,若 t 年的獨特性參數k 𝑡 顯著異於 0,則在 計算 t 年的死亡率時,將獨特性參數放入模型中計算,反之,則將該年齡組或該 年的獨特性參數b𝑥 、k 𝑡 設為 0,再代入計算死亡率。 由圖 3-5 可以發現,獨特性參數全部放入模型中,所計算出來的死亡率誤差 皆較大,因此,本文在使用 Li and Lee 的 Coherent Lee-Carter 模型時,都會先計 算獨特性參數是否顯著,只將顯著的部份放進模型中計算死亡率。. 22.
(30) 圖 3-5、比較獨特性參數的重要性. 立. 四、修勻與死亡率模型應用. 政 治 大. ‧ 國. 學. 對於小區域死亡率估計上的方式,可以分為四個面向,如圖 3-6,傳統上以 修勻和死亡率模型估計,除了分別探討二者的優缺點之外,本文嘗試將其合併使. ‧. 用,期望可以有更好的估計效果。金碩 (2011)的研究指出,若是先修勻再推估. Nat. sit. y. 和先推估再修勻,估計誤差並沒有太大的差異。因此,本文將先配模型再修勻的. n. al. er. io. 部份,改為修勻死亡率模型的參數估計值,比較先修勻再配死亡率模型或是先配. i n U. v. 死亡率模型再修勻其參數估計值,對於估計誤差的影響。修勻與死亡率模型的結. Ch. engchi. 合,主要以 Lee-Carter 模型搭配不同的修勻方法。另外,也探討使用 Li and Lee 的 Coherent Lee-Carter 模型後,再針對小區域的獨特性參數估計值a𝑥 修勻。. 23.
(31) 圖 3-6、修勻與死亡率模型. 立. (一)先修勻,再配模型. 政 治 大. ‧ 國. 學. 將二者結合時,若採用先修勻,後配模型的方式,做法為先將各年度的小區 域死亡率透過 Bayesian、Whittaker Ratio、Partial SMR 等修勻法,參考相對應年. ‧. 度的大區域死亡率,之後再將修勻後的各年度死亡率,套入 Lee-Carter 模型估計。. y. Nat. n. er. io. al. sit. (二)先配模型,再修勻. i n U. v. 先將死亡率資料代入 Lee-Carter 模型中,求取參數估計值後,再對參數進行. Ch. engchi. 修勻,由於估計出來的參數並非死亡率,若套用於在死亡率上的修勻方法,會遇 到一些問題,如參數估計值可能為負值等情形。因此,考慮的修勻方法必須做些 微調整。 具體做法如下: (a)估計參數 將大、小區域的死亡率資料代入 Lee-Carter 模型中,分別計算出參數 A𝑥 、B𝑥 、K 𝑡 估計值及a𝑥 、b𝑥 、k 𝑡 估計值。 (b)修勻參數 24.
(32) 利用 Whittaker Ratio 的概念,先將小區域和大區域的參數估計值做比值,計 β. β. 算r𝑥α =a𝑥 /A𝑥 、r𝑥 =b𝑥 /B𝑥 、r𝑥k =k 𝑡 /K 𝑡 之後,再使用 Whittaker 修勻法修勻r𝑥α 、r𝑥 、 r𝑥k ,最後再將修勻後的比值乘上大區域的參數值A𝑥 、B𝑥 、K 𝑡 得到小區域修勻後 的參數估計值,而修勻時參數 h 設定為各年齡組平均人數,而參數 Z 一樣設定 為 3。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 25. i n U. v.
(33) 第四章. 電腦模擬分析. 本章節利用台灣女性死亡率資料,探討不同修勻方法、死亡率模型以及同時 採用修勻方法和死亡率模型,對於小區域死亡率估計的影響,第一節說明不同模 擬方法產生的死亡人數造成的影響,第二節探討不同修勻方法在各種情境下對於 估計誤差的影響,第三節探討修勻和死亡率模型在小區域資料上的應用,第四節 則考慮死亡率模型在不同參數估計方法下的誤差,希望能夠透過這些分析方法, 找到在不同情況下,對於小區域死亡率估計最適合的方法。. 政 治 大. 第一節 模擬方法對於死亡率估計的影響. 立. 由於一般死亡人數假設由 Poisson 或是二項(Binomial)分配產生,而本文使用. ‧ 國. 學. 的死亡人數模擬方法,是假設各年齡層死亡人數服從 Poisson 分配1,但 Lee-Carter. ‧. 模型中,假設誤差服從常態分配。使用 Lee-Carter 模型估計死亡率時,在人口數. y. Nat. 太少時,參數估計值會有偏差2。研究中發現,若死亡率的產生方式假設為常態. n. er. io. al. sit. 分配,參數估計值的偏差程度就不會太差(圖 4-1)。. Ch. engchi. i n U. v. 圖 4-1、Lee-Carter 各年齡層參數估計值 Bias 比例(假設死亡率服從常態分配). 1 2. 模擬死亡人數的說明,見第四章第二節 關於參數估計值偏差的討論,見第四章第四節 26.
(34) 而當樣本數夠多的時候,Poisson 分配可以以常態分配近似,同樣的概念, 若當小區域人口數增加時,例如合併 3 年資料計算,或是將死亡率相似的不同小 區域合併,則可以有效降低死亡率模型的參數估計誤差,同時也能降低死亡率的 估計誤差。圖 4-2 中,使用 2010 年台北市女性人口資料為例,其中低、中、高 年齡層占全部人口比例分別為 5.56%、8.67%、1.00%,假設低、中、高齡的死亡 率分別為 0.0001、0.001、0.05,在假設死亡人數服從 Poisson 分配時,探討樣本 數的增加,對於死亡率是否近似常態分配,假設使用電腦模擬 10,000 次,在虛 無假設為此資料服從常態分配下,計算 10,000 次模擬中 P-value 小於 0.05 的次數,. 政 治 大 高,因此人口數為 400 萬人時顯著次數下降至 500 次,亦即人口數增加至 400 立. 亦即顯著不為常態分配的次數,85-89 歲年齡層雖然人數較少,但因為死亡率較. 萬人時,對於估計結果會較為穩定;45-49 歲年齡層則需要將近 22,000,000 萬人. ‧ 國. 學. 時,估計結果才會穩定,而 10-14 歲這個年齡層,則因為死亡率太低,所需要的. ‧. 人口數需要相當的大,估計結果才有可能穩定,也就是說,根據 Poisson 近似常. y. Nat. 態的概念,需要參數 λ 夠大,即期望死亡人數需要夠大時,才能夠有較小的誤差。. er. io. sit. 人口數的增加對於小區域的估計是相當有幫助的,但若是無法增加樣本數, 則必須使用一些方法去降低小區域死亡率的估計誤差,文獻探討中發現,修勻以. al. n. v i n 及死亡率模型是不錯的方法,因此,本章後續繼續探討使用修勻方法以及結合死 Ch engchi U 亡率模型對於估計死亡率的改善情況。. 27.
(35) 圖 4-2、10000 次檢定中 P 值<0.05 的次數. 第二節 修勻方法探討. 立. 政 治 大. ‧ 國. 學. 本節利用台灣 1991-2010 年女性五齡組死亡率,0 歲獨立成一組,最高年齡 組至 85-89 歲 (0 歲、1-4 歲、5-9 歲、…、85-89 歲),使用 1991-2010 年台灣女. ‧. 性死亡率代入 Lee-Carter 模型後,計算出之 2010 年死亡率估計值當作大區域理. sit. y. Nat. 論死亡率,小區域理論死亡率則照各情境設定和大區域死亡率之關係,大區域和. io. 定。. er. 小區域的人口結構則分別採用台灣女性人口結構及台北市女性人口結構作為設. al. n. v i n Ch 情境則分為七種,假設小區域各年齡層死亡率是大區域各年齡層死亡率的S 𝑥 engchi U. 倍,使用不同的修勻方法,探討 10000 次電腦模擬的結果,假設各年齡層死亡人 數服從 Poisson 分配,而參數λ則為各年齡層的期望死亡人數,期望死亡人數是 由各年齡層死亡率和各年齡層人口數相乘而得。 而S𝑥 的設定,則假設有 7 種情境,以下分別介紹之(如圖 4-3): 1、S𝑥 =0.8,代表小區域的各年齡層死亡率是大區域的 0.8 倍,此情形可能發生在 小區域整體的生活水準較好或是醫療技術較高的地方。 2、S𝑥 =1.0,代表小區域的各年齡層死亡率和大區域相同,可能發生在大、小區 域生活條件類似的地方,唯一差別只在人口數的多寡。 28.
(36) 3、S𝑥 =1.2,代表小區域的各年齡層死亡率是大區域的 1.2 倍,此情形可能發生在 小區域整體的生活水準較差或是醫療技術較低的地方。 4、S𝑥 =遞減,代表小區域各年齡死亡率隨著年齡直線遞減,此情形則可能在於高 齡人口存活率較高,而幼齡人口死亡率較高的情形。 5、S𝑥 =遞增,代表小區域各年齡死亡率隨著年齡直線遞增,此情形可能發生在高 齡人口存活率較低的情況。 6、S𝑥 =V 字型,代表小區域各年齡死亡率隨著年齡先遞減再遞增,若小區域中意 外死亡的情況發生情形較少時,則有可能會有如此的死亡率狀況。. 政 治 大 中意外死亡的情況發生情形較為頻繁時,則有可能會有如此的死亡率狀況。 立. 7、S𝑥 =倒 V 字型,代表小區域各年齡死亡率隨著年齡先遞增再遞減,若小區域. 由於台灣各縣市的情況大致包含在以上 7 種情境之中,因此,希望透過電腦模擬. ‧ 國. 學. 分析,了解到各種修勻方法對於死亡率估計的影響。. ‧. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 4-3、死亡率比值𝑆𝑥 的七種情境. 如表 4-2 所示,小區域人數 10 萬,大區域人數 200 萬時,七種情境下,資 料經過不同的修勻方法修勻,幾乎都比未修勻的情況下誤差還要小,代表修勻真 的有助於降低小區域資料的估計誤差,而在不同的情境下,選用適當的修勻方法, 29.
(37) 可以有效將估計誤差降至最低。當小區域和大區域的各年齡層死亡率比值相似時 (即𝑆𝑥 =0.8、1.0、1.2),選用 Partial SMR 修勻法可以將 MAPE 降至 10%以內,而 貝氏修勻在參數 r=0.9 時,修勻效果也不錯。而小區域和大區域各年齡層死亡率 比值較不相近時(𝑆𝑥 =遞減、遞增、V 字型、倒 V 字型),除了𝑆𝑥 =倒 V 字型之外, 皆是 Whittaker Ratio 修勻法修勻後的誤差最小。若比較貝氏修勻法不同參數下的 表現,發現當 r = 0.9 時,代表各年齡層間相關係數高,但此設定會放大變異數, 又因為樣本數和變異數成反比的概念,放大變異數的意思和樣本數縮小是相同的, r = 0.9 時縮小了大區域的樣本數而突顯了小區域的資訊,所以在大、小區域各年. 政 治 大 修勻結果比 r = 0.9 的修勻結果還要好,其他情境都是 r = 0.9 比較好;而在各年 立. 齡層死亡率比值相近時,除了Sx =1.0 時,大、小區域死亡率完全相同,r = 0.5 的. 齡層死亡率比值較不相近時,則是 r = 0.5 較好,因為此參數設定較符合情境。. ‧ 國. 學. 因為使用 r = 0.5 和 r =0.9 的結果差異不大,後續比較使用 r = 0.9 做分析。而. ‧. Whittaker Ratio 和 Partial SMR 修勻法,皆為參考大區域資料的修勻法,Whittaker. y. Nat. 修勻法為沒有參考大區域資料,雖然對於估計誤差有改善,但在大部份的情況下,. er. io. sit. 皆沒有比其他有參考大區域資料的修勻法來得好。. 表 4-1、小區域人數 10 萬、大區域人數 200 萬時之誤差. n. al. Ch. 𝑆𝑥 =1.0. engchi. 𝑆𝑥 =V 字型. 𝑆𝑥 =倒 V 字型. MAPE(%). 𝑆𝑥 =0.8. 未修勻. 42.87% 38.99% 36.05% 36.38% 43.80% 39.81% 41.26%. Whittaker Whittaker Ratio Partial SMR Bayesian(r=0.5) Bayesian(r=0.9). 32.27% 25.18% 9.45% 21.71% 15.20%. 30.13% 21.65% 9.15% 8.14% 8.88%. 𝑆𝑥 =1.2. iv 𝑆𝑥 =遞 n U. 𝑆𝑥 =遞 減. 28.24% 19.70% 9.02% 16.71% 14.10%. 30. 28.52% 19.88% 27.42% 27.67% 31.56%. 增. 33.52% 27.32% 49.04% 29.86% 31.24%. 32.12% 21.54% 30.85% 25.78% 28.18%. 29.90% 25.18% 20.70% 31.32% 31.98%.
(38) 表 4-2、小區域人數 10 萬、大區域人數 400 萬時之誤差 𝑆𝑥 =0.8. MAPE(%) 未修勻. 43.25% Whittaker 32.31% Whittaker Ratio 24.34% Partial SMR 7.45% Bayesian(r=0.5) 22.84% Bayesian(r=0.9) 16.15%. 𝑆𝑥 =1.0. 𝑆𝑥 =1.2. 𝑆𝑥 =遞 減. 𝑆𝑥 =遞 增. 𝑆𝑥 =V 字型. 𝑆𝑥 =倒 V 字型. 38.77% 29.92% 21.55% 7.15% 5.70% 6.10%. 35.68% 27.91% 18.91% 6.97% 16.46% 14.33%. 36.26% 28.57% 19.34% 27.50% 28.95% 31.58%. 44.57% 34.13% 26.42% 49.26% 30.06% 31.21%. 39.72% 31.73% 21.06% 30.21% 27.16% 28.52%. 40.61% 29.61% 24.72% 20.05% 31.90% 31.69%. 表 4-3、小區域人數 20 萬、大區域人數 200 萬時之誤差 𝑆𝑥 =0.8. MAPE(%). 政𝑆 =1.2治𝑆 =遞大𝑆 =遞. 𝑆𝑥 =1.0. 立 31.74% 29.15%. 未修勻. 𝑥. 𝑥. 𝑥. 減. 增. 𝑆𝑥 =V 字型. 𝑆𝑥 =倒 V 字型. 8.45% 24.59% 47.24% 26.25% 17.43% 16.04% 25.23% 24.68% 23.35% 26.75% 12.56% 29.75% 24.06% 27.63% 29.60%. y. er. io. sit. Nat. Partial SMR 8.73% 8.55% Bayesian(r=0.5) 18.52% 8.02% Bayesian(r=0.9) 14.35% 9.23%. ‧. ‧ 國. 學. 27.40% 27.71% 32.50% 30.92% 29.28% Whittaker 25.42% 23.73% 22.76% 23.33% 26.30% 26.52% 22.74% Whittaker Ratio 20.22% 17.77% 15.92% 15.88% 21.31% 17.57% 19.91%. 表 4-4、小區域人數 20 萬、大區域人數 400 萬時之誤差. n. al. Ch. 𝑆𝑥 =1.0. engchi. 𝑆𝑥 =V 字型. 𝑆𝑥 =倒 V 字型. MAPE(%). 𝑆𝑥 =0.8. 未修勻. 31.65% 29.17% 27.14% 27.85% 32.14% 30.62% 29.25%. Whittaker Whittaker Ratio Partial SMR Bayesian(r=0.5) Bayesian(r=0.9). 25.58% 19.27% 6.72% 20.33% 13.71%. 23.94% 17.14% 6.53% 5.73% 6.59%. 𝑆𝑥 =1.2. iv n 𝑆𝑥 =遞 U. 𝑆𝑥 =遞 減. 22.70% 15.16% 6.34% 16.01% 12.70%. 23.19% 15.34% 24.80% 27.14% 30.86%. 增. 25.90% 20.45% 47.28% 26.78% 26.48%. 26.57% 17.03% 25.30% 25.52% 28.15%. 22.60% 19.08% 16.55% 28.90% 30.12%. 如表 4-2、4-3、4-4,考量小區域和大區域的人數,對於估計誤差的影響。 當小區域人數從 10 萬增加至 20 萬時,未修勻的誤差明顯下降,代表人口數的增 加對於估計誤差是有所幫助的。而當大區域的人數從 200 萬增加至 400 萬時,修 31.
(39) 勻時有參考大區域人數的方法,會得到更穩定的結果,換言之,Whittaker Ratio 修勻法和 Partial SMR 修勻法參考了更穩定的大母體,進而得到更小的誤差。. 第三節 修勻方法及死亡率模型探討 由第一節的結果發現修勻的確可以降低死亡率的估計誤差,透過修勻可以將 原先不符合預期的死亡率觀察值做處理,使之較符合過去的經驗。Lee-Carter 模 型為死亡率模型中常用來估計的模型,本節探討此死亡率模型結合修勻方法的誤 差比較,除了將只做修勻及只採用死亡率模型的估計誤差做比較之外,也加入先. 政 治 大 也加入 Li and Lee 所提出之 Coherent Lee-Carter 模型。 立. 修勻再套死亡率模型、及先使用死亡率模型再修勻參數的估計誤差。除此之外,. ‧ 國. 學. 利用台灣 1991-2010 年女性五齡組死亡率,0 歲獨立成一組,最高年齡組至 85-89 歲 (0 歲、1-4 歲、5-9 歲、…、85-89 歲),使用 1991-2010 年台灣女性死亡. ‧. 率代入 Lee-Carter 模型後,計算出之 1991-2010 年死亡率估計值當作大區域理論. sit. y. Nat. 死亡率,小區域理論死亡率則照各情境設定和大區域死亡率之關係,大區域和小. io. er. 區域的人口結構則採用台灣女性人口結構及台北市女性人口結構,在假設小區域. al. 人數為 10 萬,大區域人數為 200 萬時,此設定和表 4-1 時的人數設定相同,進. n. v i n Ch 行分析時,由大、小區域的理論死亡率分別模擬死亡人數,假設各年齡層死亡人 engchi U. 數服從 Poisson 分配,而參數則為各年齡層的期望死亡人數,期望死亡人數是由 各年齡層死亡率和各年齡層人口數相乘而得,探討使用不同方法估計出來的死亡 率和理論死亡率的差距,以 MAPE(Mean Absolute Percentage Error)計算估計誤 差。 (一) 死亡率模型 由表 4-5 可以發現,使用死亡率模型,可以降低死亡率的估計誤差,而死亡 率模型中,單純使用 Lee-Carter 模型的估計誤差,皆可以降至 20%以內,是一個 32.
(40) 不錯的模型,而 Li and Lee 的 Coherent Lee-Carter 模型,在不同的情境下表現也 相當穩定,因為將大、小區域的資料合併,相當於增加樣本數的概念,可以將誤 差降低至接近 10%左右。 (二) 修勻方法 相較於表 4-1 單純只有使用修勻方法的估計誤差,結合修勻及死亡率模型的 估計誤差的確有比較小,使用二種方法可以使得估計值更為穩定,且原先修勻結 果就較好的修勻方法,再配死亡率模型表現也會較好,因為在放入模型前就已經 有較為準確的死亡率時,加入 Lee-Carter 後的效果會更好。. 政 治 大 (三) 比較修勻及死亡率模型的使用先後順序 立. ‧ 國. 學. 在先修勻後配死亡率模型的情況,在大區域和小區域死亡率較為接近時(即. ‧. 𝑆𝑥 =0.8、1.0、1.2),使用 Partial SMR + Lee-Carter 模型時,MAPE 可以降低至 5%, 在大區域和小區域死亡率較不接近時,(𝑆𝑥 =遞減、遞增、V 字型、倒 V 字型),. y. Nat. io. sit. 使用 Whittaker Ratio + Lee-Carter 模型誤差較小。. n. al. er. 在先配死亡率模型接著修勻參數估計值的情況,和只有使用 Lee-Carter 模型. Ch. i n U. v. 相比,有修勻參數估計值在各種情境下誤差皆較小;而和 Li and Lee 的 Coherent. engchi. Lee-Carter 模型相比,配完此模型再修勻其參數α ,有修勻參數的死亡率誤差也 x. 較小,換言之,先配模型再修勻仍然對於估計死亡率有改善。 綜合前二種先後順序來看,結合二種對於改善死亡率估計誤差確實是比只有 使用單一個方法有幫助,若取各情境下表現最佳的組合,比較修勻及配模型先後, 則是先修勻後配死亡率模型的方法在大部份的情境下表現較佳。此外,先修勻後 配死亡率模型,在操作上也較簡便,比較不容易遇到修勻參數估計值時,待修勻 的參數估計值會是負數,較難處理的問題。. 33.
(41) 表 4-5、𝛼𝑥 不同的七種情境之誤差. 30.27%. Sx =遞 Sx =遞 減 增 27.63% 28.50% 34.98%. Sx =V Sx =倒 V 字型 字型 30.36% 32.57%. 11.03%. 5.49%. 12.84% 29.58% 25.63%. 26.68%. 29.51%. 18.42%. 16.42%. 14.36% 12.90% 20.96%. 13.99%. 20.16%. 5.00%. 4.70%. 4.44%. 23.71% 43.97%. 25.04%. 17.25%. 18.25% 12.44%. 16.54% 11.76%. 15.09% 14.94% 20.14% 11.45% 12.14% 12.55%. 16.17% 12.89%. 18.66% 11.33%. 10.87%. 10.69%. 10.66% 11.46% 10.49%. 12.53%. 9.67%. 16.34%. 立15.04%. 14.05% 14.06% 17.41%. 15.39%. 16.32%. 14.49%. 13.52% 13.57% 17.63%. 14.73%. 16.29%. Sx =0.8. Sx =1.0. 原始資料 Bayesian + Lee-Carter Whittaker Ratio + Lee-Carter Partial SMR + Lee-Carter Lee-Carter Li and Lee Li and Lee + Whittaker Ratio(修勻αx ) Lee-Carter + Whittaker Ratio(修勻αx ) Lee-Carter + Whittaker Ratio(修勻βx ). 34.11%. 15.83%. Sx =1.2. 政 治 大. 學. ‧ 國. 死亡率 MAPE. ‧. Nat. sit. y. 由於大、小區域的死亡率比值(Sx )的七種情境下,Li and Lee 所提供的方法. n. al. er. io. 都能有較佳的估計誤差,本文嘗試考慮當大、小區域的相對死亡率的變化率(βx ). i n U. v. 不同時,以下幾種估計方式的誤差情形。做法為將大、小區域的資料分別代入. Ch. engchi. Lee-Carter 模型中,並且分別計算出參數估計值,之後將小區域的相對死亡率變 化率(βx )假設為大區域的Cx 倍,其大、小區域的理論死亡率關係表示為下式: βSx =Cx × βBx 其中,βSx :小區域理論死亡率之βx 。 βBx :大區域理論死亡率之βx 。 Cx :各年齡層小區域βx 為大區域βx 的Cx 倍。 而Cx 的設定,則假設有 7 種情境: 1、Cx =0.8,代表小區域的相對死亡率的變化率是大區域的 0.8 倍。 34. (4.1).
(42) 2、Cx =1.0,代表小區域的相對死亡率的變化率是大區域的 1.0 倍。 3、Cx =1.2,代表小區域的相對死亡率的變化率是大區域的 1.2 倍。 4、Cx =遞減,代表小區域的相對死亡率的變化率隨著年齡直線遞減。 5、Cx =遞增,代表小區域的相對死亡率的變化率隨著年齡直線遞增。 6、Cx =V 字型,代表小區域的相對死亡率的變化率隨著年齡先遞減再遞增。 7、Cx =倒 V 字型,代表小區域的相對死亡率的變化率隨著年齡先遞增再遞減。 由表 4-6 可知,當假設大、小區域的相對死亡率變化率不同時,Partial SMR + Lee-Carter 則在不同情境下表現皆較好,而 Li and Lee 的估計誤差就無法降低,. 政 治 大. 原因為合併資料時,是分別合併大、小區域的死亡人數及人口數,造成大區域的. 立. 資料所占的權重較多,欠缺考慮資料權數的問題,因此,在大、小區域的相對死. ‧ 國. y. MAPE (Cx =V 字型). er. io. MAPE (Cx =遞 增). sit. MAPE MAPE MAPE MAPE (Cx =遞 (Cx =0.8) (Cx =0.8) (Cx =1.2) 減). ‧. (MAPE). 表 4-6、β𝑥 不同的七種情境之誤差. Nat. 死亡率誤差. 學. 亡率變化率不同時,則無法顯現其優勢。. MAPE (Cx =倒 V字 型). 30.15%. Partial SMR + Lee-Carter. 4.68%. a30.27% iv l C 30.41% 30.48% n 30.10% h n g c h6.91% i U 7.21% 4.70% e4.74%. Lee-Carter. 16.31%. 16.54%. 15.73%. 15.47% 17.14% 16.01% 16.23%. Li and Lee. 12.28%. 11.76%. 12.22%. 12.46% 13.05% 12.49% 12.67%. 13.98%. 14.09%. 13.99%. 13.55% 14.90% 14.03% 14.10%. Lee-Carter + Whittaker Ratio(修勻. n. 原始資料. β𝑥 ). 35. 30.33% 30.15% 5.96%. 6.03%.
(43) 第四節 死亡率模型探討 由第二節發現,先修勻再配死亡率模型較能夠有效的降低死亡率的誤差,以 Whittaker Ratio 修勻法以及 Partial SMR 修勻法表現較好,此二方法皆有參考大 區域的資料,其背後的概念如同先增加樣本數,再使用 Lee-Carter 模型,所以可 以使得參數估計值以及死亡率估計值的誤差較小;而先使用 Lee-Carter 模型再修 勻參數估計值,如第二節的結論,的確也可以降低誤差,但是降低的程度並沒有 比先修勻再配模型來的多,因為修勻方法中,主要是針對死亡率來修勻,將之用 於參數修勻時,資料處理較為繁瑣,可能較容易扭曲資料,加上預防勝於治療的. 政 治 大. 概念,若能夠先處理好死亡率觀察值的不穩定問題,將整理過的資料代入. 立. Lee-Carter 模型,得到較好的估計結果,會比將不穩定的死亡率觀察值代入. ‧ 國. 學. Lee-Carter 模型中,再修勻參數來得佳。至於 Li and Lee 所提出之 Coherent. ‧. Lee-Carter 模型的估計誤差較小,原因是此方法事先合併大、小區域的資料,等 同於增加樣本數的概念,直接解決 Lee-Carter 模型在人口數較少時會遇到的問題,. y. Nat. io. sit. 然而,Li and Lee 的方法中,資料合併的方式為人數及死亡人數分別相加總,並. n. al. er. 沒有考慮大、小區域的權數,資料容易受到人數較多的大區域影響,若大、小區. Ch. i n U. v. 域資料較不相似時,則無法有較佳的估計效果(表 4-6)。. engchi. (一) Lee-Carter 模型研究 由於 Lee-Carter 模型的參數估計值有偏差,透過計算 Bias 比例: ̂x θx −θ θx. (4.2). 其中,θ𝑥 :x 歲年齡組的參數理論值。 ̂𝑥 :x 歲年齡組的參數估計值。 θ 探討使用 SVD 求解 Lee-Carter 模型的參數時,參數估計值和參數理論值的差距, 觀察 Bias 比例,如圖 4-5 所示,α𝑥 和β𝑥 的 Bias 比例,隨著小區域人口數的增加, 36.
(44) 偏差的比例隨之降低。若使用近似法求解 Lee-Carter 參數,參數的 Bias 比例降低 許多,在相同人數下,使用近似法比使用 SVD 求解 Lee-Carter 模型的參數的誤 差較低,這說明了模型愈複雜,愈容易有偏差的情況,而使用近似法估計參數時, 也是隨著人口數的增加,誤差的比例隨著降低。雖然使用近似法求解參數能夠降 低誤差,但仍然會受到樣本數大小的影響。因此,小區域死亡率的估計上,樣本 數大小是相當重要的,往後若是小區域估計的問題,解決方向建議往增加樣本數 的概念進行。. 立. 政 治 大. ‧. ‧ 國. 學 sit. y. Nat. n. al. er. io. 圖 4-4、Lee-Carter 各年齡層參數估計值 Bias 比例. Ch. engchi. (二) Li and Lee Coherent Lee-Carter 模型. i n U. v. 在 Li and Lee 提出的 Coherent Lee-Carter 模型中,如第二章所述,會先計算 獨特性參數是否顯著,只將顯著的部份放進模型中計算死亡率。在本章第一節的 研究發現,若是假設死亡人數服從 Poisson 的情況下,樣本數的大小對於估計誤 差影響很大,而此方法將大、小區域的資料合併,等同於增加樣本數的概念,能 夠有效的降低估計死亡率的誤差。雖然此做法表現相當不錯,但考慮到若直接加 總死亡人數以及人口數,因為沒有考慮到權數,資料可能會受到人口數較多的大 區域影響過多,造成估計上的誤差,基於此想法,本文嘗試修改大、小區域資料 37.
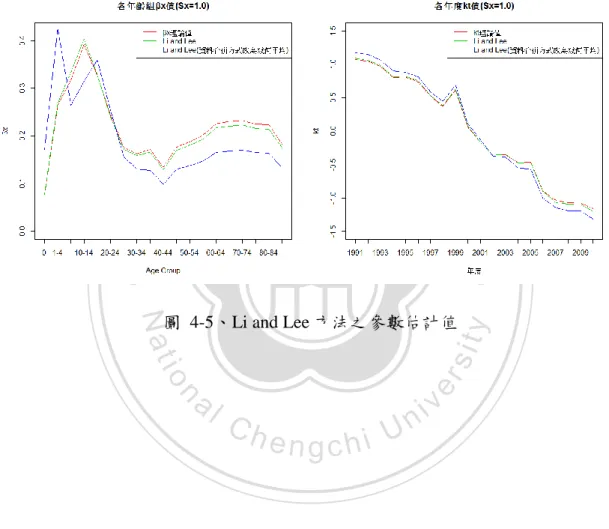
(45) 合併的方式,改變為以大、小區域死亡率取幾何平均的方式合併資料,如圖 4-6 可以發現,假設大、小區域死亡率相同的情況下,原本 Li and Lee 提供的資料合 併方法,為大、小區域的人口數和死亡人數分別相加總,此合併方法比以大、小 區域的死亡率取幾何平均來得好,前者的β𝑥、k 𝑡 參數估計值都較接近理論值,因 此,後續研究可以往如何合併大、小區域的資料,使估計過程不僅考慮更合邏輯。. 立. 政 治 大. ‧. ‧ 國. 學. Nat. n. al. er. io. sit. y. 圖 4-5、Li and Lee 方法之參數估計值. Ch. engchi. 38. i n U. v.
(46) 第五章. 結論與建議. 第一節 結論 隨著醫療的進步等因素,平均壽命逐漸延長,加上少子化的影響,台灣人口 老化的趨勢愈加明顯。由於各區域人口老化的速度不同,必須根據各地特性而調 整因應對策。因為樣本數與變異數成反比,人口較少的小區域或是高齡人口,死 亡率的觀察值通常會有較大震盪。因此,小區域死亡率的估計,往往透過修勻或 是死亡率模型的方式,對死亡率觀察值不合理的點進行修正,降低死亡率的震盪. 政 治 大. 幅度,讓死亡率更加平滑,使之符合常理。本文研究修勻方法以及死亡率模型,. 立. 再加入 Li and Lee (2005)所提出的 Coherent Lee-Carter 模型,探討在人口數較少. ‧ 國. 學. 的情況下,各種方法的估計效果,希望能夠在不同情境下,都能有適用的死亡率 估計方式。. ‧. 本研究發現,使用 Lee-Carter 模型估計死亡率時,當估計人口數較少的小區. Nat. sit. y. 域時,參數估計值會有偏差的情形發生,進而導致死亡率估計值產生偏差,若使. n. al. er. io. 用近似法估計 Lee-Carter 模型的死亡率參數,則可以降低參數估計值的誤差,但. i n U. v. 想辦法增加樣本數仍然是最佳的解決之道。而估計值偏差產生的原因,是因為. Ch. engchi. Lee-Carter 模型中,假設誤差項服從常態分配,但一般假設死亡人數服從二項分 配或是 Poisson 分配,而本研究假設死亡人數服從 Poisson 分配,所以在死亡率 固定的情況下,樣本數需要夠大,估計誤差才會較小。在高齡死亡率較高的部份, 總人口數需要達到 400 萬,才會有較穩定的估計結果,中、低齡部份則需要更多 的樣本數才能達到穩定。因此,在小區域死亡率的估計上,修勻方法以及死亡率 模型估計中,若有利用到增加樣本數概念的方法,往往能夠有較小的估計誤差。 而修勻部份,在本研究中假設的七種不同情境的大、小區域死亡率關係中, 當小區域和大區域的各年齡層死亡率比值相似時(即𝑆𝑥 =0.8、1.0、1.2),選用 Partial SMR 修勻法可以將 MAPE 降至 10%以內,因為假設大、小區域的 SMR 值介於 39.
(47) 0.8 及 1.2 之間,Partial SMR 修勻在死亡率震盪過大時,會將比值以 SMR 取代, 概念如同將比值拉回平均數,所以可以有較好的估計結果;而小區域和大區域各 年齡層死亡率比值較不相近時(𝑆𝑥 =遞減、遞增、V 字型、倒 V 字型),則是 Whittaker Ratio 修勻法可以有較好的估計效果。若結合修勻及死亡率模型,使用先修勻後 配 Lee-Carter 模型,可以達到較好的估計效果,若先配 Lee-Carter 模型再修勻參 數估計值,雖然也能夠降低估計誤差,但效果較差,操作上也較為繁瑣,因此在 小區域死亡率的估計上,建議先修勻後配 Lee-Carter 模型。而且先修勻時,若採 用參考大區域資料的修勻方法,如 Whittaker Ratio 及 Partial SMR 修勻法,不僅. 政 治 大. 有修勻的效果,也有增加樣本數的概念,再代入 Lee-Carter 模型中可以獲得較小 的估計誤差。. 立. 而 Li and Lee 所提出的 Coherent Lee-Carter 模型,因為估計方法採用合併大、. ‧ 國. 學. 小區域的資料後,再使用 Lee-Carter 模型估計參數,對於人口數較為不足的區域,. ‧. 此舉無異於增加樣本數,因此,在不同情境下的估計效果皆不錯,然而,Li and Lee. y. Nat. 的方法中,資料合併的方式為人數及死亡人數分別相加總,並沒有考慮大、小區. er. io. sit. 域的權數,資料容易受到人數較多的大區域影響,若大、小區域資料較不相似時, 則無法有較佳的估計效果。. n. al. Ch. engchi. i n U. v. 第二節 後續研究建議 由於本研究假設理論死亡率為 Lee-Carter 模型的估計值,使用此模型估計出 來的死亡率進行模擬,並且比較各種方法的差異,若無此研究假設,各種方法的 估計情況或許會有所不同,後續研究可以考慮往此方向發展。 本文對於死亡率的修勻方法,主要往參考大區域的方向進行,後續研究除了 考慮增加樣本數的概念之外,也可以使用未考慮大區域的修勻方法,如 Whittaker 修勻法,而針對估計 Lee-Carter 參數的方法,本研究使用 SVD 以及近似法估計 40.
(48) 參數,後續研究可以考慮 MLE 或是 WLS 的參數估計方式,再套用至不同情境 觀察估計誤差,而結合貝氏方法的 Lee-Carter 估計方式,也是一個相當不錯的研 究方向。 另外,先使用 Lee-Carter 模型再修勻參數時,由於參數估計值和死亡率的特 性有所不同,修勻時較難處理,本文只考慮使用 Whittaker ratio 修勻,也可以考 慮使用其他修勻方法,如 Partial SMR、貝氏修勻等方法。而 Li and Lee (2005)所 提的方法中,大、小區域合併資料的方式為將人口數及死亡人數分別加總,此方 法並沒有考慮資料權重的問題,本文考慮將資料合併方式改以計算大、小區域資. 政 治 大 時,則可以考慮往大、小區域資料如何合併的方向進行。 立. 料的幾何平均,發現估計誤差並沒有改善,因此,研究 Li and Lee 所提供的方法. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 41. i n U. v.
(49) 參考文獻 一、中文部份 王信忠、金碩、余清祥 (2012)。小區域死亡率推估之研究。Journal of Population Studies, 45, 121-154。 行政院經濟建設委員會人力規劃處 (2010)。2010 年至 2060 年臺灣人口推計。台 北市:行政院經濟建設委員會。 何正羽 (2006)。高齡人口 Gompertz 死亡率推估模型的建構與應用。東吳大學商. 政 治 大 余清祥 (1997)。修勻:統計在保險的應用。台北市:雙葉書廊。 立 用數學研究所碩士論文。. ‧ 國. 學. 周世宏 (2001)。台灣地區死亡率參數模型之研究,逢甲大學統計與精算研究所 碩士論文。. ‧. 金碩 (2011)。修勻與小區域人口之研究。國立政治大學統計學研究所碩士論文。. sit. y. Nat. 郭孟坤與余清祥 (2008)。電腦模擬, 隨機方法與人口推估的實證研究。Journal of. io. er. Population Studies, 36, 67-98。. 陳政勳與余清祥 (2010)。小區域人口推估研究:臺北市、雲嘉兩縣、澎湖縣的. al. n. v i n C h Studies,41, 153-182。 實證分析。Journal of Population engchi U. 曹郁欣 (2013)。小區域生育率與人口推計研究。國立政治大學統計學研究所碩 士論文。 曾奕翔與翁宏明 (2010)。Lee-Carter 估計模式與台灣地區死亡率推估之研究。 大同技術學院學報第十八期, 53-70。 曾奕翔 (2002)。台灣地區死亡率推估的實證方法之研究與相關年金問題之探討。 國立政治大學統計學研究所碩士論文。 蔡乙瑄 (2013)。婚姻與死亡率-優體生命表。國立政治大學風險管理與保險學研 究所碩士論文。 42.
數據
相關文件
日本九州 4 日遭到鋒面滯留的強降雨侵襲,截至 13 日止已造成 72 人死亡,其 中又以九州境內的熊本縣為重災區,死亡人數高達 64 人。根據《朝日新聞》報
探究式學習 教學類型 (四種類型).. 探究式學習教學 常見模式及實施 Stripling Model of Inquiry.. Connect, wonder, investigate, express
[7] C-K Lin, and L-S Lee, “Improved spontaneous Mandarin speech recognition by disfluency interruption point (IP) detection using prosodic features,” in Proc. “ Speech
有一個統計是美國每 10 萬人有 14 人因流感而死亡,可是有些州的死亡率遠超過這個數 字,如(1) Alabama 20.2 (2) Arkansas 19.8 (3) Hawaii 29.6 (4) Mississippi 23 (5) Nebraska
甲型禽流感 H7N9 H7N9 H7N9 H7N9 H7N9 H7N9 H7N9 H7N9 - - 疾病的三角模式 疾病的三角模式 疾病的三角模式 疾病的三角模式 疾病的三角模式
有次,他在北邊羅雲遊時,做程前往碧差汶省 (53EZ 皂的龍薩 (ZSω 詳),於中午時分.. 香光莊嚴門第六十五期〕民國九十年三月
通常把这种过去时期的,具有滞后作用的变量 叫做 滞后变量(Lagged Variable) ,含有滞后变量
住宅選擇模型一般較長應用 Probit 和多項 Logit 兩種模型來估計,其中以 後者最常被使用,因其理論完善且模型參數之估計較為簡便。不過,多項
