i
國
立
交
通
大
學
資訊科學與工程研究所
碩
士
論
文
A 型流感病毒蛋白質序列特徵之搜尋與其在時間軸上
之變化分析
Identification and Analysis of Sequence Signatures over time in
Influenza A Viruses.
研 究 生:凃博浚
指導教授:胡毓志 教授
i
A 型流感病毒蛋白質序列特徵之搜尋與其在時間軸上之變化分析
Identification and Analysis of Sequence Signatures over time in Influenza A
Viruses.
研 究 生:凃博浚 Student:Po-Chin Tu
指導教授:胡毓志 Advisor:Dr. Yhu-jyh Hu
國 立 交 通 大 學
資 訊 科 學 與 工 程 研 究 所
碩 士 論 文
A ThesisSubmitted to Institute of Computer Science and Engineering College of Computer Science
National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Master
in
Computer Science
September 2013
Hsinchu, Taiwan, Republic of China
ii A 型流感病毒蛋白質序列特徵之搜尋與其在時間軸上之變化分析 研究生:凃博浚 指導教授:胡毓志 國立交通大學資訊科學與工程研究所 碩士班
摘要
A 型流行性感冒在物種間的高變異性使得對於預測其可能演化走向的困難性隨之 提高,因為在不同物種之間的基因變異性與其獨特的物種傳遞範圍,在往年的歷史中, A 型流感往往會造成一年一度的地區性爆發,甚至在幾年之中也會發生全球性流行的大 爆發。這種影響範圍與嚴重程度使得相關的研究學者對於其研究是投注相當程度地關心 的,也因此藉由增加對物種範圍病毒特性之間特性的認識,對於製作疫苗或是防疫都是 具有相當程度的助益的。 對於其分析的方法,有相關的學者提出所謂的重要特徵位置(Signature),也就是 一些特別的胺基酸位置用來辨別不同物種的流感病毒毒性及其變化可能,藉由重要特徵 位置的計算,能夠在疫情檢體進行研究時不必大海撈針,能夠針對一些特定的位置先一 步進行相關的實驗,進而快速地得到病毒的毒性變化可能情形,因此重要特徵對於 A 型 流感的演變能夠提供一定程度的參考,所以我們針對相關學者所提出的計算方法與我們 所新選用的計算方法 ARI(Adjusted Rand Index)做了分析比較,並從中驗證對於病毒毒性分析 ARI 是最為有利的計算方式。 此外由於先前的學者對於相關的重要特徵計算皆是以全年度的年份下去計算,對於 時間軸的變化因素並沒有加以納入探討,因此我們也對於重要特徵位置納入時間軸變化 的因素分析討論,並試圖藉由此種分析能夠對於實際的病毒演化實驗提供更多的參考以 及對照分析的依據,這種分析確實是能與實際的演化走向有所呼應,並且有實際文獻支 持的,我們認為這種分析方式確實是有所助益的。
iii
Identification and Analysis of Sequence Signatures over time in Influenza A Viruses.
Student: Po-Chin Tu Advisor: Dr. Yhu-jyh Hu
Institute of Cimouter Science and Engineering College of Computer Science
National Chiao Tung University
Abstract
The high mutability makes the prediction of the host range of influenza A viruses (IAV)
difficult. Because of their vast genetic diversity and unique host range, IAV have caused recurrent annual epidemics and several major worldwide pandemics in human history. The
emergence and spread of novel IAV remain of major global concern; therefore, increased understanding of the host range is essential to maintain the efficacy of antiviral drugs and
influenza vaccines. The analysis of a considerable amount of available viral sequence data provides a cost-effective approach for the identification of host-associated genomic signatures
as host-range determinants. In this thesis, we proposed an alternative measure for the evaluation of the host-specific characteristic sites in the IAV based on the adjusted Rand index
(ARI), and produced a novel catalogue of genomic signatures from the viral sequence data in the NCBI. In addition, to chronologically analyze the genomic signatures, we divided the
virus data into chronological groups, and then identified the genomic signatures from these groups. Our chronological analytical approach provided results on the adaptive variability of signatures, which correlated with previous studies’ findings, and indicated prospective
iv
誌謝
我對於這篇論文的完成,要感謝的人真的是太多了,讓人有種想用一句話概括的想法, 像我愛大家,這四個字,就簡單的帶過,或是像國中課本課文:要謝的人太多了,那就謝天吧, 但也許只用這樣簡單的致謝詞,之後回來看這個段落時可能會感到有些荒唐,因此,在此刻, 將從珺前的一刻,還未接受軍隊制式訓練的時候,我得好好的對我要感謝的人,付諸一些些 有著崴力,真誠的感謝。免得在一些日子以後,我可能會只懂得滿口「是的,長官」呢! 一順位的當然是最為支持我的家人們,身在國外長期出差的爸爸媽媽,天天的關懷,無 論是生活的大小事,課業的遭遇,都還是藉由越洋電話傳達著,支持著我的研究,我的生活, 我的一切。住在一起的奶奶,照顧著我的生活起居,食衣住行,無微不至的關心,我簡直可以 說是世界上最幸福的孫子,當然還有已經在天上的爺爺,也是構成上述的必要條件之一。 還有我那永遠的玩伴跟偶爾的人生導師,我哥,各種偶爾的隨心提醒,也是我該好好感謝的, 我想只有那致命的腳臭,是我不想學習的。 想當然爾,也可以說是第一順位的,當然是我的指導教授,胡毓志教授,在研究的過程 中曾說過的各種金玉良言,各種悉心指導,絕對是構成這篇論文的必要條件,實驗室的成員, 好比只導我打電動的,舒服,俊昇,研究的好夥伴,以誠,旻哲,舜謙,佑隆,冠慧,給予你們真誠 的祝願,順利畢業! 君子之交的各位朋友們,從小就認識的爾廷,珺崴,政謙,振均,你們給予的鼓勵,總是會 讓我心懷感激,同是藍天之子的彥智,偉智,宋禎,家懷,一起玩樂的舒壓,也是不可或缺的,然 而好似真正會起飛的夥伴,子安,承逸,庭延,哲宇,翊安,舜亞,偉中,維元,起飛吧!還有二十 七屆我的電算社社團朋友們,政大朋友們,君豪,仁傑,昱夫,彭韻,佑儒,冠宇,建斌,睿陵,還有 我那心懷尊敬的學長們,阿慈,君寶,宗憲,定樸,文霖,振銘,冠智,鍵盤球友,博為,則維,政勳… 等等!許多沒列名字的好朋友也是各種感激,沒有你們就沒有現在的我,當然就沒有這篇 論文!謹以此簡單的致謝文,聊表我滿懷的感謝之情。v
目錄
摘要 ... ii Abstract ... iii 誌謝 ... iv 表目錄 ... vii 圖目錄 ... ix 一、緒論 ... 1 1.1 研究背景與動機 ... 1 1.2 研究目標 ... 1 1.3 論文架構 ... 1 二、背景及相關文獻研究 ... 3 2.1 流感病毒簡介 ... 3 2.2 重要特徵討論 ... 3 三、資料蒐集以及實驗方法: ... 5 3.1 資料蒐集 ... 5 3.2 亞型選擇 ... 5 3.3 病毒蛋白質選擇 ... 5 3.4 多序列排比 ... 6 3.5 Over-Sampling ... 63-6 ARI (Adjusted Rand Index) ... 7
四、實驗結果與討論: ... 10
4.1 總年代實驗結果 ... 11
4.1.1 1902 年以來至 2013 年二月底, A 型流感病毒蛋白質 Avian, Human 物種間 Top-20 重要特徵位置: ... 11
4.1.2 1902 年以來至 2013 年二月底 A 型流感病毒蛋白質 Swine Human, 物種間 Top-20 重 要特徵位置: ... 37
vi
4.1.3 1902 年以來至 2013 年二月底 A 型流感病毒蛋白質 Avian, Swine 物種間 Top-20 重要
特徵位置: ... 50 4.2 劃分年代實驗結果 ... 58 4.2.1 根據流感大爆發年代區分六個年代區間, Avian, Human A 型流感病毒蛋白質 Top-20 物種間重要特徵位置: ... 58 4.2.2 根據流感大爆發年代區分六個年代區間, Swine, Human 之 A 型流感病毒蛋白 質 Top-20 物種間重要特徵位置: ... 82 4.2.3 根據流感大爆發年代區分六個年代區間, Avian, Swine 之 A 型流感病毒蛋白質 Top-20 物種間重要特徵位置: ... 95 五、結論 ... 103 參考文獻: ... 104 附錄 ... 109
附錄一、1902 年至 2013 年 2 月份,Avian vs. Human, ARI 以及 MI 之重要特徵比較表 .... 109
附錄二、1902 年至 2013 年 2 月份, Swine vs. Human, ARI 以及 MI 之重要特徵比較表 . 117 附錄三、1902 年至 2013 年 2 月份,Avian vs. Swine, ARI 以及 MI 之重要特徵比較表 ... 125
附錄四、Avian vs. Human 以大爆發年代區隔年代區間之各區間 ARI 走勢圖 ... 133
附錄五、Swine vs. Human 以大爆發年代區隔年代區間之各區間 ARI 走勢圖 ... 154
vii
表目錄
表 2 1 流感病毒種類及結構... 4
表 3 1 1902~2013 之 A 型流感的蛋白質序列數量表 ... 6
表 3 2 8 個病毒蛋白質的序列長度表 ... 6
表 4 1 Avian VS. Human 重要特徵位置 ARI 以及 MI 在 Segment PB2 之數值以及代表胺 基酸表 ... 15
表 4 2 1902 年至 2013 年 Avian VS. Human 各 Segment 之重要特徵一覽表 ... 15
表 4 3 1902~2013 Avian VS. Human 各個 Segment 的重要特徵位置數量表 ... 20
表 4 4 相關圖表的文獻參考對照表... 24
表 4 5 Avian VS. Human 重要特徵位置, ARI 計算結果與 Miotto 結果比較之相異表 ... 25
表 4 6 Avian VS. Human 重要特徵位置, ARI 計算結果與 Chen 結果比較之相異表 . 26 表 4 7 Avian VS. Human 重要特徵位置暨胺基酸變化表 ... 26
表 4 8 Avian VS. Human 重要特徵位置暨胺基酸變化表 ... 31
表 4 9 Swine VS. Human 重要特徵位置 ARI 以及 MI 在 Segment PA 之數值以及代表胺 基酸表 ... 39
表 4 10 1902 年至 2013 年 Swine vs.Human 各 Segment 之重要特徵一覽表 ... 39
表 4 11 1902~2013 Swine VS. Human 各個 Segment 的重要特徵位置數量表 ... 41
表 4 12 Swine VS. Human 重要特徵位置, ARI 計算結果與 Guang-Wu Chen 之實驗結 果相異表 ... 46
viii
表 4 14 Avian VS. Swine 重要特徵位置 ARI 以及 MI 在 Segment PA 之數值以及代表胺 基酸表 ... 51 表 4 15 1902 年至 2013 年 Avian vs. Swine 各 Segment 之重要特徵一覽表 ... 51
表 4 16 1902~2013 Avian vs. Swine 各個 Segment 的重要特徵位置數量表 ... 53
表 4 17 以大爆發年代區分六個年代區間下,Avian VS. Human 各個 Segment 的重要 特徵位置數量表 ... 62
表 4 18 以大爆發年代區分六個年代區間下,NS1 分別於六個年代區間下,Avian 重要 VS. Human 特徵位置表 ... 62
表 4 19 以大爆發年代區分六個年代區間下,M1 分別於六個年代區間下,Avian 重要 VS. Human 特徵位置表 ... 68
表 4 20 大爆發年代區分六個年代區間情況下,Avian VS. Human 各 Segment 重要特徵 位置胺基酸的實際變化表 ... 71
表 4 21 各 Segment 之胺基酸變化比例表 ... 79
表 4 22 以大爆發年代區分六個年代區間下,Swine VS. Human 各個 Segment 的重要 特徵位置數量表 ... 85
表 4 23 大爆發年代區分六個年代區間情況下, Swine VS. Human 各個 Segment 重要 特徵位置胺基酸的實際變化表 ... 85
表 4 24 各 Segment 之胺基酸變化比例表 ... 93
表 4 25 以大爆發年代區分六個年代區間下,Avian VS. Swine 各個 Segment 的重要特 徵位置數量表 ... 96
表 4 26 大爆發年代區分六個年代區間情況下, Avian VS. Swine 各個 Segment 重要特 徵位置胺基酸的實際變化表 ... 96
ix
圖目錄
圖 4 1 PB2 Avian VS. Human 重要特徵位置分布圖 ... 20 圖 4 2 PB1 Avian VS. Human 重要特徵位置分布圖 ... 20 圖 4 3 PA Avian VS. Human 重要特徵位置分布圖 ... 21 圖 4 4 NP Avian VS. Human 重要特徵位置分布圖 ... 21 圖 4 5 M1 Avian VS. Human 重要特徵位置分布圖 ... 22 圖 4 6 M2 Avian VS. Human 重要特徵位置分布圖 ... 22 圖 4 7 NS1 Avian VS. Human 重要特徵位置分布圖 ... 23 圖 4 8 NS2 Avian VS. Human 重要特徵位置分布圖 ... 23 圖 4 9 PB2 Swine VS. Human 重要特徵位置分布圖 ... 42 圖 4 10 PB1 Swine VS. Human 重要特徵位置分布圖 ... 42 圖 4 11 PA Swine VS. Human 重要特徵位置分布圖 ... 43 圖 4 12 NP Swine VS. Human 重要特徵位置分布圖 ... 43 圖 4 13 M1 Swine VS. Human 重要特徵位置分布圖 ... 44 圖 4 14 M2 Swine VS. Human 重要特徵位置分布圖 ... 44 圖 4 15 NS1 Swine VS. Human 重要特徵位置分布圖 ... 45 圖 4 16 NS2 Swine VS. Human 重要特徵位置分布圖 ... 45 圖 4 17 PB2 Avian VS. Swine 重要特徵位置分布圖 ... 54 圖 4 18 PB1 Avian VS. Swine 重要特徵位置分布圖 ... 54 圖 4 19 PA Avian VS. Swine 重要特徵位置分布圖 ... 55 圖 4 20 NP Avian VS. Swine 重要特徵位置分布圖 ... 55 圖 4 21 M1 Avian VS. Swine 重要特徵位置分布圖 ... 56 圖 4 22 M2 Avian VS. Swine 重要特徵位置分布圖 ... 56 圖 4 23 NS1 Avian VS. Swine 重要特徵位置分布圖 ... 57 圖 4 24 NS2 Avian VS. Swine 重要特徵位置分布圖 ... 57 圖 4 25 以大爆發年代區分六個年代區間,NS1 重要特徵位置 ARI 數值位置變化圖 ... 67 圖 4 26 以大爆發年代區分六個年代區間,M1 重要特徵位置 ARI 數值位置變化圖 70 圖 4 27 在大爆發區分年代區間下,PB2 位置 590 之各個年代區間 ARI 走勢圖 ... 80 圖 4 28 在大爆發區分年代區間下,PB2 位置 591 之各個年代區間 ARI 走勢圖 ... 80 圖 4 29 在大爆發區分年代區間下,PB2 位置 627 之各個年代區間 ARI 走勢圖 ... 80 圖 4 30 在大爆發區分年代區間下,PB2 位置 271 之各個年代區間 ARI 走勢圖 ... 81 圖 4 31 在大爆發區分年代區間下,NP 位置 33 之各個年代區間 ARI 走勢圖 ... 81 圖 4 32 在大爆發區分年代區間下,NP 位置 53 之各個年代區間 ARI 走勢圖 ... 93 圖 4 33 在大爆發區分年代區間下,NP 位置 16 之各個年代區間 ARI 走勢圖 ... 94x
1
一、緒論
1.1 研究背景與動機
流行性感冒為重要且容易傳染的人類疾病,近百年來著名的流行性感冒大爆發從 1918 年的西班牙流感,1957 年的亞洲型流感,與 1968 年的香港流感,1977 年的俄羅斯 流感,以及 2009 年的墨西哥新型流感,都造成人類極大的傷亡,而這些大爆發的流感 都屬於 A 型流感,也因此 A 型流感成為我們注重的研究目標。 又由於 A 型流感的高變異性[1]提高我們應對 A 型流行性感冒的難度,因此若是能 夠提早分析檢測可能的病毒突變,就能夠對於流行性感冒進行相對應的預防以及防疫, 有相關的學者[2,3]提出所謂的重要特徵位置(Signature),也就是一些特別的胺基酸位置 用來辨別不同物種的流感病毒毒性及其變化可能,藉由重要特徵位置的計算,能夠在疫 情檢體進行研究時不必大海撈針,能夠針對一些特定的位置先一步進行相關的實驗,進 而快速地得到病毒的毒性變化可能情形,因此重要特徵對於 A 型流感的演變能夠提供一 定程度的參考,也因此我們會對於重要特徵位置進行研究。1.2 研究目標
本研究的主題主要分成兩個部分: (1)自 1902 年至 2013 年二月份以來的全年度物種 重要特徵位置計算分析,以及(2)藉由使用個個大爆發年代切割時間段,進行重要特徵位 置演變變化的趨勢分析,而所使用的計算方法為 ARI(Adjusted Rand Index),並與相關學 者所使用的方法進行比較分析,進而得到 ARI 確為較適宜的計算方法,並依此方法,對 於 Avian vs. Human, Swine vs. Human, Avian vs. Human 三組物種進行了重要特徵計算, 與相關學者進行相對的重要特徵位置比較, 並提供一些已知的蛋白質功能區段與重要 特徵位置之對應圖, 提供重要特徵位置與蛋白質功能區間的功能對照參考, 而區隔年 代段的年代分析研究企圖與實際的病毒演化研究得到相似的結果, 以期能藉由重要特 徵位置計算進而得到與實際病毒演化實驗相似的結果, 以提供相關的研究學者更多的 參考。1.3 論文架構
本篇論文的架構一共分為五個章節,各章節簡述如下: 一、緒論 說明研究背景與動機,預期達到的目標及論文架構介紹。 二、背景及相關文獻研究2 對本研究之相關文獻進行研究探討,介紹流感病毒的相關知識,並介紹相關學者研 究重要特徵問題時使用的方法及相關概念。 三、資料蒐集以及實驗方法 介紹流感病毒資料的蒐集與分析,以及研究過程中使用的方法說明。 四、實驗結果與討論 討論研究分析後得到的實驗數據,提出可能的重要特徵位置,並探討依照年代變化 得到的重要特徵位置與實際演化實驗的相關性。 五、結論 總結上述結果,說明本篇論文的研究結果貢獻,可能改進的地方及未來可能的研究 發展方向。
3
二、背景及相關文獻研究
2.1 流感病毒簡介
流感病毒可分為 A、B、C 共三種類型,在此三種流感病毒之中,與人類流感流行 有著密不可分且容易引起大規模流行(Pandemic),甚而進而致死的類型為 A 型以及 B 型 流感,而這兩者中 B 型流行性感冒僅會感染人類, A 型則有著變異性高的特性,至於 C 型雖會感染人類以及豬隻,但其所引起的症狀是最為輕微以及少見的。 又流感病毒可依循著表面的兩種醣蛋白: 血凝素( Hemagglutinin HA)以及神經胺酸 脢 ( Neuraminidase NA)來進行分類,其中 A 型流感依照此兩種醣蛋白可以細分成很多中 不同的亞型,血凝素共有 H1 至 H16 種亞型,而神經胺酸脢有著 N1 至 N9 種亞型,而兩 種醣蛋白又可以彼此組合,組合成不同的亞型流感,好比在 1918 年的西班牙流感,1977 年的俄羅斯流感,以及 2009 年的墨西哥流感都是屬於 H1N1 此種亞型,或是在 1968 年 爆發的香港流感則是屬於 H3N2 的亞型,至於 1957 年在中國爆發的亞洲流感則是 H2N2 亞型,而在 2013 年尚未造成大流行的 H7N9 亞型也是屬於 A 型流感的一員。 如同上述所提,以變異性程度來說 A 型流感是最高的,其次是 B 型流感,末之為 C 型,又變異性程度的高低與造成人類威脅呈現正相關的關係,所以 A 型流感是最為危險 也是其成為我們研究的目標的原因,而流感的變異可以分為兩類[1],其一為抗原微變 (Antigenic drift)其二為抗原移型(Antigenic shift), 抗原微變亦稱為抗原的量變,主要是因 為流行性感冒病毒的 RNA 在人體細胞複製的過程中容易發生突變,造成少數胺基酸發 生變化,導致流感病毒可能因此持續地進行輕微突變,因此抗原微變所造成的流行通常 只會是局部性的流行(epidemic),抗原移型則是屬於質變的類型,意思就是說其變異性來 的更為巨大,通常每隔幾十年才會發生一次抗原移型大變異,若依發生就等同於一種新 型流感的產生,在時機使然之下就有可能造成全球性的大流行(Pandemic)像是上述所提 到的 1918 年西班牙流感,1957 年亞洲流感,1968 年香港流感,1977 年俄羅斯流感,2009 年墨西哥流感都是屬於此種情況。其中三種類型的流行性感冒病毒同意列於 表 2-1。 又 A 型流感的變異性來自於基因重組的結果,有可能是兩種流感病毒同時在同一細 胞被感染導致的新型流感,也有可能是來自動物的流感病毒藉由突變適應人體,像是 1918 年的西班牙流感是由禽流感突變成人類的流感病毒,而 2009 年的墨西哥流感則是 由豬流感的基因重組導致的人類流感爆發。2.2 重要特徵討論
由於 A 型流感的嚴重性,以及其會在各個物種變異的特性,因此與 A 型流感以及 物種不同的相關研究也就隨之出現,當我們從流行性感冒病毒基因序列中,找出一些特4 別的胺基酸位置能夠清楚地辨別不同物種的流感病毒及其變化,我們將這些具有特定意 義的胺基酸位置稱為「重要特徵位置」(Signature)[2],至於需要重要特徵位置此種分析 的原因則是因為以往民眾感染流感導致嚴重病情時,醫師會將採樣的流感病毒檢體送到 病毒檢驗中心,將流感病毒基因一個一個分析定序,這個動作會耗費掉許多時間,藉由 透過重要特徵位置就可以提供相關的研究人員預測流感病毒的毒性或是突變的可能 性。 過去也有許多學者對於找尋重要特徵位置提出不同的方法,像是使用 Entropy 方法 計算出不同物種之間流感病毒蛋白質序列胺基酸重要特徵位置的可能性,並使用自定義 的門檻值去得到重要特徵位置的 Chen[2],以及利用 MI(Mutual Information)此種方法找出 重要特徵位置的 Miotto[3],而這些學者雖使用不同的方法,但皆是以找出重要特徵位置 進而區別物種,並透過分析結果找出病毒可能演化的趨勢,而 Pan[4]也有提到病毒演化 趨勢與大爆發年代相關的概念,我們也因此想以此種概念配合分析在現有的病毒資料上, 藉此提供相關人員預測未來流感病毒突變變化走向的參考,並希望可以減緩 A 型流感爆 發大流行的疫情嚴重程度。
表 2 1
流感病毒種類及結構表 A 型流感病毒 B 型流感病毒 C 型流感病毒 基因結構 8 個基因片段 8 個基因片段 7 個基因片段 病毒體結構 11 個蛋白質 11 個蛋白質 9 個蛋白質 抗原變異種類 抗原移型, 抗原微變 抗原微變 抗原微變 抗原變異性 變異性大 較為穩定 非常穩定 自然界宿主 人、禽鳥類、豬、 哺乳動物 人、海豹 人、豬 引起疾病嚴重度 最為嚴重 較 A 型略為輕 微,多在高危險族 群才會發生嚴重 併發症 最為輕微,甚而無 症狀 發生流行程度 有可能發生全球 大流行 有可能引發地區 性流行 無季節性 資料來源: 衛生署疾病管制局5
三、資料蒐集以及實驗方法
:
3.1 資料蒐集
關於資料蒐集的部份,我們從 NCBI(National Center of Biotechnology Information)下載 所有關於 Influenza A virus 相關的蛋白質序列(Sequences),年代的日期範圍我們採取 NCBI 有史以來現有的所有 A 型流感蛋白質序列資料直至 2013 年的 2 月底有的資料為止,而 序列採用部分,我們與相關學者 Miotto , Chen [2,3]一樣,無論是 partial sequences 或 是 Full-length sequence 都是我們所取用蒐集的資料。而在下載的過程中是各個物種分開 下載,總共採用考慮的物種共有三種,分別為人類,鳥類,以及豬,此外考慮到在計算 重要特徵位置時的公平性,所有重複長相的序列不在我們資料的蒐集範圍之內。
3.2 亞型選擇
關於亞型選擇的部分,由於相關學者指出,能夠在人類身上循環傳染的 A 型流感病 毒目前只有 H1N1, H2N2, H3N2 這三種亞型病毒,其他經由禽流感而感染人類的亞 型病毒並未證實有此特性[5],但基於 H1N2 以及 H2N2 與 H3N2 的基因相似性,我們也 將 H1N2 加入我們採用的亞型病毒當中,為了能明確地計算出不同物種之間 ,精確地說 來是計算人類與其他物種之間的重要特徵位置,我們參考 Miotto[3]的研究,整體選擇了 亞型流感病毒如下: 1.人類流感: 所有的 H1N1,H1N2,H2N2,H3N2,以及 H5N1 人類亞型流感病毒。 2.禽流感: 扣除掉所有的 H1N1,H1N2,H2N2,H3N2,以及 H5N1 以外的鳥類亞型流感 病毒。 3.豬流感: 所有的亞型病毒。3.3 病毒蛋白質選擇
關於流行性感冒病毒蛋白質選擇的部分,流行性感冒病毒蛋白質為單股反譯核糖核 酸病毒, 其基因體含八段 RNA,能被轉譯為 11 個蛋白質,這 11 個蛋白質分別為 PB2, PB1,PA,NP,PA,M1,M2,NS1,NS2,HA,NA,PB1-F2,其中我們選取了前 8 個 蛋白質作為我們的研究範圍,之所以不採用 HA 以及 NA 的原因是因為此兩種蛋白質存 在於流感病毒的表面,對於個別位置的氨基酸穩定程度相當的低落,其多樣性的變化, 導致多序列排比的排比障礙,因此這兩種蛋白質我們不列入考慮,至於 PB1-F2 此病毒 蛋白質,本質上與 PB1 十分相似,事實上他們共用同一種基因序[6,7],而 PB1-F2 只是 會提前終止,並且導致其序列長度很短,因此我們最後採用討論的病毒蛋白質分別為下6 列 8 個: PB2,PB1,PA,NP,M1,M2,NS1,NS2。 最後採用的資料筆數如表 3-1 所列
表 3 1
1902~2013 之 A 型流感的蛋白質序列數量表 Host/Protein PB2 PB1 PA NP M1 M2 NS1 NS2 Avian 4207 3823 4052 2657 1145 1406 2624 1245 Human 3216 2874 2888 1920 1061 1573 2094 875 Swine 1129 1076 1109 985 625 834 951 5793.4 多序列排比
由於我們從 NCBI 下載下來的原始流感病毒蛋白質序列,分別有 Partial sequences 以 及 Full-length sequences 所以各自的長度並不一致,因此我們必須使用多序列排比工具將 不同物種的序列同時進行多序列排比(Multiple alignment)的工作,以確定病毒蛋白質序列 能夠透過多序列排比工具達到不同物種中相同病毒蛋白質序列長度一致的結果,這些多 序列排比工具已經行之有年並且許多人在使用像是 ClustalW [8],MUSCLE[9]等等…在本 實驗中我們採用的是 MUSCLE[9]此多序列排比工具,因此我們先前所提到的條件下將 NCBI 上下載下來的人類流感病毒,鳥類流感病毒,豬流感病毒,各自套用 MUSCLE 3.6 此多序列排比工具針對 8 個先前提到的病毒蛋白質(PB1,PB2,PA,NP,M1,M2,NS1, NS2)進行多序列排比[9],而流感病毒 A/Puerto Rico/8/1934(PR8)序列為所有的流感病毒蛋 白質序列長度之基準。
表 3 2
8 個病毒蛋白質的序列長度表 Segment PB2 PB1 PA NP M1 M2 NS1 NS2 length 759 757 716 498 252 97 230 1213.5 Over-Sampling
根據表 3-1 我們可以發現不同物種彼此之間的病毒蛋白質序列,在數量上有著顯著 的差異性,在絕大多數的情況下,人類流感的序列數量約為鳥類流感的序列數量之 2/3~3/4 左右,而豬流感的序列數量與人類相比也是在絕大部分的情況少了人類流感病毒 序列數量很多, 考慮到資料不均衡會造成分類結果的偏頗(bias)此種情況,一般而言有 兩種方式可以減少資料不均衡所造成的結果,分別為 Over-sampling ,Under-sampling[10, 11],這兩種方法分別是將少數類別資料隨機抽取增加到和多數類別資料量相同,以及將 多數類別資料隨機抽取減少至和少數類別資料量相同。在本實驗中我們依照所要進行比7 較的物種之間進行 Over-Sampling 的動作,舉例來說若是要研究 1902~2013 年 PB1 此病毒 蛋白質 Avian VS. Human 之間的重要特徵時, 鳥類流感病毒序的筆數為 3823, 人類流 感病毒序列的筆數為 2874 筆, 此時 Over-sampling 就會從人類流感的 2874 筆當中隨機 抽樣增加到 3823 筆, 也就是與鳥類流感的病毒序列筆數一致。至於 Sampling 動作有可 能會因為隨機抽樣產生不確定性,因此通常我們會使用高於一定數量的 Sampling 次數, 並再加以平均,以避免遇到隨機抽樣的極端值發生,在本實驗中我們採取了 500 次 Over-sampling,並加以平均。
3-6 ARI (Adjusted Rand Index)
根據上述的步驟準備好流感病毒序列資料之後,為了找出重要特徵位置,我們所使 用的方法為 ARI(Adjusted Rand Index)[12],藉由使用 ARI 此種計算方式對於已經經過多
序列排比且經過 over-sampling 完的相異物種序列進行分析,藉此找出物種之間的重要特 徵位置。舉例來說,給定 O={o1, o2,…, on}, 假設 P={ p1, p2,…, pr} an 以及 Q={ q1, q2,…, qs} 分別為集合 O 裡面兩組不同的分群結果,且符合下列條件 and pi pi = , qj qj = for 1 i i r, 1 j j s. 在集合 O 裡面任取兩筆資料會有以下四種情形: 情形 1: oi, oj 在 P 被分在同一群,且在 Q 也被分在同一群。 情形 2: oi, oj在 P 被分在不同一群, 但在 Q 被分在同一群。 情形 3: oi, oj在 P 被分在同一群, 卻在 Q 被分在不同一群。 情形 4: oi, oj 在 P 被分在不同一群, 而在 Q 也被分在不同一群。 令 a, b, c, d 為上面四種情形各自出現的次數, 則總動成對組合的總數為 n 2 æ è ç ö ø ÷ =a+b+c+d . a 以及 d 為兩個分群結果所共同認同的部分,而 RI 定義為相同的比例, i.e. a+d a+b+c+d [13] RI 的值介於 0 到 1, 分數越高代表兩個分群的相似程度越高,當 RI 為 1 時就代表兩個 分群結果完全相同。 但因為 RI 的期望值並非為 0,因此 Hubert 以及 Arabie 在之後提
8
generalized hyper geometric model 下, 我們可以藉由一些簡單的數學公式將上述式子推 導成下列式子:
越高的 ARI 分數意味著兩個分群結果月為明顯。 在我們的實驗中 P 代表著該
sequences 屬於哪一個物種, e.g. avian vs. human, 而 Q 代表著排比後蛋白質序列代表 的胺基酸, 藉由計算每個胺基酸位置 (i.e. the site) 有著較高 ARI 值之位置即代表著各 物種的分群結果越好, 也就是我們所要尋找的重要特徵位置。 如表 3-3 假設我們有著 序列如表所述, 他們可以根據物種分成兩群,而用 P ={(s1, s2, s3, s4, s5, s6), (s7, s8, s9, s10, s11)}代表之。根據在位置 1 的胺基酸我們可以將分群用 Q ={(s1), (s2, s3, s4, s5, s6), (s7, s8, s9), (s10, s11)}代表之。如法炮製我們可以根據 在位置 2 的胺基酸以分群 R ={(s1, s7, s8, s9), (s2, s3, s4, s5, s6, s10, s11)} 代表之。 P,Q 算出來的 ARI 值為 0.58,而 P 以及 R 算出來的 ARI 值則是 0.13. 根據 此結果我們就可以得到位置 1 比起位置 2 來得更能夠分辨物種的不同,。Milligan 以及 Cooper 的研究 [14]中提到, 許多種用來衡量分群共同度與否的手法中 ARI 是他們所推 薦的方法,因此我們將 ARI 套用在計算能夠區分物種與否的重要特徵位置。 表 3-3 利用 ARI 計算流感病毒蛋白序列重要特徵位置的範例 Host Sequence Site 1 Site 2
Avian s1 s2 s3 s4 s5 s6 P Q Q Q Q Q P Q Q Q Q Q Human s7 s8 s9 s10 C C C L P P P Q
9
s11 L Q
10
四、實驗結果與討論
:
在此章節,我們針對了 Guang-Wu Chen[2]所使用的 Entropy, Miotto[3]所使用的 MI(Mutual Information)以及我們所加入討論的 ARI(Adjusted Rand Index)一共三種作為搜 尋重要特徵的方法,其中我們所認定的重要特徵位置定義為「ARI 數值排名為前二十名, 且排名優於該位置者並未出現物種代表胺基酸相同,若符合上述情形則認定該位置為重 要特徵位置」,以上述條件進行了以下實驗:
1. 自 1902 年以來至 2013 年二月底為止,物種分別為 Avian, Human, Swine, A 型 流感病毒蛋白質 Top-20 重要特徵位置:我們同時使用了 Entropy, MI, ARI 三種不同 計算方式來計算不同胺基酸位置成為重要特徵的可能性。
就 Entropy 認定 Top-20 的方式我們分別就不同物種之 Entropy 值優先從低者開始 檢查並依序檢查至高者,檢查的依據為該位置不同物種所代表的 Amino Acid 是否不 同,若不同則取用,直至取到前 20 名為止。 MI 以及 ARI 的部分,因其數值本身代表的即是搜尋重要特徵之參考相對值,故 我們將此兩種方式所算出來的數值由小至大排列,並取用前 20 名的位置,作為我們 的(Candidate signature)參考重要特徵位置,並一樣會檢查該位置不同物種所代表的 Amino Acid 是否不同,若不同我們才認定為真正的重要特徵。 而我們主要討論一共分為兩個部分:第一、針對 Human 以及 Avian 之間的重要 特徵做分析討論。第二、針對 Human 以及 Swine 之間的重要特徵做分析討論。由於 我們所採用的資料已經更新到 2013 年二月底,因此我們會將實驗結果與相關學者, 像是 Guang-Wu Chen, Miotto 等的實驗結果做一些分析比較,藉此得到重要特徵在 這幾年過後是否有哪些新增的性質或走向。主要分為兩個面向來討論, 一、在兩個 年代區間(相關學者所使用的年代資料與之後的年代資料),從重要特徵位置變成非重 要特徵位置抑或是從非重要特徵位置變成重要特徵位置(Validity);二、在前後年代區 間皆為重要特徵位置,且胺基酸沒有變化者,抑或是胺基酸有所變化者(Identity)
2. 藉由年代段的區分 Avian, Human, Swine 流感病毒蛋白質的 Top-20 重要特徵位置: 會要利用這種年代段區分的原因是因為相關學者在分析重要特徵位置時,曾提到 Pandemic 對於重要特徵位置變動的影響性具有一定的重要性[4],因此我們藉此根據 將我們的資料分別分成: A. 1902 年~1918 年 B. 1919 年~1958 年 C. 1958 年~1968 年 D. 1969 年~1977 年 E. 1978 年~2009 年
11 F. 2010 年~2013 年 以上六個年代區間。每一個年代區間的分段點即歷史上幾次流感爆發的年代,藉由 這樣的年代區間去觀察區間之重要特徵的演變趨勢,以及隨著年代段的不同,重要 特徵的位置變化。 主要討論的部分也分為兩個,我們針對在此六個年代區間重要特徵的演變趨勢 分成兩個方向來討論:一、在六個年代區間下無法一直為重要特徵位置(Validity):在 六個年代區間下無法一直為重要特徵位置此前提下,我們根據最後一個年代區間 (2010 年~2013 年)是否為重要特徵位置再細分為兩種類型討論,其一是一個位置在先 前年代區間原先是一個重要特徵位置,但是隨著時間的演變,在最後一個年代區間 段不再是一個重要特徵位置之情形;其二為在先前的年代區間段不是一個重要特徵 位置,但在最後一個年代區間段成為一個重要特徵位置。 二、在六個年代區間下一直為重要特徵位置(Identity):我們針對在六個年代區間 下一直為重要特徵位置的前提下,以該位置的胺基酸是否再分類為胺基酸一直十分 穩定者,以及胺基酸實際發生變動者。
4.1 總年代實驗結果
4.1.1 1902 年以來至 2013 年二月底, A 型流感病毒蛋白質 Avian,
Human 物種間 Top-20 重要特徵位置:
在此節中,我們主要是針對三種計算方式作比較分析,並且根據現今年代段資料與 相關學者的實驗結果進行比較分析,並且根據我們與相關學者所使用的年代資料差異性 進行分析比較的實驗,以下我們同時使用 Entropy, MI, ARI 三種方式計算 1902 年以 來至 2013 年二月底,Avian 與 Human 之間的重要特徵位置。 Entropy 所用來判斷該胺基酸位置是否是重要特徵的方式為,依照所要計算的各物種 Entropy 值相加,由小到大依序檢查各物種其位置所代表的胺基酸是否不同,取不同者 直至取到前 20 名為止,或是直至沒有不同代表位置為止。 MI 以及 ARI 則是根據其方式所計算出來的 MI 數值以及 ARI 數值由大到小排列,依序 取數值大小為前 20 名者作為我們的重要特徵參考值。 藉由分析三種方式計算出來的結果,我們可以發現以下現象, 由於 Entropy 的概念 是優先取分別物種 Entropy 值較低者,這意味著若是現今出現同一位置所代表的 Amino Acid 不為單一胺基酸的情況時,Entropy 在判斷上就會處於弱勢,舉例來說,PB2 588 這 個位置 Avian 的 Amino Acid 幾乎為 A 而 Human 的 Amino Acid 卻是 I,T 各半,這種情形, 588 對於 Entropy 而言就會被列於比較後面的名次,即使 588 應是一個區別力很強的重 要特徵位置,這也導致 Entropy 在面臨這種情況時會來的比 ARI,以及 MI 弱勢一些。 ARI 以及 MI 的重要特徵位置比較詳列於附錄一,藉由附錄一的相關實驗而言 MI 以 及 ARI 的差異性就整體而言可以說並不太大,我們針對兩種方式所計算出來的重要特徵12
排名使用 Spearman Rank Correlation 計算兩種方式的差異性,結果 Spearman Rank Correlation 的數值在八個 Segment 皆座落在 0.8~0.9 左右,由此結果我們可以瞭解這兩 種的差異性不至於到相差太大,但是藉由以下表格我們可以發現,當我們加入各個物種 重要特徵位置代表的 Amino Acid 來分析時,MI 比起 ARI 較會出現以下兩種情形:
1.重要特徵位置各物種所代表位置 Amino acid 相同位置數量較多,在觀察 8 個 Segment 之後我們發現,有一半也就是 4 個 Segment 當中(PB1, PB2, NS1 ,NS2), MI 的不正常重要特徵位置數量皆比 ARI 來的多,而其餘 4 個 Segment(PA, NP, M1, M2)雖然沒有 MI 數量大於 ARI 的情形,但也是屬於持平的狀況。 2.重要特徵位置代表的 Amino acid 相同,且此種不正常的重要特徵位置被排名 到較前面的名次,舉例來說,表 4-1 中 MI 的 14 名至 18 名即使該位置分別物種所 代表的 Amino acid 不相同,但依然比排名 13 的位置 81 來的排名落後,在分析總共 8 個 Segment 之後我們發現有 4 個 Segment (PB1,PB2, PA, M1,M2)MI 比 ARI 不正常排名發生在較高名次 ,3 個 Segment(NP,NS2)平分秋色,只有一個 Segment (NS1)ARI 落後給 MI。
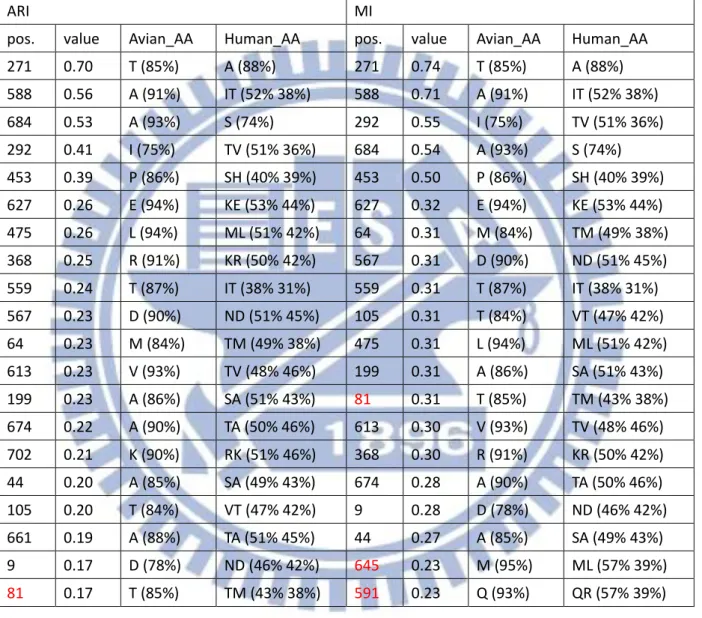
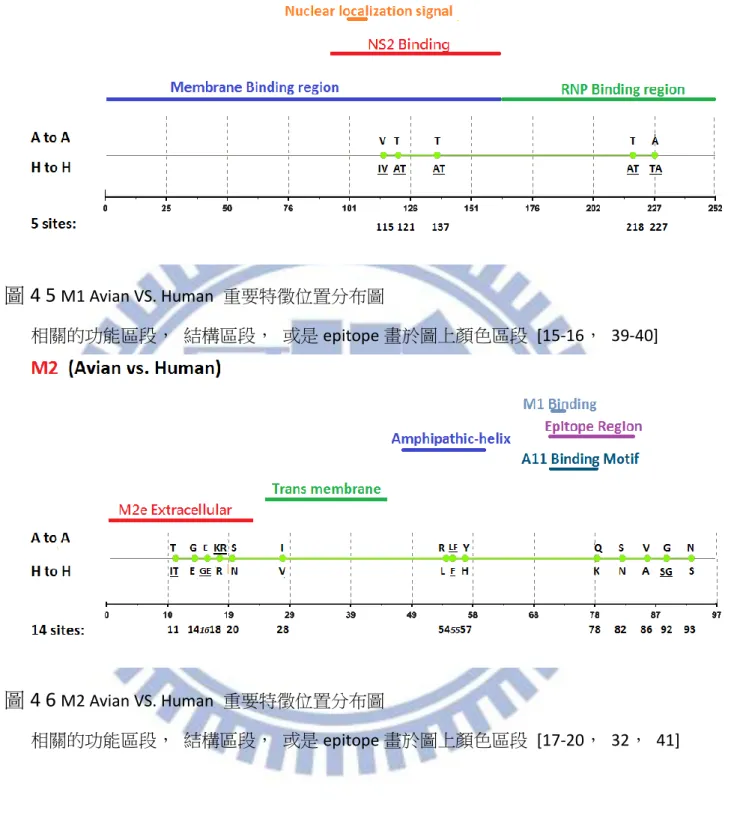
綜合以上兩點我們可以歸納出,整體而言, MI 以及 ARI 的差異性不算太多, 但若 是我們以想要得到較少不正常重要特徵位置的角度下來計算機率時,我們可以發現 ARI 有 8/8 也就是 100%的機率不會比 MI 來的多,比起 MI 的 4/8 也就是 50%高上許多;而 若是當我們取較少名次觀察時,MI 就會比較容易出現分別物種所代表的 Amino acid 相 同的不合理情形,我們以大於等於的概念來計算,若是你想要得到不正常現象較不會排 名在前面的機率,使用 ARI 在這個部份是 7/8 也就是 87.5%相對於 MI 的 4/8 也就是 50% 來得優勢,所以無論是想要得到較少不正常重要特徵位置抑或是想要得到不正常重要特 徵位置排名較後面的情形 MI 相較於 ARI 皆處於弱勢的一方,因此我們可以簡單的得出 此兩種方式當中, ARI 是一個比較沒有弱勢地方的方法。 根據上述三種方法的比較之後對於我們的重要特徵位置認定,即採用 ARI 這種方法 所計算出來的 Top-20 作為我們的參考重要特徵位置,並且依序認定重要特徵位置直到出 現第一個重要特徵位置代表之 Amino acid 相同此種不合理情形為止。對於 1902 年至 2013 年 Avian 與 Human 八個 Segment 的重要特徵位置我們將結果詳列於 表 4-2。對於我們 藉由 ARI 所得到的重要特徵位置在計算數量之後,各個 Segment 的數量可以見表 4-3, 總共數量為 104 個,其中數量為較多數的 Segment, PB1,PB2,NP,PA,可以對應到 Miotto 所提到過的 RNA 轉錄區段 PB1,PB2,NP,PA,皆都有較高數量的重要特徵位置。 而就重要特徵分布的部分在圖 4-1 至圖 4-8 可以觀察到各個 Segment 的分布情形各個圖 片的參考文獻可參照 表 4-4,在當中我們有發現了一些比較特別現象,舉 M1 為例,在 圖 4-5 中可以清楚看到重要特徵位置清楚分成兩個集團,第一集團屬於 membrane-binding-region 功能區段[15],而第二集團則位於 RNP-binding-region 功能區段 [16],像是其中 M2 的部分,重要特徵位置有著集團性的現象,在圖 4-6 中可以清楚地 看見 M2 的重要特徵位置呈 3 群集團,其中第一集團與第二集團的分隔是 Trans
membrane 功能區段[17,18],第一集團是位於 M2e Extracellular domain 區段[17,19], 第二集團屬於一段 amphipathic-helix[18],第三集團則是位於 M1binding site[20]之後的區
13 段。也因為我們藉由 ARI 得到了總數 104 個的重要特徵位置,比起相關學者 Miotto 所得 到的 68 個數量差別甚多,由於我們的資料採用的年代範圍為 1902 年至 2013 年,比起 相關學者 Miotto 所採用的年代範圍 1902 年至 2006 年來的更為更新。因此在 Avian 以及 Human 的重要特徵位置上,我們將我們利用 ARI 此計算方式所得到的重要特徵位置與 Miotto 相比,以下我們可以得到一些與其結果相異的地方,這部分我們也認為是由於年 代變動所造成的影響,以 Segment PB2 為例,位置 453,559,684 為新興的重要特徵位 置,位置 81 已經不再是重要特徵位置,Segment PB1 的部分位置 179,216,298,327, 361,375,430,486,517,581,584,621,741 為新興的重要特徵位置, Segment PA 的部分位置 204,256,277 為新興的位置,位置 65,66,400,421 則不再為重要特徵 位置,Segment NP 的部分, 109,217,293,351,353,372,422,442,452,455 為 新興的重要特徵位置, 375,423 不再是重要特徵位置,Segment M1 的部分 218,227 為新興的重要特徵位置,Segment M2 位置 16,18,82,89,55,93 我們認定為新的重 要特徵位置, Segment NS1 位置 48,59,67,70,112,114,125,171,209 為新的 重要特徵位置,位置 22,84 不再是重要特徵位置,最後 Segment NS2 的部分位置 57, 89 為新興的重要特徵位置,60 不再是重要特徵位置,整體差異如 表 4-5 所列。 至於與 Chen 的比較結果如下,由於 Chen 所使用的資料為 1902~2009 年,因此在觀 察我們與 Chen 的差異上來講,比起與 Miotto 的差別來的較為少一點,所有 Chen 所認 定的重要特徵位置,我們也都有將其認定為重要特徵位置,但藉由 ARI 以及所使用資料 較為更新的關係,我們還是比 Chen 多發現了許多重要特徵位置,比起 Chen 的 47 個重 要特徵位置,我們的 104 個還是多上許多,像是 PB2 新興的重要特徵位置 9,64,105, 292,368,453,559,661,674,684,PB1 新興的則有 179,216,298,361,375, 430,486,517,581,584,621,741, PA 的部分 204,256,277,337,382,NP 新 興的位置是 136,217,351,353,442,452,至於 M1 與 M2 分別為 218,227 以及 14, 16,18,28,54,55,82,89,最後 NS1 跟 NS2 的部分則個別為 48,59,60,67,70, 112,114,125,171,209,215,以及 57,70,89。其比較列於 表 4-6。 上述因為我們所採用的年代資料(1902 年~2013 年)與相關學者所採用的年代資料 (1902 年~2006 年、1902 年~2009 年)有所出入,所以得到了重要特徵位置有所差異的結 果,因此我們對於在 2007 年之後或是 2010 年之後與相關學者所採用的實際變化情形感 到興趣,我們將資料分成兩個區段: 一、1902 年~2006 年、2007 年~2013 年(Miotto) 二、1902 年~2009 年、2010 年~2013 年(Chen) 來討論重要特徵位置的演變情形, 主要分為兩個面向來討論, 一、在兩個年代區 段下,從重要特徵位置變成非重要特徵位置抑或是從非重要特徵位置變成重要特徵位置 (Validity);二、在前後年代區間皆為重要特徵位置,且胺基酸沒有變化者,抑或是胺基 酸有所變化者(Identity)。根據 Miotto 切割的年代區間分析列於 表 4-7,而根據 Chen 切 割的年代區間分析列於 表 4-8。我們可以看到比起單純的全年度相比較,以前後年代段 的角度,可以更清楚地看到一些從重要特徵位置變成非重要特徵位置抑或是從非重要特 徵位置變成重要特徵位置,一些確實是近幾年新興的重要特徵位置不會被全年度的序列
14
資料稀釋掉,藉由此種觀察可以將近幾年新興的重要特徵位置或是近幾年才變化為非重 要特徵位置的部分得到更為精確的結果。
15
表 4 1
Avian VS. Human 重要特徵位置 ARI 以及 MI 在 Segment PB2 之數值以及代表胺基 酸表 其中紅色所表示的位置即表示 Avian 與 Human 各自所代表的胺基酸是相同的胺基 酸。 MI 計算方式中位置 81, 591 以及 645 皆可以發現物種代表 Amino acid 相同的情 形,而 ARI 只有 81 有此種情形,以排名來看 MI 在第 13 名就已經出現代表胺基酸相同 的不正常情形,而 ARI 直至 20 名才有此種情形的發生。 ARI MIpos. value Avian_AA Human_AA pos. value Avian_AA Human_AA
271 0.70 T (85%) A (88%) 271 0.74 T (85%) A (88%) 588 0.56 A (91%) IT (52% 38%) 588 0.71 A (91%) IT (52% 38%) 684 0.53 A (93%) S (74%) 292 0.55 I (75%) TV (51% 36%) 292 0.41 I (75%) TV (51% 36%) 684 0.54 A (93%) S (74%) 453 0.39 P (86%) SH (40% 39%) 453 0.50 P (86%) SH (40% 39%) 627 0.26 E (94%) KE (53% 44%) 627 0.32 E (94%) KE (53% 44%) 475 0.26 L (94%) ML (51% 42%) 64 0.31 M (84%) TM (49% 38%) 368 0.25 R (91%) KR (50% 42%) 567 0.31 D (90%) ND (51% 45%) 559 0.24 T (87%) IT (38% 31%) 559 0.31 T (87%) IT (38% 31%) 567 0.23 D (90%) ND (51% 45%) 105 0.31 T (84%) VT (47% 42%) 64 0.23 M (84%) TM (49% 38%) 475 0.31 L (94%) ML (51% 42%) 613 0.23 V (93%) TV (48% 46%) 199 0.31 A (86%) SA (51% 43%) 199 0.23 A (86%) SA (51% 43%) 81 0.31 T (85%) TM (43% 38%) 674 0.22 A (90%) TA (50% 46%) 613 0.30 V (93%) TV (48% 46%) 702 0.21 K (90%) RK (51% 46%) 368 0.30 R (91%) KR (50% 42%) 44 0.20 A (85%) SA (49% 43%) 674 0.28 A (90%) TA (50% 46%) 105 0.20 T (84%) VT (47% 42%) 9 0.28 D (78%) ND (46% 42%) 661 0.19 A (88%) TA (51% 45%) 44 0.27 A (85%) SA (49% 43%) 9 0.17 D (78%) ND (46% 42%) 645 0.23 M (95%) ML (57% 39%) 81 0.17 T (85%) TM (43% 38%) 591 0.23 Q (93%) QR (57% 39%) a. Pos.表 position 之縮寫
b. Avian_AA 表 Avian 該位置的 Amino acid 代表 c. Human_AA 表 human 該位置的 Amino acid 代表
表 4 2
1902 年至 2013 年 Avian VS. Human 各 Segment 之重要特徵一覽表所代表的 Amino acid 只列出超過 30%的部分, 且由左至右表示大小順序, 如 SA 表示 S, A 皆超過 30%且 S>A 所占有比例。
16
1902 年~2013 年 Avian VS. Human 重要特徵位置一覽表
Segment Position Avian amino acid Human amino acid PB2 271 T (85%) A (88%) 588 A (91%) IT (52% 38%) 684 A (93%) S (74%) 292 I (75%) TV (51% 36%) 453 P (86%) SH (40% 39%)) 627 E (94%) KE (53% 44%) 475 L (94%) ML (51% 42%) 368 R (91%) KR (50% 42%) 559 T (87%) IT (38% 31%) 567 D (90%) ND (51% 45%) 64 M (84%) TM (49% 38%) 613 V (93%) TV (48% 46%) 199 A (86%) SA (51% 43%) 674 A (90%) TA (50% 46%) 702 K (90%) RK (51% 46%) 44 A (85%) SA (49% 43%) 105 T (84%) VT (47% 42%) 661 A (88%) TA (51% 45%) 9 D (78%) ND (46% 42%) PB1 336 V (93%) I (85%) 581 E (86%) D (82%) 361 S (91%) R (69%) 486 R (90%) K (69%) 741 A (82%) S (70%) 584 R (84%) Q (69%) 216 S (91%) G (66%) 621 Q (82%) RQ (65% 30%) 430 R (80%) K (72%) 179 M (90%) IM (49% 32%) 298 L (93%) IL (50% 46%) 327 R (93%) KR (49% 46%) 517 I (86%) VI (48% 47%) 375 NS (53% 32%) S (73%)
17 PA 356 K (95%) R (88%) 409 S (84%) N (89%) 204 R (88%) K (76%) 277 S (92%) HY (35% 35%) 382 E (90%) D (75%) 256 R (90%) K (61%) 268 L (95%) IL (53% 43%) 552 T (94%) ST (53% 42%) 337 A (91%) SA (53% 41%) 404 A (91%) SA (54% 41%) 225 S (88%) CS (53% 43%) 28 P (89%) LP (52% 42%) 55 D (89%) ND (53% 43%) 57 R (87%) QR (53% 42%) 100 V (56%) AV (52% 42%) NP 33 V (94%) I (86%) 305 R (93%) K (88%) 357 Q (88%) K (88%) 100 R (94%) V (64%) 313 F (92%) Y (63%) 351 R (84%) K (78%) 136 L (81%) I (58%) 283 L (93%) PL (63% 34%) 61 I (93%) LI (61% 34%) 353 V (75%) SI (45% 30%) 16 G (89%) DG (61% 33%) 214 R (92%) KR (61% 35%) 293 R (92%) KR (62% 37%) 452 R (77%) K (73%) 217 I (90%) S (43%) 422 R (89%) KR (61% 35%) 442 T (88%) AT (61% 35%) 455 D (87%) ED (60% 35%) 372 E (87%) DE (62% 36%) 109 I (91%) VI (58% 36%)
18 M1 115 V (93%) IV (56% 36%) 137 T (91%) AT (57% 35%) 121 T (88%) AT (57% 35%) 218 T (91%) AT (49% 45%) 227 A (85%) TA (48% 46%) M2 14 G (90%) E (96%) 57 Y (96%) HY (66% 30%) 20 S (93%) N (69%) 18 K (58%) R (96%) 86 V (86%) A (54%) 54 R (94%) L (44%) 78 Q (94%) K (41%) 11 T (87%) IT (68% 31%) 55 LF (60% 33%) F (90%) 16 E (85%) GE (65% 34%) 93 N (71%) S (47%) 28 I (66%) V (72%) 82 S (70%) N (52%) 89 G (73%) SG (37% 34%) NS1 60 AE (55% 40%) V (87%) 114 S (66%) P (90%) 48 S (94%) N (75%) 125 D (95%) E (70%) 227 E (73%) R (54%) 70 E (67%) K (90%) 171 D (62%) IY (37% 33%) 81 I (94%) MI (56% 36%) 209 DN (65% 30%) N (75%) 59 R (60%) HL (37% 34%) 112 AT (57% 41%) EI (37% 33%) 67 R (70%) KW (36% 34%) 215 P (77%) TP (55% 40%) NS2 70 S (86%) G (87%) 57 S (93%) YS (34% 33%)
19
89 I (61%) TA (44% 31%) 107 L (92%) FL (48% 44%)
20
表 4 3
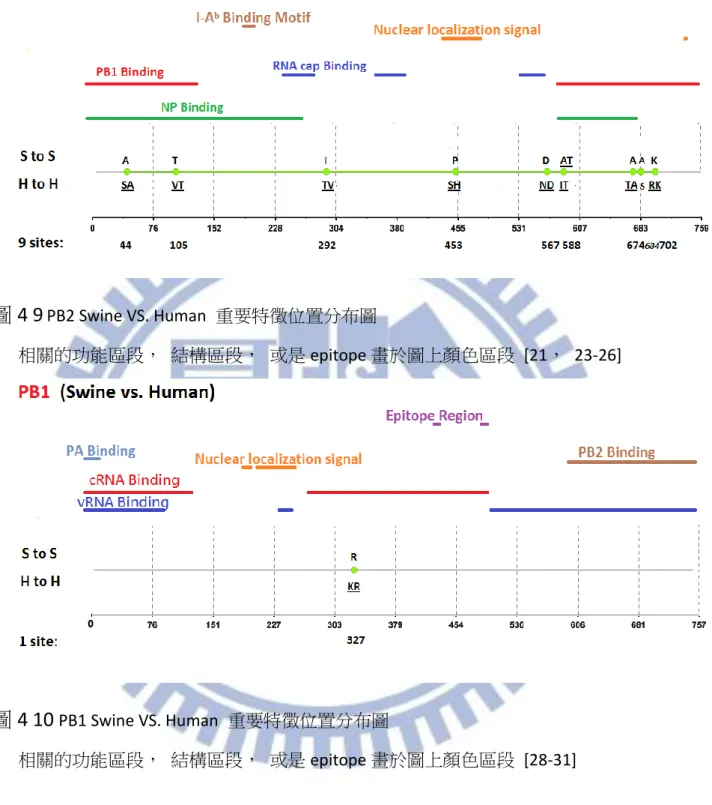
1902~2013 Avian VS. Human 各個 Segment 的重要特徵位置數量表 Num. of Signature 表示重要特徵位置的數量。 Segment PB2 PB1 PA NP M1 M2 NS1 NS2 Total Num. of Signature 19 14 15 20 5 14 13 4 104圖 4 1
PB2 Avian VS. Human 重要特徵位置分布圖 相關的功能區段, 結構區段, 或是 epitope 畫於圖上顏色區段 [21-26]圖 4 2
PB1 Avian VS. Human 重要特徵位置分布圖 相關的功能區段, 結構區段, 或是 epitope 畫於圖上顏色區段 [27-31]21
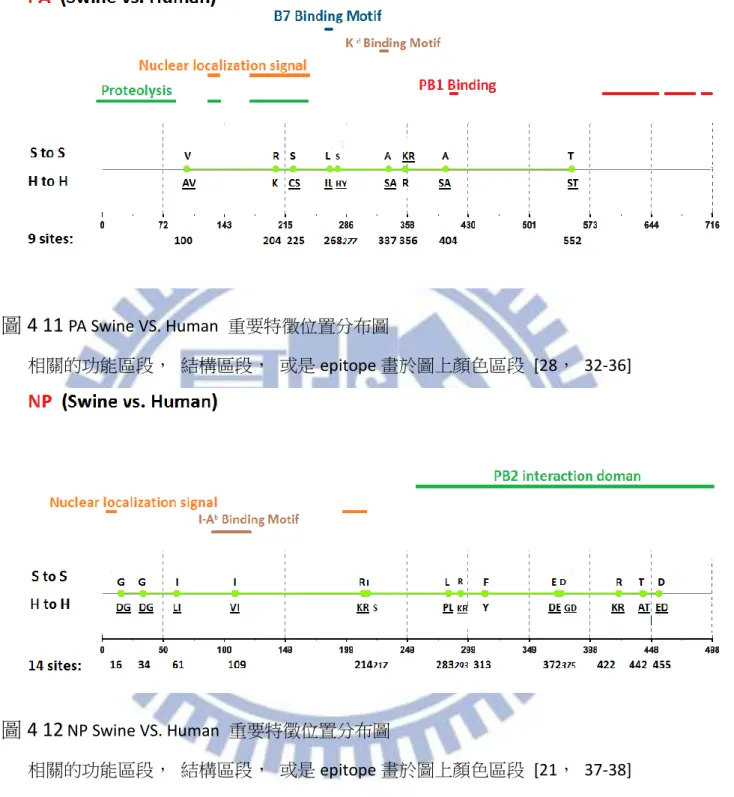
圖 4 3
PA Avian VS. Human 重要特徵位置分布圖相關的功能區段, 結構區段, 或是 epitope 畫於圖上顏色區段 [28,32-36]
圖 4 4
NP Avian VS. Human 重要特徵位置分布圖22
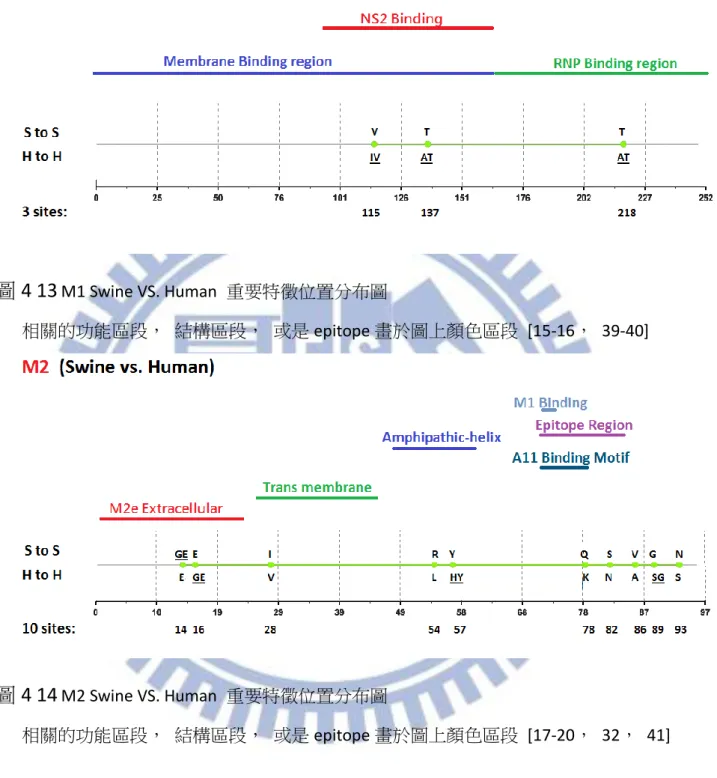
圖 4 5
M1 Avian VS. Human 重要特徵位置分布圖相關的功能區段, 結構區段, 或是 epitope 畫於圖上顏色區段 [15-16, 39-40]
圖 4 6
M2 Avian VS. Human 重要特徵位置分布圖23
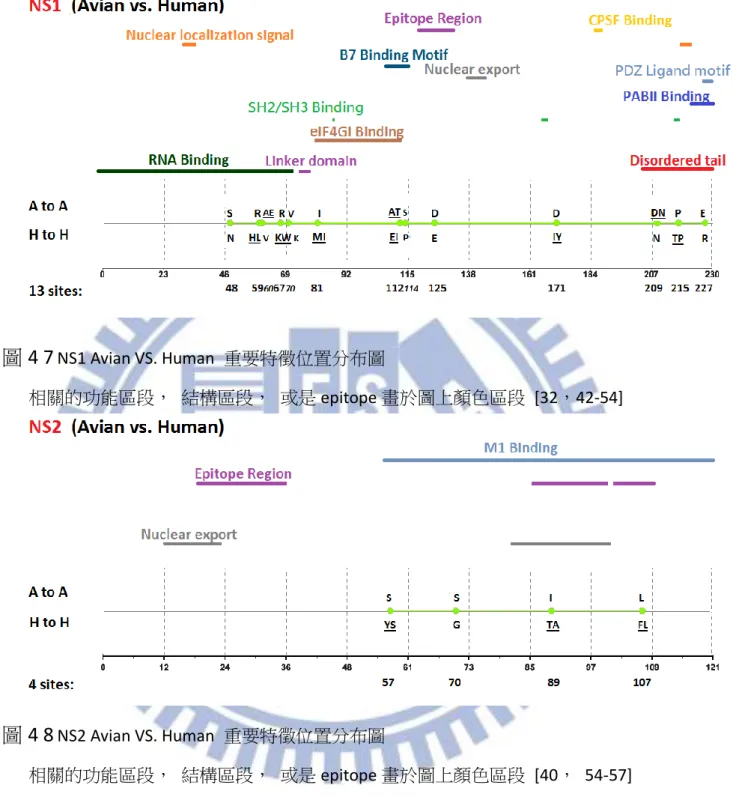
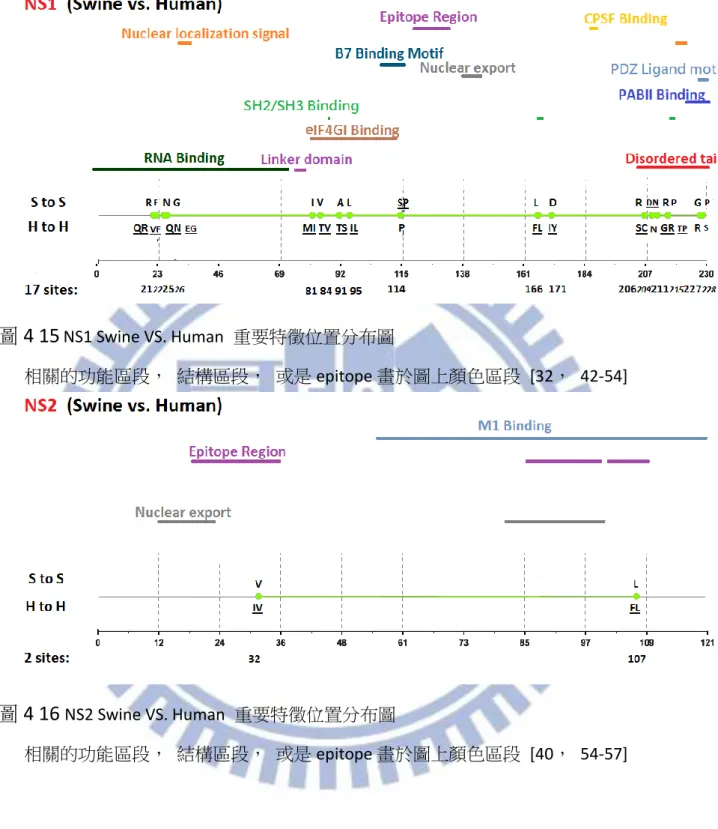
圖 4 7
NS1 Avian VS. Human 重要特徵位置分布圖相關的功能區段, 結構區段, 或是 epitope 畫於圖上顏色區段 [32,42-54]
圖 4 8
NS2 Avian VS. Human 重要特徵位置分布圖24
表 4 4
相關圖表的文獻參考對照表Segment Position Function Reference number PB2 196-210 I-Aᵇ Binding Motif [21]
590-591 SR Polymorphism [22] 449-495,736-739 Nuclear Localization Signal [23] 1-269,580-683 NP Binding [24] 1-131,580-759 PB1 Binding [24] 242-282,538-577 RNA cap Binding [25] 363-404 RNA cap Binding [26]
PB1 430-438,482-490 Epitope Region [27] 1-25 PA Binding [28] 600-747 PB2 Binding [28] 181-195,203-252 Nuclear Localization Signal [29] 1-83,233-249,494-757 vRNA Binding [30] 1-139,267-493 cRNA Binding [31]
PA 273-282 B7 Binding Motif [32] 333-341 K ͩ Binding Motif [33] 124-139,186-247 Nuclear Localization Signal [34] 1-85, 124-139, 186-247 proteolysis [35] 408-412,668-692 595-666,706-716 PB1 Binding [28][36]
NP 91-120 I-Aᵇ Binding Motif [21] 257-498 PB2 interaction domain [37] 3-13,198-216 Nuclear Localization Signal [38]
M1 1-164 Membrane binding region [15][16] 165-252 RNP Binding region [16] 101-105 Nuclear Localization Signal [39] 89-164 NS2 Binding [40]
25
1-23 M2e Extracellular domain [17][19] 46-62 Amphipathic-helix [18] 70-73 M1 binding [20] 69-84 Epitope Region [41] 70-78 A11 Binding Motif [32]
NS1 1-73 RNA Binding [42] [43] 75-79 Linker domain [44] 202-230 Disordered tail [45] 89-93,164-167,213-216 SH2/SH3 Binding [46] [47] 138-147 Nuclear export [48] 81-113 eIF4GI Binding [49] [50] 184-186 CPSF Binding [50] [51] 223-230 PABII Binding [50] [51] 227-230 PDZ ligand motif [52] 34-38,216-221 Nuclear Localization Signal [53] 106-115, 163-171 B7 Binding Motif [32] 120-136 Epitope Region [54] NS2 19-35,85-101 Epitope Region [54] 102-109 Epitope Region [55] 12-21,81-100 Nuclear export [56] [57] 54-121 M1 Binding [40]
表 4 5
Avian VS. Human 重要特徵位置, ARI 計算結果與 Miotto 結果比較之相異表 Avian VS. Human 重要特徵位置與 Miotto 相異表Segment 新興的重要特徵位置 不再為重要特 徵位置 PB2 453, 559,684 81 PB1 179,216,298,327,361,375,430,486,517,581, 584,621,741 無 PA 204,256,277 65,66,400, 421 NP 109,217,293,351,353,372,422,442,452,455 375,423 M1 218,227 無 M2 16,18,55,82,89 ,93 無
26
NS1 48,59,67,70,112,114,125,171,209 22,84
NS2 57,89 60
表 4 6
Avian VS. Human 重要特徵位置, ARI 計算結果與 Chen 結果比較之相異表 Avian VS. Human 重要特徵位置與 Chen 相異表Segment 新興的重要特徵位置 PB2 9,64,105,292,368,453,559,661,674,684 PB1 179,216,298,361,375,430,486,517,581,584,621,741 PA 204,256,277,337,382 NP 136,217,351,353,442,452 M1 218,227 M2 14,16,18,28,54,55,82,89 NS1 48,59,60,67,70,112,114,125,171,209,215 NS2 57,70,89
表 4 7
Avian VS. Human 重要特徵位置暨胺基酸變化表 所使用的年代資料以 2006 年為分段點, 分為兩個年代區間, 1902 年~2006 年以及 2007 年~2013 年, 所列出來的胺基酸以所佔比例高於 30%為基準。 表格中位置顏色分別代表的意義: 黑色(Validity), 從重要特徵位置演變成一個非重要特徵位置。 紅色(Validity), 從非重要特徵位置演變成重要特徵位置。 藍色(Identity), 在所有年代區間下一直為重要特徵位置, 其胺基酸存在著變化者。 綠色(Identity),在所有年代區間下一直為重要特徵位置, 且胺基酸十分穩定沒有發 生變化者。 Avian VS. Human 重要特徵位置暨胺基酸變化表格, 所使用的年代資料以 2006 年為分段 點, 分為兩個年代區間, 1902 年~2006 年以及 2007 年~2013 年Segment Position Avian amino acid transition Human amino acid transition
PB2 9 D=D ND 44 A=A SA 64 M=M TM 81 T=T MT 105 T=T MT 199 A=A SA 368 R=R KRK 463 I=I VII 475 L=L MLM
27 567 D=D NDN 613 V=V TV 627 E=E KEK 661 A=A TAT 674 A=A TAT 702 K=K RKR 54 K=K KRK 65 E=E EDE 147 I=I ITI 184 T=T TAT 225 S=S SGS 315 M=M MIM 340 R=R RKK 559 T=T TAI 590 G=G GS 591 Q=Q QRQ 645 M=M MLM 292 I=I TV 453 P=P HS 588 A=A ITI 684 A=A SAS 271 T=T A=A PB1 212 L=L VLL 12 V=V VIV 179 M=M MII 216 S=S GSG 298 L=L LI 339 I=I IMI 364 L=L LIL 386 R=R RK 517 I=I IV 587 A=A AVA 618 E=E EDE 638 E=E EDE 728 I=I IVI 327 R=R KRK
28 361 S=S RSR 430 R=R KRK 486 R=R KRK 584 R=R QRQ 621 Q=Q RQR 336 V=V I=I 581 E=E D=D 741 A=A S=S PA 28 P=P LPL 55 D=D NDN 57 R=R QRQ 65 S=S LS 66 G=G DG 100 V=V AVA 225 S=S CSC 268 L=L ILI 337 A=A SAS 400 PSP LPL 404 A=A SAS 421 S=S IS 552 T=T STS 85 T=T TIT 186 G=G GSG 204 R=R KRK 213 R=R RKR 256 R=R KRK 262 K=K KRK 275 P=P PLP 336 L=L LML 362 K=K KRK 407 I=I IVI 277 S=S YH 356 K=K R=R 382 E=E D=D 409 S=S N=N
29 NP 16 G=G DGD 61 I=I LIL 214 R=R KRK 283 L=L PLP 375 D=D GD 423 A=A SA 21 N=N NDN 53 E=E EDE 119 I=I IVI 189 M=M MIM 217 I=I SIV 289 Y=Y YHY 353 V=V SI 400 R=R RKR 425 I=I IVVI 430 T=T TST 444 I=I IVI 456 V=V VLV 100 R=R VIV 136 L=L MII 357 Q=Q K=K 313 F=F YVY 33 V=V I=I 305 R=R K=K 351 R=R K=K 452 R=R K=K M1 115 V=V IVI 121 T=T ATA 137 T=T ATA 167 T=T ATT 205 V=V IVV 218 T=T ATA 227 A=A TAT 239 A=A TAA 30 D=D DSD 116 A=A ASA
30 142 V=V VA 166 V=V VAV 207 S=S SNS 209 A=A ATA 214 Q=Q QHQ M2 11 T=T ITI 16 E=E GEG 20 S=S NSN 28 I=I VIV 54 R=R LR 57 Y=Y HYH 78 Q=Q KQ 82 S=S NSN 86 V=V AVA 89 G=G SG 93 N=N SSN 18 KR=KR R=R 31 S=S SN 43 L=L LTL 14 G=G E=E 55 LF=LF F=F NS1 21 R=R QRQ 22 F=F VFV 23 A=A VAA 41 K=K RKK 81 I=I MIM 84 V=V TV 98 M=M LMM 101 D=D NDD 112 AT=AT EI 166 L=L FLF 196 E=E KEE 215 P=P TPT 229 E=E KE 59 R=R HL
31 189 D=D DGD 217 K=K KE 70 E=E K=K 114 S=S P=P 125 D=D EDE 171 D=D IY 227 E=E R=R 48 S=S N=N 60 AE=AE V=V NS2 14 M=M LM 60 S=S NS 107 L=L FL 6 V=V VMV 32 I=I IVI 34 Q=Q QRQ 40 LIL LII 48 A=A ATA 57 S=S SLY 63 G=G GEG 115 T=T TAT 89 I=I TIA 70 S=S G=G
表 4 8
Avian VS. Human 重要特徵位置暨胺基酸變化表 所使用的年代資料以 2009 年為分段點, 分為兩個年代區間, 1902 年~2009 年以及 2010 年~2013 年, 所列出來的胺基酸以所佔比例高於 30%為基準。 表格中位置顏色分別代表的意義: 黑色(Validity), 從重要特徵位置演變成一個非重要特徵位置。 紅色(Validity), 從非重要特徵位置演變成重要特徵位置。 藍色(Identity), 在所有年代區間下一直為重要特徵位置, 其胺基酸存在著變化者。 綠色(Identity),在所有年代區間下一直為重要特徵位置, 且胺基酸十分穩定沒有發 生變化者。 Avian VS. Human 重要特徵位置暨胺基酸變化表格, 所使用的年代資料以 2009 年為分段 點, 分為兩個年代區間, 1902 年~2009 年以及 2010 年~2013 年32 transition transition PB2 9 D=D NDD 44 A=A SAA 64 M=M TMM 81 T=T MTT 105 T=T VTT 199 A=A SAA 368 R=R KRR 475 L=L MLL 567 D=D NDD 613 V=V TVV 627 E=E KEE 661 A=A TAA 674 A=A TAA 702 K=K RKK 54 K=K KRR 65 E=E EDD 147 I=I ITT 184 T=T TAA 225 S=S SGG 315 M=M MII 340 R=R KRK 590 G=G SGS 591 Q=Q QRR 645 M=M MLL 292 I=I TVV 453 P=P HSS 559 T=T ITI 588 A=A ITT 271 T=T A=A 684 A=A S=S PB1 327 R=R KRR 12 V=V VI 175 D=D DNN 298 L=L LII 339 I=I IMM
33 364 L=L LII 517 I=I IVV 587 A=A AV 618 E=E EDD 638 E=E EDD 728 I=I IVV 179 M=M IMI 216 S=S GSG 486 R=R KRK 336 V=V I=I 361 S=S R=R 430 R=R K=K 581 E=E D=D 584 R=R Q=Q 621 Q=Q R=R 741 A=A S=S PA 28 P=P LPP 55 D=D NDD 57 R=R QRR 100 V=V AVV 225 S=S CSS 268 L=L ILL 337 A=A SAA 404 A=A SAA 552 T=T STT 85 T=T TII 186 G=G GSSG 213 R=R RKKR 262 K=K KRR 275 P=P PLL 323 VIIV V=V 336 L=L LMML 362 K=K KRR 407 I=I IVV 277 S=S YHH 204 R=R K=K
34 256 R=R K=K 356 K=K R=R 382 E=E D=D 409 S=S N=N NP 16 G=G DGG 61 I=I LII 109 I=I VII 214 R=R KRR 283 L=L PLL 293 R=R KRR 372 E=E DEE 422 R=R KRR 442 T=T ATT 455 D=D EDD 21 N=N ND 189 M=M MIM 190 V=V VAV 289 Y=Y YHY 400 R=R RKR 425 I=I IVV 430 T=T TST 433 T=T TNT 444 I=I IVI 456 V=V VLV 100 R=R VI 136 M=M IMI 217 I=I SV 313 F=F YV 353 V=V SI 33 V=V I=I 305 R=R K=K 351 R=R K=K 357 Q=Q K=K 452 R=R K=K M1 115 V=V IVV
35 121 T=T ATT 137 T=T ATT 167 T=T ATT 205 V=V IVV 218 T=T ATT 227 A=A TAA 239 A=A TAA 30 D=D DS 116 A=A AS 142 V=V VA 166 VVA VAA 207 S=S SNN 209 A=A AT 214 Q=Q QH M2 11 T=T ITI 16 E=E GEEG 20 S=S NSN 28 IIV VIV 54 R=R LRL 55 LFFL F=F 57 Y=Y HYH 78 Q=Q KQK 82 SSN NSN 86 V=V AVA 89 G=G SGGS 93 N=N SNS 31 S=S SNN 43 L=L LTL 77 R=R RQR 14 G=G E=E 18 K=K R=R NS1 21 R=R QRR 22 F=F VFF 81 I=I MII 215 P=P TPP
36 227 E=E R=R 18 V=V IVI 25 Q=Q QN 26 E=E EGG 74 D=D DSS 78 K=K KRRK 119 M=M MLL 178 I=I IVV 189 D=D DGG 197 TNT N=N 217 K=K KE 59 R=R HL 67 R=R KWW 70 EKE K=K 112 AT=AT EII 171 D=D IY 209 DND N=N 48 S=S N=N 60 AE=AE V=V 114 S=S P=P 125 D=D E=E NS2 107 L=L FLL 6 V=V VMMV 32 I=I IVV 34 Q=Q QRRQ 40 LIL ILI 48 A=A ATTA 57 S=S SLYY 63 G=G GEEG 83 V=V VMV 89 I=I TA 115 T=T TAT 70 S=S G=G
37
4.1.2 1902 年以來至 2013 年二月底 A 型流感病毒蛋白質 Swine Human, 物
種間 Top-20 重要特徵位置:
在此節中,我們主要是針對三種計算方式作比較分析,並且根據現今年代段資料與 相關學者的實驗結果進行比較分析,並且根據我們與相關學者所使用的年代資料差異性 進行分析比較的實驗,我們同時使用 Entropy, MI, ARI 三種方式計算 1902 年以來至 2013 年二月底,Human 與 Swine 之間的重要特徵位置。 三種計算方式取重要特徵位置的方式如同 4.1.1 節所提到的方法一樣。在 Human 以 及 Swine 的關係中, ARI 以及 MI 的重要特徵位置比較詳列於附錄二,藉由附錄二的相 關實驗而言,MI 比起 ARI 一樣較會出現上述提過的兩種情形:1.不正常重要特徵位置較多, 以及 2.重要特徵位置代表的 Amino acid 相同此種不正常的重要特徵位置被排名到較前面 的名次,再次舉例來說,表 4-9 中 MI 的第三名就已經出現兩個物種所代表的 Amino Acid 相同的情形,相較起來 ARI 直到第 10 名才出現這種情形。藉由這種現象的發生,我們 可以歸納出,在 Swine VS. Human 的部分, MI 以及 ARI 的差異性不算太多, 但是若是 當我們取較少名次觀察時, MI 如同上一截的情形就會比較容易出現分別物種所代表的 Amino acid 相同的不合理情形,若是想要不正常重要特徵位置比較少的情況, ARI 有 4 個 Segment(PB1,PB2,NP,M2,NS2)不正常重要特徵位置皆少於 MI,其餘 4 個 Segment(PA, M1,NS1)也與 MI 持平,若是以機率來說使用 ARI 得到想要的結果之機率為 8/8 也就是 100%,比起 MI 的 4/8 也就是 50%要來得優勢許多在這個部份對於 MI 是相較於 ARI 弱勢 的地方,而另一部份想要不正常重要特徵位置位於比較後段排名的情形,ARI 優於 MI 的 Segment(PA,NP,M2,NS1)有 4 個,平手的 segment(PB1,M1,NS2)有 3 個,ARI 輸給 MI 的 Segment 只有 PB2 而已,換算成機率的話,ARI 比 MI 好或至少平手的機率為 7/8 也就是 87.5%而 MI 只有 4/8 也就是 50%,藉由上述比較我們可以再次的印證此三種 方式當中, ARI 是一個比較沒有弱勢地方的方法。 因此對於 Human 與 Swine 的重要特徵位置認定一樣採用與上一節相同的做法,即採 用 ARI 這種方法所計算出來的 Top-20 作為我們的參考重要特徵位置,並且依序認定重要 特徵位置直到出現第一個重要特徵位置代表之 Amino acid 相同此種不合理情形為止。對 於 1902 年至 2013 年 Swine 與 Human 八個 Segment 的重要特徵位置我們將結果詳列於 表 4-10。而重要特徵位置的分布圖分別列於圖 4-9 至圖 4-16 當中,相關文獻可參照表 4-4。
在計算我們藉由 ARI 所得到的重要特徵位置數量之後個別的 Segment 重要特徵位置 數量列於 表 4-11 總共的數量達到 65 個,相較於相關學者所提出的結果,PB2,PA,NP, NS1 這幾個部分數量皆有大量的提高,我們認為這幾個 Segment 特別是值得追蹤觀察的 部分,尤其是 NS1 不論是在 Avian VS. Human 或是 Swine VS. Human 都有大幅的提升之情 形。此外我們也有發現 NS1 在 Swine VS. Human 的分布情形頗有區段性的分布性, 藉由 圖 4-15 可以更清楚的觀察出這種特性, 第一區段位於 RNA-binding-domain [42], 第二 區段則是在 Linker domain 之功能區段 [44], 以及 disordered tail [45] NS2 的部分, 重 要特徵位置雖然沒有完全與一些 Functional 相關的序列段重疊但是每一個重要特徵位置
38
也都有實驗相關的抗原 (experimentally-determined-epitope) 有關聯 [54,55], 藉由圖 4-16 可以觀察到這個現象。
除了單純分析我們的結果之外,由於我們的資料採用的年代範圍為 1902 年至 2013 年,比起相關學者 Guang-Wu Chen 所採用的年代範圍 1902 年至 2009 年來的更為更新。 因此在 Swine 以及 Human 的重要特徵位置上,我們將我們利用 ARI 此計算方式所得到的 重要特徵位置與 Guang-Wu Chen 相比,以下我們可以得到一些與其結果相異的地方,這 部分我們認為是計算方式以及年代變動所造成的影響,以 Segment PB2 為例,位置 105, 292,453,567,588,674,684,702 為新興的重要特徵位置, Segment PB1 的部分, 位置 327 為新興的重要特徵位置, Segment PA 的部分位置 100,204,225,268,277, 337,356,404 為新興的位置, Segment NP 的部分, 16,34,61,109,214,217, 283,293,313,372,375,422,442,455 為新興的重要特徵位置,Segment M1 的部 分 115,218 為新興的重要特徵位置,Segment M2 位置 14,16,28,54,78,82,89 我們認定為新的重要特徵位置, Segment NS1 位置 21,22,25,26,81,84,91,95, 114,166,171,206,209,211,215,227,228 為新的重要特徵位置,最後 Segment NS2 的部分位置 32 為新興的重要特徵位置,整體結果如表 4-12 所列。 在這邊我們一樣以上一節的兩個面向下去討論:一、在兩個年代區段下,從重要特 徵位置變成非重要特徵位置抑或是從非重要特徵位置變成重要特徵位置(Validity);二、 在前後年代區間皆為重要特徵位置,且胺基酸沒有變化者,抑或是胺基酸有所變化者 (Identity)。而根據 Chen 所畫分的年代區間分析結果列於 表 4-13,在上一節所提到能夠 更加精確地觀察到近年來的變化之效果,在此節依然存在,因為不會被全年度序列稀釋 掉近年的變化情形,而 Identity 此種情形在 Swine VS. Human 的實驗下數量也銳減許多, 因此相對應到 Avian VS. Human 的部分, 是比較沒有那麼穩定的重要特徵位置的。
39
表 4 9
Swine VS. Human 重要特徵位置 ARI 以及 MI 在 Segment PA 之數值以及代表胺基酸 表紅色的位置表示是不正常之重要特徵位置, MI 位置 208 以及 421…等等位置皆可 以發現物種代表 Amino acid 相同的情形皆比 ARI 還早出現在前面的排名。
ARI MI
pos. value Swine_AA Human_AA pos. value Swine_AA Human_AA 204 0.31 R (72%) K (76%) 277 0.31 S (58%) HY (35% 35%) 356 0.28 KR (59% 35%) R (88%) 28 0.29 P (70%) LP (52% 42%) 268 0.23 L (89%) IL (53% 43%) 208 0.28 TK (49% 37%) T (73%) 552 0.22 T (86%) ST (53% 42%) 204 0.27 R (72%) K (76%) 225 0.22 S (86%) CS (53% 43%) 337 0.27 A (79%) SA (53% 41%) 100 0.21 V (84%) AV (52% 42%) 225 0.26 S (86%) CS (53% 43%) 337 0.20 A (79%) SA (53% 41%) 421 0.26 S (88%) SI (43% 32%) 277 0.20 S (58%) HY (35% 35%) 356 0.25 KR (59% 35%) R (88%) 404 0.20 A (84%) SA (54% 41%) 552 0.25 T (86%) ST (53% 42%) 323 0.19 VI (50% 43%) V (94%) 268 0.25 L (89%) IL (53% 43%) 28 0.17 P (70%) LP (52% 42%) 323 0.24 VI (50% 43%) V (94%) 421 0.16 S (88%) SI (43% 32%) 100 0.23 V (84%) AV (52% 42%) 385 0.13 K (90%) KR (56% 40%) 184 0.23 S (64%) SN (56% 40%) 66 0.12 G (79%) GD (43% 40%) 321 0.23 N (56%) YN (40% 39%) 208 0.12 TK (49% 37%) T (73%) 272 0.21 D (69%) DN (52% 42%) 383 0.12 D (90%) DN (57% 39%) 66 0.20 G (79%) GD (43% 40%) 668 0.12 I (86%) IV (56% 40%) 404 0.19 A (84%) SA (54% 41%) 65 0.11 S (70%) SL (42% 41%) 263 0.18 T (60%) T (95%) 57 0.11 R (73%) QR (53% 42%) 65 0.18 S (70%) SL (42% 41%) 343 0.10 A (89%) A (54%) 343 0.18 A (89%) A (54%)
表 4 10
1902 年至 2013 年 Swine vs.Human 各 Segment 之重要特徵一覽表所代表的 Amino acid 只列出超過 30%的部分, 且由左至右表示大小順序, 如 SA 表示 S, A 皆超過 30%且 S>A 所占有比例。
1902 年~2013 年 Swine VS. Human 重要特徵位置一覽表
Segment Position Swine amino acid Human amino acid PB2 292 I (60%) TV (51% 36%)
684 A (64%) S (74%) 567 D (88%) ND (51% 45%) 105 T (84%) VT (47% 42%)
40 44 A (84%) SA (49% 43%) 453 P (60%) SH (40% 39%)) 674 A (82%) TA (50% 46%) 702 K (84%) RK (51% 46%) 588 AT (41% 41%) IT (52% 38%) PB1 327 R (87%) KR (49% 46%) PA 204 R (72%) K (76%) 356 KR (59% 35%) R (88%) 268 L (89%) IL (53% 43%) 552 T (86%) ST (53% 42%) 225 S (86%) CS (53% 43%) 100 V (84%) AV (52% 42%) 337 A (79%) SA (53% 41%) 277 S (58%) HY (35% 35%) 404 A (84%) SA (54% 41%) NP 313 F (75%) Y (63%) 283 L (89%) PL (63% 34%) 372 E (89%) DE (62% 36%) 293 R (89%) KR (62% 37%) 442 T (89%) AT (61% 35%) 455 D (89%) ED (60% 35%) 16 G (85%) DG (61% 33%) 61 I (86%) LI (61% 34%) 422 R (89%) KR (61% 35%) 214 R (84%) KR (61% 35%) 109 I (85%) VI (58% 36%) 375 D (82%) GD (36% 34%) 34 G (80%) DG (46% 41%) 217 I (65%) S (43%) M1 137 T (90%) AT (57% 35%) 115 V (90%) IV (56% 36%) 218 T (92%) AT (49% 45%)