應用文字探勘技術於英文文章難易度分類 - 政大學術集成
67
0
0
全文
(2) 致謝 這一切都得感謝兩年半前政大資管系給我這個機會,得以進入夢寐以求的學 校追求更進一步的知識。但是,就在進入這個新環境的同時,考驗也接踵而來, 茫然、找尋與堅定最適合描述這兩年來的心情轉變;一度覺得研究所的路不知如 何繼續走下去,到一路上慢慢地撿石頭蒐集關鍵的線索。就在寫致謝的同時,心 中仍然感覺到一路上的煎熬微微在環繞,以及幫助我度過難關的人給我的感動, 以下一一述說這路上我所感謝的人。 首先,感謝楊建民老師這兩年來的指導,從老師的身上學到做人處事以及追 尋夢想的態度;感謝老師讓我嘗試在資管領域較少人從事的研究,並給予適當的 指導,總是能夠在這研究迷霧當中以燈塔的角色引領我前進;另外,感謝在論文 提報以及最後口試給予指導的季延平老師、劉文卿老師及邱光輝老師。當然,也 得感謝這一路上有同儕的陪伴,包括總為實驗室帶來歡笑聲的子洋、有清楚思路 並在危急時給予建議的偉志、能夠一同弄清觀念以及方向的弘業、最後階段能夠 在同實驗室中一同討論以及訴苦的智勝,以及總能成為大家話題中的“神人”,張 伯辰,還有,能夠一同歡樂及討論未來的悅岑姐。最後也感謝這一路上陪伴我兩 年的高中、淡大朋友、政大朋友以及學長姐們,以及給我機會利用暑假實習的乙 曼資訊公司,及政大社科院中動態競爭與創新平台中的 Eileen 給我英文方面、生. 立. 政 治 大. ‧ 國. 學. ‧. 活中的幫助,以及邏輯思維方面的提升。 這一路上所需感謝的人、事太多,所經歷過的一切現在回頭看起來一切這麼 清楚;雖然未來還是充滿不確定性,但兩年給我的歷練以及視野,讓自己的勇氣 增加了許多,更相信若是能夠踏出第一步,勇敢嘗試各種可能性,不要設限自己, 那最後一定能夠走出屬於自己獨一無二的道路,並找到屬於自己的夢想。 最後,把致謝最重要的一部份獻給摯愛的家人。感謝爸媽花了許多的力氣、. n. er. io. sit. y. Nat. al. Ch. i n U. v. 金錢在我的身上,不僅讓我有個強力的後盾,在最煎熬的時刻給予精神上的安慰, 並讓我無後顧之憂地往前;以及感謝大姐瑋倫、二姐瑋倩在我最混沌的時刻給我 人生建議,還有姊姊們的小孩辰澔、芯羽給予最天真的歡笑聲,當然還有兩位姐 夫的開導以及工作經驗傳承。我想到目前為止我的人生真的可以說很幸福。 這篇致謝不僅是對這兩年研究所的生涯做一個回顧,並是對這十八年來求學 後的成果做一個檢視;想到學習階段在這邊要告一段落會覺得不捨,但也對邁向. engchi. 人生另一階段感到興奮不已。這一切都值得,人生路上絕不會有白走的路,只要 用心去體會、用心去了解,人生中的每一步對自己都有所幫助。從我完成研究所 跨出校門的這一刻,將展開新的旅程,不管未來到何處,期許自己都能夠精進能 力,並且努力不懈地完成目標。 最後的最後,感謝我經歷過、體驗過的一切,我做到了! 許珀豪 謹致 於 政治大學資訊管理學系 中華民國一○二年七月 I.
(3) 摘 要 英語學習者如何能在普及的網路環境中,挑選難易度符合自身英文閱讀能力 的文章,便是一個值得探討的議題。為了提升文章難易度分類的準確度,近代研 究選取許多難易度特徵去分類。本研究希望能夠藉由英文語文難易度特徵、文字 特徵,各自歸類和綜合歸類後與原先官方文章類別比較,檢驗是否可以利用語文 特徵與文字特徵結合後的歸類結果,來提高準度。 本研究以 GEPT 的模擬試題文章作為歸類的依據。研究架構主要分成三部分: 語文難易度特徵歸類、文字特徵歸類與綜合前兩者歸類。先以語文難易度特徵組. 治 政 大 文章斷詞,並選取特徵詞 中級或中高級,並做為比較準確度的依據;再以 GEPT 立 作為特徵向量維度、TF-IDF 作特徵值進行文字特徵歸類;最後則是將前面兩種. 成特徵向量的維度,並算出各語文特徵值後,再使用 kNN 將文章歸類成初級、. ‧ 國. 學. 特徵結合作為歸類標準。分別的 F-measure 為 0.61、0.47,最後一個、也是表現 最好的結果是以兩者結合後歸類,F-measure 有 0.68。. ‧. 如何從大量的英文文章當中找到適合自己程度循序漸進的學習,是本論文期. sit. y. Nat. 望未來可以藉由最後語文難易度特徵加上文字特徵的結果來達到的目的。未來可. io. er. 以結合語文難易度特徵以及文字特徵來幫助英文文章做分類,並可以從中分類出 不同類別且不同程度的英文文章,讓使用者自行選擇並閱讀,使學習成效進而提. al. n. 升。. Ch. engchi. i n U. v. 關鍵詞:文字探勘、kNN、英文文章適讀性、英文語文難易度特徵、文字特徵. II.
(4) Abstract It is rather an important issue that how to grasp the difficulty of the articles in order to efficiently choose the English articles that match our proficiency in the popularity of Internet. Recently, researchers have selected many characteristics of difficulty degrees in order to enhance the accuracy of the classification. The study aims to simplify the former complicated procedures of article classification by using the classification results of linguistic difficulty characteristics, text characteristics respectively, and the combination of the both; in the hope to raise the accuracy of the classification through the comparison of the results.. 政 治 大 There are three parts of this study: the characteristics of the linguistic difficulty and 立 the text, and the combination of the both. First, the dimensions of the linguistic The article classification of the study is based on GEPT official practicing exams.. ‧ 國. 學. vectors will be the linguistic characteristics. The articles will be classified into primary, intermediate, or intermediate-high levels by kNN method, considered the. ‧. comparison basis for the classification of the articles’ difficulty. Second, after GEPT. sit. y. Nat. articles are broken into words, the dimensions of the text vectors will be the selected. io. er. words; the TF-IDF will be the values of the text vectors. The third part is to classify articles by using the combination of the former two results. After comparing the three,. n. al. Ch. the best method is the third, the accuracy is 0.68.. engchi. i n U. v. The study hopes the result could help people choose proper English articles to learn English step by step. In the future, we could classify the articles by the combination of the both of linguistic difficulty characteristics and text characteristics. Not only classified as the different levels, but also classified as the different categories. The learners could choose what they like and the articles could correspond their degree in order to promote the effect of learning. Key Words: text mining, kNN, the difficulty of English articles, the characteristics of the linguistic difficulty of English articles, the characteristics of the text.. III.
(5) 目錄 第一章 緒論.................................................................................................................. 1 第一節 研究背景與動機...................................................................................... 1 第二節 研究目的.................................................................................................. 2 第三節 研究架構.................................................................................................. 3 第二章 文獻探討.......................................................................................................... 4 第一節 台灣學習英語狀況與英語學習的方式.................................................. 4 2.1.1 台灣學習英語狀況.............................................................................. 4. 政 治 大 2.1.3 小結...................................................................................................... 5 立. 2.1.2 英語學習方式:廣泛閱讀.................................................................. 4. ‧ 國. 學. 第二節 英文文章適讀性分析.............................................................................. 6 2.2.1 何謂英文適讀性.................................................................................. 6. ‧. 2.2.2 適讀性公式.......................................................................................... 7. sit. y. Nat. 2.2.3 適讀性公式的價值............................................................................ 11. io. er. 2.2.4 其他英文適讀性因素以及研究........................................................ 11. al. 2.2.5 小結.................................................................................................... 13. n. v i n Ch 第三節 資料探勘與文字探勘............................................................................ 13 engchi U 2.3.1 資料探勘............................................................................................ 14 2.3.2 文字探勘............................................................................................ 15 2.3.3 資料探勘與文字探勘比較................................................................ 15 2.3.4 文字探勘過程.................................................................................... 16 2.3.5 分類績效評估.................................................................................... 19 第四節 文獻探討總結........................................................................................ 21 第三章 研究方法與設計 ........................................................................................... 22 第一節 研究架構與範圍.................................................................................... 22 IV.
(6) 3.1.1 研究範圍............................................................................................ 24 第二節 資料來源及特徵向量............................................................................ 24 3.2.1 資料來源............................................................................................ 24 3.2.2 特徵向量............................................................................................ 25 第三節 kNN 分類 ............................................................................................... 31 3.3.1 相似度計算........................................................................................ 31 3.3.2 kNN 歸類方法...................................................................................... 31 第四節 評估相似度方法.................................................................................... 32 第四章 研究結果........................................................................................................ 33. 政 治 大. 第一節 依語文難易度特徵測試結果................................................................ 33. 立. 第二節 依文字特徵測試結果............................................................................ 35. ‧ 國. 學. 第三節 以文字特徵測試語文難易度特徵之結果............................................ 37. ‧. 第四節 以語文特徵與文字特徵結合歸類之結果............................................ 40 第五節 比較與分析四個結果............................................................................ 43. y. Nat. io. sit. 第六節 k 值之分佈與篩選................................................................................. 45. n. al. er. 第五章 結論與未來研究方向 ................................................................................... 48. Ch. i n U. v. 第一節 結論與建議............................................................................................ 48. engchi. 第二節 未來研究方向........................................................................................ 49 參考文獻...................................................................................................................... 51 附錄一:依語文難易度特徵測試結果(按 F-measure 排列)................................... 55 附錄二:依文字特徵測試結果(按 F-measure 排列)............................................... 56 附錄三:以文字特徵測試語文難易度特徵之結果(按 F-measure 排列後最前面 37 筆資料) ........................................................................................................................ 57 附錄四:以語文特徵與文字特徵結合歸類之結果(按 F-measure 排列)............... 58. V.
(7) 圖目錄 圖 2-1 Fry’s Readability Graph...................................................................................... 9 圖 2-2 向量空間模型示意圖 ..................................................................................... 18 圖 2-3 kNN 概念圖 ..................................................................................................... 19 圖 3-1 研究架構圖 ..................................................................................................... 23 圖 3-2 文字特徵向量空間模型矩陣 ......................................................................... 30 圖 3-3 語文難易度特徵向量空間模型矩陣 ............................................................. 30. 政 治 大. 圖 3-4 文字特徵結合語文難易度特徵向量空間模型矩陣 ..................................... 31. 立. 圖 4-1 依語文難易度特徵測試結果-相同類別文章比例與 F-measure .................. 34. ‧ 國. 學. 圖 4-2 依語文難易度特徵測試結果-MicroF 與 MacroF ......................................... 34. ‧. 圖 4-3 依文字特徵測試結果-相同類別文章比例與 F-measure .............................. 36. sit. y. Nat. 圖 4-4 依文字特徵測試結果-MicroF 與 MacroF ..................................................... 36. al. er. io. 圖 4-5 以文字特徵測試語文難易度特徵之結果-相同類別文章比例與 F-measure. v. n. .............................................................................................................................. 39. Ch. engchi. i n U. 圖 4-6 以文字特徵測試語文難易度特徵之結果-MicroF 與 MacroF ..................... 39 圖 4-7 以語文特徵與文字特徵結合歸類之結果-相同類別文章比例與 F-measure .............................................................................................................................. 41 圖 4-8 以語文特徵與文字特徵結合歸類之結果-MicroF 與 MacroF ..................... 42 圖 4-9 測試三十次 k 值為 1 至 34 之結果散佈圖(前五筆資料)............................. 45 圖 4-10 測試三十次 k 值為 1 至 34 之結果統計次數(前五筆資料)....................... 46 圖 4-11 測試三十次 k 值為 1 至 34 之結果平均 F-measure(前五筆資料) ............. 46. VI.
(8) 表目錄 表 2-1 1923-1977 年研究學者用來評估英文文章難度的變數 ................................ 10 表 2-2 文件分類結果種類 ......................................................................................... 19 表 3-1 資料來源篇數 ................................................................................................. 25 表 3-2 詞類對照表 ..................................................................................................... 28 表 4-1 依語文難易度特徵歸類後與官方試題的各級篇數比較(k 值為 10)........... 35 表 4-2 依文字特徵歸類後與官方試題的各級篇數比較(k 值為 31)....................... 37 表 4-3 文字特徵歸類後(k 值為 21)與語文難易度特徵歸類後(k 值為 2)的各級篇數 比較...................................................................................................................... 40. 政 治 大 表 4-4 文字特徵歸類後(k 值為 3)與語文難易度特徵歸類後(k 值為 10)的各級篇數 立 比較...................................................................................................................... 40. ‧ 國. 學. 表 4-5 以語文特徵與文字特徵結合歸類後與官方試題的各級篇數比較(k 值為 23) .............................................................................................................................. 42. ‧. 表 4-6 歸類結果的各度量比較表 ............................................................................. 44. n. er. io. sit. y. Nat. al. Ch. engchi. VII. i n U. v.
(9) 第一章 緒論. 第一節 研究背景與動機 全球化的影響,英文已經變成非母語國家的第二外語,也是現在多數人以此 來進行溝通的媒介。從英語資源方面來看,世界各知名期刊、研討會及學術機構 之研究結果也大都以英文來發表或出版;從現在台灣教育制度方面來看,從國小、 國中、高中到大學,甚至向下延伸從幼稚園開始或向上到研究所都在學習英文; 各種英文檢定:全民英檢、多益、托福、雅思等都很盛行。學習英語的重要性可. 治 政 大 Revell(2007)也表示學習英文不僅是商務人士用來加強其溝通技能與增加國際競 立 爭力的必要元素,也是研究人員及學者用來汲取新知的工具。 以從我們可以獲得的資源多寡以及學習階段中英語課程佔的比例得知。. ‧ 國. 學. 英文學習不可以只靠背單字、記文法與考試的方式進行,聽、說、讀、寫四 方面都是非常重要。但以英語學習來說,閱讀是一切基礎,學習者要先熟悉詞彙. ‧. 並了解其含義。在閱讀過程當中,要先透過朗讀將字彙轉換成語音,再由大腦熟. sit. y. Nat. 記;最後,則能以適當的詞彙表達內心情緒構思出文情並茂的文章。透過大量的. io. er. 閱讀,則能將英文能力變成知識擷取工具。所以,閱讀英文文章在學習英文當中, 是非常重要的階段(Ionin et al., 2008)。. al. n. v i n Ch 在學習的過程當中,除了主動積極的學習態度外,選擇良好的學習教材也很 engchi U. 重要,因為教材的難易度對學習者而言,有非常大的影響力(Chiang & Kuo, 2005)。 在電腦、智慧型手機等設備普及與網際網路早已成熟的這個階段,想要在網路上 找英文資源(文章)並不難,但資訊過量到已經讓想要挑選適合英文文章給自己閱 讀的人感到困擾,或說是自己無法判斷英文文章難易度適不適合自己閱讀。有的 人找到的英文文章對他而言已經超出可以負荷甚至是打擊信心;而有些找到的文 章對於他而言又覺得沒有挑戰性。 在適讀性這個研究上,最早可以推回 1880 年代,L. A. Sherman 英語教授發 現在較短的句子與較具體的文字能夠幫助讀者理解文本內容;文本如果能夠更像 演講說詞,會讓人更容易理解。因為 1920 年代就開始發展適讀性公式,而英文 文章適讀性公式從以前到現在累積了各式各樣的算法,認真說起來,英文文章的 1.
(10) 難度其實牽涉到許多領域,包括語言學、認知心理學、教育學與資訊科學等都對 這一領域有所貢獻(黃昭憲,2010)。每個人覺得英文文章難度判斷標準也都不盡 相同,例如有的人覺得單字是他最大的罩門,文法還不錯,有人卻相反,此差異 隨著每個人在不同的教育背景、環境之下都會有所不同。 而較最近對於英文文章難易度分類的研究中,為了要達到準確度的提升,針 對不同的英文難易度特徵與不同的分類方法下去做研究。難易度特徵包含了不在 以往適讀性公式裡的因素,例如全民英檢初、中、中高級各占比例、句子結構、 字詞頻率等;而分類方法從 kNN、貝氏網路到決策樹等。利用許多的難度特徵 以及不同方法對於準確度上是會有幫助,但是有沒有一個較簡單、過程較不繁複, 並且準確度有一定水準以上的方法,可以幫助分類。而文字探勘這個方法是用來. 政 治 大. 比較半結構化或非結構化的文章之間的相關性,本論文所要研究的在於可否利用. 立. 文字探勘的方法與文字、語文難易度的因素來幫助難易度相似的文章分類,並且. ‧ 國. 學. 達到較高準確度的效果。. 第二節 研究目的. ‧. y. sit. n. al. er. 找出具公信力的英文文章並建立詞庫。 蒐集英文文章並利用文字探勘的方法來幫助英文文章在難易度上的歸. io. 1. 2.. Nat. 依照研究背景與動機,在這邊說明本研究的目的如下:. 3. 4.. i n U. v. 類。 比較利用語文難易度特徵所歸類出來的結果,是否可以藉由文字特徵加 入後提高準確度。 找出歸類英文文章難易度時使用的 k 值在何時有最好的準確度。. Ch. engchi. 2.
(11) 第三節 研究架構 一、緒論 說明本篇論文的研究背景與動機、研究目的,最後為整篇論文的研究架構。 二、文獻探討 說明研究相關的文獻資料。包括從台灣學習英語狀況與英語學習的方式開始, 到較早對於英文文章適讀性的分析作探討外,再探討本論文所使用到的相關技術: 資料探勘與文字探勘。 三、研究方法與設計. 政 治 大 首先提出本論文的研究架構、研究範圍,接著針對細部的研究方法做說明, 立 包括從資料來源的收集到如何利用特徵向量來表示每篇文章;之後,則說明如何. ‧ 國. 學. 利用這些英檢文章向量使用 kNN 方法來幫助英文文章歸類。. ‧. 四、研究結果. y. Nat. 此部分將會依據自己的研究架構、方法針對所歸類出來的結果做說明。過程. n. al. 五、結論與未來研究方向. Ch. engchi. er. io. 幫助預測英文文章難度的建議以及 k 值使用的推薦。. sit. 中將會嘗試各種 kNN 中的 k 值,並做各種分析與比較,最後提出往後可以如何. i n U. v. 根據研究結果,整理出本研究的結論與應用於何處之建議,並提出未來研究 方向,以作為此方面研究者的參考。. 3.
(12) 第二章 文獻探討. 第一節 台灣學習英語狀況與英語學習的方式 2.1.1 台灣學習英語狀況 英語這個語言影響了全球,英語教學融入在教育課程中的狀況在很多國 家都是很常見的。不管台灣是定位在以英語為外語(English as a Foreign Language)或是以英語為第二語言(English as a Second Language)的國家,英 語的功能不外乎是與外國人進行溝通,以及作為大量獲取資源的重要媒介,. 政 治 大. 畢竟許多世界各知名期刊、研討會及學術機構之研究結果都以英語來發表。. 立. 在台灣,大概自 1970 年代後期,兒童英語補習班開始在台北興起,而. ‧ 國. 學. 後逐漸遍及台灣各大都市。估計台北市的小學生有七成左右在畢業之前已接 受過一年以上的英語補習班的教育(黃宣範,1993)。隨著教改政策,九年一. ‧. 貫課程統整大綱更直指要讓學生提早學習英語,讓國小學生開始接受英語教 育。另外國中、高中英語也是主要科目其中之一,甚至在大一、大二也還把. y. Nat. io. sit. 英語列入必修課程之一。. n. al. er. 但是,李振清在《從閱讀到寫作,提高高中生英文能力與多元功能的致. i n U. v. 命關鍵》文章中表示台灣的大、中學生在英文閱讀素養方面,大都明顯不足,. Ch. engchi. 因而知識背景(Background Knowledge)貧乏、語言認知(Language Cognition) 與溝通(Linguistic Communication)素養自然產生缺陷。根據語言能力互補、 互動,與後設認知(Metacognition)理論的共識,輕忽閱讀,必然會引發閱讀 知識與寫作能力脫節之後遺症;以補習為核心活動的語言教學方法,長期則 會造成高中生支離破碎的英語學習方式。 2.1.2 英語學習方式:廣泛閱讀 在此研究當中我們先不管台灣教育制度正確與否,單看學習英語的這件 事情。對於學生而言,我們所熟知的學習英語過程包括了聽力訓練、抄筆記、 查字典、背單字、考試、翻譯等繁複困難的歷程。. 4.
(13) 而有個叫做廣泛閱讀的學習法適合接觸英語已有一陣子的學習者。廣泛 閱讀理論最基本的想法是認為語言的學習是快樂的、自主的。學生在閱讀英 文讀物的時候,能夠選擇適合自己程度、符合自己興趣的讀物,大量閱讀, 不必查字典、不必應付考試,把閱讀英文書當作一種休閒活動的英語學習方 法。最終的目的是使閱讀變成每個學生日常生活中的一部份,而且透過閱讀, 獨立學習,不斷提升自己的英語能力以及各領域的知識。 Bell(1998)將廣泛閱讀在外語學習中所扮演的角色歸納為十點,在此研 究當中我列出以下幾點來強調英語閱讀的重要性: 1.. 廣泛閱讀可以強化學生整體的外語能力。許多實證性研究結果說明. 政 治 大. 透過長期廣泛閱讀學生在認字、閱讀、口語及寫作上都有明顯的進 步。. 廣泛閱讀增加學生接觸英文的機會。EFL(English as a Foreign. ‧ 國. 學. 2.. 立. Language)學生和 L1(以英語為母語)學生最大的差別就是在接觸語. ‧. 言的質與量,透過廣泛閱讀可降低 EFL 學生和 L1 學生之間在接觸 語言機會上的落差。. y. Nat. 廣泛閱讀可提升學生的字彙量。Nagy and Herman(1987)的研究指出. sit. 3.. n. al. er. io. 三年級到六年級的學生平均學會約三千個字彙,其中極少數是藉由. i n U. v. 直接的字彙教學,絕大部分是透過閱讀而習得的。 4.. Ch. engchi. 廣泛閱讀可穩固學生先前學過的內容。透過廣泛閱讀,學生學過的 單字、句型及文法概念重複的出現在文本裡,讓學生透過舊知識學 習新語料。. 5.. 廣泛閱讀可以建立學生閱讀大篇幅文章的信心。學生能夠透過廣泛 閱讀漸漸對閱讀較長文章建立信心,才有機會閱讀像是原文教科書 等專業性的書籍。. 2.1.3 小結 本研究在這部分想要探討的重點並不是我們台灣的英語教育制度是對 或錯,而是就獲取資源以及能與各國進行溝通這兩件事情上面,就足以說明 5.
(14) 學習英文的重要性是很高的。以及藉由 Bell(1998)所整理出來的廣泛閱讀的 優點可以得知大量閱讀英文文章是有助於英語能力的提升。. 第二節 英文文章適讀性分析 一篇英文文章的難易要看是從什麼角度來分析,若是把麥帥祈禱文之類的英 文讀物給初學者閱讀,對他們來說是很難的文章,但對於外文系的學生來說,可 能覺得還可以接受。但這裡其實涵蓋到所選擇的文章種類,針對不同類型(報紙、 書本等)、年紀的讀者等因素,不同文章的難易度對於他們個別可能都有不同的 計算方式,也需要考慮到他們的興趣。英文適讀性所牽涉到的因素層面很廣。以 下要探討的部分在於英語適讀性是什麼、適讀性公式的功用到有哪些適讀性公 式。. 立. 政 治 大. 2.2.1 何謂英文適讀性. ‧ 國. 學. 1920 年代開始盛行的適讀性(readability)相關研究,包括對字彙掌握的 研究、適讀性評估的研究,其目的為追求出版品素材在學習及理解上的困難. ‧. 度之客觀評估方法(宋佩貞,2009)。而對於適讀性的定義從以前到現在都有. sit. y. Nat. 所不同,McLaughlin(1969)把適讀性界定為一特定群體覺得某種閱讀材料能. io. er. 引起人注意的(compelling)、必要的(necessary)且可以理解的(comprehensible) 程度;韋氏英文辭典(Merriam-Webster’s)則是對“可讀的”(Readable) 一詞定. n. al. Ch. i n U. v. 義包含四個意思:適讀的、易讀懂、形式悅人的、讀來有趣的(“fit to be read;. engchi. interesting; agreeable and attractive in style; and enjoyable.”)(賴伯勇,2005)。 這裡可以看出有三個影響適讀與否的因素:文章內容之難易、讀者的興趣與 文章之印刷形式。 這些因素可歸納成為語文與非語文因數兩類。Meyer(2003)甚至認為學 習策略,例如重複閱讀、在文字下畫線、作筆記等因素也會影響教材適讀性。 因為非語文的因素並不是語文教師所能掌握,所以比較早開始研究教材適讀 性的學者,大部分都是從語文因素入手,希望能夠指出哪些因素最重要,進 而設計各種測量方式,把教材的難易用量化方式表示出來,並假設教材難易 度就代表學生理解度。. 6.
(15) 2.2.2 適讀性公式 所謂適讀性公式(readability formula)指的是利用公式來評估適讀性,提 供文本變數的值輸入公式後,輸出單一適讀性,呈現方式有等級、年級或分 數等(宋佩貞,2009)。使用公式評估適讀性的好處,即是易於應用與理解, 且能在電腦上執行(Jeng, 2001)。 適讀性發展到今天,像是閱讀能力、先備知識、興趣與動機、閱讀效率 等是近期研究者所關注的;而大部分學者都是用公式來預測適讀性,從 1940 年代開始,適讀性公式到今天也已經有超過兩百個以上的公式,只有少部分 的公式能夠被大多人士所接受與信任的,其中影響因素包括字彙的難易度、. 治 政 大 閱讀文本的工具,它並不能百分百正確地測量出適合閱讀他的年紀或是屬於 立 哪個教育階段。而本研究所要探討的是偏向於測試出版文件 (publishing 句子的難易度、文體格式等。而適讀性公式只是一種用來大概評估教材或是. ‧ 國. 學. documents) 的適讀性公式,出版品包括報紙(newspaper)、雜誌(magazine)、 書(book)、期刊(journal)、網路媒體(online media)。公式介紹如下:. ‧. 1.. Dale-Chall 公式(1948). y. Nat. sit. 採用難字比例(Dale 的 3000 個英文常用字彙表以外的字彙)與. er. io. 每句平均字數(句子長度)來做為判斷英文文章難易度的因素。. al. n. v i n C h 個英文常用字彙表的字數即可代入公式,算 數、不在 Dale 的 3000 engchi U Dale-Chall 公式的計算過程比較簡單方便,只要算出每句的平均字. 出來的公式分數可以再利用 Dale 和 Chall 適讀性公式對應表,查出 對應的級別程度。 2.. Flesch-Kincaid 適讀性測試(1948, 1975) 這部分包含了兩個不同測試的公式,兩種公式中都包含兩個因 素:每句所包含的字數以及每個字所包含的音節數。差別在於 Flesh Reading Ease 所計算出來的是介於 0 到 100 之間的數值,越高分代 表越容易閱讀,越低則代表適合學習英文有些程度的人閱讀; Flesch –Kincaid Grade Level 則是算出適合閱讀的年級數,例如算出 來的數值是 5.3,則代表此篇文章五年級的學生來閱讀較適合。 7.
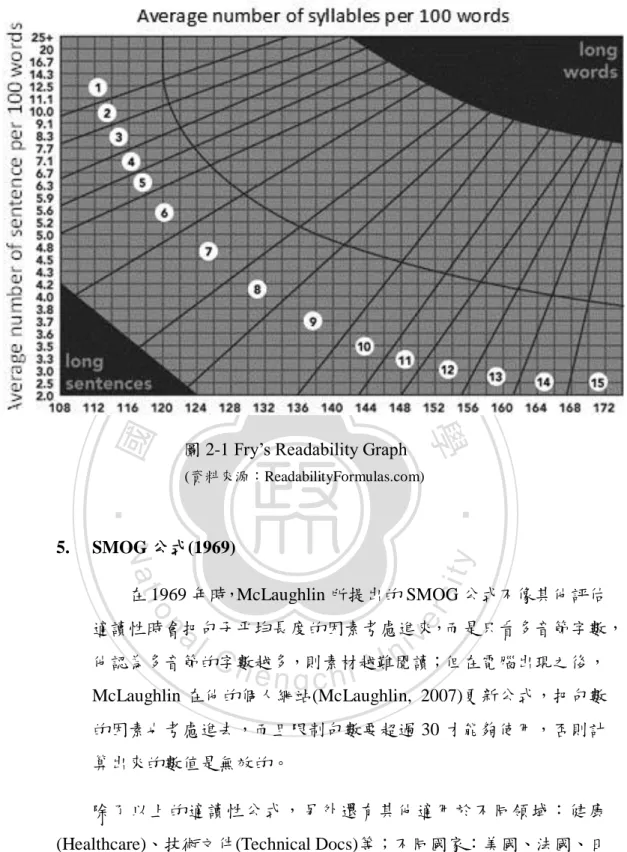
(16) 3.. Gunning Fog 指數(1952) 這個公式要先計算文章的平均句子長度,如果平均句長較長, 文章就代表比較難;而因為單字也會影響理解度,多音節字也列入 考量的因素之一,計算三個音節或以上的字在整篇文章中佔的百分 比有多少,加上平均句長後乘以 0.4 得到的指數代表年級數,即此 篇文章適合該學年的學生閱讀。 要注意的是一開始是任選文章中的一段(至少有一百個字的段 落);另外是在算三個或以上個音節的字數時,要排除專有名詞, 還有像是動詞字尾加-es、-ed 或-ing 都不算多音節。大致上的計算. 政 治 大 富萊適讀性指數(Fry Readability Graph) (1968) 立. 方式如上,還有其他較詳細的規定,不再此多做贅述。. 學. 一九六三年富萊(Fry)出版適讀性指數,到一九七七年略作修正,. ‧ 國. 這是今日適用年級最廣、教育界常用的公式。它是以句子數目與單. ‧. 字音節數為變數測量文章的難易。首先,從一篇文章中任取三個樣 本,每個樣本為連續的一百個字,然後計算這百字有多少句子、多. y. Nat. sit. 少音節數;接著,把每個樣本的平均數再求得每個百字的平均句子. io. 數目與單字平均音節數。最後把這這組數字放在富萊適讀性座標圖. er. 4.. al. n. v i n Ch 會受到廣泛使用,是因為變數較少使數值取得較為容易,且使用曲 engchi U (如圖 2-1)上,就可查出對應的適讀年級。研究者認為 Fry 的公式. 線圖較為直觀,避免繁複的計算而可以方便使用。. 8.
(17) (資料來源:ReadabilityFormulas.com). ‧. SMOG 公式(1969). sit. y. Nat. 5.. 圖 2-1 Fry’s Readability Graph. 學. ‧ 國. 立. 政 治 大. er. io. 在 1969 年時,McLaughlin 所提出的 SMOG 公式不像其他評估. al. v i n Ch 他認為多音節的字數越多,則素材越難閱讀;但在電腦出現之後, engchi U McLaughlin 在他的個人網站(McLaughlin, 2007)更新公式,把句數 n. 適讀性時會把句子平均長度的因素考慮進來,而是只看多音節字數,. 的因素也考慮進去,而且限制句數要超過 30 才能夠使用,否則計 算出來的數值是無效的。 除了以上的適讀性公式,另外還有其他適用於不同領域:健康 (Healthcare)、技術文件(Technical Docs)等;不同國家:美國、法國、日 本等的公式存在,但大部分是針對以母語為英文的國家所設計的;不同 範圍:國小、國中、高中、大學等。表 2-1 是藉由宋佩貞(2009)的影響 英文文章適讀性變數整理以及本研究加進其他評估出版文件的適讀性 公式的研究學者,來讓以往包含的可讀性公式的變數(語文因素)可以更 清楚的呈現。 9.
(18) 表 2-1 1923-1977 年研究學者用來評估英文文章難度的變數 研究學者. 影響因素(變數) 音節多寡. 備註. Flesch(1948) Farr、Jenkins 和 Paterson(1951). Flesch 公式. Gunning(1952). Fog 指數. 單音節單字數. Fry(1968) McLaughlin(1969). SMOG 公式. R D Powers, W A Sumner, and B E Kearl(1958). Power-Sumner-Kearl 公式. Meri Coleman and T. L. Liau. Coleman–Liau index 公式. 字彙 人稱代名詞. Gray 和 Leary(1935). 政 治 大. 單字長度(即 Danielson 和 Bryan(1963) 字母數) Bormuth(1966). 立 Lively 和 Pressey(1923) Gray 和 Leary(1935). Dale-Chall 的 769 個英 文常用字彙 表. Gray 和 Leary(1935). Washburne 和 Morphett(1938). n. Thorndike 的 100000 字彙 表. i n C Lively 和 Pressey(1923) hengchi U. v. Thorndike 的 Washburne 和 Morphett(1938) 1500 字彙表 Dale 和 Chall(1948) Dale-Chall 的 3000 個英 Bormuth(1966) 文常用字彙 表. 句子. sit. Lorge 公式(1939). er. io. al. y. Lorge 公式(1939). Nat. (庫). 表. Gray 和 Leary(1935). ‧. 介係詞片語. 字. 學. ‧ 國. 不同字彙數. Spache 修 訂字彙表. Spache(1953). 句子的長度. Sherman(1893) Gray 和 Leary(1935). (每句字數). 10.
(19) Lorge(1939). Lorge 公式. Flesch(1948) Farr、Jenkins 和 Paterson(1951). Flesch 公式. Gunning(1952) Danielson 和 Bryan(1963). Fog 指數. Bormuth(1966). 句數. R D Powers, W A Sumner, and B E Kearl(1958). Power-Sumner-Kearl 公式. Spache(1953). Spache 公式. Washburne 和 Morphett(1938) Fry(1977) McLaughlin(更新後的公式). 政 治 大. Meri Coleman and T. L. Liau. Coleman–Liau index 公式. 立 Alton L. Raygor (1977). Raygor 公式. ‧ 國. 學. (資料來源:(宋佩貞,2009)和本研究自行整理部分) 2.2.3 適讀性公式的價值. ‧. 適讀性公式主要探討的是對於讀者而言,這個文本(英文書、文章等)“適. sit. y. Nat. 不適合”或是“是不是可以被接受”,不管是教育方面的教材、英文新聞、英. io. er. 文使用手冊等都是利用一個比較客觀的方式來檢測文本所適合的閱讀者能 力範圍在哪一個位置,例如在教材編輯方面,美國俄亥俄法官潘特(Painter). n. al. Ch. i n U. v. 對文件書寫的要求有一條「1818」規則,意思是平均句長不得超過 18 個字,. engchi. 被動句不超過 18%,才算適當的法律文書(Painter, 2004)。另外教科書的選 擇方面,以前教師、圖書館員必須先閱讀過這本書後,知道難易度,才能夠 決定是否購買,但有了各種適讀性公式,對於不熟悉的題材、內容,他們可 以在挑選上節省很多時間。 2.2.4 其他英文適讀性因素以及研究 較近代關於英文適讀性或是對於如何推薦讀者是適合閱讀的英文文章 的研究依年代整理於下。包括他們研究的主題以及所使用到的英文難易度因 素有哪一些。 游禮志(2008)使用使用“句子平均長度”作為衡量文章難度的標準之一, 11.
(20) 認為如果句子過於冗長,則讀者無法很快知道重點是什麼;其他還使用了“單 字等級”,認為光是在 1964 年所出版的 The Brown Corpus 就已經包含了一 百萬個字彙,而我們人記憶有限,無法記住全部,但卻可以依照使用頻率而 訂定出常用字表,因此選擇全民英檢所整理出的單字等級來做為難易度的評 斷之一;最後,利用“句型結構”分成簡單句、複合句、複雜句與複合複雜句 所占文章比例來當作影響文章難度的因素之一。 雷珵麟(2010)所要研究的主題是找出一個可以區分文章難易程度的方 法,讓學習者找出適合自己閱讀的教材。所選擇的英文難易度特徵包括一般 常見的“句子長度”、“Long Word”(單字長度超過七個字母)、“難單字的列表”, 此研究所增加的部份是“文法分析”(POS N-gram):比較每個句子中利用 N 個. 政 治 大. 字來斷字後的詞性組合,找出詞性組合中,文章隨著難度上升,詞性組合那. 立. 些出現的機率是較高的,再利用這些特徵值去幫忙比較出兩篇英文文章的難. ‧ 國. 學. 度差距。. 楊子儀(2009)所要研究的主題是針對使用者的閱讀能力,設計一套適性. ‧. 化英文輔助學習系統,以提升學習的動機與效率。當中在判斷英文文章難易. y. Nat. 度方面,楊子儀所選擇的英文文章難易度特徵值有八個:“文章中字彙各占. sit. 全民英檢初、中、中高的比例”,“文章平均句長”、“文章平均音節數”、. n. al. er. io. “RE(Flesch-Kincaid Reading Ease)值”,“文章中字彙各占 Brown Group 2000. i n U. v. 字字頻及 3000 字字頻多少比例”。接著從這八種屬性當中挑選五種最重要的. Ch. engchi. 屬性來分類以利效率的提升,再利用五種屬性加上 C5.0 決策樹分類的方法 對英文文章做難度上的分類。 黃孝慈(2010)所要研究的主題在於找出各種影響英文文本難度的因素, 並探討在屬性取得的過程中可能影響最後文章分類難易度結果之因素與實 驗。所找出影響難度的特徵為:“全民英檢初、中、中高級字彙各自所占比 例”、“Brown 常用 2000 字、3000 字比例”、“Flesch-Kincaid Grade Level”、“平 均句長”、“平均音節數”、“Stop Word 字彙比例”,“全民英檢初、中、中高 級片語各自所占比例”,“句子結構”(對等子句、關係子句、副詞子句)。 黃良鈞(2009)所要研究的主題是推薦適當的英文文章給學習者閱讀學 習 。 此研究利用模 糊推論機制 (Fuzzy Inference Mechanism) 、記憶週期 12.
(21) (Memory Cycle)以及層級分析法(Analytic Hierarchy Process)的概念,找出且 推薦對學習者難易度適中並且能夠盡量符合學習者本身興趣的英文新聞文 章以供其閱讀學習。此外,期望在推薦英文文章的同時,仍能達到隨時複習 的效果,使學習者能夠逐步的增進自己的英文能力。其中一開始使用者的能 力是利用問卷讓使用者自行評估,以及勾選有興趣的新聞文章類別。當中在 判斷英文文章難度方面,黃良鈞是利用“英文文章中字彙分別佔全民英檢初、 中、中高級多少比例”,而除此之外的字彙則是歸類為“難字”類別,另外還 有“文章長度”以及“句子總數”,以此三種因素做為判斷英文文章難易度的特 徵值。 2.2.5 小結. 治 政 大 經過前兩節的探討,可以知道其實在很早以前就已經開始有英文文本難 立 易度的測量方式相關研究,只是先前所使用的都是偏向於使用語文上的一些 ‧ 國. 學. 難度特徵,接著計算出英文文本所適合在哪個年級閱讀,或是程度上面的區 分。而適讀性公式一方面是讓作者了解到自己所寫的內容難易度適不適合自. ‧. 己原先所針對的讀者範圍所寫出來的作品的一項參考依據;另一方面則是讓. y. Nat. 特定族群在選擇自己或是給別人閱讀的文本時,可以知道適不適合,就像教. io. sit. 師在挑選給學生閱讀的英文文本時,就可以參考各種可讀性公式計算出來的. n. al. er. 數值作為挑選的指標。. Ch. i n U. v. 國內學者建議應建立適合台灣本土的適讀性公式,以本國特殊環境作為. engchi. 基礎,研究修訂或重訂可行的適讀性公式(賴伯勇,2005)。即使國外適讀 性公式不能直接套用在我國英語教材之適讀性評估之上,但各研究所採取的 英文難易度影響因素還是值得本研究參考。. 第三節 資料探勘與文字探勘 當我們有了大量的資料後,要怎麼去從中找出對我們而言算是有用的資訊, 又或是如何找出從前未有人發現的規則,幫助我們去應用在其他資料的分類或是 預測,或說是作為輔助決策的參考。此節中我們將探討資料探勘與文字探勘的定 義、步驟,與特徵值選取的方式,最後在探討分群分類的方法與績效評估。. 13.
(22) 2.3.1 資料探勘 依 照 以 前 到 現 今 的 學 者 對 於 資 料 探 勘 的 定 義 如 下 。 Frawley, Piatetsky-Shapiro, Matheus(1992)認為所謂的資料探勘就是指從資料庫中挖 掘出潛在、明確、而且非常有用資訊的過程;Grupe & Owrang(1995)則認為 資料探勘是指從已經存在的資料庫當中挖掘出專家仍未知的新事實。Berry & Linoff(1997)則定義資料探勘為使用自動或半自動的方法,對大量資料作 分析,找出有意義的關係或法則。Berson (1999)指出資料探勘幫助最終使用 者從大型資料庫中萃取有用的商業資訊。 但也有學者提出對於資料探勘不一樣的見解。Fayyad(1996)等人定義資. 治 政 大 KDD)的一個過程,應用某些計算技術和分析,在可接受的運算效率限制下, 立 產生建立於資料之上的特定樣式。. 料探勘(Data Mining)是資料庫知識發現(Knowledge Discovery in Database,. ‧ 國. 學. Fayyad et al.(1996)提出了 KDD 的流程如下: 資料選擇(Selection). ‧. 1.. sit. y. Nat. 首先必需先了解該領域的資料,並在資料庫中選取欲分析的資料,再. io. al. 前置處理(Preprocessing). n. 2.. er. 整合為目標資料(target data)。. Ch. engchi. i n U. v. 在目標資料中處理不完整、遺失或錯誤的資料來消除雜訊,對資料進 行刪除和修正處理。 3.. 資料轉換(Transformation) 在龐大的資料庫中發現對我們有用的資訊是困難且複雜的工作,有時 必須對目標資料進行維度簡化、轉換,來減少變數和資料,轉換或合 併成適合探勘的格式。. 4.. 資料探勘(Data Mining) 此步驟為 KDD 中最重要的部分。透過分群、分類、關聯規則、決策 樹、回歸分析和時間序列分析等演算法找出資料的特徵或規則。 14.
(23) 5.. 解釋或評估(Interpretation/Evaluation) 將資料探勘出的特徵或模式轉換為圖形、圖表等較為容易理解的表達 方式,以供決策參考。同時也必須評估探勘結果是否合理或適用,並 進一步決定是否對各步驟進行必要的調整。. 2.3.2 文字探勘 隨著我們科技與網路越來越進步,現在網路上充滿各種不同類型(包括 影音、文字等)的數位資料,而大部分我們可以從網路上看到的幾乎都是以 文字的方式呈現,包括像是新聞、雜誌專欄、部落格、會議記錄等,通常存 在著沒辦法很快地從中看出對於我們有用或是有價值的資訊。而文字探勘的. 政 治 大. 技術就是用來分析這些文件,希望藉此找出新的、有用的資訊。. 立. 「文字探勘」(text mining)是資料探勘(data mining)、知識發現(knowledge. ‧ 國. 學. discovery)的延伸應用,其以文件內容為分析主體,目的在於從非結構的文 件中精練出有意義、有價值的範型或知識 (Simoudis, 1996)。而 Han &. ‧. Kamber(2001)也認為文字探勘屬於資料探勘中的一個重要的分支,說明文字 探勘是透過觀察文件中文字、段落、主題等關聯,希望能夠從裡面找出文件. y. Nat. sit. 趨勢,若可以則近一步進行預測。每位學者對於資料探勘的定義都有些許的. n. al. 中,方便與快速地整理出有用的資訊。. Ch. engchi. 2.3.3 資料探勘與文字探勘比較. er. io. 不同,但總結來說,文字探勘是能夠從大量半結構化或非結構化的文字內容. i n U. v. 資料探勘的目的在於發掘隱藏於「資料」之中的模式(Patterns),而文字 探勘目的是為找尋潛藏於「文字」中的模式。資料與文字之間的差別,就在 於結構化與否,資料探勘針對資料庫中所儲存的各種資料進行分析,資料庫 中的內容皆是結構化資料,例如購物交易資料庫中的真實記錄,像是交易日 期、會員等級、產品類別、交易金額等資料;反觀文字探勘所分析的文字, 是沒有組織的非結構化資料,相較於結構化資料是較難以演算法處理(黃孝 文,2010)。 而它們相同的核心概念就是找出隱含的知識或是對我們有用的資訊。但 是因為文字探勘中主要是以文字為探勘的對象,因此需要面臨幾個挑戰:第 15.
(24) 一,文字要如何量化成我們可以從中找出文件之間相關性的數值,也就是如 何轉換成結構量化指標來代表文件;第二,因為資料來源的不同,每個文件 中都有屬於作者自己的寫作風格,如何能夠降低資料之間的差異性;第三, 文件中可能包含不同的語言,如何處理這些不同語言也是需要注意的。 2.3.4 文字探勘過程 在我們從文字中要去發掘出我們需要的資料之前有幾個過程需要經歷 的,以下個別說明。 一、斷詞處理 中文與英文的斷詞都有各自的難處。中文斷詞的難處在於中文獨立. 政 治 大. 的字未必是有意義的單位,字詞與字詞間沒有明顯的邊界(喻欣凱,. 立. 2008);而英文斷詞部分,雖然 Nie(1996)表示印歐語系文件在詞與詞之. ‧ 國. 學. 間以空白及其他符號隔開,因此斷詞僅需透過空格或其他符號的分隔便 能將每一個單字斷開成為獨立詞彙;但是我們也會遇到類似“demand. ‧. deposit(活期存款)”的專有名詞,因為單看 demand 為“需求的” 的意思, 而 deposit 為“存款” 的意思,還是得經由看過的人或建立專有名詞庫才. y. Nat. io. sit. 會知道兩個字合起來是“活期存款”的意思,而可以斷成專有名詞。. n. al. er. 但是本研究不考慮這種狀況發生,因為通常專有名詞都會連在一起. i n U. v. 出現,因此,如果像是“demand”出現,而英文文章中若要表示“活期存. Ch. engchi. 款”意思的話,自然就會把“deposit”接在後面。所以本論文中的斷詞則 主要是依照英文詞與詞中間的空白特性與標點符號下去處理的。 二、文件特徵選擇 文件在斷詞處理之後,為了能夠增加效率,減少計算複雜度,通常 會先移除文件中不具代表性的詞彙,找出特徵值(Liu & Motoda, 1998)。 在許多種選擇特徵值的方式當中,最常見的挑選方法為 TF-IDF(Term-Frequency. ─. Inverse-Document-Frequency)(Salton. &. Buckley, 1988)。 1.. TF(Term Frequency)代表詞彙頻率。在一份文件當中,TF 代表 16.
(25) 說一個特定詞彙在該文件當中出現的次數,用以代表這個詞在 此文件中重要的程度。越重要的詞彙就會一直反覆出現在文件 當中,所以如果詞彙頻率越高的話,也就越能代表文件要表達 的概念。 2.. IDF(Inverse Document Frequency)代表反向文件頻率。因為當一 個詞彙出現的越頻繁的話(在這邊是指出現在一個文件集合當 中,有幾件文件出現過此詞彙),就會顯得它太過普遍而越不 重要。. 3.. TF-IDF 所代表的是將上述兩個所算出來的值相乘。意義是與. 治 政 大 的文件數成反比。 立. 在文件中出現字詞的次數成正比,但與在所有文件集合中出現. ‧ 國. 學. 三、向量空間模型. 為了能夠比較文件之間的相關性,需要將半結構化或非結構化的文. ‧. 件進行處理,處理成能夠比較的表示方式。最常被使用的方法是 Salton(1975)等人所提出的向量空間模型(Vector Space Model, VSM),主. y. Nat. sit. 要的概念在於把每個詞彙所計算出來的權重(前面所提到的 TF-IDF 值). er. io. 當作代表文章的其中一個特徵值,代表這個詞彙在這篇文章的重要性有. al. n. v i n C h Vector)時,就可以代表一篇文章在空間中 組合起來成特徵向量(Feature engchi U 多高,而每一個特徵值在空間向量中都代表一個維度,因此當這些權重. 的位置。如圖 2-2 所示,在這個三維的空間當中,有三篇文章,Wij 代. 表在地 i 篇文章 j 個詞的權重值,因為一篇文章中每個詞所算出來的權 重是不一樣的,故在空間中的位置亦不相同。. 17.
(26) D2=(W21, W22, W23). D1=(W11, W12, W13). D3=(W31, W32, W33). 政 治 大. 圖 2-2 向量空間模型示意圖 四、文件相似度計算. 立. ‧ 國. 學. 將文件用向量空間模型表達後,可以藉由各種距離的計算公式來算 出文件之間的相似程度,例如尤拉距離(Euclidean distance)、曼哈頓距. ‧. 離(Manhattan distance)。而在空間向量模型當中最常被使用來計算兩文 件之間距離的的方式是計算它們向量之間的夾角,若是夾角越小,則代. Nat. sit. y. 表兩文件越相近;若是夾角越大,則代表兩文件越不相近。. n. al. er. io. 五、分類方法 ─ k 個最近鄰演算法(k-Nearest Neighbor). Ch. i n U. v. T.M. Cover and P.E. Hart 於 1967 年所提出的 k 個最近鄰演算法,到. engchi. 現在還是最常用的分類演算法的其中一個。kNN 的概念為未知類別的 資料與「同類型資料的相似度」應該要比「不同類型資料的相似度」高 (陳柏均,2011)。如圖 2-3 所示,如果在二為空間中有三群資料:藍、 綠、橘,而現在有一個點尚未分類(圖中為紅色點),而我的 k 值如果是 7 的話,也就是我需要去抓取最接近紅色的 7 個點(如圖中灰色虛線所連 接的點),最後去計算這圖中最接近的這 7 個點當中那類的點最多,就 把紅點分為該類,此圖的紅點就屬於藍色類,因為 7 個點中有 4 個點都 是藍色。. 18.
(27) 藍色群. 橘色群. 紅色點. 綠色群. 立. 政 治 大 圖 2-3 kNN 概念圖. ‧ 國. 新進的點與各類的點相互計算出距離。 排列出前 k 個最近的點。 計算哪一類的點最多或是平均距離最小者。(此處有時需 要設定大於某門檻值,才可加入類別中,要不然就要成為 新的類別。). ‧. 1. 2. 3.. 學. 步驟大致如下所示:. er. io. sit. y. Nat. 2.3.5 分類績效評估. al. n. v i n Ch 在分群或分類結果出來後,需要進行驗證的步驟來評估結果之績效如何, engchi U 再思考是否進行調整(Sebastiani, 2002)。進行評估的方式一般有正確率. (Accuracy Rate)、精確率(Precision Rate)、召回率(Recall Rate)等三種(Makhoul, J. et al., 1999),表 2-2 為文件分類結果的種類列出。 表 2-2 文件分類結果種類 正確答案 分類結果 分為類別 A 分為非類別 A. 屬於 A 類. 不屬於 A 類. TP(True Positives). FP(False Positives). FN(False Negatives). TN(True Negatives). (資料來源:本研究自行整理). 這邊的分類績效評估是從資料檢索中的所延伸過來的。首先,假設我們 19.
(28) 有一個 A 類與非 A 類兩個類別,這是我們事先知道的答案;最後分類的結 果分為 A 類別與非 A 類別。我們所希望的結果是本來屬於 A 類別結果最後 也被分為 A 類別,以及本來不屬於 A 類的最後也被分為非 A 類。因此就有 上面三個評估方式產生,正確率(Accuracy Rate)所關注的部分是所有資料中 被正確分為原本就屬於該類別的占多少百分比;精確率(Precision Rate)則是 關注於分類結果當中分為 A 類的,真的屬於 A 類的占多少百分比;最後的 召回率(Recall Rate)則是在所有本來所有屬於 A 類的當中,正確被分為 A 類 的佔多少百分比。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 20. i n U. v.
(29) 第四節 文獻探討總結 從一開始探討到台灣學習的環境讓台灣學生缺乏廣泛的閱讀英文文章,閱讀 這項能力卻會影響聽、說、寫、譯等相關英文能力,從廣泛閱讀的好處當中可以 得知,閱讀可以讓讀者的英文單字量增加以及若循序漸進閱讀長篇英文文章則可 以幫助讀者增加閱讀長篇英文讀物時的信心等好處。 接著是探討英文適讀性的測量是由英文適讀性公式所計算出來的值作為衡 量難易度的標準。從這些英文適讀性公式所參考影響英文適讀性的因素當中,我 們可以拿來做為之後去判斷一篇英文文章是該分為初級、中級或是中高級的特徵。 而在較近代的英文難易度研究當中,其實所涵蓋的英文難易度特徵是非常多的,. 政 治 大. 包括字詞出現的頻率、出現在各等級單字的比例、句子結構、stop word 所佔比. 立. 例等。因此我們希望能夠透過較簡單的方式來幫助英文文章做難易度上的分類。. ‧ 國. 學. 從最後一個部分所探討到的是有關資料探勘與文字探勘的定義與相關步驟、 過程。從中可以發現,文字探勘所比較的是各篇文件當中,文字與文字或說是詞. ‧. 與詞之間的相關程度,本論文所要研究的部分在於可否利用文字相關度來提升語. y. Nat. 文難易度所分類的準度。目前沒有利用文字特徵的方式進行分類,因此,本研究. n. al. er. io. sit. 透過文字探勘的技術來幫助歸類過程的進行,並比較各種特徵歸類後的結果。. Ch. engchi. 21. i n U. v.
(30) 第三章 研究方法與設計 從前面的研究動機與目的及文獻探討部分了解到現在周遭的英文資源非常 多,我們卻不知道如何去選擇適合我們閱讀的英文文章,身為以英語為第二外語 的台灣學習者而言,要從廣大的網路中選擇閱讀的文章時,找到的適讀程度可能 比自己程度過高或是過低。而以往的研究當中所要抽取的英文難易度特徵值很多, 過程較繁複,因此本研究在此章節設計出利用文字探勘的技術來幫助英文文章難 易度的歸類方法。. 第一節 研究架構與範圍. 治 政 大 本研究分別蒐集過去的英檢初、中、中高級文章模擬試題,與網路上的官方 立 試題文章;接著從前面所探討過英文文章適讀性公式中影響難易度的因素做為文 ‧ 國. 學. 章的特徵值,來作為網路上官方試題的英文文章的分類依據;接著,先利用前者 來做為各等級字庫建立的來源,並用文字探勘的分類技術將所蒐集來的官方試題. ‧. 與全民英檢的文章做相似度的比對而歸類出官方英文文章各是屬於哪一等級;最. y. sit. io. er. 比較。. Nat. 後將前兩者特徵結合作歸類;結果部分則是將各歸類結果與原先文章所屬類別作. 本研究之研究架構如圖 3-1 所示:. n. al. Ch. engchi. 22. i n U. v.
(31) 蒐集 GEPT 官方試題文章. 全民英檢初 級、中級、 中高級文章. 全民英檢初 級、中級、 中高級文章. 文字特徵向量 文章 斷詞. 英文語文難易度特徵向量 特徵詞 選取. 全民英 檢詞庫. 政 治 大. 立. 結合 比較相似度歸類. ‧ 國. 學. 比較相似度 kNN 歸類. 中級. 初級. 中高級. n. sit. er. io. al. 英文語文難易度特徵歸類結果 中高級. Ch. i n U. 初級. e n g c4.h i. v. 中級. 1.. 2.. 3. 結果比較. GEPT 官方試題類別. 初級. 比較相似度 kNN 歸類. y. Nat 中級. ‧. 文字特徵與語文特徵結合歸類結果. 文字特徵歸類結果 初級. 英文文章 難易度特徵. 英文適讀性 公式. 中級. 中高級. 英文文章歸類結果 相似度比對 圖 3-1 研究架構圖 (資料來源:本研究自行設計) 23. 中高級.
(32) 3.1.1 研究範圍 由於英文文章所包含的範圍相當廣泛,像是一般書信、報章雜誌及演講 稿等,再加上現在網路上能夠取得的英文文章形式更多元,為了考慮文章的 嚴謹性,故本研究找全民英檢官方試題的文章來作為研究對象;至於研究的 讀者範圍主要是針對剛學習英語:有能力看得懂基本的英文文章,到學習英 語已有一段時間者:相當於從國中、高中到大學的三個學習階段。之所以會 以此三個階段來作為研究的範圍是要排除掉專有科目中的專有單字等問題, 針對剛學習英語的學習者而言,他們所必須習得的單字以及句型或是文法等, 都是屬於較為基礎且變動較不大的。 在此階段的學習者,廣泛而有效的英文閱讀訓練與培養,是能夠提升學. 政 治 大 幫助我們的英文的語感(Linguistic Sensitivity),對於提升英語文學習成效, 立. 生英文聽、說、寫、譯核心能力的基本途徑。經由這個英語閱讀過程,可以. ‧ 國. 學. 或任何方式的考試與測驗(如大學學測、指考或 TOEIC, TOEFL, IELTS 等), 都有正面的幫助(李振清,2009)。. ‧. 第二節 資料來源及特徵向量. sit. y. Nat. 3.2.1 資料來源. al. er. io. 最一開始的部分蒐集了賴世雄(2005)所編輯的全真模擬試題以及實戰. v. n. 模擬試題,都是針對全民英檢初級、中級、中高級各別設計的考題,每個級. Ch. 別分別對應到的程度是國中、高中、大學。. engchi. i n U. 另外在線上找已分出文章程度差異的英文文章來做為此研究的資料來 源,要找程度較有差別的英文文章是為了要讓文章之間的程度是有較明顯的 區別,盡量在分類的時候可以有顯著的差異。此處抓取的英文文章來源是全 民英檢官方網站所給的官方模擬試題裡的各級別文章。由於內文有書信以及 廣告等不同類型文章,因此有經過人工挑選的過程,主要挑選過程是將內文 抓取出來,讓文章是程式能夠處理的格式。 這邊找出分為三個級別的理由為前一節當中的研究限制講過,本論文所 要研究的年齡(或讀者程度)範圍主要是國中、高中、大學三個階段(初學、學 習三年到五年與六年或以上的階段)。 24.
(33) 以下整理各類文章抓取總數(表 3-2)。 表 3-1 資料來源篇數 初級(學習 1-3 年) 中級(學習 4-6 年). (篇數). 中高級 (學習 6 年以上). 賴世雄全真與實 戰模擬試題. 46. 56. 63. 官方模擬試題. 10. 19. 14. (資料來源:本研究自行整理). 3.2.2 特徵向量 一、英文語文難易度特徵向量. 政 治 大. (一)、適讀性公式之英文難度特徵值選取. 立. 第一部份的特徵值選取是從第二章所探討的適讀性公式當中,除. ‧ 國. 學. 了考慮到個人因素的人稱代名詞與較久以前所建立的各種英文字表 不列入特徵外,其他基本的語文難度因素都是本研究假設能夠正確分. ‧. 出英文文章難易度的特徵。特徵值計算公式如下:. n. al. 文章總字數 文章總句數. Ch. 2. 句數. engchi. 每篇文章中總共有多少句子。 3. 平均音節數 平均音節數 =. 文章總音節數 文章總字數. 4. 平均單字長度 平均單字長度 =. 文章總字母數 文章總字數. 5. 不同字彙數比例 25. er. io. 平均句子長度 =. sit. y. Nat. 1. 平均句長. i n U. v.
(34) 不同字彙數比例 =. 不同字彙個數 文章總字數. 舉例來說,下面這段文字當中,紅色的字(灰色的字)是在這個字以 前就出現過一次,所以不列入不同字彙數。所以這段文字所不同字 彙數是 40,總字數是 60,不同字彙數比例為 0.67。 Harlem Shakes are a big hit. It is a hit on the internet. Many people film videos with Harlem Shakes. But a Harlem Shake on a World War II tank wasn’t a good idea. Russian police didn’t like this idea. Five people are at the police station now because they danced on a. 政 治 大. tank and put the video on YouTube.. 立. 介係詞片語比例 =. 介係詞片語數目. 學. 文章總字數. ‧. ‧ 國. 6. 介係詞片語比例. 二、文字特徵向量. sit. y. Nat. io. er. (一)、文章斷詞. al. 全民英檢提供國內一套完整並具公信力的英語能力分級檢定系統,. n. v i n Ch 是由教育部核准財團法人語言訓練測驗中心(LTTC)辦理。自 89 年開辦 engchi U 以來,考生人次已達 530 萬人次。LTTC 也表示成績除了獲得公民營機. 構採認外,也獲得各大學/高中採用做為學習成果的依據;目前更受各 國:日本、香港、美國、英國、德國、法國、荷蘭等各地的外國大學採 認 GEPT,學生因此可用 GEPT 成績申請出國進修。(全民英檢網站,2013) 由這些資料顯示出全民英檢所做的分級制度是受到重視的,因此我將以 全民英檢來作為斷詞、建立詞庫以及特徵詞挑選的依據。 1. 斷詞處理 本研究在這個部分是需要將全民英檢各級裡的英文文章做斷詞。 而前面文獻探討的部分提到不考慮像是“demand deposit(活期存款)” 26.
(35) 這樣的專有名詞,因此是以詞與詞中間的空白與標點符號作為斷詞的 依據。 目前在處理英文文章的工具上,主要有兩個:openNLP 與 Stanford CoreNLP,兩者都有提供 API 給需 要處理 英文文章中像是斷詞 (tokenization)與詞類標記(part-of-speech tagging)等用途的工具。此研 究選擇 openNLP,它是基於機器學習的自然語言文本處理的開發工具, 裡面的工具包括前面所說的斷詞、詞類標記,以及斷句 (sentence detection)、文法剖析(parsing)、人名辨識(name entity extraction)等。 斷詞部分主要是針對句子中空白的部分去斷詞,例如“A lot of. 治 政 大 out.”這個句子會被分成“A”,“lot”,“of”,“men”等獨立的字與標點符號分 立 開。值得注意的是“couldn’t”這個字會被分成“could”與“n’t”兩個字。 這也是 openNLP 斷詞工具好處之一。. ‧. 2. 字詞處理與辭庫建立. 學. ‧ 國. men helped a small girl. She was in a washing machine. She couldn’t get. 將英文斷好詞後,接下來所要做的事情是詞類標記。詞類標記的. y. Nat. sit. 部分主要是要知道某字詞在這個句子當中的這個位置是屬於什麼詞. er. io. 性,記錄此字是什麼詞性主要目的在於相同的字詞在不同位置或是不. al. n. v i n Ch 不同的位置時,有可能因為前後詞性的變化而有不同詞性,例如, engchi U. 同字詞變化型態都有不同的詞性,因此當相同的字出現在不同句子、. “This is a book.”與“I want to book a ticket.”,前者“book”是名詞,“書” 的意思,後者“book”是動詞,是“預定”的意思。隨著不同級別的文 章當中,有可能會有相同的詞出現,卻是不同詞性,例如,“book” 是名詞時,是在初級當中較常出現;“book”是動詞時,是在中級較常 出現。由 openNLP 的詞類標記工具所標出的例子如“This is a book.” 會被標記成“This_DT is_VBZ a_DT book._NN”;“I want to book a ticket.” 會 被 標 記 成 “I_PRP want_VBP to_TO book_VB a_DT ticket._NN”。詞類對照表如表 3-2 所示。. 27.
(36) 表 3-2 詞類對照表 標記(Tag) 詞性(Speech). 標記(Tag) 詞性(Speech). CC. Coordinating conjunction. PRP$. Possessive pronoun (prolog version PRP-S). CD. Cardinal number. RB. Adverb. DT. Determiner. RBR. Adverb, comparative. EX. Existential there. RBS. Adverb, superlative. FW. Foreign word. RP. Particle. IN. Preposition or subordinating conjunction. SYM. Symbol. JJ. Adjective. TO. to. JJR. Adjective, comparative. UH. Interjection. JJS. Adjective, superlative. LS. List item marker. MD. Modal. NN. 立. base form VB 治 Verb, 政 VBD 大Verb, past tense. Noun, singular or mass. VBN. Verb, past participle. NNS. Noun, plural. VBP. NNP. Proper noun, singular. VBZ. Verb, 3rd person singular present. NNPS. Proper noun, plural. WDT. Wh-determiner. PDT. Predeterminer. WP. Wh-pronoun. POS. Possessive ending. WP$. PRP. al. Possessive wh-pronoun (prolog version WP-S). Personal pronoun. WRB. Verb, non-3rd person singular present. sit. io. er. Nat. y. ‧. ‧ 國. Verb, gerund or present participle. 學. VBG. n. v i n C h http://bulba.sdsu.edu/jeanette/thesis/PennTags.html) (資料來源:整理自 engchi U Wh-adverb. 在本研究建立辭庫的階段,所儲存進資料庫的詞主要是“字詞_ 詞類”,例如“I_PRP want_VBP to_TO book_VB a_DT ticket._NN”會以 “I_PRP”、“want_VBP” 、“to_TO” 、“book_VB” 、“a_DT” 、“ticket_NN” 各別存入。此處會保留所有字詞在句子中的原型態,不會處理掉像是 動詞後面第三人稱的時候需要加-s 或-es、過去式加-ed,以及一些字 詞在過去式、過去完成式等的變化,因為隨著級別的增加,字詞變化 的種類就會比較多,像是初級部分會以現在簡單式與一些過去式為主, 在中級、中高級的話會有越來越多完成式、未來完成式等不同。 (二)、特徵值選取 28.
(37) 挑選越多詞彙作為文章的特徵詞,則越能凸顯文章的特性;但若 是能夠把大部分文章中都出現過的字詞去掉,不納入特徵詞當中,則 能夠節省在分類時所需運算的時間;因此,若某字詞佔了初級、中級 與中高級這些所有文章當中的 80%,則不納入特徵詞當中。 在進行文件之間相似度比對之前,要將文章的特徵值轉換成向量 空間模型表示。每個向量中的每個維度的特徵值都影響著這篇文章在 空間中的位置,而特徵值本研究所使用的是 TF-IDF 詞彙權重計算方 式所算出的,因為可以同時顧慮到每個詞在文章當中的重要程度以及 在全部文章當中的普遍性,也就是說 TF-IDF 值會與詞彙在文章中出 現的頻率成正比,與詞彙在所有文章集中出現的文章數成反比。為了. 政 治 大. 不因為文章長度而影響文章中某些詞彙的權重比較,本論文將向量做. 立. 學. ‧ 國. 正規化的處理。相關特徵值計算公式如下: 1. 詞彙頻率(Term Frequency, TF) 𝑛𝑖,𝑗 ∑𝑘 𝑛𝑘,𝑗. ‧. 𝑡𝑓𝑖,𝑗 =. sit. y. Nat. 𝑛𝑖,𝑗 代表詞彙 i 在文章 j 中的出現次數;∑𝑘 𝑛𝑘,𝑗 則代表文章 j 中所. io. n. al. er. 有詞彙出現的次數總和。. i n U. v. 2. 反向文件頻率(Inverse Document Frequency, IDF) |𝑁 | idf𝑖 = log 𝑑𝑓𝑖. Ch. engchi. |𝑁|代表整個文章集中的文章總數;𝑑𝑓𝑖 則代表詞彙 i 出現在整個 文章集中的文章數。 3. TF-IDF TF– IDF = 𝑡𝑓𝑖,𝑗 × idf𝑖 4. TF-IDF 正規化之權重值 𝑊𝑖,𝑗 =. 𝑇𝐹– 𝐼𝐷𝐹𝑖,𝑗 ⃑⃑⃑𝑗‖ ‖𝑑 29.
(38) 這 TF-IDF 正規化的公式就是由個別詞彙的𝑇𝐹– 𝐼𝐷𝐹𝑖,𝑗 值除以所 ⃑⃑⃑𝑗 ‖,而‖𝑑 ⃑⃑⃑𝑗 ‖代表的意思是這個文件向量 有選中的特徵詞彙長度‖𝑑 中所有權重(也就是 TF-IDF 值)各自平方加總再開根號。 三、特徵向量轉矩陣表示法 為了讓文章之間的權重可以互相比較,可以將之前使用空間向量模 型來代表的文字特徵向量與英文語文難易度特徵向量轉換成「文章─詞 彙矩陣」與「文章─英文語文難易度特徵矩陣」的形式來表示文章與詞 彙之間的關係。如圖 3-2 與圖 3-3 所示,圖 3-2:每一列所代表的是第 i 篇文章,每一欄代表的是第 j 個特徵詞彙,對應到的 Wij 元素是指“TF-IDF. 政 治 大. 正規化之權重”;圖 3-3:每一列所代表的是第 i 篇文章,每一欄代表的. 立. 是第 j 個英文語文難易度特徵,對應到的 DWij 元素是指“此篇文章算出. ‧ 國. 學. 來的英文語文難易度特徵值”;圖 3-4:每一列所代表的是第 i 篇文章, 每一欄代表的是第 j 個特徵詞彙,第 k 個英文語文難易度特徵。 … 𝑻𝒆𝒓𝒎𝒋 … 𝑊1𝑗 … 𝑊2𝑗 … … … … … … … 𝑊𝑖𝑗. y. … … … … … … …. sit. … … … … … … …. er. io. al. 𝑻𝒆𝒓𝒎𝟐 𝑊12 𝑊22 … … … 𝑊𝑖2. ‧. Nat. 𝑫𝒐𝒄𝟏 𝑫𝒐𝒄𝟐 … … … [ 𝑫𝒐𝒄𝒊. 𝑻𝒆𝒓𝒎𝟏 𝑊11 𝑊21 … … … 𝑊𝑖1. n. v i n Ch 圖 3-2 文字特徵向量空間模型矩陣 engchi U. ]. (資料來源:改自 Salton & Gill, 1983). 𝑫𝒐𝒄𝟏 𝑫𝒐𝒄𝟐 … … … 𝑫𝒐𝒄 𝒊 [. 𝑫𝒊𝒇𝒇𝒊𝒄𝒖𝒍𝒕𝒚𝟏 𝐷𝑊11 𝐷𝑊21 … … … 𝐷𝑊𝑖1. 𝑫𝒊𝒇𝒇𝒊𝒄𝒖𝒍𝒕𝒚𝟐 𝐷𝑊12 𝐷𝑊22 … … … 𝐷𝑊𝑖2. … … … … … … …. … … … … … … …. … 𝑫𝒊𝒇𝒇𝒊𝒄𝒖𝒍𝒕𝒚𝒋 … 𝐷𝑊1𝑗 … 𝐷𝑊2𝑗 … … … … … … … 𝐷𝑊𝑖𝑗. 圖 3-3 語文難易度特徵向量空間模型矩陣 (資料來源:本研究改自 Salton & McGill, 1983). 30. ].
(39) 𝑫𝒐𝒄𝟏 𝑫𝒐𝒄𝟐 … … … 𝑫𝒐𝒄 𝒊 [. 𝑻𝒆𝒓𝒎𝟏 𝑊11 𝑊21 … … … 𝑊𝑖1. 𝑻𝒆𝒓𝒎𝟐 𝑊12 𝑊22 … … … 𝑊𝑖2. … … … … … … …. … … … … … … …. … 𝑻𝒆𝒓𝒎𝒋 … 𝑊1𝑗 … 𝑊2𝑗 … … … … … … … 𝑊𝑖𝑗. 𝑫𝒊𝒇𝒇𝒊𝒄𝒖𝒍𝒕𝒚𝟏 𝐷𝑊11 𝐷𝑊21 … … … 𝐷𝑊𝑖1. … 𝑫𝒊𝒇𝒇𝒊𝒄𝒖𝒍𝒕𝒚𝒌 … 𝐷𝑊1𝑘 … 𝐷𝑊2𝑘 … … … … … … … 𝐷𝑊𝑖𝑘. 圖 3-4 文字特徵結合語文難易度特徵向量空間模型矩陣. 第三節 kNN 分類 3.3.1 相似度計算 當特徵值都計算好,且也轉換成向量空間模型矩陣之後,就可以開始比. 政 治 大 最常用的衡量方式為計算餘弦相似度(Cosine Similarity)(Salton,1989),公式 立 較兩文件之間的相似度。在文件的向量空間模型中,計算文件間的相似程度. 如下:. ‧ 國. 學 ‧. 𝑋‧𝑌 ∑𝑛𝑖=1 𝑋𝑖 𝑌𝑖 cos(θ) = = ‖𝑋‖‖𝑌‖ √∑𝑛𝑖=1(𝑋𝑖 )2 √∑𝑛 (𝑌𝑖 )2 𝑖=1. Nat. sit. y. 餘弦相似度的概念在於兩條 N 維向量間存在一個角度,如果越相近的. al. er. io. 話則角度越小,反之越大。而 cosine 計算的結果介於 0 與 1 之間。cosine 值. n. 越接近 0 表示餘弦相似度越小;越接近 1 表示餘弦相似度越大。 3.3.2 kNN 歸類方法. Ch. engchi. i n U. v. 本研究所採用分類的技術是 k-最鄰近演算法(kNN),作法是使用之前轉 換好的空間向量模型矩陣,用餘弦相似度來計算兩兩文件之間的相似度,再 把要歸類的文件歸類給較相近的類別,歸類的步驟如下: 1.. GEPT 官方文章的特徵值計算出來並轉換為向量空間模型。. 2.. GEPT 官方文章的特徵向量與所有全民英檢文章(後面簡稱文章)的 特徵向量兩兩作餘弦相似度比較。取文章前 k 份最相似的文章。. 3.. 這 k 份相似文章所屬類别皆列為 GEPT 官方文章的候選級別。. 4.. 這 k 份相似文章當中同類別的餘弦相似度各自加總後,除以這 k 31. ].
(40) 份相似文章當中的同類別個數。 5.. 將 GEPT 官方文章歸類到相似度最高的類別,並歸類為該級別。. 6.. 1 到 5 個步驟一直做到全部 GEPT 官方文章分類完為止。. 第四節 評估相似度方法 下圖為第二章第三節最後所列的“文件分類結果種類”表格。最後評估準 確率的方式使用精確率以及召回率所結合出來的 F-measure 來評估。以及列 出 F-measure 所延伸出來的 MicroF 與 MacroF 指標。 正確答案 分類結果. 立. 分為非類別 A. 不屬於 A 類. TP(True Positives). FP(False Positives). 學. FN(False Negatives). TN(True Negatives). 𝑇𝑃 𝑇𝑃 + 𝐹𝑃. n. al. 𝑇𝑃 𝑇𝑃 + 𝐹𝑁. sit. io. 召回率(𝐑𝐞𝐜𝐚𝐥𝐥 𝐑𝐚𝐭𝐞, 𝐑) =. er. Nat. y. 精確率(𝐏𝐫𝐞𝐜𝐢𝐬𝐢𝐨𝐧 𝐑𝐚𝐭𝐞, 𝐏) =. ‧. ‧ 國. 分為類別 A. 政 治 大. 屬於 A 類. i n U. 2𝑃𝑅 𝐅 − 𝐦𝐞𝐚𝐬𝐮𝐫𝐞 = 𝑃+𝑅. Ch. engchi. v. 另外,MicroF 與 MacroF 是屬於 F-measure 的延伸度量,以不同角度來 看分成多類(大於兩類)結果的成效。由於 Micro-F是全部文件一起累加統計, 不分類別,因此容易受到少量的大類別(佔大多數文件)表現好壞的影響; Macro-F 考慮每個類別的成效後再做平均,因此容易受到大量的小類別影響 (Van Rijsbergen, 1979)。. 32.
數據

相關文件
眾所周知: 有時, 某極值題或不等式 題可利用 Cauchy 不等式定理以解 (證) 之, 但其若干類似題則否。 筆者研究發現: 由 Cauchy 不等式定理入手, 將其作適當類推, 可得廣義
教學流程 配合範疇 單元舉例 備註 第一步:你講我講大家講 讀、寫 水果圖片 字詞卡 字詞類別. 第二步:文章大電視 聽、讀
把有着相同符號的圖畫書編 成小單元,歸類施教,引導 學生認識符號的共通點,辨 別其中的細微差異,建構文 學鑑賞能力.
比較(可與不同時期、不同藝術家,對同類型/主題創 作的處理進行比較。例:Donatello的《David》)、分
• 當我們在歸類一個問題為 問題時,等於不在乎他的複雜度是 還是 之類的,只要是多項式時間就好。.
宋代文化的繁榮與當時人們從文化角度吸收佛教的養分,應用
比較不同 文化、藝 術家、時 代的形式 選擇與表 現角度的 關係 辨識不同. 文化、藝 術家、時 代的形式 選擇有何
但它不屬於水果或蔬菜 類。因為它沒有蔬菜或水 果般的營養價值。 它比較 應該像食用油 少量使 –
